Golang每日一练(leetDay0047)

目录
138. 复制带随机指针的链表 Copy List with Random-pointer 🌟🌟
139. 单词拆分 Word Break 🌟🌟
140. 单词拆分 II Word Break II 🌟🌟🌟
🌟 每日一练刷题专栏 🌟
Golang每日一练 专栏
Python每日一练 专栏
C/C++每日一练 专栏
Java每日一练 专栏
138. 复制带随机指针的链表 Copy List with Random-pointer
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val,random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
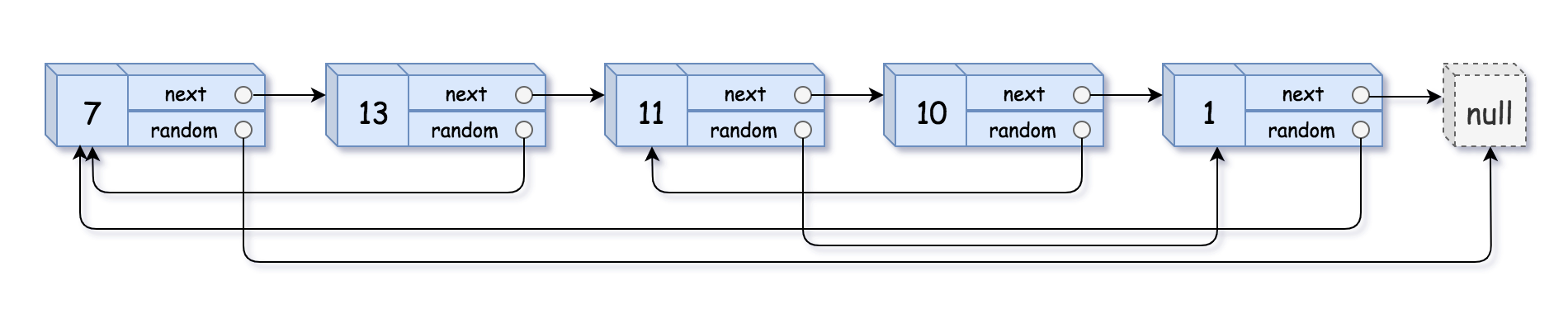
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000-10^4 <= Node.val <= 10^4Node.random为null或指向链表中的节点。
代码1: 直接在节点结构里增加Index属性
package mainimport "fmt"const null = -1 << 31type Node struct {Val intNext *NodeRandom *NodeIndex int
}func createNode(val int) *Node {return &Node{Val: val,Next: nil,Random: nil,}
}func buildRandomList(nums [][]int) *Node {if len(nums) == 0 {return nil}nodes := make([]*Node, len(nums))for i := 0; i < len(nums); i++ {nodes[i] = &Node{Val: nums[i][0], Index: i}}for i := 0; i < len(nums); i++ {if nums[i][1] != null {nodes[i].Random = nodes[nums[i][1]]}if i < len(nums)-1 {nodes[i].Next = nodes[i+1]}}return nodes[0]
}func traverseList(head *Node) {if head == nil {return}visited := make(map[*Node]bool)cur := headfmt.Print("[")for cur != nil {fmt.Print("[")fmt.Printf("%d,", cur.Val)if cur.Random != nil {fmt.Printf("%d", cur.Random.Index)} else {fmt.Print("null")}fmt.Print("]")visited[cur] = trueif cur.Next != nil && !visited[cur.Next] {fmt.Print(",")cur = cur.Next} else {break}}fmt.Println("]")
}func copyRandomList(head *Node) *Node {if head == nil {return nil}cur := headfor cur != nil {copy := &Node{cur.Val, cur.Next, nil, cur.Index}cur.Next = copycur = copy.Next}cur = headfor cur != nil {if cur.Random != nil {cur.Next.Random = cur.Random.Next}cur = cur.Next.Next}newHead := head.Nextcur = headfor cur != nil {copy := cur.Nextcur.Next = copy.Nextif copy.Next != nil {copy.Next = copy.Next.Next}cur = cur.Next}return newHead
}func copyRandomList2(head *Node) *Node {if head == nil {return nil}m := make(map[*Node]*Node)cur := headfor cur != nil {m[cur] = &Node{cur.Val, nil, nil, cur.Index}cur = cur.Next}cur = headfor cur != nil {m[cur].Next = m[cur.Next]m[cur].Random = m[cur.Random]cur = cur.Next}return m[head]
}func main() {nodes := [][]int{{7, null}, {13, 0}, {11, 4}, {10, 2}, {1, 0}}head := buildRandomList(nodes)traverseList(head)head = copyRandomList(head)traverseList(head)nodes = [][]int{{1, 1}, {2, 1}}head = buildRandomList(nodes)traverseList(head)head = copyRandomList(head)traverseList(head)nodes = [][]int{{3, null}, {3, 0}, {3, null}}head = buildRandomList(nodes)traverseList(head)head = copyRandomList(head)traverseList(head)
}
代码2: 增加getIndex()函数获取Index索引号
func getIndex(node *Node, head *Node) int
package mainimport ("fmt""strings"
)const null = -1 << 31type Node struct {Val intNext *NodeRandom *Node
}func createNode(val int) *Node {return &Node{Val: val,Next: nil,Random: nil,}
}func buildRandomList(nums [][]int) *Node {if len(nums) == 0 {return nil}nodes := make([]*Node, len(nums))for i := 0; i < len(nums); i++ {nodes[i] = &Node{Val: nums[i][0]}}for i := 0; i < len(nums); i++ {if nums[i][1] != null {nodes[i].Random = nodes[nums[i][1]]}if i < len(nums)-1 {nodes[i].Next = nodes[i+1]}}return nodes[0]
}func traverseList(head *Node) [][]int {if head == nil {return nil}visited := make(map[*Node]bool)cur := headres := make([][]int, 0)for cur != nil {visited[cur] = truerandomIndex := nullif cur.Random != nil {randomIndex = getIndex(cur.Random, head)}res = append(res, []int{cur.Val, randomIndex})if cur.Next != nil && !visited[cur.Next] {cur = cur.Next} else {break}}return res
}func getIndex(node *Node, head *Node) int {index := 0cur := headfor cur != node {index++cur = cur.Next}return index
}func copyRandomList(head *Node) *Node {if head == nil {return nil}cur := headfor cur != nil {copy := &Node{cur.Val, cur.Next, nil}cur.Next = copycur = copy.Next}cur = headfor cur != nil {if cur.Random != nil {cur.Next.Random = cur.Random.Next}cur = cur.Next.Next}newHead := head.Nextcur = headfor cur != nil {copy := cur.Nextcur.Next = copy.Nextif copy.Next != nil {copy.Next = copy.Next.Next}cur = cur.Next}return newHead
}func copyRandomList2(head *Node) *Node {if head == nil {return nil}m := make(map[*Node]*Node)cur := headfor cur != nil {m[cur] = &Node{cur.Val, nil, nil}cur = cur.Next}cur = headfor cur != nil {m[cur].Next = m[cur.Next]m[cur].Random = m[cur.Random]cur = cur.Next}return m[head]
}func Array2DToString(array [][]int) string {if len(array) == 0 {return "[]"}arr2str := func(arr []int) string {res := "["for i := 0; i < len(arr); i++ {if arr[i] == null {res += "null"} else {res += fmt.Sprint(arr[i])}if i != len(arr)-1 {res += ","}}return res + "]"}res := make([]string, len(array))for i, arr := range array {res[i] = arr2str(arr)}return strings.Join(strings.Fields(fmt.Sprint(res)), ",")
}func main() {nodes := [][]int{{7, null}, {13, 0}, {11, 4}, {10, 2}, {1, 0}}head := buildRandomList(nodes)fmt.Println(Array2DToString(traverseList(head)))head = copyRandomList(head)fmt.Println(Array2DToString(traverseList(head)))nodes = [][]int{{1, 1}, {2, 1}}head = buildRandomList(nodes)fmt.Println(Array2DToString(traverseList(head)))head = copyRandomList(head)fmt.Println(Array2DToString(traverseList(head)))nodes = [][]int{{3, null}, {3, 0}, {3, null}}head = buildRandomList(nodes)fmt.Println(Array2DToString(traverseList(head)))head = copyRandomList(head)fmt.Println(Array2DToString(traverseList(head)))
}
输出:
[[7,null],[13,0],[11,4],[10,2],[1,0]]
[[7,null],[13,0],[11,4],[10,2],[1,0]]
[[1,1],[2,1]]
[[1,1],[2,1]]
[[3,null],[3,0],[3,null]]
[[3,null],[3,0],[3,null]]
139. 单词拆分 Word Break
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true 解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false
提示:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s和wordDict[i]仅有小写英文字母组成wordDict中的所有字符串 互不相同
代码1: 暴力枚举
package mainimport ("fmt"
)func wordBreak(s string, wordDict []string) bool {return helper(s, wordDict)
}func helper(s string, wordDict []string) bool {if s == "" {return true}for i := 1; i <= len(s); i++ {if contains(wordDict, s[:i]) && helper(s[i:], wordDict) {return true}}return false
}func contains(wordDict []string, s string) bool {for _, word := range wordDict {if word == s {return true}}return false
}func main() {s := "leetcode"wordDict := []string{"leet", "code"}fmt.Println(wordBreak(s, wordDict))s = "applepenapple"wordDict = []string{"apple", "pen"}fmt.Println(wordBreak(s, wordDict))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(wordBreak(s, wordDict))
}
代码2: 记忆化搜索
package mainimport ("fmt"
)func wordBreak(s string, wordDict []string) bool {memo := make([]int, len(s))for i := range memo {memo[i] = -1}return helper(s, wordDict, memo)
}func helper(s string, wordDict []string, memo []int) bool {if s == "" {return true}if memo[len(s)-1] != -1 {return memo[len(s)-1] == 1}for i := 1; i <= len(s); i++ {if contains(wordDict, s[:i]) && helper(s[i:], wordDict, memo) {memo[len(s)-1] = 1return true}}memo[len(s)-1] = 0return false
}func contains(wordDict []string, s string) bool {for _, word := range wordDict {if word == s {return true}}return false
}func main() {s := "leetcode"wordDict := []string{"leet", "code"}fmt.Println(wordBreak(s, wordDict))s = "applepenapple"wordDict = []string{"apple", "pen"}fmt.Println(wordBreak(s, wordDict))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(wordBreak(s, wordDict))
}
代码3: 动态规划
package mainimport ("fmt"
)func wordBreak(s string, wordDict []string) bool {n := len(s)dp := make([]bool, n+1)dp[0] = truefor i := 1; i <= n; i++ {for j := 0; j < i; j++ {if dp[j] && contains(wordDict, s[j:i]) {dp[i] = truebreak}}}return dp[n]
}func contains(wordDict []string, s string) bool {for _, word := range wordDict {if word == s {return true}}return false
}func main() {s := "leetcode"wordDict := []string{"leet", "code"}fmt.Println(wordBreak(s, wordDict))s = "applepenapple"wordDict = []string{"apple", "pen"}fmt.Println(wordBreak(s, wordDict))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(wordBreak(s, wordDict))
}
输出:
true
true
false
140. 单词拆分 II Word Break II
给定一个字符串 s 和一个字符串字典 wordDict ,在字符串 s 中增加空格来构建一个句子,使得句子中所有的单词都在词典中。以任意顺序 返回所有这些可能的句子。
注意:词典中的同一个单词可能在分段中被重复使用多次。
示例 1:
输入:s = "catsanddog", wordDict = ["cat","cats","and","sand","dog"] 输出:["cats and dog","cat sand dog"]
示例 2:
输入:s = "pineapplepenapple", wordDict = ["apple","pen","applepen","pine","pineapple"] 输出:["pine apple pen apple","pineapple pen apple","pine applepen apple"] 解释: 注意你可以重复使用字典中的单词。
示例 3:
输入:s = "catsandog", wordDict = ["cats","dog","sand","and","cat"] 输出:[]
提示:
1 <= s.length <= 201 <= wordDict.length <= 10001 <= wordDict[i].length <= 10s和wordDict[i]仅有小写英文字母组成wordDict中所有字符串都 不同
代码1: 回溯法
package mainimport ("fmt""strings"
)func wordBreak(s string, wordDict []string) []string {// 构建字典dict := make(map[string]bool)for _, word := range wordDict {dict[word] = true}// 回溯函数var res []stringvar backtrack func(start int, path []string)backtrack = func(start int, path []string) {if start == len(s) {res = append(res, strings.Join(path, " "))return}for i := start + 1; i <= len(s); i++ {if dict[s[start:i]] {path = append(path, s[start:i])backtrack(i, path)path = path[:len(path)-1]}}}backtrack(0, []string{})return res
}func ArrayToString(arr []string) string {res := "[\""for i := 0; i < len(arr); i++ {res += arr[i]if i != len(arr)-1 {res += "\",\""}}res += "\"]"if res == "[\"\"]" {res = "[]"}return res
}func main() {s := "catsanddog"wordDict := []string{"cat", "cats", "and", "sand", "dog"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))s = "pineapplepenapple"wordDict = []string{"apple", "pen", "applepen", "pine", "pineapple"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))
}
代码2: 动态规划 + 回溯法
package mainimport ("fmt""strings"
)func wordBreak(s string, wordDict []string) []string {// 构建字典dict := make(map[string]bool)for _, word := range wordDict {dict[word] = true}// 动态规划n := len(s)dp := make([]bool, n+1)dp[0] = truefor i := 1; i <= n; i++ {for j := 0; j < i; j++ {if dp[j] && dict[s[j:i]] {dp[i] = truebreak}}}if !dp[n] {return []string{}}// 回溯函数var res []stringvar backtrack func(start int, path []string)backtrack = func(start int, path []string) {if start == len(s) {res = append(res, strings.Join(path, " "))return}for i := start + 1; i <= len(s); i++ {if dict[s[start:i]] {path = append(path, s[start:i])backtrack(i, path)path = path[:len(path)-1]}}}backtrack(0, []string{})return res
}func ArrayToString(arr []string) string {res := "[\""for i := 0; i < len(arr); i++ {res += arr[i]if i != len(arr)-1 {res += "\",\""}}res += "\"]"if res == "[\"\"]" {res = "[]"}return res
}func main() {s := "catsanddog"wordDict := []string{"cat", "cats", "and", "sand", "dog"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))s = "pineapplepenapple"wordDict = []string{"apple", "pen", "applepen", "pine", "pineapple"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))s = "catsandog"wordDict = []string{"cats", "dog", "sand", "and", "cat"}fmt.Println(ArrayToString(wordBreak(s, wordDict)))
}
代码3: 动态规划 + 记忆化搜索
func wordBreak(s string, wordDict []string) []string {// 构建字典dict := make(map[string]bool)for _, word := range wordDict {dict[word] = true}// 动态规划n := len(s)dp := make([]bool, n+1)dp[0] = truefor i := 1; i <= n; i++ {for j := 0; j < i; j++ {if dp[j] && dict[s[j:i]] {dp[i] = truebreak}}}if !dp[n] {return []string{}}// 记忆化搜索memo := make(map[int][][]string)var dfs func(start int) [][]stringdfs = func(start int) [][]string {if _, ok := memo[start]; ok {return memo[start]}var res [][]stringif start == len(s) {res = append(res, []string{})return res}for i := start + 1; i <= len(s); i++ {if dict[s[start:i]] {subRes := dfs(i)for _, subPath := range subRes {newPath := append([]string{s[start:i]}, subPath...)res = append(res, newPath)}}}memo[start] = resreturn res}return format(dfs(0))
}
// 格式化结果集
func format(paths [][]string) []string {var res []stringfor _, path := range paths {res = append(res, strings.Join(path, " "))}return res
}输出:
["cat sand dog","cats and dog"]
["pine apple pen apple","pine applepen apple","pineapple pen apple"]
[]
🌟 每日一练刷题专栏 🌟
✨ 持续,努力奋斗做强刷题搬运工!
👍 点赞,你的认可是我坚持的动力!
🌟 收藏,你的青睐是我努力的方向!
✎ 评论,你的意见是我进步的财富!
☸ 主页:https://hannyang.blog.csdn.net/
 | Golang每日一练 专栏 |
 | Python每日一练 专栏 |
 | C/C++每日一练 专栏 |
 | Java每日一练 专栏 |
相关文章:
Golang每日一练(leetDay0047)
目录 138. 复制带随机指针的链表 Copy List with Random-pointer 🌟🌟 139. 单词拆分 Word Break 🌟🌟 140. 单词拆分 II Word Break II 🌟🌟🌟 🌟 每日一练刷题专栏 &…...
HCL Nomad Web 1.0.7发布和新功能验证
大家好,才是真的好。 要问在HCL Notes/Domino系列产品中,谁更新得最快,那么答案一定是HCL Nomad Web。 你看上图右边,从1.0.1更新到1.0.7,都没花多少时间。 从HCL Nomad Web 1.0.5版本开始,可以支持直接…...

春招网申简历填写三技巧
网申第一关很重要,不夸张的说网申决定了你的笔试机会,从如信银行考试中心了解到,银行网申筛选过程中,有机器筛选人工筛选两道程序,掌握填写技巧后对提升简历通过率有较大帮助,一定要把握住,关于…...
计算机网络基础知识总结
经过学习我们可以知道: 关于计算机网络: ip地址端口号协议协议分层TCP五层协议协议封装两台计算机之间的通信 目录 ip地址 端口号 协议 协议分层 五层协议体系结构 (1) 应用层 (2) 运输层 (3) 网络层 (4)数据链路层 (5)物理层 封装&分用 两台主机之间的通信 …...

(下)苹果有开源,但又怎样呢?
一开始,因为 MacOS X ,苹果与 FreeBSD 过往从密,不仅挖来 FreeBSD 创始人 Jordan Hubbard,更是在此基础上开源了 Darwin。但是,苹果并没有给予 Darwin 太多关注,作为苹果的首个开源项目,它算不上…...

row_number 和 cte 使用实例:考场监考安排
row_number 和 cte 使用实例:考场监考安排 考场监考安排使用 cte 模拟两个表的原始数据使用 master..spt_values 进行数据填充优先安排时长较长的考试使用 cte 安排第一个需要安排的科目统计老师已有的监考时长尝试使用 cte 递归,进行下一场考试安排&…...

2023天梯赛记录
文章目录 L2-001 紧急救援L2-002 链表去重L2-004 这是二叉搜索树吗?L2-005 集合相似度L2-006 树的遍历L2-007 家庭房产L2-010 排座位L2-011 玩转二叉树L2-012 关于堆的判断L2-013 红色警报L2-014 列车调度L2-016 愿天下有情人都是失散多年的兄妹L2-019 悄悄关注L2-0…...
被吐槽 GitHub仓 库太大,直接 600M 瘦身到 6M,这下舒服了
大家好,我是小富~ 前言 忙里偷闲学习了点技术写了点demo代码,打算提交到我那 2000Star 的Github仓库上,居然发现有5个Issues,最近的一条日期已经是2022/8/1了,以前我还真没留意过这些,我这人懒…...
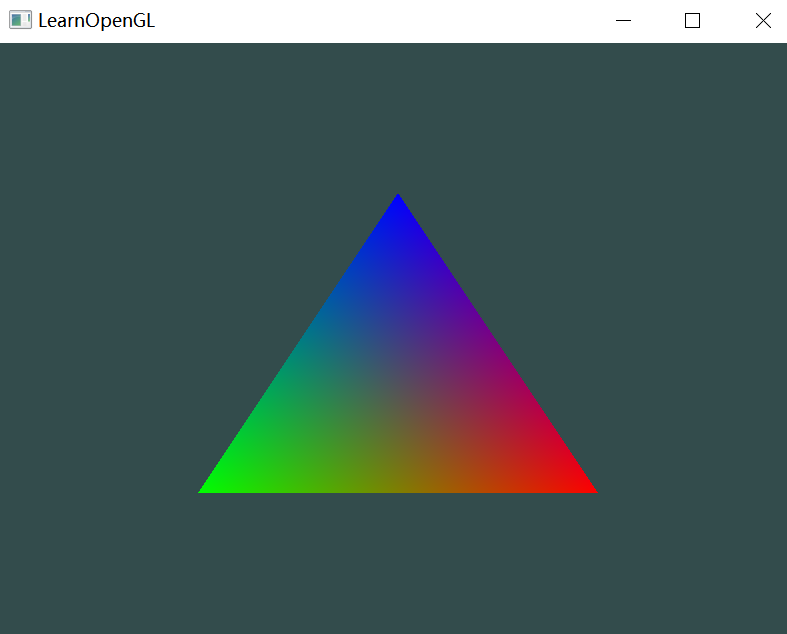
OpenGL(三)——着色器
目录 一、前言 二、Shader 2 Shader 2.1 顶点着色器 2.2 片段着色器 三、APP 2 Shader 四、顶点颜色属性 五、着色器类C 一、前言 着色器Shader是运行在GPU上的小程序,为图形渲染管线的某个特定部分而运行。各阶段着色器之间无法通信,只有输入和输…...

【MySQL】单表查询
一、表的准备 查询操作的SQL演示将基于下面这四张表进行,我们先创建好这四张数据表,并为其添加数据。 1、第一张表为部门表,名称为包含三个字段:部门编号(deptno),部门名称(dname&…...

第一章 安装Unity
使用Unity开发游戏的话,首先要安装Unity Hub和Unity Editor两个软件。大家可以去官方地址下载:https://unity.cn/releases/full/2020 (这里我们选择的是2020版本) Unity Hub 是安装 Unity Editor、创建项目、管理帐户和许可证的主…...

20230425----重返学习-vue项目-vue自定义指令-vue-cli的配置
day-057-fifty-seven-20230425-vue项目-vue自定义指令-vue-cli的配置 vue项目 vuex版 普通版纯axios:切换页面,就会重新发送一次ajax请求普通版升级:vuex版vuex的常用功能 vuex 数据通信vuex 缓存数据 前进后退,切换页面&#…...
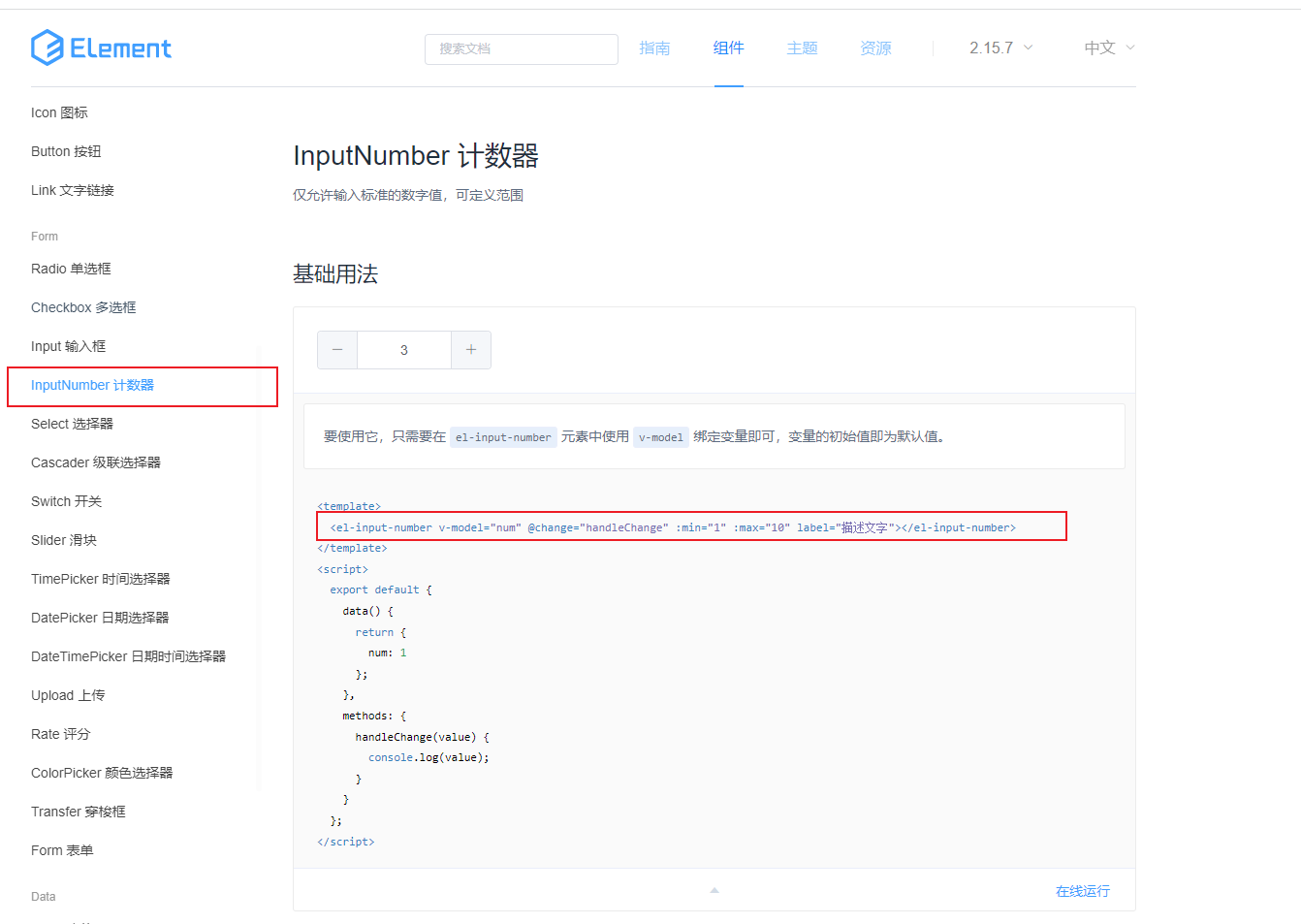
el-input 只能输入整数(包括正数、负数、0)或者只能输入整数(包括正数、负数、0)和小数
使用el-input-number标签 也可以使用typenumbe和v-model.number属性,两者结合使用,能满足大多数需求,如果还不满足,可以再结合正则表达式过滤 <el-input v-model.number"value" type"number" /> el-i…...
Docker Compose的常用命令与docker-compose.yml脚本属性配置
Docker Compose的常用命令与配置 常见命令ps:列出所有运行容器logs:查看服务日志输出port:打印绑定的公共端口build:构建或者重新构建服务start:启动指定服务已存在的容器stop:停止已运行的服务的容器&…...
)
with语句和上下文管理器(py编程)
1. with语句的使用 基础班向文件中写入数据的示例代码: # 1、以写的方式打开文件f open("1.txt", "w")# 2、写入文件内容f.write("hello world")# 3、关闭文件f.close()代码说明: 文件使用完后必须关闭,因为文件对象会占用操作系统…...

《JavaEE初阶》HTTP协议和HTTPS
《JavaEE初阶》HTTP协议和HTTPS 文章目录 《JavaEE初阶》HTTP协议和HTTPSHTTP协议是应用层协议:使用Fiddler抓取HTTP请求和响应:Fiddler的下载和基本使用:Fiddler的中间代理人身份:其他抓包工具: 先简单认识HTTP请求与HTTP响应:HTTP请求:HTTP响应: HTTP请求详解:首行࿱…...

微信小程序 | 基于高德地图+ChatGPT实现旅游规划小程序
🎈🎈效果预览🎈🎈 ❤ 路劲规划 ❤ 功能总览 ❤ ChatGPT交互 一、需求背景 五一假期即即将到来,在大家都阳过之后,截止到目前这应该是最安全的一个假期。所以出去旅游想必是大多数人的选择。 然后&#x…...

Excel技能之实用技巧,高手私藏
今天来讲一下Excel技巧,工作常用,高手私藏。能帮到你是我最大的荣幸。 与其加班熬夜赶进度,不如下班学习提效率。能力有成长,效率提上去,自然不用加班。 消化吸收,工作中立马使用,感觉真不错。…...

黑马程序员Java零基础视频教程笔记-运算符
文章目录 一、算数运算符详解和综合练习二、隐式转换和强制转换三、字符串和字符的加操作四、自增自减运算符五、赋值运算符和关系运算符六、四种逻辑运算符七、短路逻辑运算符八、三元运算符 一、算数运算符详解和综合练习 1. 运算符和表达式 ① 运算符:对字面量…...
部署方案)
Microsoft Data Loss Prevention(DLP)部署方案
目录 一、前言 二、部署流程 步骤一:确定数据需求 步骤二:规划信息保护策略...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...