Qwen 论文阅读记录
本文仅作自己初步熟悉大模型,梳理之用,慢慢会更改/增加/删除,部分细节尚未解释,希望不断学习之后,能够完善补充。若有同道之人,欢迎指正探讨。
关于后面的code-qwen and math-qwen,我个人认为依托于前三部分,这两部分大致阅读,尚未细究,暂不记录于此。
1. Abstract(Introduction补充)
QWEN is a comprehensive language model series that encompasses distinct models with varying parameter counts.
QWEN 是一个全面的语言模型系列,包含参数数量不同的多个独立模型。
It includes QWEN, the base pretrained language models, and QWEN-CHAT, the chat models finetuned with human alignment techniques.
The base language models consistently demonstrate superior performance across a multitude of downstream tasks,
and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive.
以上两句话可以根据下图综合理解:
The model series include the base pretrained language models,
chat models finetuned with human alignment techniques, i.e., supervised finetuning (SFT), reinforcement learning with human feedback (RLHF), etc.,
as well as specialized models in coding and math.

Figure 1: Model Lineage of the Qwen Series.
We have pretrained the language models, namely QWEN, on massive datasets containing trillions of tokens.
We then use SFT and RLHF to align QWEN to human preference and thus we have QWEN-CHAT and specifically its improved version QWEN-CHAT-RLHF.
Additionally, we also develop specialized models for coding and mathematics, such as CODE-QWEN, CODE-QWEN-CHAT, and MATH-QWEN-CHAT based on QWEN with similar techniques.
Note that we previously released the multimodal LLM, QWEN-VL and QWEN-VLCHAT (Bai et al., 2023), which are also based on our QWEN base models.
The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter.
这些聊天模型在创建代理应用方面,具备先进的工具使用和规划能力,即使在执行如使用代码解释器等复杂任务时,与更大的模型相比也展现出了令人印象深刻的性能。
这句话,跟Introduction这句话综合理解:
LLMs are not just limited to language tasks.
They can also function as a generalist agent, collaborating with external systems, tools, and models to achieve the objectives set by humans.
它们还可以充当通用代理,与外部系统、工具和模型协作,以实现人类设定的目标。
For example, LLMs can understand multimodal instructions, execute code, use tools, and more.
2. Pretraining
2.1 Data
To ensure the quality of our pretraining data, we have developed a comprehensive data preprocessing procedure.
为了确保预训练数据的质量,我们开发了一个全面的数据预处理程序。
2.2 Tokenization
we utilize byte pair encoding (BPE) as our tokenization method.
2.3 Model
2.3.1 Architecture
QWEN is designed using a modified version of the Transformer architecture.
Specifically, we have adopted the recent open-source approach of training large language models, LLaMA (Touvron et al., 2023a).
Our modifications to the architecture include:
- Embedding and output projection. ----嵌入和输出投影。
Based on preliminary experimental findings, we have opted for the untied embedding approach instead of tying the weights of input embedding and output projection.
基于初步的实验结果,我们选择了未绑定嵌入方法,而不是将输入嵌入和输出投影的权重绑定在一起。
This decision was made in order to achieve better performance with the price of memory costs.
这个决定是为了以牺牲内存成本为代价来获得更好的性能。
“Output projection”指的是在模型的输出层,将隐藏层的表示映射回原始的词汇或符号空间,以产生最终的输出。
“untied embedding approach”指的是输入嵌入和输出投影的权重是独立的,不共享的。这与“tied embedding”或“weight tying”相对,后者将输入嵌入和输出投影的权重设置为相同,以减少参数数量和防止过拟合。
-
Positional embedding.
We have chosen RoPE (Rotary Positional Embedding) as our preferred option for incorporating positional information into our model.
我们选择了RoPE,将位置信息融入模型。
In particular, we have opted to use FP32 precision for the inverse frequency matrix, rather than BF16 or FP16, in order to prioritize model performance and achieve higher accuracy.
特别是,我们选择了使用FP32精度来处理逆频率矩阵,而不是BF16或FP16,这是为了优先考虑模型性能并实现更高的准确性。 -
Bias.
For most layers, we remove biases following Chowdhery et al. (2022), but we add biases in the QKV layer of attention to enhance the extrapolation ability of the model (Su, 2023b).
在大多数层中移除了Bias,但在QKV层保留以提升模型的外推能力。
根据Chowdhery等人的研究,移除大多数层的偏差项,有助于提高模型的稳定性和性能。这种做法可以减少参数数量,从而降低模型的复杂度和过拟合的风险。此外,移除偏差项有助于模型在训练过程中更好地泛化,从而在不同的数据集上表现得更为一致。
在注意力机制的QKV层中添加偏差项:Su的研究指出,在注意力机制的QKV(Query,Key,Value)层中添加偏差项可以增强模型的外推能力(extrapolation ability)。
QKV层是注意力机制的核心部分,通过添加偏差项,可以更好地捕捉输入数据的特征,从而提升模型在处理未知或未见数据时的表现。这种增强外推能力的做法对于处理复杂任务和应对多样化的数据输入非常重要。
总结来说,移除大多数层的偏差项是为了提高模型的泛化能力和稳定性,而在QKV层中添加偏差项则是为了增强模型的外推能力。
-
Pre-Norm & RMSNorm.
In modern Transformer models, pre-normalization is the most widely used approach, which has been shown to improve training stability compared to post-normalization.
Additionally, we have replaced the traditional layer normalization technique described in (Ba et al., 2016) with RMSNorm(Jiang et al., 2023). This change has resulted in equivalent performance while also improving efficiency. -
Activation function.
We have selected SwiGLU (Shazeer, 2020) as our activation function, a combination of Swish (Ramachandran et al., 2017) and Gated Linear Unit (Dauphin et al., 2017).
Our initial experiments have shown that activation functions based on GLU generally outperform other baseline options, such as GeLU (Hendrycks & Gimpel, 2016).
As is common practice in previous research, we have reduced the dimension of the feed-forward network (FFN) from 4 times the hidden size to 8/3 of the hidden size.
2.3.2 Context length extension
Transformer models have a significant limitation in terms of the context length for their attention mechanism.
As the context length increases, the quadratic-complexity computation leads to a drastic increase in both computation and memory costs.
计算复杂度与输入数据量的平方成正比
为此,作者提到了四个关键词:
- NTK-aware interpolation (bloc97, 2023)
- dynamic NTK-aware interpolation(Peng et al., 2023a)
QWEN additionally incorporates two attention mechanisms:
- LogN-Scaling
- Window Attention
LogN-Scaling rescales the dot product of the query and value by a factor that depends on the ratio of the context length to the training length, ensuring that the entropy of the attention value remains stable as the context length grows.
LogN-Scaling 通过一个依赖于上下文长度与训练长度之比的因子来重新缩放查询和值的点积,从而确保随着上下文长度的增加,注意力值的熵保持稳定。
Window attention restricts the attention to a limited context window, preventing the model from attending to tokens that are too far away.
Window Attention则将注意力限制在一个有限的上下文窗口内,防止模型关注到距离过远的标记(tokens)。
Swin transformer,待启动新的记录,详细解析其细节。
We also observed that the long-context modeling ability of our model varies across layers, with lower layers being more sensitive in context length extension compared to the higher layers.
我们还观察到,我们模型的 long-context 建模能力,在不同层之间存在差异,与较高层相比,较低层在上下文长度扩展方面更为敏感。
To leverage this observation, we assign different window sizes to each layer, using shorter windows for lower layers and longer windows for higher layers.
2.4 Training
To train QWEN, we follow the standard approach of autoregressive language modeling(自回归语言建模) Radford et al. (2018).
This involves training the model to predict the next token based on the context provided by the previous tokens.
We train models with context lengths of 2048.
To improve computational efficiency and reduce memory usage, we employ Flash Attention in the attention modules (Dao et al., 2022).
FlashAttention的核心原理是,通过将输入分块并在每个块上执行注意力操作,从而减少对高带宽内存(HBM)的读写操作。它利用底层硬件的内存层次知识,例如GPU的内存层次结构,来提高计算速度和减少内存访问开销。
具体来说,FlashAttention使用平铺(tiling)和重计算(recomputation)等经典技术。它首先将输入块从HBM加载到SRAM(快速缓存),在SRAM上执行注意力操作,并将结果更新回HBM。通过这种方式,FlashAttention减少了内存读写量,从而实现了加速。
3. Alignment
Pretrained large language models have been found to be out of sync with human behavior, making them unsuitable for serving as AI assistants in most cases.
已发现,预训练的大型语言模型与人类行为不一致,因此在大多数情况下不适合担任AI助手。
Recent research has shown that the use of alignment techniques, such as supervised finetuning (SFT) and reinforcement learning from human feedback (RLHF), can significantly improve the ability of language models to engage in natural conversation.
3.1 Supervised Fine-tuning
To gain an understanding of human behavior, the initial step is to carry out supervised fine-tuning.
This process fine-tunes a pre-trained model on chat-style data, which includes both human queries and AI responses.
该过程对聊天风格数据的预训练模型进行微调,其中包括人工查询和AI响应。
Supervised finetuning is similar to text-to-text transfer, but it is capable of creating a helpful AI assistant due to the intricate and varied nature of the datasets used for finetuning.
监督式微调类似于文本到文本的迁移,但由于用于微调的数据集,具有复杂性和多样性,它能够创建出一个有用的AI助手。
In the following sections, we will delve into the details of data construction and training methods.
3.1.1 DATA
To enhance the capabilities of our supervised finetuning datasets, we have annotated conversations in multiple styles.
…
3.1.2 TRAINING
…
3.2 Rein Forcement Learning from Human Feedback
While SFT has proven to be effective, we acknowledge that its generalization and creativity capabilities may be limited, and it is prone to overfitting.
To address this issue, we have implemented Reinforcement Learning from Human Feedback (RLHF) to further align SFT models with human preferences.
This process involves training a reward model and using Proximal Policy Optimization (PPO) to conduct policy training.
这个过程包括训练一个奖励模型,并使用近端策略优化(Proximal Policy Optimization,简称PPO)来进行策略训练。
3.2.1 Reward Model
…
3.2.2 ReinForcement Learning
Our Proximal Policy Optimization (PPO) process involves four models:
- policy model,
- value model,
- reference model,
- reward model.
3.3 Automatic and Human evaluation of Aligned Models
Besides the widely used few-shot setting, we test our aligned models in the zero-shot setting to demonstrate how well the models follow instructions.
The prompt in a zero-shot setting consists of an instruction and a question without any previous examples in the context.
在零样本设置(zero-shot setting)中,提示(prompt)仅包含一个指令和一个问题,而不包含任何先前的示例作为上下文。
这种设置要求模型,仅根据给定的指令和问题本身,来生成回答或执行相应的任务。
零样本设置对于评估模型的泛化能力和理解能力尤为重要,因为它模拟了模型在面对全新、未见过的任务或问题时的表现。
在这种设置下,指令通常清晰地说明了模型需要执行的任务类型,比如生成文本、回答问题、翻译等。
问题则是模型需要处理的具体内容,它依赖于指令中指定的任务类型。
由于没有提供任何示例,模型必须依靠其预训练期间学到的知识和技能来理解和回答问题。
零样本设置的挑战在于模型需要在没有直接指导或示例的情况下,准确地理解并完成任务。这要求模型具备强大的语言理解和生成能力,以及良好的泛化能力。
因此,零样本设置是评估自然语言处理(NLP)模型性能的一个重要方面。
3.4 Tool use, Code Interpreter, and Agent
The QWEN models, which are designed to be versatile, have the remarkable ability to assist with (semi-) automating daily tasks by leveraging their skills in tool-use and planning.
QWEN模型设计得十分通用,它们具有,通过利用,其工具使用,和,规划方面的,技能,来协助(半)自动化日常任务的,显著能力。
We explore QWEN’s proficiency in the following areas:
- Utilizing unseen tools through ReAct prompting (Yao et al., 2022) (see Table 6).
通过ReAct提示利用未见过的工具; - Using a Python code interpreter to enhance math reasoning, data analysis, and more.
使用Python代码解释器来增强数学推理、数据分析等能力; - Functioning as an agent that accesses Hugging Face’s extensive collection of multimodal models while engaging with humans (see Table 9).
作为一个能够与人类交互,并访问Hugging Face庞大多模态模型库的代理;
To enhance QWEN’s capabilities as an agent or copilot, we employ the self-instruct (Wang et al., 2023c) strategy for supervised fine-tuning (SFT).
为了增强QWEN作为代理或协同工具的能力,我们采用自我指示策略进行有监督微调(SFT)。
Specifically, we utilize the in-context learning capability of QWEN for self-instruction.
具体来说,我们利用QWEN的上下文学习能力来进行自我指示。
By providing a few examples, we can prompt QWEN to generate more relevant queries and generate outputs that follow a specific format, such as ReAct.
通过提供几个示例,我们可以引导QWEN生成更多相关的查询,并产生符合特定格式(如ReAct)的输出。
We then apply rules and involve human annotators to filter out any noisy samples.
随后,我们应用规则并引入人工标注者来过滤掉任何噪声样本。
Afterwards, the samples are incorporated into QWEN’s training data, resulting in an updated version of QWEN that is more dependable for self-instruction.
之后,这些样本被纳入QWEN的训练数据中,从而得到一个在自我指示方面更加可靠的更新版QWEN。
We iterate through this process multiple times until we gather an ample number of samples that possess both exceptional quality and a widerange of diversity.
我们多次重复这个过程,直到收集到足够数量且既优质又多样化的样本。

Figure 2: A high-level overview of Self-Instruct.
The process starts with a small seed set of tasks as the task pool.
Random tasks are sampled from the task pool, and used to prompt an off-the-shelf LM to generate both new instructions and corresponding instances, followed by filtering low-quality or similar generations, and then added back to the initial repository of tasks.
从任务池中随机抽取任务,并用这些任务,提示一个现成的语言模型(LM),来生成新的指令和相应的实例。
随后,过滤掉质量低或相似的生成内容,再将它们添加回最初的任务库中。
The resulting data can be used for the instruction tuning of the language model itself later to follow instructions better.
所得数据可用于后续对语言模型本身的指令调优,以便其能更好地遵循指令。
Tasks shown in the figure are generated by GPT3.
其中,上图中的 Input-First 和 Output-First,具体可以参考下面两张图:
- Input-First

Table 7: Prompt used for the input-first approach of instance generation. The model is prompted to generate the instance first, and then generate the corresponding output.
For instructions that don’t require additional input, the output is allowed to be generated directly.
- Output-First

Table 8: Prompt used for the output-first approach of instance generation.
The model is prompted to generate the class label first, and then generate the corresponding input.
This prompt is used for generating the instances for classification tasks.
We apply the output-first approach to the classification tasks identified in the former step, and the input-first approach to the remaining non-classification tasks.
Related Work
-
QWEN TECHNICAL REPORT.
-
SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions.
相关文章:
Qwen 论文阅读记录
本文仅作自己初步熟悉大模型,梳理之用,慢慢会更改/增加/删除,部分细节尚未解释,希望不断学习之后,能够完善补充。若有同道之人,欢迎指正探讨。 关于后面的code-qwen and math-qwen,我个人认为依…...

自动驾驶:百年演进
亲爱的小伙伴们😘,在求知的漫漫旅途中,若你对深度学习的奥秘、JAVA 、PYTHON与SAP 的奇妙世界,亦或是读研论文的撰写攻略有所探寻🧐,那不妨给我一个小小的关注吧🥰。我会精心筹备,在…...

SSM 校园一卡通密钥管理系统 PF 于校园图书借阅管理的安全保障
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装校园一卡通密钥管理系统软件来发挥其高效地信息处理的作用&a…...

什么叫中间件服务器?
什么叫中间件服务器?它在软件架构中扮演着怎样的角色?在现代应用程序开发中,中间件服务器的概念很多人对它并不太熟悉,但其实它的作用却不小。 中间件服务器是一种连接不同软件应用程序的中介。想象一下,在一个大型企…...
【docker】12. Docker Volume(存储卷)
什么是存储卷? 存储卷就是将宿主机的本地文件系统中存在的某个目录直接与容器内部的文件系统上的某一目录建立绑定关系。这就意味着,当我们在容器中的这个目录下写入数据时,容器会将其内容直接写入到宿主机上与此容器建立了绑定关系的目录。 在宿主机上…...

SpringBoot【八】mybatis-plus条件构造器使用手册!
一、前言🔥 环境说明:Windows10 Idea2021.3.2 Jdk1.8 SpringBoot 2.3.1.RELEASE 经过上一期的mybatis-plus 入门教学,想必大家对它不是非常陌生了吧,这期呢,我主要是围绕以下几点展开,重点给大家介绍 里…...

OpenAI直播发布第4天:ChatGPT Canvas全面升级,免费开放!
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工…...

自学高考的挑战与应对:心理调适、学习方法改进与考试技巧提升
一、自学参加高考的成功条件 (一)报名条件 基本要求 自学参加高考,首先需严格遵守国家的法律法规,这是参与高考的基本前提。具备高中同等学力是核心要素之一,意味着考生需通过自学掌握高中阶段的知识体系与学习能力…...

2024年12月11日Github流行趋势
项目名称:maigret 项目维护者:soxoj, kustermariocoding, dependabot, fen0s, cyb3rk0tik项目介绍:通过用户名从数千个站点收集个人档案信息的工具。项目star数:12,055项目fork数:870 项目名称:uv 项目维护…...

Next.js配置教程:构建自定义服务器
更多有关Next.js教程,请查阅: 【目录】Next.js 独立开发系列教程-CSDN博客 目录 前言 1. 什么是自定义服务器? 2. 配置自定义服务器 2.1 基础配置 2.2 集成不同的服务器框架 使用Fastify 使用Koa 3. 自定义服务器的高级功能 3.1 路…...

SpringCloud 题库
这篇文章是关于 SpringCloud 面试题的汇总,包括微服务的概念、SpringCloud 的组成及相关技术,如服务注册与发现、负载均衡、容错等,还涉及 Nacos 配置中心、服务注册表结构等原理,以及微服务架构中的日志采集、服务网关、相关概念…...

基于Filebeat打造高效日志收集流水线
1. 引言 在现代的分布式系统中,日志数据的收集、存储与分析已经成为不可或缺的一部分。随着应用程序、服务和微服务架构的普及,日志数据呈现出爆炸式增长。日志不仅是系统运行的“侦探”,能够帮助我们在出现问题时进行快速排查,还…...

《HTML 的变革之路:从过去到未来》
一、HTML 的发展历程 图片: HTML 从诞生至今,经历了多个版本的迭代。 (一)早期版本 HTML 3.2 在 1997 年 1 月 14 日成为 W3C 推荐标准,提供了表格、文字绕排和复杂数学元素显示等新特性,但因实现复杂且缺乏浏览器…...
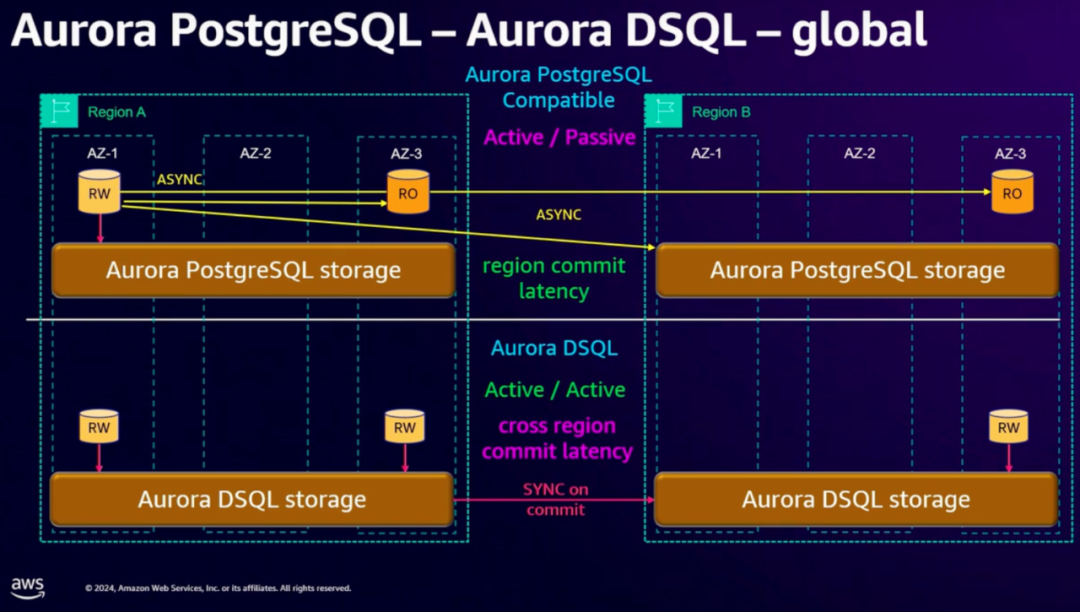
快速了解 Aurora DSQL
上周在 AWS re:Invent大会(类似于阿里云的云栖大会)上推出了新的产品 Aurora DSQL[1] ,在数据库层面提供了多区域、多点一致性写入的能力,兼容 PostgreSQL。并声称,在多语句跨区域的场景下,延迟只有Google …...

计算机视觉与医学的结合:推动医学领域研究的新机遇
目录 引言医学领域面临的发文难题计算机视觉与医学的结合:发展趋势计算机视觉结合医学的研究方向高区位参考文章结语 引言 计算机视觉(Computer Vision, CV)技术作为人工智能的重要分支,已经在多个领域取得了显著的应用成果&…...

Scala的隐式对象
Scala中,隐式对象(implicit object)是一种特殊的对象,它可以使得其成员(如方法和值)在特定的上下文中自动可用,而无需显式地传递它们。隐式对象通常与隐式参数和隐式转换一起使用,以…...

PageHelper自定义Count查询及其优化
PageHelper自定义Count查询及其优化 文章目录 PageHelper自定义Count查询及其优化一:背景1.1、解决方法 二:利用反射判断请求参数是否有模糊查询2.1、分页不执行count2.2、思路2.3、代码示例 三:自定义COUNT查询SQL(只适用于单表)3.1、局限性…...

【数据结构】哈夫曼树
哈夫曼树 路径长度:从树中一个结点到另一个结点之间的分支构成这两个节点之间的路径,路径上的分支数目称为路径长度 树的带权路径长度:树中所有叶子结点的带权路径长度之和,通常记为WPL ∑ k 1 n w k l k \sum^{n}_{k1}w_kl_k …...
springboot422甘肃旅游服务平台代码-(论文+源码)_kaic
摘 要 使用旧方法对甘肃旅游服务平台的信息进行系统化管理已经不再让人们信赖了,把现在的网络信息技术运用在甘肃旅游服务平台的管理上面可以解决许多信息管理上面的难题,比如处理数据时间很长,数据存在错误不能及时纠正等问题。这次开发的…...

docker中安装minio
1.首先需要搜索可用镜像,当然也可以不用 docker search minio/minio 2.拉取镜像 docker pull minio/minio 3.在本地新建两个文件夹路径 mkdir -p /opt/minio/datamkdir -p /opt/minio/config解释一下,data是文件存储的首路径。config是配置路径&…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...