C++7:STL-模拟实现vector
目录
vector的成员变量
构造函数
reserve
size()
capacity()
push_back
一些小BUG
赋值操作符重载
析构函数
【】操作符重载
resize
pop_back
Insert
迭代器失效
erase
二维数组问题
总结一下
vector,翻译软件会告诉你它的意思是向量,但其实它就是个顺序表容器,与我们刚开始实现的顺序表大差不差,但是模板的应用让它变得更加万能,接下来我们就尝试去了解学习源码是如何实现vector的。
vector的使用:
int main()
{vector<int> v;v = { 1,2,3,4,5 };for (auto& e : v){cout << e;}
} 
由于模板的使用,vector不仅能存放内置类型,也可以存放自定义类型,比如说用vector套vector
当然vector还有很多的应用型接口,在这里不记述,有需要的话请移步至这个网站:https://cplusplus.com/reference/
看上去vector的使用相当方便,也加入了我们的老熟人模板参数,那么我们就来模拟实现一下。
vector的成员变量
借助顺序表的前车之鉴,我们推断vector的成员变量的实现应该是如下这样的
namespace myvector
{template<class T>class vector{public:private:T* _v;size_t _size;size_t _capacity;};
}但是事与愿违,跑去查询STL的源码给了我们当头棒喝
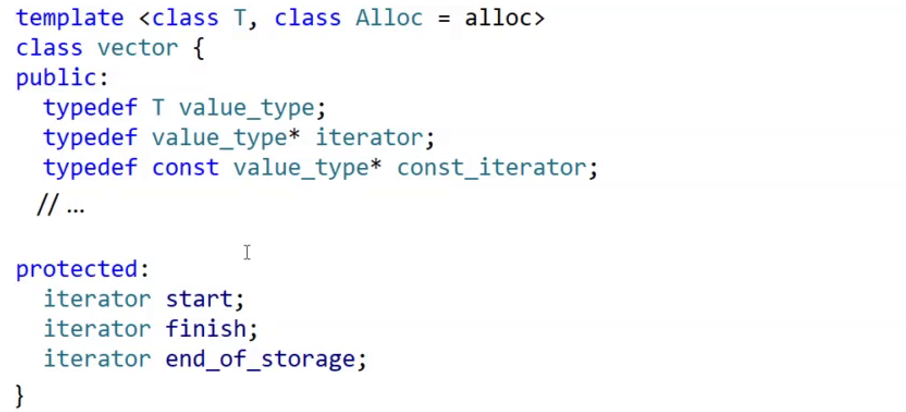
坏了,怎么是3个迭代器?我们看到,迭代器的定义是两个typedef的套娃,它的本质依旧是T*,Start我们可以理解,顺序表结构的头指针,但是为什么size和capacity变成了finish和end of storage?
在《SLT源码剖析》中我们得到了答案
那么其实它们的本质没什么太大的分别,这样也有助于范式使用。但我这边还是比较喜欢size和capacity就不更改了。
构造函数
我们先实现一个最基本的无参版本
//无参构造函数
vector():_start(nullptr), _size(nullptr), _capacity(nullptr)
{}然后是传参版本
vector(int n, const T& val = T()):_start(nullptr), _finish(nullptr), _endofstorge(nullptr){reverse(n);for (int i = 0; i < n; ++i){push_back(val);}}
reserve
为了能实现一个有基本功能的vector,我们先解决一下扩容的问题,然后就可以愉快的写push_back了。
由于扩容的前提是不要缩容,那么我们就需要得到当前vector的size,但是不同于string可以直接得到当前的size,我们需要额外写一个函数来获取,不过也不算难事,毕竟也是比较常用的函数。
两个同类型的指针相减,得到的就是它们之间的数据类型个数。
size()
size_t size()
{return _size - _start;
}capacity()
size_t capacity()
{return _capacity - _start;
}那么就可以拿来实现reserve了,重置空间的逻辑跟string差不太多,首先我们检查是否发生了缩容,然后借助传入的需要开辟的空间个数来new出来一个新空间,接着把旧空间的数据用memcpy拷贝过去,然后新空间的size和capacity还需要重置一下,因为它们的本体是指针,指向的空间已经被销毁了,我们就以当前的新头指针+=上原先的数据个数让其重归正轨。
如下的代码有小BUG,我们后面讲
void reserve(const size_t n)
{if (n > capacity()){T* tmp = new T[n];//如果旧空间就是需要被开辟的,也就是_start是个空指针,不需要拷贝直接赋值就行//重置空间的话就往下走。if (_start != nullptr){memcpy(tmp, _start, _size);delete[] _start;}_start = tmp;_size = _start + size();_capacity = _start + n;}
}push_back
有了空间开辟的函数,push_back就没什么难度了。
void push_back(const T& val){if (_size == _capacity){size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);}*_size = val;++_size;}一些小BUG
到这里时,一个基本的vector就可以使用了,但是还是有一个小问题,假如我们直接运行如上代码,就会报如下的错误。
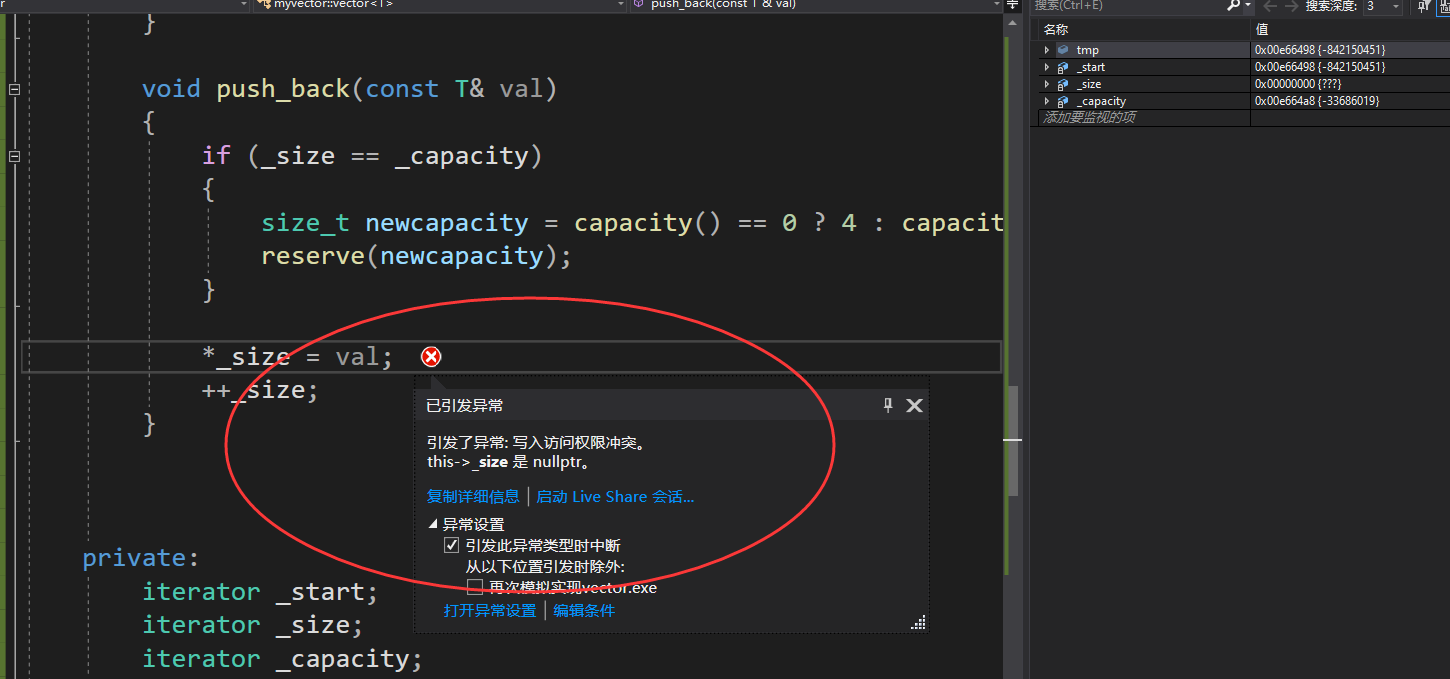
怎么回事?为什么_size 还是空?调试时已经走过了前面的过程,那么问题就应该出现在扩容的时候,_size 赋值的方法出现了问题。
我们回到reseve函数,发现我们想利用size()函数来获得当前的数据个数时,忽略了此时的_size本身还是指向旧空间的,而_start早已更新,两个指针相减根本得不出正确答案
那么我们还是需要保存一下旧空间的个数
void reserve(const size_t n){if (n > capacity()){T* tmp = new T[n];size_t oldsize = size();if (_start != nullptr){memcpy(tmp, _start, sizeof(T)*size());delete[] _start;}_start = tmp;_size = _start + oldsize;_capacity = _start + n;}
}再插入5个数据试试看

没有问题。
赋值操作符重载
为了应对赋值的问题,编译器默认生成的赋值操作符重载函数是浅拷贝会导致析构两次而崩溃的问题,所以我们还是需要实现一下
赋值的情况发生在同类型的情况下,所以返回值和参数都应该是vector
然后借用我们之前string的现代写法,也就是把一份拷贝与当前的this进行交换,我们再实现一个简单的swap函数
void swap(vector<T>& v)
{std::swap(_start, v._start);std::swap(_size, v._size);std::swap(_capacity, v._capacity);
}那么为了不影响到赋值操作符左边的值,我们不传引用,直接传值,产生一个拷贝构造然后交换。
vector<T>& operator = (vector<T> tmp)
{swap(tmp);return *this;
}析构函数
//析构函数~vector(){delete[] _start;_start = _size = _capacity = nullptr;}【】操作符重载
T& operator[](size_t n)
{assert(pos < size());return *(_start+n);
} resize
resize函数同string的逻辑没什么太多的区别,唯一需要注意的是关于填充缺省值的问题。
当n>_capacity的时候,需要扩容,当n>size的时候需要向多出来的空间填充缺省值,当n<size的时候需要重置当前size的位置到n
void resize(const size_t n,T val = T())
{if (n > capacity()){reserve(n);}if (n > size()){while (_size < _start + n){*_size = val;++_size;}}else{_size = _start + n;}
}
在这里val为了适应自定义类型,采用了匿名构造的方式来为val赋值,对于内置类型也是生效的
T val = T()pop_back
void pop_back(){assert(_size > _start);--_size;}
Insert
我们先看看描述
传入一个迭代器,然后在迭代器位置插入数据。那么我们简单实现一个迭代器
//迭代器
iterator begin()
{return _start;
}iterator end()
{return _size - 1;
}由于auto的使用原理是自动推导,所以当我们实现了某个容器的迭代器的时候,就可以正常的使用范围for了,auto可以在范围for中成功的推导出来容器的迭代器从而实现遍历。
接下来是insert的主体逻辑
void insert(iterator n, const T& val){assert(n >= _start);//若满扩容if (_size == _capacity){size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);}if (n < _size){iterator end = _size;while (end > n){*end = *(end - 1);--end;}*n = val;++_size;}}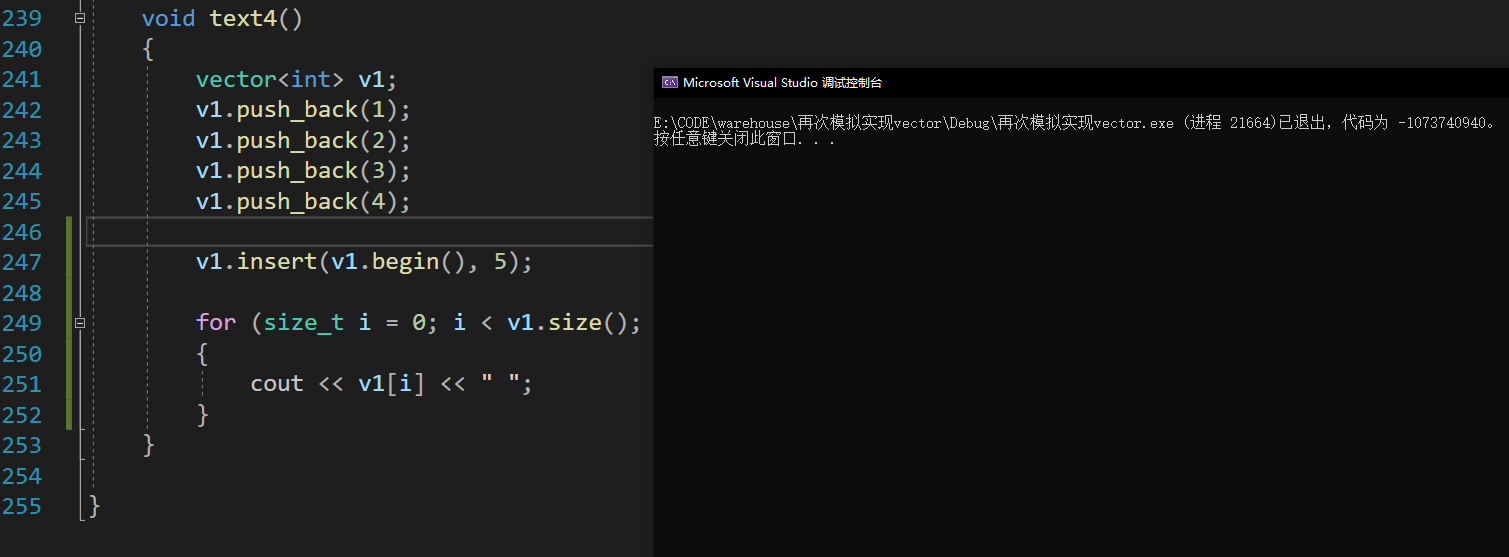
坏了,怎么崩溃了?发生什么事了?我们调试看看
通过调试,我们发现n的值完全不在当前_start 到 _size 的位置之间,这个while循环也走了非常多遍,而且这个问题是在扩容时才发生的,那么我们就得出了一个最初的结论,n所指向的位置在扩容后无法正确生效,也就是迭代器失效问题。
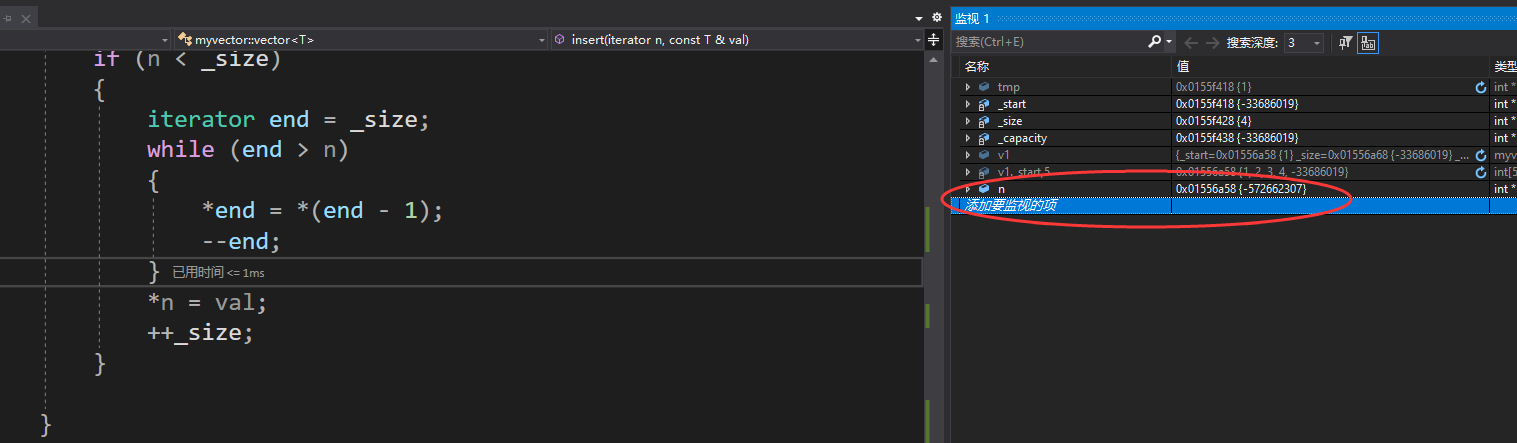
迭代器失效
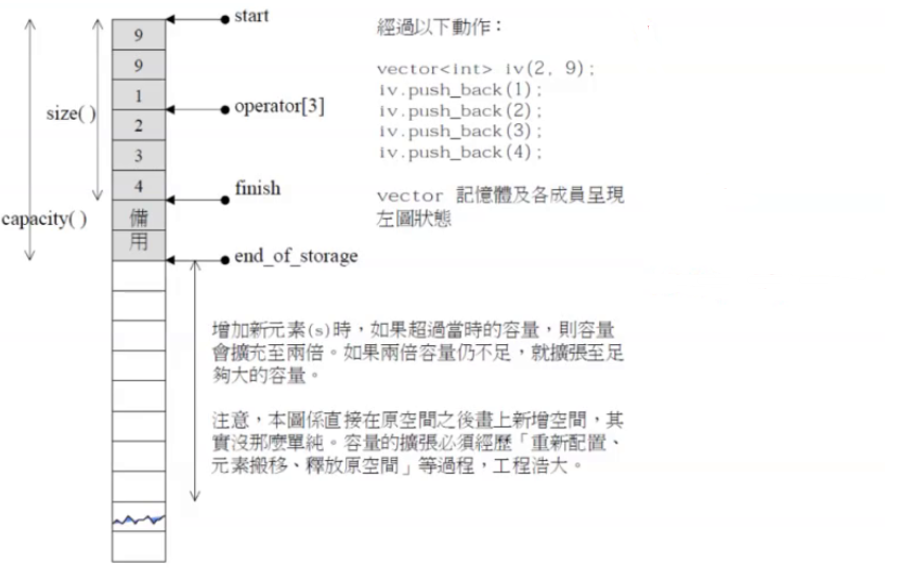
迭代器失效原因如图所示,为了更好的理解,传入的迭代器n更名为pos


那么为了能成功的修正pos的新位置,跟我们处理pushback的方法一样,我们保存之前的数据长度,然后在新的空间更新pos
void insert(iterator n, const T& val){assert(n >= _start);//扩容会引发迭代器失效的问题,需要更新迭代器if (_size == _capacity){size_t length = n - _start;size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);n = _start + length;}if (n < _size){iterator end = _size;while (end > n){*(end) = *(end - 1);end--;}*n = val;//整体大小+1,更新_size_size++;}}那么通过上面的分析,我们知晓了迭代器失效的具体原因,而迭代器失效指向的真正失效其实是inset之后的迭代器不能再使用了。因为我们是传值调用,inset外部的迭代器依然没有更新,假如我们想要继续使用很有可能发生越界访问的问题。
erase
void erase(iterator n)
{assert(n >= _start);assert(n < _size);if (n == _size - 1){pop_back();return;}iterator cur = n + 1;while (cur < _size){*(cur - 1) = *cur;++cur;}--_size;
}二维数组问题
vector容器本身服务的对象是各种各样的类型,所以当我们希望在vector内部存放其他容器类型的时候,它也应该是支持的,我们就拿我们自己实现的vector来尝试实现一个二维数组。
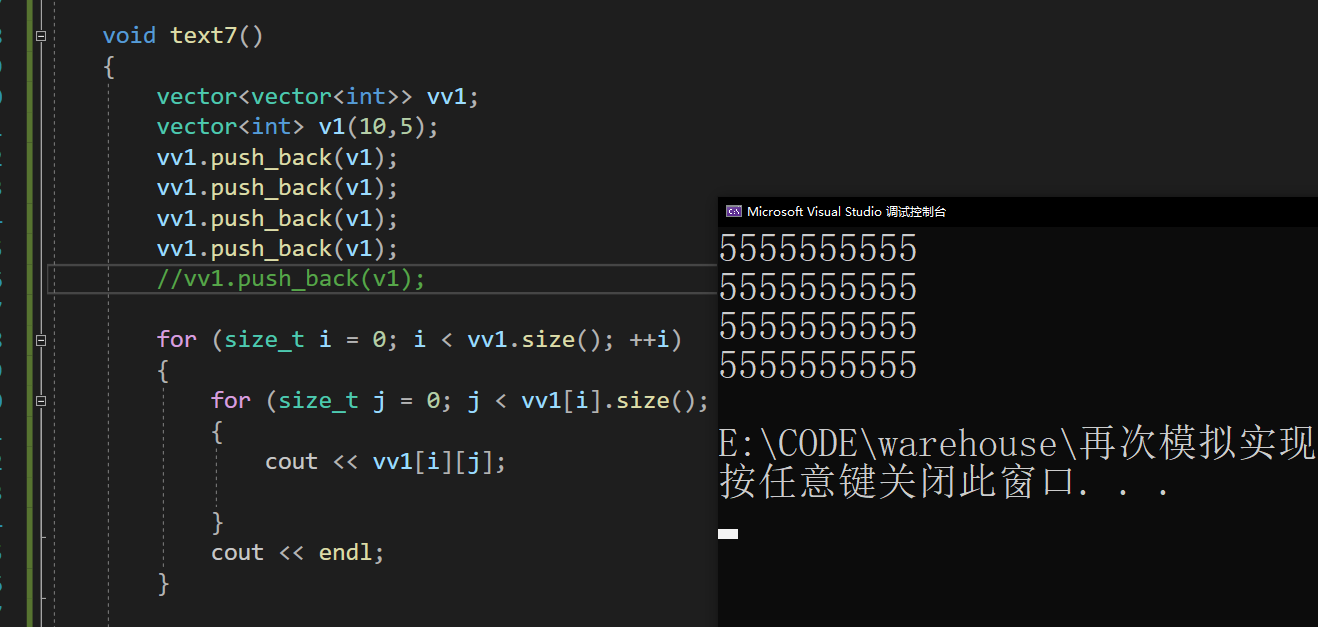
没啥问题,但是一旦发生扩容会直接崩溃
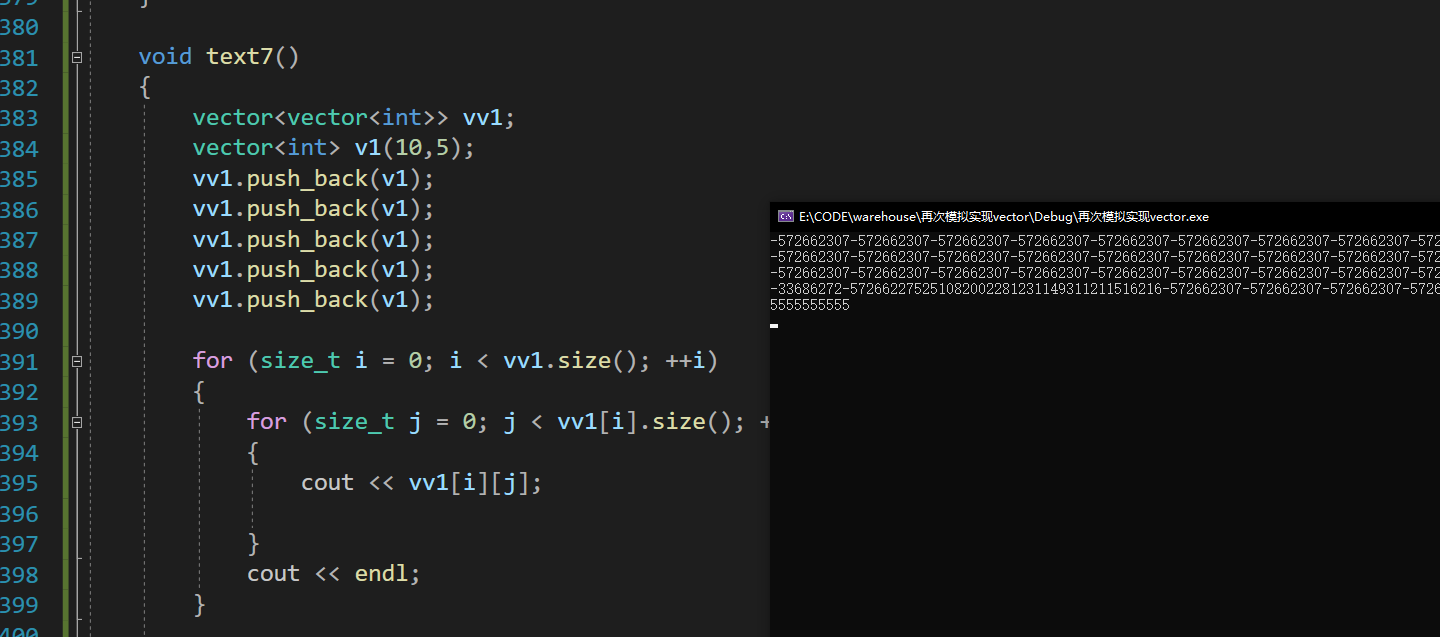
通过调试我们发现问题发生在析构的时候

但追根溯源,析构能发生错误的时候肯定是空间的开辟发生了问题,那么罪魁祸首应该就是我们的reserve了
那么为什么创建二维数组的时候才报错?还是需要画图来缕一缕。
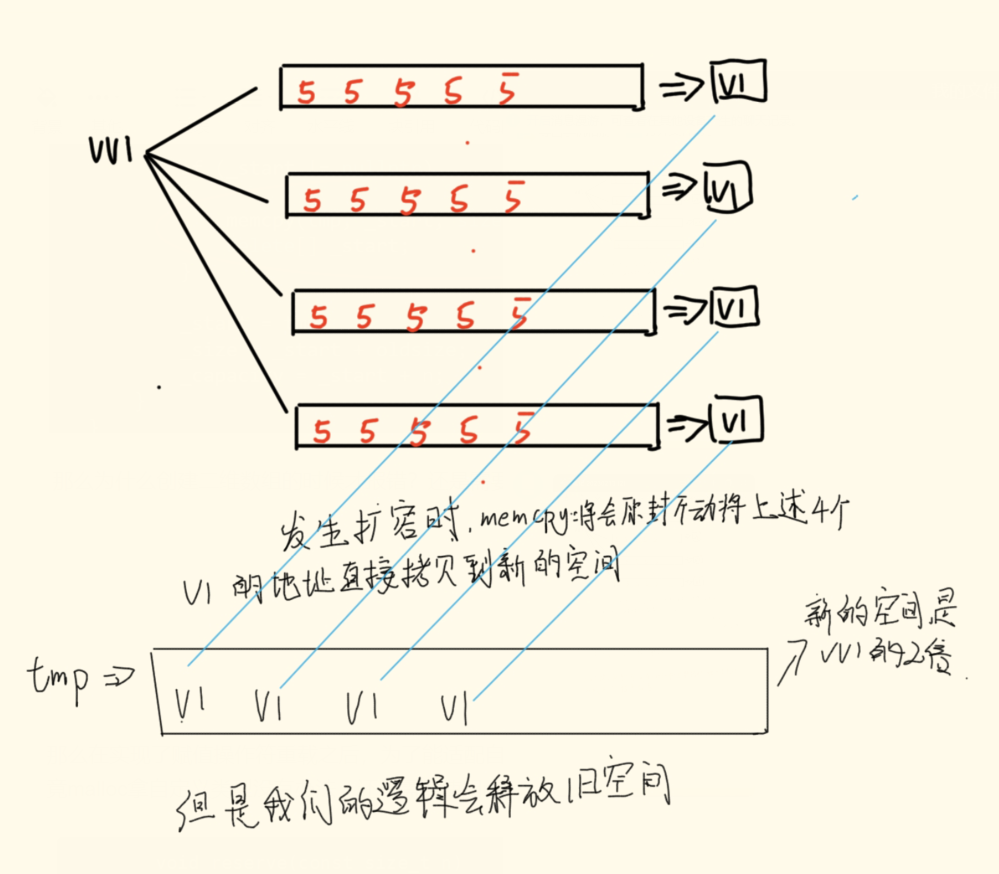

那么为了避免这种情况,我们应该抛弃malloc换成更加深层次的拷贝,也就是新开辟一个空间之后把原本的值原封不动的拷贝一份新的,也就是内容相同但是地址不同的新拷贝再放入扩容之后的空间。
void reserve(const size_t n){if (n > capacity()){T* tmp = new T[n];size_t oldsize = size();if (_start){for (size_t i = 0; i < oldsize; ++i){tmp[i] = _start[i];}//释放旧空间防止内存泄漏delete[]_start;}_start = tmp;_size = tmp + oldsize;_capacity = _start + n;}}总结一下
根据以上的模拟实现,我们基本上了解了vector的基本结构以及接口的使用,其本质不同于顺序表,为了服务于自定义类型以及泛型变成,成员变量是迭代器,而迭代器的本身则是类模板参数,实现并不算困难但是细节还是需要额外处理。

到此,模拟vector的概述就结束了,感谢阅读!希望对你有点帮助!
相关文章:
C++7:STL-模拟实现vector
目录 vector的成员变量 构造函数 reserve size() capacity() push_back 一些小BUG 赋值操作符重载 析构函数 【】操作符重载 resize pop_back Insert 迭代器失效 erase 二维数组问题 总结一下 vector,翻译软件会告诉你它的意思是向量,但其…...

笑死,面试官又问我SpringBoot自动配置原理
面试官:好久没见,甚是想念。今天来聊聊SpringBoot的自动配置吧? 候选者:嗯,SpringBoot的自动配置我觉得是SpringBoot很重要的“特性”了。众所周知,SpringBoot有着“约定大于配置”的理念,这一…...
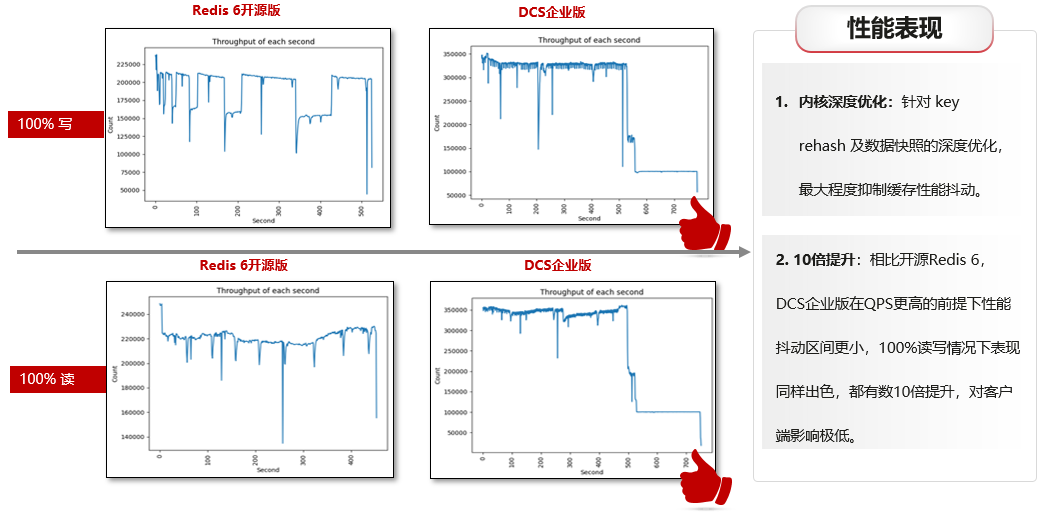
分布式缓存服务DCS-企业版性能更强,稳定性更高
背景介绍 近年来,随着各行业业务需求急速增加,数据量和并发访问量呈指数级增长,原来只能依附于关系型数据库的传统“缓存”逐渐难以支撑上层业务,开源Redis也面临着如“容量有限”、 “可靠性有限”、 “数据重复拷贝,…...

HTTP基本原理
目录URL简单定义格式HTTP和HTTPSHTTP的请求过程。请求响应响应体HTTP2.0总结URL 简单定义 通过一个链接,使我们可以找到网络上的某个资源,这个链接就是URL。 格式 URL并不是随便写的,而是有固定的格式。基本的组成格式如下。 schme://[us…...
最新版本详细保姆级安装教程)
【云原生】Kubernetes(k8s)最新版本详细保姆级安装教程
前言 Kubernetes简称k8s,是一个开源的,用于管理云平台中多个主机上的容器化的应用,k8s目标是让部署容器化的应用简单并且高效,k8s提供了应用部署,规划,更新,维护的一种机制。 本文是总结了在安…...
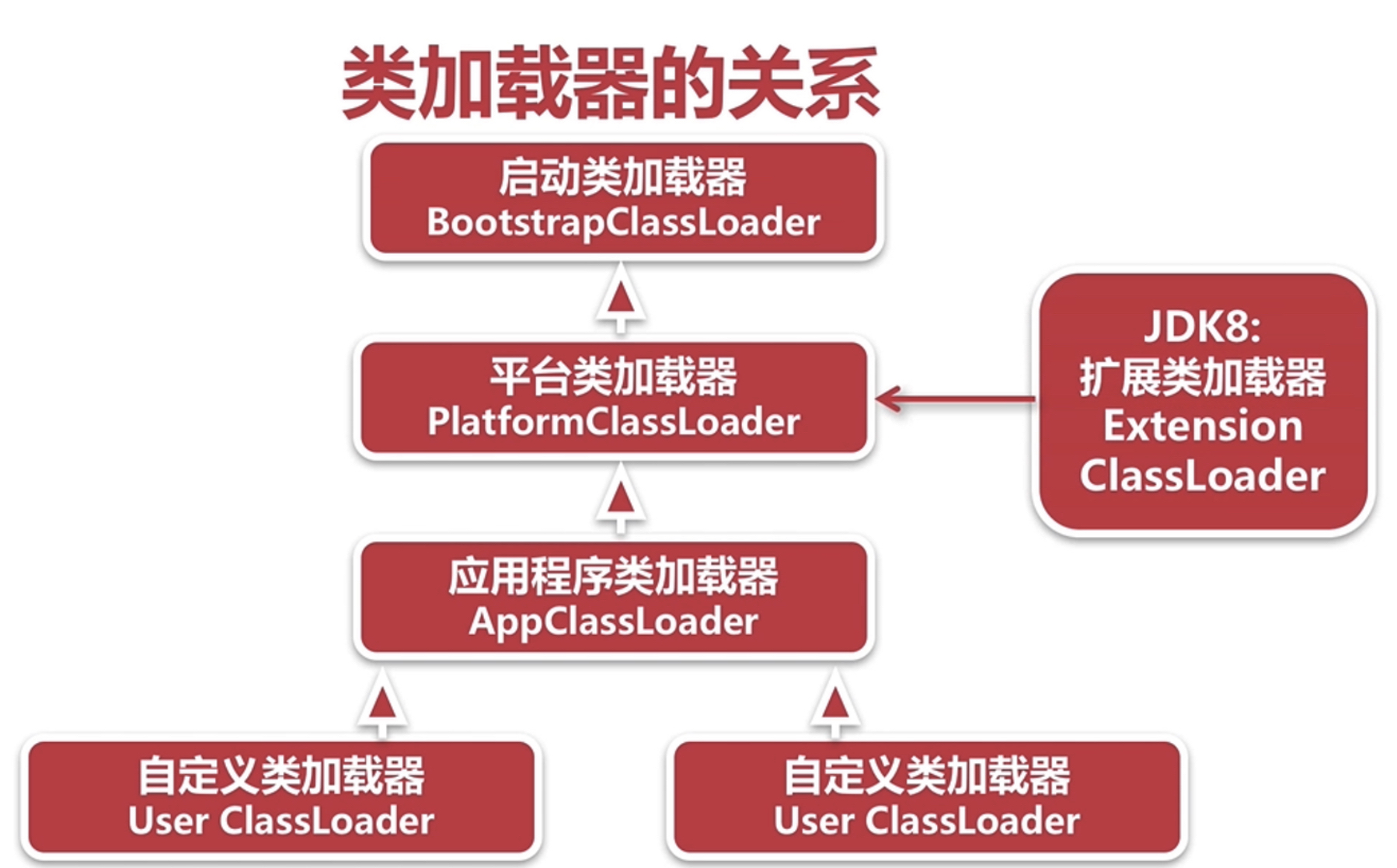
JVM - 类加载,连接和初始化
目录 类加载和类加载器 概述 类加载要完成的功能 加载类的方式 类加载器 类加载器的关系 类加载器说明 双亲委派模型 工作过程如下: 双亲委派模型说明: 破坏双亲委派模型: 类连接和初始化 类连接主要验证的内容 类连接中的解析…...
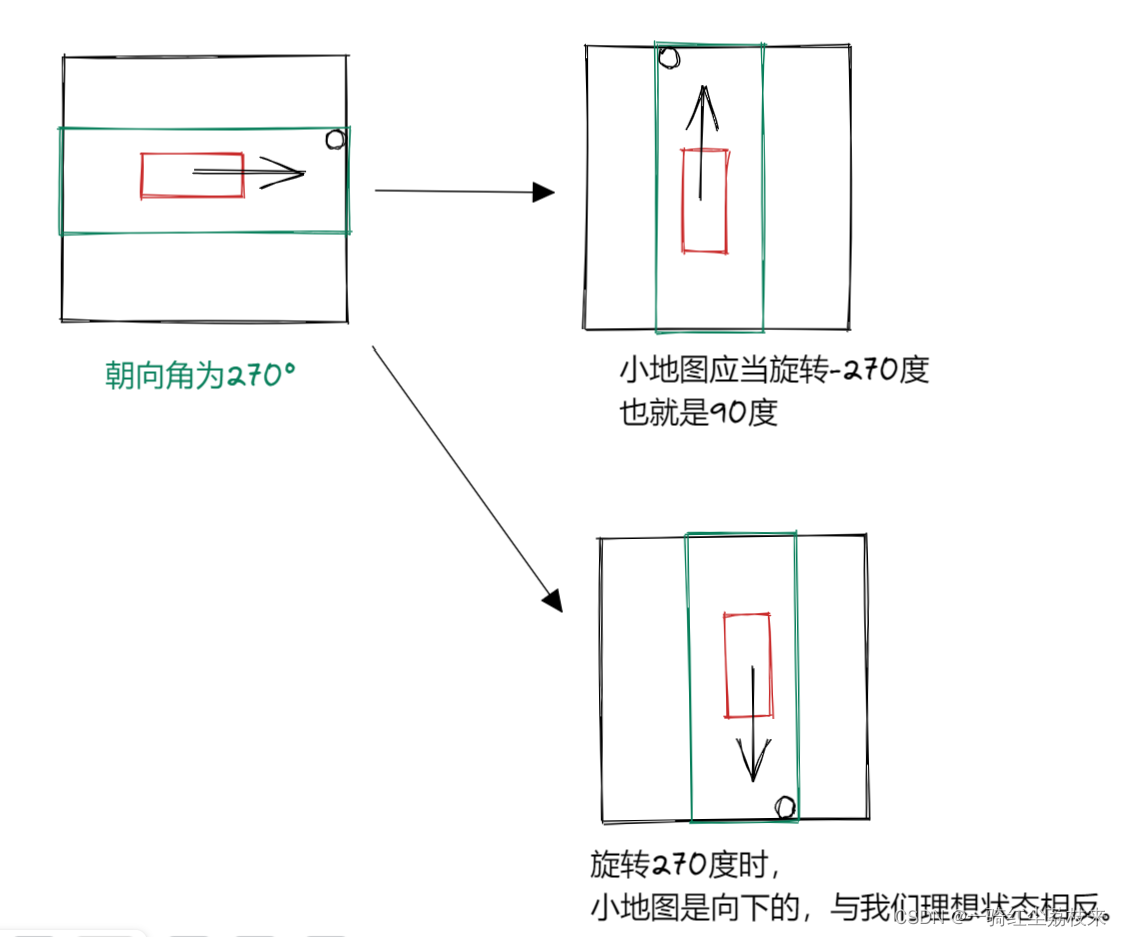
[carla]关于odometry坐标中的角度坐标系 以及 到地图的映射问题
1.获取车辆的Odometry原始信息 在carla中,通过订阅/carla/ego_vecle/odometry 可以查看车辆的全局位置信息,例如: > header: seq: 118872stamp: secs: 5946nsecs: 5720187frame_id: "map" child_frame_id: "ego_vehicle" pos…...

Python 正则表达式
正则表达式主要用来查找和匹配字符串的。 一、正在表达式基础 字符 描述 示例 TIY\ 示意特殊序列(也可用于转义特殊字符)如:空白字符 "\s" . 任何字符(换行符除外) "he..o" ^ 起始于 "^h…...

spark03-读取文件数据分区数量个数原理
代码val conf: SparkConf new SparkConf().setMaster("local").setAppName("wordcount")val sc: SparkContext new SparkContext(conf)val rdd: RDD[String] sc.textFile("datas/1.txt",2)rdd.saveAsTextFile("output")数据格式 &a…...
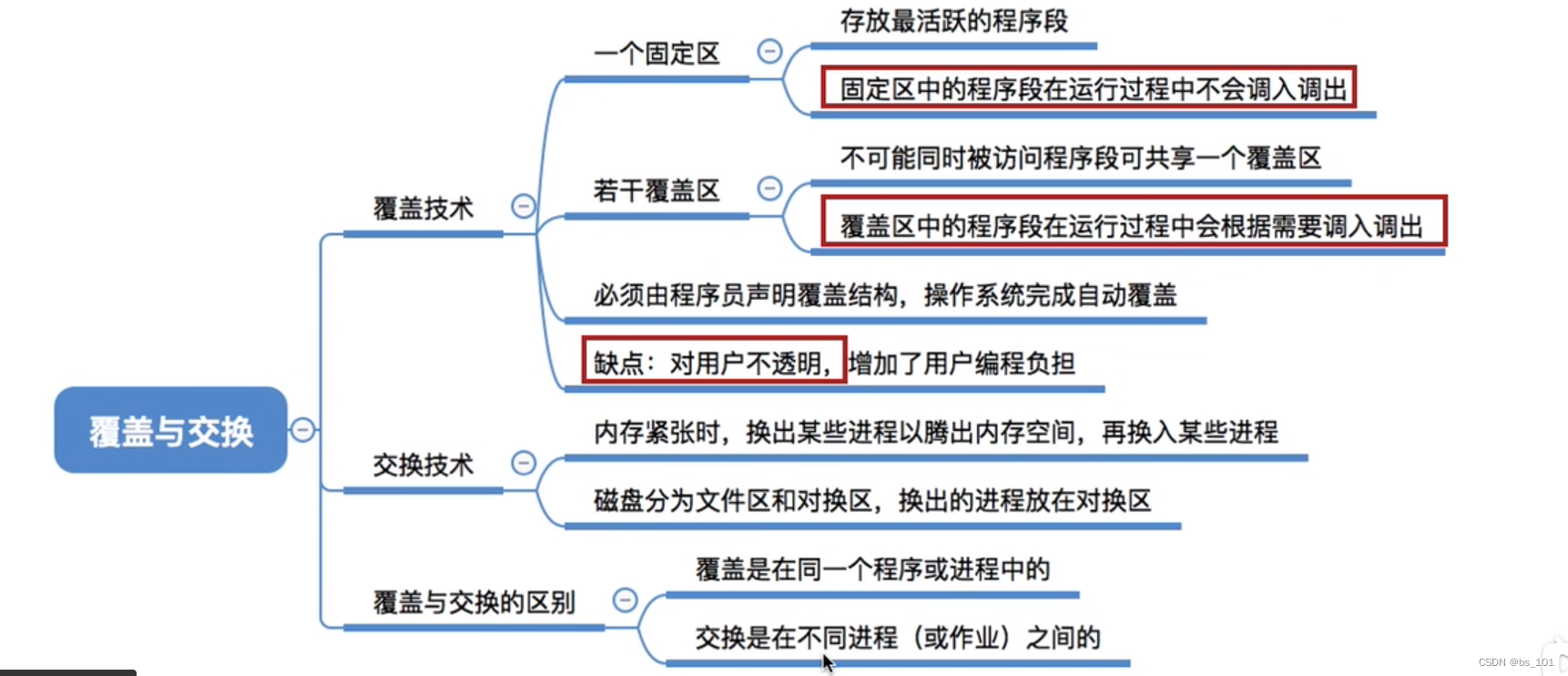
操作系统(day08)内存
存储单元 内存的几个基本概念 存储单元 内存地址从0开始,每个地址对应一个存储单元 存储单元大小根据计算机按照什么方式编址 按字节编址 则每个存储单元大小为一字节,即1B,即8个二进制位按字编址 看这个计算的字长是多少位,如…...
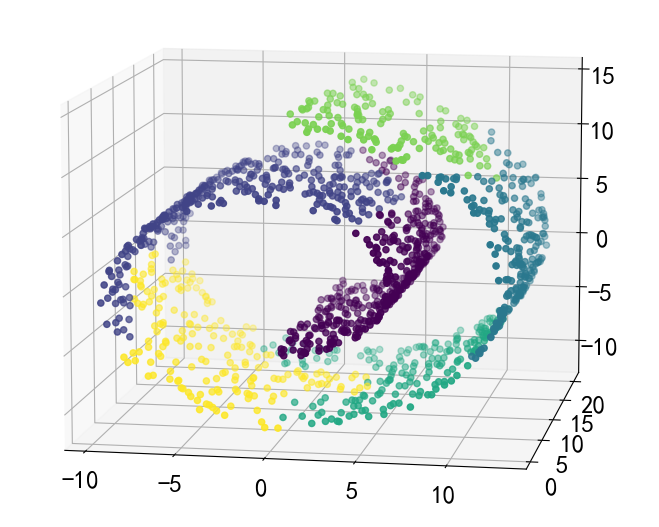
11- 聚类算法 (KMeans/DBSCAN/agg) (机器学习)
聚类算法 聚类算法和降维算法那都属于无监督算法。KMeans 是以一个值为中心, 然后所有其他点到该点距离最小值的累积和。 kmeans KMeans(n_clusters3) # n_clusters 分类数量 kmeans.fit(data.iloc[:,1:]) # 无监督,只需要给数据X就可以 DBSCAN 算法是…...

日日顺供应链|想要看清供应链发展趋势,先回答这三个问题
技术变革如何支撑供应链及管理服务的发展? 数字化与科技化开始承托供应链管理能力的升级与变革? 如何从客户需求的纬度反推供应链及管理服务的模式变革?在过去的三年中,我国的供应链企业经受了最为极端的挑战,但当下&a…...

5守护进程与线程
进程组 多个进程的集合,第一个进程就是组长,组长进程的PID等于进程组ID。 进程组生存期:进程组创建到最后一个进程离开(终止或转移到另一个进程组)。与组长进程是否终止无关。 一个进程可以为自己或子进程设置进程组 ID 相关函数 pid_t …...
EZ-Cube简易款下载器烧写使用方法
一、硬件连接 跟目标芯片接4根线 VCC、GND、TOOL、REST 四根线,如果板子芯片自己外接电源的,VCC 线可以不接。 二、 安装烧写软件和驱动 烧写软件:https://download.csdn.net/download/Stark_/87444744?spm1001.2014.3001.5503 驱动程序&a…...
sql server安装并SSMS连接
博主简介:原互联网大厂tencent员工,网安巨头Venustech员工,阿里云开发社区专家博主,微信公众号java基础笔记优质创作者,csdn优质创作博主,创业者,知识共享者,欢迎关注,点赞ÿ…...

Python_pytorch (二)
python_pytorch 小土堆pytotch学习视频链接 from的是一个个的包(package) import 的是一个个的py文件(file.py) 所使用的一般是文件中的类(.class) 第一步实例化所使用的类,然后调用类中的方法(def) Torchvision 数据集 数据集使用(CI…...
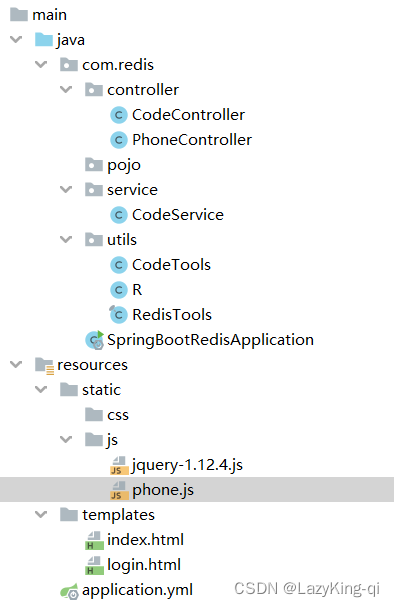
java手机短信验证,并存入redis中,验证码时效5分钟
目录 1、注册发送短信账号一个账号 2、打开虚拟机,将redis服务端打开 3、创建springboot工程,导入相关依赖 4、写yml配置 5、创建controller层,并创建controller类 6、创建service层,并创建service类 7、创建工具类&#x…...

kubectl命令控制远程k8s集群(Windows系统、Ubuntu系统、Centos系统)
文章目录1. 本地是linux2. 本地是Windows1. 本地是linux 安装kubectl命令 法一:从master的/usr/bin目录下拷贝kubectl文件到本机/usr/bin目录下法二:GitHub下载kubectl文件 在家目录下创建.kube目录config文件 法一:将master上对应用户的~/.…...
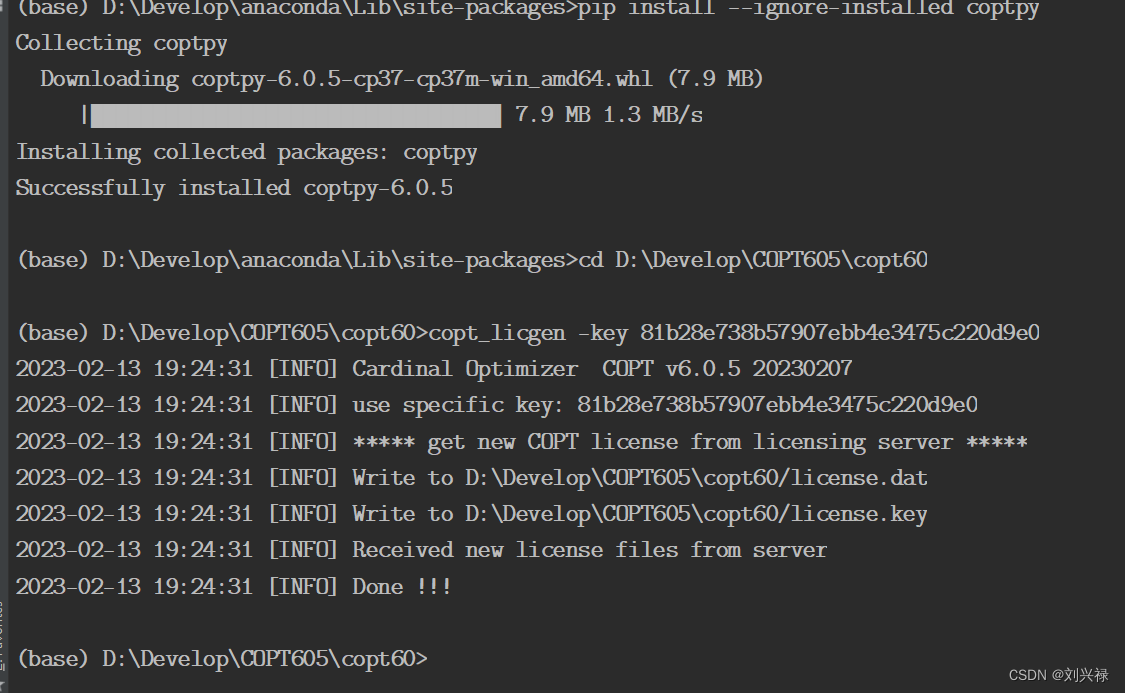
【求解器-COPT】COPT的版本更新中,老版本不能覆盖的问题
【求解器-COPT】COPT的版本更新中,老版本不能覆盖的问题方法1方法2如果license还是找不到作者:刘兴禄 参考网址: COPT的下载和配置步骤如下: 教程 | Windows系统下如何安装COPT求解器并配置许可文件: https://zhuan…...
Vue3.0文档整理:一、简介
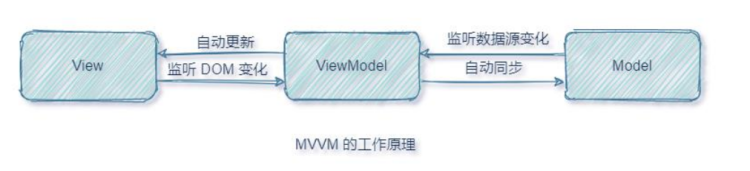
1.1:什么是vue? Vue是一款用于构建用户界面的javascript框架;它基于标准HTML、CSS和Javascript构建,并提供了一套声明式、组件化的编程模型,帮助你高效的开发用户界面。 1.2:MVVM工作原理 MVVM指的是model、view和vie…...

DSQC346G 3HAB8101-8 机器人伺服驱动单元
DSQC346G 3HAB8101‑8 机器人伺服驱动单元介绍DSQC346G(3HAB8101‑8)是一款专用于工业机器人伺服系统的驱动单元,用于控制伺服电机的运动与输出,实现机器人关节或轴的精确位置、速度和力矩控制,是机器人驱动链中的核心…...

音乐标签编辑器:让本地音乐元数据管理效率提升90%的开源工具
音乐标签编辑器:让本地音乐元数据管理效率提升90%的开源工具 【免费下载链接】music-tag-web 音乐标签编辑器,可编辑本地音乐文件的元数据(Editable local music file metadata.) 项目地址: https://gitcode.com/gh_mirrors/mu/…...

龙虾agent-browser获得chromium包问题
小龙虾非常火爆,在装agent-browser的时候,普通人往往被chromium的安装堵死了。网上的跨域安装方法一大堆,包括用镜像站点,国内所有的镜像站点都不行。但是真正能走通的,我到最后也没有试出来。最后只能自己想出一种手动…...

有偿求助 如何使用openclaw 来实现办公自动化
本地部署openclaw 需要让他帮我下载企业微信里的客户聊天记录...

让按钮并排布局的艺术
在前端开发中,我们经常需要面对如何让一系列的按钮并排显示而不堆叠在一起的问题。今天,我将带你深入了解如何使用CSS的Flexbox布局来解决这个问题,并通过一个具体的例子展示如何实现这一效果。 问题背景 假设我们有一个页面,包含多个按钮,这些按钮默认情况下是垂直堆叠…...

2026论文写作工具红黑榜:一键生成论文工具怎么选?别再瞎找了!
2026年论文写作工具红黑榜出炉!红榜优先选千笔AI、ThouPen、豆包,适配国内学术规范,内容严谨可靠;黑榜需避开低质免费工具、无真实引用平台、过度依赖全文生成的工具。选择时可参考三维模型:需求匹配度 - 数据可信度 -…...

Phi-3-mini-4k-instruct-gguf GPU利用率优化:CUDA核心占用率与吞吐量分析
Phi-3-mini-4k-instruct-gguf GPU利用率优化:CUDA核心占用率与吞吐量分析 1. 模型概述与性能挑战 Phi-3-mini-4k-instruct-gguf是微软推出的轻量级文本生成模型,基于GGUF格式优化,特别适合问答、文本改写和摘要生成等场景。虽然模型体积小巧…...

5个颠覆认知的无损视频处理能力:LosslessCut全解析
5个颠覆认知的无损视频处理能力:LosslessCut全解析 【免费下载链接】lossless-cut The swiss army knife of lossless video/audio editing 项目地址: https://gitcode.com/gh_mirrors/lo/lossless-cut 在数字内容创作爆炸的时代,视频处理已成为创…...

基于Xinference-v1.17.1的嵌入式Linux开发指南
基于Xinference-v1.17.1的嵌入式Linux开发指南 1. 引言 嵌入式设备上的AI推理一直是个技术挑战,特别是在资源受限的环境中部署大模型。Xinference-v1.17.1作为一个开源推理框架,为嵌入式Linux系统提供了轻量级的AI模型部署方案。无论你是想在树莓派上运…...

Qwen3.5-9B自动化:GitHub Actions触发模型推理+PR评论生成
Qwen3.5-9B自动化:GitHub Actions触发模型推理PR评论生成 1. 项目概述 Qwen3.5-9B是一个拥有90亿参数的开源大语言模型,具备强大的逻辑推理、代码生成和多轮对话能力。最新版本还支持多模态理解(图文输入)和长达128K tokens的上…...