深度学习:基于MindSpore的极简风大模型微调
什么是PEFT?What is PEFT?
PEFT(Parameter Efficient Fine-Tuning)是一系列让大规模预训练模型高效适应于新任务或新数据集的技术。
PEFT在保持大部分模型权重冻结,只修改或添加一小部份参数。这种方法极大得减少了计算量和存储开销,但保证了大模型在多个任务上的复用性。
为什么需要PEFT?Why do we need PEFT?
扩展性挑战
大规模预训练模型如GPT、BERT或ViT拥有大量参数。为每个具体任务全参微调这些模型不仅耗费大量计算量,同时需要巨大的存储资源,这些资源往往难以承担。
提升迁移学习效率
PEFT很好地利用了预训练模型在通用任务上的能力,同时提升了模型在具体任务上的表现。同时PEFT能减少过拟合并提供更好的通用型。
PEFT如何工作?How does PEFT work?
1. 冻结大部人预训练模型的参数
2. 修改或添加小部份参数
3. 模型训练时,只修改小部份参数即可
PEFT方法分类
Additive PEFT(加性微调):在模型特定位置添加可学习的模块或参数。如:Adapters、Prompt-Tuning
Selective PEFT(选择性微调):在微调过程只更新模型中的一部份参数,保持其余参数固定。如:BitFit、HyperNetworks
Reparameterization PEFT(重参数化微调):构建原始模型参数的低秩表示,在训练过程中增加可学习参数以实现高效微调。如:LoRA (Low-Rank Adaptation)、Prefix-Tuning

Prefix Tuning
Prefix Tuning在每个Transformer Block层加入Prefix Learnable Parameter(Embedding层),这些前缀作为特定任务的上下文,预训练模型的参数保持冻结。相当于在seq_len维度中,加上特定个数的token。
class LoRA(nn.Module):def __init__(self, original_dim, low_rank):super().__init__()self.low_rank_A = nn.Parameter(torch.randn(original_dim, low_rank)) # Low-rank matrix Aself.low_rank_B = nn.Parameter(torch.randn(low_rank, original_dim)) # Low-rank matrix Bdef forward(self, x, original_weight):# x: Input tensor [batch_size, seq_len, original_dim]# original_weight: The frozen weight matrix [original_dim, original_dim]# LoRA weight updatelora_update = torch.matmul(self.low_rank_A, self.low_rank_B) # [original_dim, original_dim]# Combined weight: frozen + LoRA updateadapted_weight = original_weight + lora_update# Forward passoutput = torch.matmul(x, adapted_weight) # [batch_size, seq_len, original_dim]return output但Prefix Tuning在需要更深层次模型调整的任务上表现较差。

Adapters
Adapters是较小的,可训练的,插入在预训练模型层之间的模块。每个Adapter由一个下采样模块,一个非线性激活和一个上采样模块组层。预训练模型参数保持冻结,adapters用于捕捉具体任务的知识。

基于MindSpore的模型微调
环境需求:2.3.0-cann 8.0.rc1-py 3.9-euler 2.10.7-aarch64-snt9b-20240525100222-259922e
Prefix-Tuning
安装mindNLP
pip install mindnlp
加载依赖
# 模块导入 and 参数初始化
import os
import mindspore
from mindnlp.transformers import AutoModelForSeq2SeqLM
# peft相关依赖
from mindnlp.peft import get_peft_config, get_peft_model, get_peft_model_state_dict, PrefixTuningConfig, TaskTypefrom mindnlp.dataset import load_dataset
from mindnlp.core import opsfrom mindnlp.transformers import AutoTokenizer
from mindnlp.common.optimization import get_linear_schedule_with_warmup
from tqdm import tqdm# 演示模型 t5-small
model_name_or_path = "t5-small"
tokenizer_name_or_path = "t5-small"
checkpoint_name = "financial_sentiment_analysis_prefix_tuning_v1.ckpt"max_length = 128
lr = 1e-2
num_epochs = 5
batch_size = 8通过mindnlp.peft库加载模型并进行prefix配置
# Prefix-Tuning参数设置以及配置模型
peft_config = PrefixTuningConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, num_virtual_tokens=20)
# 加载预训练模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
# 加载加入prefix后的模型
model = get_peft_model(model, peft_config)model.print_trainable_parameters()加载、预处理数据集
# 微调 t5 for 金融情感分析
# input: 金融短句
# output: 情感类别
# 由于华为云无法连接huggingface,因此需要先本地下载,再上传至华为云
mindspore.dataset.config.set_seed(123)
# loading dataset
dataset = load_dataset("financial_phrasebank", cache_dir='/home/ma-user/work/financial_phrasebank/')train_dataset, validation_dataset = dataset.shuffle(64).split([0.9, 0.1])classes = dataset.source.ds.features["label"].names
# 将标签号映射为文本
def add_text_label(sentence, label):return sentence, label, classes[label.item()]
# 输入为两列,输出为三列
train_dataset = train_dataset.map(add_text_label, ['sentence', 'label'], ['sentence', 'label', 'text_label'])
validation_dataset = validation_dataset.map(add_text_label, ['sentence', 'label'], ['sentence', 'label', 'text_label'])# 加载t5模型的分词器
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)# tokenize 输入和text_label
import numpy as np
from mindnlp.dataset import BaseMapFunction
from threading import Lock
# 线程锁?
lock = Lock()class MapFunc(BaseMapFunction):def __call__(self, sentence, label, text_label):lock.acquire()model_inputs = tokenizer(sentence, max_length=max_length, padding="max_length", truncation=True)labels = tokenizer(text_label, max_length=2, padding="max_length", truncation=True)lock.release()# 提取 labels 中的 input_ids# 这些 ID 实际上是模型词汇表中相应单词或子词单元的位置索引。# 因此,input_ids 是一个整数列表,代表了输入文本序列经过分词和编码后的结果,它可以直接作为模型的输入。labels = labels['input_ids']# 将 labels 中的填充标记替换为 -100,这是常见的做法,用于告诉损失函数忽略这些位置。labels = np.where(np.equal(labels, tokenizer.pad_token_id), -100, lables)return model_inputs['input_ids'], model_inputs['attention_mask'], labelsdef get_dataset(dataset, tokenizer, shuffle=True):input_colums=['sentence', 'label', 'text_label']output_columns=['input_ids', 'attention_mask', 'labels']dataset = dataset.map(MapFunc(input_colums, output_columns),input_colums, output_columns)if shuffle:dataset = dataset.shuffle(64)dataset = dataset.batch(batch_size)return datasettrain_dataset = get_dataset(train_dataset, tokenizer)
eval_dataset = get_dataset(validation_dataset, tokenizer, shuffle=False)进行微调训练
# 初始化优化器和学习策略
from mindnlp.core import optimoptimizer = optim.AdamW(model.trainable_params(), lr=lr)# 动态学习率
lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0,num_training_steps=(len(train_dataset) * num_epochs),
)from mindnlp.core import value_and_graddef forward_fn(**batch):outputs = model(**batch)loss = outputs.lossreturn lossgrad_fn = value_and_grad(forward_fn, model.trainable_params())for epoch in range(num_epochs):model.set_train()total_loss = 0train_total_size = train_dataset.get_dataset_size()for step, batch in enumerate(tqdm(train_dataset.create_dict_iterator(), total=train_total_size)):optimizer.zero_grad()loss = grad_fn(**batch)optimizer.step()total_loss += loss.float()lr_scheduler.step()model.set_train(False)eval_loss = 0eval_preds = []eval_total_size = eval_dataset.get_dataset_size()for step, batch in enumerate(tqdm(eval_dataset.create_dict_iterator(), total=eval_total_size)):with mindspore._no_grad():outputs = model(**batch)loss = outputs.losseval_loss += loss.float()eval_preds.extend(tokenizer.batch_decode(ops.argmax(outputs.logits, -1).asnumpy(), skip_special_tokens=True))# 验证集losseval_epoch_loss = eval_loss / len(eval_dataset)eval_ppl = ops.exp(eval_epoch_loss)# 测试集losstrain_epoch_loss = total_loss / len(train_dataset)train_ppl = ops.exp(train_epoch_loss)print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")模型评估
# 模型评估
correct = 0
total = 0ground_truth = []correct = 0
total = 0ground_truth = []for pred, data in zip(eval_preds, validation_dataset.create_dict_iterator(output_numpy=True)):true = str(data['text_label'])ground_truth.append(true)if pred.strip() == true.strip():correct += 1total += 1
accuracy = correct / total * 100
print(f"{accuracy=} % on the evaluation dataset")
print(f"{eval_preds[:10]=}")
print(f"{ground_truth[:10]=}")模型保存
# 模型保存
# saving model
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)加载模型进行推理
# 加载模型并推理
from mindnlp.peft import PeftModel, PeftConfigconfig = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)model.set_train(False)example = next(validation_dataset.create_dict_iterator(output_numpy=True))
print("input", example["sentence"])
print(example["text_label"])
inputs = tokenizer(example['text_label'], return_tensors="ms")with mindspore._no_grad():outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)print(tokenizer.batch_decode(outputs.numpy(), skip_special_tokens=True))BitFit
BitFit需要冻结除Bias外的所有参数,只训练Bias参数。
for n, p in model.named_parameters():if "bias" not in n:p.requires_grad = Falseelse:p.requires_grad = True其余数据预处理代码和训练代码与上述相同。
LoRA
LoRA(Low Rank Adaptation)专注于学习一个低秩矩阵。通过在冻结的预训练权重中添加可学习的低秩矩阵。在前向传递过程中,冻结的权重和新的低秩矩阵参与计算。
低秩矩阵指的是相较于原矩阵,秩更低的矩阵。加入一个矩阵的形状为m x n,矩阵的秩最多为min(m, n),低秩矩阵的秩数远远小于原本的m和n。
LoRA微调不更新原本m x n的权重矩阵,转而更新更小的低秩矩阵A(m, r), B(r, n)。假设W0为512x512,低秩矩阵的r则可以为16,这样需要更新的数据只需要(512x16+16x512)=16384,相较于原来的512x512=262144,少了93.75%。
LoRA实现的基本思路代码
class LoRA(nn.Module):def __init__(self, original_dim, low_rank):super().__init__()self.low_rank_A = nn.Parameter(torch.randn(original_dim, low_rank)) # Low-rank matrix Aself.low_rank_B = nn.Parameter(torch.randn(low_rank, original_dim)) # Low-rank matrix Bdef forward(self, x, original_weight):# x: Input tensor [batch_size, seq_len, original_dim]# original_weight: The frozen weight matrix [original_dim, original_dim]# LoRA weight updatelora_update = torch.matmul(self.low_rank_A, self.low_rank_B) # [original_dim, original_dim]# Combined weight: frozen + LoRA updateadapted_weight = original_weight + lora_update# Forward passoutput = torch.matmul(x, adapted_weight) # [batch_size, seq_len, original_dim]return output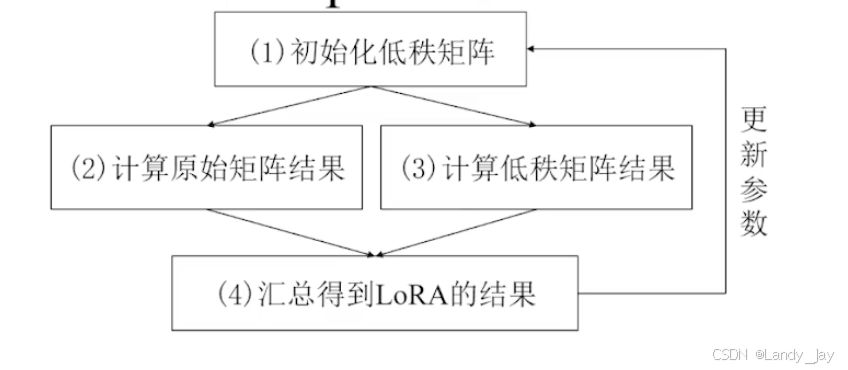
LoRA的MindSpore实现
# creating model
# r 控制适应层的秩,lora_alpha 是缩放因子,而 lora_dropout 定义了在训练期间应用于 LoRA 参数的 dropout 率。
# 缩放因子用于控制低秩矩阵对模型参数更新的影响程度。
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()其余数据预处理代码和训练代码与上述相同。
更多内容可以参考mindspore的官方视频:
【第二课】昇腾+MindSpore+MindSpore NLP:极简风的大模型微调实战_哔哩哔哩_bilibili
相关文章:
深度学习:基于MindSpore的极简风大模型微调
什么是PEFT?What is PEFT? PEFT(Parameter Efficient Fine-Tuning)是一系列让大规模预训练模型高效适应于新任务或新数据集的技术。 PEFT在保持大部分模型权重冻结,只修改或添加一小部份参数。这种方法极大得减少了计算量和存储开销&#x…...

【LeetCode力扣热题100】【LeetCode 1】两数之和
方法一:暴力循环 两层循环,遍历所有的组合,直到满足条件,返回结果。 class Solution { public:vector<int> twoSum(vector<int>& nums, int target) {for(int i0; i<nums.size()-1 ;i){for(int j i1; j<…...

定制链接类名,两类跳转传参,vue路由重定向,404,模式设置
router-link-exact-active 和 router -link-active两个类名都太长,可以在router路由对象中定制进行简化 // index.js// 路由的使用步骤 52 // 1.下载 v3.6.5 // 2.引入 // 3.安装注册Vue.use(Vue插件) // 4.创建路由对象 // 5.注入到new Vue中,建立关联…...

【ArcGIS微课1000例】0135:自动生成标识码(长度不变,前面自动加0)
文章目录 一、加载实验数据二、BSM计算方法一、加载实验数据 加载专栏《ArcGIS微课实验1000例(附数据)》配套数据中0135.rar中的建筑物数据,如下图所示: 打开属性表,BSM为数据库中要求的字段:以TD_T 1066-2021《不动产登记数据库标准》为例: 计算出来的BSM如下图: 二、B…...

ISO45001职业健康安全管理体系认证流程
前期准备 领导决策:企业高层领导需认识到实施 ISO 45001 体系的重要性和必要性,做出认证决策,并承诺提供必要的资源支持。成立工作小组:由企业各相关部门人员组成工作小组,明确各成员的职责和分工,确保工作…...

VueRouter路由
单页应用程序:例 网易云 多页应用程序:例 京东 网易云导航栏点击任一网页不会跳转京东导航栏点击任一包括导航区域就会实现网页跳转 路由介绍 VueRouter Vue路由介绍 5个步骤写完之后出现 #/,说明当前Vue实例已经被路由所管理 2个关键步骤 新…...
:需求分析)
性能测试攻略(一):需求分析
性能测试成为软件开发和运维过程中不可或缺的一环。性能测试不仅能够帮助我们了解系统在特定条件下的表现,还能帮助我们发现并解决潜在的性能问题。那么我们怎么做一次完整的性能测试呢?首先,我们需要进行需求分析,来明确我们的测…...

【24年新算法时间序列预测】黑翅鸢BKA优化Transformer时间序列预测(评估指标全,出图多)
本文采用黑翅鸢优化算法( BKA,2024年新算法)优化Transformer模型的超参数,形成了BKA-Transformer时间序列预测模型,以进一步提升其在时间序列预测中的性能,本文采用Matlab编写了BKA-Transformer时间序列预测模型代码,代…...

YOLOv8改进,YOLOv8引入CARAFE轻量级通用上采样算子,助力模型涨点
摘要 CARAFE模块的设计目的是在不增加计算复杂度的情况下,提升特征图的质量,特别是在视频超分辨率任务中,提升图像质量和细节。CARAFE结合了上下文感知机制和聚合特征的能力,通过动态的上下文注意力机制来提升细节恢复的效果。 理论介绍 传统的卷积操作通常依赖于局部区域…...

ZooKeeper节点扩容
新节点的准备工作(这里由hadoop05节点,IP地址为192.168.46.131充当) 配置新节点的主机域名映射,并将其通告给集群中的其他节点配置主机间免密登录关闭防火墙并将其加入到开机不启动项同步hadoop01节点的时间将所需要的文件分发给新…...

深度学习的unfold操作
unfold(展开)是深度学习框架中常见的数据操作。与我们熟悉的卷积类似,unfold也是使用一个特定大小的窗口和步长自左至右、自上至下滑动,不同的是,卷积是滑动后与核求乘积(所以取名为卷积)&#…...

C# 抽奖程序winform示例
C# 抽奖程序winform示例 using System; using System.Collections.Generic; using System.Linq;public class LotterySimulator {private Random random new Random();public List<string> GenerateWinners(int numberOfWinners, int totalParticipants){List<strin…...

嵌入式蓝桥杯学习9 usart串口
复制一下之前ADC的工程,打开cubemx cubemx配置 1.在Connectivity中点击USART1 Mode(模式):Asynchronous(异步模式) 2.将PA9设置为USART1_TX,PA10设置为USART1_RX。 3.配置Parameter Settings. Baud R…...

车载ADB:让汽车更智能的桥梁
随着科技的不断进步,汽车行业也在迅速迈向智能化。车载Android系统(通常称为Android Auto)正在变得越来越流行,而Android Debug Bridge (ADB) 作为连接和调试这些系统的桥梁,也变得尤为重要。在本文中,我们…...

HarmonyOS-高级(一)
文章目录 一次开发、多端部署自由流转 🏡作者主页:点击! 🤖HarmonyOS专栏:点击! ⏰️创作时间:2024年12月09日12点19分 一次开发、多端部署 布局能力 自适应布局 拉伸能力均分能力占比能力缩放…...

【优选算法-滑动窗口】长度最小的子数组、无重复字符的最长子串、最大连续1的个数、将x减为0的最小操作数、水果成篮
一、长度最小的子数组 题目链接: 209. 长度最小的子数组 - 力扣(LeetCode) 题目介绍: 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 子数组 [numsl, numsl1, .…...

Leetcode 每日一题 202.快乐数
目录 题意 算法思路 过题图片 算法实现 代码解析 复杂度分析 题目链接 结论 题意 判断正整数 n 是不是快乐数。 快乐数定义: (1)每次将正整数替换为它每个位置上的数字的平方和。 (2)重复这个过程直到这个数…...

SEC_ASA 第一天作业
拓扑: 实验需求: 注意:在开始作业之前必须先读“前言”,以免踩坑!!!(☞敢点我试试) 按照拓扑图配置VLAN连接。 注意:ASA防火墙的 Gi0/1口需要起子接口&#x…...

Fluss:面向实时分析设计的下一代流存储
摘要:本文整理自阿里云智能 Flink SQL 和数据通道负责人、Apache Flink PMC 伍翀(花名:云邪)老师,在 Flink Forward Asia 2024 主会场的分享。主要分享了一种专为流分析设计的新一代存储解决方案——Fluss,…...

【一本通】质因数分解
【一本通】质因数分解 C语言实现C 语言实现Java语言实现Python语言实现 💐The Begin💐点点关注,收藏不迷路💐 已知正整数n 是两个不同的质数的乘积,试求出较大的那个质数。 输入 输入只有一行,包含一个正…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

Unity中的transform.up
2025年6月8日,周日下午 在Unity中,transform.up是Transform组件的一个属性,表示游戏对象在世界空间中的“上”方向(Y轴正方向),且会随对象旋转动态变化。以下是关键点解析: 基本定义 transfor…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...
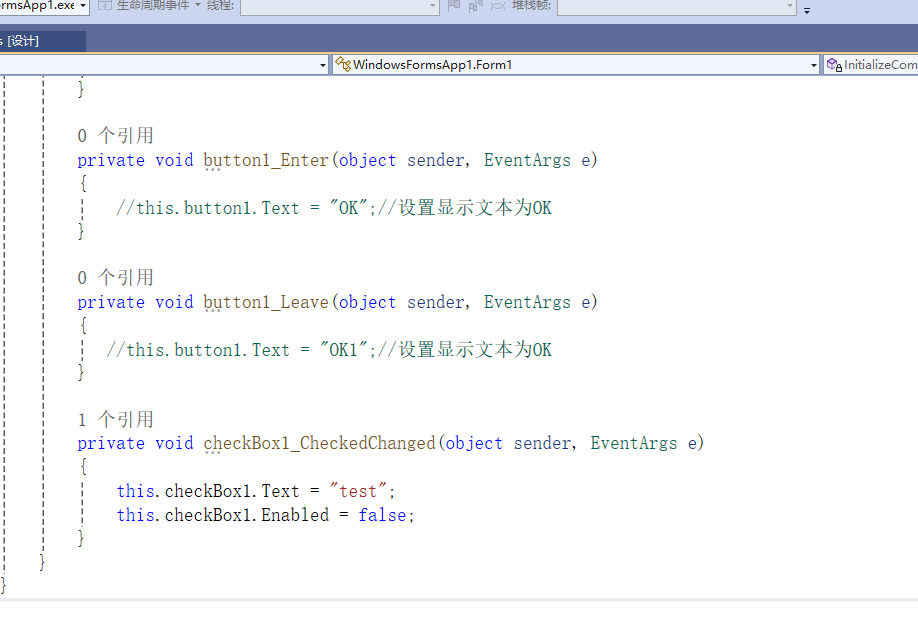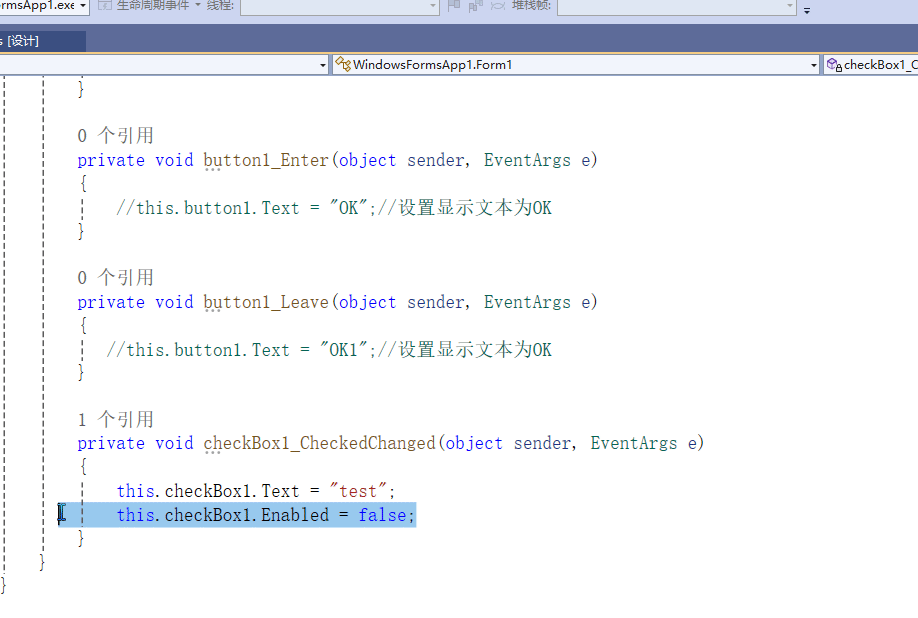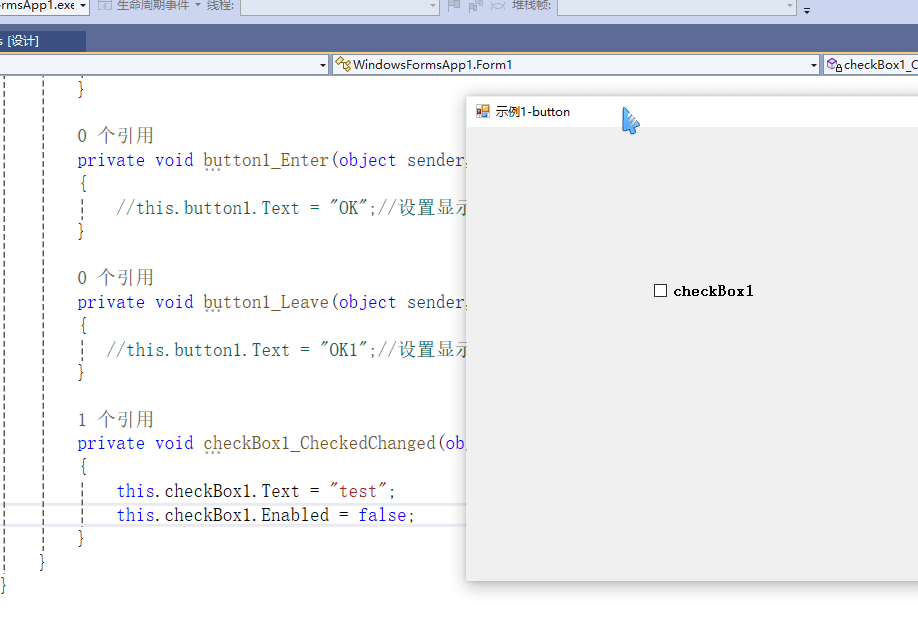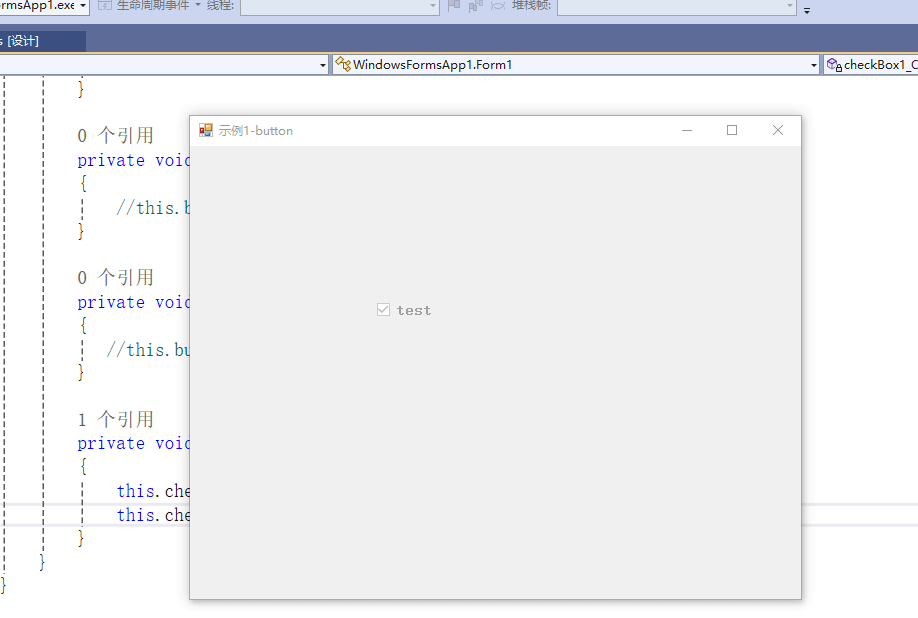
C# winform教程(二)----checkbox
一、作用 提供一个用户选择或者不选的状态,这是一个可以多选的控件。 二、属性 其实功能大差不差,除了特殊的几个外,与button基本相同,所有说几个独有的 checkbox属性 名称内容含义appearance控件外观可以变成按钮形状checkali…...