Python 爬虫工具
Python3 默认提供了urllib库,可以爬取网页信息,但其中确实有不方便的地方,如:处理网页验证和Cookies,以及Hander头信息处理。
为了更加方便处理,有了更为强大的库 urllib3 和 requests, 本节会分别介绍一下,以后我们着重使用requests。
urllib3网址:https://pypi.org/project/urllib3/requests网址:http://www.python-requests.org/en/master/
1. urllib3库的使用:
安装:通过使用pip命令来安装urllib3pip install urllib3
简单使用:import urllib3
import re
实例化产生请求对象
http = urllib3.PoolManager()
get请求指定网址
url = "http://www.baidu.com"
res = http.request("GET",url)
获取HTTP状态码
print("status:%d" % res.status)
获取响应内容
data = res.data.decode("utf-8")
正则解析并输出
print(re.findall("<title>(.*?)</title>",data))
其他设置: 增加了超时时间,请求参数等设置
import urllib3
import reurl = "http://www.baidu.com"
http = urllib3.PoolManager(timeout = 4.0) #设置超时时间res = http.request("GET",url,#headers={# 'User-Agent':'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1',#},fields={'id':100,'name':'lisi'}, #请求参数信息)print("status:%d" % res.status)data = res.data.decode("utf-8")print(re.findall("<title>(.*?)</title>",data))
- requests库的使用:
安装:通过使用pip命令来安装requests
pip install requests简单使用:import requests
import reurl = "http://www.baidu.com"
抓取信息
res = requests.get(url)#获取HTTP状态码
print("status:%d" % res.status_code)
获取响应内容
data = res.content.decode("utf-8")#解析出结果
print(re.findall("<title>(.*?)</title>",data))
图片
3. 解析库的使用–XPath:
XPath(XML Path Language)是一门在XML文档中查找信息的语言。XPath 可用来在XML文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。官方网址:http://lxml.de 官方文档:http://lxml.de/api/index.html注:XQuery 是用于 XML 数据查询的语言(类似SQL查询数据库中的数据)注:XPointer 由统一资源定位
地址(URL)中#号之后的描述组成,类似于HTML中的锚点链接python中如何安装使用XPath:①: 安装 lxml 库。②: from lxml import etree③: Selector = etree.HTML(网页源代码)④: Selector.xpath(一段神奇的符号)
- 准备工作:
要使用XPath首先要先安装lxml库:
pip install lxml
- XPath选取节点规则
表达式 描述
nodename 选取此节点的所有子节点。
/ 从当前节点选取直接子节点
// 从匹配选择的当前节点选择所有子孙节点,而不考虑它们的位置
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
述
nodename 选取此节点的所有子节点。
/ 从当前节点选取直接子节点
// 从匹配选择的当前节点选择所有子孙节点,而不考虑它们的位置
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
- 解析案例:
首先创建一个html文件:my.html 用于测试XPath的解析效果
<!DOCTYPE html>
<html>
<head><title>我的网页</title>
</head>
<body><h3 id="hid">我的常用链接</h3><ul><li class="item-0"><a href="http://www.baidu.com">百度</a></li><li class="item-1 shop"><a href="http://www.jd.com">京东</a></li><li class="item-2"><a href="http://www.sohu.com">搜狐</a></li><li class="item-3"><a href="http://www.sina.com">新浪</a></li><li class="item-4 shop"><a href="http://www.taobao.com">淘宝</a></li></ul></body>
</html>
使用XPath解析说明
导入模块
from lxml import etree
读取html文件信息(在真实代码中是爬取的网页信息)
f = open("./my.html",'r',encoding="utf-8")
content = f.read()
f.close()
解析HTML文档,返回根节点对象
html = etree.HTML(content)
#print(html) # <Element html at 0x103534c88>
获取网页中所有标签并遍历输出标签名
result = html.xpath("//*")
for t in result:print(t.tag,end=" ")
#[html head title body h3 ul li a li a ... ... td]
print()
获取节点
result = html.xpath("//li") # 获取所有li节点
result = html.xpath("//li/a") # 获取所有li节点下的所有直接a子节点
result = html.xpath("//ul//a") # 效果同上(ul下所有子孙节点)
result = html.xpath("//a/..") #获取所有a节点的父节点
print(result)
获取属性和文本内容
result = html.xpath("//li/a/@href") #获取所有li下所有直接子a节点的href属性值
result = html.xpath("//li/a/text()") #获取所有li下所有直接子a节点内的文本内容
print(result) #['百度', '京东', '搜狐', '新浪', '淘宝']result = html.xpath("//li/a[@class]/text()") #获取所有li下所有直接含有class属性子a节点内的文本内容
print(result) #['百度', '搜狐', '新浪']#获取所有li下所有直接含有class属性值为aa的子a节点内的文本内容
result = html.xpath("//li/a[@class='aa']/text()")
print(result) #['搜狐', '新浪']#获取class属性值中含有shop的li节点下所有直接a子节点内的文本内容
result = html.xpath("//li[contains(@class,'shop')]/a/text()")
print(result) #['搜狐', '新浪']
按序选择
result = html.xpath("//li[1]/a/text()") # 获取每组li中的第一个li节点里面的a的文本
result = html.xpath("//li[last()]/a/text()") # 获取每组li中最后一个li节点里面的a的文本
result = html.xpath("//li[position()<3]/a/text()") # 获取每组li中前两个li节点里面的a的文本
result = html.xpath("//li[last()-2]/a/text()") # 获取每组li中倒数第三个li节点里面的a的文本
print(result)print("--"*30)
节点轴选择
result = html.xpath("//li[1]/ancestor::*") # 获取li的所有祖先节点
result = html.xpath("//li[1]/ancestor::ul") # 获取li的所有祖先中的ul节点
result = html.xpath("//li[1]/a/attribute::*") # 获取li中a节点的所有属性值
result = html.xpath("//li/child::a[@href='http://www.sohu.com']") #获取li子节点中属性href值的a节点
result = html.xpath("//body/descendant::a") # 获取body中的所有子孙节点a
print(result)result = html.xpath("//li[3]") #获取li中的第三个节点
result = html.xpath("//li[3]/following::li") #获取第三个li节点之后所有li节点
result = html.xpath("//li[3]/following-sibling::*") #获取第三个li节点之后所有同级li节点
for v in result:print(v.find("a").text)
解析案例
导入模块
from lxml import etree
读取html文件信息(在真实代码中是爬取的网页信息)
f = open("./my.html",'r')
content = f.read()
f.close()
解析HTML文档,返回根节点对象
html = etree.HTML(content)
1. 获取id属性为hid的h3节点中的文本内容
print(html.xpath("//h3[@id='hid']/text()")) #['我的常用链接']
2. 获取li中所有超级链接a的信息
result = html.xpath("//li/a")
for t in result:# 通过xapth()二次解析结果#print(t.xpath("text()")[0], ':', t.xpath("@href")[0])# 效果同上,使用节点对象属性方法解析print(t.text, ':', t.get("href"))'''
#结果:
百度 : http://www.baidu.com
京东 : http://www.jd.com
搜狐 : http://www.sohu.com
新浪 : http://www.sina.com
淘宝 : http://www.taobao.com
''''''
HTML元素的属性:tag:元素标签名text:标签中间的文本
HTML元素的方法:find() 查找一个匹配的元素findall() 查找所有匹配的元素get(key, default=None) 获取指定属性值items()获取元素属性,作为序列返回keys()获取属性名称列表value是()将元素属性值作为字符串序列
'''
相关文章:

Python 爬虫工具
Python3 默认提供了urllib库,可以爬取网页信息,但其中确实有不方便的地方,如:处理网页验证和Cookies,以及Hander头信息处理。 为了更加方便处理,有了更为强大的库 urllib3 和 requests, 本节会分别介绍一下…...

再也不去字节跳动面试了,6年测开经验的真实面试经历.....
前几天我朋友跟我吐苦水,这波面试又把他打击到了,做了快6年软件测试员。。。为了进大厂,也花了很多时间和精力在面试准备上,也刷了很多题。但题刷多了之后有点怀疑人生,不知道刷的这些题在之后的工作中能不能用到&…...

第十五章 角色移动旋转实例
本章节我们创建一个“RoleDemoProject”工程,然后导入我们之前创建地形章节中的“TerrainDemo.unitypackage”资源包,这个场景很大,大家需要调整场景视角才能看清。 接下来,我们添加一个人物模型,操作方式就是将模型文…...
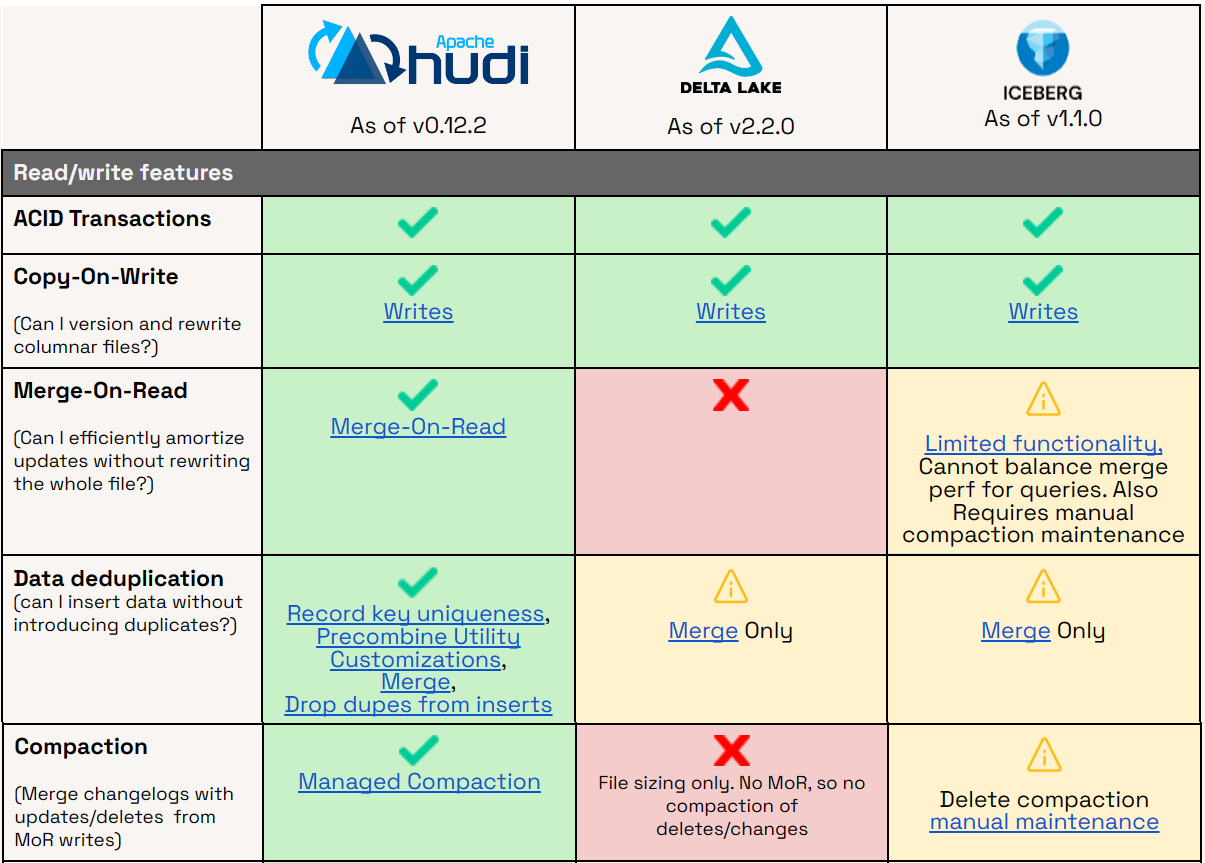
数据湖Data Lakehouse支持行级更改的策略:COW、MOR、Delete+Insert
COW:写时复制,MOR:读时合并,Delete+Insert:保证同一个主键下仅存在一条记录,将更新操作转换为Delete操作和Insert操作 COW和MOR的对比如下图,而Delete+Insert在StarRocks主键模型中用到。 目前COW、MOR在三大开源数据湖项目的使用情况,如下图。 写入时复制【Copy-On…...
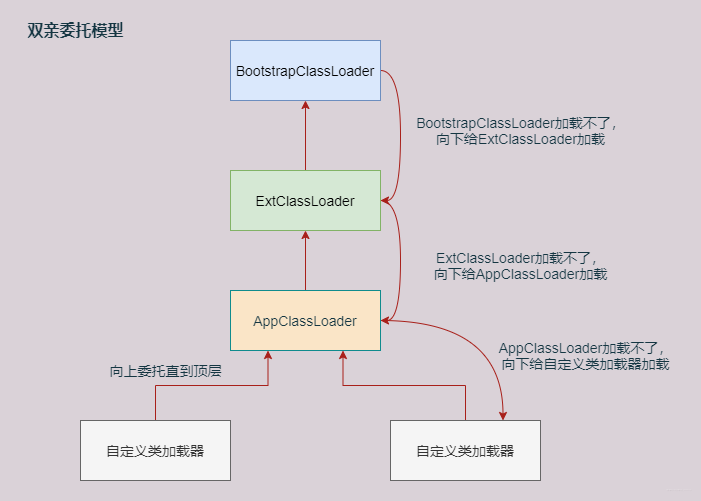
双亲委派机制的原理和作用
双亲委派机制,就必须弄清楚Java的类加载器。 什么是类加载器 Java类加载器(ClassLoader)是Java运行时环境(JRE)的一部分,负责动态的将Java类加载到Java虚拟机的内存空间。 类加载器有哪些 主要有三个: 引导类加载器(Bootstrap ClassLoade…...

mac免费杀毒软件哪个好用?如何清理mac系统需要垃圾
CleanMyMac x是一款功能强大的Mac系统优化清理工具,使用旨在帮助用户更加方便的清理您系统中的所有垃圾,从而加快电脑运行速度,保持最佳性能,更加稳定、流畅、快速!!! CleanMyMac X无疑是目前m…...

css 实现太极效果
目录 一、简述二、太极效果制作 一、简述 本次主要介绍::after,::before,box-shadow这三个属性。 ::after,::before这两个是伪类选择器,box-shaow是用来设置元素的阴影效果 before:向选定的元素前插入内容 after:向选定的元素后插…...

【前端基础知识】Vue中的变量不是响应式的吗?属性赋值后视图不变化的原因是什么?
目录 🤔问题📝回答🎨使用场景动态添加属性动态添加数组元素 ❌注意事项$set只能在响应式对象上使用$set不能用于根级别的属性$set的性能问题 📄总结 🤔问题 Vue是一款在国内非常流行的框架,采用MVVM架构&a…...

如何完全卸载linux下通过rpm安装的mysql
卸载linux下通过rpm安装的mysql 1.关闭MySQL服务2.使用 rpm 命令的方式查看已安装的mysql3. 使用rpm -ev 命令移除安装4. 查询是否还存在遗漏文件5. 删除MySQL数据库内容 1.关闭MySQL服务 如果之前安装过并已经启动,则需要卸载前请先关闭MySQL服务 systemctl stop…...
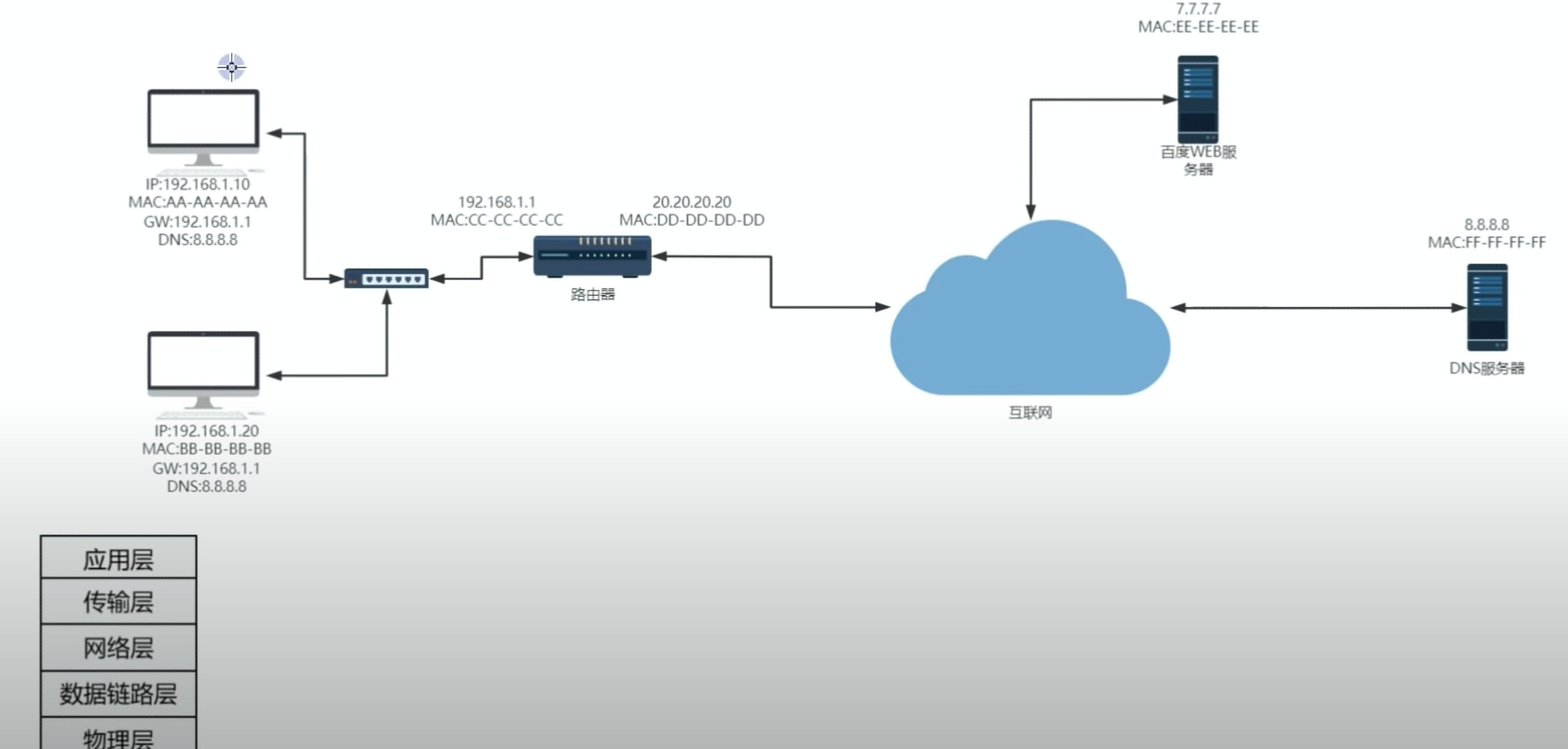
[渗透教程]-004-长城防火墙GFW的原理
文章目录 1. baidu.com 请求过程2. GFW原理2.1 GFW拦截方法1:DNS渲染2.2 通过IP黑名单2.3 VPN阻断1. baidu.com 请求过程 家庭的路由器具备了交换机的功能.域名–>ip,优先检测本地的缓存,没有的话就查找DNS服务器,传输层对应该层的数据进行封装增加了端口的信息,网络层对传输…...
LaTeX基础文本排版命令
LaTeX基础文本排版命令 1. 字体大小2. 字体的粗体与斜体2.1. 粗体2.2 斜体2.3 同时启用粗体和斜体 3. 空格长度4. 高度与宽度尺寸 在LaTeX中,文本排版可以通过简单的命令实现,这些命令可以控制字体大小、粗体与斜体、空格、行高和宽度等方面,…...
PLC模糊控制模糊PID(梯形图实现+算法分析)
博途PLC的模糊PID控制详细内容请查看下面的博客文章: Matlab仿真+博途PLC模糊PID控制完整SCL源代码参考(带模糊和普通PID切换功能)_博途怎么实现模糊pid_RXXW_Dor的博客-CSDN博客模糊PID的其它相关数学基础,理论知识大家可以参看专栏的其它文章,这里不再赘述,本文就双容…...

线程池在Java多线程中的应用
前言 随着计算机硬件和软件技术的不断发展,多线程编程在软件开发中变得越来越常见。然而,使用多线程编程时必须小心谨慎,以确保正确性和可维护性。在这个过程中,线程池成为了一个至关重要的工具。本文将介绍其应用场景、注意事项…...
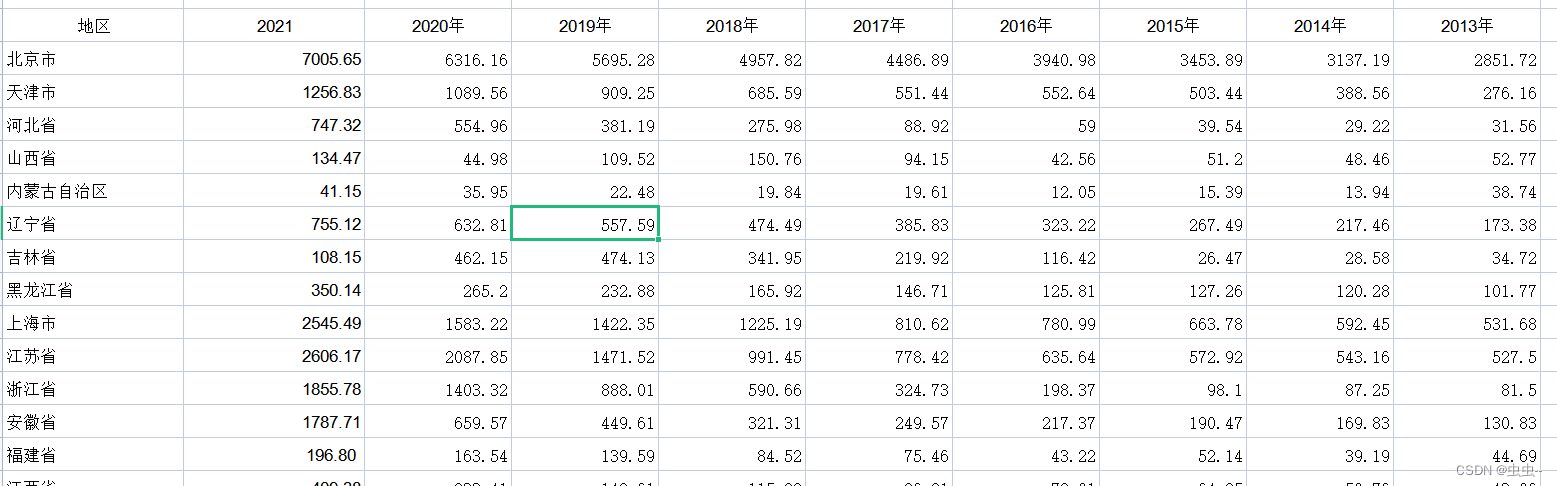
1997-2021年全国30省技术市场成交额(亿元)
1997-2021年全国30省技术市场成交额 1、时间:1997-2021年 2、范围:30省不含西藏 3、来源:国家统计J 4、指标:技术市场成交额 5、缺失情况说明:无缺失 6、指标解释及用途: 技术市场成交额是一个客观、…...

【C++】面向对象之多态
文章内的所有调试都是在vs2022下进行的, 部分小细节可能因编译器不同存在差异。 文章目录 多态的定义和实现概念引入多态的构成条件虚函数重写通过基类的指针或者引用调用虚函数 override和final 抽象类概念实现继承和接口继承 虚函数表单继承中的虚表打印虚表多继…...
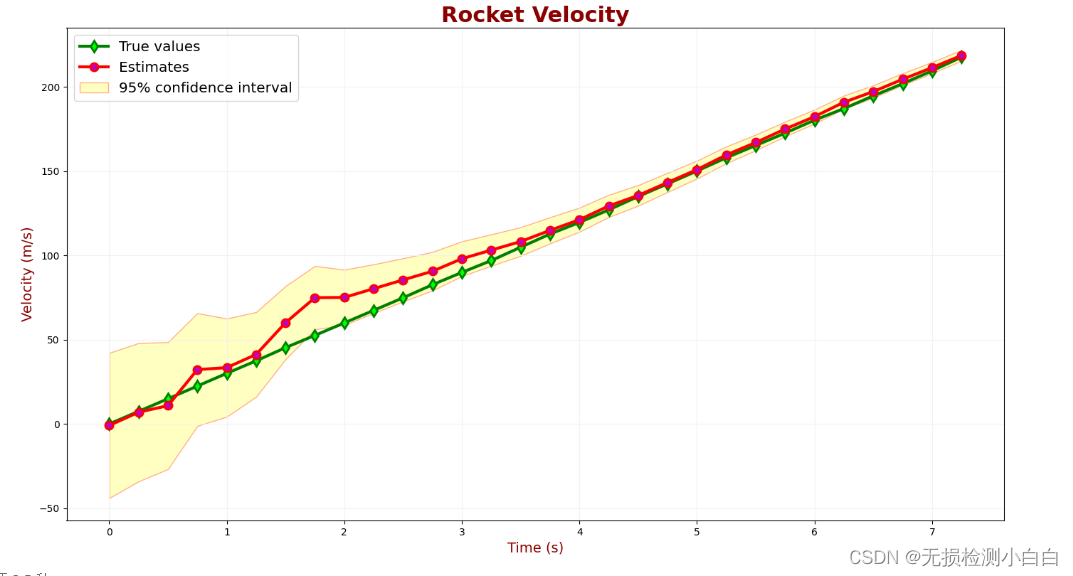
卡尔曼滤波器简介——多维卡尔曼滤波
原文:多维卡尔曼滤波 (kalmanfilter.net) 目录 前言 基本背景 状态外推方程 示例 - 飞机 - 无控制输入 示例 - 带控制输入的飞机 示例 – 坠落物体 状态外推方程维度 线性时不变系统 线性动态系统建模 状态外推方程的推导 状态空间表示形式 示例 - 等速…...

如何用 GPT-4 帮你写游戏?
你知道的,GPT-4 发布了。 目前你想要用上 GPT-4,主要的渠道是 ChatGPT Plus 。作为交了订阅费的用户,你可以在对话的时候选择模型来使用。 另一种渠道,就是申请官方 API 的排队。我在申请 New Bing Chat 的时候,耐心被…...
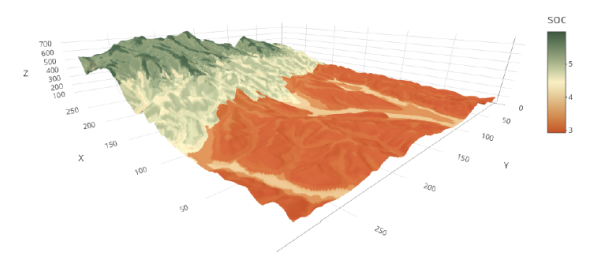
R语言的贝叶斯时空数据模型实践技术应用
时间-空间数据(以下简称“时空数据”)是最重要的观测数据形式之一,很多科学研究的数据都以时空数据的形式得以呈现,而科学研究目的可以归结为挖掘时空数据中的规律。另一方面,贝叶斯统计学作为与传统统计学…...

Lazysysadmin靶机渗透过程
准备工作 下载好靶机到本地后 VMware导入OVA 启动靶机 扫描信息 首先扫描整个C段发现主机 进一步扫描端口 从扫描结果可知: Samba服务MySQLSSH端口网站端口 先对网站进行目录遍历 发现有wordpress网站和phpmyadmin管理系统 出现了非常多遍My name is togie.可能…...

为什么网络安全缺口很大,招聘却很少?
2020年我国网络空间安全人才数量缺口超过了140万,就业人数却只有10多万,缺口高达了93%。这里就有人会问了: 1、网络安全行业为什么这么缺人? 2、明明人才那么稀缺,为什么招聘时招安全的人员却没有那么多呢࿱…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...