AWS门店人流量数据分析项目的设计与实现
这是一个AWS的数据分析项目,关于快消公司门店手机各个门店进店人流量和各个产品柜台前逗留时间(利用IoT设备采集)和销售数据之间的统计分析,必须用到但不限于Amazon Kensis Data Stream,Spark Streaming,Spark mllib,Kafka,S3和Redshift。
门店进店人数与各产品柜台前逗留时间受多方面因素的影响,需要综合考虑并采取相应的措施来提升。已知门店进店人数与各产品柜台前逗留时间主要与以下因素有关:
门店进店人数
-
门店地段与曝光度:门店所在的地段决定了其曝光次数,进而影响进店人数。地段繁华、人流量大的地方,门店曝光度高,进店人数相对较多。
-
品牌知名度:知名品牌或加盟店往往能吸引更多顾客,因为顾客对品牌有一定的信任和认可度。
-
门店外观与吸引力:包括门店的装修、招牌、灯光、整洁度等,这些因素直接影响顾客对门店的第一印象,从而决定其是否愿意进店。
-
促销活动与氛围:门店的促销活动、氛围营造(如热闹程度、导购试穿和销售演练等)也能吸引顾客进店。
-
竞争对手情况:周边竞争对手的数量和实力也会影响门店的进店人数。
6.当天天气的舒适度和是否是节假日或大型节庆或活动。
7.是否明星代言期间,以及明星或公司的的新闻热度上升期间。
各产品柜台前逗留时间
-
产品陈列与布局:产品陈列是否整齐、有序,是否能吸引顾客注意,以及柜台布局是否合理,都会影响顾客在柜台前的逗留时间。
-
商品种类与差异化:商品是否适销对路,即是否满足顾客需求,以及商品的差异化程度,也会影响顾客的逗留时间。如果商品种类丰富、差异化明显,顾客会更愿意花费时间挑选。
-
价格因素:价格是否合理、是否具有竞争力,也会影响顾客在柜台前的决策时间和逗留时间。
-
员工服务态度与专业度:员工的服务态度、专业度以及能否及时、准确地解答顾客疑问,都会影响顾客的购物体验和逗留时间。
-
店内环境与氛围:店内整体环境是否舒适、氛围是否愉悦,也会影响顾客的逗留时间。例如,通风性良好、空间配置合理的店铺能提升顾客的洄游性,延长逗留时间。
-
动线规划:有计划的动线规划可以引导顾客在卖场中的前进步伐,让顾客更加全面地浏览店铺商品,从而延长逗留时间。
-
营销手段与试用场景:如氛围道具的布置、试用场景的搭建等,能增强顾客的购物体验,提升其对产品的兴趣和购买欲望,从而延长逗留时间。
以下架构可以每小时处理超过百万级的传感器事件,支持亚秒级的实时指标计算,同时能够处理PB级的历史数据分析需求。关键业务指标(如促销期间的转化率变化)可以实现分钟级延迟的实时监控。这是一个基于AWS的实时数据分析系统架构,以下是详细的方案:
系统架构图
[IoT传感器] --> [Kinesis Data Stream]
[POS系统] --> [Kafka]↓
[Kinesis Firehose] --> [S3 Raw Zone]↓
[Spark Streaming on EMR] --> [S3 Processed Zone]↓
[Glue ETL] --> [Redshift]↓
[QuickSight] <--> [ML模型服务]
技术栈组合
- 数据采集层:IoT传感器 + AWS IoT Core + Kinesis Data Stream
- 消息队列:MSK Managed Streaming for Kafka
- 实时计算:EMR Spark Streaming (Python)
- 批处理:Glue + EMR Spark
- 机器学习:Spark MLlib + SageMaker
- 存储:S3 (数据湖) + Redshift (数据仓库)
- 可视化:QuickSight
- 元数据管理:Glue Data Catalog
- 数据治理:Lake Formation
实施步骤
第一阶段:数据采集与传输
- IoT设备部署:
# 传感器数据示例(Python伪代码)
import boto3
import jsonkinesis = boto3.client('kinesis')def send_sensor_data():data = {"store_id": "ST001","timestamp": "2023-08-20T14:30:00Z","sensor_type": "foot_traffic","counter_id": "CT001","duration": 45.2, # 逗留时间(秒)"people_count": 3}kinesis.put_record(StreamName="StoreSensorStream",Data=json.dumps(data),PartitionKey="ST001")
- Kafka生产者配置(POS销售数据):
from kafka import KafkaProducerproducer = KafkaProducer(bootstrap_servers='kafka-brokers:9092',value_serializer=lambda v: json.dumps(v).encode('utf-8')
)def send_sale_data():sale_data = {"store_id": "ST001","timestamp": "2023-08-20T14:30:05Z","product_id": "P1234","quantity": 2,"amount": 59.98}producer.send('pos-sales', sale_data)
第二阶段:实时处理
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *spark = SparkSession.builder \.appName("RealtimeStoreAnalytics") \.getOrCreate()# 定义IoT数据Schema
iot_schema = StructType([StructField("store_id", StringType()),StructField("timestamp", TimestampType()),StructField("sensor_type", StringType()),StructField("counter_id", StringType()),StructField("duration", DoubleType()),StructField("people_count", IntegerType())
])# 从Kinesis读取数据
iot_stream = spark.readStream \.format("kinesis") \.option("streamName", "StoreSensorStream") \.option("initialPosition", "LATEST") \.load() \.select(from_json(col("data").cast("string"), iot_schema).alias("parsed")) \.select("parsed.*")# 实时窗口聚合(5分钟窗口)
windowed_traffic = iot_stream \.groupBy(window("timestamp", "5 minutes"),"store_id") \.agg(sum("people_count").alias("total_visitors"),avg("duration").alias("avg_duration"))# 写入S3处理区
query = windowed_traffic.writeStream \.outputMode("update") \.format("parquet") \.option("path", "s3a://processed-data/store_metrics") \.option("checkpointLocation", "/checkpoint") \.start()
第三阶段:特征工程
from pyspark.ml.feature import VectorAssembler
from pyspark.ml import Pipeline# 构建特征管道
def build_feature_pipeline():assembler = VectorAssembler(inputCols=["total_visitors","avg_duration","holiday_flag","temperature","promo_intensity"],outputCol="features")return Pipeline(stages=[assembler])# 外部数据关联示例
def enrich_with_external_data(df):# 从S3加载天气数据weather = spark.read.parquet("s3a://external-data/weather")# 加载促销日历promotions = spark.read.parquet("s3a://external-data/promotions")return df.join(weather, ["store_id", "date"]) \.join(promotions, ["store_id", "date"], "left")
第四阶段:机器学习建模
from pyspark.ml.regression import RandomForestRegressor
from pyspark.ml.evaluation import RegressionEvaluatordef train_sales_model():# 加载历史数据df = spark.read.parquet("s3a://processed-data/training_dataset")# 拆分数据集train, test = df.randomSplit([0.8, 0.2])# 初始化模型rf = RandomForestRegressor(featuresCol="features",labelCol="sales_amount",numTrees=50,maxDepth=10)# 构建管道pipeline = build_feature_pipeline().setStages([rf])# 训练模型model = pipeline.fit(train)# 评估模型predictions = model.transform(test)evaluator = RegressionEvaluator(labelCol="sales_amount",predictionCol="prediction",metricName="rmse")rmse = evaluator.evaluate(predictions)print(f"Root Mean Squared Error (RMSE): {rmse}")# 保存模型model.save("s3a://ml-models/sales_prediction_v1")return model
第五阶段:数据可视化(QuickSight)
- 在Redshift中创建物化视图:
CREATE MATERIALIZED VIEW store_performance AS
SELECT s.store_id,s.location_score,AVG(t.avg_duration) AS avg_duration,SUM(s.sales_amount) AS total_sales,w.weather_condition
FROM store_metrics t
JOIN sales_data s ON t.store_id = s.store_id
JOIN weather_data w ON t.date = w.date
GROUP BY s.store_id, w.weather_condition;
关键创新点
- 多源数据融合:整合IoT传感器、POS系统、天气API、促销日历等多维度数据
- 实时-离线一体化:Lambda架构实现实时指标计算与离线深度分析结合
- 动态特征工程:基于窗口的实时特征计算(滚动5分钟/小时/日聚合)
- 可解释性模型:SHAP值分析各因素对销售的影响权重
运维保障措施
- 数据质量监控:在Glue中设置数据质量规则
- 自动扩缩容:使用EMR自动伸缩策略
- 模型监控:SageMaker Model Monitor进行模型漂移检测
- 安全控制:Lake Formation进行列级权限管理
性能优化建议
- 数据分区:按日期/小时进行S3分区存储
- Redshift优化:
- 使用AQUA加速查询
- 对经常JOIN的字段设置DISTKEY
- Spark调优:
spark.conf.set("spark.sql.shuffle.partitions", "2000")spark.conf.set("spark.executor.memoryOverhead", "2g")
相关文章:

AWS门店人流量数据分析项目的设计与实现
这是一个AWS的数据分析项目,关于快消公司门店手机各个门店进店人流量和各个产品柜台前逗留时间(利用IoT设备采集)和销售数据之间的统计分析,必须用到但不限于Amazon Kensis Data Stream,Spark Streaming,Sp…...

出租车特殊计费表算法解析与实现
目录 引言算法核心概念 特殊计费规则解析数据类型与输入输出算法数学原理 数字位判断与处理逻辑数值转换与累加计算算法框架图Python 实现 代码展示代码解析Python 实现的优势与局限C 语言实现 代码展示代码解析C 语言实现的性能特点性能分析与优化 性能分析 时间复杂度空间复杂…...

文档解析技术:如何高效提取PDF扫描件中的文字与表格信息?
想要高效提取PDF扫描件中的文字与表格信息,通常需要借助专业的工具或在线服务,以下是一些可行的方法: 预处理扫描件:在提取文字之前,尽量确保扫描件的图像质量清晰。如果扫描件模糊或有污渍,可以使用图像处…...

【2】高并发导出场景下,服务器性能瓶颈优化方案-异步导出
Java 异步导出是一种在处理大量数据或复杂任务时优化性能和用户体验的重要技术。 1. 异步导出的优势 异步导出是指将导出操作从主线程中分离出来,通过后台线程或异步任务完成数据处理和文件生成。这种方式可以显著减少用户等待时间,避免系统阻塞&#x…...

【DeepSeek论文精读】6. DeepSeek R1:通过强化学习激发大语言模型的推理能力
欢迎关注[【youcans的AGI学习笔记】](https://blog.csdn.net/youcans/category_12244543.html)原创作品 【DeepSeek论文精读】1. 从 DeepSeek LLM 到 DeepSeek R1 【DeepSeek论文精读】6. DeepSeek R1:通过强化学习激发大语言模型的推理能力 【DeepSeek论…...

frida 通过 loadLibrary0 跟踪 System.loadLibrary
static {System.loadLibrary("libxxx.so"); }在 ndk 开发中,常见的实践是在 static 代码块里调用 loadLibrary 加载动态库。由于 apk 从 java 层开始启动,过早地 hook 原生代码会找不到函数。所以一种常见做法是在 loadLibrary 的 hook 回调里…...

【2025最新计算机毕业设计】基于SSM的智能停车场管理系统【提供源码+答辩PPT+文档+项目部署】(高质量源码,可定制,提供文档,免费部署到本地)
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...

【含文档+PPT+源码】Python爬虫人口老龄化大数据分析平台的设计与实现
项目介绍 本课程演示的是一款Python爬虫人口老龄化大数据分析平台的设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Python学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本…...

文本生图的提示词prompt和参数如何设置(基于Animagine XL V3.1)
昨天搞了半天 Animagine XL V3.1,发现市面上很多教程只是授之以鱼,并没有授之以渔的。也是,拿来赚钱不好吗,闲鱼上部署一个 Deepseek 都能要两百块。这里我还是想写篇文章介绍一下,虽不全面,但是尽量告诉你…...
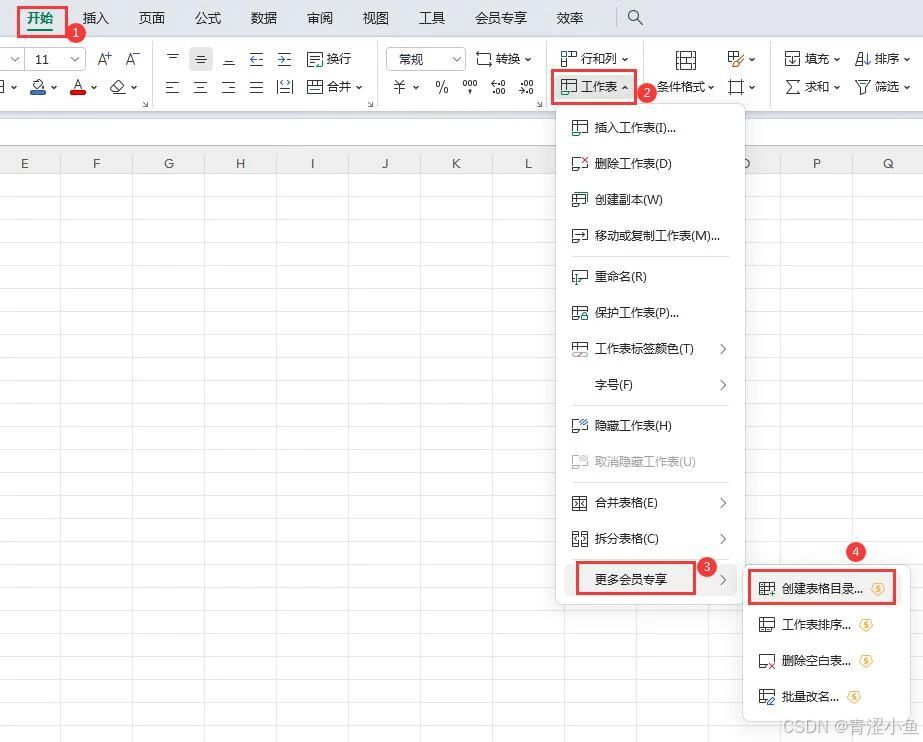
快速提取Excel工作簿中所有工作表的名称?
大家好,我是小鱼。 在Excel表格中如何快速提取工作簿中所有工作表的名称?这个问题在日常工作中也经常遇到,比如说经常使用的INDIRECT函数跨工作表汇总或者制作类似于导航的工作表快捷跳转列表,就需要每个工作表的名称。如果工作表…...

【紫光同创PG2L100H开发板】盘古676系列,盘古100Pro+开发板,MES2L676-100HP
本原创文章由深圳市小眼睛科技有限公司创作,版权归本公司所有,如需转载,需授权并注明出处(www.meyesemi.com) 一:开发系统介绍 开发系统概述 MES2L676-100HP开发板采用紫光创 logos2系列 FPGA,型号&#x…...

Node.JS 版本管理工具 Fnm 安装及配置(Windows)
Fnm 安装及配置(Windows) Fnm(Fast Node Manager)?? 一个快速而简单的 Node.js 版本管理工具,使用 Rust 编写。 1 安装 官网:Fnm(镜像网站 )。 下载:Fnm(…...

labview通过时间计数器来设定采集频率
在刚接触labview的时候,笔者通常用定时里的等待函数来实现指令的收发,但是当用到的收发消息比较多时就出现了卡顿,卡死的情况,这是因为当用队列框架时,程序卡在了其中的一个分支里,等通过相应的延时后才可以…...

汇编JCC条件跳转指令记忆
汇编中的条件跳转指令(JCC): 1. 理解标志寄存器 JCC 指令依赖于标志寄存器(FLAGS)的状态,常见的标志位有: ZF(Zero Flag):结果为0时置1。 CF(Ca…...

HTML排版标签、语义化标签、块级和行内元素详解
目录 前言 一、HTML中的排版标签 1. 文本相关标签 1.1 标题标签 ~ 1.2 段落标签 1.3 强调和加粗 1.4 换行标签 1.5 水平线标签 二、HTML中的语义化标签 2.1 语义化标签概述 2.2 常见的语义化标签 示例(核心代码部分): 三、HTM…...

【回溯+剪枝】单词搜索,你能用递归解决吗?
文章目录 79. 单词搜索解题思路:回溯(深搜) 剪枝 79. 单词搜索 79. 单词搜索 给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。 …...

《深度揭秘LDA:开启人工智能降维与分类优化的大门》
在当今人工智能蓬勃发展的时代,数据成为了驱动技术进步的核心要素。随着数据采集和存储技术的飞速发展,我们所面临的数据量不仅日益庞大,其维度也愈发复杂。高维数据虽然蕴含着丰富的信息,但却给机器学习算法带来了一系列严峻的挑…...
Linux(CentOS)安装 MySQL
CentOS版本:CentOS 7 三种安装方式: 一、通过 yum 安装,最简单,一键安装,全程无忧。 二、通过 rpm 包安装,需具备基础概念及常规操作。 三、通过 gz 包安装,需具备配置相关操作。 --------…...

C++ 使用CURL开源库实现Http/Https的get/post请求进行字串和文件传输
CURL开源库介绍 CURL 是一个功能强大的开源库,用于在各种平台上进行网络数据传输。它支持众多的网络协议,像 HTTP、HTTPS、FTP、SMTP 等,能让开发者方便地在程序里实现与远程服务器的通信。 CURL 可以在 Windows、Linux、macOS 等多种操作系…...

面试题-SpringCloud的启动流程
关键词 prepareEnvironmentBootstrapApplicationListenerBootStrap Context(启动应用上下文)Environment中bootstrap属性 面试回答 引入SpringCloud相关组件后,均会引入一个spring-cloud-context的依赖包,这个项目的META-INF/s…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...