机器学习02-发展历史补充
机器学习02-发展历史补充
文章目录
- 机器学习02-发展历史补充
- 1-机器学习个人理解
- 1-初始阶段:统计学习和模式识别(20世纪50年代至80年代)
- 2-第二阶段【集成时代】+【核方法】(20世纪90年代至2000年代初期)
- 3-第三阶段【特征工程】+【模型优化】(2000年代中期至2010年代初期)
- 4-大规模数据和分布式计算(2010年代中后期)
- 5-自动化机器学习和特征选择(2010年代末至今)
- 2-神经网络为什么会出现,是什么引发了神经网络的出现
- 1. **生物学的启发**
- 2. **计算能力的提升**
- 3. **算法和理论的进步**
- 4. **应用需求的推动**
- 5. **研究社区的活跃**
- 6. **商业和工业界的应用**
- 3-【神经网络】如何修正【感知机】缺陷
- 1. **多层结构**
- 2. **激活函数**
- 3. **梯度下降优化**
- 4. **损失函数**
- 5. **正则化技术**
- 6. **模型复杂度和灵活性**
- 7. **泛化能力**
- 8. **并行计算**
- 总结
- 4-决策树和图算法的发展历史比较
- 1. **起源和发展**
- 决策树
- 图算法
- 2. **理论与技术进步**
- 决策树
- 图算法
- 3. **应用领域**
- 决策树
- 图算法
- 4. **未来发展趋势**
- 决策树
- 图算法
- 总结
- 5-在神经网络快速发展的时代,为什么会出现决策树算法,对比神经网络有什么优点
- 1. **可解释性**
- 2. **处理非数值数据**
- 3. **计算效率**
- 4. **模型复杂度**
- 5. **特征选择**
- 6. **适用场景**
- 7. **集成学习**
- 8. **易于实现**
- 总结
- 6-有了神经网络和决策树,为什么还会出现SVM算法,SVM在当时解决了什么问题
- 1. **解决高维数据问题**
- 2. **优化问题和理论基础**
- 3. **处理小样本问题**
- 4. **鲁棒性强**
- 5. **核技巧的应用**
- 6. **多类别分类**
- 7. **理论支持**
- 8. **实际应用**
- 总结
- 7-SVM的技术想法听起来太疯狂了,为什么SVM会被科学采用
- 1. **理论基础坚实**
- 2. **解决高维数据问题**
- 3. **处理小样本问题**
- 4. **鲁棒性强**
- 5. **实际应用效果好**
- 6. **易于实现和扩展**
- 7. **与其他技术的结合**
- 8. **开源社区的支持**
- 总结
- 8-梯度提升机(Gradient Boosting Machines, GBM) 和 线性回归和逻辑回归 在模型的能力提升上分别起到了什么作用
- 梯度提升机 (Gradient Boosting Machines, GBM)
- 线性回归和逻辑回归
- 总结
- 9-补充历史年份
1-机器学习个人理解
-
Kimi搜索逻辑:https://kimi.moonshot.cn/chat/ctcn3v2v7p5nha6g8840
-
大佬知乎专栏:https://zhuanlan.zhihu.com/p/48520746?from_voters_page=true
1-初始阶段:统计学习和模式识别(20世纪50年代至80年代)

- 1)【1936年图灵机概念】认为机器可以解决世界上所有的计算问题->引发人们对图灵机的试探
- 2)但是人们只做出了【专家系统】->只能解决逻辑推理问题->导致【天下苦专家系统久已】
- 3)【感知机】发明认为是一次【图灵机】的完美尝试->但是存在缺陷,不具备完备性
- 4)【神经网络】修正了【感知机】缺陷->但是【单层的神经网络计算有限】->后面在一次比赛中有个大佬用了【多层神经网络】又给了这个世界灵感
- 5)【神经网络大行其道】但是不可解释,于是有些学者针对可解释性,还是继续研究基础数学研究出【决策树】->决策树在缺失值/训练时间段/可解释性/特征选择上都有较好表现
类比物理界在最初研究【光的波粒二象性】或者【量子力学】一样,不同学派的人都是在求索,但都不能让彼此信服,现在的我们只是接纳了这个和而不同的概念
- 6)【决策树】的成功对【基础数学】研究还是带来了【希望】,人们也愿意沉下心来继续研究【基础数学】->但是【决策树】带了一个计算问题【维度爆炸】->如果能够解决【维度爆炸】问题就就会让【基础数学】注入新的灵魂
- 7)【SVM】只选择一个数据丢弃其他数据,认为可以用线性解决分类问题->这个想法也是足够大胆,经过科学验证貌似真的还可以->确实解决了【维度爆炸问题】
SVM的技术想法听起来太疯狂了:(人有多大胆,地有多大产)
1)分类问题只找一个数据即可,其他数据都不用管可以直接丢弃
2)平面内所有的分类问题都可以用一条1维线性直线解决
3)高维内所有的分类问题都可以用一条高维线性平面解决
2-第二阶段【集成时代】+【核方法】(20世纪90年代至2000年代初期)
- 9)此后从【统计时代】进入【第二阶段【集成时代】+【核方法】】->因为【算力】和【数据】不够,人们在琢磨怎么让已经训练的模型更准确->基础想法【三个臭皮匠,顶个诸葛亮】
- 10)【集成时代】->先后出现了【AdaBoost】+【随机森林】
- 11)【核方法】->【SVM】最开始只能解决【维度爆炸问题】并假设【二维线性可分】->因为简单高效被大家给予厚望->【SVM】更大胆宣布自己可以处理高维线性可分
3-第三阶段【特征工程】+【模型优化】(2000年代中期至2010年代初期)
- 12)在【基础数学】+【神经网络】的快速推进下,越来越多的应用诞生->但是【数据预处理】还是没有太多经验(甚至没有归一化理论),【模型性能】在单个/集成表现时依然有存在很大瓶颈
- 13)于是【特征工程】方面->强调数据预处理:数据选择和处理特征
- 14)于是【模型性能】方面->【梯度提升机集成】+【对数几率曲线+线性回归】->【西瓜书的开篇讲的就是线性回归,引出的对数几率曲线】->正式将机器学习从【回归】带入【分类】世界
- 15)线性回归和逻辑回归所属的【基础数学】再次伟大
【模型性能】方面优化想法:
- 梯度提升机(Gradient Boosting Machines, GBM):由Jerome Friedman在2001年提出,通过迭代优化损失函数来提升模型性能。
- 线性回归:不同与SVM直接丢弃数据,使用发际线高度进行计算误差
- 逻辑回归:将[-∞,+∞]概率分布纳入[0,1],后续进一步优化和推广,广泛应用于回归和分类任务。
4-大规模数据和分布式计算(2010年代中后期)
- 【集成方法】势大利好,大家纷纷对GBM进行优化
- XGBoost:由Tianqi Chen在2014年提出,是GBM的优化版本,适合大规模数据和分布式计算。
- LightGBM和CatBoost:分别由微软和Yandex在2017年提出,进一步优化了GBM的性能和速度。
5-自动化机器学习和特征选择(2010年代末至今)
- 【机器学习】越来越成熟和商业化,为了让更多人入局,把技术门槛降低->【自动模型选择】+【自动超参数优化】+【自动特征工程】
- AutoML:自动化机器学习工具如Auto-sklearn和TPOT,通过自动化模型选择、超参数优化和特征工程,简化了机器学习流程。
- 特征选择算法:如LASSO(Least Absolute Shrinkage and Selection Operator)和RFECV(Recursive Feature Elimination with Cross-Validation),通过自动选择重要特征提升模型性能
2-神经网络为什么会出现,是什么引发了神经网络的出现
神经网络的出现和发展可以追溯到多个历史时期和多方面的推动因素。以下是一些关键原因和背景:
1. 生物学的启发
- 大脑结构:神经网络的概念最早受到生物神经系统结构的启发。人类大脑中的神经元通过复杂的连接进行信息处理和传递,这种并行的、分布式的计算方式启发了科学家们设计类似结构的计算模型。
- 感知机:1950年代,Frank Rosenblatt提出了感知机(Perceptron),这是一种简单的神经网络模型,旨在模仿生物神经元的功能。
2. 计算能力的提升
- 硬件发展:随着计算机硬件的发展,尤其是图形处理单元(GPU)的出现,使得并行计算能力大幅提升。这些硬件加速了神经网络的训练和推理过程,使其从理论变为实践。
- 大数据:现代数据量的爆炸性增长为神经网络提供了大量的训练数据,使得复杂的模型可以从数据中学习到更深层的特征和模式。
3. 算法和理论的进步
- 反向传播算法:1980年代,反向传播算法被广泛应用于神经网络的训练中,极大地提高了网络的学习能力。反向传播算法通过计算误差的梯度来调整网络权重,从而优化网络性能。
- 深度学习:多层的神经网络结构(深度学习)的出现,使得模型能够捕捉到更复杂的层次结构和抽象特征,显著提升了模型的表现能力。
4. 应用需求的推动
- 模式识别:在语音识别、图像识别等领域,传统的算法在处理复杂的非线性问题时表现不佳。神经网络由于其非线性的特性,在这些领域表现出色。
- 自然语言处理:随着互联网的发展,大量的文本数据需要处理。神经网络,尤其是循环神经网络(RNN)和后来的Transformer模型,在自然语言处理任务中表现优异。
5. 研究社区的活跃
- 开源文化和科研合作:开源软件和开放的数据集促进了研究社区的交流与合作。许多研究人员共享他们的代码和数据,加速了神经网络研究的进展。
- 学术会议和期刊:定期的学术会议(如NeurIPS、ICML等)和期刊(如《Journal of Machine Learning Research》)为神经网络的研究提供了交流和展示的平台。
6. 商业和工业界的应用
- 商业驱动:随着神经网络在视觉识别、语音识别等领域的成功应用,越来越多的公司开始投资于神经网络技术的研发,推动了该领域的快速发展。
- 实际应用:从自动驾驶到医疗诊断,神经网络在多个领域展示了其强大的应用潜力,进一步推动了研究和技术的进步。
总的来说,神经网络的出现和发展是多方面因素共同作用的结果,包括生物学启发、计算能力的提升、算法和理论的进步、应用需求的推动、研究社区的活跃以及商业和工业界的应用。这些因素共同促成了神经网络成为现代人工智能领域中最具影响力的技术之一。
3-【神经网络】如何修正【感知机】缺陷
神经网络在一定程度上修正了感知机(Perceptron)的缺陷,主要通过以下几个方面:
1. 多层结构
- 单层感知机的局限:单层感知机只能解决线性可分问题,对于非线性可分问题无能为力。单层感知机的决策边界是线性的,无法处理复杂的分类任务。
- 多层神经网络:神经网络通过引入多层结构(即隐层),能够学习和表示复杂的非线性关系。每层中的神经元可以捕捉不同层次的特征,从而使得模型能够处理非线性可分问题。
2. 激活函数
- 阈值函数:感知机使用的是阈值函数(如阶跃函数),这种函数在实际应用中容易导致梯度消失问题,使得模型难以优化。
- 非线性激活函数:神经网络使用了多种非线性激活函数(如sigmoid、ReLU、tanh等),这些激活函数不仅能够引入非线性,还能够在训练过程中提供更平滑的梯度,从而提高模型的训练效果和泛化能力。
3. 梯度下降优化
- 感知机的更新规则:感知机使用的是基于误分类的更新规则,这种规则在某些情况下可能导致模型收敛缓慢或陷入局部最优。
- 梯度下降:神经网络通过梯度下降(或其变种,如随机梯度下降、Adam等)来优化模型参数。梯度下降算法能够计算损失函数对模型参数的梯度,并根据梯度更新参数,使得模型逐渐逼近全局最优解。
4. 损失函数
- 感知机的损失函数:感知机的损失函数是基于误分类样本的,这种损失函数在优化过程中可能存在不稳定性。
- 多样的损失函数:神经网络可以使用多种损失函数,如均方误差(MSE)、交叉熵损失等。这些损失函数能够提供更稳定的梯度,使得模型在训练过程中更加平稳和高效。
5. 正则化技术
- 过拟合问题:感知机在处理复杂问题时容易过拟合,尤其是在数据量不足的情况下。
- 正则化:神经网络通过引入正则化技术(如L1正则化、L2正则化、Dropout等),能够有效地控制模型的复杂度,防止过拟合,提高模型的泛化能力。
6. 模型复杂度和灵活性
- 固定结构:感知机的结构相对固定,通常只有一个输入层和一个输出层,缺乏灵活的中间层来捕捉复杂特征。
- 灵活的网络结构:神经网络具有更灵活的结构,可以设计不同层数、不同神经元数量的网络结构,以适应不同复杂度的任务。这种灵活性使得神经网络能够处理从简单到复杂的各种问题。
7. 泛化能力
- 泛化能力:感知机在处理复杂问题时泛化能力较弱,通过多层结构和非线性激活函数,神经网络能够更好地学习数据中的潜在模式,从而提高泛化能力。
8. 并行计算
- 计算效率:神经网络的多层结构和大规模参数需要高效的计算资源。现代神经网络通常在GPU上进行训练,利用并行计算能力大大提高训练速度。
总结
神经网络通过引入多层结构、非线性激活函数、梯度下降优化、多样的损失函数、正则化技术、灵活的网络结构和并行计算等方法,修正了感知机在处理非线性问题、过拟合、模型复杂度等方面的缺陷。这些改进使得神经网络在处理复杂任务时表现更加出色,成为现代机器学习和深度学习的重要基础。
4-决策树和图算法的发展历史比较
决策树和图算法是两种在计算机科学和数据科学领域中非常重要的算法类型,它们各自有着独特的发展历史和应用场景。以下是对这两种算法发展历史的比较:
1. 起源和发展
决策树
- 起源:决策树的概念最早可以追溯到1960年代。1966年,Hunt等人提出了概念学习系统(Concept Learning System, CLS),这是决策树的早期形式。
- 关键发展:
- ID3算法(1986年):由Ross Quinlan提出,ID3(Iterative Dichotomiser 3)算法是第一个广泛使用的决策树算法,它使用信息增益作为属性选择的标准。
- C4.5算法(1993年):也是由Ross Quinlan提出,C4.5是ID3的改进版本,支持处理连续属性、缺失值,并引入了剪枝技术来减少过拟合。
- CART算法(1984年):由Leo Breiman等人提出,CART(Classification and Regression Trees)算法支持分类和回归任务,使用基尼系数作为属性选择的标准。
- 应用:决策树广泛应用于分类和回归任务,如信用评分、医疗诊断、市场细分等。
图算法
- 起源:图算法的历史可以追溯到1950年代和1960年代,最早的图算法主要用于解决图论中的经典问题,如最短路径、最小生成树等。
- 关键发展:
- Dijkstra算法(1959年):由Edsger Dijkstra提出,用于计算单源最短路径。
- Kruskal算法(1956年):由Joseph Kruskal提出,用于计算最小生成树。
- Prim算法(1957年):由Robert Prim提出,也是用于计算最小生成树。
- Floyd-Warshall算法(1962年):由Robert Floyd和Stephen Warshall提出,用于计算所有节点对之间的最短路径。
- 应用:图算法广泛应用于网络分析、路径规划、社交网络分析、推荐系统等。
2. 理论与技术进步
决策树
- 理论进步:决策树的理论基础主要围绕信息论和统计学习理论。信息增益、基尼系数等概念是决策树算法的核心。
- 技术进步:随着机器学习的发展,决策树算法逐渐与其他技术结合,如随机森林、梯度提升树(GBDT)等集成学习方法,进一步提升了模型的性能。
图算法
- 理论进步:图算法的理论基础主要来自图论和组合优化。图算法的研究涉及图的表示、遍历、搜索、最优化等问题。
- 技术进步:随着计算能力的提升,图算法逐渐应用于大规模图数据处理,如分布式图计算框架(如Apache Giraph、GraphX)和图神经网络(GNN)等新兴技术。
3. 应用领域
决策树
- 分类与回归:决策树主要用于分类和回归任务,如信用评分、医疗诊断、市场细分等。
- 集成学习:决策树常用于集成学习方法中,如随机森林、梯度提升树等,这些方法在许多机器学习竞赛中表现优异。
图算法
- 网络分析:图算法广泛应用于社交网络分析、网络流量分析、推荐系统等。
- 路径规划:图算法在路径规划、物流优化、交通管理等领域有重要应用。
- 图神经网络:近年来,图神经网络(GNN)成为研究热点,广泛应用于化学分子分析、知识图谱、推荐系统等。
4. 未来发展趋势
决策树
- 自动化机器学习(AutoML):随着AutoML技术的发展,决策树的自动调参和模型选择将成为可能,进一步简化模型构建过程。
- 深度学习结合:决策树与深度学习的结合,如深度森林(Deep Forest)等,可能会带来新的研究方向和应用场景。
图算法
- 大规模图计算:随着图数据规模的不断增长,大规模图计算和分布式图处理技术将继续发展。
- 图神经网络:图神经网络(GNN)在多个领域的成功应用将推动其进一步发展,尤其是在知识图谱、推荐系统、化学分子分析等领域。
总结
决策树和图算法在各自的发展历史中都经历了从理论到实践的演进过程。决策树主要用于分类和回归任务,其发展受到信息论和统计学习理论的推动;而图算法则主要用于图论中的经典问题和大规模图数据处理,其发展受到图论和组合优化理论的推动。两者在应用领域和技术进步方面各有特色,未来都将继续在各自的应用场景中发挥重要作用。
5-在神经网络快速发展的时代,为什么会出现决策树算法,对比神经网络有什么优点
在神经网络快速发展的时代,决策树算法依然保持着重要的地位,这是由于决策树在某些方面具有独特的优势。以下是决策树相对神经网络的主要优点:
1. 可解释性
- 透明性:决策树的结构非常直观,可以通过树的分支和节点直接理解模型的决策过程。每个节点上的决策规则清晰可见,这使得决策树模型具有很高的可解释性。
- 易于理解:决策树的规则通常以“如果…则…”的形式呈现,这种规则易于理解和解释,适合对模型解释性要求较高的应用场景,如医疗诊断、信用评分等。
2. 处理非数值数据
- 分类数据:决策树能够直接处理分类数据,无需进行额外的编码或转换。这使得决策树在处理混合数据类型(数值和分类数据)时更加灵活。
- 缺失数据:决策树通常能够处理缺失数据,可以通过不同的策略(如使用多数表决、插补等)来处理缺失值,而不需要预处理数据。
3. 计算效率
- 训练时间:相对于复杂的神经网络,决策树的训练时间通常较短。特别是在数据集较小或中等规模时,决策树的训练速度明显快于深度学习模型。
- 预测时间:决策树的预测过程也非常快,因为它只需要遍历树的分支即可得出结果,适用于实时预测的场景。
4. 模型复杂度
- 简单模型:决策树模型通常较为简单,不需要大量的计算资源和存储空间。这使得决策树在资源受限的环境中(如嵌入式设备、移动设备)依然能够有效运行。
- 过拟合控制:通过剪枝等技术,决策树可以有效控制过拟合问题,提高模型的泛化能力。
5. 特征选择
- 特征重要性:决策树能够提供特征重要性的评估,帮助用户了解哪些特征对预测结果影响最大。这对于特征选择和数据理解非常重要。
- 自动特征选择:在构建决策树的过程中,算法会自动选择最显著的特征进行分割,简化了特征工程的步骤。
6. 适用场景
- 小规模数据集:在数据集较小的情况下,神经网络可能由于数据不足而表现不佳,而决策树则能更有效地利用有限的数据进行建模。
- 非线性关系:决策树能够捕捉数据中的非线性关系,适用于那些复杂的、非线性的分类和回归任务。
7. 集成学习
- 随机森林:决策树可以与其他决策树结合,形成随机森林等集成学习模型,进一步提高模型的性能和鲁棒性。随机森林在很多应用场景中表现优异,尤其是在处理高维数据时。
8. 易于实现
- 算法简单:决策树的算法相对简单,实现难度低,适合初学者学习和实践。同时,许多编程语言和库(如Python的Scikit-learn)都提供了现成的决策树实现,方便使用。
总结
尽管神经网络在处理复杂任务、大规模数据和高维特征方面表现出色,但决策树在可解释性、处理非数值数据、计算效率、模型复杂度、特征选择、适用场景、集成学习和易实现性等方面具有明显优势。因此,在很多应用场景中,决策树依然是一种非常有价值的算法。
6-有了神经网络和决策树,为什么还会出现SVM算法,SVM在当时解决了什么问题
支持向量机(Support Vector Machine,简称SVM)算法在1990年代初期被提出,尽管当时已经有了决策树和神经网络等强大的机器学习算法,SVM仍然因其独特的特性和优势迅速获得了广泛的关注和应用。以下是一些关键原因,解释了为什么SVM会在那个时期出现,并解决了哪些问题:
1. 解决高维数据问题
- 高维空间:在高维数据中,传统算法(如决策树和早期的神经网络)可能会遇到“维度灾难”问题,导致模型过拟合或训练时间过长。SVM通过将数据映射到高维特征空间,利用核技巧(Kernel Trick)有效地解决了这一问题。
- 线性不可分:SVM通过核函数将非线性可分的数据转换为线性可分的数据,从而在高维空间中找到最优的超平面进行分类。
2. 优化问题和理论基础
- 最大间隔:SVM的核心思想是找到一个能够最大化分类间隔的超平面,这不仅提高了模型的分类能力,还提供了良好的泛化性能。最大间隔的思想使得SVM在处理少量样本时表现出色。
- 凸优化:SVM的优化问题是一个凸优化问题,这意味着它在大多数情况下能够找到全局最优解,避免了局部最优解的问题,这在训练过程中非常重要。
3. 处理小样本问题
- 样品效率:SVM在处理小样本数据集时表现尤为突出,这对于许多实际应用场景(如生物信息学、医学诊断等)非常关键。SVM通过支持向量(离超平面最近的数据点)来定义分类边界,因此对训练数据的数量要求相对较低。
4. 鲁棒性强
- 异常值抵抗:SVM对异常值具有较强的抵抗能力。由于SVM只依赖于支持向量,而不是所有训练数据,因此少数异常值对模型的影响较小。
- 结构风险最小化:SVM采用结构风险最小化原则,不仅考虑了经验风险(训练误差),还考虑了模型复杂度,从而在训练过程中避免了过拟合。
5. 核技巧的应用
- 核函数:SVM通过核函数(如线性核、多项式核、RBF核等)将原始数据映射到高维空间,使得原本非线性可分的问题变得线性可分。这一技巧使得SVM能够处理复杂的、非线性的问题,扩展了其应用范围。
6. 多类别分类
- 多类别扩展:SVM最初被设计用于二分类问题,但通过一些扩展方法(如一对多、一对一等),SVM也能有效处理多类别分类问题。
7. 理论支持
- 统计学习理论:SVM的理论基础是Vapnik-Chervonenkis(VC)理论,这一理论为SVM提供了坚实的数学和统计支持。VC维是衡量模型复杂度的一个重要指标,SVM通过最小化结构风险来控制模型的复杂度,从而提高泛化能力。
8. 实际应用
- 广泛的应用领域:SVM在许多领域(如图像识别、文本分类、生物信息学、金融预测等)都表现出色,尤其是在处理高维和小样本数据时。许多实际应用证明了SVM的有效性和鲁棒性。
总结
尽管在SVM出现之前已经存在决策树和神经网络等强大的算法,但SVM通过解决高维数据问题、优化问题、小样本问题、鲁棒性和核技巧等多方面的优势,填补了传统算法的不足。SVM的这些特点使其在机器学习领域中占据了重要地位,并在许多实际应用中表现出色。
7-SVM的技术想法听起来太疯狂了,为什么SVM会被科学采用
SVM(支持向量机)的技术想法确实在某些方面听起来有些“疯狂”,特别是它通过将数据映射到高维空间来解决非线性问题的“核技巧”。然而,SVM之所以被广泛采用并成为机器学习领域的重要算法,主要是因为它在理论和实践中的多方面优势。以下是SVM被科学界和产业界广泛采用的原因:
1. 理论基础坚实
- 统计学习理论:SVM的理论基础是Vapnik-Chervonenkis(VC)理论,这一理论为SVM提供了坚实的数学和统计支持。VC维是衡量模型复杂度的一个重要指标,SVM通过最小化结构风险来控制模型的复杂度,从而提高泛化能力。
- 凸优化问题:SVM的优化问题是一个凸优化问题,这意味着它在大多数情况下能够找到全局最优解,避免了局部最优解的问题。这一特性使得SVM在训练过程中非常稳定,且容易实现。
2. 解决高维数据问题
- 核技巧:SVM通过核函数将数据映射到高维空间,使得原本非线性可分的问题变得线性可分。这一技巧使得SVM能够处理复杂的、非线性的问题,扩展了其应用范围。核技巧的应用使得SVM在处理高维数据时表现出色,尤其是在图像识别、文本分类等领域。
- 维度灾难:SVM通过核技巧有效地解决了“维度灾难”问题,使得在高维空间中进行分类和回归成为可能。
3. 处理小样本问题
- 样品效率:SVM在处理小样本数据集时表现尤为突出,这对于许多实际应用场景(如生物信息学、医学诊断等)非常关键。SVM通过支持向量(离超平面最近的数据点)来定义分类边界,因此对训练数据的数量要求相对较低。
4. 鲁棒性强
- 异常值抵抗:SVM对异常值具有较强的抵抗能力。由于SVM只依赖于支持向量,而不是所有训练数据,因此少数异常值对模型的影响较小。
- 结构风险最小化:SVM采用结构风险最小化原则,不仅考虑了经验风险(训练误差),还考虑了模型复杂度,从而在训练过程中避免了过拟合。
5. 实际应用效果好
- 广泛的应用领域:SVM在许多领域(如图像识别、文本分类、生物信息学、金融预测等)都表现出色,尤其是在处理高维和小样本数据时。许多实际应用证明了SVM的有效性和鲁棒性。
- 高精度:SVM在许多分类和回归任务中表现出了高精度和良好的泛化能力,这使得它在许多实际应用中成为首选算法。
6. 易于实现和扩展
- 算法实现:SVM的算法相对简单,易于实现。许多编程语言和库(如Python的Scikit-learn)都提供了现成的SVM实现,方便使用。
- 多类别分类:SVM最初被设计用于二分类问题,但通过一些扩展方法(如一对多、一对一等),SVM也能有效处理多类别分类问题。
7. 与其他技术的结合
- 集成学习:SVM可以与其他机器学习算法结合,形成集成学习模型,进一步提高模型的性能和鲁棒性。例如,SVM可以与随机森林、梯度提升树等算法结合,形成混合模型。
- 深度学习结合:近年来,SVM与深度学习的结合也成为研究热点。例如,深度SVM(Deep SVM)将深度神经网络与SVM结合,进一步提升了模型的性能。
8. 开源社区的支持
- 广泛的开源实现:SVM的开源实现(如LIBSVM、Scikit-learn等)在学术界和产业界得到了广泛应用。这些开源工具提供了丰富的功能和高效的实现,使得SVM的部署和应用变得更加便捷。
总结
尽管SVM的技术想法在某些方面听起来有些“疯狂”,但其坚实的理论基础、解决高维数据问题的能力、处理小样本问题的样品效率、鲁棒性强、实际应用效果好、易于实现和扩展、与其他技术的结合以及开源社区的支持,使得SVM在科学界和产业界得到了广泛的应用和认可。这些优势使得SVM成为机器学习领域中不可或缺的重要算法。
8-梯度提升机(Gradient Boosting Machines, GBM) 和 线性回归和逻辑回归 在模型的能力提升上分别起到了什么作用
梯度提升机(Gradient Boosting Machines, GBM)和线性回归、逻辑回归在模型能力提升方面分别发挥了不同的作用。下面分别介绍它们的作用:
梯度提升机 (Gradient Boosting Machines, GBM)
梯度提升机是一种集成学习方法,通过组合多个弱学习器(通常是决策树)来构建一个强大的预测模型。GBM 在模型能力提升上的作用主要体现在以下几个方面:
-
序列式学习:GBM 通过顺序地训练多个弱学习器,每个新的学习器专注于纠正前一个学习器的错误。这种序列式的学习过程使得模型能够逐步提高预测性能。
-
强表达能力:GBM 使用决策树作为基础学习器,决策树能够捕捉数据中的非线性关系和高阶交互作用。通过组合多个决策树,GBM 能够拟合复杂的决策边界,从而具有很强的表达能力。
-
损失函数的优化:GBM 可以最小化各种损失函数,包括回归问题中的均方误差和绝对误差,以及分类问题中的对数损失等。通过梯度下降的方法,GBM 能够对损失函数进行优化,提高模型的预测准确性。
-
正则化技术:GBM 提供了多种正则化技术,如学习率(learning rate)、最大深度(max depth)、子采样(subsampling)等,用于防止过拟合,提高模型的泛化能力。
-
特征选择和重要性评估:GBM 能够提供特征的重要性评估,帮助理解哪些特征对预测目标影响最大,这对于特征选择和模型解释非常有用。
线性回归和逻辑回归
线性回归和逻辑回归是两种常用的广义线性模型,它们在模型能力提升上的作用主要体现在以下几个方面:
-
简单性和可解释性:线性回归和逻辑回归模型结构简单,易于理解和解释。线性回归的系数可以直接表示特征对目标变量的影响程度,逻辑回归的系数可以解释为对数几率的变化。
-
处理连续和分类数据:线性回归适用于连续型目标变量,而逻辑回归适用于二分类问题。它们可以处理数值型和分类型特征,通过特征编码(如One-Hot编码)可以将分类变量转换为数值型变量。
-
计算效率:线性回归和逻辑回归的训练和预测过程计算效率高,尤其在线性回归中,可以通过解析解(normal equation)直接求解参数,不需要迭代训练。
-
正则化:通过引入L1正则化(Lasso)或L2正则化(Ridge),可以防止过拟合,提高模型的泛化能力。弹性网络(Elastic Net)结合了L1和L2正则化,能够在高维数据中进行特征选择。
-
基础模型:线性回归和逻辑回归是许多复杂模型的基础,理解它们有助于理解更复杂的模型,如广义线性模型、支持向量机和神经网络等。
总结
梯度提升机通过组合多个弱学习器,能够捕捉复杂的数据模式和非线性关系,具有很强的表达能力和预测性能。而线性回归和逻辑回归则以其简单性、可解释性和计算效率著称,适用于处理线性可分问题,并且是许多复杂模型的基础。两者在模型能力提升方面各有优势,根据具体问题的特点选择合适的模型是非常重要的。
9-补充历史年份
- 1943年【NN基础理论】,McCulloch和Pitts提出了神经网络层次结构模型,确立了神经网络的计算模型理论,从而为机器学习的发展奠定了基础
- 1950年【重要事件】,Turing提出了著名的“图灵测试”,使人工智能成为了科学领域的一个重要研究课题
- 1957年【NN第一次崛起】,Rosenblatt提出了Perceptron(感知器)概念,用Rosenblatt算法对Perceptron进行训练。并且首次用算法精确定义了自组织自学习的神经网络数学模型,设计出了第一个计算机神经网络(NN算法),开启了NN研究活动的第一次兴起
- 1958年【正式LR】,Cox给Logistic Regression方法正式命名,用于解决美国人口普查任务
- 1959年【重要事件】,Samuel设计了一个具有学习能力的跳棋程序,曾经战胜了美国保持8年不败的冠军。这个程序向人们初步展示了机器学习的能力,Samuel将机器学习定义为无需明确编程即可为计算机提供能力的研究领域
- 1960年【NN发展】,Widrow用delta学习法则来对Perceptron进行训练,可以比Rosenblatt算法更有效地训练出良好的线性分类器(最小二乘法问题)
- 1962年【雏形CNN】,Hubel和Wiesel发现了猫脑皮层中独特的神经网络结构可以有效降低学习的复杂性,从而提出著名的Hubel-Wiese生物视觉模型,该模型卷积神经网络(CNN)的雏形,这之后提出的神经网络模型也均受此启迪
- 1963年【雏形SVM】,Vapnik和Chervonenkis发明原始支持向量方法,即起决定性作用的样本为支持向量(SVM算法)
- 1969年【NN第一次停滞】,Minsky和Papert出版了对机器学习研究有深远影响的著作《Perceptron》,其中对于机器学习基本思想的论断:解决问题的算法能力和计算复杂性,影响深远且延续至今。文章中提出了著名的线性感知机无法解决异或问题,打击了NN社区,从那以后NN研究活动直到1980s都萎靡。
- 1980年【重要事件】,在美国卡内基梅隆大学举行了第一届机器学习国际研讨会,标志着机器学习研究在世界范围内兴起,该研讨会也是著名会议ICML的前身
- 1981年【NN第二次崛起】,Werbos提出多层感知机,解决了线性模型无法解决的异或问题,第二次兴起了NN研究
- 1984年【决策树】,Breiman发表分类回归树(CART算法,一种决策树)
- 1986年【决策树】,Quinlan提出ID3算法(一种决策树)
- 1986年【NN的BP算法】,Rumelhart,Hinton和Williams联合在《Nature》杂志发表了著名的反向传播算法(BP算法)
- 1989年【正式CNN】,Yann和LeCun提出了目前最为流行的卷积神经网络(CNN)计算模型,推导出基于BP算法的高效训练方法,并成功地应用于英文手写体识别
- 1995年【正式SVM】,Vapnik和Cortes发表软间隔支持向量机(SVM算法),开启了随后的机器学习领域NN和SVM两大社区的竞争
- 1995年【NN第二次停滞】,自1995年到随后的10年,NN研究发展缓慢,SVM在大多数任务的表现上一直压制着NN,并且Hochreiter的工作证明了NN的一个严重缺陷-梯度爆炸和梯度消失问题
- 1997年【Adaboost】,Freund和Schapire提出了另一种可靠的机器学习方法-Adaboost,
- 2001年【随机森林】,Breiman发表随机森林方法(Random forest),Adaboost在对过拟合问题和奇异数据容忍上存在缺陷,而随机森林在这两个问题上更加鲁棒。
- 2005年【NN第三次崛起】,经过多年的发展,NN众多研究发现被现代NN大牛Hinton, LeCun, Bengio, Andrew Ng和其它老一辈研究者整合,NN随后开始被称为深度学习(Deep Learning),迎来了第三次崛起。
相关文章:
机器学习02-发展历史补充
机器学习02-发展历史补充 文章目录 机器学习02-发展历史补充1-机器学习个人理解1-初始阶段:统计学习和模式识别(20世纪50年代至80年代)2-第二阶段【集成时代】【核方法】(20世纪90年代至2000年代初期)3-第三阶段【特征…...

全国青少年信息学奥林匹克竞赛(信奥赛)备考实战之计数器与累加器(一)
学习背景: 在现实生活中一些需要计数的场景下我们会用到计数器,如空姐手里记录乘客的计数器,跳绳手柄上的计数器等。累加器是累加器求和,以得到最后的结果。计数器和累加器它们虽然是基础知识,但是应用广泛࿰…...

Android的SurfaceView和TextureView介绍
文章目录 前言一、什么是SurfaceView ?1.1 SurfaceView 使用示例1.2 SurfaceView 源码概述1.3 SurfaceView 的构造与初始化1.4 SurfaceHolder.Callback 回调接口1.5 SurfaceView 渲染机制 二、什么是TextureView?2.1 TextureView 使用示例2.2 TextureVie…...

Scala的集合
1 集合简介 1)Scala 的集合有三大类:序列 Seq、集 Set、映射 Map,所有的集合都扩展自 Iterable 特质。 2)对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两 个包 不可变集合&am…...

1. Flink自定义Source
一. Source 简介 DataStream是Flink的低级API,用于进行数据的实时处理,Flink编程模型分为Source、Transformation、Sink三个部分,如下图所示。 默认Flink提供了大量的内置Source,常见的Source如下: 基于文件的Sour…...

关于LinuxWindows双系统在八月更新后出现的问题
问题描述类似于:Verifying shim SBAT data failed: If you are, this is caused by a reported problem in the August update if you can get into Windows, either uninstall the August update, or open Command Prompt as administrator and run this command,…...

VMware:如何在CentOS7上开启22端口
打开虚拟机:【编辑】【虚拟机网络设置】 其中填入的虚拟机IP地址是虚拟机中centos的IP地址,虚拟机端口为需要映射的centos端口 配置好之后保存,打开宿主机 win cmd telnet 192.168.1.26 22 如果出现上述窗口,则说明已经成功开放…...

ubuntu远程桌面开启opengl渲染权限
背景 最近用windows的【远程桌面连接】登录ubuntu后(xrdp协议),发现gl环境是集显的,但是本地登录ubuntu桌面后是独显(英伟达),想要在远程桌面上也用独显渲染环境。 一、查看是独显还是集显环境…...

从小学题到技术选型哲学:以智能客服系统为例,解读相关AI技术栈20241211
🧠💡从小学题到技术选型哲学:以智能客服系统为例,解读相关AI技术栈 引言:从小学数学题到技术智慧 📚✨ 在小学数学题中,有这样一道问题: “一个长方形变成平行四边形后,…...
【C语言练习(5)—回文数判断】
C语言练习(5) 文章目录 C语言练习(5)前言问题问题解析结果总结 前言 通过回文数练习,巩固数字取余和取商如何写代码 问题 输入一个五位数判断是否为回文数? 问题解析 回文数是指正读反读都一样的整数。…...

【Rust 学习笔记】Rust 基础数据类型介绍——数组、向量和切片
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 博客内容主要围绕: 5G/6G协议讲解 高级C语言讲解 Rust语言讲解 文章目录 Rust 基础数据类型介绍——数组、向量和切片一、数组、向量和…...

2024年特别报告,「十大生活方式」研究数据报告
“一朵花成轻奢品、一只玩偶掀抢购狂潮、一片荒地变文旅圣地…” 近年爆火的野兽派、Jellycat、阿那亚等诸多品牌,与消费者选择的生活方式息息相关。 今年小红书的内容种草、直播电商,也都依循着“生活方式”的轨迹。生活方式的价值所向,可…...
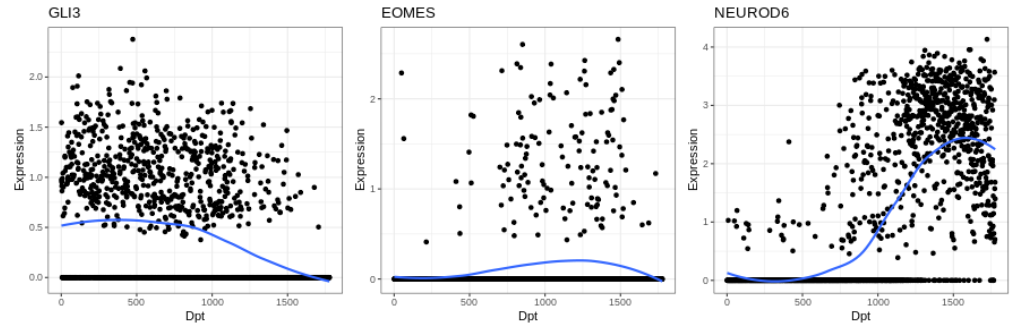
R中单细胞RNA-seq分析教程 (5)
引言 本系列开启R中单细胞RNA-seq数据分析教程[1],持续更新,欢迎关注,转发! 10. 伪时间细胞排序 如前所述,在 UMAP 嵌入中看到的背侧端脑细胞形成的类似轨迹的结构,很可能代表了背侧端脑兴奋性神经元的分化…...

openpnp - Too many misdetects - retry and verify fiducial/nozzle tip detection
文章目录 openpnp - Too many misdetects - retry and verify fiducial/nozzle tip detection概述笔记环境光最好弱一些在设备标定时,吸嘴上不要装绿色屏蔽片如果吸嘴不在底部相机中间,先检查设置底部相机坐标调整底部相机坐标 吸嘴校验的细节底部相机坐…...

不与最大数相同的数字之和
不与最大数相同的数字之和 C语言代码C 语言代码Java语言代码Python语言代码 💐The Begin💐点点关注,收藏不迷路💐 输出一个整数数列中不与最大数相同的数字之和。 输入 输入分为两行: 第一行为N(N为接下来数的个数&…...
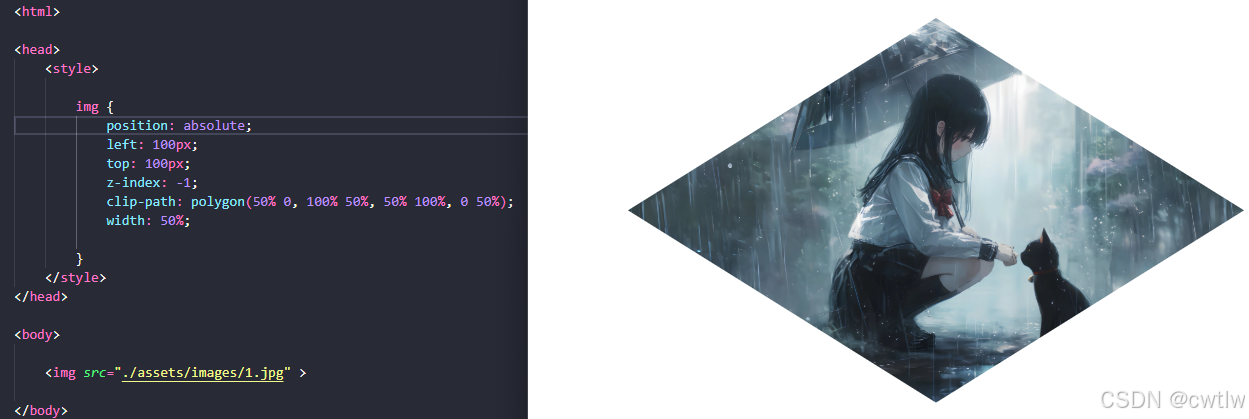
CSS学习记录11
CSS布局 - display属性 display属性是用于控制布局的最终要的CSS属性。display 属性规定是否/如何显示元素。每个HTML元素都有一个默认的display值,具体取决于它的元素类型。大多数元素的默认display值为block 或 inline。 块级元素(block element&…...

D95【python 接口自动化学习】- pytest进阶之fixture用法
day95 pytest的fixture详解(二) 学习日期:20241210 学习目标:pytest基础用法 -- pytest的fixture详解(二) 学习笔记: fixture(autouseTrue) func的autouse是TRUE时,所有函数方法…...

Abaqus断层扫描三维重建插件CT2Model 3D V1.1版本更新
更新说明 Abaqus AbyssFish CT2Model3D V1.1版本更新新增对TIF、TIFF图像文件格式的支持。本插件用户可免费获取升级服务。 插件介绍 插件说明: Abaqus基于CT断层扫描的三维重建插件CT2Model 3D 应用案例: ABAQUS基于CT断层扫描的细观混凝土三维重建…...

隐式对象和泛型
implicit object 作用: case class DatabaseConfig(driver:String,url:String)//作为函数的隐士参数的默认值implicit object MySqlDefault extends DatabaseConfig("mysql","localhost:443")def getConn(implicit config: DatabaseConfig):Uni…...

CSS的颜色表示方式
以下介绍几种常见的CSS颜色表示方式: 颜色名称 html和css规范中定义了147种可用的颜色名用的相对较少 16进制表示 css三原色:红、绿、蓝16进制的颜色值: #rrggbb16进制整数规定颜色成分,所有的值均介于 00 - ff 之间ÿ…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...