【Python基础入门学习】Python高级变量你了解多少?
认识高级变量
- 1. 列表 list
- 1.1 列表的定义
- 1.2 列表常用操作
- 关键字、函数和方法
- 1.3 循环遍历
- 1.4 列表嵌套
- 1.5 应用场景
- 2. 元组 tuple
- 2.1 元组的定义
- 2.2 元组常用操作
- 2.3 应用场景
- 3. 字典 dictionary
- 3.1 字典的含义
- 3.2 字典常用操作
- 3.3 应用场景
- 4. 字符串 string
- 4.1 字符串的定义
- 4.2 字符串常用操作
- 4.2.1 判断
- 4.2.2 查找和替换
- 4.2.3 拆分和连接
- 4.2.4 大小写转换
- 4.2.5 文本对齐
- 4.2.6 去除空白字符
- 4.3 字符串的切片
- 4.3.1 索引的顺序和倒序
- 4.3.2 练习需求
- 5. 公共语法
- 5.1 python 内置函数
- 5.2 切片
- 5.3 运算符
- 5.4 for ... else 语法
1. 列表 list
1.1 列表的定义
- list(列表)是python中使用最频繁的数据类型,在其他语言中被称为数组
- 列表是用于存储一串数据,存储的数据称为元素
- 列表用 [],元素之间使用,分隔
- 列表的索引从 0 开始
索引就是元素在列表中的位置编号,索引又可以被称为下表

name_list = ["zhangsan", "lisi", "wangwu"]
# 取出列表中元素的值
print(name_list[0])
print(name_list[1])
print(name_list[2])
# 输出 lisi

当从列表中取值时,如果超出索引范围,程序会报错
1.2 列表常用操作
| 序号 | 分类 | 关键字/函数/方法 | 解释 |
|---|---|---|---|
| 1 | 增加 | 列表.append(数据) | 在末尾追加数据 |
| 列表.insert(索引, 数据) | 在指定位置插入数据(位置前有空元素会补位) | ||
| 列表.extend(Iterable) | 将可迭代对象中的元素追加到列表 | ||
| 2 | 删除 | del 列表[索引] | 删除指定索引的数据 |
| 列表.remove(数据) | 删除第一个出现的指定数据 | ||
| 列表.pop() | 删除末尾数据,返回被删除的元素 | ||
| 列表.pop(索引) | 删除指定索引数据 | ||
| 列表.pop(索引) | 清空列表 | ||
| 3 | 修改 | 列表[索引] = 数据 | 修改指定索引的数据,数据不存在会报错 |
| 4 | 查询 | 列表[索引] | 根据索引取值,索引不存在会报错 |
| 列表.index(数据) | 根据值查询索引,返回首次出现时的索引,没有查到会报错 | ||
| 列表.count(数据) | 数据在列表中出现的次数 | ||
| len(列表) | 列表长度 | ||
| if 数据 in 列表: | 检查列表中是否包含某元素 | ||
| 5 | 排序 | 列表.sort() | 升序排序 |
| 列表.sort(reverse=True) | 降序排序 | ||
| 列表.reverse() | 逆序、反转 |
- list1.extend(list2),把list2和list1拼到一个list里,一次性给list里加多个元素
- del 是关键字,关键字后面没有括号,通用语法,还可以删除别的东西
- len是函数,因为后面有括号,还可以求字符串的长度
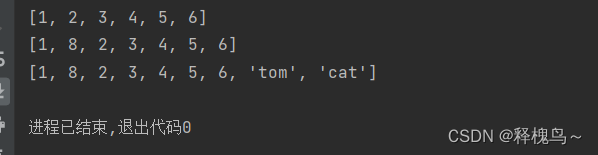
num_list=[1,2,3,4,5]
num_list.append(6)
print(num_list)
# 下标为1的位置插入8
num_list.insert(1,8)
print(num_list)
list2=['tom','cat']
num_list.extend(list2)
print(num_list)
4. list.pop()有返回值,可以赋给一个变量
num_list=[1,2,3,4,5]
num=num_list.pop()
print(num)
print(num_list)

- 一个list里元素类型可以不同,但是不同类型不能排序
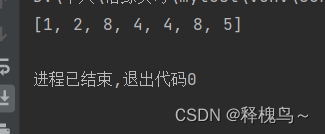
#将列表中所有的3修改为8
num_list=[1,2,3,4,4,3,5]
n=0
c=num_list.count(3)
while n<c:#这里不能写成n<num_list.count(3),因为每次循环改了个3,count次数就变少了i=num_list.index(3)num_list[i]=8n+=1
print(num_list)
关键字、函数和方法
- 关键字是 Python 内置的、具有特殊意义的标识符
import keyword
print(keyword.kwlist)
- 函数封装了独立功能,可以直接调用
函数名(参数)
- 方法和函数类似,同样是封装了独立的功能
- 方法需要通过对象来调用,表示针对这个对象要做的操作
对象.方法名(参数)
1.3 循环遍历
- 遍历就是从头到尾依次从列表中取出每一个元素,并执行相同的操作
- Python中实现遍历的方式很多,比如while循环、for循环、迭代器等
# while循环实现列表的遍历
i = 0
name_list = ["apple", "peach", "pear"]
list_count = len(name_list)
while i < list_count:name = name_list[i]print(name)i += 1

3. Python为了提高列表的遍历效率,专门提供for循环实现遍历
4. Python中for循环的本质是迭代器
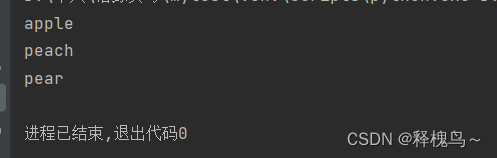
# for 实现列表的遍历
name_list = ["apple", "peach", "pear"]
for name in name_list:# 循环内部针对列表元素进行操作print(name)
1.4 列表嵌套
- 类似while循环的嵌套,列表也是支持嵌套的
- 一个列表中的元素又是一个列表,那么这就是列表的嵌套
i=1
l1=[]
l2=[]
l3=[]
while i <= 100:if i % 3 == 1:l1.append(i)elif i % 3 == 2:l2.append(i)else:l3.append(i)i += 1
print(l1,'\n',l2,'\n',l3)
list=[]
list.append(l1)
list.append(l2)
list.append(l3)
print(list)

1.5 应用场景
- 尽管Python的列表中可以存储不同类型的数据
- 但是在开发中,更多的应用场景是
a. 列表存储相同类型的数据
b. 通过for循环,在循环体内部,针对列表中的每一项元素,执行相同的操作
2. 元组 tuple
2.1 元组的定义
- 元组用()定义
- 用于存储一串数据、元素之间使用‘,’分割
- 元组的索引从0开始
# 定义元组
info_tuple = ("lxd", 22, 183)
# 取出元素的值
print(info_tuple[0],info_tuple[1])

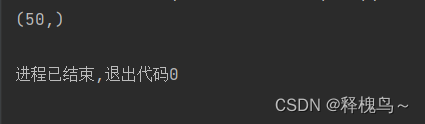
4. 元组中只包含一个元素时,需要在元素后面添加逗号
info_tuple = (50,)
print(info_tuple)
2.2 元组常用操作
- Tuple(元组)与列表类似,不同之处在于元组的元素不能修改----元祖是常量,列表是变量
- 变化的数据不能存在元祖里
info_tuple = ("lxd", 18, 1.75)
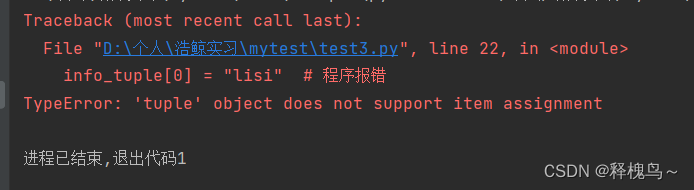
# 程序报错
info_tuple[0] = "lisi"
| 序号 | 分类 | 关键字 | 含义 |
|---|---|---|---|
| 1 | 查询 | 元组[索引] | 根据索引取值,索引不存在会报错 |
| 元组.index(数据) | 根据值查询索引,返回首次出现时的索引,没有查到会报错 | ||
| 元组.count(数据) | 数据在元组中出现的次数 | ||
| len(列表) | 元组长度 | ||
| if 数据 in 元组: | 检查元组中是否包含某元素 | ||
| 2 | 遍历 | for 数据 in 元组: | 取出元组中的每个元素 |
2.3 应用场景
作为自动组包的默认类型
info = 10, 20
print(type(info)) # 输出类型为 tuple
# 交换变量的值
a = 10
b = 20
a, b = b, a # 先自动组包,后自动解包
- 格式字符串,格式化字符串后面的()本质上就是一个元组
info = ("lxd", 22)
print("%s 的年龄是 %d" % info)

- 让列表不可以被修改,以保护数据安全
元组和列表之间的转换
使用 tuple 函数 把列表转换成元组:list1 = [10, 11] tuple1 = tuple(list1)
使用 list 函数 把元组转换成列表:list1 = list(tuple1)
3. 字典 dictionary
3.1 字典的含义
- dictionary(字典)是除列表以外Python之中最灵活的数据类型
- 字典同样可以用来存储多个数据
○ 通常用于存储描述一个物体的相关信息 - 字典用{ }定义
- 字典使用键值对存储数据,键值对之间使用,分隔
○ 键key是索引
○ 值value是数据
○ 键和值之间使用:分隔
○ 值可以取任何数据类型,但键只能使用字符串、数字或元组
○ 键必须是唯一的
# 定义字典
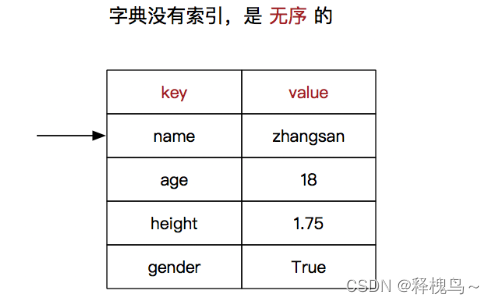
people = {"name": "小明","age": 18,"gender": True,"height": 1.75}
# 取出元素的值
print(people["name"])

3.2 字典常用操作
| 序号 | 分类 | 关键字/函数/方法 | 含义 |
|---|---|---|---|
| 1 | 增加 | 字典[键] = 数据 | 键不存在,会添加键值对;键存在,会修改键值对的值 |
| 2 | 删除 | del 字典[键] | 删除指定的键值对 |
| 字典.pop(键) | 删除指定键值对,返回被删除的值 | ||
| 字典.clear | 清空字典 | ||
| 3 | 修改 | 字典[键] = 数据 | 键不存在,会添加键值对;键存在,会修改键值对的值 |
| 字典.setdefault(键,数据) | 键值对不存在,添加键值对;存在则不做处理 | ||
| 字典.update(字典2) | 取出字典2的键值对,键值对不存在,添加键值对;存在则修改值 | ||
| 4 | 查询 | 字典[键] | 根据键取值,键值对不存在会报错 |
| 字典.get(键) | 字典.get(键) 根据键取值,键值对不存在不会报错 | ||
| 字典.keys() | 可进行遍历,获取所有键 | ||
| 字典.values() | 可进行遍历,获取所有值 | ||
| 字典.items() | 可进行遍历,获取所有(键,值) | ||
| 5 | 遍历 | for key in 字典 | 取出字典中的每个元素的key |
3.3 应用场景
在开发中,字典的应用场景是:
○ 使用多个键值对,存储描述一个物体的相关信息—— 描述更复杂的数据信息
○ 将多个字典放在一个列表中,再进行遍历,在循环体内部针对每一个字典进行相同的处理
card_list = [{"name": "张三","qq": "12345","phone": "110"},{"name": "李四","qq": "54321","phone": "10086"}]
print(card_list)

4. 字符串 string
4.1 字符串的定义
- 字符串就是一串字符,是编程语言中表示文本的数据类型
- 在 Python 中可以使用一对双引号"或者一对单引号’定义一个字符串
○ 虽然可以使用"或者’做字符串的转义,但是在实际开发中:
■ 如果字符串内部需要使用 ",可以使用 ’ 定义字符串
■ 如果字符串内部需要使用 ',可以使用 " 定义字符串 - 可以使用索引获取一个字符串中指定位置的字符,索引计数从0开始
- 也可以使用for循环遍历字符串中每一个字符
string = "Hello Python"
for c in string:print(c)
字符串取对应索引的字符:可以用负的索引你,从右往左,-1,-2……
string='12345'
print(string[0],string[1],string[2],string[3],string[4])
print(string[-5],string[-4],string[-3],string[-2],string[-1])
4.2 字符串常用操作
4.2.1 判断
| 方法 | 含义 |
|---|---|
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True |
| string.isdecimal() | 如果 string 只包含数字则返回 True |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True |
| string.startswith(str) | 检查字符串是否是以 str 开头,是则返回 True |
| string.endswith(str) | 检查字符串是否是以 str 结束,是则返回 True |
4.2.2 查找和替换
| 方法 | 含义 |
|---|---|
| string.find(str, start=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.rfind(str, start=0, end=len(string)) | 类似于 find(),不过是从右边开始查找 |
| string.index(str, start=0, end=len(string)) | 跟 find() 方法类似,不过如果 str 不在 string 会报错 |
| string.rindex(str, start=0, end=len(string)) | 类似于 index(),不过是从右边开始 |
| string.replace(old_str, new_str, num=string.count(old)) | 返回一个新字符串,把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次 |
sart和end可以省略:左闭右开,start那个位置查找,end那个索引值不查找
4.2.3 拆分和连接
| 方法 | 含义 |
|---|---|
| string.partition(str) | 返回元组,把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面) |
| string.rpartition(str) | 类似于 partition() 方法,不过是从右边开始查找 |
| string.split(str=“”, num) | 返回列表,以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 ‘\r’, ‘\t’, ‘\n’ 和空格 |
| string.splitlines() | 返回列表,按照行(‘\r’, ‘\n’, ‘\r\n’)分隔 |
| string1 + string2 | 拼接两个字符串 |
| string.join(seq) | 返回字符串,以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串,这里的seq不是字符串,可用是元祖、列表 |
左边或右边没有字符串,返回就是空串
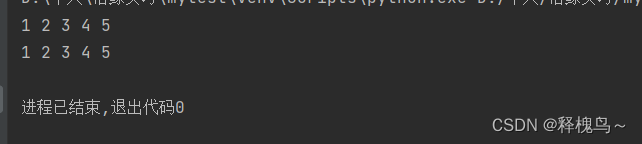
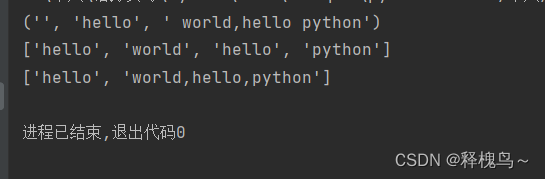
str='hello world,hello python'
print(str.partition('hello'))str='hello \t world \t hello \t python'
print(str.split())
# 指定以 ,作为分隔符切一次
str='hello,world,hello,python'
print(str.split(',',1))
4.2.4 大小写转换
| 方法 | 含义 |
|---|---|
| string.lower() | 返回新字符串,转换 string 中的大写字母为小写 |
| string.upper() | 返回新字符串,转换 string 中的小写字母为大写 |
4.2.5 文本对齐
| 方法 | 含义 |
|---|---|
| string.ljust(width) | 返回新字符串,基于原字符串左对齐,并使用空格填充至长度 width |
| string.rjust(width) | 返回新字符串,基于原字符串右对齐,并使用空格填充至长度 width |
| string.center(width) | 返回新字符串,基于原字符串居中,并使用空格填充至长度 width |
# 把list里每个字符串长度都变成6,左右用空格填充
str_list=['a','hello','abc']
for s in str_list:print(s.center(6))

4.2.6 去除空白字符
| 方法 | 含义 |
|---|---|
| string.lstrip() | 返回新字符串,截掉 string **左边(开始)**的空白字符 |
| string.rstrip() | 返回新字符串,截掉 string **右边(末尾)**的空白字符 |
| string.strip() | 返回新字符串,截掉 string 左右两边的空白字符 |
列表除了查询方法和pop方法都没有返回值,字符串所有方法都有返回值
4.3 字符串的切片
- 切片译自英文单词slice,翻译成另一个解释更好理解:一部分
- 切片使用索引值来限定范围,根据步长从原序列中取出一部分元素组成新序列
- 切片方法适用于字符串、列表、元组
字符串[开始索引:结束索引:步长]
注意:
- 指定的区间属于左闭右开型:[开始索引, 结束索引)对应开始索引 = 范围 < 结束索引
○ 从起始位开始,到结束位的前一位结束(不包含结束位本身) - 从头开始,开始索引数字可以省略,冒号不能省略
- 到末尾结束,结束索引数字和冒号都可以省略
- 步长默认为1,如果元素连续,数字和冒号都可以省略
str='hello,world,abc,python'
print(str[0:5:2])

4.3.1 索引的顺序和倒序
- 在 Python 中不仅支持顺序索引,同时还支持倒序索引
- 所谓倒序索引就是从右向左计算索引
○ 最右边的索引值是**-1**,依次递减 - 注意:如果步长为负数
○ 并省略了开始索引,则开始索引表示最后一位
○ 并省略了结束索引,则结束索引表示第一位
反向(从右往左),步长是负数 ,-1,-2不能省略,开始的死闭区间(右边),结束的是开区间(左边)
str='hello'
print(str[-3:-5:-1])

4.3.2 练习需求
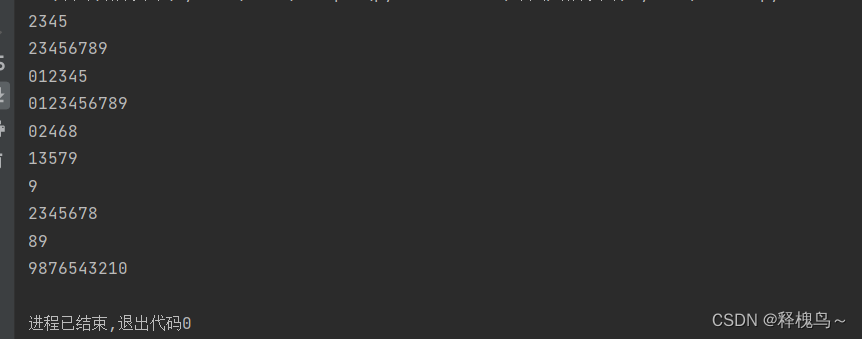
num_str = "0123456789"
# 1. 截取从 2 ~ 5 位置 的字符串
print(num_str[2:6])
# 2. 截取从 2 ~ `末尾` 的字符串
print(num_str[2:])
# 3. 截取从 `开始` ~ 5 位置 的字符串
print(num_str[:6])
# 4. 截取完整的字符串
print(num_str[:])
# 5. 从开始位置,每隔一个字符截取字符串
print(num_str[::2])
# 6. 从索引 1 开始,每隔一个取一个
print(num_str[1::2])
# 倒序切片
# -1 表示倒数第一个字符
print(num_str[-1])
# 7. 截取从 2 ~ `末尾 - 1` 的字符串
print(num_str[2:-1])
# 8. 截取字符串末尾两个字符
print(num_str[-2:])
# 9. 字符串的逆序(面试题)
print(num_str[::-1])
5. 公共语法
5.1 python 内置函数
| 函数 | 描述 |
|---|---|
| len(item) | 计算容器中元素个数 |
| del(item) | 删除变量 |
| max(item) | 返回容器中元素最大值 |
| min(item) | 返回容器中元素最小值 |
| cmp(item1, item2) | 比较两个值,-1 小于/0 相等/1 大于 |
注意
● 字符串比较符合以下规则: “0” < “A” < “a”
● del list[1],del(list[1])都可以
5.2 切片
| 描述 | Python 表达式 | 结果 | 支持的数据类型 |
|---|---|---|---|
| 切片 | “0123456789”[::-2] | “97531” | 字符串、列表、元组 |
- 切片使用索引值来限定范围,从一个大的字符串中切出小的字符串
- 列表和元组都是有序的集合,都能够通过索引值获取到对应的数据
- 字典是一个无序的集合,是使用键值对保存数据。字典无序不能切片
5.3 运算符
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | [“Hi!”] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 重复 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
| >>= == <<= | (1, 2, 3) < (2, 2, 3) | True | 元素比较 | 字符串、列表、元组 |
注意
● in在对字典操作时,判断的是字典的键
● in和not in被称为成员运算符
成员运算符
- 成员运算符用于测试序列中是否包含指定的成员
- 注意:在对字典操作时,判断的是字典的键
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False | 3 in (1, 2, 3)返回True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | 3 not in (1, 2, 3)返回False |
5.4 for … else 语法
在Python中,循环语句支持else, 语法如下:
for 变量 in 集合:循环体代码break
else:没有通过 break 退出循环,循环结束后,会执行else这块代码
str='hello'
fs='o'
for char in str:if char==fs:print('找到了')break
else:print('未找到')

应用场景
- 在迭代遍历嵌套的数据类型时,例如一个列表包含了多个字典
- 需求:要判断 某一个字典中 是否存在 指定的 值
○ 如果存在,提示并且退出循环
○ 如果不存在,在循环整体结束后,希望得到一个统一的提示
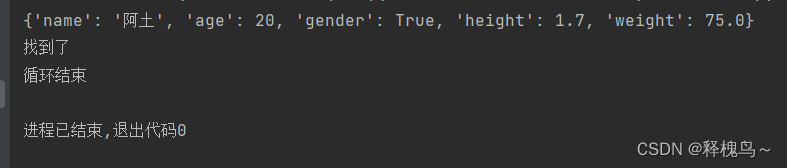
students = [{"name": "阿土","age": 20,"gender": True,"height": 1.7,"weight": 75.0},{"name": "小美","age": 19,"gender": False,"height": 1.6,"weight": 45.0},
]
find_name = "阿土"
for stu_dict in students:print(stu_dict)# 判断当前遍历的字典中姓名是否为find_nameif stu_dict["name"] == find_name:print("找到了")# 如果已经找到,直接退出循环,就不需要再对后续的数据进行比较break
else:print("没有找到")
print("循环结束")
相关文章:
【Python基础入门学习】Python高级变量你了解多少?
认识高级变量 1. 列表 list1.1 列表的定义1.2 列表常用操作关键字、函数和方法 1.3 循环遍历1.4 列表嵌套1.5 应用场景 2. 元组 tuple2.1 元组的定义2.2 元组常用操作2.3 应用场景 3. 字典 dictionary3.1 字典的含义3.2 字典常用操作3.3 应用场景 4. 字符串 string4.1 字符串的…...
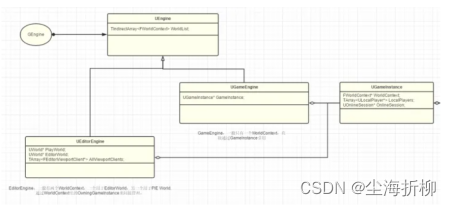
《LearnUE——基础指南:上篇—3》——GamePlay架构WorldContext,GameInstance,Engine之间的关系
目录 平行世界是真实存在的吗? 1.3.1 引言 1.3.2 世界管理局(WorldContext) 1.3.3 司法天神(GameInstance) 1.3.4 上帝(Engine) 1.4 总结 平行世界是真实存在的吗? 1.3.1 引言 …...

重大问题,Windows11出现重大BUG(开始菜单掉帧,卡顿)
重大问题,Windows11出现重大BUG 这种Windows11操作系统出现BUG已经可以说是非常常见的,但是,今天我将代表所有微软用户,解决一个关于UI设计非常不舒服的功能 关闭多平面覆盖 事情叙述问题 微软社区解决方案自己发现的解决方案解决…...

修改系统语言字体的方法及注意事项
Android修改系统语言字体 随着我们生活品质的提升,现在人们对于手机的依赖越来越高,而且对于手机的功能也有了更高的要求。其中,界面的字体对于我们视觉的体验感受非常重要。而在Android系统中,默认的字体可能并不符合我们的胃口。…...
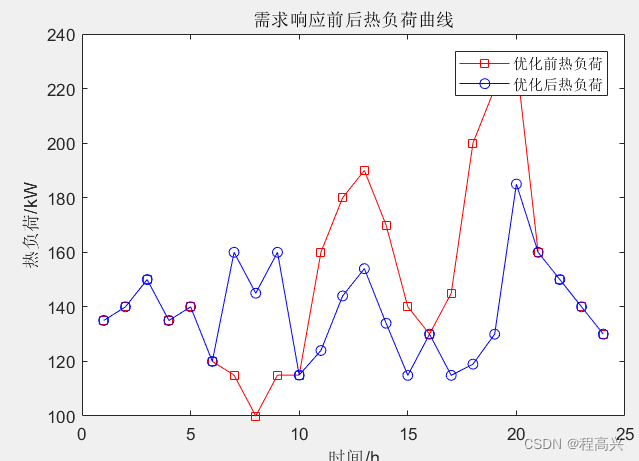
19.考虑柔性负荷的综合能源系统日前优化调度模型
说明书 MATLAB代码:考虑柔性负荷的综合能源系统日前优化调度模型 关键词:柔性负荷 需求响应 综合需求响应 日前优化调度 综合能源系统 参考文档:《考虑用户侧柔性负荷的社区综合能源系统日前优化调度》参考柔性负荷和基础模型部分…...
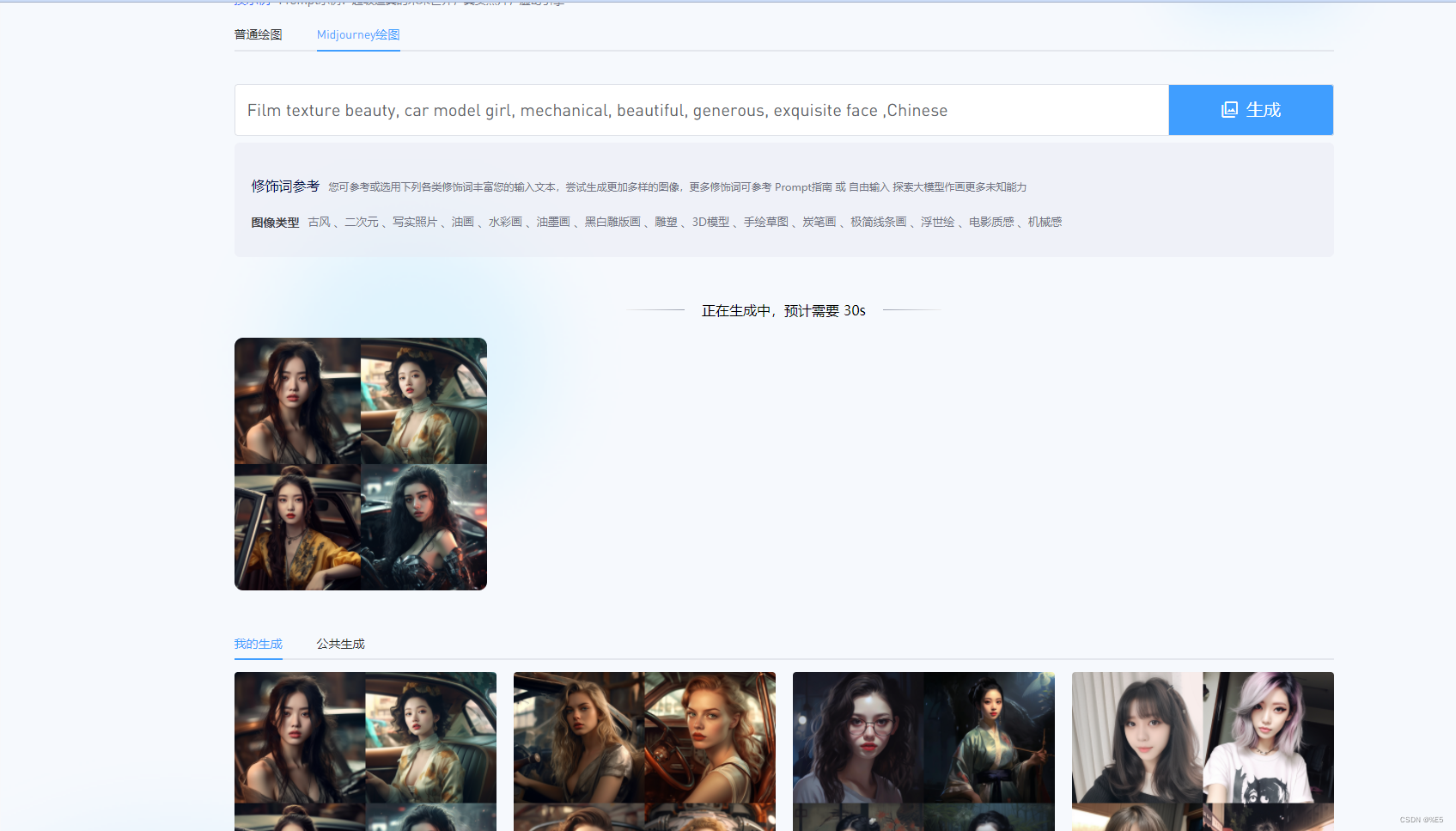
Midjourney关键词分享!附输出AI绘画参考图
Midjourney 关键词是指用于 Midjourney 这个 AI 绘画工具的文本提示,可以影响生成图像的风格、内容、细节等。Midjourney 关键词有一些基本的语法规则和套用公式,也有一些常用的风格词汇和描述词汇,这里我以10张不同风格和类型的美女图为例&a…...

网络安全行业就职岗位有哪些?
网络安全作为目前最火的行业之一,它的细分方向很多。下面介绍一下网络安全主要的方向岗位有哪些,以及职责是什么? 一、安全规划与设计方向 岗位名称:系统安全需求分析师。 岗位职责:负责对目标对象需要达到的安全目标…...

数据库设计-范式
范式 范式就是数据库的构建规则,目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、第四范式(4NF)、第五范式(5NF&#x…...

在前端开发中,何时应该使用 jQuery,何时应该使用 Vue.js
如果您是最近才开始进入 Web 前端开发领域的开发人员,那么您可能会听说过 jQuery。jQuery 是一个小巧而功能强大的 JavaScript 库,旨在简化跨浏览器 DOM 操作、事件处理、动画效果和 AJAX 等方面的操作,可以让开发人员更轻松地开发出高质量的…...

Promise类方法
这篇主要讲一下Promise的类方法的基本使用,至于Promise的基本使用这里就不赘述了,之前也有手写过Promise、实现了Promise的核心逻辑。其实我们平时用Promise也挺多的,不过又出现了两个新的语法(ES11,ES12新增了两个&am…...
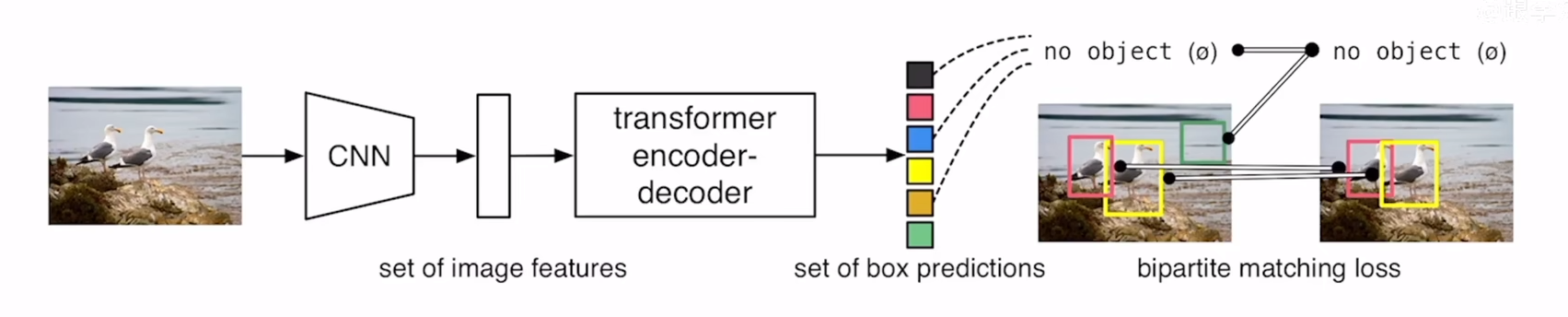
transformer and DETR
RNN 很难并行化处理 Transformer 1、Input向量x1-x4分别乘上矩阵W得到embedding向量a1-a4。 2、向量a1-a4分别乘上Wq、Wk、Wv得到不同的qi、ki、vi(i{1,2,3,4})。 3、使用q1对每个k(ki)做attention得到a1,i(i{1,2,3,4…...
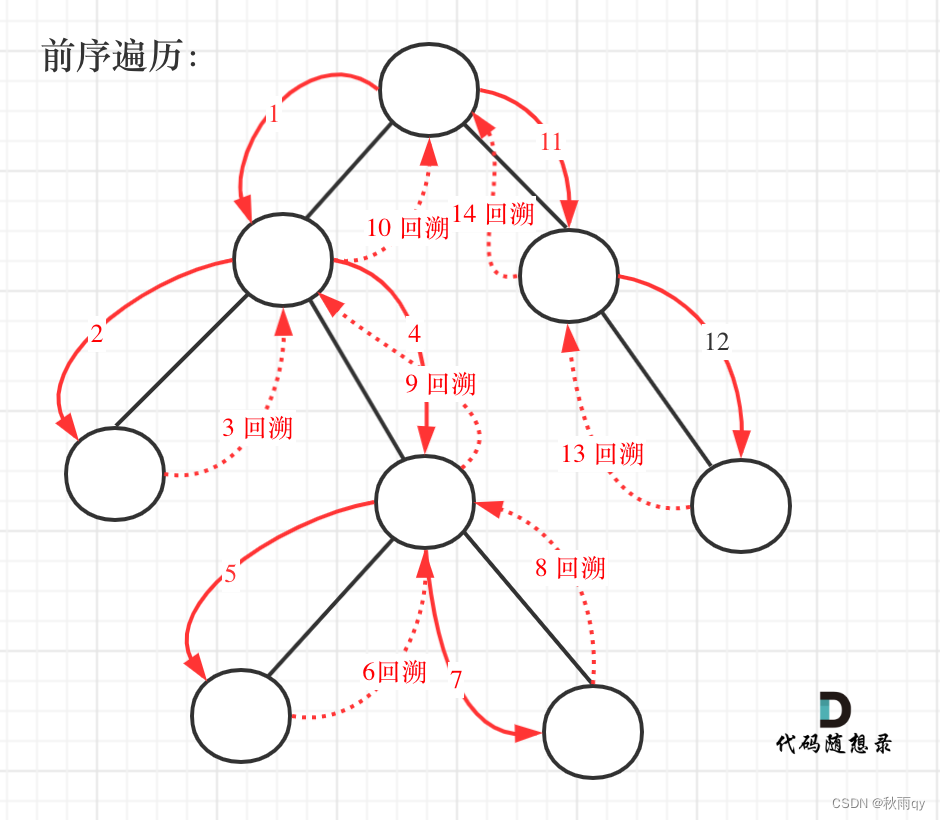
数据结构(六)—— 二叉树(4)回溯
文章目录 一、题1 257 二叉树的所有路径1.1 写法11.2 写法2 一、题 1 257 二叉树的所有路径 1.1 写法1 递归回溯:回溯是递归的副产品,只要有递归就会有回溯 首先考虑深度优先搜索;而题目要求从根节点到叶子的路径,所以需要前序…...
)
JVM基础知识(一)
1.整体架构和组件 1.Class Loader Class Loader(类加载器)负责将.class文件加载到JVM中,并生成对应的Java类对象(Class对象)。Java中有三种类加载器: Bootstram ClassLoader:加载核心类库&…...
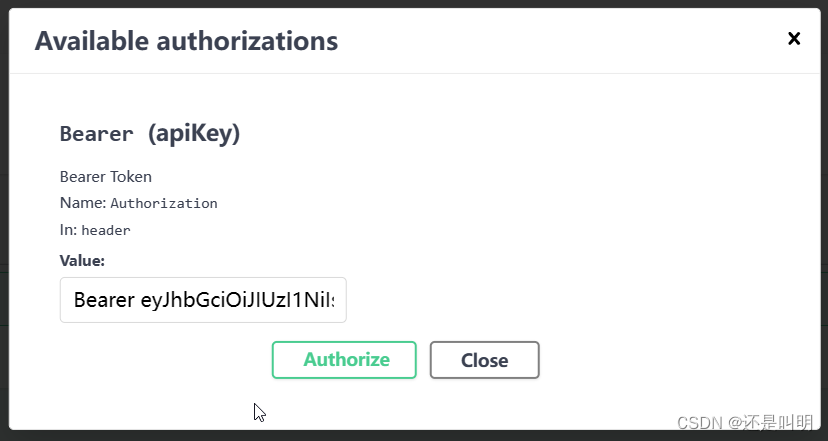
ASP.NET Core Web API用户身份验证
一、JWT介绍 ASP.NET Core Web API用户身份验证的方法有很多,本文只介绍JWT方法。JWT实现了服务端无状态,在分布式服务、会话一致性、单点登录等方面凸显优势,不占用服务端资源。简单来说,JWT的验证过程如下所示: &a…...

785. 快速排序
785. 快速排序 给定你一个长度为 n n n 的整数数列。 请你使用快速排序对这个数列按照从小到大进行排序。 并将排好序的数列按顺序输出。 输入格式 输入共两行,第一行包含整数 n n n。 第二行包含 n n n 个整数(所有整数均在 1 ∼ 1 0 9 1 \th…...

C6678学习-IPC
文章目录 1、简介2、模块MultiProc静态设置(cfg设置)动态设置 IPCNotifyMessageQShareRegion 1、简介 IPC: Inter-Processor Communication 处理器间通信,指提供多处理器环境中的处理器之间的通信、相同处理器不同线程间的通信。包括数据传递…...
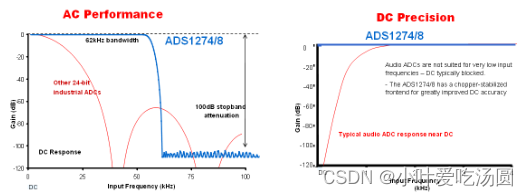
利用 Delte-Sigma ADC简化电路设计
很多时候在电路中选择合适的 ADC可以很大程度上简化前端的电路。这里我们一起来看一个电阻电桥的例子: 这里用到了一只仪表放大器和一只运算放大器,他们实际上主要完成了三个功能: 1. 抑制了 2.5V的共模信号; 2. 将-1…...
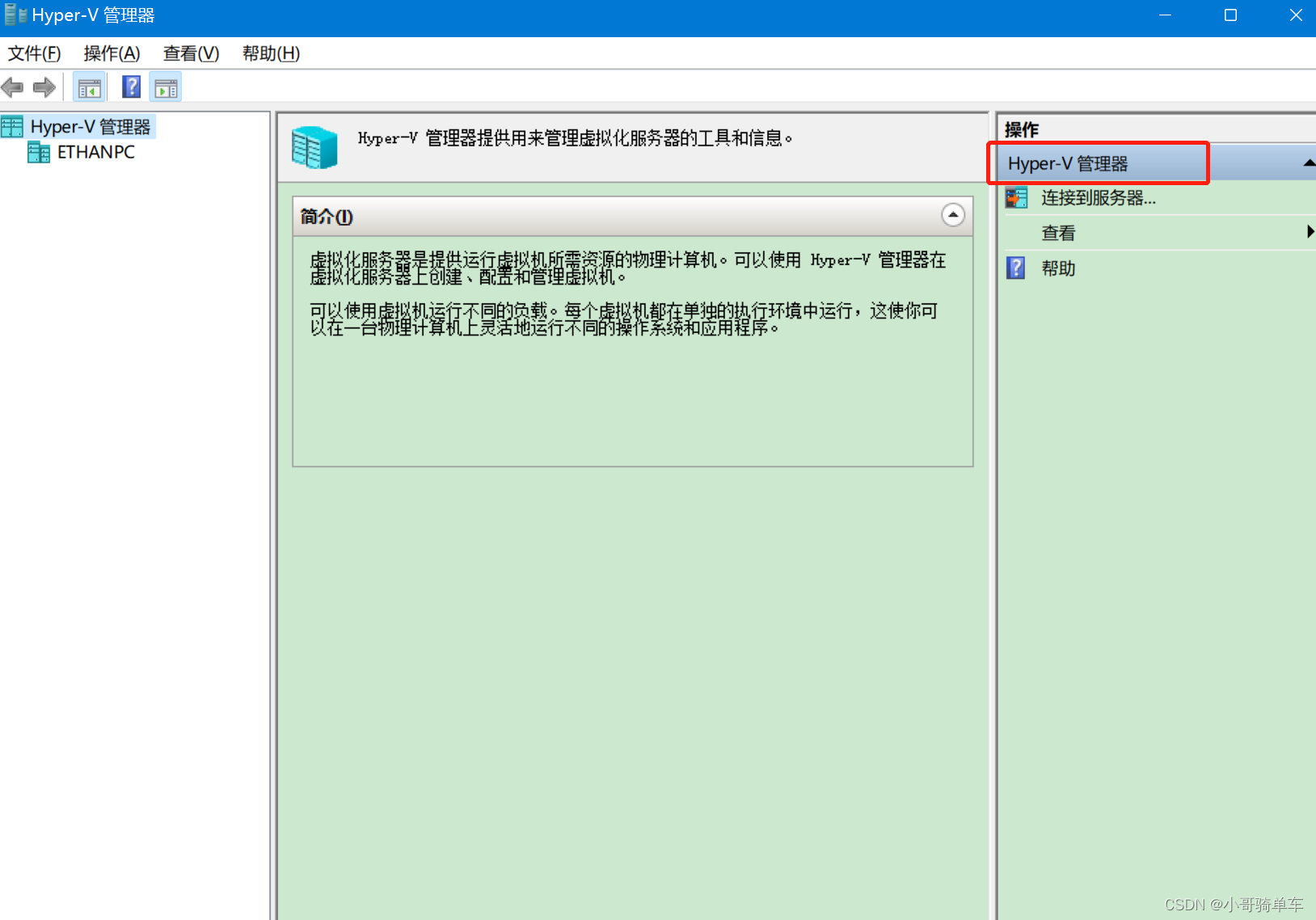
如何在 Windows 11 启用 Hyper-V
准备在本机玩一下k8s,需要先启用 Hyper-V,谁知道这一打开,没有 Hyper-V选项: 1、查看功能截图: 2、以下文件保存记事本,然后重命名为*.bat pushd "%~dp0" dir /b %SystemRoot%\servicing\Packa…...

哈希表企业应用-DNA的字符串检测
DNA的字符串检测-引言 若干年后, ikun DNA 检测部成立,专门对 这些ikun的解析检测 突然发现已经完全控制不了 因为学生已经会了 而且是太会了 所以DNA采用 以下视频测试: ikun必进曲 ikun必经曲 ikun必阶曲 如何感受到了吧!,如果你现在唱跳并且还Rap 还有打篮球 还有铁山靠 那…...

Kafka运维与监控
Kafka运维与监控 Kafka运维与监控一、简介二、运维1.安装和部署安装部署 2.优化参数配置配置文件高级配置分区和副本设置分区数量设置副本数量设置 网络参数调优传输机制设置连接数和缓冲区大小设置 消息压缩和传输设置消息压缩设置消息传输设置 磁盘设置和文件系统分区磁盘容量…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...