MySQL入门篇-MySQL MHA高可用实战
MHA简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司的youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA架构图
MHA工作原理总结为以下几条:
- 从宕机崩溃的master保存二进制日志事件(binlog events);
- 识别含有最新更新的slave;
- 应用差异的中继日志(relay log)到其他slave;
- 应用从master保存的二进制日志事件(binlog events);
- 提升一个slave为新master;
- 使用其他的slave连接新的master进行复制。
MHA特点:
- 故障切换时间 10-30秒
- 自动监控Master以及故障转移
- 在线切换Master到异机
MHA搭建
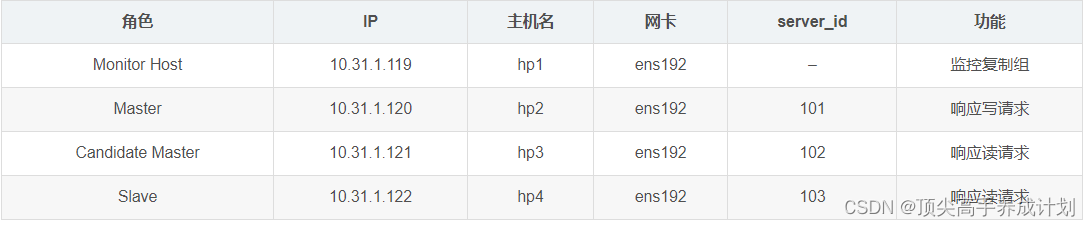
基本环境
操作系统版本:CentOS Linux release 7.8.2003 (Core)
MySQL版本 :5.7.31
VIP :10.31.1.241
主机信息:
配置主从
配置 hp3、hp4两台同步hp2的主从复制,参考主从复制blog,此处略过
安装Perl等依赖模块
用root用户在所有四个节点执行下面的操作。
# 安装一个epel源
wget -O /etc/yum.repos.d/epel-7.repo http://mirrors.aliyun.com/repo/epel-7.repo# 用yum安装依赖包
yum install perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes -y
配置SSH登录无密码验证
在hdp1 10.31.1.119(Monitor)上用root用户执行:
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.120
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.121
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.122
在hdp2 10.31.1.120(Master)上用root用户执行:
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.119
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.121
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.122
在hdp3 10.31.1.121(Candidate Master)上用root用户执行:
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.119
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.120
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.122
在hdp4 10.31.1.122(Slave)上用root用户执行:
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.119
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.120
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.31.1.121
安装MHA Node
下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
在hdp2、hdp3、hdp4上用root用户执行下面的操作。
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
安装完成后,在/usr/bin/目录下有如下MHA相关文件:
apply_diff_relay_logs
filter_mysqlbinlog
purge_relay_logs
save_binary_logs
这些脚本工具通常由MHA Manager的脚本触发,无需人为操作。脚本说明:
apply_diff_relay_logs:识别差异的中继日志事件并将其差异的事件应用于其它slave。
filter_mysqlbinlog:去除不必要的ROLLBACK事件(MHA已不再使用这个工具)。
purge_relay_logs:清除中继日志(不会阻塞SQL线程)。
save_binary_logs:保存和复制master的二进制日志。
安装MHA Manager
下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
在hdp1上用root用户执行下面的操作。
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
安装报错
[root@10-31-1-119 src]# rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
错误:依赖检测失败:mha4mysql-node >= 0.54 被 mha4mysql-manager-0.56-0.el6.noarch 需要perl(MHA::BinlogManager) 被 mha4mysql-manager-0.56-0.el6.noarch 需要perl(MHA::NodeConst) 被 mha4mysql-manager-0.56-0.el6.noarch 需要perl(MHA::NodeUtil) 被 mha4mysql-manager-0.56-0.el6.noarch 需要perl(MHA::SlaveUtil) 被 mha4mysql-manager-0.56-0.el6.noarch 需要
[root@10-31-1-119 src]#
[root@10-31-1-119 src]#
[root@10-31-1-119 src]# yum -y install mha4mysql-manager-0.56-0.el6.noarch.rpm
已加载插件:fastestmirror, langpacks
正在检查 mha4mysql-manager-0.56-0.el6.noarch.rpm: mha4mysql-manager-0.56-0.el6.noarch
mha4mysql-manager-0.56-0.el6.noarch.rpm 将被安装
正在解决依赖关系
--> 正在检查事务
---> 软件包 mha4mysql-manager.noarch.0.0.56-0.el6 将被 安装
--> 正在处理依赖关系 mha4mysql-node >= 0.54,它被软件包 mha4mysql-manager-0.56-0.el6.noarch 需要
Loading mirror speeds from cached hostfile
--> 正在处理依赖关系 perl(MHA::BinlogManager),它被软件包 mha4mysql-manager-0.56-0.el6.noarch 需要
--> 正在处理依赖关系 perl(MHA::NodeConst),它被软件包 mha4mysql-manager-0.56-0.el6.noarch 需要
--> 正在处理依赖关系 perl(MHA::NodeUtil),它被软件包 mha4mysql-manager-0.56-0.el6.noarch 需要
--> 正在处理依赖关系 perl(MHA::SlaveUtil),它被软件包 mha4mysql-manager-0.56-0.el6.noarch 需要
--> 解决依赖关系完成
错误:软件包:mha4mysql-manager-0.56-0.el6.noarch (/mha4mysql-manager-0.56-0.el6.noarch)需要:mha4mysql-node >= 0.54
错误:软件包:mha4mysql-manager-0.56-0.el6.noarch (/mha4mysql-manager-0.56-0.el6.noarch)需要:perl(MHA::NodeUtil)
错误:软件包:mha4mysql-manager-0.56-0.el6.noarch (/mha4mysql-manager-0.56-0.el6.noarch)需要:perl(MHA::BinlogManager)
错误:软件包:mha4mysql-manager-0.56-0.el6.noarch (/mha4mysql-manager-0.56-0.el6.noarch)需要:perl(MHA::NodeConst)
错误:软件包:mha4mysql-manager-0.56-0.el6.noarch (/mha4mysql-manager-0.56-0.el6.noarch)需要:perl(MHA::SlaveUtil)您可以尝试添加 --skip-broken 选项来解决该问题您可以尝试执行:rpm -Va --nofiles --nodigest
[root@10-31-1-119 src]#
监控节点需要先安装node再安装manager
[root@10-31-1-119 src]# rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
准备中... ################################# [100%]
正在升级/安装...1:mha4mysql-node-0.56-0.el6 ################################# [100%]
[root@10-31-1-119 src]#
[root@10-31-1-119 src]# rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
准备中... ################################# [100%]
正在升级/安装...1:mha4mysql-manager-0.56-0.el6 ################################# [100%]
[root@10-31-1-119 src]#
安装完成后,在/usr/bin/目录下有如下MHA相关文件:
masterha_check_repl
masterha_check_ssh
masterha_check_status
masterha_conf_host
masterha_manager
masterha_master_monitor
masterha_master_switch
masterha_secondary_check
masterha_stop
apply_diff_relay_logs
filter_mysqlbinlog
purge_relay_logs
save_binary_logs
配置MHA
在hdp1上用root用户执行下面(1)、(2)、(3)的操作。
(1)建立配置文件目录
mkdir -p /etc/masterha
(2)创建配置文件/etc/masterha/app1.cnf,内容如下:
[server default]
manager_log=/var/log/masterha/app1/manager.log
manager_workdir=/var/log/masterha/app1.log
master_binlog_dir=/var/lib/mysql
master_ip_failover_script=/usr/bin/master_ip_failover
master_ip_online_change_script=/usr/bin/master_ip_online_change
password=abc123
ping_interval=1
remote_workdir=/tmp
repl_password=abc123
repl_user=repl
secondary_check_script=/usr/bin/masterha_secondary_check -s hp2 -s hp3 --user=root --master_host=hp2 --master_ip=10.31.1.120 --master_port=3306
shutdown_script=""
ssh_user=root
user=root[server1]
hostname=10.31.1.120
port=3306[server2]
candidate_master=1
check_repl_delay=0
hostname=10.31.1.121
port=3306[server3]
hostname=10.31.1.122
port=3306
server default段是manager的一些基本配置参数,server1、server2、server3分别对应复制中的master、第一个slave、第二个slave。该文件的语法要求严格,变量值后不要有多余的空格。主要配置项说明如下。
manager_log:设置manager的日志文件。
manager_workdir:设置manager的工作目录。
master_binlog_dir:设置master保存binlog的位置,以便MHA可以找到master的日志,这里的也就是mysql的数据目录。
master_ip_failover_script:设置自动failover时候的切换脚本。
master_ip_online_change_script:设置手动切换时候的切换脚本。
password:设置mysql中root用户的密码。
ping_interval:设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行railover。
remote_workdir:设置远端mysql在发生切换时binlog的保存位置。
repl_password:设置复制用户的密码。
repl_user:设置复制环境中的复制用户名
secondary_check_script:一旦MHA到hdp4的监控之间出现问题,MHA Manager将会尝试从hdp3登录到hdp4。
shutdown_script:设置故障发生后关闭故障主机脚本。该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用。
ssh_user:设置ssh的登录用户名。
user:设置监控用户为root。
candidate_master:设置为候选master。设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave。
check_repl_delay:默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master。
(3)建立软连接
-- 这一步如果 mysqlbinlog和mysql已经可以直接使用就没问题
ln -s /home/mysql/mysql-5.6.14/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /home/mysql/mysql-5.6.14/bin/mysql /usr/bin/mysql
(4)设置复制中Slave的relay_log_purge参数
在hdp3和hdp4上用mysql用户执行:
mysql -uroot -pabc123 -e "set global relay_log_purge=0"
注意,MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF,采用手动清除relay log的方式。默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。但是在MHA环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能。定期清除中继日志需要考虑到复制延时的问题。在ext3的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在linux系统中通过硬链接删除大文件速度会很快。(在mysql数据库中,删除大表时,通常也采用建立硬链接的方式)
创建相关脚本
创建定期清理relay脚本
在hdp3、hdp4两台slave上建立/root/purge_relay_log.sh文件,内容如下:
#!/bin/bash. /home/mysql/.bashrcuser=root
passwd=abc123
port=3306
log_dir='/data'
work_dir='/data'
purge='/usr/bin/purge_relay_logs'if [ ! -d $log_dir ]
thenmkdir $log_dir -p
fi$purge --user=$user --password=$passwd --disable_relay_log_purge --port=$port --workdir=$work_dir >> $log_dir/purge_relay_logs.log 2>&1
purge_relay_logs的参数说明:
user mysql:MySQL用户名。
password mysql:MySQL用户密码。
port:MySQL端口号。
workdir:指定创建relay log的硬链接的位置,默认是/var/tmp。由于系统不同分区创建硬链接文件会失败,故需要执行硬链接具体位置,成功执行脚本后,硬链接的中继日志文件被删除。
disable_relay_log_purge:默认情况下,如果relay_log_purge=1,脚本会什么都不清理,自动退出。通过设定这个参数,当relay_log_purge=1的情况下会将relay_log_purge设置为0。清理relay log之后,最后将参数设置为OFF。
改模式为可执行:
mkdir -p /data
chmod 755 purge_relay_log.sh
添加到crontab中:
0 4 * * * /bin/bash /root/purge_relay_log.sh
创建自动failover脚本
在hdp1上创建/usr/bin/master_ip_failover文件,内容如下:
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';use Getopt::Long;my ($command, $ssh_user, $orig_master_host, $orig_master_ip,$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);my $vip = '10.31.1.241';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig ens192:$key $vip/24";
my $ssh_stop_vip = "/sbin/ifconfig ens192:$key down";GetOptions('command=s' => \$command,'ssh_user=s' => \$ssh_user,'orig_master_host=s' => \$orig_master_host,'orig_master_ip=s' => \$orig_master_ip,'orig_master_port=i' => \$orig_master_port,'new_master_host=s' => \$new_master_host,'new_master_ip=s' => \$new_master_ip,'new_master_port=i' => \$new_master_port,
);exit &main();sub main {print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";if ( $command eq "stop" || $command eq "stopssh" ) {my $exit_code = 1;eval {print "Disabling the VIP on old master: $orig_master_host \n";&stop_vip();$exit_code = 0;};if ($@) {warn "Got Error: $@\n";exit $exit_code;}exit $exit_code;}elsif ( $command eq "start" ) {my $exit_code = 10;eval {print "Enabling the VIP - $vip on the new master - $new_master_host \n";&start_vip();$exit_code = 0;};if ($@) {warn $@;exit $exit_code;}exit $exit_code;}elsif ( $command eq "status" ) {print "Checking the Status of the script.. OK \n";exit 0;}else {&usage();exit 1;}
}
sub start_vip() {`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}sub usage {print"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
注意脚本中的vip部分
chmod u+x /usr/bin/master_ip_failover
创建手动failover脚本
在hdp1上创建/usr/bin/master_ip_online_change文件,内容如下:
#!/usr/bin/env perl## Note: This is a sample script and is notcomplete. Modify the script based on your environment.use strict;
use warnings FATAL => 'all';use Getopt::Long;
use MHA::DBHelper;
use MHA::NodeUtil;
# use Time::HiRes qw( sleep gettimeofdaytv_interval );
use Time::HiRes qw(sleep gettimeofday tv_interval);
use Data::Dumper;my $_tstart;
my $_running_interval = 0.1;
my ($command, $orig_master_host, $orig_master_ip,$orig_master_port, $orig_master_user,$new_master_host, $new_master_ip, $new_master_port,$new_master_user,
);my $vip = '10.31.1.241'; # Virtual IP
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig ens32:$key $vip/24";
my $ssh_stop_vip = "/sbin/ifconfig ens160:$key down";
my $ssh_user = "root";
my $new_master_password = "123456";
my $orig_master_password = "123456";GetOptions('command=s' =>\$command,#'ssh_user=s' => \$ssh_user, 'orig_master_host=s' =>\$orig_master_host,'orig_master_ip=s' =>\$orig_master_ip,'orig_master_port=i' =>\$orig_master_port,'orig_master_user=s' =>\$orig_master_user,#'orig_master_password=s' => \$orig_master_password,'new_master_host=s' =>\$new_master_host,'new_master_ip=s' =>\$new_master_ip,'new_master_port=i' =>\$new_master_port,'new_master_user=s' =>\$new_master_user,#'new_master_password=s' =>\$new_master_password,
);exit &main();sub current_time_us {my ($sec, $microsec ) = gettimeofday();my$curdate = localtime($sec);return $curdate . " " . sprintf( "%06d", $microsec);
}sub sleep_until {my$elapsed = tv_interval($_tstart);if ($_running_interval > $elapsed ) {sleep( $_running_interval - $elapsed );}
}sub get_threads_util {my$dbh = shift;my$my_connection_id = shift;my$running_time_threshold = shift;my$type = shift;$running_time_threshold = 0 unless ($running_time_threshold);$type = 0 unless($type);my@threads;my$sth = $dbh->prepare("SHOW PROCESSLIST");$sth->execute();while ( my $ref = $sth->fetchrow_hashref() ) {my$id = $ref->{Id};my$user = $ref->{User};my$host = $ref->{Host};my$command = $ref->{Command};my$state = $ref->{State};my$query_time = $ref->{Time};my$info = $ref->{Info};$info =~ s/^\s*(.*?)\s*$/$1/ if defined($info);next if ( $my_connection_id == $id );next if ( defined($query_time) && $query_time <$running_time_threshold );next if ( defined($command) && $command eq "Binlog Dump" );next if ( defined($user) && $user eq "system user" );nextif ( defined($command)&& $command eq "Sleep"&& defined($query_time)&& $query_time >= 1 );if( $type >= 1 ) {next if ( defined($command) && $command eq "Sleep" );nextif ( defined($command) && $command eq "Connect" );}if( $type >= 2 ) {next if ( defined($info) && $info =~ m/^select/i );next if ( defined($info) && $info =~ m/^show/i );}push @threads, $ref;}return @threads;
}sub main {if ($command eq "stop" ) {##Gracefully killing connections on the current master#1. Set read_only= 1 on the new master#2. DROP USER so that no app user can establish new connections#3. Set read_only= 1 on the current master#4. Kill current queries#* Any database access failure will result in script die.my$exit_code = 1;eval {## Setting read_only=1 on the new master (to avoid accident)my $new_master_handler = new MHA::DBHelper();# args: hostname, port, user, password, raise_error(die_on_error)_or_not$new_master_handler->connect( $new_master_ip, $new_master_port,$new_master_user, $new_master_password, 1 );print current_time_us() . " Set read_only on the new master..";$new_master_handler->enable_read_only();if ( $new_master_handler->is_read_only() ) {print "ok.\n";}else {die "Failed!\n";}$new_master_handler->disconnect();# Connecting to the orig master, die if any database error happensmy $orig_master_handler = new MHA::DBHelper();$orig_master_handler->connect( $orig_master_ip, $orig_master_port,$orig_master_user, $orig_master_password, 1 );## Drop application user so that nobodycan connect. Disabling per-session binlog beforehand#$orig_master_handler->disable_log_bin_local();#print current_time_us() . " Drpping app user on the origmaster..\n";#FIXME_xxx_drop_app_user($orig_master_handler);## Waiting for N * 100 milliseconds so that current connections can exitmy $time_until_read_only = 15;$_tstart = [gettimeofday];my @threads = get_threads_util( $orig_master_handler->{dbh},$orig_master_handler->{connection_id} );while ( $time_until_read_only > 0 && $#threads >= 0 ) {if ( $time_until_read_only % 5 == 0 ) {printf "%s Waiting all running %d threads aredisconnected.. (max %d milliseconds)\n",current_time_us(), $#threads + 1, $time_until_read_only * 100;if ( $#threads < 5 ) {print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump ."\n"foreach (@threads);}}sleep_until();$_tstart = [gettimeofday];$time_until_read_only--;@threads = get_threads_util( $orig_master_handler->{dbh},$orig_master_handler->{connection_id} );}## Setting read_only=1 on the current master so that nobody(exceptSUPER) can writeprint current_time_us() . " Set read_only=1 on the orig master..";$orig_master_handler->enable_read_only();if ( $orig_master_handler->is_read_only() ) {print "ok.\n";}else {die "Failed!\n";}## Waiting for M * 100 milliseconds so that current update queries cancompletemy $time_until_kill_threads = 5;@threads = get_threads_util( $orig_master_handler->{dbh},$orig_master_handler->{connection_id} );while ( $time_until_kill_threads > 0 && $#threads >= 0 ) {if ( $time_until_kill_threads % 5 == 0 ) {printf "%s Waiting all running %d queries aredisconnected.. (max %d milliseconds)\n",current_time_us(), $#threads + 1, $time_until_kill_threads * 100;if ( $#threads < 5 ) {print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump ."\n"foreach (@threads);}}sleep_until();$_tstart = [gettimeofday];$time_until_kill_threads--;@threads = get_threads_util( $orig_master_handler->{dbh},$orig_master_handler->{connection_id} );}print "Disabling the VIPon old master: $orig_master_host \n";&stop_vip(); ## Terminating all threadsprint current_time_us() . " Killing all applicationthreads..\n";$orig_master_handler->kill_threads(@threads) if ( $#threads >= 0);print current_time_us() . " done.\n";#$orig_master_handler->enable_log_bin_local();$orig_master_handler->disconnect();## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK$exit_code = 0;};if($@) {warn "Got Error: $@\n";exit $exit_code;}exit $exit_code;}elsif ( $command eq "start" ) {##Activating master ip on the new master#1. Create app user with write privileges#2. Moving backup script if needed#3. Register new master's ip to the catalog database# We don't return error even thoughactivating updatable accounts/ip failed so that we don't interrupt slaves'recovery.
# If exit code is 0 or 10, MHA does notabortmy$exit_code = 10;eval{my $new_master_handler = new MHA::DBHelper();# args: hostname, port, user, password, raise_error_or_not$new_master_handler->connect( $new_master_ip, $new_master_port,$new_master_user, $new_master_password, 1 );## Set read_only=0 on the new master#$new_master_handler->disable_log_bin_local();print current_time_us() . " Set read_only=0 on the newmaster.\n";$new_master_handler->disable_read_only();## Creating an app user on the new master#print current_time_us() . " Creating app user on the newmaster..\n";#FIXME_xxx_create_app_user($new_master_handler);#$new_master_handler->enable_log_bin_local();$new_master_handler->disconnect();## Update master ip on the catalog database, etcprint "Enabling the VIP -$vip on the new master - $new_master_host \n";&start_vip();$exit_code = 0;};if($@) {warn "Got Error: $@\n";exit $exit_code;}exit $exit_code;}elsif ( $command eq "status" ) {#do nothingexit 0;}else{&usage();exit 1;}
}# A simple system call that enable the VIPon the new master
sub start_vip() {`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIPon the old_master
sub stop_vip() {`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}sub usage {print
"Usage: master_ip_online_change --command=start|stop|status--orig_master_host=host --orig_master_ip=ip --orig_master_port=port--new_master_host=host --new_master_ip=ip --new_master_port=port\n";die;
}
授权
chmod u+x /usr/bin/master_ip_online_change
检查MHA配置
检查SSH配置
在hdp1上用root用户操作。
[root@10-31-1-119 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf
Mon Aug 24 17:47:04 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Mon Aug 24 17:47:04 2020 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Mon Aug 24 17:47:04 2020 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Mon Aug 24 17:47:04 2020 - [info] Starting SSH connection tests..
Mon Aug 24 17:47:06 2020 - [debug]
Mon Aug 24 17:47:04 2020 - [debug] Connecting via SSH from root@10.31.1.120(10.31.1.120:22) to root@10.31.1.121(10.31.1.121:22)..
Mon Aug 24 17:47:05 2020 - [debug] ok.
Mon Aug 24 17:47:05 2020 - [debug] Connecting via SSH from root@10.31.1.120(10.31.1.120:22) to root@10.31.1.122(10.31.1.122:22)..
Mon Aug 24 17:47:06 2020 - [debug] ok.
Mon Aug 24 17:47:07 2020 - [debug]
Mon Aug 24 17:47:05 2020 - [debug] Connecting via SSH from root@10.31.1.122(10.31.1.122:22) to root@10.31.1.120(10.31.1.120:22)..
Mon Aug 24 17:47:06 2020 - [debug] ok.
Mon Aug 24 17:47:06 2020 - [debug] Connecting via SSH from root@10.31.1.122(10.31.1.122:22) to root@10.31.1.121(10.31.1.121:22)..
Mon Aug 24 17:47:07 2020 - [debug] ok.
Mon Aug 24 17:47:07 2020 - [debug]
Mon Aug 24 17:47:05 2020 - [debug] Connecting via SSH from root@10.31.1.121(10.31.1.121:22) to root@10.31.1.120(10.31.1.120:22)..
Mon Aug 24 17:47:06 2020 - [debug] ok.
Mon Aug 24 17:47:06 2020 - [debug] Connecting via SSH from root@10.31.1.121(10.31.1.121:22) to root@10.31.1.122(10.31.1.122:22)..
Mon Aug 24 17:47:06 2020 - [debug] ok.
Mon Aug 24 17:47:07 2020 - [info] All SSH connection tests passed successfully.
检查整个复制环境状况
hp2上授权
create user 'root'@'10.31.1.%' identified by 'abc123';
grant all privileges on *.* to 'root'@'10.31.1.%';
flush privileges;
在hdp1上用root用户操作。
[root@10-31-1-119 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
Mon Aug 24 17:57:22 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Mon Aug 24 17:57:22 2020 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Mon Aug 24 17:57:22 2020 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Mon Aug 24 17:57:22 2020 - [info] MHA::MasterMonitor version 0.56.
Mon Aug 24 17:57:23 2020 - [info] GTID failover mode = 0
Mon Aug 24 17:57:23 2020 - [info] Dead Servers:
Mon Aug 24 17:57:23 2020 - [info] Alive Servers:
Mon Aug 24 17:57:23 2020 - [info] 10.31.1.120(10.31.1.120:3306)
Mon Aug 24 17:57:23 2020 - [info] 10.31.1.121(10.31.1.121:3306)
Mon Aug 24 17:57:23 2020 - [info] 10.31.1.122(10.31.1.122:3306)
Mon Aug 24 17:57:23 2020 - [info] Alive Slaves:
Mon Aug 24 17:57:23 2020 - [info] 10.31.1.121(10.31.1.121:3306) Version=5.7.31-log (oldest major version between slaves) log-bin:enabled
Mon Aug 24 17:57:23 2020 - [info] Replicating from 10.31.1.120(10.31.1.120:3306)
Mon Aug 24 17:57:23 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Mon Aug 24 17:57:23 2020 - [info] 10.31.1.122(10.31.1.122:3306) Version=5.7.31-log (oldest major version between slaves) log-bin:enabled
Mon Aug 24 17:57:23 2020 - [info] Replicating from 10.31.1.120(10.31.1.120:3306)
Mon Aug 24 17:57:23 2020 - [info] Current Alive Master: 10.31.1.120(10.31.1.120:3306)
Mon Aug 24 17:57:23 2020 - [info] Checking slave configurations..
Mon Aug 24 17:57:23 2020 - [info] read_only=1 is not set on slave 10.31.1.121(10.31.1.121:3306).
Mon Aug 24 17:57:23 2020 - [info] read_only=1 is not set on slave 10.31.1.122(10.31.1.122:3306).
Mon Aug 24 17:57:23 2020 - [info] Checking replication filtering settings..
Mon Aug 24 17:57:23 2020 - [info] binlog_do_db= , binlog_ignore_db=
Mon Aug 24 17:57:23 2020 - [info] Replication filtering check ok.
Mon Aug 24 17:57:23 2020 - [info] GTID (with auto-pos) is not supported
Mon Aug 24 17:57:23 2020 - [info] Starting SSH connection tests..
Mon Aug 24 17:57:26 2020 - [info] All SSH connection tests passed successfully.
Mon Aug 24 17:57:26 2020 - [info] Checking MHA Node version..
Mon Aug 24 17:57:27 2020 - [info] Version check ok.
Mon Aug 24 17:57:27 2020 - [info] Checking SSH publickey authentication settings on the current master..
Mon Aug 24 17:57:27 2020 - [info] HealthCheck: SSH to 10.31.1.120 is reachable.
Mon Aug 24 17:57:27 2020 - [info] Master MHA Node version is 0.56.
Mon Aug 24 17:57:27 2020 - [info] Checking recovery script configurations on 10.31.1.120(10.31.1.120:3306)..
Mon Aug 24 17:57:27 2020 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/var/lib/mysql --output_file=/tmp/save_binary_logs_test --manager_version=0.56 --start_file=10-31-1-120-bin.000001
Mon Aug 24 17:57:27 2020 - [info] Connecting to root@10.31.1.120(10.31.1.120:22).. Creating /tmp if not exists.. ok.Checking output directory is accessible or not..ok.Binlog found at /var/lib/mysql, up to 10-31-1-120-bin.000001
Mon Aug 24 17:57:28 2020 - [info] Binlog setting check done.
Mon Aug 24 17:57:28 2020 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers..
Mon Aug 24 17:57:28 2020 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='root' --slave_host=10.31.1.121 --slave_ip=10.31.1.121 --slave_port=3306 --workdir=/tmp --target_version=5.7.31-log --manager_version=0.56 --relay_log_info=/var/lib/mysql/relay-log.info --relay_dir=/var/lib/mysql/ --slave_pass=xxx
Mon Aug 24 17:57:28 2020 - [info] Connecting to root@10.31.1.121(10.31.1.121:22).. Checking slave recovery environment settings..Opening /var/lib/mysql/relay-log.info ... ok.Relay log found at /var/lib/mysql, up to 10-31-1-121-relay-bin.000005Temporary relay log file is /var/lib/mysql/10-31-1-121-relay-bin.000005Testing mysql connection and privileges..mysql: [Warning] Using a password on the command line interface can be insecure.done.Testing mysqlbinlog output.. done.Cleaning up test file(s).. done.
Mon Aug 24 17:57:28 2020 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='root' --slave_host=10.31.1.122 --slave_ip=10.31.1.122 --slave_port=3306 --workdir=/tmp --target_version=5.7.31-log --manager_version=0.56 --relay_log_info=/var/lib/mysql/relay-log.info --relay_dir=/var/lib/mysql/ --slave_pass=xxx
Mon Aug 24 17:57:28 2020 - [info] Connecting to root@10.31.1.122(10.31.1.122:22).. Checking slave recovery environment settings..Opening /var/lib/mysql/relay-log.info ... ok.Relay log found at /var/lib/mysql, up to 10-31-1-122-relay-bin.000005Temporary relay log file is /var/lib/mysql/10-31-1-122-relay-bin.000005Testing mysql connection and privileges..mysql: [Warning] Using a password on the command line interface can be insecure.done.Testing mysqlbinlog output.. done.Cleaning up test file(s).. done.
Mon Aug 24 17:57:29 2020 - [info] Slaves settings check done.
Mon Aug 24 17:57:29 2020 - [info]
10.31.1.120(10.31.1.120:3306) (current master)+--10.31.1.121(10.31.1.121:3306)+--10.31.1.122(10.31.1.122:3306)Mon Aug 24 17:57:29 2020 - [info] Checking replication health on 10.31.1.121..
Mon Aug 24 17:57:29 2020 - [info] ok.
Mon Aug 24 17:57:29 2020 - [info] Checking replication health on 10.31.1.122..
Mon Aug 24 17:57:29 2020 - [info] ok.
Mon Aug 24 17:57:29 2020 - [info] Checking master_ip_failover_script status:
Mon Aug 24 17:57:29 2020 - [info] /usr/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=10.31.1.120 --orig_master_ip=10.31.1.120 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig ens192:1 down==/sbin/ifconfig ens192:1 10.31.1.241/24===Checking the Status of the script.. OK
Mon Aug 24 17:57:29 2020 - [info] OK.
Mon Aug 24 17:57:29 2020 - [warning] shutdown_script is not defined.
Mon Aug 24 17:57:29 2020 - [info] Got exit code 0 (Not master dead).MySQL Replication Health is OK.
[root@10-31-1-119 ~]#
检查MHA Manager的状态
在hdp1上用root用户操作。
[root@10-31-1-119 ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
[root@10-31-1-119 ~]#
显示"NOT_RUNNING",这代表MHA监控没有开启。执行下面的命令后台启动MHA。
mkdir -p /var/log/masterha/app1/
nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
启动参数说明:
remove_dead_master_conf:该参数代表当发生主从切换后,老的主库的ip将会从配置文件中移除。
manger_log:日志存放位置。
ignore_last_failover:在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录,也就是上面设置的/data产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件。为了方便,这里设置为–ignore_last_failover。
再次检查MHA Manager的状态:
[root@10-31-1-119 ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 monitoring program is now on initialization phase(10:INITIALIZING_MONITOR). Wait for a while and try checking again.
[root@10-31-1-119 ~]#
查看启动日志
在hdp1上用root用户操作。
[root@10-31-1-119 ~]# tail -n20 /var/log/masterha/app1/manager.logCleaning up test file(s).. done.
Mon Aug 24 18:06:00 2020 - [info] Slaves settings check done.
Mon Aug 24 18:06:00 2020 - [info]
10.31.1.120(10.31.1.120:3306) (current master)+--10.31.1.121(10.31.1.121:3306)+--10.31.1.122(10.31.1.122:3306)Mon Aug 24 18:06:00 2020 - [info] Checking master_ip_failover_script status:
Mon Aug 24 18:06:00 2020 - [info] /usr/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=10.31.1.120 --orig_master_ip=10.31.1.120 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig eth1:1 down==/sbin/ifconfig eth1:1 10.31.1.241/24===Checking the Status of the script.. OK
Mon Aug 24 18:06:00 2020 - [info] OK.
Mon Aug 24 18:06:00 2020 - [warning] shutdown_script is not defined.
Mon Aug 24 18:06:00 2020 - [info] Set master ping interval 1 seconds.
Mon Aug 24 18:06:00 2020 - [info] Set secondary check script: /usr/bin/masterha_secondary_check -s hdp2 -s hdp3 --user=root --master_host=hdp2 --master_ip=10.31.1.120 --master_port=3306
Mon Aug 24 18:06:00 2020 - [info] Starting ping health check on 10.31.1.120(10.31.1.120:3306)..
Mon Aug 24 18:06:00 2020 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
功能测试
初始绑定VIP
在hdp2 10.31.1.112(master)上用root用户执行:
/sbin/ifconfig ens192:1 10.31.1.241/24
执行记录
[root@10-31-1-120 src]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:54:f4:e5 brd ff:ff:ff:ff:ff:ffinet 10.31.1.120/24 brd 10.31.1.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet6 fe80::b3f8:a2f7:5ba0:b68d/64 scope link noprefixroute valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ffinet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ff
[root@10-31-1-120 src]#
[root@10-31-1-120 src]#
[root@10-31-1-120 src]# /sbin/ifconfig ens192:1 10.31.1.241/24
[root@10-31-1-120 src]#
[root@10-31-1-120 src]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:54:f4:e5 brd ff:ff:ff:ff:ff:ffinet 10.31.1.120/24 brd 10.31.1.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet 10.31.1.241/24 brd 10.31.1.255 scope global secondary ens192:1valid_lft forever preferred_lft foreverinet6 fe80::b3f8:a2f7:5ba0:b68d/64 scope link noprefixroute valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ffinet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ff
[root@10-31-1-120 src]#
也可以手工解除绑定
[root@10-31-1-120 keepalived-2.0.15]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:54:f4:e5 brd ff:ff:ff:ff:ff:ffinet 10.31.1.120/24 brd 10.31.1.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet 10.31.1.241/24 brd 10.31.1.255 scope global secondary ens192:1valid_lft forever preferred_lft foreverinet6 fe80::b3f8:a2f7:5ba0:b68d/64 scope link noprefixroute valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ffinet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ff
[root@10-31-1-120 keepalived-2.0.15]#
[root@10-31-1-120 keepalived-2.0.15]#
[root@10-31-1-120 keepalived-2.0.15]# ifconfig ens192:10.31.1.241/24 down
SIOCSIFFLAGS: 无法指定被请求的地址
[root@10-31-1-120 keepalived-2.0.15]#
[root@10-31-1-120 keepalived-2.0.15]#
[root@10-31-1-120 keepalived-2.0.15]# ifconfig ens192:1 down
[root@10-31-1-120 keepalived-2.0.15]#
[root@10-31-1-120 keepalived-2.0.15]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:54:f4:e5 brd ff:ff:ff:ff:ff:ffinet 10.31.1.120/24 brd 10.31.1.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet6 fe80::b3f8:a2f7:5ba0:b68d/64 scope link noprefixroute valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ffinet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ff
[root@10-31-1-120 keepalived-2.0.15]#
测试自动切换
通过vip登陆mysql
[root@uattest ~]# mysql -uroot -p -h10.31.1.241
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 27
Server version: 5.7.31-log MySQL Community Server (GPL)Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql>
停止主库hp1的mysql服务器
service mysqld stop
ip addr
[root@10-31-1-120 src]# service mysqld stop
Redirecting to /bin/systemctl stop mysqld.service
[root@10-31-1-120 src]#
[root@10-31-1-120 src]#
[root@10-31-1-120 src]#
-- 可以看到 10.31.1.241的vip已经不再hp1(master)上了
[root@10-31-1-120 src]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:54:f4:e5 brd ff:ff:ff:ff:ff:ffinet 10.31.1.120/24 brd 10.31.1.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet6 fe80::b3f8:a2f7:5ba0:b68d/64 scope link noprefixroute valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ffinet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ff
hp2和hp3查看
hp2
-- 可以看到 10.31.1.241这个vip飘到hp2上了
[root@10-31-1-121 src]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:e1:fe:b4 brd ff:ff:ff:ff:ff:ffinet 10.31.1.121/24 brd 10.31.1.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet 10.31.1.241/24 brd 10.255.255.255 scope global ens192:1valid_lft forever preferred_lft foreverinet6 fe80::9470:f61e:6e0e:48e4/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft foreverinet6 fe80::1aa1:d23e:e28a:fb62/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft foreverinet6 fe80::f974:3f03:d1f0:1672/64 scope link noprefixroute valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ffinet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ff-- hp2已经由从库变为主库了
[root@10-31-1-121 src]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 53
Server version: 5.7.31-log MySQL Community Server (GPL)Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql>
mysql> show slave status\G
Empty set (0.00 sec)mysql> show master status\G
*************************** 1. row ***************************File: 10-31-1-121-bin.000001Position: 507Binlog_Do_DB: Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)hp3
hp3变为了hp2的从库
[root@10-31-1-122 bin]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 48
Server version: 5.7.31-log MySQL Community Server (GPL)Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 10.31.1.121Master_User: replMaster_Port: 3306Connect_Retry: 60Master_Log_File: 10-31-1-121-bin.000001Read_Master_Log_Pos: 507Relay_Log_File: 10-31-1-122-relay-bin.000002Relay_Log_Pos: 679Relay_Master_Log_File: 10-31-1-121-bin.000001Slave_IO_Running: YesSlave_SQL_Running: YesReplicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0Last_Error: Skip_Counter: 0Exec_Master_Log_Pos: 507Relay_Log_Space: 892Until_Condition: NoneUntil_Log_File: Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error: Last_SQL_Errno: 0Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 102Master_UUID: 5ad1f5aa-e2cb-11ea-ba89-000c29e1feb4Master_Info_File: /var/lib/mysql/master.infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State: Slave has read all relay log; waiting for more updatesMaster_Retry_Count: 86400Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version:
1 row in set (0.00 sec)
还原环境
还原数据库复制:
-- 在hdp2、hdp3、hdp4上重置master、slave
stop slave;
reset master;
reset slave all;-- 在hdp3、hdp4上重新指向hdp2为master
change master to
master_host='10.31.1.120',
master_port=3306,
master_user='repl',
master_password='abc123',
master_log_file='10-31-1-120-bin.000001',
master_log_pos=154;start slave;
show slave status\G
还原VIP绑定:
# 在hdp3上用root用户执行
/sbin/ifconfig ens192:1 down# 在hdp2上用root用户执行
/sbin/ifconfig ens192:1 10.31.1.241/24
还原配置文件:
编辑在hdp1上/etc/masterha/app1.cnf,将[server1]段添加回去。
启动MHA Manage:
# 在hdp1上用root用户执行
nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
至此环境还原完毕。
测试手工切换
停止MHA Manage
在hp1用root用户操作
masterha_stop --conf=/etc/masterha/app1.cnf
关闭master
在hdp2上用root用户操作。
service mysqld stop
执行手工切换
在hdp1上用root用户操作。
masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=10.31.1.120 --dead_master_port=3306 --new_master_host=10.31.1.121 --new_master_port=3306 --ignore_last_failover
执行记录
[root@10-31-1-119 ~]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=10.31.1.120 --dead_master_port=3306 --new_master_host=10.31.1.121 --new_master_port=3306 --ignore_last_failover
--dead_master_ip=<dead_master_ip> is not set. Using 10.31.1.120.
Tue Aug 25 16:18:55 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Aug 25 16:18:55 2020 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Tue Aug 25 16:18:55 2020 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Tue Aug 25 16:18:55 2020 - [info] MHA::MasterFailover version 0.56.
Tue Aug 25 16:18:55 2020 - [info] Starting master failover.
Tue Aug 25 16:18:55 2020 - [info]
Tue Aug 25 16:18:55 2020 - [info] * Phase 1: Configuration Check Phase..
Tue Aug 25 16:18:55 2020 - [info]
Tue Aug 25 16:18:56 2020 - [info] GTID failover mode = 0
Tue Aug 25 16:18:56 2020 - [info] Dead Servers:
Tue Aug 25 16:18:56 2020 - [info] 10.31.1.120(10.31.1.120:3306)
Tue Aug 25 16:18:56 2020 - [info] Checking master reachability via MySQL(double check)...
Tue Aug 25 16:18:56 2020 - [info] ok.
Tue Aug 25 16:18:56 2020 - [info] Alive Servers:
Tue Aug 25 16:18:56 2020 - [info] 10.31.1.121(10.31.1.121:3306)
Tue Aug 25 16:18:56 2020 - [info] 10.31.1.122(10.31.1.122:3306)
Tue Aug 25 16:18:56 2020 - [info] Alive Slaves:
Tue Aug 25 16:18:56 2020 - [info] 10.31.1.121(10.31.1.121:3306) Version=5.7.31-log (oldest major version between slaves) log-bin:enabled
Tue Aug 25 16:18:56 2020 - [info] Replicating from 10.31.1.120(10.31.1.120:3306)
Tue Aug 25 16:18:56 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Aug 25 16:18:56 2020 - [info] 10.31.1.122(10.31.1.122:3306) Version=5.7.31-log (oldest major version between slaves) log-bin:enabled
Tue Aug 25 16:18:56 2020 - [info] Replicating from 10.31.1.120(10.31.1.120:3306)
Master 10.31.1.120(10.31.1.120:3306) is dead. Proceed? (yes/NO): yes
Tue Aug 25 16:19:01 2020 - [info] Starting Non-GTID based failover.
Tue Aug 25 16:19:01 2020 - [info]
Tue Aug 25 16:19:01 2020 - [info] ** Phase 1: Configuration Check Phase completed.
Tue Aug 25 16:19:01 2020 - [info]
Tue Aug 25 16:19:01 2020 - [info] * Phase 2: Dead Master Shutdown Phase..
Tue Aug 25 16:19:01 2020 - [info]
Tue Aug 25 16:19:01 2020 - [info] HealthCheck: SSH to 10.31.1.120 is reachable.
Tue Aug 25 16:19:01 2020 - [info] Forcing shutdown so that applications never connect to the current master..
Tue Aug 25 16:19:01 2020 - [info] Executing master IP deactivation script:
Tue Aug 25 16:19:01 2020 - [info] /usr/bin/master_ip_failover --orig_master_host=10.31.1.120 --orig_master_ip=10.31.1.120 --orig_master_port=3306 --command=stopssh --ssh_user=root IN SCRIPT TEST====/sbin/ifconfig ens192:1 down==/sbin/ifconfig ens192:1 10.31.1.241/24===Disabling the VIP on old master: 10.31.1.120
Tue Aug 25 16:19:02 2020 - [info] done.
Tue Aug 25 16:19:02 2020 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.
Tue Aug 25 16:19:02 2020 - [info] * Phase 2: Dead Master Shutdown Phase completed.
Tue Aug 25 16:19:02 2020 - [info]
Tue Aug 25 16:19:02 2020 - [info] * Phase 3: Master Recovery Phase..
Tue Aug 25 16:19:02 2020 - [info]
Tue Aug 25 16:19:02 2020 - [info] * Phase 3.1: Getting Latest Slaves Phase..
Tue Aug 25 16:19:02 2020 - [info]
Tue Aug 25 16:19:02 2020 - [info] The latest binary log file/position on all slaves is 10-31-1-120-bin.000001:154
Tue Aug 25 16:19:02 2020 - [info] Latest slaves (Slaves that received relay log files to the latest):
Tue Aug 25 16:19:02 2020 - [info] 10.31.1.121(10.31.1.121:3306) Version=5.7.31-log (oldest major version between slaves) log-bin:enabled
Tue Aug 25 16:19:02 2020 - [info] Replicating from 10.31.1.120(10.31.1.120:3306)
Tue Aug 25 16:19:02 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Aug 25 16:19:02 2020 - [info] 10.31.1.122(10.31.1.122:3306) Version=5.7.31-log (oldest major version between slaves) log-bin:enabled
Tue Aug 25 16:19:02 2020 - [info] Replicating from 10.31.1.120(10.31.1.120:3306)
Tue Aug 25 16:19:02 2020 - [info] The oldest binary log file/position on all slaves is 10-31-1-120-bin.000001:154
Tue Aug 25 16:19:02 2020 - [info] Oldest slaves:
Tue Aug 25 16:19:02 2020 - [info] 10.31.1.121(10.31.1.121:3306) Version=5.7.31-log (oldest major version between slaves) log-bin:enabled
Tue Aug 25 16:19:02 2020 - [info] Replicating from 10.31.1.120(10.31.1.120:3306)
Tue Aug 25 16:19:02 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Aug 25 16:19:02 2020 - [info] 10.31.1.122(10.31.1.122:3306) Version=5.7.31-log (oldest major version between slaves) log-bin:enabled
Tue Aug 25 16:19:02 2020 - [info] Replicating from 10.31.1.120(10.31.1.120:3306)
Tue Aug 25 16:19:02 2020 - [info]
Tue Aug 25 16:19:02 2020 - [info] * Phase 3.2: Saving Dead Master's Binlog Phase..
Tue Aug 25 16:19:02 2020 - [info]
Tue Aug 25 16:19:02 2020 - [info] Fetching dead master's binary logs..
Tue Aug 25 16:19:02 2020 - [info] Executing command on the dead master 10.31.1.120(10.31.1.120:3306): save_binary_logs --command=save --start_file=10-31-1-120-bin.000001 --start_pos=154 --binlog_dir=/var/lib/mysql --output_file=/tmp/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.56Creating /tmp if not exists.. ok.Concat binary/relay logs from 10-31-1-120-bin.000001 pos 154 to 10-31-1-120-bin.000001 EOF into /tmp/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog ..Binlog Checksum enabledDumping binlog format description event, from position 0 to 154.. ok.Dumping effective binlog data from /var/lib/mysql/10-31-1-120-bin.000001 position 154 to tail(177).. ok.Binlog Checksum enabledConcat succeeded.
saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog 100% 177 140.4KB/s 00:00
Tue Aug 25 16:19:03 2020 - [info] scp from root@10.31.1.120:/tmp/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog to local:/var/log/masterha/app1.log/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog succeeded.
Tue Aug 25 16:19:04 2020 - [info] HealthCheck: SSH to 10.31.1.121 is reachable.
Tue Aug 25 16:19:05 2020 - [info] HealthCheck: SSH to 10.31.1.122 is reachable.
Tue Aug 25 16:19:05 2020 - [info]
Tue Aug 25 16:19:05 2020 - [info] * Phase 3.3: Determining New Master Phase..
Tue Aug 25 16:19:05 2020 - [info]
Tue Aug 25 16:19:05 2020 - [info] Finding the latest slave that has all relay logs for recovering other slaves..
Tue Aug 25 16:19:05 2020 - [info] All slaves received relay logs to the same position. No need to resync each other.
Tue Aug 25 16:19:05 2020 - [info] 10.31.1.121 can be new master.
Tue Aug 25 16:19:05 2020 - [info] New master is 10.31.1.121(10.31.1.121:3306)
Tue Aug 25 16:19:05 2020 - [info] Starting master failover..
Tue Aug 25 16:19:05 2020 - [info]
From:
10.31.1.120(10.31.1.120:3306) (current master)+--10.31.1.121(10.31.1.121:3306)+--10.31.1.122(10.31.1.122:3306)To:
10.31.1.121(10.31.1.121:3306) (new master)+--10.31.1.122(10.31.1.122:3306)Starting master switch from 10.31.1.120(10.31.1.120:3306) to 10.31.1.121(10.31.1.121:3306)? (yes/NO): yes
Tue Aug 25 16:19:09 2020 - [info] New master decided manually is 10.31.1.121(10.31.1.121:3306)
Tue Aug 25 16:19:09 2020 - [info]
Tue Aug 25 16:19:09 2020 - [info] * Phase 3.3: New Master Diff Log Generation Phase..
Tue Aug 25 16:19:09 2020 - [info]
Tue Aug 25 16:19:09 2020 - [info] This server has all relay logs. No need to generate diff files from the latest slave.
Tue Aug 25 16:19:09 2020 - [info] Sending binlog..
saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog 100% 177 176.2KB/s 00:00
Tue Aug 25 16:19:10 2020 - [info] scp from local:/var/log/masterha/app1.log/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog to root@10.31.1.121:/tmp/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog succeeded.
Tue Aug 25 16:19:10 2020 - [info]
Tue Aug 25 16:19:10 2020 - [info] * Phase 3.4: Master Log Apply Phase..
Tue Aug 25 16:19:10 2020 - [info]
Tue Aug 25 16:19:10 2020 - [info] *NOTICE: If any error happens from this phase, manual recovery is needed.
Tue Aug 25 16:19:10 2020 - [info] Starting recovery on 10.31.1.121(10.31.1.121:3306)..
Tue Aug 25 16:19:10 2020 - [info] Generating diffs succeeded.
Tue Aug 25 16:19:10 2020 - [info] Waiting until all relay logs are applied.
Tue Aug 25 16:19:10 2020 - [info] done.
Tue Aug 25 16:19:10 2020 - [info] Getting slave status..
Tue Aug 25 16:19:10 2020 - [info] This slave(10.31.1.121)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(10-31-1-120-bin.000001:154). No need to recover from Exec_Master_Log_Pos.
Tue Aug 25 16:19:10 2020 - [info] Connecting to the target slave host 10.31.1.121, running recover script..
Tue Aug 25 16:19:10 2020 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=10.31.1.121 --slave_ip=10.31.1.121 --slave_port=3306 --apply_files=/tmp/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog --workdir=/tmp --target_version=5.7.31-log --timestamp=20200825161855 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.56 --slave_pass=xxx
Tue Aug 25 16:19:10 2020 - [info]
MySQL client version is 5.7.31. Using --binary-mode.
Applying differential binary/relay log files /tmp/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog on 10.31.1.121:3306. This may take long time...
Applying log files succeeded.
Tue Aug 25 16:19:10 2020 - [info] All relay logs were successfully applied.
Tue Aug 25 16:19:10 2020 - [info] Getting new master's binlog name and position..
Tue Aug 25 16:19:10 2020 - [info] 10-31-1-121-bin.000001:154
Tue Aug 25 16:19:10 2020 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.31.1.121', MASTER_PORT=3306, MASTER_LOG_FILE='10-31-1-121-bin.000001', MASTER_LOG_POS=154, MASTER_USER='repl', MASTER_PASSWORD='xxx';
Tue Aug 25 16:19:10 2020 - [info] Executing master IP activate script:
Tue Aug 25 16:19:10 2020 - [info] /usr/bin/master_ip_failover --command=start --ssh_user=root --orig_master_host=10.31.1.120 --orig_master_ip=10.31.1.120 --orig_master_port=3306 --new_master_host=10.31.1.121 --new_master_ip=10.31.1.121 --new_master_port=3306 --new_master_user='root' --new_master_password='abc123'
Unknown option: new_master_user
Unknown option: new_master_passwordIN SCRIPT TEST====/sbin/ifconfig ens192:1 down==/sbin/ifconfig ens192:1 10.31.1.241/24===Enabling the VIP - 10.31.1.241 on the new master - 10.31.1.121
Tue Aug 25 16:19:10 2020 - [info] OK.
Tue Aug 25 16:19:10 2020 - [info] ** Finished master recovery successfully.
Tue Aug 25 16:19:10 2020 - [info] * Phase 3: Master Recovery Phase completed.
Tue Aug 25 16:19:10 2020 - [info]
Tue Aug 25 16:19:10 2020 - [info] * Phase 4: Slaves Recovery Phase..
Tue Aug 25 16:19:10 2020 - [info]
Tue Aug 25 16:19:10 2020 - [info] * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase..
Tue Aug 25 16:19:10 2020 - [info]
Tue Aug 25 16:19:10 2020 - [info] -- Slave diff file generation on host 10.31.1.122(10.31.1.122:3306) started, pid: 14489. Check tmp log /var/log/masterha/app1.log/10.31.1.122_3306_20200825161855.log if it takes time..
Tue Aug 25 16:19:11 2020 - [info]
Tue Aug 25 16:19:11 2020 - [info] Log messages from 10.31.1.122 ...
Tue Aug 25 16:19:11 2020 - [info]
Tue Aug 25 16:19:10 2020 - [info] This server has all relay logs. No need to generate diff files from the latest slave.
Tue Aug 25 16:19:11 2020 - [info] End of log messages from 10.31.1.122.
Tue Aug 25 16:19:11 2020 - [info] -- 10.31.1.122(10.31.1.122:3306) has the latest relay log events.
Tue Aug 25 16:19:11 2020 - [info] Generating relay diff files from the latest slave succeeded.
Tue Aug 25 16:19:11 2020 - [info]
Tue Aug 25 16:19:11 2020 - [info] * Phase 4.2: Starting Parallel Slave Log Apply Phase..
Tue Aug 25 16:19:11 2020 - [info]
Tue Aug 25 16:19:11 2020 - [info] -- Slave recovery on host 10.31.1.122(10.31.1.122:3306) started, pid: 14491. Check tmp log /var/log/masterha/app1.log/10.31.1.122_3306_20200825161855.log if it takes time..
saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog 100% 177 170.8KB/s 00:00
Tue Aug 25 16:19:13 2020 - [info]
Tue Aug 25 16:19:13 2020 - [info] Log messages from 10.31.1.122 ...
Tue Aug 25 16:19:13 2020 - [info]
Tue Aug 25 16:19:11 2020 - [info] Sending binlog..
Tue Aug 25 16:19:12 2020 - [info] scp from local:/var/log/masterha/app1.log/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog to root@10.31.1.122:/tmp/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog succeeded.
Tue Aug 25 16:19:12 2020 - [info] Starting recovery on 10.31.1.122(10.31.1.122:3306)..
Tue Aug 25 16:19:12 2020 - [info] Generating diffs succeeded.
Tue Aug 25 16:19:12 2020 - [info] Waiting until all relay logs are applied.
Tue Aug 25 16:19:12 2020 - [info] done.
Tue Aug 25 16:19:12 2020 - [info] Getting slave status..
Tue Aug 25 16:19:12 2020 - [info] This slave(10.31.1.122)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(10-31-1-120-bin.000001:154). No need to recover from Exec_Master_Log_Pos.
Tue Aug 25 16:19:12 2020 - [info] Connecting to the target slave host 10.31.1.122, running recover script..
Tue Aug 25 16:19:12 2020 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=10.31.1.122 --slave_ip=10.31.1.122 --slave_port=3306 --apply_files=/tmp/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog --workdir=/tmp --target_version=5.7.31-log --timestamp=20200825161855 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.56 --slave_pass=xxx
Tue Aug 25 16:19:13 2020 - [info]
MySQL client version is 5.7.31. Using --binary-mode.
Applying differential binary/relay log files /tmp/saved_master_binlog_from_10.31.1.120_3306_20200825161855.binlog on 10.31.1.122:3306. This may take long time...
Applying log files succeeded.
Tue Aug 25 16:19:13 2020 - [info] All relay logs were successfully applied.
Tue Aug 25 16:19:13 2020 - [info] Resetting slave 10.31.1.122(10.31.1.122:3306) and starting replication from the new master 10.31.1.121(10.31.1.121:3306)..
Tue Aug 25 16:19:13 2020 - [info] Executed CHANGE MASTER.
Tue Aug 25 16:19:13 2020 - [info] Slave started.
Tue Aug 25 16:19:13 2020 - [info] End of log messages from 10.31.1.122.
Tue Aug 25 16:19:13 2020 - [info] -- Slave recovery on host 10.31.1.122(10.31.1.122:3306) succeeded.
Tue Aug 25 16:19:13 2020 - [info] All new slave servers recovered successfully.
Tue Aug 25 16:19:13 2020 - [info]
Tue Aug 25 16:19:13 2020 - [info] * Phase 5: New master cleanup phase..
Tue Aug 25 16:19:13 2020 - [info]
Tue Aug 25 16:19:13 2020 - [info] Resetting slave info on the new master..
Tue Aug 25 16:19:13 2020 - [info] 10.31.1.121: Resetting slave info succeeded.
Tue Aug 25 16:19:13 2020 - [info] Master failover to 10.31.1.121(10.31.1.121:3306) completed successfully.
Tue Aug 25 16:19:13 2020 - [info] ----- Failover Report -----app1: MySQL Master failover 10.31.1.120(10.31.1.120:3306) to 10.31.1.121(10.31.1.121:3306) succeededMaster 10.31.1.120(10.31.1.120:3306) is down!Check MHA Manager logs at 10-31-1-119 for details.Started manual(interactive) failover.
Invalidated master IP address on 10.31.1.120(10.31.1.120:3306)
The latest slave 10.31.1.121(10.31.1.121:3306) has all relay logs for recovery.
Selected 10.31.1.121(10.31.1.121:3306) as a new master.
10.31.1.121(10.31.1.121:3306): OK: Applying all logs succeeded.
10.31.1.121(10.31.1.121:3306): OK: Activated master IP address.
10.31.1.122(10.31.1.122:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
10.31.1.122(10.31.1.122:3306): OK: Applying all logs succeeded. Slave started, replicating from 10.31.1.121(10.31.1.121:3306)
10.31.1.121(10.31.1.121:3306): Resetting slave info succeeded.
Master failover to 10.31.1.121(10.31.1.121:3306) completed successfully.
[root@10-31-1-119 ~]#
验证VIP漂移到10.31.1.121
[root@10-31-1-121 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:e1:fe:b4 brd ff:ff:ff:ff:ff:ffinet 10.31.1.121/24 brd 10.31.1.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet 10.31.1.241/24 brd 10.31.1.255 scope global secondary ens192:1valid_lft forever preferred_lft foreverinet6 fe80::9470:f61e:6e0e:48e4/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft foreverinet6 fe80::1aa1:d23e:e28a:fb62/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft foreverinet6 fe80::f974:3f03:d1f0:1672/64 scope link noprefixroute valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ffinet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000link/ether 52:54:00:c4:b9:a5 brd ff:ff:ff:ff:ff:ff
验证复制关系
[root@10-31-1-122 bin]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 81
Server version: 5.7.31-log MySQL Community Server (GPL)Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 10.31.1.121Master_User: replMaster_Port: 3306Connect_Retry: 60Master_Log_File: 10-31-1-121-bin.000001Read_Master_Log_Pos: 154Relay_Log_File: 10-31-1-122-relay-bin.000002Relay_Log_Pos: 326Relay_Master_Log_File: 10-31-1-121-bin.000001Slave_IO_Running: YesSlave_SQL_Running: YesReplicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0Last_Error: Skip_Counter: 0Exec_Master_Log_Pos: 154Relay_Log_Space: 539Until_Condition: NoneUntil_Log_File: Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error: Last_SQL_Errno: 0Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 102Master_UUID: 5ad1f5aa-e2cb-11ea-ba89-000c29e1feb4Master_Info_File: /var/lib/mysql/master.infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State: Slave has read all relay log; waiting for more updatesMaster_Retry_Count: 86400Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version:
1 row in set (0.00 sec)mysql>
验证客户端VIP访问
[root@uattest ~]# mysql -uroot -p -h10.31.1.241
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 99
Server version: 5.7.31-log MySQL Community Server (GPL)Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)mysql>
mysql>
修复宕机的Master
通常情况下自动切换以后,原master可能已经废弃掉,待原master主机修复后,如果数据完整的情况下,可能想把原来master重新作为新主库的slave。这时我们可以借助当时自动切换时刻的MHA日志来完成对原master的修复。下面是提取相关日志的命令:
grep -i "All other slaves should start" /var/log/masterha/app1/manager.log
可以看到类似下面的信息:
All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.31.1.120', MASTER_PORT=3306, MASTER_LOG_FILE='10-31-1-121-bin.000005', MASTER_LOG_POS=120, MASTER_USER='repl', MASTER_PASSWORD='abc123';
意思是说,如果Master主机修复好了,可以在修复好后的Master执行CHANGE MASTER操作,作为新的slave库。
参考
MySQL MHA高可用实战_只是甲的博客-CSDN博客
相关文章:
MySQL入门篇-MySQL MHA高可用实战
MHA简介 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司的youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提…...
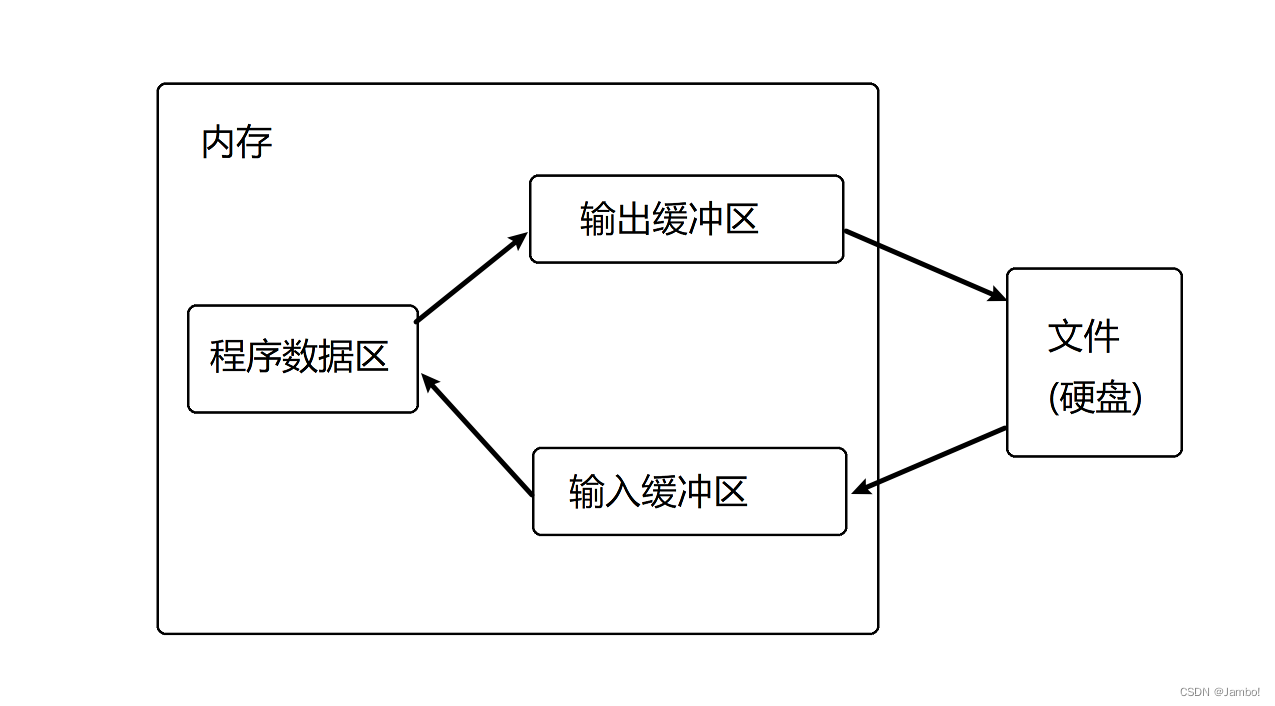
C语言文件操作
目录1.文件指针2.文件的打开和关闭3.文件的读写3.1文件的顺序读写fgetc和fputcfgets和fputsfscanf和fprintffread和fwrite3.2文件的随机读写fseekftellrewind4.文本文件和二进制文件5.文件读取结束的判定6.文件缓冲区1.文件指针 在文件操作中,一个关键的概念是文件…...
Flink中核心重点总结
目录 1. 算子链 1.1. 一对一(One-to-one, forwarding) 1.2. 重分区(Redistributing) 1.3. 为什么有算子链 2. 物理分区(Physical Partitioning) 2.1. 什么是分区 2.2. 随机分区ÿ…...

gismo中NURBS的相关函数的使用---待完善
文章目录 前言一、B样条的求值1.1 节点向量的生成1.2 基函数的调用1.3 函数里面的T指的是系数类型二、以等几何两个单元12个控制点为例输出的控制点坐标有误1.4二、#pic_center <table><tr><td bgcolor=PowderBlue>二维数2.12.22.32.4三、3.13.23.33.4四、4.…...

5.数据共享与持久化
数据共享与持久化 在容器中管理数据主要有两种方式: 数据卷(Data Volumes)挂载主机目录 (Bind mounts) 数据卷 数据卷是一个可供一个或多个容器使用的特殊目录,它绕过UFS,可以提供很多有用的特性: 数据…...

RabbitMQ-客户端源码之AMQCommand
AMQCommand不是直接包含Method等成员变量的,而是通过CommandAssembler又做了一次封装。 接下来先看下CommandAssembler类。此类中有这些成员变量: /** Current state, used to decide how to handle each incoming frame. */ private enum CAState {EXP…...

linux设置登录失败处理功能(密码错误次数限制、pam_tally2.so模块)和操作超时退出功能(/etc/profile)
一、登录失败处理功能策略 1、登录失败处理功能策略(服务器终端) (1)编辑系统/etc/pam.d/system-auth 文件,在 auth 字段所在的那一部分添加如下pam_tally2.so模块的策略参数: auth required pam_tally2…...

Centos7上Docker安装
文章目录1.Docker常识2.安装Docker1.卸载旧版本Docker2.安装Docker3.启动Docker4.配置镜像加速前天开学啦~所以可以回来继续卷了哈哈哈,放假在家效率不高,在学校事情也少点(^_−)☆昨天和今天学了学Docker相关的知识,也算是简单了解了下&…...

新瑞鹏“狂飙”,宠物医疗是门好生意吗?
宠物看病比人还贵,正在让不少年轻一族陷入尴尬境地。在知乎上,有个高赞提问叫“你愿意花光积蓄,给宠物治病吗”,这个在老一辈人看来不可思议的魔幻选择,真实地发生在当下的年轻人身上。提问底下,有人表示自…...
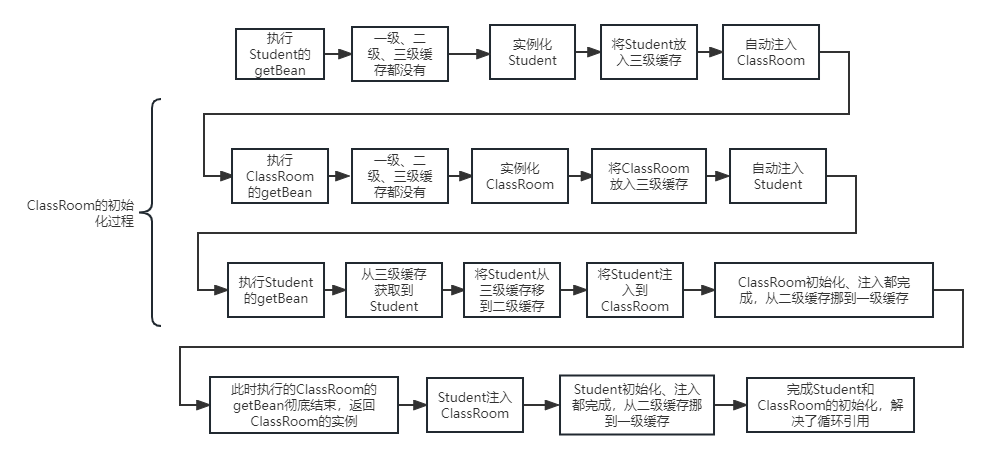
Spring循环依赖问题,Spring是如何解决循环依赖的?
文章目录一、什么是循环依赖1、代码实例2、重要信息二、源码分析1、初始化Student对Student中的ClassRoom进行Autowire操作2、Student的自动注入ClassRoom时,又对ClassRoom的初始化3、ClassRoom的初始化,又执行自动注入Student的逻辑4、Student注入Class…...
更改SAP GUI登录界面信息
在SAP GUI的登录界面,左部输入登录信息如客户端、用户名、密码等,右部空余部分可维护一些登录信息文本,如登录的产品、客户端说明及注意事项等,此项操作详见SAP Notes 205487 – Own text on SAPGui logon screen 维护文档使用的…...
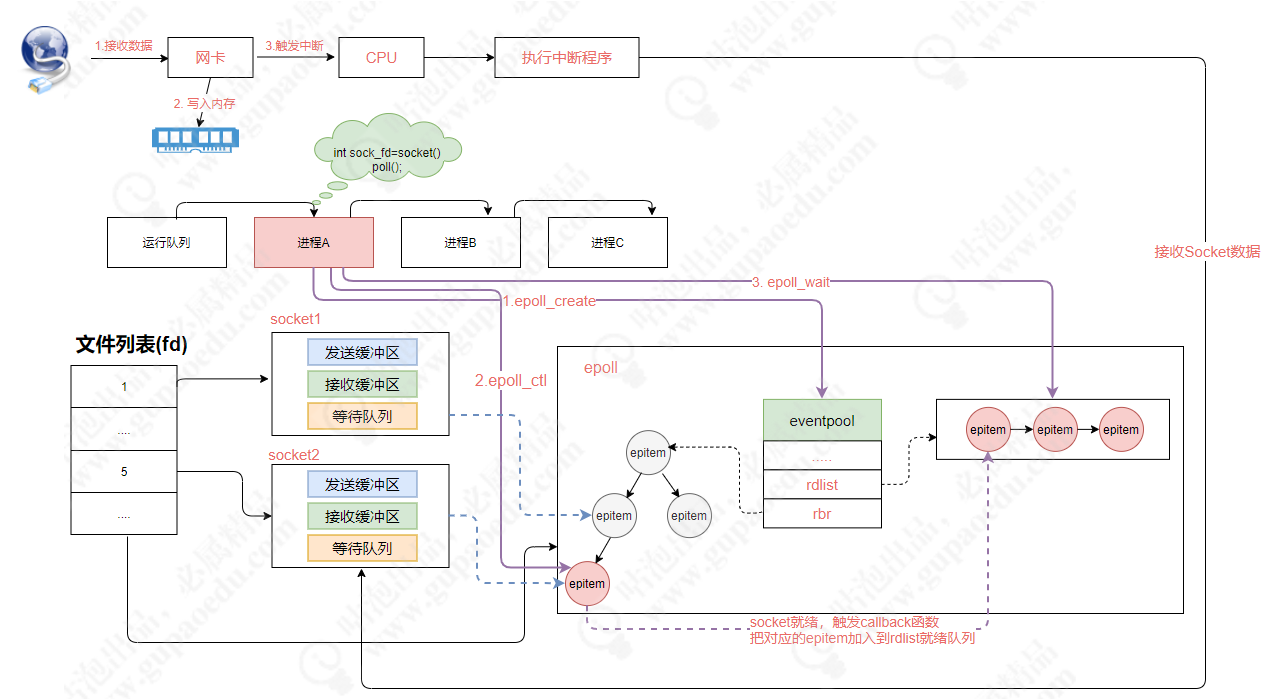
分布式微服务架构下网络通信的底层实现原理
在分布式架构中,网络通信是底层基础,没有网络,也就没有所谓的分布式架构。只有通过网络才能使得一大片机器互相协作,共同完成一件事情。 同样,在大规模的系统架构中,应用吞吐量上不去、网络存在通信延迟、我…...

进大厂必备的Java面试八股文大全(2023最新精简易懂版,八股文中的八股文)
为什么同样是跳槽,有些人薪资能翻三倍?” 最近一个粉丝发出了灵魂拷问,类似的问题我收到过很多次,身边也确实有认识的同事、朋友们有非常成功的跳槽经历和收益,先说一个典型例子: 学弟小 A 工作一年半&am…...

都说测试行业饱和了,为什么我们公司给初级测试开到了12K?
故事起因: 最近我有个刚毕业的学生问我说:我感觉现在测试行业已经饱和了,也不是说饱和了,是初级的测试根本就没有公司要,哪怕你不要工资也没公司要你,测试刚学出来,没有任何的项目经验和工作经验…...

解决Idea启动项目失败,提示Error running ‘XXXApplication‘: Command line is too long
IDEA版本为:IntelliJ IDEA 2018.2 (Ultimate Edition)一、问题描述有时当我们使用IDEA,Run/Debug一个SpringBoot项目时,可能会启动失败,并提示以下错误。Error running XXXApplication: Command line is too long. Shorten comman…...
GB/T28181-2022针对H.265、AAC的说明和技术实现
GB/T28181-2022规范说明GB/T28181-2022相对来GB/T28181-2016针对H.265、AAC的更新如下:——更改了“联网系统通信协议结构图”,媒体流通道增加了 H.265、G.722.1、AAC(见 4.3.1,2016 年版的 4.3.1)。——增加了对 H.26…...
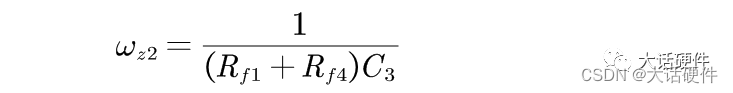
开关电源环路稳定性分析(11)——观察法找零极点
大家好,这里是大话硬件。 这篇文章主要是分享如何用观察法直接写出补偿网络中的零极点的表达式。 在前面的文章中,我们分别整理了OTA和OPA型的补偿网络,当时有下面的结论。 针对某个固定的补偿网络,我们可以用数学的方法推导补偿…...

焕新启航,「龙蜥大讲堂」2023 年度招募来了!13 场技术分享先睹为快
龙蜥大讲堂是龙蜥推出的系列技术直播活动,邀请龙蜥社区的开发者们分享围绕龙蜥技术展开,包括但不限于内核、编译器、机密计算、容器、储存等相关技术领域。欢迎社区开发者们积极参与,共享技术盛宴。往期回顾龙蜥社区技术系列直播截至目前已举…...
推广传单制作工具
临近节日如何制作推广活动呢?没有素材制作满减活动宣传单怎么办?小编教你如何使用在线设计工具乔拓云,轻松设计商品的专属满减活动宣传单,不仅设计简单,还能自动生成活动分享链接,只需跟着小编下面的设计步…...
数据结构(上))
软件设计(十一)数据结构(上)
线性结构 线性表 线性表是n个元素的有限序列,通常记为(a1,a2....an),特点如下。 存在唯一的一个称作“第一个”的元素。存在位移的一个称作“最后一个”的元素。除了表头外,表中的每一个元素均只有唯一的直接前趋除了表尾外&…...

3个实战场景×5个核心技巧:Umi-OCR本地化部署与效率提升完全指南
3个实战场景5个核心技巧:Umi-OCR本地化部署与效率提升完全指南 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置…...

智慧卤味,一码追溯:万界星空MES方案
一、行业痛点与MES目标1、主要痛点生产依赖经验:卤制时间、温度、配料比例依赖人工经验,产品口味和质量不稳定。追溯困难:一旦出现食品安全问题,难以快速精准追溯到问题源头(原料批次、生产环节、操作人员等࿰…...

探秘书匠策AI:毕业论文写作的“智慧引擎”
在学术探索的征途中,毕业论文如同一座巍峨的山峰,让无数学生既敬畏又向往。它不仅是对所学知识的综合检验,更是学术生涯的重要里程碑。然而,面对这座大山,许多人常常感到力不从心,选题迷茫、文献难觅、结构…...
前端表单验证:AsyncValidator与异步校验完整指南)
cool-admin(midway版)前端表单验证:AsyncValidator与异步校验完整指南
cool-admin(midway版)前端表单验证:AsyncValidator与异步校验完整指南 【免费下载链接】cool-admin-midway 🔥 cool-admin(midway版)一个很酷的后台权限管理框架,模块化、插件化、CRUD极速开发,永久开源免费,基于midwa…...

3大场景×5项优化:ComfyUI视频合成VHS_VideoCombine节点全场景应用指南
3大场景5项优化:ComfyUI视频合成VHS_VideoCombine节点全场景应用指南 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 一、基础认知:视频合…...

MaxKB:企业级AI知识库部署实战指南
MaxKB:企业级AI知识库部署实战指南 【免费下载链接】MaxKB 🔥 MaxKB is an open-source platform for building enterprise-grade agents. 强大易用的开源企业级智能体平台。 项目地址: https://gitcode.com/GitHub_Trending/ma/MaxKB 面对企业AI…...

如何用代码思维提升90%图表效率?揭秘Mermaid的可视化革命
如何用代码思维提升90%图表效率?揭秘Mermaid的可视化革命 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-edi…...

Pwndbg调试器实战指南:5大核心场景下的高效调试配置策略
Pwndbg调试器实战指南:5大核心场景下的高效调试配置策略 【免费下载链接】pwndbg Exploit Development and Reverse Engineering with GDB & LLDB Made Easy 项目地址: https://gitcode.com/GitHub_Trending/pw/pwndbg Pwndbg是专为漏洞利用开发和逆向工…...

百度网盘秒传链接终极指南:网页版工具全平台免费使用教程
百度网盘秒传链接终极指南:网页版工具全平台免费使用教程 【免费下载链接】baidupan-rapidupload 百度网盘秒传链接转存/生成/转换 网页工具 (全平台可用) 项目地址: https://gitcode.com/gh_mirrors/bai/baidupan-rapidupload 还在为百度网盘文件分享的繁琐…...
Qwen-Image-2512-Pixel-Art-LoRA 模型原理浅析:理解LoRA在图像生成中的作用
Qwen-Image-2512-Pixel-Art-LoRA 模型原理浅析:理解LoRA在图像生成中的作用 最近在玩AI画图的朋友,可能都遇到过这样的烦恼:想让一个通用的大模型画出特定风格,比如复古的像素风,结果要么画得不像,要么就得…...