Java面试题队列
Java中的队列都有哪些,有什么区别
1. ArrayDeque, (数组双端队列)
2. PriorityQueue, (优先级队列)
3. ConcurrentLinkedQueue, (基于链表的并发队列)
4. DelayQueue, (延期阻塞队列)(阻塞队列实现了BlockingQueue接口)
5. ArrayBlockingQueue, (基于数组的并发阻塞队列)
6. LinkedBlockingQueue, (基于链表的FIFO阻塞队列)
7. LinkedBlockingDeque, (基于链表的FIFO双端阻塞队列)
8. PriorityBlockingQueue, (带优先级的无界阻塞队列)
9. SynchronousQueue (并发同步阻塞队列)
反射中,Class.forName和classloader的区别
java中class.forName()和classLoader都可用来对类进行加载。
class.forName()前者除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static
块。
而classLoader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在
newInstance才会去执行static块。
Class.forName(name, initialize, loader)带参函数也可控制是否加载static块。并且只有调用了
newInstance()方法采用调用构造函数,创建类的对象
看下Class.forName()源码
//Class.forName(String className) 这是1.8的源码
public static Class<?> forName(String className) throws
ClassNotFoundException {
Class<?> caller = Reflection.getCallerClass();
return forName0(className, true, ClassLoader.getClassLoader(caller),
caller);
}
//注意第二个参数,是指Class被loading后是不是必须被初始化。 不初始化就是不执行static的代
码即静态代码然后就是,测试代码证明上面的结论是OK的,如下:
package com.lxk.Reflect;
/**
* Created by lxk on 2017/2/21
*/
public class Line {
static {
System.out.println("静态代码块执行:loading line");
}
}
package com.lxk.Reflect;
/**
* Created by lxk on 2017/2/21
*/
public class Point {
static {
System.out.println("静态代码块执行:loading point");
}
}
package com.lxk.Reflect;
/**
* Class.forName和classloader的区别
* <p>
* Created by lxk on 2017/2/21
*/
public class ClassloaderAndForNameTest {
public static void main(String[] args) {
String wholeNameLine = "com.lxk.Reflect.Line";
String wholeNamePoint = "com.lxk.Reflect.Point";
System.out.println("下面是测试Classloader的效果");
testClassloader(wholeNameLine, wholeNamePoint);
System.out.println("----------------------------------");
System.out.println("下面是测试Class.forName的效果");
testForName(wholeNameLine, wholeNamePoint);
}
/**
* classloader
*/
private static void testClassloader(String wholeNameLine, String
wholeNamePoint) {
Class<?> line;Class<?> point;
ClassLoader loader = ClassLoader.getSystemClassLoader();
try {
line = loader.loadClass(wholeNameLine);
point = loader.loadClass(wholeNamePoint);
//demo =
ClassloaderAndForNameTest.class.getClassLoader().loadClass(wholeNamePoint);//这个
也是可以的
System.out.println("line " + line.getName());
System.out.println("point " + point.getName());
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
/**
* Class.forName
*/
private static void testForName(String wholeNameLine, String wholeNamePoint)
{
try {
Class line = Class.forName(wholeNameLine);
Class point = Class.forName(wholeNamePoint);
System.out.println("line " + line.getName());
System.out.println("point " + point.getName());
} catch (Exception e) {
e.printStackTrace();
}
}
}
执行结果如下:备注:
根据运行结果,可以看到,classloader并没有执行静态代码块,如开头的理论所说。
而下面的Class.forName则是夹在完之后,就里面执行了静态代码块,可以看到,2个类,line和point的
静态代码块执行结果是一起的,然后才是各自的打印结果。
也说明上面理论是OK的。
因为看到有小伙伴有疑问,我就把自己以前的代码拿出来再次测试一遍,发现结果仍然是相同的。
但是,因为我的Javabean model又经历了其他的测试,所以,两个model内部的代码稍有变化,
然后,还真就测试出来了不一样的地方。
这估计是其他理论所没有的。具体看下面的代码吧。
只是修改了Line的代码,添加了几个静态的方法和变量。
package com.lxk.reflect;
/**
* Created by lxk on 2017/2/21
*/
public class Line {
static {
System.out.println("静态代码块执行:loading line");
}
public static String s = getString();
private static String getString() {
System.out.println("给静态变量赋值的静态方法执行:loading line");return "ss";
}
public static void test() {
System.out.println("普通静态方法执行:loading line");
}
{
System.out.println("要是普通的代码块呢?");
}
public Line() {
System.out.println("构造方法执行");
}
}
可以看到,除了原来的简单的一个静态代码块以外,我又添加了构造方法,静态方法,以及静态变量,
且,静态变量被一个静态方法赋值。
然后,看执行结果。
稍有不同。
除了,静态代码块的执行外,竟然还有一个静态方法被执行,就是给静态变量赋值的静态方法被执行
了。
这个估计是以前没人发现的吧。
所以
上面的结论,就可以进一步的修改啦。
也许,这个执行的也叫,static块呢。
讲讲IO里面的常见类,字节流、字符流、接口、实现类、
方法阻塞
Java IO流详解(二)——IO流的框架体系
一、IO流的概念
Java的IO流是实现输入/输出的基础,它可以方便地实现数据的输入/输出操作,在Java中把不同的输入/
输出源抽象表述为"流"。流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。
即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更
直观的进行数据操作。
流有输入和输出,输入时是流从数据源流向程序。输出时是流从程序传向数据源,而数据源可以是内
存,文件,网络或程序等。
二、IO流的分类
1.输入流和输出流
根据数据流向不同分为:输入流和输出流。
输入流:只能从中读取数据,而不能向其写入数据。
输出流:只能向其写入数据,而不能从中读取数据。
如下如所示:对程序而言,向右的箭头,表示输入,向左的箭头,表示输出。
2.字节流和字符流
字节流和字符流和用法几乎完全一样,区别在于字节流和字符流所操作的数据单元不同。
字符流的由来: 因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流
读取时,去查了指定的码表。字节流和字符流的区别:
(
1)读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次
可能读多个字节。(
2)处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的
数据。
只要是处理纯文本数据,就优先考虑使用字符流。 除此之外都使用字节流。
3.节点流和处理流
按照流的角色来分,可以分为节点流和处理流。
可以从/向一个特定的IO设备(如磁盘、网络)读/写数据的流,称为节点流,节点流也被成为低级流。
处理流是对一个已存在的流进行连接或封装,通过封装后的流来实现数据读/写功能,处理流也被称为
高级流。
当使用处理流进行输入/输出时,程序并不会直接连接到实际的数据源,没有和实际的输入/输出节点连
接。使用处理流的一个明显好处是,只要使用相同的处理流,程序就可以采用完全相同的输入/输出代码
来访问不同的数据源,随着处理流所包装节点流的变化,程序实际所访问的数据源也相应地发生变化。
实际上,Java使用处理流来包装节点流是一种典型的装饰器设计模式,通过使用处理流来包装不同的节
点流,既可以消除不同节点流的实现差异,也可以提供更方便的方法来完成输入/输出功能。
三、IO流的四大基类
根据流的流向以及操作的数据单元不同,将流分为了四种类型,每种类型对应一种抽象基类。这四种抽
象基类分别为:InputStream,Reader,OutputStream以及Writer。四种基类下,对应不同的实现类,具
有不同的特性。在这些实现类中,又可以分为节点流和处理流。下面就是整个由着四大基类支撑下,整
个IO流的框架图。
//节点流,直接传入的参数是IO设备
FileInputStream fis = new FileInputStream("test.txt");
//处理流,直接传入的参数是流对象
BufferedInputStream bis = new BufferedInputStream(fis);InputStream,Reader,OutputStream以及Writer,这四大抽象基类,本身并不能创建实例来执行输入/输
出,但它们将成为所有输入/输出流的模版,所以它们的方法是所有输入/输出流都可以使用的方法。类
似于集合中的Collection接口。
1.InputStream
InputStream 是所有的输入字节流的父类,它是一个抽象类,主要包含三个方法:
//读取一个字节并以整数的形式返回(0~255),如果返回-1已到输入流的末尾。
int read() ;
//读取一系列字节并存储到一个数组buffer,返回实际读取的字节数,如果读取前已到输入流的末尾返
回-1。
int read(byte[] buffer) ;
//读取length个字节并存储到一个字节数组buffer,从off位置开始存,最多len, 返回实际读取的字节
数,如果读取前以到输入流的末尾返回-1。
int read(byte[] buffer, int off, int len) ;2.Reader
Reader 是所有的输入字符流的父类,它是一个抽象类,主要包含三个方法:
对比InputStream和Reader所提供的方法,就不难发现两个基类的功能基本一样的,只不过读取的数据
单元不同。
在执行完流操作后,要调用 close() 方法来关系输入流,因为程序里打开的IO资源不属于内存资源,垃
圾回收机制无法回收该资源,所以应该显式关闭文件IO资源。
除此之外,InputStream和Reader还支持如下方法来移动流中的指针位置:
3.OutputStream
OutputStream 是所有的输出字节流的父类,它是一个抽象类,主要包含如下四个方法:
4.Writer
Writer 是所有的输出字符流的父类,它是一个抽象类,主要包含如下六个方法:
//读取一个字符并以整数的形式返回(0~255),如果返回-1已到输入流的末尾。
int read() ;
//读取一系列字符并存储到一个数组buffer,返回实际读取的字符数,如果读取前已到输入流的末尾返
回-1。
int read(char[] cbuf) ;
//读取length个字符,并存储到一个数组buffer,从off位置开始存,最多读取len,返回实际读取的字符
数,如果读取前以到输入流的末尾返回-1。
int read(char[] cbuf, int off, int len)
//在此输入流中标记当前的位置
//readlimit - 在标记位置失效前可以读取字节的最大限制。
void mark(int readlimit)
// 测试此输入流是否支持 mark 方法
boolean markSupported()
// 跳过和丢弃此输入流中数据的 n 个字节/字符
long skip(long n)
//将此流重新定位到最后一次对此输入流调用 mark 方法时的位置
void reset()
//向输出流中写入一个字节数据,该字节数据为参数b的低8位。
void write(int b) ;
//将一个字节类型的数组中的数据写入输出流。
void write(byte[] b);
//将一个字节类型的数组中的从指定位置(off)开始的,len个字节写入到输出流。
void write(byte[] b, int off, int len);
//将输出流中缓冲的数据全部写出到目的地。
void flush();可以看出,Writer比OutputStream多出两个方法,主要是支持写入字符和字符串类型的数据。
使用Java的IO流执行输出时,不要忘记关闭输出流,关闭输出流除了可以保证流的物理资源被回收之
外,还能将输出流缓冲区的数据flush到物理节点里(因为在执行close()方法之前,自动执行输出流的
flush()方法)
以上内容就是整个IO流的框架介绍。
讲讲NIO
NIO技术概览
NIO(Non-blocking I/O,在Java领域,也称为New I/O),是一种同步非阻塞的I/O模型,也是I/O多路
复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O处理问题的有
效方式。
IO模型的分类
按照《Unix网络编程》的划分,I/O模型可以分为:阻塞I/O模型、非阻塞I/O模型、I/O复用模型、信号
驱动式I/O模型和异步I/O模型,按照POSIX标准来划分只分为两类:同步I/O和异步I/O。
如何区分呢?首先一个I/O操作其实分成了两个步骤:发起IO请求和实际的IO操作。同步I/O和异步I/O的
区别就在于第二个步骤是否阻塞,如果实际的I/O读写阻塞请求进程,那么就是同步I/O,因此阻塞I/O、
非阻塞I/O、I/O复用、信号驱动I/O都是同步I/O,如果不阻塞,而是操作系统帮你做完I/O操作再将结果
返回给你,那么就是异步I/O。
阻塞I/O和非阻塞I/O的区别在于第一步,发起I/O请求是否会被阻塞,如果阻塞直到完成那么就是传统的
阻塞I/O,如果不阻塞,那么就是非阻塞I/O。
阻塞I/O模型 :在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是
这样:
//向输出流中写入一个字符数据,该字节数据为参数b的低16位。
void write(int c);
//将一个字符类型的数组中的数据写入输出流,
void write(char[] cbuf)
//将一个字符类型的数组中的从指定位置(offset)开始的,length个字符写入到输出流。
void write(char[] cbuf, int offset, int length);
//将一个字符串中的字符写入到输出流。
void write(String string);
//将一个字符串从offset开始的length个字符写入到输出流。
void write(String string, int offset, int length);
//将输出流中缓冲的数据全部写出到目的地。
void flush()非阻塞I/O模型:linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking
socket执行读操作时,流程是这个样子:
I/O复用模型:我们可以调用 select 或 poll ,阻塞在这两个系统调用中的某一个之上,而不是真
正的IO系统调用上:信号驱动式I/O模型:我们可以用信号,让内核在描述符就绪时发送SIGIO信号通知我们:
异步I/O模型:用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从内核
的角度,当它受到一个asynchronousread之后,首先它会立刻返回,所以不会对用户进程产生任
何block。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,
内核会给用户进程发送一个signal,告诉它read操作完成了:以上参考自:《UNIX网络编程》
从前面 I/O 模型的分类中,我们可以看出 AIO 的动机。阻塞模型需要在 I/O 操作开始时阻塞应用程序。
这意味着不可能同时重叠进行处理和 I/O 操作。非阻塞模型允许处理和 I/O 操作重叠进行,但是这需要
应用程序来检查 I/O 操作的状态。对于异步I/O ,它允许处理和 I/O 操作重叠进行,包括 I/O 操作完成的
通知。除了需要阻塞之外,select 函数所提供的功能(异步阻塞 I/O)与 AIO 类似。不过,它是对通知
事件进行阻塞,而不是对 I/O 调用进行阻塞。
参考下知乎上的回答:
同步与异步:同步和异步关注的是消息通信机制 (synchronous communication/
asynchronous communication)。所谓同步,就是在发出一个调用时,在没有得到结果之
前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动
等待这个调用的结果;
阻塞与非阻塞:阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态。阻
塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返
回;而非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
两种IO多路复用方案:Reactor和Proactor
一般地,I/O多路复用机制都依赖于一个事件多路分离器(Event Demultiplexer)。分离器对象可将来自
事件源的I/O事件分离出来,并分发到对应的read/write事件处理器(Event Handler)。开发人员预先注
册需要处理的事件及其事件处理器(或回调函数);事件分离器负责将请求事件传递给事件处理器。
两个与事件分离器有关的模式是Reactor和Proactor。Reactor模式采用同步I/O,而Proactor采用异步
I/O。在Reactor中,事件分离器负责等待文件描述符或socket为读写操作准备就绪,然后将就绪事件传
递给对应的处理器,最后由处理器负责完成实际的读写工作。
而在Proactor模式中,处理器或者兼任处理器的事件分离器,只负责发起异步读写操作。I/O操作本身由
操作系统来完成。传递给操作系统的参数需要包括用户定义的数据缓冲区地址和数据大小,操作系统才
能从中得到写出操作所需数据,或写入从socket读到的数据。事件分离器捕获I/O操作完成事件,然后将
事件传递给对应处理器。比如,在windows上,处理器发起一个异步I/O操作,再由事件分离器等待IOCompletion事件。典型的异步模式实现,都建立在操作系统支持异步API的基础之上,我们将这种实
现称为“系统级”异步或“真”异步,因为应用程序完全依赖操作系统执行真正的I/O工作。
举个例子,将有助于理解Reactor与Proactor二者的差异,以读操作为例(写操作类似)。
在Reactor中实现读:
注册读就绪事件和相应的事件处理器;
事件分离器等待事件;
事件到来,激活分离器,分离器调用事件对应的处理器;
事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
在Proactor中实现读:
处理器发起异步读操作(注意:操作系统必须支持异步I/O)。在这种情况下,处理器无视I/O就绪
事件,它关注的是完成事件;
事件分离器等待操作完成事件;
在分离器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自
定义缓冲区,最后通知事件分离器读操作完成;
事件分离器呼唤处理器;
事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分
离器。
可以看出,两个模式的相同点,都是对某个I/O事件的事件通知(即告诉某个模块,这个I/O操作可以进
行或已经完成)。在结构上,两者的相同点和不同点如下:
相同点:demultiplexor负责提交I/O操作(异步)、查询设备是否可操作(同步),然后当条件满
足时,就回调handler;
不同点:异步情况下(Proactor),当回调handler时,表示I/O操作已经完成;同步情况下
(Reactor),回调handler时,表示I/O设备可以进行某个操作(can read or can write)。
传统BIO模型
BIO是同步阻塞式IO,通常在while循环中服务端会调用accept方法等待接收客户端的连接请求,一旦接
收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客
户端连接请求,只能等待同当前连接的客户端的操作执行完成。
如果BIO要能够同时处理多个客户端请求,就必须使用多线程,即每次accept阻塞等待来自客户端请
求,一旦受到连接请求就建立通信套接字同时开启一个新的线程来处理这个套接字的数据读写请求,然
后立刻又继续accept等待其他客户端连接请求,即为每一个客户端连接请求都创建一个线程来单独处
理。
我们看下传统的BIO方式下的编程模型大致如下:
public class BIODemo {public static void main(String[] args) throws IOException {
ExecutorService executor = Executors.newFixedThreadPool(128);
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(1234));
// 循环等待新连接
while (true) {
Socket socket = serverSocket.accept();
// 为新的连接创建线程执行任务
executor.submit(new ConnectionTask(socket));
}
}
}
class ConnectionTask extends Thread {
private Socket socket;
public ConnectionTask(Socket socket) {
this.socket = socket;
}
public void run() {
while (true) {
InputStream inputStream = null;
OutputStream outputStream = null;
try {
inputStream = socket.getInputStream();
// read from socket...
inputStream.read();
outputStream = socket.getOutputStream();
// write to socket...
outputStream.write();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭资源...
}
}
}
}
这里之所以使用多线程,是因为socket.accept()、inputStream.read()、outputStream.write()都是同步
阻塞的,当一个连接在处理I/O的时候,系统是阻塞的,如果是单线程的话在阻塞的期间不能接受任何请
求。所以,使用多线程,就可以让CPU去处理更多的事情。其实这也是所有使用多线程的本质:
利用多核。当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。
使用线程池能够让线程的创建和回收成本相对较低。在活动连接数不是特别高(小于单机1000)的情况
下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,也不用过多考虑系
统的过载、限流等问题。线程池可以缓冲一些过多的连接或请求。
但这个模型最本质的问题在于,严重依赖于线程。但线程是很”贵”的资源,主要表现在:
1. 线程的创建和销毁成本很高,在Linux这样的操作系统中,线程本质上就是一个进程。创建和销毁
都是重量级的系统函数;
2. 线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间,如果系统中的线程数
过千,恐怕整个JVM的内存都会被吃掉一半;
3. 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统
调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现
往往是系统load偏高、CPU sy使用率特别高(超过20%以上),导致系统几乎陷入不可用的状态;
4. 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部
网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载
压力过大。
所以,当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。随着移动端应用的兴起和各
种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的I/O处理模型。
NIO的实现原理
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题,即在使用同步I/O的网络
应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多
线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的
要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也
叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程
序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知应用程序进行处理,应
用再将流读取到缓冲区或写入操作系统。
也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,
当连接没有数据时,是没有工作线程来处理的。
下面看下代码的实现:
NIO服务端代码(新建连接):
NIO服务端代码(监听):
//获取一个ServerSocket通道
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.configureBlocking(false);
serverChannel.socket().bind(new InetSocketAddress(port));
//获取通道管理器
selector = Selector.open();
//将通道管理器与通道绑定,并为该通道注册SelectionKey.OP_ACCEPT事件,
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
while(true){
//当有注册的事件到达时,方法返回,否则阻塞。
selector.select();
for(SelectionKey key : selector.selectedKeys()){
if(key.isAcceptable()){NIO模型示例如下:
Acceptor注册Selector,监听accept事件;
当客户端连接后,触发accept事件;
服务器构建对应的Channel,并在其上注册Selector,监听读写事件;
当发生读写事件后,进行相应的读写处理。
Reactor模型
有关Reactor模型结构,可以参考Doug Lea在 Scalable IO in Java中的介绍。这里简单介绍一下Reactor
模式的典型实现:
Reactor单线程模型
这是最简单的单Reactor单线程模型。Reactor线程负责多路分离套接字、accept新连接,并分派请求到
处理器链中。该模型适用于处理器链中业务处理组件能快速完成的场景。不过,这种单线程模型不能充
分利用多核资源,所以实际使用的不多。
这个模型和上面的NIO流程很类似,只是将消息相关处理独立到了Handler中去了。
代码实现如下:
ServerSocketChannel server =
(ServerSocketChannel)key.channel();
SocketChannel channel = server.accept();
channel.write(ByteBuffer.wrap(
new String("send message to client").getBytes()));
//在与客户端连接成功后,为客户端通道注册SelectionKey.OP_READ事件。
channel.register(selector, SelectionKey.OP_READ);
}else if(key.isReadable()){//有可读数据事件
SocketChannel channel = (SocketChannel)key.channel();
ByteBuffer buffer = ByteBuffer.allocate(10);
int read = channel.read(buffer);
byte[] data = buffer.array();
String message = new String(data);
System.out.println("receive message from client, size:"
+ buffer.position() + " msg: " + message);
}
}
}public class Reactor implements Runnable {
final Selector selector;
final ServerSocketChannel serverSocketChannel;
public static void main(String[] args) throws IOException {
new Thread(new Reactor(1234)).start();
}
public Reactor(int port) throws IOException {
selector = Selector.open();
serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(port));
serverSocketChannel.configureBlocking(false);
SelectionKey key = serverSocketChannel.register(selector,
SelectionKey.OP_ACCEPT);
key.attach(new Acceptor());
}
@Override
public void run() {
while (!Thread.interrupted()) {
try {
selector.select();
Set<SelectionKey> selectionKeys = selector.selectedKeys();
for (SelectionKey selectionKey : selectionKeys) {
dispatch(selectionKey);
}
selectionKeys.clear();
} catch (IOException e) {
e.printStackTrace();
}
}
}
private void dispatch(SelectionKey selectionKey) {
Runnable run = (Runnable) selectionKey.attachment();
if (run != null) {
run.run();
}
}
class Acceptor implements Runnable {
@Override
public void run() {
try {
SocketChannel channel = serverSocketChannel.accept();
if (channel != null) {
new Handler(selector, channel);
}
} catch (IOException e) {
e.printStackTrace();
}}
}
}
class Handler implements Runnable {
private final static int DEFAULT_SIZE = 1024;
private final SocketChannel socketChannel;
private final SelectionKey seletionKey;
private static final int READING = 0;
private static final int SENDING = 1;
private int state = READING;
ByteBuffer inputBuffer = ByteBuffer.allocate(DEFAULT_SIZE);
ByteBuffer outputBuffer = ByteBuffer.allocate(DEFAULT_SIZE);
public Handler(Selector selector, SocketChannel channel) throws IOException
{
this.socketChannel = channel;
socketChannel.configureBlocking(false);
this.seletionKey = socketChannel.register(selector, 0);
seletionKey.attach(this);
seletionKey.interestOps(SelectionKey.OP_READ);
selector.wakeup();
}
@Override
public void run() {
if (state == READING) {
read();
} else if (state == SENDING) {
write();
}
}
class Sender implements Runnable {
@Override
public void run() {
try {
socketChannel.write(outputBuffer);
} catch (IOException e) {
e.printStackTrace();
}
if (outIsComplete()) {
seletionKey.cancel();
}
}}
private void write() {
try {
socketChannel.write(outputBuffer);
} catch (IOException e) {
e.printStackTrace();
}
while (outIsComplete()) {
seletionKey.cancel();
}
}
private void read() {
try {
socketChannel.read(inputBuffer);
if (inputIsComplete()) {
process();
System.out.println("接收到来自客户端(" +
socketChannel.socket().getInetAddress().getHostAddress()
+ ")的消息:" + new String(inputBuffer.array()));
seletionKey.attach(new Sender());
seletionKey.interestOps(SelectionKey.OP_WRITE);
seletionKey.selector().wakeup();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public boolean inputIsComplete() {
return true;
}
public boolean outIsComplete() {
return true;
}
public void process() {
// do something...
}
}
虽然上面说到NIO一个线程就可以支持所有的IO处理。但是瓶颈也是显而易见的。我们看一个客户端的
情况,如果这个客户端多次进行请求,如果在Handler中的处理速度较慢,那么后续的客户端请求都会
被积压,导致响应变慢!所以引入了Reactor多线程模型。Reactor多线程模型
相比上一种模型,该模型在处理器链部分采用了多线程(线程池):
Reactor多线程模型就是将Handler中的IO操作和非IO操作分开,操作IO的线程称为IO线程,非IO操作的
线程称为工作线程。这样的话,客户端的请求会直接被丢到线程池中,客户端发送请求就不会堵塞。
可以将Handler做如下修改:
class Handler implements Runnable {
private final static int DEFAULT_SIZE = 1024;
private final SocketChannel socketChannel;
private final SelectionKey seletionKey;
private static final int READING = 0;
private static final int SENDING = 1;
private int state = READING;
ByteBuffer inputBuffer = ByteBuffer.allocate(DEFAULT_SIZE);
ByteBuffer outputBuffer = ByteBuffer.allocate(DEFAULT_SIZE);
private Selector selector;
private static ExecutorService executorService =
Executors.newFixedThreadPool(Runtime.getRuntime()
.availableProcessors());
private static final int PROCESSING = 3;
public Handler(Selector selector, SocketChannel channel) throws IOException
{
this.selector = selector;
this.socketChannel = channel;
socketChannel.configureBlocking(false);
this.seletionKey = socketChannel.register(selector, 0);
seletionKey.attach(this);
seletionKey.interestOps(SelectionKey.OP_READ);
selector.wakeup();
}
@Override
public void run() {
if (state == READING) {read();
} else if (state == SENDING) {
write();
}
}
class Sender implements Runnable {
@Override
public void run() {
try {
socketChannel.write(outputBuffer);
} catch (IOException e) {
e.printStackTrace();
}
if (outIsComplete()) {
seletionKey.cancel();
}
}
}
private void write() {
try {
socketChannel.write(outputBuffer);
} catch (IOException e) {
e.printStackTrace();
}
if (outIsComplete()) {
seletionKey.cancel();
}
}
private void read() {
try {
socketChannel.read(inputBuffer);
if (inputIsComplete()) {
process();
executorService.execute(new Processer());
}
} catch (IOException e) {
e.printStackTrace();
}
}
public boolean inputIsComplete() {
return true;
}
public boolean outIsComplete() {
return true;
}但是当用户进一步增加的时候,Reactor会出现瓶颈!因为Reactor既要处理IO操作请求,又要响应连接
请求。为了分担Reactor的负担,所以引入了主从Reactor模型。
主从Reactor多线程模型
主从Reactor多线程模型是将Reactor分成两部分,mainReactor负责监听server socket,accept新连
接,并将建立的socket分派给subReactor。subReactor负责多路分离已连接的socket,读写网络数据,
对业务处理功能,其扔给worker线程池完成。通常,subReactor个数上可与CPU个数等同:
这时可以把Reactor做如下修改:
public void process() {
}
synchronized void processAndHandOff() {
process();
state = SENDING; // or rebind attachment
seletionKey.interestOps(SelectionKey.OP_WRITE);
selector.wakeup();
}
class Processer implements Runnable {
public void run() {
processAndHandOff();
}
}
}
public class Reactor {
final ServerSocketChannel serverSocketChannel;
Selector[] selectors; // also create threads
AtomicInteger next = new AtomicInteger(0);
ExecutorService sunReactors =
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public static void main(String[] args) throws IOException {
new Reactor(1234);
}
public Reactor(int port) throws IOException {
serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(port));
serverSocketChannel.configureBlocking(false);
selectors = new Selector[4];
for (int i = 0; i < 4; i++) {Selector selector = Selector.open();
selectors[i] = selector;
SelectionKey key = serverSocketChannel.register(selector,
SelectionKey.OP_ACCEPT);
key.attach(new Acceptor());
new Thread(() -> {
while (!Thread.interrupted()) {
try {
selector.select();
Set<SelectionKey> selectionKeys =
selector.selectedKeys();
for (SelectionKey selectionKey : selectionKeys) {
dispatch(selectionKey);
}
selectionKeys.clear();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
private void dispatch(SelectionKey selectionKey) {
Runnable run = (Runnable) selectionKey.attachment();
if (run != null) {
run.run();
}
}
class Acceptor implements Runnable {
@Override
public void run() {
try {
SocketChannel connection = serverSocketChannel.accept();
if (connection != null)
sunReactors.execute(new
Handler(selectors[next.getAndIncrement() % selectors.length], connection));
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
可见,主Reactor用于响应连接请求,从Reactor用于处理IO操作请求。AIO
与NIO不同,当进行读写操作时,只须直接调用API的read或write方法即可。这两种方法均为异步的,
对于读操作而言,当有流可读取时,操作系统会将可读的流传入read方法的缓冲区,并通知应用程序;
对于写操作而言,当操作系统将write方法传递的流写入完毕时,操作系统主动通知应用程序。
即可以理解为,read/write方法都是异步的,完成后会主动调用回调函数。
在JDK1.7中,这部分内容被称作NIO.2,主要在java.nio.channels包下增加了下面四个异步通道:
AsynchronousSocketChannel
AsynchronousServerSocketChannel
AsynchronousFileChannel
AsynchronousDatagramChannel
我们看一下AsynchronousSocketChannel中的几个方法:
其中的read/write方法,有的会返回一个 Future 对象,有的需要传入一个 CompletionHandler 对象,
该对象的作用是当执行完读取/写入操作后,直接该对象当中的方法进行回调。
public abstract class AsynchronousSocketChannel
implements AsynchronousByteChannel, NetworkChannel
{
public abstract Future<Integer> read(ByteBuffer dst);
public abstract <A> void read(ByteBuffer[] dsts,
int offset,
int length,
long timeout,
TimeUnit unit,
A attachment,
CompletionHandler<Long,? super A> handler);
public abstract <A> void write(ByteBuffer src,
long timeout,
TimeUnit unit,
A attachment,
CompletionHandler<Integer,? super A>
handler);
public final <A> void write(ByteBuffer src,
A attachment,
CompletionHandler<Integer,? super A> handler)
{
write(src, 0L, TimeUnit.MILLISECONDS, attachment, handler);
}
public abstract Future<Integer> write(ByteBuffer src);
public abstract <A> void write(ByteBuffer[] srcs,
int offset,
int length,
long timeout,
TimeUnit unit,
A attachment,
CompletionHandler<Long,? super A> handler);
}对于 AsynchronousSocketChannel 而言,在windows和linux上的实现类是不一样的。
在windows上,AIO的实现是通过IOCP来完成的,实现类是:
实现的接口是:
而在linux上,实现类是:
实现的接口是:
AIO是一种接口标准,各家操作系统可以实现也可以不实现。在不同操作系统上在高并发情况下最好都
采用操作系统推荐的方式。Linux上还没有真正实现网络方式的AIO。
select和epoll的区别
当需要读两个以上的I/O的时候,如果使用阻塞式的I/O,那么可能长时间的阻塞在一个描述符上面,另
外的描述符虽然有数据但是不能读出来,这样实时性不能满足要求,大概的解决方案有以下几种:
1. 使用多进程或者多线程,但是这种方法会造成程序的复杂,而且对与进程与线程的创建维护也需要
很多的开销(Apache服务器是用的子进程的方式,优点可以隔离用户);
2. 用一个进程,但是使用非阻塞的I/O读取数据,当一个I/O不可读的时候立刻返回,检查下一个是否
可读,这种形式的循环为轮询(polling),这种方法比较浪费CPU时间,因为大多数时间是不可
读,但是仍花费时间不断反复执行read系统调用;
3. 异步I/O,当一个描述符准备好的时候用一个信号告诉进程,但是由于信号个数有限,多个描述符
时不适用;
4. 一种较好的方式为I/O多路复用,先构造一张有关描述符的列表(epoll中为队列),然后调用一个
函数,直到这些描述符中的一个准备好时才返回,返回时告诉进程哪些I/O就绪。select和epoll这
两个机制都是多路I/O机制的解决方案,select为POSIX标准中的,而epoll为Linux所特有的。
它们的区别主要有三点:
1. select的句柄数目受限,在linux/posix_types.h头文件有这样的声明: #define __FD_SETSIZE
1024 表示select最多同时监听1024个fd。而epoll没有,它的限制是最大的打开文件句柄数目;
2. epoll的最大好处是不会随着FD的数目增长而降低效率,在selec中采用轮询处理,其中的数据结构
类似一个数组的数据结构,而epoll是维护一个队列,直接看队列是不是空就可以了。epoll只会对”
活跃”的socket进行操作—这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那
么,只有”活跃”的socket才会主动的去调用 callback函数(把这个句柄加入队列),其他idle状态
句柄则不会,在这点上,epoll实现了一个”伪”AIO。但是如果绝大部分的I/O都是“活跃的”,每个I/O
端口使用率很高的话,epoll效率不一定比select高(可能是要维护队列复杂);
3. 使用mmap加速内核与用户空间的消息传递。无论是select,poll还是epoll都需要内核把FD消息通知
给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间
mmap同一块内存实现的。
WindowsAsynchronousSocketChannelImpl
Iocp.OverlappedChannel
UnixAsynchronousSocketChannelImpl
Port.PollableChannelNIO与epoll
上文说到了select与epoll的区别,再总结一下Java NIO与select和epoll:
Linux2.6之后支持epoll
windows支持select而不支持epoll
不同系统下nio的实现是不一样的,包括Sunos linux 和windows
select的复杂度为O(N)
select有最大fd限制,默认为1024
修改sys/select.h可以改变select的fd数量限制
epoll的事件模型,无fd数量限制,复杂度O(1),不需要遍历fd
以下代码基于Java 8。
下面看下在NIO中Selector的open方法:
这里使用了SelectorProvider去创建一个Selector,看下provider方法的实现:
看下 sun.nio.ch.DefaultSelectorProvider.create() 方法,该方法在不同的操作系统中的代码是
不同的,在windows中的实现如下:
在Mac OS中的实现如下:
在linux中的实现如下:
public static Selector open() throws IOException {
return SelectorProvider.provider().openSelector();
}
public static SelectorProvider provider() {
synchronized (lock) {
if (provider != null)
return provider;
return AccessController.doPrivileged(
new PrivilegedAction<SelectorProvider>() {
public SelectorProvider run() {
if (loadProviderFromProperty())
return provider;
if (loadProviderAsService())
return provider;
provider = sun.nio.ch.DefaultSelectorProvider.create();
return provider;
}
});
}
}
public static SelectorProvider create() {
return new WindowsSelectorProvider();
}
public static SelectorProvider create() {
return new KQueueSelectorProvider();
}我们看到create方法中是通过区分操作系统来返回不同的Provider的。其中SunOs就是Solaris返回的是
DevPollSelectorProvider,对于Linux,返回的Provder是EPollSelectorProvider,其余操作系统,返回
的是PollSelectorProvider。
Zero Copy
许多web应用都会向用户提供大量的静态内容,这意味着有很多数据从硬盘读出之后,会原封不动的通
过socket传输给用户。
这种操作看起来可能不会怎么消耗CPU,但是实际上它是低效的:
1. kernel把从disk读数据;
2. 将数据传输给application;
3. application再次把同样的内容再传回给处于kernel级的socket。
这种场景下,application实际上只是作为一种低效的中间介质,用来把磁盘文件的数据传给socket。
数据每次传输都会经过user和kernel空间都会被copy,这会消耗cpu,并且占用RAM的带宽。
传统的数据传输方式
像这种从文件读取数据然后将数据通过网络传输给其他的程序的方式其核心操作就是如下两个调用:
其上操作看上去只有两个简单的调用,但是其内部过程却要经历四次用户态和内核态的切换以及四次的
数据复制操作:
public static SelectorProvider create() {
String str = (String)AccessController.doPrivileged(new
GetPropertyAction("os.name"));
if (str.equals("SunOS"))
return createProvider("sun.nio.ch.DevPollSelectorProvider");
if (str.equals("Linux"))
return createProvider("sun.nio.ch.EPollSelectorProvider");
return new PollSelectorProvider();
}
File.read(fileDesc,buf,len);
Socket.send(socket,buf,len);上图展示了数据从文件到socket的内部流程。
下面看下用户态和内核态的切换过程:
步骤如下:
1. read()的调用引起了从用户态到内核态的切换(看图二),内部是通过sys_read()(或者类似的方
法)发起对文件数据的读取。数据的第一次复制是通过DMA(直接内存访问)将磁盘上的数据复制
到内核空间的缓冲区中;
2. 数据从内核空间的缓冲区复制到用户空间的缓冲区后,read()方法也就返回了。此时内核态又切换
回用户态,现在数据也已经复制到了用户地址空间的缓存中;
3. socket的send()方法的调用又会引起用户态到内核的切换,第三次数据复制又将数据从用户空间缓
冲区复制到了内核空间的缓冲区,这次数据被放在了不同于之前的内核缓冲区中,这个缓冲区与数
据将要被传输到的socket关联;
4. send()系统调用返回后,就产生了第四次用户态和内核态的切换。随着DMA单独异步的将数据从内
核态的缓冲区中传输到协议引擎发送到网络上,有了第四次数据复制。Zero Copy的数据传输方式
java.nio.channels.FileChannel 中定义了两个方法:transferTo( )和 transferFrom( )。
transferTo( )和 transferFrom( )方法允许将一个通道交叉连接到另一个通道,而不需要通过一个中间缓
冲区来传递数据。只有 FileChannel 类有这两个方法,因此 channel-to-channel 传输中通道之一必须
是 FileChannel。您不能在 socket 通道之间直接传输数据,不过 socket 通道实现
WritableByteChannel 和 ReadableByteChannel 接口,因此文件的内容可以用 transferTo( ) 方
法传输给一个 socket 通道,或者也可以用 transferFrom( )方法将数据从一个 socket 通道直接读取到一
个文件中。
下面根据 transferTo() 方法来说明。
根据上文可知, transferTo() 方法可以把bytes直接从调用它的channel传输到另一个
WritableByteChannel,中间不经过应用程序。
下面看下该方法的定义:
下图展示了通过transferTo实现数据传输的路径:
下图展示了内核态、用户态的切换情况:
使用transferTo()方式所经历的步骤:
1. transferTo调用会引起DMA将文件内容复制到读缓冲区(内核空间的缓冲区),然后数据从这个缓冲
区复制到另一个与socket输出相关的内核缓冲区中;
public abstract long transferTo(long position, long count,
WritableByteChannel target)
throws IOException;2. 第三次数据复制就是DMA把socket关联的缓冲区中的数据复制到协议引擎上发送到网络上。
这次改善,我们是通过将内核、用户态切换的次数从四次减少到两次,将数据的复制次数从四次减少到
三次(只有一次用到cpu资源)。但这并没有达到我们零复制的目标。如果底层网络适配器支持收集操作的
话,我们可以进一步减少内核对数据的复制次数。在内核为2.4或者以上版本的linux系统上,socket缓
冲区描述符将被用来满足这个需求。这个方式不仅减少了内核用户态间的切换,而且也省去了那次需要
cpu参与的复制过程。从用户角度来看依旧是调用transferTo()方法,但是其本质发生了变化:
1. 调用transferTo方法后数据被DMA从文件复制到了内核的一个缓冲区中;
2. 数据不再被复制到socket关联的缓冲区中了,仅仅是将一个描述符(包含了数据的位置和长度等信
息)追加到socket关联的缓冲区中。DMA直接将内核中的缓冲区中的数据传输给协议引擎,消除了
仅剩的一次需要cpu周期的数据复制。
NIO存在的问题
使用NIO != 高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。
NIO并没有完全屏蔽平台差异,它仍然是基于各个操作系统的I/O系统实现的,差异仍然存在。使用NIO
做网络编程构建事件驱动模型并不容易,陷阱重重。
推荐大家使用成熟的NIO框架,如Netty,MINA等。解决了很多NIO的陷阱,并屏蔽了操作系统的差
异,有较好的性能和编程模型。
总结
最后总结一下NIO有哪些优势:
事件驱动模型
避免多线程
单线程处理多任务
非阻塞I/O,I/O读写不再阻塞
基于block的传输,通常比基于流的传输更高效
更高级的IO函数,Zero Copy
I/O多路复用大大提高了Java网络应用的可伸缩性和实用性
相关文章:

Java面试题队列
Java中的队列都有哪些,有什么区别 1. ArrayDeque, (数组双端队列) 2. PriorityQueue, (优先级队列) 3. ConcurrentLinkedQueue, (基于链表的并发队列) 4. DelayQueue, (延期…...

大型Saas系统的权限体系设计(二)
X0 上期回顾 上文《大型Saas系统的权限体系设计(一)》提到2B的Saas系统的多层次权限体系设计的难题,即平台、平台的客户、客户的客户,乃至客户的客户的客户如何授权,这个可以通过“权限-角色-岗位”三级结构来实现。 但这个只是功能权限&am…...
HTML(四) -- 多媒体设计
目录 1. 视频标签 2. 音频标签 3. 资源标签(定义媒介资源 ) 1. 视频标签 属性值描述autoplayautoplay如果出现该属性,则视频在就绪后马上播放。controlscontrols表示添加标准的视频控制界面,包括播放、暂停、快进、音量等…...
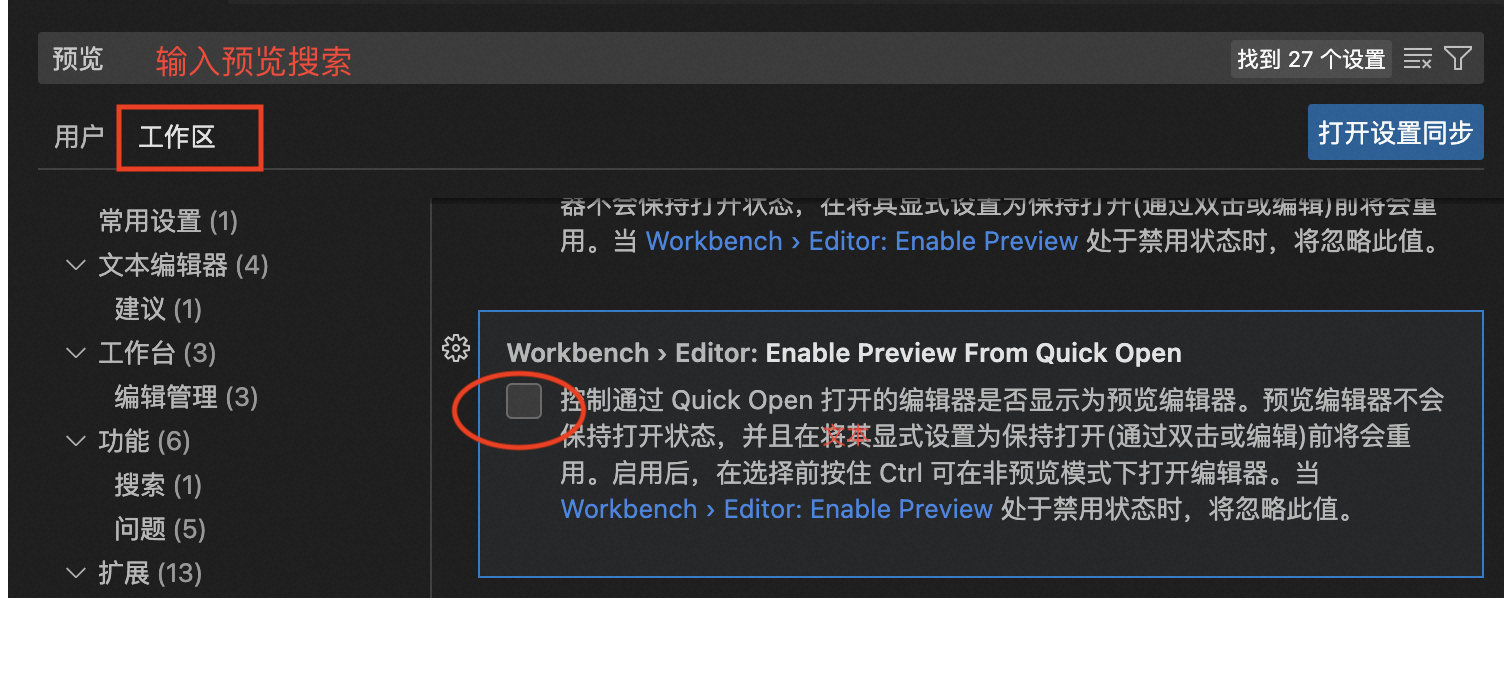
设置苹果电脑vsode在新窗口中打开文件
0、前言 最近切换到mac电脑工作,又得重新安装一些工具软件并设置。虽然这些设置并表示啥复杂的设置,但是久了不设置还是会忘记。于是记录之,也希望给能帮助到需要的人。 我们使用vscode阅读或者编辑文件时,有时候希望同时打开多…...

第二章创建模式—单例设计模式
文章目录 单例模式的结构如何控制只有一个对象呢怎么设计这个类的内部对象外部怎么访问 单例模式的主要有以下角色 单例模式的实现饿汉式 1:静态变量饿汉式 2:静态代码块懒汉式 1:线程不安全懒汉式 2:线程安全—方法级上锁懒汉式 …...
数据结构学习记录——堆的插入(堆的结构类型定义、最大堆的创建、堆的插入:堆的插入的三种情况、哨兵元素)
目录 堆的结构类型定义 最大堆的创建 堆的插入 堆的插入的三种情况 代码实现 哨兵元素 堆的结构类型定义 #define ElementType int typedef struct HNode* Heap; /* 堆的类型定义 */ struct HNode {ElementType* Data; /* 存储元素的数组 */int Size; /* 堆中…...

netperf测试
netperf测试 目录 批量网络流量性能测试 TCP_STREAM测试UDP_STREAM 测试请求/应答网络流量测试 TCP_RR TCP_CRR Netperf 是一个网络性能测试工具,它可以测试网络协议栈的性能,例如TCP和UDP协议。Netperf可以测量网络吞吐量、延迟和CPU利用率等指标。…...

ORACLE常用语句
1.修改用户密码 alter user 用户名 identified by 新密码; 2.表空间扩容 1.增加数据文件 alter tablespace AA add datafile ‘DATA’ size 20G autoextend off; 2.修改数据文件大小 ALTER DATABASE DATAFILE ‘E:\ORACLE\PRODUCT\10.2.0\ORADATA\aa\aa.DBF’ RESIZE 400M;…...
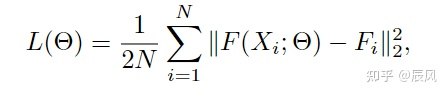
[论文笔记]C^3F,MCNN:图片人群计数模型
(万能代码)CommissarMa/Crowd_counting_from_scratch 代码:https://github.com/CommissarMa/Crowd_counting_from_scratch (万能代码)C^3 Framework开源人群计数框架 科普中文博文:https://zhuanlan.zhihu.com/p/65650998 框架网址:https…...
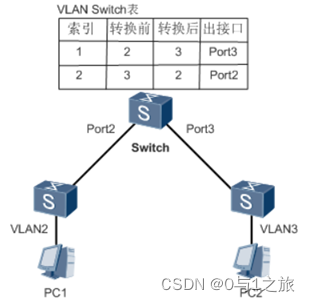
HCIP-7.2VLAN间通信单臂、多臂、三层交换方式学习
VLAN间通信单臂、多臂、三层交换方式学习 1、单臂路由2、多臂路由3、三层交换机的SVI接口实现VLAN间通讯3.1、VLANIF虚拟接口3.2、VLAN间路由3.2.1、单台三层路由VLAN间通信,在一台三层交换机内部VLAN之间直连。3.2.2、两台三层交换机的之间的VLAN通信。3.2.3、将物…...

PHP快速入门17-用spl_autoload_register实现类的自动加载
文章目录 前言实现过程创建两个类创建入口文件 总结 前言 本文已收录于PHP全栈系列专栏:PHP快速入门与实战 PHP类自动载入是指在PHP应用程序中,当需要使用某个类文件时,系统会自动加载该类文件,无需手动引入。 在PHP中…...
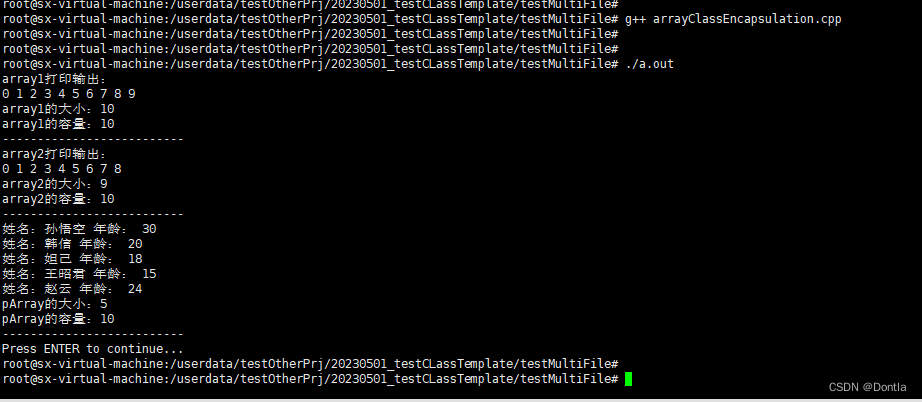
【黑马程序员 C++教程从0到1入门编程】【笔记8】 泛型编程——模板
https://www.bilibili.com/video/BV1et411b73Z?p167 C泛型编程是一种编程范式,它的核心思想是编写通用的代码,使得代码可以适用于多种不同的数据类型。 而模板是C中实现泛型编程的一种机制,它允许我们编写通用的代码模板,然后在需…...
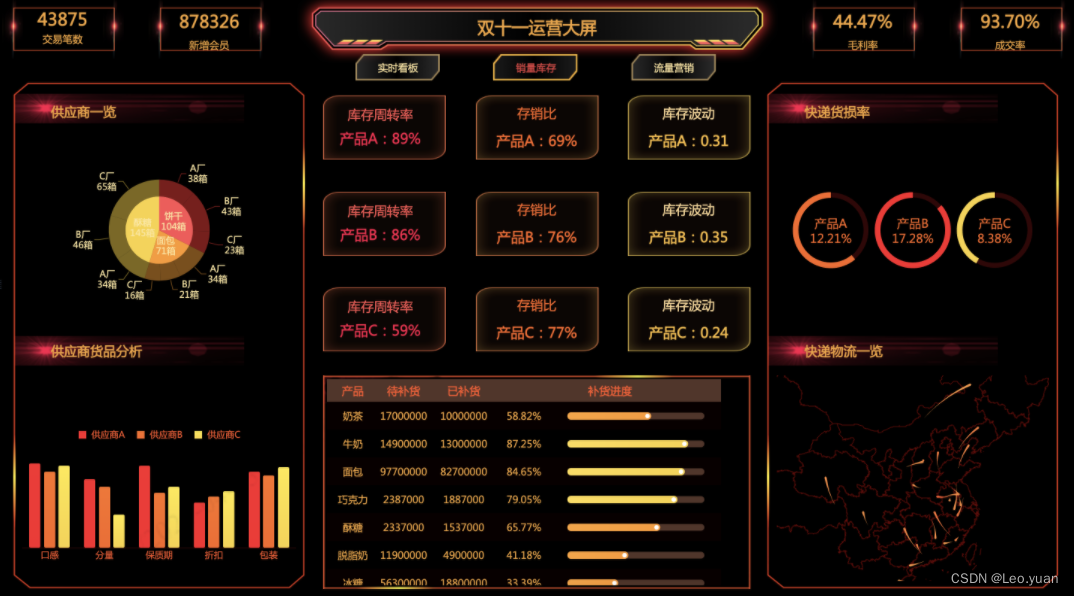
分享10个精美可视化模板,解决95%的大屏需求!
前段时间和朋友一起喝茶,我吐槽着excel表格做报表的繁琐,他惊讶的问我竟然不知道大屏模板这种东西,说是直接套用数据就可以,我震惊的同时吃下了这个安利。 回来之后,我好好研究了一番这个叫可视化大屏的“新鲜玩意儿”…...

好用的项目管理软件的具体功能有哪些
随着企业规模不断的扩大,项目管理往往会面临更多的挑战与难题,最常见的会出现以下几个问题:资源消耗失控,而项目部门和相关部门之间沟通越来越困难;团队凝聚力下降、项目进度难以把控,项目成本几乎失控&…...

< 每日小技巧: 基于Vue状态的过渡动画 - Transition 和 TransitionGroup>
》基于Vue状态的过渡动画 - Transition 和 TransitionGroup 👉 一、Vue Transition 简介> Transition 和 TransitionGroup 之间的区别 👉 二、<Transition> 组件> 触发 <Transition> 组件的场景:> 基于 CSS 的过渡效果&…...
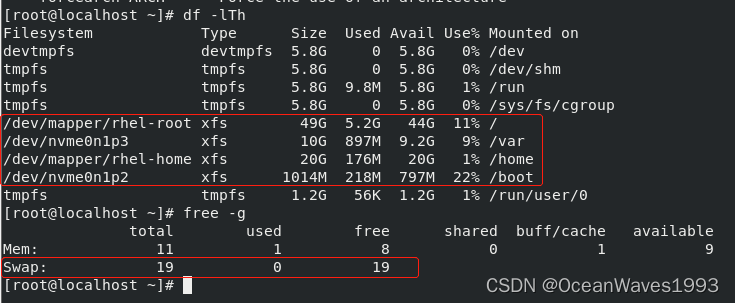
vmware安装redhat 8
vmware安装redhat 8 1、下载镜像文件1.1 镜像文件 2、安装系统2.1、选择自定义安装2.2、兼容性选择2.3、选择镜像文件导入2.4、设置用户名密码2.5、选择虚拟机在磁盘上的位置2.6、选择处理器数量2.7、选择内存大小2.8、选择桥接或NAT2.9、选择SCSI控制器类型2.10、选择虚拟机磁…...

OpenCV C++案例实战三十一《动态时钟》
OpenCV C案例实战三十一《动态时钟》 前言一、绘制表盘二、绘制刻线三、获取系统时间四、结果展示五、源码总结 前言 本案例将使用OpenCV C实现动态时钟效果。原理也很简单,主要分为绘制表盘、以及获取系统时间两步。 一、绘制表盘 首先为了效果显示美观一点&…...

字节后端入门 - Go 语言原理与实践
1.1什么是Go语言 1.2Go语言入门 环境 1.3基础语法 1.3.1变量 var name"value" 自己推断变量类型; 也可以显式类型 var c int 1 name: type(value) 常量: const name "value" g : a"foo" 字符串拼接 1.3.2 if else {}花括号…...

锂电材料浆料匀浆搅拌设备轴承经常故障如何处理?
锂电材料浆料匀浆搅拌设备是锂电池生产中重要的设备之一,用于将活性材料、导电剂、粘结剂和溶剂混合成均匀的浆料,是电极制备过程中不可或缺的步骤。然而,由于高速搅拌和化学腐蚀等因素的影响,轴承经常会出现故障,导致…...
设计模式——设计模式介绍和单例设计模式
导航: 【黑马Java笔记踩坑汇总】JavaSEJavaWebSSMSpringBoot瑞吉外卖SpringCloud黑马旅游谷粒商城学成在线设计模式牛客面试题 目录 一、设计模式概述和分类 1.1 设计模式介绍 1.2 设计模式分类 二、创建型设计模式-单例模式 2.1 介绍 2.2 八种单例模式的创…...

1756-L55处理器单元
1756-L55 处理器单元(ControlLogix 系列PLC CPU)一、主要特点高性能处理器,适合中大型控制系统支持多任务运行与快速扫描支持在线编程与程序修改模块化结构,扩展灵活支持本地及远程I/O控制可实现冗余系统,提高可靠性支…...
 - 领先的渗透测试发行版)
Kali Linux 2026.1 发布 (2026 主题 BackTrack 模式) - 领先的渗透测试发行版
Kali Linux 2026.1 发布 (2026 主题 & BackTrack 模式) - 领先的渗透测试发行版 The most advanced Penetration Testing Distribution 请访问原文链接:https://sysin.org/blog/kali-linux/ 查看最新版。原创作品,转载请保留出处。 作者主页&…...

手把手教你解决Unity视频播放问题:H264编码设置与RawImage的正确用法
Unity视频播放全攻略:H264编码优化与RawImage实战解析 在Unity项目开发中,视频播放功能看似简单,却暗藏诸多技术细节。许多开发者都曾遇到过视频不同步、颜色失真或性能低下的困扰。本文将深入剖析视频播放的核心技术要点,从编码格…...
)
电工必看:正弦交流电路中的相量法实战技巧(附计算示例)
电工必看:正弦交流电路中的相量法实战技巧(附计算示例) 在电气工程领域,正弦交流电路的分析是每位电工和电气工程师必须掌握的核心技能。面对复杂的电路计算,传统的三角函数解析法往往让从业者陷入繁琐的运算泥潭。相量…...

告别低效写作:盘点2026年标杆级的AI论文网站
一天写完毕业论文在2026年已不再是天方夜谭。2026年最炸裂、实测能大幅提速的AI论文网站,覆盖选题构思、文献整理、内容生成、格式排版全流程,帮你高效搞定论文写作。 一、全流程王者:一站式搞定论文全链路(一天定稿首选ÿ…...

ReplaceItems.jsx:Adobe Illustrator批量对象替换的终极解决方案
ReplaceItems.jsx:Adobe Illustrator批量对象替换的终极解决方案 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Illustrator中重复的替换操作而烦恼吗࿱…...

音频可视化工具:Lano Visualizer打造沉浸式桌面音乐体验
音频可视化工具:Lano Visualizer打造沉浸式桌面音乐体验 【免费下载链接】Lano-Visualizer A simple but highly configurable visualizer with rounded bars. 项目地址: https://gitcode.com/gh_mirrors/la/Lano-Visualizer 在数字生活中,音乐不…...

构建全渠道智能通知系统:从高可用架构到用户体验优化
1. 全渠道智能通知系统的核心价值 想象一下这样的场景:你在电商平台下单后,系统立即通过短信发送订单确认通知;当你忘记支付时,APP推送会及时提醒;订单发货后,邮箱里静静躺着物流信息;而站内信则…...

nli-distilroberta-base环境部署:Docker容器内Python依赖与模型权重加载验证
nli-distilroberta-base环境部署:Docker容器内Python依赖与模型权重加载验证 1. 项目概述 nli-distilroberta-base是一个基于DistilRoBERTa模型的自然语言推理(NLI)Web服务。它能智能分析两个句子之间的关系,判断它们之间的逻辑关联。这项技术在智能客…...

瑞萨RA6E2评估板Keil MDK5开发全攻略:从RA Smart Configurator到烧录调试
瑞萨RA6E2评估板Keil MDK5开发全流程实战指南 对于嵌入式开发者而言,瑞萨RA6E2系列MCU凭借其高性能和丰富外设正成为工业控制、物联网终端设备的优选方案。而Keil MDK5作为Arm生态中最成熟的开发环境之一,与瑞萨官方工具链的深度整合为开发者提供了高效…...