C++ 链表List使用与实现:拷贝交换与高效迭代器细致讲解
目录
list的使用:
构造与赋值
元素访问
修改操作
容量查询
链表特有操作
拼接(Splice)
C++11 新增方法
注意:
stl_list的模拟实现:
一、链表节点设计的艺术
1.1 结构体 vs 类的选择
二、迭代器实现的精髓
2.1 为什么需要自定义迭代器?(迭代器在本文章后面还会更新)
2.2 运算符重载的细节实现
三、链表类的完整实现
3.1 构造函数与哨兵节点
3.2 迭代器范围获取
3.3 核心操作实现解析
插入操作:insert()
尾插:push_back()
头插:push_front()
删除操作:erase()
尾删:pop_back()
头删:pop_front()
辅助函数实现size()、empty()
析构函数销毁链表x~list()、清除数据clear()
拷贝构造list(const list& lt)
赋值list& operator==()、swap()
为什么参数要「按值传递」?
运作原理:
优势:
四、关键问题深度探讨
自定义类型(更新原iterator类)编辑
3.方法三:重载 operator->()
内存布局可视化
PrintList()、const_iterator
方法二:方法一使代码冗余,我们需要学习一种方法能够解决这个问题。
完整代码:
本文章主要简要讲解list容器的使用与详细讲解list模拟实现以及相关问题上,所用到完整代码在文章末尾
list的使用:
构造与赋值
-
构造函数
list<int> lt; // 空链表 list<int> lt2(5, 10); // 5 个元素,每个初始化为 10 list<int> lt3(lt2.begin(), lt2.end()); // 通过迭代器范围构造 list<int> lt4 = {1, 2, 3}; // 初始化列表(C++11) -
赋值操作
lt = lt2; // 深拷贝赋值 lt.assign(3, 100); // 替换内容为 3 个 100 lt.assign(lt2.begin(), lt2.end()); // 通过迭代器赋值
元素访问
-
首尾元素front()、back()
int front = lt.front(); // 首元素(不可修改空链表) int back = lt.back(); // 尾元素(不可修改空链表) -
迭代器begin()、rbegin()
list<int>::iterator it = lt.begin(); // 正向迭代器 list<int>::reverse_iterator rit = lt.rbegin(); // 反向迭代器
修改操作
-
插入
lt.push_front(0); // 头部插入 lt.push_back(4); // 尾部插入auto pos = lt.begin(); lt.insert(pos, 99); // 在迭代器位置前插入 lt.insert(pos, 3, 88); // 插入 3 个 88 -
删除
lt.pop_front(); // 删除头部元素 lt.pop_back(); // 删除尾部元素lt.erase(pos); // 删除迭代器位置元素 lt.erase(pos, lt.end()); // 删除迭代器范围lt.remove(4); // 删除所有值为 4 的节点 -
清空链表(clear)
lt.clear(); // 清空所有元素
容量查询
bool isEmpty = lt.empty(); // 是否为空
size_t size = lt.size(); // 元素个数(O(n) 时间复杂度!)
lt.resize(10); // 调整链表大小链表特有操作
-
拼接(Splice)
// 将 lt2 的全部内容移动到 lt 的 pos 位置前 lt.splice(pos, lt2); // lt2 会被清空// 移动单个元素 auto it2 = lt2.begin(); //pos为目标位置,it2为需要移动的单个元素,拿走it2,再尾差pos,改变节点的指向 lt.splice(pos, lt2, it2);// 移动范围 lt.splice(pos, lt2, lt2.begin(), lt2.end());注意:被转移的节点会被清空
-
合并(Merge)
// 前提:lt 和 lt2 必须已按相同顺序排序(升序或降序) lt.sort(); // 默认升序 lt2.sort(); lt.merge(lt2); // 合并后 lt2 为空 -
排序(Sort)
lt.sort(); // 默认升序 lt.sort(greater<int>()); // 降序(需包含 <functional>) -
去重(Unique)
lt.sort(); // 必须先排序! lt.unique(); // 删除连续重复元素 -
反转(Reverse)
lt.reverse(); // 反转链表顺序
C++11 新增方法
-
原地构造(Emplace)
lt.emplace_front(10); // 在头部直接构造对象(避免拷贝) lt.emplace_back(20); // 尾部构造 lt.emplace(pos, 30); // 指定位置构造 -
移动语义
list<int> lt5 = std::move(lt); // 移动构造(高效转移资源)
注意:
-
merge 前必须排序
// 错误示例:lt 是降序,lt1 是升序 lt.sort(greater<int>()); // 降序 lt1.sort(); // 升序 lt.merge(lt1); // 未定义行为!// 正确做法:统一顺序 lt.sort(); // 升序 lt1.sort(); lt.merge(lt1); -
unique 必须配合 sort
// 错误用法:未排序时去重 lt.unique(); // 只能删除连续重复// 正确用法 lt.sort(); lt.unique(); // 删除所有重复 -
迭代器失效
-
在插入/删除操作后,指向被修改位置的迭代器会失效,需重新获取。
-
stl_list的模拟实现:
一、链表节点设计的艺术
1.1 结构体 vs 类的选择
template<class T>
struct ListNode {ListNode<T>* _next; // 后继指针ListNode<T>* _prev; // 前驱指针T _data; // 存储数据// 默认构造函数初始化三要素ListNode(const T& x = T()):_next(nullptr),_prev(nullptr),_data(x){}
};设计要点分析:
使用
struct而非class的深层考量:
默认public访问权限,便于链表类直接操作节点指针
符合C++标准库实现惯例,增强代码可读性
节点本身无需封装,属于链表内部实现细节
三指针设计哲学:
_next和_prev构成双向链接的基石
_data采用模板类型,支持任意数据类型存储默认构造函数的巧妙设计:同时支持无参构造和值初始化
内存布局可视化:
+------+ +------+ +------+ | prev |<-->| prev |<-->| prev | | data | | data | | data | | next |--->| next |--->| next | +------+ +------+ +------+
二、迭代器实现的精髓
2.1 为什么需要自定义迭代器?(迭代器在本文章后面还会更新)
template<class T>
struct ListIterator {typedef ListNode<T> Node;typedef ListIterator<T> Self;Node* _node; // 核心:封装节点指针// 构造函数实现指针到迭代器的转换ListIterator(Node* node):_node(node){}
};关键问题解答:
原生指针的局限性:
无法直接通过++操作跳转到下一个节点
解引用操作不符合链表数据访问需求
无法正确比较链表节点的位置关系
迭代器设计模式的优势:
统一容器访问接口
隐藏底层数据结构差异
支持算法泛型编程
2.2 运算符重载的细节实现
// 前置++:直接修改自身
Self& operator++() {_node = _node->_next; // 关键跳转逻辑return *this;
}// 后置++:返回临时对象
Self operator++(int) {Self tmp(*this); // 拷贝当前状态_node = _node->_next;return tmp; // 返回旧值
}//1. --it
Self& operator--()
{_node = _node->_prev;return *this;
}
//2. it--
Self operator--(int)
{Self tmp(*this);_node = _node->_prev;return tmp;
}// 解引用:访问节点数据
T& operator*() {return _node->_data; // 返回引用支持修改
}//两个迭代器是否相等?
bool operator!=(const Self& it)
{//即比较节点的指针,节点的指针相同,他们就相同return _node != it._node;
}// 相等性比较的本质
bool operator==(const Self& it) {return _node == it._node; // 指针地址比较
}实现细节剖析:
前置与后置++的差异:
性能考量:避免不必要的拷贝
语法区分:int参数占位符
解引用操作的注意事项:
返回引用以实现左值操作
与const迭代器的兼容性设计
比较大小是否需要重载?不需要,一个类是否要重载一个运算符,需要看他是否有意义,节点后面的地址不能保证比前面的地址大,所以没什么意义。不需要重载
三、链表类的完整实现
3.1 构造函数与哨兵节点
重新定义类型名称便于阅读:
template<class T>class list {typedef ListNode<T> Node;public://在这里定义好类型typedef ListIterator<T> iterator;};
list() {_head = new Node; // 创建哨兵节点_head->_next = _head; // 自环初始化_head->_prev = _head;_size = 0; // 尺寸计数器
}哨兵节点的精妙之处:
统一空链表和非空链表的操作
简化边界条件处理
保证迭代器end()的有效性
内存布局示意图:
[HEAD] <-> [NODE1] <-> [NODE2] <-> [HEAD]
3.2 迭代器范围获取
iterator begin() {// 1.有名对象//iterator it(_head->_next);//return it;// 2.隐式类型转换(单参数的构造函数支持隐式类型的转换)://return _head->_next;// 3.匿名对象 return iterator(_head->_next); // 隐式转换 }iterator end() {return iterator(_head); // 哨兵即终点 }
统一使用匿名对象构造迭代器
begin()指向首元节点,end()指向哨兵节点
支持C++11范围for循环的关键
3.3 核心操作实现解析
插入操作:insert()
选定位置插入:insert()
//在pos位置插入data
void insert(iterator pos, const T& data) {Node* current = pos._node;Node* newnode = new Node(data); // 内存申请// 四步链接法Node* prev = current->_prev;prev->_next = newnode;newnode->_prev = prev;newnode->_next = current;current->_prev = newnode;++_size; // 维护尺寸
}尾插:push_back()
void push_back(const T& x)
{//1.还未写insert()时写的push_back()//Node* newnode = new Node(x);//Node* tail = _head->_prev; //指定被插的节点//tail->_next = newnode;//newnode->_prev = tail;//newnode->_next = _head;//_head->_prev = newnode;//2.写了insert()后写的push_back()insert(end(), x);
}头插:push_front()
void push_front(const T& x)
{insert(begin(), x);
}四步链接法示意图:
Before: [PREV] <-> [CURRENT]
After: [PREV] <-> [NEWNODE] <-> [CURRENT]删除操作:erase()
iterator erase(iterator pos) {Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;// 重新链接相邻节点prev->_next = next;next->_prev = prev;delete cur; // 释放内存--_size; // 更新尺寸return iterator(next); // 返回有效迭代器 }迭代器失效问题:
删除操作使当前迭代器失效
返回新迭代器的必要性
正确使用模式示例:
auto it = lst.begin(); while(it != lst.end()) {if(condition) {it = lst.erase(it); // 接收返回值} else {++it;} }
尾删:pop_back()
//尾删 ,要--,不然删的是head(哨兵位) void pop_back() {erase(--end()); }
头删:pop_front()
//头删 void pop_front() {erase(begin()); }
辅助函数实现size()、empty()
size_t size() const { return _size; } // O(1)时间复杂度bool empty() { return _size == 0; } // 高效判空性能优化点:
使用_size变量避免遍历计数
empty()的常数时间复杂度
clear()的通用实现方式
析构函数销毁链表x~list()、清除数据clear()
//清除掉所有数据,有没有清除掉头结点?并没有(在析构函数中清除)
void clear()
{iterator it = begin();while (it != end()){it = erase(it);}
}~list()
{clear();delete _head;_head = nullptr;
}拷贝构造list(const list<T>& lt)
为了拷贝构造的实现方便我们将空链表的制作做了一个成员函数,因此默认的无参构造函数可以直接使用这个成员函数
void empty_init(){//创建一个头结点_head = new Node;_head->_next = _head;_head->_prev = _head;_size = 0;x}//构造函数 list(){empty_init();}拷贝构造,默认拷贝构造是浅拷贝,所以需要我们自己实现一个深拷贝(防止指向同一个空间,析构两次同一空间导致错误)
//lt2(lt1) list(const list<T>& lt) {//首先:在这里我们先创建空链表//也就是:lt2.empty_init()直接给lt2创建一个空链表即创建一个哨兵位头结点empty_init();//直接遍历一遍lt1,尾插for (auto& e : lt)//这里一定要加引用,因为如果T是string,就浅拷贝了{push_back(e);} }
赋值list<T>& operator==()、swap()
调用库里的swap(<algorithm>)
void swap(list<T>& lt)
{std::swap(_head, lt._head);std::swap(_size, lt._size);
}//赋值
//lt1 = lt3
list<T>& operator=(list<T> lt) //lt = lt3;
{swap(lt);
}为什么参数要「按值传递」?
我的代码中赋值运算符的实现如下:
list<T>& operator=(list<T> lt) { // 参数按值传递swap(lt);return *this; }运作原理:
按值传递参数:调用
operator=时,lt是传入对象的副本(触发拷贝构造函数)。交换资源:通过
swap将当前对象的_head和_size与副本lt交换。自动析构副本:函数结束时,临时副本
lt被析构,释放原对象的旧资源。优势:
天然处理自我赋值:即使
lt1 = lt1;,参数lt是原对象的副本,交换后旧资源由副本释放。异常安全:拷贝过程(生成
lt)在交换前完成,若拷贝失败不会影响原对象。
小技巧:需要析构,就需要自己写深拷贝,不需要析构,默认浅拷贝
四、关键问题深度探讨
自定义类型(更新原iterator类)
出现报错的原因是:内置类型才支持流插入提取,而A是自定义类型,所以在这里不支持,需要自己写运算符重载。
1.方法一:改变提取方式
cout << (*it)._a1 << ":" << (*it)._a2 << endl;2.方法二:写流插入
省略
3.方法三:重载 operator->()
//it->T* operator->(){return &_node->_data;//返回的是_data的地址}实际上用箭头会方便很多。
编译器为了可读性,省略了一个→
cout << it->_a1 << ":" << it->_a2 << endl;实现原理:
编译器隐藏了一个箭头实际上是:
it->->_a1
(it.operator->())->_a1, (it.operator->())返回的是data的地址即T*,在这里就是我们的自定义类型 A*,有了A*此时就可以访问直接访问结构体成员_a1,_a2。从而得到他们的值。这里将it的行为当成A* 。
内存布局可视化
+---------------------+ | ListIterator对象 | | _node: 0x1000 | +---------------------+|v +---------------------+ +---------------------+ | ListNode<A>节点 | | A结构体实例 | | _prev: 0x2000 | | _a1: 1 | | _next: 0x3000 | | _a2: 5 | | _data: 0x4000 |--->+---------------------+ +---------------------+当调用
it->_a1时:
通过
_node找到数据节点获取
_data的内存地址(0x4000)通过指针访问结构体成员
_a1



PrintList()、const_iterator

因为现在的clt是一个const成员变量,而begin()、end()还未加const
加完const后编译通过:权限可以缩小但是不能扩大,非const成员可以调用const成员,const成员不能调用非const成员
iterator begin() const{return iterator(_head->_next);}iterator end() const{return iterator(_head);}这样真的就没有问题了吗?
按理来说,普通迭代器是能够修改的,但这里是const,是不能修改的:

实际上我们测试了一下,被修改了,说明代码有问题
原因出在这里,由于这里可以让非const对象访问,访问后返回的是普通迭代器,普通迭代器是支持被修改的

所以我们需要再重载const版本的,返回值也要记得修改
//const版本
const_iterator begin() const
{return const_iterator(_head->_next);
}const_iterator end() const
{return const_iterator(_head);
}const迭代器,需要的不是是迭代器不能被修改,而是迭代器指向的的内容不能被修改,所以不能用const iterator,因为它是避免迭代器被修改。
方法一:需要重新定义一个ListConstIterator的类,且在链表前面定义类型的时候加上const_iterator:
对于ListConstIterator类,实际上只有的这里的逻辑和ListIterator不同:*it += 10会显示报错了

图示:


方法二:方法一使代码冗余,我们需要学习一种方法能够解决这个问题。

而我们知道,凡是类型不同就可以用模版来解决

Ref-->reference,引用 Ptr -->Pointer
如图:本质相当于我们写了一个类模版,编译器实例化生成了两个类

最后达到目的。
完整代码:
#pragma once
#include<assert.h>
#include<iostream>
//#include<vector>
//#include<list>
#include<algorithm>using namespace std;
namespace bit
{template<class T>//注意一下这里用的struct,数据想要全部公有的时候用structstruct ListNode{ListNode<T>* _next;ListNode<T>* _prev;T _data;ListNode(const T& x = T()):_next(nullptr),_prev(nullptr),_data(x){}private:};//普通迭代器template<class T ,class Ref , class Ptr>struct ListIterator{typedef ListNode<T> Node;typedef ListIterator<T, Ref, Ptr> Self;Node* _node;//从本源来说迭代器还是一个节点的指针ListIterator(Node* node):_node(node){}//我们最想实现的是对于指针的++,即运算符的重载://1.++itSelf& operator++(){//++是怎么+到下一个节点的,即交换值_node = _node->_next;return *this;}//2.it++Self operator++(int){//1.调用拷贝构造,这里是一个浅拷贝,把一个迭代器给另外一个迭代器,it1,it2都指向一个节点Self tmp(*this);_node = _node->_next;//2.迭代器是否需要写析构?不需要,因为资源是属于链表的return tmp;}//1. --itSelf& operator--(){_node = _node->_prev;return *this;}//2. it--Self operator--(int){Self tmp(*this);_node = _node->_prev;return tmp;}//解引用:*it 返回的是_data//T& operator*()Ref operator*(){return _node->_data;}//it->//T* operator->()Ptr operator->(){return &_node->_data;//返回的是_data的地址}//两个迭代器是否相等?bool operator!=(const Self& it){//即比较节点的指针,节点的指针相同,他们就相同return _node != it._node;}bool operator==(const Self& it){return _node == it._node;}//比较大小是否需要重载?不需要,一个类是否要重载一个运算符,需要看他是否有意义//节点后面的地址不能保证比前面的地址大,所以没什么意义。不需要重载//迭代器的重点:指针,用类似指针的方式来访问容器//begin()和end()谁能提供,链表};//迭代器//template<class T>//struct ListConstIterator//{// typedef ListNode<T> Node;// typedef ListConstIterator<T> Self;// Node* _node;// //从本源来说迭代器还是一个节点的指针// ListConstIterator(Node* node)// :_node(node)// {// }// //我们最想实现的是对于指针的++,即运算符的重载:// //1.++it// Self& operator++()// {// //++是怎么+到下一个节点的,即交换值// _node = _node->_next;// return *this;// }// //2.it++// Self operator++(int)// {// //1.调用拷贝构造,这里是一个浅拷贝,把一个迭代器给另外一个迭代器,it1,it2都指向一个节点// Self tmp(*this);// _node = _node->_next;// //2.迭代器是否需要写析构?不需要,因为资源是属于链表的// return tmp;// }// //1. --it// Self& operator--()// {// _node = _node->_prev;// return *this;// }// //2. it--// Self operator--(int)// {// Self tmp(*this);// _node = _node->_prev;// return tmp;// }// //如何控制*it不能被修改,即在这里加const// const T& operator*()// {// return _node->_data;// }// //如何控制it->不能被修改,即在这里加const // const T* operator->()// {// return &_node->_data;//返回的是_data的地址// }// //两个迭代器是否相等?// bool operator!=(const Self& it)// {// //即比较节点的指针,节点的指针相同,他们就相同// return _node != it._node;// }// bool operator==(const Self& it)// {// return _node == it._node;// }// //比较大小是否需要重载?不需要,一个类是否要重载一个运算符,需要看他是否有意义// //节点后面的地址不能保证比前面的地址大,所以没什么意义。不需要重载// //迭代器的重点:指针,用类似指针的方式来访问容器// //begin()和end()谁能提供,链表//};template<class T>class list {typedef ListNode<T> Node;public://在这里定义好类型//typedef ListIterator<T> iterator;//typedef ListConstIterator<T> const_iterator;typedef ListIterator<T, T&, T*> iterator;typedef ListIterator<T,const T&,const T*> const_iterator;void empty_init(){//创建空链表_head = new Node;_head->_next = _head;_head->_prev = _head;_size = 0;}//构造函数 list(){empty_init();}//清除掉所有数据,有没有清除掉头结点?并没有(在析构函数中清除)void clear(){iterator it = begin();while (it != end()){it = erase(it);}}//析构函数~list(){clear();delete _head;_head = nullptr;}//lt2(lt1)//拷贝构造,默认拷贝构造是浅拷贝,所以需要我们自己实现一个list(const list<T>& lt){//首先:在这里我们先创建空链表//也就是:lt2.empty_init()直接给lt2创建一个空链表empty_init();//直接遍历一遍lt1,尾插for (auto& e : lt)//这里一定要加引用,因为如果T是string,就浅拷贝了{push_back(e);}}void swap(list<T>& lt){std::swap(_head, lt._head);std::swap(_size, lt._size);}//赋值,按值传递//lt1 = lt3list<T>& operator=(list<T> lt) //lt = lt3;{swap(lt);return *this;}//迭代器//1.原生指针能不能充当迭代器?不可以,这是建立在物理空间连续的情况下(画图解释)//2.++Node*能不能加到下一个节点,节点的解引用能取到当前节点的数据吗?不能//并且新new出来的地址和原来的地址也不会相同,头插和中间插入怎么保证在物理空间连续?从功能上未解决//因此我们在此重新封装一个类(内嵌类、typedef(在类域)),想一想日期类,可以日期相加,做各种操作的是合理的,使用封装的类//来重载运算符,重载运算符后我就可以自定义这些运算符的行为//普通版本iterator begin() {// 1.有名对象//iterator it(_head->_next);//return it;// 2.隐式类型转换(单参数的构造函数支持隐式类型的转换)://return _head->_next;// 3.匿名对象return iterator(_head->_next);}//end()是最后一个数据的下一个位置iterator end() {return iterator(_head);}//const版本const_iterator begin() const{// 1.有名对象//iterator it(_head->_next);//return it;// 2.隐式类型转换(单参数的构造函数支持隐式类型的转换)://return _head->_next;// 3.匿名对象return const_iterator(_head->_next);}//end()是最后一个数据的下一个位置const_iterator end() const{return const_iterator(_head);}//注意这里我们都应该通过begin()、end()控制迭代器而不是控制节点了//尾插void push_back(const T& x){//1.还未写insert()时写的push_back()//Node* newnode = new Node(x);//Node* tail = _head->_prev; //指定被插的节点//tail->_next = newnode;//newnode->_prev = tail;//newnode->_next = _head;//_head->_prev = newnode;//2.写了insert()后写的push_back()insert(end(), x);}//头插void push_front(const T& x){insert(begin(), x);}//尾删 ,要--,不然删的是head(哨兵位)void pop_back(){erase(--end()); }//头删void pop_front(){erase(begin());}//在pos位置插入datavoid insert(iterator pos, const T& data){Node* current = pos._node; Node* newnode = new Node(data);Node* prev = current->_prev;//prev newnode current prev->_next = newnode;newnode->_prev = prev;newnode->_next = current;current->_prev = newnode;++_size;}//删除pos位置iterator erase(iterator pos) //请注意这里的pos位置迭代器会失效,为什么?可以看我的上篇vector中目录的更新erase(){//拿到当前位置Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;//prev cur nextprev->_next = next;next->_prev = prev;delete cur;--_size;return iterator(next);//解决办法就是返回下一个位置的迭代器}size_t size() const{库里面:1. 遍历一遍计数//for ()//{//}//2. 我们通过构造函数来初始化,给insert、erase加上_size便于计数return _size;}bool empty(){return _size == 0;}//resize()不常用,我们这里不做模拟,没有扩容的概念,比我当前的_size大就尾插入,比当前的_size小就尾删private:Node* _head;size_t _size;};void test_list1(){list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_back(5);//迭代器测试代码//这里需要遍历数据,所以要用到迭代器,于是现在我们写迭代器代码:list<int>::iterator it = lt.begin();cout << *it << endl;while (it != lt.end()){cout << *it << " ";++it;}cout << endl;lt.push_front(10);lt.push_front(20);lt.push_front(30);for (auto e : lt){cout << e << " ";}cout << endl;lt.pop_back();lt.pop_front();for (auto e : lt){cout << e << " ";}cout << endl;}//迭代器进一步优化struct A{int _a1;int _a2;A(int a1 = 0, int a2 = 0):_a1(a1),_a2(a2){}};void test_list2(){list<A> lt;//如果这里有自定义类型AA aa1(1, 5);A aa2 = { 1,1 };lt.push_back(aa1);lt.push_back(A(2, 3));lt.push_back({ 4,5 });lt.push_back(aa2);list<A>::iterator it = lt.begin();while (it != lt.end()){cout << it->_a1 << ":" << it->_a2 << endl;++it;}} void PrintList(const list<int>& clt){list<int>::const_iterator it = clt.begin();while (it != clt.end()){//*it += 10;cout << *it << " ";++it;}}void test_list3(){list<int> lt1;lt1.push_back(1);lt1.push_back(2);lt1.push_back(3);lt1.push_back(4);lt1.push_back(5);PrintList(lt1);cout << endl;//拷贝构造list<int> lt2(lt1);PrintList(lt2);cout << endl;list<int> lt3 = lt1;PrintList(lt3);}}结语:
随着这篇关于题目解析的博客接近尾声,我衷心希望我所分享的内容能为你带来一些启发和帮助。学习和理解的过程往往充满挑战,但正是这些挑战让我们不断成长和进步。我在准备这篇文章时,也深刻体会到了学习与分享的乐趣。
在此,我要特别感谢每一位阅读到这里的你。是你的关注和支持,给予了我持续写作和分享的动力。我深知,无论我在某个领域有多少见解,都离不开大家的鼓励与指正。因此,如果你在阅读过程中有任何疑问、建议或是发现了文章中的不足之处,都欢迎你慷慨赐教。
你的每一条反馈都是我前进路上的宝贵财富。同时,我也非常期待能够得到你的点赞、收藏,关注,这将是对我莫大的支持和鼓励。当然,我更期待的是能够持续为你带来有价值的内容,让我们在知识的道路上共同前行。
相关文章:
C++ 链表List使用与实现:拷贝交换与高效迭代器细致讲解
目录 list的使用: 构造与赋值 元素访问 修改操作 容量查询 链表特有操作 拼接(Splice) C11 新增方法 注意: stl_list的模拟实现: 一、链表节点设计的艺术 1.1 结构体 vs 类的选择 二、迭代器实现的精髓 2…...

Manus联创澄清:我们并未使用MCP技术
摘要 近日,Manus联创针对外界关于其产品可能涉及“沙盒越狱”的疑问进行了正式回应。公司明确表示并未使用Anthropic的MCP(模型上下文协议)技术,并强调MCP是一个旨在标准化应用程序与大型语言模型(LLM)之间…...
ACE学习2——write transaction
用于处理缓存行的数据更新到主内存(main memory)的操作。 以下是用于更新主内存的几种事务类型: WriteBack: WriteBack事务用于将cache中的dirty态的cacheline写回主存,以释放cache中的cacheline,用于存…...

c++ 返回引用
在C中,返回引用是一种常见的做法,特别是在需要返回大型对象时,以避免不必要的复制,从而提高程序的效率。返回引用通常有两种情况:返回局部变量的引用和返回成员变量的引用。下面分别讨论这两种情况以及如何安全地实现它…...

Docker篇
1.docker环境搭建: 1.1软件仓库的配置rhel9: #cd/etc/yum.repos.d #vim docker.repo [docker] namedocker-ce baseurlhttps://mirrors.aliyun.com/docker-ce/linux/rhel/9/x86_64/stable gpgcheck0 1.2安装docker并且启动服务 yum install -y dock…...

TypeScript基础类型详解:与JavaScript的对比与核心价值
TypeScript作为JavaScript的超集,最大的特性是引入了静态类型系统。本文将基于TypeScript官网内容,解析其基础类型设计,并与ES/JavaScript进行对比,揭示类型系统的实际价值。 一、基础类型全景图 1. 原生类型的强化 JavaScript原…...

Linux《基础开发工具(中)》
在之前的Linux《基础开发工具(上)》当中已经了解了Linux当中到的两大基础的开发工具yum与vim;了解了在Linux当中如何进行软件的下载以及实现的基本原理、知道了编辑器vim的基本使用方式,那么接下来在本篇当中将接下去继续来了解另…...

CPU 负载 和 CPU利用率 的区别
简单记录下 top 命令中,CPU利用率核CPU负载的概念, (1)CPU利用率:指在一段时间内 表示 CPU 实际工作时间占总时间的百分比。表示正在执行进程的时间比例,包括用户空间和内核空间程序的执行时间。通常包含以…...
vue源码(二)
文章目录 数据代理示例 初始化组件实例计算属性基本用法ComputedReflmpl类计算属性的创建 Vue3的特点及优势声明式框架采用虚拟DOM区分编译时和进行时 Vue3设计思想 数据代理 示例 以下代码主要是有一个msg的响应式数据,点击按钮后修改msg的内容。根据代码可知有两…...

Ubuntu切换lowlatency内核
文章目录 一. 前言二. 开发环境三. 具体操作 一. 前言 低延迟内核(Lowlatency Kernel) 旨在为需要低延迟响应的应用程序设计的内核版本。Linux-lowlatency特别适合音频处理、实时计算、游戏和其他需要及时响应的实时任务。其主要特点是优化了中断处理、调…...
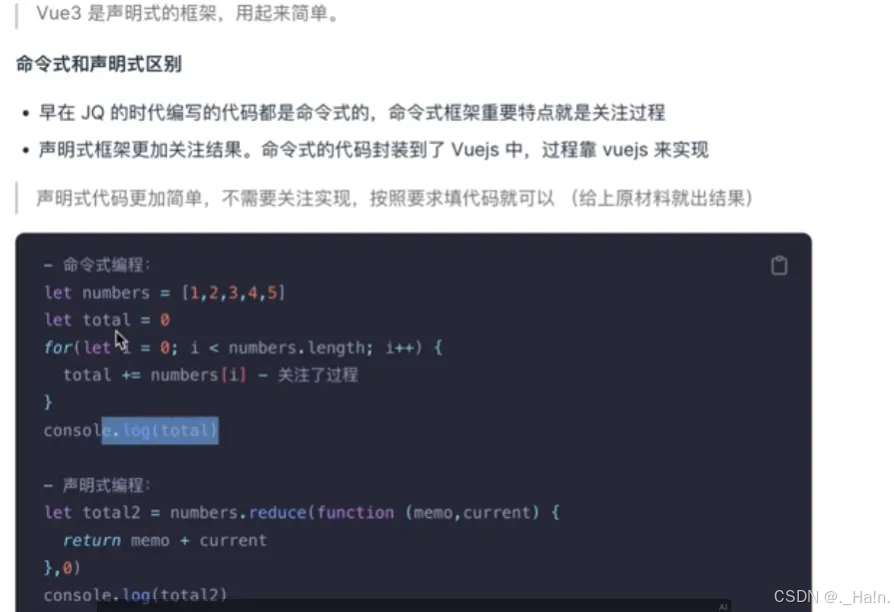
C++算法——差分
1.差分 差分与前缀和的核心思想相同,是预处理,可以在暴力枚举的过程中,快速给出查询的结果,从而优化时间复杂度。 是经典的用空间替换时间的做法。 2.一维差分数组 前缀和与差分是⼀对互逆的运算,对差分数组做前缀…...
猫耳大型活动提效——组件低代码化
1. 引言 猫耳前端在开发活动的过程中,经历过传统的 pro code 阶段,即活动页面完全由前端开发编码实现,直到 2020 年接入公司内部的低代码活动平台,满足了大部分日常活动的需求,运营可自主配置活动并上线,释…...
亿级分布式系统架构演进实战(二)- 横向扩展(服务无状态化)
亿级分布式系统架构演进实战(一)- 总体概要 服务无状态化详细设计 目标:确保服务实例完全无状态,可任意扩缩容 1. 会话存储改造(Session Management) 核心问题:传统单体应用中,用…...

零成本短视频爆款制造手册
——Q版+情感+互动的流量密码拆解 适用平台:抖音/快手/视频号 核心指标:点赞率>10% | 完播率>40% | 涨粉成本<0.3元 一、底层逻辑框架 1. 爆款元素融合公式 [ 3秒钩子 ] + [ 7秒沉浸 ] + [ 5秒引爆 ] = 15秒黄金结构 │ │ └─▶ 互动指令+情感…...

红队思想:Live off the Land - 靠山吃山,靠水吃水
在网络安全领域,尤其是红队(Red Team)渗透测试中,“Live off the Land”(简称 LotL,中文可译为“靠山吃山,靠水吃水”)是一种极具隐秘性和实用性的攻击策略。这一理念源于现实生活中…...

C语言八股---预处理,编译,汇编与链接篇
前言 从多个.c文件到达一个可执行文件的四步: 预处理–>编译–>汇编–>链接 预处理 预处理过程就是预处理器处理这些预处理指令(要不然编译器完全不认识),最终会生成 main.i的文件 主要做的事情有如下几点: 展开头文件展开宏条件编译删除注释添加行号等信息保留…...
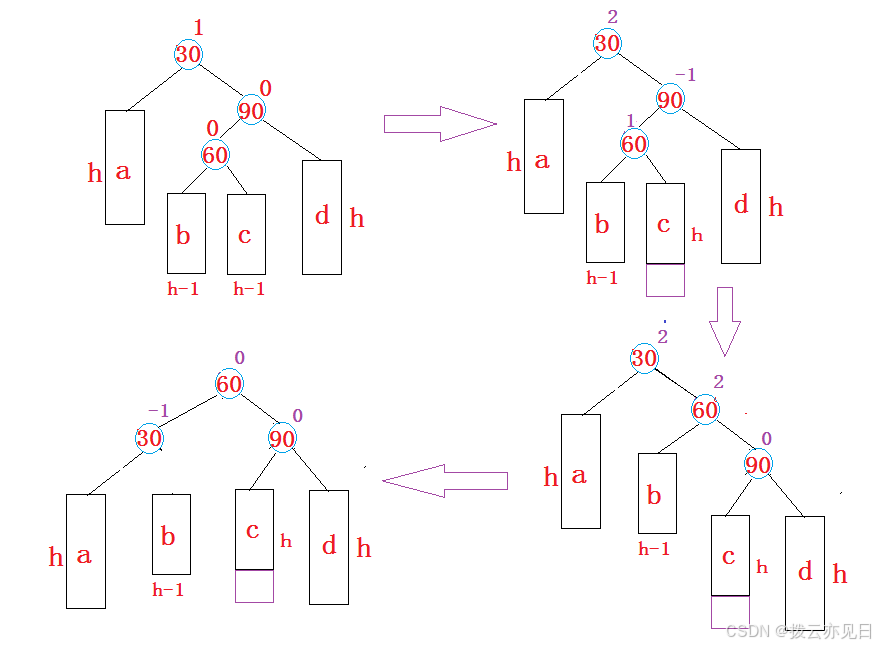
平衡二叉树(AVL树)
平衡二叉树是啥我就不多说了,本篇博客只讲原理与方法。 首先引入平衡因子的概念。平衡因子(Balance Factor),以下简称bf。 bf 右子树深度 - 左子树深度。平衡结点的平衡因子可为:-1,0,1。除此…...
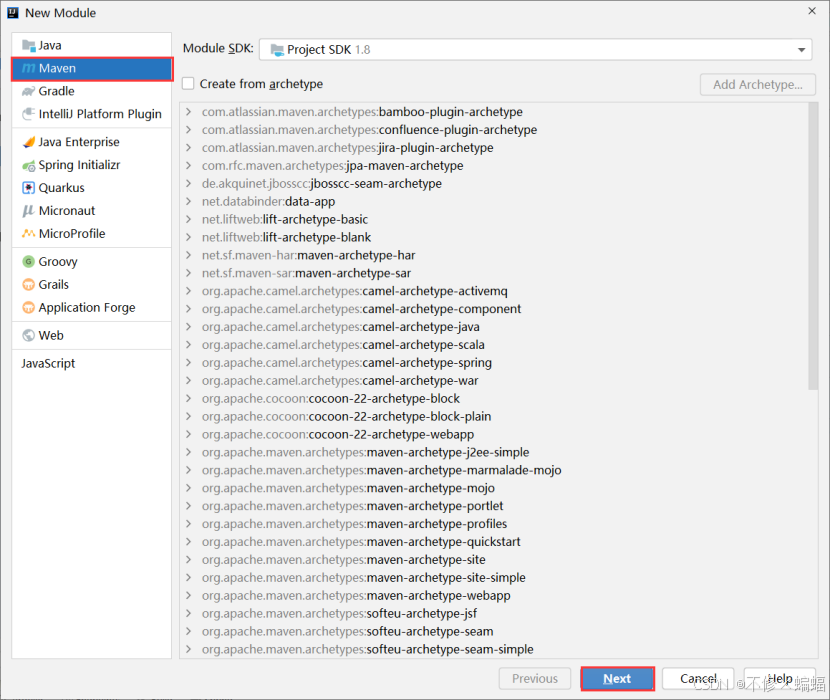
SpringBoot(一)--搭建架构5种方法
目录 一、⭐Idea从spring官网下载打开 2021版本idea 1.打开创建项目 2.修改pom.xml文件里的版本号 2017版本idea 二、从spring官网下载再用idea打开 三、Idea从阿里云的官网下载打开 编辑 四、Maven项目改造成springboot项目 五、从阿里云官网下载再用idea打开 Spri…...
RabbitMQ使用延迟消息
RabbitMQ使用延迟消息 1.什么情况下使用延迟消息 延迟消息适用于需要在一段时间后执行某些操作的场景,常见的有以下几类: 1.1. 订单超时取消(未支付自动取消) 场景: 用户下单后,如果 30 分钟内未付款&a…...

MyBatis-Plus 分页查询接口返回值问题剖析
在使用 MyBatis-Plus 进行分页查询时,很多开发者会遇到一个常见的问题:当分页查询接口返回值定义为 Page<T> 时,执行查询会抛出异常;而将返回值修改为 IPage<T> 时,分页查询却能正常工作。本文将从 MyBatis-Plus 的分页机制入手,详细分析这一问题的根源,并提…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...