重写-linux内存管理-伙伴分配器(一)
文章目录
- 一、伙伴系统的结构
- 二、初始化
- 三、分配内存
- 3.1 prepare_alloc_pages
- 3.2 get_page_from_freelist
- 3.2.1 zone_watermark_fast
- 3.2.2 zone_watermark_ok
- 3.2.3 rmqueue
- 3.2.3.1 rmqueue_pcplist
- 3.2.3.2 __rmqueue
- 3.2.3.2.1 __rmqueue_smallest
- 3.2.3.2.2 __rmqueue_fallback
- 3.3 __alloc_pages_slowpath
一、伙伴系统的结构
我从网上找了一个图片,它很好的把整个伙伴系统免描绘出来: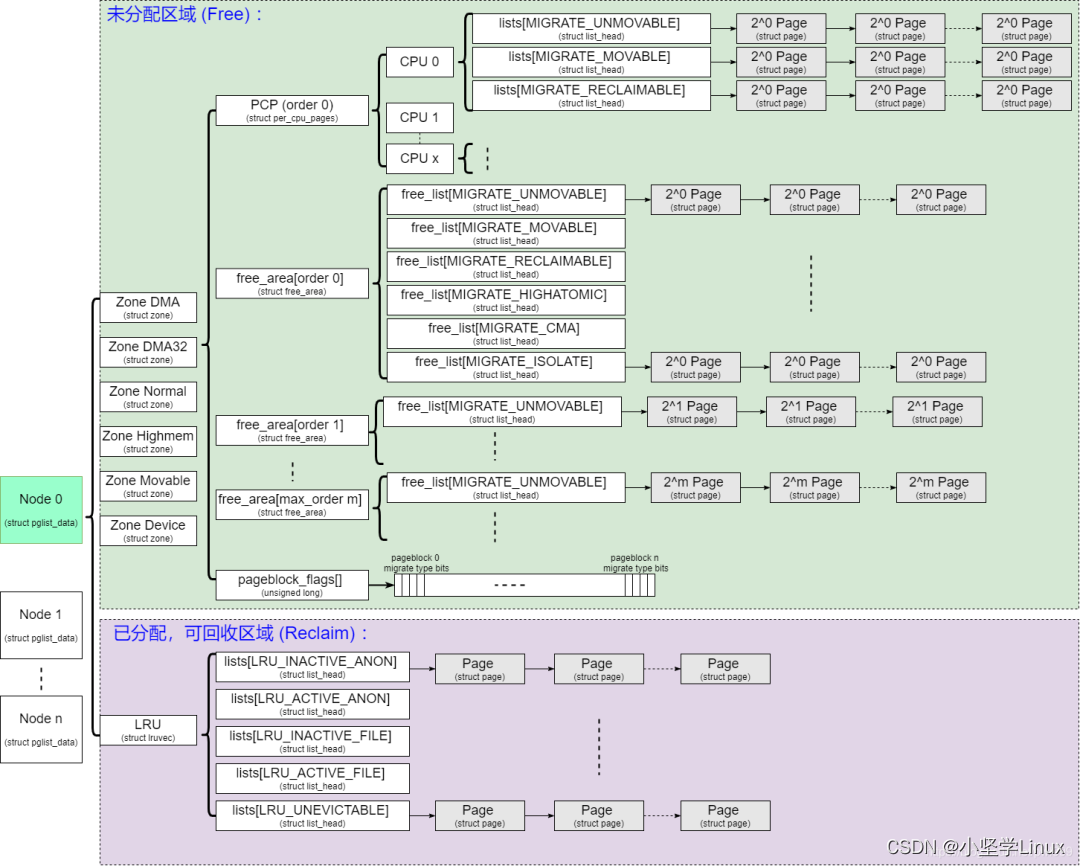
对比他们的系统,我们先看看自己的伙伴系统支持哪些内存页:
jian@ubuntu:~/share/note/p5$ sudo cat /proc/pagetypeinfo
...
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 0 0 0 0 0 0 0 1 0 0 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 1 3
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 46 9 12 113 105 28 7 3 3 4 4
Node 0, zone DMA32, type Movable 1 1 1 0 0 1 1 1 0 1 135
Node 0, zone DMA32, type Reclaimable 7 3 2 5 1 1 1 0 0 0 0
Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 17 19 1 8 9 5 0 1 0 1 3
Node 0, zone Normal, type Movable 0 0 1 0 0 0 1 1 0 0 0
Node 0, zone Normal, type Reclaimable 0 1 0 1 2 1 0 1 0 1 0
Node 0, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
...
可以看到我们的内存只有一个节点,也就是node 0 ,这是正常的,一般普通PC只有一个节点,只有服务器才有多个节点;节点包含3个区域:DMA、DMA32和Normal;每个区域都有5中类型:Unmovable、Movable、Reclaimable、HighAtomic和Isolate。
二、初始化
后面补充。
三、分配内存
从伙伴算法分配函数主要有两个:alloc_pages和__get_free_pages。前者返回一个 page 实例,后者返回返回虚拟地址, 后者对前者做了封装。
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{struct page *page;page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);if (!page)return 0;return (unsigned long) page_address(page);
}
__get_free_pages首先通过alloc_pages函数分配物理内存,然后通过函数page_address把分配到的page结构体转化为虚拟地址返回。所以我们只要分析alloc_pages就可以了:
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)
{return alloc_pages_node(numa_node_id(), gfp_mask, order);
}static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,unsigned int order)
{if (nid == NUMA_NO_NODE)nid = numa_mem_id();return __alloc_pages_node(nid, gfp_mask, order);
}static inline struct page *
__alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
{VM_BUG_ON(nid < 0 || nid >= MAX_NUMNODES);VM_WARN_ON((gfp_mask & __GFP_THISNODE) && !node_online(nid));return __alloc_pages(gfp_mask, order, nid);
}static inline struct page *
__alloc_pages(gfp_t gfp_mask, unsigned int order, int preferred_nid)
{return __alloc_pages_nodemask(gfp_mask, order, preferred_nid, NULL);
}
__alloc_pages_nodemask是伙伴分配器分配物理内存的核心函数:
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,nodemask_t *nodemask)
{struct page *page;unsigned int alloc_flags = ALLOC_WMARK_LOW;gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */struct alloc_context ac = { };if (unlikely(order >= MAX_ORDER)) {//如果申请order超过上限WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN));return NULL;//返回失败}gfp_mask &= gfp_allowed_mask;alloc_mask = gfp_mask;//根据标志位设置好alloc_context和alloc_flagsif (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags))return NULL;//修改alloc_flagsalloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp_mask);//第一次分配尝试,也叫快速路径page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);if (likely(page))//分配成功goto out;//返回//将任务的gfp上下文应用到分配标志中。GFP_NOFS和GFP_NOIOalloc_mask = current_gfp_context(gfp_mask);ac.spread_dirty_pages = false;ac.nodemask = nodemask;//恢复原始的节点掩码page = __alloc_pages_slowpath(alloc_mask, order, &ac);//慢速路径申请内存out:if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&unlikely(__memcg_kmem_charge_page(page, gfp_mask, order) != 0)) {__free_pages(page, order);page = NULL;}trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);return page;
}
我们看到__alloc_pages_nodemask首先判断申请的代销是否超出上限,超出则退出,然后调用函数prepare_alloc_pages主要做分配内存的准备工作,根据标志位设置好alloc_context和alloc_flags,主要是alloc_context里面的备用节点zonelist,首选区域和首选可迁移类型;接着调用函数get_page_from_freelist进行第一次内存分配,也叫快速路径,成功就直接返回page;失败则修改alloc_mask 后调用函数__alloc_pages_slowpath进行慢速路径申请内存。我们需要分析3个函数:prepare_alloc_pages、get_page_from_freelist和__alloc_pages_slowpath。
3.1 prepare_alloc_pages
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order,int preferred_nid, nodemask_t *nodemask,struct alloc_context *ac, gfp_t *alloc_mask,unsigned int *alloc_flags)
{ac->highest_zoneidx = gfp_zone(gfp_mask);//根据gfp_mask选择合适的zoneac->zonelist = node_zonelist(preferred_nid, gfp_mask);//找到当前节点的备用分区列表ac->nodemask = nodemask;ac->migratetype = gfp_migratetype(gfp_mask);//根据gfp_mask选择合适迁移类型if (cpusets_enabled()) {//开启cpuset*alloc_mask |= __GFP_HARDWALL;/** When we are in the interrupt context, it is irrelevant* to the current task context. It means that any node ok.*/if (!in_interrupt() && !ac->nodemask)//如果不在中断上下文ac->nodemask = &cpuset_current_mems_allowed;//可以申请任意内存节点else*alloc_flags |= ALLOC_CPUSET;//设置支持CPUSET}fs_reclaim_acquire(gfp_mask);//空函数fs_reclaim_release(gfp_mask);//空函数might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM);//可能会睡眠,如果支持申请者表示可以收回if (should_fail_alloc_page(gfp_mask, order))return false;*alloc_flags = current_alloc_flags(gfp_mask, *alloc_flags);//根据current情况修改可以申请的可迁移类型//打算脏化该页。以避免所有脏页面都位于一个区域(公平的区域分配策略)。ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE);/** The preferred zone is used for statistics but crucially it is* also used as the starting point for the zonelist iterator. It* may get reset for allocations that ignore memory policies.*///设置申请内存的首选区域ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,ac->highest_zoneidx, ac->nodemask);return true;
}
prepare_alloc_pages调用函数gfp_zone根据gfp_mask选择合适的zone,调用 node_zonelis选择当前节点的备用分区列表,调用gfp_migratetype根据gfp_mask选择合适迁移类型,调用函数first_zones_zonelist设置申请内存的首选区域。中间还有就是对alloc_flags 的一些修,就不一一说了,自己看上面的代码注释。
3.2 get_page_from_freelist
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,const struct alloc_context *ac)
{struct zoneref *z;struct zone *zone;struct pglist_data *last_pgdat_dirty_limit = NULL;bool no_fallback;retry:/** Scan zonelist, looking for a zone with enough free.* See also __cpuset_node_allowed() comment in kernel/cpuset.c.*/no_fallback = alloc_flags & ALLOC_NOFRAGMENT;z = ac->preferred_zoneref;//遍历备用区域列表中每一个满足条件的区域,如果区域类型小于等于首选区域类型,并且内存节点在节点掩码中的相应位被设置for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx,ac->nodemask) {struct page *page;unsigned long mark;if (cpusets_enabled() && //如果编译了cpuset功能(alloc_flags & ALLOC_CPUSET) && //调用者设置ALLOC_CPUSET要求使用cpuset检查!__cpuset_zone_allowed(zone, gfp_mask))//cpuset不允许当前进程从这个内存节点分配页continue;//不能从这个区域分配页,进行下一个区域的遍历//如果调用者设置标志位__GFP_WRITE表示文件系统申请分配一个页缓存页用于写文件if (ac->spread_dirty_pages) {if (last_pgdat_dirty_limit == zone->zone_pgdat)//如果内存节点为NULLcontinue;//不能从这个区域分配页,进行下一个区域的遍历if (!node_dirty_ok(zone->zone_pgdat)) {//如果内存节点的脏页数量是否超过限制last_pgdat_dirty_limit = zone->zone_pgdat;continue;//不能从这个区域分配页,进行下一个区域的遍历}}if (no_fallback && nr_online_nodes > 1 &&zone != ac->preferred_zoneref->zone) {int local_nid;/** If moving to a remote node, retry but allow* fragmenting fallbacks. Locality is more important* than fragmentation avoidance.*/local_nid = zone_to_nid(ac->preferred_zoneref->zone);if (zone_to_nid(zone) != local_nid) {alloc_flags &= ~ALLOC_NOFRAGMENT;goto retry;}}//获取申请内存的限制水位线,是普通申请的LOW还是最低限制的MINmark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);//如果(区域的空闲页数− 申请的页数)小于水线if (!zone_watermark_fast(zone, order, mark,ac->highest_zoneidx, alloc_flags,gfp_mask)) {int ret;/* Checked here to keep the fast path fast */BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);if (alloc_flags & ALLOC_NO_WATERMARKS)//如果调用者要求不检查水线goto try_this_zone;//那么可以从这个区域分配页if (node_reclaim_mode == 0 || //如果没有开启节点回收功能,!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))//当前节点和首选节点之间的距离大于回收距离continue;//不能从这个区域分配页,进行下一个区域的遍历//尝试通过回收从该节点释放一些页面,我们UMA直接返回不扫描ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);switch (ret) {case NODE_RECLAIM_NOSCAN://不扫描/* did not scan */continue;case NODE_RECLAIM_FULL://扫描但是回收失败/* scanned but unreclaimable */continue;default://回收到内存if (zone_watermark_ok(zone, order, mark,//如果回收后内存足够ac->highest_zoneidx, alloc_flags))goto try_this_zone;//那么可以从这个区域分配页continue;}}try_this_zone://从当前区域分配页page = rmqueue(ac->preferred_zoneref->zone, zone, order,gfp_mask, alloc_flags, ac->migratetype);if (page) {//如果分配成功,调用函数 prep_new_page 以初始化页prep_new_page(page, order, gfp_mask, alloc_flags);//如果这是一个高阶原子分配,并且区域中高阶原子类型的页数没有超过限制if (unlikely(order && (alloc_flags & ALLOC_HARDER))) //把分配的页所属的页块转换为高阶原子类型reserve_highatomic_pageblock(page, zone, order);return page;} }if (no_fallback) {//如果存在no_fallbackalloc_flags &= ~ALLOC_NOFRAGMENT;//设置alloc_flags的ALLOC_NOFRAGMENTgoto retry;//回到开头再试一次}return NULL;
}
get_page_from_freelist首先遍历备用区域列表中每一个满足条件的区域,如果区域类型小于等于首选区域类型,并且内存节点在节点掩码中的相应位被设置了,则进行下面一系列的复杂操作:
- 如果编译了cpuset功能,并且调用者设置了ALLOC_CPUSET要求使用cpuset检查,但是cpuset不允许当前进程从这个内存节点分配页,那么不能从这个区域分配页,进行下一个区域的遍历。
- 如果调用者设置标志位__GFP_WRITE表示文件系统申请分配一个页缓存页用于写文件,并且内存节点为NULL或者脏页数量是否超过限制,那么不能从这个区域分配页,进行下一个区域的遍历。
- 调用函数wmark_pages获取申请内存的限制水位线,如果(区域的空闲页数− 申请的页数)小于水线,并且调用者要求检查水线或者没有开启节点回收功能,都不能从这个区域分配页,进行下一个区域的遍历;否则调用node_reclaim函数尝试通过回收从该节点释放一些页面,如果回收到内存,调用函数zone_watermark_ok检查水位线,水位线还是不足,那么不能从这个区域分配页,进行下一个区域的遍历。
- 来都这里说明水位线是足够的,或者不检查水位线,可以调用函数rmqueue开始分配当前区域的内存了。如果分配成功,调用函数 prep_new_page 以初始化页内存;如果这是一个高阶原子分配,并且区域中高阶原子类型的页数没有超过限制,就把分配的页所属的页块转换为高阶原子类型。返回page。
- 如果失败了,如果存在no_fallback,则设置alloc_flags的ALLOC_NOFRAGMENT,回到开头再试一次。
我们继续看zone_watermark_fast、zone_watermark_ok和rmqueue。
3.2.1 zone_watermark_fast
static inline bool zone_watermark_fast(struct zone *z, unsigned int order,unsigned long mark, int highest_zoneidx,unsigned int alloc_flags, gfp_t gfp_mask)
{long free_pages;free_pages = zone_page_state(z, NR_FREE_PAGES);//获取区域空闲物理页数量//针对0阶执行快速检查if (!order) {long usable_free;long reserved;usable_free = free_pages;//计算不可用的空闲页,可能包含高阶原子和CMAreserved = __zone_watermark_unusable_free(z, 0, alloc_flags);/* reserved may over estimate high-atomic reserves. */usable_free -= min(usable_free, reserved);//计算出可用空闲页//如果空闲页数大于(水线 + 低端内存保留页数)if (usable_free > mark + z->lowmem_reserve[highest_zoneidx])return true;//水位线足够,允许从这个区域分配页}if (__zone_watermark_ok(z, order, mark, highest_zoneidx, alloc_flags,free_pages))// 高阶调用__zone_watermark_ok检查水位return true;//如果是高阶原子分配,并且允许从最低水位分配if (unlikely(!order && (gfp_mask & __GFP_ATOMIC) && z->watermark_boost&& ((alloc_flags & ALLOC_WMARK_MASK) == WMARK_MIN))) {mark = z->_watermark[WMARK_MIN];//修改为水低水位线return __zone_watermark_ok(z, order, mark, highest_zoneidx,alloc_flags, free_pages);}return false;
}
zone_watermark_fast调用函数zone_page_state获取区域空闲物理页数量,如果是0阶,调用__zone_watermark_unusable_free计算不可用的空闲页,最后计算出可用的空闲页,然后判断如果可用空闲页数大于(水线 + 低端内存保留页数),说明内存足够,返回ture;剩下就是高阶了,调用__zone_watermark_ok检查水位,水位线足够则返回真。如果水位不足,再判断是高阶原子分配,并且允许调用__zone_watermark_ok从最低水位分配。我们看看__zone_watermark_ok:
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,int highest_zoneidx, unsigned int alloc_flags,long free_pages)
{long min = mark;int o;const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));//空闲页减去不可用的空闲页,得到可用的空闲页数量free_pages -= __zone_watermark_unusable_free(z, order, alloc_flags);if (alloc_flags & ALLOC_HIGH)//如果调用者是高优先级的min -= min / 2;//把水线减半if (unlikely(alloc_harder)) {//如果调用者要求更努力分配if (alloc_flags & ALLOC_OOM)//如果是OOM触发的内存分配min -= min / 2;//把水线减半else//不是OOM触发的内存分配min -= min / 4;//把水线减去四分之一}//如果可用空闲页小于等于(水线 + 低端内存保留页数)if (free_pages <= min + z->lowmem_reserve[highest_zoneidx])return false;//不能从这个区域分配页if (!order)//如果只申请一页return true;//允许从这个区域分配页for (o = order; o < MAX_ORDER; o++) {//如果申请阶数大于0struct free_area *area = &z->free_area[o];int mt;if (!area->nr_free)//如果该区域没有空闲页continue;//不可移动、可移动和可回收任何一种迁移类型,for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {if (!free_area_empty(area, mt))//只要该区域不是空return true;//允许从这个区域分配页}#ifdef CONFIG_CMAif ((alloc_flags & ALLOC_CMA) && //如果调用者允许从 CMA 迁移类型分配, !free_area_empty(area, MIGRATE_CMA)) {//只要该区域不是空return true;//允许从这个区域分配页}
#endif//如果调用者要求更努力分配,并且高阶原子区域不为空if (alloc_harder && !free_area_empty(area, MIGRATE_HIGHATOMIC))return true;//允许从这个区域分配页}return false;//不能从这个区域分配页
}
__zone_watermark_ok调用函数__zone_watermark_unusable_free计算不可用的空闲页,空闲页减去不可用的空闲页,得到可用的空闲页数量,如果调用者是高优先级的,把水线减半;如果调用者要求更努力分配,再根据是否oom设置把水线;接着判断如果可用空闲页小于等于(水线 + 低端内存保留页数),说明不能从这个区域分配页,返回false。如果只申请一页,允许从这个区域分配页,返回true。如果申请阶数大于0,则遍历不可移动、可移动和可回收任何一种迁移类型,只要该区域不是空,允许从这个区域分配页返回true。如果调用者允许从 CMA 迁移类型分配, 只要CMA区域不是空,也允许从这个区域分配页,返回true。如果调用者要求更努力分配,并且高阶原子区域不为空,允许从这个区域分配页,返回true。
3.2.2 zone_watermark_ok
bool zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,int highest_zoneidx, unsigned int alloc_flags)
{return __zone_watermark_ok(z, order, mark, highest_zoneidx, alloc_flags,zone_page_state(z, NR_FREE_PAGES));
}
zone_watermark_ok是调用zone_watermark_ok函数判断水位的,zone_watermark_ok函数我们前面讲过了。
3.2.3 rmqueue
static inline
struct page *rmqueue(struct zone *preferred_zone,struct zone *zone, unsigned int order,gfp_t gfp_flags, unsigned int alloc_flags,int migratetype)
{unsigned long flags;struct page *page;if (likely(order == 0)) {//如果申请阶数是 0 /** MIGRATE_MOVABLE pcplist could have the pages on CMA area and* we need to skip it when CMA area isn't allowed.*/if (!IS_ENABLED(CONFIG_CMA) || alloc_flags & ALLOC_CMA ||migratetype != MIGRATE_MOVABLE) {//允许CMA或者不是可移动的page = rmqueue_pcplist(preferred_zone, zone, gfp_flags,migratetype, alloc_flags);//从每处理器页集合分配页goto out;}}//如果申请阶数大于1,不要试图无限次重试WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));spin_lock_irqsave(&zone->lock, flags);//自旋锁do {page = NULL;/** order-0 request can reach here when the pcplist is skipped* due to non-CMA allocation context. HIGHATOMIC area is* reserved for high-order atomic allocation, so order-0* request should skip it.*/if (order > 0 && alloc_flags & ALLOC_HARDER) {//如果调用者要求更努力分配page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);//先尝试从高阶原子类型分配页。if (page)trace_mm_page_alloc_zone_locked(page, order, migratetype);}if (!page)//高阶原子类型分配失败page = __rmqueue(zone, order, migratetype, alloc_flags);//从指定迁移类型分配页。} while (page && check_new_pages(page, order));//检查分配到的每一个page是否是新的spin_unlock(&zone->lock);//自旋锁解锁if (!page)goto failed;__mod_zone_freepage_state(zone, -(1 << order),//修改每cpu的zone的迁移属性get_pcppage_migratetype(page));__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order);zone_statistics(preferred_zone, zone);local_irq_restore(flags);//恢复中断out://从应急列表中申请内存会设置ZONE_BOOSTED_WATERMARKif (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags)) {clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);wakeup_kswapd(zone, 0, 0, zone_idx(zone));//都应急了,说明内存不足,需要唤醒kswapd}VM_BUG_ON_PAGE(page && bad_range(zone, page), page);return page;failed:local_irq_restore(flags);return NULL;
}
- 如果申请阶数是 0 ,并且允许CMA或者不是可移动的,那么调用rmqueue_pcplist函数从每处理器页集合分配页,成功就返回;
- 如果申请阶数大于1,不要试图无限次重试,自旋锁上锁
- 如果调用者要求更努力分配,调用函数__rmqueue_smallest先尝试从高阶原子类型分配页。
- 如果高阶原子类型分配失败,调用函数__rmqueue从指定迁移类型分配页。
- 如果成功分配则调用check_new_pages检查分配到的每一个page是否是新的,是就往下走,不是就回到2重新分配
- 自旋锁解锁
- 调用函数__mod_zone_freepage_state修改每cpu的zone的迁移属性
- 如果从应急列表中申请内存会设置ZONE_BOOSTED_WATERMARK,调用函数wakeup_kswapd唤醒kswapd回收内存
下面我们需要分析rmqueue_pcplist、__rmqueue_smallest和__rmqueue函数。
3.2.3.1 rmqueue_pcplist
static struct page *rmqueue_pcplist(struct zone *preferred_zone,struct zone *zone, gfp_t gfp_flags,int migratetype, unsigned int alloc_flags)
{struct per_cpu_pages *pcp;struct list_head *list;struct page *page;unsigned long flags;local_irq_save(flags);//关闭中断pcp = &this_cpu_ptr(zone->pageset)->pcp;//找到pcplist = &pcp->lists[migratetype];//选择pcp中3个类型链表中的一个//从每cpu列表中删除页面page = __rmqueue_pcplist(zone, migratetype, alloc_flags, pcp, list);if (page) {__count_zid_vm_events(PGALLOC, page_zonenum(page), 1);//计数加一zone_statistics(preferred_zone, zone);//更新NUMA命中/错过统计数据}local_irq_restore(flags);//恢复中断return page;
}
rmqueue_pcplist:
- 关中断,找到pcp,从pcp取出需要申请的类型链表
- 调用该函数__rmqueue_pcplist从每cpu列表中删除页面
- 如果每cpu列表中取到内存,pcp的计数加一,更新NUMA命中/错过统计数据
- 恢复中断
我们再看看__rmqueue_pcplist是怎么从每cpu列表中拿到内存的:
static struct page *__rmqueue_pcplist(struct zone *zone, int migratetype,unsigned int alloc_flags,struct per_cpu_pages *pcp,struct list_head *list)
{struct page *page;do {if (list_empty(list)) {//如果每处理器页集合中指定迁移类型的链表是空的,//批量申请页加入链表pcp->count += rmqueue_bulk(zone, 0,pcp->batch, list,migratetype, alloc_flags);if (unlikely(list_empty(list)))return NULL;}page = list_first_entry(list, struct page, lru);//从lru list中找到第一个pagelist_del(&page->lru);//把page移出lru列表pcp->count--;//pcp计数减一} while (check_new_pcp(page));//检查page是否新页return page;
}
__rmqueue_pcplist:
- 如果每处理器页集合中指定迁移类型的链表是空的,调用rmqueue_bulk函数批量申请页加入链表,
- 调用函数list_first_entry从lru list中找到第一个page,
- 调用函数list_del把page移出lru列表,pcp计数减一
- 调用check_new_pcp检查page是否是新的,如果是,返回page,如果不是,回到1重新来过
rmqueue_bulk是从当pcp为空的时候,批量申请页放入pcp链表中,我们看看过程:
static int rmqueue_bulk(struct zone *zone, unsigned int order,unsigned long count, struct list_head *list,int migratetype, unsigned int alloc_flags)
{int i, alloced = 0;spin_lock(&zone->lock);//自旋锁上锁for (i = 0; i < count; ++i) {//循环调用__rmqueue从指定迁移类型分配页struct page *page = __rmqueue(zone, order, migratetype,alloc_flags);//从指定迁移类型分配页。if (unlikely(page == NULL))//中途失败返回break;if (unlikely(check_pcp_refill(page)))continue;list_add_tail(&page->lru, list);//把该页加到空闲链表alloced++;//申请数量加一//如果page的类型是CMAif (is_migrate_cma(get_pcppage_migratetype(page)))__mod_zone_page_state(zone, NR_FREE_CMA_PAGES,-(1 << order));//zone的CMA类型数量减去相应的数值}//zone的空闲页数量减去相应的数值__mod_zone_page_state(zone, NR_FREE_PAGES, -(i << order));spin_unlock(&zone->lock);//自旋锁解锁return alloced;
}
rmqueue_bulk:
- 自旋锁上锁
- 在for循环里面调用__rmqueue函数从伙伴系统中的指定区域的指定迁移类型分配页出来,
- 每取出一个page就把这个page加入到pcp的空闲链表中,
- 如果取出的是CMA区域的内存,调用__mod_zone_page_state函数修改CMA空闲页的数量
- 直到分配失败或者数量达到pcp->batch,就退出循环
- 最后调用__mod_zone_page_state修改zone的全部空闲页数量,自旋锁解锁
这里还有一个很重要的函数,__rmqueue,这个函数是从伙伴系统中取出指定zone指定迁移类型指定order的page的函数,下面一点点会讲的。
3.2.3.2 __rmqueue
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype,unsigned int alloc_flags)
{struct page *page;if (IS_ENABLED(CONFIG_CMA)) {//当CMA区域的空闲页数量大于全部区域空闲页的一半的时候if (alloc_flags & ALLOC_CMA &&zone_page_state(zone, NR_FREE_CMA_PAGES) >zone_page_state(zone, NR_FREE_PAGES) / 2) {//从CMA区域分配,从而平衡常规区域和CMA区域之间的可移动分配page = __rmqueue_cma_fallback(zone, order);if (page)goto out;}}
retry://分配指定类型的内存页page = __rmqueue_smallest(zone, order, migratetype);if (unlikely(!page)) {if (alloc_flags & ALLOC_CMA)//如果允许从CMA区域分配内存page = __rmqueue_cma_fallback(zone, order);//从CMA区域分配if (!page && __rmqueue_fallback(zone, order, migratetype,alloc_flags))//从备用迁移类型盗用页goto retry;}
out:if (page)trace_mm_page_alloc_zone_locked(page, order, migratetype);return page;
}
__rmqueue 的处理过程如下:
- 如果CMA区域内存很多,那么调用函数__rmqueue_cma_fallback从CMA区域分配内存,如果分配成功,那么处理结束;如果分配失败往下走,
- 调用函数__rmqueue_smallest从指定的zone、指定迁移类型分配指定order的页,如果分配成功,那么处理结束;如果分配失败往下走,
- 如果调用者允许从CMA区域分配内存,那么调用函数__rmqueue_cma_fallback从 CMA 类型分配。如果分配成功,那么处理结束;如果分配失败往下走,
- 调用函数__rmqueue_fallback从备用迁移类型盗用页,如果分配成功,那么处理结束;如果分配失败,回到2再试试。
函数就是调用__rmqueue_smallest指定CMA类型从CMA区域分配内存的,所以我们需要__rmqueue_smallest和__rmqueue_fallback。
3.2.3.2.1 __rmqueue_smallest
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,int migratetype)
{unsigned int current_order;struct free_area *area;struct page *page;//从申请阶数到最大分配阶数逐个尝试for (current_order = order; current_order < MAX_ORDER; ++current_order) {area = &(zone->free_area[current_order]);//找到order对应的区域page = get_page_from_free_area(area, migratetype);//从区域中获取第一个页if (!page)//找不到continue;//尝试下一个order//从zone中取出找到的page,修改zone的统计数量del_page_from_free_list(page, zone, current_order);//分裂page,把多余部分放到其他页块链表里面expand(zone, page, order, current_order, migratetype);set_pcppage_migratetype(page, migratetype);//设置page的类型return page;}return NULL;
}
__rmqueue_smallest的处理过程如下:
使用for循环从申请的order到最大的order,执行下面的操作:
- 找到zone对应order的area,然后从area拿到第一个页,如果拿不到,尝试下一个order,
- 拿到了,调用del_page_from_free_list函数从zone中取出找到的page,修改zone的统计数量,
- 调用函数expand,把page分裂,然后把多余部分放到其他页块链表里面,
- 最后设置page的类型,返回page
expand(zone, page, order, current_order, migratetype)函数就是把刚刚从zone区域的拿到的page,这个page的阶是current_order,需要分裂出我们需要的阶为order的页,把其他的页放入zone的migratetype类型空闲链表中。
static inline void expand(struct zone *zone, struct page *page,int low, int high, int migratetype)
{unsigned long size = 1 << high;while (high > low) {//如果申请到的order大于申请的orderhigh--;//逐步把high阶的内存分裂,直到成成low阶的内存,size >>= 1;VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]);//标记为保护页,当其伙伴被释放时,允许合并,这里是空函数if (set_page_guard(zone, &page[size], high, migratetype))continue;//把另一个页面放入空闲链表中add_to_free_list(&page[size], zone, high, migratetype);set_buddy_order(&page[size], high);//修改页的private}
}
expand的处理过程如下:
使用for循环,从申请到的阶数high开始,直到需要的阶数order,逐步把page分裂,执行下面的操作:
- 阶数减1,意思是把一个阶数为high的page分裂成两个阶数为high-1的page,size减半,order减少了,page 的大小也要修改
- 调用函数set_page_guard把第二个page标记一下,因为第一个page是我们需要的
- 调用函数add_to_free_list把第二个page放入zone的hight阶migratetype类型的链表中,因为第一个page是我们需要的,
- 调用函数set_buddy_order修改page的private参数,这个参数存放pag的order大小。
3.2.3.2.2 __rmqueue_fallback
static __always_inline bool
__rmqueue_fallback(struct zone *zone, int order, int start_migratetype,unsigned int alloc_flags)
{struct free_area *area;int current_order;int min_order = order;struct page *page;int fallback_mt;bool can_steal;if (alloc_flags & ALLOC_NOFRAGMENT)//如果设置了ALLOC_NOFRAGMENT,避免页面太分散min_order = pageblock_order;//设置最小偷取的阶层,这里是9//从最大分配阶数开始逐个尝试,直到刚刚设置的最小申请页面for (current_order = MAX_ORDER - 1; current_order >= min_order;--current_order) {area = &(zone->free_area[current_order]);//找到order对应的区域fallback_mt = find_suitable_fallback(area, current_order,start_migratetype, false, &can_steal);//查找适合的类型if (fallback_mt == -1)continue;//如果我们可以偷,并且要偷的类型是可移动的if (!can_steal && start_migratetype == MIGRATE_MOVABLE&& current_order > order)goto find_smallest;//我们不要偷太大,偷个最小的goto do_steal;//否则就偷个最大的}return false;find_smallest://从申请阶数到最大分配阶数逐个尝试for (current_order = order; current_order < MAX_ORDER;current_order++) {area = &(zone->free_area[current_order]);//找到order对应的区域fallback_mt = find_suitable_fallback(area, current_order,start_migratetype, false, &can_steal);查找适合的类型if (fallback_mt != -1)break;}/** This should not happen - we already found a suitable fallback* when looking for the largest page.*/VM_BUG_ON(current_order == MAX_ORDER);do_steal:page = get_page_from_free_area(area, fallback_mt);//从区域中获取第一个页//实际的偷窃函数steal_suitable_fallback(zone, page, alloc_flags, start_migratetype,can_steal);trace_mm_page_alloc_extfrag(page, order, current_order,start_migratetype, fallback_mt);return true;}
__rmqueue_fallback是从同一个zone的其他类型偷取一个大的page过来使用的函数,处理过程如下:
- 如果设置了ALLOC_NOFRAGMENT,避免页面太分散,设置最小偷取的阶层,这里是9
- for循环从最大分配阶数开始逐个尝试,直到刚刚设置的最小申请页面,在循环里面执行:
- 找到自己的zone对应阶层的frea,
- 调用函数find_suitable_fallback查找其他类型,查找可以偷的类型的index,找到就退出循环。
- 如果我们偷的类型是可移动的,我们不要偷太大,去到6偷个最小的,否则去到7开始偷。
- 进入for循环,从申请阶数到最大分配阶数逐个尝试,循环体中调用函数查找适合的类型。然后去到7开始偷
- 调用函数get_page_from_free_area从备用区域找到第一个ye
- 调用函数steal_suitable_fallback从zone的备用区域偷取出一整块内存。
steal_suitable_fallback主要作用是把从找到的类型中拿出一个大的page,我们一起看看:
static void steal_suitable_fallback(struct zone *zone, struct page *page,unsigned int alloc_flags, int start_type, bool whole_block)
{unsigned int current_order = buddy_order(page);//获取当前页面的orderint free_pages, movable_pages, alike_pages;int old_block_type;old_block_type = get_pageblock_migratetype(page);//获取要偷的页的迁移类型if (is_migrate_highatomic(old_block_type))goto single_page;/* Take ownership for orders >= pageblock_order */if (current_order >= pageblock_order) {change_pageblock_range(page, current_order, start_type);goto single_page;}//如果调用boost_watermark提高水位线,并且调用者允许KSWAPDif (boost_watermark(zone) && (alloc_flags & ALLOC_KSWAPD))set_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);//设置ZONE_BOOSTED_WATERMARK位if (!whole_block)//如果不允许偷一整块goto single_page;//去偷一页free_pages = move_freepages_block(zone, page, start_type,&movable_pages);//偷取一整块的页面/** Determine how many pages are compatible with our allocation.* For movable allocation, it's the number of movable pages which* we just obtained. For other types it's a bit more tricky.*/if (start_type == MIGRATE_MOVABLE) {//如果偷取的类型为可移动alike_pages = movable_pages;} else {/** If we are falling back a RECLAIMABLE or UNMOVABLE allocation* to MOVABLE pageblock, consider all non-movable pages as* compatible. If it's UNMOVABLE falling back to RECLAIMABLE or* vice versa, be conservative since we can't distinguish the* exact migratetype of non-movable pages.*/if (old_block_type == MIGRATE_MOVABLE)alike_pages = pageblock_nr_pages- (free_pages + movable_pages);elsealike_pages = 0;}if (!free_pages)//整个块的移动失败了,goto single_page;//去偷一页/** If a sufficient number of pages in the block are either free or of* comparable migratability as our allocation, claim the whole block.*///如果块中有足够多的空闲页面if (free_pages + alike_pages >= (1 << (pageblock_order-1)) ||page_group_by_mobility_disabled)set_pageblock_migratetype(page, start_type);//修改整块的类型return;single_page:将page从盗用freelist 移动到需要的freelist中move_to_free_list(page, zone, current_order, start_type);
}
steal_suitable_fallback过程如下:
- 首先调用函数buddy_order获取传入页面的order,
- 调用函数get_pageblock_migratetype获取要偷的页的迁移类型,
- 如果迁移类型是高阶原子,去到进行末尾执行盗取单页,
- 如果调用boost_watermark提高水位线,并且调用者允许KSWAPD,设置ZONE_BOOSTED_WATERMARK位,前面讲的ZONE_BOOSTED_WATERMARK决定我们是否启动进程KSWAPD就是在这里被设置的,
- 开始调用函数move_freepages_block偷取一整块内存页,
- 如果整个块的偷取失败了,去到进行末尾执行盗取单页,
- 如果块中有足够多的空闲页面,修改整块的类型,然后返回。
- 调用函数move_to_free_list将page从盗用freelist 移动一个page到需要的freelist中
move_freepages_block是怎么拿到一整块内存的:
int move_freepages_block(struct zone *zone, struct page *page,int migratetype, int *num_movable)
{unsigned long start_pfn, end_pfn;struct page *start_page, *end_page;if (num_movable)*num_movable = 0;start_pfn = page_to_pfn(page);//根据盗用的页,获取页的页帧start_pfn = start_pfn & ~(pageblock_nr_pages-1);//对齐页帧,找到起始页帧start_page = pfn_to_page(start_pfn);//根据页帧找到对应的pageend_page = start_page + pageblock_nr_pages - 1;//计算出页最后一个pageend_pfn = start_pfn + pageblock_nr_pages - 1;//计算出页尾的页帧//根据zone,避免越过区域边界if (!zone_spans_pfn(zone, start_pfn))start_page = page;if (!zone_spans_pfn(zone, end_pfn))return 0;return move_freepages(zone, start_page, end_page, migratetype,num_movable);
}
move_freepages_block的过程如下所示:
- 调用函数page_to_pfn根据盗用的页,获取页的页帧
- 对齐页帧,找到起始页帧
- 根据页帧找到对应的page
- 计算出页最后一个page
- 计算出页尾的页帧
- 根据zone,避免越过区域边界
- 最后调用move_freepages移动整块页面
move_freepages:
static int move_freepages(struct zone *zone,struct page *start_page, struct page *end_page,int migratetype, int *num_movable)
{struct page *page;unsigned int order;int pages_moved = 0;//for循环来进行移动每一个页for (page = start_page; page <= end_page;) {if (!pfn_valid_within(page_to_pfn(page))) {//如果此page的页帧不是有效的page++;continue;//则跳过,下一个}if (!PageBuddy(page)) {//如果page不在buddy中if (num_movable &&(PageLRU(page) || __PageMovable(page)))(*num_movable)++;page++;continue;//则跳过}/* Make sure we are not inadvertently changing nodes */VM_BUG_ON_PAGE(page_to_nid(page) != zone_to_nid(zone), page);VM_BUG_ON_PAGE(page_zone(page) != zone, page);order = buddy_order(page);//记录page的order//将page从盗用freelist 移动到需要的freelist中move_to_free_list(page, zone, order, migratetype);page += 1 << order;pages_moved += 1 << order;}return pages_moved;
}
move_freepages的过程如下:
使用for循环来进行移动每一个页,从start_page到end_page,执行下面的操作:
- 调用函数pfn_valid_within判断page的页帧不是有效的,如果不是则跳过,执行下一个page
- 调用函数PageBuddy判断一个page在不在伙伴系统中,如果不在则跳过,执行下一个page
- 调用函数buddy_order记录page的order,然后调用函数move_to_free_list把一个page移出来
3.3 __alloc_pages_slowpath
如果使用低水线分配失败,那么执行慢速路径,慢速路径是在函数__alloc_pages_slowpath 中实现的:
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,struct alloc_context *ac)
{bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;struct page *page = NULL;unsigned int alloc_flags;unsigned long did_some_progress;enum compact_priority compact_priority;enum compact_result compact_result;int compaction_retries;int no_progress_loops;unsigned int cpuset_mems_cookie;unsigned int zonelist_iter_cookie;int reserve_flags;/** We also sanity check to catch abuse of atomic reserves being used by* callers that are not in atomic context.*/if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==(__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)))gfp_mask &= ~__GFP_ATOMIC;restart:compaction_retries = 0;no_progress_loops = 0;compact_priority = DEF_COMPACT_PRIORITY;//后面可能会检查cpuset是否允许当前进程从哪些内存节点申请页cpuset_mems_cookie = read_mems_allowed_begin();zonelist_iter_cookie = zonelist_iter_begin();//把分配标志位转换成内部分配标志位alloc_flags = gfp_to_alloc_flags(gfp_mask);//获取首选的内存区域ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,ac->highest_zoneidx, ac->nodemask);if (!ac->preferred_zoneref->zone)goto nopage;if (alloc_flags & ALLOC_KSWAPD)//如果调用者允许异步回收页,wake_all_kswapds(order, gfp_mask, ac);//唤醒页回收线程/** The adjusted alloc_flags might result in immediate success, so try* that first*///调整alloc_flags后可能会立即申请成功,所以再尝试一下page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);if (page)//如果申请到内存goto got_pg;//可以返回了if (can_direct_reclaim && //如果可以直接回收(costly_order || //如果大于3阶或者申请不可移动的连续页(order > 0 && ac->migratetype != MIGRATE_MOVABLE))&& !gfp_pfmemalloc_allowed(gfp_mask)) {//不允许使用紧急保留内存//尝试对高阶分配进行异步内存压缩,然后尝试分配page = __alloc_pages_direct_compact(gfp_mask, order,alloc_flags, ac,INIT_COMPACT_PRIORITY,&compact_result);if (page)//如果申请到内存goto got_pg;//可以返回了如果申请的内存大于等于3阶,并且调用者表示不再尝试if (costly_order && (gfp_mask & __GFP_NORETRY)) {//如果压缩过了但是失败,或者压缩过了导致一段时间内不会再次压缩if (compact_result == COMPACT_SKIPPED ||compact_result == COMPACT_DEFERRED)goto nopage;//返回失败compact_priority = INIT_COMPACT_PRIORITY;//使用异步压缩}}retry:/* Ensure kswapd doesn't accidentally go to sleep as long as we loop */if (alloc_flags & ALLOC_KSWAPD)//如果调用者允许KSWAPDwake_all_kswapds(order, gfp_mask, ac);//如果调用者没有反对CMA分配,则允许CMA分配reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);if (reserve_flags)alloc_flags = current_alloc_flags(gfp_mask, reserve_flags);//如果调用者没有要求使用cpuset,那么重新获取区域列表if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) {ac->nodemask = NULL;ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,ac->highest_zoneidx, ac->nodemask);}//重新调整alloc_flags后尝试分配page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);if (page)goto got_pg;if (!can_direct_reclaim)//调用者要求直接分配,不能等待goto nopage;//返回失败//直接回收页的时候给进程设置了标志位PF_MEMALLOCif (current->flags & PF_MEMALLOC)//如果设置了PF_MEMALLOC,避免递归goto nopage;//返回失败//尝试直接回收页page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,&did_some_progress);if (page)goto got_pg;//执行同步模式的内存碎片整理page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,compact_priority, &compact_result);if (page)goto got_pg;if (gfp_mask & __GFP_NORETRY)//如果调用者要求不要重试goto nopage;//如果申请阶数大于3,并且调用者没有要求重试,if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))goto nopage;//如果认为有必要重新尝试回收页if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,did_some_progress > 0, &no_progress_loops))goto retry;/** It doesn't make any sense to retry for the compaction if the order-0* reclaim is not able to make any progress because the current* implementation of the compaction depends on the sufficient amount* of free memory (see __compaction_suitable)*/if (did_some_progress > 0 && //之前直接回收页有进展should_compact_retry(ac, order, alloc_flags,//如果认为有必要重新尝试压缩compact_result, &compact_priority,&compaction_retries))goto retry;if (check_retry_cpuset(cpuset_mems_cookie, ac) || //如果cpuset更新check_retry_zonelist(zonelist_iter_cookie)) //如果zonelist更新 goto restart;//使用内存耗尽杀手选择一个进程杀死page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);if (page)goto got_pg;if (tsk_is_oom_victim(current) && //如果当前进程正在被内存耗尽杀手杀死(alloc_flags & ALLOC_OOM || //调用者允许OOM(gfp_mask & __GFP_NOMEMALLOC))) //不允许使用紧急内存goto nopage;if (did_some_progress) {//如果内存耗尽杀手取得进展no_progress_loops = 0;goto retry;}nopage:/** Deal with possible cpuset update races or zonelist updates to avoid* a unnecessary OOM kill.*/if (check_retry_cpuset(cpuset_mems_cookie, ac) || //如果cpuset更新check_retry_zonelist(zonelist_iter_cookie)) //如果zonelist更新 goto restart;/** Make sure that __GFP_NOFAIL request doesn't leak out and make sure* we always retry*/if (gfp_mask & __GFP_NOFAIL) {//如果调用者要求不能失败if (WARN_ON_ONCE(!can_direct_reclaim))//同时要求不能失败和不能直接回收页goto fail;WARN_ON_ONCE(current->flags & PF_MEMALLOC);WARN_ON_ONCE(order > PAGE_ALLOC_COSTLY_ORDER);//先使用标志位ALLOC_CPUSET尝试分配,失败再使用ALLOC_HARDER尝试分配page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_HARDER, ac);if (page)goto got_pg;cond_resched();goto retry;}
fail:warn_alloc(gfp_mask, ac->nodemask,"page allocation failure: order:%u", order);
got_pg:return page;
}
- 如果允许异步回收页,那么调用函数wake_all_kswapds针对每个目标区域,唤醒区域所属内存节点的页回收线程。
- 调整alloc_flags后调用函数get_page_from_freelist尝试分配
- 如果申请阶数大于 3 并且允许直接回收页,那么调用函数__alloc_pages_direct_compact执行异步模式的内存碎片整理,然后尝试分配。
- 重新调整alloc_flags后调用函数get_page_from_freelist尝试分配
- 调用函数__alloc_pages_direct_reclaim直接回收页,然后尝试分配。
- 调用函数__alloc_pages_direct_compact执行同步模式的内存碎片整理,然后尝试分配。
- 如果多次尝试直接回收页和同步模式的内存碎片整理,仍然分配失败,那么调用函数__alloc_pages_may_oom使用杀伤力比较大的内存耗尽杀手选择一个进程杀死,然后尝试分配。
wake_all_kswapds函数主要作用是遍历每一个zone,然后回调zone所在的pglist_data的kcompactd_wait方法和kswapd_wait方法来实现异步压缩和回收的。get_page_from_freelist我们在快速路径中已经分析过了。__alloc_pages_cpuset_fallback就是两次调用函数get_page_from_freelist而已。都是很简单的我们不会继续展开。
下面的函数我们会继续分析,但是放在下一章:
a. 内存压缩函数:__alloc_pages_direct_compact
b. 内存回收函数:__alloc_pages_direct_reclaim
c. 内存杀手函数:__alloc_pages_may_oom
相关文章:
重写-linux内存管理-伙伴分配器(一)
文章目录一、伙伴系统的结构二、初始化三、分配内存3.1 prepare_alloc_pages3.2 get_page_from_freelist3.2.1 zone_watermark_fast3.2.2 zone_watermark_ok3.2.3 rmqueue3.2.3.1 rmqueue_pcplist3.2.3.2 __rmqueue3.2.3.2.1 __rmqueue_smallest3.2.3.2.2 __rmqueue_fallback3.…...
为什么要用springboot进行开发呢?
文章目录前言1、那么Springboot是怎么实现自动配置的1.1 启动类1.2 SpringBootApplication1.3 Configuration1.4 ComponentScan1.5 EnableAutoConfiguration1.6 两个重要注解1.7 AutoConfigurationPackage注解1.8 Import(AutoConfigurationImportSelector.class)注解1.9自动配置…...

设备树信息解析相关函数
一。可以通过三种不同的方式解析设备树节点: 1.根据设备树节点的名字解析设备树节点 struct device_node *of_find_node_by_name(struct device_node *from, const char *name); 参数: from:当前节点父节点首地址 name:设备树节点名字 …...

LeetCode-1124. 表现良好的最长时间段【哈希表,前缀和,单调栈】
LeetCode-1124. 表现良好的最长时间段【哈希表,前缀和,单调栈】题目描述:解题思路一:查字典。cur是当前的前缀和(劳累与不劳累天数之差),向前遍历。有两种情况。情况一,若cur大于0则是[0,i]的劳累与不劳累天…...
vue-router路由配置
介绍:路由配置主要是用来确定网站访问路径对应哪个文件代码显示的,这里主要描述路由的配置、子路由、动态路由(运行中添加删除路由) 1、npm添加 npm install vue-router // 执行完后会自动在package.json中添加 "vue-router…...

中国计算机设计大赛来啦!用飞桨驱动智慧救援机器狗
中国大学生计算机设计大赛是我国高校面向本科生最早的赛事之一,自2008年开赛至今,一直由教育部高校与计算机相关教指委等或独立或联合主办。大赛的目的是以赛促学、以赛促教、以赛促创,为国家培养德智体美劳全面发展的创新型、复合型、应…...

嘉定区2022年高新技术企业认定资助申报指南
各镇人民政府,街道办事处,嘉定工业区、菊园新区管委会,各相关企业: 为推进实施创新驱动发展战略,加快建设具有全球影响力的科技创新中心,根据《嘉定区关于加快本区高新技术企业发展的实施方案(…...

【C++】关键字、命名空间、输入和输出、缺省参数、函数重载
C关键字(C98)命名空间产生背景命名空间定义命名空间使用输入&输出缺省参数什么叫缺省参数缺省参数分类函数重载函数重载概念C支持函数重载的原理--名字修饰C关键字(C98) C总计63个关键字,C语言32个关键字。 下面我们先看一下C有多少关键字,不对关键…...

【一道面试题】关于HashMap的一系列问题
HashMap底层数据结构在1.7与1.8的变化 1.7是基于数组链表实现的,1.8是基于数组链表红黑树实现的,链表长度达到8时会树化 使用哈希表的好处 使用hash表是为了提升查找效率,比如我现在要在数组中查找一个A对象,在这种情况下是无法…...

论文笔记: Monocular Depth Estimation: a Review of the 2022 State of the Art
中文标题:单目深度估计:回顾2022年最先进技术 本文对比了物种最近的基于深度学习的单目深度估计方法: GPLDepth(2022)[15]: Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepthAdabins(2021)[1]: Adabins:…...
Springmvc补充配置
Controller配置总结 控制器通常通过接口定义或注解定义两种方法实现 在用接口定义写控制器时,需要去Spring配置文件中注册请求的bean;name对应请求路径,class对应处理请求的类。 <bean id"/hello" class"com.demo.Controller.HelloCo…...

MySQL 的 datetime等日期和时间处理SQL函数及格式化显示
MySQL 的 datetime等日期和时间处理SQL函数及格式化显示MySQL 时间相关的SQL函数:MySQL的SQL DATE_FORMAT函数:用于以不同的格式显示日期/时间数据。DATE_FORMAT(date, format) 根据格式串 format 格式化日期或日期和时间值 date,返回结果串。…...

基于微信云开发的防诈反诈宣传教育答题小程序
基于微信云开发的防诈反诈宣传教育答题小程序一、前言介绍作为当代大学生,诈骗事件的发生屡见不鲜,但却未能引起大家的重视。高校以线上宣传、阵地展示为主,线下学习、实地送法为辅,从而构筑立体化反诈骗防线。在线答题考试是一种…...
Map和Set
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。数据的一般查找方式有两种:直接遍历和二分查找。但这两种查找方式都有很大的局限性,也不便于对数据进行增删查改等操作。对于这一类数据的查找&…...
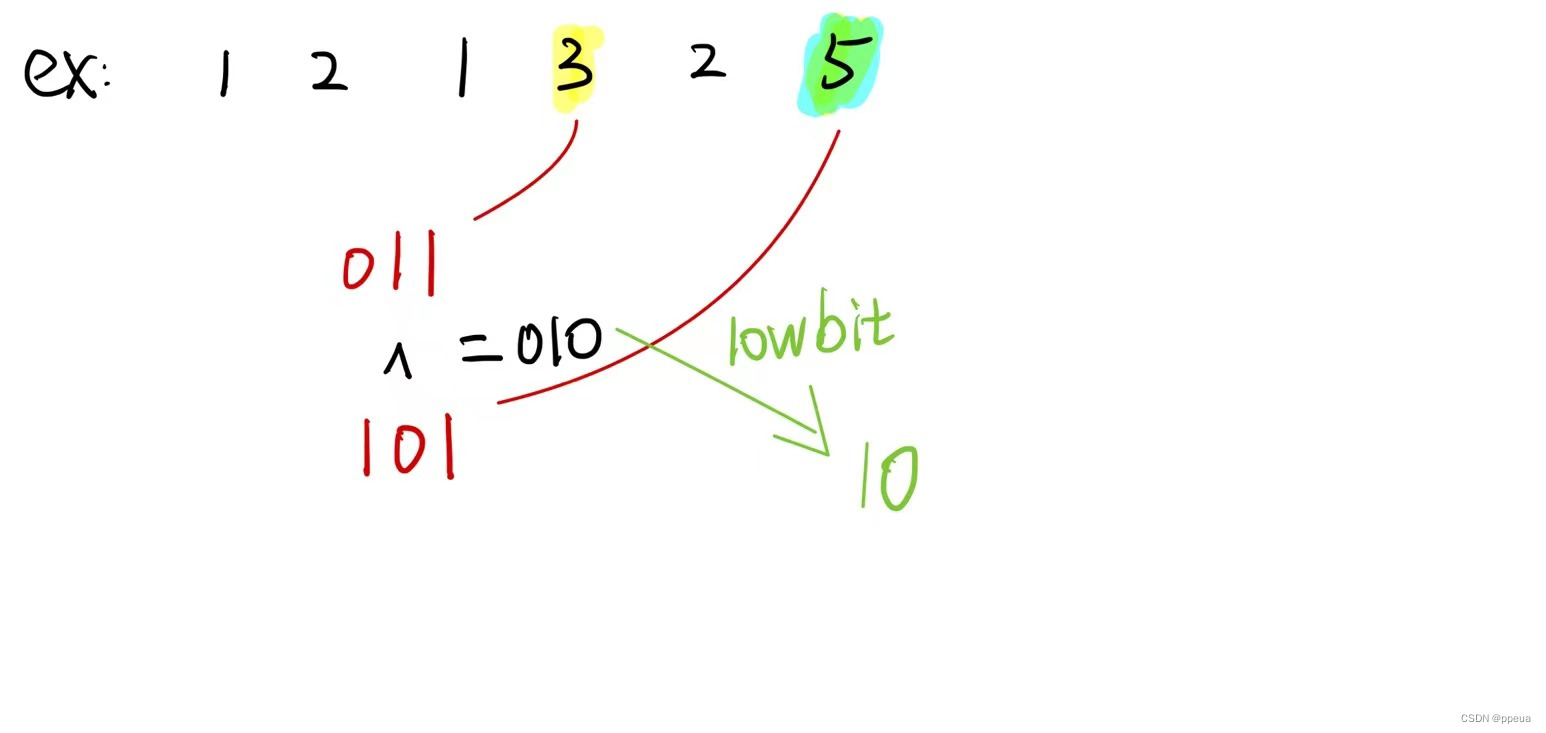
【位运算问题】Leetcode 136、137、260问题详解及代码实现
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

同花顺2023届春招内推
同花顺2023届春招开始啦! 同花顺是国内首家上市的互联网金融信息服务平台,如果你对互联网金融感兴趣,如果你有志向在人工智能方向发挥所长,如果你也是一个激情澎湃的小伙伴,欢迎加入我们!岗位类别…...
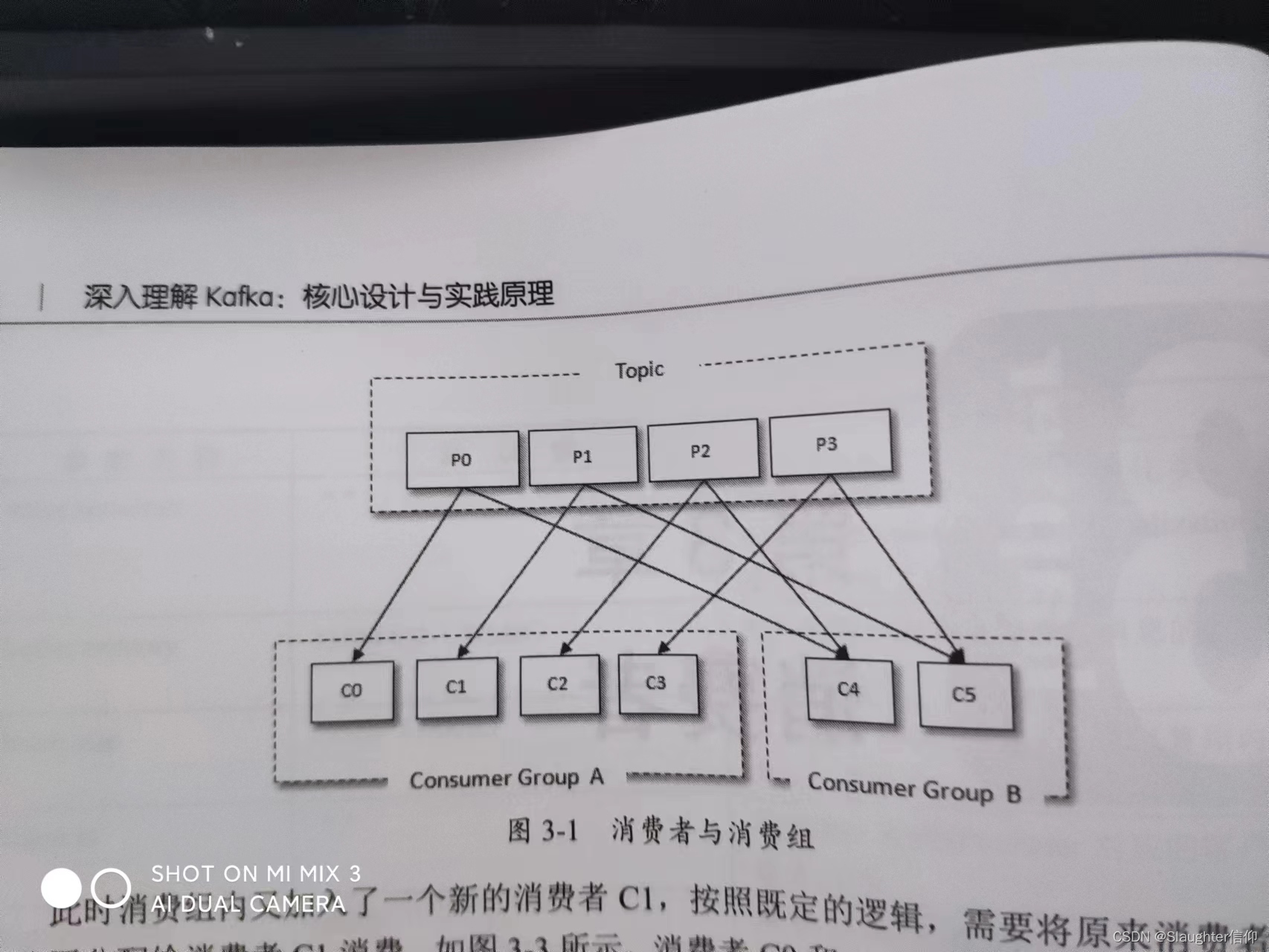
深入Kafka核心设计与实践原理读书笔记第三章消费者
消费者 消费者与消费组 消费者Consumer负责定于kafka中的主题Topic,并且从订阅的主题上拉取消息。与其他消息中间件不同的在于它有一个消费组。每个消费者对应一个消费组,当消息发布到主题后,只会被投递给订阅它的消费组的一个消费者。 如…...

IDEA 中使用 Git 图文教程详解
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

【Linux系统】进程概念
目录 1 冯诺依曼体系结构 2 操作系统(Operator System) 概念 设计OS的目的 定位 总结 系统调用和库函数概念 3 进程 3.1 基本概念 3.2 描述进程-PCB 3.2 组织进程 3.3 查看进程 3.4 通过系统调用获取进程标示符 3.5 进程状态 在了解进程概念前我们还得了解下冯诺…...
)
上课睡觉(2023寒假每日一题 4)
有 NNN 堆石子,每堆的石子数量分别为 a1,a2,…,aNa_1,a_2,…,a_Na1,a2,…,aN。 你可以对石子堆进行合并操作,将两个相邻的石子堆合并为一个石子堆,例如,如果 a[1,2,3,4,5]a[1,2,3,4,5]a[1,2,3,4,5],合并第 2,32…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...