代码随想录算法训练营Day51 | 101.孤岛的总面积、102.沉没孤岛、103.水流问题、104.建造最大岛屿
文章目录
- 101.孤岛的总面积
- 思路与重点
- 102.沉没孤岛
- 思路与重点
- 103.水流问题
- 思路与重点
- 104.建造最大岛屿
- 思路与重点
101.孤岛的总面积
- 题目链接:101.孤岛的总面积
- 讲解链接:代码随想录
- 状态:直接看题解了。
思路与重点
- nextx或者nexty越界了则说明当前的x或y处于边界处,所以当前的岛不是孤岛,不能记入总面积。
#include<iostream>
#include<vector>
using namespace std;
int dir[4][2] = {0, 1, 0, -1, 1, 0 ,-1, 0};
void dfs(int& tempans, bool& flag, const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y){for(int i = 0; i < 4; i++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()){flag = false;continue;}if(!visited[nextx][nexty] && grid[nextx][nexty] == 1){visited[nextx][nexty] = 1;tempans++;dfs(tempans, flag, grid, visited, nextx, nexty);}}
}int main(){int ans = 0;int n, m;cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cin >> grid[i][j];}}vector<vector<bool>> visited(n, vector<bool>(m, false));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(!visited[i][j] && grid[i][j] == 1){visited[i][j] = true;bool flag = true;int tempans = 1;dfs(tempans, flag, grid, visited, i, j);if(flag) ans += tempans;}}} cout << ans << endl;
}
- 也可以将地图边缘的陆地全部变成海洋,再遍历一遍陆地统计面积即可。
#include <iostream>
#include <vector>
using namespace std;
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1}; // 保存四个方向
int count; // 统计符合题目要求的陆地空格数量
void dfs(vector<vector<int>>& grid, int x, int y) {grid[x][y] = 0;count++;for (int i = 0; i < 4; i++) { // 向四个方向遍历int nextx = x + dir[i][0];int nexty = y + dir[i][1];// 超过边界if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue;// 不符合条件,不继续遍历if (grid[nextx][nexty] == 0) continue;dfs (grid, nextx, nexty);}return;
}int main() {int n, m;cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}// 从左侧边,和右侧边 向中间遍历for (int i = 0; i < n; i++) {if (grid[i][0] == 1) dfs(grid, i, 0);if (grid[i][m - 1] == 1) dfs(grid, i, m - 1);}// 从上边和下边 向中间遍历for (int j = 0; j < m; j++) {if (grid[0][j] == 1) dfs(grid, 0, j);if (grid[n - 1][j] == 1) dfs(grid, n - 1, j);}count = 0;for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 1) dfs(grid, i, j);}}cout << count << endl;
}
102.沉没孤岛
- 题目链接:102.沉没孤岛
- 讲解链接:代码随想录
- 状态:一遍AC。
思路与重点
- 先找到孤岛进行标记,然后再DFS把孤岛全部沉没。
#include<iostream>
#include<vector>
using namespace std;
int dir[4][2] = {0, 1, 0, -1, 1, 0 ,-1, 0};
void dfs(bool& flag, vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y){for(int i = 0; i < 4; i++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()){flag = false;continue;}if(!visited[nextx][nexty] && grid[nextx][nexty] == 1){visited[nextx][nexty] = 1;dfs(flag, grid, visited, nextx, nexty);}}
}void isoDfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y){for(int i = 0; i < 4; i++){int nextx = x + dir[i][0];int nexty = y + dir[i][1];if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()){continue;}if(!visited[nextx][nexty] && grid[nextx][nexty] == 1){visited[nextx][nexty] = 1;grid[nextx][nexty] = 0;isoDfs(grid, visited, nextx, nexty);}}
}int main(){int n, m;cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cin >> grid[i][j];}}vector<vector<bool>> visited(n, vector<bool>(m, false));vector<pair<int, int>> isoland;for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(!visited[i][j] && grid[i][j] == 1){visited[i][j] = true;bool flag = true;dfs(flag, grid, visited, i, j);if(flag) isoland.push_back(make_pair(i,j));}}}for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){visited[i][j] = false;}}for(auto tempPair : isoland){grid[tempPair.first][tempPair.second] = 0;isoDfs(grid, visited, tempPair.first, tempPair.second);}for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(j == 0) cout << grid[i][j];else cout << ' ' << grid[i][j];}cout << endl;}
}
- 不用额外定义空间了,标记周边的陆地,可以直接改陆地为其他特殊值作为标记。步骤一:深搜或者广搜将地图周边的 1 (陆地)全部改成 2 (特殊标记);步骤二:将水域中间 1 (陆地)全部改成 水域(0);步骤三:将之前标记的 2 改为 1 (陆地)
#include <iostream>
#include <vector>
using namespace std;
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1}; // 保存四个方向
void dfs(vector<vector<int>>& grid, int x, int y) {grid[x][y] = 2;for (int i = 0; i < 4; i++) { // 向四个方向遍历int nextx = x + dir[i][0];int nexty = y + dir[i][1];// 超过边界if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue;// 不符合条件,不继续遍历if (grid[nextx][nexty] == 0 || grid[nextx][nexty] == 2) continue;dfs (grid, nextx, nexty);}return;
}int main() {int n, m;cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}// 步骤一:// 从左侧边,和右侧边 向中间遍历for (int i = 0; i < n; i++) {if (grid[i][0] == 1) dfs(grid, i, 0);if (grid[i][m - 1] == 1) dfs(grid, i, m - 1);}// 从上边和下边 向中间遍历for (int j = 0; j < m; j++) {if (grid[0][j] == 1) dfs(grid, 0, j);if (grid[n - 1][j] == 1) dfs(grid, n - 1, j);}// 步骤二、步骤三for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 1) grid[i][j] = 0;if (grid[i][j] == 2) grid[i][j] = 1;}}for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cout << grid[i][j] << " ";}cout << endl;}
}
103.水流问题
- 题目链接:103.水流问题
- 讲解链接:代码随想录
- 状态:自己写了会儿再看题解。
思路与重点
- 我自己的代码过不了test5和test7,也没找出问题在哪儿,等二刷的时候再看看。
- 感觉是**到达左边界和上边界的方法会包含先往右走再往上走,**不能直接把dir分成两组来做。
- 还是会超时,直接看题解吧。
#include<iostream>
#include<vector>
using namespace std;
int dir[2][2][2] = {-1, 0, 0, -1, 1, 0, 0, 1};
bool dfs(const vector<vector<int>>& grid, vector<vector<bool>>& ans, int x, int y, int dirIdx){for(int i = 0; i < 2; i++){int nextx = x + dir[dirIdx][i][0];int nexty = y + dir[dirIdx][i][1];if(nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()){return true;}if(grid[nextx][nexty] <= grid[x][y]){if(ans[nextx][nexty]) return true;if(dfs(grid, ans, nextx, nexty, dirIdx)) return true;}}return false;
}int main(){int n, m;cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));vector<vector<bool>> ans(n, vector<bool>(m, false));for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){cin >> grid[i][j];}}ans[n-1][0] = true;ans[0][m-1] = true;for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(ans[i][j] == false){bool flag1 = dfs(grid, ans, i, j, 0);bool flag2 = dfs(grid, ans, i, j, 1);if(flag1 && flag2){ans[i][j] = true;}}} }for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){if(ans[i][j] == true){cout << i << ' ' << j << endl;}} }return 0;
}
- 我们可以反过来想,从第一组边界上的节点逆流而上,将遍历过的节点都标记上。同样从第二组边界的边上节点逆流而上,将遍历过的节点也标记上。然后两方都标记过的节点就是既可以流太平洋也可以流大西洋的节点。
#include <iostream>
#include <vector>
using namespace std;
int n, m;
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1};
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) {if (visited[x][y]) return;visited[x][y] = true;for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= n || nexty < 0 || nexty >= m) continue;if (grid[x][y] > grid[nextx][nexty]) continue; // 注意:这里是从低向高遍历dfs (grid, visited, nextx, nexty);}return;
}int main() {cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}// 标记从第一组边界上的节点出发,可以遍历的节点vector<vector<bool>> firstBorder(n, vector<bool>(m, false));// 标记从第一组边界上的节点出发,可以遍历的节点vector<vector<bool>> secondBorder(n, vector<bool>(m, false));// 从最上和最下行的节点出发,向高处遍历for (int i = 0; i < n; i++) {dfs (grid, firstBorder, i, 0); // 遍历最左列,接触第一组边界dfs (grid, secondBorder, i, m - 1); // 遍历最右列,接触第二组边界}// 从最左和最右列的节点出发,向高处遍历for (int j = 0; j < m; j++) {dfs (grid, firstBorder, 0, j); // 遍历最上行,接触第一组边界dfs (grid, secondBorder, n - 1, j); // 遍历最下行,接触第二组边界}for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {// 如果这个节点,从第一组边界和第二组边界出发都遍历过,就是结果if (firstBorder[i][j] && secondBorder[i][j]) cout << i << " " << j << endl;;}}}
104.建造最大岛屿
- 题目链接:104.建造最大岛屿
- 讲解链接:代码随想录
- 状态:暴力解法直接AC了。
思路与重点
- 依次将所有海洋变成陆地,然后从变化的陆地出发找当前岛屿最大面积,注意没有海洋的特殊情况。
#include <iostream>
#include <vector>
using namespace std;
int ans = 1;
int n, m;
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1};
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y, int& tempans) {if (visited[x][y]) return;visited[x][y] = true;tempans++;for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= n || nexty < 0 || nexty >= m) continue;if (grid[nextx][nexty] == 0) continue; // 注意:这里是从低向高遍历dfs (grid, visited, nextx, nexty, tempans);}return;
}int main() {cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));bool changeFlag = false;for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if(grid[i][j] == 0){changeFlag = true;vector<vector<bool>> visited(n, vector<bool>(m, false));int tempans = 0;grid[i][j] = 1;dfs(grid, visited, i, j, tempans);ans = ans > tempans ? ans : tempans;grid[i][j] = 0;}}} if(changeFlag) cout << ans << endl;else cout << n * m << endl;return 0;
}
- 其实每次深搜遍历计算最大岛屿面积,我们都做了很多重复的工作。只要用一次深搜把每个岛屿的面积记录下来就好。
- 第一步:一次遍历地图,得出各个岛屿的面积,并做编号记录。可以使用map记录,key为岛屿编号,value为岛屿面积
- 第二步:再遍历地图,遍历0的方格(因为要将0变成1),并统计该1(由0变成的1)周边岛屿面积,将其相邻面积相加在一起,遍历所有 0 之后,就可以得出 选一个0变成1 之后的最大面积。
#include <iostream>
#include <vector>
#include <unordered_set>
#include <unordered_map>
using namespace std;
int n, m;
int count;int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y, int mark) {if (visited[x][y] || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水visited[x][y] = true; // 标记访问过grid[x][y] = mark; // 给陆地标记新标签count++;for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= n || nexty < 0 || nexty >= m) continue; // 越界了,直接跳过dfs(grid, visited, nextx, nexty, mark);}
}int main() {cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}vector<vector<bool>> visited(n, vector<bool>(m, false)); // 标记访问过的点unordered_map<int ,int> gridNum;int mark = 2; // 记录每个岛屿的编号bool isAllGrid = true; // 标记是否整个地图都是陆地for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 0) isAllGrid = false;if (!visited[i][j] && grid[i][j] == 1) {count = 0;dfs(grid, visited, i, j, mark); // 将与其链接的陆地都标记上 truegridNum[mark] = count; // 记录每一个岛屿的面积mark++; // 记录下一个岛屿编号}}}if (isAllGrid) {cout << n * m << endl; // 如果都是陆地,返回全面积return 0; // 结束程序}// 以下逻辑是根据添加陆地的位置,计算周边岛屿面积之和int result = 0; // 记录最后结果unordered_set<int> visitedGrid; // 标记访问过的岛屿for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {count = 1; // 记录连接之后的岛屿数量visitedGrid.clear(); // 每次使用时,清空if (grid[i][j] == 0) {for (int k = 0; k < 4; k++) {int neari = i + dir[k][1]; // 计算相邻坐标int nearj = j + dir[k][0];if (neari < 0 || neari >= n || nearj < 0 || nearj >= m) continue;if (visitedGrid.count(grid[neari][nearj])) continue; // 添加过的岛屿不要重复添加// 把相邻四面的岛屿数量加起来count += gridNum[grid[neari][nearj]];visitedGrid.insert(grid[neari][nearj]); // 标记该岛屿已经添加过}}result = max(result, count);}}cout << result << endl;}
相关文章:

代码随想录算法训练营Day51 | 101.孤岛的总面积、102.沉没孤岛、103.水流问题、104.建造最大岛屿
文章目录 101.孤岛的总面积思路与重点 102.沉没孤岛思路与重点 103.水流问题思路与重点 104.建造最大岛屿思路与重点 101.孤岛的总面积 题目链接:101.孤岛的总面积讲解链接:代码随想录状态:直接看题解了。 思路与重点 nextx或者nexty越界了…...
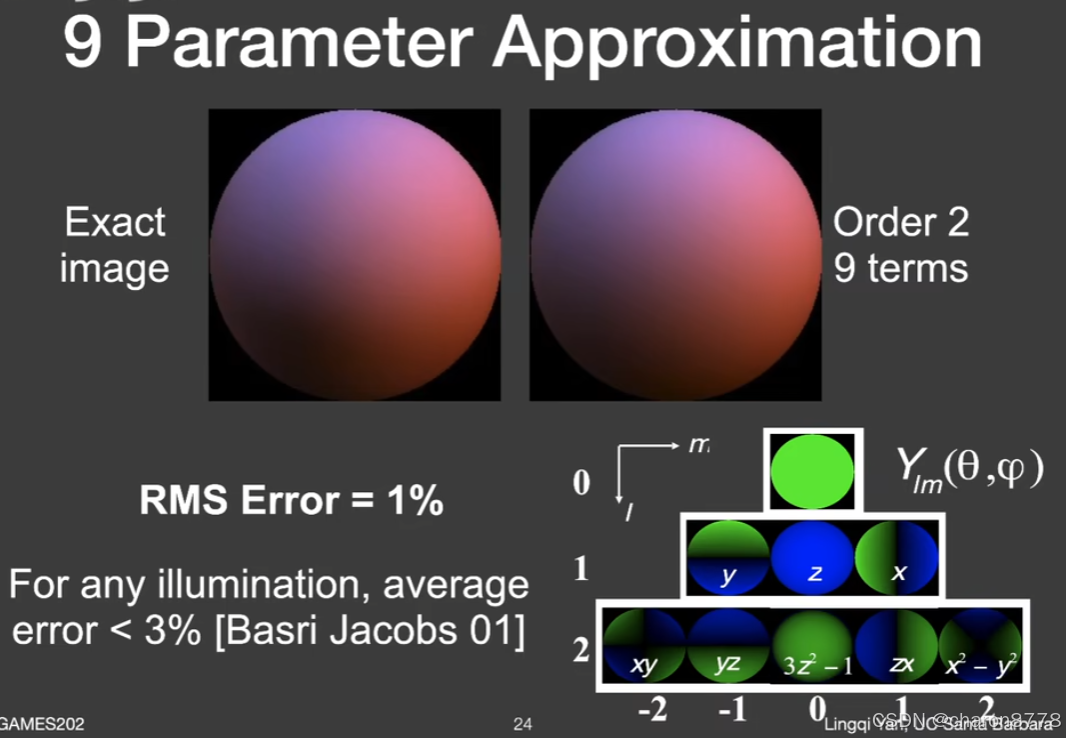
Games202Lecture 6 Real-time Environment Mapping
RTRT RTRT(real time ray tracing): path tracingdenoising PRT PRT (Precomputed radiance transfer):离线预计算,运行时快速内积。 预计算(Offline Precomputation): 传输函数(Transfer Function&…...

在 Zemax 中使用布尔对象创建光学光圈
在 Zemax 中,布尔对象用于通过组合或减去较简单的几何形状来创建复杂形状。布尔运算涉及使用集合运算(如并集、交集和减集)来组合或修改对象的几何形状。这允许用户在其设计中为光学元件或机械部件创建更复杂和定制的形状。 本视频中…...
)
MySQL知识点总结(十八)
说明你对InnoDB集群的整体认知。 MySQL组复制技术是InnoDB集群实现的基础,组复制安装在集群中的每个服务器实例上。组复制能够创建弹性复制拓扑,在集群中的服务器脱机时可以自动重新配置自己。必须至少有三台服务器才能组成一个可以提供高可用性的组。组…...

[论文总结] 深度学习在农业领域应用论文笔记14
当下,深度学习在农业领域的研究热度持续攀升,相关论文发表量呈现出迅猛增长的态势。但繁荣背后,质量却不尽人意。相当一部分论文内容空洞无物,缺乏能够落地转化的实际价值,“凑数” 的痕迹十分明显。在农业信息化领域的…...

MySQL和Redis的区别
MySQL和Redis都是流行的数据存储解决方案,但它们在设计、用途和特性上有显著区别。理解这些区别有助于选择合适的数据库来满足不同的应用需求。本文将详细介绍MySQL和Redis的区别,包括它们的架构、使用场景、性能和其他关键特性。 一、基本概述 MySQL&…...

Rust 中的注释使用指南
Rust 中的注释使用指南 注释是代码中不可或缺的一部分,它帮助开发者理解代码的逻辑和意图。Rust 提供了多种注释方式,包括行注释、块注释和文档注释。本文将详细介绍这些注释的使用方法,并通过一个示例展示如何在实际代码中应用注释。 1. 行…...
)
2025年2月2日(tcp3次握手4次挥手)
TCP(三次握手和四次挥手)是建立和关闭网络连接的标准过程,确保数据在传输过程中可靠无误。下面是详细解释: 1. 三次握手(TCP连接建立过程) 三次握手是为了在客户端和服务器之间建立一个可靠的连接&#x…...

一文了解制造业中的QC是什么
制造业中的QC QC :Quality Control,品质控制,产品的质量检验,发现质量问题后的分析、改善和不合格品控制相关人员的总称。中文意思是品质控制、质量检验。为达到品质要求所采取的作业技术和活动。有些推行ISO9000的组织会设置这样…...

【NEXT】网络编程——上传文件(不限于jpg/png/pdf/txt/doc等),或请求参数值是file类型时,调用在线服务接口
最近在使用华为AI平台ModelArts训练自己的图像识别模型,并部署了在线服务接口。供给客户端(如:鸿蒙APP/元服务)调用。 import核心能力: import { http } from kit.NetworkKit; import { fileIo } from kit.CoreFileK…...

在CentOS服务器上部署DeepSeek R1
在CentOS服务器上部署DeepSeek R1,并通过公网IP与其进行对话,可以按照以下步骤操作: 一、环境准备 系统要求: CentOS 8+(需支持AVX512指令集)。 硬件配置: GPU版本:NVIDIA驱动520+,CUDA 11.8+。 CPU版本:至少16核处理器,64GB内存。 存储空间:原始模型需要30GB,量…...

算法随笔_36: 复写零
上一篇:算法随笔_35: 每日温度-CSDN博客 题目描述如下: 给你一个长度固定的整数数组 arr ,请你将该数组中出现的每个零都复写一遍,并将其余的元素向右平移。 注意:请不要在超过该数组长度的位置写入元素。请对输入的数组 就地 进行上述修改…...
)
MoonBit 编译器(留档学习)
MoonBit 编译器 MoonBit 是一个用户友好,构建快,产出质量高的编程语言。 MoonBit | Documentation | Tour | Core This is the source code repository for MoonBit, a programming language that is user-friendly, builds fast, and produces high q…...

使用 DeepSeek-R1 与 AnythingLLM 搭建本地知识库
一、下载地址Download Ollama on macOS 官方网站:Ollama 官方模型库:library 二、模型库搜索 deepseek r1 deepseek-r1:1.5b 私有化部署deepseek,模型库搜索 deepseek r1 运行cmd复制命令:ollama run deepseek-r1:1.5b 私有化…...

网络工程师 (13)时间管理
一、定义与重要性 项目时间管理是指为确保项目按时完成而采取的一系列规划、安排和控制活动。它始于项目启动阶段,贯穿整个项目生命周期,直至项目结束。时间管理对于项目的成功至关重要,它有助于项目团队明确工作目标和时间节点,增…...

【xdoj-离散线上练习】T251(C++)
解题反思: 开始敲代码前想清楚整个思路比什么都重要嘤嘤嘤!看到输入m, n和矩阵,注意不能想当然地认为就是高m,宽n的矩阵,细看含义 比如本题给出了树的邻接矩阵,就是n*n的,代码实现中没有用到m这…...

定时器按键tim_key模版
低优先级放在高优先级内势必是程序卡死 把高优先级放到低优先级内,会使程序卡死 可修改 Debuger调试方法 Pwm rcc #include "my_main.h" uint8_t led_sta0x10; char text[30]; void LED_Disp(uint8_t dsLED) {HAL_GPIO_WritePin(GPIOC,GPIO_PIN_All,GPI…...

Kanass快速安装配置教程(入门级)
Kanass是一款国产开源免费的项目管理工具,工具简洁易用、开源免费,本文将介绍如何快速安装配置kanass,以快速上手。 1、快速安装 1.1 Linux 安装 点击官网 -> 演示与下载 ->下载,下载Linux安装包,…...

无用知识之:std::initializer_list的秘密
先说结论,用std::initializer_list初始化vector,内部逻辑是先生成了一个临时数组,进行了拷贝构造,然后用这个数组的起终指针初始化initializer_list。然后再用initializer_list对vector进行初始化,这个动作又触发了拷贝…...

论文阅读笔记 —— 英文论文常见缩写及含义
正文 缩写全称含义Reference发音w.r.twith reference to关于, 根据WRT - Wikiet al.拉丁语et alia的缩写等等Et Al. | Meaning & Use in APA, MLA & Chicago–etc拉丁语et cetera的缩写等等ETC - Cambridge DictionaryWhat’s ‘etc.’ an abbreviation of (and what …...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...
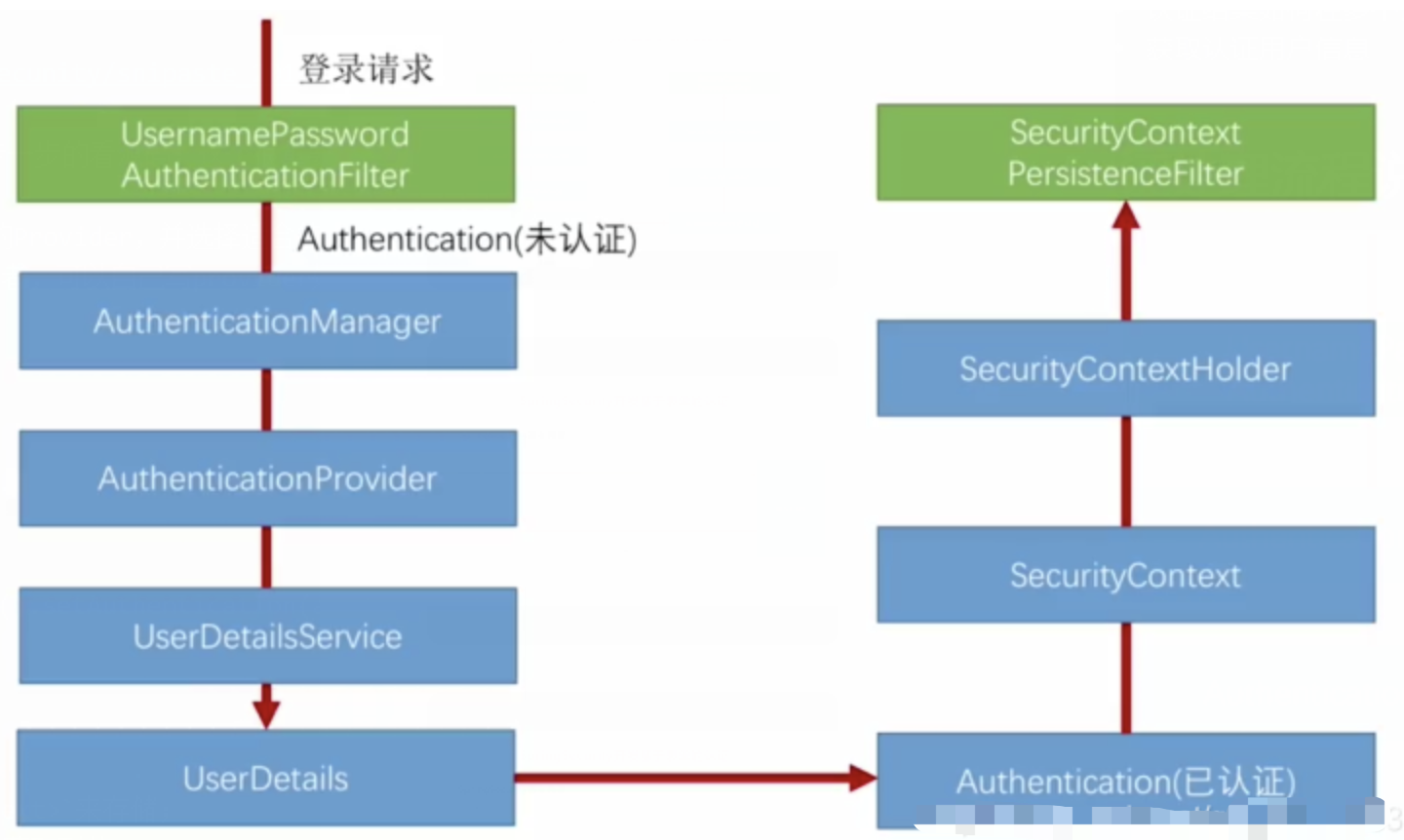
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...