【Elasticsearch】 Intervals Query
Elasticsearch Intervals Query
返回基于匹配术语的顺序和接近度的文档。
intervals 查询使用 匹配规则,这些规则由一小组定义构建而成。这些规则然后应用于指定 field 中的术语。
这些定义生成覆盖文本中术语的最小间隔序列。这些间隔可以进一步由父源组合和过滤。
以下 intervals 查询返回包含 my favorite food(没有任何间隔),后跟 hot water 或 cold porridge 的文档。查询应用于 my_text 字段。
这个查询将匹配 my_text 值为 my favorite food is cold porridge,但不匹配 when it's cold my favorite food is porridge。
JSON复制
POST _search
{"query": {"intervals" : {"my_text" : {"all_of" : {"ordered" : true,"intervals" : [{"match" : {"query" : "my favorite food","max_gaps" : 0,"ordered" : true}},{"any_of" : {"intervals" : [{ "match" : { "query" : "hot water" } },{ "match" : { "query" : "cold porridge" } }]}}]}}}}
}Intervals 查询的顶级参数
<field>
(必需,规则对象)您希望搜索的字段。
此参数的值是一个规则对象,用于基于匹配术语、顺序和接近度匹配文档。
有效的规则包括:
-
match -
prefix -
wildcard -
regexp -
fuzzy -
range -
all_of -
any_of
match 规则参数
match 规则匹配分析过的文本。
-
query:-
(必需,字符串)您希望在提供的
<field>中找到的文本。
-
-
max_gaps:-
(可选,整数)匹配术语之间的最大位置数。超过此距离的术语不被视为匹配。默认值为
-1。 -
如果未指定或设置为
-1,则匹配没有宽度限制。如果设置为0,术语必须相邻。
-
-
ordered:-
(可选,布尔值)如果为
true,匹配术语必须按指定顺序出现。默认值为false。
-
-
analyzer:-
(可选,字符串)用于分析
query中术语的分析器。默认值为顶级<field>的分析器。
-
-
filter:-
(可选,间隔过滤规则对象)可选的间隔过滤器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。术语使用此字段的搜索分析器进行分析。这允许您跨多个字段进行搜索,就像它们是同一个字段一样;例如,您可以将相同的文本索引到词干和非词干字段中,并搜索词干标记附近的非词干标记。
-
prefix 规则参数
prefix 规则匹配以指定字符集开头的术语。此前缀可以扩展以匹配最多 indices.query.bool.max_clause_count 搜索设置术语。如果前缀匹配更多术语,Elasticsearch 将返回错误。您可以在字段映射中使用 index-prefixes 选项来避免此限制。
-
prefix:-
(必需,字符串)您希望在顶级
<field>中找到的术语的起始字符。
-
-
analyzer:-
(可选,字符串)用于规范化
prefix的分析器。默认值为顶级<field>的分析器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。
-
wildcard 规则参数
wildcard 规则使用通配符模式匹配术语。此模式可以扩展以匹配最多 indices.query.bool.max_clause_count 搜索设置术语。如果模式匹配更多术语,Elasticsearch 将返回错误。
-
pattern:-
(必需,字符串)用于查找匹配术语的通配符模式。
-
此参数支持两个通配符操作符:
-
?,匹配任何单个字符 -
*,匹配零个或多个字符,包括空字符
-
-
-
analyzer:-
(可选,字符串)用于规范化
pattern的分析器。默认值为顶级<field>的分析器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。
-
regexp 规则参数
regexp 规则使用正则表达式模式匹配术语。此模式可以扩展以匹配最多 indices.query.bool.max_clause_count 搜索设置术语。如果模式匹配更多术语,Elasticsearch 将返回错误。
-
pattern:-
(必需,字符串)用于查找匹配术语的正则表达式模式。
-
避免使用通配符模式,如
.*或.*?+。这可能会增加找到匹配术语所需的迭代次数,并降低搜索性能。
-
-
analyzer:-
(可选,字符串)用于规范化
pattern的分析器。默认值为顶级<field>的分析器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。
-
fuzzy 规则参数
fuzzy 规则匹配与提供的术语相似的术语,编辑距离由 Fuzziness 定义。如果模糊扩展匹配的术语超过 indices.query.bool.max_clause_count 搜索设置术语,Elasticsearch 将返回错误。
-
term:-
(必需,字符串)要匹配的术语。
-
-
prefix_length:-
(可选,整数)创建扩展时保持不变的起始字符数。默认值为
0。
-
-
transpositions:-
(可选,布尔值)指示编辑是否包括两个相邻字符的换位(ab → ba)。默认值为
true。
-
-
fuzziness:-
(可选,字符串)允许匹配的最大编辑距离。参见 Fuzziness 以获取有效值和更多信息。默认值为
auto。
-
-
analyzer:-
(可选,字符串)用于规范化
term的分析器。默认值为顶级<field>的分析器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。
-
range 规则参数
range 规则匹配包含在提供范围内的术语。此范围可以扩展以匹配最多 indices.query.bool.max_clause_count 搜索设置术语。如果范围匹配更多术语,Elasticsearch 将返回错误。
-
gt:-
(可选,字符串)大于:匹配大于提供术语的术语。
-
-
gte:-
(可选,字符串)大于或等于:匹配大于或等于提供术语的术语。
-
-
lt:-
(可选,字符串)小于:匹配小于提供术语的术语。
-
-
lte:-
(可选,字符串)小于或等于:匹配小于或等于提供术语的术语。
-
all_of 规则参数
all_of 规则返回跨多个其他规则组合的匹配项。
-
intervals:-
(必需,规则对象数组)要组合的规则数组。所有规则必须在文档中生成匹配项,整体源才能匹配。
-
-
max_gaps:-
(可选,整数)匹配术语之间的最大位置数。规则生成的间隔超过此距离的不被视为匹配。默认值为
-1。
-
-
ordered:-
(可选,布尔值)如果为
true,规则生成的间隔应按指定顺序出现。默认值为false。
-
-
filter:-
(可选,间隔过滤规则对象)用于过滤返回间隔的规则。
-
any_of 规则参数
any_of 规则返回其子规则生成的任何间隔。
-
intervals:-
(必需,规则对象数组)要匹配的规则数组。
-
-
filter:-
(可选,间隔过滤规则对象)用于过滤返回间隔的规则。
-
filter 规则参数
filter 规则基于查询返回间隔。有关示例,请参见过滤器示例。
-
after:-
(可选,查询对象)返回跟随
filter规则间隔的间隔的查询。
-
-
before:-
(可选,查询对象)返回在
filter规则间隔之前发生的间隔的查询。
-
-
contained_by:-
(可选,查询对象)返回被
filter规则间隔包含的间隔的查询。
-
-
containing:-
(可选,查询对象)返回包含
filter规则间隔的间隔的查询。
-
-
not_contained_by:-
(可选,查询对象)返回不被
filter规则间隔包含的间隔的查询。
-
-
not_containing:-
(可选,查询对象)返回不包含
filter规则间隔的间隔的查询。
-
-
not_overlapping:-
(可选,查询对象)返回不与
filter规则间隔重叠的间隔的查询。
-
-
overlapping:-
(可选,查询对象)返回与
filter规则间隔重叠的间隔的查询。
-
-
script:-
(可选,脚本对象)返回匹配文档的脚本。此脚本必须返回布尔值
true或false。
-
示例
以下查询包含一个 filter 规则。它返回包含 hot 和 porridge 且两者之间不超过 10 个位置的文档,且两者之间没有 salty。
JSON复制
POST _search
{"query": {"intervals" : {"my_text" : {"match" : {"query" : "hot porridge","max_gaps" : 10,"filter" : {"not_containing" : {"match" : {"query" : "salty"}}}}}}}
}脚本过滤器
您可以使用脚本根据间隔的起始位置、结束位置和内部间隔数过滤间隔。以下 filter 脚本使用 interval 变量及其 start、end 和 gaps 方法:
JSON复制
POST _search
{"query": {"intervals" : {"my_text" : {"match" : {"query" : "hot porridge","filter" : {"script" : {"source" : "interval.start > 10 && interval.end < 20 && interval.gaps == 0"}}}}}}
}注意事项
-
最小化间隔:
-
intervals查询始终最小化间隔,以确保查询可以在线性时间内运行。这有时会导致意外结果,特别是在使用max_gaps限制或过滤器时。例如,考虑以下查询,搜索hot porridge中包含的salty:
JSON复制
POST _search {"query": {"intervals" : {"my_text" : {"match" : {"query" : "salty","filter" : {"contained_by" : {"match" : {"query" : "hot porridge"}}}}}}} }-
此查询不会匹配包含
hot porridge is salty porridge的文档,因为hot porridge的匹配查询返回的间隔仅覆盖此文档中的前两个术语,这些术语不与覆盖salty的间隔重叠。
-
相关文章:

【Elasticsearch】 Intervals Query
Elasticsearch Intervals Query 返回基于匹配术语的顺序和接近度的文档。 intervals 查询使用 匹配规则,这些规则由一小组定义构建而成。这些规则然后应用于指定 field 中的术语。 这些定义生成覆盖文本中术语的最小间隔序列。这些间隔可以进一步由父源组合和过滤…...

DeepSeek技术深度解析:从不同技术角度的全面探讨
DeepSeek技术深度解析:从不同技术角度的全面探讨 引言 DeepSeek是一个集成了多种先进技术的平台,旨在通过深度学习和其他前沿技术来解决复杂的问题。本文将从算法、架构、数据处理以及应用等不同技术角度对DeepSeek进行详细分析。 一、算法层面 深度学…...

Docker 部署 Starrocks 教程
Docker 部署 Starrocks 教程 StarRocks 是一款高性能的分布式分析型数据库,主要用于 OLAP(在线分析处理)场景。它最初是由百度的开源团队开发的,旨在为大数据分析提供一个高效、低延迟的解决方案。StarRocks 支持实时数据分析&am…...

【LLM-agent】(task6)构建教程编写智能体
note 构建教程编写智能体 文章目录 note一、功能需求二、相关代码(1)定义生成教程的目录 Action 类(2)定义生成教程内容的 Action 类(3)定义教程编写智能体(4)交互式操作调用教程编…...

29.Word:公司本财年的年度报告【13】
目录 NO1.2.3.4 NO5.6.7 NO8.9.10 NO1.2.3.4 另存为F12:考生文件夹:Word.docx选中绿色标记的标题文本→样式对话框→单击右键→点击样式对话框→单击右键→修改→所有脚本→颜色/字体/名称→边框:0.5磅、黑色、单线条:点…...
)
14 2D矩形模块( rect.rs)
一、 rect.rs源码 // Copyright 2013 The Servo Project Developers. See the COPYRIGHT // file at the top-level directory of this distribution. // // Licensed under the Apache License, Version 2.0 <LICENSE-APACHE or // http://www.apache.org/licenses/LICENS…...
【Unity3D】实现2D角色/怪物死亡消散粒子效果
核心:这是一个Unity粒子系统自带的一种功能,可将粒子生成控制在一个Texture图片网格范围内,并且粒子颜色会自动采样图片的像素点颜色,之后则是粒子编辑出消散效果。 Particle System1物体(爆发式随机速度扩散10000个粒…...
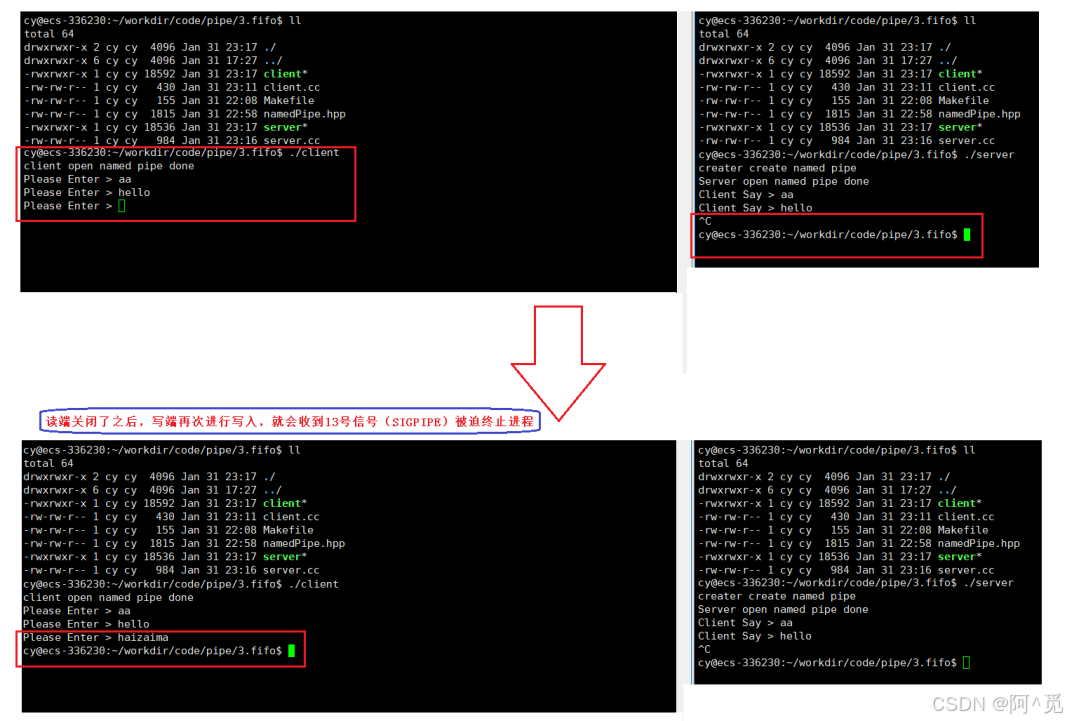
Linux - 进程间通信(3)
目录 3、解决遗留BUG -- 边关闭信道边回收进程 1)解决方案 2)两种方法相比较 4、命名管道 1)理解命名管道 2)创建命名管道 a. 命令行指令 b. 系统调用方法 3)代码实现命名管道 构建类进行封装命名管道&#…...
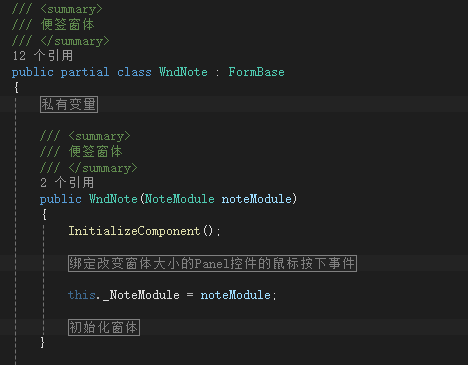
3、C#基于.net framework的应用开发实战编程 - 实现(三、三) - 编程手把手系列文章...
三、 实现; 三.三、编写应用程序; 此文主要是实现应用的主要编码工作。 1、 分层; 此例子主要分为UI、Helper、DAL等层。UI负责便签的界面显示;Helper主要是链接UI和数据库操作的中间层;DAL为对数据库的操…...
)
C++编程语言:抽象机制:泛型编程(Bjarne Stroustrup)
泛型编程(Generic Programming) 目录 24.1 引言(Introduction) 24.2 算法和(通用性的)提升(Algorithms and Lifting) 24.3 概念(此指模板参数的插件)(Concepts) 24.3.1 发现插件集(Discovering a Concept) 24.3.2 概念与约束(Concepts and Constraints) 24.4 具体化…...

Python面试宝典13 | Python 变量作用域,从入门到精通
今天,我们来深入探讨一下 Python 中一个非常重要的概念——变量作用域。理解变量作用域对于编写清晰、可维护、无 bug 的代码至关重要。 什么是变量作用域? 简单来说,变量作用域就是指一个变量在程序中可以被访问的范围。Python 中有四种作…...

基于最近邻数据进行分类
人工智能例子汇总:AI常见的算法和例子-CSDN博客 完整代码: import torch import numpy as np from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt# 生成一个简单的数据…...

DeepSeek V3 vs R1:大模型技术路径的“瑞士军刀“与“手术刀“进化
DeepSeek V3 vs R1:——大模型技术路径的"瑞士军刀"与"手术刀"进化 大模型分水岭:从通用智能到垂直突破 2023年,GPT-4 Turbo的发布标志着通用大模型进入性能瓶颈期。当模型参数量突破万亿级门槛后,研究者们开…...
一、TensorFlow的建模流程
1. 数据准备与预处理: 加载数据:使用内置数据集或自定义数据。 预处理:归一化、调整维度、数据增强。 划分数据集:训练集、验证集、测试集。 转换为Dataset对象:利用tf.data优化数据流水线。 import tensorflow a…...

指导初学者使用Anaconda运行GitHub上One - DM项目的步骤
以下是指导初学者使用Anaconda运行GitHub上One - DM项目的步骤: 1. 安装Anaconda 下载Anaconda: 让初学者访问Anaconda官网(https://www.anaconda.com/products/distribution),根据其操作系统(Windows、M…...

7层还是4层?网络模型又为什么要分层?
~犬📰余~ “我欲贱而贵,愚而智,贫而富,可乎? 曰:其唯学乎” 一、为什么要分层 \quad 网络通信的复杂性促使我们需要一种分层的方法来理解和管理网络。就像建筑一样,我们不会把所有功能都混在一起…...

C++:抽象类习题
题目内容: 求正方体、球、圆柱的表面积,抽象出一个公共的基类Container为抽象类,在其中定义一个公共的数据成员radius(此数据可以作为正方形的边长、球的半径、圆柱体底面圆半径),以及求表面积的纯虚函数area()。由此抽象类派生出…...
)
C++ 泛型编程指南02 (模板参数的类型推导)
文章目录 一 深入了解C中的函数模板类型推断什么是类型推断?使用Boost TypeIndex库进行类型推断分析示例代码关键点解析 2. 理解函数模板类型推断2.1 指针或引用类型2.1.1 忽略引用2.1.2 保持const属性2.1.3 处理指针类型 2.2 万能引用类型2.3 传值方式2.4 传值方式…...
——FFmpeg源码中,解析SDP的实现)
音视频入门基础:RTP专题(5)——FFmpeg源码中,解析SDP的实现
一、引言 FFmpeg源码中通过ff_sdp_parse函数解析SDP。该函数定义在libavformat/rtsp.c中: int ff_sdp_parse(AVFormatContext *s, const char *content) {const char *p;int letter, i;char buf[SDP_MAX_SIZE], *q;SDPParseState sdp_parse_state { { 0 } }, *s1…...

计算机网络 应用层 笔记 (电子邮件系统,SMTP,POP3,MIME,IMAP,万维网,HTTP,html)
电子邮件系统: SMTP协议 基本概念 工作原理 连接建立: 命令交互 客户端发送命令: 服务器响应: 邮件传输: 连接关闭: 主要命令 邮件发送流程 SMTP的缺点: MIME: POP3协议 基本概念…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...