[EAI-028] Diffusion-VLA,能够进行多模态推理和机器人动作预测的VLA模型
Paper Card
论文标题:Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression
论文作者:Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chaomin Shen, Feifei Feng
论文链接:https://arxiv.org/abs/2412.03293
项目主页:https://diffusion-vla.github.io/
论文出处:/
论文被引:/
Abstract
本文提出了 DiVLA,它将自回归模型与扩散模型结合,用于学习视觉运动策略(visuomotor policy)。目标是 next token prediction,使模型能够有效地根据当前观测结果进行推理。随后,连接一个扩散模型来生成动作。为了通过 self-reasoning 增强策略学习,引入了推理注入模块,将推理句子直接集成到策略学习过程中。使用多个真实机器人进行了大量的实验,以验证DiVLA的有效性。包括一个工厂分拣任务,其中DiVLA成功地对物体进行了分类,包括那些在训练期间未见过的物体。推理模块增强了解释性,能够理解模型的思维过程并识别策略失败的潜在原因。此外,在零样本抓取任务上测试了DiVLA,在102个未见物体上实现了63.7%的准确率。证明了对视觉变化(例如干扰物和新的背景)的鲁棒性,并且易于适应新的机器人本体。DiVLA可以遵从新的指令并保持对话能力。DiVLA的数据效率高,推理速度快;DiVLA-2B在单个A6000 GPU上运行速度达到82Hz,并且可以从<50个演示中学习一个复杂任务。 最后,将模型从20亿参数扩展到720亿参数,展示了随着模型规模的增加而改进的泛化能力。
Summary

受到 pi0 启发,跟进的挺快的。把 PaliGemma-3B 的骨干换成了 Qwen2-VL 系列的 2B/7B/72B,同时增加了一个细粒度的特征提取模块,来更好的注入到扩散部分。并且实现了多模态推理,能够做 VQA,原始的pi0是没有的。利用预训练VLM作为VLA的骨干,提供了对视觉概念的强大先验理解,可以显著增强复杂任务中的下游性能。用了SigLIP编码器,又用了Qwen2-VL骨干,看起来像是用了两次视觉编码器?另外就是,微调阶段用的数据太少,看起来像是单任务,扩散+VLM构建VLA的实现长周期任务和复杂灵巧类双臂操作任务的优势没有发挥出来,可能是先占坑,期待后续工作~
研究背景
基于离散token自回归预测建模的方式实现的VLA模型,例如 RT-2、OpenVLA 面临的问题是:将连续的机器人动作离散化为固定大小的 token 破坏了动作的连续性和精确性。其次,NTP 的方式推理频率很低,难以满足端侧高频动作推理需求,限制了模型的应用。
近两年,基于扩散的视觉运动策略模型取得了较大的进展。通过将动作序列生成建模为去噪过程,很多方法表现出不错的性能。这种方法能够更好地捕获机器人动作的多模态性质,并能够更快的生成动作序列。但问题是基于扩散的模型缺乏推理能力,因为没有LLM。
所以能不能结合二者的优势构建一个VLA,融合自回归模型的推理能力和扩散模型的高频动作生成能力?
方法介绍
本文提出了 DiffusionVLA(DiVLA),结合了多模态理解模型和扩散模型。其中,多模态理解模型VLM具备良好的基于文本的推理能力,扩散模型能够通过去噪过程学习机器人的动作分布。这使得 DiVLA可以做多模态推理也可以做动作生成。但是有一点需要注意,逻辑推理和可操作的机器人策略之间存在gap,因此引入了推理注入模块,该模块重用了VLM的推理输出并将其直接应用于扩散策略,从而使用显式的推理信号丰富策略学习过程。DiVLA具备的优势:
- 快速的推理速度:DiVLA-2B 在单个 A6000 GPU 上的推理速率达到 82Hz,DiVLA-7B 的推理速率为 42Hz。
- 增强的视觉泛化能力:DiVLA不受视觉干扰或新背景的影响,在视觉动态环境中表现出鲁棒性。
- 可泛化的推理能力:DiVLA能够准确识别和分类未见的物体,展示其跨新输入泛化推理的能力。
- 对新指令的适应性和对话能力:可以解释和执行复杂的新指令,同时保持对话流畅性,在交互场景中提供多样的响应范围。
- 对其他机器人本体的泛化能力:DiVLA可以轻松微调以部署在双臂机器人上,只需少量微调即可实现高性能,证明其在各种机器人本体上的适应性。
- 可扩展性:提供了可扩展的模型系列——DiVLA-2B、7B 和 72B——证明泛化能力和性能随着模型大小的增加而提高,符合 Scaling Law。
模型架构
最终目标是创建一个统一的框架,将擅长预测语言序列以进行推理的自回归模型与擅长生成机器人动作的扩散模型结合起来。 开发这样一个集成模型面临着巨大的挑战:(i)设计一个能够无缝且高效地集成自回归和扩散机制的架构;(ii)利用自生成的推理来增强动作生成,而不会增加推理计算开销。
视觉编码器:SigLIP,将视觉输入转换为固定数量的 token。每个视角的图像单独编码,之后对 token 做拼接,各个视图是共享的。有个疑问,过了两遍视觉编码器?VLM还有自带的 ViT,论文貌似也没说清楚。通过View- adaptive tokenization 方法,将腕部相机视角的图像输入的token数量减少到 16,降低计算量。
VLM骨干:Qwen2-VL-2B/7B/72B
动作解码器:将 LLM 输出的 token 作为condition输入到扩散模型中以进行动作解码,采用标准的 Diffusion Policy 设计,权重随机出实话。之后接多层 MLP 用于解码动作,预测机器人的关节空间,如果用于不同设置的机器人本体,会随机初始化 MLP 的部分,而不是直接复用训练好的。
推理注入模块:目的是将显式的推理注入到VLA模型,避免了迭代输入-输出循环的计算和操作复杂性。使用 RT-1 和 YAY 使用的 FiLM 将其注入到扩散模型部分。
损失函数:两部分,一部分为扩散损失,一部分是 token prediction 损失,其中后者用了超参数,以平衡不同损失的贡献。实验发现,后者比前者小10倍。
训练策略:参考 pi0,使用 lora 微调 VLM,预训练学习率为 2e-5。
数据构建
预训练数据:2B/7B模型使用 Droid 数据,72B模型使用 OXE和Droid数据。使用 GPT-4o 将Droid数据语言注释部分转换为包含推理的形式。
微调数据:四种实验设置 sorting,(500 episodes) bin picking(未采集,评估零样本泛化能力), multi-task learning(580 episodes), and table bussing(400 episodes)。前三种使用 Franka 单机械臂,后者使用双臂 AgileX 机器人。

消融实验
Real-World Multi-Task Learning
设计了 5 个任务:
- object selection
- flip the vertically placed pot
- placing a cube into a designated box
- placing a cup onto a plate
- placing a cube inside a box
对视觉变化的泛化能力:评估模型在多样化、动态环境中的鲁棒性和适应性。三个场景:1) 在周围添加额外的干扰物以增加视觉杂乱和复杂性;2) 改变背景以测试对场景上下文变化的适应能力;3) 实现多彩的灯光效果以引入不同的照明和色彩色调。图 4 显示了这些场景,以说明每次变化对视觉环境的影响,实验结果如表1所示。

评估表明,虽然所有方法的性能都因这些视觉变化而下降,但DiVLA在五个不同的任务中始终保持最高的平均成功率。说明了模型固有的鲁棒性和适应性,尽管在训练过程中没有任何特定的数据增强技术。
End-to-End Sorting on Real Robot
在工业环境中评估了DiVLA的能力:将物品分为四类:1)玩具汽车,2)针织手套,3)毛绒玩具和 4)内六角扳手。语言指令是“将所有物品分类到相应的区域”。总共收集了500条轨迹作为训练数据。只有当机器人成功抓取物体并将其放置到正确的区域时,才认为任务成功。实验装置如图1所示。
在两种难度设置下评估:简单和困难。简单模式——桌子上放置的物品少于5件;困难模式——6到11件物品被随机排列。 此外,已见物体和未见物体在这两种场景中混合在一起。 在杂乱的场景中,物品可能会重叠或随机分布在桌面上,增加了排序任务的复杂性。
实验结果如图2所示。DiVLA在所有实验设置下的平均成功率为66.2%。 当场景复杂度增加(即物体数量和杂乱程度增加)时,其他方法的性能会显著下降(例如,在高度杂乱的混合场景中,DP的成功率急剧下降到9.2%),而DiVLA保持了60%的成功率。这种持续的性能突显了DiVLA有效处理复杂和动态的现实世界场景的能力。
通过检查推理结果来诊断策略模型。因为模型使用自然语言推理生成输出,所以可以通过观察其推理短语来了解模型的“思考”过程。如图5所示,模型识别出一辆玩具车并决定将其拾起。如果放一个内六角扳手来进行干预,推理短语就会从“抓取玩具车”转变为“抓取内六角扳手”,从而使模型能够适应并准确地对物品进行排序。这种动态推理使模型的决策过程更加透明和可解释。推理注入模块也受益于推理自我校正,从而使机器人动作更加鲁棒。
Zero-Shot Bin Picking of Unseen Objects
评估DiVLA的实例泛化能力,重点关注 Bin Picking 任务——这是评估机器人模型性能的基准。使用102个独特的物体,都没有包含在训练数据中。图6显示了其中一些物体。任务指令“将右侧面板上的任何物体移到左侧篮筐中”。图1(右)展示了实验设置。此次评估的挑战在于物体之间存在显著差异,这不仅包括尺寸差异,还包括不同的颜色图案、纹理和可变形程度。图7是该实验的五个不同尺寸物体的示例。

实验结果如图3所示,DiVLA 达到了 63.7% 的成功率。相比之下,扩散策略、Octo、TinyVLA 和 OpenVLA 的成功率分别为 8.9%、19.6%、23.5% 和 28.4%。这些结果表明,DiVLA 可以理解各种物体形状和尺寸,而其他模型往往由于依赖于可能无法很好地泛化到新实例的特定于物体的特征而失败。这突出了其在动态、非结构化环境中的应用潜力,在这些环境中,机器人会遇到不熟悉的物体,并且必须在最少人工干预的情况下执行任务。

Adapt to Real-World Bimanual Robot
研究 DiVLA 对双臂机器人的适应性。 受π0的启发,设计了一个桌子整理任务,该任务涉及清理带有各种物体的桌子。 此任务已针对双臂机器人设置进行了调整:所有餐具都应放置在左侧的面板上,而垃圾则应丢入右侧的垃圾箱。 与工厂分拣任务类似,使用可见物体和可见物体与未见物体的组合来评估模型的性能。图8显示了环境设置以及用于训练和评估的所有物体。 评估包括十二次试验,每次试验在桌子上随机放置3到5个物体。成功率由正确放置的物体数量计算得出。


实验结果表明,当物体出现在训练数据中时,在可见物体上的平均成功率达到72.9%。相比之下,Diffusion Policy和OpenVLA的成功率分别为45.8%和0%。 对于涉及可见物体和不可见物体的任务,DiVLA的成功率高达70.8%,与可见物体相比略有下降,这表明其对不同颜色和形状的物体的泛化能力显著。最后,DiVLA展示了识别未见物体的能力,特别是通过对物体颜色做出敏感的反应。例如,它将雪碧罐分类为“绿色罐”,并将其正确地放入垃圾箱。 这一观察结果进一步支持了推理有助于泛化的观点。
Following Novel Instruction
评估模型遵循新指令的能力,特别关注其对未见指令的泛化能力。引入新的指令来提示模型:
对四个物体进行了测试:1)西瓜,2)柠檬水,3)蓝色纸垃圾,4)红辣椒。 这是一项极具挑战性的任务,因为这些新指令在Droid数据集和我们收集的数据中都不存在。评估了四个新的指令,结果总结在表2中。

研究结果表明,OpenVLA和DiVLA-2B都可以识别这些未见过的物体并执行基本的拾取和放置任务。 然而,当涉及到复杂的顺序任务时,OpenVLA无法准确解释指令;相反,它会随机选择项目。 相比之下,DiVLA 正确地遵循了指令,按指定的顺序拾取物体。通过学习将长期任务分解成子任务,DiVLA获得了理解复杂的多步骤指令的泛化能力。 虽然OpenVLA可以执行更简单的命令,例如“拿起西瓜”,但它难以处理需要按特定顺序选择项目的更高级指令。当模型处理新指令时抓取精度下降,这表明指令的新颖性给任务执行带来了进一步的复杂性。
实验结论
这项工作提出了视觉-语言-动作模型 DiVLA,它在模拟和现实场景中都具有强大的性能,包括单臂和双臂机器人。核心在于结合下一个 token 预测目标和扩散模型:前者用于任务推理,后者用于动作预测。 引入了一个推理重用模块来增强动作生成,并实现自适应视图的符元化以降低计算成本。 通过在模拟和多个真实世界实现中的广泛评估,DiVLA 优于几种 SOTA 机器人模型。 此外,DiVLA 具有强大的泛化能力,能够有效地适应新的指令、任务和环境。
相关文章:
[EAI-028] Diffusion-VLA,能够进行多模态推理和机器人动作预测的VLA模型
Paper Card 论文标题:Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression 论文作者:Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chao…...

实现数组的扁平化
文章目录 1 实现数组的扁平化1.1 递归1.2 reduce1.3 扩展运算符1.4 split和toString1.5 flat1.6 正则表达式和JSON 1 实现数组的扁平化 1.1 递归 通过循环递归的方式,遍历数组的每一项,如果该项还是一个数组,那么就继续递归遍历,…...
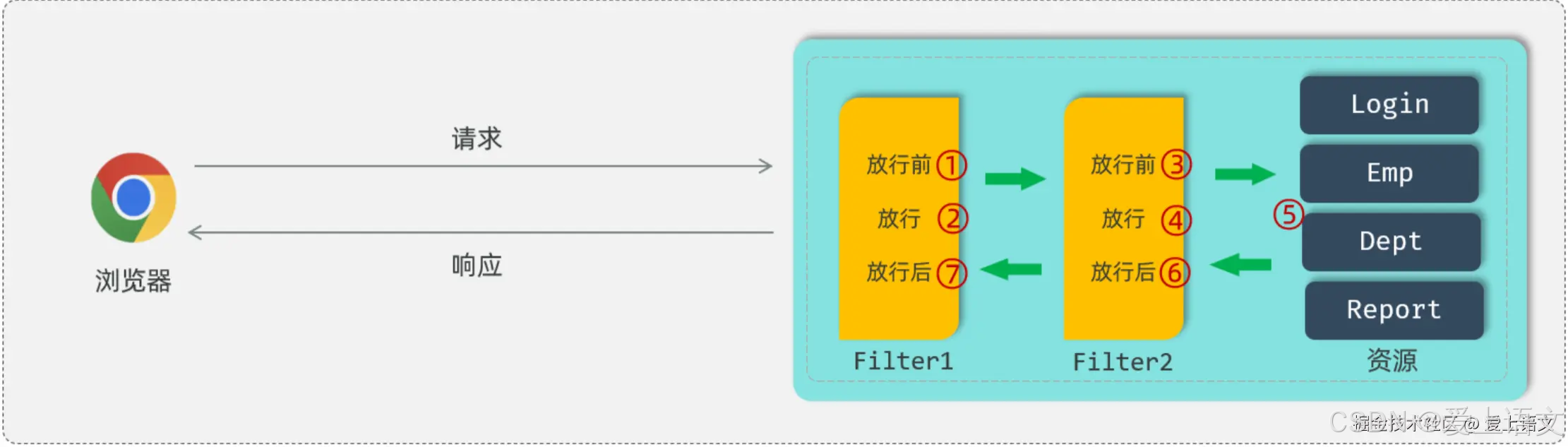
登录认证(5):过滤器:Filter
统一拦截 上文我们提到(登录认证(4):令牌技术),现在大部分项目都使用JWT令牌来进行会话跟踪,来完成登录功能。有了JWT令牌可以标识用户的登录状态,但是完整的登录逻辑如图所示&…...

pytorch实现门控循环单元 (GRU)
人工智能例子汇总:AI常见的算法和例子-CSDN博客 特性GRULSTM计算效率更快,参数更少相对较慢,参数更多结构复杂度只有两个门(更新门和重置门)三个门(输入门、遗忘门、输出门)处理长时依赖一般适…...

Word List 2
词汇颜色标识解释 词汇表中的生词 词汇表中的词组成的搭配、派生词 例句中的生词 我自己写的生词(用于区分易混淆的词,无颜色标识) 不认识的单词或句式 单词的主要汉语意思 不太理解的句子语法和结构 Word List 2 英文音标中文regi…...

机器学习常用包numpy篇(四)函数运算
目录 前言 一、三角函数 二、双曲函数 三、数值修约 四、 求和、求积与差分 五、 指数与对数 六、算术运算 七、 矩阵与向量运算 八、代数运算 九、 其他数学工具 总结 前言 Python 的原生运算符可实现基础数学运算(加减乘除、取余、取整、幂运算&#…...

CSS in JS
css in js css in js 的核心思想是:用一个 JS 对象来描述样式,而不是 css 样式表。 例如下面的对象就是一个用于描述样式的对象: const styles {backgroundColor: "#f40",color: "#fff",width: "400px",he…...

TCP 丢包恢复策略:代价权衡与优化迷局
网络物理层丢包是一种需要偿还的债务,可以容忍低劣的传输质量,这为 UDP 类服务提供了空间,而对于 TCP 类服务,可以用另外两类代价来支付: 主机端采用轻率的 GBN 策略恢复丢包,节省 CPU 资源,但…...

面经--C语言——内存泄漏、malloc和new的区别 .c文件怎么转换为可执行程序 uart和usart的区别 继承的访问权限总结
文章目录 内存泄漏预防内存泄漏的方法: malloc和new的区别.c文件怎么转换为可执行程序uart和usart的区别继承的访问权限总结访问控制符总结1. **public**:2. **protected**:3. **private**:继承类型: 内存泄漏 内存泄漏是指程序在运行时动态分配内存后&…...

Denavit-Hartenberg DH MDH坐标系
Denavit-Hartenberg坐标系及其规则详解 6轴协作机器人的MDH模型详细图_6轴mdh-CSDN博客 N轴机械臂的MDH正向建模,及python算法_mdh建模-CSDN博客 运动学3-----正向运动学 | 鱼香ROS 机器人学:MDH建模 - 哆啦美 - 博客园 机械臂学习——标准DH法和改进MDH…...

力扣动态规划-20【算法学习day.114】
前言 ###我做这类文章一个重要的目的还是记录自己的学习过程,我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非常非常高滴!!! 习题 1.网格中的最小路径代价 题目链接…...

计算机视觉-边缘检测
一、边缘 1.1 边缘的类型 ①实体上的边缘 ②深度上的边缘 ③符号的边缘 ④阴影产生的边缘 不同任务关注的边缘不一样 1.2 提取边缘 突变-求导(求导也是一种卷积) 近似,1(右边的一个值-自己可以用卷积做) 该点f(x,y)…...

文字加持:让 OpenCV 轻松在图像中插上文字
前言 在很多图像处理任务中,我们不仅需要提取图像信息,还希望在图像上加上一些文字,或是标注,或是动态展示。正如在一幅画上添加一个标语,或者在一个视频上加上动态字幕,cv2.putText 就是这个“文字魔术师”,它能让我们的图像从“沉默寡言”变得生动有趣。 今天,我们…...

掌握 HTML5 多媒体标签:如何在所有浏览器中顺利嵌入视频与音频
系列文章目录 01-从零开始学 HTML:构建网页的基本框架与技巧 02-HTML常见文本标签解析:从基础到进阶的全面指南 03-HTML从入门到精通:链接与图像标签全解析 04-HTML 列表标签全解析:无序与有序列表的深度应用 05-HTML表格标签全面…...

在Mac mini M4上部署DeepSeek R1本地大模型
在Mac mini M4上部署DeepSeek R1本地大模型 安装ollama 本地部署,我们可以通过Ollama来进行安装 Ollama 官方版:【点击前往】 Web UI 控制端【点击安装】 如何在MacOS上更换Ollama的模型位置 默认安装时,OLLAMA_MODELS 位置在"~/.o…...

【电脑系统】电脑突然(蓝屏)卡死发出刺耳声音
文章目录 前言问题描述软件解决方案尝试硬件解决方案尝试参考文献 前言 在 更换硬盘 时遇到的问题,有时候只有卡死没有蓝屏 问题描述 更换硬盘后,电脑用一会就卡死,蓝屏,显示蓝屏代码 UNEXPECTED_STORE_EXCEPTION 软件解决方案…...

Docker使用指南(二)——容器相关操作详解(实战案例教学,创建/使用/停止/删除)
目录 1.容器操作相关命令编辑 案例一: 案例二: 容器常用命令总结: 1.查看容器状态: 2.删除容器: 3.进入容器: 二、Docker基本操作——容器篇 1.容器操作相关命令 下面我们用两个案例来具体实操一…...

Java中的常见对象类型解析
在Java开发中,数据的组织和传递是一个重要的概念。为了确保代码的清晰性、可维护性和可扩展性,我们通常会根据不同的用途,设计和使用不同类型的对象。这些对象的作用各不相同,但它们共同为构建高效、模块化的软件架构提供支持。 …...

Dijkstra算法解析
Dijkstra算法,用于求解图中从一个起点到其他所有节点的最短路径。解决单源最短路径问题的有效方法。 条件 有向 带权路径 时间复杂度 O(n平方) 方法步骤 1 把图上的点分为两个集合 要求的起点 和除了起点之外的点 。能直达的写上权值 不…...

C++ Primer 多维数组
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...