【机器学习与数据挖掘实战】案例01:基于支持向量回归的市财政收入分析

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈机器学习与数据挖掘实战 ⌋ ⌋ ⌋ 机器学习是人工智能的一个分支,专注于让计算机系统通过数据学习和改进。它利用统计和计算方法,使模型能够从数据中自动提取特征并做出预测或决策。数据挖掘则是从大型数据集中发现模式、关联和异常的过程,旨在提取有价值的信息和知识。机器学习为数据挖掘提供了强大的分析工具,而数据挖掘则是机器学习应用的重要领域,两者相辅相成,共同推动数据科学的发展。本专栏介绍机器学习与数据挖掘的相关实战案例。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/ML-DM_cases。
文章目录
- 一、目标分析
- (一)背景
- (二)数据说明
- (三)分析目标
- 二、数据准备
- 三、特征工程
- (一)Lasso回归
- (二)特征选择
- 四、模型训练
- (一)灰色预测模型
- (二)关键特征预测
- (三)SVR模型预测
- 五、性能度量
- 小结
一、目标分析
(一)背景
财政收入是政府理财的重要环节,是政府进行宏观调控的重要手段之一,也是政府提供公共产品满足公共支出需要的重要经济基础。财政收入规模是衡量一个国家或一个地区财力和相关政府在社会经济生活中职能范围的重要指标。只有在组织财政收入的过程中正确处理各种物质利益关系,才能达到充分调动各方面的积极性,达到优化资源配置,协调分配关系的目的。财政收入的变化受到经济发展水平和分配政策的制约,同时也会影响到后续财政支出的规划,从而影响到下一阶段的发展规划与相关决策。
本案例利用某市财政收入的历史数据,建立合理的模型,对该市2014年和2015年财政收入进行预测,希望预测结果能够帮助政府合理的控制财政收支,优化财源建设,为制政府定相关决策提供依据。
(二)数据说明
考虑到数据的可得性,本案例所用的财政收入数据分为地方一般预算收入和政府性基金收入。
地方一般预算收入包括以下两个部分。
- 税收收入。主要包括企业所得税与地方所得税中中央和地方共享的40%,地方享有的25%的增值税、营业税和印花税等。
- 非税收收入。包括专项收入、行政事业性收费收入、罚没收入、国有资本经营收入和其他收入等。
政府性基金收入是国家通过向社会征收以及出让土地、发行彩票等方式取得收入。并专项用于支持特定基础设施建设和社会事业发展的收入。
本案例所用数据集data.csv内容如下。

本案例所用数据特征名称及说明如下表所示。
| 特征名称 | 特征说明 |
|---|---|
| 社会从业人数 x 1 x_1 x1 | 就业人数的上升伴随着居民消费水平的提高,从而间接影响财政收入的增加。 |
| 在岗职工工资总额 x 2 x_2 x2 | 反映的是社会分配情况,主要影响财政收入中的个人所得税,房产税以及潜在消费能力。 |
| 社会消费品零售总额 x 3 x_3 x3 | 代表社会整体消费情况,是可支配收入在经济生活中的实现。当社会消费品零售总额增长时,表明社会消费意愿强烈,部分程度上会导致财政收入中增值税的增长,当消费增长时,也会引起经济系统中其他方面发生变动,最终导致财政收入的增长。 |
| 城镇居民人均可支配收入 x 4 x_4 x4 | 居民收入越高消费能力越强,同时意味着其工作积极性越高,创造出的财富越多,从而能带来财政收入更快和持续的增长。 |
| 城镇居民人均消费性支出 x 5 x_5 x5 | 居民在消费商品的过程中会产生各种税费,税费又是调节生产规模的手段之一。在商品经济发达的如今,居民消费的越多,对财政收入的贡献就越大。 |
| 年末总人口 x 6 x_6 x6 | 在地方经济发展水平既定的条件下,人均地方财政收入与地方人口数呈反比例变化。 |
| 全社会固定资产投资额 x 7 x_7 x7 | 全社会固定资产投资是建造和购置固定资产的经济活动,即固定资产再生产活动。主要通过投资来促进经济增长,扩大税源,进而拉动财政税收收入整体增长。 |
| 地区生产总值 x 8 x_8 x8 | 表示地方经济发展水平。一般来讲,政府财政收入来源于当期的地区生产总值。在国家经济政策不变、社会秩序稳定的情况下,地方经济发展水平与地方财政收入之间存在着密切的相关性,越是经济发达的地区,其财政收入的规模就越大。 |
| 第一产业产值 x 9 x_9 x9 | 由于取消农业税,实施三农政策,使得第一产业产值对财政收入的影响更小。 |
| 税收 x 10 x_{10} x10 | 由于其具有征收的强制性、无偿性和固定性特点,可以为政府履行其职能提供充足的资金来源。因此,各国都将其作为政府财政收入的最重要的收入形式和来源。 |
| 居民消费价格指数 x 11 x_{11} x11 | 反映居民家庭购买的消费品及服务价格水平的变动情况,影响城乡居民的生活支出和国家的财政收入。 |
| 第三产业与第二产业产值比 x 12 x_{12} x12 | 表示产业结构。第三产业生产总值代表国民经济水平,是财政收入的主要影响因素,当产业结构逐步优化时,财政收入也会随之增加。 |
| 居民消费水平 x 13 x_{13} x13 | 在很大程度上受整体经济状况GDP的影响,从而间接影响地方财政收入。 |
(三)分析目标
结合某市财政收入的数据情况,可以实现以下目标。
- 分析、识别影响地方财政收入的关键特征。
- 预测2014年和2015年的财政收入。
本案例包括以下步骤。
- 对原始数据进行探索性分析,了解原始特征之间的相关性。
- 利用Lasso特征选择模型进行特征提取。
- 建立单个特征的灰色预测模型以及支持向量回归预测模型。
- 使用支持向量回归预测模型得出2014–2015年财政收入的预测值。
- 对上述建立的财政收入预测模型进行评价。
本案例的总体流程图如下图所示。

二、数据准备
本案例采用的数据是某市财政收入数据,均来自某市的统计年鉴。本案例仅对1994–2013年的数据进行分析。获取数据后,发现影响地方财政收入的特征有很多,在建立模型之前需要判断财政收入与所给特征之间的相关性、各特征之间的相关性,以此判断所给特征是否可以用作建模的关键特征,不能用作关键特征的需要删除,本案例利用Pearson相关系数判断各特征之间的相关性。
相关代码如下。
import numpy as np
import pandas as pddata = pd.read_csv('../data/data.csv') # 读取数据
# 保留两位小数,并将结果保存为’.csv’文件
np.round(data.corr(method = 'pearson'), 2).to_csv('../tmp/data_cor.csv')
print('相关系数矩阵为:\n', np.round(data.corr(method = 'pearson'), 2))

数据各特征之间的Pearson相关系数,如下表所示。
| x 1 x_1 x1 | x 2 x_2 x2 | x 3 x_3 x3 | x 4 x_4 x4 | x 5 x_5 x5 | x 6 x_6 x6 | x 7 x_7 x7 | x 8 x_8 x8 | x 9 x_9 x9 | x 10 x_{10} x10 | x 11 x_{11} x11 | x 12 x_{12} x12 | x 13 x_{13} x13 | y y y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x 1 x_1 x1 | 1.00 | 0.95 | 0.95 | 0.97 | 0.97 | 0.99 | 0.95 | 0.97 | 0.98 | 0.98 | -0.29 | 0.94 | 0.96 | 0.94 |
| x 2 x_2 x2 | 0.95 | 1.00 | 1.00 | 0.99 | 0.99 | 0.92 | 0.99 | 0.99 | 0.98 | 0.98 | -0.13 | 0.89 | 1.00 | 0.98 |
| x 3 x_3 x3 | 0.95 | 1.00 | 1.00 | 0.99 | 0.99 | 0.92 | 1.00 | 0.99 | 0.98 | 0.99 | -0.15 | 0.89 | 1.00 | 0.99 |
| x 4 x_4 x4 | 0.97 | 0.99 | 0.99 | 1.00 | 1.00 | 0.95 | 0.99 | 1.00 | 0.99 | 1.00 | -0.19 | 0.91 | 1.00 | 0.99 |
| x 5 x_5 x5 | 0.97 | 0.99 | 0.99 | 1.00 | 1.00 | 0.95 | 0.99 | 1.00 | 0.99 | 1.00 | -0.18 | 0.90 | 0.99 | 0.99 |
| x 6 x_6 x6 | 0.99 | 0.92 | 0.92 | 0.95 | 0.95 | 1.00 | 0.93 | 0.95 | 0.97 | 0.96 | -0.34 | 0.95 | 0.94 | 0.91 |
| x 7 x_7 x7 | 0.95 | 0.99 | 1.00 | 0.99 | 0.99 | 0.93 | 1.00 | 0.99 | 0.98 | 0.99 | -0.15 | 0.89 | 1.00 | 0.99 |
| x 8 x_8 x8 | 0.97 | 0.99 | 0.99 | 1.00 | 1.00 | 0.95 | 0.99 | 1.00 | 0.99 | 1.00 | -0.15 | 0.90 | 1.00 | 0.99 |
| x 9 x_9 x9 | 0.98 | 0.98 | 0.98 | 0.99 | 0.99 | 0.97 | 0.98 | 0.99 | 1.00 | 0.99 | -0.23 | 0.91 | 0.99 | 0.98 |
| x 10 x_{10} x10 | 0.98 | 0.98 | 0.99 | 1.00 | 1.00 | 0.96 | 0.99 | 1.00 | 0.99 | 1.00 | -0.17 | 0.90 | 0.99 | 0.99 |
| x 11 x_{11} x11 | -0.29 | -0.13 | -0.15 | -0.19 | -0.18 | -0.34 | -0.15 | -0.15 | -0.23 | -0.17 | 1.00 | -0.43 | -0.16 | -0.12 |
| x 12 x_{12} x12 | 0.94 | 0.89 | 0.89 | 0.91 | 0.90 | 0.95 | 0.89 | 0.90 | 0.91 | 0.90 | -0.43 | 1.00 | 0.90 | 0.87 |
| x 13 x_{13} x13 | 0.96 | 1.00 | 1.00 | 1.00 | 0.99 | 0.94 | 1.00 | 1.00 | 0.99 | 0.99 | -0.16 | 0.90 | 1.00 | 0.99 |
| y y y | 0.94 | 0.98 | 0.99 | 0.99 | 0.99 | 0.91 | 0.99 | 0.99 | 0.98 | 0.99 | -0.12 | 0.87 | 0.99 | 1.00 |
根据相关系数表所示的结果得到以下分析。
居民消费价格指数( x 11 x_{11} x11)与财政收入( y y y)的线性关系不显著,呈现一定程度的负相关。其余特征均与财政收入呈现高度的正相关关系。按相关性大小,依次是 x 3 , x 4 , x 5 , x 7 , x 8 , x 10 , x 13 , x 2 , x 9 , x 1 , x 6 x_3, x_4, x_5, x_7, x_8, x_{10}, x_{13}, x_2, x_9, x_1, x_6 x3,x4,x5,x7,x8,x10,x13,x2,x9,x1,x6 和 x 12 x_{12} x12。
同时,各特征之间存在着严重的共线性。特征 x 1 , x 4 , x 5 , x 6 , x 8 , x 9 , x 10 x_1, x_4, x_5, x_6, x_8, x_9, x_{10} x1,x4,x5,x6,x8,x9,x10 与除了 x 11 x_{11} x11之外的特征均存在严重的共线性,特征 x 2 , x 3 , x 7 x_2, x_3, x_7 x2,x3,x7 与除了 x 11 x_{11} x11和 x 12 x_{12} x12外的其他特征存在着严重的共线性。 x 11 x_{11} x11与各特征的共线性不明显, x 12 x_{12} x12与除了 x 2 , x 3 , x 7 , x 11 x_2, x_3, x_7, x_{11} x2,x3,x7,x11 之外的其他特征有严重的共线性, x 13 x_{13} x13与除了 x 11 x_{11} x11之外的各特征有严重的共线性。 x 2 x_2 x2和 x 3 x_3 x3, x 2 x_2 x2和 x 13 x_{13} x13, x 3 x_3 x3和 x 13 x_{13} x13等多对特征之间存在完全的共线性。
根据对相关系数表分析可知以下两点。选取的各特征除了 x 11 x_{11} x11外,其他特征与 y y y的相关性很强,可以用作财政收入预测分析的关键特征,特征之间存在着信息的重复,在建立模型之前需要对特征进行进一步筛选。
三、特征工程
虽然在数据准备过程中对特征进行了初步筛选,但是引入的特征太多,而且这些特征之间存在着信息的重复。为了保留重要的特征,建立精确、简单的模型,需要对原始特征进一步筛选,考虑到传统的特征选择方法存在一定的局限性,本案例采用最近广泛使用的Lasso特征选择方法对原始特征进一步筛选。
(一)Lasso回归
Lasso回归方法以缩小特征集(降阶)为思想,是一种收缩估计方法。Lasso方法可以将特征的系数进行压缩并使某些回归系数变为0,进而达到特征选择的目的,可以广泛地应用于模型改进与选择。通过选择惩罚函数,借用Lasso思想和方法实现特征选择的目的。模型选择本质上是寻求模型稀疏表达的过程,而这种过程可以通过优化一个“损失”+“惩罚”的函数问题来完成。
Lasso参数估计如下式所示。
β ^ ( lasso ) = arg min β 2 ∥ y − ∑ j = 1 p x i β i ∥ 2 + λ ∑ j = 1 p ∣ β i ∣ \hat\beta(\text{lasso}) = \argmin_\beta^2 \left\Vert y-\sum_{j=1}^p x_i\beta_i\right\Vert^2 + \lambda\sum_{j=1}^p|\beta_i| β^(lasso)=βargmin2 y−j=1∑pxiβi 2+λj=1∑p∣βi∣
λ \lambda λ为非负正则参数,控制着模型的复杂程度, λ \lambda λ越大对特征较多的线性模型的惩罚力度就越大,从而最终获得一个特征较少的模型; λ ∑ j = 1 p ∣ β i ∣ \lambda\sum_{j=1}^p|\beta_i| λ∑j=1p∣βi∣称为惩罚项。调整参数 λ \lambda λ可以采用交叉验证法,选取交叉验证误差最小的 λ \lambda λ值。最后,按照得到的 λ \lambda λ值,用全部数据重新拟合模型即可。
值得注意的是,当原始特征中存在共线性时,Lasso回归不失为一种很好的处理共线性的方法,它可以有效地对存在共线性的特征进行筛选。
(二)特征选择
根据相关系数表的结果分析可知,原始数据中各特征之间存在严重的共线性。
- 特征 x 1 、 x 4 、 x 5 、 x 6 、 x 8 、 x 9 、 x 10 x_1、x_4、x_5、x_6、x_8、x_9、x_{10} x1、x4、x5、x6、x8、x9、x10与除了 x 11 x_{11} x11之外的特征均存在严重的共线性。
- 特征 x 2 、 x 3 、 x 7 x_2、x_3、x_7 x2、x3、x7与除了 x 11 x_{11} x11和 x 12 x_{12} x12外的其他特征存在着严重的共线性。
本案例可以利用Lasso回归方法进行特征筛选。相关代码如下。
import pandas as pd
import numpy as np
from sklearn.linear_model import Lassodata = pd.read_csv('../data/data.csv') # 读取数据
# 调用Lasso()函数,设置λ的值为1000
lasso = Lasso(1000)
lasso.fit(data.iloc[:, 0:13], data['y'])
print('相关系数为:', np.round(lasso.coef_, 5)) # 输出结果,保留五位小数print('相关系数非零个数为:', np.sum(lasso.coef_ != 0)) # 计算相关系数非零的个数# 返回一个相关系数是否为零的布尔数组
mask = lasso.coef_ != 0
print('相关系数是否为零:', mask)data = data.iloc[:, 0:13]
new_reg_data = data.iloc[:, mask] # 返回相关系数非零的数据
new_reg_data.to_csv('../tmp/new_reg_data.csv') # 存储数据
print('输出数据的维度为:', new_reg_data.shape) # 查看输出数据的维度

各特征对应的系数如下表所示。从表的结果可以看出,利用Lasso回归方法识别影响财政收入的关键影响因素是社会从业人数( x 1 x_1 x1)、社会消费品零售总额( x 3 x_3 x3)、城镇居民人均可支配收入( x 4 x_4 x4)、城镇居民人均消费性支出( x 5 x_5 x5)、全社会固定资产投资额( x 7 x_7 x7)、地区生产总值( x 8 x_8 x8)、第一产业产值( x 9 x_9 x9) 、居民消费水平( x 13 x_{13} x13)。
| x 1 x_1 x1 | x 2 x_2 x2 | x 3 x_3 x3 | x 4 x_4 x4 | x 5 x_5 x5 | x 6 x_6 x6 | x 7 x_7 x7 | x 8 x_8 x8 | x 9 x_9 x9 | x 10 x_{10} x10 | x 11 x_{11} x11 | x 12 x_{12} x12 | x 13 x_{13} x13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -0.0001 | 0.000 | 0.124 | -0.010 | 0.065 | 0.000 | 0.317 | 0.035 | -0.001 | 0.000 | 0.000 | 0.000 | -0.040 |
四、模型训练
为实现对2014年和2015年的财政预测,本案例利用SVR(Support Vector Regression,支持向量回归)建立预测模型。由于原始数据中没有提供关键特征2014年和2015年的数据,所以本案例利用灰色预测模型预测关键特征2014年和2015年的值。利用支持向量回归(Support Vector Regression,SVR)预测模型和灰色模型预测值预测2014年和2015年的财政收入。
(一)灰色预测模型
灰色预测模型是一种对含有不确定因素的系统进行预测的方法。在建立灰色预测模型之前,需先对原始时间序列进行数据处理,经过数据处理后的时间序列即称为生成列,灰色系统常用的数据处理方式有累加、累减和加权累加3种。灰色预测模型是利用离散随机数经过生成变为随机性被显著削弱而且较有规律的生成数,建立起的微分方程形式的模型。灰色预测是以灰色模型为基础的,在众多的灰色模型中,GM(1,1)模型最为常用。
设特征 X ( 0 ) = { X ( 0 ) ( i ) , i = 1 , 2 , ⋯ , n } X^{(0)}=\{X^{(0)}(i), i=1,2,\cdots,n\} X(0)={X(0)(i),i=1,2,⋯,n} 为一非负单调原始数据序列,建立灰色预测模型如下。
对 X ( 0 ) X^{(0)} X(0) 进行一次累加得到累加序列 X ( 1 ) = { X ( 1 ) ( k ) , k = 0 , 1 , 2 , ⋯ , n } X^{(1)} = \{X^{(1)}(k), k=0,1,2,\cdots,n\} X(1)={X(1)(k),k=0,1,2,⋯,n}。
对 X ( 1 ) X^{(1)} X(1) 建立一阶线性微分方程,如下式所示,即GM(1,1)模型。
d X ( 1 ) d t + a X ( 1 ) = μ \frac{\mathrm{d}X^{(1)}}{\mathrm{d}t} + aX^{(1)} = \mu dtdX(1)+aX(1)=μ
求解微分方程,得到预测模型如下式所示。
X ^ ( 1 ) ( k + 1 ) = [ X ( 0 ) ( 1 ) − μ a ] e − a k + μ a \hat X^{(1)}(k+1) = \left[X^{(0)}(1)-\frac{\mu}{a}\right]\mathrm{e}^{-ak}+\frac{\mu}{a} X^(1)(k+1)=[X(0)(1)−aμ]e−ak+aμ
由于GM(1,1)模型得到的是一次累加量,将GM(1,1)模型所得数据 X ^ ( 1 ) ( k + 1 ) \hat X^{(1)}(k+1) X^(1)(k+1) 经过累减还原为 X ^ ( 0 ) ( k + 1 ) \hat X^{(0)}(k+1) X^(0)(k+1) 即 X ( 0 ) X^{(0)} X(0) 的灰色预测模型如下式所示。
X ^ ( 0 ) ( k + 1 ) = ( e − a ^ − 1 ) [ X ( 0 ) ( n ) − μ ^ a ^ ] e − a ^ k \hat X^{(0)}(k+1) = (\mathrm{e}^{-\hat a}-1)\left[X^{(0)}(n)-\frac{\hat\mu}{\hat a}\right]\mathrm{e}^{-\hat ak} X^(0)(k+1)=(e−a^−1)[X(0)(n)−a^μ^]e−a^k
灰色预测模型可以利用后验差检验模型精度,使用后验差检验法的判别规则如下表所示。
| P | C | 模型精度 |
|---|---|---|
| >0.95 | <0.35 | 好 |
| >0.80 | <0.5 | 合格 |
| >0.70 | <0.65 | 勉强合格 |
| <0.70 | >0.65 | 不合格 |
在后验差检验判别参照表中,P和C计算公式如下式所示。
C = σ ( delta ) σ ( X ( 0 ) ) C=\frac{\sigma(\text{delta})}{\sigma(X^{(0)})} C=σ(X(0))σ(delta) P = S L P=\frac{S}{L} P=LS
在C的计算公式中, delta = ∣ X ( 0 ) − X ^ ( 0 ) ∣ \text{delta}=|X^{(0)}-\hat X^{(0)}| delta=∣X(0)−X^(0)∣, σ \sigma σ表示标准差, S S S表示的 ∣ delta − mean ( delta ) ∣ < 0.6745 ⋅ σ ( X ( 0 ) ) |\text{delta} - \text{mean}(\text{delta})|<0.6745\cdot\sigma(X^{(0)}) ∣delta−mean(delta)∣<0.6745⋅σ(X(0)) 数量,mean(delta)表示delta的平均值, L L L表示 X ( 0 ) X^{(0)} X(0)的长度。
灰色预测法的通用性比较强些,一般的时间序列场合都可以用,尤其适合那些规律性差且不清楚数据产生机理的情况。
相关代码如下。
# 自定义灰色预测函数
def GM11(x0): # x0为矩阵形式import numpy as npx1 = x0.cumsum() # 1-AGO序列# 紧邻均值(MEAN)生成序列z1 = (x1[:len(x1) - 1] + x1[1:]) / 2.0z1 = z1.reshape((len(z1), 1))B = np.append(-z1, np.ones_like(z1), axis = 1)Yn = x0[1:].reshape((len(x0)-1, 1))# 计算参数[[a], [b]] = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Yn) # 还原值f = lambda k: (x0[0] - b / a) * np.exp(-a * (k - 1)) - (x0[0] - b / a) * np.exp(-a * (k - 2)) delta = np.abs(x0 - np.array([f(i) for i in range(1, len(x0) + 1)]))C = delta.std() / x0.std()P = 1.0 * (np.abs(delta - delta.mean()) < 0.6745 * x0.std()).sum() / len(x0)# 返回灰色预测函数、a、b、首项、方差比、小残差概率return f, a, b, x0[0], C, P
(二)关键特征预测
利用灰色预测模型得到以下特征的2014年和2015年的预测值。
- 社会从业人数( x 1 x_1 x1)
- 社会消费品零售总额( x 3 x_3 x3)
- 城镇居民人均可支配收入( x 4 x_4 x4)
- 城镇居民人均消费性支出( x 5 x_5 x5)
- 年末总人口( x 6 x_6 x6)
- 全社会固定资产投资额( x 7 x_7 x7)
- 地区生产总值( x 8 x_8 x8)
- 居民消费水平( x 13 x_{13} x13)
相关代码如下。
import pandas as pd
import numpy as npnew_reg_data = pd.read_csv('../tmp/new_reg_data.csv') # 读取经过特征选择后的数据
data = pd.read_csv('../data/data.csv') # 读取总的数据
new_reg_data.index = range(1994, 2014)
new_reg_data.loc[2014] = None
new_reg_data.loc[2015] = None
Accuracy = [] # 存放灰色预测模型精度
l = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13']
for i in l:f = GM11(new_reg_data.loc[range(1994, 2014), i].as_matrix())[0]new_reg_data.loc[2014, i] = f(len(new_reg_data) - 1) # 2014年预测结果new_reg_data.loc[2015, i] = f(len(new_reg_data)) # 2015年预测结果new_reg_data[i] = new_reg_data[i].round(2) # 保留两位小数C = GM11(new_reg_data.loc[range(1994, 2014), 'x1'].as_matrix())[4]P = GM11(new_reg_data.loc[range(1994, 2014), 'x1'].as_matrix())[5]if P>0.95 and C<0.35:Accuracy.append('好')elif 0.8<P<=0.95 and 0.35<=C<0.5:Accuracy.append('合格')elif 0.7<P<=0.8 and 0.5<=C<0.65:Accuracy.append('勉强合格')else :Accuracy.append('不合格')new_reg_data = new_reg_data.iloc[:, 1:]
new_reg_data.loc['模型精度', :] = Accuracy
outputfile = '../tmp/new_reg_data_GM11.xls' # 灰色预测后保存的路径
# 提取财政收入列,合并至新数据框中
y = list(data['y'].values)
y.extend([np.nan, np.nan])
new_reg_data.loc[range(1994, 2016),'y'] = y
new_reg_data.to_excel(outputfile) # 结果输出
# 预测结果展示
print('预测结果为:\n', new_reg_data.loc[[2014, 2015, '模型精度'], :])

(三)SVR模型预测
构建支持向量回归预测模型,并将关键特征灰色预测代码中的预测结果代入建立的地方财政收入支持向量回归预测模型,预测2014年和2015年的财政收入。地方财政收入真实值与预测值的对比图如下图所示。
相关代码如下。
from sklearn.svm import LinearSVR
import matplotlib.pyplot as pltdata = pd.read_excel('../tmp/new_reg_data_GM11.xls') # 读取数据
data = data.drop('Unnamed: 0', axis=1, errors='ignore') # 如果该列存在则删除,不存在则跳过
data = data.drop(labels='模型精度', axis=0, errors='ignore') # 删除行
feature = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13'] # 特征所在列
data_train = data.loc[range(1994, 2014)].copy() # 取2014年前的数据建模
data_mean = data_train.mean()
data_std = data_train.std()
data_train = (data_train - data_mean) / data_std # 数据标准化
x_train = data_train[feature].as_matrix() # 特征数据
y_train = data_train['y'].as_matrix() # 标签数据
linearsvr = LinearSVR(random_state=123) # 调用LinearSVR()函数
linearsvr.fit(x_train, y_train)# 预测2014年和2015年财政收入,并还原结果。
x = ((data[feature] - data_mean[feature]) / data_std[feature]).as_matrix()
data[u'y_pred'] = linearsvr.predict(x) * data_std['y'] + data_mean['y']
outputfile = '../tmp/new_reg_data_GM11_revenue.xls'
data.to_excel(outputfile)
print('真实值与预测值分别为:\n', data[['y', 'y_pred']])print('预测图为:', data[['y', 'y_pred']].plot(style = ['b-o', 'r-*'])) # 画出预测结果图
plt.xlabel('年份')
plt.xticks(range(1994,2015,2))
plt.show()

五、性能度量
整理关键特征灰色预测的结果,如下表所示。从表中可以看出,2014年和2015年关键特征的灰色模型预测值精度均较高,可以用于预测2014年和2015年财政收入的关键特征数据。
| 2014预测值 | 2015预测值 | 预测精度等级 | |
|---|---|---|---|
| x 1 x_1 x1 | 8142148.24 | 8460489.28 | 好 |
| x 3 x_3 x3 | 7042.31 | 8166.92 | 好 |
| x 4 x_4 x4 | 43611.84 | 47792.22 | 好 |
| x 5 x_5 x5 | 35046.63 | 38384.22 | 好 |
| x 6 x_6 x6 | 8505522.58 | 8627139.31 | 好 |
| x 7 x_7 x7 | 4600.4 | 5214.78 | 好 |
| x 8 x_8 x8 | 18686.28 | 21474.47 | 好 |
| x 13 x_{13} x13 | 44506.47 | 49945.88 | 好 |
利用关键特征灰色预测的结果中的预测值和SVR模型预测2014年和2015年财政收入。整理后如下表所示,y_pred表示预测值。
| 年份 | y | y_pred | 年份 | y | y_pred | 年份 | y | y_pred |
|---|---|---|---|---|---|---|---|---|
| 1994 | 64.87 | 37.825855 | 2002 | 269.1 | 220.02944 | 2010 | 1399.16 | 1378.7089 |
| 1995 | 99.75 | 84.460566 | 2003 | 300.55 | 300.82194 | 2011 | 1535.14 | 1536.3989 |
| 1996 | 88.11 | 95.400722 | 2004 | 338.45 | 383.72498 | 2012 | 1579.68 | 1739.0082 |
| 1997 | 106.07 | 107.01212 | 2005 | 408.86 | 463.34936 | 2013 | 2088.14 | 2085.4473 |
| 1998 | 137.32 | 151.49711 | 2006 | 476.72 | 554.94385 | 2014 | 2187.1799 | |
| 1999 | 188.14 | 188.54074 | 2007 | 838.99 | 691.35772 | 2015 | 2538.0938 | |
| 2000 | 219.91 | 219.91 | 2008 | 843.14 | 843.01617 | |||
| 2001 | 271.91 | 230.76462 | 2009 | 1107.67 | 1087.4603 |
支持向量回归预测模型的代码结果中已给出地方财政收入真实值与预测值的对比图。利用回归模型性能度量指标对地方财政收入预测模型进行性能度量。如下表所示,平均绝对误差与中值绝对误差较小,可解释方差值与R方值十分接近1,从真实值与预测值的对比图可以看出,预测值和真实值曲线基本重合,表明建立的支持向量回归模型拟合效果优良,可以用于预测财政收入。
相关代码如下。
from sklearn.metrics import mean_absolute_error # 平均绝对误差
from sklearn.metrics import median_absolute_error # 中值绝对误差
from sklearn.metrics import explained_variance_score # 可解释方差
from sklearn.metrics import r2_score # R方值
import pandas as pddata = pd.read_excel('../tmp/new_reg_data_GM11_revenue.xls') # 读取数据
data = data.drop('Unnamed: 0', axis=1, errors='ignore') # 如果该列存在则删除,不存在则跳过
mean_ab_error = mean_absolute_error(data.loc[range(1994, 2014), 'y'], data.loc[range(1994,2014), 'y_pred'], multioutput = 'raw_values')
median_ab_error = median_absolute_error(data.loc[range(1994, 2014), 'y'], data.loc[range(1994, 2014), 'y_pred'])
explain_var_score = explained_variance_score(data.loc[range(1994, 2014), 'y'], data.loc[range(1994, 2014), 'y_pred'], multioutput = 'raw_values')
r2 = r2_score(data.loc[range(1994, 2014), 'y'], data.loc[range(1994, 2014), 'y_pred'], multioutput = 'raw_values')print('平均绝对误差:', mean_ab_error, '\n', '中值绝对误差:', median_ab_error, '\n', '可解释方差:', explain_var_score, '\n', 'R方值:', r2)

| 指标 | 指标值 |
|---|---|
| 平均绝对误差 | 34.26585201 |
| 中值绝对误差 | 17.749581395641485 |
| 可解释方差 | 0.99086819 |
| R方值 | 0.99085796 |
小结
本案例结合某市财政收入原始数据,重点介绍了SVR模型在财政预测方面的应用,主要内容包含数据探索、特征选取、模型构建和性能度量。其中利用Pearson相关系数探对原始数据进行相关性分析,得到与财政收入相关性较高的特征,并且了解到各特征之间存在严重的共线性。利用Lasso回归模型对原始特征进行筛选,得到用于建模的关键特征。
针对历史数据,构建灰色预测模型,对所选关键特征2014年和2015年的值进行预测。最后根据所选特征原始数据建立SVR模型,然后利用灰色预测模型对所选特征的预测值进行预测,最终得到2014年和2015年的财政收入预测值。利用回归模型性能度量指标对SVR模型进行评价,模型精度较高,可以用于指导实际工作。
附:以上文中的数据集及相关资源下载地址:
链接:https://pan.quark.cn/s/bc0a61378df2
提取码:n2Kw
相关文章:
【机器学习与数据挖掘实战】案例01:基于支持向量回归的市财政收入分析
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈机器学习与数据挖掘实战 ⌋ ⌋ ⌋ 机器学习是人工智能的一个分支,专注于让计算机系统通过数据学习和改进。它利用统计和计算方法,使模型能够从数据中自动提取特征并做出预测或决策。数据挖掘则是从大型数…...

Idea实现定时任务
定时任务 什么是定时任务? 可以自动在项目中根据设定的时长定期执行对应的操作 实现方式 Spring 3.0 版本之后自带定时任务,提供了EnableScheduling注解和Scheduled注解来实现定时任务功能。 使用SpringBoot创建定时任务非常简单,目前主要…...

Linux 安装NFS共享文件夹
程序默认使用2049端口,如果被占用需要修改端口104设置为服务端 122设置为客户端 一、在线安装(服务端和客户端执行) yum install nfs-utils rpcbind -y二、配置启动参数(服务端执行) 104服务器/mnt路径下创建shareda…...

bash 判断内存利用率是否高于60%
在 Bash 脚本中,可以通过 free 命令获取内存利用率,然后结合 awk 和条件判断语句实现监控内存利用率是否高于 60%。以下是一个示例脚本: 1. 示例脚本 #!/bin/bash# 获取总内存和已使用内存 total_mem$(free | awk /Mem:/ {print $2}) used_…...

推送(push)项目到gitlab
文章目录 1、git init1.1、在当前目录中显示隐藏文件:1.2、查看已有的远程仓库1.3、确保你的本地机器已经生成了 SSH 密钥:1.4、将生成的公钥文件(通常位于 ~/.ssh/id_rsa.pub)复制到 GitLab 的 SSH 设置中:1.5、测试 …...

centos9升级OpenSSH
需求 Centos9系统升级OpenSSH和OpenSSL OpenSSH升级为openssh-9.8p1 OpenSSL默认为OpenSSL-3.2.2(根据需求进行升级) 将源码包编译为rpm包 查看OpenSSH和OpenSSL版本 ssh -V下载源码包并上传到服务器 openssh最新版本下载地址 wget https://cdn.openb…...

硬件成本5元-USB串口采集电表数据完整方案-ThingsPanel快速入门
ThingsPanel开源物联网平台支持广泛的协议,灵活自由,本文介绍ThingsPanel通过串口来采集电表数据,简单易行,成本低廉,适合入门者学习试验,也适合一些特定的应用场景做数据采集。 适用场景: 降低…...

在AWS EMR上用Hive、Spark、Airflow构建一个高效的ETL程序
在AWS EMR(Elastic MapReduce)上构建一个高效的ETL程序,使用Hive作为数据仓库,Spark作为计算引擎,Airflow作为调度工具时,有几个关键的设计与实施方面需要注意。 在AWS EMR上构建高效的ETL程序,…...
css选择器、css的三大特性)
前端(四)css选择器、css的三大特性
css选择器、css的三大特性 文章目录 css选择器、css的三大特性一、css介绍二、css选择器2.1 基本选择器2.2 组合选择器2.3 交集并集选择器2.4序列选择器2.5属性选择器2.6伪类选择器2.7伪元素选择器 三、css三大特性3.1 继承性3.2 层叠性3.3 优先级 一、css介绍 CSS全称为Casca…...

vscode 打开 setting.json
按下Ctrl Shift P(Windows/Linux)或Cmd Shift P(Mac)来打开命令面板。输入open settings,然后选择 Open User Settings(JSON)。打开settings.json文件 ------修改设置-----: 1、 html代码的行长度&am…...

关于网络安全攻防演化博弈的研究小议
1. 拉高视角,从宏观看网络安全攻防 伴随着信息化的发展,网络安全的问题就一直日益突出,与此同时,网络安全技术也成为研究热点,直到今日也没有停止。 从微观来看,网络安全技术研究指的是针对某项或某几项…...
)
【FAQ】HarmonyOS SDK 闭源开放能力 —Push Kit(7)
1.问题描述: 推送通知到手机,怎么配置拉起应用指定的页面? 解决方案: 1、如果点击通知栏打开默认Ability的话, actionType可以设置为0, 同时可以在.clickAction.data中,指定待跳转的page页面…...

远程桌面防护的几种方式及优缺点分析
远程桌面登录是管理服务器最主要的方式,于是很多不法分子打起了远程桌面的歪心思。他们采用暴力破解或撞库的方式破解系统密码,悄悄潜入服务器而管理员不自知。 同时远程桌面服务中的远程代码执行漏洞也严重威胁着服务器的安全,攻击者可以利…...

ASP.NET|日常开发中连接Sqlite数据库详解
ASP.NET|日常开发中连接Sqlite数据库详解 前言一、安装和引用相关库1.1 安装 SQLite 驱动1.2 引用命名空间 二、配置连接字符串2.1 连接字符串的基本格式 三、建立数据库连接3.1 创建连接对象并打开连接 四、执行数据库操作4.1 创建表(以简单的用户表为例…...

python的自动化seleium安装配置(包含谷歌的chromedriver)
目录 前言介绍 一、下载谷歌浏览器chromedriver (一)查看谷歌浏览器版本 (二)去官网下载谷歌驱动(chromdriver) (三)谷歌浏览器安装位置解压 (四)配置环境变量 二、pychram里下载安装selenium 三、测试selenium是否成功 前言介绍 Selenium是一个开源的自动化测试工具&…...

QT requested database does not belong to the calling thread.线程中查询数据报错
QT requested database does not belong to the calling thread.线程中查询数据报错 QString name "ttx"; QSqlQueryModel* sql_model; QString sql_comm QString("select * from dssb_moddve_loddt_tab where name%1").arg(name); sql_model->set…...

服务器一般装什么系统?
在服务器管理中,操作系统的选择是一个关键因素,它直接影响到服务器的稳定性、性能和可维护性。那么为什么有些服务器选择Linux,而不是Windows?选择合适的操作系统对服务器的性能和安全性有多么重要? 在众多操作系统中…...

Linux vi/vim 编辑器使用教程
Linux vi/vim 编辑器使用教程 引言 Linux 系统中的 vi 和 vim 是非常强大的文本编辑器,它们以其高效性和灵活性而闻名。vim 是 vi 的增强版,提供了更多的功能和改进的用户界面。本文将详细介绍 vi/vim 的基本用法,包括打开文件、编辑文本、…...

JavaEE多线程案例之阻塞队列
上文我们了解了多线程案例中的单例模式,此文我们来探讨多线程案例之阻塞队列吧 1. 阻塞队列是什么? 阻塞队列是⼀种特殊的队列.也遵守"先进先出"的原则. 阻塞队列是⼀种线程安全的数据结构,并且具有以下特性: 当队列满的时候,继续⼊队列就会…...

梳理你的思路(从OOP到架构设计)_基本OOP知识04
目录 1、 主动型 vs.基於被动型 API 1)卡榫函数实现API 2)API的分类 3)回顾历史 4)API >控制力 2、 结语&复习: 接口与类 1)接口的表示 2)Java的接口表示 1、 主动型 vs.基於被动…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...
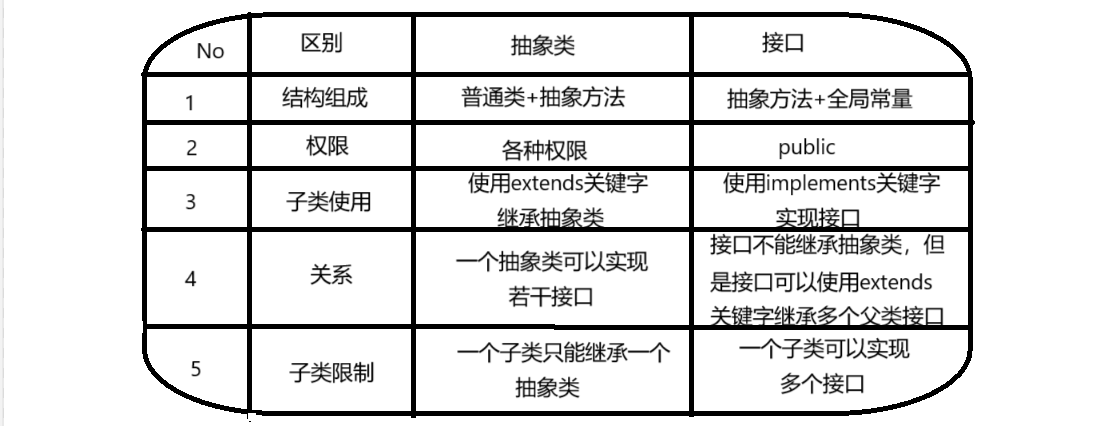
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...
消息队列系统设计与实践全解析
文章目录 🚀 消息队列系统设计与实践全解析🔍 一、消息队列选型1.1 业务场景匹配矩阵1.2 吞吐量/延迟/可靠性权衡💡 权衡决策框架 1.3 运维复杂度评估🔧 运维成本降低策略 🏗️ 二、典型架构设计2.1 分布式事务最终一致…...
高考志愿填报管理系统---开发介绍
高考志愿填报管理系统是一款专为教育机构、学校和教师设计的学生信息管理和志愿填报辅助平台。系统基于Django框架开发,采用现代化的Web技术,为教育工作者提供高效、安全、便捷的学生管理解决方案。 ## 📋 系统概述 ### 🎯 系统定…...