Linux【模拟实现C语言文件流】
✨个人主页: 北 海
🎉所属专栏: Linux学习之旅
🎃操作环境: CentOS 7.6 阿里云远程服务器

文章目录
- 🌇前言
- 🏙️正文
- 1、FILE 结构设计
- 2、函数使用及分析
- 3、文件打开 fopen
- 4、文件关闭 fclose
- 5、缓冲区刷新 fflush
- 6、数据写入 fwrite
- 7、数据读取 fread
- 8、实际效果
- 9、小结
- 10、源码
- 🌆总结
🌇前言
在 C语言 的文件流中,存在一个 FILE 结构体类型,其中包含了文件的诸多读写信息以及重要的文件描述符 fd,在此类型之上,诞生了 C语言 文件相关操作,如 fopen、fclose、fwrite 等,这些函数本质上都是对系统调用的封装,因此我们可以根据系统调用和缓冲区相关知识,模拟实现出一个简单的 C语言 文件流

本文重点 : 模拟实现 FILE 及 C语言 文件操作相关函数
注意: 本文实现的只是一个简单的 demo,重点在于理解系统调用及缓冲区
🏙️正文
1、FILE 结构设计
在设计 FILE 结构体前,首先要清楚 FILE 中有自己的缓冲区及冲刷方式

图片来源:《Linux基础IO》 - 2021dragon
缓冲区的大小和刷新方式因平台而异,这里我们将 大小设置为 1024 刷新方式选择 行缓冲,为了方便对缓冲区进行控制,还需要一个下标 _current,当然还有 最重要的文件描述符 _fd
#define BUFFER_SIZE 1024 //缓冲区大小//通过位图的方式,控制刷新方式
#define BUFFER_NONE 0x1 //无缓冲
#define BUFFER_LINE 0x2 //行缓冲
#define BUFFER_ALL 0x4 //全缓冲typedef struct MY_FILE
{char _buffer[BUFFER_SIZE]; //缓冲区size_t _current; //缓冲区下标int _flush; //刷新方式,位图结构int _fd; //文件描述符
}MY_FILE;
当前模拟实现的 FILE 只具备最基本的功能,重点在于呈现原理
在模拟实现 C语言 文件操作相关函数前,需要先来简单回顾下
2、函数使用及分析
主要实现的函数有以下几个:
fopen打开文件fclose关闭文件fflush进行缓冲区刷新fwrite对文件中写入数据fread读取文件数据
#include <stdio.h>
#include <assert.h>
#include <string.h>int main()
{//打开文件,写入数据FILE* fp = fopen("file.txt", "w");assert(fp);const char* str = "露易斯湖三面环山,层峦叠嶂,翠绿静谧的湖泊在宏伟山峰及壮观的维多利亚冰川的映照下更加秀丽迷人";char buff[1024] = { 0 };snprintf(buff, sizeof(buff), str);fwrite(buff, 1, sizeof(buff), fp);fclose(fp);return 0;
}

#include <stdio.h>
#include <assert.h>
#include <string.h>int main()
{//打开文件,并从文件中读取信息FILE* fp = fopen("file.txt", "r+");assert(fp);char buff[1024] = { 0 };int n = fread(buff, 1, sizeof(buff) - 1, fp);buff[n] = '\0';printf("%s", buff);fclose(fp);return 0;
}

fopen
- 打开指定文件,可以以多种方式打开,若是以读方式打开时,文件不存在会报错
fclose
- 根据
FILE*关闭指定文件,不能重复关闭
fwrite
- 对文件中写入指定数据,一般是借助缓冲区进行写入
fread
- 读取文件数据,同理一般是借助缓冲区先进行读取
不同的缓冲区有不同的刷新策略,如果未触发相应的刷新策略,会导致数据滞留在缓冲区中,比如如果内存中的数据还没有刷新就断电的话,会导致数据丢失;除了通过特定方式进行缓冲区冲刷外,还可以手动刷新缓冲区,在 C语言 中,手动刷新缓冲区的函数为 fflush
#include <stdio.h>
#include <unistd.h>int main()
{int cnt = 20;while(cnt){printf("he"); //故意不触发缓冲cnt--;if(cnt % 10 == 5) {fflush(stdout); //刷新缓冲区printf("\n当前已冲刷,cnt: %d\n", cnt);}sleep(1);}return 0;
}
总的来说,这些文件操作相关函数,都是在对缓冲区进行写入及冲刷,将数据拷贝给内核缓冲区,再由内核缓冲区刷给文件
3、文件打开 fopen
MY_FILE *my_fopen(const char *path, const char *mode); //打开文件
打开文件分为以下几步:
- 根据传入的
mode确认打开方式 - 通过系统接口
open打开文件 - 创建
MY_FILE结构体,初始化内容 - 返回创建好的
MY_FILE类型
因为打开文件存在多种失败情况:权限不对 / open 失败 / malloc 失败等,所以当打开文件失败后,需要返回 NULL
注意: 假设是因 malloc 失败的,那么在返回之前需要先关闭 fd,否则会造成资源浪费
// 打开文件
MY_FILE *my_fopen(const char *path, const char *mode)
{assert(path && mode);// 确定打开方式int flags = 0; // 打开方式// 读:O_RDONLY 读+:O_RDONLY | O_WRONLY// 写:O_WRONLY | O_CREAT | O_TRUNC 写+:O_WRONLY | O_CREAT | O_TRUNC | O_RDONLY// 追加: O_WRONLY | O_CREAT | O_APPEND 追加+:O_WRONLY | O_CREAT | O_APPEND | O_RDONLY// 注意:不考虑 b 二进制读写的情况if (*mode == 'r'){flags |= O_RDONLY;if (strcmp("r+", mode) == 0)flags |= O_WRONLY;}else if (*mode == 'w' || *mode == 'a'){flags |= (O_WRONLY | O_CREAT);if (*mode == 'w')flags |= O_TRUNC;elseflags |= O_APPEND;if (strcmp("w+", mode) == 0 || strcmp("a+", mode) == 0)flags |= O_RDONLY;}else{// 无效打开方式assert(false);}// 根据打开方式,打开文件// 注意新建文件需要设置权限int fd = 0;if (flags & O_CREAT)fd = open(path, flags, 0666);elsefd = open(path, flags);if (fd == -1){// 打开失败的情况return NULL;}// 打开成功了,创建 MY_FILE 结构体,并返回MY_FILE *new_file = (MY_FILE *)malloc(sizeof(MY_FILE));if (new_file == NULL){// 此处不能断言,需要返回空close(fd); // 需要先把 fd 关闭perror("malloc FILE fail!");return NULL;}// 初始化 MY_FILEmemset(new_file->_buffer, '\0', BUFFER_SIZE); // 初始化缓冲区new_file->_current = 0; // 下标置0new_file->_flush = BUFFER_LINE; // 行刷新new_file->_fd = fd; // 设置文件描述符return new_file;
}
4、文件关闭 fclose
int my_fclose(MY_FILE *fp); //关闭文件
文件在关闭前,需要先将缓冲区中的内容进行冲刷,否则会造成数据丢失
注意: my_fclose 返回值与 close 一致,因此可以复用
// 关闭文件
int my_fclose(MY_FILE *fp)
{assert(fp);// 刷新残余数据if (fp->_current > 0)my_fflush(fp);// 关闭 fdint ret = close(fp->_fd);// 释放已开辟的空间free(fp);fp = NULL;return ret;
}
5、缓冲区刷新 fflush
int my_fflush(MY_FILE *stream); //缓冲区刷新
缓冲区冲刷是一个十分重要的动作,它决定着 IO 是否正确,这里的 my_fflush 是将用户级缓冲区中的数据冲刷至内核级缓冲区
冲刷的本质:拷贝,用户先将数据拷贝给用户层面的缓冲区,再系统调用将用户级缓冲区拷贝给内核级缓冲区,最后才将数据由内核级缓冲区拷贝给文件
因此 IO 是非常影响效率的。数据传输过程必须遵循冯诺依曼体系结构
函数 fsync
- 将内核中的数据手动拷贝给目标文件(内核级缓冲区的刷新策略极为复杂,为了确保数据能正常传输,可以选择手动刷新)
注意: 在冲刷完用户级缓冲区后(write),需要将缓冲区清空,否则缓冲区就一直满载了
// 缓冲区刷新
int my_fflush(MY_FILE *stream)
{assert(stream);// 将数据写给文件int ret = write(stream->_fd, stream->_buffer, stream->_current);stream->_current = 0; // 每次刷新后,都需要清空缓冲区fsync(stream->_fd); // 将内核中的数据强制刷给磁盘(文件)if (ret != -1) return 0;else return -1;
}
6、数据写入 fwrite
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream); //数据写入
数据写入用户级缓冲区的步骤:
- 判断当前用户级缓冲区是否满载,如果满了,需要先刷新,再进行后续操作
- 获取当前待写入的数据大小
user_size及用户级缓冲区剩余大小my_size,方便进行后续操作 - 如果
my_size>=user_size,说明缓冲区容量足够,直接进行拷贝;否则说明缓冲区容量不足,需要重复冲刷->拷贝->再冲刷 的过程,直到将数据全部拷贝 - 拷贝完成后,需要判断是否触发相应的刷新策略,比如 行刷新->最后一个字符是否为
\n,如果满足条件就刷新缓冲区 - 数据写入完成,返回实际写入的字节数(简化版,即
user_size)
如果是一次写不完的情况,需要通过循环写入数据,并且在缓冲区满后进行刷新,因为循环写入时,目标数据的读取位置是在不断变化的(一次读取一部分,不断后移),所以需要对读取位置和读取大小进行特殊处理
// 数据写入
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream)
{// 写入先判断缓冲区是否已满if (stream->_current == BUFFER_SIZE)my_fflush(stream);size_t user_size = size * nmemb; // 用户想写入的字节数size_t my_size = BUFFER_SIZE - stream->_current; // 缓冲区中剩余可用空间size_t writen = 0; // 成功写入数据的大小if (my_size >= user_size){// 直接可用全部写入memcpy(stream->_buffer + stream->_current, ptr, user_size);stream->_current += user_size;writen = user_size;}else{// 一次写不完,需要分批写入size_t tmp = user_size; // 用于定位 ptr 的读取位置while (user_size > my_size){// 一次写入 my_size 个数据。user_size 会减小memcpy(stream->_buffer + stream->_current, ptr + (tmp - user_size), my_size);stream->_current += my_size; // 切记实时更新下标my_fflush(stream); // 写入后,刷新缓冲区user_size -= my_size;my_size = BUFFER_SIZE - stream->_current;}// 最后空间肯定足够,再把数据写入缓冲区中memcpy(stream->_buffer + stream->_current, ptr + (tmp - user_size), user_size);stream->_current += user_size;writen = tmp;}// 通过刷新方式,判断是否进行刷新if (stream->_flush & BUFFER_NONE){// 无缓冲,直接冲刷my_fflush(stream);}else if (stream->_flush & BUFFER_LINE){// 行缓冲,遇见 '\n' 才刷新if (stream->_buffer[stream->_current - 1] == '\n')my_fflush(stream);}else{// 全缓冲,满了才刷新if (stream->_current == BUFFER_SIZE)my_fflush(stream);}// 为了简化,这里返回用户实际写入的字节数,即 user_sizereturn writen;
}
7、数据读取 fread
在进行数据读取时,需要经历 文件->内核级缓冲区->用户级缓冲区->目标空间 的繁琐过程,并且还要考虑 用户级缓冲区是否能够一次读取完所有数据,若不能,则需要多次读取
注意:
- 读取前,如果用户级缓冲区中有数据的话,需要先将数据刷新给文件,方便后续进行操作
- 读取与写入不同,读取结束后,需要考虑
\0的问题(在最后一个位置加),如果不加的话,会导致识别错误;系统(内核)不需要\0,但C语言中的字符串结尾必须加\0,现在是 系统->用户(C语言)
// 数据读取
size_t my_fread(void *ptr, size_t size, size_t nmemb, MY_FILE *stream)
{// 数据读取前,需要先把缓冲区刷新if (stream->_current > 0)my_fflush(stream);size_t user_size = size * nmemb;size_t my_size = BUFFER_SIZE;// 先将数据读取到FILE缓冲区中,再赋给 ptrif (my_size >= user_size){// 此时缓冲区中足够存储用户需要的所有数据,只需要读取一次read(stream->_fd, stream->_buffer, my_size);memcpy(ptr, stream->_buffer, my_size);*((char *)ptr + my_size - 1) = '\0';}else{int ret = 1;size_t tmp = user_size;while (ret){// 一次读不完,需要多读取几次ret = read(stream->_fd, stream->_buffer, my_size);stream->_buffer[ret] = '\0';memcpy(ptr + (tmp - user_size), stream->_buffer, my_size);stream->_current = 0;user_size -= my_size;}}size_t readn = strlen(ptr);return readn;
}
8、实际效果
现在通过自己写的 myStdio 测试C语言文件流操作
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <unistd.h>int main()
{//打开文件,写入一段话FILE* fp = fopen("log.txt", "w+");assert(fp);char inPutBuff[512] = "2110年1月1日,距离地球能源完全枯竭还有3650天。为了解决地球能源危机,\n人类制造了赛尔机器人和宇宙能源探索飞船赛尔号,去寻找神秘精灵看守的无尽能源。";int n = fwrite(inPutBuff, 1, strlen(inPutBuff), fp);printf("本次成功写入 %d 字节的数据", n);fclose(fp);printf("\n==============================\n");//重新打开文件fp = fopen("log.txt", "r");assert(fp);char outPutBuff[512] = { '\0' };n = fread(outPutBuff, 1, sizeof(outPutBuff), fp);printf("本次成功读取 %d 字节的数据,具体内容为: \n%s\n", n, outPutBuff);fclose(fp);fp = NULL;return 0;
}
结果:

下面是库函数的结果:

可以看出结果是一样的
9、小结
用户在进行文件流操作时,实际要进行至少三次的拷贝:用户->用户级缓冲区->内核级缓冲区->文件,C语言 中众多文件流操作都是在完成 用户->用户级缓冲区 的这一次拷贝动作,其他语言也是如此,最终都是通过系统调用将数据冲刷到磁盘(文件)中

此时上一篇文章中的最后一个例子为什么会打印两次 hello fprintf 就很好理解了:因为没有触发刷新条件(文件一般为全缓冲),所以数据滞留在用户层缓冲区中,fork 创建子进程后,子进程结束,刷新用户层缓冲区[子进程],此时会触发写时拷贝机制,父子进程的用户层缓冲区不再是同一个;父进程结束后,刷新用户层缓冲区[父进程],因此会看见打印两次的奇怪现象

最后再简单提一下 printf 和 scanf 的工作原理
无论是什么类型,最终都要转为字符型进行存储,程序中的各种类型只是为了更好的解决问题
printf
- 根据格式读取数据,如整型、浮点型,并将其转为字符串
- 定义缓冲区,然后将字符串写入缓冲区(
stdout)- 最后结合一定的刷新策略,将数据进行冲刷
scanf
- 读取数据至缓冲区(
stdin)- 根据格式将字符串扫描分割,存入字符指针数组
- 最后将字符串转为对应的类型,赋值给相应的变量
这也就解释了为什么要确保 输出/输入 格式与数据匹配,如果不匹配的话,会导致 读取/赋值 错误
10、源码
关于 myStdio 的源码可以点击下方链接进行获取
模拟实现C语言文件流

🌆总结
以上就是本次关于 Linux【模拟实现C语言文件流】的全部内容了,通过 系统调用+缓冲区,我们模拟实现了一个简单版的 myStdio 库,在模拟实现过程中势必会遇到很多问题,而这些问题都能帮助你更好的理解缓冲区的本质:提高 IO 效率

相关文章推荐
Linux基础IO【重定向及缓冲区理解】
Linux基础IO【文件理解与操作】 ===============
Linux【模拟实现简易版bash】
Linux进程控制【进程程序替换】
Linux进程控制【创建、终止、等待】
相关文章:
Linux【模拟实现C语言文件流】
✨个人主页: 北 海 🎉所属专栏: Linux学习之旅 🎃操作环境: CentOS 7.6 阿里云远程服务器 文章目录 🌇前言🏙️正文1、FILE 结构设计2、函数使用及分析3、文件打开 fopen4、文件关闭 fclose5、缓…...

APK文件结构
文件结构 assets文件用来存放需要打包到Android 应用程序的静态资源文件,例如图片资源文件,JSON配置文件,渠道配置文件,二进制数据文件,HTML5离线资源文件等 与res/raw目录不同的数,assets目录支持任意深度…...
RabbitMQ死信队列延迟交换机
RabbitMQ死信队列&延迟交换机 1.什么是死信 死信&死信队列 死信队列的应用: 基于死信队列在队列消息已满的情况下,消息也不会丢失实现延迟消费的效果。比如:下订单时,有15分钟的付款时间 2. 实现死信队列 2.1 准备E…...

武忠祥老师每日一题||不定积分基础训练(六)
解法一: 求出 f ( x ) , 进而对 f ( x ) 进行积分。 求出f(x),进而对f(x)进行积分。 求出f(x),进而对f(x)进行积分。 令 ln x t , 原式 f ( t ) ln ( 1 e t ) e t 令\ln xt,原式f(t)\frac{\ln (1e^t)}{e^t} 令lnxt,原式f(t)etln(1et) 则 ∫ f ( x ) d…...

C语言结构体详解
结构体是C语言中的一种高级数据类型,它可以将不同的数据类型组合在一起,形成一个自定义的数据类型。结构体为程序员提供了一种组织数据的方式,它为程序开发带来了极大的灵活性和扩展性。 C语言中的结构体定义如下: struct 结构体…...

非盲去模糊简单介绍
文章目录 非盲去模糊简单介绍基于频域的方法1. Wiener滤波器2. 逆滤波器和半正定滤波器 基于空域的方法1. 均值滤波器2. 高斯滤波器3. 双边滤波器 基于偏微分的方法1. 非线性扩散滤波2. 全变分模型3. Laplacian正则化模型 振铃效应应用总结 非盲去模糊简单介绍 非盲去模糊是一…...

C语言动态内存管理与文件操作:打造高效通讯录
本篇博客会讲解如何使用C语言实现一个通讯录。实现通讯录的过程中,会大量用到C语言的知识点,包括但不限于:函数、自定义类型、指针、动态内存管理、文件操作,这些知识点在我的其他博客中都有讲解过,欢迎大家阅读&#…...
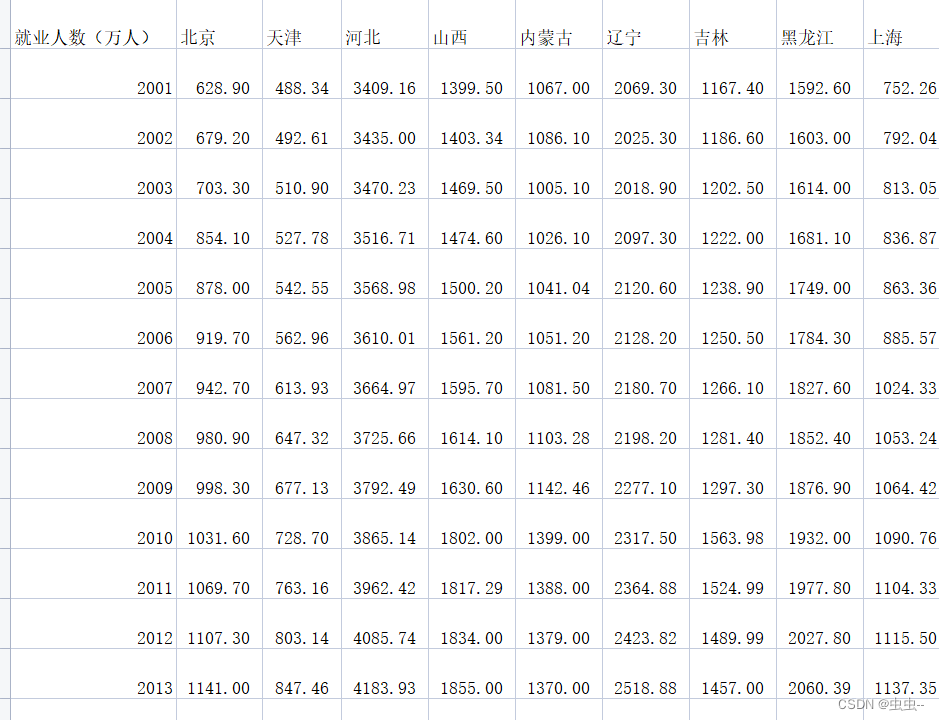
2001-2021年全国30省就业人数数据
2001-2021年全国30省就业人数数据/各省就业人数数据 1、时间:2001-2021年 2、范围:包括30个省市不含西藏 3、指标:就业人数 4、来源:各省NJ、社会统计NJ 5、缺失情况说明:无缺失 6、指标说明: 就业人…...

自然语言处理知识抽取(pkuseg、DDParser安装及使用)
一、分词简介 1.基本概念 分词是自然语言处理中的一个重要步骤,它可以帮助我们将文本分成一个个词语,以便更好地理解和分析文本。在计算机视觉、语音识别、机器翻译等领域,分词都扮演着重要的角色。 目前,常用的分词库包括 jie…...

Linux内核面试知识总结
Linux启动过程 1、主机加电自检,加载BIOS硬件信息 2、读取MBR引导文件 3、引导linux内核 4、启动第一个进程init(进程号永远为1) 5、进度相应的运行级别 6、运行终端,输入用户名和密码 linux系统缺省的运行级别 关机、单机…...
深度学习模型压缩与优化加速
1. 简介 深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、系统优化加速、异构计算等方法突破瓶颈,即分别在算法模型、计算图或算子优化以及硬件加速等层…...

Kali 更换源(超详细,附国内优质镜像源地址)
1.进入管理员下的控制台。 2. 输入密码后点击“授权”。 3.在控制台内输入下面的内容。 vim /etc/apt/sources.list 4.敲击回车后会进入下面的页面。 5.来到这个页面后的第一部是按键盘上的“i”键,左下角出现“插入”后说明操作正确。 6.使用“#”将原本的源给注释…...

Java版工程项目管理系统平台+java版企业工程系统源码+助力工程企业实现数字化管理
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显示1…...
搜索引擎测试报告
文章目录 一、项目背景二、项目功能三、测试目的四、测试环境五、测试计划1、功能测试2、自动化测试 六、测试结果 一、项目背景 java官方文档是我们在学习java语言中不可或缺的权威资料。相比于各种网站的Java资料,官方文档无论是语言表达还是组织方式都要更加全面…...

4年的测试工程师,你遇到过自身瓶颈期吗?又是怎样度过的?
从毕业到现在已经快4年啦,一直软件测试行业混迹。我不是牛人,但是自我感觉还算是个合格的测试工程师,有必要写下自己将近4年来的经历,给自我以提示,给刚入行的朋友提供点参考。 貌似这一点适应的行业最广,…...

【Python零基础学习入门篇④】——第四节:Python的列表、元组、集合和字典
⬇️⬇️⬇️⬇️⬇️⬇️ ⭐⭐⭐Hello,大家好呀我是陈童学哦,一个普通大一在校生,请大家多多关照呀嘿嘿😁😊😘 🌟🌟🌟技术这条路固然很艰辛,但既已选择&…...

3.6 cache存储器
学习步骤: 我会采取以下几个步骤来学习Cache存储器: 确定学习目标:Cache存储器作为一种高速缓存存储器,通常用于提高计算机系统的运行效率。因此,我需要明确学习Cache存储器的目的,包括了解其原理、结构和…...
Ubuntu零基础安装
Ubuntu零基础安装 首先我们需要安装VM,再安装ubuntu。 1、安装VM 进入VM官网 VM官网地址 选择下载试用版 下载Windows版本 下载完成后,点击安装包进行安装 至此就安装完毕了。 桌面会出现VM的图标。 点击打开,弹出如下画面: …...

热门的常用 API 大全分享
天气/环境 空气质量查询: 查询国内3400个城市的整点观测,获取指定城市的整点观测空气质量。未来7天生活指数:支持国内3400个城市以及国际4万个城市的天气指数数据,包括晨练、洗车、穿衣(12项,有详细说明&a…...
利用粒子群算法设计无线传感器网络中的最优安全路由模型(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 无线传感器网络(WSN)由数十个、数百个甚至数千个自主传感器组成。这些传感器以无线方式嵌入环境中&…...

Rust的匹配中的通配符模式与变量绑定在模式忽略中的语义区别
Rust语言中的模式匹配是其强大特性的核心之一,而通配符模式与变量绑定在模式忽略中的语义区别,是开发者容易混淆却至关重要的细节。理解这两者的差异不仅能提升代码的清晰度,还能避免潜在的错误。本文将深入探讨它们的区别,帮助读…...
)
网页视频下载神器Video DownloadHelper:从安装到实战(含企业微信直播案例)
网页视频高效下载全攻略:从基础配置到企业级应用实战 在数字化内容爆炸的时代,网页视频已成为知识获取和信息传播的重要载体。无论是企业培训视频、在线课程还是直播回放,能够快速、安全地下载这些资源对于提升工作效率和学习灵活性都至关重要…...

Ostrakon-VL-8B在复杂光照下的鲁棒性优化实战
Ostrakon-VL-8B在复杂光照下的鲁棒性优化实战 最近和几个做餐饮智能化的朋友聊天,他们都在吐槽同一个问题:后厨和大堂的摄像头识别系统一到晚上或者光线变化大的时候就“罢工”。要么是把土豆认成洋葱,要么是数不清盘子里还剩几块肉。这听起…...

ROS2 编译依赖缺失的排查与修复指南
1. ROS2编译依赖缺失的典型表现 第一次用ROS2编译功能包时,看到满屏红色报错确实容易懵。最常见的就是CMake哭着告诉你"找不到某某包",就像你去超市买酱油却发现货架空空如也。这种报错通常长这样: CMake Error at CMakeLists.txt:…...

bb_epaper:面向MCU的无缓冲电子墨水屏驱动框架
1. bb_epaper 库概述:面向资源受限嵌入式系统的无缓冲电子墨水屏驱动框架1.1 设计哲学与工程定位bb_epaper(BitBank e-paper library)并非又一个“能点亮屏幕”的演示级驱动,而是一个以系统级可靠性、内存零冗余、跨平台一致性为设…...

DHT11温湿度传感器与51单片机通信的时序图详解:从波形分析到代码调试
DHT11温湿度传感器与51单片机通信的时序图详解:从波形分析到代码调试 在嵌入式系统开发中,温湿度传感器的应用极为广泛,而DHT11作为一款性价比极高的数字温湿度传感器,常与51单片机搭配使用。然而,许多开发者在实际项目…...
)
华为OD机考双机位C卷 - 文件存储系统的排序 (Java)
文件存储系统的排序 2026华为OD机试双机位C卷 - 华为OD上机考试双机位C卷 华为OD机试双机位C卷真题目录(Java)点击查看: 【全网首发】2026华为OD机位C卷 机考真题题库含考点说明以及在线OJ(Java题解) 题目描述 在一个网络文件存储系统中,有众多的文件按照不同的文件夹进…...

常见的数据泄露风险与保密与防范策略,一文详解!
常见的数据泄露风险与保密与防范策略,一文详解!常见的数据泄露风险与保密与防范策略 大数据、云计算、物联网、人工智能等新技术的迅猛发展和广泛应用,为我们带来工作便利的同时,数据泄露与数据窃取渠道、手段也更加多样ÿ…...
:用3个量化指标预判协议层侧信道泄露风险——仅限首批200位架构师获取)
MCP 2.0生产部署安全熵值评估模型(独家):用3个量化指标预判协议层侧信道泄露风险——仅限首批200位架构师获取
第一章:MCP 2.0生产部署安全熵值评估模型的演进逻辑与核心定位MCP 2.0(Mission-Critical Platform 2.0)在金融与能源等高保障场景中承担着实时决策、多源异构数据融合与自主策略执行的关键职能。其生产部署的安全熵值评估模型并非对传统风险评…...
实战指南)
别再手动跳纤了!用MEMS光开关搭建智能光配线架(iODF)实战指南
MEMS光开关构建智能光配线架(iODF)的工程实践 凌晨三点的数据中心,运维工程师小王面对密密麻麻的ODF配线架,手中的光纤跳线在昏暗的灯光下泛着微光。业务部门紧急要求的链路调整,意味着他又要在这个狭小空间里完成数十…...