【论文阅读】COPA:验证针对中毒攻击的离线强化学习的稳健策略
COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks
作者:Fan Wu, Linyi Li, Chejian Xu
发表会议:2022ICRL
摘要
目前强化学习完成任务的水平已经和人类相接近,因此研究人员的目光开始转向强化学习的鲁棒性研究。目前在强化学习测试阶段的攻击和防御已经有了比较多的研究,但是针对强化学习在训练阶段的攻击防御还没有太多涉及。本文专注于证明离线RL在存在中毒攻击时的鲁棒性,其中训练轨迹的子集可以被任意操纵。作者提出了一个认证框架COPA,以认证不同认证标准下可容忍的中毒轨迹数量。本文提出了两个认证标准:每个状态行为稳定性和累积奖励界限。实验结果显示:(1)所提出的鲁棒聚合协议可以显着提高鲁棒性; (2) 对每个状态的动作稳定性和累积奖励界限的认证是高效且严格的; (3) 不同训练算法和环境的认证是不同的,暗示了它们内在的鲁棒性。
Introduction
目前强化学习已经被广泛应用,对于离线强化学习更是被赋予了较大的期望,因为这种学习方式不需要与环境交互,或者像在线学习一样收集训练数据,可以在重复使用训练数据的情况下得到较好的模型策略。但相比于在线强化学习,离线方式在面对训练数据中毒的情况时往往会产生更严重的问题。尽管现在已经有一些针对于分类问题的防御方法,但这些方法无法适用于执行复杂任务的强化学习。因此本文在实际计算上验证了离线强化学习在遭受中毒攻击时的鲁棒性,同时提出了第一个针对中毒攻击(COPA)的通用离线RL的鲁棒策略认证框架来解决这个问题。
-
认证标准
- 每个状态动作稳定性:保证通过COPA学习的策略在面对特定攻击前后执行的动作不变,比如在看到行人时应该刹车,不能在受到攻击后,看到行人不再刹车
- 累计奖励界限:保证策略累计奖励的下限,也保证了策略在受到攻击后的整体性能不会变的很低
-
COPA框架
包含三部分,分别是策略划分、聚合协议和鲁棒性认证
Related Work
强化学习中的中毒攻击
- policy poisoning
利用RL算法的漏洞进行针对性的训练数据投毒,导致训练失败或者生成攻击者想要的策略,目前多用在在线学习,对于离线学习的攻击还是空白
VULNERABILITY-AWARE POISONING MECHANISM
FOR ONLINE RL WITH UNKNOWN DYNAMICS
Policy teachingvia environment poisoning: Training-time adversarial attacks against reinforcement learning - reward poisoning
攻击者可以修改离线数据集中的奖励或在线交互期间的奖励信号,攻击者的目标是使受害者强制学习某一个策略或者在真实任务中表现差
Policy Poisoning in Batch Reinforcement Learning and Control
Deceptive Reinforcement Learning Under Adversarial Manipulations on Cost Signals
经典的鲁棒强化学习
-
Randomization methods
首先为强化学习的鲁棒性研究提供思路,后续出现的NoisyNet是将噪声添加到训练网络的权重中
Whatever does not kill deep reinforcement learning, makes itstronger
Mitigation of policy manipulation attacks on deep q-networkswith parameter-space noise -
对抗性训练
在最开始使用随机噪声和FGSM对策略进行在训练,提高了模型的鲁棒性。而后提出了RS-DQN,这是一种基于模仿学习的方法,将鲁棒的DQN与常规DQN并行训练,被纳入了SOTA。SA-DQN是一种基于正则化的方法,在损失函数中添加正则项使得策略在扰动下原本概率最高的动作不会改变
Robust deep reinforcement learning against adversarial perturbations on state obser-vations
对抗中毒攻击的鲁棒强化学习
Banihashem等人考虑了Ma等人提出的三种中毒攻击模型,其中攻击者旨在强制学习目标策略,同时最大限度地降低奖励操作的成本,这个优化问题是可行的并且存在最优解,利用这个定义,Banihashem将防御问题定义为优化防御者在最坏情况下的最优性能。
Defense against reward poisoning attacksin reinforcement learning
强化学习鲁棒性认证
Wu等人(2022)根据随机平滑的工作路线,为RL提供了第一个针对测试时间规避攻击的鲁棒性认证,同时提出了一种自适应搜索算法来搜索所有可能的轨迹
Crop: Certify-ing robust policies for reinforcement learning through functional smoothing
COPA的两个鲁棒性认证标准
投毒攻击
训练数据集 D D D,对于数据集中的每一条轨迹都允许攻击者进行替换,生成一个相关的数据集 D ^ \hat D D^,定义了一个对称差 D ⊖ D ^ = ( D / D ^ ) ∪ ( D ^ / D ) D\ominus\hat D=(D / \hat D)\cup(\hat D / D) D⊖D^=(D/D^)∪(D^/D),也就是添加或者删除一条轨迹会造成1对称差,替换一条轨迹会造成2对称差
验证目标
验证经过训练的策略在test-time的最佳性能,在训练过程中,将强化学习算法和COPA框架的聚合协议用 M M M来表示, M = ( D → ( S ∗ → A ) ) M=(D →(S^*→ A)) M=(D→(S∗→A)),其中D表示训练数据集, S ∗ S^* S∗表示所有状态序列。我们的目标是在给定中毒范围的条件下,为中毒聚合策略提供鲁棒性验证
两个标准
- Per-State Action Stability
每个状态的动作稳定性,对于任何一个满足 ∣ D ⊖ D ^ ∣ ≤ K |D\ominus\hat D|\le K ∣D⊖D^∣≤K情况下,中毒策略和干净策略对状态(或状态序列)的动作预测是相同的。将K成为可容忍中毒阈值 - 累计奖励下限
在满足 ∣ D ⊖ D ^ ∣ ≤ K |D\ominus\hat D|\le K ∣D⊖D^∣≤K的条件下,使用聚合数据集训练得到的策略累计奖励值不低于 J K J_K JK
COPA的验证流程
基于划分的训练协议
COPA的训练过程分为两部分:划分过程和训练过程
- Partitioning Stage
在这个部分把训练数据集划分为u个,每个划分出来的数据集互不相交,每条轨迹是一个划分单位,使用散列函数进行划分即 D i = τ ∈ D ∣ h ( τ ) = i ( m o d u ) D_i = \tau \in D | h(\tau) = i (mod u) Di=τ∈D∣h(τ)=i(modu) - Training Stage
对于每个划分出来的数据集独立使用RL算法进行训练,那么也就会生成u个策略,在后文中将这些训练得到的策略成为subpolicies策略,来区分后文所使用的聚合策略。这些subpolicies用 1 i , a 1_{i,a} 1i,a来表示,定义 1 i , a ( s ) : = 1 [ π i ( s ) = a ] 1_{i,a}(s) :=1[π_i(s) =a] 1i,a(s):=1[πi(s)=a],也就是每个策略在状态s下选择的动作a。聚合动作数量也就是这些subpolicies在状态s时选择动作a的总和, n a ( s ) : = ∣ i ∣ π i ( s ) = a , i ∈ [ u ] ∣ = ∑ i = 0 u − 1 1 i , a ( s ) n_a(s) :=|{i|π_i(s) =a,i∈[u]}|=∑^{u−1}_{i=0}1_{i,a}(s) na(s):=∣i∣πi(s)=a,i∈[u]∣=∑i=0u−11i,a(s)
这是训练过程的算法

聚合协议
在上一个训练过程中得到了u个subpolicies,在这一部分提出了三种聚合协议,来将subpolicies聚合
- PARL
PARL通过选择得票率最高的行动来聚合子策略。PARL所使用的直觉是当数据集有K个投毒数据,那么最多会有K个subpolicies被改变,只有保证最高和第二高的动作票数大于2K才能使得中毒前后在给定状态的动作不会改变 - TPARL
在RL的顺序决策过程中,某些重要状态很可能更容易受到中毒攻击,这种攻击被称为瓶颈状态。因此,攻击者可能只是改变对这些瓶颈状态的行动预测,从而降低整体性能,例如累积奖励。例如,在乒乓球比赛中,当球接近球拍时,我们选择了一个立即糟糕的动作,可能会输掉比赛。因此想要提高策略的整体鲁棒性,就需要在这种重要时刻提高对中毒数据的容忍度,从而提出了时间分区聚合
在TPARL中可能会出现票数第一和第二的动作之间差距很小,同时由于强化学习的顺序决策特性,可能会出现相邻状态和动作相似的情况,因此在这种聚合协议中加入相邻状态的投票从而扩大票数边界,提高对中毒数据阈值的容忍度。在TPARL中设置了窗口大小W,会在相邻W个状态中选择票数最高的动作 - DPARL
在TPARL中提出了固定窗口W的概念,但是在实际应用中窗口大小很难确定,而且也会根据场景的不同而有不同的窗口大小,因此提出了动态窗口大小的概念。因此在DPARL中会对每一步动态选择窗口大小,而我们只需要设置最大窗口大小 W m a x W_{max} Wmax即可
状态动作稳定性验证
这一部分主要是对上述三种聚合协议的状态动作稳定性给出中毒数据容忍阈值(证明太多了先略过)

累积奖励下限
认证目标是在给定有界中毒大小K的情况下,在中毒攻击下获得累积奖励的下限,使用了一种新的自适应搜索算法COPA-Search
该方法从基本情况开始:当中毒阈值 K c u r = 0 K_{cur}=0 Kcur=0时,累积回报的下限 J K c u r J_{K_{cur}} JKcur恰好是没有中毒的回报。然后,该方法逐渐增加中毒阈值 K c u r K_{cur} Kcur,通过找到立即更大的 K ′ > K c u r K'>K_{cur} K′>Kcur可以沿着轨迹扩展可能的动作集。随着 K c u r K_{cur} Kcur的增加,攻击可能会导致中毒策略π在某些状态下采取不同的行动,从而产生新的轨迹。我们需要找出一组所有可能的动作,以穷尽所有可能的轨迹。有了这个可能的动作集合,该方法通过将这些新轨迹公式化为轨迹树的扩展分支来有效地探索这些新轨迹。在探索了所有新的轨迹后,该方法检查了树的所有叶节点,并计算出其中的最小回报,即新中毒大小K′下累积回报 J K ′ J_{K′} JK′的新下界。然后,我们重复这个从K′增加中毒大小并用新轨迹扩展的过程,直到我们达到中毒大小K的预定义阈值
- PARL动作集合
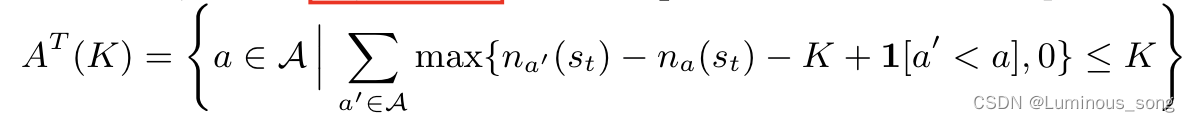
- 伪代码

Experiment
在本节使用DQN、QR-DQN和C51离线算法进行验证。实验结果发现:
- QR-DQN和C51比DQN具有更好的鲁棒性
- TPARL和DPARL在时间连续性更高的环境中如HighWay得到了鲁棒性验证
- 更大的分区数提高了鲁棒性
- FreeWay是最稳定、最强健的环境
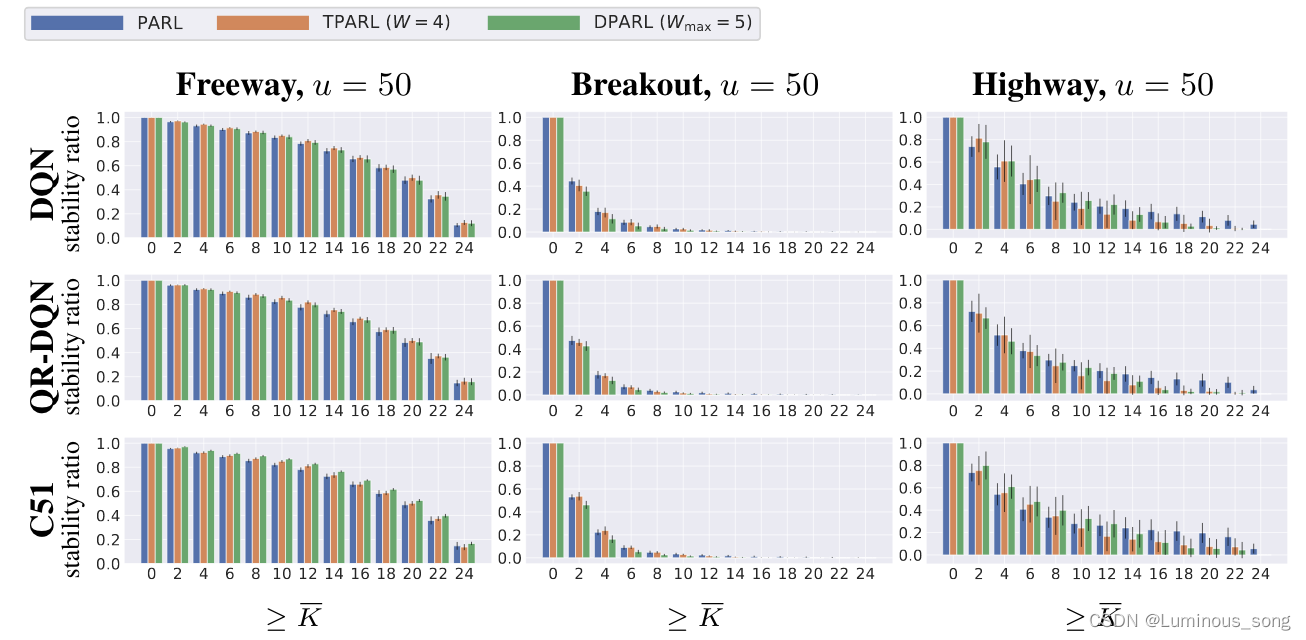
状态动作稳定性验证
在每一次运行中,运行一条序列数为H的轨迹,计算每一步的中毒阈值,将中毒阈值大于规定值的比例定义为tability ratio作为metric, ∑ t = 0 H − 1 1 [ K t ≥ K ] / H ∑^{H−1}_{t=0}1[K_t≥K]/H ∑t=0H−11[Kt≥K]/H
在RL算法层面上,QR-DQN和C51相比于DQN具有更好的表现,C51更是具有显著优势,尤其是在高速公路方面。在集合协议层面上,我们观察到不同环境下的不同行为。在Freeway上,具有时间聚合的方法(TPARL和DPARL)实现了更高的鲁棒性,并且DPARL在大多数情况下实现了最高的认证鲁棒性;而在Breakout和Highway上,单步聚合PARL通常更好。这种差异是由于环境的不同性质造成的。在分区数级别上,较大的分区数通常允许更大的可容忍的中毒次数
累积奖励下限
本质上,在每个中毒大小K下,比较了不同RL算法和认证方法实现的累积奖励的下限。下限的高值意味着更强的鲁棒性。在RL算法层面上,QR-DQN和C51几乎总是优于基线DQN算法,在一些情况下DPARL结果不如TPARL健壮,其原因可能是动态机制更容易受到攻击,以及在DPARL中计算可能的动作集的困难程度更高
Conclusion
这篇文章提出了COPA,这是第一个用于证明离线RL-抵御中毒攻击的稳健策略的框架。COPA包括三种策略聚合协议。对于每个聚合协议,COPA为每个状态的动作稳定性和累积奖励下界提供了一个可靠的证明。对不同环境和不同离线RL训练算法的实验评估表明,这种训练方法得到的策略在各种场景中都是较为稳健的
相关文章:
【论文阅读】COPA:验证针对中毒攻击的离线强化学习的稳健策略
COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks 作者:Fan Wu, Linyi Li, Chejian Xu 发表会议:2022ICRL 摘要 目前强化学习完成任务的水平已经和人类相接近,因此研究人员的目光开始转向…...
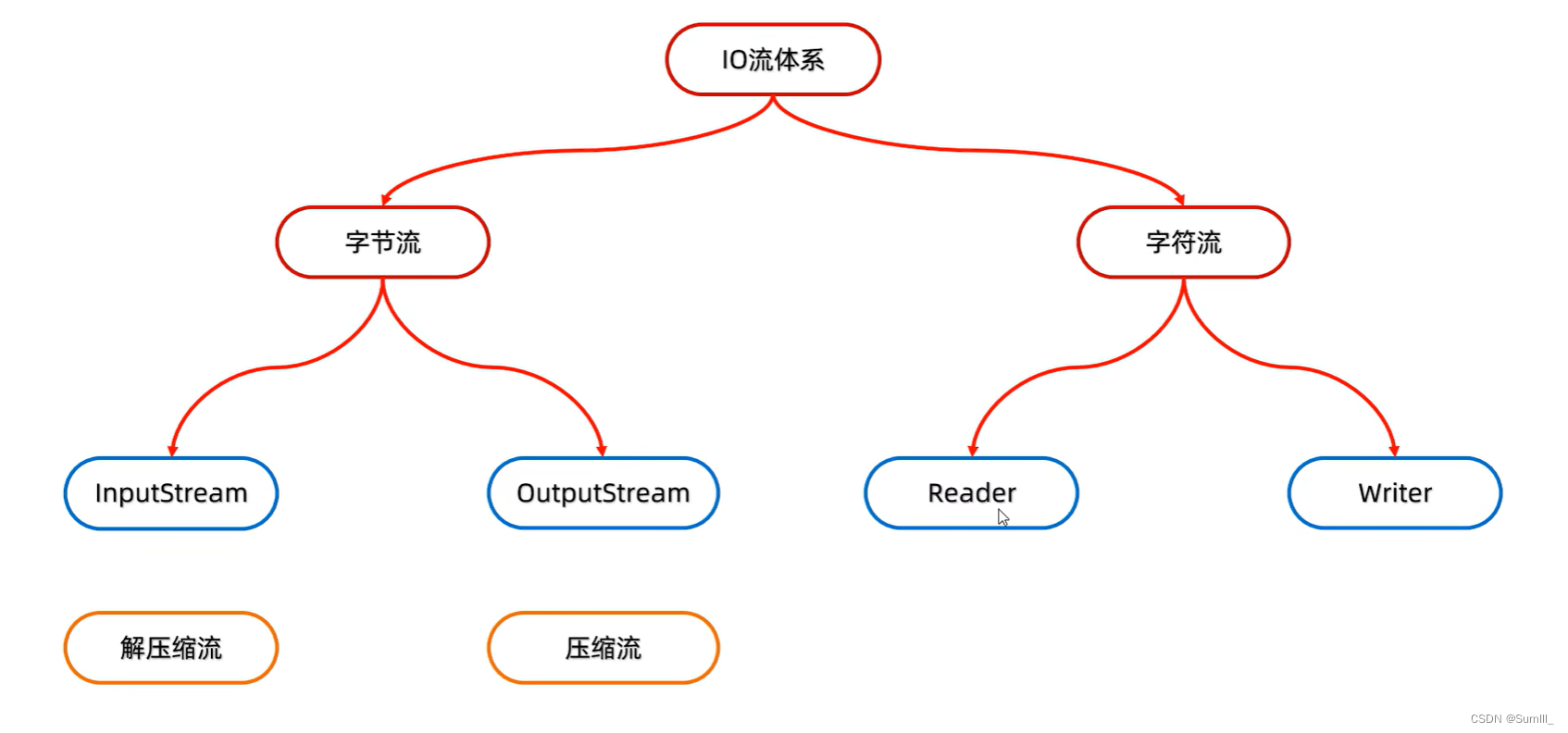
Java笔记_18(IO流)
Java笔记_18 一、IO流1.1、IO流的概述1.2、IO流的体系1.3、字节输出流基本用法1.4、字节输入流基本用法1.5、文件拷贝1.6、IO流中不同JDK版本捕获异常的方式 二、字符集2.1、GBK、ASCII字符集2.2、Unicode字符集2.3、为什么会有乱码2.4、Java中编码和解码的代码实现2.5、字符输…...
前端vue3一键打包发布
一键打包发布可以分为两种,一是本地代码,编译打包后发布至服务器,二是直接在服务器上拉去代码打包发布至指定目录中。 两种各有使用场景,第一种是前端开发自己调试发布用的比较多,第二种是测试或者其他人员用的多&…...
13 | visual studio与Qt的结合
1 前提 Qt 5.15.2 visual studio 2019 vsaddin 2.8 2 具体操作 2.1 visual studio tool 2.1.1 下载 https://visualstudio.microsoft.com/zh-hans/downloads/2.1.2 安装 开发...
纯手动搭建大数据集群架构_记录019_集群机器硬盘爆满了_从搭建虚拟机开始_做个200G的虚拟机---大数据之Hadoop3.x工作笔记0179
今天突然就发现,使用nifi的时候集群满了...气死了.. 而在vmware中给centos去扩容,给根目录扩容,做的时候,弄了一天...最后还是报错, 算了从头搭建一个200G的,希望这次够用吧.后面再研究一下扩容的问题. 2023-05-12 11:06:48 原来的集群的机器,硬盘太小了,扩容不知道怎么回事…...

变量大小:—揭开不同类型的字节数
变量大小:一一揭开不同类型的字节数 在编程中,我们会使用各种类型的变量来存储数据,但是你是否知道这些变量在内存中所占用的字节数是多少呢?随着不同编程语言和不同的操作系统,这些变量的字节数可能会有所不同。在本…...
23.自定义指令
像是 v-if,v-for,v-model 这些是官方指令,vue允许开发者自定义指令 目录 1 mounted 1.1 基本使用 1.2 第一个形参 1.3 第二个形参 2 updated 3 函数简写 4 全局自定义指令 1 mounted 当指令绑定到元素身上的时候,就会自动触发mounted()…...

OPNET Modeler 例程——停等协议的建模和仿真
文章目录 一、概述二、链路模型和包格式创建三、进程模型1.src 进程模型2.sink 进程模型 四、节点模型五、网络模型六、仿真结果 一、概述 本例程是在 OPNET Modeler 中对停等协议的建模和仿真,其中停等协议的操作过程如下: (1)发…...
JavaScript - 基础+WebAPI(笔记)
前言: 求关注😭 本篇文章主要记录以下几部分: 基础: 输入输出语法;数据类型;运算符;流程控制 - 分支语句;流程控制 - 循环语句;数组 - 基础;函数 - 基础&…...

API调用的注意事项及好处!
API调用是指一个软件系统通过预定格式、协议和框架,向另一个软件系统发送请求并获得响应的过程。 在进行API调用时需要注意以下事项: 1. 认真阅读API文档:在调用API前,一定要认真仔细地阅读相关的API文档,了解API接口…...

ros2中常用命令,与ros1的区别
文章目录 1. ros1 中的rosrun tf tf_echo 在ros2中使用办法2. rqt 中 tf 树的查看3. roscd 在ros2中使用办法4. ros2获取时间的方法: 1. ros1 中的rosrun tf tf_echo 在ros2中使用办法 # ros2 run tf2_ros tf2_echo [reference_frame] [target_frame] ros2 run tf2…...

利用MySQL语句批量替换指定wordpress文章中的图片路径
很多时间我们将服务器中的图片下载到本地,然后删掉,但是有一个问题就是,所有文章中的图片路径还是以前的,没有根据域名来。导致下午某些时间段图片都是无法显示的,后来想到用MySQL直接批量替换,执行才不到1…...

Linux必会100个命令(六十)curl
在Linux中curl是一个利用URL规则在命令行下工作的文件传输工具,可以说是一款很强大的http命令行工具。它支持文件的上传和下载,是综合传输工具。 curl选项比较多,使用man curl或者curl -h获取帮助信息。 -a/--append …...
)
物联网硬件安全与整改梳理(1)
物联网安全工作梳理(0)_luozhonghua2000的博客-CSDN博客 上篇讲了物联网总体安全知识框架和工作梳理,这篇单独讲下硬件安全方面的问题和整改知识技能点。硬件安全主要分5个方面来讲:硬件安全现状,硬件安全技术分析,典型案例,安全架构整改,安全整改措施。 智能硬件安全总…...
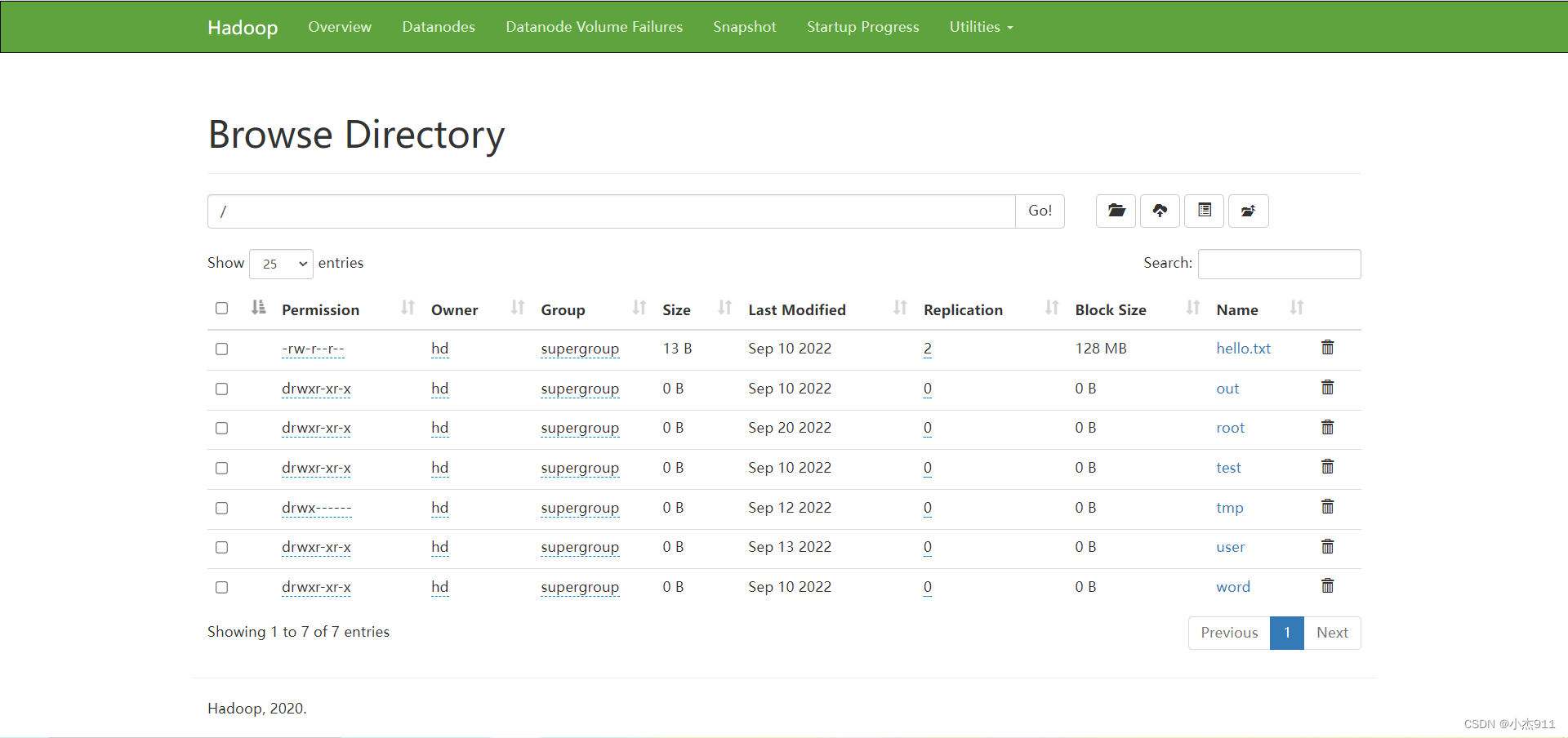
【大数据学习篇3】HDFS命令操作与MR单词统计
1. HDFS命令使用 [rootmaster bin]# su hd[hdmaster bin]$ #查看/目录[hdmaster bin]$ hdfs dfs -ls / 5 #在/目录创建一个为test名字的文件夹[hdmaster bin]$ hdfs dfs -mkdir /test#查看/目录[hdmaster bin]$ hdfs dfs -ls Found 1 itemsdrwxr-xr-x - hd supergroup …...

java中设计模式总结
设计模式是实际工作中写的各种代码进行高层次抽象的总结,其中最出名的当属 Gang of Four (GoF) 的分类了,他们将设计模式分类为 23 种经典的模式,根据用途又可以分为三大类,分别为创建型模式、结构型模式和行为型模式。 有一些重…...

ChatGPT不到1分钟生成全部代码,你就说慌不慌吧?
生成过程视频: 如何使用ChatGPT快速生成代码 (qq.com) 如何使用ChatGPT快速生成SpringBoot集成Dubbo的完整案例 1、Dubbo最新版本有哪些新特性 Dubbo最新版本是2.7.9,于2021年6月发布。以下是该版本的一些新特性: 1)增加Dubbo-go…...

Python进阶知识(1)—— 什么是爬虫?爬文档,爬图片,万物皆可爬,文末附模板
文章目录 01 | 🍒 什么是 P y t h o n 爬虫? \color{red}{什么是Python爬虫?} 什么是Python爬虫?🍒02 | 🍊 怎么发起网络请求? \color{orange}{怎么发起网络请求?} 怎么发起网络请求…...

如何在andorid native layer中加log function.【转】
在开发Android一些应用或是链接库, 在程序代码中埋一些log是一定有需要的, 因为谁也无法保证自己所写出来的程序一定没有问题, 而log机制正是用来追踪bug途径的一种常用的方法. 在andorid中提供了logcat的机制来作log的目的, 在javalayer有logcat class可以用,哪在nativelayer呢…...
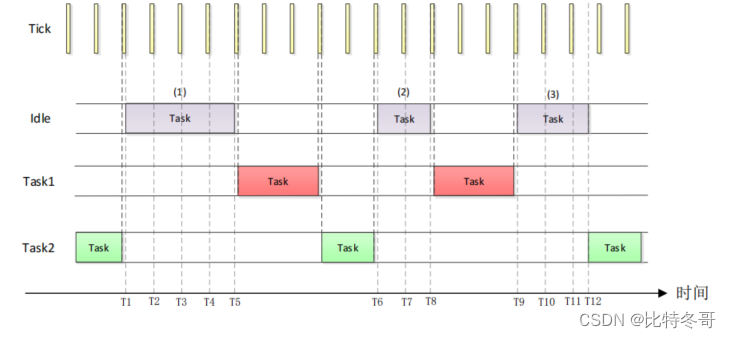
FreeRTOS 空闲任务
文章目录 一、空闲任务详解1. 空闲任务简介2. 空闲任务的创建3. 空闲任务函数 二、空闲任务钩子函数详解1. 钩子函数2. 空闲任务钩子函数 三、空闲任务钩子函数实验 一、空闲任务详解 1. 空闲任务简介 当 FreeRTOS 的调度器启动以后就会自动的创建一个空闲任务,这…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...