【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
原文地址:A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using transformers, accelerate and bitsandbytes
相关博客
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】Chain of Thought:从大模型中引导出推理能力
【自然语言处理】【ChatGPT系列】InstructGPT:遵循人类反馈指令来训练语言模型
【自然语言处理】【ChatGPT系列】大模型的涌现能力
一、简介
语言模型正变的越来越大,PaLM已有有540B的参数量,而OPT、GPT-3和BLOOM则大约有176B参数量。下图是近些年语言模型的尺寸。

这些模型很难在常用设备上运行。例如,仅仅推理BLOOM-176B就需要8x 80GB A00 GPUs。而为了微调BLOOM-176B则需要72个GPU。PaLM则需要更多的资源。
这些巨型模型需要太多GPUs才能运行,因此需要寻找方法来减少资源需求并保证模型的性能。已经有各种技术用来减小模型尺寸,例如量化、蒸馏等。在完成BLOOM-176B训练后,HuggingFace和BigScience逐步探索在少量GPU上运行大模型的方法。最终,设计出了Int8量化方法,该方法在不降低大模型性能的情况下,将显存占用降低了1至2倍。
二、机器学习中常用的数据类型
浮点数在机器学习中也被称为"精度"。模型大小是有参数量及参数精度决定的,通常是float32、float16和bfloat16。
我们开始于不同浮点数的基本理解,在机器学习的背景下也被称为"精度"。模型的大小由其参数数量和精度决定,通常是float32、float16和bfloat16。下图:
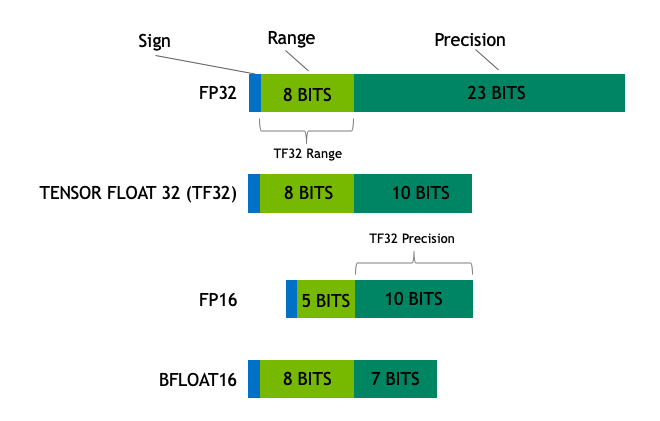
Float32(FP32)是标准的IEEE 32-bit浮点数表示,使用这种类型可以表示范围广泛的浮点数。在FP32中,8bits被用于"指数",23bits被用于"尾数", 1 bit则用于符号位。大多数的硬件都支持FP32操作和指令。
在Float16(FP16)数据类型中,5 bits被用作"指数",10 bits用于"尾数"。这使得FP16数的表示范围明显小于FP32,导致有上溢和下溢的风险。例如,若你做10k×10k10k\times 10k10k×10k,最终得到100k。这在FP16中是不可能的,因为其最大表示为64K。因此你会得到NaN的结果,若像神经网络那样顺序执行,所有先前的工作都会被破坏。通常,loss缩放能够一定程度上克服这个问题,但并不总是有用。
因此,创建了一种新格式bfloat15(BF16)来避免这种问题。在BF16中,8bits被用于表示"指数", 7bits被用于表示"尾数"。这意味着BF16能够保留和FP32相同的动态范围,但是损失了3bits的精度。BF16可以表示巨大的数,但是精度上比FP16差。
在Ampere架构中,NVIDIA也引入了TensorFloat-32(TF32)精度格式,其仅使用19 bits就合并了BF16的动态范围和FP16的精度。其目前仅在内部某些操作中使用。
在机器学习的术语中FP32被称为全精度(4 bytes),BF16和FP16则称为半精度(2 bytes)。int8(INT8)数据类型则是由8 bits表示的数,其能够存储282^828个不同的值([0,255]或者[-128, 127])
理想情况下,训练和推理应该在FP32上进行,但是其比FP16/BF16慢两倍。因此,采用一种混合精度的方法,模型权重仍然是FP32,前向和后向传播则使用FP16/BF16,从而加快训练速度。P16/BF16被用来更新FP32权重。
可以通过参数量乘以浮点数精度的大小来计算模型所占用的bytes量。例如,若模型使用bfloat16版本的BLOOM-176B模型,那么模型大小为176*10**9 x 2 bytes = 352GB!这个量级对于适配少量GPU来说相当有挑战。
但是我们是否可以使用不同的数据类型以更少的存储空间来保存这些权重?一种称为量化的方法被广泛的应用于Deep Learning。
三、模型量化介绍
通过实验发现,在推理中使用2 bytes的BF16/FP16精度能够几乎达到4 bytes的FP32精度相同的效果,而且模型尺寸可以减少一半。若能够进一步削减那就太棒了,但是在更低的精度上推理质量开始急剧下降。为了解决这个问题,我们引入了8 bits量化。该方法使用四分之一的精度,这样仅需要1/4的模型尺寸!但是,其不是通过丢掉另外一半bits来实现的。
量化基本上是从一种数据类型"舍入"为另一种数据类型来完成的。例如,若一个数量类型范围0…9,另一个范围则是0…4。那么第一个数据类型中的"4"将会被舍入为第二种数据类型中的"2"。然而,若第一种数据类型中的"3",其会位于第二种数据类型的1和2之间,然后通常会被舍入为"2"。也就是说第一种数据类型中的"4"和"3"都会对应第二种数据类型中的"2"。这表明量化是可能带来信息丢失的噪音过程,一种有损压缩。
有两种常见的8-bit量化技术:zero-point量化和absolute maximum(absmax)量化。zero-point量化和absmax量化会将浮点数值映射至更加紧凑的int8(1 byte)值。这些方法首先会将输入按照量化常数进行缩放,从而实现规范化。
举例来说,在zero-point量化中,若范围是[−1.0…1.0][-1.0\dots1.0][−1.0…1.0]并希望量化至范围[−127…127][-127\dots127][−127…127]。那么应该按照因子127进行缩放,然后四舍五入至8-bit精度。为了还原原始值,需要将int8的值除以量化因子127。例如,0.3被缩放为0.3×127=38.10.3\times127=38.10.3×127=38.1,然后四舍五入为38。若要恢复,则38/127=0.299238/127=0.299238/127=0.2992。在这个例子中量化误差为0.008。随着这些微小的误差在模型各个层中传播,会逐步积累和增长并导致性能下降。
再来看看absmax量化的细节。为了在absmax量化中完成fp16和int8的映射,需要先除以张量中的绝对最大值(令整个张量介于-1至1之间),然后在乘以目标数据类型的总范围。例如,在一个向量上应用absmax量化,该向量为
v=[1.2−0.5−4.31.2−3.10.82.45.4]v=\begin{bmatrix} 1.2&-0.5&-4.3&1.2&-3.1&0.8&2.4&5.4 \end{bmatrix} v=[1.2−0.5−4.31.2−3.10.82.45.4]
从向量中选择最大值,即5.4。而int8的范围为[-127,127],所以量化过程为v/5.4×127=v×1275.4≈v×23.5v/5.4\times 127=v\times\frac{127}{5.4}\approx v\times 23.5v/5.4×127=v×5.4127≈v×23.5,即整个向量乘以缩放因子23.5。最终得到的量化后向量为
[28−12−10128−731956127]\begin{bmatrix} 28&-12&-101&28&-73&19&56&127 \end{bmatrix} [28−12−10128−731956127]
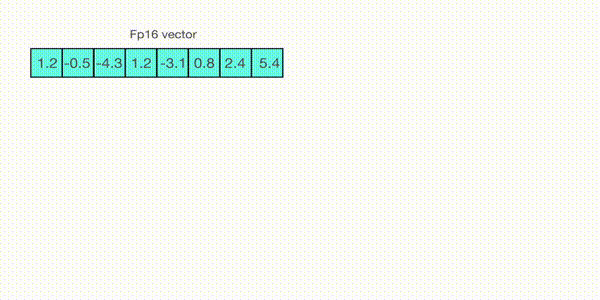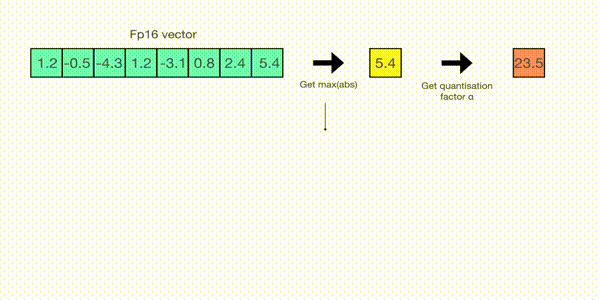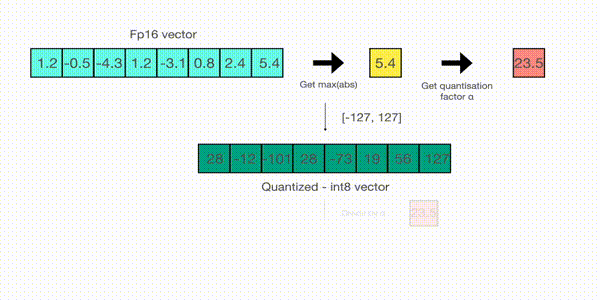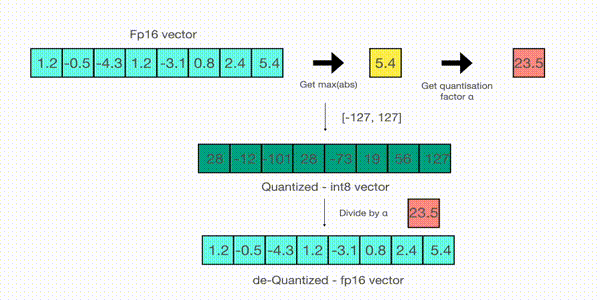
为了还原原始值,可以使用全精度的int8数除以量化因子23.5。但是由于四舍五入的原因,会丢失一些精度。
这些技巧能够以多种方式组合。例如,当涉及矩阵乘法时,ow-wise或者vector-wise量化可以使得结果更加准确。以矩阵乘法A×B=CA\times B=CA×B=C为例,相对于使用每个张量的绝对最大值来规范张量,vector-vise量化则会寻找矩阵A每行的绝对最大值和矩阵B每列的绝对最大值。然后通过除以这些绝对最大值向量来规范化矩阵A和B。然后执行A×BA\times BA×B来得到C。为了最终返回FP16精度的值,通过计算A和B绝对最大值向量的外积来反规范化。
这些技术虽然能够量化模型,但是在较大模型上会带来性能下降。Hugging Face Transformers和Accelerate库集成了一种称为LLM.int8()的8-bit量化算法,能够在176B参数量模型上使用且不降低模型效果。
四、LLM.int8()简介
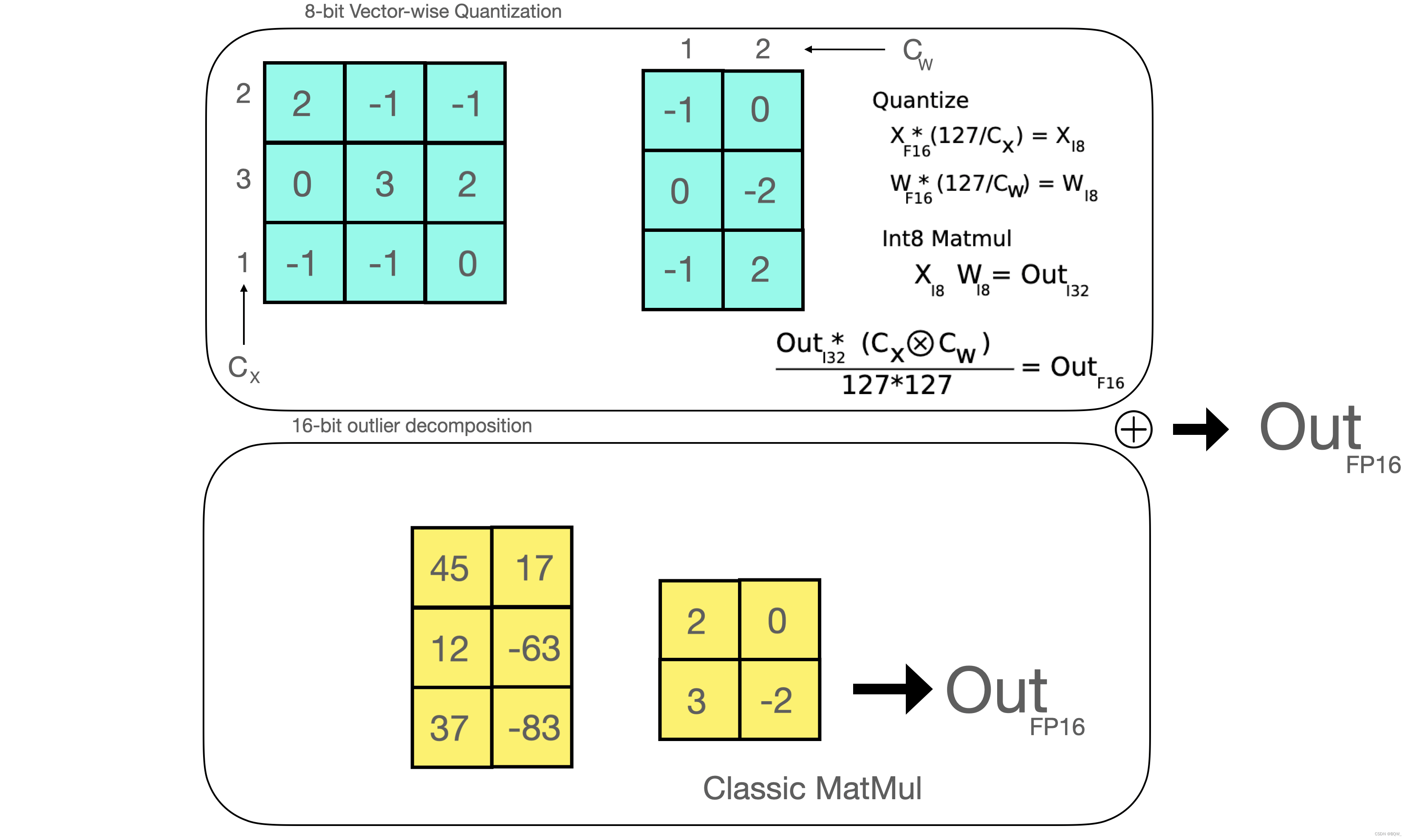
理解Transformer中与规模相关的涌现特性对于理解为什么传统量化方式在大模型中失败至关重要。性能的下降是由异常特征值导致的,会在后面解释这一情况。LLM.int8()算法本质上可以由三个步骤来完成矩阵乘法:
- 对输入的hidden states逐列的提取异常值(即大于某个阈值的值);
- 分别对FP16中的异常值和INT8中的非异常值执行矩阵乘法;
- 对非异常的结果进行反量化,并将两者结果合并来获得最终的FP16结果;
三个步骤如下图所示:

1. 异常值特征
在整个分布之外的值,称为异常值。异常值检测被广泛使用,而拥有特征分布的先验知识有助于异常值检测任务。
具体来说,我们观察到经典的量化算法在超过6B参数量的transformer模型上失效了。虽然在较小的模型上也能观测到较大的异常值特征。但是,我们观察到一个参数量的阈值,transformer中的异常值会系统性的出现在每个层中。
由于8-bit精度的局限性,因此仅使用几个特别大的值来量化向量将导致非常差的结果。此外,transformer架构的内在特征就是将所有的元素连接在一起,这将导致错误跨越多层传播并被加剧。因此,开发出了混合精度分解来实现这种极端异常值的量化。
2. MatMul内部
一旦得到hidden state,使用自定义阈值来抽取异常值并分解矩阵为上述两部分。我们发现使用6作为阈值进行抽取可以完整的恢复推理性能。异常值部分以fp16实现,所以是经典的矩阵乘法;而8-bit则是通过vector-wise量化将模型权重和hidden state量化至8-bit的精度。即hidden-state使用row-wise量化,模型权重使用column-wise量化。经过这个步骤后,再将结果反量化并以半精度返回。
3. 零退化意味着什么
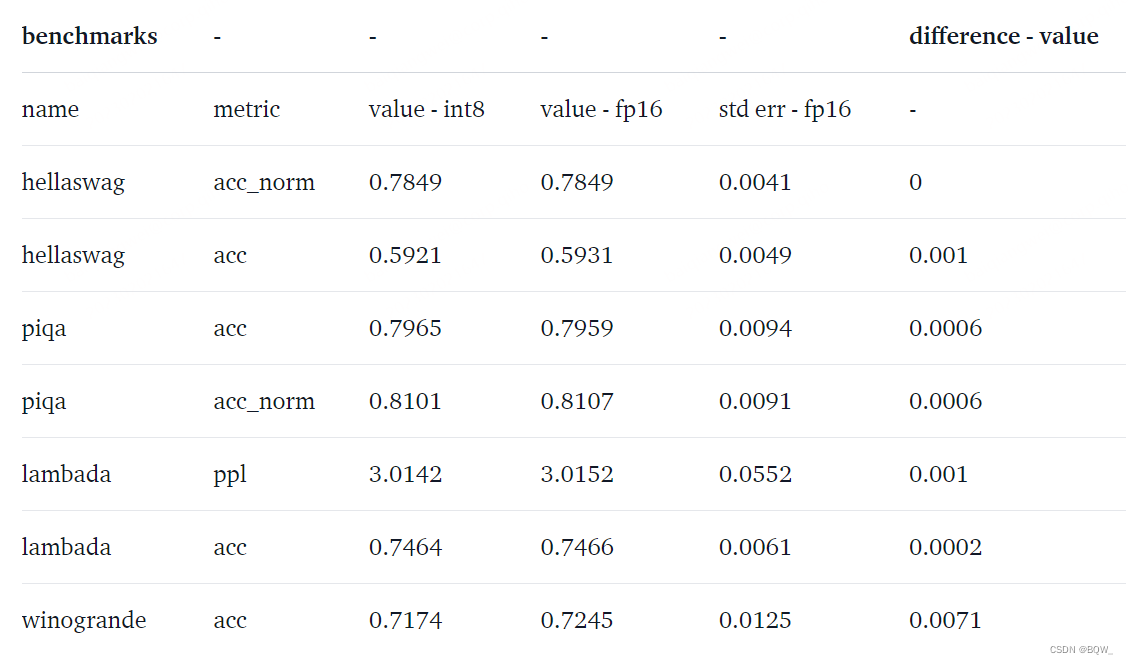
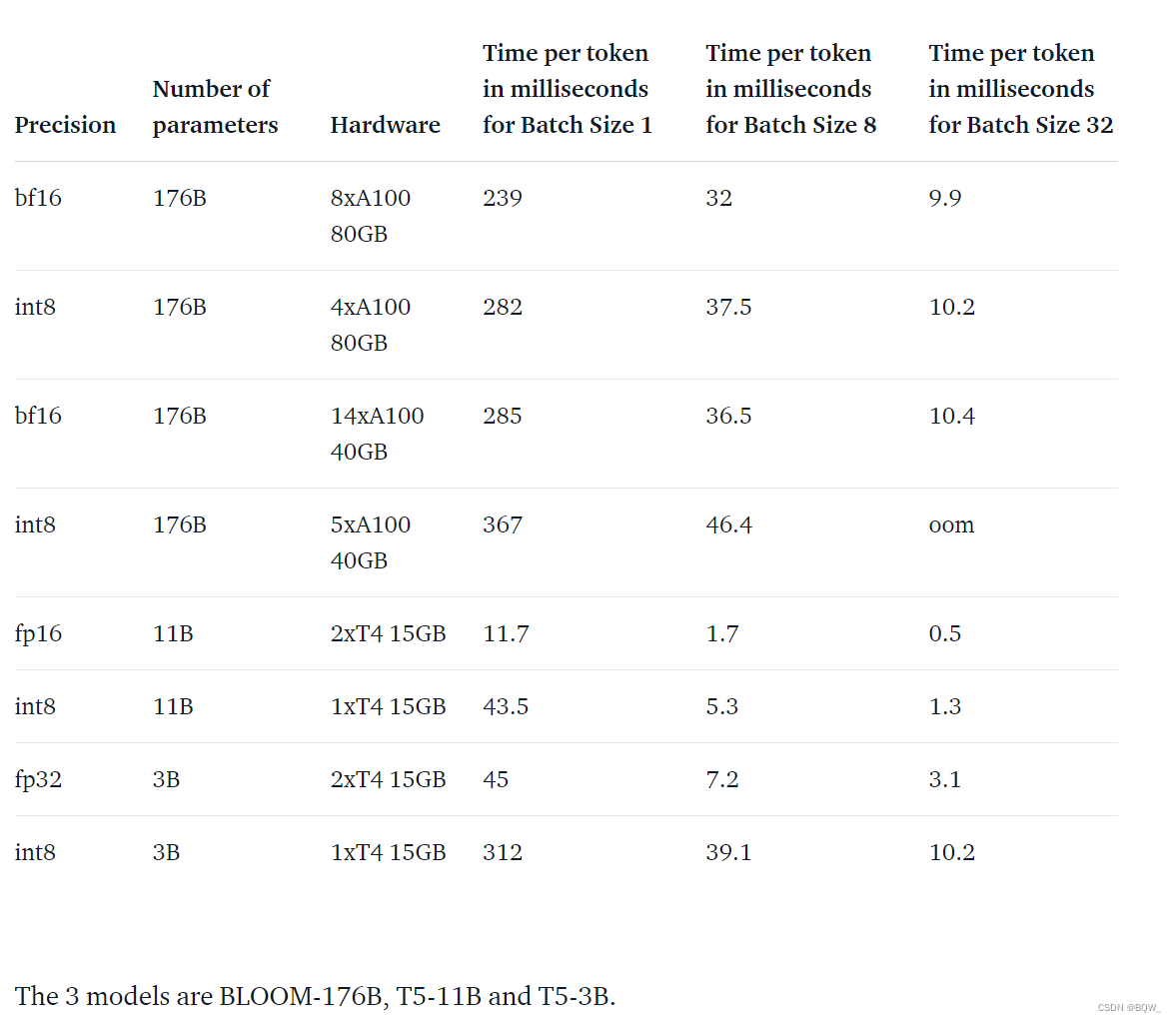
如何评估性能下降?8-bit模型到底损失了多少性能?这里在8-bit模型和native模型上运行了常见的基准,分别针对OPT-175B和BLOOM-176B。
- 对于OPT-175B
- 对于BLOOM-176B
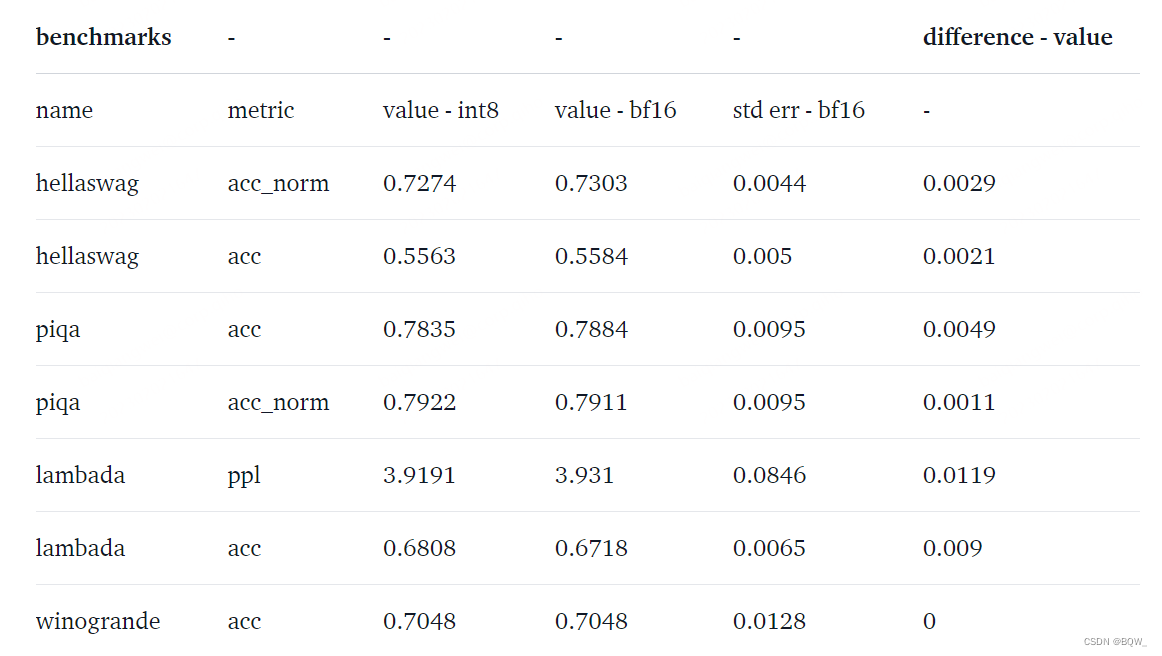
可以看到这些模型的性能下降为0,因为这些指标的绝对差值小于标准误差。
4. 比native模型更快?
LLM.int8()方法的主要目标在不降低性能的情况下,使得大模型更容易被使用。但是,如果该方法非常的慢则就不实用了。所以,我们对多个模型的生成速度进行了基准测试。实验发现使用LLM.int8()的BLOOM-176B要比fp16版本慢15%至23%,这是一个可以接受的范围。但是较小的模型下降会更多。开发人员正在逐步优化这个问题。
五、Transformers集成
1. 使用
本文重点描述的模块是Linear8bitLt,你可以直接从bitsandbytes库中引入。其来自于经典的torch.nn模块,并使用下面的代码来轻易的使用和部署。
下面是一个使用bitsandbytes将一个小模型转换为int8类型。
- 正确的引入
import torch
import torch.nn as nnfrom bitsandbytes.nn import Linear8bitLt
- 先定义一个fp16的模型
fp16_model = nn.Sequential(nn.Linear(64, 64),nn.Linear(64, 64))
- 假设该模型已经完成训练,保存模型
torch.save(fp16_model.state_dict(), "model.pt")
- 现在再定义一个int8模型
int8_model = nn.Sequential(Linear8bitLt(64, 64, has_fp16_weights=False),Linear8bitLt(64, 64, has_fp16_weights=False)
)
添加参数has_fp16_weights很重要。默认值为True,其被用于Int8/FP16混合精度训练。然而,这里关注的是推理,所以将其设置为False。
- 现在将fp16的模型加载至int8模型中
int8_model.load_state_dict(torch.load("model.pt"))
# print(int8_model[0].weight)
int8_model = int8_model.to("cuda:0") # 执行该代码时会进行量化
# print(int8_model[0].weight)
通过输出print(int8_model[0].weight)可以看到模型被量化为Int8类型,那么怎么还原为FP16权重呢?
(int8_model[0].weight.CB * int8_model[0].weight.SCB) / 127
- 使用int8模型进行推理
input_ = torch.randn((1,64), dtype=torch.float16)
hidden_states = int8_model(input_.to(torch.device('cuda:0')))
2. 你只需要accelerate
当使用大模型时,acceleate库包含了有用的程序。init_empty_weights方法特别有用,因为任何模型(无论大小)都可以作为上下文管理器使用此方法进行初始化,而无需为模型权重分配任何内存。
import torch.nn as nn
from accelerate import init_empty_weightswith init_empty_weights():model = nn.Sequential(*[nn.Linear(100000, 100000) for _ in range(1000)])
这个初始化的模型会被放置至Pytorch的元设备上,其是一种不用分配存储空间来表示shape和dtype的潜在机制。
起初,该函数在.from_pretrained函数中被调用,并将所有参数重写为torch.nn.Parameter。但是,这不符合我们的需求,因为希望在Linear8bitLt模块中保留Int8Params类。因此我们将
module._parameters[name] = nn.Parameter(module._parameters[name].to(torch.device("meta")))
修改为
param_cls = type(module._parameters[name])
kwargs = module._parameters[name].__dict__
module._parameters[name] = param_cls(module._parameters[name].to(torch.device("meta")), **kwargs)
通过这个修改,我们可以通过自定义函数在没有任何内存消耗的情况下,利用这个上下文管理器将所有的nn.Linear替换为bnb.nn.Linear8bitLt。
def replace_8bit_linear(model, threshold=6.0, module_to_not_convert="lm_head"):for name, module in model.named_children():if len(list(module.children())) > 0:# 递归replace_8bit_linear(module, threshold, module_to_not_convert)if isinstance(module, nn.Linear) and name != module_to_not_convert:with init_empty_weights():model._modules[name] = bnb.nn.Linear8bitLt(module.in_features,module.out_features,module.bias is not None,has_fp16_weights=False,threshold=threshold,)return model
该函数会递归的将元设备上的所有nn.Linear替换为Linear8bitLt模块。属性has_fp16_weights必须被设置为False,以便加载int8权重和量化信息。
3. 如何在transformers中使用
from transformers import AutoTokenizer, AutoModelForCausalLMdef inference(payload, model, tokenizer):input_ids = tokenizer(payload, return_tensors="pt").input_ids.to(model.device)print(f"输入:\n {payload}")logits = model.generate(input_ids, num_beams=1, max_new_tokens=128)print(f"生成:\n {tokenizer.decode(logits[0].tolist()[len(input_ids[0]):])}")model_name = "bigscience/bloomz-7b1-mt"
payload = "一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
model_native = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
# 比较推理结果
inference(payload, model_8bit, tokenizer)
inference(payload, model_native, tokenizer)
# 计算显存节约程度
mem_fp16 = model_native.get_memory_footprint()
mem_int8 = model_8bit.get_memory_footprint()
print(mem_fp16/mem_int8)
相关文章:
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
用于大型Transformer的8-bit矩阵乘法介绍原文地址:A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using transformers, accelerate and bitsandbytes 相关博客 【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介…...
设计模式之工厂模式详解和应用
目录1 工厂模式的历史由来2.简单工厂模式2.1 简单工厂模式定义2.2 简单工厂模式案例2.3 简单工厂模式相关源码2.4 简单工厂模式优缺点3 工厂方法模式3.1 工厂方法模式定义3.2 工厂方法模式案例3.3 工厂方法模式源码3.4 工厂方法模式优缺点4 抽象工厂模式4.1 抽象工厂模式定义4.…...

ArcGIS中的附件功能
从ArcGIS10起,空间数据库增加了"附件"的功能,可灵活管理与要素相关的附加信息,可以是图像、PDF、文本文档或任意其他文件类型。例如,如果用某个要素表示建筑物,则可以使用附件来添加多张从不同角度拍摄的建筑物照片。 启动附件功能 要想使用附件功能,要素类必…...

epoll单台设备支持百万并发连接
一些概念: linux下一切接文件,文件描述符fd,文件I/O(包含socket,文本文件等),I/O多路复用,reactor模型,水平触发,边沿触发,多线程模型,阻塞和非阻塞…...

网络字节序
文章目录网络字节序网络字节序 内存中的多字节数据相对于内存地址有大端和小端之分, 磁盘文件中的多字节数据相对于文件中的偏移地址也有大端小端之分, 网络数据流同样有大端小端之分. 网络数据流的地址统一按大端处理 发送主机通常将发送缓冲区中的数据按内存地址从低到高的…...

03- SVC 支持向量机做人脸识别 (项目三)
数据集描述: sklearn的lfw_people函数在线下载55个外国人图片文件夹数据集来精确实现人脸识别并提取人脸特征向量数据集地址: sklearn.datasets.fetch_lfw_people — scikit-learn 1.2.1 documentationPCA降维: pca PCA(n_components0.9) 数据拆分: X_train, X_test, y_tra…...
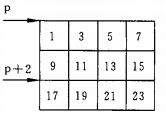
浅谈指向二维数组元素的指针变量
(1)指向数组元素的指针变量 例1.有一个3X4的二维数组,要求用指向元素的指针变量输出二维数组各元素的值. 编写程序 1 #include <stdio.h>2 int main()3 {4 int a[3][4] { 1,3,5,7,9,11,13,15,17,19,21,23 };5 int *p;6 for (p a[0]; p < a[0] 12; p) …...

左右值引用和移动语义
文章首发公众号:iDoitnow 1. 左右值和左右值引用 什么是左值、右值呢?一种极不严谨的理解为:在赋值的时候,能够被放到等号左边的值为左值,放在右边的值为右值。例如: int sum(int x, int y){return x y;…...

一起学习用Verilog在FPGA上实现CNN----(七)全连接层设计
1 全连接层设计 1.1 Layer 进行线性计算的单元layer,原理图如图所示: 1.2 processingElement Layer中的线性计算单元processingElement,原理图如图所示: processingElement模块展开原理图,如图所示,包含…...
tomcat打debug断点调试
windows debug调试 jdk版本:1.8.0_181 tomcat版本:apache-tomcat-9.0.68.0 idea版本:2020.1 方法一 修改catalina.bat 在%CATALINA_HOME%\bin\catalina.bat中找到 set “JAVA_OPTS%JAVA_OPTS% -Djava.protocol.handler.pkgsorg.apache…...

如果持有互斥锁的线程没有解锁退出了,该如何处理?
文章目录如果持有互斥锁的线程没有解锁退出了,该如何处理?问题引入PTHREAD_MUTEX_ROBUST 和 pthread_mutex_consistent登场了结论:如果持有互斥锁的线程没有解锁退出了,该如何处理? 问题引入 看下面一段代码…...
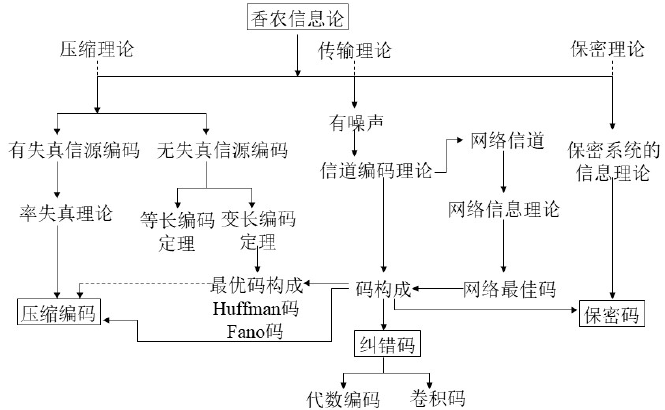
信息论绪论
本专栏针包含信息论与编码的核心知识,按知识点组织,可作为教学或学习的参考。markdown版本已归档至【Github仓库:information-theory】,需要的朋友们自取。或者关注公众号【AIShareLab】,回复 信息论 也可获取。 文章目…...

Buffer Status Reporting(BSR)
欢迎关注同名微信公众号“modem协议笔记”。 以一个实网中的异常场景开始,大概流程是有UL data要发送,UE触发BSR->no UL grant->SR->no UL grant->trigger RACH->RACH fail->RLF->RRC reestablishment:简单描述就是UE触…...

代码随想录LeetCode | 单调栈问题
前沿:撰写博客的目的是为了再刷时回顾和进一步完善,其次才是以教为学,所以如果有些博客写的较简陋,是为了保持进度不得已而为之,还请大家多多见谅。 预:看到题目后的思路和实现的代码。 见:参考…...

C++之可调用对象、bind绑定器和function包装器
可调用对象在C中,可以像函数一样调用的有:普通函数、类的静态成员函数、仿函数、lambda函数、类的非静态成员函数、可被转换为函数的类的对象,统称可调用对象或函数对象。可调用对象有类型,可以用指针存储它们的地址,可…...
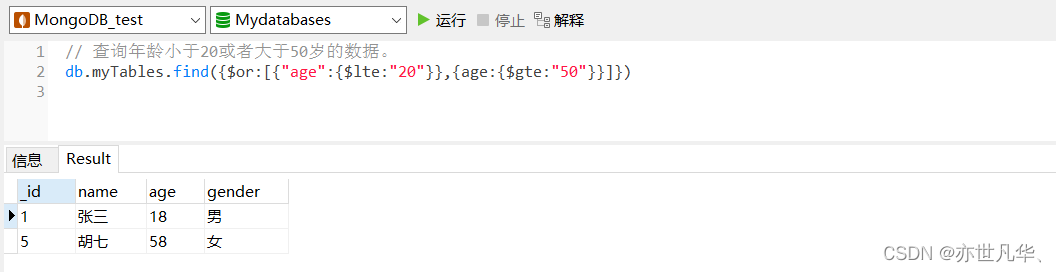
MongoDB--》文档查询的详细具体操作
目录 统计查询 分页列表查询 排序查询 正则的复杂条件查询 比较查询 包含查询 条件连接查询 统计查询 统计查询使用count()方法,其语法格式如下: db.collection.count(query,options) ParameterTypeDescriptionquerydocument查询选择条件optio…...
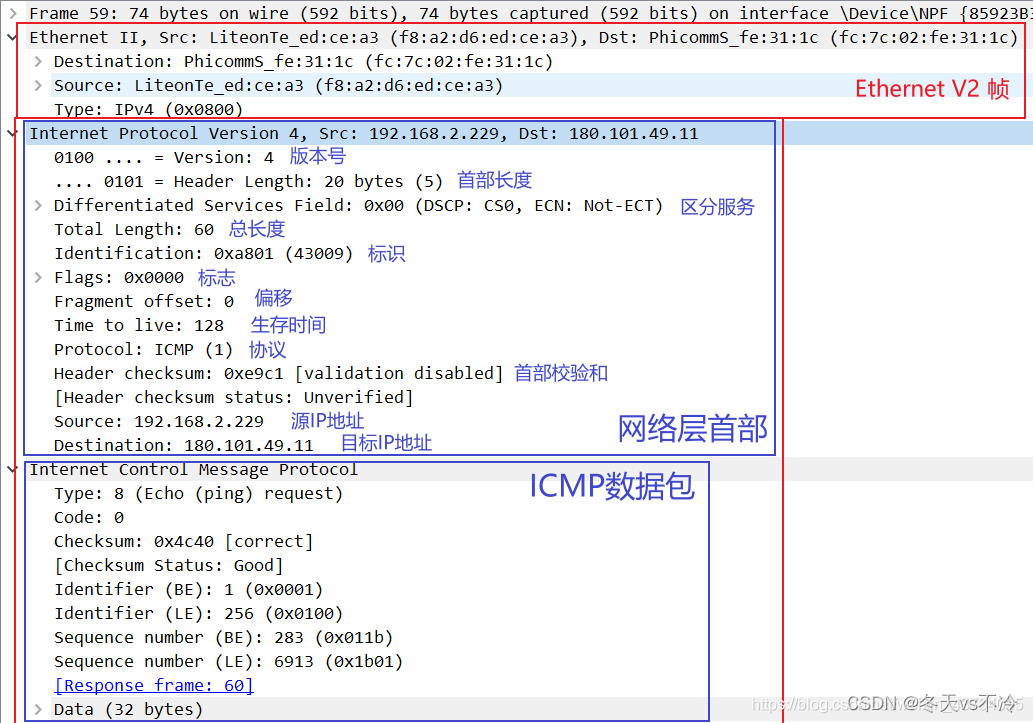
网络协议(六):网络层
网络协议系列文章 网络协议(一):基本概念、计算机之间的连接方式 网络协议(二):MAC地址、IP地址、子网掩码、子网和超网 网络协议(三):路由器原理及数据包传输过程 网络协议(四):网络分类、ISP、上网方式、公网私网、NAT 网络…...

热启动预示生态起航的Smart Finance,与深度赋能的SMART通证
2023年初加密市场的回暖,意味着各个赛道都将在新的一年里走向新的叙事。最近,我们看到GameFi赛道也在市场回暖的背景下,逐渐走出阴霾。从融资数据上看,1月获得融资的GameFi项目共12个,融资突破8000万美元,1…...

提分必练,中创教育PMP全真模拟题分享
湖南中创教育每日五题分享来啦,“日日行,不怕千万里;常常做,不怕千万事。”,每日五题我们练起来! 1、在系统测试期间,按已识别原因的类型或类别记录了失败测试的数量。项目经理首先需要从最大故…...

PID控制算法基础介绍
PID控制的概念 生活中的一些小电器,比如恒温热水器、平衡车,无人机的飞行姿态和飞行速度控制,自动驾驶等等,都有应用到 PID——PID 控制在自动控制原理中是一套比较经典的算法。 为什么需要 PID 控制器呢? 你一定用…...

从C到汇编:深入理解Linux系统调用的底层实现原理
从C到汇编:深入理解Linux系统调用的底层实现原理 当你在C语言中调用write()函数向屏幕输出文字时,背后究竟发生了什么?这个看似简单的操作,实际上经历了一场从用户态到内核态的复杂旅程。本文将带你穿越高级语言与机器指令的边界&…...
Pixel Dimension Fissioner显存优化:长文本裂变显存占用<3.2GB实测报告
Pixel Dimension Fissioner显存优化:长文本裂变显存占用<3.2GB实测报告 1. 工具概述 像素语言维度裂变器(Pixel Dimension Fissioner)是一款基于MT5-Zero-Shot-Augment核心引擎构建的文本改写与增强工具。与传统AI工具不同,它采用了独特的16-bit像素…...

Qwen3-32B-Chat百度热搜标题:国产大模型Qwen3-32B私有部署最佳实践
Qwen3-32B-Chat私有部署最佳实践:RTX4090D 24G显存深度优化指南 1. 开箱即用的私有部署方案 Qwen3-32B作为国产大模型的优秀代表,其强大的语言理解和生成能力备受关注。但对于大多数开发者而言,如何高效部署这个参数量庞大的模型仍是一个挑…...

解决Pandas HDF5 PyTables版本冲突:ImportError: Pandas requires version ‘3.10.1‘ or newer of ‘tables‘ (versi
# 导出为 HDF5 df.to_hdf("data/students.h5", key"students", format"table", indexFalse)# 从 HDF5 读取并验证 df_loaded pd.read_hdf("data/students.h5", key"students")运行时报错:我们面对的问题是&…...

Qwen3-TTS-12Hz-1.7B-CustomVoice提示词工程:打造自然对话语音
Qwen3-TTS-12Hz-1.7B-CustomVoice提示词工程:打造自然对话语音 想让AI语音听起来像真人对话一样自然流畅?掌握提示词技巧是关键! 不知道你有没有遇到过这种情况:用TTS生成的语音听起来机械生硬,就像机器人在念稿&#…...

Qwen3-0.6B-FP8完整指南:上下文长度512→32K扩展能力实测
Qwen3-0.6B-FP8完整指南:上下文长度512→32K扩展能力实测 1. 引言:当“小模型”遇上“大胃口” 你可能听过很多关于大模型的讨论——动辄几百亿参数,需要昂贵的显卡才能运行。但今天我想和你聊点不一样的:一个只有6亿参数的“小…...

Elsevier投稿监控插件:告别手动刷新,实现智能追踪的终极解决方案
Elsevier投稿监控插件:告别手动刷新,实现智能追踪的终极解决方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 你是否也曾为频繁登录Elsevier投稿系统检查审稿状态而烦恼?每周花…...

10分钟实现AI编程助手与Figma设计工具的无缝集成完整指南
10分钟实现AI编程助手与Figma设计工具的无缝集成完整指南 【免费下载链接】cursor-talk-to-figma-mcp Cursor Talk To Figma MCP 项目地址: https://gitcode.com/GitHub_Trending/cu/cursor-talk-to-figma-mcp 想要让AI编程助手直接操控Figma设计文件,实现代…...

圣女司幼幽-造相Z-Turbo部署审计:SELinux/AppArmor安全策略配置最佳实践
圣女司幼幽-造相Z-Turbo部署审计:SELinux/AppArmor安全策略配置最佳实践 1. 部署环境安全审计概述 圣女司幼幽-造相Z-Turbo是基于Z-Image-Turbo的LoRA版本模型,专门用于生成牧神记圣女司幼幽角色图片。该模型通过Xinference框架部署,并使用…...

通义千问3-Reranker-0.6B效果展示:法律文档检索Top3重排结果可视化
通义千问3-Reranker-0.6B效果展示:法律文档检索Top3重排结果可视化 你是不是也遇到过这样的烦恼?在搜索引擎里输入一个法律问题,比如“公司股东会决议无效的情形有哪些?”,结果搜出来一大堆文档,有的讲的是…...