Python期末复习知识点大合集(期末不挂科版)
Python期末复习知识点大合集(期末不挂科版)
文章目录
- Python期末复习知识点大合集(期末不挂科版)
- 一、输入及类型转换
- 二、格式化输出:字符串的format方法
- 三、流程控制
- 四、随机数生成
- 五、字符串
- 六、序列索(含字符串) 索引(正向、反向)与切片
- 七、列表的相关方法
- 八、字典的相关方法
- 九、函数
- 十、文件
- 十一、排序与词频统计
- 十二、对象定义

本期博客总结了老师给出的考试范围的相关知识点,知识点总结的并不是很完整,更多详细细致的知识点可以去看一下我的Python专栏:
- Python编程基础
- Python每日一学
知识点总结仅供参考,总结不易,期待得到你们的点赞收藏转发三连,谢谢!祝大家期末考试顺利通过!!!
一、输入及类型转换
在Python中,可以通过input()函数获取用户的输入。input()函数返回一个字符串类型的值,需要通过类型转换将其转换为其他数据类型。以下是常用的类型转换及其说明:
-
int(input()): 将用户输入的字符串转换为整数类型。如果用户输入的字符串不是一个合法的整数,会引发ValueError异常。例如:
age = int(input("请输入您的年龄:")) print(f"您的年龄是{age}岁,明年您就{age+1}岁了。") -
float(input()): 将用户输入的字符串转换为浮点数类型。如果用户输入的字符串不是一个合法的浮点数,会引发ValueError异常。例如:
height = float(input("请输入您的身高(单位:米):")) print(f"您的身高是{height}米,如果以厘米为单位,则为{height*100}厘米。") -
eval(input()): 将用户输入的字符串当作Python表达式进行求值,并返回结果。使用eval()函数需要非常小心,因为它可以执行任意的Python代码,包括危险的代码。建议只在非常信任用户输入的情况下使用。例如:
result = eval(input("请输入一个数学表达式:")) print(f"表达式的值为{result}。")
总之,在Python中,输入类型转换是非常常见的操作,可以根据需要使用不同的类型转换函数来将用户输入转换为需要的数据类型。
二、格式化输出:字符串的format方法
在Python中,可以使用字符串的format()方法进行格式化输出。format()方法使用花括号 {} 作为占位符,可以通过不同的参数对占位符进行填充、对齐等操作。以下是常见的格式化输出操作及其说明:
-
基本用法
使用位置参数
{}进行基本的格式化输出。name = "Alice" age = 18 print("My name is {}, and I am {} years old.".format(name, age)) -
关键字参数
使用关键字参数进行格式化输出可以使代码更加清晰易懂。
print("My name is {name}, and I am {age} years old.".format(name="Bob", age=20)) -
按顺序填入
在占位符
{}中可以使用数字来指定填充的顺序。print("{0} {1} {2}".format("I", "love", "Python")) -
对齐
可以通过在占位符
{}中添加格式说明符来对齐字符串。print("{:<10s} | {:^10s} | {:>10s}".format("left", "center", "right"))其中,
<表示左对齐,^表示居中对齐,>表示右对齐。 -
等宽输出
使用格式说明符可以使输出的宽度相等。
print("{:10s} | {:^10s} | {:10s}".format("left", "center", "right"))其中,
10表示输出的宽度为10个字符。 -
字符串类型
%s:用于输出字符串,可以输出任意类型的对象。%10s:用于指定输出宽度为10个字符的字符串,如果不足10个字符则在左边补空格。%-10s:用于指定输出宽度为10个字符的字符串,如果不足10个字符则在右边补空格。
name = "Alice" age = 18 print("My name is %s, and I am %d years old." % (name, age)) print("%10s" % "Hello") print("%-10s" % "Hello") -
整数类型
d:用于输出十进制整数。%x:用于输出十六进制整数。%o:用于输出八进制整数。%b:用于输出二进制整数。%10d:用于指定输出宽度为10个字符的整数,如果不足10个字符则在左边补空格。%-10d:用于指定输出宽度为10个字符的整数,如果不足10个字符则在右边补空格。%04d:用于指定输出宽度为4个字符的整数,如果不足4个字符则在左边补0。
num = 42 print("The number is %d." % num) print("%10d" % 123) print("%-10d" % 123) print("%04d" % 12) -
浮点数类型
%f:用于输出浮点数,保留6位小数。%.2f:用于输出浮点数,保留2位小数。%10.2f:用于指定输出宽度为10个字符的浮点数,保留2位小数,如果不足10个字符则在左边补空格。%-10.2f:用于指定输出宽度为10个字符的浮点数,保留2位小数,如果不足10个字符则在右边补空格。
pi = 3.141592653589793 print("The value of pi is %f." % pi) print("The value of pi is %.2f." % pi) print("%10.2f" % pi) print("%-10.2f" % pi)
总之,在Python中,格式化输出是非常常见的操作,可以根据需要使用不同的格式说明符对占位符进行填充、对齐等操作,以获得所需的输出效果。l另外,使用格式说明符进行格式化输出时可以灵活地控制输出格式,适用于不同的数据类型。格式说明符可以指定输出的宽度、对齐方式、保留小数位数等,非常实用。
三、流程控制
在Python中,流程控制语句包括条件语句和循环语句。下面对常见的流程控制语句进行介绍。
-
条件语句
条件语句用于根据条件判断执行不同的操作,常用的条件语句是if语句。if语句的基本语法如下:
if condition:statement1 else:statement2其中,
condition是一个表达式,如果它的值为True,则执行statement1,否则执行statement2。例如:
x = 10 if x > 0:print("x is positive") else:print("x is non-positive") -
循环语句
循环语句用于重复执行一段代码,常用的循环语句有for循环和while循环。
- for循环
for循环用于对一个序列(例如列表、元组、字符串等)进行循环,每次循环可以获取序列中的一个元素进行操作。for循环的基本语法如下:
for var in sequence:statement else:statement2其中,
var是一个变量,用于保存序列中的元素,sequence是一个序列,statement是需要执行的语句块。for循环会将序列中的每个元素依次赋值给var,并执行statement。如果for循环执行完所有的元素后仍然没有遇到break语句,就会执行statement2。例如:
fruits = ["apple", "banana", "cherry"] for fruit in fruits:print(fruit) else:print("No more fruits")-
while循环
while循环用于根据条件重复执行一段代码。while循环的基本语法如下:
while condition:statementif some_condition:breakif some_other_condition:continue else:statement2其中,
condition是一个表达式,如果它的值为True,则重复执行statement,直到condition的值变为False。while循环可以用break语句跳出循环,用continue语句跳过当前循环。如果while循环执行完所有的语句后仍然没有遇到break语句,就会执行statement2。例如:
x = 0 while x < 5:print(x)x += 1 else:print("x is no longer less than 5")
以上是if语句和for循环、while循环的基本语法和使用方法,这些流程控制语句可以帮助我们根据不同的条件和需要,控制程序的执行流程。
四、随机数生成
在Python中,可以使用内置的random模块来生成随机数。下面介绍常用的随机数生成函数以及相关的知识点。
-
random()函数random()函数用于生成一个[0, 1)之间的随机小数。使用方法如下:import random x = random.random() -
randint()函数randint()函数用于生成指定范围内的整数随机数,使用方法如下:import random x = random.randint(a, b)其中,
a和b是两个整数,生成的随机数在[a, b]区间内。 -
seed()函数seed()函数用于设置随机数生成器的种子,使得每次生成的随机数序列相同。使用方法如下:import random random.seed(42)在上述例子中,随机数生成器的种子被设置为42,因此每次运行程序时,生成的随机数序列都是相同的。
总之,在Python中使用random模块可以很方便地生成随机数,可以用于各种需要随机性的场合,例如游戏、密码生成等。
五、字符串
在Python中,字符串是一种基本的数据类型,用于表示文本。下面介绍字符串相关的一些基本知识点和常用函数:
-
字符串的创建和访问
以使用单引号
'或双引号"来创建一个字符串,如:s = 'hello'字符串中的每个字符都有一个对应的索引,可以通过下标来访问字符串中的某个字符,如:
s = 'hello' print(s[0]) # 输出'h' -
字符串长度
使用
len()函数可以获取字符串的长度,即字符串中字符的个数,如:s = 'hello' print(len(s)) # 输出5 -
字符串转义字符
在字符串中,可以使用
\来表示转义字符,例如\n表示换行,\t表示制表符等。 -
ord()和chr()函数ord()函数用于获取某个字符的ASCII码值,chr()函数用于将一个ASCII码值转换为对应的字符。例如:print(ord('A')) # 输出65 print(chr(65)) # 输出'A' -
字符串对象的常用方法
Python中的字符串对象具有很多常用的方法,如:
-
join()方法用于将一个字符串序列连接成一个新的字符串,例如:s = '-'.join(['hello', 'world']) print(s) # 输出'hello-world' -
split()方法用于将一个字符串按照指定分隔符分割成一个字符串列表,例如:s = 'hello-world' lst = s.split('-') print(lst) # 输出['hello', 'world'] -
strip()方法用于去除字符串两端的空白字符(空格、制表符、换行符等),例如:s = ' hello ' s = s.strip() print(s) # 输出'hello'
-
-
字符串存在性和相关统计
可以使用
in和not in来判断一个字符串是否包含另一个字符串,例如:s = 'hello world' print('world' in s) # 输出True还可以使用
count()函数来统计一个字符串中某个子串出现的次数,以及isnumeric()、isalpha()、isalnum()等函数来判断一个字符串是否只包含数字、字母等,例如:s = 'hello world' print(s.count('l')) # 输出3 print('123'.isnumeric()) # 输出True print('hello'.isalpha()) # 输出True print('hello123'.isalnum()) # 输出True
综上所述,字符串在Python中是非常常用的数据类型,掌握其基本知识和常用方法对于编写Python程序非常重要。
六、序列索(含字符串) 索引(正向、反向)与切片
在Python中,序列是一种基本的数据类型,包括字符串、列表、元组等。序列中的每个元素都有一个对应的索引,可以通过索引来访问序列中的元素,如:
s = 'hello'
print(s[0]) # 输出'h'
Python中的序列索引是从0开始的,也可以使用负数索引,如:
s = 'hello'
print(s[-1]) # 输出'o'
使用冒号:可以进行切片操作,切片的语法为[start:end:step],其中start表示起始索引(包括该索引),end表示结束索引(不包括该索引),step表示步长,默认为1,如:
s = 'hello'
print(s[1:4]) # 输出'ell'
切片操作可以截取序列中的一段子序列,也可以通过设置步长来实现对序列的跳跃式访问,如:
s = 'hello'
print(s[::2]) # 输出'hlo'
此外,切片还可以用来复制序列,如:
s = 'hello'
print(s[:]) # 输出'hello'
需要注意的是,序列的索引和切片操作都不能越界,否则会抛出IndexError异常。同时,序列是不可变对象,即不能直接对序列中的某个元素进行赋值,但是可以通过切片操作来修改序列,如:
s = 'hello'
s = s[:2] + 'x' + s[3:]
print(s) # 输出'hexlo'
需要注意的是,这种修改操作会生成一个新的字符串,而不是直接在原字符串上进行修改。
除了基本的索引和切片操作之外,Python中还支持一些高级的切片操作。其中,step参数可以控制切片时的步长,即每隔多少个元素进行一次切片。例如:
s = 'hello'
print(s[::2]) # 输出'hlo'
上述代码中,[::2]表示从开始到结束,步长为2。
此外,Python还支持负数索引和切片,即从后往前数的索引和切片。例如:
s = 'hello'
print(s[-1]) # 输出'o'
print(s[-3:]) # 输出'llo'
上述代码中,-1表示倒数第一个元素,-3:表示从倒数第三个元素开始到末尾的切片。
总之,在Python中,字符串是一种常见的序列类型,可以使用索引和切片来访问和修改字符串中的元素。同时,Python还提供了一些高级的切片操作,使得序列的处理更加方便和灵活。
七、列表的相关方法
在Python中,列表是一种常见的序列类型,用于存储一组有序的数据。下面介绍列表中常用的一些方法:
-
增
append(x):在列表末尾添加一个元素x,类似于栈的进栈操作。extend(iterable):在列表末尾添加可迭代对象iterable中的所有元素。insert(i, x):在列表的第i个位置插入元素x。
例如:
lst = [1, 2, 3] lst.append(4) print(lst) # 输出[1, 2, 3, 4]lst.extend([5, 6]) print(lst) # 输出[1, 2, 3, 4, 5, 6]lst.insert(2, 7) print(lst) # 输出[1, 2, 7, 3, 4, 5, 6] -
删
del lst[i]:删除列表中索引为i的元素。lst.pop(i):删除列表中索引为i的元素并返回该元素的值,如果不指定i,则删除末尾元素。lst.remove(x):删除列表中第一个值为x的元素。lst.clear():清空列表中的所有元素。
例如:
lst = [1, 2, 3, 4, 5] del lst[2] print(lst) # 输出[1, 2, 4, 5]x = lst.pop(1) print(x) # 输出2 print(lst) # 输出[1, 4, 5]lst.remove(4) print(lst) # 输出[1, 5]lst.clear() print(lst) # 输出[] -
改
带索引或切片的赋值:通过索引或切片可以对列表中的元素进行修改。
例如:
lst = [1, 2, 3, 4, 5] lst[2] = 6 print(lst) # 输出[1, 2, 6, 4, 5]lst[1:4] = [7, 8, 9] print(lst) # 输出[1, 7, 8, 9, 5] -
查
索引切片:通过索引和切片可以访问列表中的元素。
例如:lst = [1, 2, 3, 4, 5] print(lst[2]) # 输出3print(lst[1:4]) # 输出[2, 3, 4] -
统计
max(lst):返回列表中的最大值。min(lst):返回列表中的最小值。sum(lst):返回列表中所有元素的和。
例如:
lst = [1, 2, 3, 4, 5] print(max(lst)) # 输出 5 print(min(lst)) # 输出 1 print(sum(lst)) # 输出 215 -
其他
除了这些常用的统计函数外,列表还支持其他一些常用的操作,例如:
index(x[, start[, end]]):返回列表中第一个值为x的元素的索引,如果没有找到则抛出ValueError异常。如果指定了可选参数start和end,则在列表中的指定范围内查找。count(x):返回列表中值为x的元素的数量。sort(key=None, reverse=False):对列表进行原地排序。如果指定了可选参数key,则该参数应该是一个函数,用来指定排序关键字,比如可以根据元素的某个属性进行排序。如果指定了可选参数reverse=True,则会进行降序排序,默认为升序排序。reverse():将列表中的元素原地反向排序。
举个例子,假设有一个数字列表
numbers:numbers = [3, 5, 1, 4, 2]# 获取列表中的最大值和最小值 max_number = max(numbers) min_number = min(numbers) print(max_number, min_number) # 输出:5 1# 计算列表中所有元素的和 total = sum(numbers) print(total) # 输出:15# 查找列表中某个元素的索引 index = numbers.index(4) print(index) # 输出:3# 统计列表中某个元素的出现次数 count = numbers.count(2) print(count) # 输出:1# 对列表进行排序 numbers.sort() print(numbers) # 输出:[1, 2, 3, 4, 5]# 将列表中的元素反向排序 numbers.reverse() print(numbers) # 输出:[5, 4, 3, 2, 1]
八、字典的相关方法
Python中的字典是一种无序的键值对集合,其中每个键对应一个值。以下是一些常用的字典方法:
-
增:可以通过赋值语句来增加一个键值对,或者使用update()方法增加多个键值对。
# 增加一个键值对 dict1 = {'name': 'Alice', 'age': 25} dict1['gender'] = 'female' print(dict1) # {'name': 'Alice', 'age': 25, 'gender': 'female'}# 增加多个键值对 dict2 = {'name': 'Bob', 'age': 30} dict2.update({'gender': 'male', 'city': 'New York'}) print(dict2) # {'name': 'Bob', 'age': 30, 'gender': 'male', 'city': 'New York'} -
改:可以通过赋值语句来修改一个键的值。
# 修改一个键的值 dict1 = {'name': 'Alice', 'age': 25} dict1['age'] = 26 print(dict1) # {'name': 'Alice', 'age': 26} -
删:可以使用del语句或pop()方法来删除一个键值对。
# 删除一个键值对 dict1 = {'name': 'Alice', 'age': 25} del dict1['age'] print(dict1) # {'name': 'Alice'}# 删除一个键值对并返回该值 dict2 = {'name': 'Bob', 'age': 30} age = dict2.pop('age') print(age) # 30 print(dict2) # {'name': 'Bob'} -
查:可以使用keys()、values()、get()和items()方法来获取字典中的键、值、键值对。
# 获取所有的键 dict1 = {'name': 'Alice', 'age': 25} keys = dict1.keys() print(keys) # dict_keys(['name', 'age'])# 获取所有的值 dict2 = {'name': 'Bob', 'age': 30} values = dict2.values() print(values) # dict_values(['Bob', 30])# 获取指定键的值,如果不存在返回默认值 dict3 = {'name': 'Charlie', 'age': 35} age = dict3.get('age', 0) gender = dict3.get('gender', 'unknown') print(age) # 35 print(gender) # unknown# 获取所有的键值对 dict4 = {'name': 'David', 'age': 40} items = dict4.items() print(items) # dict_items([('name', 'David'), ('age', 40)])
九、函数
函数是一段封装了特定功能的可重复使用的代码块。以下是Python中有关函数的一些常见知识点:
-
函数定义:可以使用
def关键字来定义函数,如下所示:def add(a, b):return a + b该函数名为
add,接受两个位置参数a和b,并将它们相加并返回。 -
返回值:函数可以通过
return语句来返回一个值。如果没有指定返回值,则函数将默认返回None。例如:def multiply(a, b):return a * bresult = multiply(2, 3) print(result) # 6 -
位置参数:位置参数是指在函数调用中按照参数位置来传递的参数。例如:
def greet(name, message):print(f"{name}, {message}")greet("Alice", "Hello") # 输出:Alice, Hello -
默认值参数:默认值参数是指在函数定义时为参数指定默认值,使得在调用函数时可以省略这些参数。例如:
def greet(name, message="Hello"):print(f"{name}, {message}")greet("Alice") # 输出:Alice, Hello greet("Bob", "Hi") # 输出:Bob, Hi -
可变参数:可变参数是指在函数定义时指定的不定数量的参数,它们会被打包成一个元组传递给函数。在函数调用时,可以使用
*操作符来展开可迭代对象,以便将其作为可变参数传递给函数。例如:def calculate_average(*args):return sum(args) / len(args)result = calculate_average(1, 2, 3, 4) print(result) # 输出:2.5 -
调用时的命名参数:调用函数时可以使用命名参数来指定参数的值。这样可以使得代码更加易读,而且允许省略某些参数。例如:
def greet(name, message="Hello"):print(f"{name}, {message}")greet(message="Hi", name="Alice") # 输出:Alice, Hi -
变量作用域:变量作用域指的是变量的可见范围。在Python中,有三种变量作用域:
- 全局作用域(global):定义在模块级别的变量,可以在模块中的任何函数中使用。
- 局部作用域(local):定义在函数内部的变量,只能在函数内部使用。
- 非局部作用域(nonlocal):定义在嵌套函数中的变量,可以在内部函数和外部函数之间共享
x = 10 # 全局变量def foo():y = 20 # 局部变量def bar():nonlocal yy = 30 # 非局部变量print(f"y in bar: {y}")bar()print(f"y in foo: {y}")foo() print(f"x in main: {x}")上述代码是一个嵌套函数的示例,其中包含全局变量和局部变量。当我们在函数中定义一个变量时,该变量默认是局部变量,只在该函数内可见。如果想要在函数中访问外部变量,可以使用
global、nonlocal等关键字。在上述示例中,
x是全局变量,在整个程序中都可以访问,而y是foo()函数内部的局部变量。bar()函数在foo()函数中定义,因此可以访问foo()函数中的变量。在bar()函数中,我们使用nonlocal关键字将y标记为非局部变量,以便可以修改foo()函数中的y变量。当我们调用
foo()函数时,它将创建一个名为y的局部变量,并将其值设置为20。然后它调用bar()函数,该函数将y标记为非局部变量,将其值设置为30,并打印出y的值。最后,foo()函数打印出y的值,因此它将输出30,而不是20。最后,我们在主程序中打印出全局变量
x的值,应该输出10。需要注意的是,在函数内部使用
global或nonlocal关键字可以修改外部作用域中的变量,但这并不是一个好的编程实践。通常最好避免使用全局变量或嵌套函数,以便使代码更容易理解和调试。 -
递归函数:递归函数指的是在函数中调用函数本身的函数。递归函数通常用于处理具有递归结构的问题,如树结构等。例如:
def factorial(n):if n == 0:return 1else:return n * factorial(n - 1)result = factorial(5) print(result) # 输出:120在上面的例子中,
factorial()函数计算给定数n的阶乘。当n等于0时,函数返回1,否则返回n和factorial(n - 1)的乘积,以此递归地计算阶乘。
十、文件
在Python中,文件操作是通过内置的open()函数来实现的。使用该函数,可以打开文件、读取文件内容、向文件写入内容以及关闭文件等操作。下面是一些常见的文件操作和示例:
-
打开文件
使用
open()函数打开文件,需要指定文件名和打开模式。打开模式通常有以下几种:'r':只读模式,打开文件后只能读取文件内容,不能写入或修改文件。'w':写入模式,打开文件后只能写入文件内容,不能读取文件内容。如果文件不存在,则创建新文件,如果文件已经存在,则覆盖原文件内容。'a':追加模式,打开文件后只能写入文件内容,不能读取文件内容。如果文件不存在,则创建新文件,如果文件已经存在,则在文件末尾追加内容。
示例代码:
# 打开文件 f = open('file.txt', 'r') -
读取文件内容
使用
read()、readline()或readlines()方法读取文件内容。read()方法读取整个文件内容,readline()方法读取文件的一行内容,readlines()方法读取所有行的内容并以列表形式返回。示例代码:
# 读取整个文件 content = f.read() print(content)# 读取一行内容 line = f.readline() print(line)# 读取所有行的内容 lines = f.readlines() print(lines) -
写入文件内容
使用
write()或writelines()方法向文件写入内容。write()方法可以写入单行文本内容,writelines()方法可以写入多行文本内容。示例代码:
# 写入单行文本内容 f.write('Hello World!\n')# 写入多行文本内容 f.writelines(['Python\n', 'Java\n', 'C++\n']) -
文件指针操作
使用
seek()方法来移动文件指针,可以定位文件中的特定位置。seek()方法接受一个整数参数,该参数指定文件指针要移动的字节数。当读取文件时,文件指针指向已经读取的最后一个字节的下一个字节;当写入文件时,文件指针指向已经写入的最后一个字节的下一个字节。示例代码:
# 移动文件指针到文件开头 f.seek(0)# 读取文件指针所在位置到文件末尾的所有内容 content = f.read() print(content) -
关闭文件
使用
close()方法关闭文件。在文件使用完成后,应该及时关闭文件,以释放文件资源。示例代码:
# 关闭文件 f.close()
十一、排序与词频统计
在Python中,可以使用字典来统计词频,其基本思想是将单词作为字典的键,出现次数作为对应键的值。下面是一个例子:
text = 'the quick brown fox jumps over the lazy dog'
word_counts = {}
for word in text.split():word_counts[word] = word_counts.get(word, 0) + 1
print(word_counts)
输出结果如下:
{'the': 2, 'quick': 1, 'brown': 1, 'fox': 1, 'jumps': 1, 'over': 1, 'lazy': 1, 'dog': 1}
在上面的代码中,我们使用text.split()方法将文本分割成单词列表,然后使用字典的get()方法来获取单词对应的计数器,如果计数器不存在,则默认为0,最后再将计数器加1。
另外,我们可以使用list()函数将字典转换成列表,然后使用sorted()函数或列表对象的sort()方法进行排序,如下所示:
sorted_word_counts = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
print(sorted_word_counts)
输出结果如下:
[('the', 2), ('quick', 1), ('brown', 1), ('fox', 1), ('jumps', 1), ('over', 1), ('lazy', 1), ('dog', 1)]
在上面的代码中,我们使用word_counts.items()方法将字典转换成列表,然后使用lambda x: x[1]指定排序规则为按值(计数器)降序排列,最后使用reverse=True参数指定按降序排列。另外,也可以使用列表对象的sort()方法进行排序,如下所示:
sorted_word_counts = list(word_counts.items())
sorted_word_counts.sort(key=lambda x: x[1], reverse=True)
print(sorted_word_counts)
输出结果与上面相同。
十二、对象定义
在Python中,可以使用下划线来定义私有属性和方法,这些属性和方法只能在类的内部访问,无法从类的外部访问。Python并没有严格意义上的私有属性和方法,而是采用一种命名惯例来实现,即在属性和方法名前面加上一个下划线。
下面是一个示例代码,其中定义了一个Person类,包含了一个私有属性_age和一个私有方法_say_hello:
class Person:def __init__(self, name, age):self.name = nameself._age = age # 定义私有属性def say_hello(self):self._say_hello() # 调用私有方法def _say_hello(self):print("Hello, I'm", self.name, ", and I'm", self._age, "years old.") # 定义私有方法
在上面的代码中,我们定义了一个Person类,包含了一个公有的say_hello方法和一个私有的_say_hello方法。在__init__方法中,我们定义了一个私有属性_age,在say_hello方法中,我们调用了私有方法_say_hello。由于_age和_say_hello都是以一个下划线开头,因此它们都是私有的,无法从类的外部直接访问。
下面是一个示例代码,介绍了如何创建Person对象并访问其私有属性和方法:
person = Person("Alice", 30)
# print(person._age) # 无法从类的外部直接访问私有属性
person.say_hello() # 调用公有方法,内部调用了私有方法
在上面的代码中,我们创建了一个Person对象person,虽然不能从类的外部直接访问私有属性_age,但是可以通过公有方法say_hello来间接访问私有属性和方法。
需要注意的是,Python中的私有属性和方法并不是真正的私有,而是通过命名惯例来实现的。因此,如果一定要从类的外部访问私有属性和方法,也是可以做到的,只需要使用对象的特殊方法__dict__来访问对象的属性和方法,如下所示:
person = Person("Alice", 30)
print(person.__dict__["_age"]) # 可以从类的外部访问私有属性
person.__dict__["_say_hello"](person) # 可以从类的外部调用私有方法
self._say_hello() # 调用私有方法
def _say_hello(self):
print(“Hello, I’m”, self.name, “, and I’m”, self._age, “years old.”) # 定义私有方法
在上面的代码中,我们定义了一个`Person`类,包含了一个公有的`say_hello`方法和一个私有的`_say_hello`方法。在`__init__`方法中,我们定义了一个私有属性`_age`,在`say_hello`方法中,我们调用了私有方法`_say_hello`。由于`_age`和`_say_hello`都是以一个下划线开头,因此它们都是私有的,无法从类的外部直接访问。下面是一个示例代码,介绍了如何创建`Person`对象并访问其私有属性和方法:```python
person = Person("Alice", 30)
# print(person._age) # 无法从类的外部直接访问私有属性
person.say_hello() # 调用公有方法,内部调用了私有方法
在上面的代码中,我们创建了一个Person对象person,虽然不能从类的外部直接访问私有属性_age,但是可以通过公有方法say_hello来间接访问私有属性和方法。
需要注意的是,Python中的私有属性和方法并不是真正的私有,而是通过命名惯例来实现的。因此,如果一定要从类的外部访问私有属性和方法,也是可以做到的,只需要使用对象的特殊方法__dict__来访问对象的属性和方法,如下所示:
person = Person("Alice", 30)
print(person.__dict__["_age"]) # 可以从类的外部访问私有属性
person.__dict__["_say_hello"](person) # 可以从类的外部调用私有方法
虽然可以这样做,但是不建议从类的外部访问私有属性和方法,因为这样会破坏类的封装性,使代码变得不可预测。因此,应该尽可能遵守命名惯例,将私有属性和方法限制在类的内部,只通过公有方法提供对外的接口。
相关文章:
Python期末复习知识点大合集(期末不挂科版)
Python期末复习知识点大合集(期末不挂科版) 文章目录Python期末复习知识点大合集(期末不挂科版)一、输入及类型转换二、格式化输出:字符串的format方法三、流程控制四、随机数生成五、字符串六、序列索(含字…...

Echarts 雷达图设置拐点大小和形状,tooltip后文字不居中对齐
第017个点击查看专栏目录Echarts的雷达图的拐点大小和形状是可以设置的,在series中设置symbol 相应的属性即可。 使用tooltip的时候,默认状态文字是居中对齐的,不好看。需要在tooltip属性中设置一下,如图所示,效果比较…...
Lesson 7.1 无监督学习算法与 K-Means 快速聚类
文章目录一、聚类算法与无监督学习二、K-Means 快速聚类的算法原理1. K-Means 快速聚类的基本执行流程2. K-Means 快速聚类的背后的数学意义三、K-Means 快速聚类的 sklearn 实现方法1. sklearn 中实现 K-Means 快速快速聚类2. 轮廓系数基本概念与 sklearn 中实现方法从现在开始…...

优维低代码:Legacy Templates 构件模板
优维低代码技术专栏,是一个全新的、技术为主的专栏,由优维技术委员会成员执笔,基于优维7年低代码技术研发及运维成果,主要介绍低代码相关的技术原理及架构逻辑,目的是给广大运维人提供一个技术交流与学习的平台。 连载…...

最全面的SpringBoot教程(五)——整合框架
前言 本文为 最全面的SpringBoot教程(五)——整合框架 相关知识,下边将对SpringBoot整合Junit,SpringBoot整合Mybatis,SpringBoot整合Redis等进行详尽介绍~ 📌博主主页:小新要变强 的主页 &…...

信息安全保障
信息安全保障信息安全保障基础信息安全保障背景信息安全保障概念与模型基于时间的PDR模型PPDR模型(时间)IATF模型--深度防御保障模型(空间)信息安全保障实践我国信息安全保障实践各国信息安全保障我国信息安全保障体系信息安全保障…...

windows/linux,mosquitto插件mosquitto-auth-plug说明,重点讲解windows下
先贴代码,再讲方法 #ifndef AUTH_PLUG_H #define AUTH_PLUG_H#ifdef _WIN32 #ifdef AUTH_PLUG_EXPORTS # define AUTH_PLUG_AP...

GWAS:mtag (Multi-Trait Analysis of GWAS) 分析
mtag (Multi-Trait Analysis of GWAS)作用:通过对多个表型相似的GWAS summary结果进行联合分析,发现更多的表型相关基因座。 以抑郁症状、神经质和主观幸福感这三个表型为例,分别对他们进行GWAS分析,鉴定得到32、9 和 13个基因座与…...

MATLAB--imadjust函数
目录 一、功能 二、使用 1.格式 2.具体用法 3.代码 总结 一、功能 功能:通过灰度变换调整对比度 二、使用 1.格式 Jimadjust(I,[low high],[bottom top],gamma)2.具体用法 将图像I中的灰度值映射到J中的新值,即将灰度在[low high]之间的值映射到…...

前端开发这次几个非常经典的常用技巧,学会了之后事半功倍
对于一个刚入前端的新手来说,在前端开发过程中会遇到各种各样的麻烦和坑,这样很多时候回让开发者的信息受到打击,作为一个稍微好一点的前端菜鸟来说,今天就给刚入前端的新手们分享一些比较实用的开发技巧,让之少走一些…...
Zookeeper配置化中心
zookeeper的基本知识 zookeeper的数据结构:zookeeper提供的命名空间非常类似于标准的文件系统,key-value的形式存储,名称key由/分割的一系列路径元素,zookeeper名称空间中的每个节点都是一个路径标志。 windows下的zookeeper安装&#…...
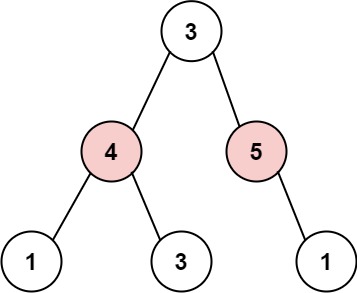
【LeetCode】打家劫舍 III [M](递归)
337. 打家劫舍 III - 力扣(LeetCode) 一、题目 小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。 除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识…...
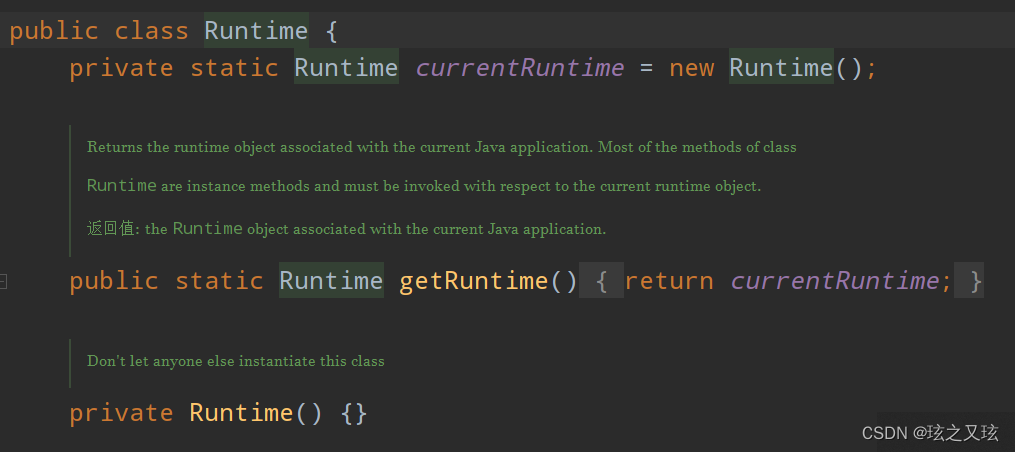
设计模式——单例模式
单例模式分为懒汉式和饿汉式两种 在有些系统中,为了节省内存资源、保证数据内容的一致性,对某些类要求只能创建一个实例,这就是所谓的单例模式. 例如,Windows 中只能打开一个任务管理器,这样可以避免因打开多个任务管理…...

json-server环境搭建及使用
json-server环境搭建 一个在前端本地运行,可以存储json数据的server。 基于node环境,可以指定一个 json 文件作为 API 的数据源。 文章目录json-server环境搭建前提下载安装监听服务启动成功修改端口号方式一:方式二:数据操作测试…...
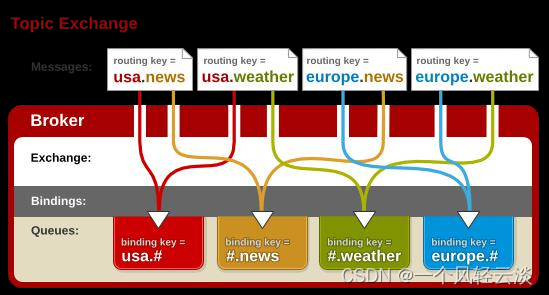
RabbitMQ运行机制
消息的TTL(Time To Live) 消息的TTL就是消息的存活时间。 • RabbitMQ可以对队列和消息分别设置TTL。 • 对队列设置就是队列没有消费者连着的保留时间,也可以对每一个单独的消息做单独的 设置。超过了这个时间,我们认为这个消息…...

【Spring Cloud Alibaba】(三)OpenFeign扩展点实战 + 源码详解
系列目录 【Spring Cloud Alibaba】(一)微服务介绍 及 Nacos注册中心实战 【Spring Cloud Alibaba】(二)微服务调用组件Feign原理实战 本文目录系列目录前言一、Feign扩展点配置二、OpenFeign扩展点配置1. 通过配置文件配置有效范…...

面向对象设计原则
在面向对象的设计过程中, 我们要对代码进行一个设计, 从而提高一个软件系统的可维护性和可复用性, 那么遵从面向对象的设计原则,可以在进行设计方案时减少错误设计的产生,从不同的角度提升一个软件结构的设计水平。 面向对象有以下七大原则:1.单一职责原…...

2022年“网络安全”赛项湖南省赛选拔赛 任务书
2022年“网络安全”赛项湖南省赛选拔赛 任务书2022年“网络安全”赛项湖南省赛选拔赛 任务书A模块基础设施设置/安全加固(200分)B模块安全事件响应/网络安全数据取证/应用安全(400分)C模块 CTF夺旗-攻击 (200分&#x…...

学习笔记:Java 并发编程⑥_并发工具_JUC
若文章内容或图片失效,请留言反馈。 部分素材来自网络,若不小心影响到您的利益,请联系博主删除。 视频链接:https://www.bilibili.com/video/av81461839配套资料:https://pan.baidu.com/s/1lSDty6-hzCWTXFYuqThRPw&am…...

Linux文件隐藏属性(修改与显示):chattr和lsattr
文件除了基本的九个权限以外还有隐藏属性存在,这些隐藏属性对于系统有很大的帮助,尤其是系统安全(Security)上 chattr(配置文件隐藏属性) chattr 【-】【ASacdistu】文件或目录名称 选项与参数:…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...