Flink中核心重点总结
目录
1. 算子链
1.1. 一对一(One-to-one, forwarding)
1.2. 重分区(Redistributing)
1.3. 为什么有算子链
2. 物理分区(Physical Partitioning)
2.1. 什么是分区
2.2. 随机分区(shuffle)
2.3. 轮询分区(Round-Robin)
2.4. 重缩放分区(rescale)
2.5. 广播(broadcast)
2.6. 全局分区(global)
2.7. 自定义分区(Custom)
3. 输出算子(Sink)
3.1. 连接到外部系统
3.2. 输出到文件
3.3. 输出到 Kafka
3.4. 输出到 Redis
3.5. 输出到 Elasticsearch
3.6. 输出到 MySQL(JDBC)
3.7. 自定义 Sink 输出
4. 设置watermark以及延迟时间
4.1. 在1.11版本以及之前
4.2. 在1.12版本以及之后
5. Flink中的窗口
5.1. 窗口函数
5.2. 窗口的触发器
6. 多流转换
6.1. 分流
6.2. 基本合流操作
6.3. 基于时间的合流——双流联结(Join)
6.4. 窗口同组联结(Window CoGroup)
7. 状态编程
7.1. 状态的分类
7.2. 状态生存时间(TTL)
7.3. 状态后端
8. 容错机制
8.1. 检查点(Checkpoint )
8.2. 保存点(Savepoint)
8.3. 状态一致性
9. Table API 和 SQL
9.1. TableAPI依赖说明
9.2. 执行环境的创建
1. 算子链
1.1. 一对一(One-to-one, forwarding)
这种模式下,数据流维护着分区以及元素的顺序。比如图中的 source 和 map 算子, source算子读取数据之后,可以直接发送给 map 算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着 map 算子的子任务,看到的元素个数和顺序跟 source 算子的子任务产生的完全一样,保证着“一对一”的关系。 map、 filter、 flatMap 等算子都是这种 one-to-one的对应关系。
1.2. 重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。比图中的 map 和后面的 keyBy/window 算子之间(这里的 keyBy 是数据传输算子,后面的 window、 apply 方法共同构成了 window 算子) ,以及 keyBy/window 算子和 Sink 算子之间,都是这样的关系。
每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。例如,keyBy()是分组操作,本质上基于键(key)的哈希值(hashCode)进行了重分区;而当并行度改变时,比如从并行度为 2 的 window 算子,要传递到并行度为 1 的 Sink 算子,这时的数据传输方式是再平衡(rebalance),会把数据均匀地向下游子任务分发出去。这些传输方式都会引起重分区(redistribute)的过程,这一过程类似于 Spark 中的 shuffle。
1.3. 为什么有算子链
Flink 为什么要有算子链这样一个设计呢?这是因为将算子链接成 task 是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
Flink 默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置:
// 禁用算子链
.map(word -> Tuple2.of(word, 1L)).disableChaining();
// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()2. 物理分区(Physical Partitioning)
2.1. 什么是分区
顾名思义,“分区”(partitioning) 操作就是要将数据进行重新分布,传递到不同的流分区去进行下一步处理。其实我们对分区操作并不陌生,前面介绍聚合算子时,已经提到了 keyBy,它就是一种按照键的哈希值来进行重新分区的操作。只不过这种分区操作只能保证把数据按key“分开”,至于分得均不均匀、每个 key 的数据具体会分到哪一区去,这些是完全无从控制的——所以我们有时也说, keyBy 是一种逻辑分区(logical partitioning)操作。
如果说 keyBy 这种逻辑分区是一种“软分区”,那真正硬核的分区就应该是所谓的“物理分区”(physical partitioning)。也就是我们要真正控制分区策略,精准地调配数据,告诉每个数据到底去哪里。其实这种分区方式在一些情况下已经在发生了:例如我们编写的程序可能对多个处理任务设置了不同的并行度,那么当数据执行的上下游任务并行度变化时,数据就不应该还在当前分区以直通(forward)方式传输了——因为如果并行度变小,当前分区可能没有下游任务了;而如果并行度变大,所有数据还在原先的分区处理就会导致资源的浪费。 所以这种情况下,系统会自动地将数据均匀地发往下游所有的并行任务,保证各个分区的负载均衡。
有些时候,我们还需要手动控制数据分区分配策略。比如当发生数据倾斜的时候,系统无法自动调整,这时就需要我们重新进行负载均衡,将数据流较为平均地发送到下游任务操作分区中去。 Flink 对于经过转换操作之后的 DataStream,提供了一系列的底层操作接口,能够帮我们实现数据流的手动重分区。为了同 keyBy 相区别,我们把这些操作统称为“物理分区”操作。物理分区与 keyBy 另一大区别在于, keyBy 之后得到的是一个 KeyedStream,而物理分区之后结果仍是 DataStream,且流中元素数据类型保持不变。从这一点也可以看出,分区算子并不对数据进行转换处理,只是定义了数据的传输方式。
常见的物理分区策略有随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast),下边我们分别来做了解。
2.2. 随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区,如图 5-9 所示。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
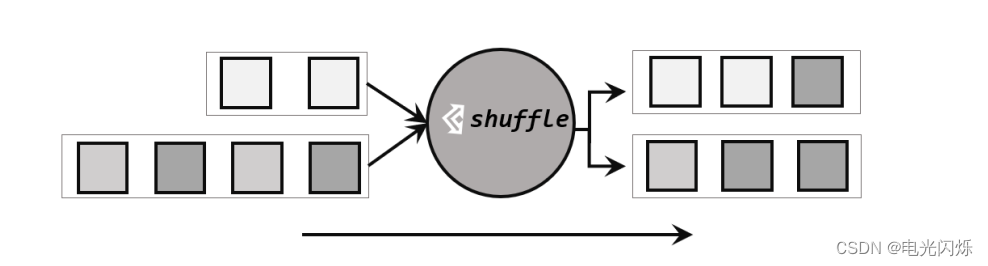
经过随机分区之后,得到的依然是一个 DataStream。我们可以做个简单测试:将数据读入之后直接打印到控制台,将输出的并行度设置为 4,中间经历一次 shuffle。执行多次,观察结果是否相同。
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class ShuffleTest {public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 读取数据源,并行度为 1DataStreamSource<Event> stream = env.addSource(new ClickSource());// 经洗牌后打印输出,并行度为 4stream.shuffle().print("shuffle").setParallelism(4);env.execute();}
}可以得到如下形式的输出结果:
shuffle:1> Event{user='Bob', url='./cart', timestamp=...}
shuffle:4> Event{user='Cary', url='./home', timestamp=...}
shuffle:3> Event{user='Alice', url='./fav', timestamp=...}
shuffle:4> Event{user='Cary', url='./cart', timestamp=...}
shuffle:3> Event{user='Cary', url='./fav', timestamp=...}
shuffle:1> Event{user='Cary', url='./home', timestamp=...}
shuffle:2> Event{user='Mary', url='./home', timestamp=...}
shuffle:1> Event{user='Bob', url='./fav', timestamp=...}
shuffle:2> Event{user='Mary', url='./home', timestamp=...}2.3. 轮询分区(Round-Robin)
轮询也是一种常见的重分区方式。简单来说就是“发牌”,按照先后顺序将数据做依次分发,如图 5-10 所示。通过调用 DataStream 的.rebalance()方法,就可以实现轮询重分区。 rebalance使用的是 Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。
注: Round-Robin 算法用在了很多地方,例如 Kafka 和 Nginx。
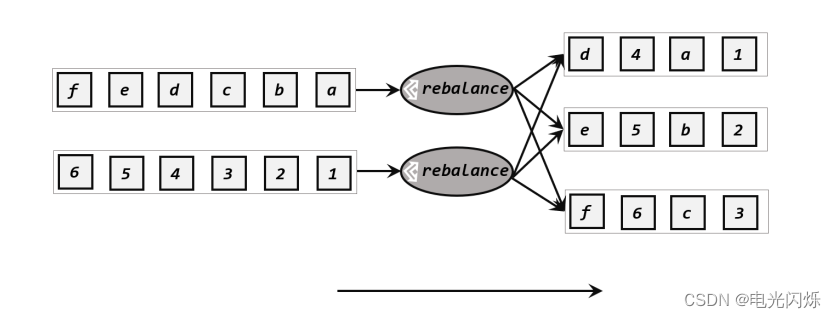
我们同样可以在代码中进行测试:
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class RebalanceTest {public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 读取数据源,并行度为 1DataStreamSource<Event> stream = env.addSource(new ClickSource());// 经轮询重分区后打印输出,并行度为 4stream.rebalance().print("rebalance").setParallelism(4);env.execute();}}输出结果的形式如下所示,可以看到,数据被平均分配到所有并行任务中去了。
rebalance:2> Event{user='Cary', url='./fav', timestamp=...}
rebalance:3> Event{user='Mary', url='./cart', timestamp=...}
rebalance:4> Event{user='Mary', url='./fav', timestamp=...}
rebalance:1> Event{user='Cary', url='./home', timestamp=...}
rebalance:2> Event{user='Cary', url='./cart', timestamp=...}
rebalance:3> Event{user='Alice', url='./prod?id=1', timestamp=...}
rebalance:4> Event{user='Cary', url='./prod?id=2', timestamp=...}
rebalance:1> Event{user='Bob', url='./prod?id=2', timestamp=...}
rebalance:2> Event{user='Alice', url='./prod?id=1', timestamp=...}2.4. 重缩放分区(rescale)
重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中,如图 5-11 所示。也就是说,“发牌人”如果有多个,那么 rebalance 的方式是每个发牌人都面向所有人发牌;而 rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
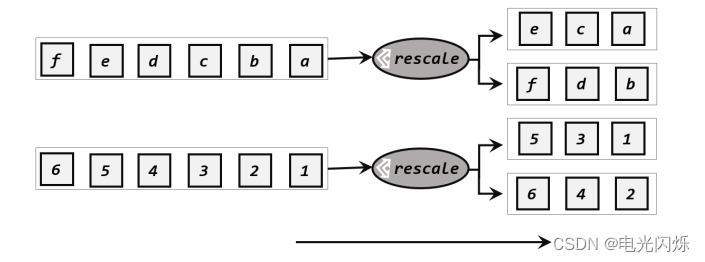
当下游任务(数据接收方)的数量是上游任务(数据发送方)数量的整数倍时, rescale的效率明显会更高。比如当上游任务数量是 2,下游任务数量是 6 时,上游任务其中一个分区的数据就将会平均分配到下游任务的 3 个分区中。
由于 rebalance 是所有分区数据的“重新平衡”,当 TaskManager 数据量较多时,这种跨节点的网络传输必然影响效率;而如果我们配置的 task slot 数量合适,用 rescale 的方式进行“局部重缩放”,就可以让数据只在当前 TaskManager 的多个 slot 之间重新分配,从而避免了网络传输带来的损耗。
从底层实现上看, rebalance 和 rescale 的根本区别在于任务之间的连接机制不同。 rebalance将会针对所有上游任务(发送数据方)和所有下游任务(接收数据方)之间建立通信通道,这是一个笛卡尔积的关系;而 rescale 仅仅针对每一个任务和下游对应的部分任务之间建立通信通道,节省了很多资源。
可以在代码中测试如下:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;public class RescaleTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 这里使用了并行数据源的富函数版本// 这样可以调用 getRuntimeContext 方法来获取运行时上下文的一些信息env.addSource(new RichParallelSourceFunction<Integer>() {@Overridepublic void run(SourceContext<Integer> sourceContext) throws Exception {for (int i = 0; i < 8; i++) {// 将奇数发送到索引为 1 的并行子任务// 将偶数发送到索引为 0 的并行子任务if ((i + 1) % 2 == getRuntimeContext().getIndexOfThisSubtask()) {sourceContext.collect(i + 1);}}}@Overridepublic void cancel() {}}).setParallelism(2).rescale().print().setParallelism(4);env.execute();}
}这里使用 rescale 方法,来做数据的分区,输出结果是:
4> 3
3> 1
1> 2
1> 6
3> 5
4> 7
2> 4
2> 8可以将 rescale 方法换成 rebalance 方法,来体会一下这两种方法的区别。
2.5. 广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
具体代码测试如下:
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class BroadcastTest {public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 读取数据源,并行度为 1DataStreamSource<Event> stream = env.addSource(new ClickSource());// 经广播后打印输出,并行度为 4stream.broadcast().print("broadcast").setParallelism(4);env.execute();}
}输出结果的形式如下所示:
broadcast:3> Event{user='Mary', url='./cart', timestamp=...}
broadcast:1> Event{user='Mary', url='./cart', timestamp=...}
broadcast:4> Event{user='Mary', url='./cart', timestamp=...}
broadcast:2> Event{user='Mary', url='./cart', timestamp=...}
broadcast:2> Event{user='Alice', url='./fav', timestamp=...}
broadcast:1> Event{user='Alice', url='./fav', timestamp=...}
broadcast:3> Event{user='Alice', url='./fav', timestamp=...}
broadcast:4> Event{user='Alice', url='./fav', timestamp=...}可以看到,数据被复制然后广播到了下游的所有并行任务中去了。
2.6. 全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了 1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
2.7. 自定义分区(Custom)
当Flink提供的所有分区策略都不能满足用户的需求时,我们可以通过使用partitionCustom()方法来自定义分区策略。
在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个是应用分区器的字段,它的指定方式与keyBy指定key基本一样:可以通过字段名称指定,也可以通过字段位置索引来指定,还可以实现一个KeySelector。
例如,我们可以对一组自然数按照奇偶性进行重分区。代码如下:
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class CustomPartitionTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 将自然数按照奇偶分区env.fromElements(1, 2, 3, 4, 5, 6, 7, 8).partitionCustom(new Partitioner<Integer>() {@Overridepublic int partition(Integer key, int numPartitions) {return key % 2;}}, new KeySelector<Integer, Integer>() {@Overridepublic Integer getKey(Integer value) throws Exception {return value;}}).print().setParallelism(2);env.execute();}
}3. 输出算子(Sink)

3.1. 连接到外部系统
在 Flink 中,如果我们希望将数据写入外部系统,其实并不是一件难事。我们知道所有算子都可以通过实现函数类来自定义处理逻辑,所以只要有读写客户端,与外部系统的交互在任何一个处理算子中都可以实现。例如在 MapFunction 中,我们完全可以构建一个到 Redis 的连接,然后将当前处理的结果保存到 Redis 中。如果考虑到只需建立一次连接,我们也可以利用RichMapFunction,在 open() 生命周期中做连接操作。
这样看起来很方便,却会带来很多问题。 Flink 作为一个快速的分布式实时流处理系统,对稳定性和容错性要求极高。一旦出现故障,我们应该有能力恢复之前的状态,保障处理结果的正确性。这种性质一般被称作“状态一致性”。 Flink 内部提供了一致性检查点(checkpoint)来保障我们可以回滚到正确的状态;但如果我们在处理过程中任意读写外部系统,发生故障后就很难回退到从前了。
为了避免这样的问题, Flink 的 DataStream API 专门提供了向外部写入数据的方法:addSink。与 addSource 类似, addSink 方法对应着一个“Sink”算子,主要就是用来实现与外部系统连接、并将数据提交写入的; Flink 程序中所有对外的输出操作,一般都是利用 Sink 算子完成的。
Sink 一词有“下沉”的意思,有些资料会相对于“数据源”把它翻译为“数据汇”。不论怎样理解, Sink 在 Flink 中代表了将结果数据收集起来、输出到外部的意思,所以我们这里统一把它直观地叫作“输出算子”。
之前我们一直在使用的 print 方法其实就是一种 Sink,它表示将数据流写入标准控制台打印输出。查看源码可以发现, print 方法返回的就是一个 DataStreamSink。
public DataStreamSink<T> print(String sinkIdentifier) {
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>(sinkIdentifier, false);return addSink(printFunction).name("Print to Std. Out");
}与 Source 算子非常类似,除去一些 Flink 预实现的 Sink,一般情况下 Sink 算子的创建是通过调用 DataStream 的.addSink()方法实现的。
stream.addSink(new SinkFunction(…));addSource 的参数需要实现一个 SourceFunction 接口;类似地, addSink 方法同样需要传入一个参数,实现的是 SinkFunction 接口。在这个接口中只需要重写一个方法 invoke(),用来将指定的值写入到外部系统中。这个方法在每条数据记录到来时都会调用:
default void invoke(IN value, Context context) throws Exception当然, SinkFuntion 多数情况下同样并不需要我们自己实现。 Flink 官方提供了一部分的框架的 Sink 连接器。如下图所示,列出了 Flink 官方目前支持的第三方系统连接器:

我们可以看到,像 Kafka 之类流式系统, Flink 提供了完美对接, source/sink 两端都能连接,可读可写;而对于 Elasticsearch、文件系统(FileSystem)、 JDBC 等数据存储系统,则只提供了输出写入的 sink 连接器。
除 Flink 官方之外, Apache Bahir 作为给 Spark 和 Flink 提供扩展支持的项目,也实现了一些其他第三方系统与 Flink 的连接器,如下图所示:

除此以外,就需要用户自定义实现 sink 连接器了。
3.2. 输出到文件
最简单的输出方式,当然就是写入文件了。对应着读取文件作为输入数据源, Flink 本来也有一些非常简单粗暴的输出到文件的预实现方法:如 writeAsText()、 writeAsCsv(),可以直接将输出结果保存到文本文件或 Csv 文件。但我们知道,这种方式是不支持同时写入一份文件的;所以我们往往会将最后的 Sink 操作并行度设为 1,这就大大拖慢了系统效率;而且对于故障恢复后的状态一致性,也没有任何保证。所以目前这些简单的方法已经要被弃用。
Flink 为此专门提供了一个流式文件系统的连接器: StreamingFileSink,它继承自抽象类RichSinkFunction,而且集成了 Flink 的检查点(checkpoint)机制,用来保证精确一次(exactlyonce)的一致性语义。
StreamingFileSink 为批处理和流处理提供了一个统一的 Sink,它可以将分区文件写入 Flink支持的文件系统。它可以保证精确一次的状态一致性, 大大改进了之前流式文件 Sink 的方式。它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶”的操作; 默认的分桶方式是基于时间的,我们每小时写入一个新的桶。换句话说,每个桶内保存的文件,记录的都是 1 小时的输出数据。
StreamingFileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded, 比如 Parquet)格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用StreamingFileSink 的静态方法:
- 行编码: StreamingFileSink.forRowFormat(basePath, rowEncoder)。
- 批量编码: StreamingFileSink.forBulkFormat(basePath, bulkWriterFactory)。
在创建行或批量编码 Sink 时,我们需要传入两个参数,用来指定存储桶的基本路径(basePath)和数据的编码逻辑(rowEncoder 或 bulkWriterFactory)。
下面我们就以行编码为例,将一些测试数据直接写入文件:
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.util.concurrent.TimeUnit;public class SinkToFileTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(4);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice", "./prod?id=100", 3000L),new Event("Alice", "./prod?id=200", 3500L),new Event("Bob", "./prod?id=2", 2500L),new Event("Alice", "./prod?id=300", 3600L),new Event("Bob", "./home", 3000L),new Event("Bob", "./prod?id=1", 2300L),new Event("Bob", "./prod?id=3", 3300L));StreamingFileSink<String> fileSink = StreamingFileSink.<String>forRowFormat(new Path("./output"), new SimpleStringEncoder<>("UTF-8")).withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(TimeUnit.MINUTES.toMillis(15)).withInactivityInterval(TimeUnit.MINUTES.toMillis(5)).withMaxPartSize(1024 * 1024 * 1024).build()).build();// 将 Event 转换成 String 写入文件stream.map(Event::toString).addSink(fileSink);env.execute();}}这里我们创建了一个简单的文件 Sink,通过.withRollingPolicy()方法指定了一个“滚动策略”。“滚动”的概念在日志文件的写入中经常遇到:因为文件会有内容持续不断地写入,所以我们应该给一个标准,到什么时候就开启新的文件,将之前的内容归档保存。也就是说,上面的代码设置了在以下 3 种情况下,我们就会滚动分区文件:
- 至少包含 15 分钟的数据
- 最近 5 分钟没有收到新的数据
- 文件大小已达到 1 GB
3.3. 输出到 Kafka
Kafka 是一个分布式的基于发布/订阅的消息系统,本身处理的也是流式数据,所以跟Flink“天生一对”,经常会作为 Flink 的输入数据源和输出系统。Flink 官方为 Kafka 提供了 Source和 Sink 的连接器,我们可以用它方便地从 Kafka 读写数据。如果仅仅是支持读写,那还说明不了 Kafka 和 Flink 关系的亲密;真正让它们密不可分的是, Flink 与 Kafka 的连接器提供了端到端的精确一次(exactly once)语义保证,这在实际项目中是最高级别的一致性保证。关于这部分内容,我们会在后续章节做更详细的讲解。
现在我们要将数据输出到 Kafka,整个数据处理的闭环已经形成,所以可以完整测试如下:
步骤一:添加 Kafka 连接器依赖
步骤二:启动 Kafka 集群
步骤三:编写输出到 Kafka 的示例代码(我们可以直接将用户行为数据保存为文件 clicks.csv,读取后不做转换直接写入 Kafka,主题(topic)命名为“clicks”)
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;import java.util.Properties;public class SinkToKafkaTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);Properties properties = new Properties();properties.put("bootstrap.servers", "hadoop102:9092");DataStreamSource<String> stream = env.readTextFile("input/clicks.csv");stream.addSink(new FlinkKafkaProducer<String>("clicks",new SimpleStringSchema(),properties));env.execute();}}这里我们可以看到, addSink 传入的参数是一个 FlinkKafkaProducer。这也很好理解,因为需要向 Kafka 写入数据,自然应该创建一个生产者。 FlinkKafkaProducer 继承了抽象类TwoPhaseCommitSinkFunction,这是一个实现了“两阶段提交”的 RichSinkFunction。两阶段提交提供了 Flink 向 Kafka 写入数据的事务性保证,能够真正做到精确一次(exactly once)的状态一致性。
步骤四:运行代码,在 Linux 主机启动一个消费者, 查看是否收到数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic clicks我们可以看到消费者可以正常消费数据,证明向 Kafka 写入数据成功。另外,我们也可以读取其它的任意数据源,进行更多的完整测试。比较有趣的一个实验是,我们可以同时将 Kafka 作为 Flink 程序的数据源和写入结果的外部系统。只要将输入和输出的数据设置为不同的 topic,就可以看到整个系统运行的路径: Flink 从 Kakfa 的一个 topic 读取消费数据,然后进行处理转换,最终将结果数据写入 Kafka 的另一个 topic——数据从 Kafka 流入、经 Flink处理后又流回到 Kafka 去,这就是所谓的“数据管道” 应用。
3.4. 输出到 Redis
Redis 是一个开源的内存式的数据存储,提供了像字符串(string)、哈希表(hash)、列表(list)、集合(set)、排序集合(sorted set)、位图(bitmap)、地理索引和流(stream)等一系列常用的数据结构。因为它运行速度快、支持的数据类型丰富,在实际项目中已经成为了架构优化必不可少的一员,一般用作数据库、缓存,也可以作为消息代理。
Flink 没有直接提供官方的 Redis 连接器,不过 Bahir 项目还是担任了合格的辅助角色,为我们提供了 Flink-Redis 的连接工具。但版本升级略显滞后,目前连接器版本为 1.0,支持的Scala 版本最新到 2.11。由于我们的测试不涉及到 Scala 的相关版本变化,所以并不影响使用。在实际项目应用中,应该以匹配的组件版本运行。
具体测试步骤如下:
步骤一:导入的 Redis 连接器依赖
<dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.0</version>
</dependency>步骤二:启动 Redis 集群
步骤三:编写输出到 Redis 的示例代码
连接器为我们提供了一个 RedisSink,它继承了抽象类 RichSinkFunction,这就是已经实现好的向 Redis 写入数据的 SinkFunction。我们可以直接将 Event 数据输出到 Redis:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;public class SinkToRedisTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 创建一个到 redis 连接的配置FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("hadoop102").build();env.addSource(new ClickSource()).addSink(new RedisSink<Event>(conf, new MyRedisMapper()));env.execute();}}这里 RedisSink 的构造方法需要传入两个参数:
- JFlinkJedisConfigBase: Jedis 的连接配置
- RedisMapper: Redis 映射类接口,说明怎样将数据转换成可以写入 Redis 的类型
接下来主要就是定义一个 Redis 的映射类,实现 RedisMapper 接口。
public static class MyRedisMapper implements RedisMapper<Event> {@Overridepublic String getKeyFromData(Event e) {return e.user;}@Overridepublic String getValueFromData(Event e) {return e.url;}@Overridepublic RedisCommandDescription getCommandDescription() {return new RedisCommandDescription(RedisCommand.HSET, "clicks");}
}在这里我们可以看到,保存到 Redis 时调用的命令是 HSET,所以是保存为哈希表(hash),表名为“clicks”;保存的数据以 user 为 key,以 url 为 value,每来一条数据就会做一次转换。
步骤四:运行代码, Redis 查看是否收到数据
$ redis-cli
hadoop102:6379>hgetall clicks
1) “Mary”
2) “./home”
3) “Bob”
4) “./cart”我们会发现, 发送了多条数据, Redis 中只有 2 条数据. 原因是 hash 中的 key 重复了, 后面的会把前面的覆盖掉。
3.5. 输出到 Elasticsearch
ElasticSearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据。 ElasticSearch有着简洁的 REST 风格的 API,以良好的分布式特性、速度和可扩展性而闻名,在大数据领域应用非常广泛。
Flink 为 ElasticSearch 专门提供了官方的 Sink 连接器, Flink 1.13 支持当前最新版本的ElasticSearch。
写入数据的 ElasticSearch 的测试步骤如下:
步骤一:添加 Elasticsearch 连接器依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>步骤二:启动 Elasticsearch 集群
步骤三:编写输出到 Elasticsearch 的示例代码
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.HashMap;public class SinkToEsTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice", "./prod?id=100", 3000L),new Event("Alice", "./prod?id=200", 3500L),new Event("Bob", "./prod?id=2", 2500L),new Event("Alice", "./prod?id=300", 3600L),new Event("Bob", "./home", 3000L),new Event("Bob", "./prod?id=1", 2300L),new Event("Bob", "./prod?id=3", 3300L));ArrayList<HttpHost> httpHosts = new ArrayList<>();httpHosts.add(new HttpHost("hadoop102", 9200, "http"));// 创建一个 ElasticsearchSinkFunctionElasticsearchSinkFunction<Event> elasticsearchSinkFunction = new ElasticsearchSinkFunction<Event>() {@Overridepublic void process(Event element, RuntimeContext ctx, RequestIndexer indexer) {HashMap<String, String> data = new HashMap<>();data.put(element.user, element.url);IndexRequest request = Requests.indexRequest().index("clicks").type("type") // Es 6 必须定义 type.source(data);indexer.add(request);}};stream.addSink(new ElasticsearchSink.Builder<Event>(httpHosts, elasticsearchSinkFunction).build());stream.addSink(esBuilder.build());env.execute();}
}与RedisSink类似,连接器也为我们实现了写入到Elasticsearch的SinkFunction——ElasticsearchSink。区别在于,这个类的构造方法是私有(private)的,我们需要使用ElasticsearchSink的Builder内部静态类,调用它的build()方法才能创建出真正的SinkFunction。
而Builder的构造方法中又有两个参数:
- httpHosts:连接到的 Elasticsearch 集群主机列表
- elasticsearchSinkFunction:这并不是我们所说的 SinkFunction,而是用来说明具体处理逻辑、准备数据向 Elasticsearch 发送请求的函数
具体的操作需要重写中 elasticsearchSinkFunction 中的 process 方法,我们可以将要发送的数据放在一个 HashMap 中,包装成 IndexRequest 向外部发送 HTTP 请求。
步骤四:运行代码,访问 Elasticsearch 查看是否收到数据,查询结果如下所示
{"_shards": {"failed": 0,"skipped": 0,"successful": 1,"total": 1},"hits": {"hits": [{"_id": "dAxBYHoB7eAyu-y5suyU","_index": "clicks","_score": 1.0,"_source": {"Mary": "./home"},"_type": "_doc"},{},{}],"max_score": 1.0,"total": {"relation": "eq","value": 9}},"timed_out": false,"took": 5
}3.6. 输出到 MySQL(JDBC)
关系型数据库有着非常好的结构化数据设计、方便的 SQL 查询,是很多企业中业务数据存储的主要形式。 MySQL 就是其中的典型代表。尽管在大数据处理中直接与 MySQL 交互的场景不多,但最终处理的计算结果是要给外部应用消费使用的,而外部应用读取的数据存储往往就是 MySQL。所以我们也需要知道如何将数据输出到 MySQL 这样的传统数据库。
写入数据的 MySQL 的测试步骤如下:
步骤一:添加依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version>
</dependency>步骤二:启动 MySQL,在 database 库下建表 clicks
create table clicks(user varchar(20) not null,url varchar(100) not null
);步骤三:编写输出到 MySQL 的示例代码
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class SinkToMySQL {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice", "./prod?id=100", 3000L),new Event("Alice", "./prod?id=200", 3500L),new Event("Bob", "./prod?id=2", 2500L),new Event("Alice", "./prod?id=300", 3600L),new Event("Bob", "./home", 3000L),new Event("Bob", "./prod?id=1", 2300L),new Event("Bob", "./prod?id=3", 3300L));stream.addSink(JdbcSink.sink("INSERT INTO clicks (user, url) VALUES (?, ?)",(statement, r) -> {statement.setString(1, r.user);statement.setString(2, r.url);},JdbcExecutionOptions.builder().withBatchSize(1000).withBatchIntervalMs(200).withMaxRetries(5).build(),new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://localhost:3306/userbehavior") // 对于 MySQL 5.7, 用"com.mysql.jdbc.Driver".withDriverName("com.mysql.cj.jdbc.Driver").withUsername("username").withPassword("password").build()));env.execute();}}步骤四:运行代码,用客户端连接 MySQL,查看是否成功写入数据
mysql> select * from clicks;
+------+--------------+
| user | url |
+------+--------------+
| Mary | ./home |
| Alice| ./prod?id=300 |
| Bob | ./prod?id=3 |
+------+---------------+
3 rows in set (0.00 sec)3.7. 自定义 Sink 输出
如果我们想将数据存储到我们自己的存储设备中,而 Flink 并没有提供可以直接使用的连接器,又该怎么办呢?
与 Source 类似, Flink 为我们提供了通用的 SinkFunction 接口和对应的 RichSinkDunction抽象类,只要实现它,通过简单地调用 DataStream 的.addSink()方法就可以自定义写入任何外部存储。之前与外部系统的连接,其实都是连接器帮我们实现了 SinkFunction,现在既然没有现成的,我们就只好自力更生了。 例如, Flink 并没有提供 HBase 的连接器,所以需要我们自己写。
在实现 SinkFunction 的时候,需要重写的一个关键方法 invoke(),在这个方法中我们就可以实现将流里的数据发送出去的逻辑。
我们这里使用了 SinkFunction 的富函数版本,因为这里我们又使用到了生命周期的概念,创建 HBase 的连接以及关闭 HBase 的连接需要分别放在 open()方法和 close()方法中。
步骤一:导入依赖
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version>
</dependency>步骤二:编写输出到 HBase 的示例代码
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;import java.nio.charset.StandardCharsets;public class SinkCustomtoHBase {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.fromElements("hello", "world").addSink(new RichSinkFunction<String>() {// 管理 Hbase 的配置信息,这里因为 Configuration 的重名问题,将类以完整路径导入public org.apache.hadoop.conf.Configuration configuration;// 管理 Hbase 连接public Connection connection;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);configuration = HBaseConfiguration.create();configuration.set("hbase.zookeeper.quorum", "hadoop102:2181");connection = ConnectionFactory.createConnection(configuration);}@Overridepublic void invoke(String value, Context context) throws Exception {// 表名为 testTable table = connection.getTable(TableName.valueOf("test"));// 指定 rowkeyPut put = new Put("rowkey".getBytes(StandardCharsets.UTF_8));// 添加数据put.addColumn("info".getBytes(StandardCharsets.UTF_8), // 指定列名value.getBytes(StandardCharsets.UTF_8), // 写入的数据"1".getBytes(StandardCharsets.UTF_8) // 写入的数据);// 执行 put 操作table.put(put);// 将表关闭table.close();}@Overridepublic void close() throws Exception {// 关闭连接super.close();connection.close();}});env.execute();}}步骤三:可以在 HBase 查看插入的数据
4. 设置watermark以及延迟时间
注意:在Flink中,1.12版本之前需要手动指定时间类型(EventTime还是ProcessTime等),但是在1.12版本及以后,就默认使用事件时间,当使用事件时间时就不要去手动指定了。
4.1. 在1.11版本以及之前
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<JSONObject>(Time.seconds(60)) {@Overridepublic long extractTimestamp(JSONObject element) {return element.getLongValue("time") * 1000L;}
})4.2. 在1.12版本以及之后
.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(60)).withTimestampAssigner((SerializableTimestampAssigner<JSONObject>) (element, recordTimestamp) -> element.getLongValue("time") * 1000L)
)5. Flink中的窗口
5.1. 窗口函数
Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。
各流之间的转换:

- 增量聚合函数(incremental aggregation functions)
- 归约函数(ReduceFunction):输入类型、中间状态和输出类型一致;
- AggregateFunction:输入类型、中间状态和输出类型可以不一致;
- 全窗口函数(full window functions)
- 窗口函数(WindowFunction):能进行基本事件处理;
- 处理窗口函数(ProcessWindowFunction):在基本事件处理上还有窗口的上下文环境;
窗口API总结(下图):

5.2. 窗口的触发器
Trigger 源码:
import org.apache.flink.streaming.api.windowing.triggers.TriggerResult;public abstract class Trigger<T, W extends Window> implements Serializable {/*** 只要有元素落⼊到当前窗⼝, 就会调⽤该⽅法** @param element 收到的元素* @param timestamp 元素抵达时间.* @param window 元素所属的window窗口.* @param ctx ⼀个上下⽂对象,通常⽤该对象注册 timer(ProcessingTime/EventTime) 回调.*/public abstract TriggerResult onElement(T var1, long var2, W var4, Trigger.TriggerContext var5) throws Exception;/*** processing-time 定时器回调函数** @param time 定时器触发的时间.* @param window 定时器触发的窗口对象.* @param ctx ⼀个上下⽂对象,通常⽤该对象注册 timer(ProcessingTime/EventTime) 回调.*/public abstract TriggerResult onProcessingTime(long var1, W var3, Trigger.TriggerContext var4) throws Exception;/*** event-time 定时器回调函数** @param time 定时器触发的时间.* @param window 定时器触发的窗口对象.* @param ctx ⼀个上下⽂对象,通常⽤该对象注册 timer(ProcessingTime/EventTime) 回调.*/public abstract TriggerResult onEventTime(long var1, W var3, Trigger.TriggerContext var4) throws Exception;/*** 当 多个窗口合并到⼀个窗⼝的时候,调用该方法法,例如系统SessionWindow** @param window 合并后的新窗口对象* @param ctx ⼀个上下⽂对象,通常用该对象注册 timer(ProcessingTime/EventTime)回调以及访问状态*/public void onMerge(W window, Trigger.OnMergeContext ctx) throws Exception {throw new UnsupportedOperationException("This trigger does not support merging.");}/*** 当窗口被删除后执⾏所需的任何操作。例如:可以清除定时器或者删除状态数据*/public abstract void clear(W var1, Trigger.TriggerContext var2) throws Exception;
}
TriggerResult 源码:
public enum TriggerResult {// 表示对窗口不执行任何操作。即不触发窗口计算,也不删除元素。CONTINUE(false, false),// 触发窗口计算,输出结果,然后将窗口中的数据和窗口进行清除。FIRE_AND_PURGE(true, true),// 触发窗口计算,但是保留窗口元素FIRE(true, false),// 不触发窗口计算,丢弃窗口,并且删除窗口的元素。PURGE(false, true);private final boolean fire;private final boolean purge;private TriggerResult(boolean fire, boolean purge) {this.purge = purge;this.fire = fire;}public boolean isFire() {return this.fire;}public boolean isPurge() {return this.purge;}
}
Flink 预置的Trigger:
- EventTimeTrigger:通过对比EventTime和窗口的Endtime确定是否触发窗口计算,如果EventTime大于Window EndTime则触发,否则不触发,窗口将继续等待。
- ProcessTimeTrigger:通过对比ProcessTime和窗口EndTme确定是否触发窗口,如果ProcessTime大于EndTime则触发计算,否则窗口继续等待。
- ContinuousEventTimeTrigger:根据间隔时间周期性触发窗口或者Window的结束时间小于当前EndTime触发窗口计算。
- ContinuousProcessingTimeTrigger:根据间隔时间周期性触发窗口或者Window的结束时间小于当前ProcessTime触发窗口计算。
- CountTrigger:根据接入数据量是否超过设定的阙值判断是否触发窗口计算。
- DeltaTrigger:根据接入数据计算出来的Delta指标是否超过指定的Threshold去判断是否触发窗口计算。
- PurgingTrigger:可以将任意触发器作为参数转换为Purge类型的触发器,计算完成后数据将被清理。
- NeverTrigger:任何时候都不触发窗口计算
使用示例:
- 按次数触发: .trigger(CountTrigger.of(1))
- 按时间触发: .trigger(ContinuousEventTimeTrigger.of(Time.seconds(30)))
6. 多流转换
6.1. 分流
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,得到完全平等的多个子 DataStream。一般来说,我们会定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。
- 实现方式一:使用filter() 方法进行过滤
- 实现方式二:使用侧输出流( ctx.output() )
方式一会造成流数据重复,所以一般情况下,是使用方式二的侧输出流。
6.2. 基本合流操作
方式一:联合(Union)
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”( union)。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。这种合流方式非常简单粗暴,就像公路上多个车道汇在一起一样。
实现方式: stream1.union(stream2, stream3, ...)
注意:多条流的合并,某种意义上也可以看作是多个并行任务向同一个下游任务汇合的过程。所以水位线也使用最小的那个为准。

方式二:连接(Connect)
- 连接流(ConnectedStreams):两条流的连接就像是“一国两制”,两条流可以保持各自的数据类型、处理方式也可以不同,不过最终还是会统一到同一个 DataStream 中。这里可以的调用的同处理方法有.map()/.flatMap(),以及.process()方法。因为2条流的类型不同,所以在处理算子中有2个处理方法,分别对2条流的数据进行处理。
- CoProcessFunction:在通过连接流后的处理方法中,还可以使用 CoProcessFunction 方法来处理。在这个方法中,可以分别对2条流进行处理,并且可以设置状态和定时器。可以用来实现实时对账等功能。注意:使用此方法之前需要进行keyBy。
方式三:广播连接流(BroadcastConnectedStream)
关于两条流的连接,还有一种比较特殊的用法: DataStream 调用.connect()方法时,传入的参数也可以不是一个 DataStream,而是一个“广播流”(BroadcastStream),这时合并两流得到的就变成了一个“广播连接流”(BroadcastConnectedStream)。
这种连接方式往往用在需要动态定义某些规则或配置的场景。因为规则是实时变动的,所以我们可以用一个单独的流来获取规则数据;而这些规则或配置是对整个应用全局有效的,所以不能只把这数据传递给一个下游并行子任务处理,而是要“广播”(broadcast)给所有的并行子任务。而下游子任务收到广播出来的规则,会把它保存成一个状态,这就是所谓的“广播状态”(broadcast state)。DataStream<String> output=stream.connect(ruleBroadcastStream).process(new BroadcastProcessFunction<>(){...});import org.apache.flink.streaming.api.functions.co.BaseBroadcastProcessFunction;public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {...public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;...}
6.3. 基于时间的合流——双流联结(Join)
- 方式一:窗口联结(Window Join)
stream1.join(stream2).where(<KeySelector>).equalTo(<KeySelector>).window(<WindowAssigner>).apply(<JoinFunction>)- 方式二:间隔联结(Interval Join)
stream1.keyBy(<KeySelector>).intervalJoin(stream2.keyBy(<KeySelector>)).between(Time.milliseconds(-2),Time.milliseconds(1)).process(new ProcessJoinFunction<Integer, Integer, String(){@Overridepublic void processElement(Integer left,Integer right,Context ctx,Collector<String> out){out.collect(left+","+right);}});6.4. 窗口同组联结(Window CoGroup)
除窗口联结和间隔联结之外, Flink 还提供了一个“窗口同组联结”(window coGroup)操作。它的用法跟 window join 非常类似,也是将两条流合并之后开窗处理匹配的元素,调用时只需要将.join()换为.coGroup()就可以了。
stream1.coGroup(stream2).where(<KeySelector>).equalTo(<KeySelector>).window(TumblingEventTimeWindows.of(Time.hours(1))).apply(<CoGroupFunction>)与 window join 的区别在于,调用.apply()方法定义具体操作时,传入的是一个CoGroupFunction。这也是一个函数类接口,源码中定义如下:
public interface CoGroupFunction<IN1, IN2, O> extends Function, Serializable {void coGroup(Iterable<IN1> first, Iterable<IN2> second, Collector<O> out) throws Exception;
}7. 状态编程
7.1. 状态的分类
分类一:托管状态(Managed State)和原始状态(Raw State)
托管状态就是由 Flink 统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由 Flink 实现,我们只要调接口就可以;而原始状态则是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。
- 托管状态:Flink提供了值状态(ValueState)、列表状态(ListState)、映射状态(MapState)、聚合状态(AggregateState)等多种结构,内部支持各种数据类型。聚合、窗口等算子中内置的状态,就都是托管状态;我们也可以在富函数类(RichFunction)中通过上下文来自定义状态,这些也都是托管状态。
- 原始状态:Flink 不会对状态进行任何自动操作,也不知道状态的具体数据类型,只会把它当作最原始的字节(Byte)数组来存储。我们需要花费大量的精力来处理状态的管理和维护。(不建议使用,也一般不会使用)
分类二:算子状态(Operator State)和按键分区状态(Keyed State)
这两个状态都是托管状态(Managed State)。不同的 slot 在计算资源上是物理隔离的,所以 Flink能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。而很多有状态的操作(比如聚合、窗口)都是要先做 keyBy 进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前 key 有效,所以状态也应该按照 key 彼此隔离。在这种情况下,状态的访问方式又会有所不同。基于这样的想法,我们又可以将托管状态分为两类:算子状态和按键分区状态。
- 算子状态(Operator State):状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效。这就意味着对于一个并行子任务,占据了一个“分区”,它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的。
- 按键分区状态(Keyed State):状态是根据输入流中定义的键( key)来维护和访问的,所以只能定义在按键分区流(KeyedStream)中,也就 keyBy 之后才可以使用。除了聚合的结果是以 Keyed State 的形式保存的,通过富函数类(Rich Function)来自定义的状态也是 Keyed State (在富函数中,我们可以调用.getRuntimeContext()获取当前的运行时上下文( RuntimeContext),进而获取到访问状态的句柄;这种富函数中自定义的状态也是 Keyed State) 。所以即使是 map、 filter 这样无状态的基本转换算子,我们也可以通过富函数类给它们“追加” Keyed State,或者实现 CheckpointedFunction 接口来定义 Operator State;从这个角度讲,Flink 中所有的算子都可以是有状态的,不愧是“有状态的流处理”。需要注意,使用 Keyed State 必须基于 KeyedStream。没有进行 keyBy 分区的 DataStream,即使转换算子实现了对应的富函数类,也不能通过运行时上下文访问 Keyed State。
无论是 Keyed State 还是 Operator State,它们都是在本地实例上维护的,也就是说每个并行子任务维护着对应的状态,算子的子任务之间状态不共享。

7.2. 状态生存时间(TTL)
在实际应用中,很多状态会随着时间的推移逐渐增长,如果不加以限制,最终就会导致存储空间的耗尽。一个优化的思路是直接在代码中调用.clear()方法去清除状态,但是有时候我们的逻辑要求不能直接清除。这时就需要配置一个状态的“生存时间”(time-to-live, TTL),当状态在内存中存在的时间超出这个值时,就将它清除。
具体实现上,如果用一个进程不停地扫描所有状态看是否过期,显然会占用大量资源做无用功。状态的失效其实不需要立即删除,所以我们可以给状态附加一个属性,也就是状态的“失效时间”。状态创建的时候,设置 失效时间 = 当前时间 + TTL;之后如果有对状态的访问和修改,我们可以再对失效时间进行更新;当设置的清除条件被触发时(比如,状态被访问的时候,或者每隔一段时间扫描一次失效状态),就可以判断状态是否失效、从而进行清除了。
配置状态的 TTL 时,需要创建一个 StateTtlConfig 配置对象,然后调用状态描述器的.enableTimeToLive()方法启动 TTL 功能。
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(10)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("mystate", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);这里用到了几个配置项:
- .newBuilder():状态 TTL 配置的构造器方法,必须调用,返回一个 Builder 之后再调用.build()方法就可以得到 StateTtlConfig 了。方法需要传入一个 Time 作为参数,这就是设定的状态生存时间。
- .setUpdateType():设置更新类型。更新类型指定了什么时候更新状态失效时间,这里的 OnCreateAndWrite表示只有创建状态和更改状态(写操作)时更新失效时间。另一种类型 OnReadAndWrite 则表示无论读写操作都会更新失效时间,也就是只要对状态进行了访问,就表明它是活跃的,从而延长生存时间。这个配置默认为 OnCreateAndWrite。
- .setStateVisibility():设置状态的可见性。所谓的“状态可见性”,是指因为清除操作并不是实时的,所以当状态过期之后还有可能基于存在,这时如果对它进行访问,能否正常读取到就是一个问题了。这里设置的 NeverReturnExpired 是默认行为,表示从不返回过期值,也就是只要过期就认为它已经被清除了,应用不能继续读取;这在处理会话或者隐私数据时比较重要。对应的另一种配置是 ReturnExpireDefNotCleanedUp,就是如果过期状态还存在,就返回它的值。
除此之外, TTL 配置还可以设置在保存检查点(checkpoint)时触发清除操作,或者配置增量的清理(incremental cleanup),还可以针对 RocksDB 状态后端使用压缩过滤器(compactionfilter)进行后台清理。
这里需要注意,目前的 TTL 设置只支持处理时间。另外,所有集合类型的状态(例如ListState、 MapState)在设置 TTL 时,都是针对每一项(per-entry)元素的。也就是说,一个列表状态中的每一个元素,都会以自己的失效时间来进行清理,而不是整个列表一起清理。
7.3. 状态后端
1. 状态后端的分类:
- 哈希表状态后端(HashMapStateBackend):把状态存放在内存里。
- 内嵌 RocksDB 状态后端(EmbeddedRocksDBStateBackend):可以把数据持久化到本地硬盘。
2. 在flink-conf.yaml 中使用state.backend 来配置默认状态后端:
- state.backend: hashmap
- state.backend: rocksdb
# 默认状态后端
state.backend: hashmap
# 存放检查点的文件路径
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints3. 为每个作业(Per-job)单独配置状态后端:
- env.setStateBackend(new HashMapStateBackend());
- env.setStateBackend(new EmbeddedRocksDBStateBackend());
<!--需要在idea中导入rocksdb包,但Flink 发行版中默认就包含了 RocksDB,所以打包时不需要导入-->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId><version>1.13.0</version>
</dependency>8. 容错机制
8.1. 检查点(Checkpoint )
1. 启用检查点:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每隔 1 秒启动一次检查点保存(单位:毫秒)
env.enableCheckpointing(1000);2. 检查点存储(Checkpoint Storage):
- 配置存储检查点到 JobManager 堆内存:env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());
- 配置存储检查点到文件系统:env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://namenode:40010/flink/checkpoints"));
3. 示例代码:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 启用检查点,间隔时间 1 秒
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();// 设置精确一次模式
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);// 最小间隔时间 500 毫秒
checkpointConfig.setMinPauseBetweenCheckpoints(500);// 超时时间 1 分钟
checkpointConfig.setCheckpointTimeout(60000);// 同时只能有一个检查点
checkpointConfig.setMaxConcurrentCheckpoints(1);// 开启检查点的外部持久化保存,作业取消后依然保留
checkpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 启用不对齐的检查点保存方式
checkpointConfig.enableUnalignedCheckpoints();// 设置检查点存储,可以直接传入一个 String,指定文件系统的路径
checkpointConfig.setCheckpointStorage("hdfs://my/checkpoint/dir")8.2. 保存点(Savepoint)
保存点与检查点最大的区别,就是触发的时机。检查点是由 Flink 自动管理的,定期创建,发生故障之后自动读取进行恢复,这是一个“自动存盘”的功能;而保存点不会自动创建,必须由用户明确地手动触发保存操作,所以就是“手动存盘”。因此两者尽管原理一致,但用途就有所差别了:检查点主要用来做故障恢复,是容错机制的核心;保存点则更加灵活,可以用来做有计划的手动备份和恢复。
保存点适用的具体场景有:
- 版本管理和归档存储
- 更新 Flink 版本
- 更新应用程序
- 调整并行度
- 暂停应用程序
需要注意的是,保存点能够在程序更改的时候依然兼容,前提是状态的拓扑结构和数据类型不变。我们知道保存点中状态都是以算子 ID-状态名称这样的 key-value 组织起来的,算子ID 可以在代码中直接调用 SingleOutputStreamOperator 的.uid()方法来进行指定:
DataStream<String> stream = env.addSource(new StatefulSource()).uid("source-id").map(new StatefulMapper()).uid("mapper-id").print();对于没有设置 ID 的算子, Flink 默认会自动进行设置,所以在重新启动应用后可能会导致ID 不同而无法兼容以前的状态。 所以为了方便后续的维护,强烈建议在程序中为每一个算子手动指定 ID。
创建保存点操作如下:
# 要在命令行中为运行的作业创建一个保存点镜像,只需要执行:
bin/flink savepoint :jobId [:targetDirectory]# 这里 jobId 需要填充要做镜像保存的作业 ID,目标路径 targetDirectory 可选,表示保存点存储的路径。
# 对于保存点的默认路径,可以通过配置文件 flink-conf.yaml 中的 state.savepoints.dir 项来设定:
state.savepoints.dir: hdfs:///flink/savepoints# 当然对于单独的作业,我们也可以在程序代码中通过执行环境来设置:
env.setDefaultSavepointDir("hdfs:///flink/savepoints");# 由于创建保存点一般都是希望更改环境之后重启,所以创建之后往往紧接着就是停掉作业的操作。除了对运行的作业创建保存点,我们也可以在停掉一个作业时直接创建保存点:
bin/flink stop --savepointPath [:targetDirectory] :jobId从保存点重启应用操作如下:
# 从保存点重启应用,只需要增加一个-s 参数,指定保存点的路径就可以了
bin/flink run -s :savepointPath [:runArgs]8.3. 状态一致性
1. 一致性的级别
- 最多一次(AT-MOST-ONCE)
- 至少一次(AT-LEAST-ONCE)
- 精确一次(EXACTLY-ONCE)
2. 端到端精确一次(end-to-end exactly-once)
- 输入端保证:外部数据源就必须拥有重放数据的能力
- 输出端保证:幂等(idempotent)写入 和 事务(transactional)写入
3. Flink 和 Kafka 连接时的精确一次保证
- Flink 内部:Flink 内部可以通过检查点机制保证状态和处理结果的 exactly-once 语义
- 输入端:输入数据源端的 Kafka 可以对数据进行持久化保存,并可以重置偏移量(offset)
- 输出端:输出端保证 exactly-once 的最佳实现,当然就是两阶段提交(2PC)
4. Flink 和 Kafka 连接时的精确一次保证需要的配置
- 必须启用检查点
- 在 FlinkKafkaProducer 的构造函数中传入参数 Semantic.EXACTLY_ONCE
- 配置 Kafka 读取数据的消费者的隔离级别
这里所说的 Kafka,是写入的外部系统。预提交阶段数据已经写入,只是被标记为“未提交”(uncommitted),而 Kafka 中默认的隔离级别 isolation.level 是 read_uncommitted,也就是可以读取未提交的数据。这样一来,外部应用就可以直接消费未提交的数据,对于事务性的保证就失效了。所以应该将隔离级别配置为read_committed, 表示消费者遇到未提交的消息时,会停止从分区中消费数据,直到消息被标记为已提交才会再次恢复消费。当然,这样做的话,外部应用消费数据就会有显著的延迟。
- 事务超时配置
Flink 的 Kafka连接器中配置的事务超时时间 transaction.timeout.ms 默认是 1小时,而Kafka集群配置的事务最大超时时间 transaction.max.timeout.ms 默认是 15 分钟。所以在检查点保存时间很长时,有可能出现 Kafka 已经认为事务超时了,丢弃了预提交的数据;而 Sink 任务认为还可以继续等待。如果接下来检查点保存成功,发生故障后回滚到这个检查点的状态,这部分数据就被真正丢掉了。所以这两个超时时间,前者应该小于等于后者。
9. Table API 和 SQL
9.1. TableAPI依赖说明
Java 的“桥接器”(bridge),主要就是负责 Table API 和下层 DataStreamAPI 的连接支持,按照不同的语言分为 Java 版和 Scala 版:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>如果我们希望在本地的集成开发环境(IDE)里运行 Table API 和 SQL,还需要引入以下依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>这里主要添加的依赖是一个“计划器”(planner),它是 Table API 的核心组件,负责提供运行时环境,并生成程序的执行计划。这里我们用到的是新版的 blink planner。由于 Flink 安装包的 lib 目录下会自带 planner,所以在生产集群环境中提交的作业不需要打包这个依赖。
而在 Table API 的内部实现上,部分相关的代码是用 Scala 实现的,所以还需要额外添加一个Scala 版流处理的相关依赖。
另外,如果想实现自定义的数据格式来做序列化,可以引入下面的依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version>
</dependency>9.2. 执行环境的创建
方案一:
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode() // 使用流处理模式.build();TableEnvironment tableEnv = TableEnvironment.create(settings);方案二:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);TableAPI、FlinkSQL和FlinkCEP还未完全完成,待续...
相关文章:
Flink中核心重点总结
目录 1. 算子链 1.1. 一对一(One-to-one, forwarding) 1.2. 重分区(Redistributing) 1.3. 为什么有算子链 2. 物理分区(Physical Partitioning) 2.1. 什么是分区 2.2. 随机分区ÿ…...

gismo中NURBS的相关函数的使用---待完善
文章目录 前言一、B样条的求值1.1 节点向量的生成1.2 基函数的调用1.3 函数里面的T指的是系数类型二、以等几何两个单元12个控制点为例输出的控制点坐标有误1.4二、#pic_center <table><tr><td bgcolor=PowderBlue>二维数2.12.22.32.4三、3.13.23.33.4四、4.…...

5.数据共享与持久化
数据共享与持久化 在容器中管理数据主要有两种方式: 数据卷(Data Volumes)挂载主机目录 (Bind mounts) 数据卷 数据卷是一个可供一个或多个容器使用的特殊目录,它绕过UFS,可以提供很多有用的特性: 数据…...

RabbitMQ-客户端源码之AMQCommand
AMQCommand不是直接包含Method等成员变量的,而是通过CommandAssembler又做了一次封装。 接下来先看下CommandAssembler类。此类中有这些成员变量: /** Current state, used to decide how to handle each incoming frame. */ private enum CAState {EXP…...

linux设置登录失败处理功能(密码错误次数限制、pam_tally2.so模块)和操作超时退出功能(/etc/profile)
一、登录失败处理功能策略 1、登录失败处理功能策略(服务器终端) (1)编辑系统/etc/pam.d/system-auth 文件,在 auth 字段所在的那一部分添加如下pam_tally2.so模块的策略参数: auth required pam_tally2…...

Centos7上Docker安装
文章目录1.Docker常识2.安装Docker1.卸载旧版本Docker2.安装Docker3.启动Docker4.配置镜像加速前天开学啦~所以可以回来继续卷了哈哈哈,放假在家效率不高,在学校事情也少点(^_−)☆昨天和今天学了学Docker相关的知识,也算是简单了解了下&…...

新瑞鹏“狂飙”,宠物医疗是门好生意吗?
宠物看病比人还贵,正在让不少年轻一族陷入尴尬境地。在知乎上,有个高赞提问叫“你愿意花光积蓄,给宠物治病吗”,这个在老一辈人看来不可思议的魔幻选择,真实地发生在当下的年轻人身上。提问底下,有人表示自…...
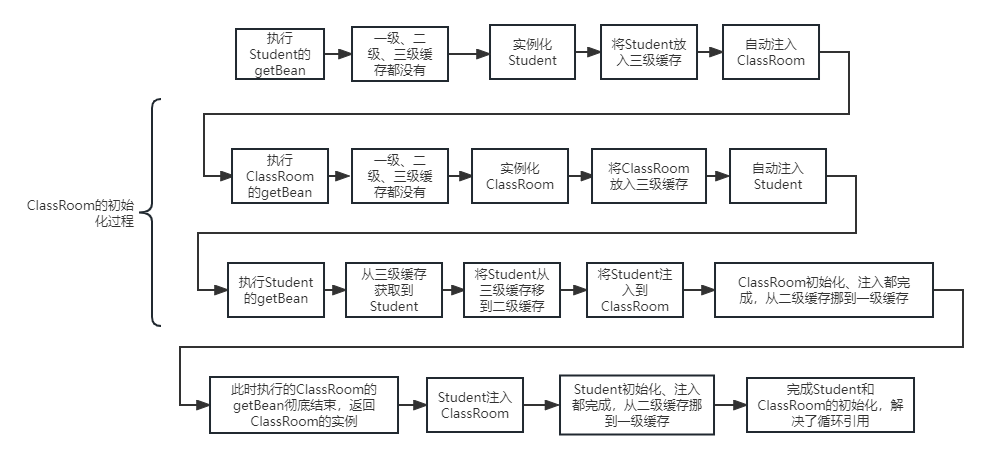
Spring循环依赖问题,Spring是如何解决循环依赖的?
文章目录一、什么是循环依赖1、代码实例2、重要信息二、源码分析1、初始化Student对Student中的ClassRoom进行Autowire操作2、Student的自动注入ClassRoom时,又对ClassRoom的初始化3、ClassRoom的初始化,又执行自动注入Student的逻辑4、Student注入Class…...
更改SAP GUI登录界面信息
在SAP GUI的登录界面,左部输入登录信息如客户端、用户名、密码等,右部空余部分可维护一些登录信息文本,如登录的产品、客户端说明及注意事项等,此项操作详见SAP Notes 205487 – Own text on SAPGui logon screen 维护文档使用的…...
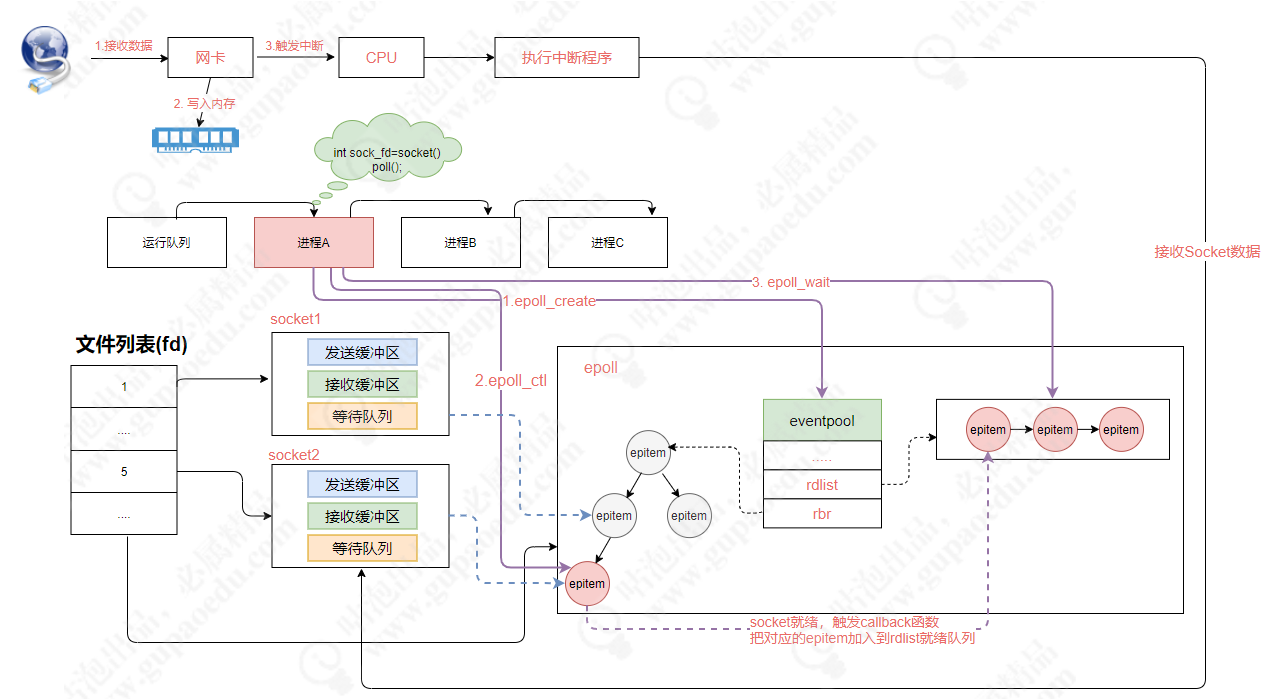
分布式微服务架构下网络通信的底层实现原理
在分布式架构中,网络通信是底层基础,没有网络,也就没有所谓的分布式架构。只有通过网络才能使得一大片机器互相协作,共同完成一件事情。 同样,在大规模的系统架构中,应用吞吐量上不去、网络存在通信延迟、我…...

进大厂必备的Java面试八股文大全(2023最新精简易懂版,八股文中的八股文)
为什么同样是跳槽,有些人薪资能翻三倍?” 最近一个粉丝发出了灵魂拷问,类似的问题我收到过很多次,身边也确实有认识的同事、朋友们有非常成功的跳槽经历和收益,先说一个典型例子: 学弟小 A 工作一年半&am…...

都说测试行业饱和了,为什么我们公司给初级测试开到了12K?
故事起因: 最近我有个刚毕业的学生问我说:我感觉现在测试行业已经饱和了,也不是说饱和了,是初级的测试根本就没有公司要,哪怕你不要工资也没公司要你,测试刚学出来,没有任何的项目经验和工作经验…...

解决Idea启动项目失败,提示Error running ‘XXXApplication‘: Command line is too long
IDEA版本为:IntelliJ IDEA 2018.2 (Ultimate Edition)一、问题描述有时当我们使用IDEA,Run/Debug一个SpringBoot项目时,可能会启动失败,并提示以下错误。Error running XXXApplication: Command line is too long. Shorten comman…...
GB/T28181-2022针对H.265、AAC的说明和技术实现
GB/T28181-2022规范说明GB/T28181-2022相对来GB/T28181-2016针对H.265、AAC的更新如下:——更改了“联网系统通信协议结构图”,媒体流通道增加了 H.265、G.722.1、AAC(见 4.3.1,2016 年版的 4.3.1)。——增加了对 H.26…...
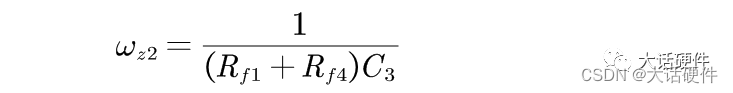
开关电源环路稳定性分析(11)——观察法找零极点
大家好,这里是大话硬件。 这篇文章主要是分享如何用观察法直接写出补偿网络中的零极点的表达式。 在前面的文章中,我们分别整理了OTA和OPA型的补偿网络,当时有下面的结论。 针对某个固定的补偿网络,我们可以用数学的方法推导补偿…...

焕新启航,「龙蜥大讲堂」2023 年度招募来了!13 场技术分享先睹为快
龙蜥大讲堂是龙蜥推出的系列技术直播活动,邀请龙蜥社区的开发者们分享围绕龙蜥技术展开,包括但不限于内核、编译器、机密计算、容器、储存等相关技术领域。欢迎社区开发者们积极参与,共享技术盛宴。往期回顾龙蜥社区技术系列直播截至目前已举…...
推广传单制作工具
临近节日如何制作推广活动呢?没有素材制作满减活动宣传单怎么办?小编教你如何使用在线设计工具乔拓云,轻松设计商品的专属满减活动宣传单,不仅设计简单,还能自动生成活动分享链接,只需跟着小编下面的设计步…...
数据结构(上))
软件设计(十一)数据结构(上)
线性结构 线性表 线性表是n个元素的有限序列,通常记为(a1,a2....an),特点如下。 存在唯一的一个称作“第一个”的元素。存在位移的一个称作“最后一个”的元素。除了表头外,表中的每一个元素均只有唯一的直接前趋除了表尾外&…...
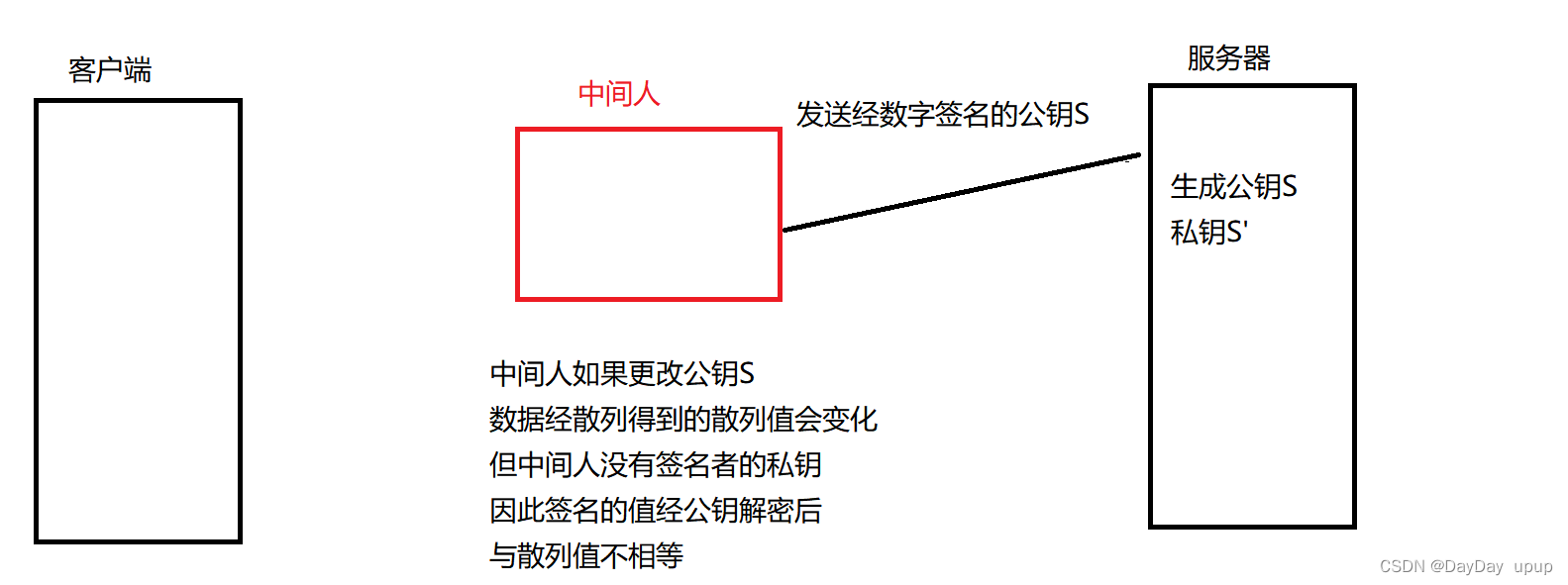
https协议
文章目录对称加密方案非对称加密方案对称加密方案非对称加密方案对称加密方案非对称加密方案数字证书因为HTTP是明文传输,所以会很有可能产生中间人攻击(获取并篡改传输在客户端及服务端的信息并不被人发觉),HTTPS加密应运而生。 …...
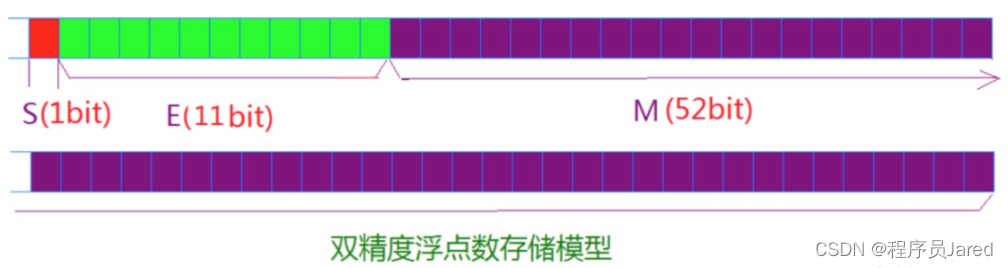
深入浅出C语言——数据在内存中的存储
文章目录一、数据类型详细介绍1. C语言中的内置类型2. 类型的基本归类:二. 整形在内存中的存储1. 原码、反码、补码2. 大小端三.浮点数存储规则一、数据类型详细介绍 1. C语言中的内置类型 C语言的内置类型有char、short、int、long、long long、float、double&…...

N_m3u8DL-CLI-SimpleG:让M3U8视频下载变得简单高效的图形化工具
N_m3u8DL-CLI-SimpleG:让M3U8视频下载变得简单高效的图形化工具 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 在数字内容日益丰富的今天,我们经常遇到需…...

终极Redis可视化工具:Another Redis Desktop Manager完全使用指南
终极Redis可视化工具:Another Redis Desktop Manager完全使用指南 【免费下载链接】AnotherRedisDesktopManager 🚀🚀🚀A faster, better and more stable Redis desktop manager [GUI client], compatible with Linux, Windows, …...

PaddleNLP:面向产业级应用的大语言模型全流程开发套件技术深度解析
PaddleNLP:面向产业级应用的大语言模型全流程开发套件技术深度解析 【免费下载链接】PaddleNLP PaddleNLP是一款基于飞桨深度学习框架的大语言模型(LLM)开发套件,支持在多种硬件上进行高效的大模型训练、无损压缩以及高性能推理。PaddleNLP 具备简单易用…...
)
从嵌入式到云原生:手把手教你根据项目规模选对MQTT Broker(EMQX vs Mosquitto实战避坑)
从嵌入式到云原生:手把手教你根据项目规模选对MQTT Broker(EMQX vs Mosquitto实战避坑) 当你在设计一个物联网系统时,选择正确的MQTT Broker就像为你的房子选择合适的地基。选得太轻量级,系统可能无法承载未来的增长&…...

手把手教你用AT32F403A实现串口空闲中断接收完整数据帧
深入解析AT32F403A串口空闲中断实现高效数据帧接收 在嵌入式系统开发中,串口通信是最基础也最常用的外设接口之一。面对实际应用中常见的不定长数据帧接收需求,传统轮询方式不仅效率低下,还容易丢失数据。而国产MCU雅特力AT32F403A提供的**串…...

别再手动写Excel了!用Coze+GPT-4o,5分钟把Word需求文档变成测试用例表格
从Word到Excel:零代码打造智能测试用例生成流水线 每次产品需求文档更新后,测试团队最头疼的莫过于手动编写成百上千条测试用例。传统方式下,测试工程师需要反复阅读PRD文档,逐条提取功能点,再按照固定模板填充到Excel…...

当 Go 还在追求极简时,C++ 26 却又加了四大“史诗级”新特性
大家好,我是Tony Bai。在这个 Go、Zig 等“小而美”新语言颇受青睐的时代,如果你去技术社区里问一句:“C 这门语言怎么样?”你大概率会得到一堆充满戏谑的回答:“太复杂了,别学”、“从入门到放弃”、“面试…...

3个步骤,让猫抓帮你轻松捕获网页视频资源
3个步骤,让猫抓帮你轻松捕获网页视频资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过这样的情况?在网…...

PyTorch 2.8镜像工业设计:CAD图纸→AI生成产品渲染视频→营销素材输出
PyTorch 2.8镜像工业设计:CAD图纸→AI生成产品渲染视频→营销素材输出 1. 工业设计新范式:从CAD到营销视频的全流程AI化 传统工业设计流程中,从CAD图纸到产品营销素材的转化往往需要耗费大量时间和人力成本。设计师需要先完成3D建模&#x…...

TDengine IDMP 工业数据建模 —— 数据标准化
3.4 数据标准化 工业环境通常从多个数据源采集数据,这些数据往往命名不一致、物理单位各异、数据结构不同。如果没有标准化,跨资产分析、AI 生成洞察和数据汇聚将变得不可靠甚至无法实现。TDengine IDMP 提供了多种机制,对整个资产模型中的数…...