Transformation(转换算子)
分布式代码的分析
启动spark程序的代码
在yarn中启动(没有配置环境变量)
/export/server/spark/bin/spark-submit --master yarn --num-executors 6 /root/helloword.py
# 配置环境变量
spark-submit --master yarn --num-executors 6 /root/helloword.py
RDD的五大特征
1、RDD是分区的
2、计算方法都在作用在每一个分区上
3、RDD之间是有依赖关系的(RDD之间有血缘关系)
4、kv型RDD是可以有分区器的
5、RDD分区数据的读取都会接近数据所在地
RDD的创建
通过并行集合进行创建(并行化创建)
概念:并行化创建是指将本地集合-> 转向分布式RDD
这一步就是分布式的开端:本地转分布式
API:
rdd = Sparkcontext.parallelize(参数1,参数2)
参数1:集合即对象,比如list
参数2:分区数
使用案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':# 初始化执行环境,构建sparkContext对象conf = SparkConf().setAppName("TEST").setMaster("local[*]")# 通过conf创建一个SparkContext对象sc = SparkContext(conf=conf)# 通过并行化集合的方式去创建RDDrdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)分区数的参与度很小print('分区数:',rdd.getNumPartitions())print("rdd的内容:",rdd.collect())
读取外部数据源(读取文件)
读取文件创建RDD使用textfile的API
textfile 可以读取本地数据,也可以读取hdfs数据
使用方法:
sparkcontext.textFile(参数1,参数2)
# 参数1:必填,文件路径支持本地文件
# 参数2:可选,表示最小分区数量,最小分区数是参考值
wholeTextFile
读取文件API使用场景:适合读取一堆小文件
使用方法:
Sparkcontext。wholeTextfiles(参数1,参数2)# 参数1:必填,文件路径,支持本地文件,支持HDFS 也支持一些协议例如s3协议# 参数:可选,最小分区数
RDD算子
算子定义
算子:分布式集合对象的api称之为算子
方法函数:本地对象的API,叫做方法\函数
算子:分布式对象的API叫做算子
算子分类
RDD的算子分为两类:
Transformation:转换算子
Action:动作(行动)算子
Transformation(转换算子)
定义:RDD算子,返回值仍旧是一个RDD的,称之为转换算子
特性:这类算子就是 lazy 懒加载的如果没有action算子,Transformation算子是不工作的
常用的Transformation算子
map算子:
功能:map算子是将rdd的数据一条条的处理(处理的逻辑 基于map算子中接收的处理函数),并且返回新的rdd
API:
rdd.map(func)
# func: f:(T)->U
# f:表示一个函数或者方法
# (T)——》表示的是方法的定义:
# ()表示传入的参数 (T)表示 传入一个参数 ()
# T 是泛型的代称,在这里表示 任意类型
# U 也是泛型代称,在这里表示,任意类型
# -> 表示返回值
# (T)—> U 总结起来的意思是:这是一个方法,这个方法接受一个参数据传入,传入的方式类型不限,返回一个返回值,返回的类型不限
# (A)-> A 总结起来的意思是:这是一个方法,这个方法接受一个参数传入,传入的参数的类型不限,返回一个返回值,但是返回值的传入参数类型一致
map的定义方法:
# 作为算子传入函数体
rdd = sc.parallelize([1,2,3,4,5,6],3)def add(data):return data*10print(rdd.map(add).collect())reduceByKey算子
功能:针对kv型RDD自动按照key分组,然后根据自己提供的聚合逻辑完成子内数据的聚合操作
api
rdd.reduceByKey(func)
# func:(v,v)-> v
# 接受2个传入参数(类型要一致),返回一个返回值,类型和传入要求一致
代码实现案例:
rdd = sc.parallelize([('a',1),('a',1),('b',1),('b',1),('a',1)])
print(rdd.reduceByKey(lambda a,b:a+b).collect())
mapValues算子
功能:针对二元元组RDD,对其内部的二元元组的value执行map操作
api:
rdd.mapValues(func)
# func:(V)->u
# 注意,传入的参数,是二元元组的value值
# 我们这个传入的方法,只对value进行处理
案例:
rdd = sc.parallelize([('a',1),('a',11),('a',6),('b',3)])
print(rdd.mapValues(lambda values :values * 10).collect())
groupBy算子
功能:将rdd的数据进行分组
API:
rdd.groupBy(func)
# func 函数
# func:(t)->k
# 函数要求传入一个参数,返回一个返回值,类型无所谓
# 这个函数是 拿到你的返回值后,将相同返回值的放入一个组中
# 分组完成后,每个组是一个二元元组,key就是返回值,所有的数据放入一个迭代器中作为value
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('groupby').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',1),('a',1),('b',1),('b',1),('b',1)])# 通过group by 对数据机型分组# group By 传入的函数意思是:这个函数确定按照谁来分组# 分组规则和SQL是一致的,相同的在一组result = rdd.groupBy(lambda t: t[0])print(result.collect())print(result.map(lambda t:(t[0] ,list(t[1]))).collect())
ilter算子
功能:过滤不想要的数据
算子案例:
from pyspark import SparkConf,SparkContext
conf = SparkConf().setAppName('filer').setMaster('local[*]')
sc = SparkContext(conf=conf)rdd = sc.parallelize([1,2,3,4,5,6])
# 使用filer进行过滤
rdd_filer = rdd.filter(lambda x:x>1)
print(rdd_filer.collect())
distinct算子
功能:对rdd的数据进行去重,并且返回新的RDD
api:
rdd.distinct(参数1)
# 参数1:去重分区数量,一般不用
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':Conf = SparkConf().setMaster('local[*]').setAppName('distin')sc = SparkContext(conf=Conf)rdd = sc.parallelize([1,1,1,1,1,2,2,2,22,3,3,3,3,3,34])# 使用distinct对RDD数据进行去重处理rdd_distinct = rdd.distinct()print(rdd_distinct.collect())# 结果[1, 2, 34, 3, 22]
union算子
功能:将两个rdd合并成为一个rdd返回
算子特点:
1、rdd的类型不同也是可以进行合并的
2、union算子时不可以自动去重的
api:
rdd.union(other_rdd)
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('union').setMaster('local[*]')sc = SparkContext(conf=conf)rdd1 = sc.parallelize([1,2,3,4,5])rdd2 = sc.parallelize(['a','s','d','f','f'])rdd_union = rdd1.union(rdd2)print(rdd_union.collect())join算子
功能:join算子对两个RDD执行join操作(可实现SQL的内/外连接)
对于join算子来说 关联条件 是按照二元元组的key进行关联的
注意:join算子只能用于二元元组
API:
rdd.join(other_rdd)# 内连接
rdd.leftoutherjoin(other_rdd)# 左外
rdd.rightOutherjoin(other_rdd)# 右外
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('JOIN')sc = SparkContext(conf=conf)rdd1 = sc.parallelize([(1001,"文章"),(1002,'英文')])rdd2 = sc.parallelize([(1001,"于金陵"),(1002,'yujn=inlong'),(1003,'尽情与')])rdd_join = rdd1.join(rdd2)print(rdd_join.collect())rdd_left = rdd1.leftOuterJoin(rdd2)print(rdd_left.collect())rdd_right = rdd1.rightOuterJoin(rdd2)print(rdd_right.collect())intersection算子
功能:求2个rdd的交集,返回一个新的rdd
api:
rdd.instersection(other_rdd)
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('instersection').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([1,2,3,4])rdd2 = sc.parallelize([1,2,3,44,550])rdd1 = rdd.intersection(rdd2)print(rdd1.collect())
glom算子
功能:将RDD的数据加上嵌套,这个嵌套按照分区来进行
当需要解嵌套是可以使用
flaimap算子进行转换
api:
rdd.glom()
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('instersection').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)print(rdd.glom().collect())
groupByKey算子
功能:针对kv型rdd,自动按照key进行分组
api:
rdd.groupByKey()# 自动按照key分组
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('groupbykey').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',1),("a",2),('a',3),('b',1),('b',2),('b',3)])rdd_bykey = rdd.groupByKey()print(rdd_bykey.map(lambda x: (x[0],list(x[1]))).collect())
sortBy算子
功能:对rdd数据进行排序,基于你指定的排序依据
api:
rdd.sortby(func,ascending=false,numparttions=1)
# func(T)->U:告知按照rdd中的哪个数据排序比如:lambda x: x[1]表示按照rdd中的第二列元素进行排序
# ascending True 升序 false 降序
# numPartitons:用多少分区排序
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('sortBy').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',11),('c',4),('f',3),('g',2)])rdd_sort = rdd.sortBy(lambda x: x[1], ascending=True,numPartitions=3)print(rdd_sort.collect())
sortByKey算子
功能:针对kv型RDD按照key进行排序
aip:
sortByKey(ascending= True,numPartitions=None,keyfunc=<function RDD.<lambda>)
# ascending:升序或者降序 true是升序,False是降序,默认是升序
# numPartitions:按照几个分区排序,如果全局有序,设置1
# Keyfunc :在排序前对key进行处理,语法(k)->u,一个参数传入,返回一个值
算子案例演示:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('sortBy').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',11),('c',4),('f',3),('g',2),('E',1),('s',10),('Q',8)])print(rdd.sortByKey(ascending=True, numPartitions=1, keyfunc=lambda key: str(key).lower()).collect())
综合案例:
import json
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('sortBy').setMaster('local[*]')sc = SparkContext(conf=conf)#1、 读取数据文件rdd = sc.textFile(r'C:\Users\HONOR\Desktop\测试数据\order.text')# 2、flatMap算子进行数据整理rdd_json = rdd.flatMap(lambda x: x.split('|'))# 3、通过json 库进行数据类型的转换rdd_json_j =rdd_json.map(lambda x: json.loads(x))# 4、筛选出数据中城市为北京的数据rdd_json_biejing = rdd_json_j.filter(lambda x: x['areaName'] == '北京')# 5、将城市为北京的所有商品数据类型进行的字符段进行合并并且去重rdd_l = rdd_json_biejing.map(lambda x: x['areaName']+":"+x['category']).distinct()#6、 对筛选的数据进行总结输出print(rdd_l.collect())将案例提交道YARN集群中运行
# 改动1:加入环境变量,让pycharm直接提交到yarn的时候,知道Hadoop的配置在哪,可以读取yarn的信息
import os
os.environ['HADOOP_CONF_DIR'] = '/export/server/hadoop/etc/hadoop'
# 在集群运行,本地文件就不可以用了,需要用hdfs文件
rdd = sc.textFile('hdfs://node1:8020/input/order.text')
如果在pycharm中直接提交到yarn,那么依赖的其他的python文件,可以通过设置文件属性来指定依赖代码
# 如果在代码中运行,那么依赖的文件,可以通过spark.sumbit.pyFiles属性来设置
#conf对象,可以通过setAPI 设置数据,参数1:key 参数2是value
conf.set('spark.submit.pyFiles',"defs.py")
在服务器上通过spark-submit提交到集群运行
# --py-files 可以帮你指定 你依赖的其他python代码,支持.zip(一堆),也可以单个.py文件 都行
/export/server/spark/bin/spark-submit --master yarn --py-files ./defs.[文件格式] ./mian.py
相关文章:
Transformation(转换算子)
分布式代码的分析 启动spark程序的代码 在yarn中启动(没有配置环境变量) /export/server/spark/bin/spark-submit --master yarn --num-executors 6 /root/helloword.py # 配置环境变量 spark-submit --master yarn --num-executors 6 /root/helloword.py RDD的五大特征 1、…...
总结如何设计一款营销低代码可视化海报平台
背景 我所在的部门负责的是活动业务,每天都有很多的营销活动,随之而来的就是大量的H5活动页面。而这些H5活动已经沉淀出了比较固定的玩法交互,我们开发大多数的工作也只是在复制粘贴这种大量的重复工作。 在基于此背景下我开始了低代码平台…...
spark04-文件读取分区数据分配原理
接 https://blog.csdn.net/oracle8090/article/details/129013345?spm1001.2014.3001.5502通过上一节知道 总字节数为7 每个分区字节数为3代码val conf: SparkConf new SparkConf().setMaster("local").setAppName("wordcount")val sc: SparkContext ne…...

常见的网络安全攻击及防御技术概述
网络安全技术涉及从物理层到业务层的各个层面,贯穿产品设计到产品上线运营的全流程。现阶段网络攻击的方式和种类也随着互联网技术的发展而不断迭代,做好网络安全防护的前提是我们要对网络攻击有充分的了解。下文将抛砖引玉对常见的网络安全攻击及防御技…...
NetSuite Balancing Segment平衡段
春节假期偷了一段时间懒,现在开始工作了。今朝谈一个偏门题目,于未知领域再下一城。说这个题目偏,就要讲讲渊源。话说在Oracle的EBS和Fusion产品中的COA领域有个功能叫做“Balancing Segment”。 问了几位Oracle老炮,也说是对第二…...
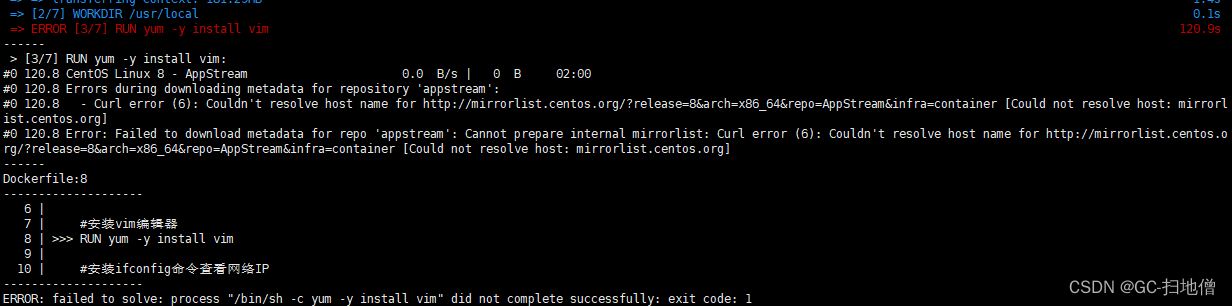
Docker 中遇到的问题
1:docker-tomcat 篇 第一天启动主机和虚拟机都可以正常访问,晚上睡觉的时候就挂起关机睡觉了,但到了第二天主机访问不了了,ping 也能ping 通,后来停掉容器,重启了虚拟机就好了,就很离谱。 这是成…...

树莓派用默认账号和密码登录不上怎么办;修改树莓派的密码
目录 一、重置树莓派的默认账号和密码 二、修改树莓派的密码 三、超级用户和普通用户的切换 一、重置树莓派的默认账号和密码 在SD卡中根目录建立文件userconf 在userconf中输入如下内容: pi:$6$/4.VdYgDm7RJ0qM1$FwXCeQgDKkqrOU3RIRuDSKpauAbBvP11msq9X58c8Q…...

【LeetCode】不同的二叉搜索树 [M](卡特兰数)
96. 不同的二叉搜索树 - 力扣(LeetCode) 一、题目 给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。 示例 1: 输入:n 3 输出&a…...

【软件相关】文献管理工具——Zotero
文章目录0 前期教程1 前言2 一些说明3 下载安装4 功能一:插入文献引用格式5 功能二:从网页下载文献pdf和题录6 功能三:数据多平台同步7 功能四:通过DOI添加条目及添加订阅8 安装xpi插件9 功能五:智能识别中英文文献10 …...
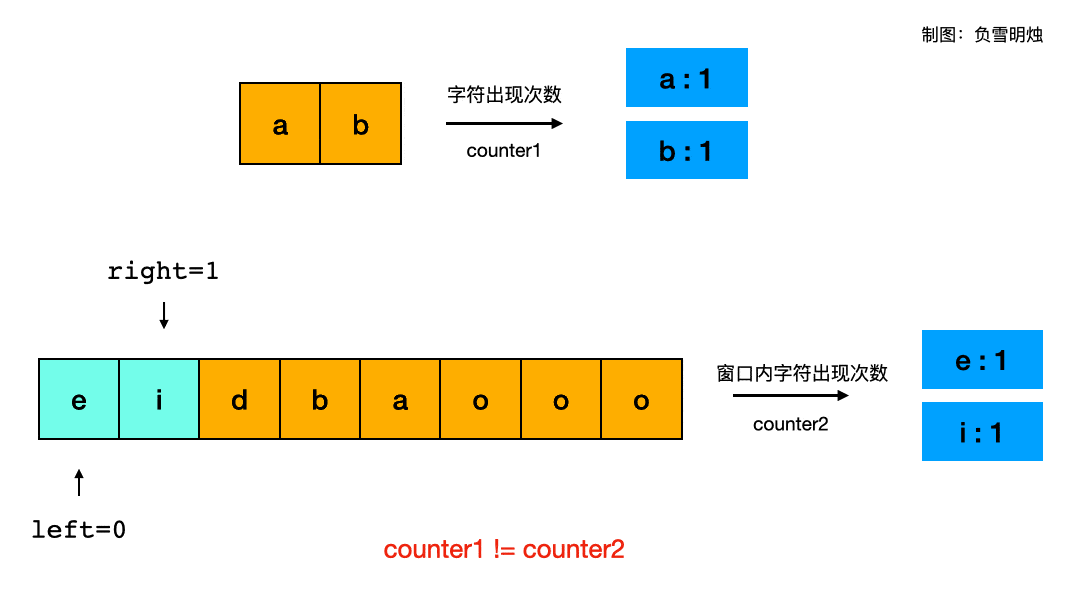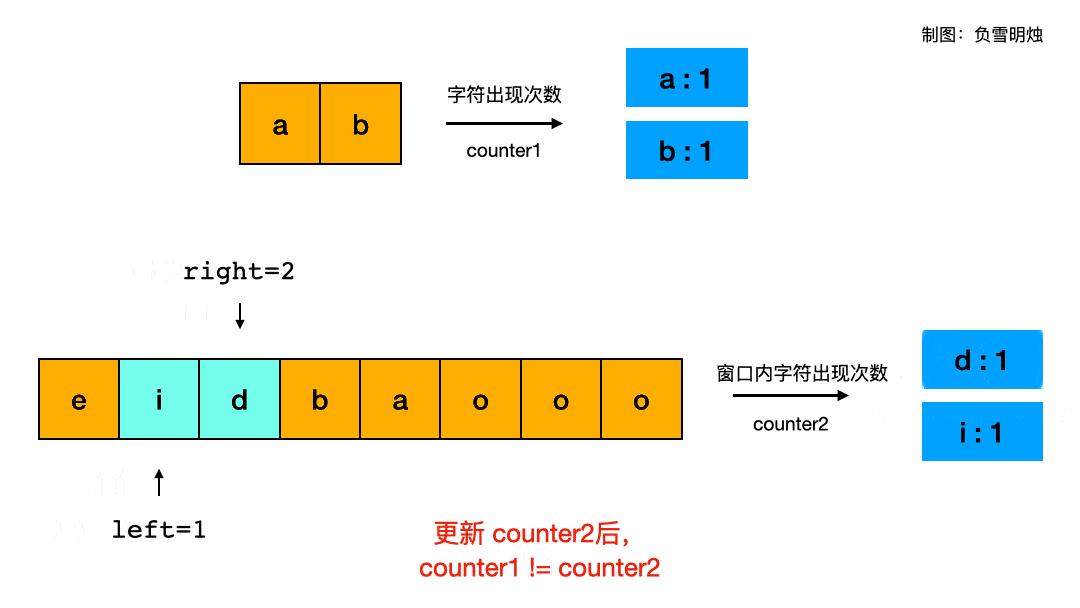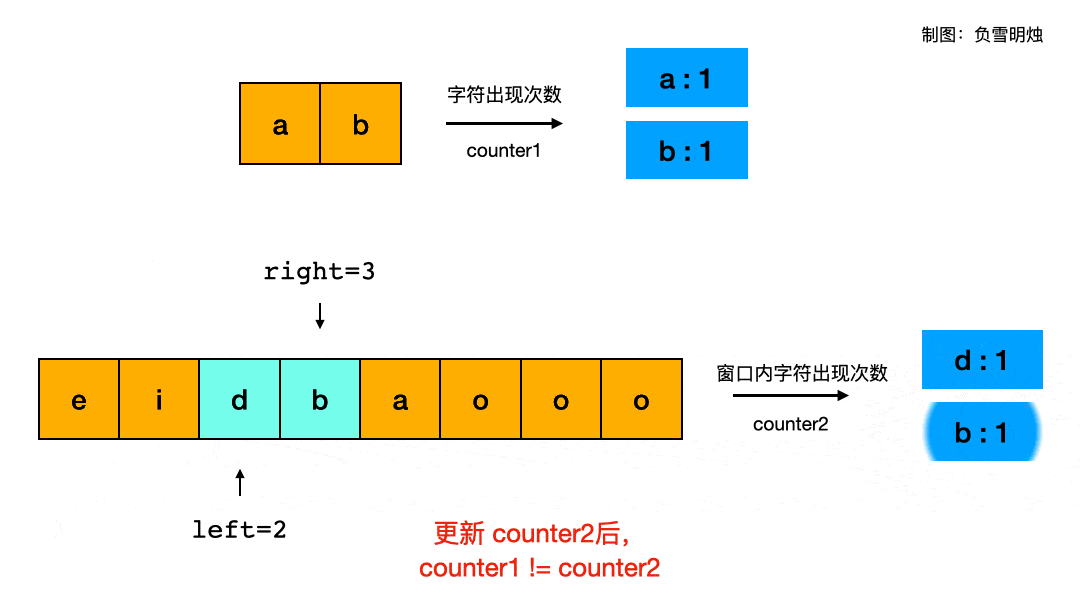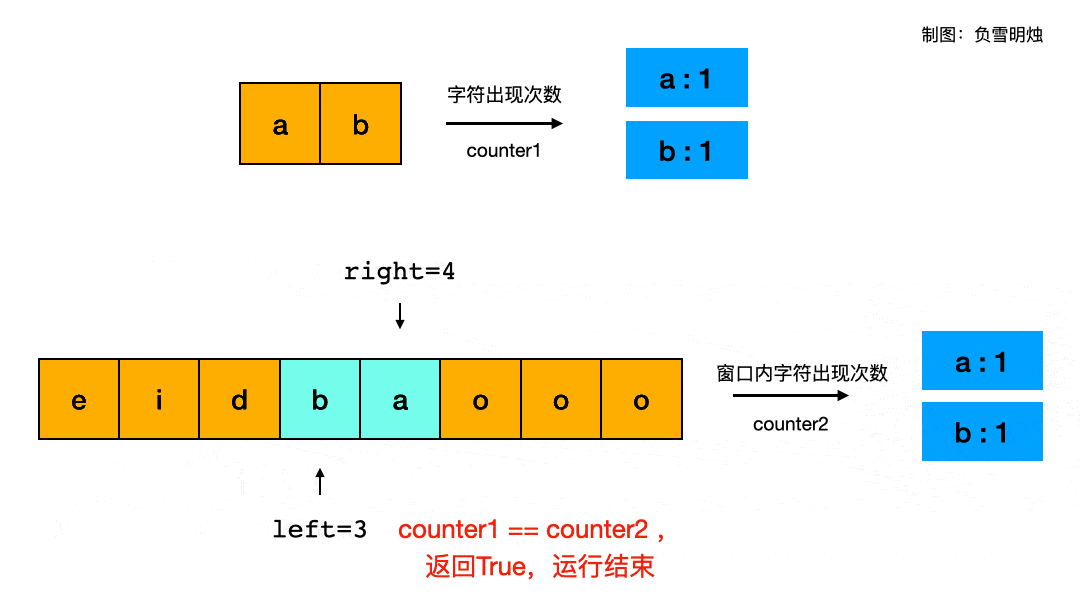
leetcode练习一:数组(二分查找、双指针、滑动窗口)
文章目录一、 数组理论基础二、 二分查找2.1 解题思路2.2 练习题2.2.1 二分查找(题704)2.2.2 搜索插入位置(题35)2.2.3 查找排序数组元素起止位置(题34)2.2.4 有效的完全平方数(题367)2.2.5 x 的平方根&…...
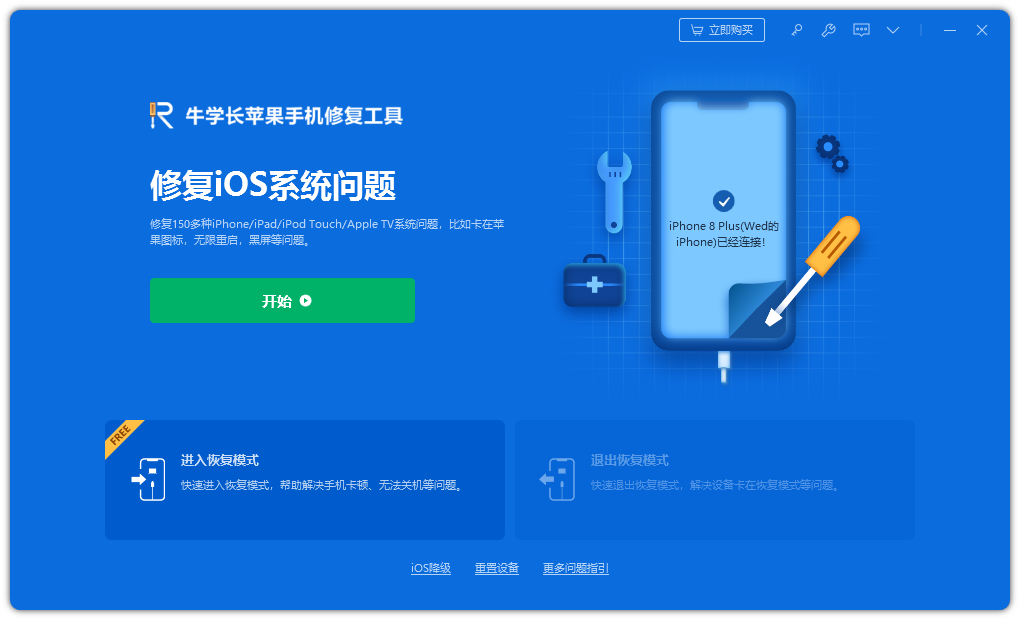
iPhone更新iOS 16.3出现应用卡死、闪退的问题怎么办?
在升级最新的 iOS 16.3 系统后,有些用户可能遇到了个别应用无法正常打开,卡死的异常情况。大家可以尝试通过如下方式解决问题。 1.重新启动应用: 如果应用出现卡死或闪退,可从 iPhone 屏幕由底往上滑(或连续按两次 H…...
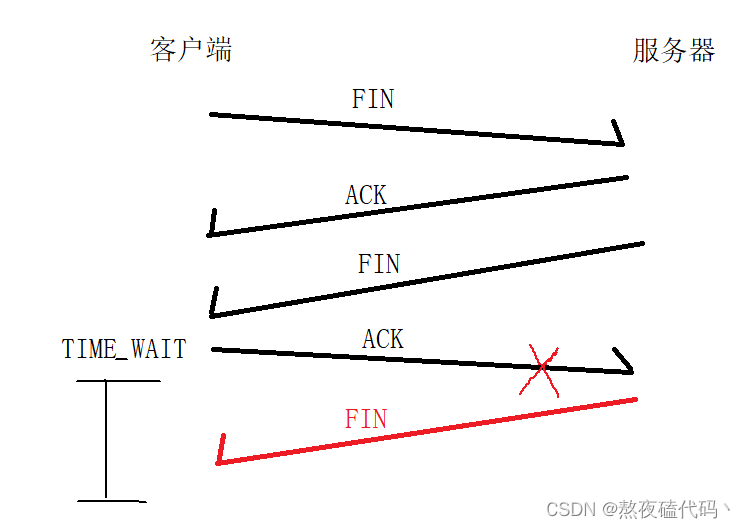
TCP协议原理一
文章目录一、TCP协议二、TCP工作机制1.确认应答2.超时重传3.连接管理三次握手四次挥手一、TCP协议 我们的TCP协议相比于UDP协议复杂不少,今天我们就来一起学习一下TCP协议报文和原理 首先我们报头第一行里的端口号和UDP的端口号是一致的,都是用两个字节…...

【黑马SpringCloud(6)】Sentinel解决雪崩问题
微服务保护雪崩问题服务保护技术Sentinel微服务整合Sentinel流量控制簇点链路入门练习流控模式关联链路流控效果Warm Up排队等待热点参数限流隔离和降级FeignClient整合Sentinel线程隔离(舱壁模式)实现线程隔离熔断降级慢调用异常比例/异常数授权规则获取origin给网关添加请求头…...
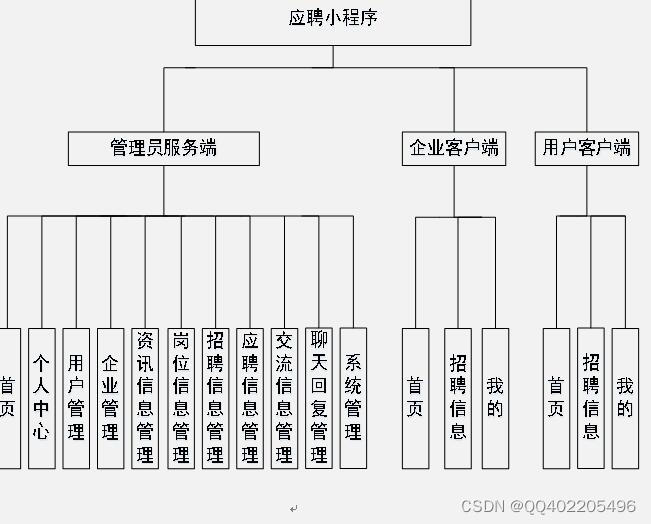
微信小程序 java springboot招聘求职应聘简历系统
应聘系统是基于微信小程序,java编程语言,mysql数据库,springboot框架,idea工具开发,本系统主要分为用户,企业,管理员三个角色,用户注册登陆小程序,查看应聘分类ÿ…...

亿级高并发电商项目-- 实战篇 --万达商城项目 四(Dashboard服务、设置统一返回格式与异常处理、Postman测试接口 )
专栏:高并发---前后端分布式项目 👏作者简介:大家好,我是小童,Java开发工程师,CSDN博客博主,Java领域新星创作者 📕系列专栏:前端、Java、Java中间件大全、微信小程序、…...
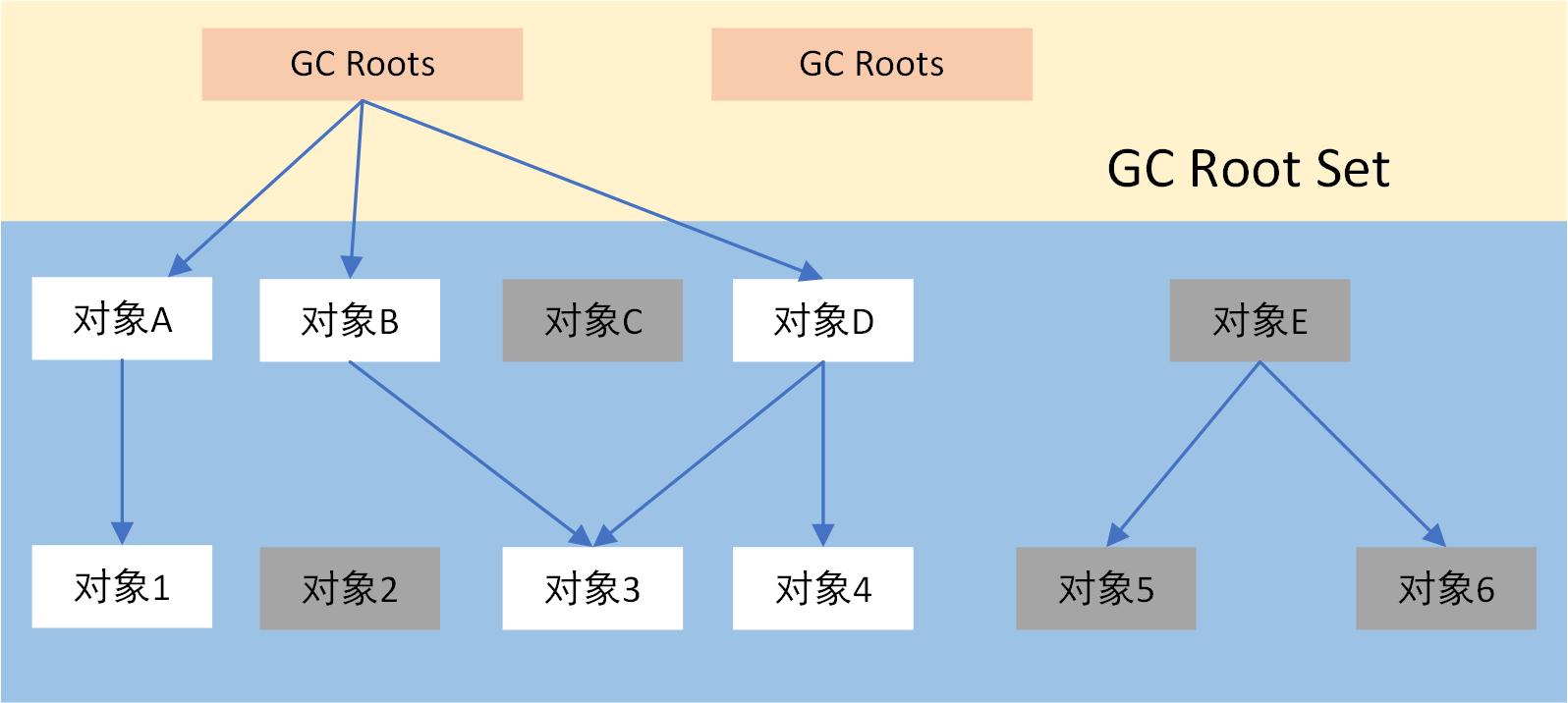
为什么这11道JVM面试题这么重要(附答案)
本文内容整理自 博学谷狂野架构师 运行时数据区都包含什么 虚拟机的基础面试题 程序计数器Java 虚拟机栈本地方法栈Java 堆方法区 程序计数器 程序计数器是线程私有的,并且是JVM中唯一不会溢出的区域,用来保存线程切换时的执行行数 程序计数器ÿ…...

概率统计之概率篇
概率统计之概率篇 一 随机变量及其四种研究方法 为了更深入地研究随机现象,需要把随机试验的结果数量化,也就是要引进随机变量来描述随机试验的结果。 一般地,把表示随机现象的各种结果或描述随机事件的变量叫做随机变量。随机变量通常用大…...
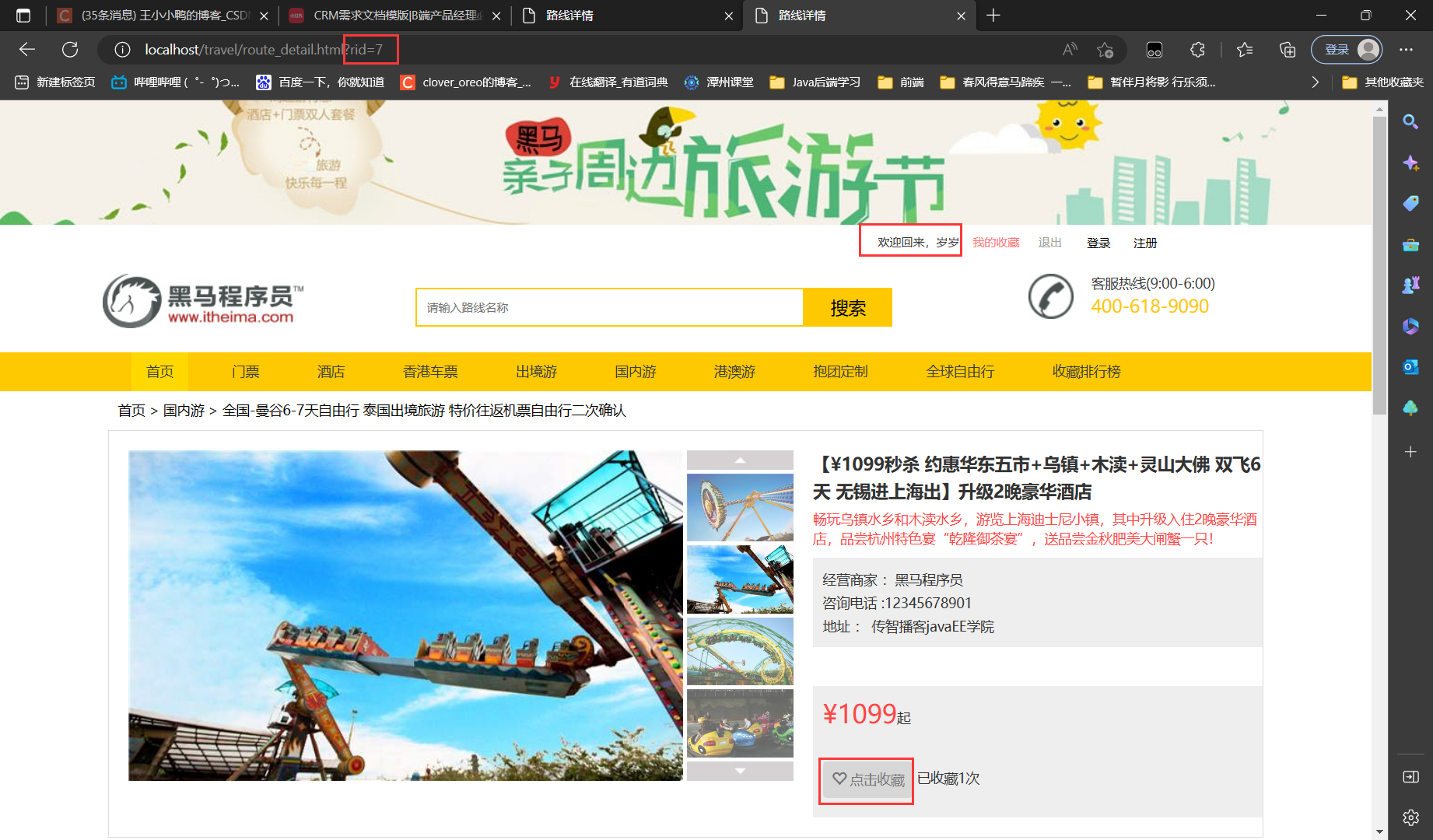
综合项目 旅游网 【5.旅游线路收藏功能】
分析判断当前登录用户是否收藏过该线路当页面加载完成后,发送ajax请求,获取用户是否收藏的标记根据标记,展示不同的按钮样式编写代码后台代码RouteServlet/*** 判断当前登录用户是否收藏过该路线*/ public void isFavorite(HttpServletReques…...
【ArcGIS Pro二次开发】(3):UI管理_显示隐藏Tab、Group、Control等控件
在ArcGIS Pro工作中,有时候会涉及到工具栏UI的管理,比如,打开模型构建器时,工具栏才会出现新的选项卡(Tab)【ModelBuilder】,工程未做更改,则【保存】按钮显示灰色不可用。 下面以一个小例子来学习一下。 一…...
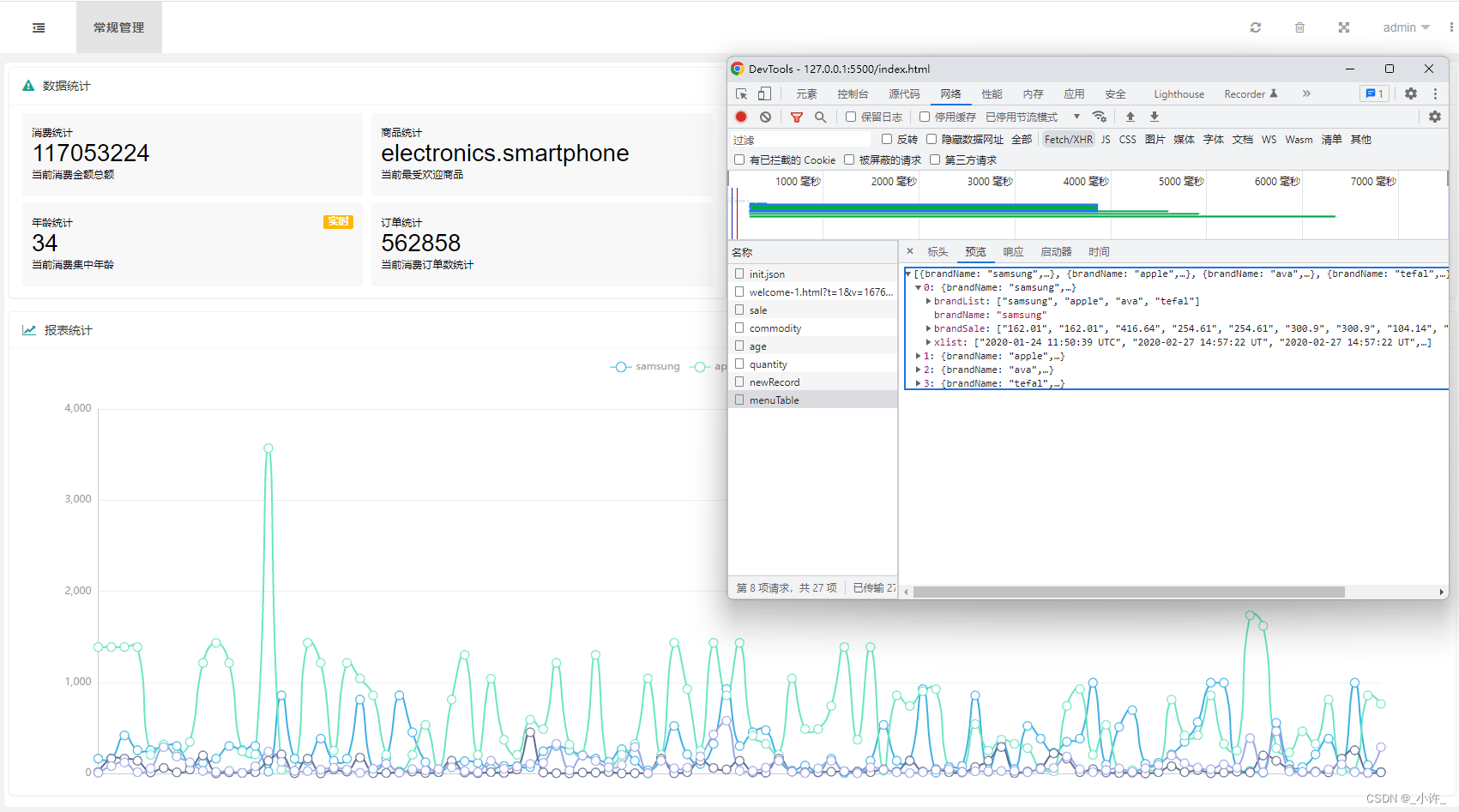
Spring Boot开发实战——echarts图标填充数据
echarts模块的导入 先看看成品吧! 有的图标的数据用了一些计算框架不是直接查数据库所以有点慢。 ok!😃 上正文,接上节Spring boot项目开发实战——(LayUI实现前后端数据交换与定义方法渲染数据)讲解了一般…...

峰值电流模式CCM BUCK转换器的环路稳定性分析与设计
1. 峰值电流模式CCM BUCK转换器基础 第一次接触峰值电流模式控制时,我被它的"电流内环电压外环"双环结构惊艳到了。这种架构就像给BUCK转换器装上了双重保险:内环快速响应电流变化,外环精确控制输出电压。在连续导通模式(CCM)下工作…...

com的本质是什么,和动态库有什么关系
COM(Component Object Model,组件对象模型)的本质可以概括为:一种二进制层面的软件组件交互标准,它定义了不同软件模块之间如何通信、如何创建对象、如何管理生命周期,而不依赖于具体的编程语言、编译器或源…...

SPIRAN ART SUMMONER能做什么?从角色设计到场景构建全解析
SPIRAN ART SUMMONER能做什么?从角色设计到场景构建全解析 1. 认识SPIRAN ART SUMMONER SPIRAN ART SUMMONER是一款融合了顶尖AI图像生成技术与《最终幻想10》艺术风格的视觉创作工具。它不仅仅是一个普通的图像生成器,而是一个沉浸式的数字艺术创作平…...
)
AI绘画进阶:用Stable Diffusion的LoRA模型打造专属画风(附最新v4.10模型包)
AI绘画进阶:用Stable Diffusion的LoRA模型打造专属画风 最近在Civitai社区看到不少创作者用LoRA模型生成的惊艳作品——从赛博朋克风的城市夜景到水墨风格的奇幻角色,这些作品背后都离不开对LoRA模型的深度调校。作为SD玩家,掌握LoRA模型的运…...
)
从零搭建Shopify主题:如何用Liquid实现动态商品展示(附Flex布局实战代码)
从零搭建Shopify主题:如何用Liquid实现动态商品展示(附Flex布局实战代码) 在独立站电商领域,Shopify凭借其完善的商业基础设施和灵活的模板系统,成为品牌展示个性化形象的首选平台。对于开发者而言,掌握Liq…...

Python项目实战:从零构建分层架构的学生成绩管理系统
1. 为什么需要分层架构? 当你第一次接触Python项目开发时,可能会把所有代码都写在一个文件里。我刚开始学Python时也是这样,一个脚本文件搞定所有功能。但随着项目规模扩大,这种写法很快就会变成一团乱麻。想象一下,如…...

XFTP连接服务器后文件夹一片空白?别慌,关掉这个选项就能搞定
XFTP连接服务器后文件夹一片空白?被动模式可能是罪魁祸首 刚接触服务器管理的开发者,十有八九会在使用XFTP时遇到这个令人抓狂的场景:明明输入了正确的IP地址、用户名和密码,连接状态也显示"已连接",但远程…...

智能眼镜如何帮助规避AI垃圾内容
到2020年代中期,世界正被“AI垃圾”淹没。无论是图像、视频、音乐、邮件、广告、演讲还是电视节目,许多人的互动对象都是由人工智能生成的、愚蠢的内容。有时这种体验很有趣且相对无害,但往往令人厌倦并消耗脑力。最糟糕的情况下,…...

navigation2-humble从零带读笔记第一篇:nav2_core
navigation2-humble从零带读笔记第一篇:nav2_core免责声明:本文内容为笔者从零学习 Nav2 的学习笔记,为结合官方注释、个人理解及 AI 辅助解析整理而成。若存在解读偏差,欢迎大家指正,我会及时修正完善。 nav2_core 的…...
)
【时频融合+一致性评估】基于复Morlet小波和Bland-Altman分析的信号一致性检验算法(Python)
在科学研究与工程应用中,经常需要比较2个测量方法或重复测量得到的时间序列数据,以评估它们之间的一致性。例如,在生物医学领域比较新型传感器与传统金标准的呼吸信号,在机械故障诊断中比较不同传感器的振动信号,或在环…...