【redis进阶】集群 (Cluster)
目录
一、基本概念
二、数据分片算法
2.1 哈希求余
2.2 一致性哈希算法
3.3 哈希槽分区算法 (Redis 使用)
三、集群搭建 (基于 docker)
3.1 创建目录和配置
3.2 编写 docker-compose.yml
3.3 启动容器
3.4 构建集群
四、主节点宕机
4.1 处理流程
五、集群扩容
六、集群缩容 (选学)
redis学习🥳
📚 本章节相关操作不需要记忆!!! 后续工作中如果用到了能查到即可.
重点大家理解流程和原理.
一、基本概念
集群这个词,广义的集群,只要你是多个机器,构成了分布式系统,都可以称为是一个“集群”。狭义
的集群, redis 提供的集群模式,这个集群模式之下,主要是要解决,存储空间不足的问题(拓展存储
空间)前面主从结构,哨兵模式,也可以称为是“广义的集群"上述的 哨兵 模式,提高了系统的可用性.
但是真正用来存储数据的还是 master 和 slave节点. 所有的数据都需要存储在单个 master 和 slave 节
点中. 如果数据量很大,接近超出了 master / slave 所在机器的物理内存,就可能出现严重问题了.
🚅虽然硬件价格在不断降低,一些中大厂的服务器内存已经可以达到 TB 级别了,但是 1TB 在当前这个 "大数据" 时代,俨然不算什么,有的时候我们确实需要更大的内存空间来保存更多的数据.
如何获取更大的空间?加机器即可!所谓 "大数据" 的核心,其实就是一台机器搞不定了,用多台机器
来搞.
Redis 的集群就是在上述的思路之下,引入多组 Master / Slave,每一组 Master / Slave 存储数据全集
的一部分,从而构成一个更大的整体,称为 Redis 集群 (Cluster).
✏ 假定整个数据全集是 1 TB, 引入三组 Master / Slave 来存储. 那么每一组机器只需要存储整个数据全集的 1/3 即可.
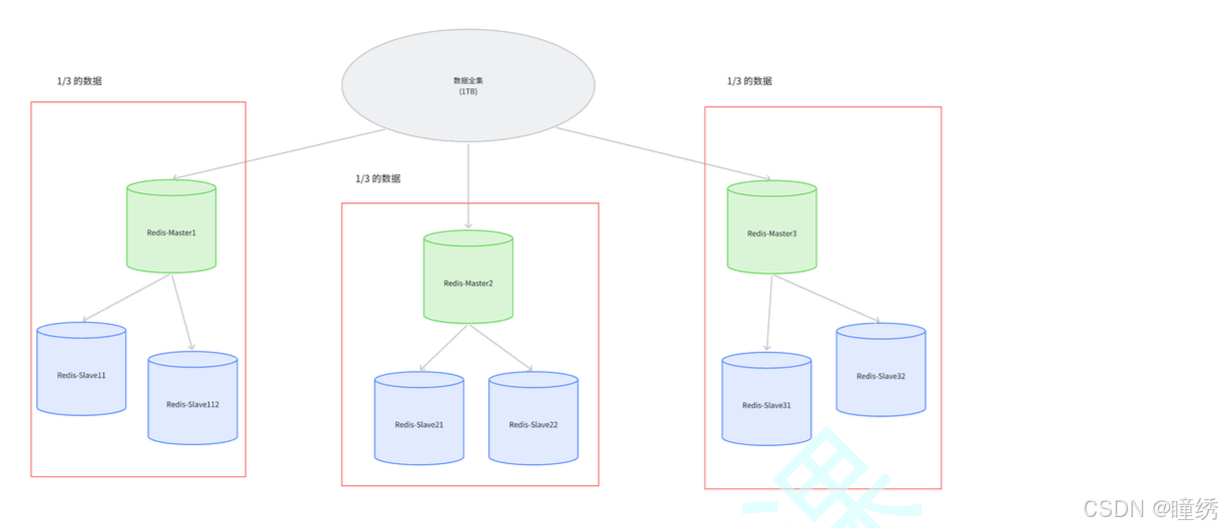
在上述图中,
- Master1 和 Slave11 和 Slave12 保存的是同样的数据. 占总数据的 1/3
- Master2 和 Slave21 和 Slave22 保存的是同样的数据. 占总数据的 1/3
- Master3 和 Slave31 和 Slave32 保存的是同样的数据. 占总数据的 1/3
这三组机器存储的数据都是不同的.
每个 Slave 都是对应 Master 的备份(当 Master 挂了,对应的 Slave 会补位成 Master).
每个红框部分都可以称为是一个 分片(Sharding).
如果全量数据进一步增加,只要再增加更多的分片,即可解决.
🌟 可能有的同学认为,数据量多了,使用硬盘来保存不就行了?不要忘了硬盘只是存储多了,但是访问速度是比内存慢很多的. 但是事实上,还是存在很多的应用场景,既希望存储较多的数据,又希望有非常高的读写速度.
比如搜索引擎.
二、数据分片算法
Redis cluster 的核心思路是用多组机器来存数据的每个部分. 那么接下来的核心问题就是,给定一个数
据(一个具体的 key),那么这个数据应该存储在哪个分片上?读取的时候又应该去哪个分片读取?
围绕这个问题,业界有三种比较主流的实现方式.
2.1 哈希求余
设有 N 个分片,使用 [0, N-1] 这样序号进行编号.
针对某个给定的 key,先计算 hash值,再把得到的结果 % N,得到的结果即为分片编号.
例如,N 为 3. 给定 key 为 hello, 对 hello 计算 hash 值(比如使用 md5 算法),得到的结果为 bc4b2a76b9719d91,再把这个结果 % 3,结果为 0,那么就把 hello 这个 key 放到 0 号分片上.
当然,实际工作中涉及到的系统,计算 hash 的方式不一定是 md5,但是思想是一致的.
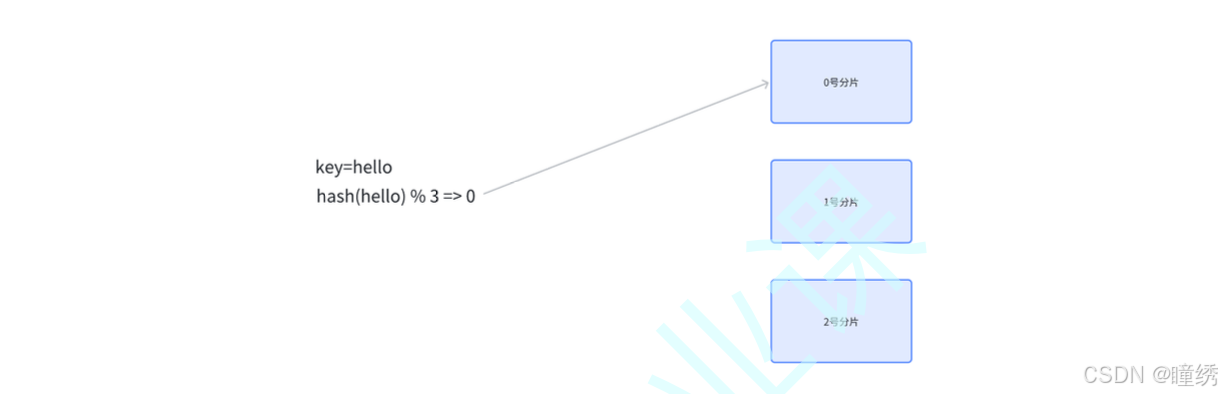
后续如果要取某个 key 的记录,也是针对 key 计算 hash再对 N 求余,就可以找到对应的分片编号了.
优点:简单高效,数据分配均匀.
缺点:一旦需要进行扩容,N 改变了,原有的映射规则被破坏,就需要让节点之间的数据相互传输,
重新排列,以满足新的映射规则. 此时需要搬运的数据量是比较多的,开销较大.
N 为 3 的时候,[100, 120] 这 21 个 hash 值的分布(此处假定计算出的 hash 值是一个简单的整数,
方便肉眼观察)
当引入一个新的分片,N 从 3 => 4 时,大量的 key 都需要重新映射. (某个key % 3 和 % 4 的结果不
一样,就映射到不同机器上了).

如上图可以看到,整个扩容一共 21 个 key,只有 3 个 key 没有经过搬运,其他的 key 都是搬运过的.
2.2 一致性哈希算法
为了降低上述的搬运开销,能够更高效扩容,业界提出了"一致性哈希算法".
key 映射到分片序号的过程不再是简单求余了,而是改成以下过程:
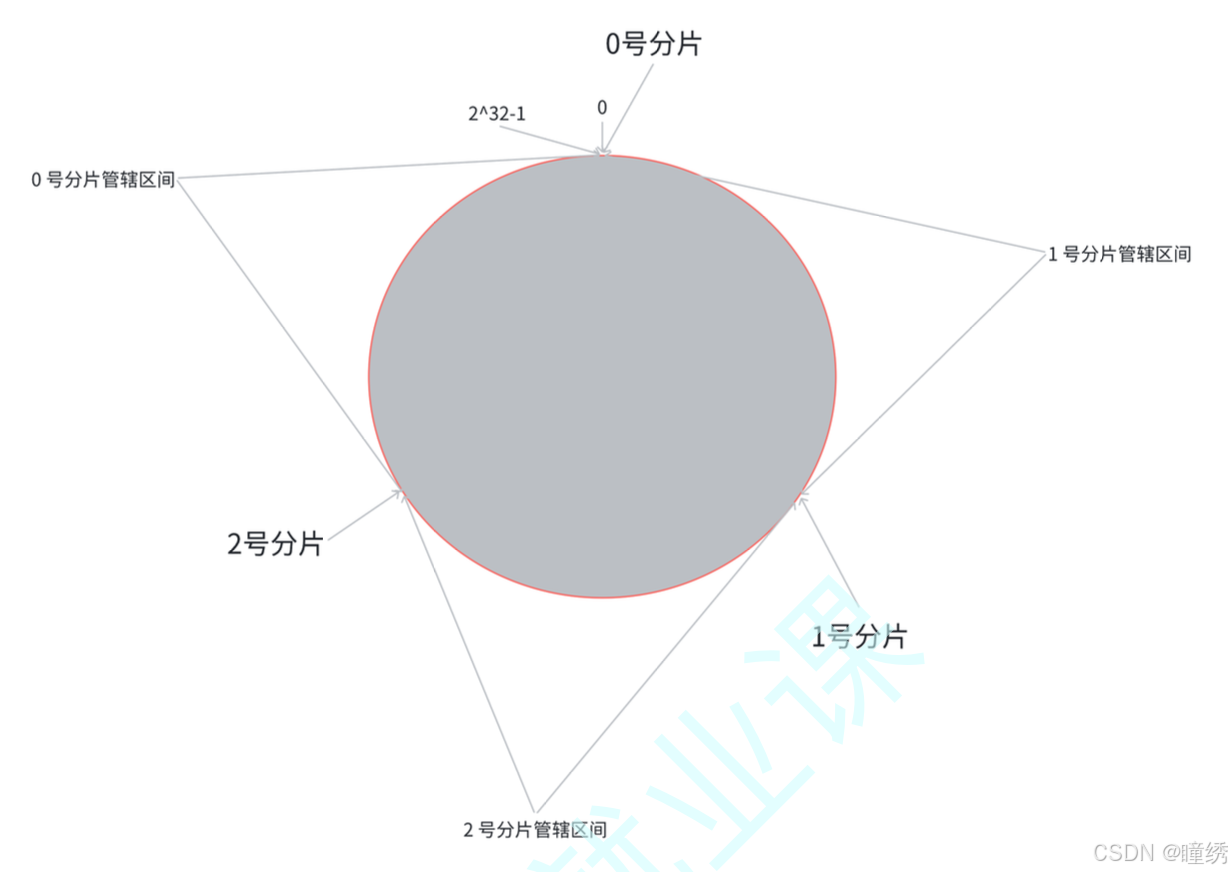
第一步:把 0 -> 2^32-1 这个数据空间,映射到一个圆环上. 数据按照顺时针方向增长.
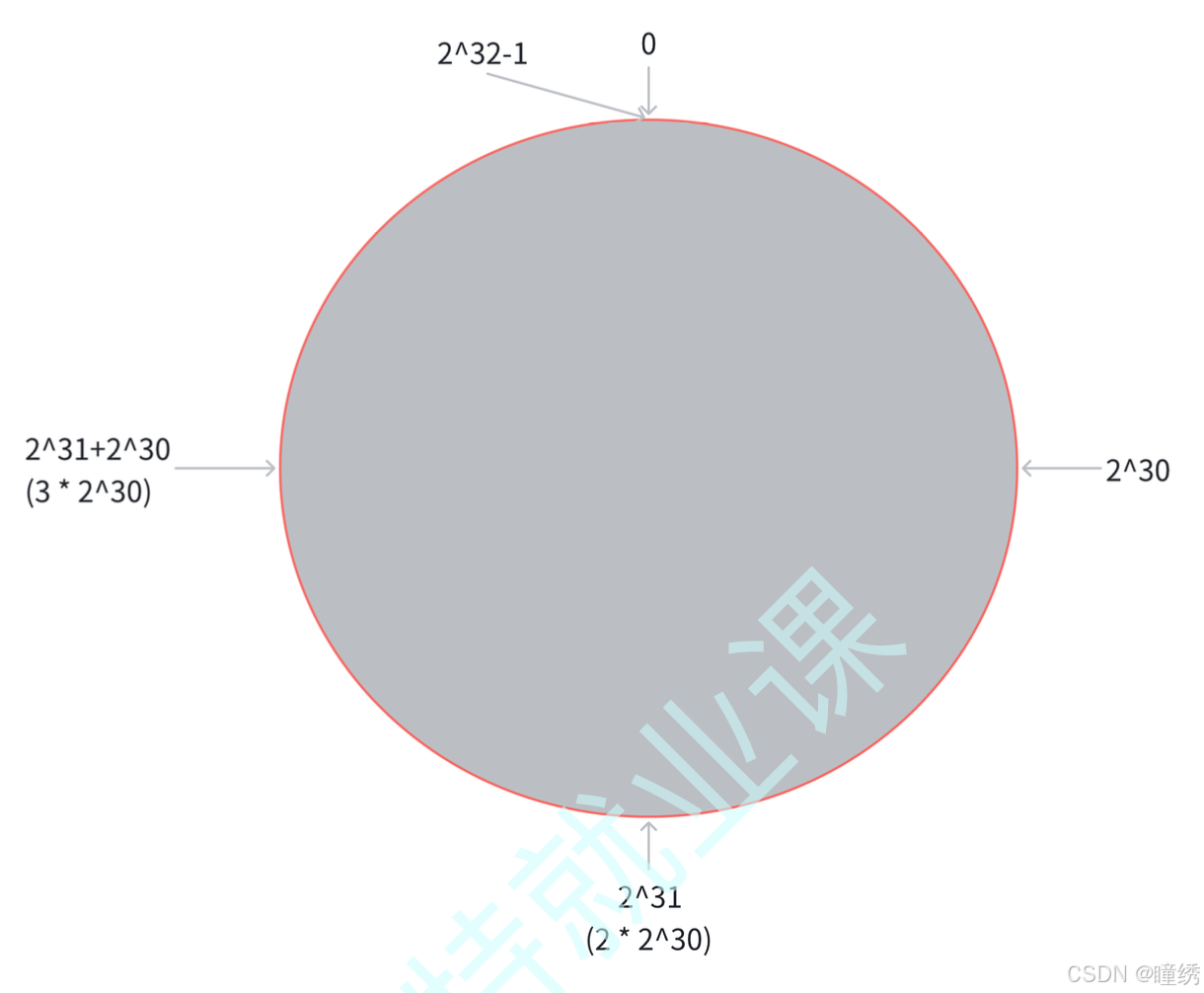
第二步:假设当前存在三个分片,就把分片放到圆环的某个位置上.

第三步:假定有一个 key,计算得到 hash 值 H,那么这个 key 映射到哪个分片呢?规则很简单,就是
从 H 所在位置,顺时针往下找,找到的第一个分片,即为该 key 所从属的分片.
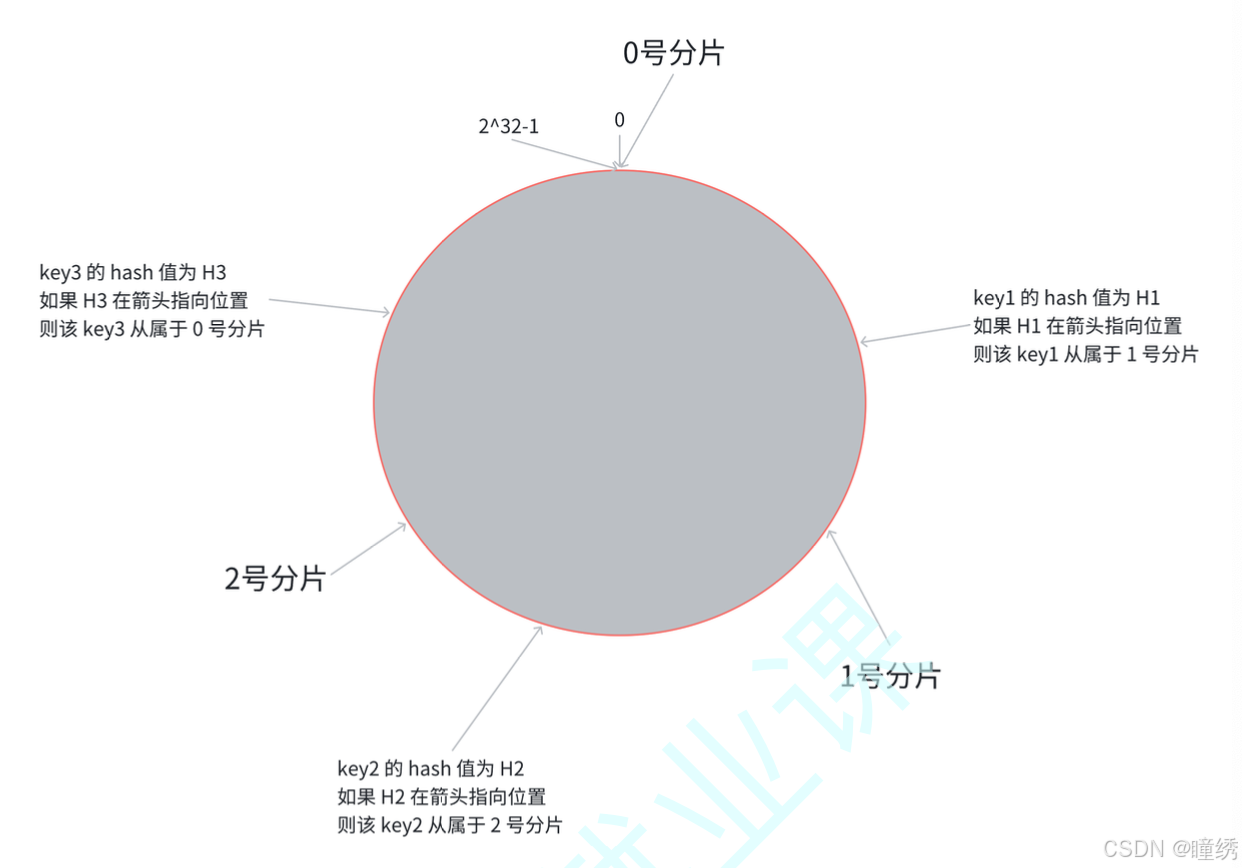
这就相当于,N 个分片的位置,把整个圆环分成了 N 个管辖区间. Key 的 hash 值落在某个区间内,就
归对应区间管理.
🎹 上述一致性哈希算法的过程,类似于去高铁站取票.
现在的高铁站都可以直接刷身份证了. 但是以前的时候需要网上先购票,然后再去高铁站的取票机上把票取出来.
想象下列场景:
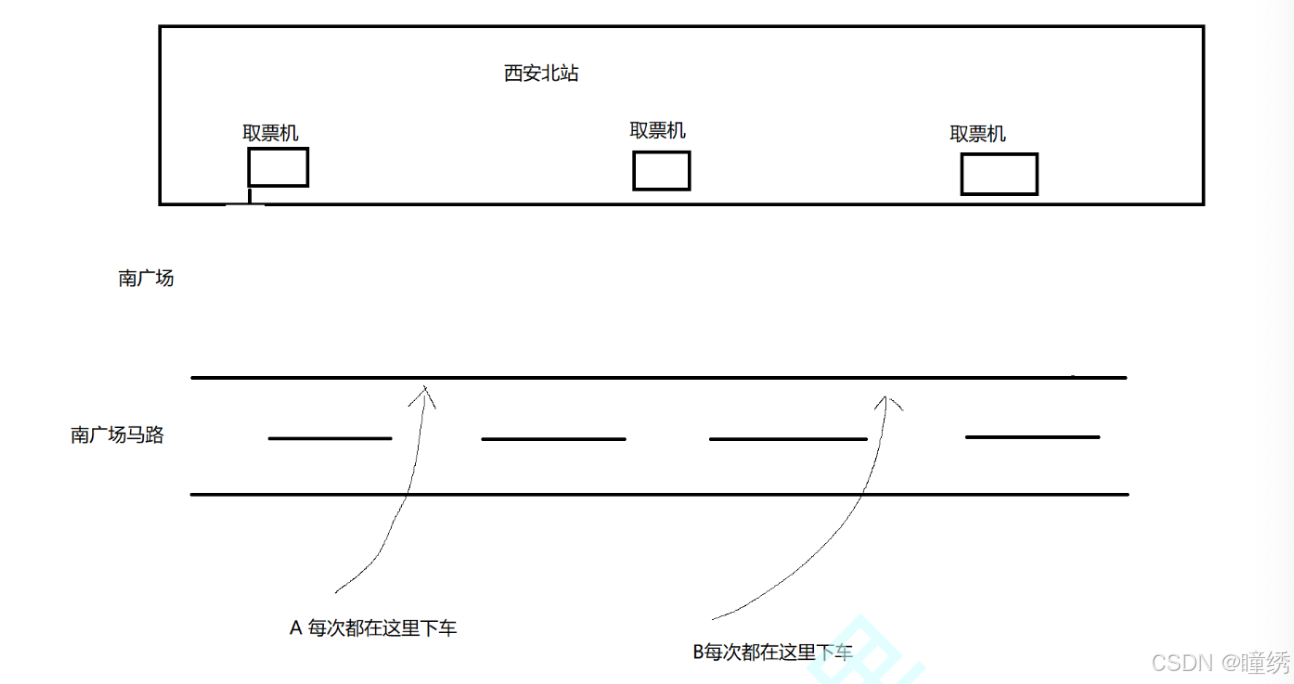
假设,一个人每次来高铁站,都会停车在同一个位置. (不同的人停车位置不同).
每个人下车之后,都往右手方向走,遇到第一个取票机就进行取票.
在这个情况下,如果扩容一个分片,如何处理呢?
原有分片在环上的位置不动,只要在环上新安排一个分片位置即可.

此时,只需要把 0 号分片上的部分数据,搬运给 3 号分片即可. 1 号分片和 2 号分片管理的区间都是不
变的.
优点:大大降低了扩容时数据搬运的规模,提高了扩容操作的效率.
缺点:数据分配不均匀 (有的多有的,少数据倾斜).
3.3 哈希槽分区算法 (Redis 使用)
为了解决上述问题(搬运成本高 和 数据分配不均匀),Redis cluster 引入了哈希槽 (hash slots) 算法.
hash_slot = crc16(key) % 16384其中 crc16 也是一种 hash 算法.
16384 其实是 16 * 1024, 也就是 2^14.
相当于是把整个哈希值,映射到 16384 个槽位上,也就是 [0, 16383].
然后再把这些槽位比较均匀的分配给每个分片,每个分片的节点都需要记录自己持有哪些分片.
假设当前有三个分片,一种可能的分配方式:
- 0 号分片: [0, 5461], 共 5462 个槽位
- 1 号分片: [5462, 10923], 共 5462 个槽位
- 2 号分片: [10924, 16383], 共 5460 个槽位
🏖 这里的分片规则是很灵活的,每个分片持有的槽位也不一定连续.
每个分片的节点使用 位图 来表示自己持有哪些槽位. 对于 16384 个槽位来说,需要 2048 个字节(2KB) 大小的内存空间表示.
如果需要进行扩容,比如新增一个 3 号分片,就可以针对原有的槽位进行重新分配.
比如可以把之前每个分片持有的槽位,各拿出一点,分给新分片.
一种可能的分配方式:
- 0 号分片: [0, 4095], 共 4096 个槽位
- 1 号分片: [5462, 9557], 共 4096 个槽位
- 2 号分片: [10924, 15019], 共 4096 个槽位
- 3 号分片: [4096, 5461] + [9558, 10923] + [15019, 16383], 共 4096 个槽位
✍ 我们在实际使用 Redis 集群分片的时候,不需要手动指定哪些槽位分配给某个分片,只需要告诉某个分片应该持有多少个槽位即可,Redis 会自动完成后续的槽位分配,以及对应的 key 搬运的工作.
此处还有两个问题:
问题一: Redis 集群是最多有 16384 个分片吗?
并非如此. 如果一个分片只有一个槽位,这对于集群的数据均匀其实是难以保证的,有的槽位可能是有
多个 key,有的槽位可能是没有 key。key 是要先映射到槽位,再映射到分片的. 如果每个分片包含的
槽位比较多,如果槽位个数相当,就可以认为是包含的 key 数量相当的. 如果每个分片包含的槽位非常
少,槽位个数不一定能直观的反应到 key 的数目(大锅饭、浑水摸鱼一把好手).
实际上 Redis 的作者建议集群分片数不应该超过 1000.
而且,16000 这么大规模的集群,本身的可用性也是一个大问题. 一个系统越复杂,出现故障的概率是
越高的.
问题二: 为什么是 16384 个槽位?
Redis 作者的答案: https://github.com/antirez/redis/issues/2576
大概意思是:
• 节点之间通过心跳包通信,心跳包中包含了该节点持有哪些 slots,这个是使用位图这样的数据结构表示的,表示 16384(16k)个 slots,需要的位图大小是 2KB.如果给定的slots 数更多了,比如65536 个了,此时就需要消耗更多的空间,8KB位图表示了.8 KB,对于内存来说不算什么,但是在频繁的网络心跳包中,还是一个不小的开销的.
• 另一方面,Redis 集群一般不建议超过 1000 个分片.所以 16k 对于最大 1000 个分片来说是足够用的,同时也会使对应的槽位配置位图体积不至于很大.
三、集群搭建 (基于 docker)
接下来基于 docker,搭建一个集群,每个节点都是一个容器.
拓扑结构如下:
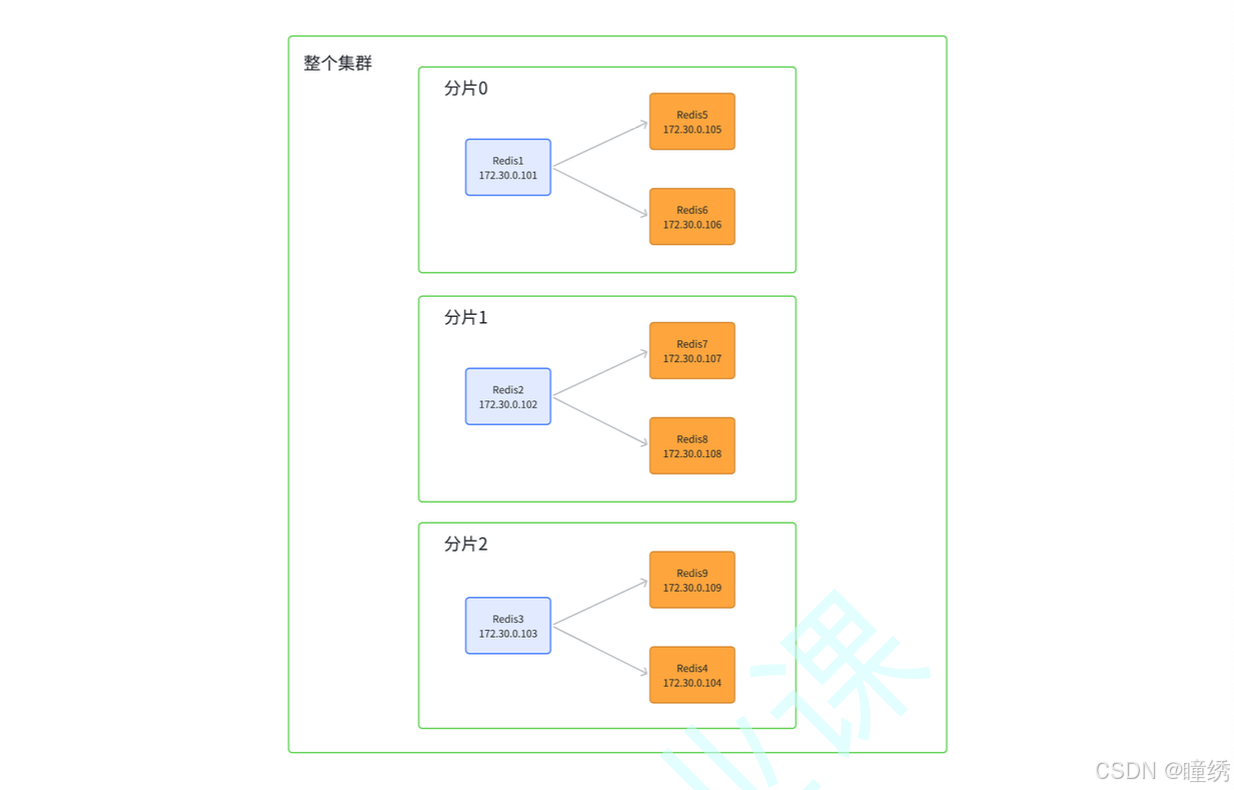
🎁 注意!此处我们先创建出 11 个 redis 节点,其中前 9 个用来演示集群的搭建.
后两个用来演示集群扩容.
3.1 创建目录和配置
创建 redis-cluster 目录. 内部创建两个文件
redis-cluster/
├── docker-compose.yml
└── generate.shgenerate.sh 内容如下
for port in $(seq 1 9); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done# 注意 cluster-announce-ip 的值有变化.
for port in $(seq 10 11); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.1${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done\ 是续行符:把下一行的内容和当前行,合并成一行. shell 默认情况下,要求把所有的代码都写到一行里的,使用续行符来换行.
shell 中{}:用来表示变量了,不是表示代码块. 对于 for,就是使用 do 和 done 来表示 代码块 开始 和 结束的.(上古时期的编程语言是这么搞的).
一个服务器,可以绑定多个端口号.
业务端口:用来进行业务数据通信的,响应 redis 客户端的请求的..
管理端口:为了完成一些管理上的任务来进行通信的.(如果某个分片中的 redis 主节点挂了,就需要让从节点成为主节点,就需要通过刚才管理端口来完成对应的操作.)
上述配置的 IP 和 port 都是代表容器内部的,不是容器外部的;
执行命令:
bash generate.sh生成目录如下:
redis-cluster/
├── docker-compose.yml
├── generate.sh
├── redis15
│ └── redis.conf
├── redis10
│ └── redis.conf
├── redis11
│ └── redis.conf
├── redis2
│ └── redis.conf
├── redis3
│ └── redis.conf
├── redis4
│ └── redis.conf
├── redis5
│ └── redis.conf
├── redis6
│ └── redis.conf
├── redis7
│ └── redis.conf
├── redis8
│ └── redis.conf
└── redis9
└── redis.conf
其中 redis.conf 每个都不同. 以 redis1 为例:
区别在于每个配置中配置的 cluster-announce-ip 是不同的,其他部分都相同.
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.101
cluster-announce-port 6379
cluster-announce-bus-port 16379
后续会给每个节点分配不同的 ip 地址.
🏆 配置说明:
• cluster-enabled yes 开启集群.
• cluster-config-file nodes.conf 集群节点生成的配置.
• cluster-node-timeout 5000 节点失联的超时时间.
• cluster-announce-ip 172.30.0.101 节点自身 ip.
• cluster-announce-port 6379 节点自身的业务端口.
• cluster-announce-bus-port 16379 节点自身的总线端口. 集群管理的信息交互是通过这个端口进行的.
3.2 编写 docker-compose.yml
• 先创建 networks,并分配网段为 172.30.0.0/24
• 配置每个节点. 注意配置文件映射,端口映射,以及容器的 ip 地址. 设定成固定 ip 方便后续的观察和操作.
此处的端口映射不配置也可以,配置的目的是为了可以通过宿主机 ip + 映射的端口进行访问. 通过容器自身 ip:6379 的方式也可以访问.
version: '3.7'
networks:mynet:ipam:config:- subnet: 172.30.0.0/24services:redis1:image: 'redis:5.0.9'container_name: redis1restart: alwaysvolumes:- ./redis1/:/etc/redis/ports:- 6371:6379- 16371:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.101redis2:image: 'redis:5.0.9'container_name: redis2restart: alwaysvolumes:- ./redis2/:/etc/redis/ports:- 6372:6379- 16372:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.102redis3:image: 'redis:5.0.9'container_name: redis3restart: alwaysvolumes:- ./redis3/:/etc/redis/ports:- 6373:6379- 16373:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.103redis4:image: 'redis:5.0.9'container_name: redis4restart: alwaysvolumes:- ./redis4/:/etc/redis/ports:- 6374:6379- 16374:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.104redis5:image: 'redis:5.0.9'container_name: redis5restart: alwaysvolumes:- ./redis5/:/etc/redis/ports:- 6375:6379- 16375:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.105redis6:image: 'redis:5.0.9'container_name: redis6restart: alwaysvolumes:- ./redis6/:/etc/redis/ports:- 6376:6379- 16376:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.106redis7:image: 'redis:5.0.9'container_name: redis7restart: alwaysvolumes:- ./redis7/:/etc/redis/ports:- 6377:6379- 16377:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.107redis8:image: 'redis:5.0.9'container_name: redis8restart: alwaysvolumes:- ./redis8/:/etc/redis/ports:- 6378:6379- 16378:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.108redis9:image: 'redis:5.0.9'container_name: redis9restart: alwaysvolumes:- ./redis9/:/etc/redis/ports:- 6379:6379- 16379:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.109redis10:image: 'redis:5.0.9'container_name: redis10restart: alwaysvolumes:- ./redis10/:/etc/redis/ports:- 6380:6379- 16380:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.110redis11:image: 'redis:5.0.9'container_name: redis11restart: alwaysvolumes:- ./redis11/:/etc/redis/ports:- 6381:6379- 16381:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.1113.3 启动容器
docker-compose up -d
3.4 构建集群
启动一个 docker 客户端.
❤ 此处是把前 9 个主机构建成集群,3 主 6 从. 后 2 个主机暂时不用.
redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379 172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379 172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2- --cluster create 表示建立集群. 后面填写每个节点的 ip 和 port,端口都是写容器内部的端口号.
- --cluster-replicas 2 表示每个主节点需要两个从节点备份.
执行之后,容器之间会进行加入集群操作.
redis 在构建集群的时候,谁是主节点,谁是从节点?谁和谁是一个分片?都不是固定的!
本身从集群的角度来看,提供的这些节点之间本身就应该是等价的.
日志中会描述哪些是主节点,哪些从节点跟随哪个主节点.
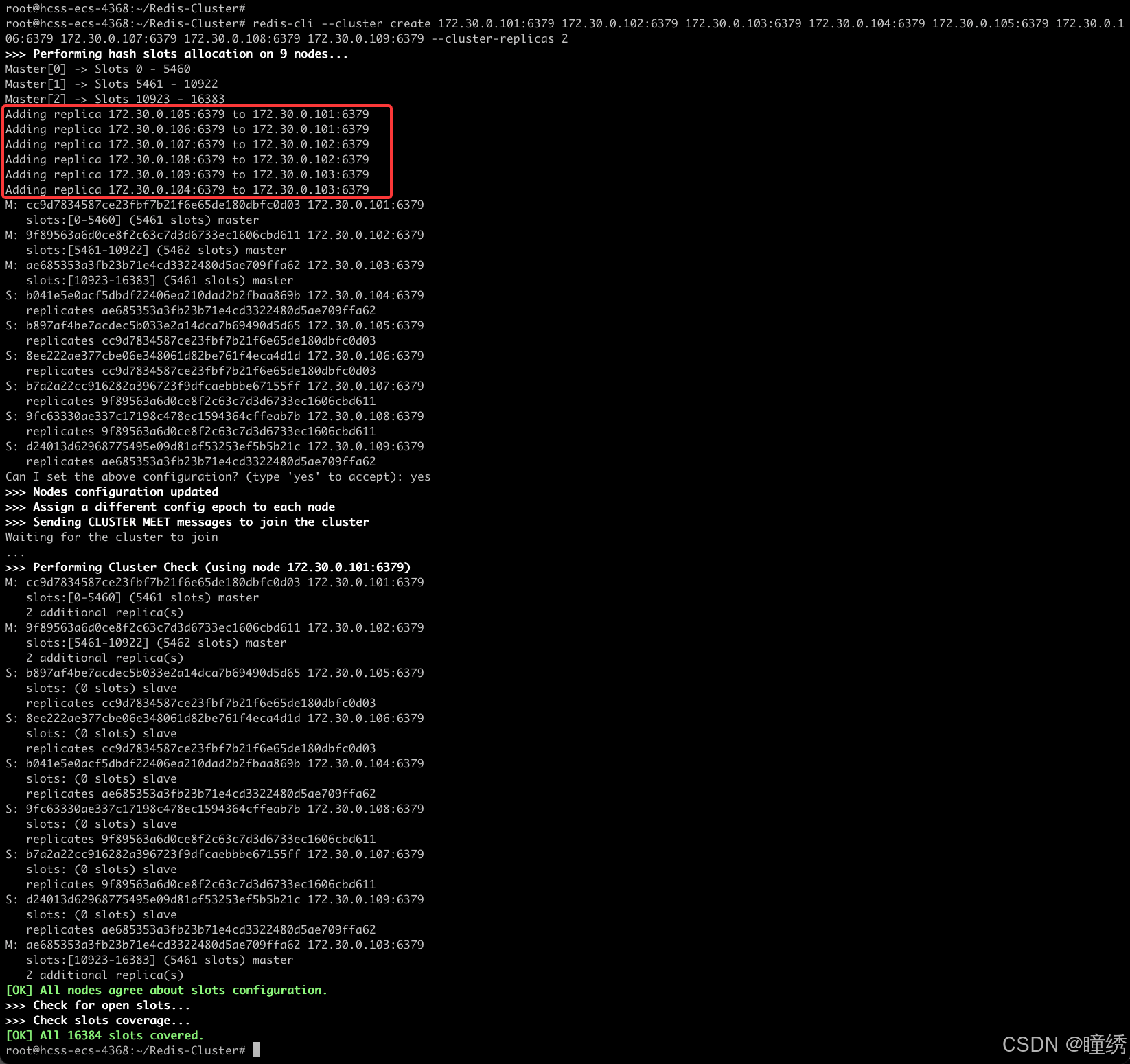
见到下方的 [OK] 说明集群建立完成.
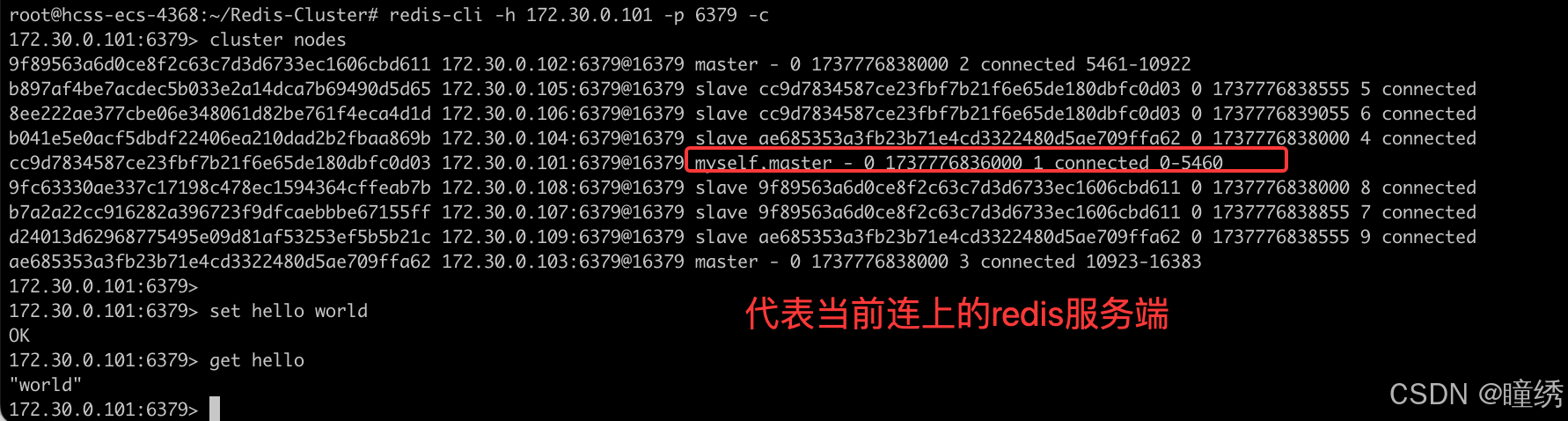
此时,使用客户端连上集群中的任何一个节点,都相当于连上了整个集群.
- 客户端后面要加上 -c 选项,否则如果 key 没有落到当前节点上,是不能操作的. -c 会自动把请求重定向到对应节点.
- 使用 cluster nodes 可以查看到整个集群的情况.
四、主节点宕机
演示效果
手动停止一个 master 节点,观察效果.
比如上述拓扑结构中,可以看到 redis1 redis2 redis3 是主节点,随便挑一个停掉.
docker stop redis1连上 redis2,观察结果.
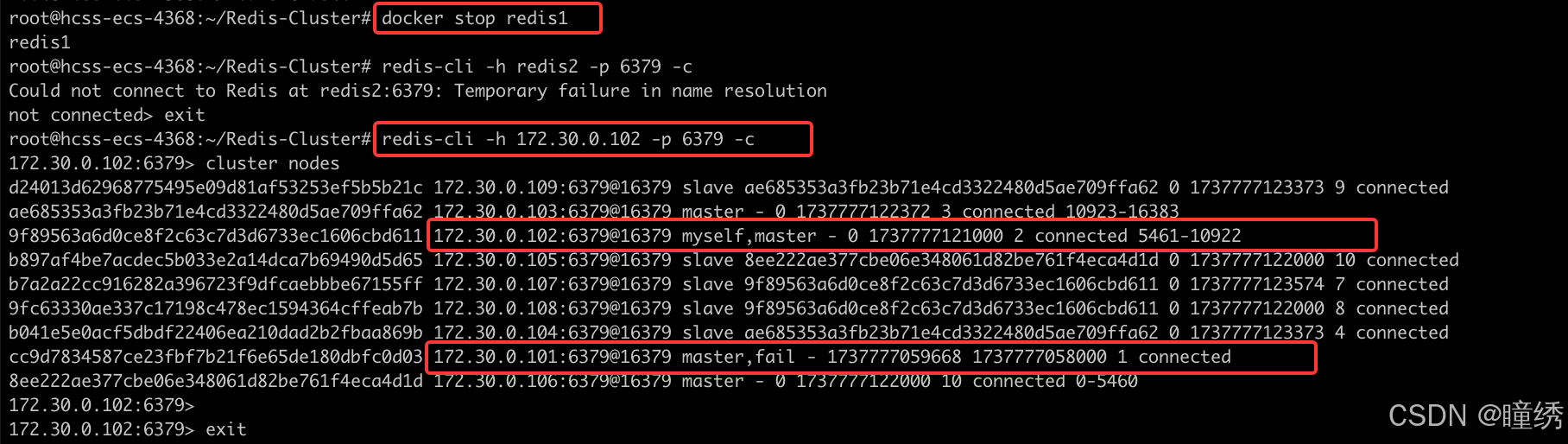
可以看到,101 已经提示 fail,然后 原本是 slave 的 105 成了新的 master.
如果重新启动 redis1
docker start redis1再次观察结果. 可以看到 101 启动了,仍然是 slave.
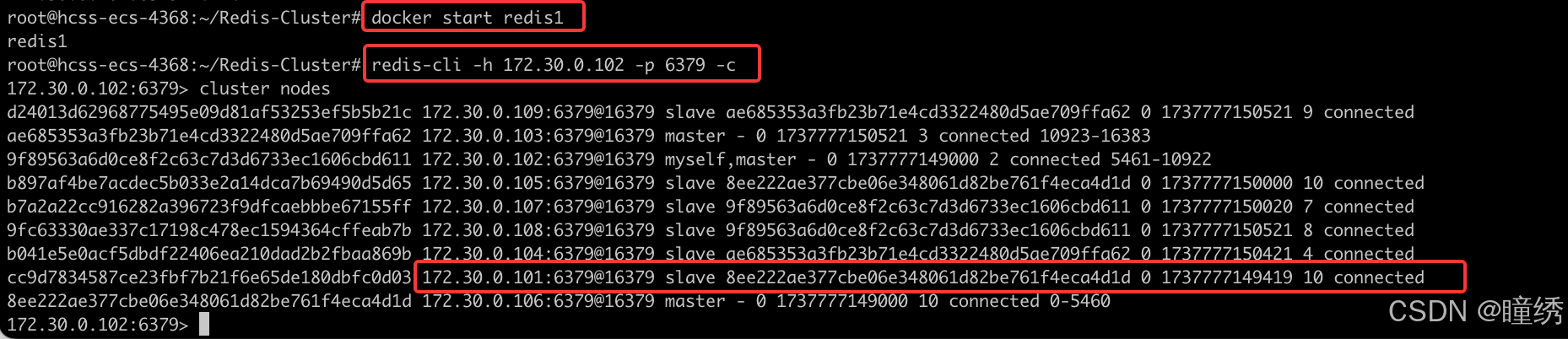
可以使用 cluster failover 进行集群恢复. 也就是把 101 重新设定成 master. (登录到 101 上执行)
4.1 处理流程
1) 故障判定
集群中的所有节点,都会周期性的使用心跳包进行通信.
1. 节点 A 给节点 B 发送 ping 包,B 就会给 A 返回一个 pong 包. ping 和 pong 除了 message type
属性之外,其他部分都是一样的. 这里包含了集群的配置信息(该节点的id,该节点从属于哪个分片,
是主节点还是从节点,从属于谁,持有哪些 slots 的位图...).
2. 每个节点,每秒钟都会给一些随机的节点发起ping 包,而不是全发一遍. 这样设定是为了避免在节
点很多的时候,心跳包也非常多(比如有 9 个节点,如果全发,就是 9 * 8 有 72 组心跳了,而且这是
按照 N^2 这样的级别增长的).
3. 当节点 A 给节点 B 发起 ping 包,B 不能如期回应的时候,此时 A 就会尝试重置 和 B 的 tcp 连接,
看能否连接成功. 如果仍然连接失败,A 就会把 B 设为 PFAIL 状态(相当于主观下线).
4. A 判定 B 为 PFAIL 之后,会通过 redis 内置的 Gossip 协议,和其他节点进行沟通,向其他节点确
认 B 的状态. (每个节点都会维护一个自己的 "下线列表",由于视角不同,每个节点的下线列表也不一
定相同).
5. 此时 A 发现其他很多节点,也认为 B 为 PFAIL,并且数目超过总集群个数的一半,那么 A 就会把 B
标记成 FAIL (相当于客观下线),并且把这个消息同步给其他节点(其他节点收到之后,也会把 B 标记成
FAIL). 至此,B 就彻底被判定为故障节点了.
某个或者某些节点宕机,有的时候会引起整个集群都宕机 (称为 fail 状态).
以下三种情况会出现集群宕机:
• 某个分片,所有的主节点和从节点都挂了.
• 某个分片,主节点挂了,但是没有从节点.
• 超过半数的 master 节点都挂了.
📌 核心原则是保证每个 slots 都能正常工作(存取数据).
2) 故障迁移
上述例子中,B 故障,并且 A 把 B FAIL 的消息告知集群中的其他节点.
• 如果 B 是从节点,那么不需要进行故障迁移.
• 如果 B 是主节点,那么就会由 B 的从节点 (比如 C 和 D) 触发故障迁移了.
所谓故障迁移,就是指把从节点提拔成主节点,继续给整个 redis 集群提供支持.
具体流程如下:
1. 从节点判定自己是否具有参选资格. 如果从节点和主节点已经太久没通信(此时认为从节点的数据和主
节点差异太大了),时间超过阈值,就失去竞选资格.
2. 具有资格的节点,比如 C 和 D,就会先休眠一定时间. 休眠时间 = 500ms 基础时间 + [0, 500ms]
随机时间 + 排名 * 1000ms. offset 的值越大,则排名越靠前(越小).
3. 比如 C 的休眠时间到了,C 就会给其他所有集群中的节点,进行拉票操作. 但是只有主节点才有投
票资格.
4. 主节点就会把自己的票投给 C (每个主节点只有 1 票). 当 C 收到的票数超过主节点数目的一半,C
就会晋升成主节点. (C 自己负责执行 slaveof no one,并且让 D 执行 slaveof C).
5. 同时,C 还会把自己成为主节点的消息,同步给其他集群的节点. 大家也都会更新自己保存的集群结
构信息.
🥇 上述选举的过程,称为 Raft 算法,是一种在分布式系统中广泛使用的算法.
在随机休眠时间的加持下,基本上就是谁先唤醒,谁就能竞选成功.
五、集群扩容
扩容是一个在开发中比较常遇到的场景.
随着业务的发展,现有集群很可能无法容纳日益增长的数据. 此时给集群中加入更多新的机器,就可以
使存储的空间更大了.
🍞 所谓分布式的本质,就是使用更多的机器,引入更多的硬件资源.
第一步: 把新的主节点加入到集群
上面已经把 redis1 - redis9 重新构成了集群. 接下来把 redis10 和 redis11 也加入集群.
此处我们把 redis10 作为主机,redis11 作为从机.
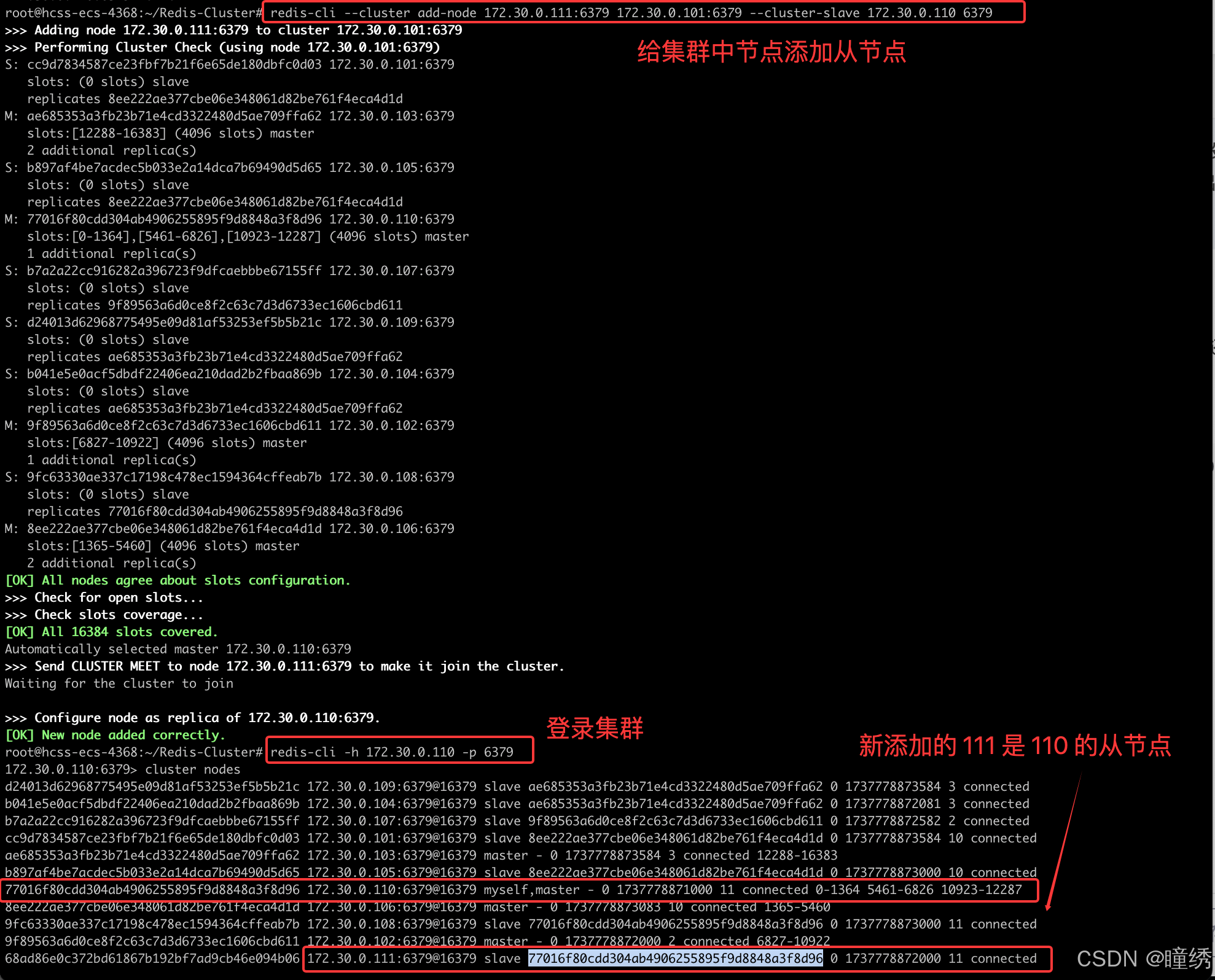
redis-cli --cluster add-node 172.30.0.110:6379 172.30.0.101:6379🌟 add-node 后的第一组地址是新节点的地址. 第二组地址是集群中的任意节点地址.
执行结果
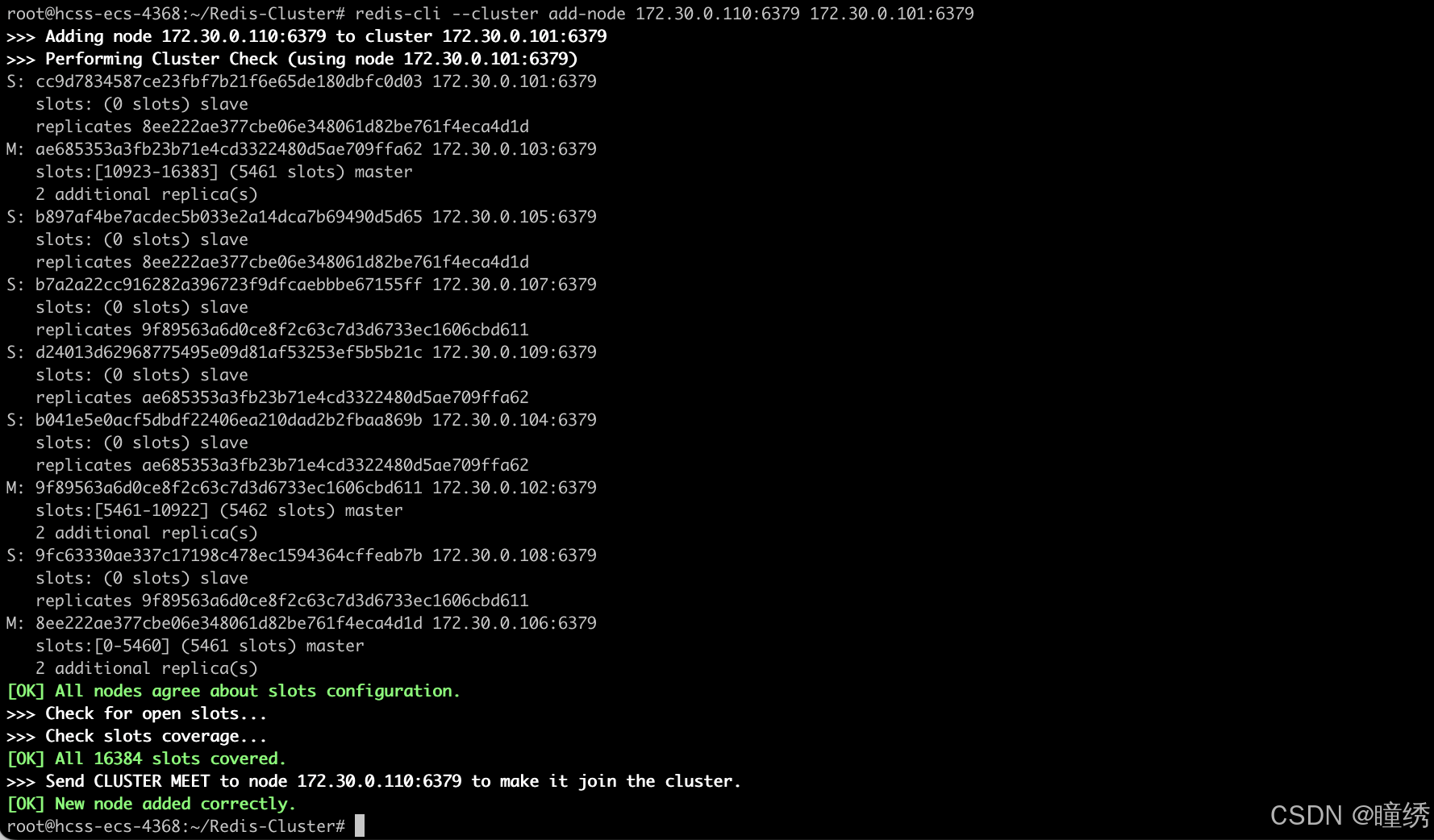
此时的集群状态如下,可以看到 172.30.0.110 这个节点已经成为了集群中的主节点.

第二步: 重新分配 slots
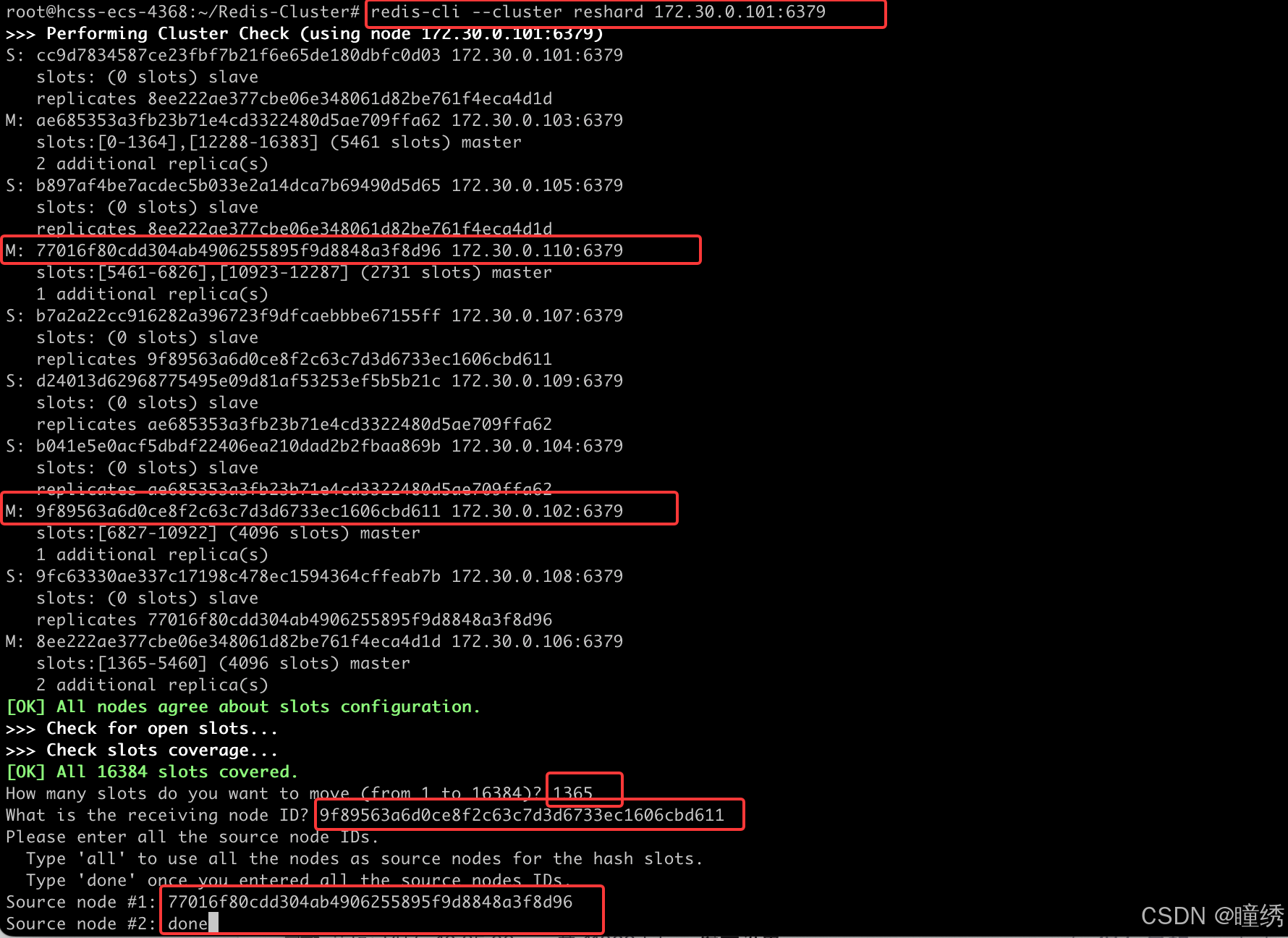
redis-cli --cluster reshard 172.30.0.101:6379🌟 reshard 后的地址是集群中的任意节点地址.
另外,注意单词拼写,是 reshard (重新切分),不是 reshared (重新分享),不要多写个 e.
执行之后,会进入交互式操作,redis 会提示用户输入以下内容:
• 多少个 slots 要进行 reshard ? (此处我们填写 4096)
• 哪个节点来接收这些 slots ? (此处我们填写 172.30.0.110 这个节点的集群节点 id)
• 这些 slots 从哪些节点搬运过来 ? (此处我们填写 all, 表示从其他所有的节点都进行搬运)
执行结果如下:
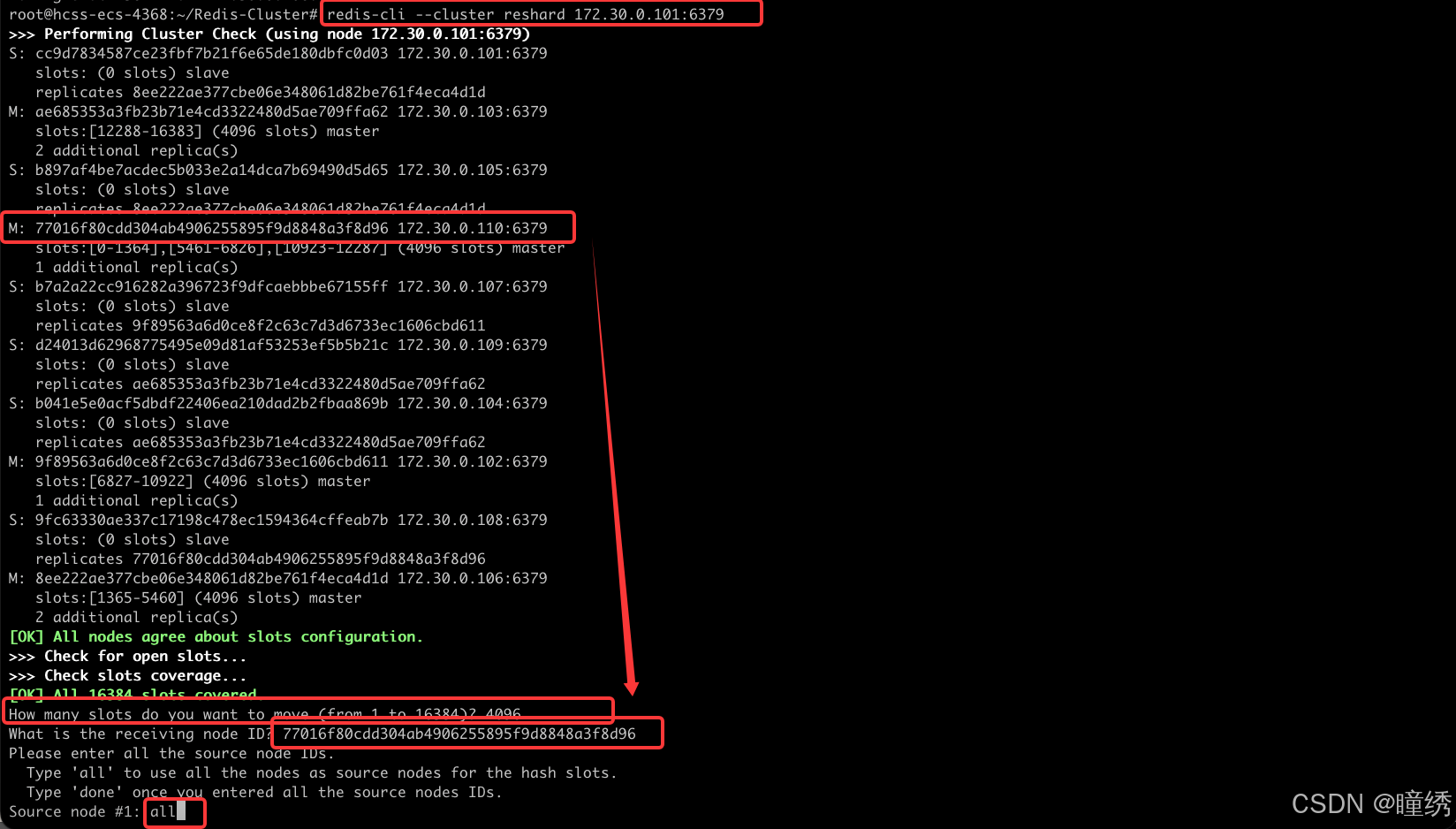
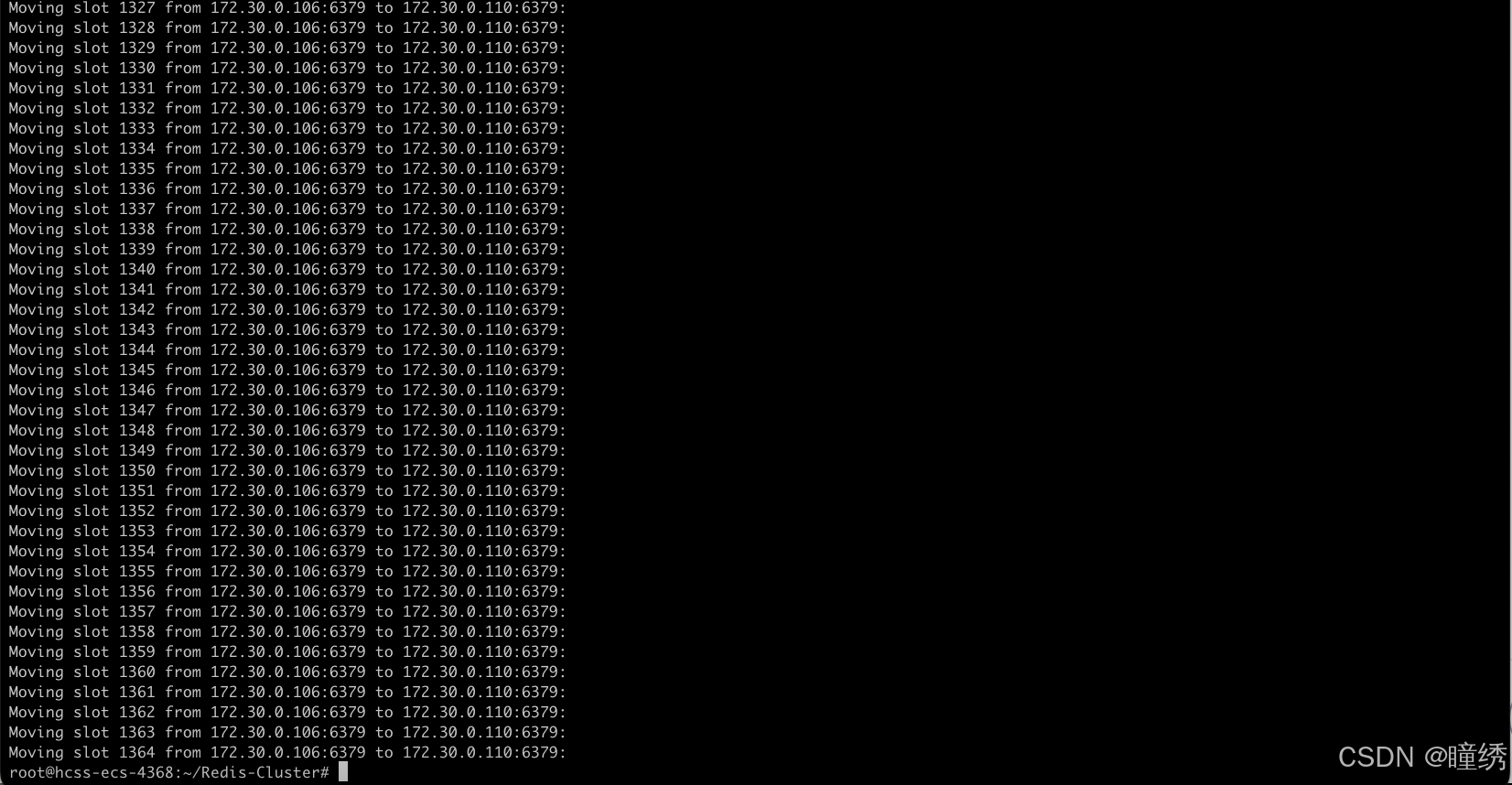
确定之后,会初步打印出搬运方案,让用户确认.
之后就会进行集群的 key 搬运工作. 这个过程涉及到数据搬运. 可能需要消耗一定的时间.
📌如果在搬运 slots / key 的过程中,此时客户端能否访问咱们 redis 集群呢?
搬运 key, 大部分的 key 是不用搬运的,针对这些未搬运的 key,此时可以正常访问的。
针对这些正在搬运中的 key, 是有可能会出现访问出错的情况 (key 的位置出现了变化),假设 客户端 访问 k1,集群通过分片算法,得到k1 是第一个分片的数据,就会重定向到第一个分片的节点,就可能在重定向过去之后,正好 k1 被搬走了,自然就无法访问了,随着搬运完成,这样的错误自然就恢复了.
如果想针对生产环境进行扩容操作,还是得悠着点.比如,找个夜深人静,没啥客户端访问集群的时候,进行扩容,就可以把损失降到最低。
很明显,要想追求更高的可用性,让扩容对于用户影响更小,就需要搞一组新的机器,重新搭建集群,并且把数据导入过来使用新集群代替旧集群.(成本最高的)
第三步: 给新的主节点添加从节点
光有主节点了,此时扩容的目标已经初步达成. 但是为了保证集群可用性,还需要给这个新的主节点添
加从节点,保证该主节点宕机之后,有从节点能够顶上.
redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id cluster-master-port执行完毕后,从节点就已经被添加完成了.
六、集群缩容 (选学)
扩容是比较常见的,但是缩容其实非常少见. 此处我们简单了解缩容的操作步骤即可.
接下来演示把 110 和 111 这两个节点删除.
第一步: 删除从节点
此处删除的节点 nodeId 是 111 节点的 id.
redis-cli --cluster del-node [集群中任一节点ip:port] [要删除的从机节点 nodeId]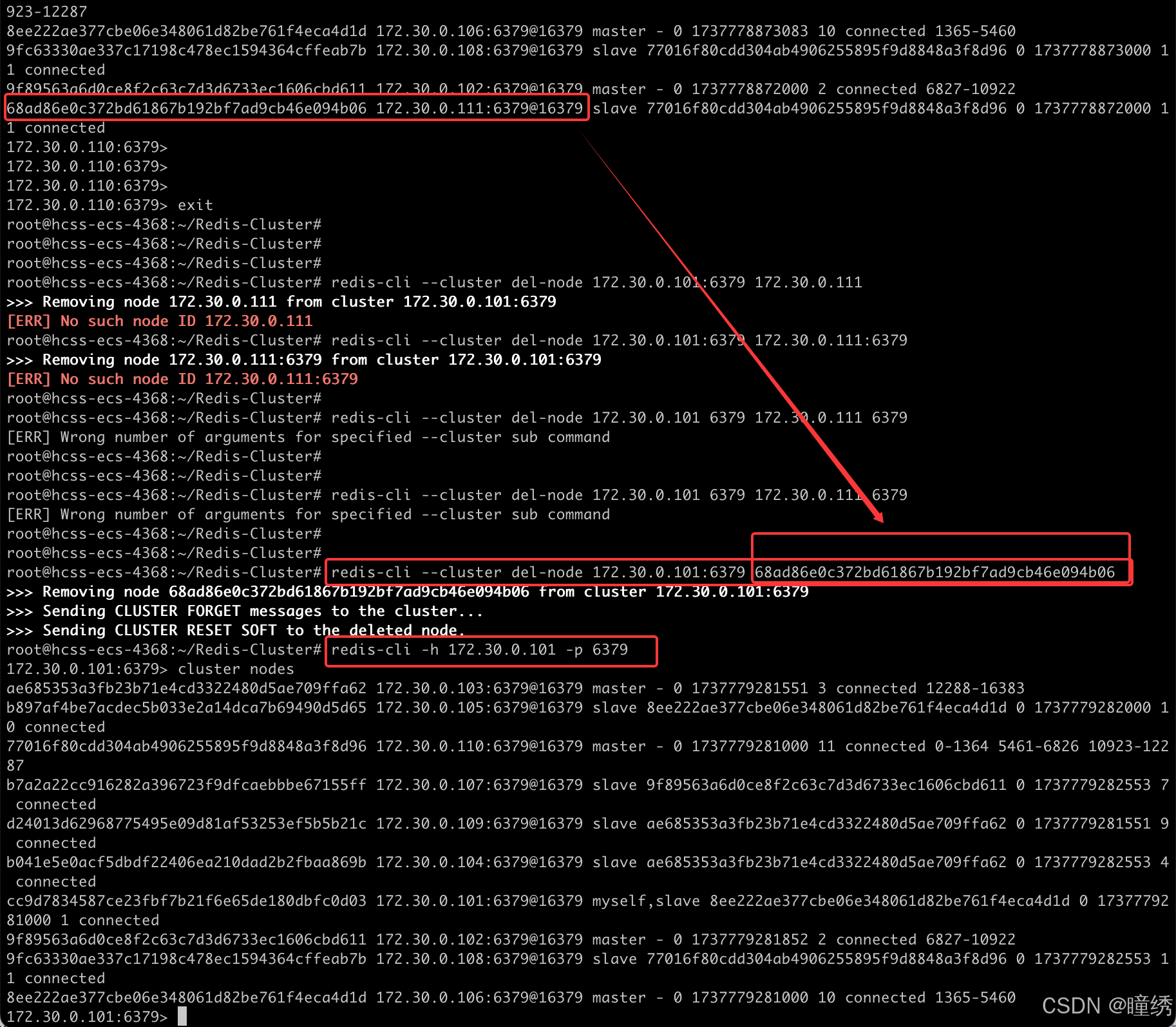
第二步: 重新分配 slots
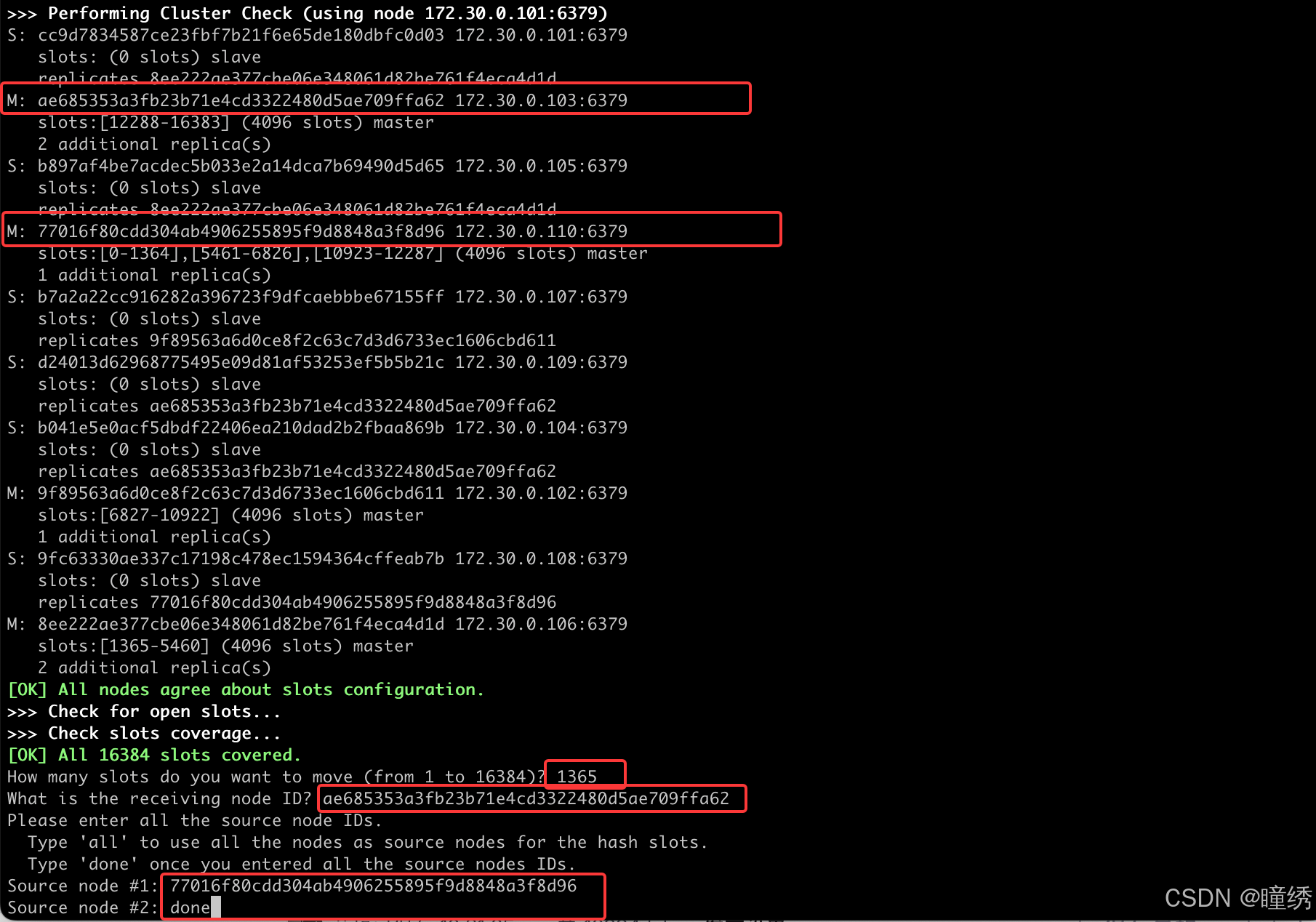
redis-cli --cluster reshard 172.30.0.101:6379执行后仍然进入交互式操作.
✍ 注意!! 此时要删除的主节点,包含 4096 个 slots. 我们把 110 这个注解上的这 4096 个 slots分成三份 (1365 + 1365 + 1366),分别分给其他三个主节点.
这样可以使 reshard 之后的集群各个分片 slots 数目仍然均匀.
第一次重分配: 分配给 103 1365 个 slots
接收 slots 的 nodeId 填写 103 的 nodeId. Source Node 填写 110 的 nodeId
第二次重分配: 分配给 102 1365 个 slots
接收 slots 的 nodeId 填写 102 的 nodeId. Source Node 填写 110 的 nodeId
第三次重分配: 分配给 106 1366 个 slots
接收 slots 的 nodeId 填写 106 的 nodeId. Source Node 填写 110 的 nodeId
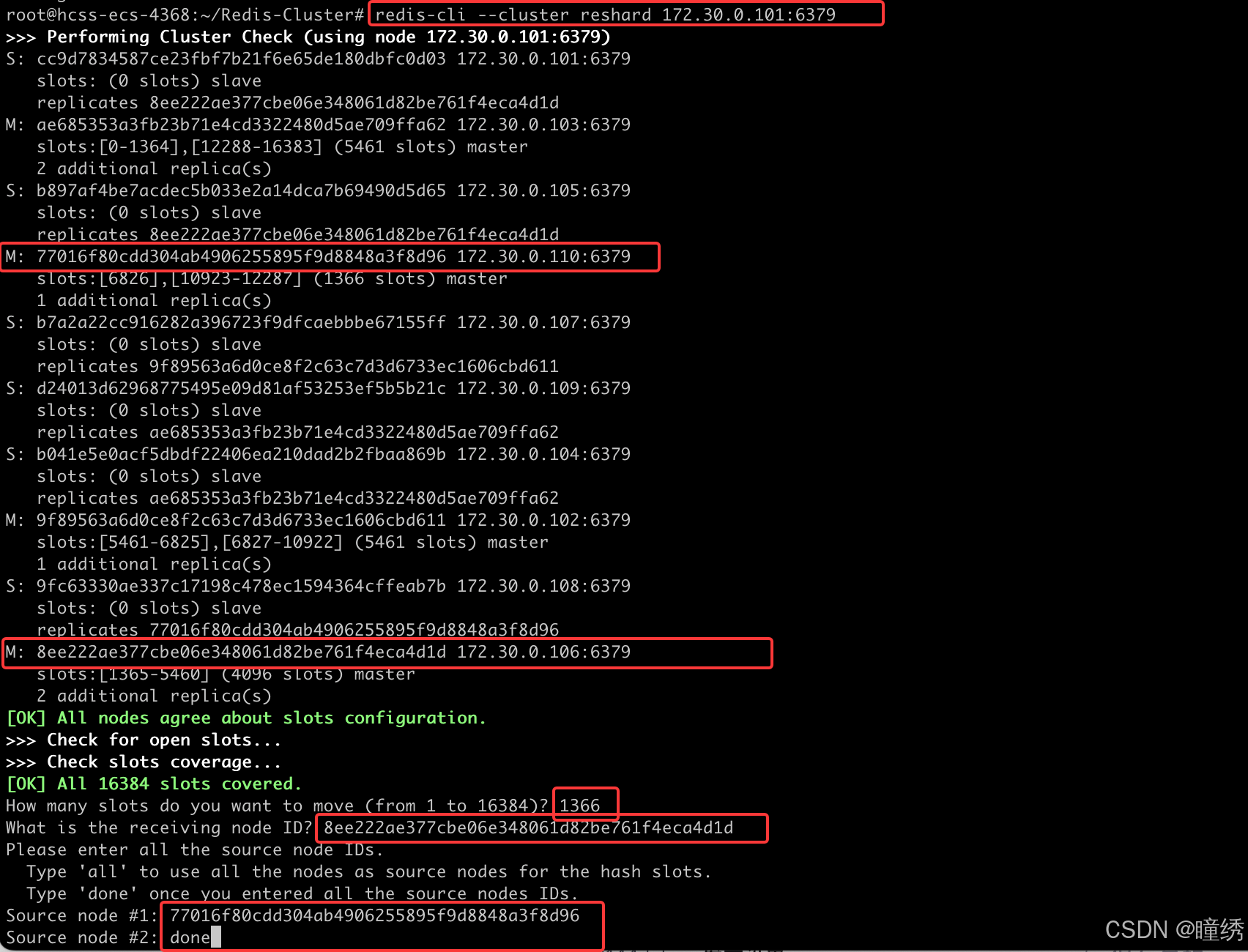
此时查看集群状态,可以看到 110 节点已经不再持有 slots 了.

第三步: 删除主节点
把 110 节点从集群中删除.
redis-cli --cluster del-node [集群中任一节点ip:port] [要删除的从机节点 nodeId]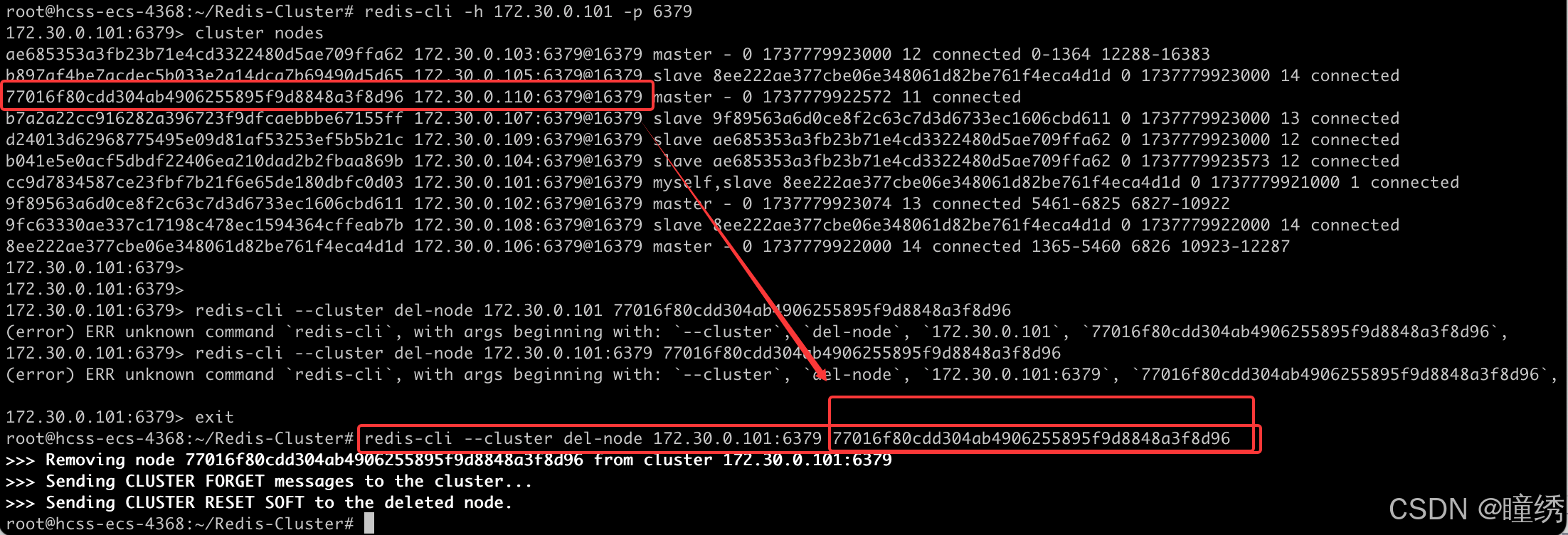
再次查看集群节点信息, 110 节点已经不在集群中了.

至此,缩容操作完成.
redis学习打卡🥳
相关文章:
【redis进阶】集群 (Cluster)
目录 一、基本概念 二、数据分片算法 2.1 哈希求余 2.2 一致性哈希算法 3.3 哈希槽分区算法 (Redis 使用) 三、集群搭建 (基于 docker) 3.1 创建目录和配置 3.2 编写 docker-compose.yml 3.3 启动容器 3.4 构建集群 四、主节点宕机 4.1 处理流程 五、集群扩容 六、集群缩容 (选…...

Python案例--100到200的素数
一、问题描述 素数(Prime Number)是指在大于1的自然数中,除了1和它本身以外不再有其他因数的数。判断一个数是否为素数是计算机科学和数学中的一个经典问题。本实例的目标是找出101到200之间的所有素数,并统计它们的数量。 二、…...

C语言,无法正常释放char*的空间
问题描述 #include <stdio.h> #include <stdio.h>const int STRSIZR 10;int main() {char *str (char *)malloc(STRSIZR*sizeof(char));str "string";printf("%s\n", str);free(str); } 乍一看,这块代码没有什么问题。直接书写…...
C语言错误处理)
重回C语言之老兵重装上阵(十五)C语言错误处理
C语言错误处理 在C语言中,错误处理是非常重要的一部分。C语言没有像高级语言(例如Python、Java)那样内建的异常处理机制(如try-catch),但它提供了几种方法来捕捉和处理错误。正确的错误处理可以提高程序的稳…...

基于微信的课堂助手小程序设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

Effective C++ 规则50:了解 new 和 delete 的合理替换时机
1、背景 在 C 中,new 和 delete 是动态分配内存的核心操作符。然而,直接使用它们有时会增加程序的复杂性,甚至导致内存泄漏和其他问题。因此,了解何时替换 new 和 delete 并选择更适合的内存管理策略,是编写高效、健壮…...

Alfresco Content Services dockerCompose自动化部署详尽操作
Alfresco Content Services docker社区部署文档 Alfresco Content Services简介 Alfresco Content Services(简称ACS)是一款功能完备的企业内容管理(ECM)解决方案,主要面向那些对企业级内容管理有高要求的组织。具体…...

学习第七十六行
提高github下载速度方法 1.github转码云 2.https://github.com.cnpmjs.org com后面加东西 对于面试笔试,最好方法刷力扣,1000题包进大厂的...

YOLOv11改进,YOLOv11检测头融合DynamicHead,并添加小目标检测层(四头检测),适合目标检测、分割等任务
摘要 作者提出一种新的检测头,称为“动态头”,旨在将尺度感知、空间感知和任务感知统一在一起。如果我们将骨干网络的输出(即检测头的输入)视为一个三维张量,其维度为级别 空间 通道,这样的统一检测头可以看作是一个注意力学习问题,直观的解决方案是对该张量进行全自…...

一个基于Python+Appium的手机自动化项目~~
本项目通过PythonAppium实现了抖音手机店铺的自动化询价,可以直接输出excel,并带有详细的LOG输出。 1.excel输出效果: 2. LOG效果: 具体文件内容见GitCode: 项目首页 - douyingoods:一个基于Pythonappium的手机自动化项目,实现了…...

【后端开发】字节跳动青训营之性能分析工具pprof
性能分析工具pprof 一、测试程序介绍二、pprof工具安装与使用2.1 pprof工具安装2.2 pprof工具使用 资料链接: 项目代码链接实验指南pprof使用指南 一、测试程序介绍 package mainimport ("log""net/http"_ "net/http/pprof" // 自…...

Linux:线程池和单例模式
一、普通线程池 1.1 线程池概念 线程池:一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价&…...

使用iis服务器模拟本地资源服务器unityaddressables热更新出错记录
editor中设置了using exculexing 模拟远程加载addressable可以实现资源热更新,build后的软件却没有成功。 iis服务器中mime中需要设置bundle的文件扩展名,时editor成功,build后失败 原因没有设置hash的扩展名,设置后editor和buil…...

TikTok广告投放优化策略:提升ROI的核心技巧
在短许多品牌和商家纷纷投入广告营销,争夺这片潜力巨大的市场。然而,在激烈的竞争环境中,如何精准有效地投放广告,优化广告效果,实现更高的投资回报率(ROI)成为了广告主关注的核心。 一. 精准受…...

Hash表
哈希表存储结构(开放寻址法,拉链法)字符串哈希方式(添加、查找h(x)) 常见从0~10^9映射到0~10^5就要对10^5取mod(取模一般要质数最好)但是可能会有冲突 1.拉链法:O(1),每…...

题解:P10972 I-Country
题目传送门 思路 因为占据的连通块的左端点先递减、后递增,右端点先递增、后递减,所以设 f i , j , l , r , x ( 0 / 1 ) , y ( 0 / 1 ) f_{i,j,l,r,x(0/1),y(0/1)} fi,j,l,r,x(0/1),y(0/1) 为前 i i i 行中,选择 j j j 个方格&#x…...

linux常用加固方式
目录 一.系统加固 二.ssh加固 三.换个隐蔽的端口 四.防火墙配置 五.用户权限管理 六.暴力破解防护 七.病毒防护 八.磁盘加密 九.双因素认证2FA 十.日志监控 十一.精简服务 一.系统加固 第一步:打好系统补丁 sudo apt update && sudo apt upgra…...
:自然语言处理)
笔灵ai写作技术浅析(二):自然语言处理
一、词法分析(Lexical Analysis) 1.1 概述 词法分析是NLP的第一步,主要任务是将连续的文本分割成有意义的单元(词或词组),并对这些单元进行标注,如词性标注(POS tagging)。词法分析的质量直接影响后续的句法分析和语义理解。 1.2 技术细节 1.分词(Tokenization)…...

PyCharm介绍
PyCharm的官网是https://www.jetbrains.com/pycharm/。 以下是在PyCharm官网下载和安装软件的步骤: 下载步骤 打开浏览器,访问PyCharm的官网https://www.jetbrains.com/pycharm/。在官网首页,点击“Download”按钮进入下载页面。选择适合自…...

深度解析:基于Vue 3与Element Plus的学校管理系统技术实现
一、项目架构分析 1.1 技术栈全景 核心框架:Vue 3 TypeScript UI组件库:Element Plus(含图标动态注册) 状态管理:Pinia(用户状态持久化) 路由方案:Vue Router(动态路…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...