MySQL面试题:SQL语句的基本语法
MySQL目录
- 一、数据库入门
- 1. 数据管理技术的三个阶段
- 2. 关系型数据库与非关系型数据库
- 3. 四大非关系型数据库
- a. 基于列的数据库(column-oriented)
- b. 键值对存储(Key-Value Stores)
- c. 文档存储(Document Stores)
- d. 图形数据库(Graph Database)
- 二、SQL语句学习
- 1. DCL数据控制语言
- 1.1 创建用户
- 1.2 修改用户名
- 1.3 修改密码
- 1.4 删除用户
- 1.5 授权
- 1.6 查看权限
- 1.7 回收权限
- 2. DDL数据定义语言
- 2.1 操作数据库
- 2.2 操作数据表
- 2.3 操作数据
- 3. DQL数据查询语言
- 基本语法
- 3.1 单表查询
- 3.1.1选择表中的若干列
- 3.1.2 选择表中的若干元组
- 3.1.3 ORDER BY
- 3.1.4 聚合函数
- 3.1.5 GROUP BY
- 3.2 连接查询
- 3.2.1 等值连接
- 3.2.2 非等值连接
- 3.2.3 自身连接
- 3.2.4 外连接
- 3.3 嵌套查询
- 3.3.1 嵌套查询概述
- 3.3.2 不相关子查询与相关子查询(非常重要,关乎子查询)
- 3.3.3 带有IN谓词的子查询
- 3.3.4 带有比较运算符的子查询
- 3.3.5 带有ANY(SOME)或ALL谓词的子查询
- 3.3.6 带有EXISTS谓词的子查询
- 3.4 集合查询
- 3.5 基于派生表的查询
- 4. 约束
- 4.1 非空约束
- 4.2 唯一约束
- 4.3 主键约束
- 4.4 自动增长约束
- 4.5 外键约束
- 三、候选码、主码、主属性
- 四、函数依赖、部分函数依赖、完全函数依赖、传递函数依赖、多值依赖
- 1. 函数依赖
- 2. 完全依赖
- 3. 部分函数依赖
- 4. 传递函数依赖
- 5. 多值依赖
- 五、数据库之六大范式
- 1. 第一范式1NF(数据项唯一)
- 2. 第二范式2NF(必须有组件)
- 3. 第三范式3NF(没有传递依赖和部分函数依赖)
- 4. BC范式BCBF(非主属性不能做决定)
- 5. 第四范式4NF(消除多值依赖)
- 6. 第五范式5NF
- 六、数据类型
- 1. MySQL整数类型
- 2. 小数类型
- 3. 日期和时间类型
- a. YEAR类型
- b. TIME类型
- c. DATE类型
- d. DATETIME类型
- e. TIMESTAMP类型
- 4. 字符串类型
- 七、java向MySQL插入当前时间的几种方式
- 方式一
- 方式二
- 八、 mysql中int类型单引号问题
- 九、空值的处理
- 十、视图
- 1. 创建视图
- 2. 删除视图
- 3. 查询视图
- 4. 更新视图
参考文章:数据库系统学习
参考文章:非关系型数据库讲解
参考文章:mysql学习(详细)
参考文章:函数依赖
参考文章1:范式
参考文章2:范式
一、数据库入门
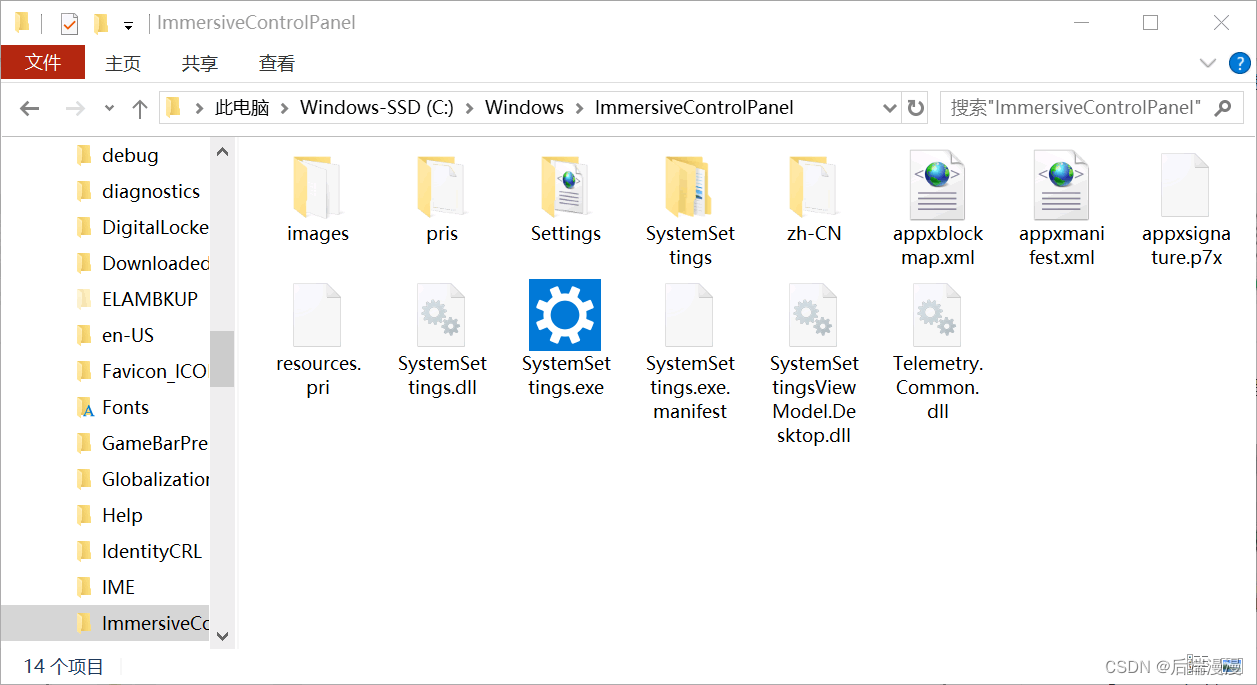
1. 数据管理技术的三个阶段
- 人工管理阶段:在计算机出现之前,人们主要利用纸张和计算工具(如算盘和计算尺)来进行数据的记录和计算,依靠大脑来管理和利用数据。
- 文件系统阶段:将数据存储在计算机的磁盘上。这些数据都以文件的形式存储,然后通过文件系统来管理这些文件。
- 数据库系统阶段:相对于文件系统来说,数据库系统实现了数据结构化。在文件系统中,独立文件内部的数据一般是有结构的,但文件之间不存在联系,因此整体来说是没有结构的。 数据库系统虽然也常常分成许多单独的数据文件,但是它更注意同一数据库中各数据文件之间的相互联系。
2. 关系型数据库与非关系型数据库
- 关系型数据库是由多张能互相连接的表组成的数据库。
- 非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定。
- 相信大家对关系型数据库已经非常了解,下面将以四大非关系型数据库讲解,来让我们看看两者区别
3. 四大非关系型数据库
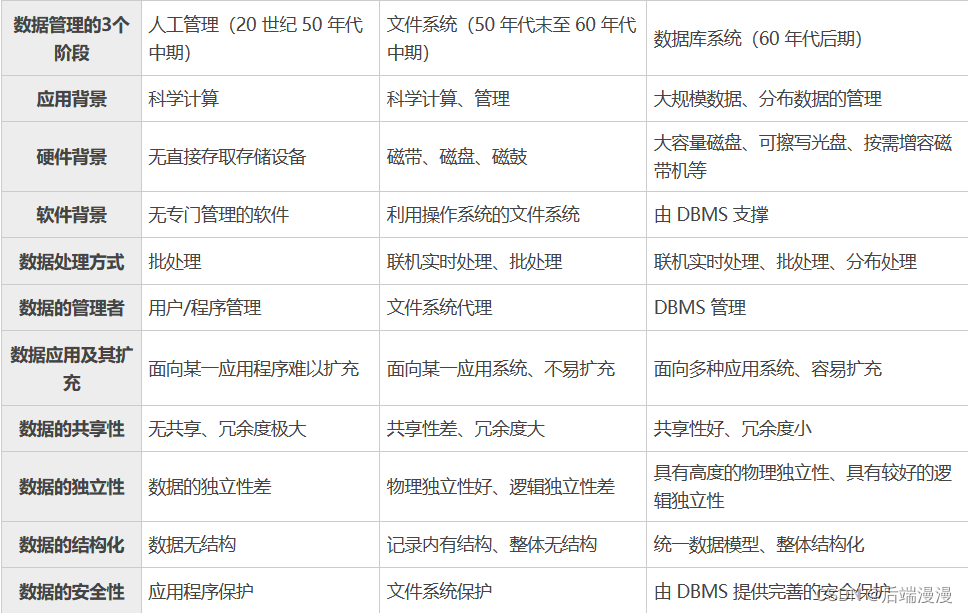
简述:目前对于非关系型数据库主要有四种数据存储类型:键值对存储(key-value),文档存储(document store),基于列的数据库(column-oriented),还有就是图形数据库(graph database)。每一种都会解决相应的问题,这些问题是关系型数据库所不能解决的。而在实际应用中都会将这几种情况结合起来实现相应的功能。
在开始介绍NoSQL数据库之前,我们先来回顾一下关系型数据库,这样我们可以对非关系数据库和关系型数据库做一个深入的比较。
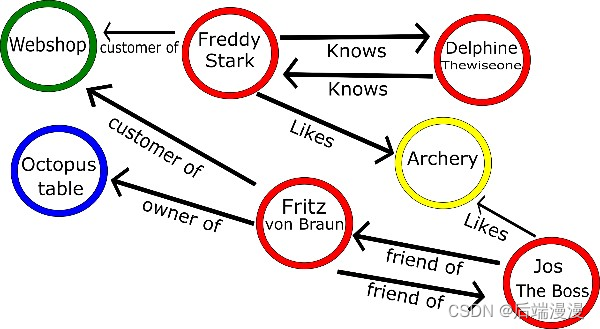
例如:如果你想存储一个人的信息和这个人的爱好这样的数据,你可以创建两个表:一个用来存储这个人的信息,另一个表用来存储这个人的爱好。正如你在图一中看到的,你必须有一张额外的映射表,这张表将人的信息表和爱好表建立其对应的关系。这是因为他们的关系是多对多的关系,一个人可以有多个爱好,并且多个人可能会有相同的爱好。
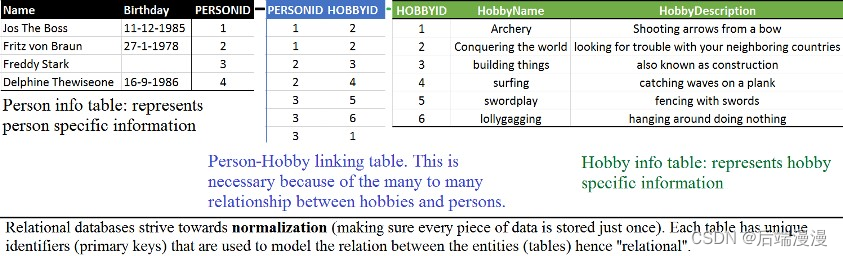
a. 基于列的数据库(column-oriented)
- 这里你就需要注意了,这种请款下你已经有一点违反关系型数据库严格遵循的标准化了,因为爱好是有重复的。

- 在基于行的数据库中进行查找的时候,每次都会对每一行进行遍历,不管某一列数据是否是你需要的都会进行遍历。假如你只需要生日是九月的人的数据,基于行的数据库会对这张表从上到下从左至右遍历一遍,正像下图看到的那样,最后再返回你需要的那些数据。对特定列的数据进行索引能有效的提高查找速度,但是索引每一列同样会带来额外的负载,并且数据库同样也是会遍历所有的列来取得要查找的数据。基于列的数据库会将每一列分开单独存放,当查找一个数量较小的列的时候其查找速度是很快的。

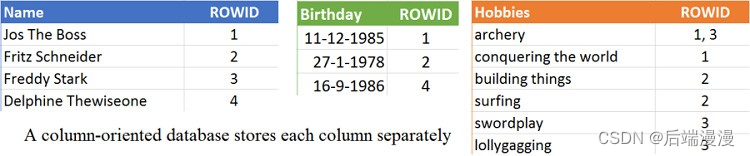
- 说了这么多,那应该在什么时候使用基于行的数据库,在什么时候使用基于列的数据库呢?在基于列的数据库中要想增加一列新的数据是很容易的,因为现有的那些列是不会受新增列的影响的。但是要想增加一整条记录就需要适应所有的表,防止各个表的数据之间对应关系出现错误。因此这使得基于行的数据库在事务处理的时候要优胜于基于列的数据库,因为它很好的实现了数据的实时更新。
b. 键值对存储(Key-Value Stores)
键值对中存储的数据的类型是不受限制的,可以是一个字符串,也可以是一个数字,甚至是由一系列的键值对封装成的对象等

c. 文档存储(Document Stores)
文档存储是基于键值对存储的,其结构较之于键值对存储更为复杂,可以说在键值对的基础上更深入了一步。

d. 图形数据库(Graph Database)
现在剩下的是最后一个NoSQL数据库存储类型,也是最复杂的一个,主要使用一种高效的方式来存储各个实体之间的关系。当数据之间是紧密联系的,例如社会关系、科学论文的引文抑或是资本资产定价模型等等,使用图形数据库时最好的选择。图形或者网络数据有两部分组成:
- Node-:实体本身,在一个社会关系中可以认为是一个人。
- Edge-:实体之间的关系。这个关系可以用一条线来表示,这条线有它自己的属性。这条线可以有方向,箭头可以表明谁是谁的上级。
如果给予足够的关系和实体类型,图形会变得非常的复杂,其发杂程度简直难以置信。
二、SQL语句学习
- DDL(Data Definition Language)数据定义语言
用来定义数据库对象:数据库,表,列等。关键字:create, drop,alter 等 - DML(Data Manipulation Language)数据操作语言
用来对数据库中表的数据进行增删改。关键字:insert, delete, update 等 - DQL(Data Query Language)数据查询语言
用来查询数据库中表的记录(数据)。关键字:select, where 等 - DCL(Data Control Language)数据控制语言(了解)
用来定义数据库的访问权限和安全级别,及创建用户。关键字:GRANT, REVOKE 等 - TCL(Transition Language) :事务控制语言,用来管理事务
1. DCL数据控制语言
1.1 创建用户
- ’alian’@'localhost’ :表示只允许本机登录
- ’alian’@’%’ :表示任意地址登录
- ’alian’@'192.168.0.100’ :表示只允许ip为192.168.0.100的地址登录
- ’alian’@‘192.168..’ :表示只允许ip为192.168网段的地址登录
# 格式
create user '用户名'@'IP地址' identified WITH mysql_native_password by '密码';
flush privileges;# 实例
CREATE USER 'alian'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
flush privileges;
1.2 修改用户名
rename user '用户名'@'IP地址' to '新用户名'@'IP地址';
1.3 修改密码
#切换到mysql库
use mysql;
#更新密码
UPDATE user SET password=password('新密码') WHERE user='用户名' AND host='IP地址';
#刷新权限
FLUSH PRIVILEGES;
或者
ALTER USER '用户名'@'IP地址' IDENTIFIED WITH mysql_native_password BY '新密码';
flush privileges;
或者
#普通用户登录后
SET PASSWORD=password('新密码');
FLUSH PRIVILEGES;
1.4 删除用户
#注意这里的IP地址,一个用户可能会有多个
drop user '用户名'@'IP地址';
#比如
drop user 'Alian'@'192.168.0.100';
1.5 授权
grant 权限1, 权限2, 权限3,… ,权限n on 数据库名.表名 to 用户名@地址;
数据库名.表名
- . 表示任意库的任意表(不建议)
- mysql.* 表示mysql库的任意表
- mysql.user 表示mysql库的user表
用户名@地址
- ’alian’@'localhost’ :表示只允许本机登录
- ’alian’@’%’ :表示任意地址登录
- ’alian’@'192.168.0.100’ :表示只允许ip为192.168.0.100的地址登录
- ’alian’@‘192.168..’ :表示只允许ip为192.168网段的地址登录
实例
#把数据库的所有库的所有权限都给alian,并且是任意ip地址都可以操作
grant all privileges on *.* to 'alian'@'%';
flush privileges;#把mysql数据库的所有权限都给alian,并且是任意ip地址都可以操作
grant all privileges on mysql.* to 'alian'@'%';
flush privileges;#把mysql数据库的user表的所有权限都给alian,并且是只能通过192.138.0.10才可以操作
grant all privileges on mysql.user to 'alian'@'192.138.0.10';
flush privileges;#把mysql数据库的user表的(查询,插入,更新,删除)的权限都给alian,并且是任意ip地址都可以操作
grant SELECT, INSERT, UPDATE, DELETE on mysql.user to 'alian'@'%';
flush privileges;
1.6 查看权限
show grants for 'alian'@'%';
1.7 回收权限
#格式
revoke 权限1, 权限2…权限n on 数据库名.表名 from 用户名@地址;#实例:回收用户的更新和删除mysql(默认的库)数据库的权限
revoke update,delete on mysql.user from 'alian'@'%';
2. DDL数据定义语言
2.1 操作数据库
创建
# 创建数据库,判断不存在,再创建:create database if not exists 数据库名称;# 创建数据库,并指定字符集create database 数据库名称 character set 字符集名;
查询
* 查询所有数据库的名称:show databases;* 查询某个数据库的字符集:查询某个数据库的创建语句show create database 数据库名称;
修改
* 修改数据库的字符集alter database 数据库名称 character set 字符集名称;
删除
* 删除数据库drop database 数据库名称;* 判断数据库存在,存在再删除drop database if exists 数据库名称;
2.2 操作数据表
创建
create table 表名(列名1 数据类型1,列名2 数据类型2,....列名n 数据类型n
);# 数据库类型1. int:整数类型 2. double:小数类型3. date:日期,只包含年月日,yyyy-MM-dd4. datetime:日期,包含年月日时分秒 yyyy-MM-dd HH:mm:ss5. timestamp:时间错类型 包含年月日时分秒 yyyy-MM-dd HH:mm:ss 6. varchar:字符串,* zhangsan 8个字符 张三 2个字符
查询
* 查询某个数据库中所有的表名称show tables;* 查询表结构desc 表名;
修改
1. 修改表名alter table 表名 rename to 新的表名;2. 修改表的字符集alter table 表名 character set 字符集名称;3. 添加一列alter table 表名 add 列名 数据类型;4. 修改列名称 类型alter table 表名 change 列名 新列别 新数据类型;alter table 表名 modify 列名 新数据类型;5. 删除列alter table 表名 drop 列名;
删除
* drop table 表名;* drop table if exists 表名 ;
2.3 操作数据
添加
insert into 表名(列名1,列名2,…列名n) values(值1,值2,…值n);
删除
delete from 表名 [where 条件]
修改
update 表名 set 列名1 = 值1, 列名2 = 值2,… [where 条件];
3. DQL数据查询语言
基本语法
select字段列表
from表名列表
where条件列表
group by分组字段
having分组之后的条件
order by 排序
limit分页限定
3.1 单表查询
3.1.1选择表中的若干列
# 查询全体学生的学号与姓名。
SELECT Sno,Sname FROM Student; # 查询全体学生的详细记录
SELECT Sno,Sname,Ssex,Sage,Sdept FROM Student;
SELECT * FROM Student; # 查询经过计算的值:查全体学生的姓名及其出生年份。
SELECT Sname,2023-Sage FROM Student;# 使用列别名改变查询结果:Sname(NAME)
SELECT Sname NAME FROM Student;3.1.2 选择表中的若干元组
# 如果没有指定DISTINCT关键词,则缺省为ALL
SELECT Sno FROM SC;
SELECT ALL Sno FROM SC;# 指定DISTINCT关键词,去掉表中重复的行
SELECT DISTINCT Sno FROM SC;
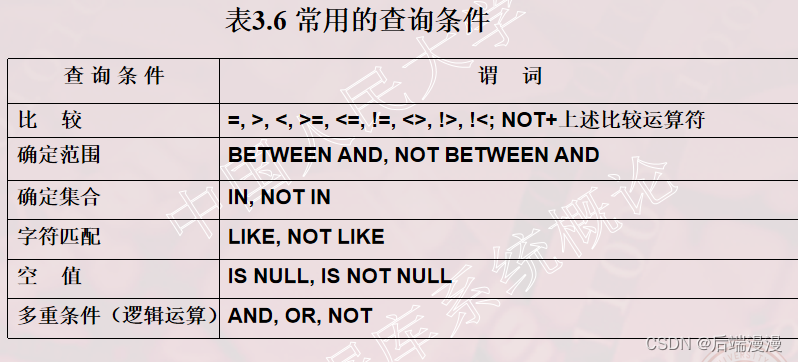
# 1. 比较大小# 查询计算机科学系全体学生的名单。SELECT Sname FROM Student WHERE Sdept=‘CS’; # 查询所有年龄在20岁以下的学生姓名及其年龄。SELECT Sname,Sage FROM Student WHERE Sage < 20;# 2. 确定范围# 查询年龄在20~23岁(包括20岁和23岁)之间的学生的姓名、系别和年龄SELECT Sname,Sdept,Sage FROM Student WHERE Sage BETWEEN 20 AND 23; # 3. 确定集合# 查询既不是计算机科学系、数学系,也不是信息系的学生的姓名和性别。SELECT Sname, Ssex FROM Student WHERE Sdept NOT IN ('IS','MA’,'CS');# 查询计算机科学系(CS)、数学系(MA)和信息系(IS)学生的姓名和性别。SELECT Sname,Ssex FROM Student WHERE Sdept NOT IN ('IS','MA','CS');# 4. 字符匹配# 查询学号为201215121的学生的详细情况。SELECT * FROM Student WHERE Sno LIKE ‘201215121';# 查询所有姓刘学生的姓名、学号和性别。SELECT Sname, Sno, Ssex FROM Student WHERE Sname LIKE '刘%';# 5. 涉及空值的查询# 查所有有成绩的学生学号和课程号。SELECT Sno,Cno FROM SC WHERE Grade IS NOT NULL;# 6. 多重条件查询(AND优先级大于OR)# 查询计算机系年龄在20岁以下的学生姓名。SELECT Sname FROM Student WHERE Sdept= 'CS' AND Sage<20;
3.1.3 ORDER BY
# 查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序排列。
SELECT Sno, Grade FROM SC WHERE Cno= ' 3 ' ORDER BY Grade DESC;# 查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
SELECT * FROM Student ORDER BY Sdept, Sage DESC;
3.1.4 聚合函数
聚合函数的计算,排序null值
用COUNT([DISTINCT|ALL] <列名>)函数和GROUP BY关键字一起来计算不同分组中的记录总数
select o_num count(f_id) from orderitems group by o_num;#SUM([DISTINCT|ALL] <列名>)可以与GROUP BY一起使用,来计算每个分组的总和
select o_num,sum(quantity) as items_total from orderitems group by o_num;#AVG([DISTINCT|ALL] <列名>)可以与GROUP BY一起使用,来计算每个分组的平均值
select s_id,AVG(f_price) as avg_price from fruits group by s_id;#MAX([DISTINCT|ALL] <列名>)也可以和GROUP BY关键字一起使用,求每个分组中的最大值。
select s_id,max(f_price) as max_price from fruits group by s_id;#MIN([DISTINCT|ALL] <列名>)也可以和GROUP BY关键字一起使用,求出每个分组中的最小值。
select s_id,min(f_price) as min_price from fruits group by s_id;
WHERE子句中是不能用聚集函数作为条件表达式
# i查询平均成绩大于等于90分的学生学号和平均成绩,下面的语句是不对的:SELECT Sno, AVG(Grade)FROM SCWHERE AVG(Grade)>=90GROUP BY Sno;# 因为WHERE子句中是不能用聚集函数作为条件表达式正确的查询语句应该是:SELECT Sno, AVG(Grade)FROM SCGROUP BY SnoHAVING AVG(Grade)>=90;3.1.5 GROUP BY
- where 在分组之前进行限定,如果不满足条件,则不参与分组。
- having在分组之后进行限定,如果不满足结果,则不会被查询出来
- where 后不可以跟聚合函数
- having可以进行聚合函数的判断。
-- 按照性别分组。分别查询男、女同学的平均分SELECT sex , AVG(math) FROM student GROUP BY sex;-- 按照性别分组。分别查询男、女同学的平均分,人数SELECT sex , AVG(math),COUNT(id) FROM student GROUP BY sex;-- 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex;-- 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组,分组之后。人数要大于2个人SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex HAVING COUNT(id) > 2;SELECT sex , AVG(math),COUNT(id) 人数 FROM student WHERE math > 70 GROUP BY sex HAVING 人数 > 2;3.2 连接查询
3.2.1 等值连接
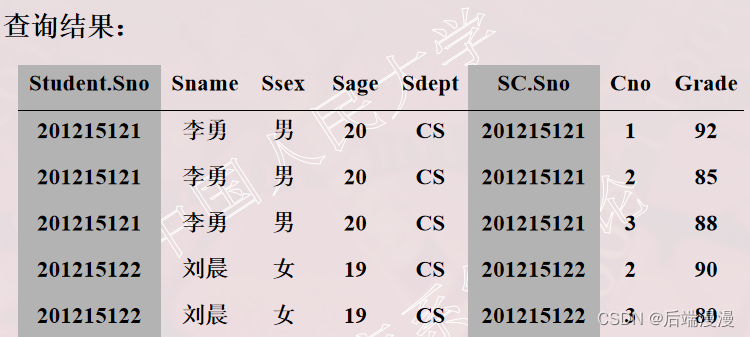
- SQL语句
SELECT Student.*, SC.*FROM Student, SCWHERE Student.Sno = SC.Sno;
- 执行结果
- 执行过程
- 嵌套循环法(NESTED-LOOP)
- 首先在表1中找到第一个元组,然后从头开始扫描表2,逐一查找满足连接件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组。
表2全部查找完后,再找表1中第二个元组,然后再从头开始扫描表2,逐一查找满足连接条件的元组,找到后就将表1中的第二个元组与该元组拼接起来,形成结果表中一个元组。
重复上述操作,直到表1中的全部元组都处理完毕
- 排序合并法(SORT-MERGE)
- 常用于=连接
- 首先按连接属性对表1和表2排序,对表1的第一个元组,从头开始扫描表2,顺序查找满足连接条件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组。当遇到表2中第一条大于表1连接字段值的元组时,对表2的查询不再继续
找到表1的第二条元组,然后从刚才的中断点处继续顺序扫描表2,查找满足连接条件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组。直接遇到表2中大于表1连接字段值的元组时,对表2的查询不再继续
重复上述操作,直到表1或表2中的全部元组都处理完毕为止
- 索引连接(INDEX-JOIN)
- 对表2按连接字段建立索引
- 对表1中的每个元组,依次根据其连接字段值查询表2的索引,从中找到满足条件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组
3.2.2 非等值连接
# 查询选修2号课程且成绩在90分以上的所有学生的学号和姓名。SELECT Student.Sno, SnameFROM Student, SCWHERE Student.Sno=SC.Sno AND SC.Cno=' 2 ' AND SC.Grade>90;
执行过程:
- 先从SC中挑选出Cno='2’并且Grade>90的元组形成一个中间关系,再和Student中满足连接条件的元组进行连接得到最终的结果关系
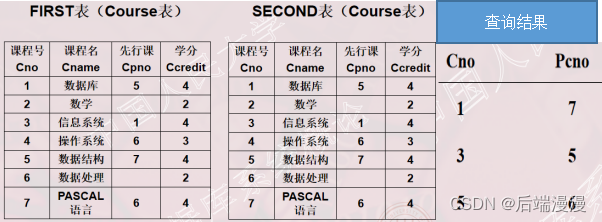
3.2.3 自身连接
- 自身连接:一个表与其自己进行连接
- 需要给表起别名以示区别
- 由于所有属性名都是同名属性,因此必须使用别名前缀
# 查询每一门课的间接先修课(即先修课的先修课)SELECT FIRST.Cno, SECOND.CpnoFROM Course FIRST, Course SECONDWHERE FIRST.Cpno = SECOND.Cno;
3.2.4 外连接
- 外连接与普通连接的区别
- 普通连接操作只输出满足连接条件的元组
- 外连接操作以指定表为连接主体,将主体表中不满足连接条件的元组一并输出
- 左外连接:列出左边关系中所有的元组
- 右外连接:列出右边关系中所有的元组
- SQL语句
# LEFT OUT,左边的全部输出SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,GradeFROM Student LEFT OUT JOIN SC ON (Student.Sno=SC.Sno);
- 执行结果
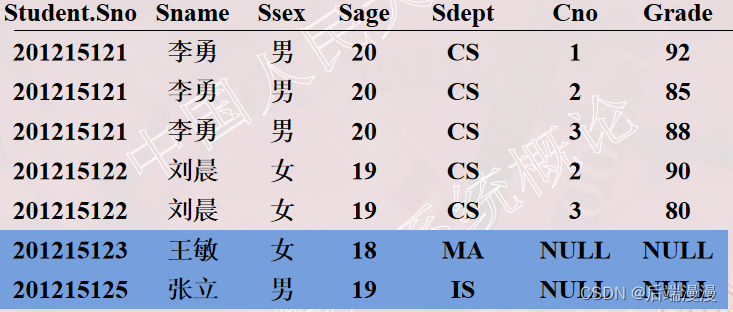
3.3 嵌套查询
3.3.1 嵌套查询概述
- 一个SELECT-FROM-WHERE语句称为一个查询块
- 将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询
- 子查询不能使用ORDER BY子句
- SQL语句
SELECT Sname /*外层查询/父查询*/FROM StudentWHERE Sno IN( SELECT Sno /*内层查询/子查询*/FROM SCWHERE Cno= ' 2 ');
3.3.2 不相关子查询与相关子查询(非常重要,关乎子查询)
- 子查询的查询条件不依赖于父查询
- 由里向外 逐层处理。即每个子查询在上一级查询处理之前求解,子查询的结果用于建立其父查询的查找条件。
- 子查询的查询条件依赖于父查询
- 首先取外层查询中表的第一个元组,根据它与内层查询相关的属性值处理内层查询,若WHERE子句返回值为真,则取此元组放入结果表
- 然后再取外层表的下一个元组
- 重复这一过程,直至外层表全部检查完为止
3.3.3 带有IN谓词的子查询
# 查询与“刘晨”在同一个系学习的学生。SELECT Sno, Sname, SdeptFROM StudentWHERE Sdept IN(SELECT SdeptFROM StudentWHERE Sname= ' 刘晨 ');# 也可以通过自身连接完成查询要求SELECT S1.Sno, S1.Sname,S1.SdeptFROM Student S1,Student S2WHERE S1.Sdept = S2.Sdept ANDS2.Sname = '刘晨';
3.3.4 带有比较运算符的子查询
# 找出每个学生超过他选修课程平均成绩的课程号。SELECT Sno, CnoFROM SC xWHERE Grade >=(SELECT AVG(Grade) FROM SC yWHERE y.Sno=x.Sno);
3.3.5 带有ANY(SOME)或ALL谓词的子查询
# 查询非计算机科学系中比计算机科学系任意一个学生年龄小的学生姓名和年龄SELECT Sname,SageFROM StudentWHERE Sage < ANY (SELECT SageFROM StudentWHERE Sdept= ' CS ')AND Sdept <> ‘CS ' ; /*父查询块中的条件 */
3.3.6 带有EXISTS谓词的子查询
带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”。
- 若内层查询结果非空,则外层的WHERE子句返回真值
- 若内层查询结果为空,则外层的WHERE子句返回假值
# 查询所有选修了1号课程的学生姓名SELECT SnameFROM StudentWHERE EXISTS(SELECT *FROM SCWHERE Sno=Student.Sno AND Cno= ' 1 ');# 本查询涉及Student和SC关系
# 在Student中依次取每个元组的Sno值,用此值去检查SC表
# 若SC中存在这样的元组,其Sno值等于此Student.Sno值,并且其Cno= ‘1’,则取此Student.Sname送入结果表
3.4 集合查询
- 集合操作的种类:并操作UNION、交操作INTERSECT、差操作EXCEPT
- 集合操作限制:参加集合操作的各查询结果的列数必须相同;对应项的数据类型也必须相同
# 查询计算机科学系的学生及年龄不大于19岁的学生。
# UNION:将多个查询结果合并起来时,系统自动去掉重复元组
# UNION ALL:将多个查询结果合并起来时,保留重复元组 SELECT *FROM StudentWHERE Sdept= 'CS'UNIONSELECT *FROM StudentWHERE Sage<=19;# 查询计算机科学系的学生与年龄不大于19岁的学生 的交集。SELECT *FROM StudentWHERE Sdept='CS' INTERSECTSELECT *FROM StudentWHERE Sage<=19 # 查询计算机科学系的学生与年龄不大于19岁的学生的差集。SELECT *FROM StudentWHERE Sdept='CS'EXCEPTSELECT *FROM StudentWHERE Sage <=19;
3.5 基于派生表的查询
- 派生表:子查询不仅可以出现在WHERE子句中,还可以出现在FROM子句中,这时子查询生成的临时派生表(Derived Table)成为主查询的查询对象
# 找出每个学生超过他自己选修课程平均成绩的课程号 SELECT Sno, CnoFROM SC, (SELECT Sno, Avg(Grade) FROM SC GROUP BY Sno)AS Avg_sc(avg_sno,avg_grade)WHERE SC.Sno = Avg_sc.avg_snoAND SC.Grade >=Avg_sc.avg_grade
4. 约束
主键约束:primary key
非空约束:not null
唯一约束:unique
外键约束:foreign key
默认值 :Default
4.1 非空约束
# 创建表时,添加非空约束
CREATE TABLE stu(id INT,NAME VARCHAR(20) NOT NULL -- name为非空
);# 创建表后,添加非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;# 删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);
4.2 唯一约束
# 创建表时,添加唯一约束
CREATE TABLE stu(id INT,phone_number VARCHAR(20) UNIQUE -- 添加了唯一约束);# 在创建表后,添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE;# 删除唯一约束
ALTER TABLE stu DROP INDEX phone_number;
4.3 主键约束
# 创建表时,添加主键约束
create table stu(id int primary key,-- 给id添加主键约束name varchar(20)
);# 创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;# 删除主键:错误 alter table stu modify id int ;
ALTER TABLE stu DROP PRIMARY KEY;
4.4 自动增长约束
# 创建表时,添加自动增长约束
create table stu(id int primary key auto_increment,-- 给id添加主键约束name varchar(20));# 创建表后,添加自动增长约束
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;# 删除自动增长
ALTER TABLE stu MODIFY id INT;
4.5 外键约束
在创建数据表时添加约束。
下面语句执行成功之后,在表 tb_emp6 上添加了名称为 fk_emp_dept1 的外键约束,外键名称为 deptId,其依赖于表 tb_dept1 的主键 id。
mysql> CREATE TABLE tb_dept1-> (-> id INT(11) PRIMARY KEY,-> name VARCHAR(22) NOT NULL,-> location VARCHAR(50)-> );
mysql> CREATE TABLE tb_emp6-> (-> id INT(11) PRIMARY KEY,-> name VARCHAR(25),-> deptId INT(11),-> salary FLOAT,-> CONSTRAINT fk_emp_dept1-> FOREIGN KEY(deptId) REFERENCES tb_dept1(id)-> );
在修改表时添加外键约束
mysql> ALTER TABLE tb_emp2-> ADD CONSTRAINT fk_tb_dept1-> FOREIGN KEY(deptId)-> REFERENCES tb_dept1(id);
删除外键约束
mysql> ALTER TABLE tb_emp2-> DROP FOREIGN KEY fk_tb_dept1;
三、候选码、主码、主属性
- 候选码: 若关系中的某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选码。
- 主码: 若一个关系中有多个候选码,则选定其中一个为主码。
- 主属性: 所有候选码的属性称为主属性。不包含在任何候选码中的属性称为非主属性或非码属性。
四、函数依赖、部分函数依赖、完全函数依赖、传递函数依赖、多值依赖
1. 函数依赖
有一个关系模式S(Sno,Sname,Sage):如果知道了一个学生的学号Sno,那我就能确定他的姓名Sname和年龄Sage。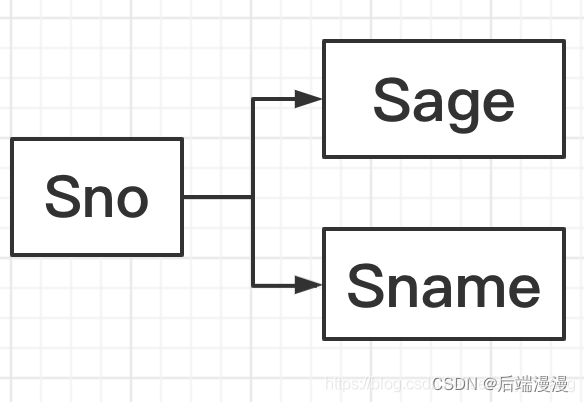
2. 完全依赖
如果我想知道某位学生的某一门课的成绩Grade,那我必须得同时知道他的学号Sno和课程号Cno。
但如果我只知道一部分信息,比如他的Sno或者Cno可以吗?答案是不行的!此时称Y[Grade]完全依赖于X[Sno,Cno]。
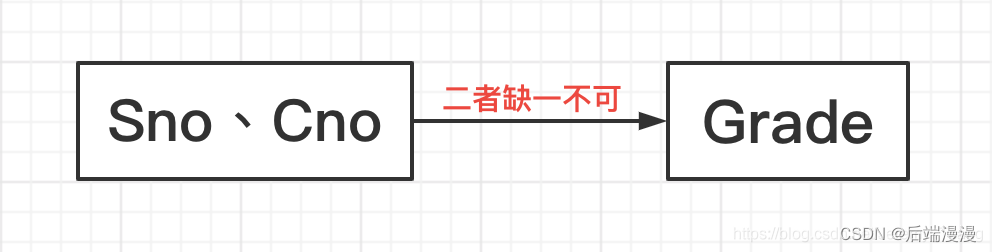
3. 部分函数依赖
如果我想知道某位学生的姓名Sname,那我知道他的学号Sno就可以了。也就是说Y[Sname]只函数依赖于X[Sno,Cno]中的子集x[Sno],此时称Y部分函数依赖于X。
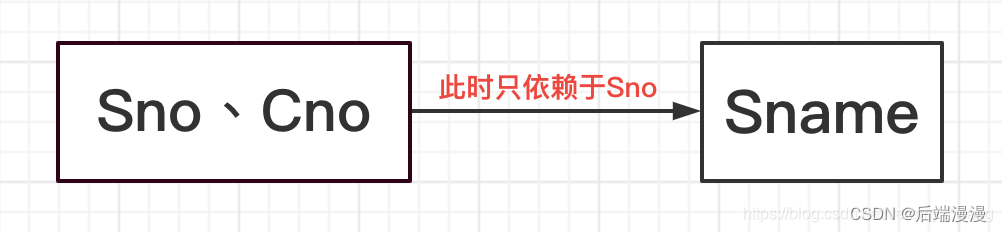
4. 传递函数依赖
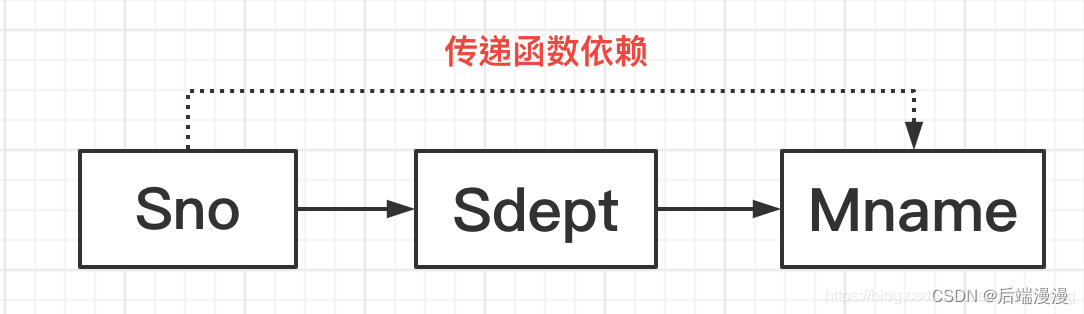
有一个关系模式S(Sno,Sdept,Mname)
如果我知道了一个学生的学号Sno,那我就能知道他所在的系Sdept。(因为理论上一个学生只属于一个系)
如果我知道了某一个系Sdept,那么我就能知道这个系的系主任的姓名Mname。(一个系只有一个正的系主任,别杠,你赢了。)
也就是说,我知道了一个学生的学号Sno,其实我就知道了他所在系的系主任的姓名Mname。但这个过程中,他们是不存在直接函数依赖的,我需要通过系名称Sdept作为一个桥梁去把二者联系起来的。
5. 多值依赖
定义: 一个关系,至少存在三个属性(A、B、C),才能存在这种关系。对于每一个A值,有一组确定的B值和C值,并且这组B的值独立于这组C的值。
实例: 比如我们建立课程教师和教材的模型,我们规定,每门课程有对应的一组教师,每门课程也有对应的一组教材,一门课程使用的教程和教师没有关系。
五、数据库之六大范式
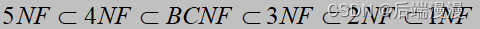
1. 第一范式1NF(数据项唯一)
定义: 所有属性都不可再分,即数据项不可分
理解: 第一范式强调数据表的原子性,是其他范式的基础

上表将商品这一数据项又划分为名称和数量两个数据项,故不符合第一范式关系。改正之后如下图所示:

2. 第二范式2NF(必须有组件)
概念: 若某关系R属于第一范式,且每一个非主属性完全函数依赖于任何一个候选码,则关系R属于第二范式。
理解 : 第二范式是指每个表必须有一个(有且仅有一个)数据项作为关键字或主键(primary key),其他数据项与关键字或者主键一一对应,即其他数据项完全依赖于关键字或主键。由此可知单主属性的关系均属于第二范式。
3. 第三范式3NF(没有传递依赖和部分函数依赖)
概念: 非主属性既不传递依赖于码,也不部分依赖于码。
理解 :第三范式要求在满足第二范式的基础上,任何非主属性不依赖于其他非主属性,即在第二范式的基础上,消除了传递依赖。
4. BC范式BCBF(非主属性不能做决定)
理解: 根据定义我们可以得到结论,一个满足BC范式的关系模式有:
- 所有非主属性对每一个码都是完全函数依赖;
- 所有主属性对每一个不包含它的码也是完全函数依赖;
- 没有任何属性完全函数依赖于非码的任何一组属性。
实例: 比如我们有一个学生导师表,其中包含字段:学生ID,专业,导师,专业GPA,这其中学生ID和专业是联合主键。
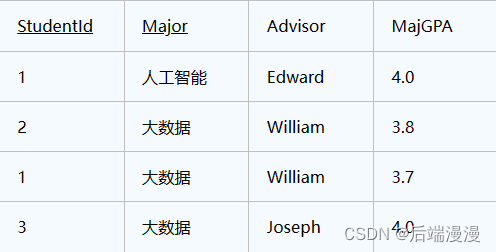
这个表的设计满足三范式,有主键,不存在主键的部分依赖,不存在非主键的传递依赖。但是这里存在另一个依赖关系,“专业”函数依赖于“导师”,也就是说每个导师只做一个专业方面的导师,只要知道了是哪个导师,我们自然就知道是哪个专业的了。
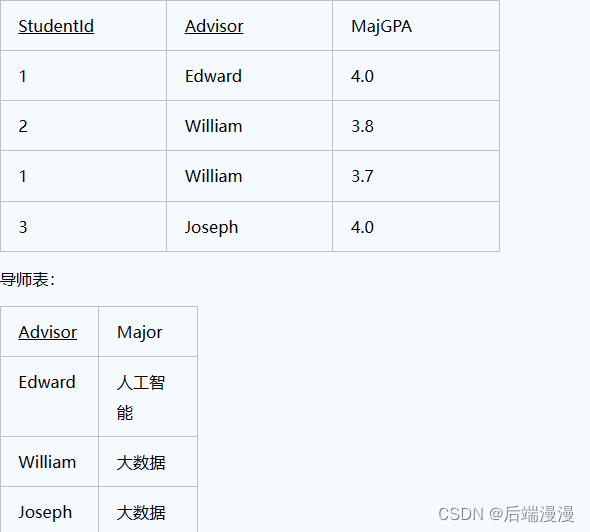
所以这个表的部分主键依赖于非主键部分,那么我们可以进行以下的调整,拆分成2个表:
5. 第四范式4NF(消除多值依赖)
实例: 这样我们首先肯定有三个实体表,分别表示课程,教师和教材。现在我们要建立这三个对象的关系,于是我们建立的关系表,定义如下:
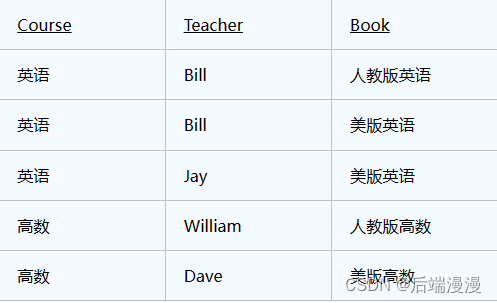
这个表除了主键,就没有其他字段了,所以肯定满足BC范式,但是却存在多值依赖导致的异常。
假如我们下学期想采用一本新的英版高数教材,但是还没确定具体哪个老师来教,那么我们就无法在这个表中维护Course高数和Book英版高数教材的的关系。
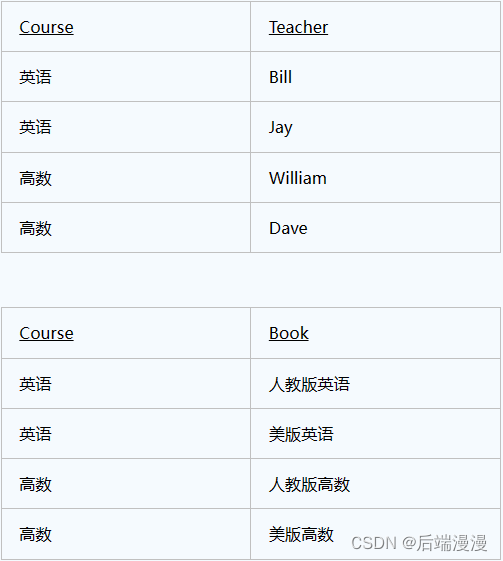
解决办法是我们把这个多值依赖的表拆解成2个表,分别建立关系。这是我们拆分后的表:
6. 第五范式5NF
除了第四范式外,我们还有更高级的第五范式和域键范式(DKNF),第五范式处理的是无损连接问题,这个范式基本没有实际意义,因为无损连接很少出现,而且难以察觉。而域键范式试图定义一个终极范式,该范式考虑所有的依赖和约束类型,但是实用价值也是最小的,只存在理论研究中。
六、数据类型
参考文章:数据类型
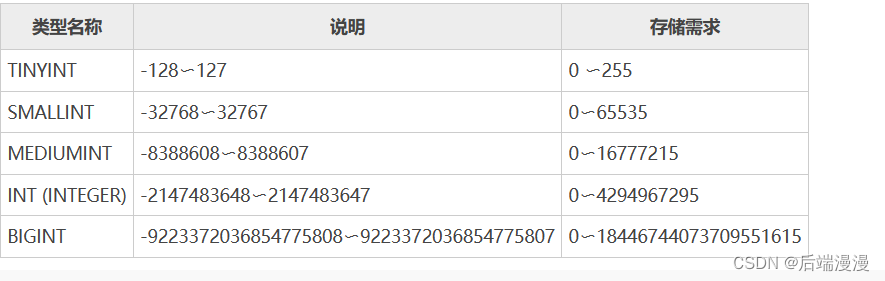
1. MySQL整数类型
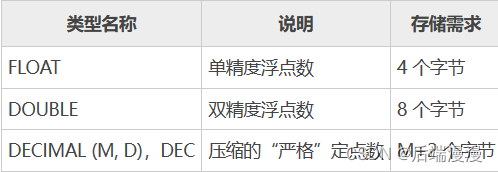
2. 小数类型
3. 日期和时间类型
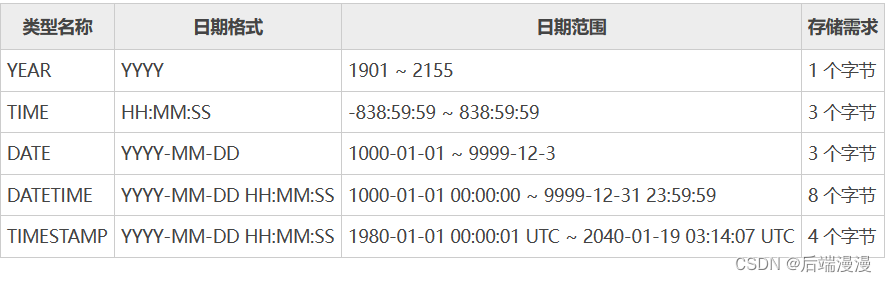
a. YEAR类型
YEAR 类型是一个单字节类型,用于表示年,在存储时只需要 1 个字节。可以使用各种格式指定 YEAR,如下所示:
以 4 位字符串或者 4 位数字格式表示的 YEAR,范围为 ‘1901’~’2155’。输入格式为 ‘YYYY’ 或者 YYYY,例如,输入 ‘2010’ 或 2010,插入数据库的值均为 2010。
以 2 位字符串格式表示的 YEAR,范围为 ‘00’ 到 ‘99’。‘00’~’69’ 和 ‘70’~’99’ 范围的值分别被转换为 2000~2069 和 1970~1999 范围的 YEAR 值。‘0’ 与 ‘00’ 的作用相同。插入超过取值范围的值将被转换为 2000。
以 2 位数字表示的 YEAR,范围为 1~99。1~99 和 70~99 范围的值分别被转换为 2001~2069 和 1970~1999 范围的 YEAR 值。注意,在这里 0 值将被转换为 0000,而不是 2000。
提示:两位整数范围与两位字符串范围稍有不同。例如,插入 3000 年,读者可能会使用数字格式的 0 表示 YEAR,实际上,插入数据库的值为 0000,而不是所希望的 3000。只有使用字符串格式的 ‘0’ 或 ‘00’,才可以被正确解释为 3000,非法 YEAR值将被转换为 0000。
b. TIME类型
可以使用各种格式指定 TIME 值,如下所示。
‘D HH:MM:SS’ 格式的字符串。还可以使用这些“非严格”的语法:‘HH:MM:SS’、‘HH:MM’、‘D HH’ 或 ‘SS’。这里的 D 表示日,可以取 0~34 之间的值。在插入数据库时,D 被转换为小时保存,格式为 “D*24+HH”。
‘HHMMSS’ 格式、没有间隔符的字符串或者 HHMMSS 格式的数值,假定是有意义的时间。例如,‘101112’ 被理解为’10:11:12’,但是 ‘106112’ 是不合法的(它有一个没有意义的分钟部分),在存储时将变为 00:00:00。
提示:为 TIME 列分配简写值时应注意:如果没有冒号,MySQL 解释值时,假定最右边的两位表示秒。(MySQL 解释 TIME 值为过去的时间而不是当前的时间)。例如,读者可能认为 ‘1112’ 和 1112 表示 11:12:00(即 11 点过 12 分钟),但MySQL 将它们解释为 00:11:12(即 11 分 12 秒)。同样 ‘12’ 和 12 被解释为00:00:12。相反,TIME 值中如果使用冒号则肯定被看作当天的时间,也就是说,‘11:12’ 表示 11:12:00,而不是 00:11:12。
c. DATE类型
在给 DATE 类型的字段赋值时,可以使用字符串类型或者数字类型的数据插入,只要符合 DATE 的日期格式即可。如下所示:
以 ‘YYYY-MM-DD’ 或者 ‘YYYYMMDD’ 字符中格式表示的日期,取值范围为 ‘1000-01-01’~’9999-12-3’。例如,输入 ‘2015-12-31’ 或者 ‘20151231’,插入数据库的日期为2015-12-31。
以 ‘YY-MM-DD’ 或者 ‘YYMMDD’ 字符串格式表示日期,在这里YY表示两位的年值。MySQL 解释两位年值的规则:‘00~69’ 范围的年值转换为 ‘20002069’,'7099’ 范围的年值转换为 ‘1970~1999’。例如,输入 ‘15-12-31’,插入数据库的日期为 2015-12-31;输入 ‘991231’,插入数据库的日期为 1999-12-31。
以 YYMMDD 数字格式表示的日期,与前面相似,00~69 范围的年值转换为 2000~2069,80~99 范围的年值转换为 1980~1999。例如,输入 151231,插入数据库的日期为 2015-12-31,输入 991231,插入数据库的日期为 1999-12-31。
使用 CURRENT_DATE 或者 NOW(),插入当前系统日期。
提示:MySQL 允许“不严格”语法:任何标点符号都可以用作日期部分之间的间隔符。例如,‘98-11-31’、‘98.11.31’、‘98/11/31’和’98@11@31’ 是等价的,这些值也可以正确地插入数据库。
d. DATETIME类型
如下所示。
以 ‘YYYY-MM-DD HH:MM:SS’ 或者 ‘YYYYMMDDHHMMSS’ 字符串格式表示的日期,取值范围为 ‘1000-01-01 00:00:00’~’9999-12-3 23:59:59’。例如,输入 ‘2014-12-31 05:05:05’ 或者 '20141231050505’,插入数据库的 DATETIME 值都为 2014-12-31 05:05:05。
以 ‘YY-MM-DD HH:MM:SS’ 或者 ‘YYMMDDHHMMSS’ 字符串格式表示的日期,在这里 YY 表示两位的年值。与前面相同,‘00~79’ 范围的年值转换为 ‘2000~2079’,‘80~99’ 范围的年值转换为 ‘1980~1999’。例如,输入 ‘14-12-31 05:05:05’,插入数据库的 DATETIME 为 2014-12-31 05:05:05;输入 141231050505,插入数据库的 DATETIME 为 2014-12-31 05:05:05。
以 YYYYMMDDHHMMSS 或者 YYMMDDHHMMSS 数字格式表示的日期和时间。例如,输入 20141231050505,插入数据库的 DATETIME 为 2014-12-31 05:05:05;输入 140505050505,插入数据库的 DATETIME 为 2014-12-31 05:05:05。
提示:MySQL 允许“不严格”语法:任何标点符号都可用作日期部分或时间部分之间的间隔符。例如,‘98-12-31 11:30:45’、‘98.12.31 11+30+35’、‘98/12/31 113045’ 和 ‘98@12@31 113045’ 是等价的,这些值都可以正确地插入数据库。
e. TIMESTAMP类型
TIMESTAMP 的显示格式与 DATETIME 相同,显示宽度固定在 19 个字符,日期格式为 YYYY-MM-DD HH:MM:SS,在存储时需要 4 个字节。但是 TIMESTAMP 列的取值范围小于 DATETIME 的取值范围,为 '1970-01-01 00:00:01’UTC~’2038-01-19 03:14:07’UTC。在插入数据时,要保证在合法的取值范围内。
TIMESTAMP 也有一个 DATETIME 不具备的属性。默认情况下,当插入一条记录但并没有指定 TIMESTAMP 这个列值时,MySQL 会把 TIMESTAMP 列设为当前的时间。因此当需要插入记录和当前时间时,使用 TIMESTAMP 是方便的,另外 TIMESTAMP 在空间上比 DATETIME 更有效。
提示:协调世界时(英:Coordinated Universal Time,法:Temps Universel Coordonné)又称为世界统一时间、世界标准时间、国际协调时间。英文(CUT)和法文(TUC)的缩写不同,作为妥协,简称 UTC。
TIMESTAMP 与 DATETIME 除了存储字节和支持的范围不同外,还有一个最大的区别是:
DATETIME 在存储日期数据时,按实际输入的格式存储,即输入什么就存储什么,与时区无关;
而 TIMESTAMP 值的存储是以 UTC(世界标准时间)格式保存的,存储时对当前时区进行转换,检索时再转换回当前时区。即查询时,根据当前时区的不同,显示的时间值是不同的。
提示:如果为一个 DATETIME 或 TIMESTAMP 对象分配一个 DATE 值,结果值的时间部分被设置为 ‘00:00:00’,因此 DATE 值未包含时间信息。如果为一个 DATE 对象分配一个 DATETIME 或 TIMESTAMP 值,结果值的时间部分被删除,因此DATE 值未包含时间信息。
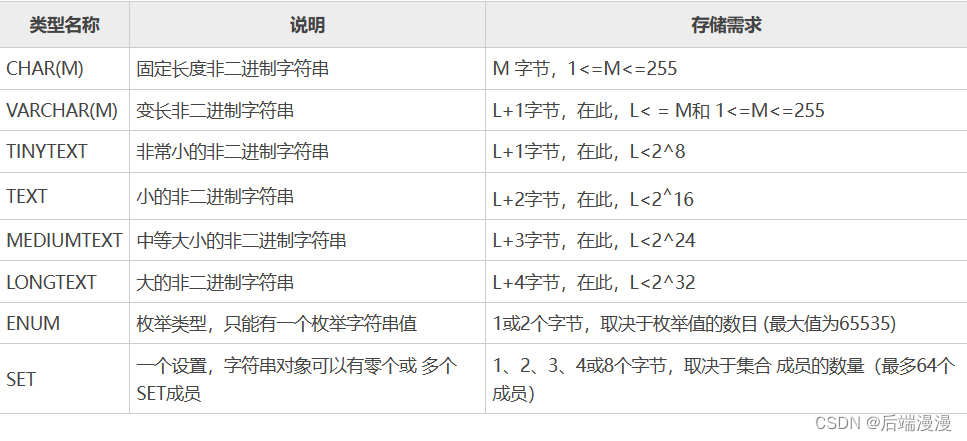
4. 字符串类型
七、java向MySQL插入当前时间的几种方式
方式一
Date date = new Date();//获得系统时间.SimpleDateFormat sdf = new SimpleDateFormat( " yyyy-MM-dd HH:mm:ss " );String nowTime = sdf.format(date);Date time = sdf.parse( nowTime );
方式二
Date date = new Date();//得到一个timestamp格式的时间,存入mysql中的时间格式为"yyyy-MM-dd HH:mm:ss"Timestamp timestamp = new Timestamp(date.getTime());
八、 mysql中int类型单引号问题
今天写mysql的时候发现了一个问题,在查询的时候不小心把int类型的id加上引号查询了,但是也能查询出来,
SELECT * FROM `account` WHERE aid='1';
于是查询了很多资料,最后得出的结论是,mysql会自动转换:当你类型为int 但传入的值为varchar 他会把前几个’数字挑出来’
转换为int 类型来进行查询
如果你的 aid = 1 你查询语句是SELECT * FROM 表名 WHERE aid=‘1dasd’;
在编译的时候,编译器会把 1 挑出来进行转换,在进行查询,
如果你的 aid = 1 你查询语句是SELECT * FROM 表名 WHERE aid=‘dasd’;
第一个不为数字,所以无法转换,查询出来的结果就为空(不会报错),
如果你的 aid = 1 你查询语句是SELECT * FROM 表名 WHERE aid=‘123da’;
在编译的时候,编译器会把 123 挑出来进行转换,在进行查询,但查询结果为空(找不到这个对应的id);
如果你的 aid = 1 你查询语句是SELECT * FROM 表名 WHERE aid=‘da1sd’;
查询结果为空,因为编译期是从第一个开始查看是否为数字,如果不是不会往后查;
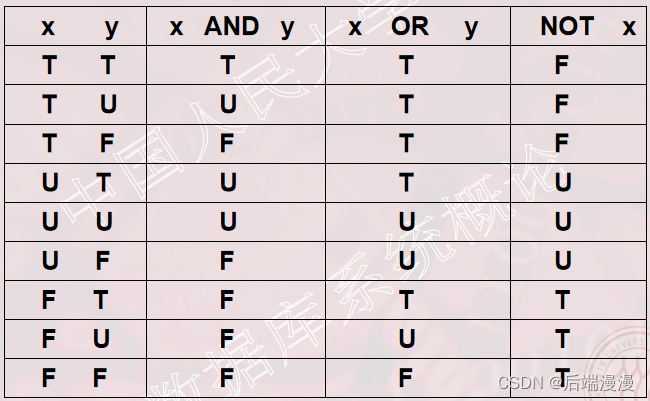
九、空值的处理
- 规则一
- 空值与另一个值(包括另一个空值)的算术运算的结果为空值
- 空值与另一个值(包括另一个空值)的比较运算的结果为UNKNOWN。
有UNKNOWN后,传统二值(TRUE,FALSE)逻辑就扩展成了三值逻辑- 空值与另一个值(包括另一个空值)的逻辑运算
十、视图
概述
- 虚表,是从一个或几个基本表(或视图)导出的表
- 只存放视图的定义,不存放视图对应的数据
- 基表中的数据发生变化,从视图中查询出的数据也随之改变
1. 创建视图
# 建立信息系学生的视图。CREATE VIEW IS_StudentAS SELECT Sno,Sname,SageFROM StudentWHERE Sdept= 'IS';WITH CHECK OPTION; # 对视图进行UPDATE,INSERT和DELETE操作时要保证 # 更新、插入或删除的行 满足视图定义中的谓词条件(即子查询中的条件表达式)
2. 删除视图
# 如果该视图上还导出了其他视图,使用CASCADE级联删除语句,把该视图和由它导出的所有视图一起删除
DROP VIEW IS_S1 CASCADE;
3. 查询视图
# 在信息系学生的视图中找出年龄小于20岁的学生。SELECT Sno,SageFROM IS_StudentWHERE Sage<20;
4. 更新视图
# 将信息系学生视图IS_Student中学号”201215122”的学生姓名改为”刘辰”。
UPDATE IS_Student SET Sname= '刘辰' WHERE Sno= ' 201215122 ';
相关文章:
MySQL面试题:SQL语句的基本语法
MySQL目录一、数据库入门1. 数据管理技术的三个阶段2. 关系型数据库与非关系型数据库3. 四大非关系型数据库a. 基于列的数据库(column-oriented)b. 键值对存储(Key-Value Stores)c. 文档存储(Document Storesÿ…...
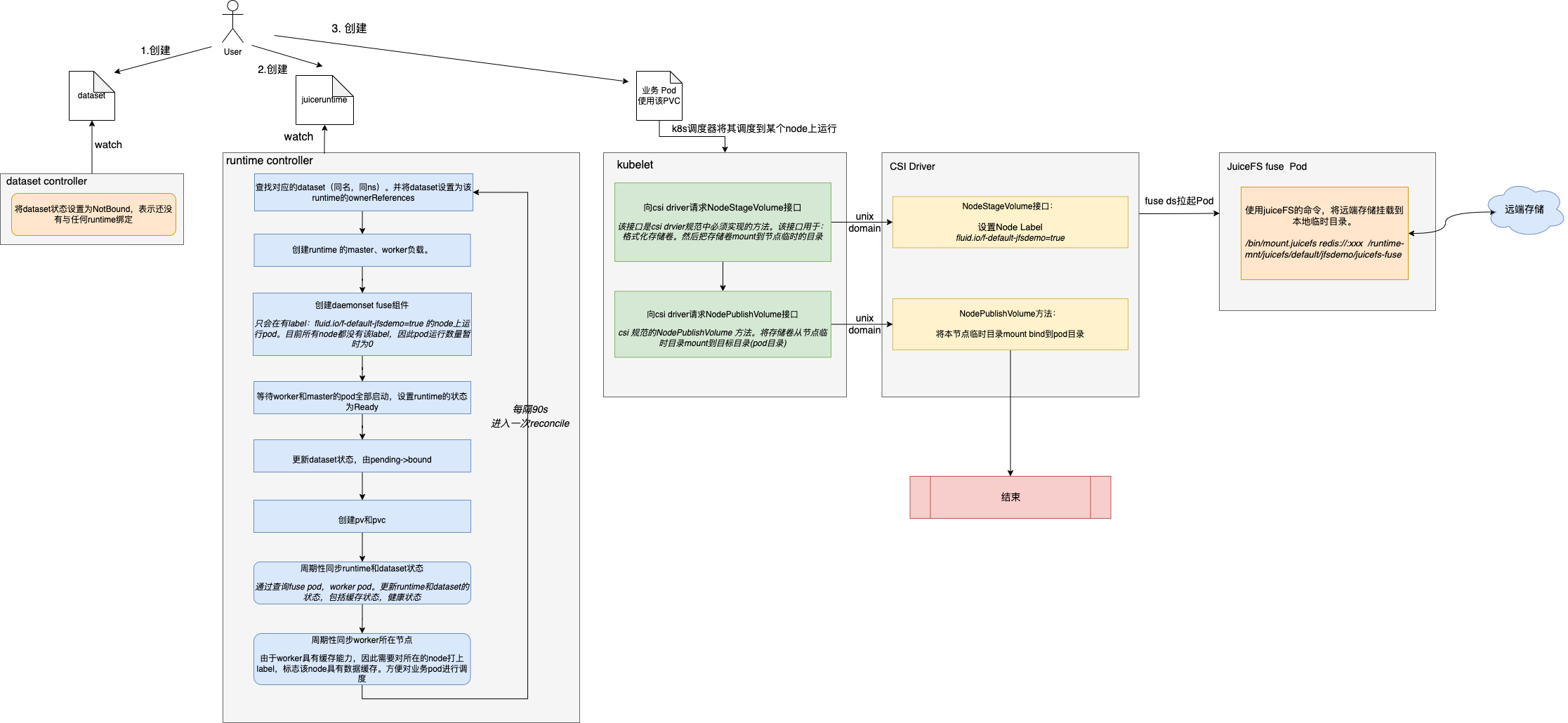
Fluid-数据编排能力原理解析
前言本文对Fluid基础功能-数据编排能力进行原理解析。其中涉及到Fluid架构和k8s csi driver相关知识。建议先了解相关概念,为了便于理解,本文使用JuiceFS作为后端runtime引擎。原理概述Fuild数据编排能力,主要是在云原生环境中,能…...
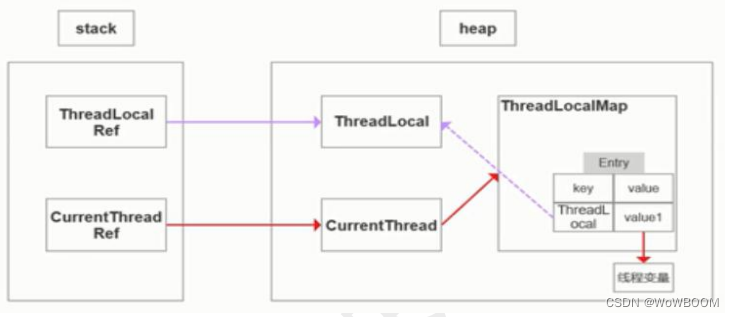
并发线程、锁、ThreadLocal
并发编程并发编程Java内存模型(JMM)并发编程核心问题—可见性、原子性、有序性volatile关键字原子性原子类CAS(Compare-And-Swap 比较并交换)ABA问题Java中的锁乐观锁和悲观锁可重入锁读写锁分段锁自旋锁共享锁/独占锁公平锁/非公平锁偏向锁/轻量级锁/重…...

CMMI-结项管理
结项管理(ProjectClosing Management, PCM)是指在项目开发工作结束后,对项目的有形资产和无形资产进行清算;对项目进行综合评估;总结经验教训等。结项管理过程域是SPP模型的重要组成部分。本规范阐述了结项管理的规程&…...
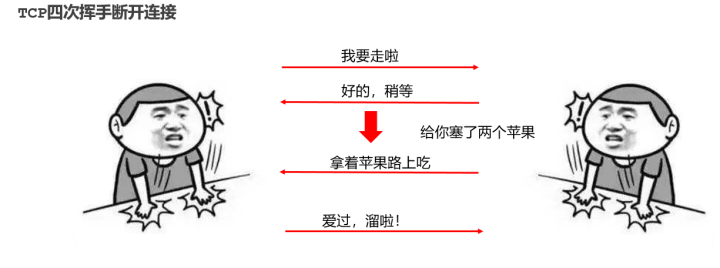
网络通信协议是什么?
网络通信基本模式 常见的通信模式有如下2种形式:Client-Server(CS) 、 Browser/Server(BS) 实现网络编程关键的三要素 IP地址:设备在网络中的地址,是唯一的标识。 端口:应用程序在设备中唯一的标识。 协议: 数据在网络中传输的…...

阶段5:Java分布式与微服务实战
目录 第33-34周 Spring Cloud电商实战 一、Eureka-server模块开发 1、引入依赖 2、配置文件 3、启动注解 一、Eureka-server模块开发 第33-34周 Spring Cloud电商实战 一、Eureka-server模块开发 1、引入依赖 父项目依赖:cloud-mall-practice springboot的…...

我的创作纪念日
目录 机缘 收获 日常 憧憬 机缘 其实本来从大一上学期后半段(2017)就开始谢谢零星的博客,只不过当时是自己用hexo搭建了一个小网站,还整了个域名:jiayoudangdang.top,虽然这个早就过期; 后来发现了CSDNÿ…...
Qml学习——动态加载控件
最近在学习Qml,但对Qml的各种用法都不太熟悉,总是会搞忘,所以写几篇文章对学习过程中的遇到的东西做一个记录。 学习参考视频:https://www.bilibili.com/video/BV1Ay4y1W7xd?p1&vd_source0b527ff208c63f0b1150450fd7023fd8 目…...

设计模式之职责链模式
什么是职责链模式 职责链模式是避免请求发送者与接受者耦合在一起,让多个对象都可以接受到请求,从而将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理为止。 职责链模式包含以下几个角色: …...

MySQL入门篇-MySQL 8.0 延迟复制
备注:测试数据库版本为MySQL 8.0 这个blog我们来聊聊MySQL 延迟复制 概述 MySQL的复制一般都很快,虽然有时候因为 网络原因、大事务等原因造成延迟,但是这个无法人为控制。 生产中可能会存在主库误操作,导致数据被删除了,Oracl…...
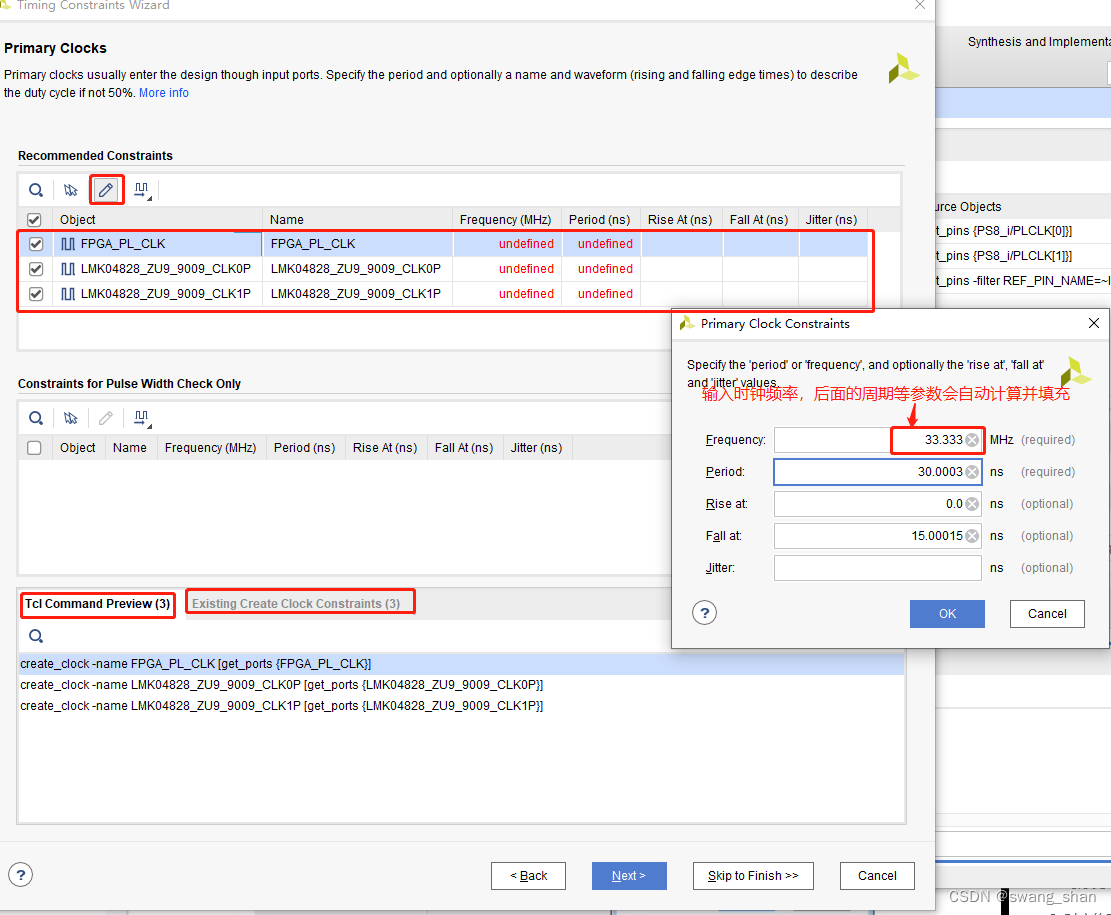
FPGA时序约束与分析 --- 实例教程(1)
注意: 时序约束辅助工具或者相关的TCL命令,都必须在 open synthesis design / open implemention design 后才能有效运行。 1、时序约束辅助工具 2、查看相关时序信息 3、一般的时序约束顺序 1、 时序约束辅助工具(1)时序约束编辑…...

go深拷贝和浅拷贝
1、深拷贝(Deep Copy)拷贝的是数据本身,创造一个样的新对象,新创建的对象与原对象不共享内存,新创建的对象在内存中开辟一个新的内存地址,新对象值修改时不会影响原对象值。既然内存地址不同,释…...

linux网络系统层面的配置、管理及操作命令汇总
前几篇文章一一介绍了LINUX进程管理控制命令,关于linux系统中的软件包管理内容等,作为一名运维工程师,前两天刚处理了一起linux网络层面的情况,那么今天这篇文章就以linux网络层面为主题吧。当说到linux网络系统层面,e…...

R数据分析:孟德尔随机化中介的原理和实操
中介本身就是回归,基本上我看到的很多的调查性研究中在中介分析的方法部分都不会去提混杂,都是默认一个三角形画好,中介关系就算过去了,这里面默认的逻辑就是前两步回归中的混杂是一样的,计算中介效应的时候就自动消掉…...

【C++】 类和对象 (下)
文章目录📕再谈构造函数1. 构造函数体赋值2. 初始化列表3. explicit 关键字📕static 成员1. 概念2. static 成员变量3. static 成员函数📕 友元1. 友元函数2. 友元类📕内部类📕编译器优化📕再谈构造函数 1…...

asp获取毫秒时间戳的方法 asp获取13位时间戳的方案
一、背景。时间戳就是计算当前与"1970-01-01 08:00:00"的时间差,在asp中通常是使用Datediff函数来计算两个日期差,代码:timestamp Datediff("s", "1970-01-01 08:00:00",now)返回结果:1675951060可…...
-- Python程序接入MySQL数据库)
Python基础篇(十五)-- Python程序接入MySQL数据库
程序运行时,数据都在内存中,程序终止时,需要将数据保存到磁盘上。为了便于程序保存和读取,并能直接通过条件快速查询到指定数据,数据库(Database)应运而生,本篇主要学习使用Python操作数据库,在…...
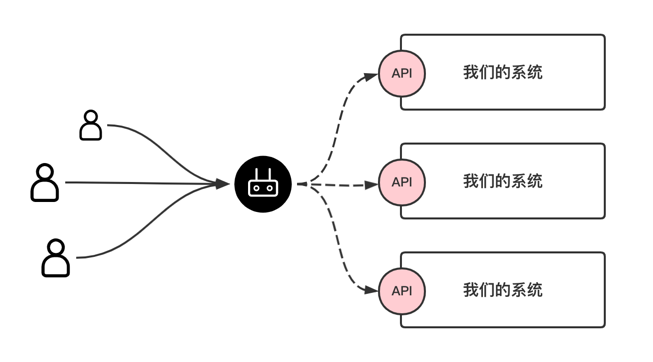
程序员不得不知道的 API 接口常识
说实话,我非常希望自己能早点看到本篇文章,大学那个时候懵懵懂懂,跟着网上的免费教程做了一个购物商城就屁颠屁颠往简历上写。 至今我仍清晰地记得,那个电商教程是怎么定义接口的: 管它是增加、修改、删除、带参查询…...
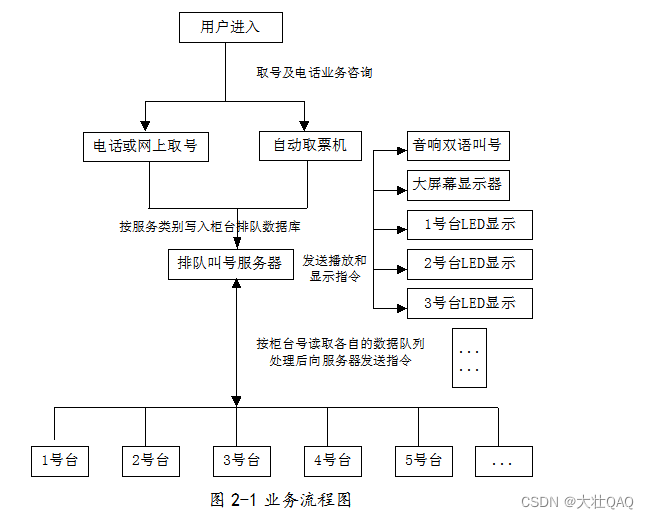
【项目精选】基于Java的银行排号系统的设计与实现
银行排号系统是为解决一些服务业营业大厅排队问题而设计的,它能够有效地提高工作人员的工作效率,也能够使顾客合理的安排等待时间,让顾客感到服务的公平公正。论文首先讨论了排号系统的背景、意义、应用现状以及研究与开发现状。本文在对C/S架…...
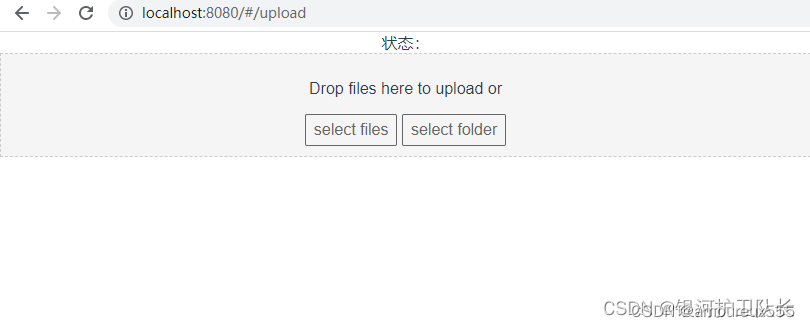
前端 基于 vue-simple-uploader 实现大文件断点续传和分片上传
文章目录一、前言二、后端部分新建Maven 项目后端pom.xml配置文件 application.ymlHttpStatus.javaAjaxResult.javaCommonConstant.javaWebConfig.javaCheckChunkVO.javaBackChunk.javaBackFileList.javaBackChunkMapper.javaBackFileListMapper.javaBackFileListMapper.xmlBac…...

荣耀XD21路由器IPTV设置指南:不用VLAN交换机实现单线复用
荣耀XD21路由器单线复用实战:无需VLAN交换机实现IPTV与网络并行传输 客厅弱电箱仅预留单根网线却需要同时承载IPTV和无线网络信号——这是许多家庭网络改造中遇到的典型难题。传统方案往往依赖价格不菲的VLAN交换机实现单线复用,但通过荣耀XD21路由器的隐…...

Acode:重新定义Android移动代码编辑体验
Acode:重新定义Android移动代码编辑体验 【免费下载链接】Acode Acode - powerful text/code editor for android 项目地址: https://gitcode.com/gh_mirrors/ac/Acode 在移动开发日益普及的今天,拥有一款高效的移动代码编辑器成为开发者的迫切需…...

【JavaEE】多线程 -- 初识线程
目录认识线程线程是什么为啥要有线程进程和线程的区别(重要)第一个多线程程序为什么先打印main再打印thread抛异常的小问题创建多线程的方式继承Thread, 重写run方法实现Runnable接口继承Thread, 使用匿名内部类实现Runnable接口, 使用匿名内部类lambda表达式(推荐写法)Thread类…...

深入解析BLE空口报文抓取:从GAP广播到LESC安全通信全流程
1. BLE空口报文抓取基础 想要分析BLE设备间的通信过程,抓取空口报文是最直接有效的方法。这就像在两个人对话时,用录音设备记录下他们的每一句话。不过BLE通信使用的是2.4GHz无线频段,我们无法直接用耳朵听到这些"对话",…...

IAR平台华大HC32F460工程搭建避坑指南:从零到调试成功的全流程解析
1. 从KEIL到IAR的转型背景 最近两年芯片市场的价格波动,让很多工程师不得不重新评估开发工具链的选择。我作为一个用了五年KEIL的老用户,最近也被迫开始学习IAR平台。原因很简单——当ST单片机价格涨到华大HC32F460的十倍时,任何成本敏感的项…...
)
告别Moom!用Hammerspoon实现Mac窗口精准控制(附完整快捷键表+配置文件)
用Hammerspoon打造Mac高效工作流:从窗口管理到自动化脚本 每次看到同事花十几秒拖动窗口调整大小,或者在不同显示器间来回切换应用时,我总忍不住想分享这个改变我工作效率的神器。Hammerspoon——这个完全免费的开源工具,让我彻底…...

STM32F103 SPI+DMA驱动WS2812B的时序实现原理
1. WS2812B_STM32_Libmaple 库深度解析:基于 SPI DMA 的高性能 NeoPixel 驱动实现WS2812B(常被称作 NeoPixel)是当前嵌入式系统中最主流的单线协议可寻址 RGB LED。其核心挑战在于严格的时序要求:T0H(逻辑 0 的高电平时…...

避开RK3568 MPP开发的那些坑:V4L2缓冲区管理与实时码流稳定性优化实战
RK3568 MPP开发实战:V4L2缓冲区管理与码流稳定性优化指南 在嵌入式视频处理领域,RK3568凭借其强大的多媒体处理能力成为中高端项目的首选方案。但当我们真正将其应用于工业视觉、安防监控等对稳定性要求严苛的场景时,开发者常常会遇到令人头疼…...

LyricsX深度解析:macOS平台终极歌词解决方案的技术实现与高级应用
LyricsX深度解析:macOS平台终极歌词解决方案的技术实现与高级应用 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的终极歌词应用,通过…...

技术深度解析:ER-Save-Editor如何实现跨平台艾尔登法环存档编辑
技术深度解析:ER-Save-Editor如何实现跨平台艾尔登法环存档编辑 【免费下载链接】ER-Save-Editor Elden Ring Save Editor. Compatible with PC and Playstation saves. 项目地址: https://gitcode.com/GitHub_Trending/er/ER-Save-Editor 艾尔登法环存档编辑…...