【Agent的革命之路——LangGraph】如何使用config
有时我们希望在调用代理时能够对其进行配置。这包括配置使用哪个语言模型(LLM)等例子。下面我们将通过一个示例来详细介绍如何进行这样的配置。
在介绍 configurable 之前我们先介绍一下 Langchain 的 RunnableConfig。RunnableConfig是一个配置对象,用于自定义运行链(Chain)、工具(Tool)或任何可运行组件的行为。它允许我们控制执行过程中的各种参数和行为,是LangChain统一接口的重要组成部分。
它的主要功能和属性包括:
- callbacks: 允许你注册回调函数,在执行过程中的不同阶段触发,用于日志记录、监控或调试。
- tags:为执行添加标签,便于追踪和分类。
- metadata: 添加元数据信息,可用于记录额外的上下文信息。
- run_name:为当前运行指定一个名称,在追踪和日志中使用。
- configurable: 允许你在运行时动态配置组件。 运行时为此Runnable或子Runnable上通过.configurable_fields()或.configurable_alternatives()方法之前设为可配置的属性提供的值。查看.output_schema()获取已设为可配置的属性的描述。
- max_concurrency: 控制并发执行的最大数量。
- recursion_limit: 设置递归调用的最大次数。如果未提供,则默认为25。
- run_id: 这是调用的追踪器运行的唯一标识符。如果未提供,将生成一个新的UUID。
定义图
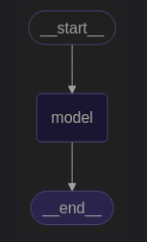
首先我们先创建一个非常简单的图:
import operator
from typing import Annotated, Sequence
from typing_extensions import TypedDictfrom langchain_openai import ChatOpenAI
from langchain_core.messages import BaseMessage, HumanMessagefrom langgraph.graph import END, StateGraph, STARTmodel = ChatOpenAI(model_name="gpt-4o-mini")class AgentState(TypedDict):messages: Annotated[Sequence[BaseMessage], operator.add]def _call_model(state):# state["messages"]response = model.invoke(state["messages"])return {"messages": [response]}# Define a new graph
builder = StateGraph(AgentState)
builder.add_node("model", _call_model)
builder.add_edge(START, "model")
builder.add_edge("model", END)graph = builder.compile()from IPython.display import display, Image
display(Image(graph.get_graph().draw_mermaid_png()))
得到如下图
configurable
然后为了扩展这个例子以允许用户从多个语言模型(LLM)中进行选择,并通过配置传递这些信息,我们可以将配置信息放在一个名为 configurable 的 key 内。这种方式可以确保配置信息与输入数据分离,不作为状态的一部分进行跟踪。
from langchain_openai import ChatOpenAI
from typing import Optional
from langchain_core.runnables.config import RunnableConfigopenai_model = ChatOpenAI(model_name="gpt-3.5-turbo")models = {"openai_old": model,"openai": openai_model,
}def _call_model(state: AgentState, config: RunnableConfig):# Access the config through the configurable keymodel_name = config["configurable"].get("model", "openai_old")model = models[model_name]response = model.invoke(state["messages"])return {"messages": [response]}# Define a new graph
builder = StateGraph(AgentState)
builder.add_node("model", _call_model)
builder.add_edge(START, "model")
builder.add_edge("model", END)graph = builder.compile()from IPython.display import display, Image
display(Image(graph.get_graph().draw_mermaid_png()))
然后我们调用这个选择特定配置的图,
graph.invoke({"messages": [HumanMessage(content="hi")]})
得到结果
{'messages': [HumanMessage(content='hi', additional_kwargs={}, response_metadata={}),AIMessage(content='Hello! How can I assist you today?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 9, 'prompt_tokens': 8, 'total_tokens': 17, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_b705f0c291', 'finish_reason': 'stop', 'logprobs': None}, id='run-78fbb4d3-e64e-41dc-871f-fe08e3317f07-0', usage_metadata={'input_tokens': 8, 'output_tokens': 9, 'total_tokens': 17, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
我们可以通过传入配置来调用它,以使其使用不同的模型。
config = {"configurable": {"model": "openai"}}
graph.invoke({"messages": [HumanMessage(content="hi")]}, config=config)
得到下面结果
{'messages': [HumanMessage(content='hi', additional_kwargs={}, response_metadata={}),AIMessage(content='Hello! How can I assist you today?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 9, 'prompt_tokens': 8, 'total_tokens': 17, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': 'fp_0165350fbb', 'finish_reason': 'stop', 'logprobs': None}, id='run-1fe66150-1579-4bba-b35f-06c3f66cd2d2-0', usage_metadata={'input_tokens': 8, 'output_tokens': 9, 'total_tokens': 17, 'input_token_details': {}, 'output_token_details': {}})]}
我们还可以调整图形以进行更多配置!例如系统消息。
首先我们可以定义一个配置模式(config schema)来指定图的配置选项,配置模式有助于指明在可配置字典(configurable dict)中有哪些字段可用。
from langchain_core.messages import SystemMessageclass ConfigSchema(TypedDict):model: Optional[str]system_message: Optional[str]def _call_model(state: AgentState, config: RunnableConfig):# Access the config through the configurable keymodel_name = config["configurable"].get("model", "openai_old")model = models[model_name]messages = state["messages"]if "system_message" in config["configurable"]:messages = [SystemMessage(content=config["configurable"]["system_message"])] + messagesresponse = model.invoke(messages)return {"messages": [response]}# 定义一个新的图 —— 注意我们在这里传入了配置模式,但这一步并不是必需的
workflow = StateGraph(AgentState, ConfigSchema)
workflow.add_node("model", _call_model)
workflow.add_edge(START, "model")
workflow.add_edge("model", END)graph = workflow.compile()
得到下面结果:
graph.invoke({"messages": [HumanMessage(content="hi")]})
{'messages': [HumanMessage(content='hi', additional_kwargs={}, response_metadata={}),AIMessage(content='Hello!', additional_kwargs={}, response_metadata={'id': 'msg_01VgCANVHr14PsHJSXyKkLVh', 'model': 'claude-2.1', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 10, 'output_tokens': 6}}, id='run-f8c5f18c-be58-4e44-9a4e-d43692d7eed1-0', usage_metadata={'input_tokens': 10, 'output_tokens': 6, 'total_tokens': 16})]}
config = {"configurable": {"system_message": "用韩语回答"}}
graph.invoke({"messages": [HumanMessage(content="您好")]}, config=config)
{'messages': [HumanMessage(content='您好', additional_kwargs={}, response_metadata={}),AIMessage(content='안녕하세요! 어떻게 도와드릴까요?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 16, 'total_tokens': 26, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_ded0d14823', 'finish_reason': 'stop', 'logprobs': None}, id='run-1046d220-3a32-4792-9665-0a14528f9d53-0', usage_metadata={'input_tokens': 16, 'output_tokens': 10, 'total_tokens': 26, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
相关文章:
【Agent的革命之路——LangGraph】如何使用config
有时我们希望在调用代理时能够对其进行配置。这包括配置使用哪个语言模型(LLM)等例子。下面我们将通过一个示例来详细介绍如何进行这样的配置。 在介绍 configurable 之前我们先介绍一下 Langchain 的 RunnableConfig。RunnableConfig是一个配置对象&…...

ArcGIS操作:15 计算点的经纬度,并添加到属性表
注意:需要转化为地理坐标系 1、打开属性表,添加字段 2、计算字段(以计算纬度为例 !Shape!.centroid.Y ) 3、效果...

Docker基础入门
第 1 章:核心概念与安装配置 本章首先介绍Docker 的三大核心概念: 镜像 (Image)容器(Container)仓库(Repository) 只有理解了这三个核心概念,才能顺利地理解Docker容器的整个生命周期。 随后࿰…...

【Linux】详谈 基础I/O
目录 一、理解文件 狭义的理解: 广义理解: 文件操作的归类认知 系统角度 二、系统文件I/O 2.1 标志位的传递 系统级接口open 编辑 open返回值 写入文件 读文件 三、文件描述符 3.1(0 & 1 & 2) 3.2 文件描…...

爬虫案例七Python协程爬取视频
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Python协程爬取视频 前言 提示:这里可以添加本文要记录的大概内容: 爬虫案例七协程爬取视频 提示:以下是本篇文章正文…...

[20250304] 关于 RISC-V芯片 的介绍
[20250304] 关于 RISC-V芯片 的介绍 1. 调研报告 一、RISC-V 芯片结构分析 RISC-V 芯片基于开源指令集架构(ISA),其核心优势在于模块化设计与高度灵活性。 指令集架构 基础指令集:包含 RV32I(32 位)、R…...
一学就会:A*算法详细介绍(Python)
📢本篇文章是博主人工智能学习以及算法研究时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在&am…...
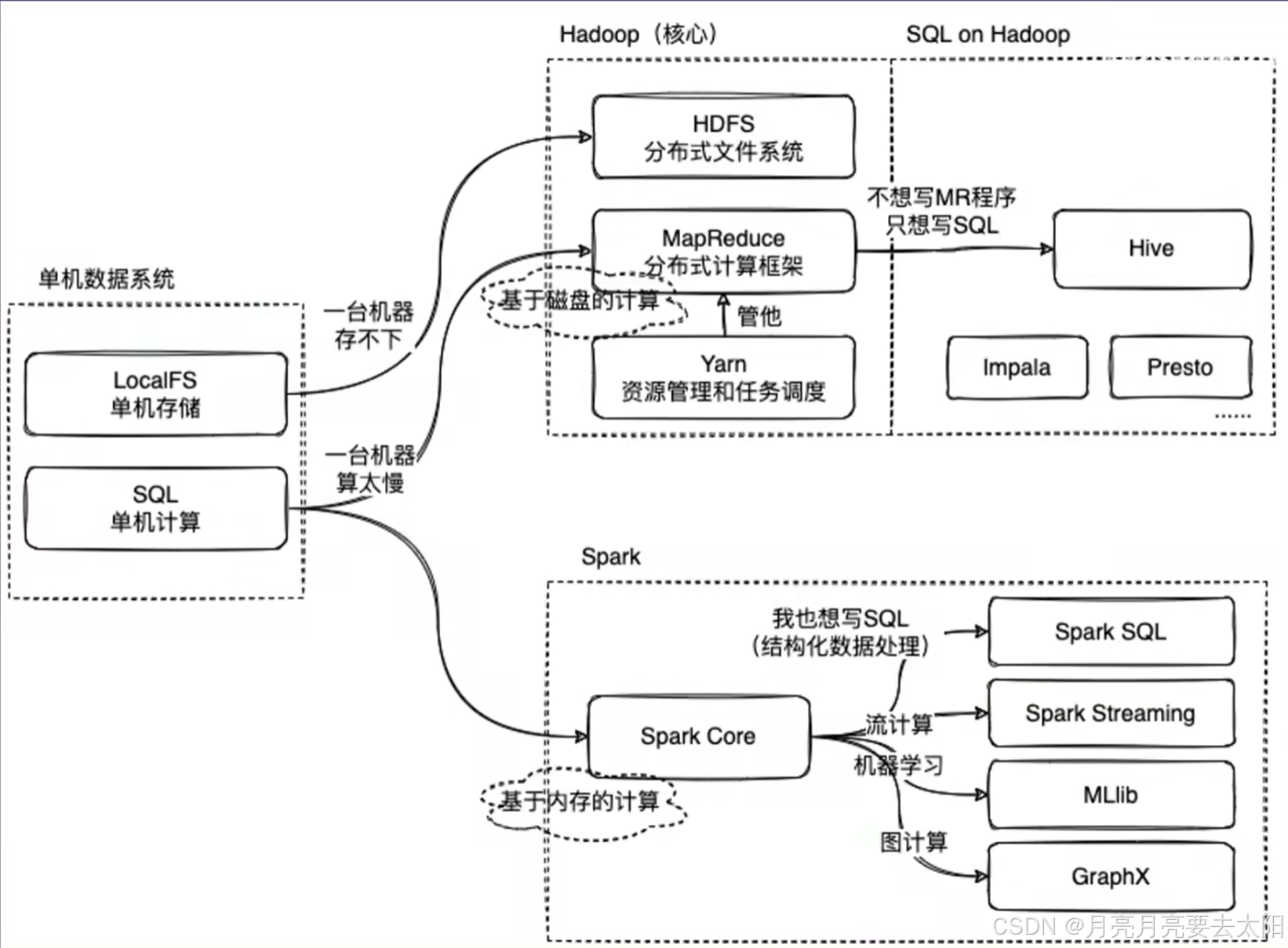
Hadoop、Hive、Spark的关系
Part1:Hadoop、Hive、Spark关系概览 1、MapReduce on Hadoop 和spark都是数据计算框架,一般认为spark的速度比MR快2-3倍。 2、mapreduce是数据计算的过程,map将一个任务分成多个小任务,reduce的部分将结果汇总之后返回。 3、HIv…...

Excel·VBA江西省预算一体化工资表一键处理
每月制作工资表导出为Excel后都需要调整格式,删除0数据的列、对工资表项目进行排序、打印设置等等,有些单位还分有“行政”、“事业”2个工资表就需要操作2次。显然,这种重复操作的问题,可以使用VBA代码解决 目录 代码使用说明1&a…...
23种设计模式简介
一、创建型(5种) 1.工厂方法 总店定义制作流程,分店各自实现特色披萨(北京店-烤鸭披萨,上海店-蟹粉披萨) 2.抽象工厂 套餐工厂(家庭装含大披萨薯条,情侣装含双拼披萨红酒&#…...

python fire 库与 sys.argv 处理命令行参数
fire库 Python Fire 由Google开发,它使得命令行接口(CLI)的创建变得容易。使用Python Fire,可以将Python对象(如类、函数或字典)转换为可以从终端运行的命令行工具。这能够以一种简单而直观的方式与你的Py…...

PDF处理控件Aspose.PDF,如何实现企业级PDF处理
PDF处理为何成为开发者的“隐形雷区”? “手动调整200页PDF目录耗时3天,扫描件文字识别错误导致数据混乱,跨平台渲染格式崩坏引发客户投诉……” 作为开发者,你是否也在为PDF处理的复杂细节消耗大量精力?Aspose.PDF凭…...
Spring(1)——mvc概念,部分常用注解
1、什么是Spring Web MVC? Spring MVC 是一种基于 Java 的实现了 MVC(Model-View-Controller,模型 - 视图 - 控制器)设计模式的 Web 应用框架,它是 Spring 框架的一个重要组成部分,用于构建 Web 应用程序。…...
C语言(23)
字符串函数 11.strstr函数 1.1函数介绍: 头文件:string.h char *strstr ( const char * str1,const char *str2); 作用:在一个字符串(str1)中寻找另外一个字符串(str2)是否出现过 如果找到…...
Immich自托管服务的本地化部署与随时随地安全便捷在线访问数据
文章目录 前言1.关于Immich2.安装Docker3.本地部署Immich4.Immich体验5.安装cpolar内网穿透6.创建远程链接公网地址7.使用固定公网地址远程访问 前言 小伙伴们,你们好呀!今天要给大家揭秘一个超炫的技能——如何把自家电脑变成私人云相册,并…...
基于SpringBoot的在线付费问答系统设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

【Linux】信号处理以及补充知识
目录 一、信号被处理的时机: 1、理解: 2、内核态与用户态: 1、概念: 2、重谈地址空间: 3、处理时机: 补充知识: 1、sigaction: 2、函数重入: 3、volatile&…...

pandas——to_datatime用法
Pandas中pd.to_datetime的用法及示例 pd.to_datetime 是 Pandas 库中用于将字符串、整数或列表转换为日期时间(datetime)对象的核心函数。它在处理时间序列数据时至关重要,能够灵活解析多种日期格式并统一为标准时间类型。以下是其核心用法及…...

《DataWorks 深度洞察:量子机器学习重塑深度学习架构,决胜复杂数据战场》
在数字化浪潮汹涌澎湃的当下,大数据已然成为推动各行业发展的核心动力。身处这一时代洪流,企业对数据的处理与分析能力,直接关乎其竞争力的高低。阿里巴巴的DataWorks作为大数据领域的扛鼎之作,凭借强大的数据处理与分析能力&…...

Java 大视界 -- 基于 Java 的大数据实时数据处理框架性能评测与选型建议(121)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...
一些实用的chrome扩展0x01
简介 浏览器扩展程序有助于自动化任务、查找隐藏的漏洞、隐藏自身痕迹。以下列出了一些必备扩展程序,无论是测试应用程序、搜寻漏洞还是收集情报,它们都能提升工作流程。 FoxyProxy 代理管理工具,此扩展简化了使用代理(如 Burp…...

Python的__call__ 方法
在 Python 中,__call__ 是一个特殊的魔术方法(magic method),它允许一个类的实例像函数一样被调用。当你在一个对象后面加上 () 并执行时(例如 obj()),Python 会自动调用该对象的 __call__ 方法…...