Python从0到100(八十六):神经网络-ShuffleNet通道混合轻量级网络的深入介绍

前言:零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学习学习和学业的先行者!
欢迎大家订阅专栏:零基础学Python:Python从0到100最新最全教程!
本文目录:
- 一、ShuffleNet架构详解
- 1. 通道混合机制(Channel Shuffle)
- 2. 深度可分离卷积(Depthwise Separable Convolution)
- 3. 轻量化设计
- 4. 自适应平均池化(Adaptive Average Pooling)
- 二、ShuffleNet架构
- 1.网络结构概述
- 2.代码实现
- 2.1 ChannelShuffleModule 详解
- 初始化方法 `__init__`
- 前向传播方法 `forward`
- 2.2 ShuffleNet 网络结构详解
- 初始化方法 `__init__`
- 前向传播方法 `forward`
- 完整代码
- 三、网络结构特点
- 1. 深度可分离卷积:高效计算的核心
- 2. 通道数的变化:动态调整通道数以优化性能
- 3. 批量归一化和 ReLU:提升训练效率和稳定性
- 4. 通道混合:增强通道间的信息流动
- 5. 自适应平均池化:适应不同输入尺寸
- 四、ShuffleNet 的优势总结
ShuffleNet是一种轻量级的深度学习模型,它在保持MobileNet的Depthwise Separable Convolution(深度可分离卷积)的基础上,引入了通道混合(Channel Shuffle)机制,以进一步提升模型的性能和效率。
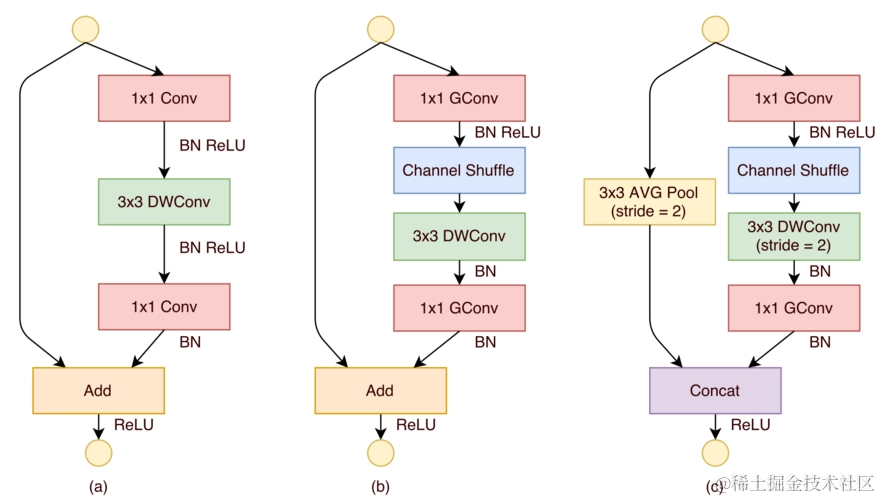
一、ShuffleNet架构详解
1. 通道混合机制(Channel Shuffle)
通道混合是 ShuffleNet 的核心创新之一。在传统的深度学习模型中,卷积层的输出通道通常在空间上是高度相关的,这种相关性限制了模型的表示能力。ShuffleNet 通过通道混合机制打破了这种限制。具体来说,通道混合通过在组间重新排列通道,增强了通道间的信息流动,从而提高了模型的性能。
在实际应用中,通道混合模块的工作原理如下:假设输入张量的通道数为 C,我们将这些通道分成 G 个组,每个组包含 C/G 个通道。然后,我们在每个组内对通道进行重新排列,使得不同组的通道能够相互“交流”。这种重新排列的操作类似于洗牌,因此得名“通道混合”。
2. 深度可分离卷积(Depthwise Separable Convolution)
ShuffleNet 继承了 MobileNet 的深度可分离卷积技术。深度可分离卷积将标准的卷积操作分解为两个步骤:深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。深度卷积为每个输入通道单独应用一个卷积核,而逐点卷积则通过 1×1 卷积核将深度卷积的输出通道进行组合。这种分解方式显著减少了模型的参数数量和计算量,使得 ShuffleNet 能够在计算资源受限的设备上高效运行。
3. 轻量化设计
ShuffleNet 的设计目标是实现轻量化,以便在移动和嵌入式设备上高效运行。为了达到这一目标,ShuffleNet 在多个方面进行了优化。首先,它通过深度可分离卷积减少了参数数量和计算量。其次,ShuffleNet 采用了通道混合机制,进一步提高了模型的效率。此外,ShuffleNet 还引入了自适应平均池化(Adaptive Average Pooling),允许模型接受任意尺寸的输入,并将其转换为固定尺寸的输出,为后续的全连接层提供了便利。
4. 自适应平均池化(Adaptive Average Pooling)
自适应平均池化是 ShuffleNet 的一个重要组成部分。它允许模型接受任意尺寸的输入,并将其转换为固定尺寸的输出。这种灵活性使得 ShuffleNet 能够适应不同的输入尺寸,而无需对模型结构进行调整。在实际应用中,自适应平均池化通常用于将特征图的尺寸调整为 1×1,以便为全连接层提供输入。
二、ShuffleNet架构
1.网络结构概述
ShuffleNet主要由以下几个部分组成:
- 输入层:接收输入数据。
- 深度可分离卷积层:减少参数数量和计算量。
- 批量归一化层:提高训练效率和稳定性。
- ReLU激活函数:引入非线性。
- 通道混合模块:增强通道间的信息流动。
- 自适应平均池化层:适应不同尺寸的输入。
- 全连接层:输出分类结果。
这种结构设计使得 ShuffleNet 在保持高效性的同时,也具备了较强的特征提取能力。
2.代码实现
2.1 ChannelShuffleModule 详解
ChannelShuffleModule 是 ShuffleNet 中用于增强通道间信息流动的关键组件。它通过将输入张量的通道分成多个组,并在组内进行洗牌,从而实现通道间的信息重组。
初始化方法 __init__
在初始化方法中,我们接收两个参数:channels 和 groups。channels 是输入张量的通道数,而 groups 是我们想要将这些通道分成的组数。我们通过一个断言来确保 channels 可以被 groups 整除,以保证每个组内的通道数是均匀的。
assert channels % groups == 0
接着,我们存储这些值,并计算每个组应有的通道数。
self.channel_per_group = self.channels // self.groups
前向传播方法 forward
在前向传播方法中,我们首先获取输入张量的尺寸,这包括批量大小 batch、通道数 _、序列长度 series 和模态数 modal。
batch, _, series, modal = x.size()
然后,我们将输入张量重新排列成 groups 个组,每组包含 self.channel_per_group 个通道。这一步通过 reshape 方法实现。
x = x.reshape(batch, self.groups, self.channel_per_group, series, modal)
接下来是洗牌操作,这是通过 permute 方法实现的。我们交换 permute 方法中指定维度的顺序,从而在组内打乱通道的顺序。
x = x.permute(0, 2, 1, 3, 4)
最后,我们再次使用 reshape 方法将张量恢复到原始的形状,并将其返回。
x = x.reshape(batch, self.channels, series, modal)
return x
2.2 ShuffleNet 网络结构详解
ShuffleNet 类定义了整个网络的结构,它由多个组件组成,包括卷积层、批量归一化层、ReLU 激活函数、通道混合模块、自适应平均池化层和全连接层。
初始化方法 __init__
在初始化方法中,我们接收三个参数:train_shape 表示训练样本的形状,category 表示类别的数量,kernel_size 表示卷积核的尺寸。
def __init__(self, train_shape, category, kernel_size=3):
我们使用 nn.Sequential 来组织网络中的多个层,包括卷积层、批量归一化层、ReLU 激活函数和通道混合模块。
self.layer = nn.Sequential(# 第一个卷积层,用于减少输入通道并进行空间维度的下采样nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1),# ...
)
这里,我们首先使用一个深度可分离卷积来减少输入通道,并进行空间维度的下采样。然后,我们添加一个1x1的卷积层来扩展通道数,接着是批量归一化层、ReLU 激活函数和通道混合模块。
我们还添加了一个自适应平均池化层,它可以根据输入特征图的实际尺寸动态调整池化尺寸,以确保输出尺寸的一致性。
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
最后,我们添加一个全连接层,它将展平的特征图映射到最终的分类结果。
self.fc = nn.Linear(512*train_shape[-1], category)
前向传播方法 forward
在前向传播方法中,我们首先将输入数据 x 通过 self.layer 中定义的卷积层和通道混合模块。
x = self.layer(x)
然后,我们将结果通过自适应平均池化层,以获得固定尺寸的特征图。
x = self.ada_pool(x)
接下来,我们将特征图展平,以适配全连接层。
x = x.view(x.size(0), -1)
最后,我们通过全连接层 self.fc 得到最终的分类结果,并将其返回。
x = self.fc(x)
return x
完整代码
import torch.nn as nn
class ChannelShuffleModule(nn.Module):def __init__(self, channels, groups):super().__init__()assert channels % groups == 0self.channels = channelsself.groups = groupsself.channel_per_group = self.channels // self.groupsdef forward(self, x):'''x.shape: [b, c, series, modal]'''batch, _, series, modal = x.size()x = x.reshape(batch, self.groups, self.channel_per_group, series, modal)x = x.permute(0, 2, 1, 3, 4)x = x.reshape(batch, self.channels, series, modal)return xclass ShuffleNet(nn.Module):def __init__(self, train_shape, category, kernel_size=3):super(ShuffleNet, self).__init__()self.layer = nn.Sequential(nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1),nn.Conv2d(1, 64, 1, 1, 0),nn.BatchNorm2d(64),nn.ReLU(),ChannelShuffleModule(channels=64, groups=8),nn.Conv2d(64, 64, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=64),nn.Conv2d(64, 128, 1, 1, 0),nn.BatchNorm2d(128),nn.ReLU(),ChannelShuffleModule(channels=128, groups=8),nn.Conv2d(128, 128, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=128),nn.Conv2d(128, 256, 1, 1, 0),nn.BatchNorm2d(256),nn.ReLU(),ChannelShuffleModule(channels=256, groups=16),nn.Conv2d(256, 256, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=256),nn.Conv2d(256, 512, 1, 1, 0),nn.BatchNorm2d(512),nn.ReLU(),ChannelShuffleModule(channels=512, groups=16))self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))self.fc = nn.Linear(512*train_shape[-1], category)def forward(self, x):x = self.layer(x)x = self.ada_pool(x)x = x.view(x.size(0), -1)x = self.fc(x)return x
在 ShuffleNet 的初始化方法中,我们定义了一个包含多个卷积层、批量归一化层、ReLU 激活函数和通道混合模块的序列。每个卷积层都使用了深度可分离卷积技术,以减少参数数量和计算量。自适应平均池化层用于将不同尺寸的特征图转换为固定尺寸的输出,最后通过全连接层输出分类结果。
三、网络结构特点
1. 深度可分离卷积:高效计算的核心
深度可分离卷积 是 ShuffleNet 的关键特性之一,它将传统的卷积操作分解为两个独立的步骤:深度卷积(Depthwise Convolution) 和 逐点卷积(Pointwise Convolution) 。这种分解方式极大地减少了模型的参数数量和计算量。
- 深度卷积:深度卷积为每个输入通道单独应用一个卷积核,而不涉及通道间的交互。这种方式显著减少了卷积操作的计算复杂度。
- 逐点卷积:逐点卷积使用 1×1 的卷积核对深度卷积的输出进行组合,增加了通道间的交互。这种组合方式不仅减少了参数数量,还保留了模型的表达能力。
在 ShuffleNet 中,深度可分离卷积被广泛应用于多个卷积层中。例如,在第一个卷积层中,深度可分离卷积将输入通道数减少到 1,然后通过 1×1 卷积将通道数扩展到 64。这种设计不仅减少了参数数量,还为后续的卷积层提供了足够的通道数。
2. 通道数的变化:动态调整通道数以优化性能
ShuffleNet 在网络的不同阶段动态调整通道数,以优化性能和计算效率。通过 1×1 卷积层,模型能够灵活地增加或减少通道数。例如,在第一个卷积层中,输入通道数被扩展到 64,为后续的深度可分离卷积提供了足够的输入通道。这种动态调整通道数的设计不仅提高了模型的灵活性,还减少了计算量。
此外,ShuffleNet 在后续的卷积层中逐步增加通道数,以适应更复杂的特征提取需求。例如,在第二个卷积层中,通道数从 64 增加到 128;在第三个卷积层中,通道数进一步增加到 256。这种逐步增加通道数的设计使得模型能够在不同阶段提取不同层次的特征,从而提高了模型的性能。
3. 批量归一化和 ReLU:提升训练效率和稳定性
在深度学习模型中,批量归一化(Batch Normalization) 和 ReLU 激活函数 是两个重要的组件,它们能够显著提高模型的训练效率和稳定性。
- 批量归一化:批量归一化通过归一化每个特征的输入,减少了内部协变量偏移(Internal Covariate Shift),从而加快了模型的收敛速度。在 ShuffleNet 中,每个卷积层后都添加了批量归一化层,以提高训练效率和模型的稳定性。
- ReLU 激活函数:ReLU 激活函数通过引入非线性,使得模型能够学习复杂的特征表示。在 ShuffleNet 中,ReLU 激活函数被广泛应用于每个卷积层后,以提高模型的非线性表达能力。
4. 通道混合:增强通道间的信息流动
通道混合(Channel Shuffle) 是 ShuffleNet 的核心创新之一。在传统的卷积神经网络中,卷积层的输出通道通常在空间上是高度相关的,这种相关性限制了模型的表示能力。ShuffleNet 通过通道混合机制打破了这种限制。
通道混合模块的工作原理如下:假设输入张量的通道数为 C,我们将这些通道分成 G 个组,每个组包含 C/G 个通道。然后,我们在每个组内对通道进行重新排列,使得不同组的通道能够相互“交流”。这种重新排列的操作类似于洗牌,因此得名“通道混合”。
通道混合机制不仅增强了通道间的信息流动,还提高了模型的特征提取能力。在 ShuffleNet 中,通道混合模块被广泛应用于每个深度可分离卷积块后,以增强通道间的信息交互。
5. 自适应平均池化:适应不同输入尺寸
自适应平均池化(Adaptive Average Pooling) 是 ShuffleNet 的一个重要组成部分。它允许模型接受任意尺寸的输入,并将其转换为固定尺寸的输出。这种灵活性使得 ShuffleNet 能够适应不同的输入尺寸,而无需对模型结构进行调整。
在实际应用中,自适应平均池化通常用于将特征图的尺寸调整为 1×1,以便为全连接层提供输入。在 ShuffleNet 中,自适应平均池化层被放置在卷积层之后,以确保模型能够处理不同尺寸的输入数据。
ShuffleNet 的设计哲学在于通过 轻量化的设计 实现高效的特征提取。它通过 深度可分离卷积 和 通道混合技术 减少了模型的参数数量和计算量,同时保持了较高的性能。这种设计使得 ShuffleNet 非常适合在计算资源受限的移动和嵌入式设备上部署,用于图像识别和处理任务。
具体来说,ShuffleNet 的轻量化设计主要体现在以下几个方面:
- 深度可分离卷积:通过将卷积操作分解为深度卷积和逐点卷积,显著减少了参数数量和计算量。
- 通道混合:通过在组内重新排列通道,增强了通道间的信息流动,提高了模型的特征提取能力。
- 自适应平均池化:通过将特征图的尺寸调整为固定尺寸,使得模型能够适应不同尺寸的输入数据。
- 动态调整通道数:通过 1×1 卷积层动态调整通道数,优化了模型的性能和计算效率。
这种轻量化设计不仅提高了 ShuffleNet 的计算效率,还使得它能够在移动和嵌入式设备上高效运行。ShuffleNet 的高效性和灵活性使其成为一种理想的轻量级深度学习模型,适用于各种资源受限的场景。
四、ShuffleNet 的优势总结
ShuffleNet 的设计哲学和轻量化设计使其具有以下优势:
- 高效性:通过 深度可分离卷积 和 通道混合技术,ShuffleNet 显著减少了参数数量和计算量,提高了模型的计算效率。
- 灵活性:通过 自适应平均池化 和动态调整通道数,ShuffleNet 能够适应不同尺寸的输入数据,具有很强的灵活性。
- 高性能:尽管参数数量和计算量减少,但 ShuffleNet 通过通道混合机制增强了通道间的信息流动,保持了较高的性能。
- 适用性:ShuffleNet 的轻量化设计使其能够在移动和嵌入式设备上高效运行,适用于各种资源受限的场景。
尽管 ShuffleNet 在轻量级深度学习模型中已经取得了显著的成果,但仍有进一步优化的空间。未来,随着技术的不断发展,ShuffleNet 可以在更多领域进行应用,如 自动驾驶、医疗影像分析 和 自然语言处理 等。
相关文章:
Python从0到100(八十六):神经网络-ShuffleNet通道混合轻量级网络的深入介绍
前言: 零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Pyth…...

【网络】传输层协议TCP(重点)
文章目录 1. TCP协议段格式2. 详解TCP2.1 4位首部长度2.2 32位序号与32位确认序号(确认应答机制)2.3 超时重传机制2.4 连接管理机制(3次握手、4次挥手 3个标志位)2.5 16位窗口大小(流量控制)2.6 滑动窗口2.7 3个标志位 16位紧急…...

海思ISP开发说明
1、概述 ISP(Image Signal Processor)图像信号处理器是专门用于处理图像信号的硬件或处理单元,广泛应用于图像传感器(如 CMOS 或 CCD 传感器)与显示设备之间的信号转换过程中。ISP通过一系列数字图像处理算法完成对数字…...

实验十 Servlet(一)
实验十 Servlet(一) 【实验目的】 1.了解Servlet运行原理 2.掌握Servlet实现方式 【实验内容】 1、参考课堂例子,客户端通过login.jsp发出登录请求,请求提交到loginServlet处理。如果用户名和密码相同则视为登录成功,…...

doris:聚合模型的导入更新
这篇文档主要介绍 Doris 聚合模型上基于导入的更新。 整行更新 使用 Doris 支持的 Stream Load,Broker Load,Routine Load,Insert Into 等导入方式,往聚合模型(Agg 模型)中进行数据导入时,都…...

Java NIO_非阻塞I/O的实现与优化
1. 引言 1.1 背景介绍 随着互联网应用的快速发展,传统的阻塞I/O模型已经无法满足高并发、高性能的需求。Java NIO(Non-blocking I/O)提供了高效的非阻塞I/O操作,使得开发者能够构建高性能的网络应用和文件处理系统。 1.2 Java NIO的重要性 Java NIO通过非阻塞I/O和多路…...

代码随想录算法训练营Day51 | 101.孤岛的总面积、102.沉没孤岛、103.水流问题、104.建造最大岛屿
文章目录 101.孤岛的总面积思路与重点 102.沉没孤岛思路与重点 103.水流问题思路与重点 104.建造最大岛屿思路与重点 101.孤岛的总面积 题目链接:101.孤岛的总面积讲解链接:代码随想录状态:直接看题解了。 思路与重点 nextx或者nexty越界了…...
Games202Lecture 6 Real-time Environment Mapping
RTRT RTRT(real time ray tracing): path tracingdenoising PRT PRT (Precomputed radiance transfer):离线预计算,运行时快速内积。 预计算(Offline Precomputation): 传输函数(Transfer Function&…...

在 Zemax 中使用布尔对象创建光学光圈
在 Zemax 中,布尔对象用于通过组合或减去较简单的几何形状来创建复杂形状。布尔运算涉及使用集合运算(如并集、交集和减集)来组合或修改对象的几何形状。这允许用户在其设计中为光学元件或机械部件创建更复杂和定制的形状。 本视频中…...
)
MySQL知识点总结(十八)
说明你对InnoDB集群的整体认知。 MySQL组复制技术是InnoDB集群实现的基础,组复制安装在集群中的每个服务器实例上。组复制能够创建弹性复制拓扑,在集群中的服务器脱机时可以自动重新配置自己。必须至少有三台服务器才能组成一个可以提供高可用性的组。组…...

[论文总结] 深度学习在农业领域应用论文笔记14
当下,深度学习在农业领域的研究热度持续攀升,相关论文发表量呈现出迅猛增长的态势。但繁荣背后,质量却不尽人意。相当一部分论文内容空洞无物,缺乏能够落地转化的实际价值,“凑数” 的痕迹十分明显。在农业信息化领域的…...

MySQL和Redis的区别
MySQL和Redis都是流行的数据存储解决方案,但它们在设计、用途和特性上有显著区别。理解这些区别有助于选择合适的数据库来满足不同的应用需求。本文将详细介绍MySQL和Redis的区别,包括它们的架构、使用场景、性能和其他关键特性。 一、基本概述 MySQL&…...

Rust 中的注释使用指南
Rust 中的注释使用指南 注释是代码中不可或缺的一部分,它帮助开发者理解代码的逻辑和意图。Rust 提供了多种注释方式,包括行注释、块注释和文档注释。本文将详细介绍这些注释的使用方法,并通过一个示例展示如何在实际代码中应用注释。 1. 行…...
)
2025年2月2日(tcp3次握手4次挥手)
TCP(三次握手和四次挥手)是建立和关闭网络连接的标准过程,确保数据在传输过程中可靠无误。下面是详细解释: 1. 三次握手(TCP连接建立过程) 三次握手是为了在客户端和服务器之间建立一个可靠的连接&#x…...

一文了解制造业中的QC是什么
制造业中的QC QC :Quality Control,品质控制,产品的质量检验,发现质量问题后的分析、改善和不合格品控制相关人员的总称。中文意思是品质控制、质量检验。为达到品质要求所采取的作业技术和活动。有些推行ISO9000的组织会设置这样…...

【NEXT】网络编程——上传文件(不限于jpg/png/pdf/txt/doc等),或请求参数值是file类型时,调用在线服务接口
最近在使用华为AI平台ModelArts训练自己的图像识别模型,并部署了在线服务接口。供给客户端(如:鸿蒙APP/元服务)调用。 import核心能力: import { http } from kit.NetworkKit; import { fileIo } from kit.CoreFileK…...

在CentOS服务器上部署DeepSeek R1
在CentOS服务器上部署DeepSeek R1,并通过公网IP与其进行对话,可以按照以下步骤操作: 一、环境准备 系统要求: CentOS 8+(需支持AVX512指令集)。 硬件配置: GPU版本:NVIDIA驱动520+,CUDA 11.8+。 CPU版本:至少16核处理器,64GB内存。 存储空间:原始模型需要30GB,量…...

算法随笔_36: 复写零
上一篇:算法随笔_35: 每日温度-CSDN博客 题目描述如下: 给你一个长度固定的整数数组 arr ,请你将该数组中出现的每个零都复写一遍,并将其余的元素向右平移。 注意:请不要在超过该数组长度的位置写入元素。请对输入的数组 就地 进行上述修改…...
)
MoonBit 编译器(留档学习)
MoonBit 编译器 MoonBit 是一个用户友好,构建快,产出质量高的编程语言。 MoonBit | Documentation | Tour | Core This is the source code repository for MoonBit, a programming language that is user-friendly, builds fast, and produces high q…...

使用 DeepSeek-R1 与 AnythingLLM 搭建本地知识库
一、下载地址Download Ollama on macOS 官方网站:Ollama 官方模型库:library 二、模型库搜索 deepseek r1 deepseek-r1:1.5b 私有化部署deepseek,模型库搜索 deepseek r1 运行cmd复制命令:ollama run deepseek-r1:1.5b 私有化…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...