数据结构与算法:7种必须会的排序以及3种非基于比较排序
1.什么是排序
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
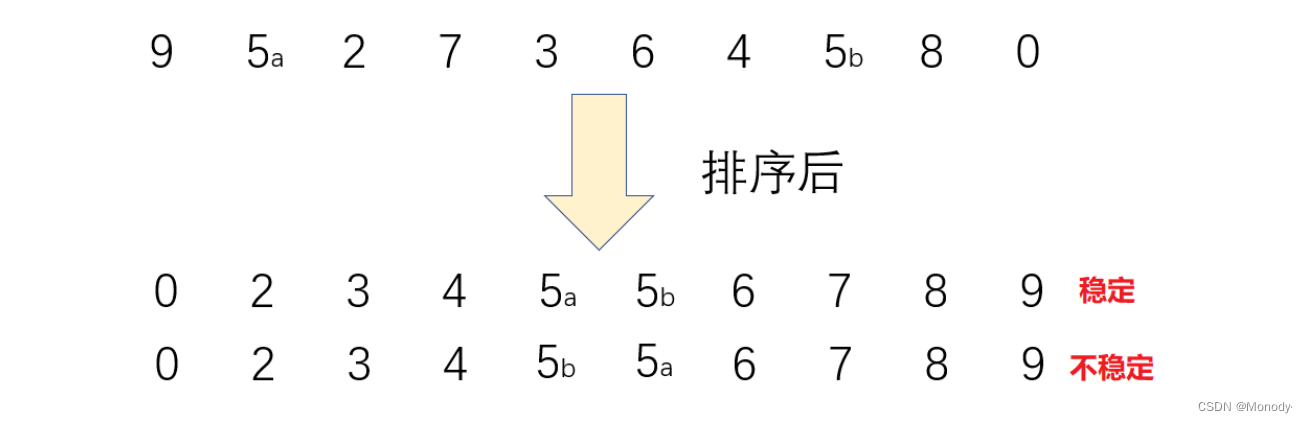
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
常见的排序算法:直接插入排序,希尔排序,选择排序,堆排序,冒泡排序,快速排序,归并排序等等
2.常见排序算法的实现
1.插入排序
1.基本思想
直接插入排序是一种简单的插入排序法,其基本思想是:
把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。实际中我们玩扑克牌时,就用了插入排序的思想。
2.直接插入排序
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置后;
- 重复步骤2~5。
//直接插入排序
/*** 时间复杂度O(N^2)* 最好情况的时间复杂度O(N)* 当数据趋于有序的时候,排序速度会非常的快* 一般情景就是数据基本有序建议使用直接插入排序** 空间复杂度O(1)* 稳定性:稳定* 如果一个排序是稳定的那么就可以实现为不稳定的* 但是如果一个排序本身就是不稳定的,你没有办法实现为稳定的排序** @param arr*/
public static void insertSort(int[] arr) {for (int i = 1; i < arr.length; i++) {int tmp = arr[i];int j = i - 1;for (; j >= 0 ; j--) {if (arr[j] > tmp) {arr[j + 1] = arr[j];} else {arr[j + 1] = tmp;break;}}arr[j + 1] = tmp;}
}
直接插入排序的特性总结:
- 元素集合越接近有序,直接插入排序算法的时间效率越高
- 时间复杂度:O(N^2)
- 空间复杂度:O(1),它是一种稳定的排序算法
- 稳定性:稳定
3.希尔排序
希尔排序法又称缩小增量法。
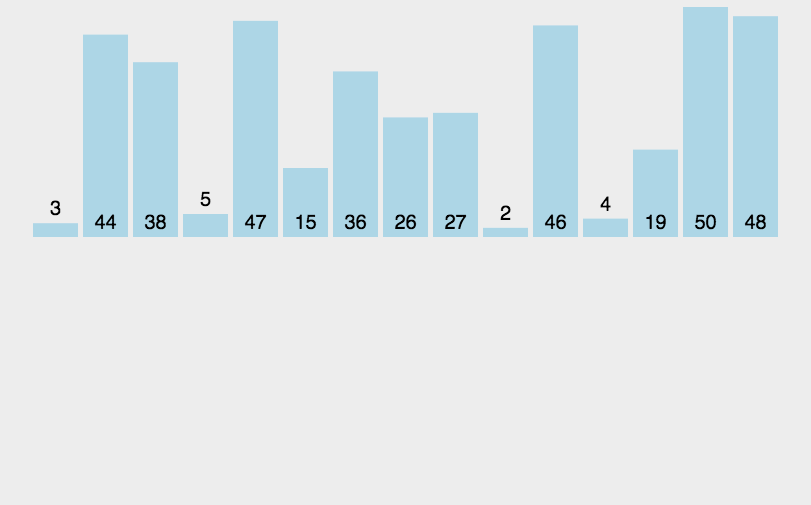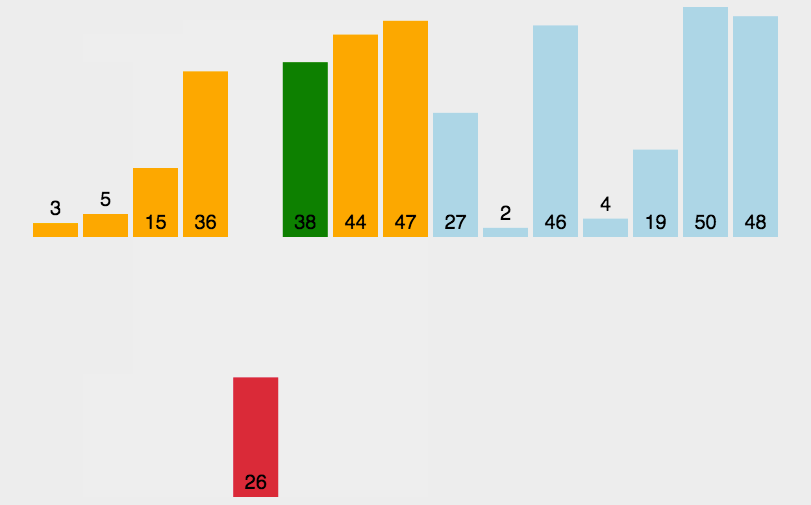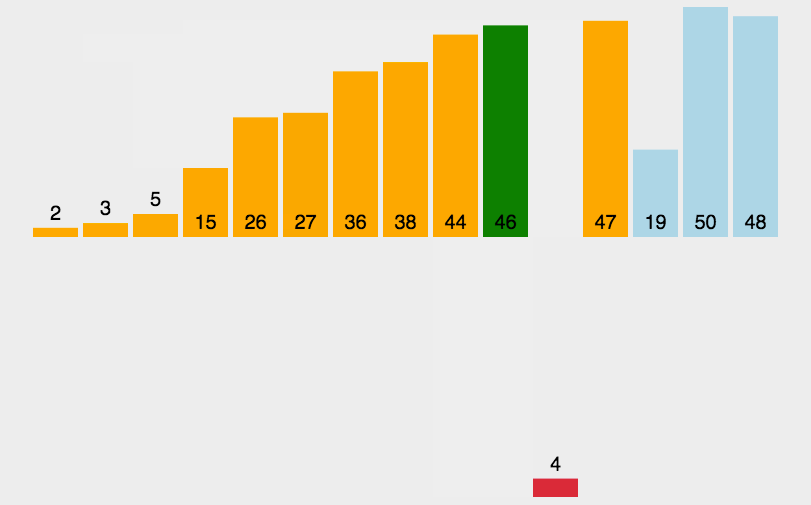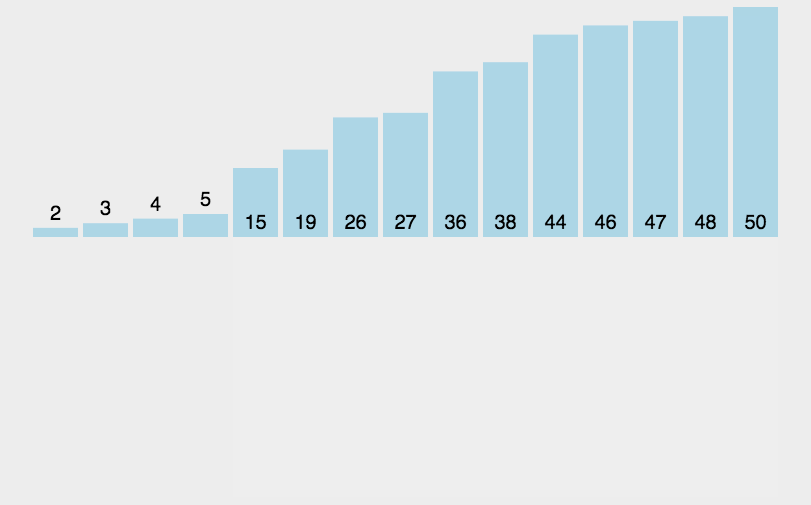
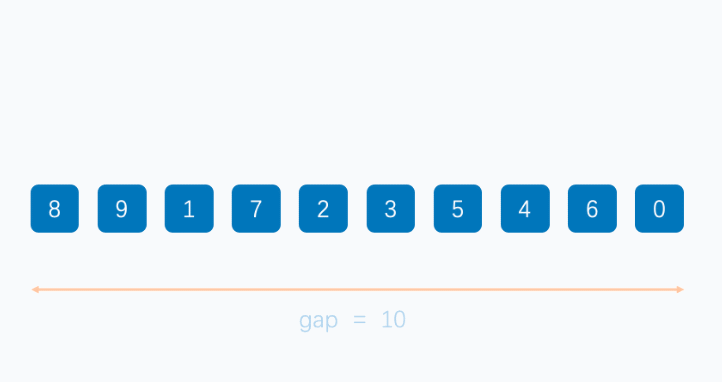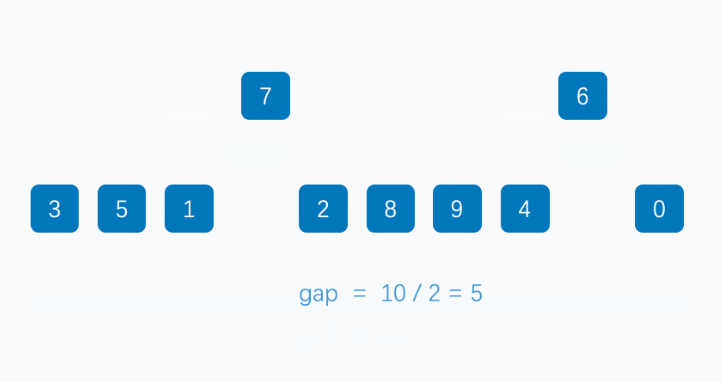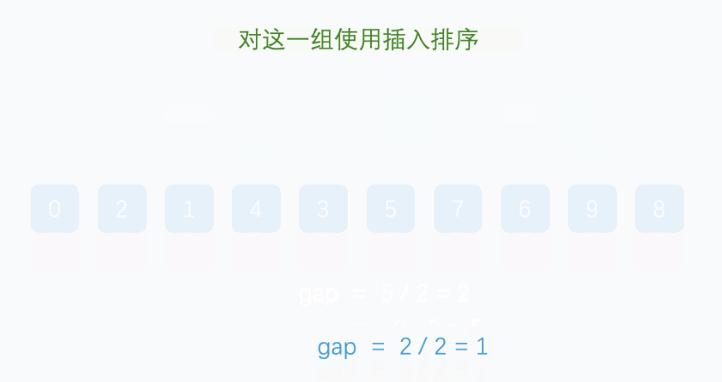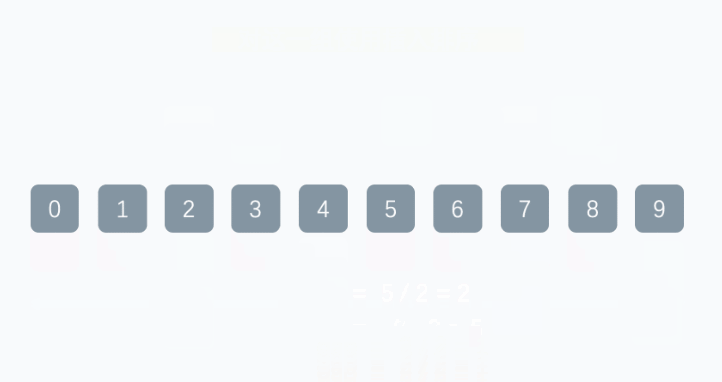
- 首先,选择增量 gap = 10/2 ,缩小增量继续以 gap = gap/2 的方式
- 初始增量为 gap = 10/2 = 5,整个数组分成了 5 组
- 按颜色划分为【 8 , 3 】,【 9 , 5 】,【 1 , 4 】,【 7 , 6 】,【 2 , 0 】
- 对这分开的 5 组分别使用上节所讲的插入排序
- 结果可以发现,这五组中的相对小元素都被调到前面了
- 缩小增量 gap = 5/2 = 2,整个数组分成了 2 组
- 【 3 , 1 , 0 , 9 , 7 】,【 5 , 6 , 8 , 4 , 2 】
- 对这分开的 2 组分别使用上节所讲的插入排序
- 此时整个数组的有序性是很明显的
- 再缩小增量 gap = 2/2 = 1,整个数组分成了 1 组
- 【 0, 2 , 1 , 4 , 3 , 5 , 7 , 6 , 9 , 0 】
- 此时,只需要对以上数列进行简单的微调,不需要大量的移动操作即可完成整个数组的排序
//希尔排序 -> 插入排序的一种优化/*** 希尔排序* @param arr*/
public static void shellSort(int[] arr) {int gap = arr.length;while (gap > 1) {shell(arr, gap);gap /= 2;}//整体进行插入排序shell(arr, 1);
}public static void shell(int[] arr, int gap) {for (int i = gap; i < arr.length; i++) {int tmp = arr[i];int j = i - gap;for (; j >= 0 ; j -= gap) {if (arr[j] > tmp) {arr[j + gap] = arr[j];} else {break;}}arr[j + gap] = tmp;}
}
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
- 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排序的时间复杂度都不固定:
因为咋们的gap是按照Knuth提出的方式取值的,而且Knuth进行了大量的试验统计,我们暂时就按照:时间复杂度:O(n ^1.2−1.5 )到 来算。 - 稳定性:不稳定
2.选择排序
1.基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
2. 直接选择排序
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
/*** 选择排序* 时间复杂度O(N^2)* 空间复杂度O(1)* 稳定性:不稳定*/
public static void selectSort(int[] array) {for (int i = 0; i < array.length; i++) {int minIndex = i;int j = i + 1;for (; j < array.length; j++) {if (array[j] < array[minIndex]) {minIndex = j;}}swap(array, i, minIndex);}
}private static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;
}public static void selectSort2(int[] array) {int left = 0;int right = array.length - 1;while (left < right) {int minIndex = left;int maxIndex = left;for (int i = left + 1; i <= right; i++) {if (array[i] < array[minIndex]) {maxIndex = i;}if (array[i] > array[maxIndex]) {maxIndex = i;}}//这里有可能把最大值换到minIndex的位置上//言外之意,最大值正好在left这个地方swap(array, minIndex, left);if (maxIndex == left) {maxIndex = minIndex;}swap(array, maxIndex, right);left++;right--;}
}
直接选择排序的特性总结:
- 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:不稳定
3.堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
- 构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。
- 将堆顶元素与末尾元素进行交换,使末尾元素最大。
- 重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。

/*** 堆排序* 时间复杂度O(N*logN)* 空间复杂度O(1)* 稳定性;不稳定的排序*/
public static void heapSort(int[] arr) {createBigHeap(arr);int end = arr.length - 1;while (end > 0) {swap(arr, 0, end);shiftDown(arr, 0, end);end--;}
}private static void createBigHeap(int[] arr) {//i -> parentfor (int i = (arr.length - 1 - 1) / 2; i >= 0; i--) {shiftDown(arr, i, arr.length);}
}private static void shiftDown(int[] array, int i, int len) {int child = 2 * i + 1;while (child < len) {if (child + 1 < len && array[child] < array[child + 1]) {child++;}if (array[child] > array[i]) {swap(array, child, i);i = child;child = 2 * i + 1;} else {break;}}
}
private static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;
}
堆排序的特性总结
- 堆排序使用堆来选数,效率就高了很多。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
- 稳定性:不稳定
3.交换排序
1.基本思想
所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
2.冒泡排序
每次循环时将相邻的两个元素进行比较,如果前者较大,则交换两元素,这里以升序进行讲解,逆序则为前者小的时候进行交换。则每次循环一个周期以后,就能确定一个最大值或者最小值,如此持续下去,数组将会有序,每进行一次循环,会确定一个元素。

public void bubbleSort(int[] arr) {// 记录最后一次交换的索引,最后一次交换,则后续就已经有序,不用排序int index = arr.length - 1;for (int i = 0; i < arr.length - 1; i++) {boolean isSorted = true;int k = 0;for (int j = 0; j < index; j++) {if (arr[j] > arr[j + 1]) {swap(arr, j, j + 1);isSorted = false;k = j + 1;}}// 如果没有进行交换,则已经有序。// 或者 当 i == index 时候if (isSorted || i == index){break;}index = k;}
}private static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;
}
冒泡排序的特性总结
- 冒泡排序是一种非常容易理解的排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
3.快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
1.Hoare法
- right指针直到找到小于key的值才停下来
- left指针直到找到大于key的值才停下来
- 将left和right所对应的值进行交换。重复上述过程直到两者相遇
- 相遇后,将key下标的值与相遇处的值交换
- 此时相遇处就是基准
private static int partitionHoare(int[] array, int left, int right) { int i = left;int pivot = array[left];while (left < right) {//left < right && 这个条件不能少 预防后面都比基准大while (left < right && array[right] >= pivot) {right--;}//代码走到这里表示right下标的值 小于pivotwhile (left < right && array[left] <= pivot) {left++;}//left下标的值 大于pivotswap(array, left, right);}//交换 和 原来的leftswap(array, left, i);return left;
}private static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;
}
2.挖坑法
- 我们需要设定一个基准值(一般为序列的最左边元素,也可以是最右边元素)此时最左边的是一个坑。
- 开辟两个指针left和right,分别指向序列的头节点和尾节点(选取的基准值在左边,则从右边开始出发,反之,异然)
- 假如让right从右往左走,找到第一个比基准小的元素,如果有,则把该值放到坑里,lefr从前往后遍历。
- 找到比基准大的元素的下标,然后用这个元素放到坑里。
- 依次循环,直到left指针和right指针重合时,我们把基准值放入这连个指针重合的位置。
private static int partition(int[] array, int left,int right) { int pivot = array[left];while (left < right) {//left < right && 这个条件不能少 预防后面都比基准大while (left < right && array[right] >= pivot) {right--;}array[left] = array[right];//right下标的值 小于pivotwhile (left < right && array[left] <= pivot) {left++;}array[right] = array[left];}//交换 和 原来的leftarray[left] = pivot;return left;
}
3.前后指针
- prev每次都需要指向从左到它本身之间最后一个小于基准值的数
- 如果cur的值大于基准值,这时只让cur++
- 如果cur指向的位置小于基准值
- 这时我们让prev++
- 判断prev++后是否与cur的位置相等
- 若不相等,则交换cur和prev的值
- 直到cur > R后,我们再交换prev和key,这样基准值的位置也就确定了
private static int partition(int[] array, int left, int right) {int cur = left + 1;while (cur <= right) {if (array[cur] < array[left] && array[++prev] != array[cur]) {swap(array, cur, prev);}cur++;}swap(array, prev, left);return prev;
}private static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;
}
4.优化快速排序
每次递归的时候,数据都是再慢慢变成有序的
当数据量少且趋于有序的时候,我们可以直接使用插入排序进行优化
public static int partitionHole(int[] array, int low, int high) {int tmp = array[low];while (low < high) {while (low < high && array[high] >= tmp) {high--;}array[low] = array[high];while (low < high && array[low] <= tmp) {low++;}array[high] = array[low];}array[low] = tmp;return low;}
public static void quickSort(int[] array, int left, int right) {if (left >= right) return;if (right - left + 1 <=10000) { //某个区间内的小规模排序直接插入排序//进行插入排序insertSortRange(array, left, right);return;}int pivot = partitionHole(array, left, right);quickSort(array, left, pivot - 1);quickSort(array, pivot + 1, right);
}
public static void insertSortRange(int[] array, int low, int end) {for (int i = low + 1 ; i <= end ; i++) {int tmp = array[i];int j = i - 1;for (; j >= low ; j--) {if (array[j] > tmp) {array[j + 1] = array[j];} else {break;}}array[j + 1] = tmp;}
}
但是这个优化并没有根本解决 有序情况下 递归深度太深的优化
我们用 三数取中法 选key
三数取中:头,尾,中间元素中 大小居中 的那一个,再把这个元素和队头元素互换,作为key
public static int partitionHole(int[] array, int low, int high) {int tmp = array[low];while (low < high) {while (low < high && array[high] >= tmp) {high--;}array[low] = array[high];while (low < high && array[low] <= tmp) {low++;}array[high] = array[low];}array[low] = tmp;return low;}
//三数取中,找到首,中,尾三个数中 中等大小的数的下标
private static int medianOfThreeIndex(int[] array, int left, int right) {int mid = left + ((right - left) >>> 1);//int mid = (right+left)/2 ;if (array[left] < array[right]) {if (array[mid] < array[left]) {return left;} else if (array[mid] > array[right]) {return right;} else {return mid;}} else {if (array[mid] < array[right]) {return right;} else if (array[mid] > array[left]) {return left;} else {return mid;}}
}
public static void quickSort(int[] array, int left, int right) {if (left >= right) return;//1.某个区间内的小规模排序直接插入排序【优化的是区间内的比较】if (right - left + 1 <= 10000) {//进行插入排序insertSortRange(array, left, right);return;}//2.三数取中法【优化的是本身的分割】int index = medianOfThreeIndex(array, left, right);swap(array, left, index);int pivot = partitionHole(array, left, right);quickSort(array, left, pivot - 1);quickSort(array, pivot + 1, right);
}
5.非递归实现快速排序
- 将数组左右下标入栈,
- 若栈不为空,两次取出栈顶元素,分别为闭区间的左右界限
- 将区间中的元素按照前后指针法排序(其余两种也可)得到基准值的位置
- 再以基准值为界限,若基准值左右区间中有元素,则将区间入栈
- 重复上述步骤直到栈为空
public static void quickSortNor(int[] array, int left, int right) {Stack<Integer> stack = new Stack<>();int pivot = partitionHole(array, left, right);if (pivot > left + 1) {//说明左边有两个或两个以上数据stack.push(left);stack.push(pivot - 1);}if (pivot < right - 1) {stack.push(pivot + 1);stack.push(right);}while (!stack.isEmpty()) {right = stack.pop();left = stack.pop();pivot = partitionHole(array, left, right);if (pivot > left + 1) {//说明左边有两个或两个以上数据stack.push(left);stack.push(pivot - 1);}if (pivot < right - 1) {stack.push(pivot + 1);stack.push(right);}}
}
快速排序总结
6. 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
7. 时间复杂度:O(NlogN)
8. 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
9. 时间复杂度:O(NlogN)
4.归并排序
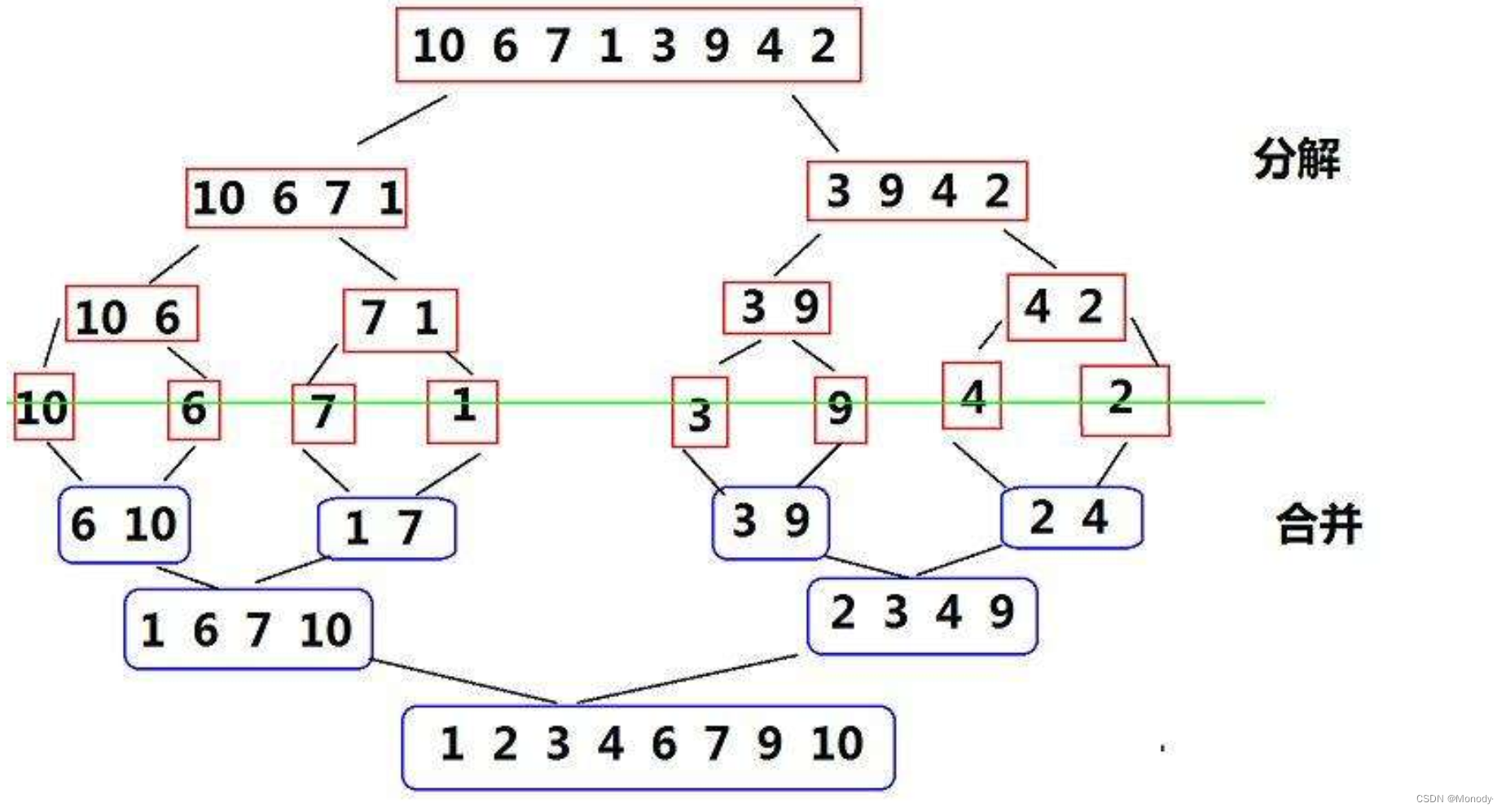
1.基本思想
归并排序是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
2.归并排序
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
- 重复步骤 3 直到某一指针达到序列尾;
- 将另一序列剩下的所有元素直接复制到合并序列尾。

public static void MergeSort(int[] array) {mergeSortChild(array, 0, array.length - 1);
}private static void mergeSortChild(int[] array, int left, int right) {if (left == right) {return;}int mid = (left + right) / 2;mergeSortChild(array, left, mid);mergeSortChild(array, mid + 1, right);//合并merge(array, left, mid, right);
}private static void merge(int[] array, int left, int mid, int right) { //归并int s1 = left;int e1 = mid;int s2 = mid + 1;int e2 = right;int[] tmpArr = new int[right - left + 1];int k = 0;//表示tmpArr 的下标while (s1 <= e1 && s2 <= e2) {if (array[s1] <= array[s2]) {tmpArr[k++] = array[s1++];} else {tmpArr[k++] = array[s2++];}}while (s1 <= e1) {tmpArr[k++] = array[s1++];}while (s2 <= e2) {tmpArr[k++] = array[s2++];}//tmpArr当中 的数据 是right left 之间有序的数据for (int i = 0; i < k; i++) {array[i + left] = tmpArr[i];}
}
3.非递归实现归并排序
根据递归的结构不难看出,归并排序的本质也是分割区间分别进行处理,并且归并前要求两个区间范围要分别有序,因此第一步是通过迭代来控制边界到达最小的区间也就是两个区间重叠的位置开始归并,然后不断扩大区间继续归并。
public static void MergeSort1(int[] array) {int gap = 1;while (gap < array.length) {for (int i = 0; i < array.length; i += gap * 2) {int left = i;int mid = left + gap - 1;int right = mid + gap;if (mid >= array.length) {mid = array.length - 1;}if (right >= array.length) {right = array.length - 1;}merge(array, left, mid, right);}gap *= 2;}
}
归并排序总结
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
3.排序算法复杂度及稳定性分析

4.其他非基于比较排序
1.计数排序
- 找出待排序的数组中最大和最小的元素
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
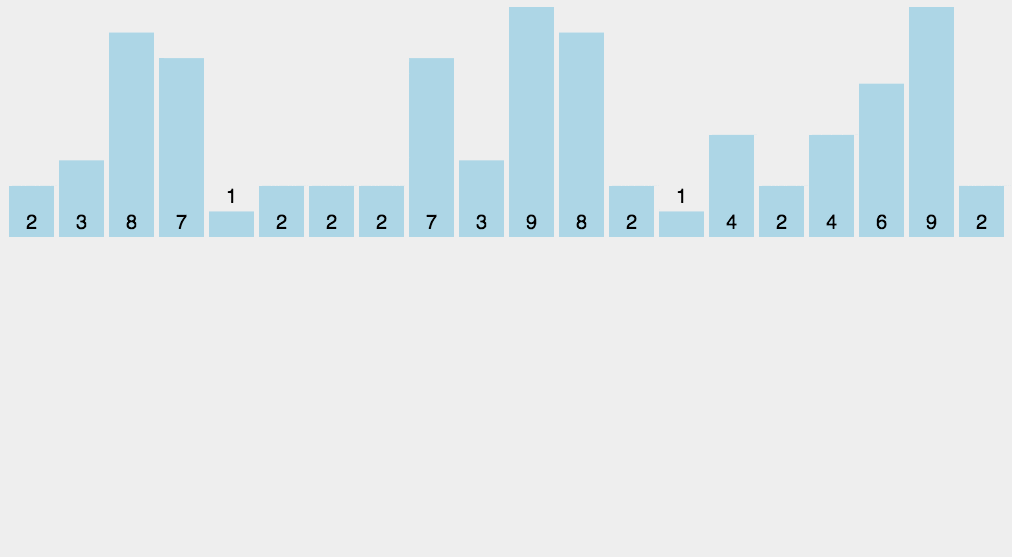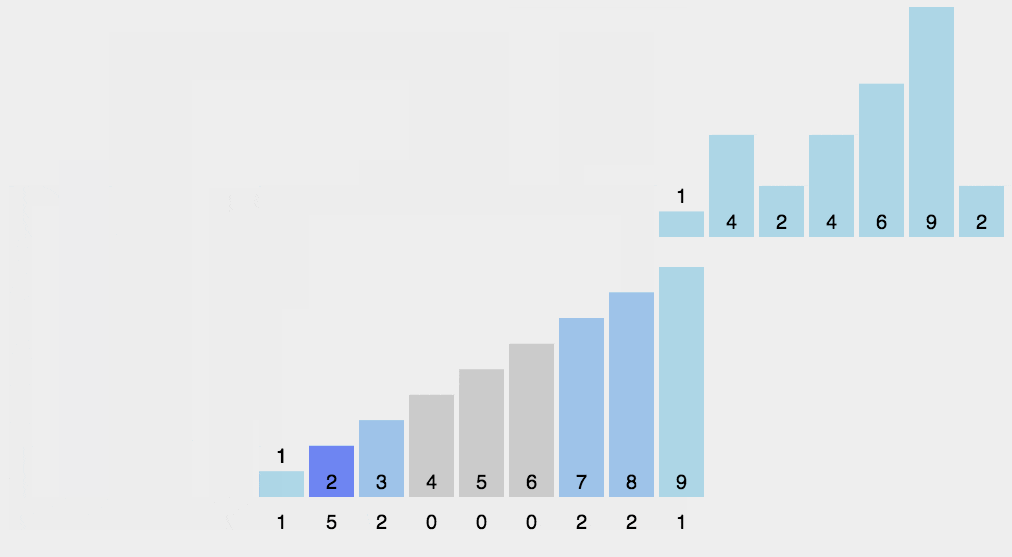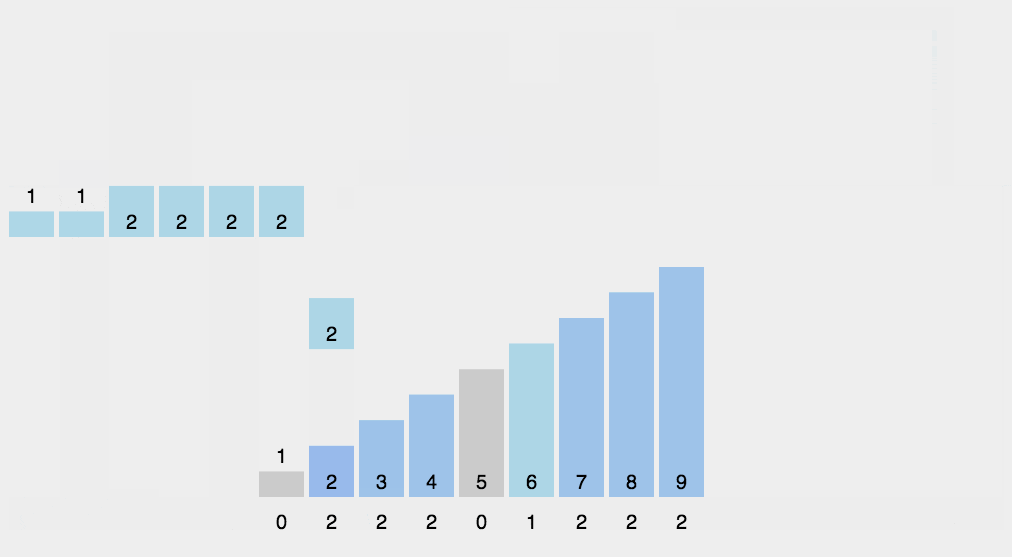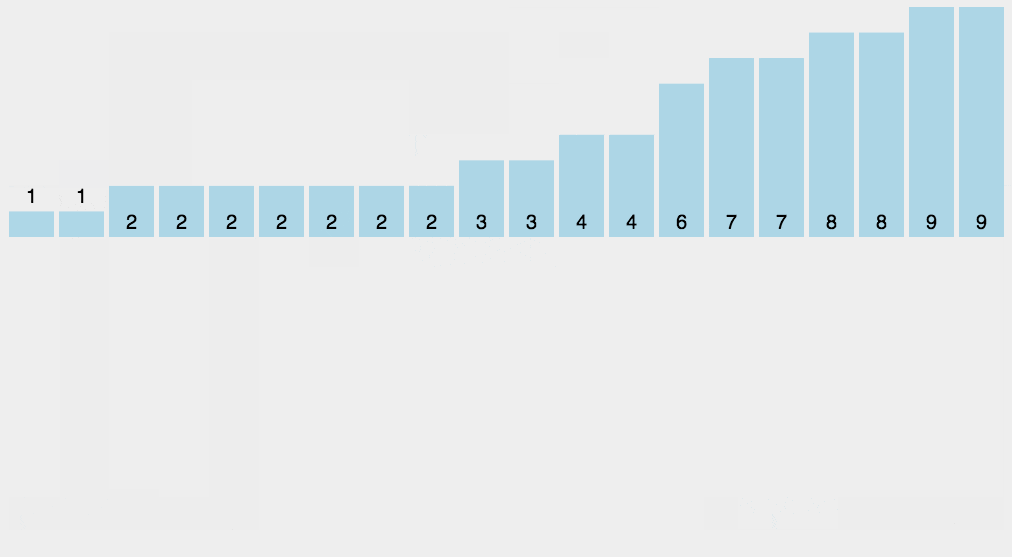
/*** 计数排序* 时间复杂度: O(N + 范围)* 空间复杂度: O(范围)* 稳定性: 不确定* @param arr*/
public static void countSort(int[] arr) {//1.遍历数组 找到最大值和最小值int max = arr[0];int min = arr[0];//O(N)for (int i = 1; i < arr.length; i++) {if (arr[i] < min) {min = arr[i];}if (arr[i] > max) {max = arr[i];}}//2.根据范围 定义计数数组的长度int len = max - min + 1;int[] count = new int[len];//3.遍历数组,在计数数组当中纪录每个数字出现的次数 O(N)for (int i = 0; i < arr.length; i++) {count[arr[i] - min]++;}//4.遍历计数数组 O(范围)int index = 0;//array数组的新下标for (int i = 0; i < count.length; i++) {while (count[i] > 0) {//这里要加最小值 才能反映真实的数据arr[index] = i + min;index++;count[i]--;}}
}
计数排序的特性总结
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,范围))
- 空间复杂度:O(范围)
- 稳定性:稳定
2.基数排序
将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。

public static void radixSort(int[] arr) {// 假定arr[0] 是最大数// 1. 通过遍历arr, 找到数组中真正最大值// 2. 目的是确定要进行多少轮排序int max = arr[0];for (int i = 1; i < arr.length; i++) {if (arr[i] > max) {max = arr[i];}}// 计算最大数字是几位数int maxLength = (max + "").length();// 定义一个二维数组, 就是10个桶// 1. 该二维数组有10个一维数组 0-9// 2. 为了防止溢出,每个一维数组(桶),大小定为 arr.length// 3. 很明确, 基数排序是空间换时间int[][] bucket = new int[10][arr.length];// 用于记录在每个桶中,实际存放了多少个数据,这样才能正确的取出int[] bucketElementCounts = new int[10];// 根据最大长度的数决定比较的次数// 1. 大循环的次数就是 最大数有多少位,前面分析过// 2. n = 1, n *= 10 是为了每轮循环排序时,分别求出各个元素的 个位,十位,百位,千位 ...// 就是一个小算法// 3. 这个基础排序,完全可以使用 冒泡分步写代码来完成,比较简单!!for (int i = 0, n = 1; i < maxLength; i++, n *= 10) {// 把每一个数字分别计算本轮循环的位数的值,比如第1轮是个位...for (int j = 0; j < arr.length; j++) {// 计算int digitOfElement = arr[j] / n % 10;// 把当前遍历的数据放入指定的数组中bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];// 记录数量bucketElementCounts[digitOfElement]++;}// 记录取的元素需要放的位置int index = 0;// 把各个桶中(10个桶)存放的数字取出来, 放入到arr中for (int k = 0; k < bucketElementCounts.length; k++) {// 如果这个桶中,有数据才取,没有数据就不取了if (bucketElementCounts[k] != 0) {// 循环取出元素for (int l = 0; l < bucketElementCounts[k]; l++) {// 取出元素arr[index++] = bucket[k][l];}// 把这个桶的对应的记录的数据个数置为0,注意,桶本身数据(前面存的数据还在)bucketElementCounts[k] = 0; //}}}
}
3.桶排序
桶排序是计数排序的扩展版本,计数排序可以看成每个桶只存储相同元素,而桶排序每个桶存储一定范围的元素,通过映射函数,将待排序数组中的元素映射到各个对应的桶中,对每个桶中的元素进行排序,最后将非空桶中的元素逐个放入原序列中。
桶排序需要尽量保证元素分散均匀,否则当所有数据集中在同一个桶中时,桶排序失效。
public static void bucketSort(int[] arr){// 计算最大值与最小值int max = Integer.MIN_VALUE;int min = Integer.MAX_VALUE;for(int i = 0; i < arr.length; i++){max = Math.max(max, arr[i]);min = Math.min(min, arr[i]);}// 计算桶的数量int bucketNum = (max - min) / arr.length + 1;ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum);for(int i = 0; i < bucketNum; i++){bucketArr.add(new ArrayList<Integer>());}// 将每个元素放入桶for(int i = 0; i < arr.length; i++){int num = (arr[i] - min) / (arr.length);bucketArr.get(num).add(arr[i]);}// 对每个桶进行排序for(int i = 0; i < bucketArr.size(); i++){Collections.sort(bucketArr.get(i));}// 将桶中的元素赋值到原序列int index = 0;for(int i = 0; i < bucketArr.size(); i++){for(int j = 0; j < bucketArr.get(i).size(); j++){arr[index++] = bucketArr.get(i).get(j);}}
}
相关文章:
数据结构与算法:7种必须会的排序以及3种非基于比较排序
1.什么是排序 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序…...

数据库用户数
Oracle的用户数 oracle软件内部并没对用户数做限制,买5个用户数,指你买了5个user licences,从法律上只能连5个session,超过5个的连接都是非法的。oracle不给你技术上的限制,可是给你法律上的限制。 一般来讲…...

nginx如何用html显示多个图片并加入播放链接
需求背景通过nginx来做个点播服务,ffmpeg截取视频中的某一帧作为视频的封面,前端页面展示这个封面,,并链接到对应的视频播放链接,加载播放器进行播放简单介绍一下ffmpeg截取视频中的某一帧的方式截取视频的第一帧&…...

【蓝桥杯集训·每日一题】Acwing 3729. 改变数组元素
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴一维差分区间合并一、题目 1、原题链接 3729. 改变数组元素 2、题目描述 给定一个空数组 V 和一个整数数组 a1,a2,…,an。 现在要对数组 V 进行 n 次操作。 第 i 次操作的…...
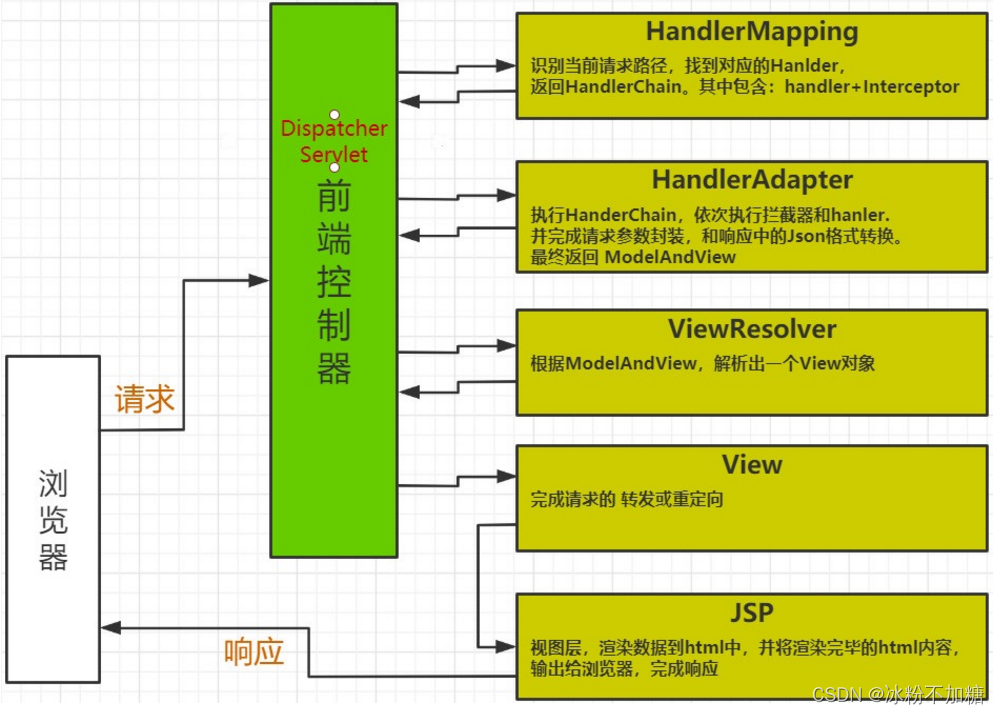
springmvc执行流程
文章目录前言一、springMVC请求执行流程二、组件说明以下组件通常使用框架提供实现:总结前言 本篇文章是对springmvc的补充 接上篇文章springmvc入门https://blog.csdn.net/l_zl2021/article/details/127120873 一、springMVC请求执行流程 1.用户发送请求至前端控制…...
SpringMVC(2)
一)接受到JSON格式的数据:使用RequestBody来进行接收 ResponseBody表示的是返回一个非页面的数据 RequestBody表示的是后端要接受JSON格式的数据 一)接收单个格式的JSON格式的数据,我们使用一个对象来进行接收 1)我们之前接受GET请求中的queryString中的参数的时候&…...

Jackson序列化json时null转成空串或空对象
在项目中可能会遇到需要将null转"",可以通过以下方法解决。一:添加JacksonConfig 配置import com.fasterxml.jackson.core.JsonGenerator;import com.fasterxml.jackson.databind.JsonSerializer;import com.fasterxml.jackson.databind.Objec…...

如何将Python的上级目录的文件导入?【from.import】
假如有如下目录: -python ----file1 ---------file1_1 ------------------pfile1_1.py ---------pfile1.py ----file2 ---------pfile2.py ----pfile.py ----data.py 在pfile1_1.py中想要将pfile.py 导入怎么办? 首先将其上级目录添加到系统目…...

Java实现碧蓝航线连续作战
目录一.实现功能二.主要思路三.代码实现四.用exe4j生成.exe程序五.最终效果六.代码开源一.实现功能 主线图作战结束到结算页自动点击再次前往 二.主要思路 判断是否进入了结算界面:记录结算界面某个像素点的RGB值,每隔3秒对这个像素点进行比对 移动鼠标…...
Docker笔记
文章目录1.docker为什么会出现2.docker是什么3.传统虚拟机和容器的对比3.1虚拟机3.2容器虚拟化技术3.3两者对比3.4为什么Docker会比VM虚拟机快?4.docker能干嘛6.docker的应用场景7.docker三要素一:镜像(Image)二:容器&…...
情人节使用AI TOOL来创建一个甜言蜜语的女伴
一、首先使用chatgpt生成一段情侣间的对话,需要反复几次,达到满意的程度,然后将女方的话归在一起。 这是一个情侣私下谈话的场景,女方表示对男朋友精心准备的情人节安排和礼物表示很满意 二、 打开网站:https://lexic…...
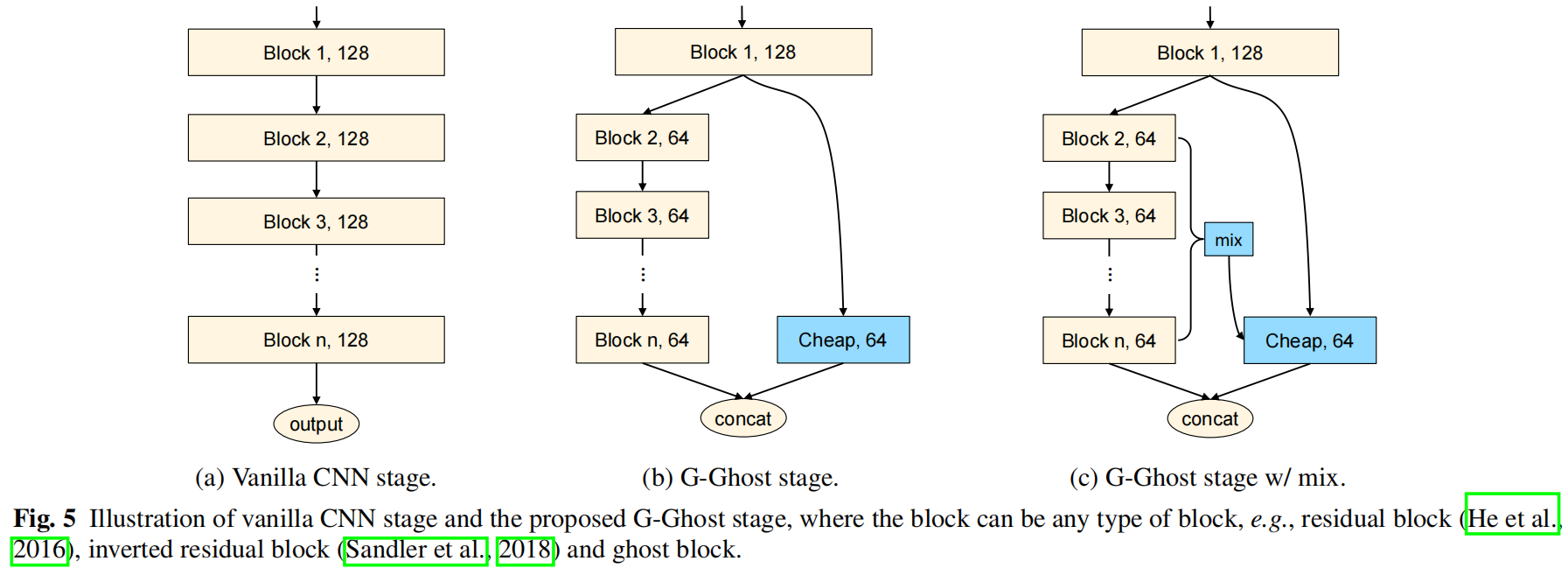
G-GhostNet(IJCV 2022)原理与代码解析
paper:GhostNets on Heterogeneous Devices via Cheap Operationscode:https://github.com/huawei-noah/Efficient-AI-Backbones/blob/master/g_ghost_pytorch/g_ghost_regnet.py前言本文提出了两种轻量网路,用于CPU端的C-GhostNet和用于GPU端…...
Ethercat系列(5)TWcat3激活过程的协议分析(续1)
顺序写系统时间偏移从-》主顺序写时间延迟主-》从从-》主顺序写分布式时钟启动主-》从从-》主读多重写系统时间主-》从从-》主顺序写应用层控制主-》从从-》主顺序读错误计数器主-》从从-》主顺序读应用层状态主-》从从-》主顺序读应用层,广播写错误计数器主-》从从…...
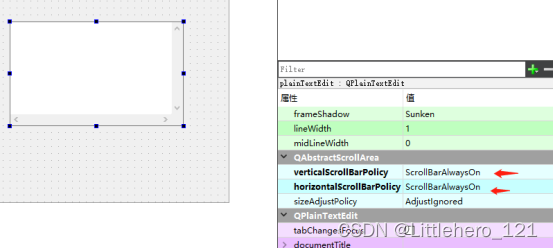
QT入门Input Widgets之QScrollBar
目录 一、界面布局功能 1、界面位置介绍 2、控件界面基本属性 2.1 horizontalScrollBar界面属性 3、样式设置 此文为作者原创,创作不易,转载请标明出处! 一、界面布局功能 1、界面位置介绍 QScrollBar主要分为两种,一种垂直…...
)
【ML】基于机器学习的心脏病预测研究(附代码和数据集,多层感知机模型)
写在前面: 首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大努力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。 之前创作过心脏病预测研究文章如下: 【ML】基于机器学习的心脏病预测研究(附代码和数据集,逻辑回归模型) 【ML】基于机…...

工序排序问题--约翰逊法精讲
什么是约翰逊法?约翰逊法是作业排序中的一种排序方法。选出最短加工时间i*,若最短加工时间有多个,任选1个.若i*出现在机床1,它对应的工件先安排加工,否则放在最后安排,安排后划去该工件,重复上两个步骤,直…...

WebDAV之葫芦儿·派盘+网盘精灵
网盘精灵 支持WebDAV方式连接葫芦儿派盘。 推荐一款让您的iPhone、iPod、iPad 变成WebDav客户端的软件,支持从WebDav服务器连接葫芦儿派盘服务进行上传和下载件。 网盘精灵让您的iPhone、iPod、iPad 变成WebDav客户端。功能:WebDav操作、文件共享、本地文件管理...

计算机网络期末知识点总结
计算机网络期末知识点总结第四章—网络层:数据面4.1概述4.2虚电路和数据报网络4.3路由器工作原理4.4网际协议:因特网中的转发和编址第五章 网络层:控制面5.1路由选择算法5.2路由器中的路由选择5.3广播和多播路由选择第六章 链路层(…...

【Vue3 组件封装】vue3 轮播图组件封装
文章目录轮播图功能-获取数据轮播图-通用轮播图组件轮播图-数据渲染轮播图-逻辑封装轮播图功能-获取数据 目标: 基于pinia获取轮播图数据 核心代码: (1)在types/data.d.ts文件中定义轮播图数据的类型声明 // 所有接口的通用类型 export typ…...
电力国家(行业)标准目录
1、3~63kV交流高压负荷开关 GB 3804-90 代替 GB 3804-882、电气装置安装工程35kV及以下架空电力线路施工及验收规范Code for construction and acceptance of 35kVand umder over head power levels electricequipment installation engineeringGB50173—923、带电作…...

避坑指南:OpenClaw连接Qwen3-32B镜像的5大常见错误
避坑指南:OpenClaw连接Qwen3-32B镜像的5大常见错误 1. 为什么连接Qwen3-32B镜像容易踩坑? 上周我在本地尝试用OpenClaw对接Qwen3-32B镜像时,经历了从满怀期待到怀疑人生的全过程。本以为有了官方镜像就能一键连通,结果从环境配置…...

别再傻傻匀速拖滑块了!用Python模拟真人鼠标轨迹,轻松过Geetest验证码
突破验证码防线:Python模拟人类行为轨迹的实战艺术 验证码系统正变得越来越智能,Geetest等平台已经能够通过分析用户行为模式来区分人类和机器。传统的匀速滑块操作在这些系统面前几乎无所遁形。本文将带你深入理解现代验证码系统的工作原理,…...

手把手教你用FreeRTOS创建第一个任务:从栈初始化到SVC调用的完整流程
深入解析FreeRTOS任务启动机制:从栈初始化到任务切换的实战指南 在嵌入式开发领域,实时操作系统(RTOS)已成为复杂项目的标配工具。作为开源RTOS中的佼佼者,FreeRTOS凭借其轻量级、可移植性强等特点,在STM32等Cortex-M系列MCU上广…...

如何通过League-Toolkit智能工具提升英雄联盟操作效率
如何通过League-Toolkit智能工具提升英雄联盟操作效率 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾因错过对局确认而被…...

毕业季论文救星:深度解析百考通AI如何智能攻克文献综述与开题报告
又到一年毕业季,无数莘莘学子在为自己学术生涯的“终极答卷”——毕业论文而挑灯夜战。其中,文献综述的浩如烟海与开题报告的千头万绪,无疑是横亘在大多数同学面前的两座大山。你是否也曾面对海量文献不知如何筛选梳理?是否为构建…...
Pixel Mind Decoder 效果惊艳展示:多语言文本情绪解码对比
Pixel Mind Decoder 效果惊艳展示:多语言文本情绪解码对比 1. 情绪解码技术的新突破 在数字沟通日益频繁的今天,准确理解文字背后的情绪成为AI领域的重要挑战。Pixel Mind Decoder作为新一代多语言情绪分析工具,通过深度学习模型实现了对文…...

告别Swagger原生UI!用Knife4j给你的SpringBoot API文档做个‘美容’
从Swagger到Knife4j:打造专业级API文档的终极指南 如果你已经厌倦了Swagger原生UI那千篇一律的界面和笨拙的操作体验,那么是时候给你的API文档来一次全面升级了。在当今这个注重用户体验的时代,一个美观、易用且功能强大的API文档界面&#x…...

别再手动组合特征了!用GBDT+LR搞定CTR预估,附Python实战代码与调参心得
GBDTLR:自动化特征工程的CTR预估实战指南 在推荐系统和广告投放领域,点击率(CTR)预估的准确性直接影响着平台的核心商业指标。传统手动特征工程方法在面对高维稀疏特征时往往力不从心,而GBDTLR的组合策略为我们提供了一…...

基于Go + gin+gorm+ rag+千问大模型 + pgvector 构建市场监管智能问答智能体
基于Go 千问大模型 pgvector构建市场监管智能问答智能体 一、项目背景 随着"放管服"改革的深入推进,市场监管领域政策法规不断更新,企业和公众对政策咨询的需求日益增长。传统的政策咨询模式存在响应慢、效率低、准确性差等问题,…...

AI视频生成工具ComfyUI-WanVideoWrapper零基础配置指南
AI视频生成工具ComfyUI-WanVideoWrapper零基础配置指南 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 还在为视频生成工具的复杂配置烦恼?想快速掌握AI视频创作却被技术门槛劝退&am…...