【TensorFlow】T1:实现mnist手写数字识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
1、设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0]tf.config.experimental.set_memory_growth(gpu0, True)tf.config.set_visible_devices([gpu0],"GPU")print(gpus)
# 输出:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
固定模板,直接调用即可
2、导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt# 导入mnist数据集
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# train_images -- 训练集图片
# train_labels -- 训练集标签
# test_images -- 测试集图片
# test_labels -- 测试机标签
此处所需数据直接联网下载,故无需数据集
3、归一化
将图像数据从0-255缩放到0-1,主要是为了加快训练速度和提高模型的性能,使得模型训练过程更加稳定高效:
- 加速收敛:帮助优化算法更快找到最优解。
- 提升性能:确保不同规模的数据对模型的影响均衡,提高预测准确性。
- 简化调参:使超参数的选择更加简单有效。
- 数值稳定:避免因数据尺度问题导致的计算异常,如梯度爆炸。
train_images, test_images = train_images / 255.0, test_images / 255.0
print(train_images.shape, train_labels.shape,test_images.shape, test_labels.shape)
# 输出:(60000, 28, 28) (60000,) (10000, 28, 28) (10000,)
4、可视化
# figure函数--设置画布大小
# figsize--指定了画布的宽度(20英寸)和高度(10英寸)
plt.figure(figsize=(20, 10))# 遍历前20张图片
for i in range(20):# subplot函数--创建子图# 2--2行,10--10列,i+1--第i+1个位置plt.subplot(2, 10, i+1)# xticks函数--隐藏x轴plt.xticks([])# yticks函数--隐藏y轴plt.yticks([])# grid函数--关闭网格线plt.grid(False)# imshow函数--绘制图像# train_images[i]--需要显示的图片,cmap--设置颜色映射(binary)plt.imshow(train_images[i], cmap=plt.cm.binary)# xlabel函数--给图像添加标签plt.xlabel(train_labels[i])plt.show()
输出:

5、调整格式
# reshape函数--只改变数据形状,不改变数据内容
# 6000--6000个样本,28--28*28像素,1--颜色通道数(灰度)
train_images = train_images.reshape((60000, 28, 28, 1))
# 1000--1000个样本,28--28*28像素,1--颜色通道数(灰度)
test_images = test_images.reshape((10000, 28, 28, 1))print(train_images.shape, train_labels.shape,test_images.shape, test_labels.shape)
# 输出:(60000, 28, 28, 1) (60000,) (10000, 28, 28, 1) (10000,)
6、构建CNN网络模型
关键组件:
- 卷积层(Conv2D):主要用于提取图像的特征。它通过滑动窗口(即滤波器或核)在输入图像上移动,计算每个位置上的点积来生成特征图。每个滤波器可以识别特定类型的特征,如边缘或纹理。
- 激活函数(Activation function):如ReLU(Rectified Linear Unit),用于引入非线性因素,使模型能够学习更复杂的模式。
- 最大池化层(MaxPooling2D):用于减小特征图的空间维度(宽度和高度),同时保留最重要的信息。这有助于减少计算量并控制过拟合。
- 展平层(Flatten):将多维的卷积层输出转换为一维向量,以便将其输入到全连接层中。
- 全连接层(Dense):在这里,每个神经元与前一层的所有神经元相连,用于最终的分类任务。最后一层通常不使用激活函数(或者使用softmax函数),以直接输出每个类别的得分。
# Sequential函数--创建了一个Sequential模型,允许按顺序堆叠各层
model = models.Sequential([# Conv2D--第一个二维卷积层# 32--32个滤波器,(3, 3)--每个滤波器的大小为(3, 3),activation0--激活函数(relu),input_shape--输入数据的大小(28*28像素、单通道)layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),# MaxPooling2D--第一个二维最大池化层# 2--池化窗口的大小为2*2,用于下采样时减少特征维度layers.MaxPooling2D(2, 2),# Conv2D--第二个二维卷积层layers.Conv2D(64, (3, 3), activation='relu'),# MaxPooling2D--第二个二维最大池化层layers.MaxPooling2D(2, 2),# Flatten--将多维的卷积层输出展平为一维向量,方便输入全连接层layers.Flatten(),# Dense--全连接层# 64--64个节点,activation0--激活函数(relu)layers.Dense(64, activation='relu'),# Dense--输出层# 10--10个节点(此处对应0-9),默认线性激活函数layers.Dense(10)
])# 打印模型结构和参数信息,包括每一层的输出形状和参数数量
print(model.summary())
输出:

7、编译模型
# compile函数--配置模型的编译设置
model.compile(# optimizer--优化器(adam)# Adam:一种基于一阶梯度的优化算法,能自适应地调整不同参数的学习率,适用于大规模数据和高维空间问题optimizer='adam',# loss--损失函数(Sparse Categorical Crossentropy)# Sparse Categorical Crossentropy(稀疏分类交叉熵损失):适用于多分类问题,特别是标签是整数形式时# from_logits=True:表示网络输出未经过softmax激活函数处理。这种情况下,损失函数会自动应用softmax来计算最终的分类概率loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),# metrics--性能指标# accuracy(准确率):表示预测正确的样本数占总样本数的比例metrics=['accuracy']
)
8、训练模型
- 主要参数:
- x:训练数据的输入(特征)。它可以是一个 Numpy 数组或者一个 TensorFlow 数据集等。对于图像数据,这通常是一个形状为 (样本数量, 高度, 宽度, 颜色通道) 的四维数组。
- y:目标数据(标签)。与 x 对应,表示每个输入样本的真实类别或值。对于分类任务,这通常是一个一维数组,长度等于训练样本的数量;对于多分类问题,可能是一个二维数组,采用 one-hot 编码。
- batch_size:每次梯度更新时使用的样本数。默认值是 32。较大的批量大小可以使计算更高效,但需要更多的内存。
- epochs:整个训练集迭代的次数。每次迭代称为一个 epoch。增加 epoch 数量可以让模型有更多机会学习数据中的模式,但也增加了过拟合的风险。
- verbose:日志显示模式。0 表示不输出日志到屏幕上,1 表示输出进度条记录,2 表示每个epoch输出一行记录。
- validation_data:在每个 epoch 结束后用于评估模型性能的数据集。这是一个元组 (x_val, y_val) 或者一个包含输入和目标数据的列表。这对于监控模型在未见过的数据上的表现非常重要。
- validation_split:从训练数据中划分出一定比例的数据作为验证集,取值范围是 (0, 1)。注意,这个参数只会在 x 是 Numpy 数组时有效。
- shuffle:在每个 epoch 开始前是否打乱训练数据。这对于确保模型不会因为数据顺序而产生偏差非常重要,默认值为 True。
- callbacks:一个列表,其中包含各种回调函数对象,在训练过程中这些回调函数会在特定时间点被调用(如每轮结束、训练开始或结束等),可用于实现提前停止、动态调整学习率等功能。
- 返回值:
- History对象:该对象包含了一个 history 属性,这是一个字典,包含了训练过程中损失值和评估指标的变化情况。可以访问 history.history[‘loss’] 来获取每个 epoch 的训练损失值,或 history.history[‘val_accuracy’] 获取每个 epoch 的验证准确率。
“”"
history = model.fit(train_images,train_labels,epochs=10,validation_data=(test_images, test_labels),
)
9、模型预测
plt.imshow(test_images[1])
plt.show()pre = model.predict(test_images)
print(pre[1])
# 输出:[-0.0146451 0.11037247 -0.01110678 0.03087252 -0.02923543 -0.10968889 -0.00841374 0.04551534 -0.02969249 -0.00869128]
输出:
10、完整代码
# 1.设置GPU
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0]tf.config.experimental.set_memory_growth(gpu0, True)tf.config.set_visible_devices([gpu0], "GPU")print(gpus)# 2.导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()# 3.归一化
train_images, test_images = train_images / 255.0, test_images / 255.0print(train_images.shape,test_images.shape,train_labels.shape,test_labels.shape)# 4.可视化
plt.figure(figsize=(20,10))
for i in range(20):plt.subplot(2,10,i+1)plt.xticks([])plt.yticks([])plt.grid(False)plt.imshow(train_images[i], cmap=plt.cm.binary)plt.xlabel(train_labels[i])plt.show()# 5.调整图片格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))print(train_images.shape,test_images.shape,train_labels.shape,test_labels.shape)# 6.构建CNN网络模型
model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(10)
])
print(model.summary())# 7.编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 8.训练模型
history = model.fit(train_images,train_labels,epochs=10,validation_data=(test_images, test_labels))# 9.模型预测
plt.imshow(test_images[1])
plt.show()pre = model.predict(test_images)
print(pre[1])
相关文章:

【TensorFlow】T1:实现mnist手写数字识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 1、设置GPU import tensorflow as tf gpus tf.config.list_physical_devices("GPU")if gpus:gpu0 gpus[0]tf.config.experimental.set_memory_g…...

Rapidjson 实战
Rapidjson 是一款 C 的 json 库. 支持处理 json 格式的文档. 其设计风格是头文件库, 包含头文件即可使用, 小巧轻便并且性能强悍. 本文结合样例来介绍 Rapidjson 一些常见的用法. 环境要求 有如何的几种方法可以将 Rapidjson 集成到您的项目中. Vcpkg安装: 使用 vcpkg instal…...

【React】受控组件和非受控组件
目录 受控组件非受控组件基于ref获取DOM元素1、在标签中使用2、在组件中使用 受控组件 表单元素的状态(值)由 React 组件的 state 完全控制。组件的 state 保存了表单元素的值,并且每次用户输入时,React 通过事件处理程序来更新 …...

Ollama+deepseek+Docker+Open WebUI实现与AI聊天
1、下载并安装Ollama 官方网址:Ollama 安装好后,在命令行输入, ollama --version 返回以下信息,则表明安装成功, 2、 下载AI大模型 这里以deepseek-r1:1.5b模型为例, 在命令行中,执行&…...

DEEPSEKK GPT等AI体的出现如何重构工厂数字化架构:从设备控制到ERP MES系统的全面优化
随着深度学习(DeepSeek)、GPT等先进AI技术的出现,工厂的数字化架构正在经历前所未有的变革。AI的强大处理能力、预测能力和自动化决策支持,将大幅度提升生产效率、设备管理、资源调度以及产品质量管理。本文将探讨AI体(…...

阿莱(arri)mxf文件变0字节的恢复方法
阿莱(arri)是专业级的影视产品软硬件供应商,很多影视作品都是使用阿莱(arri)的设备拍摄出来的。总体上来讲阿莱(arri)的文件格式有mov和mxf两种,这次恢复的是阿莱(arri)的mxf,机型是arri mini,素材保存在一个8t的硬盘上,使用的是e…...

初识 Node.js
在当今快速发展的互联网技术领域,Node.js 已经成为了一个非常流行且强大的平台。无论是构建高性能的网络应用、实时协作工具还是微服务架构,Node.js 都展示了其独特的优势。本文将带您走进 Node.js 的世界,了解它的基本概念、核心特性以及如何…...

debug-vscode调试方法
debug - vscode gdb调试指南 文章目录 debug - vscode gdb调试指南前言一、调试代码二、命令查看main反汇编查看寄存器打印某个变量打印寄存器,如pc打印当前函数栈信息(当前执行位置)打印程序栈局部变量x命令的语法如下所示:打印某…...

Cypher进阶(函数、索引)
文章目录 Cypher进阶Aggregationcount()函数统计函数collect()函数 unwindforeachmergeunionload csvcall 函数断言函数all()any()~~exists()~~is not nullnone()single() 标量函数coalesce()startNode()/endNode()id()length()size() 列表函数nodes()keys()range()reduce() 数…...

XML Schema 数值数据类型
XML Schema 数值数据类型 引言 XML Schema 是一种用于描述 XML 文档结构的语言。它定义了 XML 文档中数据的有效性和结构。在 XML Schema 中,数值数据类型是非常重要的一部分,它定义了 XML 文档中可以包含的数值类型。本文将详细介绍 XML Schema 中常用的数值数据类型,以及…...

Window获取界面空闲时间
GetLastInputInfo是一种Windows API函数,用于获取上次输入操作的时间。 该函数通过LASTINPUTINFO结构返回最后一次输入事件的时间。 原型如下 BOOL WINAPI GetLastInputInfo(PLASTINPUTINFO plii);那么可以利用GetLastInputInfo来得到界面没有操作的时长 uint…...

Java进阶(vue基础)
目录 1.vue简单入门 ?1.1.创建一个vue程序 1.2.使用Component模板(组件) 1.3.引入AXOIS ?1.4.vue的Methods(方法) 和?compoted(计算) 1.5.插槽slot 1.6.创建自定义事件? 2.Vue脚手架安装? 3.Element-UI的…...

Mac电脑上好用的压缩软件
在Mac电脑上,有许多优秀的压缩软件可供选择,这些软件不仅支持多种压缩格式,还提供了便捷的操作体验和强大的功能。以下是几款被广泛推荐的压缩软件: BetterZip 功能特点:BetterZip 是一款功能强大的压缩和解压缩工具&a…...

Ubuntn24.04安装
1.镜像下载 https://cn.ubuntu.com/download Ubuntu 24.04.1 (Noble Numbat) 进入下载即可 2.安装系统 打开虚拟机 选择语言 输入用户名和密码 安装ssh 安装完成重启即可。 3.可能出现的问题 关于Ubuntu系统虚拟机出现频繁闪屏,移动和屏幕适应大小问题_vmware安…...

基于ansible部署elk集群
ansible部署 ELK部署 ELK常见架构 (1)ElasticsearchLogstashKibana:这种架构是最常见的一种,也是最简单的一种架构,这种架构通过Logstash收集日志,运用Elasticsearch分析日志,最后通过Kibana中…...

解锁.NET Fiddle:在线编程的神奇之旅
在.NET 开发的广袤领域中,快速验证想法、测试代码片段以及便捷地分享代码是开发者们日常工作中不可或缺的环节。而.NET Fiddle 作为一款卓越的在线神器,正逐渐成为众多.NET 开发者的得力助手。它打破了传统开发模式中对本地开发环境的依赖,让…...

记录pve中使用libvirt创建虚拟机
pve中创建虚拟机 首先在pve网页中创建一个linux虚拟机,我用的是debian系统,过程省略 注意虚拟机cpu类型要设置为host 检查是否支持虚拟化 ssh分别进入pve和debian虚拟机 检查cpu是否支持虚拟化 egrep --color vmx|svm /proc/cpuinfo # 结果高亮显示…...

【HTML性能优化】提升网站加载速度:GZIP、懒加载与资源合并
系列文章目录 01-从零开始学 HTML:构建网页的基本框架与技巧 02-HTML常见文本标签解析:从基础到进阶的全面指南 03-HTML从入门到精通:链接与图像标签全解析 04-HTML 列表标签全解析:无序与有序列表的深度应用 05-HTML表格标签全面…...

三维空间全局光照 | 及各种扫盲
Lecture 6 SH for diffuse transport Lecture 7关于 SH for glossy transport 三维空间全局光照 diffuse case和glossy case的区别 在Lambertian模型中,BRDF是一个常数 diffuse case 跟outgoing point无关 glossy case 跟outgoing point有关 (Gloss…...
——SQL性能判断标准及索引误区(1))
数据库开发常识(10.6)——SQL性能判断标准及索引误区(1)
10.6. 数据库开发常识 作为一名专业数据库开发人员,不但需要掌握数据库开发相关的语法和功能实现,还要掌握专业数据库开发的常识。这样,才能在保量完成工作任务的同时,也保质的完成工作任务,避免了为应用的日后维护埋…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...
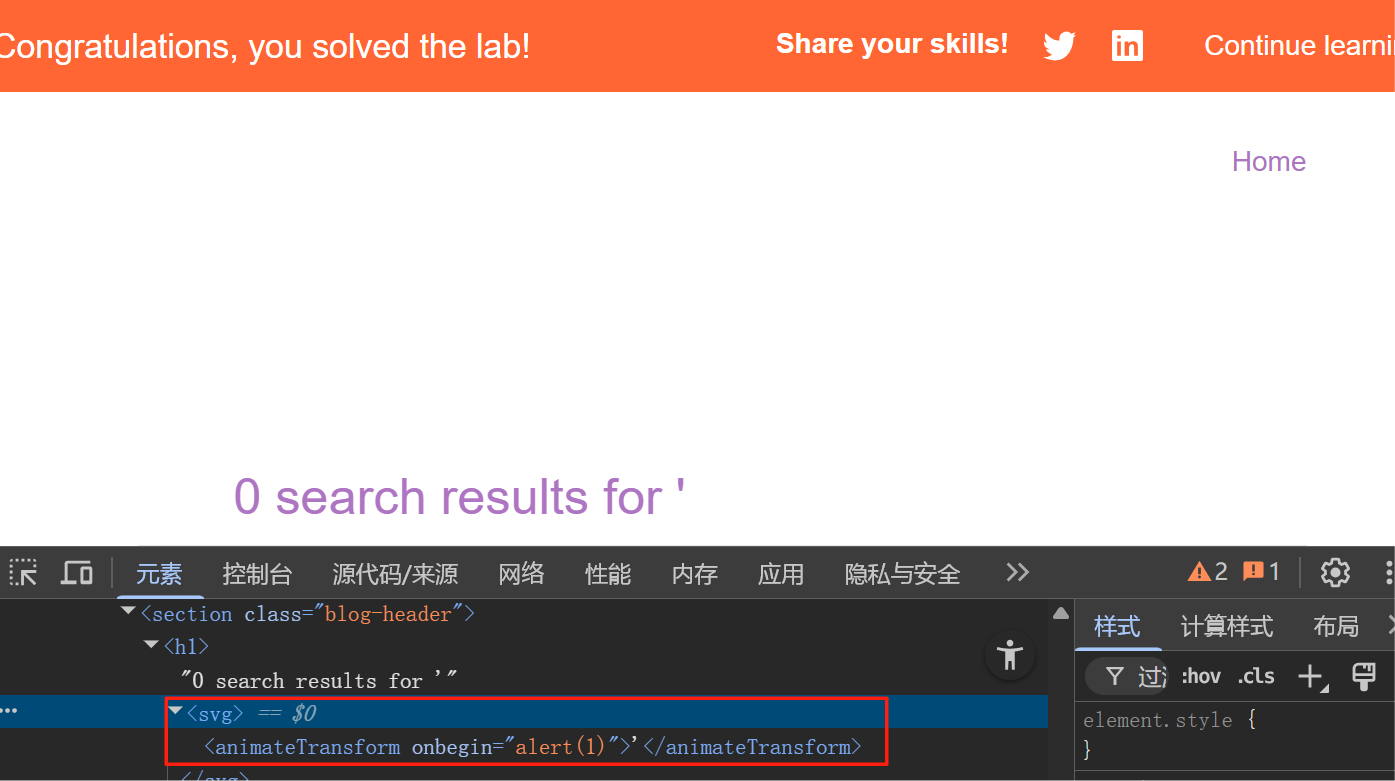
渗透实战PortSwigger Labs指南:自定义标签XSS和SVG XSS利用
阻止除自定义标签之外的所有标签 先输入一些标签测试,说是全部标签都被禁了 除了自定义的 自定义<my-tag onmouseoveralert(xss)> <my-tag idx onfocusalert(document.cookie) tabindex1> onfocus 当元素获得焦点时(如通过点击或键盘导航&…...
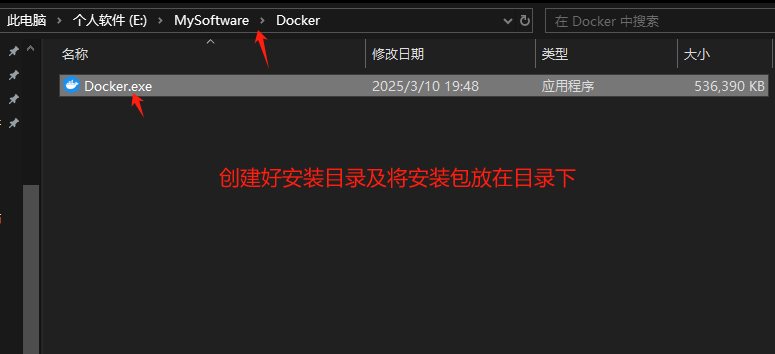
大模型——基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程 下载安装Docker Docker官网:https://www.docker.com/ 自定义Docker安装路径 Docker默认安装在C盘,大小大概2.9G,做这行最忌讳的就是安装软件全装C盘,所以我调整了下安装路径。 新建安装目录:E:\MyS…...

Win系统权限提升篇UAC绕过DLL劫持未引号路径可控服务全检项目
应用场景: 1、常规某个机器被钓鱼后门攻击后,我们需要做更高权限操作或权限维持等。 2、内网域中某个机器被钓鱼后门攻击后,我们需要对后续内网域做安全测试。 #Win10&11-BypassUAC自动提权-MSF&UACME 为了远程执行目标的exe或者b…...
ZYNQ学习记录FPGA(二)Verilog语言
一、Verilog简介 1.1 HDL(Hardware Description language) 在解释HDL之前,先来了解一下数字系统设计的流程:逻辑设计 -> 电路实现 -> 系统验证。 逻辑设计又称前端,在这个过程中就需要用到HDL,正文…...