wow-agent 学习笔记
wow-agent-课程详情 | Datawhale
前两课比较基础,无笔记
第三课
阅卷智能体这一块,曾经做过一点和AI助教相关的内容,也是用了一个prompt去进行CoT,但是风格和课程中的不太相同,在下面附上我的prompt
你是一名资深教师助理,负责帮助老师批改和评分学生提交的主观题答案。这些题目主要涉及语文作文、英语作文等内容。你将根据以下六个评分标准,对学生的答案进行评估和打分。请确保你的评估详细且准确,并在最后提供总分。评分标准如下:i1. **准确性**(0-5分):- 根据学生对问题的理解和回答的准确程度进行评分。如果答案完全正确,描述了算法或概念的关键要点,并且算法选择合理,得5分。如果存在小错误、偏离题意的地方或算法选择不当,视其严重程度扣分。完全错误或无关答案得0分。2. **逻辑性**(0-5分):- 根据学生答案的逻辑结构、推理过程以及算法流程的清晰度进行评分。如果答案逻辑严密,推理过程清晰且算法步骤明确,得5分。如果逻辑混乱,推理不连贯或算法流程描述不清,视其严重程度扣分。没有逻辑或推理过程的答案得0分。3. **表达清晰度**(0-5分):- 根据学生表达的清晰度和语言的准确性进行评分。如果表达流畅、语言精准且无语法错误,术语使用正确,得5分。如果存在表达不清、语法错误或术语使用不当,视其严重程度扣分。表达不清或充满错误的答案得0分。4. **深度分析**(0-5分):- 根据学生对算法或概念的深入分析和理解进行评分。如果学生能提供超出题目要求的深入见解、分析算法的优缺点,或对算法选择进行了全面的讨论,得5分。如果答案只是表面分析,缺乏深度或未能充分考虑算法选择的合理性,视其程度扣分。缺乏任何分析的答案得0分。5. **创新性**(0-5分):- 根据学生答案的独特性和创新性进行评分。如果学生能提出新颖的算法改进、独特的概念理解,或提供有创意的解决方案,得5分。如果答案中规中矩,缺乏创新,视其程度扣分。完全缺乏创新的答案得0分。6. **完整性**(0-5分):- 根据学生回答是否涵盖了题目要求的所有方面,并提供了全面的分析或算法流程进行评分。如果答案非常全面,涵盖了所有必要的要点,并对问题进行了完整的回答,得5分。如果有些要点未涵盖或有重要内容遗漏,视其程度扣分。严重不完整的答案得0分。请根据以上评分标准和老师提供的标准答案,详细评估以下学生的答案,并分别给出每个评分标准的具体得分与评分理由。最后,计算并提供该学生答案的总分。学生的主观题题目:{subjective_question}学生的答案:{student_answer}老师提供的标准答案:{standard_answer}请对上述学生的答案进行详细的评估,并分别对每个标准进行打分(0-5分),同时给出具体的评分理由,并将所有项目得分相加,得出该学生答案的总分数。教程给的prompt对格式要求更多,但我是拿字符串出来自己拼一个json交给后端,所以重心更多的放在了给分上
第四课
OurLLM类中
@llm_completion_callback()def stream_complete(self, prompt: str, **kwargs: Any) -> Generator[CompletionResponse, None, None]:response = self.client.chat.completions.create(model=self.model_name,messages=[{"role": "user", "content": prompt}],stream=True)try:for chunk in response:chunk_message = chunk.choices[0].deltaif not chunk_message.content:continuecontent = chunk_message.contentyield CompletionResponse(text=content, delta=content)except Exception as e:raise Exception(f"Unexpected response format: {e}")做了一个流式输出,每次yield丢出一个content非空的chunk,chunk的content为空则代表比起上次没有更新文本内容(可能更新了元数据)
流式输出就是不等整段话全部生成完全,而是生成一点输出一点,相较于全部输出的效率更高,在业务场景下对用户体验更友好
api_key: str = Field(default=api_key)
base_url: str = Field(default=base_url)
model_name: str = Field(default=chat_model)
client: OpenAI = Field(default=None, exclude=True)类的开头定义的Field可以帮助缓解Agent传参数,输入输出等的幻觉
llama_index调tools的小demo
multiply_tool = FunctionTool.from_defaults(fn=multiply)
add_tool = FunctionTool.from_defaults(fn=add)# 创建ReActAgent实例
agent = ReActAgent.from_tools([multiply_tool, add_tool], llm=llm, verbose=True)response = agent.chat("20+(2*4)等于多少?使用工具计算每一步")第五课
Ollama是很好用的搭大模型的框架,包括Xinference、openai这些都挺好的
与数据库交互:
query_engine = NLSQLTableQueryEngine( sql_database=sql_database, tables=["section_stats"], llm=Settings.llm
)第六课
llama_index + faiss:
构建索引
from llama_index.core import SimpleDirectoryReader,Document
documents = SimpleDirectoryReader(input_files=['./docs/问答手册.txt']).load_data()# 构建节点
from llama_index.core.node_parser import SentenceSplitter
transformations = [SentenceSplitter(chunk_size = 512)]from llama_index.core.ingestion.pipeline import run_transformations
nodes = run_transformations(documents, transformations=transformations)# 构建索引
from llama_index.vector_stores.faiss import FaissVectorStore
import faiss
from llama_index.core import StorageContext, VectorStoreIndexvector_store = FaissVectorStore(faiss_index=faiss.IndexFlatL2(3584))
storage_context = StorageContext.from_defaults(vector_store=vector_store)index = VectorStoreIndex(nodes = nodes,storage_context=storage_context,embed_model = embedding,
)简单分了个512的chunk,也就是512个token在一起向量化存入数据库
3584是指定的向量的维度
这里处理文档,llama_index提供了很多方法:
简单文件节点解析器 (SimpleFileNodeParser)
我们可以使用 SimpleFileNodeParser 来解析简单的文件类型,如 Markdown 文件。下面是一个例子:from llama_index.core.node_parser import SimpleFileNodeParser
from llama_index.readers.file import FlatReader
from pathlib import Path# 加载 Markdown 文档
md_docs = FlatReader().load_data(Path("./test.md"))# 创建解析器实例
parser = SimpleFileNodeParser()# 从文档中获取节点
md_nodes = parser.get_nodes_from_documents(md_docs)
HTML 节点解析器 (HTMLNodeParser)
HTMLNodeParser 使用 BeautifulSoup 来解析原始 HTML。默认情况下,它会解析一些特定的 HTML 标签。from llama_index.core.node_parser import HTMLNodeParser
# 创建 HTML 解析器,指定需要解析的标签
parser = HTMLNodeParser(tags=["p", "h1"])# 从 HTML 文档中获取节点
nodes = parser.get_nodes_from_documents(html_docs)
JSON 节点解析器 (JSONNodeParser)
JSONNodeParser 用于解析原始 JSON 文本。from llama_index.core.node_parser import JSONNodeParser
# 创建 JSON 解析器实例
parser = JSONNodeParser()# 从 JSON 文档中获取节点
nodes = parser.get_nodes_from_documents(json_docs)
Markdown 节点解析器 (MarkdownNodeParser)
MarkdownNodeParser 用于解析原始的 Markdown 文本。from llama_index.core.node_parser import MarkdownNodeParser
# 创建 Markdown 解析器实例
parser = MarkdownNodeParser()# 从 Markdown 文档中获取节点
nodes = parser.get_nodes_from_documents(markdown_docs)
代码分割器 (CodeSplitter)
CodeSplitter 根据代码的语言将原始代码文本进行分割。from llama_index.core.node_parser import CodeSplitter
# 创建代码分割器实例
splitter = CodeSplitter(
language="python",
chunk_lines=40, # 每块的行数
chunk_lines_overlap=15, # 块之间的重叠行数
max_chars=1500, # 每块的最大字符数
)# 从文档中获取节点
nodes = splitter.get_nodes_from_documents(documents)
句子分割器 (SentenceSplitter)
SentenceSplitter 尝试在尊重句子边界的情况下进行文本分割。from llama_index.core.node_parser import SentenceSplitter
# 创建句子分割器实例
splitter = SentenceSplitter(
chunk_size=1024,
chunk_overlap=20,
)# 从文档中获取节点
nodes = splitter.get_nodes_from_documents(documents)
使用 Langchain 的节点解析器 (LangchainNodeParser)
你还可以用 Langchain 提供的文本分割器来包装节点解析器。from langchain.text_splitter import RecursiveCharacterTextSplitter
from llama_index.core.node_parser import LangchainNodeParser# 创建 Langchain 解析器实例
parser = LangchainNodeParser(RecursiveCharacterTextSplitter())# 从文档中获取节点
nodes = parser.get_nodes_from_documents(documents)
原文链接:https://blog.csdn.net/qq_29929123/article/details/140745604
构建问答引擎
# 构建检索器
from llama_index.core.retrievers import VectorIndexRetriever
# 想要自定义参数,可以构造参数字典
kwargs = {'similarity_top_k': 5, 'index': index, 'dimensions': 3584} # 必要参数
retriever = VectorIndexRetriever(**kwargs)# 构建合成器
from llama_index.core.response_synthesizers import get_response_synthesizer
response_synthesizer = get_response_synthesizer(llm=llm, streaming=True)# 构建问答引擎
from llama_index.core.query_engine import RetrieverQueryEngine
engine = RetrieverQueryEngine(retriever=retriever,response_synthesizer=response_synthesizer,)# 提问
question = "请问商标注册需要提供哪些文件?"
response = engine.query(question)
for text in response.response_gen:print(text, end="")检索top的5个chunk作为上下文
打包RetrieverQueryEngine作为function tool
# 配置查询工具
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tools = [QueryEngineTool(query_engine=engine,metadata=ToolMetadata(name="RAG工具",description=("用于在原文中检索相关信息"),),),
]第七课
找个接口请求一下打包成function tool,无笔记
第八课
AgentLite
Langchain实现新的智体推理类型和架构过于复杂。为新的研究场景重构Langchain库是相当具有挑战性的,因为它在创建智体时会产生大量开销。
Autogen虽然已经成功地构建了 LLM 代理,但它的代理接口有固定的推理类型,这使得它很难适应其他研究任务。此外,它的架构仅限于多智能体对话和代码执行,可能不适合所有的新场景或基准测试。
AgentLite框架包括Individual Agent和Manager Agent:
Individual Agent是AgentSite中的基本Agent类。它由四个模块组成:即PromptGen、LLM、Actions和Memory。
Manager Agent是一个individual agent的子类,根据给定的任务指令创建子任务和相应的TaskPackage,这些TP被依次转发到相关联的各个智体。
DuckDuckGo是一个互联网搜索引擎
Zigent创建搜索代理:
class DuckSearchAgent(BaseAgent):def __init__(self,llm: BaseLLM,actions: List[BaseAction] = [DuckSearchAction()],manager: ABCAgent = None,**kwargs):name = "duck_search_agent"role = "You can answer questions by using duck duck go search content."super().__init__(name=name,role=role,llm=llm,actions=actions,manager=manager,logger=agent_logger,)执行代理:
def do_search_agent():# 创建代理实例search_agent = DuckSearchAgent(llm=llm)# 创建任务task = "what is the found date of microsoft"task_pack = TaskPackage(instruction=task)# 执行任务并获取响应response = search_agent(task_pack)print("response:", response)第九课
多智能体交互是必要的,不同职责的智能体相互交流,更好地完成任务
编排动作:
和给大模型one-shot、few-shot一样,如果能指导智能体去思考和合作是更好的
from zigent.commons import AgentAct, TaskPackage
from zigent.actions import ThinkAct, FinishAct
from zigent.actions.InnerActions import INNER_ACT_KEY
from zigent.agents.agent_utils import AGENT_CALL_ARG_KEY# 为哲学家智能体添加示例任务
# 设置示例任务:询问生命的意义
exp_task = "What do you think the meaning of life?"
exp_task_pack = TaskPackage(instruction=exp_task)# 第一个动作:思考生命的意义
act_1 = AgentAct(name=ThinkAct.action_name,params={INNER_ACT_KEY: f"""Based on my thought, we are born to live a meaningful life, and it is in living a meaningful life that our existence gains value. Even if a life is brief, if it holds value, it is meaningful. A life without value is merely existence, a mere survival, a walking corpse."""},
)
# 第一个动作的观察结果
obs_1 = "OK. I have finished my thought, I can pass it to the manager now."# 第二个动作:总结思考结果
act_2 = AgentAct(name=FinishAct.action_name, params={INNER_ACT_KEY: "I can summarize my thought now."})
# 第二个动作的观察结果
obs_2 = "I finished my task, I think the meaning of life is to pursue value for the whold world."
# 将动作和观察组合成序列
exp_act_obs = [(act_1, obs_1), (act_2, obs_2)]# 为每个哲学家智能体添加示例
# 为孔子添加示例
Confucius.prompt_gen.add_example(task = exp_task_pack, action_chain = exp_act_obs
)
# 为苏格拉底添加示例
Socrates.prompt_gen.add_example(task = exp_task_pack, action_chain = exp_act_obs
)
# 为亚里士多德添加示例
Aristotle.prompt_gen.add_example(task = exp_task_pack, action_chain = exp_act_obs
)先执行后思考总结的动作模板提交给三个智能体
Manager Agent:
用一个智能体调控其他智能体的交互,和MetaGPT一样用team进行管理
# 定义管理者代理
from zigent.agents import ManagerAgent# 设置管理者代理的基本信息
manager_agent_info = {"name": "manager_agent","role": "you are managing Confucius, Socrates and Aristotle to discuss on questions. Ask their opinion one by one and summarize their view of point."
}
# 设置团队成员
team = [Confucius, Socrates, Aristotle]
# 创建管理者代理实例
manager_agent = ManagerAgent(name=manager_agent_info["name"], role=manager_agent_info["role"], llm=llm, TeamAgents=team)# 为管理者代理添加示例任务
exp_task = "What is the meaning of life?"
exp_task_pack = TaskPackage(instruction=exp_task)# 第一步:思考如何处理任务
act_1 = AgentAct(name=ThinkAct.action_name,params={INNER_ACT_KEY: f"""I can ask Confucius, Socrates and Aristotle one by one on their thoughts, and then summary the opinion myself."""},
)
obs_1 = "OK."# 第二步:询问孔子的观点
act_2 = AgentAct(name=Confucius.name,params={AGENT_CALL_ARG_KEY: "What is your opinion on the meaning of life?",},
)
obs_2 = """Based on my thought, I think the meaning of life is to pursue value for the whold world."""# 第三步:思考下一步行动
act_3 = AgentAct(name=ThinkAct.action_name,params=xxx
)
obs_3 = xxx# 第四步:询问苏格拉底的观点
act_4 = AgentAct(name=Socrates.name,params=xxx
)
obs_4 = xxx# 第五步:继续思考下一步
act_5 = AgentAct(name=ThinkAct.action_name,params=xxx
)
obs_5 = "OK."# 第六步:询问亚里士多德的观点
act_6 = AgentAct(name=Aristotle.name,params=xxx
)
obs_6 = xxx# 最后一步:总结所有观点
act_7 = AgentAct(name=FinishAct.action_name, params=xxx)
obs_7 = xxx# 将所有动作和观察组合成序列
exp_act_obs = [(act_1, obs_1), (act_2, obs_2), (act_3, obs_3), (act_4, obs_4), (act_5, obs_5), (act_6, obs_6), (act_7, obs_7)]# 将示例添加到管理者代理的提示生成器中
manager_agent.prompt_gen.add_example(task = exp_task_pack, action_chain = exp_act_obs
)调用 ManagerAgent:
from zigent.commons import AgentAct, TaskPackageexp_task = "先有鸡还是先有蛋?"
exp_task_pack = TaskPackage(instruction=exp_task)
manager_agent(exp_task_pack)第十课
WriteDirectoryAction类中通过prompt对生成的json进行规范,然而有时会出现幻觉导致json出错,在这仍然可以用Field规范一下输出
定义两个动作:写目录和填内容,并增加示例,完成创作
相关文章:

wow-agent 学习笔记
wow-agent-课程详情 | Datawhale 前两课比较基础,无笔记 第三课 阅卷智能体这一块,曾经做过一点和AI助教相关的内容,也是用了一个prompt去进行CoT,但是风格和课程中的不太相同,在下面附上我的prompt 你是一名资深教…...

使用Cilium/eBPF实现大规模云原生网络和安全
大家读完觉得有帮助记得关注和点赞!!! 目录 抽象 1 Trip.com 云基础设施 1.1 分层架构 1.2 更多细节 2 纤毛在 Trip.com 2.1 推出时间表 2.2 自定义 2.3 优化和调整 2.3.1 解耦安装 2.3.2 避免重试/重启风暴 2.3.3 稳定性优先 2…...
回调函数)
“深入浅出”系列之C++:(4)回调函数
在写项目的时候遇见一个问题,现在的需求是主项目需要拿到子项目的结果来进行显示,那么如何集成呢,子项目里面有一个MainWindow类,类里 回调函数是一种通过函数指针将函数作为参数传递给另一个函数的编程技术。这种机制允许程序在特…...

Mysql--运维篇--主从复制和集群(主从复制I/O线程,SQL线程,二进制日志,中继日志,集群NDB)
一、主从复制 MySQL的主从复制(Master-Slave Replication)是一种数据冗余和高可用性的解决方案,它通过将一个或多个从服务器(Slave)与主服务器(Master)同步来实现。主从复制的基本原理是&#…...

设计模式 行为型 状态模式(State Pattern)与 常见技术框架应用 解析
状态模式(State Pattern)是一种行为型设计模式,它允许对象在内部状态改变时改变其行为,使得对象看起来好像修改了它的类。这种设计模式的核心思想是将对象的状态和行为封装成不同的状态类,通过状态对象的行为改变来避免…...

计算机网络 (38)TCP的拥塞控制
前言 TCP拥塞控制是传输控制协议(Transmission Control Protocol,TCP)避免网络拥塞的算法,是互联网上主要的一个拥塞控制措施。 一、目的 TCP拥塞控制的主要目的是防止过多的数据注入到网络中,使网络能够承受现有的网络…...

鸿蒙面试 2025-01-09
鸿蒙分布式理念?(个人认为理解就好) 鸿蒙操作系统的分布式理念主要体现在其独特的“流转”能力和相关的分布式操作上。在鸿蒙系统中,“流转”是指涉多端的分布式操作,它打破了设备之间的界限,实现了多设备…...

【关于for循环的几种写法】
关于for循环的几种写法 在 C 中,for(int i 0; i < n; i) 是一种常见的循环写法,用于遍历从 0 到 n-1 的索引。如果你希望简化这种写法,可以使用以下几种方法: 1. 使用范围 for 循环 如果你需要遍历一个容器(如数…...

Apache和PHP:构建动态网站的黄金组合
在当今的互联网世界,网站已经成为了企业、个人和机构展示自己、与用户互动的重要平台。而在这些动态网站的背后,Apache和PHP无疑是最受开发者青睐的技术组合之一。这一组合提供了高效、灵活且可扩展的解决方案,帮助您快速搭建出强大的网站&am…...

免费开源的下载工具Xdown
软件介绍 Xdown是一款功能强大的开源免费下载工具,专为PC端用户设计,支持多种协议和下载方式。 1、多线程下载 Xdown支持最高128线程的并发下载,能够将文件分割成多个部分同时下载,从而显著提升下载速度。 2、多种协议支持 该…...

Three.js 数学工具:构建精确3D世界的基石
文章目录 前言一、向量(Vectors)二、矩阵(Matrices)三、四元数(Quaternions)四、欧拉角(Euler Angles)五、颜色(Colors)六、几何体生成器(Geometr…...

如何明智地提问
如何明智地提问的重要总结,让我为主要观点添加一些具体的实践建议: 提问前的准备工作 尝试在 Google、Stack Overflow 等平台搜索相似问题阅读相关文档和错误日志尝试自己调试和排查问题记录下已尝试过的解决方案 选择合适的提问平台 Stack Overflow…...

Microsoft Sql Server 2019 函数理解
说到函数,首先和存储过程作个比较吧,两者有一个共同点都是预编译优化后存储在磁盘中,所以效率 要比T-SQL高一点点。值得注意的是,存储过程可以创建或访问临时表,而函数不可以; 同时函数不可 以修改表中的数…...

自定义日期转换配置
文章目录 1.日期问题出现原因以及解决方案概述1.图示2.三种解决方案概述1.对于表单数据 application/x-www-form-urlencoded2.对于JSON数据1.使用JsonFormat注解2.自定义Jackson日期转换配置 2.解决方案common-web-starter1.目录2.BaseController.java 使用InitBinder解决表单数…...

“AI智能服务平台系统,让生活更便捷、更智能
大家好,我是资深产品经理老王,今天咱们来聊聊一个让生活变得越来越方便的高科技产品——AI智能服务平台系统。这个系统可是现代服务业的一颗璀璨明珠,它究竟有哪些魅力呢?下面我就跟大家伙儿闲聊一下。 一、什么是AI智能服务平台系…...

SQL美化器优化
文章目录 1.目录2.代码 1.目录 2.代码 package com.sunxiansheng.mybatis.plus.inteceptor;import org.apache.ibatis.executor.statement.StatementHandler; import org.apache.ibatis.mapping.*; import org.apache.ibatis.plugin.*; import org.apache.ibatis.reflection.*…...

我的128天创作之路:回顾与展望
大家好呀!今天来和你们分享一下我的创作历程😁。 一、机缘 最开始创作呢,是因为在学习 C 的 STL 时,像 string、list、vector 这些模板可把我折腾得够呛,但也让我学到了超多东西!我就想,要是把我…...

内核配置参数整理
#参考网页 linux5.2 <.config>文件注释 详细解释 CONFIG_ARMy:启用ARM架构支持,这是ARM处理器专用的内核配置选项。 CONFIG_ARM_HAS_SG_CHAINy:启用对散列表(scatter-gather)链的支持…...

SpringBoot整合Easy-es
一.什么是Easy-Es Easy-Es(简称EE)是一款基于ElasticSearch(简称Es)官方提供的RestHighLevelClient打造的ORM开发框架,在 RestHighLevelClient 的基础上,只做增强不做改变,为简化开发、提高效率而生,您如果有用过Mybatis-Plus(简称…...

于交错的路径间:分支结构与逻辑判断的思维协奏
大家好啊,我是小象٩(๑ω๑)۶ 我的博客:Xiao Xiangζั͡ޓއއ 很高兴见到大家,希望能够和大家一起交流学习,共同进步。* 这一节内容很多,文章字数达到了史无前例的一万一,我们要来学习分支与循环结构中…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...

数据分析六部曲?
引言 上一章我们说到了数据分析六部曲,何谓六部曲呢? 其实啊,数据分析没那么难,只要掌握了下面这六个步骤,也就是数据分析六部曲,就算你是个啥都不懂的小白,也能慢慢上手做数据分析啦。 第一…...

【2D与3D SLAM中的扫描匹配算法全面解析】
引言 扫描匹配(Scan Matching)是同步定位与地图构建(SLAM)系统中的核心组件,它通过对齐连续的传感器观测数据来估计机器人的运动。本文将深入探讨2D和3D SLAM中的各种扫描匹配算法,包括数学原理、实现细节以及实际应用中的性能对比,特别关注…...
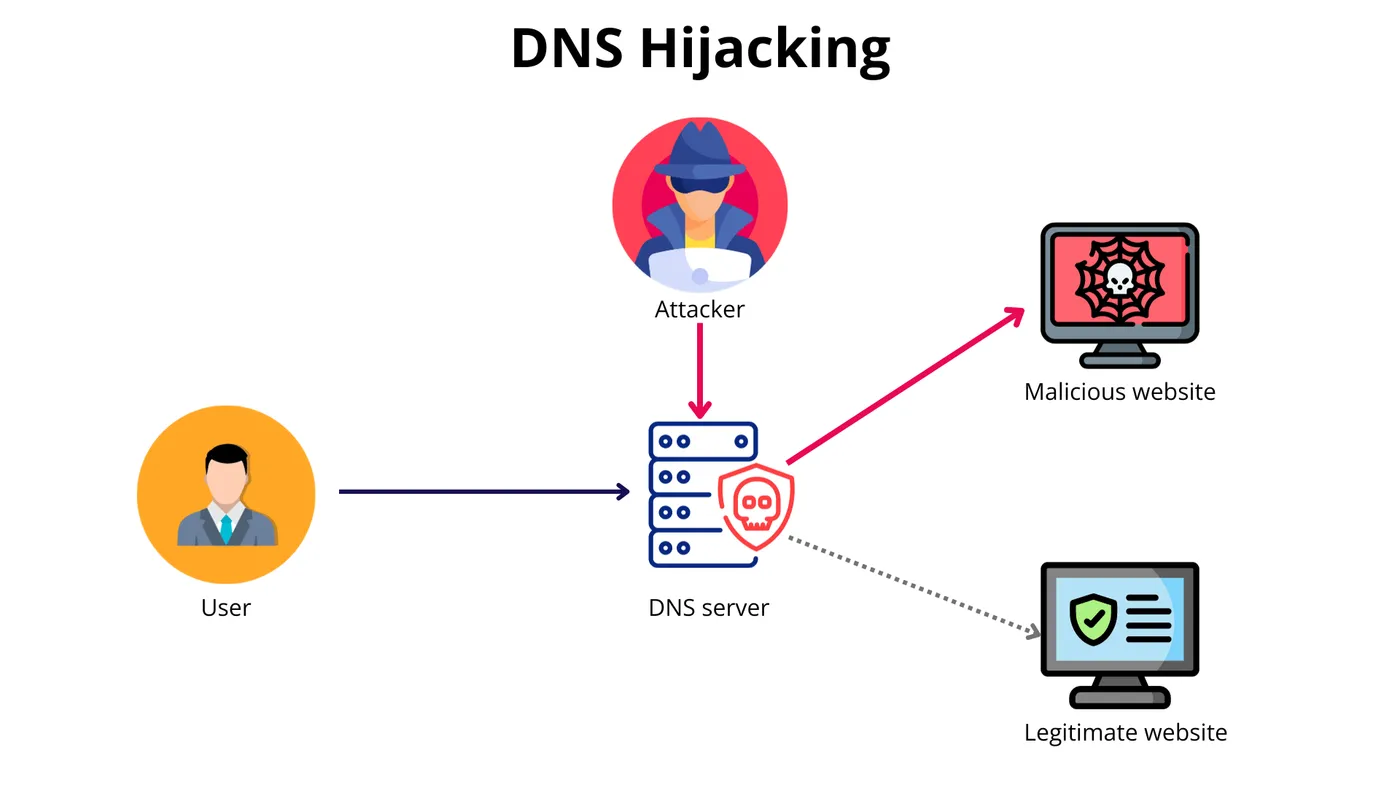
简单聊下阿里云DNS劫持事件
阿里云域名被DNS劫持事件 事件总结 根据ICANN规则,域名注册商(Verisign)认定aliyuncs.com域名下的部分网站被用于非法活动(如传播恶意软件);顶级域名DNS服务器将aliyuncs.com域名的DNS记录统一解析到shado…...