【AI面试】目标检测中one-stage、two-stage算法的内容和优缺点对比汇总
在深度学习领域中,图像分类,目标检测和目标分割是三个相对来说较为基础的任务了。再加上图像生成(GAN,VAE,扩散模型),keypoints关键点检测等等,基本上涵盖了图像领域大部分场景了。
尤其是在目标检测,一直是各大比赛(Pascal VOC, COCO, ImageNet)的主要任务。与此同时,检测任务中的两大流派:one-stage、two-stage一直是热议的话题。同时,也是面试官最喜欢问的话题。
针对本文的这个问题,我也帮你们提前问了chatGPT,也给出了一个较为总结性的回答,如下所示。你们觉得它回答的如何呢?
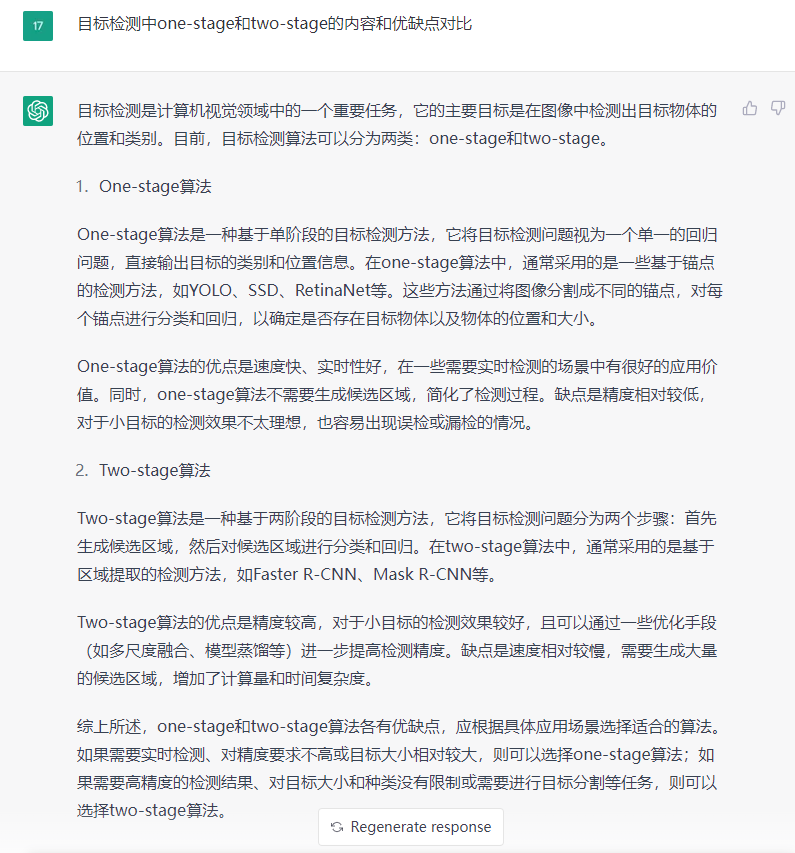
chatGPT已经对本节的内容,给出了一个大体的概括,总结下,包括
算法模型呢:
- one stage的算法包括SSD、yolo、Retina Net等等
- two stage的算法包括fast RCNN系列,和用于分割的Mask RCNN系列
优点呢:
- one stage的算法速度非常快,适合做实时检测的任务,比如视频
- two stage的算法速度慢,
缺点呢?
- one stage的算法通常相比于two stage的算法,效果不太好
- two stage的算法经过了一步初筛,通常效果会更好,更准确
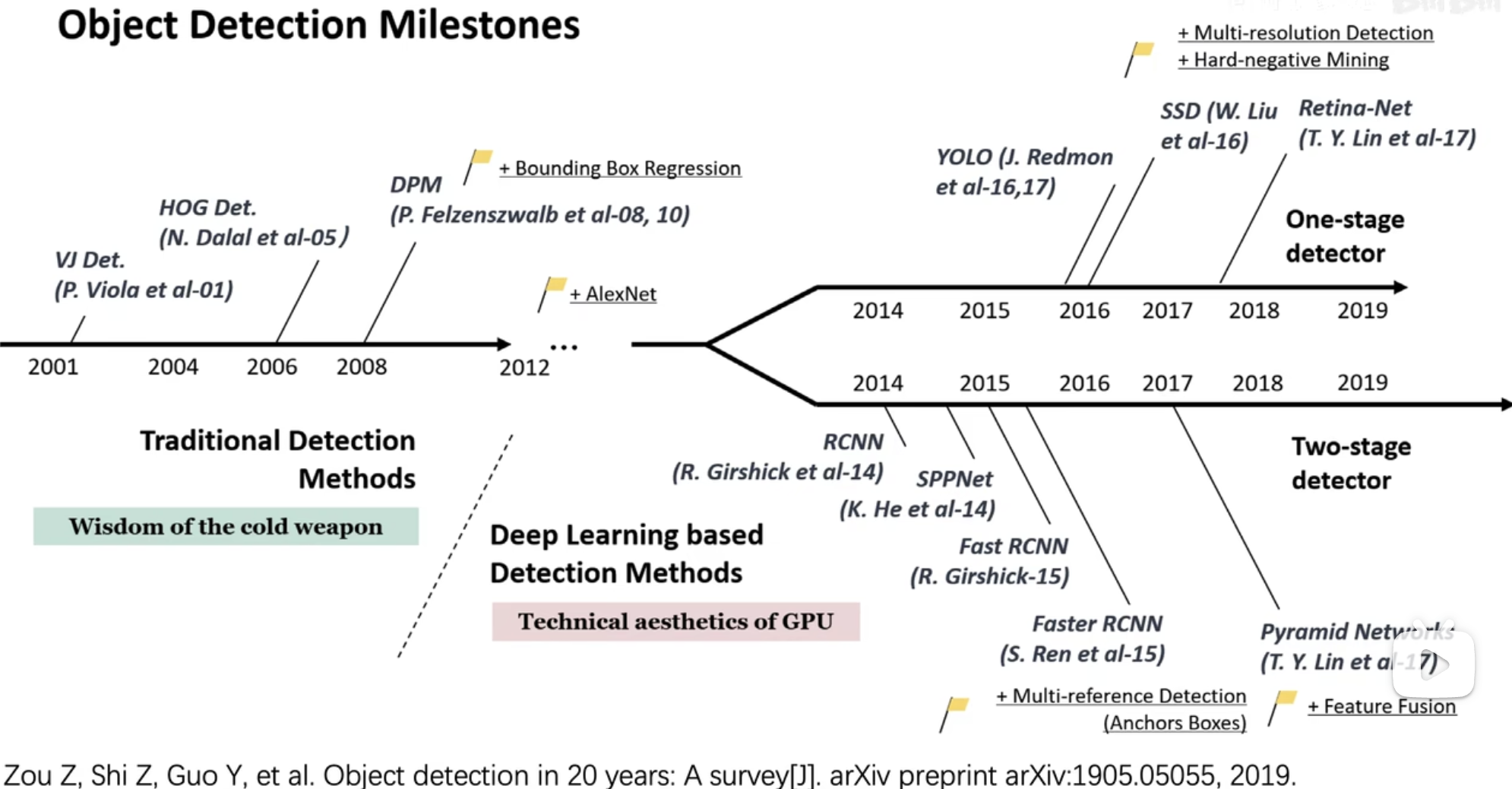
目标检测算法综述截图,展示了随时间发展,one- stage和two- stage的发展分枝。从2014年RCNN开始,再到后来SSD和YOLO的横空出世,基本上奠定了两条路的主基调。
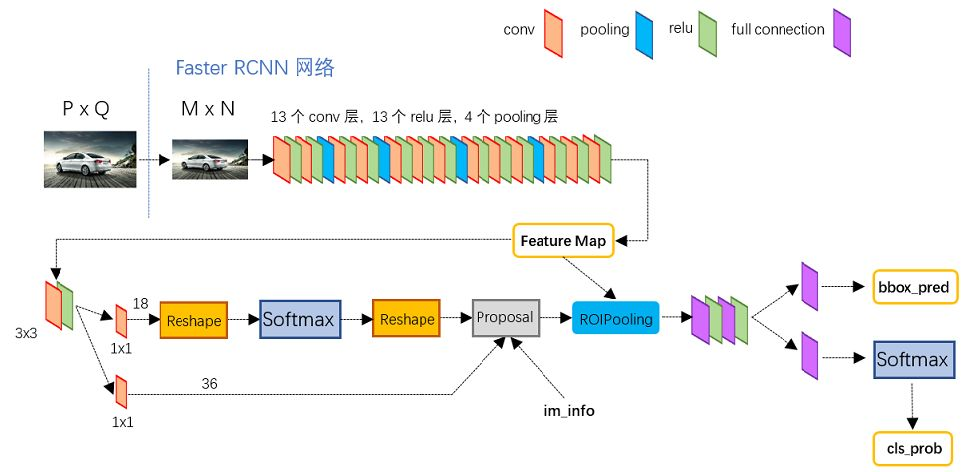
一、two stage
two stage的代表faster RCNN的模型结构图。稍微简述下:
- 特征提取模块
backbone,主要用于对输入图像进行特征抽取,输出特征图Feature Map,一般会采用resnet、VGG,GoogLeNet的主干部分(去掉全连接层)作为backbone. - 第一阶段的
RPN(region proposal network)区域推荐网络,主要就是基于backbone输出的Feature Map,筛选目标候选框,给出进一步判断的Proposal - 在
RPN完成后,得到的候选框还只是区分出它是前景positive和背景negative,还不能区分是猫,还是狗 - 于是,就有了第二阶段,对第一阶段提议的
阳性positive候选框Proposal,与backbone输出的Feature Map,裁剪出区域,经过ROI Pooling,统一到一致的尺寸,进入到ROI Head阶段。 - 经过卷积和全连接层,区分出具体的
类别cls和bbox coor(cx, cy, pw, ph)的偏移量(tx, ty, tw, th),进一步修正目标框,得到最终的位置(bx=σ(tx)+cx, by=σ(ty)+cy, bw=pw*tw, bh=ph*th)。
如下图所示,这样看,是不是真的把预测目标检测的任务,给拆分成两个阶段分段的来进行预测的呢?更多内容推荐阅读这里:一文读懂Faster RCNN
1.1、训练和验证阶段
其实,要理解faster RCNN的整理工作方式,需要区分成训练阶段train 和推理阶段inference,区别对待。
先说简单的推理阶段inference。
推理阶段与训练阶段最大的不同,就是推理阶段没有金标准target, 也就没有计算损失,更没有办法更新网络模型:
backbone的特征提取阶段,接触不到target,所以这个阶段没有损失值,两个阶段都是一样的,就是负责把输入图像,转成特征图;- RPN阶段就不同了,因为这个阶段是要为最后的分类,提供proposal的。这个proposal需要引入anchor box,所有的proposal都会被传入ROI Pooling层进行分类和回归;
- 在ROI Head阶段,RPN推荐的proposal会经过ROI Pooling层,调整到统一大小,例如7x7。经过两个fc层,输出具体的类别+背景,和坐标框。
- RPN阶段返回的proposal相互之间是高度重叠的,采用了NMS降低数量。
然后是训练阶段train。
训练阶段就要计算损失了,就要更新模型了,这块都是与推理阶段不一样的:
- backbone的特征提取阶段,一样;
- RPN阶段就不同了,因为这个阶段,需要区分
positive还是negative。咋知道这个anchor是阳性,还是阴性呢?那就需要使用标记target进行区分。在这个阶段,有了IOU,就是PD与GT计算IOU。如何区分阳性还是阴性呢?
IOU值大于0.7的是阳性,IOU值小于0.3的是阴性,其他丢弃掉;
we randomly sample 256 anchors in an image to compute the loss function of a mini-batch, where the sampled positive and negative anchors have a ratio of up to 1:1. If there are fewer than 128 positive samples in an image, we pad the mini-batch with negative ones.
上段部分来自于论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 的Training RPNs部分。
翻译过来的意思就是:在RPN阶段计算一个mini batch的loss function时候,我们随机的在一张图片中选择256个anchor,阳性和阴性的样本比例1:1。如果一种图片中的阳性anchor少于128个,就用negative补上。
- 此时,RPN阶段的损失,也是由
2分之一(0.5)的positive和2分之1的negative组成的,参与损失计算,包括阳性or阴性类别损失和位置偏移损失; - 最后,在
ROI Head阶段,输出具体的类别,和坐标框,这两块都要参与到损失的计算,比较的好理解。 - NMS在训练阶段,不参与。(我理解是因为在训练阶段,NMS会去除掉很多的正样本,使得正负样本就更加的不均衡了)
在训练阶段,会有哪些损失值?
-
RPN 损失函数:在 RPN 阶段,会使用 RPN 模型生成一系列 anchor,并根据这些 anchor 来进行目标检测。RPN 损失函数一般包括两个部分:分类损失(交叉熵损失)和回归损失(Smooth L1 )。分类损失用于判断 anchor 是否为前景(即是否包含目标),回归损失用于精确预测目标的位置。 -
Fast R-CNN (ROI Head)损失函数:在 Fast R-CNN 阶段,会使用 RoI Pooling 对 RPN 生成的 proposal 进行特征提取,并对提取的特征进行分类和回归。Fast R-CNN 损失函数同样包括分类损失和回归损失。 -
总损失函数:在训练过程中,RPN 和 Fast R-CNN 的损失函数需要同时进行优化。因此,一般会将 RPN 和 Fast R-CNN 的损失函数合并为一个总损失函数(当然,也可以分别进行回归调整),并使用反向传播算法来进行优化。
两个阶段的位置损失都是 Smooth L1,同样一个位置,为啥需要计算两次损失呢?然后回归两次位置呢?
-
RPN 阶段和 Fast R-CNN 阶段中的位置都是反映在原图上的同一块像素区域,都是表示物体的位置偏移量。
-
对于RPN阶段,先对anchor进行一次位置回归,得到一组粗略的预测框,再利用这些预测框去RoI pooling得到RoI,最后对RoI进行第二次位置回归,得到最终的目标框位置。
-
在 RPN 阶段中,每个 anchor 与其对应的 ground-truth bbox 之间的位置偏移量会被计算,并通过 Smooth L1 损失函数来度量它们之间的差异。这个损失函数的计算仅涉及到对 anchor 的位置回归。
-
在 Fast R-CNN 阶段中,由于每个 RoI 的形状都是不同的,所以每个 RoI 与其对应的 ground-truth bbox 之间的位置偏移量也需要被计算,并通过 Smooth L1 损失函数来度量它们之间的差异。这个损失函数的计算涉及到对 RoI 的位置回归。
-
因此,Faster R-CNN 中需要计算两次位置损失,是因为两个阶段都需要对物体的位置进行回归。需要注意的是,这两个阶段的位置回归所针对的对象是不同的:
- RPN 阶段中的位置回归是针对 anchor 的;
- 而 Fast R-CNN 阶段中的位置回归是针对 RoI 的。
-
两次位置回归的目的都是为了使目标框的位置预测更加准确。
1.2、RCNN、fast RCNN、faster RCNN横评
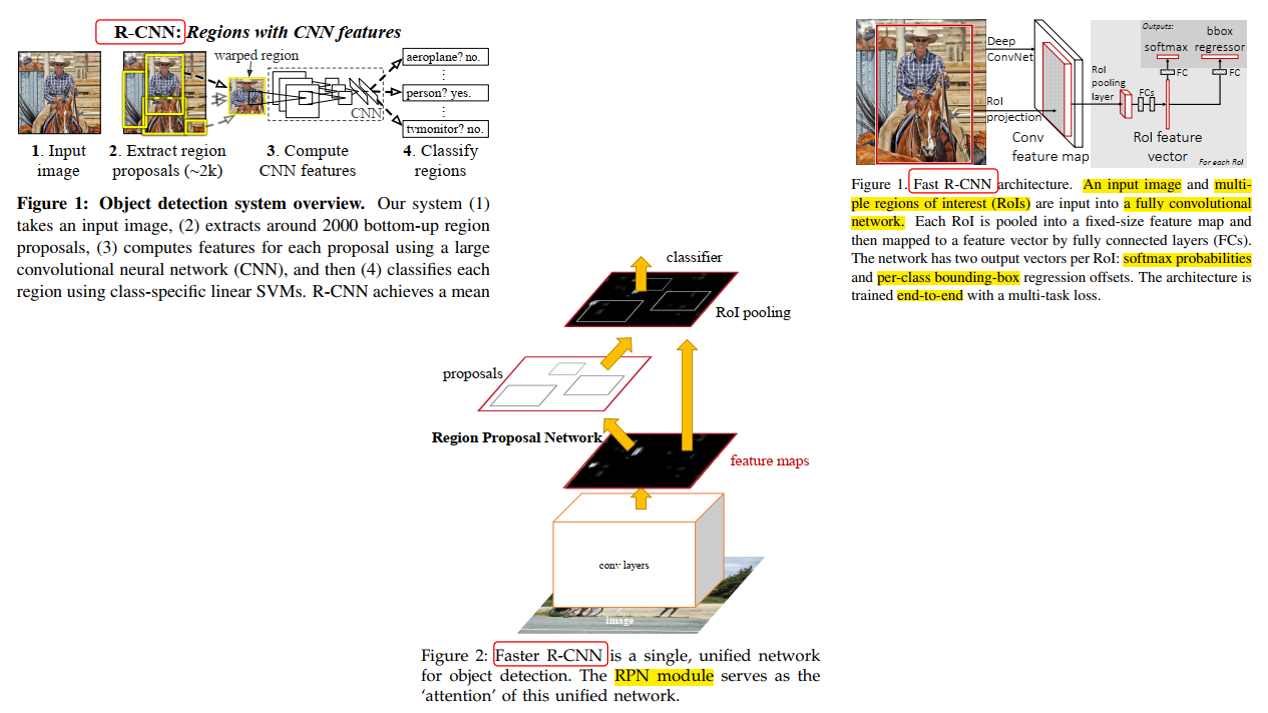
1.2.1、RCNN(Region-based Convolutional Neutal Network)
- 目标框的获取方式:select search(选择性搜索算法)来生成候选区域,从原图裁剪出ROIs
- 分类方式:SVM
- 目标位置:bounding-box regressor
缺点:
- 训练是多阶段的:先fine tunes目标proposal;再训练SVM分类器;再训练bounding box回归器
- 训练再内存空间和时间上开销大:分阶段训练,不同阶段的输出需要写入内存
- 目标检测很慢
1.2.2、 fast RCNN
- 目标框的获取方式:input image和region of interest(ROIs)在特征层阶段相遇、裁剪,经过RoI max pooling,调整成一致尺寸(学习了SPP Net,例如7x7大小),送入fully convolutional network.
- 分类方式:分类分支,经过softmax输出类别,
- 目标位置:Bbox regressor输出位置偏移
缺点:候选区域的生成仍然采用选择性搜索算法,速度仍有提升空间
1.2.3、faster RCNN
- 目标框的获取方式:基于anchor base的RPN阶段,用于输出候选的proposal,和特征层相遇、经过
RoI max pooling,调整成一致尺寸,送入fully convolutional network. - 分类方式:分类分支,经过
softmax输出类别, - 目标位置:
Bbox regressor输出位置偏移
1.3、mask RCNN
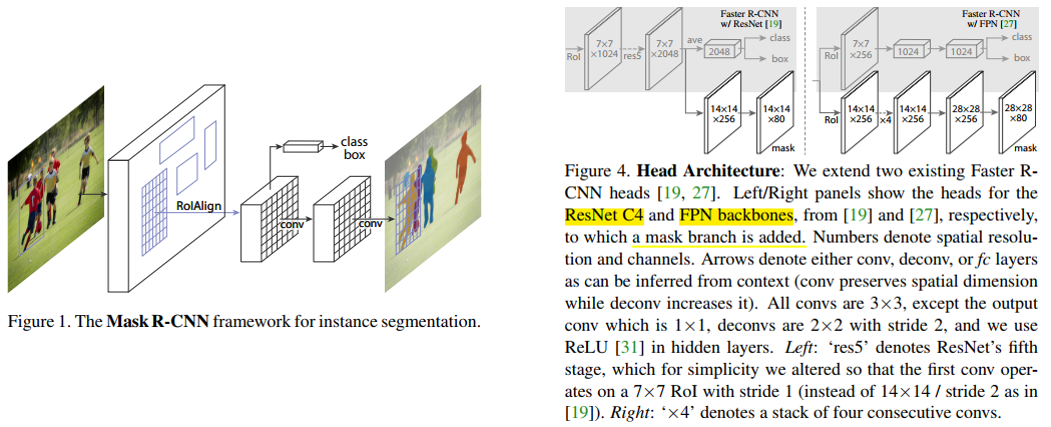 mask RCNN是在faster RCNN的基础上,增加了一个mask预测分值。其中为了得到更好的mask精细分割结果,在fast rcnn head阶段,将之前目标检测的roi pooling,替换成roi align。
mask RCNN是在faster RCNN的基础上,增加了一个mask预测分值。其中为了得到更好的mask精细分割结果,在fast rcnn head阶段,将之前目标检测的roi pooling,替换成roi align。
在分类和Bbox预测,均和faster RCNN是一样的,在mask预测有差别,其中:
- 在分类部分,输出的shape为(N, num_classes),其中N为RoI的数量,num_classes为类别数量(包括背景类)。每个RoI对应着num_classes个概率值,分别表示该RoI属于不同类别的概率。
- 在Bbox回归部分,输出的shape也为(N, 4 x num_classes),其中每个RoI对应着4 x num_classes个偏移量,分别表示该RoI相对于目标框的水平偏移量、垂直偏移量、宽度缩放比例和高度缩放比例。
- binary mask预测部分,每个RoI对应的特征图块上应用一个全卷积网络(Fully Conv Network, FCN),输出的shape为(N, mask_height, mask_width, num_classes),其中:
- N为RoI的数量
- mask_height和mask_width为输出mask的高度和宽度,
- num_classes为类别数量,
- 输出的每个元素表示该RoI属于对应类别时,每个像素点经过per-pixel sigmoid操作,输出为前景(即目标物体)的概率,
- mask 采用binary cross-entropy loss(only defined on the k-th mask ,other mask outputs do not contribute to the loss.)
为什么在分类阶段,已经对roi的类别进行了预测,在mask预测阶段,还要对每一个classes进行mask预测呢?
答:在传统的目标检测中,通常是先使用分类器对目标进行分类,然后使用回归器对目标的位置进行精确定位,最后再使用分割模型对目标进行像素级别的分割。这种做法将分类、定位和分割三个任务放在了不同的阶段进行,每个任务都需要单独地训练模型,而且彼此之间存在一定的耦合关系。
相比之下,Mask R-CNN 将分类、定位和分割三个任务整合到了同一个网络中进行联合训练,通过共享网络层来解耦三个任务之间的关系。具体来说,Mask R-CNN 在 RoI pooling 的基础上增加了一个分割分支,该分支由一个全卷积网络组成,负责对每个 RoI 中的像素进行分类,并生成相应的掩码。因此,分类、定位和分割三个任务可以在同一个网络中共享特征,同时也能够互相影响和优化。
Mask R-CNN 的这种设计方式可以使不同任务之间的关系更加松散,同时也能够提高网络的训练效率和泛化能力,使得网络更加容易学习到目标的语义信息,从而提高目标检测和分割的准确率。
二、one stage
one stage的开山之作yolo v1(论文地址:you only look once)。其中下面是一张网络模型的简图,可以看到:
- 输入图像,经过一连串的卷积层操作
(24 convolutional layers),得到了一个channel=1024维的向量; - 得到下采样特征图后,连接
2个 fully connected layers。 - 直接得到预测输出的
output,大小是:7x7x30,S ×S×(B∗5+C) tensor。For evaluating YOLO on PASCAL VOC, we use S = 7, B =2. PASCAL VOC has 20 labelled classes so C = 20. Our final prediction is a 7 × 7 × 30 tensor.
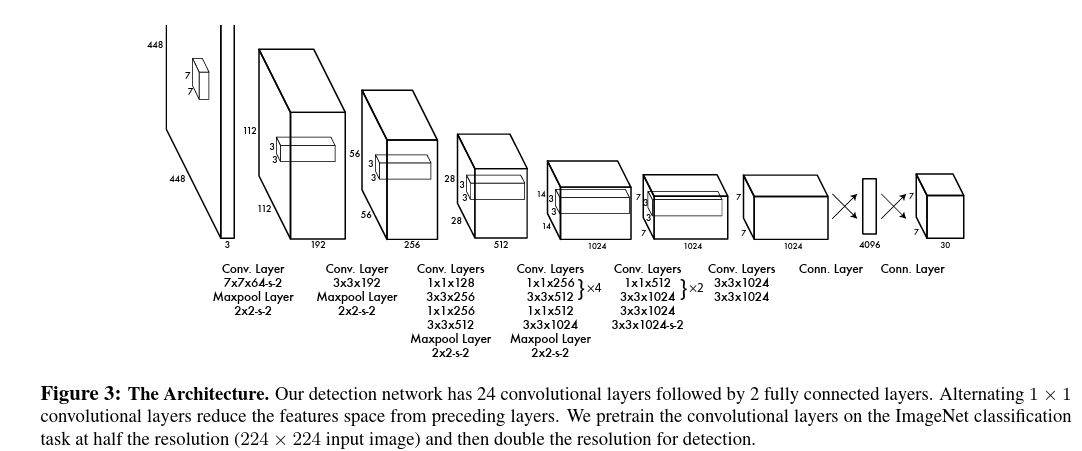
可以看出来,yolo v1将目标检测问题,转化为了回归问题。把中间网络模型学习做的事情,都当做了一个黑箱,就是输入图像,输出目标。具体中间网络是如何办到的?这个不管,全部交由网络模型的监督信号,自己拟合。
2.1、训练和验证阶段
要理解单阶段YOLO V1的整体工作方式,需要区分成训练阶段train 和推理阶段inference,区别对待。
训练阶段train:
损失函数定义如下:

要想要看到上面的损失函数公式,首先要了解这些字母,都表示是什么?其中:
- S, grid cell size,论文里面是7
- B, bounding box个数,论文里面是2
- x, y, w, h, 分别表示bounding box的中心点坐标,和宽、高
- C, Confidence,是否有目标的概率
- p, Pr(Classi|Object),有目标下类别的条件概率
- obj,noobj,表示有物体的权重和没有物体
- λcoord = 5 ,λnoobj = .5,有物体的权重和没有物体的权重
每两项之间,都是算距离的,都是按照回归的方式进行求损失的。其他的建议参考这里:YOLO(You Only Look Once)算法详解
在inference阶段,步骤如下:
- 对于输入图像,
resize为一个正方形(416x416) - split the image into grid,大小为7x7
- 每一个grid cell 都预测B各bounding box框,论文里面B=2
- 每一个grid cell 只预测一个类。B=2两个网格,那一个grid cell就是2个网格,两个类
- 每一个bounding box框,有
4个位置参数(x_c,y_c,w,h)和1个置信度P(Object),表示有物体的概率,用于区分存在目标物体,还是背景 - 到这里,就有了
7x7x2=98个bounding box框,每一个框都包含5个参数(x_c,y_c,w,h,confidence) - 每个bounding box框的中心点,都在对应的grid cell像素内。一个grid cell预测2个bounding box,就是10个参数,再加上目标条件概率20个类,每一个类都有一个
条件概率P(Car|Object)。在该阶段,最后对应类的概率=P(Car|Object) x P(Object)。 - 这样一个grid cell对应的输出向量就是
2x5+20=30个。再加上一张输入图像被划分为7x7个grid cell,最后的输出就是7x7x30个张量大小。 - 至此,我们就预测得到了一堆框框,个数是7x7x2=98。最后经过NMS,去掉用于的框,得到最终的预测结果。

(在没有理解清楚这段之前,我一直在疑惑:
为什么2个bounding box已经有了一个概率,这个概率是什么?后面20个类,是可以区分具体这个bounding
box属于哪个类的,他们之间又是什么关系。不知道你到这里,是否理解清楚了)
这块视频详解,参考这里:【精读AI论文】YOLO V1目标检测,看我就够了-同济子豪兄
一步到位,没有two stage的先预测出前景还是背景,然后在预测具体类别的过程,简化了很多,端到端的过程。
YOLO v1算法的缺点:
1、位置精确性差,对于小目标物体以及物体比较密集的也检测不好(grid cell的原因,因为只能预测98个框),比如一群小鸟。
2、YOLO虽然可以降低将背景检测为物体的概率,但同时导致召回率较低。
2.2、YOLOv1、 YOLOv2、 YOLOv3、横评
YOLOv2 进行了许多改进,包括以下几个方面:
- 使用 batch normalization:YOLOv2 在卷积层后加入 Batch Normalization,可以加速训练,提高模型的精度和鲁棒性。
- 改进网络结构:YOLOv2 采用了更深的网络结构,引入了残差网络(ResNet)的结构,和NIN结构,增加了网络层数
- anchor boxes: 替代了之前的固定网格grid cell来提高物体检测的精度,kmean聚类确定anchor尺寸。
- passthrough layer 细粒度特征
- 采用了多尺度训练和预测: 引入了多尺度训练方法,可以提高模型对不同尺度物体的检测能力。(不同于FPN,他是在训练阶段每10个batch,会重新选择一个新的图像尺寸,包括{320,352,…,608}等等32倍数的尺寸)
YOLOv3 的改进主要集中在以下几个方面:
- 使用了更深的 Darknet-53 网络:YOLOv3 使用了一个名为 Darknet-53 的更深的卷积神经网络,相较于之前的 Darknet-19 网络,它具有更强的特征提取能力,可以提高目标检测的准确性。
- 引入了 FPN 特征金字塔:YOLOv3 引入了 FPN(Feature Pyramid Network)特征金字塔,可以利用不同层级的特征信息进行目标检测(predicts boxes at 3 different scales. predict 3 boxes at each scale),从而提高检测的准确性。
- 使用更多的 Anchor Boxes:YOLOv3 使用了更多的 Anchor Boxes,可以更好地适应不同大小和形状的目标物体,依旧使用 k-means clustering。
- 首次binary cross-entropy loss 用于分类
yolo v3之后,作者就不在更新YOLO系列了,再之后的改版,都是其他人或者团队继续更新的。YOLOv5再YOLOv4更新的没多久就出来了,且是pytorch的开源代码,所以相比于YOLOv4的C版本,受众更多。
YOLOv5 (没有论文)的改进主要集中在以下几个方面:
- 自适应anchor:在训练模型时,YOLOv5 会自己学习数据集中的最佳 anchor boxes,而不再需要先离线运行 K-means 算法聚类得到 k 个 anchor box 并修改 head 网络参数。总的来说,YOLOv5 流程简单且自动化了。
- 自适应图片缩放(letterBox)
- Focus结构
结构图:
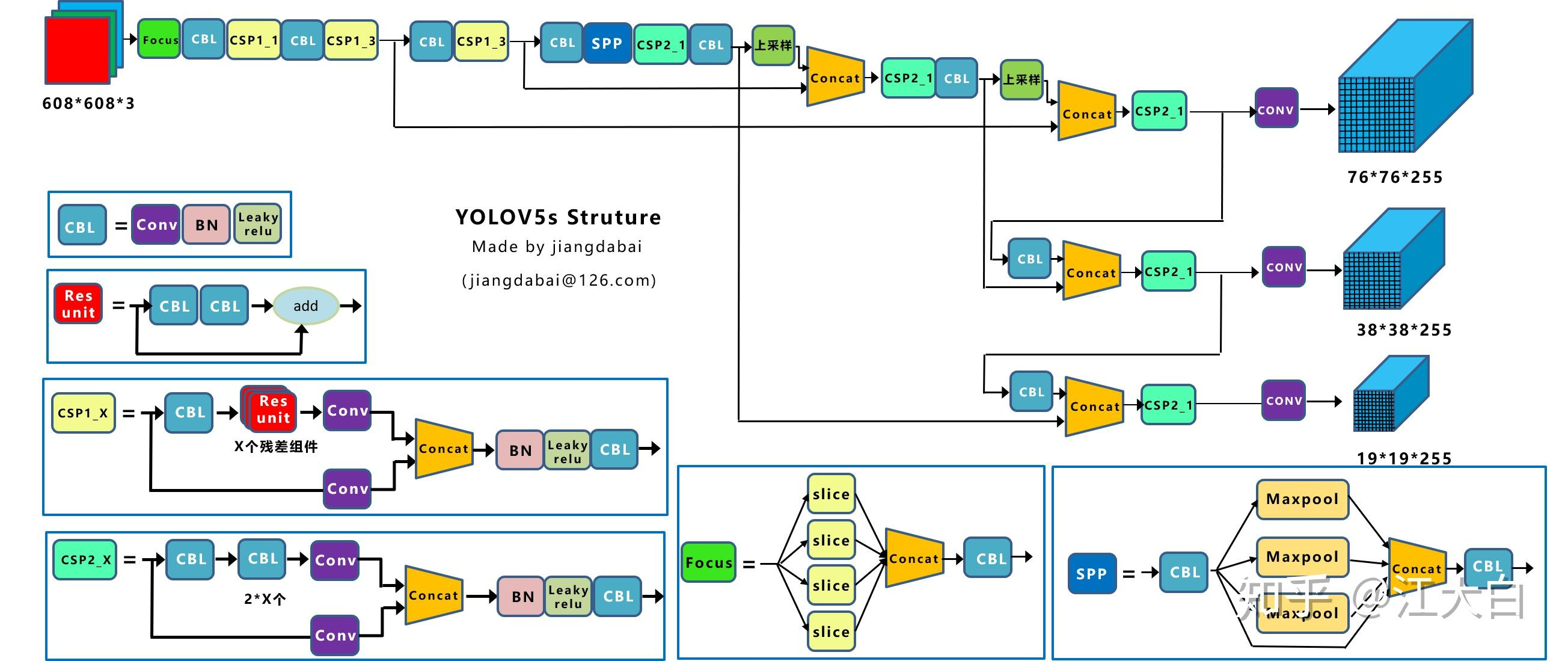
Focus结构中:
- 原始的640 × 640 × 3的图像输入Focus结构,采用切片操作。
- 具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样。
- 将一个channel上,W、H信息就集中到了通道空间,输入通道扩充了4倍;RGB 3个通道,就变成了12个channel。
- 先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。
- 最终得到了没有信息丢失情况下的二倍下采样特征图。
- 目的是:减少传统下采样带来的信息损失。
- 切片操作如下:
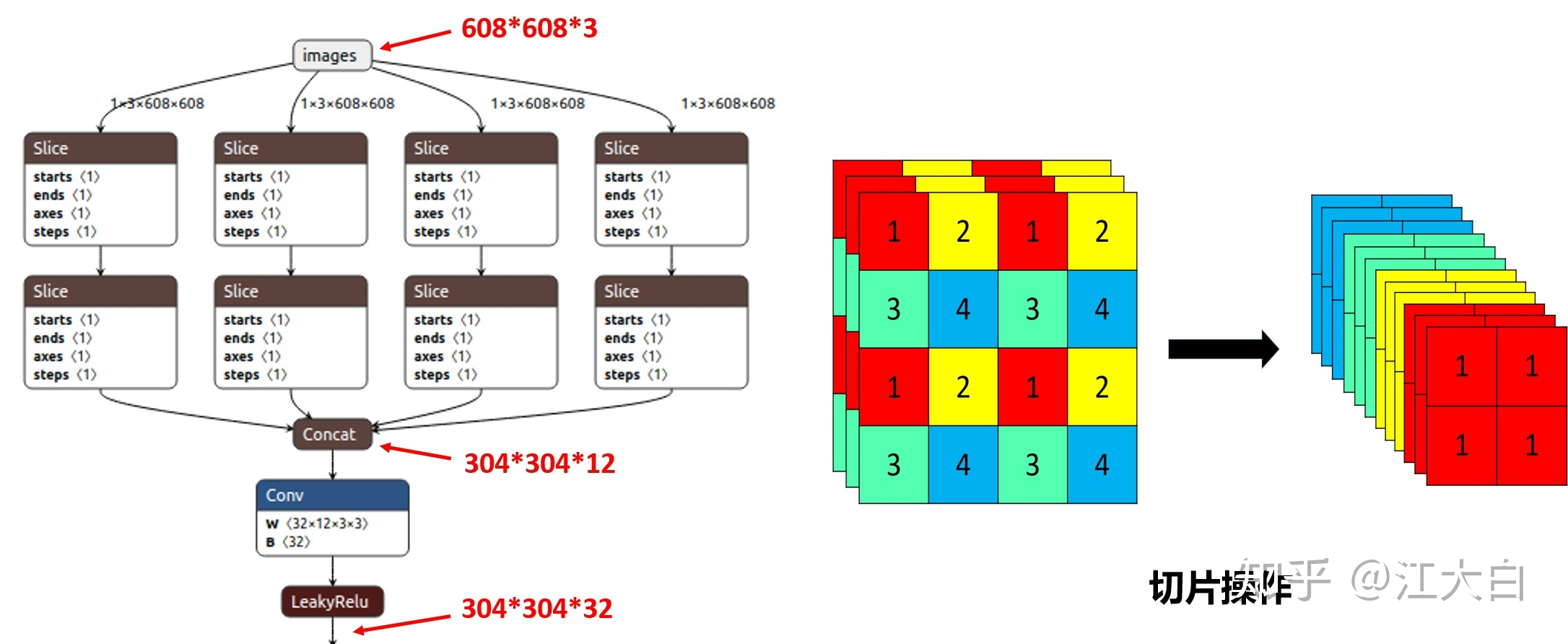
详尽内容建议参考这里:yolov5中的Focus模块的理解
YOLOv5 4个大结构,分别是:
8. 输入端:Mosaic数据增强(对于小目标的检测效果好)、cutMix、MixUP。自适应锚框计算、自适应图片缩放
9. Backbone:Focus结构(slice切片操作,把高分辨率的图片(特征图)拆分成多个低分辨率的图片/特征图,即隔列采样+拼接,可以减少下采样带来的信息损失),CSP结构
10. Neck:FPN+PAN结构
11. Prediction:GIOU_Loss
三、性能对比
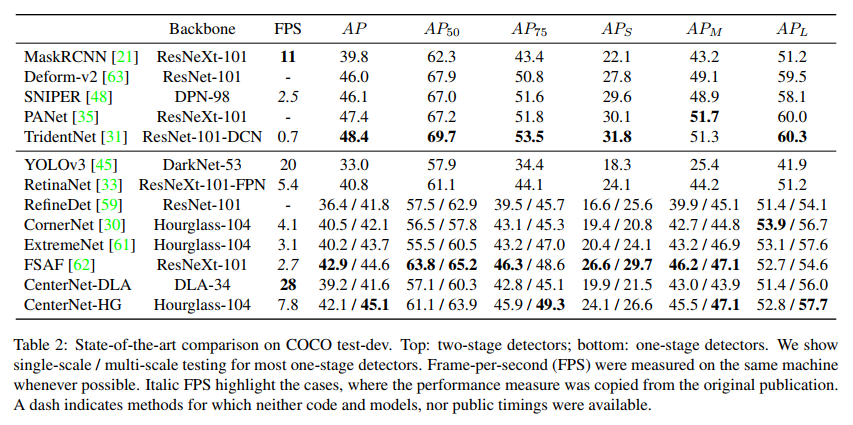
下面是在论文centerNet中,作者对普遍常用的目标检测、分割模型做了次系统的测试。其中,上部分是two stage的主要算法,下部分是one stage的主要算法。可以发现:
FPS帧率这块,one stage都是相对比较快的,尤其是yolo系列。two stage就慢了很多。- two stage的
AP就比较的高,最高能到48.4,低的也有46,而one stage的就比较低,最高才45。尤其是TridentNet,几乎是这些里面,各个领域都是最佳的。
四、总结
到这里,目标检测中one-stage、two-stage算法的内容基本上就结束了。但是,面试官是不会罢休的,他会沿着目标检测算法,继续深入展开,比如:
anchor base(anchor boxes)和anchor free分别是什么?有什么区别和优缺点?faster RCNN的ROI Pooling和mask RCNN的ROI Align分别是什么?有什么有缺点?yolo的损失函数式什么?faster RCNN的损失函数又是什么?- 等等
所以说,目标检测是深度学习领域的一个重点,能够考察的内容很多,主要还是因为在各个企业里面,这块的内容,是真实可以落地的。所以,这块内容是真要吃透。
(上文内容,比较的丰富,和比较的杂。是根据论文和一些网络资料综合记录的。如果你对其中的内容,存在异议或需要纠正的地方,欢迎评论区留言,一起进步,谢谢)
相关文章:
【AI面试】目标检测中one-stage、two-stage算法的内容和优缺点对比汇总
在深度学习领域中,图像分类,目标检测和目标分割是三个相对来说较为基础的任务了。再加上图像生成(GAN,VAE,扩散模型),keypoints关键点检测等等,基本上涵盖了图像领域大部分场景了。 …...

stack、queue和priority_queue的使用介绍--C++
目录 一、stack介绍 使用方法 二、queue介绍 queue的使用 三、priority_queeue 优先级队列介绍 一、stack介绍 1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。 2. stack是作为容器…...

python遍历数组
在Python中,有多种方式可以遍历数组,以下是其中的几种方式: 1. 使用for循环: my_list [1, 2, 3, 4, 5] for x in my_list: print(x) 2. 使用while循环和索引: my_list [1, 2, 3, 4, 5] i 0 while i < len(m…...
红黑树理论详解与Java实现
文章目录 基本定义五大性质红黑树和2-3-4树的关系红黑树和2-3-4树各结点对应关系添加结点到红黑树注意事项添加的所有情况 添加导致不平衡叔父节点不是红色节点(祖父节点为红色)添加不平衡LL/RR添加不平衡LR/RL 叔父节点是红色节点(祖父节点为…...

container的讲解
我们做开发经常会遇到这样的一个需求,要开发一个响应式的网站,但是我们需要我们的元素样式跟随着我们的元素尺寸大小变化而变化。而我们常用的媒体查询(Media Queries)检测的是视窗的宽高,根本无法满足我们的业务需求&…...

JavaScript 箭头函数
(许多人所谓的成熟,不过是被习俗磨去了棱角,变得世故而实际了。那不是成熟,而是精神的早衰和个性的消亡。真正的成熟,应当是独特个性的形成,真实自我的发现,精神上的结果和丰收。——周国平&…...

简单理解Transformer注意力机制
这篇文章是对《动手深度学习》注意力机制部分的简单理解。 生物学中的注意力 生物学上的注意力有两种,一种是无意识的,零一种是有意识的。如下图1,由于红色的杯子比较突出,因此注意力不由自主指向了它。如下图2,由于…...

Vue3面试题:20道含答案和代码示例的练习题
Vue3中响应式数据的实现原理是什么? 答:Vue3中使用Proxy对象来实现响应式数据。当数据发生变化时,Proxy会自动触发更新。 const state {count: 0 }const reactiveState new Proxy(state, {set(target, key, value) {target[key] valueco…...

Oracle数据库创建用户
文章目录 1 查看当前连接的容器2 查看pdb下库的信息3 将连接改到XEPDB1下,并查看当前连接4 创建表空间5 创建用户6 用户赋权7 删除表空间、用户7.1 删除表空间7.2 删除用户 8 CDB与PDB的概念 1 查看当前连接的容器 SQL> show con_name;CON_NAME ---------------…...
)
互联网摸鱼日报(2023-04-30)
互联网摸鱼日报(2023-04-30) InfoQ 热门话题 被ChatGPT带火的大模型,如何实际在各行业落地? Service Mesh的未来在于网络 百度 Prometheus 大规模业务监控实战 软件技术栈商品化:应用优先的云服务如何改变游戏规则…...

第二章--第一节--什么是语言生成
一、什么是语言生成 1.1. 说明语言生成的概念及重要性 语言生成是指使用计算机程序来生成符合人类自然语言规范的文本的过程。它是自然语言处理(NLP)领域中的一个重要分支,涉及到语言学、计算机科学和人工智能等领域的交叉应用。语言生成技术可以被广泛地应用于自动问答系…...

HTML <!--...--> 标签
实例 HTML 注释: <!--这是一段注释。注释不会在浏览器中显示。--><p>这是一段普通的段落。</p>浏览器支持 元素ChromeIEFirefoxSafariOpera<!--...-->YesYesYesYesYes 所有浏览器都支持注释标签。 定义和用法 注释标签用于在源代码中…...

TinyML:使用 ChatGPT 和合成数据进行婴儿哭声检测
故事 TinyML 是机器学习的一个领域,专注于将人工智能的力量带给低功耗设备。该技术对于需要实时处理的应用程序特别有用。在机器学习领域,目前在定位和收集数据集方面存在挑战。然而,使用合成数据可以以一种既具有成本效益又具有适应性的方式训练 ML 模型,从而消除了对大量…...

JavaScript中的Concurrency并发:异步操作下的汉堡制作示例
这篇文章想讲一下JavaScript中同步与异步操作在一个简单的示例中的应用。我们将以制作汉堡为例,展示如何使用同步方法、回调函数(callbacks)和Promise与async/await来实现该过程。 Let’s imagine we’re trying to make a burger: 1. Get …...
微信小程序开发一个多少钱
小程序开发是当前比较流行的一项技术服务,能够为企业和个人带来巨大的商业价值和社会价值,但是小程序开发费用也是潜在的成本之一。在选择小程序开发服务时,了解开发费用如何计算、影响价格的因素以及如何降低成本等方面的知识,可…...

Python基础入门(2)—— 什么是控制语句、列表、元组和序列?
文章目录 01 | 🚄控制语句02 | 🚅列表03 | 🚈元组04 | 🚝序列05 | 🚞习题 A bold attempt is half success. 勇敢的尝试是成功的一半。 前面学习了Python的基本原则、变量、字符串、运算符和数据类型等知识,…...
计算机专业大一的一些学习规划建议!
大家好,我是小北。 五一嗖的一下就过啦~ 对于还在上学的同学五一一过基本上意味着这学期过半了,很多大一、大二的同学会有专业分流、转专业等事情。 尤其是大二的时候,你会发现身边有些同学都加入各种实验室了,有忙着打ACM、学生…...
万万没想到在生产环境翻车了,之前以为很熟悉 CountDownLatch
前言 需求背景 具体实现 解决方案 总结 前言 之前我们分享了CountDownLatch的使用。这是一个用来控制并发流程的同步工具,主要作用是为了等待多个线程同时完成任务后,在进行主线程任务。然而,在生产环境中,我们万万没想到会…...

Springboot整合Jasypt实战
Springboot整合Jasypt实战 引入依赖 <dependency><groupId>com.github.ulisesbocchio</groupId><artifactId>jasypt-spring-boot-starter</artifactId><version>3.0.5</version> </dependency>配置jasypt # 配置jasypt相关信息…...
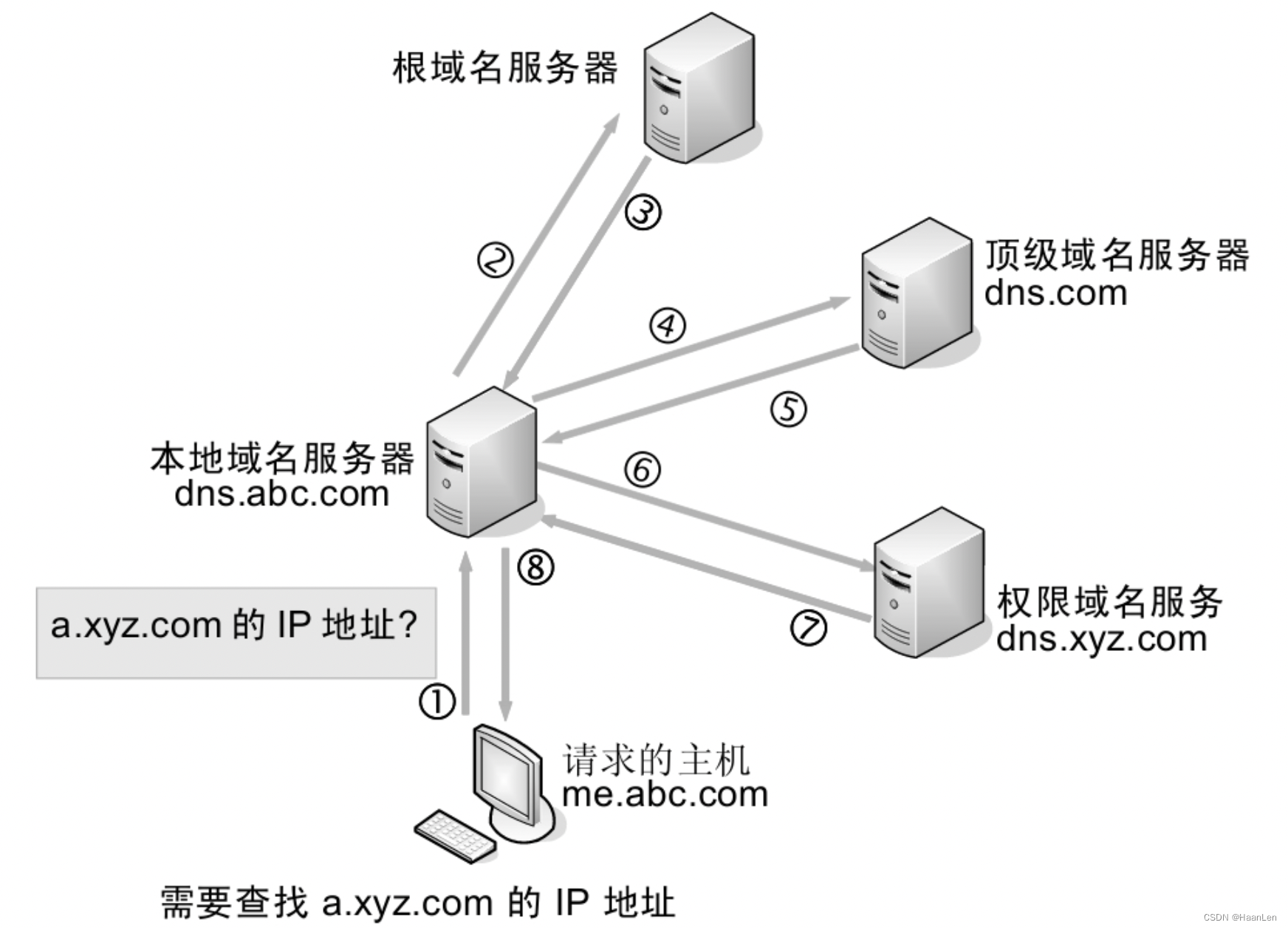
计算机网络笔记:DNS域名解析过程
基本概念 DNS是域名系统(Domain Name System)的缩写,也是TCP/IP网络中的一个协议。在Internet上域名与IP地址之间是一一对应的,域名虽然便于人们记忆,但计算机之间只能互相认识IP地址,域名和IP地址之间的转…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...
Ansys Maxwell:线圈和磁体的静磁 3D 分析
本博客展示了如何在 Ansys Maxwell 中执行静磁 3D 分析,以计算载流线圈和永磁体之间相互作用产生的扭矩。在这个例子中,线圈中的电流产生一个沿 Y 轴指向的磁场,而永磁体沿 X 轴被磁化。这种配置导致围绕 Z 轴的扭矩。分步工作流程包括构建几…...

spring中的@KafkaListener 注解详解
KafkaListener 是 Spring Kafka 提供的一个核心注解,用于标记一个方法作为 Kafka 消息的消费者。下面是对该注解的详细解析: 基本用法 KafkaListener(topics "myTopic", groupId "myGroup") public void listen(String message)…...
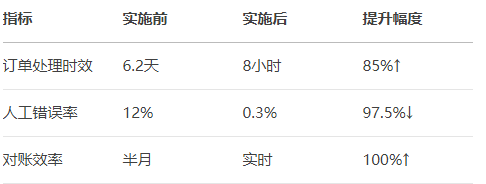
低代码采购系统搭建:鲸采云+能源行业订单管理自动化案例
在能源行业数字化转型浪潮下,某大型能源集团通过鲸采云低代码平台,仅用3周时间就完成了采购订单管理系统的定制化搭建。本文将揭秘这一成功案例的实施路径与关键成效。 项目背景与挑战 该企业面临: 供应商分散:200供应商使用不同…...

服务器中僵尸网络攻击是指什么?
随着网络业务的不断发展,网络攻击的手段也变得越来越多,各个企业都会受到网络攻击的威胁,其中常见的网络攻击主要有DDOS攻击和CC攻击等类型,今天小编则为大家来介绍僵尸网络攻击是指什么! 僵尸网络主要是指采用一种或者…...

Java编程中常见的条件链与继承陷阱
格式错误的if-else条件链 典型结构与常见错误模式 在Java编程中,if-else条件链是一种常见的多条件处理模式,其标准结构如下: if (condition1) {// 处理逻辑1 } else if (condition2) {// 处理逻辑2 } else...