mybatis plus 持久化使用技巧及场景
mybatis plus提供了很多强大的持久化工具,新手容易对这些工具使用困难,下面我总结了一下mybatis plus持久化的使用技巧及使用场景。
一、持久化
官方文档:https://baomidou.com/guides/data-interface/
(一)通过service持久化
最简单的是使用service进行持久化。如果没什么业务逻辑,优先使用service接口进行持久化。
public interface ISysUserService extends IService<SysUser> {}
通过继承 IService 接口,可以快速实现对数据库的基本操作,同时保持代码的简洁性和可维护性。
@Service
public class SysUserServiceImpl extends ServiceImpl<SysUserMapper, SysUser> implements ISysUserService {}
IService 接口中的方法命名遵循了一定的规范,如 get 用于查询单行,remove 用于删除,list 用于查询集合,page 用于分页查询,这样可以避免与 Mapper 层的方法混淆。
以下是service接口的方法:
// 插入一条记录(选择字段,策略插入)
boolean save(T entity);
// 插入(批量)
boolean saveBatch(Collection<T> entityList);
// 插入(批量)
boolean saveBatch(Collection<T> entityList, int batchSize);
// TableId 注解属性值存在则更新记录,否插入一条记录
boolean saveOrUpdate(T entity);
// 根据updateWrapper尝试更新,否继续执行saveOrUpdate(T)方法
boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);
// 根据 queryWrapper 设置的条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset
boolean update(Wrapper<T> updateWrapper);
// 根据 whereWrapper 条件,更新记录
boolean update(T updateEntity, Wrapper<T> whereWrapper);
// 根据 ID 选择修改
boolean updateById(T entity);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList, int batchSize);
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1")
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
// 查询所有
List<T> list();
// 查询列表
List<T> list(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
Collection<T> listByIds(Collection<? extends Serializable> idList);
// 查询(根据 columnMap 条件)
Collection<T> listByMap(Map<String, Object> columnMap);
// 查询所有列表
List<Map<String, Object>> listMaps();
// 查询列表
List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper);
// 查询全部记录
List<Object> listObjs();
// 查询全部记录
<V> List<V> listObjs(Function<? super Object, V> mapper);
// 根据 Wrapper 条件,查询全部记录
List<Object> listObjs(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录
<V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
// 无条件分页查询
IPage<T> page(IPage<T> page);
// 条件分页查询
IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper);
// 无条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page);
// 条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);
1.批量插入
有很多数据需要插入时,做一次SQL语句批量插入,当然要比执行多次SQL语句性能要好。
// 假设有一组 User 实体对象
List<User> users = Arrays.asList(new User("Alice", "alice@example.com"),new User("Bob", "bob@example.com"),new User("Charlie", "charlie@example.com")
);
// 使用默认批次大小进行批量插入
boolean result = userService.saveBatch(users); // 调用 saveBatch 方法,默认批次大小
if (result) {System.out.println("Users saved successfully.");
} else {System.out.println("Failed to save users.");
}
生成的 SQL(假设默认批次大小为 3):
INSERT INTO user (name, email) VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com'),
('Charlie', 'charlie@example.com')
但是如果你尝试一次性插入大量数据,那么所有待插入的数据都需要先加载到内存中。这可能会导致内存耗尽,特别是当数据集非常大时。这时候需要使用分批次进行处理。
// 假设有一组 User 实体对象
List<User> users = Arrays.asList(new User("David", "david@example.com"),new User("Eve", "eve@example.com"),new User("Frank", "frank@example.com"),new User("Grace", "grace@example.com")
);
// 指定批次大小为 2进行批量插入
boolean result = userService.saveBatch(users, 2); // 调用 saveBatch 方法,指定批次大小
if (result) {System.out.println("Users saved successfully.");
} else {System.out.println("Failed to save users.");
}
生成的 SQL(指定批次大小为 2):
-- 第一批次
INSERT INTO user (name, email) VALUES
('David', 'david@example.com'),
('Eve', 'eve@example.com')-- 第二批次
INSERT INTO user (name, email) VALUES
('Frank', 'frank@example.com'),
('Grace', 'grace@example.com')
一般批次在50到500之间调试,具体根据服务器性能而定。
2.条件更新与批量更新
通过指定条件更新符合条件的记录。
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset
boolean update(Wrapper<T> updateWrapper);
// 根据 whereWrapper 条件,更新记录
boolean update(T updateEntity, Wrapper<T> whereWrapper);
// 根据 ID 选择修改
boolean updateById(T entity);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList, int batchSize);
一般updateById方法是根据ID更新的,使用得比较多,而条件更新中的入参UpdateWrapper用得比较少,是如下的使用方式:
// 假设有一个 UpdateWrapper 对象,设置更新条件为 name = 'John Doe',更新字段为 email
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("name", "John Doe").set("email", "john.doe@newdomain.com");
boolean result = userService.update(updateWrapper); // 调用 update 方法
if (result) {System.out.println("Record updated successfully.");
} else {System.out.println("Failed to update record.");
}
生成的 SQL:
UPDATE user SET email = 'john.doe@newdomain.com' WHERE name = 'John Doe'
同样的,批量更新时,若数据集合过大,也可以指定批次来更新。
// 假设有一组 User 实体对象,批量更新,并指定批次大小为 1
List<User> users = Arrays.asList(new User(1, null, "new.email1@example.com"),new User(2, null, "new.email2@example.com")
);
boolean result = userService.updateBatchById(users, 1); // 调用 updateBatchById 方法,指定批次大小
if (result) {System.out.println("Records updated successfully.");
} else {System.out.println("Failed to update records.");
}
生成的 SQL(假设指定批次大小为 1):
-- 第一批次
UPDATE user SET email = 'new.email1@example.com' WHERE id = 1d
-- 第二批次
UPDATE user SET email = 'new.email2@example.com' WHERE id = 2
3.查询部分字段
通过list方法就可以查询到内容,但这个是查询所有字段,如果需要查询部分字段,可以使用listObjs方法。
// 查询所有用户,并将结果转换为 String 列表
List<String> userNames = userService.listObjs(obj -> ((User) obj).getName()); // 调用 listObjs 方法
for (String userName : userNames) {System.out.println("User Name: " + userName);
}
生成的 SQL:
SELECT * FROM user
加上条件
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25,并将结果转换为 String 列表
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 25);
List<String> userNames = userService.listObjs(queryWrapper, obj -> ((User) obj).getName()); // 调用 listObjs 方法
for (String userName : userNames) {System.out.println("User Name: " + userName);
}
生成的 SQL:
SELECT * FROM user WHERE age > 25
(二)通过Mapper持久化
当有业务逻辑时,单纯使用service就不方便了。这时候应该使用Mapper进行持久化。
public interface SysUserMapper extends BaseMapper<SysUser>{}
BaseMapper 是 Mybatis-Plus 提供的一个通用 Mapper 接口,它封装了一系列常用的数据库操作方法,包括增、删、改、查等。通过继承 BaseMapper,开发者可以快速地对数据库进行操作,而无需编写繁琐的 SQL 语句。
以下为BaseMapper接口的方法:
// 插入一条记录
int insert(T entity);
// 根据 entity 条件,删除记录
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);
// 删除(根据ID 批量删除)
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 ID 删除
int deleteById(Serializable id);
// 根据 columnMap 条件,删除记录
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 whereWrapper 条件,更新记录
int update(@Param(Constants.ENTITY) T updateEntity, @Param(Constants.WRAPPER) Wrapper<T> whereWrapper);
// 根据 ID 修改
int updateById(@Param(Constants.ENTITY) T entity);
// 根据 ID 查询
T selectById(Serializable id);
// 根据 entity 条件,查询一条记录
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 查询(根据ID 批量查询)
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
这也是最经常使用的持久化方法。
(三)Chain链式调用
Chain 是 Mybatis-Plus 提供的一种链式编程风格,它允许开发者以更加简洁和直观的方式编写数据库操作代码。Chain 分为 query 和 update 两大类,分别用于查询和更新操作。每类又分为普通链式和 lambda 链式两种风格
1.链式查询
// 链式查询 普通
QueryChainWrapper<T> query();
// 链式查询 lambda 式。注意:不支持 Kotlin
LambdaQueryChainWrapper<T> lambdaQuery();
提供链式查询操作,可以连续调用方法来构建查询条件。
// 普通链式查询示例
query().eq("name", "John").list(); // 查询 name 为 "John" 的所有记录// lambda 链式查询示例
lambdaQuery().eq(User::getAge, 30).one(); // 查询年龄为 30 的单条记录
2.链式更新
提供链式更新操作,可以连续调用方法来构建更新条件。
// 链式更改 普通
UpdateChainWrapper<T> update();
// 链式更改 lambda 式。注意:不支持 Kotlin
LambdaUpdateChainWrapper<T> lambdaUpdate();
链式操作通过返回 QueryChainWrapper 或 UpdateChainWrapper 的实例,允许开发者连续调用方法来构建查询或更新条件。
// 普通链式更新示例
update().set("status", "inactive").eq("name", "John").update(); // 将 name 为 "John" 的记录 status 更新为 "inactive"// lambda 链式更新示例
User updateUser = new User();
updateUser.setEmail("new.email@example.com");
lambdaUpdate().set(User::getEmail, updateUser.getEmail()).eq(User::getId, 1).update(); // 更新 ID 为 1 的用户的邮箱
3.使用示例
@Service
public class UserService {@Autowiredprivate UserMapper userMapper;public List<User> getUsersByAge(int age) {return new LambdaQueryChainWrapper<>(userMapper).gt(User::getAge, age).list();}public boolean updateUserStatus(Long userId, Integer status) {return new LambdaUpdateChainWrapper<>(userMapper).eq(User::getId, userId).set(User::getStatus, status).update();}
}
(四)ActiveRecord(活动记录)
ActiveRecord 模式是一种设计模式,它允许实体类直接与数据库进行交互,实体类既是领域模型又是数据访问对象。在 Mybatis-Plus 中,实体类只需继承 Model 类即可获得强大的 CRUD 操作能力。
在小型项目或原型开发中,ActiveRecord 模式可以简化代码,减少 DAO 层的编写。实体类直接操作数据库,无需额外编写 Mapper 接口和 XML 文件。
1.简单的业务逻辑封装
如果业务逻辑比较简单,可以直接在实体类中封装相关方法,减少 Service 层的代码量。
//继承 Model 类
public class User extends Model<User> {private Long id;private String name;private Integer age;// 自定义业务方法public boolean isAdult() {return this.age != null && this.age >= 18;}
}/** 调用 CRUD 方法 */
// 查询某个ID的用户
User user = new User().selectById(1L);
if (user.isAdult()) {System.out.println("User is an adult.");
}
// 创建新用户并插入数据库
User user = new User();
user.setName("John Doe");
user.setAge(30);
boolean isInserted = user.insert(); // 返回值表示操作是否成功// 查询所有用户
List<User> allUsers = user.selectAll();// 根据 ID 更新用户信息
user.setId(1L);
user.setName("Updated Name");
boolean isUpdated = user.updateById(); // 返回值表示操作是否成功// 根据 ID 删除用户
boolean isDeleted = user.deleteById(); // 返回值表示操作是否成功
使用技巧:
- 在 ActiveRecord 模式下,实体类可以直接调用 insert、selectAll、updateById、deleteById 等方法进行数据库操作。
- 实体类继承 Model 类后,会自动获得一系列数据库操作方法,无需手动编写 SQL 语句。
- 实体类中的字段需要与数据库表中的列对应,通常通过注解(如 @TableField、@TableId 等)来指定字段与列的映射关系。
- 在进行更新或删除操作时,通常需要先查询出实体对象,然后修改其属性,最后调用更新或删除方法。
- 插入和更新操作通常会返回一个布尔值,表示操作是否成功。
- 查询操作会返回相应的查询结果,如单个实体对象或实体对象列表。
通过使用 ActiveRecord 模式,开发者可以更加简洁地编写数据库操作代码,同时保持代码的清晰和可维护性。这种模式尤其适合于简单的 CRUD 操作,可以大大减少重复代码的编写。
2.简单的关联查询
虽然 ActiveRecord 模式主要用于单表操作,但也可以通过手动编写 SQL 或使用 @TableField 注解实现简单的关联查询。
public class User extends Model<User> {private Long id;private String name;private Integer age;@TableField(exist = false)private List<Order> orders;// 手动实现关联查询public List<Order> getOrders() {if (orders == null) {orders = new Order().selectList(new QueryWrapper<Order>().eq("user_id", this.id));}return orders;}
}
3.数据校验、手动缓存、软删除
ActiveRecord 模式可以结合数据校验框架(如 Hibernate Validator)直接在实体类中实现数据校验。
public class User extends Model<User> {@NotNullprivate String name;@Min(0)private Integer age;// 插入时校验数据public boolean insertWithValidation() {Set<ConstraintViolation<User>> violations = Validation.buildDefaultValidatorFactory().getValidator().validate(this);if (!violations.isEmpty()) {throw new ConstraintViolationException(violations);}return this.insert();}
}
在需要缓存的场景中,可以在实体类中直接实现缓存逻辑。
public class User extends Model<User> {private Long id;private String name;private Integer age;// 带缓存的查询public User selectByIdWithCache(Long id) {User user = CacheUtils.get("user:" + id);if (user == null) {user = this.selectById(id);CacheUtils.put("user:" + id, user);}return user;}
}
快速实现软删除
public class User extends Model<User> {@TableLogicprivate Integer deleted;// 软删除public boolean softDeleteById(Long id) {User user = this.selectById(id);if (user != null) {user.setDeleted(1);return user.updateById();}return false;}
}
(五)SimpleQuery
为了简化常见场景的代码,提高开发效率、降低学习成本,让新手开发者更容易上手、提供一种更直观、函数式的编程风格、在简单场景中减少不必要的性能开销,Mybatis-Plus 提供了一个工具类SimpleQuery ,它对 selectList 查询后的结果进行了封装,使其可以通过 Stream 流的方式进行处理,从而简化了 API 的调用。
SimpleQuery 的一个特点是它的 peeks 参数,这是一个可变参数,类型为 Consumer…,意味着你可以连续添加多个操作,这些操作会在查询结果被处理时依次执行。
引入 SimpleQuery 工具类
import com.baomidou.mybatisplus.core.toolkit.support.SFunction;
import com.baomidou.mybatisplus.core.toolkit.support.SerializedLambda;
import com.baomidou.mybatisplus.core.toolkit.support.SimpleQuery;
使用 SimpleQuery 进行查询
// 假设有一个 User 实体类和对应的 BaseMapper
List<Long> ids = SimpleQuery.list(Wrappers.lambdaQuery(User.class), // 使用 lambda 查询构建器User::getId, // 提取的字段,这里是 User 的 idSystem.out::println, // 第一个 peek 操作,打印每个用户user -> userNames.add(user.getName()) // 第二个 peek 操作,将每个用户的名字添加到 userNames 列表中
);
使用提示
- SimpleQuery 工具类提供了一种简洁的方式来处理查询结果,它允许你在查询结果上应用多个操作,这些操作会按照添加的顺序依次执行。
- 在使用 SimpleQuery 时,你需要提供一个查询构建器(如 Wrappers.lambdaQuery()),一个用于提取结果的字段(如 User::getId),以及一个或多个 Consumer 类型的 peek 操作。
- peek 操作可以用于执行任何副作用操作,如打印日志、更新缓存、发送通知等,而不会影响查询结果本身。
- SimpleQuery 返回的结果是一个列表,包含了所有查询到的实体对象,这些对象已经应用了所有的 peek 操作。
- 通过使用 SimpleQuery,你可以将查询和结果处理逻辑分离,使代码更加清晰和易于维护。
通过使用 SimpleQuery 工具类,开发者可以更加高效地处理查询结果,同时保持代码的简洁性和可读性。这种工具类尤其适合于需要对查询结果进行复杂处理的场景。
1.返回Map结构数据
有时我们希望从数据库获取的结果直接返回的是一个Map结构的数据,而不是List结构的数据。因为Map结构相比于List结构用于查找性能会更好。
例如,从远程的物料主数据库中获取的几万条数据,需要转换为物料编码和实体的Map映射结构到本地内存再进行处理(判断物料编码、名称是否存在等等)。如果返回List,又得转成Map结构才能使用,比较耗时。
SimpleQuery 的 keyMap 方法提供了一种便捷的方式来查询数据库,并将查询结果封装成一个 Map,其中实体的某个属性作为键(key),实体本身作为值(value)。这个方法还支持在处理查询结果时执行额外的副作用操作,如打印日志或更新缓存。
// 查询表内记录,封装返回为 Map<属性,实体>
Map<A, E> keyMap(LambdaQueryWrapper<E> wrapper, SFunction<E, A> sFunction, Consumer<E>... peeks);// 查询表内记录,封装返回为 Map<属性,实体>,考虑了并行流的情况
Map<A, E> keyMap(LambdaQueryWrapper<E> wrapper, SFunction<E, A> sFunction, boolean isParallel, Consumer<E>... peeks);
使用示例:
// 假设有一个 User 实体类和对应的 BaseMapper
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getStatus, "active"); // 查询状态为 "active" 的用户// 使用 keyMap 方法查询并封装结果
Map<String, User> userMap = SimpleQuery.keyMap(queryWrapper, // 查询条件构造器User::getUsername, // 使用用户名作为键user -> System.out.println("Processing user: " + user.getUsername()) // 打印处理的用户名
);// 遍历结果
for (Map.Entry<String, User> entry : userMap.entrySet()) {System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
2.提取某个字段
使用 SimpleQuery:
List<String> names = SimpleQuery.list(Wrappers.lambdaQuery(User.class), User::getName
);
使用 Mapper:
List<User> userList = userMapper.selectList(Wrappers.lambdaQuery(User.class));
List<String> names = userList.stream().map(User::getName).collect(Collectors.toList());
从示例中可以看出,SimpleQuery 的代码更简洁,尤其是在只需要某个字段或简单结果时。
3.快速查询键值对
使用 SimpleQuery:
Map<Long, String> idNameMap = SimpleQuery.keyMap(Wrappers.lambdaQuery(User.class), User::getId, User::getName
);
使用 Mapper:
List<User> userList = userMapper.selectList(Wrappers.lambdaQuery(User.class));
Map<Long, String> idNameMap = userList.stream().collect(Collectors.toMap(User::getId, User::getName));
SimpleQuery 的代码更直观,且无需手动处理结果集。
4.快速查询并转换为自定义对象
当需要将查询结果转换为自定义的 DTO 对象时,SimpleQuery 可以快速实现。
// 查询用户ID和名称,并转换为UserDTO
List<UserDTO> userDTOList = SimpleQuery.list(Wrappers.lambdaQuery(User.class).select(User::getId, User::getName), user -> new UserDTO(user.getId(), user.getName())
);
5. 快速查询分组统计
在需要对某个字段进行分组统计时,SimpleQuery 可以快速返回分组结果。
// 按年龄分组统计用户数量
Map<Integer, Long> ageCountMap = SimpleQuery.group(Wrappers.lambdaQuery(User.class).select(User::getAge), User::getAge, Collectors.counting()
);
// 假设有一个 User 实体类和对应的 BaseMapper
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getStatus, "active"); // 查询状态为 "active" 的用户// 使用 group 方法查询并封装结果,按照用户名分组
Map<String, List<User>> userGroup = SimpleQuery.group(queryWrapper, // 查询条件构造器User::getUsername, // 使用用户名作为分组键user -> System.out.println("Processing user: " + user.getUsername()) // 打印处理的用户名
);
(六)Db Kit
Db Kit 是 Mybatis-Plus 提供的一个工具类,它允许开发者通过静态调用的方式执行 CRUD 操作,从而避免了在 Spring 环境下可能出现的 Service 循环注入问题,简化了代码,提升了开发效率。
使用技巧
- Db Kit 提供了一系列静态方法,可以直接调用进行数据库操作,无需通过 Service 层,简化了代码结构。
- 在使用 Db Kit 时,确保传入的参数正确,特别是当使用 Wrapper 时,需要指定实体类或实体对象。
- 对于批量操作,如批量插入或更新,建议使用 Db Kit 提供的批量方法,以提高效率。
- 避免在循环中频繁调用 Db Kit 的方法,这可能会导致性能问题。
通过使用 Db Kit,开发者可以更加高效地执行数据库操作,同时保持代码的简洁性和可读性。这种工具类尤其适合于简单的 CRUD 操作,可以大大减少重复代码的编写。
1. 基于实体类的快速操作
Db Kit 主要用于简化基于实体类的 CRUD 操作,适合不需要复杂 SQL 的场景。
// 插入数据
User user = new User();
user.setName("John");
user.setAge(25);
Db.save(user);// 查询数据
User result = Db.getById(user.getId(), User.class);// 更新数据
user.setAge(30);
Db.updateById(user);// 删除数据
Db.removeById(user.getId(), User.class);
适用场景
-
简单的单表 CRUD 操作。
-
不需要编写复杂的 SQL。
2. 基于 Wrapper 的动态查询
Db Kit 支持通过 QueryWrapper 或 LambdaQueryWrapper 构建动态查询条件。
// 动态查询
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 18).like("name", "J");List<User> userList = Db.list(queryWrapper, User.class);
适用场景
- 需要动态生成查询条件。
- 查询逻辑简单,不需要复杂的 SQL。
3. 批量操作
Db Kit 支持批量插入、更新和删除操作。
// 批量插入
List<User> userList = new ArrayList<>();
userList.add(new User("John", 25));
userList.add(new User("Alice", 30));
Db.saveBatch(userList);// 批量更新
Db.updateBatchById(userList);
适用场景
- 需要快速执行批量操作。
- 数据量较大,但业务逻辑简单。
(七)总结
1. Service持久化
场景: 业务逻辑复杂,需要封装多个数据库操作时。
特点: 通过 IService 接口及其实现类 ServiceImpl,提供常见的 CRUD 操作和批量操作。
适用场景:
- 需要处理复杂业务逻辑。
- 需要事务管理。
- 需要调用多个 Mapper 或 Service 方法。
2. Mapper持久化
场景: 直接操作数据库表,执行简单的 CRUD 操作。
特点: 通过 BaseMapper 接口提供基本的 CRUD 方法。
适用场景:
- 简单的单表操作。
- 需要自定义 SQL 查询。
- 需要直接操作数据库表。
3. Chain 链式调用
场景: 需要连续执行多个操作时。
特点: 通过 QueryChainWrapper 和 UpdateChainWrapper 实现链式调用,简化代码。
适用场景:
- 需要连续执行多个查询或更新操作。
- 代码简洁性要求高。
4. ActiveRecord
场景: 实体类直接操作数据库。
特点: 实体类继承 Model 类,可以直接调用 CRUD 方法。
适用场景:
- 简单的单表操作。
- 实体类与数据库表一一对应。
- 代码简洁性要求高。
5. SimpleQuery
场景: 需要快速执行简单的查询操作。
特点: 通过 SimpleQuery 工具类提供快速查询方法。
适用场景:
- 需要快速获取单条记录或某个字段。
- 查询条件简单。
6. Db Kit
场景: 需要执行复杂的 SQL 操作或批量操作。
特点: 通过 Db 工具类提供直接执行 SQL 的方法。
适用场景:
- 需要执行复杂的 SQL 语句。
- 需要批量操作。
- 需要直接操作数据库。
二、条件构造器
在 MyBatis-Plus 中,Wrapper 类是构建查询和更新条件的核心工具。以下是主要的 Wrapper 类及其功能:
-
AbstractWrapper:这是一个抽象基类,提供了所有 Wrapper 类共有的方法和属性。它定义了条件构造的基本逻辑,包括字段(column)、值(value)、操作符(condition)等。所有的 QueryWrapper、UpdateWrapper、LambdaQueryWrapper 和 LambdaUpdateWrapper 都继承自 AbstractWrapper。 -
QueryWrapper:专门用于构造查询条件,支持基本的等于、不等于、大于、小于等各种常见操作。它允许你以链式调用的方式添加多个查询条件,并且可以组合使用 and 和 or 逻辑。 -
UpdateWrapper:用于构造更新条件,可以在更新数据时指定条件。与 QueryWrapper 类似,它也支持链式调用和逻辑组合。使用 UpdateWrapper 可以在不创建实体对象的情况下,直接设置更新字段和条件。 -
LambdaQueryWrapper:这是一个基于 Lambda 表达式的查询条件构造器,它通过 Lambda 表达式来引用实体类的属性,从而避免了硬编码字段名。这种方式提高了代码的可读性和可维护性,尤其是在字段名可能发生变化的情况下。 -
LambdaUpdateWrapper:类似于 LambdaQueryWrapper,LambdaUpdateWrapper 是基于 Lambda 表达式的更新条件构造器。它允许你使用 Lambda 表达式来指定更新字段和条件,同样避免了硬编码字段名的问题。
1.lambda表达式
这里的lambda表达式的理解意思不是说链式调用,条件构造器都可以链式调用,而是来表达引用实体类的属性。
例如,普通的Wrapper需要写入字段名称,容易写错,不方便排查。特别是某些时候数据库的字段的字母大小写可能与下划线相互转换。
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("name", "老王");
而采用lambda表达式的Wrapper包含类型检查,在编译期就能检查出来,就不容易写错了。
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.eq(User::getName, "老王");
所以一般建议用LambdaQueryWrapper和LambdaUpdateWrapper的条件构造器。
这可以通过QueryWrapper 和UpdateWrapper的lambda方法进行转换。
// 从 QueryWrapper 获取 LambdaQueryWrapper
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
LambdaQueryWrapper<User> lambdaQueryWrapper = queryWrapper.lambda();
// 使用 Lambda 表达式构建查询条件
lambdaQueryWrapper.eq(User::getName, "张三");// 从 UpdateWrapper 获取 LambdaUpdateWrapper:
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
LambdaUpdateWrapper<User> lambdaUpdateWrapper = updateWrapper.lambda();
// 使用 Lambda 表达式构建更新条件
lambdaUpdateWrapper.set(User::getName, "李四");
2.Wrappers
幸好MyBatis-Plus 提供了 Wrappers 类,它是一个静态工厂类,用于快速创建 QueryWrapper、UpdateWrapper、LambdaQueryWrapper 和 LambdaUpdateWrapper 的实例。使用 Wrappers 可以减少代码量,提高开发效率。
// 创建 QueryWrapper
QueryWrapper<User> queryWrapper = Wrappers.query();
queryWrapper.eq("name", "张三");// 创建 LambdaQueryWrapper
LambdaQueryWrapper<User> lambdaQueryWrapper = Wrappers.lambdaQuery();
lambdaQueryWrapper.eq(User::getName, "张三");// 创建 UpdateWrapper
UpdateWrapper<User> updateWrapper = Wrappers.update();
updateWrapper.set("name", "李四");// 创建 LambdaUpdateWrapper
LambdaUpdateWrapper<User> lambdaUpdateWrapper = Wrappers.lambdaUpdate();
lambdaUpdateWrapper.set(User::getName, "李四");
3.使用 Wrapper 自定义 SQL
有时候我们自定义SQL语句时,想使用MyBatis-Plus 提供的强大的 Wrapper 条件构造器。
public interface UserMapper extends BaseMapper<User> {// 使用 QueryWrapper 自定义updatevoid updateEmailByAges(@Param(Constants.WRAPPER) QueryWrapper<User> wrapper, @Param("email") String email);}
使用注意事项:
- 参数命名:在自定义 SQL 时,传递 Wrapper 对象作为参数时,参数名必须为 ew,或者使用注解 @Param(Constants.WRAPPER) 明确指定参数为 Wrapper 对象。
- 使用 ${ew.customSqlSegment}:在 SQL 语句中,使用 ${ew.customSqlSegment} 来引用 Wrapper 对象生成的 SQL 片段。
<update id="updateEmailByAges">update userset email = #{email}${ew.customSqlSegment}
</update>
使用方法:
List<Integer> ages = Arrays.asList(10,55);
String email = "789";// 使用 QueryWrapper 自定义update
QueryWrapper<User> wrapper = new QueryWrapper<User>().in("age",ages);
userMapper.updateEmailByAges(wrapper,email);
三、流式查询
当需要从数据库中查询大量数据时,如果一次性将所有数据加载到内存中,可能会导致内存溢出(OOM)。流式查询可以逐行处理数据,每次只从数据库中读取一小部分数据到内存中进行处理,处理完后释放内存,从而避免了内存压力过大的问题。
MyBatis-Plus 支持流式查询,这是 MyBatis 的原生功能,通过 ResultHandler 接口实现结果集的流式查询。这种查询方式适用于数据跑批或处理大数据的业务场景。
1.逐行读取处理
假设你需要从一个包含数百万条记录的用户表中查询所有用户信息,并将这些信息导出到一个 CSV 文件中。使用流式查询可以避免一次性将数百万条记录加载到内存中,而是逐行读取并写入 CSV 文件。
// 从数据库获取表所有记录,做数据处理
baseMapper.selectList(Wrappers.emptyWrapper(), new ResultHandler<User>() {int count = 0;@Overridepublic void handleResult(ResultContext<? extends User> resultContext) {User user = resultContext.getResultObject();// 处理每一条用户记录,例如写入 CSV 文件System.out.println("当前处理第" + (++count) + "条记录: " + user);}
});
2.实时数据处理
在一些实时数据处理的场景中,需要及时对数据库中的数据进行处理,而不是等待所有数据加载完成。流式查询可以在数据从数据库中读取出来后立即进行处理,提高了数据处理的实时性。
例如,实时监控系统需要对数据库中的日志数据进行实时分析,每当有新的日志记录插入数据库时,通过流式查询可以立即获取这些记录并进行分析,及时发现异常情况。
@Service
public class LogMonitorService {@Autowiredprivate LogMapper logMapper;private long lastCheckTime = Instant.now().getEpochSecond();public void startMonitoring() {ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);executorService.scheduleAtFixedRate(this::monitorLogs, 0, 5, TimeUnit.SECONDS);}private void monitorLogs() {QueryWrapper<Log> queryWrapper = new QueryWrapper<>();queryWrapper.ge("UNIX_TIMESTAMP(create_time)", lastCheckTime);logMapper.selectList(queryWrapper, new ResultHandler<Log>() {int count = 0;@Overridepublic void handleResult(com.baomidou.mybatisplus.core.metadata.IPage<Log> page, Log log) {analyzeLog(log);System.out.println("当前处理第" + (++count) + "条记录: " + log);}});lastCheckTime = Instant.now().getEpochSecond();}private void analyzeLog(Log log) {if ("ERROR".equals(log.getLevel())) {System.out.println("发现异常日志:" + log.getMessage());}}
}
3.其它场景
(1)减少数据库连接占用时间
如果一次性查询大量数据,数据库连接会被长时间占用,可能会影响其他业务的正常运行。流式查询可以在处理数据的过程中逐步释放数据库连接资源,减少数据库连接的占用时间,提高数据库的并发处理能力。
在一个高并发的 Web 应用中,多个用户可能同时发起数据查询请求。如果每个请求都一次性查询大量数据并长时间占用数据库连接,会导致数据库连接池耗尽,影响系统的性能。使用流式查询可以有效减少数据库连接的占用时间,提高系统的并发处理能力。
(2)数据迁移和同步
在进行数据迁移或同步时,需要将一个数据库中的大量数据复制到另一个数据库中。流式查询可以逐行读取源数据库中的数据,并逐行写入目标数据库,避免了一次性加载大量数据到内存中,提高了数据迁移和同步的效率。
例如,将一个旧的 MySQL 数据库中的用户数据迁移到一个新的 PostgreSQL 数据库中。使用流式查询可以逐行读取 MySQL 数据库中的用户数据,并逐行插入到 PostgreSQL 数据库中。
相关文章:

mybatis plus 持久化使用技巧及场景
mybatis plus提供了很多强大的持久化工具,新手容易对这些工具使用困难,下面我总结了一下mybatis plus持久化的使用技巧及使用场景。 一、持久化 官方文档:https://baomidou.com/guides/data-interface/ (一)通过ser…...

JVM监控和管理工具
基础故障处理工具 jps jps(JVM Process Status Tool):Java虚拟机进程状态工具 功能 1:列出正在运行的虚拟机进程 2:显示虚拟机执行主类(main()方法所在的类) 3:显示进程ID(PID,Process Identifier) 命令格式 jps […...

记录 | 基于MaxKB的文字生成视频
目录 前言一、安装SDK二、创建视频函数库三、调试更新时间 前言 参考文章:如何利用智谱全模态免费模型,生成大家都喜欢的图、文、视并茂的文章! 自己的感想 本文记录了创建文字生成视频的函数库的过程。如果想复现本文,需要你逐一…...

生成式AI安全最佳实践 - 抵御OWASP Top 10攻击 (下)
今天小李哥将开启全新的技术分享系列,为大家介绍生成式AI的安全解决方案设计方法和最佳实践。近年来生成式 AI 安全市场正迅速发展。据IDC预测,到2025年全球 AI 安全解决方案市场规模将突破200亿美元,年复合增长率超过30%,而Gartn…...

现场流不稳定,EasyCVR视频融合平台如何解决RTSP拉流不能播放的问题?
视频汇聚EasyCVR安防监控视频系统采用先进的网络传输技术,支持高清视频的接入和传输,能够满足大规模、高并发的远程监控需求。平台灵活性强,支持国标GB/T 28181协议、部标JT808、GA/T 1400协议、RTMP、RTSP/Onvif协议、海康Ehome、海康SDK、大…...

文献阅读 250205-Global patterns and drivers of tropical aboveground carbon changes
Global patterns and drivers of tropical aboveground carbon changes 来自 <Global patterns and drivers of tropical aboveground carbon changes | Nature Climate Change> 热带地上碳变化的全球模式和驱动因素 ## Abstract: Tropical terrestrial ecosystems play …...

算法与数据结构(括号匹配问题)
思路 从题干可以看出,只要给出的括号对应关系正确,那么就可以返回true,否则返回false。这个题可以使用栈来解决 解题过程 首先从第一个字符开始遍历,如果是括号的左边(‘(‘,’[‘,’}‘&…...

订单状态监控实战:基于 SQL 的状态机分析与异常检测
目录 1. 背景与问题 2. 数据准备 2.1 表结构设计 3. 场景分析与实现 3.1 场景 1:检测非法状态转换...

C# 中记录(Record)详解
从C#9.0开始,我们有了一个有趣的语法糖:记录(record) 为什么提供记录? 开发过程中,我们往往会创建一些简单的实体,它们仅仅拥有一些简单的属性,可能还有几个简单的方法,比如DTO等等…...

YOLOv11-ultralytics-8.3.67部分代码阅读笔记-autobackend.py
autobackend.py ultralytics\nn\autobackend.py 目录 autobackend.py 1.所需的库和模块 2.def check_class_names(names): 3.def default_class_names(dataNone): 4.class AutoBackend(nn.Module): 1.所需的库和模块 # Ultralytics 🚀 AGPL-3.0 License …...

Docker使用指南(一)——镜像相关操作详解(实战案例教学,适合小白跟学)
目录 1.镜像名的组成 2.镜像操作相关命令 镜像常用命令总结: 1. docker images 2. docker rmi 3. docker pull 4. docker push 5. docker save 6. docker load 7. docker tag 8. docker build 9. docker history 10. docker inspect 11. docker prune…...

Rust 变量特性:不可变、和常量的区别、 Shadowing
Rust 变量特性:不可变、和常量的区别、 Shadowing Rust 是一门以安全性和性能著称的系统编程语言,其变量系统设计独特且强大。本文将从三个角度介绍 Rust 变量的核心特性:可变性(Mutability)、变量与常量的区别&#…...

NFT Insider #167:Champions Tactics 角色加入 The Sandbox;AI 助力 Ronin 游戏生态
引言:NFT Insider 由 NFT 收藏组织 WHALE Members、BeepCrypto 联合出品, 浓缩每周 NFT 新闻,为大家带来关于 NFT 最全面、最新鲜、最有价值的讯息。每期周报将从 NFT 市场数据,艺术新闻类,游戏新闻类,虚拟…...

鹧鸪云无人机光伏运维解决方案
在新能源产业蓬勃发展的当下,光伏电站作为清洁能源供应的关键一环,其稳定运行和高效运维至关重要。随着光伏电站规模持续扩大,数量不断增加,传统人工巡检方式的弊端日益显著。人工巡检不仅效率低、人力和时间成本高,而…...

NeuralCF 模型:神经网络协同过滤模型
实验和完整代码 完整代码实现和jupyter运行:https://github.com/Myolive-Lin/RecSys--deep-learning-recommendation-system/tree/main 引言 NeuralCF 模型由新加坡国立大学研究人员于 2017 年提出,其核心思想在于将传统协同过滤方法与深度学习技术相结…...

【前端】【Ts】【知识点总结】TypeScript知识总结
一、总体概述 TypeScript 是 JavaScript 的超集,主要通过静态类型检查和丰富的类型系统来提高代码的健壮性和可维护性。它涵盖了从基础数据类型到高级类型、从函数与对象的类型定义到类、接口、泛型、模块化及装饰器等众多知识点。掌握这些内容有助于编写更清晰、结…...

JAVA架构师进阶之路
JAVA架构师进阶之路 前言 苦于网络上充斥的各种java知识,多半是互相抄袭,导致很多后来者在学习java知识中味同嚼蜡,本人闲暇之余整理了进阶成为java架构师所必须掌握的核心知识点,后续会不断扩充。 废话少说,直接上正…...

掌握@PostConstruct与@PreDestroy,优化Spring Bean的初始化和销毁
在Spring中,PostConstruct和PreDestroy注解就像是对象的“入职”和“离职”仪式。 1. PostConstruct注解:这个注解标记的方法就像是员工入职后的“岗前培训”。当一个对象(比如一个Bean)被Spring容器创建并注入依赖后,…...

Java设计模式:行为型模式→状态模式
Java 状态模式详解 1. 定义 状态模式(State Pattern)是一种行为型设计模式,它允许对象在内部状态改变时改变其行为。状态模式通过将状态需要的行为封装在不同的状态类中,实现对象行为的动态改变。该模式的核心思想是分离不同状态…...

景联文科技:专业数据采集标注公司 ,助力企业提升算法精度!
随着人工智能技术加速落地,高质量数据已成为驱动AI模型训练与优化的核心资源。据统计,全球AI数据服务市场规模预计2025年突破200亿美元,其中智能家居、智慧交通、医疗健康等数据需求占比超60%。作为国内领先的AI数据服务商,景联文…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...
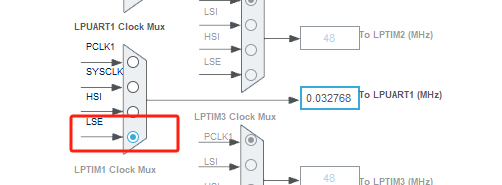
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...
沙箱虚拟化技术虚拟机容器之间的关系详解
问题 沙箱、虚拟化、容器三者分开一一介绍的话我知道他们各自都是什么东西,但是如果把三者放在一起,它们之间到底什么关系?又有什么联系呢?我不是很明白!!! 就比如说: 沙箱&#…...

aardio 自动识别验证码输入
技术尝试 上周在发学习日志时有网友提议“在网页上识别验证码”,于是尝试整合图像识别与网页自动化技术,完成了这套模拟登录流程。核心思路是:截图验证码→OCR识别→自动填充表单→提交并验证结果。 代码在这里 import soImage; import we…...

ArcGIS Pro+ArcGIS给你的地图加上北回归线!
今天来看ArcGIS Pro和ArcGIS中如何给制作的中国地图或者其他大范围地图加上北回归线。 我们将在ArcGIS Pro和ArcGIS中一同介绍。 1 ArcGIS Pro中设置北回归线 1、在ArcGIS Pro中初步设置好经纬格网等,设置经线、纬线都以10间隔显示。 2、需要插入背会归线…...