【大数据之Hadoop】二十九、HDFS存储优化
纠删码和异构存储测试需要5台虚拟机。准备另外一套5台服务器集群。
环境准备:
(1)克隆hadoop105为hadoop106,修改ip地址和hostname,然后重启。
vim /etc/sysconfig/network-scripts/ifcfg-ens33
vim /etc/hostname
reboot
(2)关闭集群,删除所有服务器Hadoop的data和logs文件。
rm -rf data/ logs/
(3)在hadoop102上修改xsync和jpsall文件,把hadoop105和hadoop106加上。
xsync存储地址:/bin,在root下修改,然后后分发xsync:xsync xsync
jpsall、myhadoop.sh 、xsync存储地址:/home/liaoyanxia/bin,修改后退出到liaoyanxia目录然后分发:xsync bin/
(4)在hadoop102上修改blacklist、whitelist、hdfs-site.xml、workers。
删除blacklist里的内容;在workers和whitelist加上所有的主机(即hadoop102-106);修改hdfs-site.xml的多目录:namenode只留一个节点name、datanode只留一个节点data:
<property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/dfs/name</value>
</property><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
(5)退出到hadoop-3.3.1/etc目录,分发hadoop,然后启动集群。
xsync hadoop/
myhadoop-sh start
jpsall查看进程,集群启动没问题。
(6)关闭集群和所有服务器,把5个主机依次克隆。
1 纠删码
1.1 原理
HDFS默认情况下,一个文件有3个副本,这样提高了数据的可靠性,但也带来了2倍的冗余存储开销。
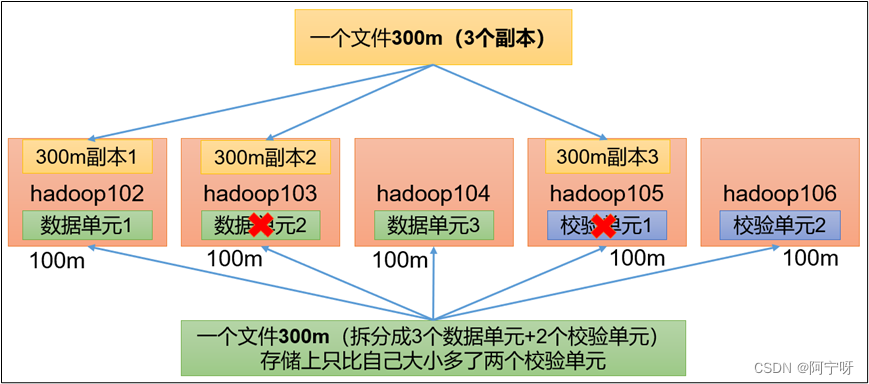
Hadoop3.x引入了纠删码(假如如上图一个文件拆分为3个数据单元和2个校验单元),任意两个节点挂掉都可以采用计算的方式恢复(所以占用了计算资源即占用cpu时间,以cpu换存储空间),可以节省约50%左右的存储空间。
纠删码相关命令:
hdfs ec[-listPolicies] 查看当前支持的纠删策略[-addPolicies -policyFile<file>][-getPolicy -path <path>] 针对某个路径的获得其策略[-removePolicy -policy<policy>] 删除策略[-setPolicy -path <path> [-policy <policy>][-replicate]] 针对某个路径的设置其策略[-unsetPolicy -path <path>][-listCodecs][-enablePolicy -policy <policy>] 开启纠删策略[-disablePolicy -policy <policy>] 关闭纠删策略[-help <command-name>].
纠删码策略解释:
RS-A-B-1024k:使用RS编码,每A个数据单元(cell),生成B个校验单元,共A+B个单元,也就是说:这A+B个单元中,只要有任意的A个单元存在(不管是数据单元还是校验单元,只要总数=A),就可以得到原始数据。每个单元的大小是1024k=10241024=1048576,即拆分时先按1m进行拆分。
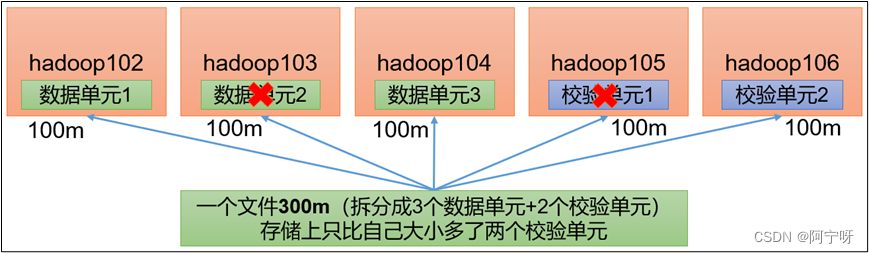
如RS-3-2-1024k:使用RS编码,每3个数据单元,生成2个校验单元,共5个单元,也就是说:这5个单元中,只要有任意的3个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是1024k=10241024=1048576,即拆分时先按1m进行拆分,对上图来说,再将100个1m的数据放在一起。
RS-LEGACY-6-3-1024k:策略和RS-6-3-1024k一样,只是编码的算法用的是rs-legacy。
XOR-2-1-1024k:使用XOR编码(速度比RS编码快)。
1.2 案例
纠删码策略针对具体路径设置,所有在此路径下存储的文件都会执行此策略。
把/input目录设置为RS-3-2-1024k策略。
(1)开启RS-3-2-1024k策略:
hdfs ec -enablePolicy -policy RS-3-2-1204k
(2)在HDFS创建目录并设置RS-3-2-1204k策略:
hdfs dfs -mkdir /input
hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
(3)在该目录下上传大于2M的文件,在HDFS上可以看到replication(副本)只有1份,因为数据分成了3份数据单元放在不同的节点,另外两个节点存放校验单元。
hdfs dfs -put web.log /input
(4)查看存储路径的数据单元和校验单元,并作破坏实验
查看data/dfs/current/…用cat 看数据,看哪些节点是数据单元和校验单元。
删除两个节点的以上数据(快速删除)可以在hdfs文件系统里下载,且观察到删除的数据有恢复。
2 异构存储(冷热数据分离)
经常使用和存储的数据为热数据,否则为冷数据。
异构存储主要解决:不同的数据,存储在不同类型的硬盘中,达到最佳性能的问题。
存储类型:
RAM_DISK:内存
SSD:固态硬盘
DISK:机械硬盘,即普通磁盘
ARCHIVE:归档,不指定某种存储介质,主要指计算能力较弱但存储密度高的介质。
存储策略:

2.1 异构存储shell操作
(1)查看当前有哪些存储策略可以用
hdfslistPolicies storagepolicies -listPolicies(2)为指定路径(数据存储目录)设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -path 路径 -policy 存储策略(3)获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getStoragePolicy -path 路径(4)取消存储策略;执行改命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是HOT
hdfs storagepolicies -unsetStoragePolicy-path 路径(5)查看文件块的分布
bin/hdfs fsck xxx -files -blocks -locations(6)查看集群节点
hadoop dfsadmin -report
2.2 测试环境准备
服务器5台,副本数为2,提前创建带有 存储类型的目录。
集群规划:

配置文件:
hadoop102的hdfs-site.xml添加:
<property><name>dfs.replication</name><value>2</value>
</property>
<property><name>dfs.storage.policy.enabled</name><value>true</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>[SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[RAM_DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/ram_disk</value>
</property>
hadoop103的hdfs-site.xml添加:
<property><name>dfs.replication</name><value>2</value>
</property>
<property><name>dfs.storage.policy.enabled</name><value>true</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>[SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk</value>
</property>
hadoop104的hdfs-site.xml添加:
<property><name>dfs.replication</name><value>2</value>
</property>
<property><name>dfs.storage.policy.enabled</name><value>true</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>[RAM_DISK]file:///opt/module/hdfsdata/ram_disk,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk</value>
</property>
hadoop105的hdfs-site.xml添加:
<property><name>dfs.replication</name><value>2</value>
</property>
<property><name>dfs.storage.policy.enabled</name><value>true</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>[ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive</value>
</property>
hadoop106的hdfs-site.xml添加:
<property><name>dfs.replication</name><value>2</value>
</property>
<property><name>dfs.storage.policy.enabled</name><value>true</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>[ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive</value></property>
重新格式化namenode,启动集群
hdfs namenode -format
myhadoop.sh start
在HDFS创建目录并上传资料
hadoop fs -mkdir /hdfsdata
hadoop fs -put /opt/module/hadoop-3.3.1/NOTICE.txt /hdfsdata
2.3 HOT存储策略案例
刚开始没有设置存储策略,先获取目录存储策略:
hdfs storagepolicies -getStoragePolicy -path /hdfsdata
查看上传的文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

可以看到没有设置存储策略的情况下所有的文件块都存储在DISK下,即默认存储处理为HOST。
2.4 WARM存储策略测试
先给数据降温:
hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy WARM
查看上传的文件块分布,还是在原处
hdfs fsck /hdfsdata -files -blocks -locations

让HDFS按照存储策略自行移动文件块(不会自动改变存储策略,需要手动移动):
hdfs mover /hdfsdata
再查看文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations
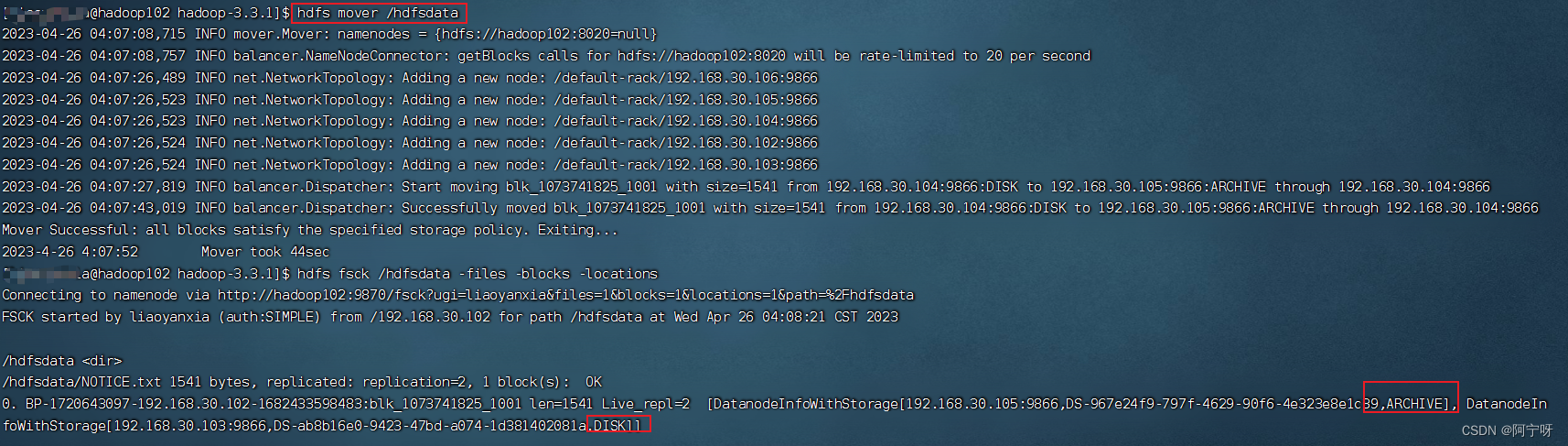
文件块一半在DISK,一半在ARCHIVE,符合设置的WARM策略。
2.5 COLD策略测试
数据降温为COLD:
hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy COLD
在上传文件到COLD策略的目录前需要配置ARCHIVE存储目录,不然会报异常。
手动移动:
hdfs mover /hdfsdata
检查文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

所有文件都在ARCHIVE,符合COLD存储策略。
2.6 ONE_SSD策略测试
存储策略改为ONE_SSD:
hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy One_SSD
手动移动:
hdfs mover /hdfsdata
检查文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

文件块分布一半在SSD,一半在DISK,符合ONE_SSD存储策略。
2.7 ALL_SSD策略测试
存储策略改为ALL_SSD:
hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy ALL_SSD
手动移动:
hdfs mover /hdfsdata
检查文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

文件块全部存储在SSD,符合ALL_SSD存储策略。
2.8 LAZY_PERSIST策略测试
存储策略改为lazy_persist:
hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy lazy_persist
手动移动:
hdfs mover /hdfsdata
检查文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

理论上结果为一个副本存储在RAM_DISK,其它都存储在DISK,但最终发现所有的文件块都存储在DISK。
原因:
(1)当客户端所在的DataNode节点没有RAM_DISK时,则会写入客户端所在的DataNode节点的DISK磁盘,其余副本会写入其他节点的DISK磁盘。
(2)当客户端所在的DataNode有RAM_DISK,但“dfs.datanode.max.locked.memory”参数值未设置或者设置过小(小于“dfs.block.size”参数值)时,会写入客户端所在的DataNode节点的DISK磁盘,其余副本会写入其他节点的DISK磁盘。
解决:
配置“dfs.datanode.max.locked.memory”,“dfs.block.size”参数。但是由于虚拟机的“max locked memory”为64KB,所以,如果参数配置过大,还会报错。
相关文章:
【大数据之Hadoop】二十九、HDFS存储优化
纠删码和异构存储测试需要5台虚拟机。准备另外一套5台服务器集群。 环境准备: (1)克隆hadoop105为hadoop106,修改ip地址和hostname,然后重启。 vim /etc/sysconfig/network-scripts/ifcfg-ens33 vim /etc/hostname r…...
SuperMap GIS基础产品组件GIS FAQ集锦(2)
SuperMap GIS基础产品组件GIS FAQ集锦(2) 【iObjects for Spark】读取GDB参数该如何填写? 【解决办法】可参考以下示例: val GDB_params new util.HashMapString, java.io.Serializable GDB_params.put(FeatureRDDProviderParam…...
函数中整型格式说明符详解)
C语言printf()函数中整型格式说明符详解
每个整型在printf()函数中对应不同的格式说明符,以实现该整型的打印输出。格式说明符必须使用小写。现在让我们看看各个整型及其格式说明符: 短整型(short) 10进制:%hd16进制:无负数格式,正数使用%hx8进制:无负数格式,正数使用%ho c short s 34; printf("%hd", s…...
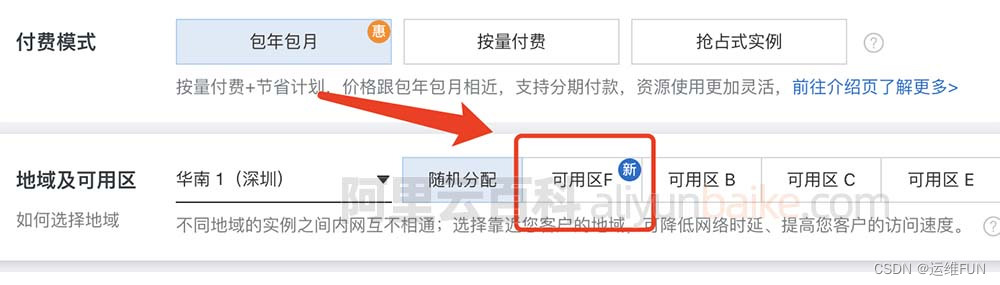
阿里云服务器地域和可用区怎么选择合适?
阿里云服务器地域和可用区怎么选择?地域是指云服务器所在物理数据中心的位置,地域选择就近选择,访客距离地域所在城市越近网络延迟越低,速度就越快;可用区是指同一个地域下,网络和电力相互独立的区域&#…...
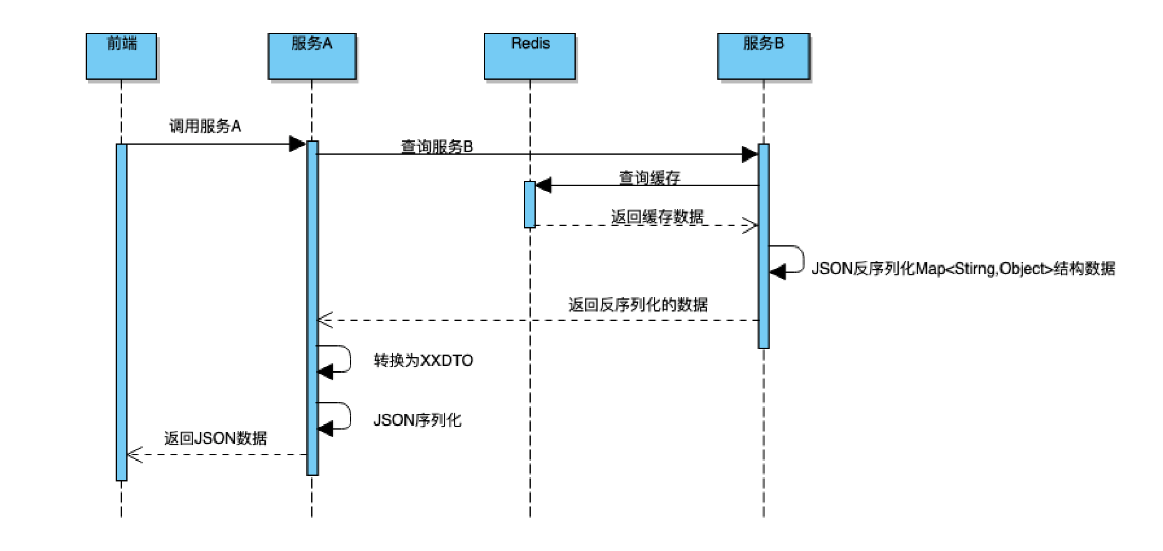
Java序列化引发的血案
1、引言 阿里巴巴Java开发手册在第一章节,编程规约中OOP规约的第15条提到: **【强制】**序列化类新增属性时,请不要修改serialVersionUID字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱&#x…...

为Linux系统添加一块新硬盘,并扩展根目录容量
我的原来ubuntu20.04系统装的时候不是LVM格式的分区, 所以先将新硬盘转成LVM,再将原来的系统dd到新硬盘,从新硬盘的分区启动,之后再将原来的分区转成LVM,在融入进来 1:将新硬盘制作成 LVM分区 我的新硬盘…...

树莓派Opencv调用摄像头(Raspberry Pi 11)
前言:本人初玩树莓派opencv,使用的是树莓派Raspberry Pi OS 11,系统若不一致请慎用,本文主要记录在树莓派上通过Opencv打开摄像头的经验。 1、系统版本 进入树莓派,打开终端输入以下代码(查看系统的版本&…...

国产ChatGPT命名图鉴
很久不见这般热闹的春天。 随着ChatGPT的威名席卷全球,大洋对岸的中国厂商也纷纷亮剑,各式本土大模型你方唱罢我登场,声势浩大的发布会排满日程表。 有趣的是,在这些大模型产品初入历史舞台之时,带给世人的第一印象其…...

操作系统——进程管理
0.关注博主有更多知识 操作系统入门知识合集 目录 0.关注博主有更多知识 4.1进程概念 4.1.1进程基本概念 思考题: 4.1.2进程状态 思考题: 4.1.3进程控制块PCB 4.2进程控制 思考题: 4.3线程 思考题: 4.4临界资源与临…...

第四十一章 Unity 输入框 (Input Field) UI
本章节我们学习输入框 (Input Field),它可以帮助我们获取用户的输入。我们点击菜单栏“GameObject”->“UI”->“Input Field”,我们调整一下它的位置,效果如下 我们在层次面板中发现,这个InputField UI元素包含两个子元素&…...

10.集合
1.泛型 1.1泛型概述 泛型的介绍 泛型是JDK5中引入的特性,它提供了编译时类型安全检测机制 泛型的好处 把运行时期的问题提前到了编译期间避免了强制类型转换 泛型的定义格式 <类型>: 指定一种类型的格式.尖括号里面可以任意书写,一般只写一个字母.例如:…...

强化学习p3-策略学习
Policy Network (策略网络) 我们无法知道策略函数 π \pi π所以要做函数近似,求一个近似的策略函数 使用策略网络 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ) 去近似策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s) ∑ a ∈ A π ( a ∣ s ; θ ) 1 \sum_{a\in …...

初学Verilog语言基础笔记整理(实例点灯代码分析)持续更新~
实例:点灯学习 一、Verilog语法学习 1. 参考文章 刚接触Verilog,作为一个硬件小白,只能尝试着去理解,文章未完…持续更新。 参考博客文章: Verilog语言入门学习(1)Verilog语法【Verilog】一文…...
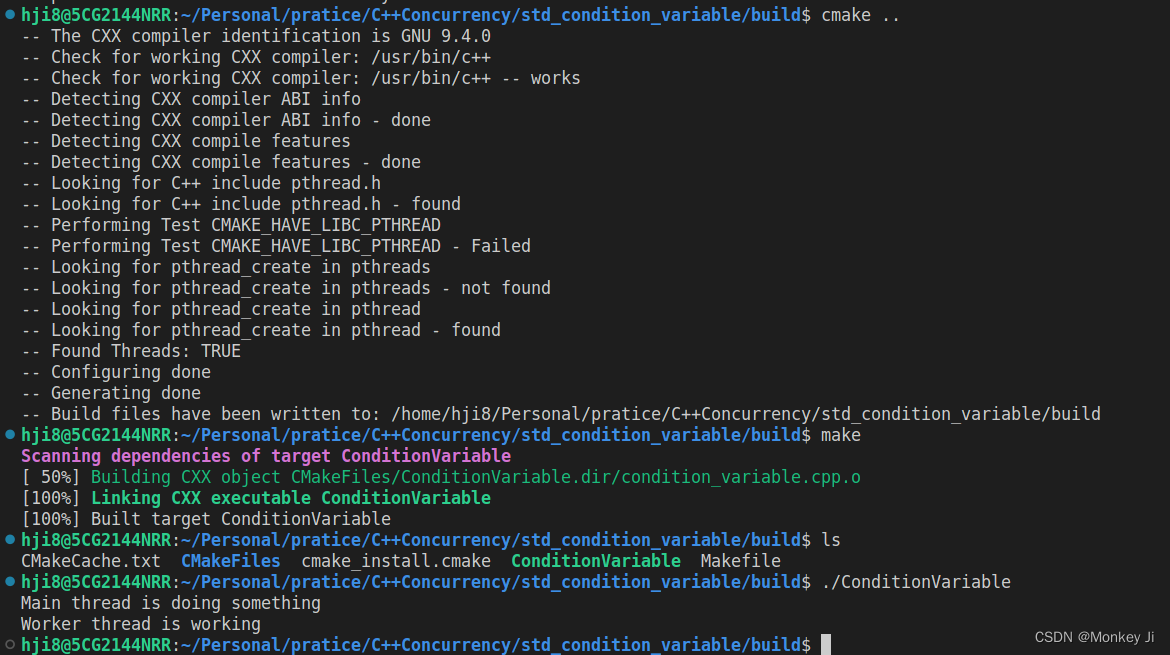
关于 std::condition_variable
一. std::condition_variable是什么? std::condition_variable 是 C 标准库提供的一个线程同步的工具,用于实现线程间的条件变量等待和通知机制。 条件变量的发生通常与某个共享变量的状态改变相关。 在多线程编程中,条件变量通常和互斥锁…...
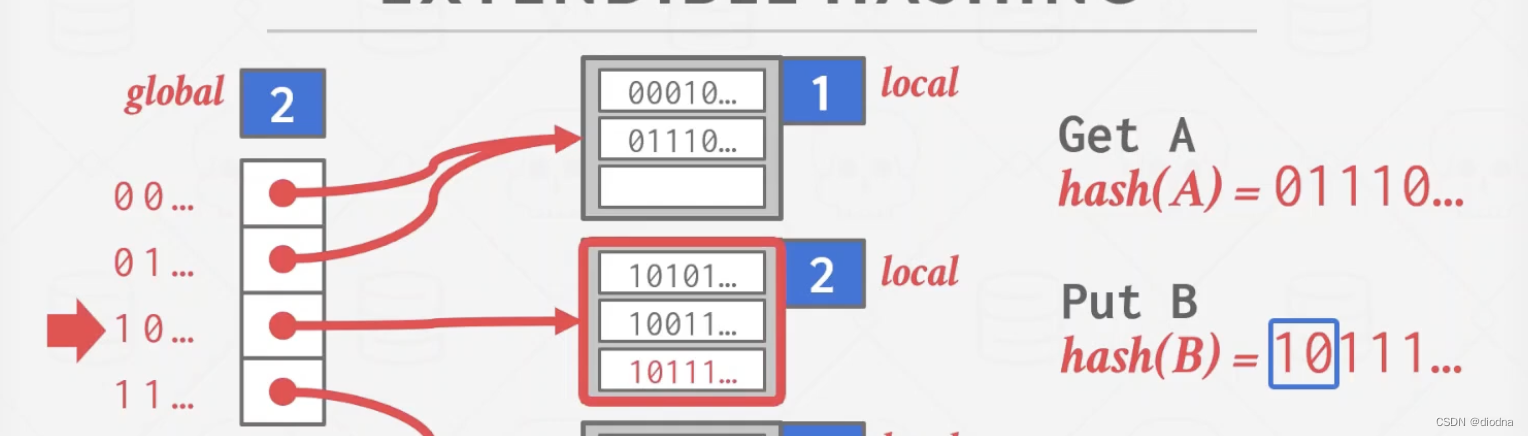
可拓展哈希
可拓展哈希 借CMU 15445的ppt截图来说明问题。 我们传统静态hash的过程是hash函数后直接将值存入对应的bucket,但是在可扩展hash中,得查询Directory(左),存入directory指向的bucket(右)。 下面…...

Java 版 spring cloud 工程系统管理 +二次开发 工程项目管理系统源码
工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和查看用户角色 4、菜单管理:实现对系统菜单的增删改查操…...

通过伴随矩阵怎么求逆矩阵
设矩阵A为n阶方阵,其伴随矩阵为Adj(A),则A的逆矩阵为: A⁻ (1/|A|) Adj(A) |A|为A的行列式 Adj(A)为A的伴随矩阵 具体步骤如下: 求出A的行列式|A| 求出A的伴随矩阵 Adj(A) 。伴随矩阵的定义为:对于A的第i行第j列…...

巡检机器人之仪表识别系统
作者主页:爱笑的男孩。 博客简介:分享机器学习、深度学习、python相关内容、日常BUG解决方法及Windows&Linux实践小技巧。 如发现文章有误,麻烦请指出,我会及时去纠正。有其他需要可以私信我或者发我邮箱:zhilong666foxmail.c…...
)
面试官反感的求职者(下)
上期给大家总结了面试中常见的一些问题,今天就接着上次的话题再给大家说说HR反感的求职者,希望同学们可以自省,避免踩雷。小编从如信银行考试中心了解到的有: 第一、缺乏个性者 这种考生在答题中往往表现得千篇一律,从…...
-生存曲线(LM曲线)(补充篇))
可视化绘图技巧100篇分析篇(二)-生存曲线(LM曲线)(补充篇)
目录 前言 知识储备 生存分析中的基本概念 生存分析 (survival analysis) 事件 (event)...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...