机器学习详解(4):多层感知机MLP之理论学习
文章目录
- 1 MLP知识引入
- 1.1 深度学习的发展
- 1.2 神经元(Neuron)
- 1.3 感知机(Perception)
- 1.3.1 介绍
- 1.3.2 感知机在二分类中的应用
- 1.3.2.1 理论
- 1.3.2.2 感知机计算实例
- 1.3.3 感知机总结
- 2 MLP(Multilayer Perceptron)
- 2.1 介绍
- 2.2 反向传播
- 2.2.1 实例
- 2.2.2 反向传播计算实例
- 3 总结
多层感知机(MLP) 是一种基础的人工神经网络(
Artificial Neural Network, ANN)结构,主要用于分类和回归任务。它采用
全连接层结构,每一层的所有神经元与下一层的所有神经元相连。由于其能够逼近复杂的非线性映射关系,MLP 成为机器学习模型中的重要组成部分。
1 MLP知识引入
1.1 深度学习的发展
深度学习的核心 是基于人工神经网络的算法,这些算法无需在特征设计和工程阶段依赖领域专家的输入。传统机器学习模型的性能高度依赖于数据质量以及特征的有效性,而深度学习通过自动学习数据的特征来解决这一问题。算法会从数据集中提取模式,并将这些特征组合成更高层次的抽象表示。这种减少人工干预的特性使得深度学习算法能够更快速地适应新数据。
深度学习为何颠覆传统:
- 自动化特征提取:深度学习算法能够自主学习数据的特征,而无需手动设计特征。
- 多层次特征表示:通过多层神经网络结构,深度学习可以从简单到复杂逐层学习数据中的模式和特征。
- 广泛的实际应用:从自动驾驶到语音助手,从人脸识别到语音转文本,深度学习的应用已经深入日常生活。
神经网络的灵感:
神经网络的设计受大脑神经元结构的启发,但并不是对其的精确建模。尽管我们仍然对大脑的工作原理了解有限,但其智能的演化能力为科学研究提供了启示。今天的深度学习不试图复制大脑的工作方式,而是专注于实现能够学习多层模式表示的系统。
历史与发展:
深度学习的进步并非一蹴而就,而是硬件性能提升与数据可用性满足复杂算法计算需求的结果。从最初模仿神经元的简单结构到如今广泛应用的复杂模型,深度学习经历了漫长的探索和发展路径。
结论:
深度学习的快速发展得益于自动化的特征学习能力和多层模式表示的强大功能。
1.2 神经元(Neuron)
神经元的起源
在20世纪40年代,神经生理学家 Warren McCulloch 和逻辑学家 Walter Pitts 合作创建了一个模型,用于模拟大脑的工作方式。他们的模型是一种简单的线性模型,能够根据一组输入值和权重生成正或负的输出,其数学形式为:
f ( x , w ) = x 1 w 1 + x 2 w 2 + ⋯ + x n w n f(x, w) = x_1w_1 + x_2w_2 + \cdots + x_nw_n f(x,w)=x1w1+x2w2+⋯+xnwn
其中:
- x i x_i xi 是输入。
- w i w_i wi 是对应的权重。
- 输出值决定模型的激活情况。
这种计算模型被命名为“神经元”,因为它试图模仿大脑神经元的核心工作机制。类似于大脑神经元接收电信号,McCulloch 和 Pitts 的神经元 通过接收输入信号,并在信号足够强时将其传递给其他神经元。
神经元模型与逻辑门
最早的神经元应用是复制逻辑门的功能,它处理一到两个二进制输入,并使用布尔函数来实现激活。例如:
- 与门 (AND Gate):
x 1 ∧ x 2 当且仅当输入之和 ≥ 2 时激活 x_1 \land x_2 \quad \text{当且仅当输入之和 $\geq 2$ 时激活} x1∧x2当且仅当输入之和 ≥2 时激活 - 或门 (OR Gate):
x 1 ∨ x 2 当输入至少一个为 1 时激活 x_1 \lor x_2 \quad \text{当输入至少一个为 1 时激活} x1∨x2当输入至少一个为 1 时激活

这些逻辑门展示了神经元如何通过简单的权重和阈值实现布尔逻辑操作。
模型的局限性
尽管 McCulloch 和 Pitts 的神经元模型具有创新性,但它存在一个关键问题:它不能像大脑一样“学习”。权重需要提前手动设定,模型无法根据数据自适应地调整参数。
Frank Rosenblatt 的感知机
十年后,Frank Rosenblatt 扩展了 McCulloch 和 Pitts 的神经元模型,提出了一种能够“学习”权重的算法。这种算法通过数据训练来调整权重,从而生成目标输出。这一改进发展出了感知机模型,为神经网络的进一步发展奠定了基础。
1.3 感知机(Perception)
1.3.1 介绍
尽管如今的感知机已经非常成熟,但最初它被设计为一种图像识别机器,其名称来源于人类的感知功能,如感知、识别和分析图像。
感知机的核心思想 是构建一种能够直接从物理环境(如光、声音、温度等)中获取输入,并对其进行处理的机器,而无需人类的干预。感知机基于神经元的计算单元,类似于之前的模型,每个神经元接收一系列输入和权重。
感知机的主要特点
-
加权和与阈值:
在感知机模型中,输入按照权重进行加权求和,当加权和超过预定义的阈值时,神经元会“激活”,产生输出。其数学形式为:
y = { 1 , if ∑ i w i x i − T > 0 0 , otherwise y = \begin{cases} 1, & \text{if } \sum_i w_i x_i - T > 0 \\ 0, & \text{otherwise} \end{cases} y={1,0,if ∑iwixi−T>0otherwise
其中 T T T 是阈值。 -
激活函数:
感知机使用激活函数决定神经元是否激活。最初的感知机使用 阶跃函数 或 Sigmoid 函数,它们将连续的加权和映射到 0 或 1。
1.3.2 感知机在二分类中的应用
1.3.2.1 理论
感知机可以作为一个 二分类模型,通过控制激活函数的输出定义一个线性决策边界。目标是找到一个分隔超平面,最小化误分类点与决策边界之间的距离。其损失函数为:
D ( w , c ) = − ∑ i ∈ M y i ( x i w i + c ) D ( w , c ) = − ∑ i ∈ M y i ( x i w i + c ) D(w, c) = - \sum_{i \in M} y_i (x_i w_i + c)D(w, c) = - \sum_{i \in M} y_i (x_i w_i + c) D(w,c)=−i∈M∑yi(xiwi+c)D(w,c)=−i∈M∑yi(xiwi+c)
其中:
-
M M M 是所有误分类样本的集合。
- 对于正确分类的样本,没有惩罚,也就是它们不会触发权重和偏置的更新。
-
y i y_i yi 是样本的真实标签( 1 1 1 或 − 1 -1 −1), x i x_i xi 是样本的输入值。
-
w w w 是权重, c c c 是偏置。
损失函数的目的是惩罚误分类样本,并通过优化 w w w 和 c c c,使误分类样本尽量减少。
优化方向
感知机通过 随机梯度下降(Stochastic Gradient Descent, SGD) 优化损失函数。如果数据是线性可分的,SGD 保证在有限步数内收敛。通过最小化损失 D ( w , c ) D(w, c) D(w,c),更新参数 w w w 和 c c c,使得误分类被纠正:
-
权重 w w w 和偏置 c c c 将根据误分类样本的贡献进行调整。
-
直到所有样本被正确分类或损失达到最小。
损失函数的核心思想是只惩罚误分类样本,最终通过调整参数找到一个决策边界来正确分类所有数据。
权重和偏执的更新梯度计算
(1)权重
对权重 w w w 的偏导数:
∂ D ∂ w = ∂ ∂ w ( − ∑ i ∈ M y i ⋅ ( x i ⋅ w + c ) ) \frac{\partial D}{\partial w} = \frac{\partial}{\partial w} \left( - \sum_{i \in M} y_i \cdot (x_i \cdot w + c) \right) ∂w∂D=∂w∂(−i∈M∑yi⋅(xi⋅w+c))
展开后:
∂ D ∂ w = − ∑ i ∈ M y i ⋅ ∂ ∂ w ( x i ⋅ w + c ) \frac{\partial D}{\partial w} = - \sum_{i \in M} y_i \cdot \frac{\partial}{\partial w} (x_i \cdot w + c) ∂w∂D=−i∈M∑yi⋅∂w∂(xi⋅w+c)
由于偏置 c c c 与 w w w 无关,忽略它的导数部分,得:
∂ D ∂ w = − ∑ i ∈ M y i ⋅ x i \frac{\partial D}{\partial w} = - \sum_{i \in M} y_i \cdot x_i ∂w∂D=−i∈M∑yi⋅xi
梯度为误分类样本的 y i ⋅ x i y_i \cdot x_i yi⋅xi 之和。
(2)偏置
对偏置 c c c 的偏导数:
∂ D ∂ c = ∂ ∂ c ( − ∑ i ∈ M y i ⋅ ( x i ⋅ w + c ) ) \frac{\partial D}{\partial c} = \frac{\partial}{\partial c} \left( - \sum_{i \in M} y_i \cdot (x_i \cdot w + c) \right) ∂c∂D=∂c∂(−i∈M∑yi⋅(xi⋅w+c))
展开后:
∂ D ∂ c = − ∑ i ∈ M y i ⋅ ∂ ∂ c ( x i ⋅ w + c ) \frac{\partial D}{\partial c} = - \sum_{i \in M} y_i \cdot \frac{\partial}{\partial c} (x_i \cdot w + c) ∂c∂D=−i∈M∑yi⋅∂c∂(xi⋅w+c)
由于 x i ⋅ w x_i \cdot w xi⋅w 与 c c c 无关,其导数为 0,偏置 c c c 的导数为 1,因此:
∂ D ∂ c = − ∑ i ∈ M y i \frac{\partial D}{\partial c} = - \sum_{i \in M} y_i ∂c∂D=−i∈M∑yi
梯度为误分类样本的 y i y_i yi 之和。
(3)权重和偏置的更新公式
利用随机梯度下降(SGD),根据学习率 η \eta η,权重和偏置的更新公式如下:
-
权重 w w w 的更新公式:
w = w + η ⋅ ∑ i ∈ M y i ⋅ x i w = w + \eta \cdot \sum_{i \in M} y_i \cdot x_i w=w+η⋅i∈M∑yi⋅xi -
偏置 c c c 的更新公式:
c = c + η ⋅ ∑ i ∈ M y i c = c + \eta \cdot \sum_{i \in M} y_i c=c+η⋅i∈M∑yi
激活函数
损失函数优化完成后,模型的权重 w w w 和偏置 c c c 用于预测新的样本。激活函数将模型输出值转化为分类结果。
-
Sigmoid 函数:
- 定义为: f ( x ) = 1 1 + e − x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1
- 将任意实数映射到 [ 0 , 1 ] [0, 1] [0,1],使其适合输出概率值。在分类问题中,一般小于0.5为0,大于等于0.5为1。
- Sigmoid 的非线性特性使其在感知机的早期应用中广泛使用。
-
ReLU(修正线性单元):
- 定义为: f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
- ReLU 是近年来深度学习中最常用的激活函数之一。
- 优势:
- 计算高效。
- 避免了 Sigmoid 的梯度消失问题。
- 对输入尺度不敏感(缩放不影响其特性)。

1.3.2.2 感知机计算实例
假设以下数据集用于二分类任务:
| 样本编号 | x i x_i xi | y i y_i yi(真实标签) |
|---|---|---|
| 1 | 2 | 1 |
| 2 | -1 | -1 |
| 3 | 0.5 | -1 |
模型初始参数为:权重 w = 0.5 w = 0.5 w=0.5,偏置 c = − 1 c = -1 c=−1
模型输出计算
计算每个样本的线性输出 z = x i ⋅ w + c z = x_i \cdot w + c z=xi⋅w+c:
| 样本编号 | z = x i ⋅ w + c z = x_i \cdot w + c z=xi⋅w+c |
|---|---|
| 1 | 2 ⋅ 0.5 − 1 = 0 2 \cdot 0.5 - 1 = 0 2⋅0.5−1=0 |
| 2 | − 1 ⋅ 0.5 − 1 = − 1.5 -1 \cdot 0.5 - 1 = -1.5 −1⋅0.5−1=−1.5 |
| 3 | 0.5 ⋅ 0.5 − 1 = − 0.75 0.5 \cdot 0.5 - 1 = -0.75 0.5⋅0.5−1=−0.75 |
激活函数
这里以ReLU激活函数为例,其定义为: f ( z ) = max ( 0 , z ) f(z) = \max(0, z) f(z)=max(0,z)
对上述线性输出应用 ReLU 激活函数,得到:
| 样本编号 | z z z | ReLU 输出 f ( z ) f(z) f(z) |
|---|---|---|
| 1 | 0 0 0 | 0 0 0 |
| 2 | − 1.5 -1.5 −1.5 | 0 0 0 |
| 3 | − 0.75 -0.75 −0.75 | 0 0 0 |
误分类判断
分类规则:
- 对于正类样本( y i = 1 y_i = 1 yi=1): f ( z ) > 0 f(z) > 0 f(z)>0。
- 对于负类样本( y i = − 1 y_i = -1 yi=−1): f ( z ) = 0 f(z) = 0 f(z)=0。
分类结果:
- 样本 1: f ( z ) = 0 f(z) = 0 f(z)=0,但 y 1 = 1 y_1 = 1 y1=1,误分类。
- 样本 2: f ( z ) = 0 f(z) = 0 f(z)=0,符合 y 2 = − 1 y_2 = -1 y2=−1,正确分类。
- 样本 3: f ( z ) = 0 f(z) = 0 f(z)=0,符合 y 3 = − 1 y_3 = -1 y3=−1,正确分类。
误分类样本集合: M = { 1 } M = \{1\} M={1}。
使用随机梯度下降(SGD)更新参数
感知机的损失函数定义为: D ( w , c ) = − ∑ i ∈ M y i ⋅ z D(w, c) = -\sum_{i \in M} y_i \cdot z D(w,c)=−∑i∈Myi⋅z
对权重 w w w 和偏置 c c c 的更新公式为:
- 权重更新: w = w + η ⋅ y i ⋅ x i w = w + \eta \cdot y_i \cdot x_i w=w+η⋅yi⋅xi
- 偏置更新: c = c + η ⋅ y i c = c + \eta \cdot y_i c=c+η⋅yi
设学习率 η = 0.1 \eta = 0.1 η=0.1,对于误分类样本 1:
- 更新权重: w = 0.5 + 0.1 ⋅ 1 ⋅ 2 = 0.5 + 0.2 = 0.7 w = 0.5 + 0.1 \cdot 1 \cdot 2 = 0.5 + 0.2 = 0.7 w=0.5+0.1⋅1⋅2=0.5+0.2=0.7
- 更新偏置: c = − 1 + 0.1 ⋅ 1 = − 1 + 0.1 = − 0.9 c = -1 + 0.1 \cdot 1 = -1 + 0.1 = -0.9 c=−1+0.1⋅1=−1+0.1=−0.9
更新后的模型参数为:
- w = 0.7 w = 0.7 w=0.7
- c = − 0.9 c = -0.9 c=−0.9
重新计算模型输出并分类
使用更新后的参数,重新计算线性输出 z = x i ⋅ w + c z = x_i \cdot w + c z=xi⋅w+c:
| 样本编号 | x i x_i xi | z = x i ⋅ w + c z = x_i \cdot w + c z=xi⋅w+c |
|---|---|---|
| 1 | 2 | 2 ⋅ 0.7 − 0.9 = 0.5 2 \cdot 0.7 - 0.9 = 0.5 2⋅0.7−0.9=0.5 |
| 2 | -1 | − 1 ⋅ 0.7 − 0.9 = − 1.6 -1 \cdot 0.7 - 0.9 = -1.6 −1⋅0.7−0.9=−1.6 |
| 3 | 0.5 | 0.5 ⋅ 0.7 − 0.9 = − 0.55 0.5 \cdot 0.7 - 0.9 = -0.55 0.5⋅0.7−0.9=−0.55 |
对 z z z 应用 ReLU 激活函数:
| 样本编号 | z z z | ReLU 输出 f ( z ) f(z) f(z) |
|---|---|---|
| 1 | 0.5 0.5 0.5 | 0.5 0.5 0.5 |
| 2 | − 1.6 -1.6 −1.6 | 0 0 0 |
| 3 | − 0.55 -0.55 −0.55 | 0 0 0 |
分类结果:
- 样本 1: f ( z ) = 0.5 > 0 f(z) = 0.5 > 0 f(z)=0.5>0,分类为正类,正确分类。
- 样本 2: f ( z ) = 0 f(z) = 0 f(z)=0,分类为负类,正确分类。
- 样本 3: f ( z ) = 0 f(z) = 0 f(z)=0,分类为负类,正确分类。
我们可以发现这个例子中没有激活函数的非线性参与,其更新公式只依赖线性输出 z = x i ⋅ w + c z = x_i \cdot w + c z=xi⋅w+c。在求梯度时,完全由输入值 x i x_i xi 和标签 y i y_i yi 决定,这意味着在感知机模型中没有梯度消失的问题吗?
从计算流程来看,确实没有直接涉及 激活函数的斜率(导数),而是简单地采用了 ReLU 激活函数的值来判断正负输出,从而决定分类结果。上面的例子本质上是在模拟一个感知机的行为,而不是一个典型的 MLP 或深度神经网络中的反向传播过程。
在感知机的流程中,由于激活函数的输出是离散的(如正值或零),参数的更新规则直接基于分类错误的样本,而不是梯度的具体值。这种情况和 MLP 或深度学习中 通过梯度下降法更新权重 的逻辑不同。也就是说,在感知机模型中,梯度消失问题几乎不会出现,因为:感知机的更新规则只依赖于分类错误的样本。每次更新都是直接加减一个学习率乘以样本特征的调整量,没有涉及梯度衰减的问题。但实际上感知机肯定是有梯度消失的问题的。
总结
- 误分类样本触发参数更新:仅误分类样本影响模型的权重和偏置。
- ReLU 的作用:对线性输出进行截断,保留正值,表示神经元激活。
- 优化流程:
- 每次迭代通过 SGD 更新参数,使误分类样本数量逐步减少。
- 最终模型通过 ReLU 激活函数对输出值进行分类,实现正确分类。
1.3.3 感知机总结
感知机接受输入并为每个输入分配一个初始权重。通过计算加权和 z = ∑ x i w i + c z = \sum x_i w_i + c z=∑xiwi+c 后,ReLU 激活函数决定输出值。ReLU 的定义为:
f ( z ) = max ( 0 , z ) f(z) = \max(0, z) f(z)=max(0,z)
感知机使用随机梯度下降(SGD)来优化权重,以最小化误分类点与分类边界之间的距离。一旦 SGD 收敛,数据集将被一个线性超平面分为两个区域。
感知机的局限性
尽管感知机可以表示任意逻辑电路,但它无法表示 XOR 问题(即当输入不同的时候输出为 1)。例如 XOR 问题的输入和输出如下:
- 输入 ( 0 , 0 ) (0, 0) (0,0),输出 0 0 0
- 输入 ( 1 , 1 ) (1, 1) (1,1),输出 0 0 0
- 输入 ( 0 , 1 ) (0, 1) (0,1) 或 ( 1 , 0 ) (1, 0) (1,0),输出 1 1 1
感知机的线性性质导致它无法解决这种非线性问题,即单一感知机无法应用于非线性数据。举一个例子:
| 是否下雨 ( x 1 x_1 x1) | 是否有车 ( x 2 x_2 x2) | 是否需要带伞 ( y y y) |
|---|---|---|
| 0 (不下雨) | 0 (没有车) | 0 (不需要带伞) |
| 0 (不下雨) | 1 (有车) | 0 (不需要带伞) |
| 1 (下雨) | 0 (没有车) | 1 (需要带伞) |
| 1 (下雨) | 1 (有车) | 0 (不需要带伞) |
2 MLP(Multilayer Perceptron)
2.1 介绍
MLP是为了解决单层感知机的局限性而发展起来的。它是一种神经网络,其中输入与输出之间的映射是非线性的。MLP 包括输入层、输出层和一个或多个隐藏层,每个隐藏层由多个神经元堆叠在一起。
在单层感知机中,神经元必须具有一个激活函数(如 ReLU 或 Sigmoid),用于设置阈值。而在 MLP 中,神经元可以使用任意的激活函数。

MLP 属于前馈算法 (Feedforward Algorithms) 的范畴,具体工作过程如下:
- 输入数据与初始权重结合,通过加权和计算出中间值。
- 结果通过激活函数处理(如 ReLU),将线性组合映射到非线性空间。
- 每一层的输出会传递到下一层,逐层传播,直到最终输出层。
这种逐层计算的方式确保每一层都能够基于输入生成更高层次的特征表示,最终输出层得出最终的预测结果。
2.2 反向传播
2.2.1 实例
如果算法仅仅在每个神经元中计算加权和,将结果传播到输出层并停止,模型将无法学习能够最小化损失函数的权重。这种方式不会实际优化模型参数。
反向传播 (Backpropagation) 的引入解决了这个问题:
- 它通过链式法则从输出层向输入层逐层计算梯度。
- 更新每一层的权重,以最小化损失函数,确保模型能够逐渐优化。
反向传播的引入使得 MLP 成为一种功能强大的神经网络,能够在复杂的非线性任务中表现优异。
反向传播是允许多层感知机(MLP)学习的机制。它通过迭代调整网络中的权重,以最小化损失函数的值。
反向传播正常工作的一个关键要求是:神经元中将输入和权重组合的函数(如加权和)和激活函数(如 ReLU)必须是可微分的。这些函数必须具有有界的导数,因为梯度下降(Gradient Descent)通常是 MLP 中的优化方法。

反向传播的步骤
-
前向传播:
- 输入层通过初始权重计算加权和,将结果传递给隐藏层。
- 激活函数应用于隐藏层输出,结果继续传播至输出层。
- 损失函数(如均方误差 MSE)计算预测值与实际值的差异。
-
反向传播:
- 计算损失函数相对于每个权重的梯度。
- 从输出层开始,通过链式法则,将误差逐层传播回去。
- 更新每一层的权重以最小化损失函数。
梯度下降中的权重更新公式
在每次迭代中,通过前向传播计算所有层的加权和后,利用均方误差(Mean Squared Error, MSE)计算损失,并基于损失对所有输入-输出对计算梯度。然后,通过反向传播将梯度从输出层传递回第一个隐藏层,逐层更新权重。
权重的更新公式如下:
Δ w ( t ) = − ϵ d E d w ( t ) + α Δ w ( t − 1 ) \Delta w(t) = -\epsilon \frac{dE}{dw(t)} + \alpha \Delta w(t-1) Δw(t)=−ϵdw(t)dE+αΔw(t−1)
其中:
- Δ w ( t ) \Delta w(t) Δw(t) 表示当前迭代的权重更新值。
- ϵ \epsilon ϵ 表示学习率,用于控制每次更新的步长。
- d E d w ( t ) \frac{dE}{dw(t)} dw(t)dE 表示损失函数 E E E 对权重 w ( t ) w(t) w(t) 的梯度。
- α Δ w ( t − 1 ) \alpha \Delta w(t-1) αΔw(t−1) 是动量项,其中 α \alpha α 是动量系数, Δ w ( t − 1 ) \Delta w(t-1) Δw(t−1) 是上一轮的权重更新值。
更新过程
-
梯度计算:通过均方误差对权重 w ( t ) w(t) w(t) 计算损失函数的偏导数 d E d w ( t ) \frac{dE}{dw(t)} dw(t)dE。
-
动量引入:动量项 α Δ w ( t − 1 ) \alpha \Delta w(t-1) αΔw(t−1) 可以加速梯度下降,特别是在梯度方向变化较小时避免震荡。
-
权重更新:当前权重更新值 Δ w ( t ) \Delta w(t) Δw(t) 是梯度下降和动量的加权组合。
收敛条件
这个过程会持续迭代,直到每对输入-输出的梯度收敛,即新计算的梯度变化小于指定的收敛阈值(convergence threshold)。一旦收敛,网络的权重被优化到能够最小化损失函数的值。
2.2.2 反向传播计算实例
假设我们有以下公式:
z = ( x + y ) × w z = (x + y) \times w z=(x+y)×w
这里,我们有三个变量:x、y 和 w。假设这些变量有如下数值:
- x = 2 x = 2 x=2, y = 3 y = 3 y=3, w = 4 w = 4 w=4
根据公式 z = ( x + y ) × w z = (x + y) \times w z=(x+y)×w,我们可以拆解计算过程:
- 计算 q = x + y q = x + y q=x+y,得到 q = 2 + 3 = 5 q = 2 + 3 = 5 q=2+3=5。
- 计算 z = q × w z = q \times w z=q×w,得到 z = 5 × 4 = 20 z = 5 \times 4 = 20 z=5×4=20。
问题:如何计算每个变量对输出 z z z 的影响?
假设我们想知道,如果 x、y 或 w 的值发生一点变化,输出 z 会受到多大影响。这就是 梯度 的作用,反向传播可以帮助我们计算这些梯度。
反向传播
反向传播的目标是计算每个变量的梯度,即:
- ∂ z ∂ x \frac{\partial z}{\partial x} ∂x∂z:
x对z的影响; ∂ z ∂ y \frac{\partial z}{\partial y} ∂y∂z:y对z的影响; ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z:w对z的影响
我们使用 链式法则(Chain Rule)从输出 z 逐步回溯计算每个变量的梯度。
具体计算步骤
(1)计算 ∂ z ∂ q \frac{\partial z}{\partial q} ∂q∂z
因为 z = q × w z = q \times w z=q×w,对 q 求偏导数:
∂ z ∂ q = w = 4 \frac{\partial z}{\partial q} = w = 4 ∂q∂z=w=4
这表示 q 每增加 1,z 将增加 4。
(2)计算 ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z
继续计算 w 对 z 的影响,因为 z = q × w z = q \times w z=q×w,对 w 求偏导数:
∂ z ∂ w = q = 5 \frac{\partial z}{\partial w} = q = 5 ∂w∂z=q=5
这表示 w 每增加 1,z 将增加 5。
(3)计算 ∂ z ∂ x \frac{\partial z}{\partial x} ∂x∂z 和 ∂ z ∂ y \frac{\partial z}{\partial y} ∂y∂z
因为 q = x + y q = x + y q=x+y,我们可以对 x 和 y 分别求偏导数:
∂ q ∂ x = 1 \frac{\partial q}{\partial x} = 1 ∂x∂q=1
∂ q ∂ y = 1 \frac{\partial q}{\partial y} = 1 ∂y∂q=1
接着利用链式法则,我们可以得到 x 和 y 对 z 的影响:
∂ z ∂ x = ∂ z ∂ q × ∂ q ∂ x = 4 × 1 = 4 \frac{\partial z}{\partial x} = \frac{\partial z}{\partial q} \times \frac{\partial q}{\partial x} = 4 \times 1 = 4 ∂x∂z=∂q∂z×∂x∂q=4×1=4
∂ z ∂ y = ∂ z ∂ q × ∂ q ∂ y = 4 × 1 = 4 \frac{\partial z}{\partial y} = \frac{\partial z}{\partial q} \times \frac{\partial q}{\partial y} = 4 \times 1 = 4 ∂y∂z=∂q∂z×∂y∂q=4×1=4
通过反向传播,我们得到了每个变量的梯度:
- ∂ z ∂ x = 4 \frac{\partial z}{\partial x} = 4 ∂x∂z=4, ∂ z ∂ y = 4 \frac{\partial z}{\partial y} = 4 ∂y∂z=4, ∂ z ∂ w = 5 \frac{\partial z}{\partial w} = 5 ∂w∂z=5
这些梯度告诉我们:
x和y每增加 1,z会增加 4。w每增加 1,z会增加 5。
反向传播的意义
- 反向传播帮助我们计算每个变量的梯度,这是优化模型参数的关键。
- 通过梯度,我们知道如何调整
x、y和w来增加或减少z。
反向传播是从输出开始回溯,逐层计算每个变量对最终输出的影响(梯度)。在深度学习中,这一过程用于计算模型参数的梯度,从而更新模型的权重,以最小化损失函数并提高模型的预测准确性
- 注意:直接对各个变量求导非常复杂,这里通过链式法则一步步计算各个变量的梯度,确保了梯度的计算可以复用中间结果,提高了计算效率,特别是对于深度神经网络而言
3 总结
MLP(多层感知机)是一种前馈神经网络,由输入层、一个或多个隐藏层和输出层组成。与单层感知机相比,MLP 通过引入非线性激活函数(如 ReLU、Sigmoid)和隐藏层,可以捕捉复杂的非线性关系,从而解决感知机无法处理的问题(例如 XOR 问题)。其主要优点包括:
- 表达能力强:能够拟合任意复杂的非线性函数。
- 自动特征提取:隐藏层通过学习数据的隐含模式,实现对输入的多层次表示。
- 灵活性:可扩展多个隐藏层和神经元,适应不同任务需求。
下一篇文章中,我们将通过一个实际的 MLP 代码例子,深入学习如何实现 MLP 解决实际问题的完整过程。
相关文章:
机器学习详解(4):多层感知机MLP之理论学习
文章目录 1 MLP知识引入1.1 深度学习的发展1.2 神经元(Neuron)1.3 感知机(Perception)1.3.1 介绍1.3.2 感知机在二分类中的应用1.3.2.1 理论1.3.2.2 感知机计算实例 1.3.3 感知机总结 2 MLP(Multilayer Perceptron)2.1 介绍2.2 反向传播2.2.1 实例2.2.2 反向传播计算实例 3 总结…...

【C++】类中的特殊成员——静态成员,友元成员,常量成员
下图为笔者根据自己的理解做的图,仅供参考~ 文章目录 一.静态成员static*类外 1.1静态数据成员1.2静态函数成员*不同属性下的静态成员 1.3局部静态(Local Static) 二.常量成员2.1常量数据成员2.2常量函数成员2.3常量对象 三.友元成员3.1友元函数3.2友元类友元的特…...
开源 Agent 小屋
知乎:何枝地址:https://zhuanlan.zhihu.com/p/9096314010 Live Demo(网站在进入前可能会加载一段时间,需要等一等) 人物观测:Agent Life Live Demo[1] 行为统计:Agent Life Action Logging Bo…...

Mina之账户模型
为了能真正提升自己的能力,而不是机械低效的Ctrl C / Ctrl V,先从基本概念入手,利用ChatGPT来弄懂Mina。 Mina Mina Protocol 是一种轻量级区块链,被称为“世界上最轻的区块链”。其目标是通过极小的链上数据大小和强大的隐私…...

STM32 ADC 配置
ADC(模数转换器)用于将模拟信号转换为数字信号,以便单片机处理。 模数转换器(Analog-to-Digital Converter, ADC)是电子系统中不可或缺的一部分,它负责将现实世界中的连续物理量,如温度、声音、…...
练9:进制转换
欢迎大家订阅【蓝桥杯Python每日一练】 专栏,开启你的 Python数据结构与算法 学习之旅! 文章目录 1 进制转换2 例题分析 1 进制转换 ①任意制转为十进制 【示例】 ②十进制转为任意制 【法一】 【法二】 2 例题分析 题目地址:https:/…...

善于运用指针--函数与指针
文章目录 前言一、函数的指针二、函数指针运用 1函数名地址2指针变量调用函数3指向函数的指针变量做函数参数二、返回指针值的函数总结 前言 如果在程序中定义了一个函数,在编译时会把函数的源代码转换为可执行代码并分配一段空间。这段空间有一个起始地址…...

Microi吾码低代码平台:前端源码的本地运行探索
文章目录 1.前端源码运行环境要求1.1 操作系统1.2 必备软件工具1.3 项目源码依赖 2.从Git仓库克隆前端源码3.安装项目依赖4.启动本地开发服务器5.常见问题与解决方案5.1 依赖安装失败5.2 端口冲突5.3 代码更新未生效 6.提升本地开发体验的技巧6.1 使用代理解决跨域问题6.2 集成…...

十一、容器化 vs 虚拟化-Docker 使用
文章目录 前言一、Docker Hello World二、Docker 容器使用三、Docker 镜像使用四、Docker 容器连接五、Docker 仓库管理六、Docker Dockerfile七、Docker Compose八、Docker Machine九、Swarm 集群管理 前言 Docker 使用 Docker 容器使用、镜像使用、容器连接、仓库管理、Do…...

实践项目2-自动计价电子秤
自动计价电子秤 一、功能说明 基于AVR单片机设计一自动计价电子秤。根据输入的价格以及检测的重量自动计算总价并打印(串口模拟)。 二、具体要求 1、开机后实时检测重量并显示; 2、通过按键输入并显示价格,具有修改功能&#…...

iOS如何操作更新推送证书
最近收到一份邮件,应该如何操作呢,证书还是跟以前一样冲钥匙串直接申请吗 Hello, As we announced in October, the Certification Authority (CA) for Apple Push Notification service (APNs) is changing. APNs will update the server certificates in sandbox on January…...
WSL2 在vscode无法连接copilot
报错情况: 本机可以使用copilot,但在WSL2上无法连接,报错信息如下: 检查网络情况: ping api.github.com 发现无法连接: github.com:Temporary failure in name resolution 在网上搜集的解决方法&#…...
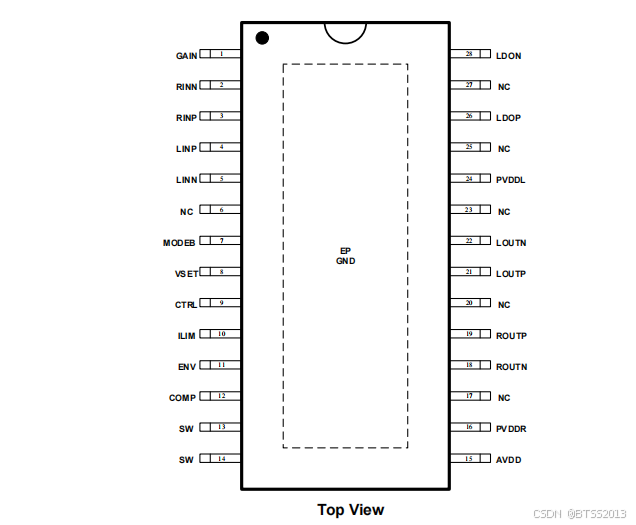
HTA8998 实时音频跟踪的高效内置升压2x10W免电感立体声ABID类音频功放
1、特征 输出功率(fIN1kHz,RL4Ω,BTL) VBAT 4V, 2x10.6W(VOUT9V,THDN10%) VBAT 4V, 2x8.6W (VOUT9V,THDN1%) 内置升压电路模式可选择:自适应实时音频跟踪 升压(可提升播放时间50%以上)、强制升压 最大升压值可选择,升压限流值可设置 ACF防破音功能 D类…...
用ChatGPT-o1进行论文内容润色效果怎么样?
目录 1.引导问题发现 2.角色设定 3.整理常问修改 4.提供样例 5.小细节 小编在这篇文章中分享如何充分利用ChatGPT-o1-preview来提升论文润色的技巧。小编将持续跟进最新资源和最新的调研尝试结果,为宝子们补充更多实用的写作技巧。这些技巧将有助于您更有效地利…...

《探索 Jetpack Compose:构建现代化 Android UI 的利器》
Jetpack Compose 是谷歌推出的现代化 UI 框架,用于简化 Android 应用开发中的 UI 构建。它使用声明式编程方式,允许开发者以简洁直观的方式创建动态和响应式的 UI。本文将从基础概念到进阶用法,带你全面了解 Compose 的核心功能和使用技巧。 …...

cocos creator 的 widget组件的使用及踩坑
以下的内容基于cocos creator 3.8版本,如有错误,恳请指出。 👉官方文档的指引 应用:以上官方指引有非常清晰的使用方式,接下来说明一些注意事项: 1、与canvas搭配的使用,解决多分别率适配问题。…...
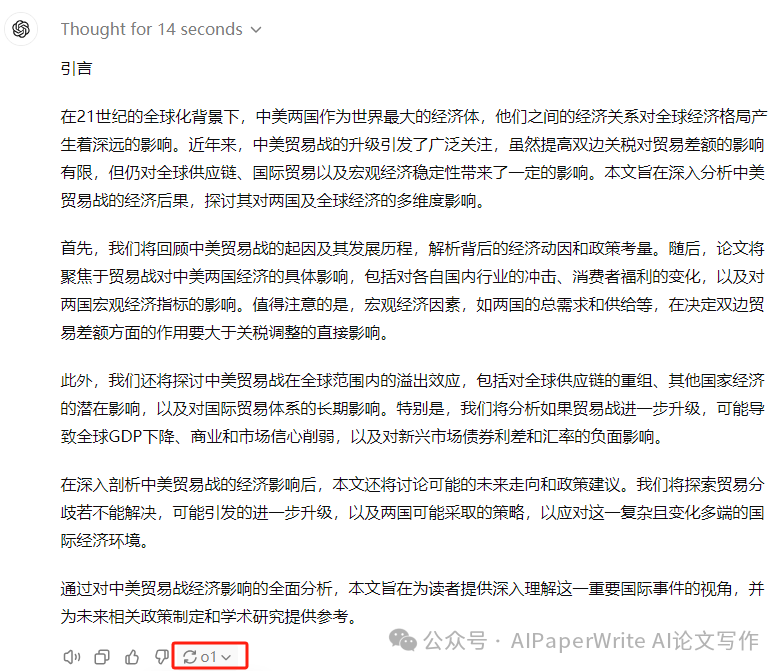
Baumer工业相机的EMVA1288 数据报告简介
项目场景: Baumer工业相机堡盟VCX系列和VLX系列为堡盟全系列相机中的主流常用相机和高端相机,性能强大、坚固可靠,易于集成,常用与一般行业的检测定位识别使用。 对应的高端相机系列具有极为丰富的强大技术功能,可轻…...
Docker 安装 中文版 GitLab
Docker 安装系列 安装GitLab、解决服务器内存不足问题、使用域名/IP地址访问项目 1、拉取 [rootTseng ~]# docker pull twang2218/gitlab-ce-zh:latest latest: Pulling from twang2218/gitlab-ce-zh 8ee29e426c26: Pull complete 6e83b260b73b: Pull complete e26b65fd11…...
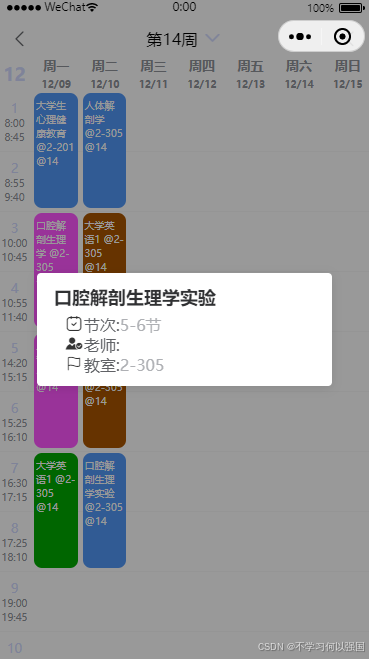
uni-app 个人课程表页面
uni-app 个人课程表页面 插件参考地址 大部分代码都是参考了上述代码,只对代码做出了优化 1. 页面模板 在 schedule.vue 文件中,编写页面结构: <template><view><u-navbar title"个人中心"><view class&q…...
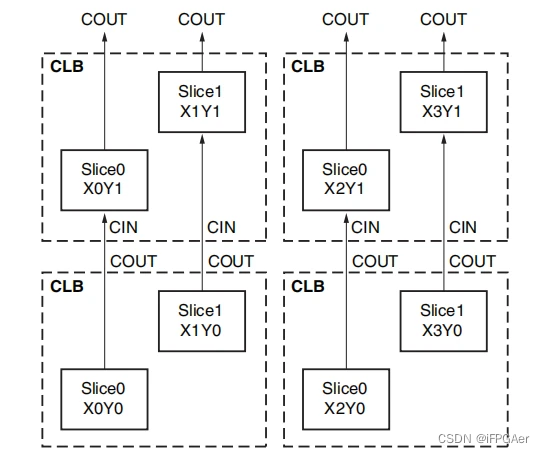
FPGA工作原理、架构及底层资源
FPGA工作原理、架构及底层资源 文章目录 FPGA工作原理、架构及底层资源前言一、FPGA工作原理二、FPGA架构及底层资源 1.FPGA架构2.FPGA底层资源 2.1可编程输入/输出单元简称(IOB)2.2可配置逻辑块2.3丰富的布线资源2.4数字时钟管理模块(DCM)2.5嵌入式块 …...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...