二十五、SQL 数据分析实战(9个中等难度的SQL题目)
文章目录
- 题目1: App 使用频率分析
- 题目2: App 下载情况统计
- 题目3: 寻找活跃学习者
- 题目4: 商品分类整理
- 题目5: 商品销售分析
- 题目6: 网约车司机收益统计
- 题目7: 网站登录时间间隔统计
- 题目8: 不同区域商品收入统计
- 题目9: 信贷逾期情况统计
题目1: App 使用频率分析
现有一张用户使用 App 时间表 middle_app_login,middle_app_login 表的数据如下表所示:
mysql> SELECT * FROM middle_app_login;
-- user_id(用户ID):VARCHAR start_time(登录App时间):DATETIME end_time(退出App时间):DATETIME
+---------+---------------------+---------------------+
| user_id | start_time | end_time |
+---------+---------------------+---------------------+
| u001 | 2021-04-01 10:12:30 | 2021-04-01 11:13:21 |
| u002 | 2021-04-02 08:40:21 | 2021-04-02 10:13:41 |
| u003 | 2021-04-02 15:31:01 | 2021-04-02 15:54:42 |
| u001 | 2021-04-04 13:25:40 | 2021-04-04 17:52:46 |
| u003 | 2021-04-06 07:10:20 | 2021-04-06 08:03:15 |
| u001 | 2021-04-09 18:20:34 | 2021-04-09 18:23:58 |
| u001 | 2021-04-10 14:25:55 | 2021-04-10 15:01:25 |
+---------+---------------------+---------------------+
7 rows in set (0.00 sec)
【题目1】根据该表统计出每个用户每次退出App与下一次登录App间隔的平均时间,如果用户只登录过一次App,则不统计,要求输出的平均时间的单位为分钟,并将其四舍五入保留一位小数。输出内容包括:user_id(用户ID)、avg_minute(平均间隔时间),结果样例如下图所示:
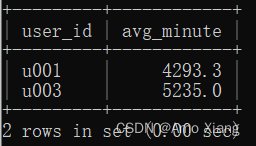
【题目1解析】本题使用LEAD()函数对每个用户登录App的时间进行分组排序,生成新的一列,以构造出上一次退出App的时间与下一次登录App的时间在同一行的表格结构,方便之后进行处理。然后筛选出为非空的行,使用TIMESTAMPDIFF()函数计算start_time_lead与end_time的分钟差,再求平均值,并将其四舍五入保留一位小数即可得到结果。涉及知识点:子查询、日期/时间处理函数、窗口函数、空值处理、小数保留、分组聚合。参考代码如下:
mysql> -- ① 按照解析的写法
mysql> SELECT user_id-> , ROUND(AVG(TIMESTAMPDIFF(MINUTE, end_time, start_time_lead)), 1) AS avg_minute-> FROM (SELECT user_id-> , start_time-> , end_time-> , LEAD(start_time, 1) OVER (PARTITION BY user_id ORDER BY start_time) AS start_time_lead-> FROM middle_app_login) a-> WHERE start_time_lead IS NOT NULL-> GROUP BY user_id;
+---------+------------+
| user_id | avg_minute |
+---------+------------+
| u001 | 4293.3 |
| u003 | 5235.0 |
+---------+------------+
2 rows in set (0.00 sec)mysql> -- ② 第二种写法
mysql> SELECT user_id, ROUND(AVG(end_time_lag), 1) AS avg_minute-> FROM (SELECT a1.user_id,-> TIMESTAMPDIFF(MINUTE, LAG(end_time, 1) OVER (PARTITION BY a1.user_id ORDER BY start_time), a1.start_time-> ) AS end_time_lag-> FROM middle_app_login a1-> INNER JOIN (SELECT user_id FROM middle_app_login GROUP BY user_id HAVING COUNT(*) > 1) a2-> ON a1.user_id = a2.user_id) a-> WHERE a.end_time_lag IS NOT NULL-> GROUP BY user_id;
+---------+------------+
| user_id | avg_minute |
+---------+------------+
| u001 | 4293.3 |
| u003 | 5235.0 |
+---------+------------+
2 rows in set (0.00 sec)
题目2: App 下载情况统计
现有一张 App 累计下载情况表 middle_app_download,该表记录了应用商品中 App 累计下载次数的信息,middle_app_download 表的数据如下所示:
mysql> SELECT * FROM middle_app_download;
-- app_id(AppID):VARCHAR app_type(App类型):VARCHAR download(下载次数):INT
+--------+----------+----------+
| app_id | app_type | download |
+--------+----------+----------+
| a001 | A | 12432 |
| a002 | B | 9853 |
| a003 | A | 1924 |
| a004 | C | 2679 |
| a005 | C | 29104 |
| a006 | A | 10235 |
| a007 | B | 5704 |
| a008 | B | 2850 |
| a009 | B | 8235 |
| a010 | C | 9746 |
+--------+----------+----------+
10 rows in set (0.00 sec)
【题目2】查询不同类型App的平均下载次数,需要将下载次数排在前10%与后10%的App排除在外。输出内容包括:app_type(App类型)、avg_download(平均下载次数),结果样例如下图所示:
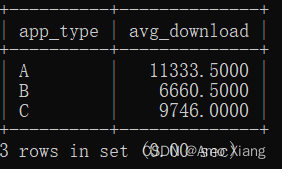
【题目2解析】使用RANK()函数生成新的一列作为下载量排名(ranking),将该部分作为子查询内部,并在子查询外部通过WHERE筛选出符合要求的记录,分组统计平均下载次数即可。涉及知识点:子查询、窗口函数、空值处理、分组聚合。参考代码如下:
mysql> SELECT a.app_type, AVG(a.download) as avg_download-> FROM (SELECT app_id, app_type, download, RANK() OVER (ORDER BY download DESC ) AS download_rank-> FROM middle_app_download) a-> WHERE a.download_rank > (SELECT COUNT(*) FROM middle_app_download) * 0.1-> AND a.download_rank < (SELECT COUNT(*) FROM middle_app_download) * 0.9-> GROUP BY a.app_type;
题目3: 寻找活跃学习者
现有一张用户学习打卡表 middle_active_learning,middle_active_learning 表中数据如下所示:
mysql> SELECT * FROM middle_active_learning;
-- user_id(用户ID):VARCHAR study_date(打卡日期):DATE
+---------+------------+
| user_id | study_date |
+---------+------------+
| u001 | 2021-04-01 |
| u002 | 2021-04-01 |
| u003 | 2021-04-03 |
| u001 | 2021-04-06 |
| u003 | 2021-04-07 |
| u001 | 2021-04-12 |
| u001 | 2021-04-13 |
| u002 | 2021-04-14 |
| u001 | 2021-04-23 |
| u002 | 2021-04-24 |
| u001 | 2021-04-26 |
| u003 | 2021-04-27 |
| u002 | 2021-04-30 |
+---------+------------+
13 rows in set (0.00 sec)
【题目3】根据该表统计2021年4月中每周都学习打卡的用户。输出内容包括: user_id(用户ID),结果样例如下图所示:
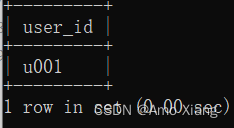
【题目3解析】使用WEEKOFYEAR函数获取周数,限制study_date为2021年4月,由于用户可能一周内打卡多次,因此使用DISTINCT进行去重,为之后的统计操作做铺垫,通过GROUP BY对用户进行分组,统计出打卡周的数量等于5的用户(2021年4月跨越5周),即可得到每周打卡的用户。涉及知识点:子查询、DISTINCT、日期/时间处理函数。参考代码如下:
mysql> SELECT a.user_id-> FROM (SELECT DISTINCT user_id-> , WEEKOFYEAR(study_date) AS study_week-> FROM middle_active_learning-> WHERE study_date >= '2021-04-01'-> AND study_date <= '2021-04-30') a-> GROUP BY a.user_id-> HAVING COUNT(a.study_week) = 5;
题目4: 商品分类整理
现有一张商品分类表 middle_commodity_classification,middle_commodity_classification 表的数据如下表所示:
mysql> SELECT * FROM middle_commodity_classification;
-- current_category(商品当前分类):VARCHAR parent_category(商品父类别):VARCHAR
+------------------+-----------------+
| current_category | parent_category |
+------------------+-----------------+
| 刀 | 厨具 |
| 厨具 | 生活用品 |
| 碗 | 餐具 |
| 水果刀 | 刀 |
| 剔骨刀 | 刀 |
| 餐具 | 生活用品 |
| 汤碗 | 碗 |
+------------------+-----------------+
7 rows in set (0.00 sec)
【题目4】查询得到下图所示的结果样例。输出内容包括:三级类目、二级类目、一级类目、根类目,结果样例如下图所示:
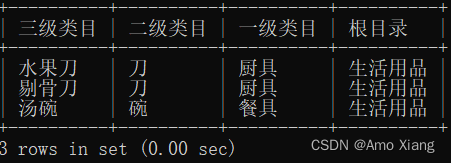
【题目4解析】本题是分类关系的整理,显示的结果样例中有4层类别关系,需要通过3次表的自连接来实现。涉及知识点:自连接。参考代码如下:
mysql> SELECT m1.current_category AS '三级类目',-> m1.parent_category AS '二级类目',-> m2.parent_category AS '一级类目',-> m3.parent_category AS '根目录'-> FROM middle_commodity_classification m1,-> middle_commodity_classification m2,-> middle_commodity_classification m3-> WHERE m1.parent_category = m2.current_category-> AND m2.parent_category = m3.current_category;
题目5: 商品销售分析
现有一张商品信息表 middle_commodity_info,该表记录了商品的基础信息,middle_commodity_info 数据如下所示:
mysql> SELECT * FROM middle_commodity_info;
-- sku_id(商品SKU):VARCHAR commodity_category(商品类别):VARCHAR director(商品销售负责人):VARCHAR
+--------+--------------------+----------+
| sku_id | commodity_category | director |
+--------+--------------------+----------+
| u001 | c001 | a001 |
| u003 | c002 | a001 |
| u002 | c003 | a002 |
+--------+--------------------+----------+
3 rows in set (0.00 sec)
还有一张商品销售金额表 middle_commodity_sale,该表记录了每天商品的销售情况,middle_commodity_sale 数据如下所示:
mysql> SELECT * FROM middle_commodity_sale;
-- date(日期):DATE sku_id(商品SKU):VARCHAR sales(商品销售金额):INT
+------------+--------+-------+
| date | sku_id | sales |
+------------+--------+-------+
| 2020-12-20 | u001 | 12000 |
| 2020-12-20 | u002 | 8000 |
| 2020-12-20 | u003 | 11000 |
| 2020-12-21 | u001 | 20000 |
| 2020-12-21 | u003 | 16000 |
| 2020-12-22 | u003 | 11000 |
| 2020-12-22 | u001 | 34000 |
| 2020-12-22 | u002 | 11000 |
| 2020-12-23 | u003 | 18000 |
| 2020-12-23 | u001 | 30000 |
+------------+--------+-------+
10 rows in set (0.00 sec)
【题目5】查询商品销售负责人为a001在2020年每个商品类别销量最高的两天的信息,输出内容包括:commodity_category(商品分类)、date(日期)、total_sales(销量),结果样例如下图所示:
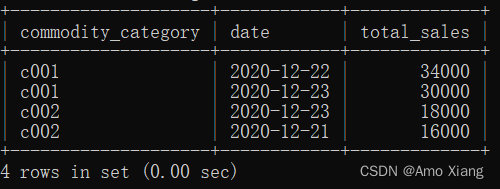
【题目5】参考代码如下:
mysql> SELECT commodity_category-> , `date`-> , total_sales-> FROM (-> SELECT commodity_category-> , `date`-> , RANK() OVER (PARTITION BY commodity_category ORDER BY total_sales DESC) AS ranking-> , total_sales-> FROM (-> SELECT b.commodity_category-> , a.`date`-> , SUM(a.sales) AS total_sales-> FROM middle_commodity_sale a-> JOIN middle_commodity_info b-> ON a.sku_id = b.sku_id-> WHERE b.director = 'a001'-> AND YEAR(a.`date`) = 2020-> GROUP BY b.commodity_category-> , a.`date`-> ) c-> ) d-> WHERE ranking <= 2;
题目6: 网约车司机收益统计
现有一张网约车订单表 middle_car_order,该表记录了某天的网约车订单相关信息,middle_car_order 数据如下表所示:
mysql> SELECT * FROM middle_car_order;
-- order_id(订单ID):VARCHAR driver_id(司机ID):VARCHAR order_amount(订单金额):DOUBLE
+----------+-----------+--------------+
| order_id | driver_id | order_amount |
+----------+-----------+--------------+
| o001 | d001 | 15.6 |
| o002 | d002 | 36.5 |
| o003 | d001 | 30.1 |
| o004 | d002 | 10.6 |
| o005 | d001 | 26.2 |
| o006 | d001 | 14.6 |
| o007 | d003 | 28.9 |
| o008 | d001 | 8.8 |
| o009 | d002 | 13.3 |
| o010 | d001 | 29.4 |
+----------+-----------+--------------+
10 rows in set (0.00 sec)
【题目6】司机的收入为订单金额的80%(表中订单金额的单位为元),如果司机当天的订单数量>=5且总订单金额>=100,则能收到额外补贴10元。请统计当天各司机的收入,并将结果按照收入降序排列且四舍五入保留两位小数。输出内容包括:driver_id(司机ID)、total_order(总订单量)、total_income(总收入),结果样例如下图所示:
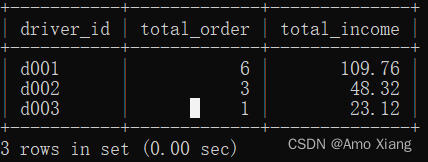
【题目6】参考代码如下:
mysql> SELECT a.driver_id,-> a.total_order,-> CASE-> WHEN total_order >= 5 AND total_amount >= 100 THEN ROUND(total_amount * 0.8 + 10, 2)-> ELSE ROUND(total_amount * 0.8, 2) END AS 'total_income'-> FROM (SELECT driver_id, COUNT(driver_id) AS 'total_order', SUM(order_amount) AS 'total_amount'-> FROM middle_car_order-> GROUP BY driver_id) a ORDER BY total_income DESC;
题目7: 网站登录时间间隔统计
现有一张网站登录情况表 middle_login_info,该表记录了所有用户的网站登录信息,middle_login_info 表的数据如下所示:
mysql> SELECT * FROM middle_login_info;
-- user_id(用户ID):VARCHAR login_time(用户登录日期):DATE
+---------+------------+
| user_id | login_time |
+---------+------------+
| a001 | 2021-01-01 |
| b001 | 2021-01-01 |
| a001 | 2021-01-03 |
| a001 | 2021-01-06 |
| a001 | 2021-01-07 |
| b001 | 2021-01-07 |
| a001 | 2021-01-08 |
| a001 | 2021-01-09 |
| b001 | 2021-01-09 |
| b001 | 2021-01-10 |
| b001 | 2021-01-15 |
| a001 | 2021-01-16 |
| a001 | 2021-01-18 |
| a001 | 2021-01-19 |
| b001 | 2021-01-20 |
| a001 | 2021-01-23 |
+---------+------------+
16 rows in set (0.00 sec)
【题目7】计算每个用户登录日期间隔小于5天的次数。输出内容包括:user_id(用户ID)、num(用户登录日期间隔小于5天的次数),结果样例如下图所示:
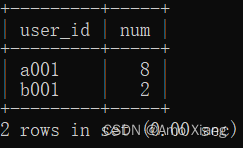
【题目7】参考代码如下:
mysql> SELECT a.user_id, COUNT(*) AS 'num'-> FROM (SELECT user_id,-> login_time,-> TIMESTAMPDIFF(DAY, LAG(login_time) OVER (PARTITION BY user_id ORDER BY login_time),-> login_time) AS date_diff-> FROM middle_login_info) a-> WHERE a.date_diff < 5-> GROUP BY a.user_id;
题目8: 不同区域商品收入统计
现有一张不同城市的商品收入情况表 middle_sale_volume,该表记录了年份和区域等信息,middle_sale_volume 数据如下表所示:
mysql> SELECT * FROM middle_sale_volume;
-- year(年份):YEAR region(区域):VARCHAR city(城市):VARCHAR money(收入):INT
+------+--------+------+-------+
| year | region | city | money |
+------+--------+------+-------+
| 2018 | 东区 | A 市 | 1125 |
| 2019 | 东区 | A 市 | 1305 |
| 2020 | 东区 | A 市 | 1623 |
| 2018 | 东区 | C 市 | 845 |
| 2019 | 东区 | C 市 | 986 |
| 2020 | 东区 | C 市 | 1134 |
| 2018 | 西区 | M 市 | 638 |
| 2019 | 西区 | M 市 | 1490 |
| 2020 | 西区 | M 市 | 1120 |
| 2018 | 西区 | V 市 | 1402 |
| 2019 | 西区 | V 市 | 1209 |
| 2020 | 西区 | V 市 | 1190 |
+------+--------+------+-------+
12 rows in set (0.00 sec)
【题目8】统计每个区域的总收入和平均收入,并将结果四舍五入保留一位小数。输出内容包括:year(年份)、不同区域的总收入和平均收入,结果样例如下图所示:
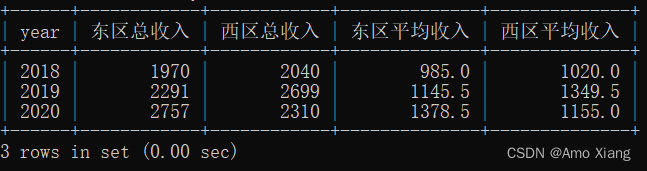
【题目8】参考代码如下:
-- 第①种写法
mysql> SELECT a.`year`-> , ROUND(SUM(IF(a.region = '东区', a.money, 0)), 1)-> AS '东区总收入'-> , ROUND(SUM(IF(a.region = '西区', a.money, 0)), 1)-> AS '西区总收入'-> , ROUND(SUM(IF(a.region = '东区', a.money, 0)) / SUM(a.east_area), 1)-> AS '东区平均收入'-> , ROUND(SUM(IF(a.region = '西区', a.money, 0)) / SUM(a.west_area), 1)-> AS '西区平均收入'-> FROM (-> SELECT `year`-> , region-> , money-> , IF(region = '东区', 1, 0) AS east_area-> , IF(region = '西区', 1, 0) AS west_area-> FROM sale_volume-> GROUP BY `year`-> , region-> , money-> ) AS a-> GROUP BY a.`year`;
-- 第②种写法
mysql> SELECT a.year,-> ROUND(a.收入, 1) AS '东区总收入',-> ROUND(b.收入, 1) AS '西区总收入',-> ROUND(a.平均收入, 1) AS '东区平均收入',-> ROUND(b.平均收入, 1) AS '西区平均收入'-> FROM (SELECT year,-> region,-> SUM(money) AS '收入',-> AVG(money) AS '平均收入'-> FROM middle_sale_volume-> GROUP BY year, region) a-> INNER JOIN (SELECT year,-> region,-> SUM(money) AS '收入',-> AVG(money) '平均收入'-> FROM middle_sale_volume-> GROUP BY year, region) b ON a.region < b.region AND a.year = b.year;
题目9: 信贷逾期情况统计
现有一张用户贷款情况表 middle_credit_overdue,middle_credit_overdue 表中的数据如下所示:
mysql> SELECT * FROM middle_credit_overdue;
-- user_id(用户ID):VARCHAR overdue_date(贷款逾期日期):DATE
+---------+--------------+
| user_id | overdue_date |
+---------+--------------+
| u001 | 2020-10-20 |
| u002 | 2020-11-03 |
| u003 | 2020-10-04 |
| u004 | 2021-01-05 |
| u005 | 2021-01-15 |
| u006 | 2020-09-04 |
| u007 | 2021-01-03 |
| u008 | 2020-12-24 |
| u009 | 2020-12-10 |
+---------+--------------+
9 rows in set (0.00 sec)
【题目9】统计日期截至2021年1月20日,不同逾期月份的逾期1-29天,逾期30-59天和逾期60天以上的样本个数。输出内容包括:overdue_month(逾期月份)、逾期1~29天,逾期30~59天,逾期60天以上,结果样例如下图所示:
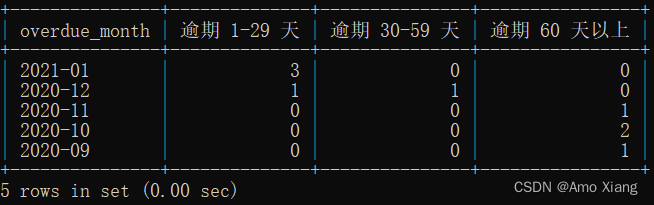
【题目9】参考代码如下:
-- 第①种写法参考:
mysql> SELECT LEFT(overdue_date, 7),-> SUM(CASE-> WHEN TIMESTAMPDIFF(DAY, overdue_date, '2021-01-20') BETWEEN 1 AND 29 THEN 1-> ELSE 0 END) AS '逾期1-29天',-> SUM(CASE-> WHEN TIMESTAMPDIFF(DAY, overdue_date, '2021-01-20') BETWEEN 30 AND 59 THEN 1-> ELSE 0 END) AS '逾期30-59天',-> SUM(CASE-> WHEN TIMESTAMPDIFF(DAY, overdue_date, '2021-01-20') > 60 THEN 1-> ELSE 0 END) AS '逾期60天以上'-> FROM middle_credit_overdue-> GROUP BY LEFT(overdue_date, 7)-> ORDER BY LEFT(overdue_date, 7)-> DESC;
-- 第②种写法参考:
mysql> SELECT overdue_month-> , COUNT(CASE-> WHEN overdue_days >= 1 AND overdue_days < 30-> THEN user_id END)-> AS '逾期 1-29 天'-> , COUNT(CASE-> WHEN overdue_days >= 30 AND overdue_days < 60-> THEN user_id END)-> AS '逾期 30-59 天'-> , COUNT(CASE-> WHEN overdue_days >= 60-> THEN user_id END)-> AS '逾期 60 天以上'-> FROM (-> SELECT user_id-> , DATE_FORMAT(overdue_date, '%Y-%m') AS overdue_month-> , DATEDIFF('2021-01-20', overdue_date)-> AS overdue_days-> FROM middle_credit_overdue-> ) a-> GROUP BY overdue_month-> ORDER BY overdue_month DESC;
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习数据库的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
相关文章:
二十五、SQL 数据分析实战(9个中等难度的SQL题目)
文章目录 题目1: App 使用频率分析题目2: App 下载情况统计题目3: 寻找活跃学习者题目4: 商品分类整理题目5: 商品销售分析题目6: 网约车司机收益统计题目7: 网站登录时间间隔统计题目8: 不同区域商品收入统计题目9: 信贷逾期情况统计 题目1: App 使用频率分析 现有一张用户使…...

JavaSE_02基本语法-编程单词词汇
boolean [bʊlɪən] 变量的基本数据类型之一:布尔型const [kɒnst] n. 常量,常数constant [kɒnst(ə)nt] n. [数] 常数;恒量continue [kən’tɪnjuː] vi. 继续,连续;default [dɪ’fɔːlt; diːfɔːlt] 默认的,缺…...
区间预测 | MATLAB实现QRDNN深度神经网络分位数回归时间序列区间预测
区间预测 | MATLAB实现QRDNN深度神经网络分位数回归时间序列区间预测 目录 区间预测 | MATLAB实现QRDNN深度神经网络分位数回归时间序列区间预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 MATLAB实现QRDNN深度神经网络分位数回归时间序列区间预测。QRDNN模型…...

如何使用aframe.js构建一个简单的VR播放器
在当今这个信息化的时代,虚拟现实(VR)已经开始逐渐成为一种新的生活方式。作为一名前端开发工程师,在学习和探索VR技术方面,aframe.js是一个非常有趣和有用的工具。在本文中,我将介绍如何使用aframe.js构建…...
Fiddler抓包工具常见功能介绍,还不会的进来看
目录 Fiddler的功能面板 一、Statistics数据统计面板,性能分析 二、Inspectors查看请求与响应 三、Filters过滤器 1、User Filters启用 2、Action 3、过滤器实际应用 四、AutoResponder请求重定向 1、什么是请求重定向? 2、为什么要用这个功能&…...
基于海鸥算法优化的核极限学习机(KELM)分类算法-附代码
基于海鸥算法优化的核极限学习机(KELM)分类算法 文章目录 基于海鸥算法优化的核极限学习机(KELM)分类算法1.KELM理论基础2.分类问题3.基于海鸥算法优化的KELM4.测试结果5.Matlab代码 摘要:本文利用海鸥算法对核极限学习机(KELM)进行优化,并用于分类 1.KE…...
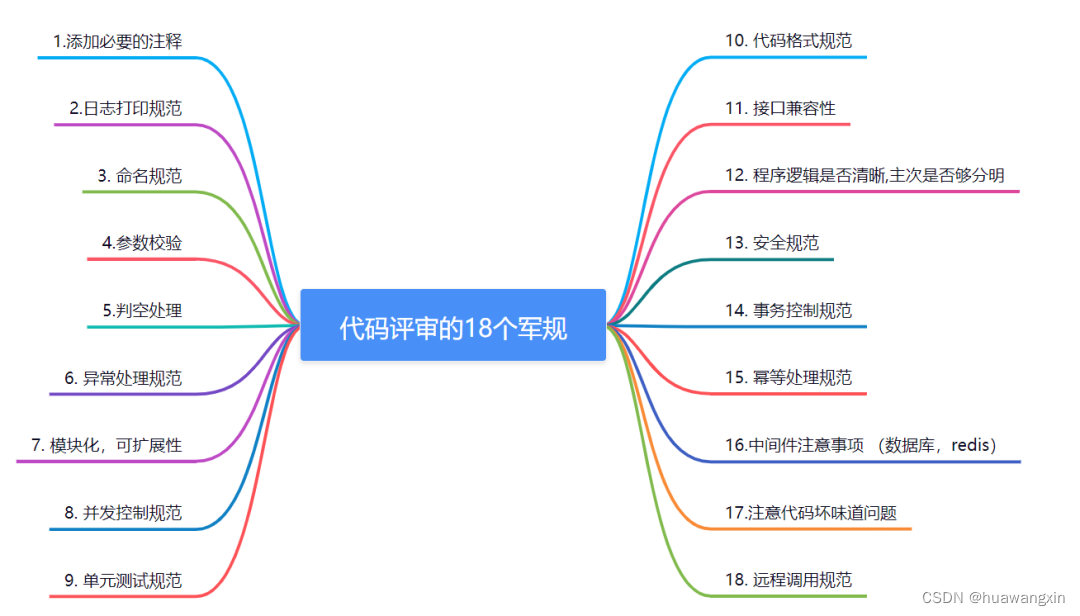
JAVA代码规范审查
JAVA代码规范审查 1. 添加必要的注释 所有的类都必须添加创建者和创建日期,以及简单的注释描述 方法内部的复杂业务逻辑或者算法,需要添加清楚的注释 一般情况下,注释描述类、方法、变量的作用 任何需要提醒的警告或TODO,也要注…...

Centos8安装redis7
1.下载: 官网下载:Download | Redis 把安装包上传至服务器: 2.安装: 解压redis: [rootnode202 ~]# cd /usr/local/soft/ [rootnode202 soft]# tar -zxvf redis-7.0.11.tar.gz 安装: 进入redis-7.0.1…...
RabbitMQ详解(一):Linux安装
消息队列概念 消息队列是在消息的传输过程中保存消息的容器。队列的主要目的是提供路由并保证消息的传递;如果发送消息时接收者不可用,消息队列会保留消息,直到可以成功地传递它。 常见的消息队列 RabbitMQ 基于AMQP(高级消息队列协议)基础上…...

Mojo:比 Python 快 35000 倍的 AI 编程语言
Mojo:比 Python 快 35000 倍的 AI 编程语言 Mojo是一门刚刚发布的面向 AI 开发人员的编程语言。 Mojo 被设计为 Python 的超集,所以如果你已经掌握了 Python,学习 Mojo 会很容易。关键是 Mojo 将 Python 的易用性与 C 语言的性能相结合&am…...
1703_LibreOffice常用功能使用体验
全部学习汇总: GreyZhang/windows_skills: some skills when using windows system. (github.com) 首先需要说明的是我不是一个重度Office用户,甚至算不上一个重度的Office用户。我使用的Office软件最多的功能就是文档编辑,绝大多数时候还是文…...
Postgres:Win/Linux环境安装及一键部署脚本
1.Win安装Postgres (1)下载安装包 (2)开始安装 修改安装目录 选择要安装的组件 data也就是库表及数据的.dba文件存放目录 密码设置 端口设置 next next 开始安装 安装完成,Stack Builder 根据需要选择是否安装。仅仅是…...

每日一题144——数组大小减半
给你一个整数数组 arr。你可以从中选出一个整数集合,并删除这些整数在数组中的每次出现。 返回 至少 能删除数组中的一半整数的整数集合的最小大小。 示例 1: 输入:arr [3,3,3,3,5,5,5,2,2,7] 输出:2 解释:选择 {3,…...

运维必懂的13条高效工作秘诀
正确做事,更要做正确的事 “正确地做事”强调的是效率,重视做一件工作的最好方法;“做正确的事”强调的是效能,重视时间的最佳利用——这包括是做或者不做某项工作。 实际上,第一重要的却是效能而非效率,…...
【牛客刷题专栏】0x26:JZ25 合并两个排序的链表(C语言编程题)
前言 个人推荐在牛客网刷题(点击可以跳转),它登陆后会保存刷题记录进度,重新登录时写过的题目代码不会丢失。个人刷题练习系列专栏:个人CSDN牛客刷题专栏。 题目来自:牛客/题库 / 在线编程 / 剑指offer: 目录 前言问…...

5/5~5/7总结
把socket通信改成了分成短连接和长连接,登录前的所有操作都是短连接,每次都关闭连接,如果登录成功了就保持该socket连接,登录成功之后的所有操作,修改资料,发信息等都用该socket, 服务端和客户…...

重要通知|Sui测试网将于5月11日重置
致Sui社区成员们: 正如之前公告所述,部分社区成员发现测试网可能会定期清除数据并重新启动。鉴于此,我们宣布计划将于2023年5月11日进行首次测试网清除。 对于想要继续读取和访问当前测试网络的社区成员,请使用由Mysten Labs在…...
教你快速把heic格式转化jpg,4种方法操作简单
教你快速把heic格式转化jpg的方法,因为HEIC格式图片通常出现在苹果公司的iOS 11操作系统及之后的版本中,这是因为苹果公司在这些版本中采用了HEIF(高效图像格式)作为默认的照片格式来替代JPEG格式。同时,需要注意的是&…...

交互式数据分析和处理新方法:pandas-ai =Pandas + ChatGPT
Python Pandas是一个为Python编程提供数据操作和分析功能的开源工具包。这个库已经成为数据科学家和分析师的必备工具。它提供了一种有效的方法来管理结构化数据(Series和DataFrame)。 在人工智能领域,Pandas经常用于机器学习和深度学习过程的预处理步骤。Pandas通…...
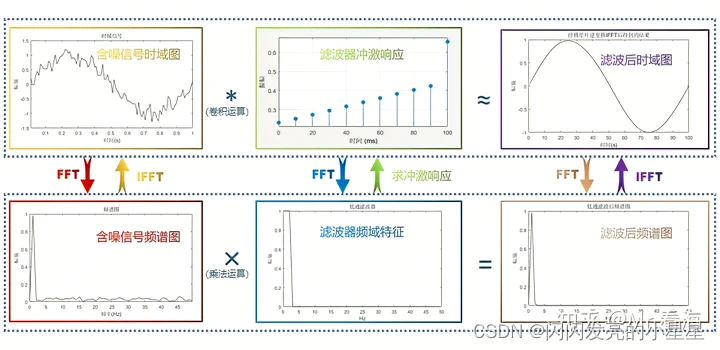
FIR滤波
参考来源: https://www.zhihu.com/question/323353814 本节主要围绕以下几个问题进行描述: 什么是FIR滤波器时域的卷积频域的相乘 关于FIR FIR滤波就是在时域上卷积的过程。将含噪声信号与低通滤波器的傅里叶逆变换值进行卷积,这个过程就是…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...