二叉树--链式存储
1我们之前学了二叉树的顺序存储(这种顺序存储的二叉树被称为堆),我们今天来学习一下二叉树的链式存储:
我们使用链表来表示一颗二叉树:
⽤链表来表⽰⼀棵⼆叉树,即⽤链来指⽰元素的逻辑关系。通常的⽅法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别⽤来给出该结点左孩⼦和右孩⼦所在的链结点的存储地址。

比如这就是我们的二叉树的链式存储,跟链表是不是比较像,就是使用链表来进行存储我们的二叉树;
但是我想你也一定发现了我们使用链式存储的二叉树不一定是完全的二叉树;
我们之前在讲堆的时候,我们的二叉树使用的一定是完全二叉树;因为我们的堆的话,使用的是顺序存储,使用完全二叉树的话,可以节省我们的内存空间;
但是我们的二叉树在进行链式存储的时候,没有这个要求;我们可以是完全二叉树,也可以是其他的二叉树,没有什么要求;
我们的链式存储,我们该怎样定义我们的结点呢?
我们可以知道,我们的二叉树的度最大为2,最小为0,所以,我们就设置两个指针,一个左指针,还有一个右指针;分别指向我们的左孩子和右孩子;

这就是我们的二叉树的结点的定义;
二叉树的前中后序遍历:
对二叉树的操作离不开二叉树的遍历,我们来看一下二叉树的遍历;
前序遍历:先遍历根节点,在遍历左子树,最后便利右子树;
中序遍历:先遍历左子树,在遍历根节点,最后遍历右子树;
后序遍历:先遍历左子树,在遍历右子树,最后便利根节点;
//我们的前中后分别表示的是根节点的位置,前就表示根节点在第一个位置,中就表示根节点在中间位置,后就表示根节点在最后面的位置。



接下来我们来实现一下前序遍历的代码;

这就是我们的前序遍历;我们在函数里面进行递归调用;我们先把我们的根节点的数据进行打印,然后遍历我们的左子树,然后遍历右子树;当我们遇到的结点的数据是NULL的时候,我们打印并返回;
接下来我们来实现一下中序遍历:

这个就是我们的中序遍历,当然,你可以发现,他和前序遍历是比较像的,我们只是改变了位置,我们先进行了左子树的遍历,然后当我们的左子树一直下去知道是空的时候,我们返回,然后打印我们的这课子树的根节点,然后再进行这棵树的右孩子的遍历;这样不断地递归;

这就是我们的中序遍历的结果;
接下来我们来看后序遍历:
 12
12
这就是我们的后序遍历,我们还是可以发现,那就是我们的基本代码还是没有什么大的改变;我们还是只是改变了原来代码的顺序,我们先让左子树进行遍历,左子树无限的递归,直到左子树的尽头,然后在左子树的尽头我们先遍历右子树,然后打印我们的根节点。

这就是我们的结果;
然后我们来实现一下有关二叉树的代码的实现,但是我们在这里对二叉树的插入操作这一些并不进行讲解,因为我们进行链式存储的二叉树并不是完全二叉树,只要是二叉树的话都可以进行链式存储,这样的话,我们的二叉树的插入位置就是非常多了,这就没有了限制,这就不是很好,等到我们后面学习的红黑树,平衡树的话,这些对二叉树的插入操作是有限制的,我们就可以实现一下插入操作;
我们先来实现一下:计算二叉树的结点个数;
计算二叉树的结点的个数有两种方法:
第一种的话,我们对二叉树进行遍历,然后设置计数器,之前我们遇到根节点的话,我们就打印数据,这下我们不打印数据,我们让计数器+1,遇到空结点的话,我们不操作计数器,但是这时候就出现问题了,我们的size计数器不知道是使用局部变量还是全局变量,这两个都不行,局部变量的话,因为我们遍历树我们的函数要不断地进行递归,我们每次进入我们的函数的话,我们的计数器都会被清零。。那我们使用全局变量呢?也不行,全局变量看着好像可以,每次进入函数的话,我们的计数器没有被清零,但是有一个问题,那就是我们的全局变量,在我们递归调用遍历完我们的二叉树的时候,我们的全局变量没有变化,这就导致我们再一次调用我们的二叉树的时候,size就加倍了,这就累加了,那怎么办呢?我们还有方法就是我们不设置计数器了,我们直接使用递归来进行。
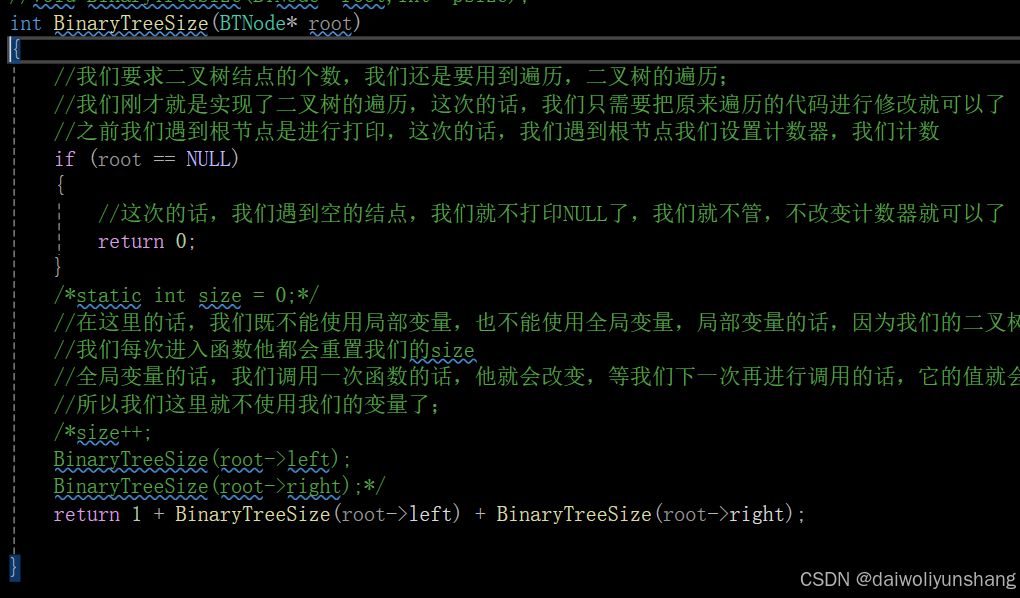
实际的代码只有几行,我们进行判断,如果是空的的话,我们就返回0,但是如果不是空的的话,我们就返回1+判断根节点的左右子树;
我们然后来继续看我们的下一个要实现的方法:
二叉树的叶子结点的个数:
我们要求二叉树里面叶子结点的个数,那我们就要判断一下我们遍历到的这个结点是不是叶子节点,那么我们要怎样判断他是不是叶子节点呢?我们就看他的两个孩子是不是NULL,如果他的两个孩子都是NULL的话,我们就说这个结点是一个叶子节点。
我们在进行遍历的时候,我们就看他是不是叶子结点,如果是叶子节点的话,我们就返回1,不是叶子节点的话,如果是根节点或者是空的结点,我们就不管,或者返回0,然后我们还是使用遍历

我们来看我们的代码,进入到我们的函数里面以后,我们先判断它是不是空的结点,如果是空的结点的话,这就不是叶子节点,我们返回0,然后的话,我们就再次进行遍历,和我们的第一个判断结点个数其实是比较次相似的,我们判断它的结点的个数的时候,我们先进行判断看他是不是NULL,不是的话,我们进行return的时候进行+1,因为一颗正常的二叉树,(在进行链式存储的时候不需要是完全二叉树),我们如果可以遍历到的话,他不是NULL,就是一个正常的结点, 所以我们要统计结点的个数的话,我们就+1,然后遍历这个结点的左子树和右子树,然后不断的递归调用我们的函数,最终就可以得到我们的二叉树的节点的个数,这里的话,我们就不+1了,我们进行额外的叶子节点的判定。
二叉树第K层结点的个数:
这里的话,我们就传两个参数,我们的第一个参数还是我们的二叉树的根节点,当然我们传的还是一级指针的,我们不需要修改我们的二叉树,我们传一级指针就可以了,然后我们的第二个参数,我们就传一个计数器,我们传一个k,我们不断地让k--,当我们的k等于1的时候,就来到了我们的第k层然后我们遍历到k等于1的结点的时候,我们就返回1。

我们来看我们的代码,我们进入到我们的函数,我们先判断是不是NULL,是的话我们就返回0,因为我们的链式存储的二叉树不要求是完全二叉树,所以还没到第k层的时候就先出现了NULL,所以我们还是要对NULL进行一下判断,是NULL的话,我们就返回0,不是的话,我们就继续,这时候我们可以继续进行就说明我们的这个结点他不是NULL,所以的话,我们就判断一下他是不是第k层就可以了,是的话,我们就返回1,然后我们的return还是和之前一样,我们直接进行他的左右子树的判断,进行不断的递归判断。
求二叉树的深度或者高度:
我们还是要根据递归的思想来进行判断,首先我们开始的时候进入的就是根节点,然后根节点不是NULL,然后我们就继续,我们就求他的左子树的大小,然后我们再求右子树的大小,然后我们1+一个三目操作符,判断左右子树哪个比较大,加的1就是我们的根节点,

我们来看我们的函数,我们进入我们的函数,进入到函数里面以后我们还是遇到NULL的话,我们返回0,然后的话,我们就根据我们的思路,我们先把左子树的高度求出来,然后把右子树的高度求出来,然后return 1+左右子树里面比较大的那个,我们在求他的左右子树的时候,我们还是使用我们的这个函数,假如我们要求这个左子树的高度的时候,我们就求这个左子树的左子树的高度和右子树的高度,然后return 1+比较大的子树,然后这就是我们的左子树,我们就这样不断地进行递归,直到我们的左右子树变成NULL的时候,我们就递归到尽头了。这时候就返回,我们就可以求出我们的二叉树的高度。
然后接下来我们要实现的是,
查找二叉树节点值为x的结点:

我们直接来看我们的代码:
当然,我们这次函数的传值传的还是两个参数,第一个参数为根节点,第二个参数是我们的x值,进入到函数里面,我们还是遇到NULL的结点的时候,我们就返回NULL,如果他不是NULL的话,我们就判断这个非空的结点的data是不是x,如果这个结点的数据恰好就是我们的x的话,我们就返回这个结点,但是如果这个结点的x不是我们要求的x的话,我们就看他的左孩子是不是我们要求的x,我们再次进入到我们的函数里面,我们先进行判空,如果不是NULL的话,我们就看他的data是不是我们要求的x,如果是的话,我们就返回,然后返回到我们的第一个函数里面,然后我们把返回值存起来,判断它是不是NULL,如果不是NULL的话,我们就把他返回,在这里可能你觉得有点草率,(你可能会说,我们只进行判空,那会不会返回的虽然不是NULL,但是有可能是其他的不是data为x的结点呢?),但是其实你继续看,当我们的结点的左孩子不是NULL,并且左孩子的数据的data不是我们的x的话,我们的函数就不会返回他,我们就会判断我们的这个左孩子的左孩子,看他是不是,我们一定是不会返回我们的无效的数据的,我们看我们的函数,我们进行返回的条件一定是他为NULL,或者不为NULL,但是他的data为x,这时候我们才会进行返回,至于下面的两个左右孩子我们其实就是函数进行递归,我们的返回的条件永远是不变的。。
接下来我们来看
二叉树的销毁:

直接来看我们的代码,我们可以很清楚的发现,我们的函数的参数是一个二级指针,为什么这里是二级指针呢?
因为这里的话,我们是要改变我们的结点了,我们的一级指针就可以代表我们的结点,我们要修改我们的结点,就相当于是修改一级指针,所以这里我们要传二级指针。
然后我们看我们的函数,我们进入到我们的函数里面,还是我们先判断我们的结点是不是NULL,如果是的话,我们就出节点,什么都不返回直接return就可以,但是如果我们得这个不是NULL的话,我们就要进行遍历销毁我们的结点了,这里就有一个问题,我们是采用什么遍历方式,在这里的话,我们采用后序遍历,我们把根节点放在最后面进行删除,因为如果我们先删除根节点的话,我们的这个结点的左右孩子就找不到了,所以在这里我们只能使用后序遍历来进行销毁。
接下来我们来看下一个函数--
层序遍历:
什么是层序遍历呢?
之前我们学的前序遍历,中序遍历,后序遍历都是从左往右的进行遍历。
我们得层序遍历指的就是我们按层序的进行遍历,先是第一层,然后第二层的进行遍历,,,

就比如我们的这个二叉树,他进行遍历的结果就是A,B,C,D,E,F.
那我们该怎样才能实现我们的这个方法;
我们在这里可以创建一个队列来进行,

我们可以先把我们的第一个二叉树的结点放入到队列里面,然后取第一个结点,第一个结点出队列,然后把第一个结点的左右非空孩子入队列,然后继续取队头结点,然后把队头结点的左右孩子(非空孩子入队列)。

我们来看我们的函数,进入到我们的函数里面以后我们创建一个队列,然后初始化一个空的队列,然后把我们的根节点压入队列,,,,最后结束以后我们把我们的队列销毁;
接下来我们来看
判断是否为完全二叉树:
在这里我们判断一个二叉树是不是完全的二叉树,

我们来看我们的这个二叉树,这就不是一个完全二叉树,显然这是一个非完全的二叉树,他的数据就是不连续的,我们在进行层序遍历的时候,我们遍历的结果是 A,BC,D,NULL,E,F. 我们遍历完后的结果就是我们中间会有一个NULL,这样的数据就是不连续的,我们在实现我们的堆二叉树的时候,我们采用的是完全的二叉树,堆二叉树就是没有什么数据空间的浪费,他的数据是连续的,堆二叉树的底层就是一个数组,我们的这个链式存储底层成了链表;
所以我们就可以看这个二叉树的数据是不是连续的就可以了,所以我们在这里就还是使用我们的层序遍历来进行,我们的层序遍历就是按层的来进行遍历。

我们来看我们的非完全的二叉树层序遍历的结果就是当我们的队列取到空的结点以后,我们的队列里面还有非空的结点,这就是我们的非完全的二叉树。
但是我们的完全二叉树,我们的队列在取到NULL的时候,我们的队列里面的数据的结点就都是空的结点了。
我们来看我们的代码:

相关文章:
二叉树--链式存储
1我们之前学了二叉树的顺序存储(这种顺序存储的二叉树被称为堆),我们今天来学习一下二叉树的链式存储: 我们使用链表来表示一颗二叉树: ⽤链表来表⽰⼀棵⼆叉树,即⽤链来指⽰元素的逻辑关系。通常的⽅法是…...

Windows 中的 WSL:开启你的 Linux 之旅
今天在安装windows上安装Docker Desktop的时候,遇到了WSL。下面咱们就学习下。 欢迎来到涛涛聊AI 一、什么是 WSL? WSL,全称为 Windows Subsystem for Linux,是微软为 Windows 系统开发的一个兼容层,它允许用户在 Win…...

2.3学习总结
今天做了下上次测试没做出来的题目,作业中做了一题,看了下二叉树(一脸懵B) P2240:部分背包问题 先求每堆金币的性价比(价值除以重量),将这些金币由性价比从高到低排序。 对于排好…...

前端力扣刷题 | 6:hot100之 矩阵
73. 矩阵置零 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 法一: var setZeroes function(matrix) {let setX new Set(); // 用于存储需要置零的行索引let setY new Set(); //…...
docker gitlab arm64 版本安装部署
前言: 使用RK3588 部署gitlab 平台作为个人或小型团队办公代码版本使用 1. docker 安装 sudo apt install docker* 2. 获取arm版本的gitlab GitHub - zengxs/gitlab-arm64: GitLab docker image (CE & EE) for arm64 git clone https://github.com/zengxs…...

路径规划之启发式算法之二十九:鸽群算法(Pigeon-inspired Optimization, PIO)
鸽群算法(Pigeon-inspired Optimization, PIO)是一种基于自然界中鸽子群体行为的智能优化算法,由Duan等人于2014年提出。该算法模拟了鸽子在飞行过程中利用地标、太阳和磁场等导航机制的行为,具有简单、高效和易于实现的特点,适用于解决连续优化问题。 更多的仿生群体算法…...

【AudioClassificationModelZoo-Pytorch】基于Pytorch的声音事件检测分类系统
源码:https://github.com/Shybert-AI/AudioClassificationModelZoo-Pytorch 模型测试表 模型网络结构batch_sizeFLOPs(G)Params(M)特征提取方式数据集类别数量模型验证集性能EcapaTdnn1280.486.1melUrbanSound8K10accuracy0.974, precision0.972 recall0.967, F1-s…...

一文讲解Java中的ArrayList和LinkedList
ArrayList和LinkedList有什么区别? ArrayList 是基于数组实现的,LinkedList 是基于链表实现的。 二者用途有什么不同? 多数情况下,ArrayList更利于查找,LinkedList更利于增删 由于 ArrayList 是基于数组实现的&#…...
:平均精度均值(mean Average Precision, mAP))
CNN的各种知识点(五):平均精度均值(mean Average Precision, mAP)
平均精度均值(mean Average Precision, mAP) 1. 平均精度均值(mean Average Precision, mAP)概念:计算步骤:具体例子:重要说明:典型值范围: 总结: 1. 平均精度…...

【优先算法】专题——前缀和
目录 一、【模版】前缀和 参考代码: 二、【模版】 二维前缀和 参考代码: 三、寻找数组的中心下标 参考代码: 四、除自身以外数组的乘积 参考代码: 五、和为K的子数组 参考代码: 六、和可被K整除的子数组 参…...

gitea - fatal: Authentication failed
文章目录 gitea - fatal: Authentication failed概述run_gitea_on_my_pkm.bat 笔记删除windows凭证管理器中对应的url认证凭证启动gitea服务端的命令行正常用 TortoiseGit 提交代码备注END gitea - fatal: Authentication failed 概述 本地的git归档服务端使用gitea. 原来的用…...

基于Spring Security 6的OAuth2 系列之八 - 授权服务器--Spring Authrization Server的基本原理
之所以想写这一系列,是因为之前工作过程中使用Spring Security OAuth2搭建了网关和授权服务器,但当时基于spring-boot 2.3.x,其默认的Spring Security是5.3.x。之后新项目升级到了spring-boot 3.3.0,结果一看Spring Security也升级…...

蓝桥与力扣刷题(234 回文链表)
题目:给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。 示例 1: 输入:head [1,2,2,1] 输出:true示例 2: 输入&…...

Google C++ Style / 谷歌C++开源风格
文章目录 前言1. 头文件1.1 自给自足的头文件1.2 #define 防护符1.3 导入你的依赖1.4 前向声明1.5 内联函数1.6 #include 的路径及顺序 2. 作用域2.1 命名空间2.2 内部链接2.3 非成员函数、静态成员函数和全局函数2.4 局部变量2.5 静态和全局变量2.6 thread_local 变量 3. 类3.…...
-QT-C/C++ - QT Tab Widget)
Windows图形界面(GUI)-QT-C/C++ - QT Tab Widget
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 一、概述 1.1 什么是 QTabWidget? 1.2 使用场景 二、常见样式 2.1 选项卡式界面 2.2 动态添加和删除选项卡 2.3 自定义选项卡标题和图标 三、属性设置 3.1 添加页面&…...

【大数据技术】教程05:本机DataGrip远程连接虚拟机MySQL/Hive
本机DataGrip远程连接虚拟机MySQL/Hive datagrip-2024.3.4VMware Workstation Pro 16CentOS-Stream-10-latest-x86_64-dvd1.iso写在前面 本文主要介绍如何使用本机的DataGrip连接虚拟机的MySQL数据库和Hive数据库,提高编程效率。 安装DataGrip 请按照以下步骤安装DataGrip软…...

C++:结构体和类
在之前的博客中已经讲过了C语言中的结构体概念了,重复的内容在这儿就不赘述了。C中的结构体在C语言的基础上还有些补充,在这里说明一下,顺便简单地讲一下类的概念。 一、成员函数 结构体类型声明的关键字是 struct ,在C中结构体…...

MATLAB的数据类型和各类数据类型转化示例
一、MATLAB的数据类型 在MATLAB中 ,数据类型是非常重要的概念,因为它们决定了如何存储和操作数据。MATLAB支持数值型、字符型、字符串型、逻辑型、结构体、单元数组、数组和矩阵等多种数据类型。MATLAB 是一种动态类型语言,这意味着变量的数…...

UE求职Demo开发日志#19 给物品找图标,实现装备增加属性,背包栏UI显示装备
1 将用到的图标找好,放一起 DataTable里对应好图标 测试一下能正确获取: 2 装备增强属性思路 给FMyItemInfo添加一个枚举变量记录类型(物品,道具,装备,饰品,武器)--> 扩展DataT…...

C++泛型编程指南09 类模板实现和使用友元
文章目录 第2章 类模板 Stack 的实现2.1 类模板 Stack 的实现 (Implementation of Class Template Stack)2.1.1 声明类模板 (Declaration of Class Templates)2.1.2 成员函数实现 (Implementation of Member Functions) 2.2 使用类模板 Stack脚注改进后的叙述总结脚注2.3 类模板…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...