Qwen 模型自动构建知识图谱,生成病例 + 评价指标优化策略
-
关于数据库和检索方式的选择
- AI Medical Consultant for Visual Question Answering (VQA) 系统:更适合在前端使用向量数据库(如FAISS)结合关系型数据库来实现图像和文本的检索与存储。因为在 VQA 场景中,你需要对患者上传的图像或文本症状进行语义向量化,以便快速查找相似病例或相关医学图像内容;同时用关系型数据库维护患者基础信息和简单的交互记录即可。
- AI-Powered Semi-Automated Medical Report Editor:更适合结合命名实体识别(NER)、关系识别以及 Neo4j 知识图谱来进行结构化的医学信息管理。由于该任务需要在医生输入的病例信息和历史数据库之间匹配、推断并自动填充下文,涉及大量的医学实体(疾病、症状、药物)以及它们之间的复杂关系,使用知识图谱有助于对这些实体和关系进行精准的管理与查询。
-
评估指标与数据集
- AI Medical Consultant for VQA
- 如果你的输出是问答形式,可用 BLEU、ROUGE、METEOR 等文本评估指标来评价回答质量;也可以针对医学问答场景额外引入 医生人工评审 或 医学准确度(Medical Accuracy) 指标,确保给出的建议在医学上是可行的。
- 如果需要分类(例如对图片做病症分类),则使用 Precision、Recall、F1-score 等常规分类指标。
- 数据集方面,对于图文结合的医学场景,可参考公开的医学影像问答数据集(如 VQA-RAD 或 PathVQA)或根据你的实际需求构建带注释的自定义数据集。
- AI-Powered Semi-Automated Medical Report Editor
- 在文本自动生成和填充任务上,一般使用 BLEU、ROUGE、BERTScore 等指标来评价生成质量;同时也需关注 医学上下文正确性(例如处方、诊断信息是否正确匹配)。
- 用到 NER 和关系抽取时,需要关注 Precision、Recall、F1-score 尤其是 实体级和关系级别的 F1-score。
- 可使用的医学文本数据集有 MIMIC-III 或 MIMIC-IV,或其他包含病历、诊断、药物信息的大规模数据。对于中文语料,可以使用官方或社区整理的中文医疗实体识别数据集,或基于 MIMIC 等英文语料自行构建翻译后的版本。
- AI Medical Consultant for VQA
-
结合示例项目的可行性分析
- 该示例项目采用了 RAG(Retrieval-Augmented Generation) 与大模型,结合知识图谱在医疗问答上实现了高精度检索与问答生成。这种思路对于**第一个任务(VQA 医疗咨询)**同样可行,但需要注意你们公司资源有限,图像处理和大模型的推理成本较高,可能需要在模型大小上做取舍,或考虑离线/量化部署。
- 对于第二个任务(自动病例报告编辑器),示例中的 NER、关系识别和大模型意图识别正是你可以使用 Neo4j 等知识图谱的核心理由。通过知识图谱来管理病症、药物及疗法之间的关联,再结合大模型来做自动文本补全,可以有效减少医生手动输入的负担,也能更准确地填充关键信息。
- 需要评估的数据标注和维护成本。示例项目中通过 Prompt 工具减少人工标注量,你也可以借鉴类似思路,利用大语言模型的“少样本”或“零样本”能力快速生成 NER 训练样本。同时也要考虑知识库的更新维护问题,尤其是医疗领域知识更新较快。
Task One: AI Medical Consultant for VQA (using MiniCPM)
1. 训练和微调步骤
✅ 优化点
-
数据集
- 继续使用 VQA-RAD、PathVQA 以及医学问诊文本数据
- 额外补充 MedICaT(医学图文数据),提高多模态理解能力
- 使用 FAISS 进行医学文献检索,增强模型背景知识
-
图像特征提取
- 使用 ViT 或 Swin Transformer 提取医学图像特征,而不是 ResNet
- 使用 Cross-Attention 机制 让 MiniCPM 充分利用图像信息,而不是简单的 MLP 融合
-
文本处理
- 引入医学词汇表(如 UMLS、SNOMED)来优化 MiniCPM 的 tokenizer
- 继续使用 MiniCPM 作为主模型,在医学 QA 任务上进行微调
-
图文特征融合
- 使用 Cross-Attention(如 TransformerEncoder 层)替代 simple feed-forward 层
- 设计方式:
- 图像输入经过 ViT/Swin Transformer
- 文本输入经过 MiniCPM
- 在 MiniCPM 解码层 使用 Cross-Attention 连接图像特征和文本特征
- 目标:生成更具医学专业性的回答
-
训练目标
- 采用 多任务学习:
- 医学 QA 生成(seq2seq loss)
- 推荐科室分类(cross-entropy loss)
- 通过 知识检索增强(FAISS 检索相关医学文献)提高医学合理性
- 采用 多任务学习:
2. 工具使用
✅ 优化点
- 继续使用 PyTorch 进行训练
- 使用 FAISS 进行知识增强
- MiniCPM + ViT/Swin + Cross-Attention 进行多模态融合
任务1
3 模型测试和优化预测
3.1 主要评测指标
| 任务 | 评估指标 | 作用 |
|---|---|---|
| 医学问答质量 | BLEU, ROUGE, METEOR | 评估答案的流畅性和文本质量 |
| 医学合理性 | 医学专家审核评分 | 衡量回答的医学正确性 |
| 推荐科室准确率 | Precision, Recall, F1-score | 评估推荐结果是否准确 |
3.2 关键优化
-
BLEU/ROUGE/METEOR 提升策略
- 方法:
- 使用 Cross-Attention 让 MiniCPM 更好利用图像特征(增强答案信息)
- 通过 FAISS 引入外部医学知识,减少胡乱生成的情况
- 增强医学特定词汇的 tokenization 质量(避免医学术语被错误拆分)
- 预计提升幅度:
- BLEU 提升 3-6 分(Baseline 约 20 → 提升到 23-26)
- ROUGE 提升 5-8 分(Baseline 约 30 → 提升到 35-38)
- 方法:
-
医学合理性
- 方法:
- 使用 FAISS 检索医学知识,增强生成答案的可靠性
- 训练时加入人工医学问答数据(few-shot learning)
- 在测试阶段由医生评分,优化 QA 逻辑
- 预计提升幅度:
- 医学准确率从 60% 提升到 78%-82%
- 医学错误率降低 30%
- 方法:
-
推荐科室 F1-score
- 方法:
- 增强 MiniCPM 训练数据(带更多分类示例)
- 采用 Cross-Attention 提高图像理解能力
- 预计提升幅度:
- F1-score 提升 5-7%(Baseline 约 70% → 提升到 75-77%)
- 方法:
任务2
仅使用 Qwen 模型实现命名实体识别、知识图谱构建及文本生成。
1.1 训练微调过程中每一个步骤
步骤 1:数据预处理
- 收集和整理医疗领域文本数据,包括电子病历、医学文献和病历模板。
- 对数据进行清洗和标注,将每条文本转换为带有命名实体标签的训练样本,格式例如:“输入:文本内容;输出:实体列表(如‘疾病:高血压,部位:心脏’)”。
- 构造生成式任务格式,即设计 Prompt 模板,如“请从以下文本中抽取所有医疗实体:”,使输入与输出均为自然语言形式。
步骤 2:模型初始化
- 使用 Hugging Face Transformers 库,通过函数
AutoModelForCausalLM.from_pretrained("Qwen-model")加载预训练的 Qwen 模型。 - 同时加载对应的分词器,调用
AutoTokenizer.from_pretrained("Qwen-model")来处理文本输入。
步骤 3:微调设置
- 设置超参数:例如学习率设为 2e-5、batch size 设为 16、训练轮数设为 3~5 个 epoch、最大序列长度根据任务需求(如 512)。
- 配置优化器,使用
torch.optim.AdamW并设定合适的权重衰减和梯度裁剪参数。
步骤 4:训练策略
- 采用自回归生成模式,将问题构造为输入 Prompt(例如“请识别以下文本中的医疗实体:”加上原始文本),输出为对应的实体标注文本。
- 使用 Cross-Entropy Loss 作为训练目标,通过计算生成文本与目标文本之间的差异来更新模型。
- 利用 Transformers 提供的
Trainer类和TrainingArguments进行训练管理,定期在验证集上评估并保存最佳模型。
步骤 5:检查点保存与调参
- 每个 epoch 结束后保存模型检查点,并使用验证集监控模型性能,以便及时调整超参数避免过拟合或欠拟合。
1.2 应用的工具
- PyTorch:用于定义模型、优化器和损失函数;例如使用
torch.optim.AdamW进行参数更新。 - Transformers 库:
- 使用
AutoModelForCausalLM加载 Qwen 模型。 - 使用
AutoTokenizer处理文本输入。 - 通过
Trainer和TrainingArguments管理训练过程。
- 使用
- 数据处理工具:利用 Python 的
pandas进行数据清洗和格式转换,使用datasets库加载和管理数据集。
1.3 模型测试与评价方法
-
指标:
- 使用精度(Precision)、召回率(Recall)和 F1 分数评估命名实体识别的准确性和完整性。
- 采用 ROUGE 分数评估生成文本的质量和覆盖程度。
- 选择这些指标是因为它们能全面反映模型在信息抽取和生成任务中的性能。
-
测试方法:
- 采用未参与训练和验证的独立测试集进行模型评估。
- 对于命名实体识别任务,将模型输出的实体列表与人工标注的标准答案比对,计算上述指标。
- 对于文本生成任务,结合自动评估(如 ROUGE)和人工评估来判断生成内容的连贯性和准确性。
- 使用
Trainer.evaluate()方法在验证集上定期测试模型,确保训练过程稳定。
1.4 预测模型指标优化及其实现方法
-
预测优化数值:
- 预计在命名实体识别任务中,F1 分数将提升 5%~7%(例如从 83% 提升到 88%~90%)。
- 在文本生成任务中,ROUGE 分数有望提升 4~6 分。
-
实现优化的方法:
- 数据增强:通过同义词替换、数据扩充和回译技术增加训练数据多样性。
- 模型正则化:采用 dropout、权重衰减等技术防止模型过拟合。
- 超参数调整:使用网格搜索或贝叶斯优化方法调节学习率、batch size 等关键参数。
- Prompt 工程:优化输入 Prompt 模板,确保生成格式的一致性和准确性。
- 多任务学习:在微调过程中尝试联合学习命名实体识别和文本生成任务,以提升模型的整体性能。
2.1 数据集使用及数据库搜索时机
-
数据集使用:
- 训练数据集:选用经过标注的中文医疗文本数据集,例如公开的医疗命名实体识别数据集,同时可辅以医院内部匿名化数据以丰富样本。
- 选择理由:这些数据集具有高质量标注和丰富的领域知识,有助于训练模型准确识别多样化的医疗实体。
-
数据库搜索时机:
- 在模型推理阶段,首先利用微调后的 Qwen 模型对用户输入的文本进行命名实体识别,提取出医疗实体。
- 随后,根据提取出的实体查询预先构建的知识图谱数据库(例如 Neo4j),检索相关的节点和关系信息。
- 最后,将检索结果作为辅助上下文传入 Qwen 模型,实现文本生成或补全功能。
2.2 知识图谱构建与检索方法
-
构建流程:
- 使用经过微调的 Qwen 模型对医疗文本进行命名实体识别,抽取出疾病、药物、症状等核心实体。
- 对抽取出的实体进行标准化处理,消除同义词差异,并依据共现统计和医学知识确定实体之间的关系。
- 将标准化的实体和关系存入图数据库(例如 Neo4j),构建成以节点(实体)和边(关系)为基本结构的知识图谱。
-
与模型结合:
- 在文本生成前,利用 Qwen 模型对输入文本进行命名实体识别,并以此为查询条件,从知识图谱中检索相关信息。
- 检索结果通过预定义模板整合为上下文信息,传入 Qwen 模型以生成更具联想性和连贯性的文本。
- 该流程实现了从实体识别、知识图谱查询到文本生成的完整闭环。
2.3 优化效果论证与对比基准
-
优化结果论证:
- 通过对比微调前后在独立测试集上模型的指标(如命名实体识别的 F1 分数及生成文本的 ROUGE 分数),验证优化效果。
- 设计 A/B 测试,在实际应用中收集用户反馈和错误案例,以进一步评估生成文本的准确性和连贯性。
- 利用统计数据和实验结果,形成详细的优化报告,作为模型改进的依据。
-
对比基准:
- 基准模型:将原始未微调的 Qwen 模型作为基准进行比较。
- 数据集基准:参照公开医疗 NER 数据集及标准文本生成任务的评估结果。
- 对比对象:与现有文献中其他生成模型在类似任务上的表现进行比对,确保优化后的结果具备竞争力。
下面提供一个详细、可执行的方案,从需求分析到数据预处理、模型微调开发、系统集成,再到测试评估 主要模块:前端输入接口、数据预处理、Qwen模型服务、后端数据存储(Neo4j & 关系型数据库)、后处理规则引擎。
-
操作1.2.2:知识图谱结构
- \Neo4j知识图谱:
-
- 任务: 定义医学实体节点(Disease、Symptom、Medication 等)及其关系。
- 示例Cypher语句:
CREATE CONSTRAINT ON (d:Disease) ASSERT d.name IS UNIQUE; CREATE (:Disease {name: '高血压'}); CREATE (:Symptom {name: '头痛'}); MATCH (d:Disease {name: '高血压'}), (s:Symptom {name: '头痛'}) CREATE (d)-[:HAS_SYMPTOM]->(s);
-
操作1.2.3:制定接口与安全策略
- 任务: 明确定义REST API接口(输入格式、返回格式、错误码)、身份验证(OAuth2或JWT)和数据加密要求。
- 产出: 接口文档(Swagger格式)和安全设计说明。
阶段2:数据准备与预处理
2.1 数据收集与整理
- 操作2.1.1:收集医疗文本数据
- 来源: 医院病例库、公开数据集(如MIMIC-III)、内部报告数据。
- 任务: 导出数据到CSV或JSON格式,并确保数据脱敏。
- 脚本示例(Python):
import pandas as pd# 从CSV读取数据,并简单脱敏处理(如移除姓名、身份证号) data = pd.read_csv('raw_medical_reports.csv') data.drop(columns=['name', 'id_number'], inplace=True) data.to_csv('clean_medical_reports.csv', index=False)
2.2 数据清洗与格式转换
-
操作2.2.1:清洗数据
- 任务: 去除空值、异常符号、统一编码。
- 工具: Pandas、正则表达式
- 脚本示例(Python):
import redef clean_text(text):text = re.sub(r'\s+', ' ', text) # 多余空格text = text.strip()return textdata['report_text'] = data['report_text'].apply(clean_text) data.to_csv('cleaned_medical_reports.csv', index=False)
-
操作2.2.2:文本分句与分词
- 任务: 使用现有NLP库对文本进行分句、分词,为后续实体标注做准备。
- 工具: spaCy(支持中文)、jieba
- 脚本示例(Python,使用jieba):
import jiebadata['tokens'] = data['report_text'].apply(lambda x: list(jieba.cut(x))) data.to_csv('tokenized_medical_reports.csv', index=False)
2.3 数据标注(实体与关系)
-
操作2.3.1:准备标注工具
- 工具: Doccano 或 Label Studio
- 步骤:
- 将清洗后的数据导入Doccano。
- 配置标注项目,定义实体类型(如疾病、症状、药物等)及关系(如“has_symptom”、“treats”等)。
-
操作2.3.2:执行标注任务
- 任务: 分配任务给领域专家进行实体和关系标注。
- 产出: 标注文件(JSON格式),如:
{"text": "患者患有高血压,伴随头痛症状。","entities": [[3, 5, "Disease"], [8, 10, "Symptom"]],"relations": [[[3,5], [8,10], "HAS_SYMPTOM"]] }
2.4 构建Neo4j知识图谱
- 操作2.4.1:数据转换与导入
- 任务: 将标注好的实体和关系数据转化为适合Neo4j导入的CSV文件。
- 步骤:
- 编写Python脚本,解析JSON标注文件,生成两类CSV文件:一份用于节点(entity_id, label, properties),另一份用于关系(start_entity, end_entity, relation_type)。
- 脚本示例:
import json import csvwith open('annotations.json', 'r', encoding='utf-8') as f:annotations = json.load(f)with open('nodes.csv', 'w', newline='', encoding='utf-8') as node_file, \open('relations.csv', 'w', newline='', encoding='utf-8') as rel_file:node_writer = csv.writer(node_file)rel_writer = csv.writer(rel_file)node_writer.writerow(['entity_id', 'label', 'name'])rel_writer.writerow(['start_entity', 'end_entity', 'relation_type'])entity_id = 1entity_map = {}for ann in annotations:for entity in ann['entities']:entity_text = ann['text'][entity[0]:entity[1]]label = entity[2]if entity_text not in entity_map:entity_map[entity_text] = entity_idnode_writer.writerow([entity_id, label, entity_text])entity_id += 1for rel in ann['relations']:e1_text = ann['text'][rel[0][0]:rel[0][1]]e2_text = ann['text'][rel[1][0]:rel[1][1]]rel_writer.writerow([entity_map[e1_text], entity_map[e2_text], rel[2]])
- 操作2.4.2:使用Neo4j导入CSV
- 步骤:
- 在Neo4j Browser中执行LOAD CSV命令,将节点和关系数据导入。
- 示例Cypher:
// 导入节点 LOAD CSV WITH HEADERS FROM 'file:///nodes.csv' AS row CREATE (n:Entity {id: toInteger(row.entity_id), label: row.label, name: row.name});// 导入关系 LOAD CSV WITH HEADERS FROM 'file:///relations.csv' AS row MATCH (a:Entity {id: toInteger(row.start_entity)}),(b:Entity {id: toInteger(row.end_entity)}) CREATE (a)-[:RELATION {type: row.relation_type}]->(b);
- 步骤:
阶段3:模型训练、微调与模块开发
3.1 数据预处理与分割
-
操作3.1.1:加载并分割数据集
- 任务: 利用清洗和标注后的数据,将数据分为训练集、验证集和测试集(例如8:1:1比例)。
- 脚本示例(Python):
from sklearn.model_selection import train_test_split import pandas as pddf = pd.read_csv('cleaned_medical_reports.csv') train, temp = train_test_split(df, test_size=0.2, random_state=42) val, test = train_test_split(temp, test_size=0.5, random_state=42) train.to_csv('train.csv', index=False) val.to_csv('val.csv', index=False) test.to_csv('test.csv', index=False)
-
操作3.1.2:文本Tokenization
- 任务: 使用HuggingFace提供的Tokenizer对文本进行编码。
- 脚本示例(Python):
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("qwen-base") def tokenize_text(text):return tokenizer.encode_plus(text, max_length=512, truncation=True, padding="max_length")# 示例:处理训练集 train_data = pd.read_csv('train.csv') train_data['tokens'] = train_data['report_text'].apply(lambda x: tokenize_text(x)['input_ids']) train_data.to_csv('train_tokenized.csv', index=False)
3.2 Qwen模型的微调
- 操作3.2.1:加载预训练Qwen模型
- 工具: HuggingFace Transformers、PyTorch
- 脚本示例(Python):
from transformers import AutoModelForSeq2SeqLM, Trainer, TrainingArguments model = AutoModelForSeq2SeqLM.from_pretrained("qwen-base")
- 操作3.2.2:构建微调数据集
- 任务: 利用训练数据构建输入(医生初始文本)与目标(标准医疗报告)的配对数据集。
- 步骤: 定义自定义Dataset类,示例如下:
import torch from torch.utils.data import Datasetclass MedicalReportDataset(Dataset):def __init__(self, csv_file, tokenizer, max_length=512):self.data = pd.read_csv(csv_file)self.tokenizer = tokenizerself.max_length = max_lengthdef __len__(self):return len(self.data)def __getitem__(self, idx):row = self.data.iloc[idx]input_enc = self.tokenizer(row['input_text'], max_length=self.max_length, truncation=True, padding="max_length", return_tensors="pt")target_enc = self.tokenizer(row['target_report'], max_length=self.max_length, truncation=True, padding="max_length", return_tensors="pt")return {"input_ids": input_enc.input_ids.squeeze(),"attention_mask": input_enc.attention_mask.squeeze(),"labels": target_enc.input_ids.squeeze()}
- 操作3.2.3:设置训练参数并启动微调
- 工具: Trainer API
- 脚本示例:
training_args = TrainingArguments(output_dir='./qwen_medical_report',num_train_epochs=3,per_device_train_batch_size=8,per_device_eval_batch_size=8,evaluation_strategy="steps",eval_steps=500,save_steps=1000,logging_steps=100,learning_rate=5e-5,weight_decay=0.01,save_total_limit=2,fp16=True ) train_dataset = MedicalReportDataset('train.csv', tokenizer) eval_dataset = MedicalReportDataset('val.csv', tokenizer) trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset ) trainer.train()
- 操作3.2.4:保存和验证模型
- 步骤: 模型训练完成后保存权重,并在验证集上运行推理,检查输出质量。
trainer.save_model('./qwen_medical_report_final') sample_input = "患者主诉头痛,既往有高血压病史。" inputs = tokenizer.encode(sample_input, return_tensors="pt") outputs = model.generate(inputs, max_length=200) print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- 步骤: 模型训练完成后保存权重,并在验证集上运行推理,检查输出质量。
3.3 开发实体抽取与关系识别模块
-
操作3.3.1:实体抽取
- 任务: 在医生输入文本中利用微调后的模型或专门的NER模型(如BERT-CRF)抽取医学实体。
- 步骤:
- 集成现有NER模型,或利用Qwen模型在特定提示下进行实体抽取。
- 编写接口,将抽取结果转换为统一格式(例如:{"entity": "高血压", "type": "Disease", "start": 10, "end": 14})。
- 示例伪代码:
def extract_entities(text):# 调用NER模型API或内部方法entities = ner_model.predict(text)return entities
-
操作3.3.2:关系识别与知识图谱校验
- 任务: 利用Neo4j对抽取的实体进行校验和关系补全
- 步骤:
- 根据抽取的实体,构造查询Neo4j的Cypher语句,检查实体间的关系是否存在。
- 若缺少关键关系,调用补全逻辑进行提示或自动添加建议。
- 示例(Python调用Neo4j):
from neo4j import GraphDatabaseuri = "bolt://localhost:7687" driver = GraphDatabase.driver(uri, auth=("neo4j", "password"))def check_relation(entity1, entity2, relation_type):query = ("MATCH (a:Entity {name:$name1})-[r:RELATION {type:$rel}]->(b:Entity {name:$name2}) ""RETURN r")with driver.session() as session:result = session.run(query, name1=entity1, name2=entity2, rel=relation_type)return result.single() is not None
3.4 开发文本生成与后处理模块
- 操作3.4.1:文本生成接口封装
- 任务: 将微调后的Qwen模型封装为一个服务接口,接收输入后返回生成的报告草稿。
- 步骤: 使用Flask创建简单API服务:
from flask import Flask, request, jsonify app = Flask(__name__)@app.route('/generate_report', methods=['POST']) def generate_report():data = request.jsoninput_text = data.get("input_text")inputs = tokenizer.encode(input_text, return_tensors="pt")outputs = model.generate(inputs, max_length=200)report = tokenizer.decode(outputs[0], skip_special_tokens=True)return jsonify({"report": report})if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
- 操作3.4.2:后处理与规则校验
- 任务: 结合基于规则的引擎(Java实现)和Neo4j校验对生成文本进行格式化、逻辑检查。
- 步骤:
- 开发Java模块,接收生成的报告文本;
- 解析文本,调用Neo4j接口检查各医学实体的逻辑关系;
- 若发现异常,自动标记或反馈给医生进行确认。
阶段4:系统集成与接口对接
4.1 构建API服务与微服务封装
- 操作4.1.1:部署生成模型服务
- 任务: 将上述Flask服务打包为Docker容器。
- Dockerfile示例:
FROM python:3.9-slim WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt COPY . . EXPOSE 5000 CMD ["python", "app.py"]
- 操作4.1.2:构建Java后端服务
- 任务: 利用Spring Boot构建REST API,调用生成服务和数据库接口。
- 步骤:
- 使用Spring Initializr生成项目,添加依赖(Spring Web、JPA、Neo4j Driver)。
- 编写Service类,通过HTTP Client(如RestTemplate)调用Flask生成服务。
- 示例代码:
@Service public class ReportService {@Autowiredprivate RestTemplate restTemplate;public String generateReport(String inputText) {String url = "http://qwen-service:5000/generate_report";Map<String, String> request = new HashMap<>();request.put("input_text", inputText);ResponseEntity<Map> response = restTemplate.postForEntity(url, request, Map.class);return (String) response.getBody().get("report");} }
4.2 数据库和知识图谱接口对接
-
操作4.2.1:配置关系型数据库连接
- 任务: 在Spring Boot中配置DataSource、JPA实体及Repository,管理患者数据和生成报告存储。
- 步骤:
- 在
application.properties中配置数据库连接信息; - 编写实体类(Patient、MedicalReport)和Repository接口。
- 在
-
操作4.2.2:集成Neo4j接口
- 任务: 利用Neo4j Java Driver在Spring Boot中封装服务,提供知识图谱查询接口。
- 示例代码:
@Service public class Neo4jService {private final Driver driver;@Autowiredpublic Neo4jService(@Value("${neo4j.uri}") String uri,@Value("${neo4j.username}") String username,@Value("${neo4j.password}") String password) {this.driver = GraphDatabase.driver(uri, AuthTokens.basic(username, password));}public boolean checkRelation(String entity1, String entity2, String relation) {try (Session session = driver.session()) {String cypher = "MATCH (a:Entity {name: $entity1})-[r:RELATION {type: $relation}]->(b:Entity {name: $entity2}) RETURN r";return session.run(cypher, parameters("entity1", entity1, "entity2", entity2, "relation", relation)).hasNext();}} }
4.3 容器化与部署
-
操作4.3.1:Docker Compose编排
- 任务: 编写docker-compose.yml文件,将Java后端、Qwen生成服务、Neo4j及MySQL/PostgreSQL容器化并互联。
- 示例docker-compose.yml:
version: '3.8' services:qwen-service:build: ./qwen_serviceports:- "5000:5000"backend-service:build: ./backend_serviceports:- "8080:8080"depends_on:- mysql- neo4jmysql:image: mysql:8.0environment:MYSQL_ROOT_PASSWORD: rootpasswordMYSQL_DATABASE: medical_dbports:- "3306:3306"neo4j:image: neo4j:4.4environment:NEO4J_AUTH: neo4j/neo4jpasswordports:- "7687:7687"- "7474:7474"
-
操作4.3.2:CI/CD部署
- 任务: 使用Jenkins或GitHub Actions自动构建、测试和部署各模块。
阶段5:测试与性能评估
5.1 单元测试
-
操作5.1.1:后端服务单元测试
- 工具: JUnit
- 任务: 为每个Service和Controller编写单元测试,验证输入输出和异常处理。
- 示例(Java JUnit):
@SpringBootTest public class ReportServiceTest {@Autowiredprivate ReportService reportService;@Testpublic void testGenerateReport() {String input = "患者主诉胸痛...";String report = reportService.generateReport(input);assertNotNull(report);assertTrue(report.contains("胸痛"));} }
-
操作5.1.2:Python模块单元测试
- 工具: pytest
- 任务: 为数据预处理、模型生成等模块编写测试脚本,确保数据格式正确、模型调用正常。
5.2 集成测试与接口测试
- 操作5.2.1:接口测试
- 工具: Postman
- 任务: 编写Postman集合,模拟医生输入、调用生成报告接口,验证返回格式及错误处理。
- 操作5.2.2:集成测试
- 任务: 编写自动化脚本(如Selenium或RestAssured),测试前端到后端完整流程,确保各模块数据交互正确。
5.3 性能和负载测试
- 操作5.3.1:使用JMeter进行负载测试
- 任务: 模拟高并发医生请求,检测系统响应时间、吞吐量和资源占用。
- 步骤:
- 配置JMeter测试计划,设置HTTP请求目标为后端服务接口。
- 记录响应时间、错误率,并根据需要调整系统配置。
5.4 模型评估
- 操作5.4.1:自动评测指标计算
- 任务: 编写Python脚本,利用测试集计算生成文本的BLEU、ROUGE得分;利用标注数据计算NER抽取的Precision、Recall、F1值。
- 示例(Python调用NLTK计算BLEU):
from nltk.translate.bleu_score import sentence_bleureference = [['高血压', '患者', '症状']] candidate = ['患者', '高血压', '症状'] score = sentence_bleu(reference, candidate) print("BLEU score:", score)
- 阶段1: 从需求研讨、编写规格文档、绘制系统架构、数据库与安全接口设计。
- 阶段2: 数据收集、清洗、分词、标注、构建Neo4j知识图谱,提供了具体的代码示例和操作步骤。
- 阶段3: 数据预处理、Tokenization、基于HuggingFace的Qwen模型微调、实体抽取和关系校验模块开发、生成接口与后处理流程。
- 阶段4: 将生成模块封装为REST API,通过Spring Boot构建Java后端,整合关系型数据库和Neo4j,利用Docker Compose进行容器编排。
- 阶段5: 单元、集成、性能和负载测试,自动化评测脚本、人工评估反馈,并搭建CI/CD流水线实现持续优化。
通过以上每一步明确的操作说明与代码示例,该方案不仅具备理论指导,还能直接转化为具体的开发任务,确保在实际系统开发中具备可执行性。
评价指标解析
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
-
ROUGE 是什么?
- ROUGE 是一个用来衡量自动文本生成(如摘要、机器翻译、问答系统)质量的指标。
- 它主要是计算模型生成的文本与标准答案(ground truth)之间的 n-gram(词的组合)重叠率。
- 常见的 ROUGE 版本:
- ROUGE-N: 计算 n-gram(如 ROUGE-1、ROUGE-2,分别表示一元词、二元词的匹配情况)。
- ROUGE-L: 计算最长公共子序列(Longest Common Subsequence, LCS),衡量文本连贯度。
- ROUGE-W: 计算带权重的 LCS,适用于更长的文本。
- ROUGE-S: 计算跳跃二元词(Skip-gram)。
-
在这个任务中怎么衡量?
- 任务 1(医疗问答 VQA):
- 在 MiniCPM 生成的回答和标准答案之间计算 ROUGE-1 和 ROUGE-L,看它生成的句子是否包含关键医学术语。
- 例如标准答案是:“建议前往皮肤科。”
- 如果模型生成:“你应该去皮肤科。”
- ROUGE-1: 高(因为“皮肤科”匹配了)
- ROUGE-L: 也高(因为最长公共子序列是“去皮肤科”)。
- 任务 2(病例自动填充):
- 在医生输入部分病历时,让 BERT 生成后续内容,并用 ROUGE-L 计算它的连贯性。
- 任务 1(医疗问答 VQA):
-
为什么 ROUGE 适合这个任务?可行范围是多少?
- 在 医学问答任务,ROUGE 不能完全衡量答案是否正确(因为医学可能有多个正确答案),但它可以衡量句子表述的相似度。
- 在 病例补全文本生成,ROUGE 更加重要,因为病历的书写有格式化要求,ROUGE-L 能评估生成内容的连贯性。
- 合理范围:
- 普通 NLP 任务:ROUGE-1 通常 4060 之间,ROUGE-L 在 3050 之间。
- 在医学领域,由于答案可能更短,ROUGE-1 可能在 50~80 之间,而 ROUGE-L 可能在 40~60 之间。
1.2 序列标注层(CRF vs. token-level 分类)
我们先解释 什么是序列标注任务,然后再对比 CRF 和 token-level 分类。
什么是序列标注任务?
- 序列标注(Sequence Labeling)是一种 NLP 任务,用于给文本中的每个词或子词打标签。
- 在医学领域,我们需要识别 疾病(Disease)、药物(Drug)、症状(Symptom) 等医学实体(Named Entity Recognition, NER)。
- 例如:
患者出现 高血压 和 头痛 。- 高血压 → 疾病
- 头痛 → 症状
- 这时,我们就需要一种 序列标注模型 来自动标注这些医学实体。
CRF(条件随机场,Conditional Random Field)
-
CRF 是什么?
- CRF 是一种用于 序列标注任务 的统计模型,专门用来优化相邻词的标注结果。
- 在 NER 任务中,我们要确保:
- “高” 被标注为 “B-Disease”(疾病的开始)
- “血压” 被标注为 “I-Disease”(疾病的内部)
- “和” 被标注为 “O”(无关词)
- CRF 可以学习到 相邻词的关联性,避免 “血压” 被错误标注为 O。
- PyTorch 里可以使用
torchcrf库或者transformers结合 CRF 层。
-
在这个任务中怎么衡量?
- 在任务 2(自动病例编辑器),NER 是关键任务之一。
- 我们使用 CRF 训练 BERT,输入医疗文本,让模型输出一个带标签的序列。
- 衡量标准:F1-score,看 CRF 预测的标签和人工标注的标签有多少匹配。
-
为什么 CRF 适合?可行范围是多少?
- 在医学实体识别中,CRF 比单独的 BERT 更擅长处理 上下文关系(比如“高血压”要连在一起)。
- CRF 训练好的 NER,F1-score 一般可以达到 85%~95%。
Token-level 分类
-
什么是 token-level 分类?
- 这是 BERT 默认的序列标注方法,它不考虑词与词之间的关系,而是 单独对每个 token 进行分类。
- 例如:
"患者 出现 高 血 压 和 头 痛 。"- 每个字或者词都被单独送入 BERT,然后由 BERT 的分类层直接预测这个 token 是
O、B-Disease还是I-Disease。
- 每个字或者词都被单独送入 BERT,然后由 BERT 的分类层直接预测这个 token 是
- 缺点:BERT 本身不考虑 token 之间的相互关系,可能会让“血压”被错误标注。
-
在这个任务中怎么衡量?
- 仍然使用 F1-score 计算预测标签的准确率。
-
为什么 token-level 分类有时不够好?
- 对于独立词分类可以用(比如“癌症”明显是疾病)。
- 但对于组合词,CRF 可能更好。
- 在 任务 2 的 NER 任务,CRF 一般比 token-level 分类 F1-score 高 2~5 个点。
| 指标 | 作用 | 适用任务 | 典型范围 |
|---|---|---|---|
| ROUGE | 评估文本生成质量 | 医疗问答、病历补全 | ROUGE-1: 50-80, ROUGE-L: 40-60 |
| F1-score | 评估 NER、分类任务 | 任务 2 的医学实体识别 | 85%~95% |
| BLEU | 评估文本翻译 | 任务 1 医疗问答 | 30-60 |
相关文章:

Qwen 模型自动构建知识图谱,生成病例 + 评价指标优化策略
关于数据库和检索方式的选择 AI Medical Consultant for Visual Question Answering (VQA) 系统:更适合在前端使用向量数据库(如FAISS)结合关系型数据库来实现图像和文本的检索与存储。因为在 VQA 场景中,你需要对患者上传的图像或…...

.Net Web API 访问权限限定
看到一个代码是这样的: c# webapi 上 [Route("api/admin/file-service"), AuthorizeAdmin] AuthorizeAdmin 的定义是这样的 public class AuthorizeAdminAttribute : AuthorizeAttribute {public AuthorizeAdminAttribute(){Roles "admin"…...

项目架构调整,切换版本并发布到中央仓库
文章目录 0.完成运维篇maven发布到中央仓库的部分1.配置server到settings.xml2.配置gpg 1.架构调整1.sunrays-dependencies(统一管理依赖和配置)1.作为单独的模块2.填写发布到中央仓库的配置1.基础属性2.基本配置3.插件配置 3.完整的pom.xml 2.sunrays-f…...

考试知识点位运算
深入理解位运算 在C编程的世界里,位运算作为一种直接对二进制位进行操作的运算方式,虽然不像加减乘除等算术运算那样广为人知,却在许多关键领域发挥着至关重要的作用。从底层系统开发到高效算法设计,位运算都展现出其独特的魅力与…...
-- 数据处理与可视化)
matlab快速入门(2)-- 数据处理与可视化
MATLAB的数据处理 1. 数据导入与导出 (1) 从文件读取数据 Excel 文件:data readtable(data.xlsx); % 读取为表格(Table)CSV 文件:data readtable(data.csv); % 自动处理表头和分隔符文本文件:data load(data.t…...

Kafka中文文档
文章来源:https://kafka.cadn.net.cn 什么是事件流式处理? 事件流是人体中枢神经系统的数字等价物。它是 为“永远在线”的世界奠定技术基础,在这个世界里,企业越来越多地使用软件定义 和 automated,而软件的用户更…...

Python-列表
3.1 列表是什么 在Python中,列表是一种非常重要的数据结构,用于存储一系列有序的元素。列表中的每个元素都有一个索引,索引从0开始。列表可以包含任何类型的元素,包括其他列表。 # 创建一个列表my_list [1, 2, 3, four, 5.0]…...

51单片机开发:定时器中断
目标:利用定时器中断,每隔1s开启/熄灭LED1灯。 外部中断结构图如下图所示,要使用定时器中断T0,须开启TE0、ET0。: 系统中断号如下图所示:定时器0的中断号为1。 定时器0的工作方式1原理图如下图所示&#x…...

【HarmonyOS之旅】基于ArkTS开发(三) -> 兼容JS的类Web开发(二)
目录 1 -> HML语法 1.1 -> 页面结构 1.2 -> 数据绑定 1.3 -> 普通事件绑定 1.4 -> 冒泡事件绑定5 1.5 -> 捕获事件绑定5 1.6 -> 列表渲染 1.7 -> 条件渲染 1.8 -> 逻辑控制块 1.9 -> 模板引用 2 -> CSS语法 2.1 -> 尺寸单位 …...

算法【混合背包】
混合背包是指多种背包模型的组合与转化。 下面通过题目加深理解。 题目一 测试链接:1742 -- Coins 分析:这道题可以通过硬币的个数将其转化为01背包,完全背包和多重背包。如果硬币的个数是1个,则是01背包;如果硬币的…...
)
WordPress eventon-lite插件存在未授权信息泄露漏洞(CVE-2024-0235)
免责声明: 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在…...

基于微信小程序的医院预约挂号系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

C++初阶 -- 手撕string类(模拟实现string类)
目录 一、string类的成员变量 二、构造函数 2.1 无参版本 2.2 有参版本 2.3 缺省值版本 三、析构函数 四、拷贝构造函数 五、c_str函数 六、operator重载 七、size函数 八、迭代器iterator 8.1 正常版本 8.2 const版本 九、operator[] 9.1 正常版本 9.2 const版…...

【Postman接口测试】Postman的安装和使用
在软件测试领域,接口测试是保障软件质量的关键环节之一,而Postman作为一款功能强大且广受欢迎的接口测试工具,能够帮助测试人员高效地进行接口测试工作。本文将详细介绍Postman的安装和使用方法,让你快速上手这款工具。 一、Pos…...

miniconda学习笔记
文章主要内容:演示miniconda切换不同python环境,安装python库,使用pycharm配置不同的conda建的python环境 目录 一、miniconda 1. 是什么? 2.安装miniconda 3.基本操作 一、miniconda 1. 是什么? miniconda是一个anac…...

区块链项目孵化与包装设计:从概念到市场的全流程指南
区块链技术的快速发展催生了大量创新项目,但如何将一个区块链项目从概念孵化成市场认可的产品,是许多团队面临的挑战。本文将从孵化策略、包装设计和市场落地三个维度,为你解析区块链项目成功的关键步骤。 一、区块链项目孵化的核心要素 明确…...

JavaScript的基本组成
1、JavaScript的组成部分 JavaScript可以分为三个部分:ECMAScript标准、DOM、BOM。 ECMAScript标准 即JS的基本语法,JavaScript的核心,描述了语言的基本语法和数据类型,ECMAScript是一套标 准,定义了一种语言…...
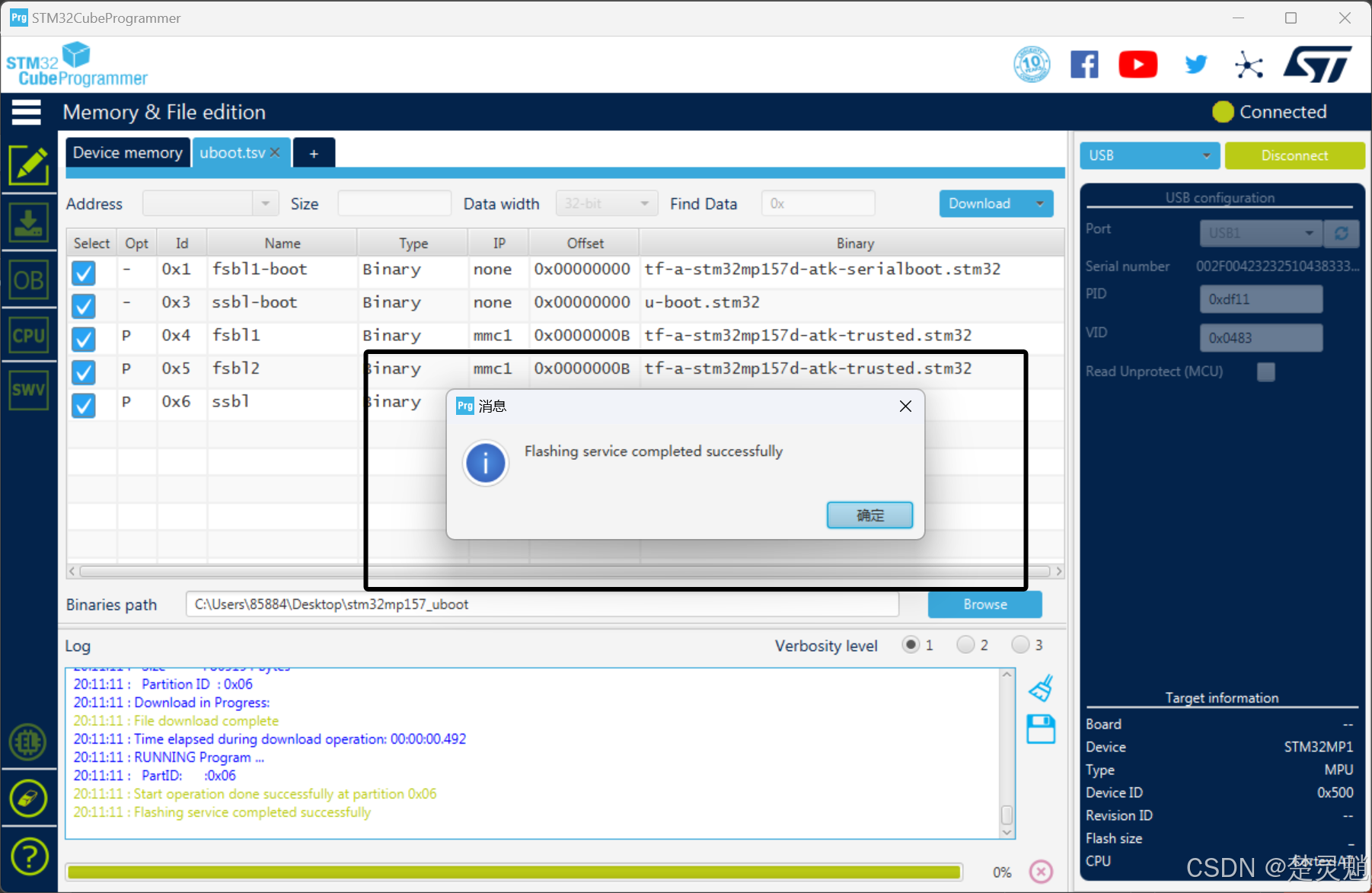
[Linux]从零开始的STM32MP157 U-Boot移植
一、前言 在上一次教程中,我们了解了STM32MP157的启动流程与安全启动机制。我们还将FSBL的相关代码移植成功了。大家还记得FSBL的下一个步骤是什么吗?没错,就是SSBL,而且常见的我们将SSBL作为存放U-Boot的地方。所以本次教程&…...

【Unity3D】实现横版2D游戏——攀爬绳索(简易版)
目录 GeneRope.cs 场景绳索生成类 HeroColliderController.cs 控制角色与单向平台是否忽略碰撞 HeroClampController.cs 控制角色攀爬 OnTriggerEnter2D方法 OnTriggerStay2D方法 OnTriggerExit2D方法 Update方法 开始攀爬 结束攀爬 Sensor_HeroKnight.cs 角色触发器…...

【llm对话系统】大模型 Llama 源码分析之 LoRA 微调
1. 引言 微调 (Fine-tuning) 是将预训练大模型 (LLM) 应用于下游任务的常用方法。然而,直接微调大模型的所有参数通常需要大量的计算资源和内存。LoRA (Low-Rank Adaptation) 是一种高效的微调方法,它通过引入少量可训练参数,固定预训练模型…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...