Elasticsearch --- 数据聚合、自动补全
一、数据聚合
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
-
什么品牌的手机最受欢迎?
-
这些手机的平均价格、最高价格、最低价格?
-
这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
1.1、聚合的种类
聚合常见的有三类:
-
桶(Bucket)聚合:用来对文档做分组
-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
-
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
-
Avg:求平均值
-
Max:求最大值
-
Min:求最小值
-
Stats:同时求max、min、avg、sum等
-
-
管道(pipeline)聚合:其它聚合的结果为基础做聚合
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
1.2、DSL实现聚合
我们要统计所有数据中的酒店品牌有几种,其实就是按照品牌对数据分组。此时可以根据酒店品牌的名称做聚合,也就是Bucket聚合。
Bucket聚合语法
语法如下:
GET /hotel/_search {"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", // 参与聚合的字段"size": 20 // 希望获取的聚合结果数量}}} }结果如图:

聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为count,并且按照count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search {"size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","order": {"_count": "asc" // 按照_count升序排列},"size": 20}}} }
限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
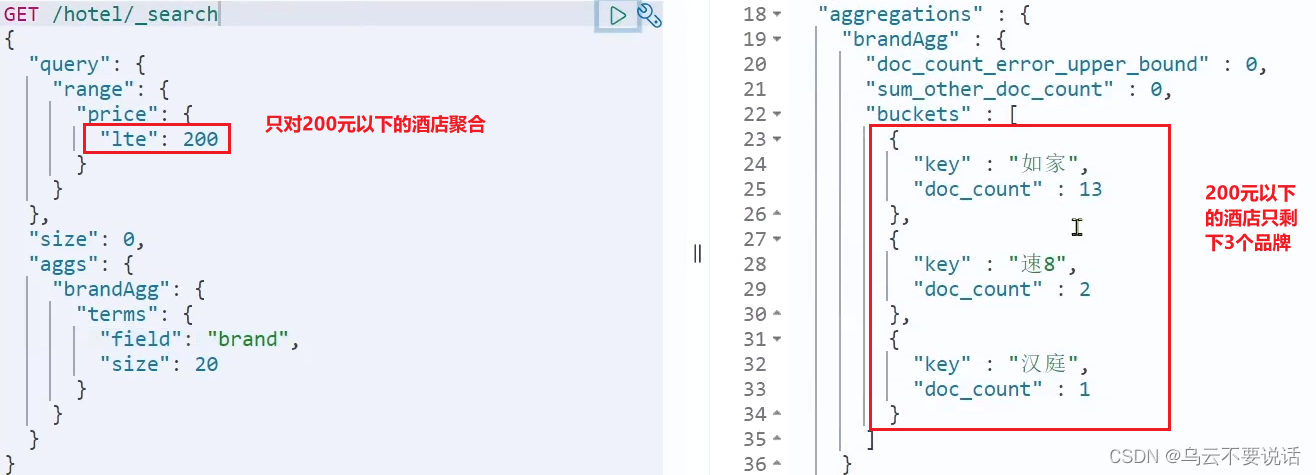
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search {"query": {"range": {"price": {"lte": 200 // 只对200元以下的文档聚合}}}, "size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","size": 20}}} }这次,聚合得到的品牌明显变少了:
Metric聚合语法
对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
语法如下:
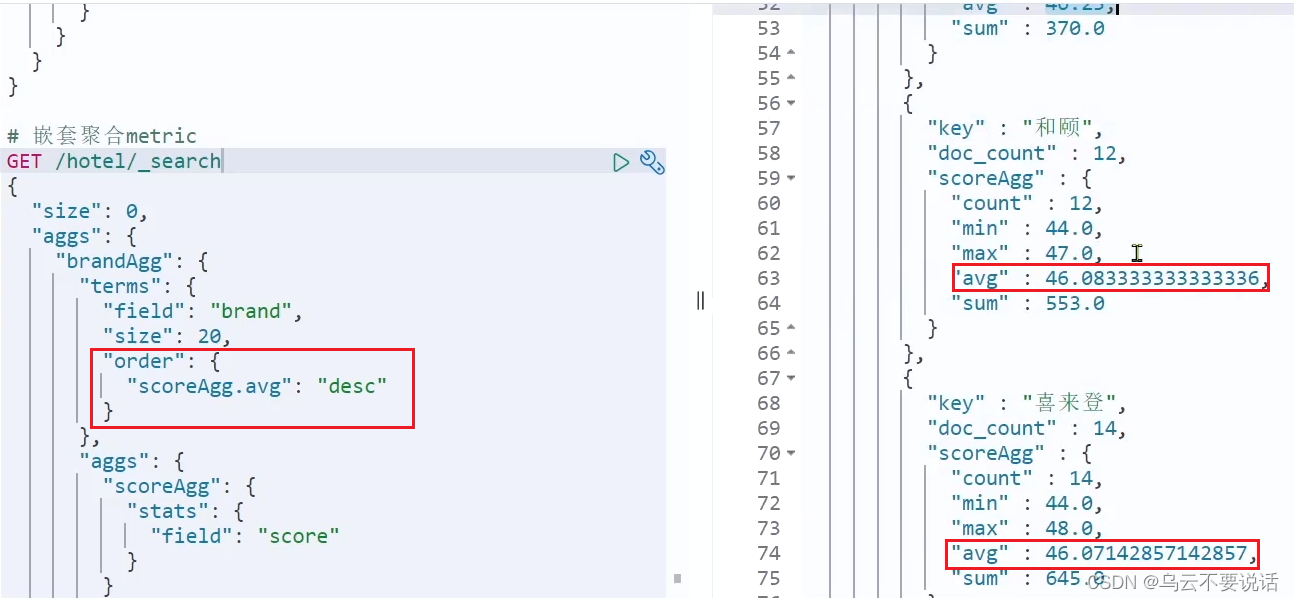
GET /hotel/_search {"size": 0, "aggs": {"brandAgg": { "terms": { "field": "brand", "size": 20},"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算"score_stats": { // 聚合名称"stats": { // 聚合类型,这里stats可以计算min、max、avg等"field": "score" // 聚合字段,这里是score}}}}} }这次的score_stats聚合是在brandAgg的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算。
另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:
小结
aggs代表聚合,与query同级,此时query的作用是?
-
限定聚合的的文档范围
聚合必须的三要素:
-
聚合名称
-
聚合类型
-
聚合字段
聚合可配置属性有:
-
size:指定聚合结果数量
-
order:指定聚合结果排序方式
-
field:指定聚合字段
1.3、RestAPI实现聚合
API语法
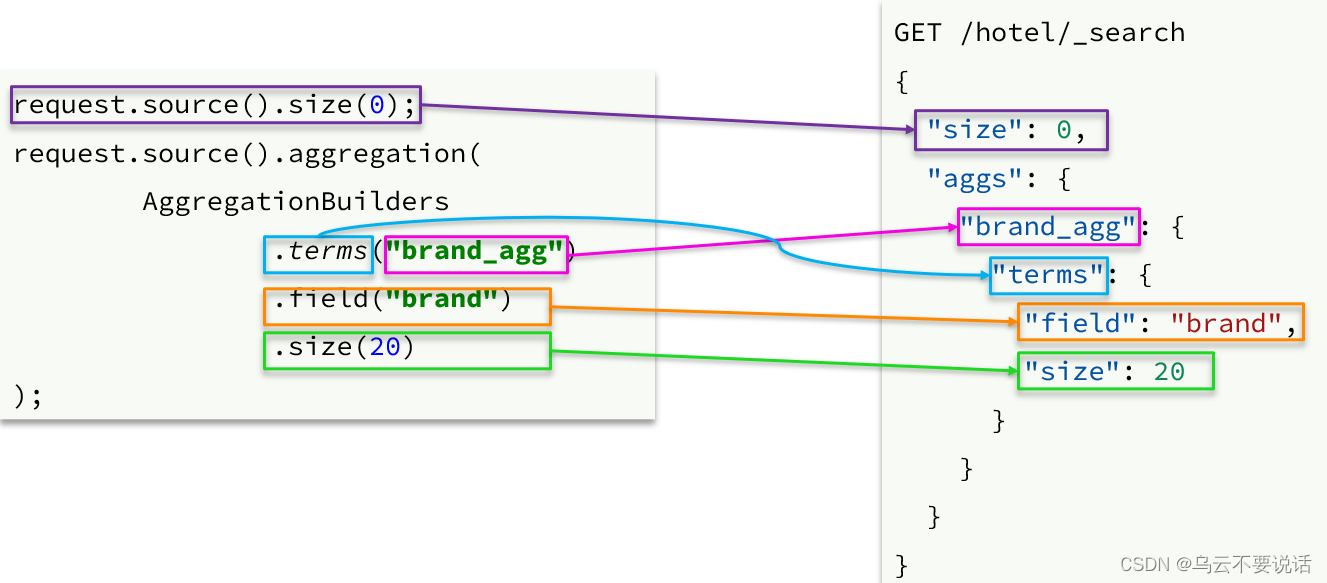
聚合条件与query条件同级别,因此需要使用request.source()来指定聚合条件。
聚合条件的语法:
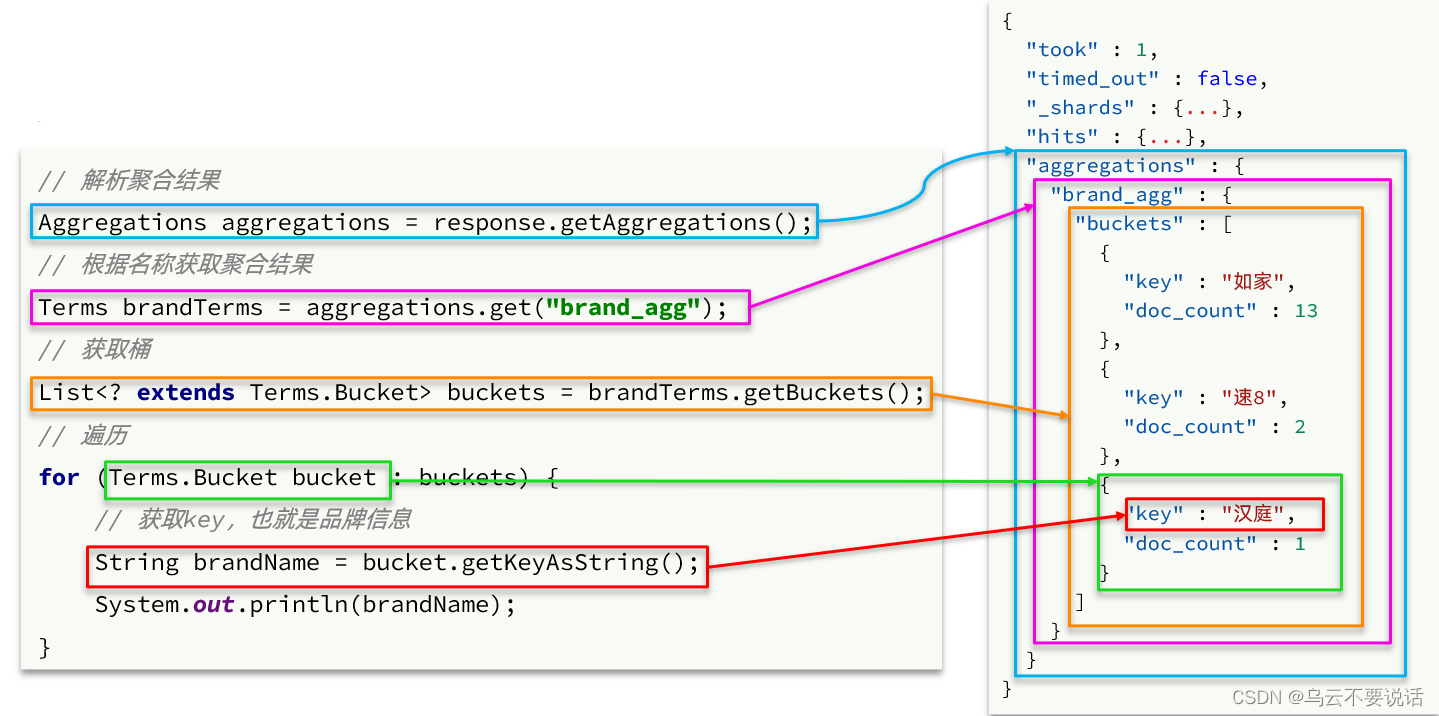
聚合的结果也与查询结果不同,API也比较特殊。不过同样是JSON逐层解析:
业务需求
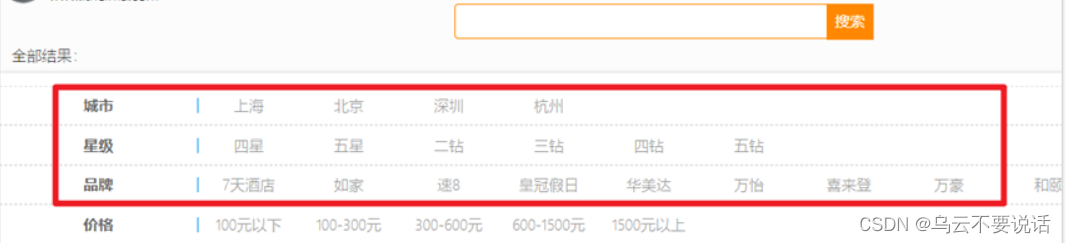
需求:搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的:
分析:
目前,页面的城市列表、星级列表、品牌列表都是写死的,并不会随着搜索结果的变化而变化。但是用户搜索条件改变时,搜索结果会跟着变化。
例如:用户搜索“东方明珠”,那搜索的酒店肯定是在上海东方明珠附近,因此,城市只能是上海,此时城市列表中就不应该显示北京、深圳、杭州这些信息了。
也就是说,搜索结果中包含哪些城市,页面就应该列出哪些城市;搜索结果中包含哪些品牌,页面就应该列出哪些品牌。
如何得知搜索结果中包含哪些品牌?如何得知搜索结果中包含哪些城市?
使用聚合功能,利用Bucket聚合,对搜索结果中的文档基于品牌分组、基于城市分组,就能得知包含哪些品牌、哪些城市了。
因为是对搜索结果聚合,因此聚合是限定范围的聚合,也就是说聚合的限定条件跟搜索文档的条件一致。
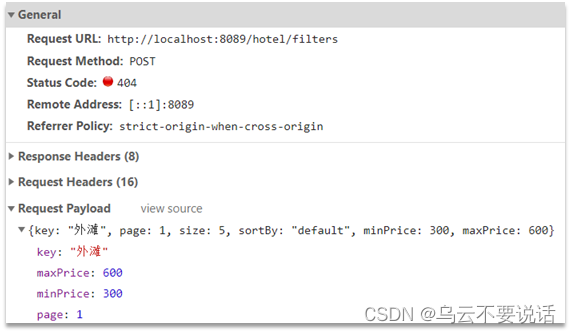
查看浏览器可以发现,前端其实已经发出了这样的一个请求:
请求参数与搜索文档的参数完全一致。
返回值类型就是页面要展示的最终结果:
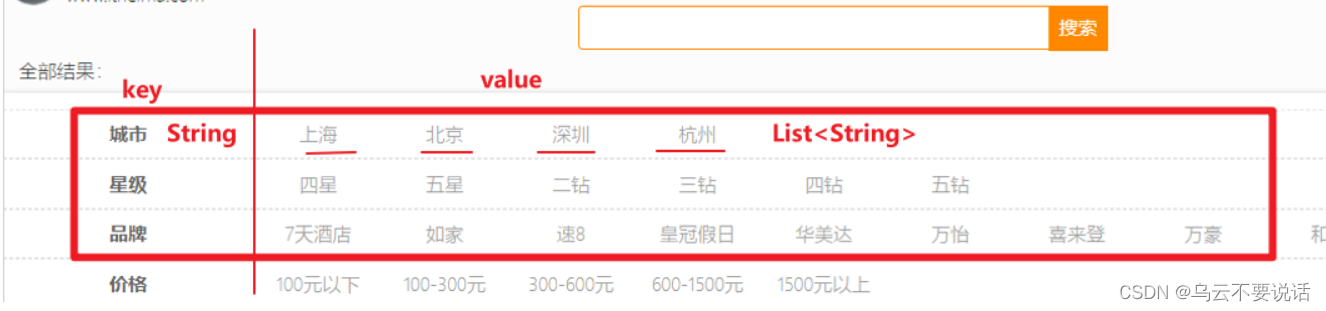
结果是一个Map结构:
key是字符串,城市、星级、品牌、价格
value是集合,例如多个城市的名称
业务实现
在
cn.itcast.hotel.web包的HotelController中添加一个方法,遵循下面的要求:
请求方式:
POST请求路径:
/hotel/filters请求参数:
RequestParams,与搜索文档的参数一致返回值类型:
Map<String, List<String>>代码:
@PostMapping("filters")public Map<String, List<String>> getFilters(@RequestBody RequestParams params){return hotelService.getFilters(params);}这里调用了IHotelService中的getFilters方法,尚未实现。
Map<String, List<String>> filters(RequestParams params);@Override public Map<String, List<String>> filters(RequestParams params) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.querybuildBasicQuery(params, request);// 2.2.设置sizerequest.source().size(0);// 2.3.聚合buildAggregation(request);// 3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Map<String, List<String>> result = new HashMap<>();Aggregations aggregations = response.getAggregations();// 4.1.根据品牌名称,获取品牌结果List<String> brandList = getAggByName(aggregations, "brandAgg");result.put("品牌", brandList);// 4.2.根据品牌名称,获取品牌结果List<String> cityList = getAggByName(aggregations, "cityAgg");result.put("城市", cityList);// 4.3.根据品牌名称,获取品牌结果List<String> starList = getAggByName(aggregations, "starAgg");result.put("星级", starList);return result;} catch (IOException e) {throw new RuntimeException(e);} }private void buildAggregation(SearchRequest request) {request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100)); }private List<String> getAggByName(Aggregations aggregations, String aggName) {// 4.1.根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);// 4.2.获取bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 4.3.遍历List<String> brandList = new ArrayList<>();for (Terms.Bucket bucket : buckets) {// 4.4.获取keyString key = bucket.getKeyAsString();brandList.add(key);}return brandList; }
二、自动补全
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:
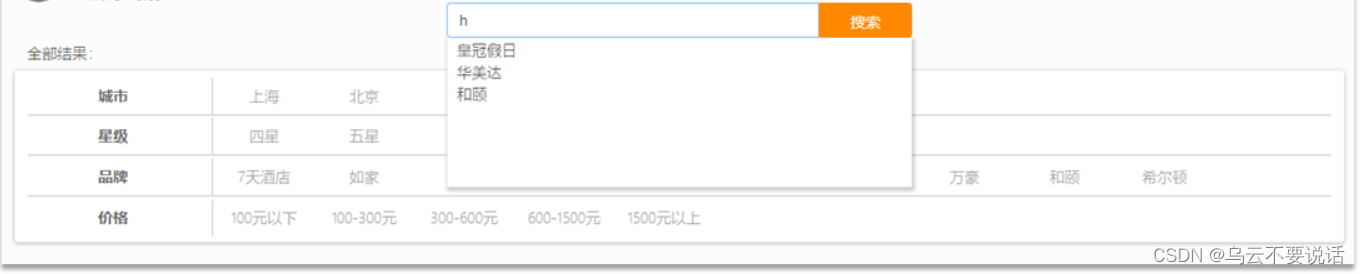
这种根据用户输入的字母,提示完整词条的功能,就是自动补全了。
因为需要根据拼音字母来推断,因此要用到拼音分词功能。
2.1、拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
安装方式与IK分词器一样,分三步:
- 下载解压
- 上传到虚拟机中,elasticsearch的plugin目录
- 重启elasticsearch
- 测试
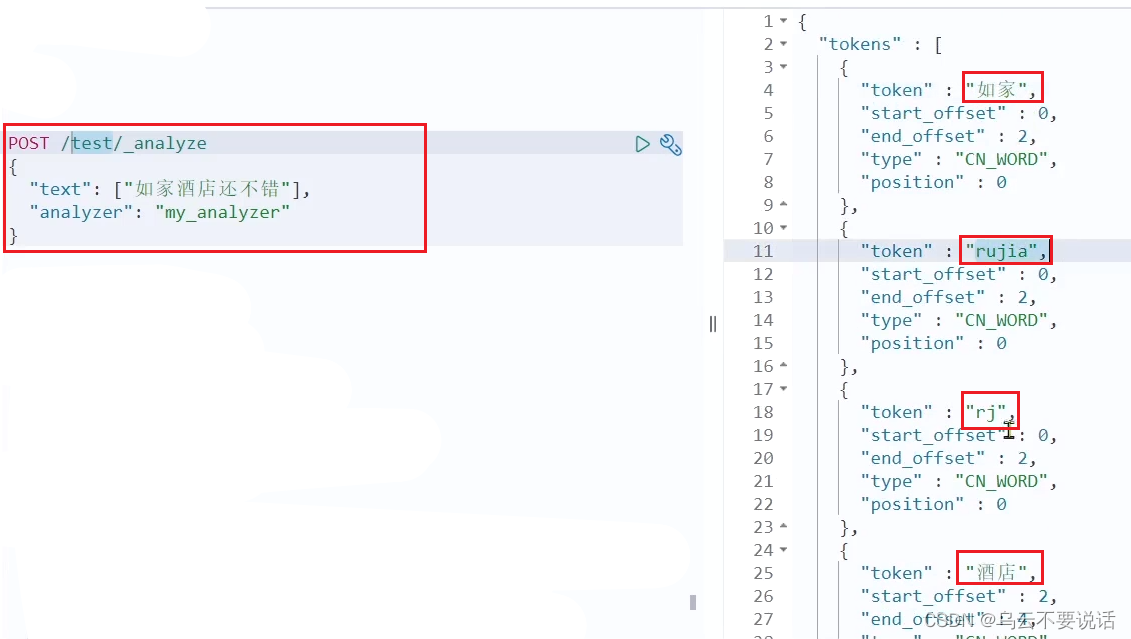
测试用法如下:
POST /_analyze
{"text": "如家酒店还不错","analyzer": "pinyin"
}结果:

2.2、自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
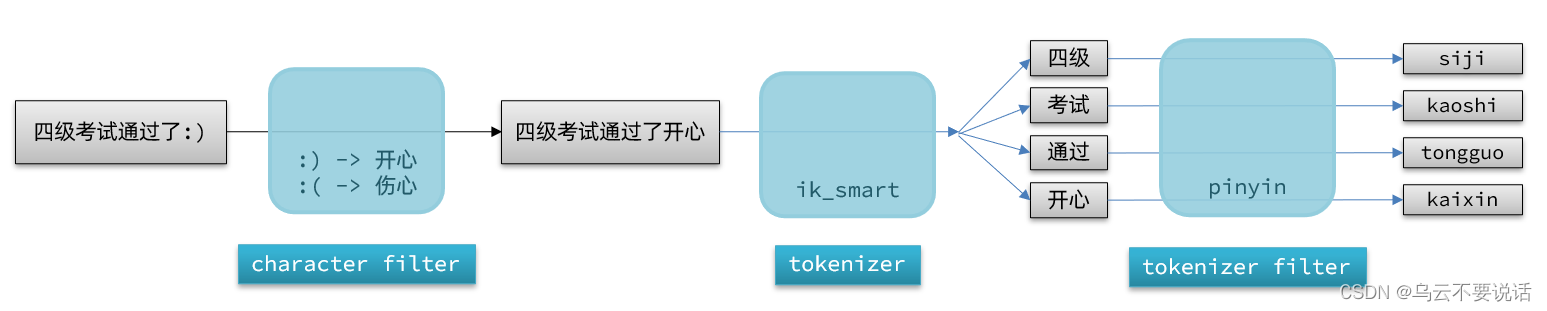
elasticsearch中分词器(analyzer)的组成包含三部分:
-
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
-
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
-
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:
声明自定义分词器的语法如下:
PUT /test
{"settings": {"analysis": {"analyzer": { // 自定义分词器"my_analyzer": { // 分词器名称"tokenizer": "ik_max_word","filter": "py"}},"filter": { // 自定义tokenizer filter"py": { // 过滤器名称"type": "pinyin", // 过滤器类型,这里是pinyin"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}测试:
总结:
如何使用拼音分词器?
-
①下载pinyin分词器
-
②解压并放到elasticsearch的plugin目录
-
③重启即可
如何自定义分词器?
-
①创建索引库时,在settings中配置,可以包含三部分
-
②character filter
-
③tokenizer
-
④filter
拼音分词器注意事项?
-
为了避免搜索到同音字,搜索时不要使用拼音分词器
2.3、自动补全查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
-
参与补全查询的字段必须是completion类型。
-
字段的内容一般是用来补全的多个词条形成的数组。
比如,一个这样的索引库:
// 创建索引库
PUT test
{"mappings": {"properties": {"title":{"type": "completion"}}}
}然后插入下面的数据:
// 示例数据
POST test/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{"title": ["SK-II", "PITERA"]
}
POST test/_doc
{"title": ["Nintendo", "switch"]
}查询的DSL语句如下:
// 自动补全查询
GET /test/_search
{"suggest": {"title_suggest": {"text": "s", // 关键字"completion": {"field": "title", // 补全查询的字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
2.4、实现搜索框自动补全
现在,我们的hotel索引库还没有设置拼音分词器,需要修改索引库中的配置。但是我们知道索引库是无法修改的,只能删除然后重新创建。
另外,我们需要添加一个字段,用来做自动补全,将brand、suggestion、city等都放进去,作为自动补全的提示。
因此,总结一下,我们需要做的事情包括:
-
修改hotel索引库结构,设置自定义拼音分词器
-
修改索引库的name、all字段,使用自定义分词器
-
索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
-
给HotelDoc类添加suggestion字段,内容包含brand、business
-
重新导入数据到hotel库
修改映射结构
代码如下:
// 酒店数据索引库 PUT /hotel {"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}} }
修改HotelDoc实体
HotelDoc中要添加一个字段,用来做自动补全,内容可以是酒店品牌、城市、商圈等信息。按照自动补全字段的要求,最好是这些字段的数组。
因此我们在HotelDoc中添加一个suggestion字段,类型为
List<String>,然后将brand、city、business等信息放到里面。代码如下:
@Data @NoArgsConstructor public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;private Object distance;private Boolean isAD;private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();// 组装suggestionif(this.business.contains("/")){// business有多个值,需要切割String[] arr = this.business.split("/");// 添加元素this.suggestion = new ArrayList<>();this.suggestion.add(this.brand);Collections.addAll(this.suggestion, arr);}else {this.suggestion = Arrays.asList(this.brand, this.business);}} }
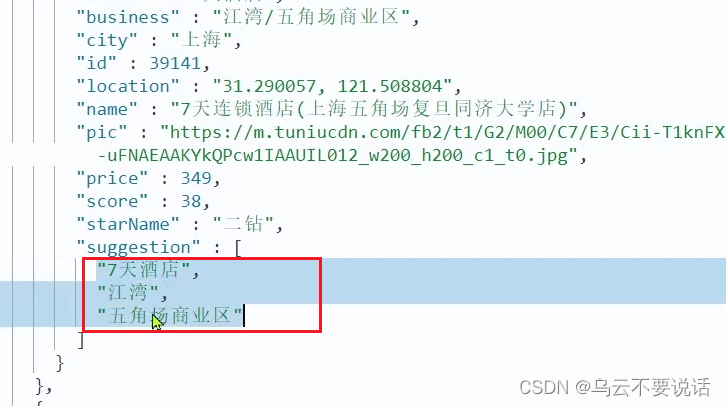
重新导入
重新执行之前编写的导入数据功能,可以看到新的酒店数据中包含了suggestion:
自动补全查询的JavaAPI
JavaAPI,这里给出一个示例:
而自动补全的结果也比较特殊,解析的代码如下:


实现搜索框自动补全
查看前端页面,可以发现当我们在输入框键入时,前端会发起ajax请求:
返回值是补全词条的集合,类型为
List<String>1)
HotelController中添加新接口,接收新的请求:
@GetMapping("suggestion") public List<String> getSuggestions(@RequestParam("key") String prefix) {return hotelService.getSuggestions(prefix); }2)
IhotelService中添加方法:List<String> getSuggestions(String prefix);3)
HotelService中实现该方法:@Override public List<String> getSuggestions(String prefix) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));// 3.发起请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Suggest suggest = response.getSuggest();// 4.1.根据补全查询名称,获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");// 4.2.获取optionsList<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();// 4.3.遍历List<String> list = new ArrayList<>(options.size());for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();list.add(text);}return list;} catch (IOException e) {throw new RuntimeException(e);} }
相关文章:

Elasticsearch --- 数据聚合、自动补全
一、数据聚合 聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如: 什么品牌的手机最受欢迎? 这些手机的平均价格、最高价格、最低价格? 这些手机每月的销售情况如何? 实现这…...
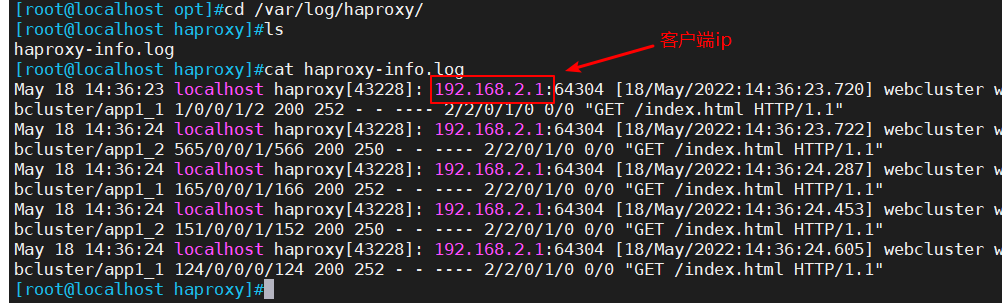
Haproxy搭建web群集
一.常见的web集群调度器 1、目前常见的web集群调度器分为软件和硬件 2、软件通常使用开源的LVS、Haproxy、Nginx LVS 性能最好,但搭建复杂。Nginx并发量,性能低于Haproxy 3、硬件一般使用比较多的是F5,也有很多人使用国内的一些产品&a…...
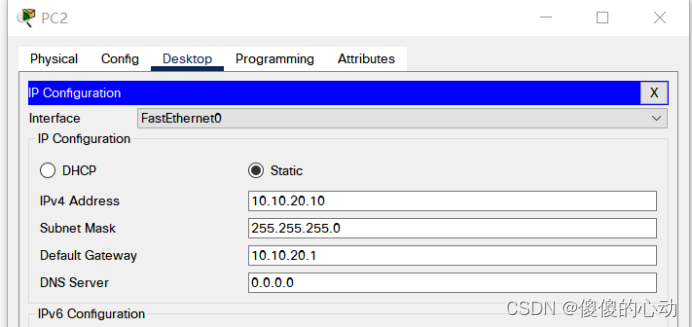
Packet Tracer - 配置和验证小型网络
Packet Tracer - 配置和验证小型网络 地址分配表 设备 接口 IP 地址 子网掩码 默认网关 RTA G0/0 10.10.10.1 255.255.255.0 不适用 G0/1 10.10.20.1 255.255.255.0 不适用 SW1 VLAN1 10.10.10.2 255.255.255.0 10.10.10.1 SW2 VLAN1 10.10.20.2 255.25…...
)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK获取相机设备的各种固件信息如DeviceID或者SerialNumber等(C++)
项目场景 Baumer工业相机堡盟相机是一种高性能、高质量的工业相机,可用于各种应用场景,如物体检测、计数和识别、运动分析和图像处理。 Baumer的万兆网相机拥有出色的图像处理性能,可以实时传输高分辨率图像。此外,该相机还具…...
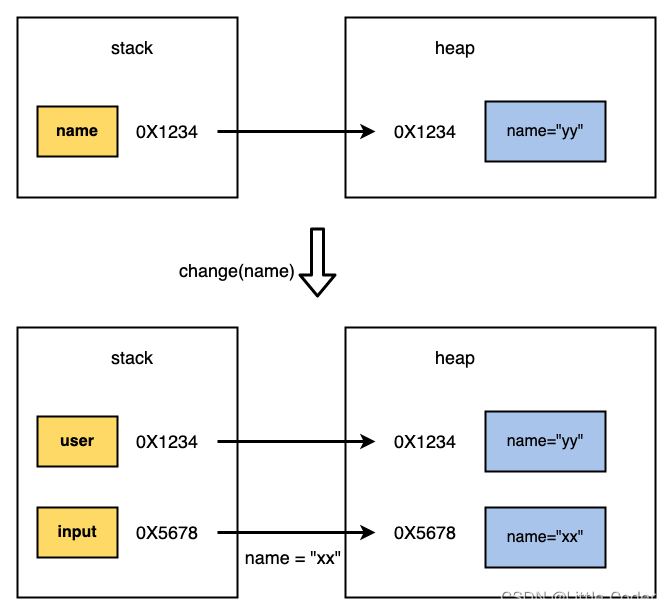
java 的参数传递
一、疑惑引入 首先,我们从一个例子来引出这个问题: public static void main(String[] args) throws IOException {List<String> mockList Lists.newArrayList("a", "b");System.out.println("1: " mockList);L…...

【面试长文】HashMap的数据结构和底层原理以及在JDK1.6、1.7和JDK8中的演变差异
文章目录 HashMap的数据结构和底层原理以及在JDK1.6、1.7和JDK8中的演变差异HashMap的数据结构和原理JDK1.6、1.7和1.8中的HashMap源码演变JDK1.6JDK1.7JDK1.8 总结自己实现一个简单的HashMapHashMap的时间复杂度分析HashMap的空间复杂度分析HashMap的应用场景HashMap的弊端及解…...
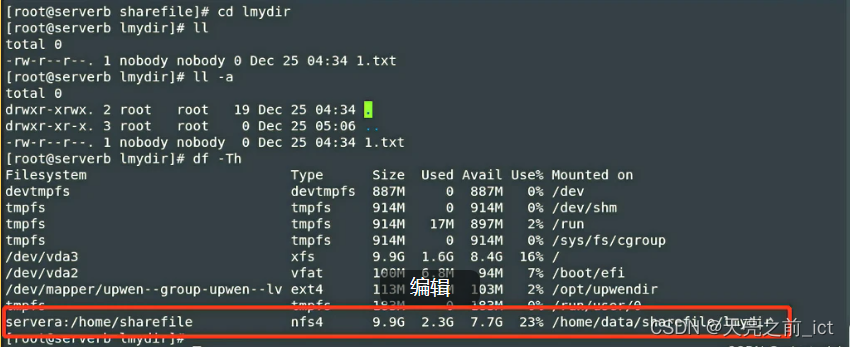
【25】linux进阶——网络文件系统NFS
大家好,这里是天亮之前ict,本人网络工程大三在读小学生,拥有锐捷的ie和红帽的ce认证。每天更新一个linux进阶的小知识,希望能提高自己的技术的同时,也可以帮助到大家 另外其它专栏请关注: 锐捷数通实验&…...

JAVA入坑之JAVADOC(Java API 文档生成器)与快速生成
目录 一、JAVADOC(Java API 文档生成器) 1.1概述 1.2Javadoc标签 1.3Javadoc命令 1.4用idea自带工具生成API帮助文档 二、IDEA如何生成get和set方法 三、常见快捷方式 3.1快速生成main函数 3.2快速生成println()语句 3.3快速生成for循环 3.4“…...
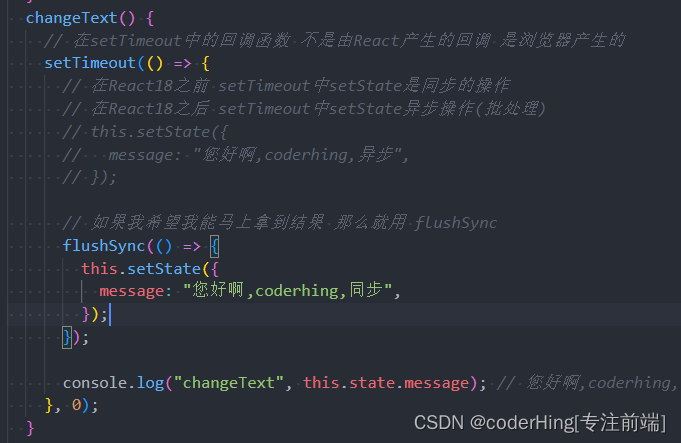
React | React组件化开发
✨ 个人主页:CoderHing 🖥️ React .js专栏:React .js React组件化开发 🙋♂️ 个人简介:一个不甘平庸的平凡人🍬 💫 系列专栏:吊打面试官系列 16天学会Vue 11天学会React Node…...

云计算的优势与未来发展趋势
一、前言二、云计算的基础概念2.1 云计算的定义2.2 云计算的发展历程2.3 云计算的基本架构2.4 云计算的主要服务模式 三、企业采用云计算的优势3.1 降低成本3.2 提高效率和灵活性3.3 提升信息系统的安全性和可靠性3.4 拥有更加丰富的应用和服务 四、行业应用案例4.1 金融行业4.…...

shell编程lesson01
命令行和脚本关系 命令行:单一shell命令,命令行中编写与执行; 脚本:众多shell命令组合成一个完成特定功能的程序,在脚本文件中进行编写维护。 脚本是一个文件,一个包含有一组命令的文件。 编写一个shel…...
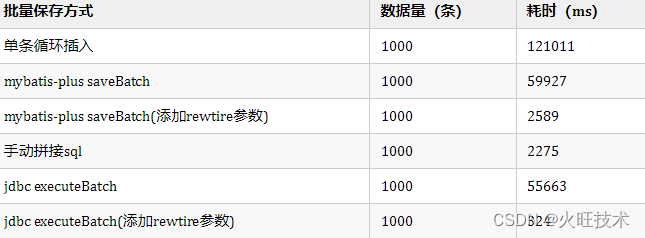
看看人家的MyBatis批量插入数据优化,从120s到2.5s,那叫一个优雅!
粗略的实验 最后 最近在压测一批接口的时候,我发现接口处理速度比我们预期的要慢。这让我感到有点奇怪,因为我们之前已经对这些接口进行了优化。但是,当我们进行排查时,发现问题出在数据库批量保存这块。 我们的项目使用了 myb…...

软件和信息服务业专题讲座
软件和信息服务业专题讲座 单选题(共 10 题,每题 3 分) 1、根据本讲,我国要加强物联网应用领域()开发和应用。 A、大数据 2、根据本讲,要充分发挥软件对城市管理和惠民服务的(&am…...
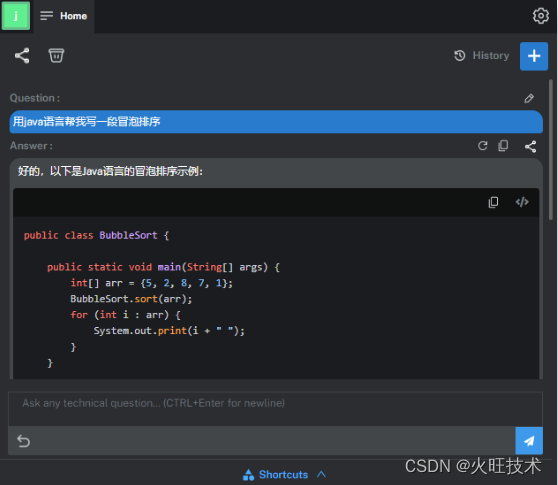
由 ChatGPT 团队开发,堪称辅助神器!IntelliJ IDEA 神级插件
什么是Bito? 为什么要使用Bito? 如何安装Bito插件 如何使用Bito插件 什么是Bito? Bito是一款由ChatGPT团队开发的IntelliJ IDEA编辑器插件,旨在提高开发人员的工作效率。此插件强大之处在于它不仅可以帮助开发人员更快地提交…...
spass modeler
课时1:SPSS Modeler 简介 本课时一共分为五个模块,分别是Modeler概述、工具安装、窗口说明以及功能介绍和应用案例。相信通过本课时内容的学习,大家将会对SPSS Modeler有个基础的了解. 在学习本节课内容之前,先来看看本节课我们究…...

kafka的push、pull分别有什么优缺点
文章目录 kafka的push、pull分别有什么优缺点Push 模式优点缺点 Pull 模式优点缺点 实践操作 kafka的push、pull分别有什么优缺点 Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,广泛应用于各大互联网公司的消息系统中。在 Kafka 中,生产者使用…...

【Canvas入门】从零开始在Canvas上绘制简单的动画
这篇文章是观看HTML5 Canvas Tutorials for Beginners教程做的记录,所以代码和最后的效果比较相似,教程的内容主要关于这四个部分: 创建并设置尺寸添加元素让元素动起来与元素交互 设置Canvas的大小 获取到canvas并设置尺寸为当前窗口的大…...

【技术整合】各技术解决方案与对应解决的问题
文章目录 基本实现性能安全 本文将框架分为三大类: 基本实现:包括某个供能或者提供web、移动端、桌面端、或者上述端上的某种功能性能:提升高可用、高并发的框架安全:包括网络安全、权限与容灾等 基本实现 .NET CORE、.NET web基…...
公网远程访问公司内网象过河ERP系统「内网穿透」
文章目录 概述1.查看象过河服务端端口2.内网穿透3. 异地公网连接4. 固定公网地址4.1 保留一个固定TCP地址4.2 配置固定TCP地址 5. 使用固定地址连接 概述 ERP系统对于企业来说重要性不言而喻,不管是财务、生产、销售还是采购,都需要用到ERP系统来协助。…...

Win11的两个实用技巧系列之修改c盘大小方法、功能快捷键大全
Win11 c盘无法更改大小什么原因?Win11修改c盘大小方法 有不少朋友反应Win11 c盘无法更改大小是怎么回事?本文就为大家带来了详细的更改方法,需要的朋友一起看看吧 Win11 c卷无法更改大小什么原因?有用户电脑的系统盘空间太小了,…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...