Kafka运维与监控
Kafka运维与监控
- Kafka运维与监控
- 一、简介
- 二、运维
- 1.安装和部署
- 安装
- 部署
- 2.优化参数配置
- 配置文件
- 高级配置
- 分区和副本设置
- 分区数量设置
- 副本数量设置
- 网络参数调优
- 传输机制设置
- 连接数和缓冲区大小设置
- 消息压缩和传输设置
- 消息压缩设置
- 消息传输设置
- 磁盘设置和文件系统分区
- 磁盘容量和性能设置
- 文件系统分区设置
- 监控和热插拔
- 监控设置
- 热插拔设置
- 3.数据的备份与恢复
- 数据备份
- 全量备份
- 增量备份
- 数据恢复
- 全量恢复
- 增量恢复
- 脚本编写(备份和恢复)
- 4.性能调优
- 性能调优指南
- 性能指标
- 安全性和认证
- 三、监控
- 1.监控健康状态
- 监控指标(Broker Producer Consumer)
- Broker 状态
- Producer 状态
- Consumer 状态
- 监控工具
- 2.监控吞吐量和延迟
- 读写比例
- 分区和副本数量
- 数据生产和消费速度
- 监控指标
- 3.监控存储和网络使用情况
- 存储和网络使用情况
- 监控指标
- 4.报警通知
- 报警设置
- 四、日志管理
- 1.日志清理策略
- 日志压缩
- 日志清理策略
- 日志管理工具
- 2.错误处理和故障排除
- 监控Kafka的运行状态
- 日志记录和分析
- Kafka故障排除
- 五、小结
Kafka运维与监控
一、简介
Kafka是由Apache Software Foundation开发的一款分布式流处理平台和消息队列系统
可以处理大规模的实时数据流,具有高吞吐量、低延迟、持久性和可扩展性等优点
常用于数据架构、数据管道、日志聚合、事件驱动等场景,对Kafka的运维和监控十分必要
本文旨在介绍Kafka的运维和监控相关内容
二、运维
1.安装和部署
安装
在官网下载 Kafka 源码包,并解压到指定路径
配置环境变量、内存和文件描述符等参数
# 从Apache官网下载Kafka最新版本(latest.gz)文件到本地
wget http://apache.com/kafka/latest.gz
# 解压缩 Kafka 压缩包(tar -xzf kafka-latest.gz)
tar -xzf kafka-latest.gz
# 将解压缩后的文件夹kafka-x.x.x移动到/usr/local/kafka/目录下
mv kafka-x.x.x /usr/local/kafka/
# 设置KAFKA_HOME环境变量为/usr/local/kafka
export KAFKA_HOME=/usr/local/kafka
# 将Kafka的bin目录添加到PATH环境变量中,方便后续使用Kafka命令
export PATH="$PATH:$KAFKA_HOME/bin"部署
根据业务需求决定Kafka的部署方式,当前提供三种部署模式:单机部署、分布式部署和容器化部署,需要根据具体业务场景和要求来进行选择
在生产环境中部署 Kafka 还需要考虑高可用和容错等问题
2.优化参数配置
配置文件
Kafka的配置文件为 config/server.properties,可以在此文件中进行 Kafka 的基础配置,例如端口、日志目录、Zookeeper 信息和 Broker ID 等。
您还可以自定义配置文件和属性,通过指定 -D 参数来加载。例如:
# 启动脚本命令,其中参数 -daemon 代表以守护进程方式启动,config/server.properties 指定Kafka的配置文件路径,-Dname=mykafka 指定Kafka进程的名称为 mykafka
bin/kafka-server-start.sh -daemon config/server.properties -Dname=mykafka -Dlog.dirs=/home/kafka/logs/
高级配置
在生产环境中为了获得更好的性能和稳定性,需要进行高级配置调优
这样可以更好地适应不同的业务场景和负载压力以下是一些需要注意的配置项:
分区和副本设置
分区数量设置
分区的数量可以通过 num.partitions 参数设置,不同的业务场景可能需要不同的分区数。通常情况下每个分区的大小建议不要超过1GB,否则可能会影响读写性能
副本数量设置
Kafka副本数的设置需要考虑到数据可靠性和容错性。副本数可以通过 replication.factor 参数设置,建议设置为大于等于2,以保证数据的可靠性。对于需要更高容错性的生产环境,可以将副本数设置为大于等于3,这样即使有一台 Broker 故障也不会影响数据可用性
网络参数调优
传输机制设置
Kafka支持两种传输机制:plaintext 和 SSL/TLS。如果希望数据传输更加安全可以使用 SSL/TLS 传输机制。但需要注意的是使用 SSL/TLS 会增加 CPU 的负载
连接数和缓冲区大小设置
在处理高负载的情况下Kafka Broker可能会遇到连接数和缓冲区大小的限制,这会导致发送和接收消息的性能下降。可以通过修改 max.connections 和 socket.send.buffer.bytes/socket.receive.buffer.bytes 参数来优化连接数和缓冲区大小
消息压缩和传输设置
消息压缩设置
Kafka支持多种压缩算法可以通过 compression.type 参数设置。不同的压缩算法适用于不同类型的消息,需要根据具体业务场景进行调优。
消息传输设置
Kafk 的消息传输可以通过 max.message.bytes 参数来限制消息的大小。如果需要处理大量的大型消息可以通过修改该参数来提高性能
磁盘设置和文件系统分区
磁盘容量和性能设置
Kafka存储数据需要占用磁盘空间为了确保消息持久化建议设置合理的磁盘容量大小,并使用高效的 SSD硬盘来提高性能
文件系统分区设置
将Kafka存储在单独的文件系统分区中可以提高磁盘读写性能。如果使用多个分区,应该将 Broker 的日志文件平均分配到每个分区中以避免出现磁盘空间不足的情况
监控和热插拔
监控设置
为了更好地监控 Kafka 的运行情况需要设置正确的监控参数。可以通过修改 log.dirs 参数来指定Broker 的日志目录,并设置正确的日志滚动策略。
热插拔设置
Kafka支持热插拔可以在运行时添加或删除Broker,以适应不同的业务需求和负载压力。在添加或删除 Broker时,需要注意保证数据的可靠性和一致性
// 以下是一些常用的 Kafka 配置参数示例// 分区数量
Properties props = new Properties();
props.put("num.partitions", "3");// 副本数量
props.put("replication.factor", "2");// SSL/TLS 传输
props.put("security.protocol", "SSL");
props.put("ssl.truststore.location", "/path/to/truststore");// 连接数和缓冲区大小
props.put("max.connections", "100");
props.put("socket.send.buffer.bytes", "102400");
props.put("socket.receive.buffer.bytes", "102400");// 消息压缩
props.put("compression.type", "gzip");// 消息传输
props.put("max.message.bytes", "100000000");// 磁盘容量和性能
props.put("log.dirs", "/path/to/kafka/logs");
props.put("log.segment.bytes", "1073741824");
props.put("log.roll.hours", "24");// 文件系统分区
props.put("log.dirs", "/mnt/kafka1,/mnt/kafka2,/mnt/kafka3");// 监控和热插拔
props.put("log.retention.ms", "604800000");
props.put("controller.socket.timeout.ms", "30000");
3.数据的备份与恢复
数据备份
Kafka的数据备份包括两种类型:全量备份和增量备份
全量备份是将整个 Kafka 的数据复制到一个不同的地方
增量备份是在全量备份后仅仅备份增量的数据
下面分别介绍两种备份方式:
全量备份
# 指定备份的主题
BACKUP_TOPIC=test# 指定备份的数据目录
BACKUP_DIR=/tmp/backup# 创建备份目录
mkdir -p $BACKUP_DIR# 备份主题数据
kafka-console-consumer.sh \--bootstrap-server localhost:9092 \--topic $BACKUP_TOPIC \--from-beginning \> $BACKUP_DIR/$BACKUP_TOPIC.txt
上述代码使用 kafka-console-consumer.sh 工具将主题 $BACKUP_TOPIC 的数据备份到 $BACKUP_DIR 目录下的 $BACKUP_TOPIC.txt 文件中。
注意:该脚本是同步备份会阻塞线程,备份时间较长时,建议使用异步备份方式。
增量备份
增量备份需要借助第三方工具
例如 Kafka 的 MirrorMaker 等实现
下面是 MirrorMaker 的用法示例:
# 指定源和目的地址
SOURCE_HOST=localhost:9092
DESTINATION_HOST=backup-host:9092# 创建 MirrorMaker 配置文件
cat > /tmp/mirror-maker.properties <<EOF
consumer.bootstrap.servers=$SOURCE_HOST
producer.bootstrap.servers=$DESTINATION_HOST
EOF# 运行 MirrorMaker
kafka-run-class.sh kafka.tools.MirrorMaker \--consumer.config /tmp/mirror-maker.properties \--producer.config /tmp/mirror-maker.properties \--whitelist $BACKUP_TOPIC
上述代码中创建一个 MirrorMaker 配置文件将源端的数据同步到目标端--whitelist 参数指定备份的主题
数据恢复
下面介绍Kafka数据恢复
全量恢复
# 指定恢复的主题
RESTORE_TOPIC=test# 指定备份文件路径
BACKUP_FILE=/tmp/backup/$RESTORE_TOPIC.txt# 恢复主题数据
kafka-console-producer.sh \--broker-list localhost:9092 \--topic $RESTORE_TOPIC \--new-producer \< $BACKUP_FILE
上述代码将$BACKUP_FILE 文件中的数据恢复到 $RESTORE_TOPIC 主题中
注意:该脚本也是同步操作,恢复时间较长时建议使用异步操作
增量恢复
增量恢复需要使用 MirrorMaker 来实现,下面是 MirrorMaker 的用法示例:
# 创建MirrorMaker 配置文件
cat > /tmp/mirror-maker.properties <<EOF
consumer.bootstrap.servers=backup-host:9092
producer.bootstrap.servers=localhost:9092
EOF# 运行MirrorMaker
kafka-run-class.sh kafka.tools.MirrorMaker \--consumer.config /tmp/mirror-maker.properties \--producer.config /tmp/mirror-maker.properties \--whitelist $RESTORE_TOPIC
上述代码中创建一个 MirrorMaker 配置文件将备份端的数据同步到目标端 $RESTORE_TOPIC 主题中
注意:增量恢复会将备份端数据的变化同步到目标端,因此恢复时必须先将备份端数据同步完整
脚本编写(备份和恢复)
下面是一个简单的脚本,用于备份和恢复 Kafka 数据:
#!/bin/bashfunction backup_topic() {local topic=$1local backup_dir=$2echo "Starting backup for topic: $topic"mkdir -p $backup_dirkafka-console-consumer.sh \--bootstrap-server localhost:9092 \--topic $topic \--from-beginning \> $backup_dir/$topic.txtecho "Backup completed for topic: $topic"
}function restore_topic() {local topic=$1local backup_file=$2echo "Starting restore for topic: $topic"kafka-console-producer.sh \--broker-list localhost:9092 \--topic $topic \--new-producer \< $backup_fileecho "Restore completed for topic: $topic"
}backup_topic example-topic /tmp/backup
restore_topic example-topic /tmp/backup/example-topic.txt
上述代码中定义了两个函数 backup_topic 和 restore_topic,分别用于备份和恢复 Kafka 主题数据
在这个脚本中备份的主题是 example-topic,备份数据存储的目录是 /tmp/backup
要恢复数据,请调用 restore_topic 函数,并通过参数指定要恢复的主题和备份文件的路径。在脚本的最后示例恢复了 example-topic 主题的备份数据。
4.性能调优
性能调优指南
Kafka 是一个高吞吐量、低延迟、分布式的消息中间件,但还是有必要进行性能调优以确保其正常运行。下面是一些性能调优的建议:
- 配置适当的
num.io.threads参数使每个Kafka实例的网络I/O线程数量与CPU核心数大致相等 - 调整
max.message.bytes和replica.fetch.max.bytes参数,以提高 Kafka 的吞吐量和延迟性能 - 为每个Kafka的分区配置适当数量的ISR (in-sync replicas),避免ISR集合太小而导致消息在网络上的长时间等待
- 使用SSD硬盘可提高 Kafka 的读写I/O性能和稳定性
性能指标
为了理解 Kafka 的性能表现需要监控以下指标:
(使用 Apache Kafka Metrics 与 JMX MBeans 支持监控这些指标)
- 生产者延迟 (producer latency)
- 消费者延迟 (consumer latency)
- 消息吞吐量 (message throughput)
- 磁盘使用情况 (disk usage)
- 网络使用情况 (network usage)
安全性和认证
Kafka 支持针对传输层进行SSL加密和对客户端身份进行基于SSL的认证机制,关键在于使用适当的加密算法和 TLS/SSL 协商协议。这可以通过设置以下参数来实现:
ssl.keystore.location=/path/to/keystore.jks
ssl.keystore.password=password
ssl.key.password=password
ssl.truststore.location=/path/to/truststore.jks
ssl.truststore.password=password
security.protocol=SSL
此外还支持基于Kerberos和OAuth2.0的身份验证机制。对于生产环境而言建议使用基于 Kerberos的认证。这可以通过未来证书的身份验证机制实现:
sasl.kerberos.service.name=kafka
sasl.mechanism=GSSAPI
根据上述设置Kafka生产者和消费者将使用使用 Kerberos KDC进行身份验证以确保只有经过身份验证的用户才能访问 Kafka
三、监控
1.监控健康状态
为了了解 Kafka 的运作状态和性能状况需要对 Kafka 进行监控和诊断
通过Kafka提供的监控工具和插件可以诊断出 Kafka 的异常、错误、瓶颈和故障等问题并及时采取对应的措施
监控指标(Broker Producer Consumer)
以下是监控的健康指标:
Broker 状态
- 运行状态可以通过 Kafka 文件夹下的
kafka-server-start.sh和kafka-server-stop.sh脚本来启动和停止 broker。 - 错误信息可以在
kafkaServer.log文件中找到。可以使用tail -f /path/to/kafkaServer.log命令来跟踪最新日志信息。 - 同步状态可以通过在
config/server.properties文件中进行配置来达到最佳表现。
Producer 状态
- 提交速度可以通过 Kafka 生产者默认的
batch.size参数来控制,此参数默认值为16KB。可以根据需要调整此参数以达到最佳性能
batch.size=32768
- 发送成功率可以通过设置生产者确认级别(acks)参数来实现。可配置的选项包括:ack = 0 (fire and forget), ack = 1 (awaiting for receipt) 或 ack = -1 (all)
acks=1
- 错误率可以通过在配置文件中设置
retries和retry.backoff.ms参数来控制,达到重试并逐渐递增时间的目的。如果发生无法恢复的错误,则会返回无法恢复的错误
retries=3
retry.backoff.ms=1000
Consumer 状态
- 消费速度可以通过设置
fetch.min.bytes和fetch.max.bytes参数来控制,以读取指定数量的字节。建议将fetch.min.bytes参数设置得足够大,否则会导致大量短暂的网络请求。
fetch.min.bytes=65536
fetch.max.bytes=524288
- 消费成功率可以通过运行多个消息消费者并监控每个消费者的消费进度,以确定 Kafka 是否实时消费每个消息。如果消息消费迟缓,则可以增加消费端的数量或增加消费端读取的批量大小。
- 失败率可以通过设置消费端的
auto.offset.reset参数来控制。该参数表示消费者应当在无法从上一个偏移量处读取消息时进行的操作,可以设置为earliest或latest。如果设置为earliest,消费者将从 Kafka 的起始偏移量开始重新读取。如果设置为latest,消费者将从另一侧开始读取。
监控工具
Kafka提供了一些自带的监控工具,例如:jConsole、JMX、Kafka Monitor 和 Kafka Manager
除此之外还有第三方监控解决方案,例如:Prometheus、Grafana、ELK 等。
2.监控吞吐量和延迟
吞吐量是衡量性能的关键指标之一,指的是在单位时间内Kafka能够处理的消息数
延迟是指从消息产生到消息被消费所经历的时间
在监控Kafka的吞吐量和延迟时,需要注意以下几个关键数据:
读写比例
在Kafka集群中,读和写的比例必须是平衡的。如果读的速度比写的速度快,那么Kafka就会变成一个缓慢的读取服务。反之如果写的速度比读的速度快那么Kafka将成为一个缓慢的写入服务。因此要确保读写比例的平衡。
分区和副本数量
分区和副本数量对Kafka的吞吐量和延迟都有很大的影响。增加分区和副本数量可以提高吞吐量但同时也会增加延迟。因此需要平衡这两个指标
数据生产和消费速度
数据生产和消费的速度都可以影响Kafka的吞吐量和延迟。如果生产者速度过快或者消费者速度过慢就会导致Kafka缓存消息进而影响延迟。反之如果生产者速度过慢或者消费者速度过快也会导致吞吐量下降,因此需要确保生产和消费速度的平衡。
监控指标
可以通过如下几个监控指标来了解Kafka的吞吐量和延迟情况:
# 监控来自代理的每秒字节数,可以反应消息生产速度
kafka.server:name=BytesInPerSec, type=BrokerTopicMetrics# 监控代理发送的每秒字节数,可以体现消息的传输速度
kafka.server:name=BytesOutPerSec, type=BrokerTopicMetrics# 监控代理每秒钟接收到的消息数量,可以反应消息的生产速度
kafka.server:name=MessagesInPerSec, type=BrokerTopicMetrics# 监控代理每秒发送的消息数量,可以反应消息的传输速度
kafka.server:name=MessagesOutPerSec, type=BrokerTopicMetrics# 监控消费端每个分区的消息滞后情况
kafka.consumer:name=FetchConsumer,client-id=([-.\w]+)-([-\w]+)-(?<name>\w+)-fetcher-\d+, topic=(.*),partition=(.*):records-lag# 监控Kafka每个分区的末尾偏移量,可以确定消息是否已被成功传输到Kafka集群中的所有副本
kafka.log:name=LogEndOffset,partition=(.*)以上指标可以通过Kafka内置JMX导出器暴露为JMX bean或通过集成Prometheus导出器来作为Prometheus指标可视化
3.监控存储和网络使用情况
存储和网络使用情况
和任何一个分布式系统一样Kafka的存储和网络使用情况也是我们需要关注和监控的指标
只有对存储和网络状态进行充分的监控才能及时发现问题并规避风险
监控指标
监控 Kafka 的存储和网络使用情况时,需要关注以下指标:
- 存储容量和占用情况
- 网络速度和带宽使用率
- 磁盘I/O速度和响应时间等。
4.报警通知
在Kafka运维和监控的过程中及时发现并解决潜在的问题非常重要,这需要针对Kafka的指标和参数设置报警阀值,当超过阀值时及时发送通知信息给Kafka负责的人员或者通过机器人来进行通知
报警设置
Kafka可以通过架构模型使用系统包和第三方解决方案来设置定期或触发报警,例如:Nagios、Zabbix、Prometheus、Sensu 和 PagerDuty 等。
四、日志管理
Kafka在运行时会生成大量的日志记录信息,包含了运行状态、错误信息、性能指标等。
这些日志文件会占用很大的磁盘空间,过多的日志文件也会影响Kafka的性能,因此需要采取一些日志管理措施来清理无用的日志记录减少磁盘空间的占用并提高Kafka的性能
1.日志清理策略
日志压缩
对Kafka的日志进行压缩以减少磁盘空间占用,Kafka提供了两种日志压缩方式:gzip和snappy。
gzip会导致CPU负载的增加但能够获得更高的压缩比
snappy则需要更少的CPU负载但压缩比相对较低
可以根据自己的需求选择适合的压缩方式。
日志清理策略
使用Kafka内置的日志清理工具来清除无用的日志记录,Kafka的日志清理工具会根据一些配置参数来删除旧的日志记录。
例如可以指定一个保留期限来决定多长时间之前的日志记录需要被删除
设定一个日志最大大小当每个分区的日志大小超过该值时就会删除最早的日志
日志管理工具
可以使用一些第三方日志管理工具如ELK(Elasticsearch、Logstash和Kibana)
能够对Kafka的日志进行集中管理和分析从而更好地了解Kafka的运行状况
2.错误处理和故障排除
当Kafka出现错误或故障时,您需要采取一些措施来排查和解决问题
监控Kafka的运行状态
监控Kafka的运行状态了解Kafka当前的负载、内存占用、网络流量等情况
可以使用JMX来监控Kafka的运行情况也可以使用第三方监控工具如Zabbix、Grafana等
日志记录和分析
对Kafka的日志进行记录和分析来查找错误的现象可以通过修改log4j配置引入Kafka的日志,也可以使用第三方日志集中管理工具如ELK来集中收集和分析日志记录
Kafka故障排除
当Kafka发生故障时需要迅速排查问题并采取措施。在排除问题时可以参考Kafka的官方文档,或者向社区发帖求助。同时也需要思考并采用针对性的方案来解决具体问题,如增加分区数量、增加副本数量、修改消息传输模式等。
五、小结
在本文中介绍了Kafka的运维和监控,并提供了一些实用的技术方案和最佳实践。同时也提出了运维和监控中的一些挑战和问题进行了分析和探讨
相信在Apache Software Foundation 及相关开发者的努力下Kafka一定可以发展成为更加完善、更加稳定和更加适用于复杂场景的技术
相关文章:

Kafka运维与监控
Kafka运维与监控 Kafka运维与监控一、简介二、运维1.安装和部署安装部署 2.优化参数配置配置文件高级配置分区和副本设置分区数量设置副本数量设置 网络参数调优传输机制设置连接数和缓冲区大小设置 消息压缩和传输设置消息压缩设置消息传输设置 磁盘设置和文件系统分区磁盘容量…...
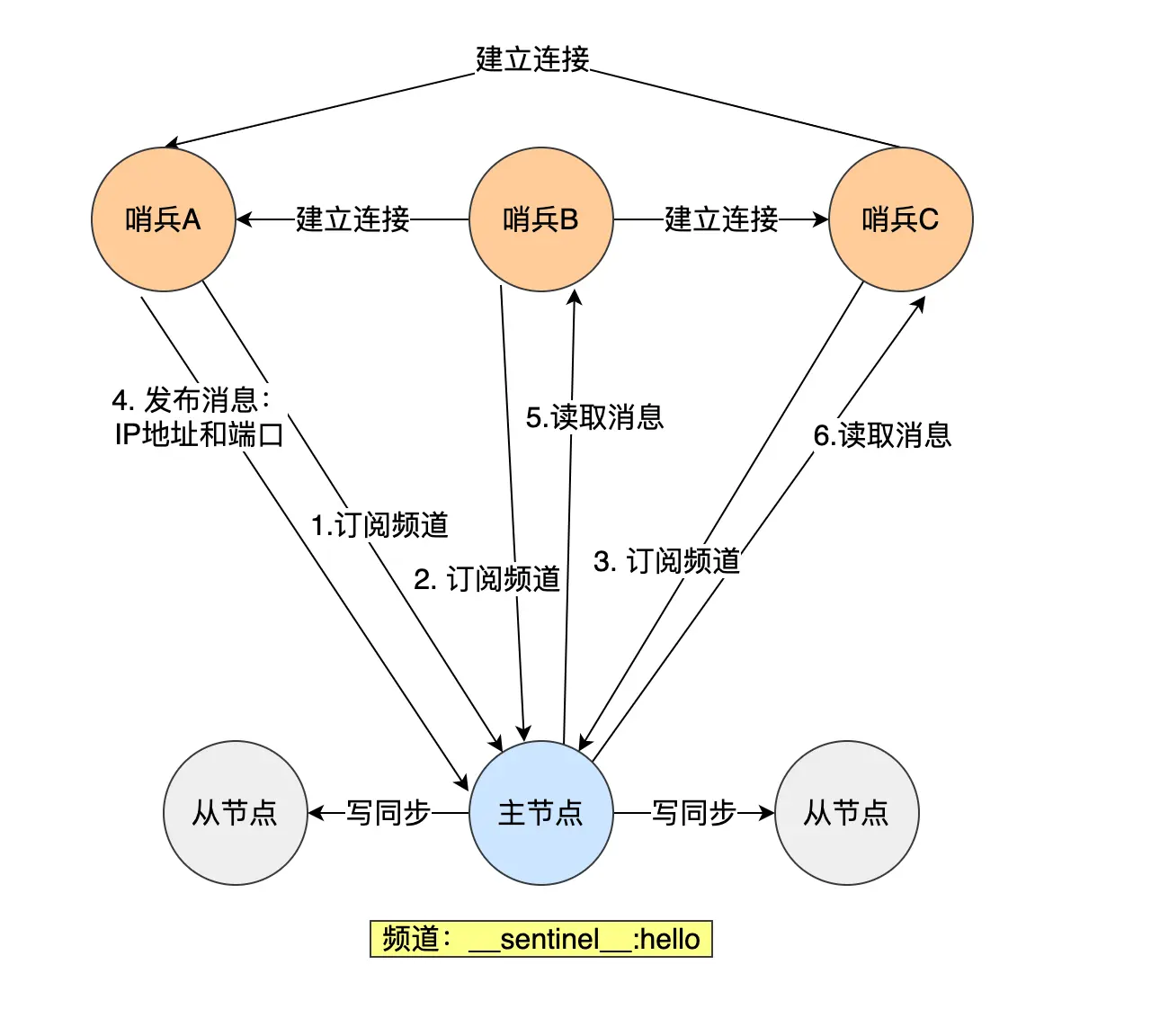
【Redis—哨兵机制】
文章目录 概念哨兵机制如何工作的监控(如何判断主节点真的故障了)哪个哨兵进行主从故障转移?故障转移流程哨兵集群 概念 当进行主从复制时,如果主节点挂掉了,那么没有主节点来服务客户端的写操作请求了,也…...
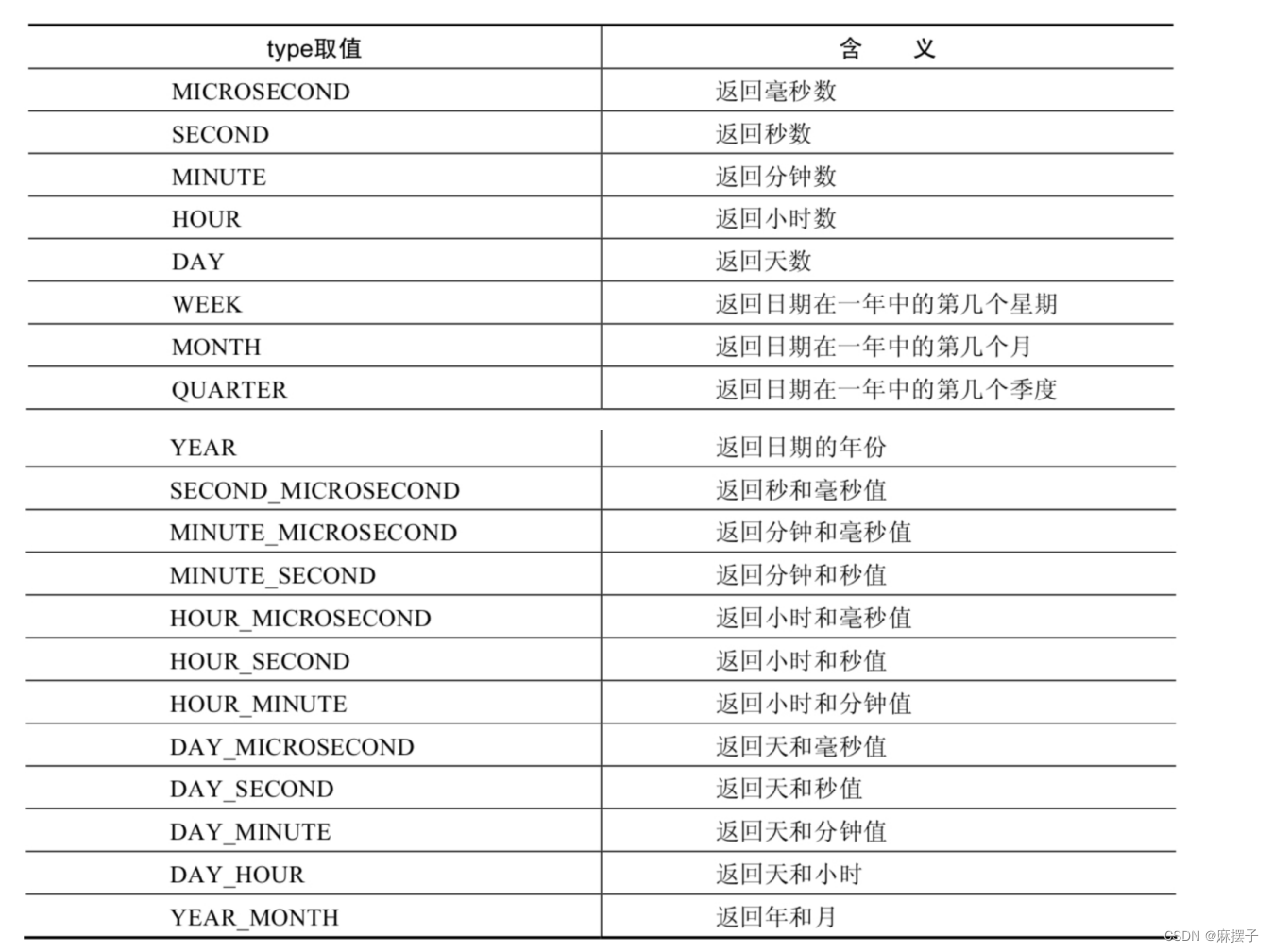
MySQL学习笔记第七天
第07章单行函数 2. 数值函数 2.4 指数函数、对数函数 函数用法POW(x,y),POWER(X,Y)返回x的y次方EXP(X)返回e的x次方,其中e是一个常数,2.718281828459045LN(X),LOG(X)返回以e为底的X的对数,当x<0时,返…...

中级软件设计师备考---程序设计语言和法律法规知识
目录 需要掌握的程序语言特点法律法规知识---保护期限法律法规知识---知识产权人确定法律法规知识---侵权判定标准化基础知识 需要掌握的程序语言特点 Fortran语言:科学计算、执行效率高Pascal语言:为教学而开发的、表达能力强,演化出了Delp…...
Leetcode434. 字符串中的单词数
Every day a leetcode 题目来源:434. 字符串中的单词数 解法1:istringstream 我们知道,C默认通过空格(或回车)来分割字符串输入,即区分不同的字符串输入。 istringstream类用于执行C风格的串流的输入操…...

C++ cmake工程引入qt6和Quick 教程
目录标题 前言QML简介锻炼C水平 cmake修改方法方式一(qt6_add_resources)方式二 (qt_add_qml_module ) 其他相关知识为什么会有_other_files?qt_standard_project_setup() 函数qt_add_qml_module() 和 qt6_add_resources()的方式差异const QU…...
JavaEE - 网络编程
一、网络编程基础 为什么需要网络编程? 用户在浏览器中,打开在线视频网站,如优酷看视频,实质是通过网络,获取到网络上的一个视频资源。 与本地打开视频文件类似,只是视频文件这个资源的来源是网络。 相比本…...
【Android车载系列】第11章 系统服务-SystemServer自定义服务
1 编写自定义系统服务 1.1 AIDL接口定义 系统源码目录/frameworks/base/core/java/android/app/下新建AIDL接口IYvanManager.aidl package android.app;/** * 目录:/frameworks/base/core/java/android/app/IYvanManager.aidl */ interface IYvanManager{String …...

Lerna
Lerna Lerna是一个优化基于gitnpm的多pagkage项目的管理工具 解决的痛点 痛点一:重复操作 多Package本地link多Package依赖安装多Package单元测试多Package代码提交多Package代码发布 痛点二:版本一致性 发布时版本一 致性发布后相互依赖版本升级 package越多,管…...

迁移学习 pytorch
迁移学习(Transfer Learning)是通过使用一个预训练模型来快速训练一个新的网络模型,通常应用于数据集较小或计算资源较少的情况下。在 PyTorch 中,由于 torchvision 库中已经内置了一些经典的预训练模型,因此我们可以通过简单的调用函数来实现迁移学习。 下面是一个基于 …...
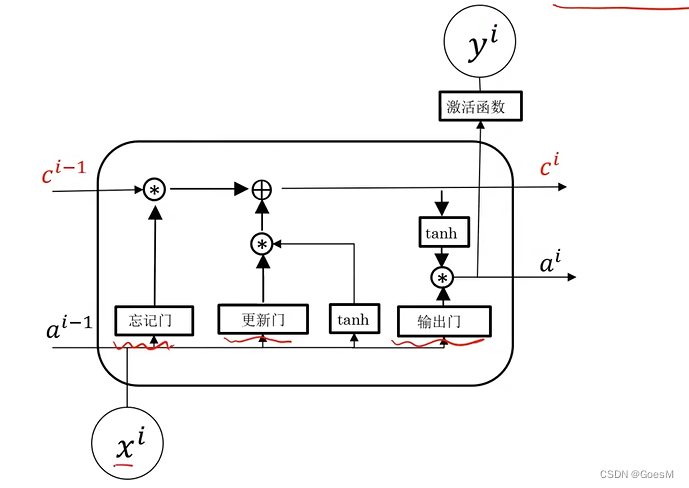
【python】keras包:深度学习( RNN循环神经网络 Recurrent Neural Networks)
RNN循环神经网络 应用: 物体移动位置预测、股价预测、序列文本生成、语言翻译、从语句中自动识别人名、 问题总结 这类问题,都需要通过历史数据,对未来数据进行预判 序列模型 两大特点 输入(输出)元素具有顺序关系…...

vue框架快速入门
vue 1、第一个Vue程序1.1、什么是Vue程序1.2、为什么要使用MVVM1.3、Vue1.4、第一个vue程序 2、基础语法2.1、v-bind2.2、v-if, v-else2.3、v-for2.4、v-on 3、Vue表单双绑、组件3.1、什么是双向数据绑定3.2、在表单中使用双向数据绑定3.3、什么是组件 4、Axios异步…...
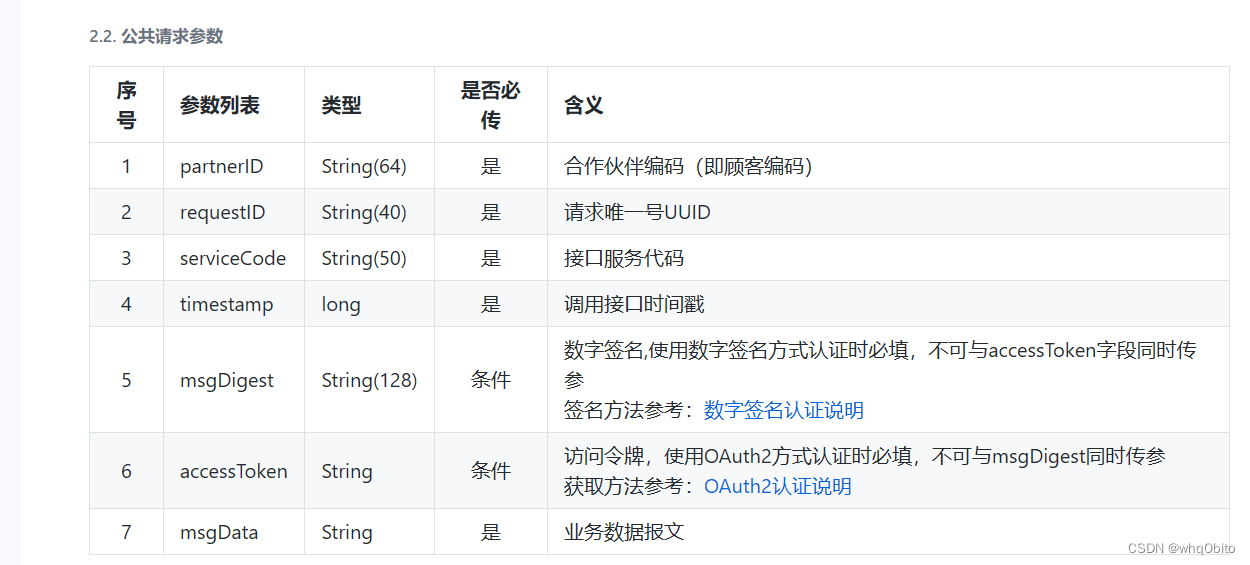
Java连接顺丰开放平台
今天使用Java去访问顺丰的开放平台时,JSON转换一直不成功,最终发现是 可以看到这里是 "apiResultData": "{\"success\": .........它是以 " 开头的!!!如果是对象的话,那么…...

前端三剑客 - HTML
前言 前面都是一些基础的铺垫,现在就正式进入到web开发环节了。 我们的目标就是通过学习 JavaEE初阶,搭建出一个网站出来。 一个网站分成两个部分: 前端(客户端) 后端(服务器) 通常这里的客户端…...
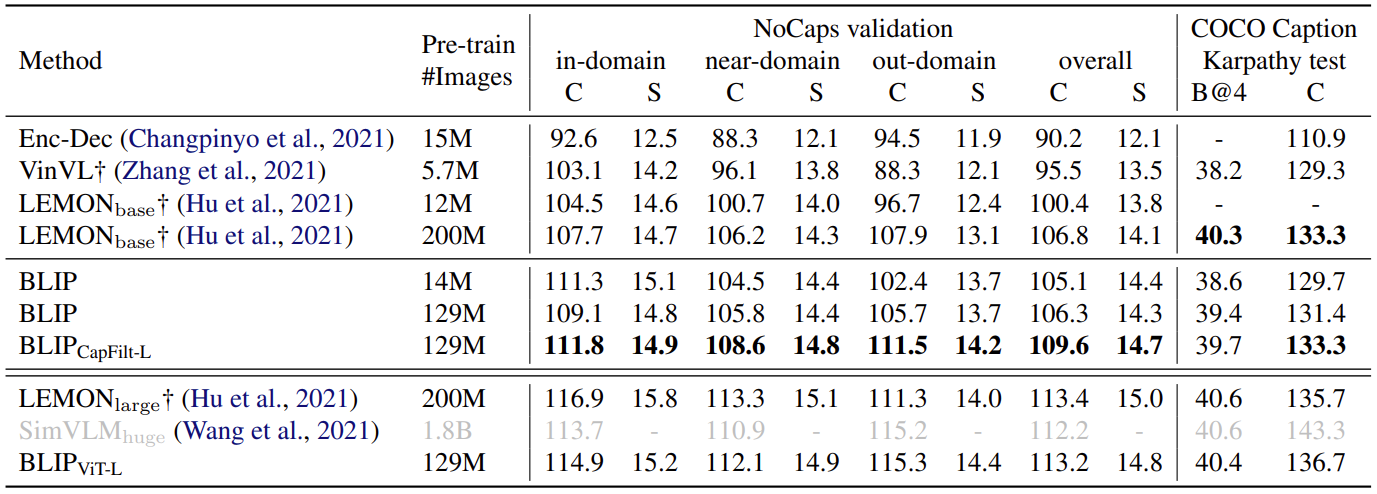
【计算机视觉 | 自然语言处理】BLIP:统一视觉—语言理解和生成任务(论文讲解)
文章目录 一、前言二、试玩效果三、研究背景四、模型结构五、Pre-training objectives六、CapFilt架构七、Experiment八、结论 一、前言 今天我们要介绍的论文是 BLIP,论文全名为 Bootstrapping Language-Image Pre-training for Unified Vision-Language Understa…...
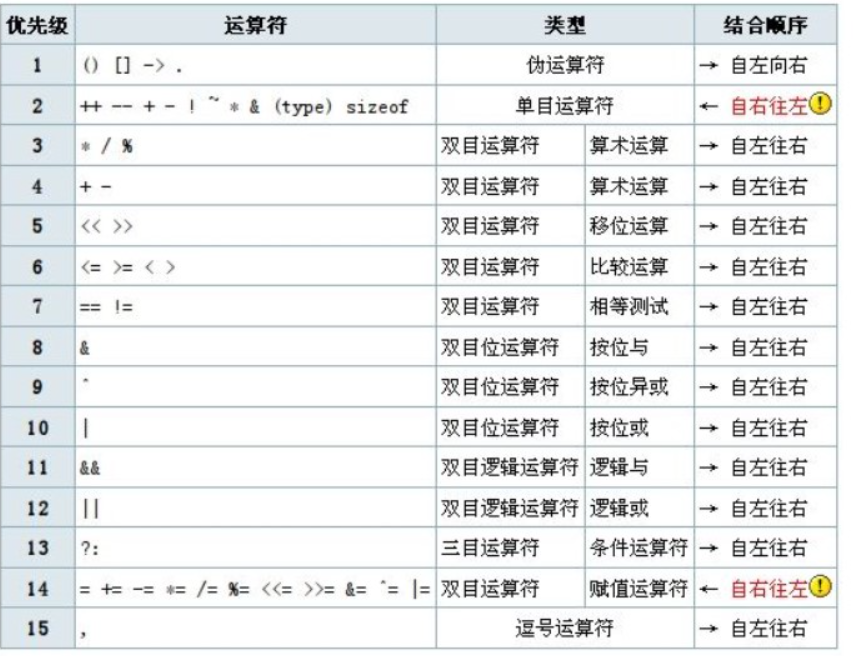
c++基础-运算符
目录 1关系运算符 2运算符优先级 3关系表达式的书写 代码实例: 下面是面试中可能遇到的问题: 1关系运算符 C中有6个关系运算符,用于比较两个值的大小关系,它们分别是: 运算符描述等于!不等于<小于>大于<…...

美术馆c++
题目: 杜老师非常喜欢玩一种叫做“美术馆”的数字游戏,蜗蜗看了之后决定也来试一试,他改编了这个游戏,规则如下: 有一个 n� 行 m� 列的方格,每一个格子中有一个数,数字…...

浅谈MySQL索引以及执行计划
MySQL索引及执行计划 🐪索引的作用🐫索引的分类(算法)🦙BTREE索引算法演变🦒Btree索引功能上的分类4.1 辅助索引4.2 聚集索引4.3 辅助索引和聚集索引的区别 🐘辅助索引分类🦏索引树高…...

在c++项目中使用rapidjson(有具体的步骤,十分详细) windows10系统
具体的步骤: 先下载rapidjson的依赖包 方式1:直接使用git去下载 地址:git clone https://github.com/miloyip/rapidjson.git 方式2:下载我上传的依赖包 将依赖包引入到项目中 1 将解压后的文件放在你c项目中 2 将rapidjson文…...

编译方式汇总:Makefile\configure\autogen.sh\configure.ac、Makefile.am文件
一、前言 文章目的:针对各种开源项目,由于部分项目文档写的不够详细,(或者是我太菜了),没有进行详细的介绍怎么编译该项目,导致花费过多时间在查找如何编译该项目上。因此该篇文章针对目前遇到的…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...