阿里云数据库ClickHouse产品和技术解读
摘要:社区ClickHouse的单机引擎性能十分惊艳,但是部署运维ClickHouse集群,以及troubleshoot都不是很好上手。本次分享阿里云数据库ClickHouse产品能力和特性,包含同步MySQL库、ODPS库、本地盘及多盘性价比实例以及自建集群上云的迁移工具。最后介绍阿里云在云原生ClickHouse的进展情况。
在2023云数据库技术沙龙 “MySQL x ClickHouse” 专场上,阿里云数据库ClickHouse技术研发刘扬宽,为大家分享一下《阿里云数据库ClickHouse产品和技术》的一些技术内容。

刘扬宽,阿里花名留白,从事数据存储与数据处理系统研发十余年,先后在中科院计算所,中国移动苏州研发中心参与存储系统研发。2019年加入阿里云参与内部产品的存储计算分离的架构升级。在云原生ClickHouse的研发中,承担存储模块的负责人,根据计算层访问存储系统的特点,有针对地优化了存储系统,提升了云原生ClickHouse的整体性能。
本文内容根据演讲录音以及PPT整理而成。

首先来说,我们的ClickHouse是在2019年中旬开源的。虽然开源时间较晚,但它的上升势头非常迅猛。我们可以看到在DB-Engine的关系型数据库类目中,ClickHouse排在第28位,相比去年上升了29位。在DB-Engine的趋势图中,红色曲线表示ClickHouse的增长情况。右侧是GitHub上的Star数,可以看到,虽然ClickHouse开源时间较晚,但相比其他同类型的分布式数据库,其热度排名遥遥领先。

让我们来看看社区版ClickHouse的系统架构。如前面的嘉宾所介绍,ClickHouse是一个Sharding架构。对于集群版的ClickHouse实例来说,首先需要创建分布式表,并在分布式表上定义Sharding key。数据将被下载到不同的计算节点上,并通过节点副本、复制同步机制来保证数据的高可用性。
接下来,让我们来看看查询的链路。用户在查询数据时,必须使用分布式表,并将查询分发到某个查询节点。查询节点会解析分布式表并找到对应的本地表,确定集群分布式表下载到哪些节点上,并将查询发送到这些节点上。然后,每个节点都会进行本地计算,并将中间结果返回给Push节点。最终,Push节点将所有中间结果进行汇总,并返回给用户。这就是ClickHouse上的分布式查询。

ClickHouse提供了多种表引擎,其中Meterialized MySQL主要使用ReplacingMergeTree进行去重操作,而MergeTree系列是其主打的就是表引擎。此外,其他的聚合表引擎,都是通过后台合并数据,根据自定义的合并逻辑进行聚合运算,并不断地聚合数据。因为已经在后台完成了合并,所以直接查询这些数据的效率更高。
在ClickHouse的其他社区生态或数据同步系统中,创建这些外部表引擎有利于从其他系统同步数据到ClickHouse。右侧的SQL示例展示了ClickHouse用户需要创建的本地表和分布式表,其中本地表必须包含排序键。另外,如果没有指定分区键,它将默认将整个表作为一个分区。用户可以根据某些字段的时间属性或其他属性,指定数据的生命周期,并告知系统哪些数据可以移动到冷存储或删除。
包括这个tbl可以作用于某些列,对这些列进行生命周期管理。例如,当数据到达某个确定的状态时,可以对其进行更高级别的压缩。在ClickHouse中,我们有多个节点的分布式实例,必须定义分布式表,并指定Sharding key。默认的话,就是随机的rand Sharding key。

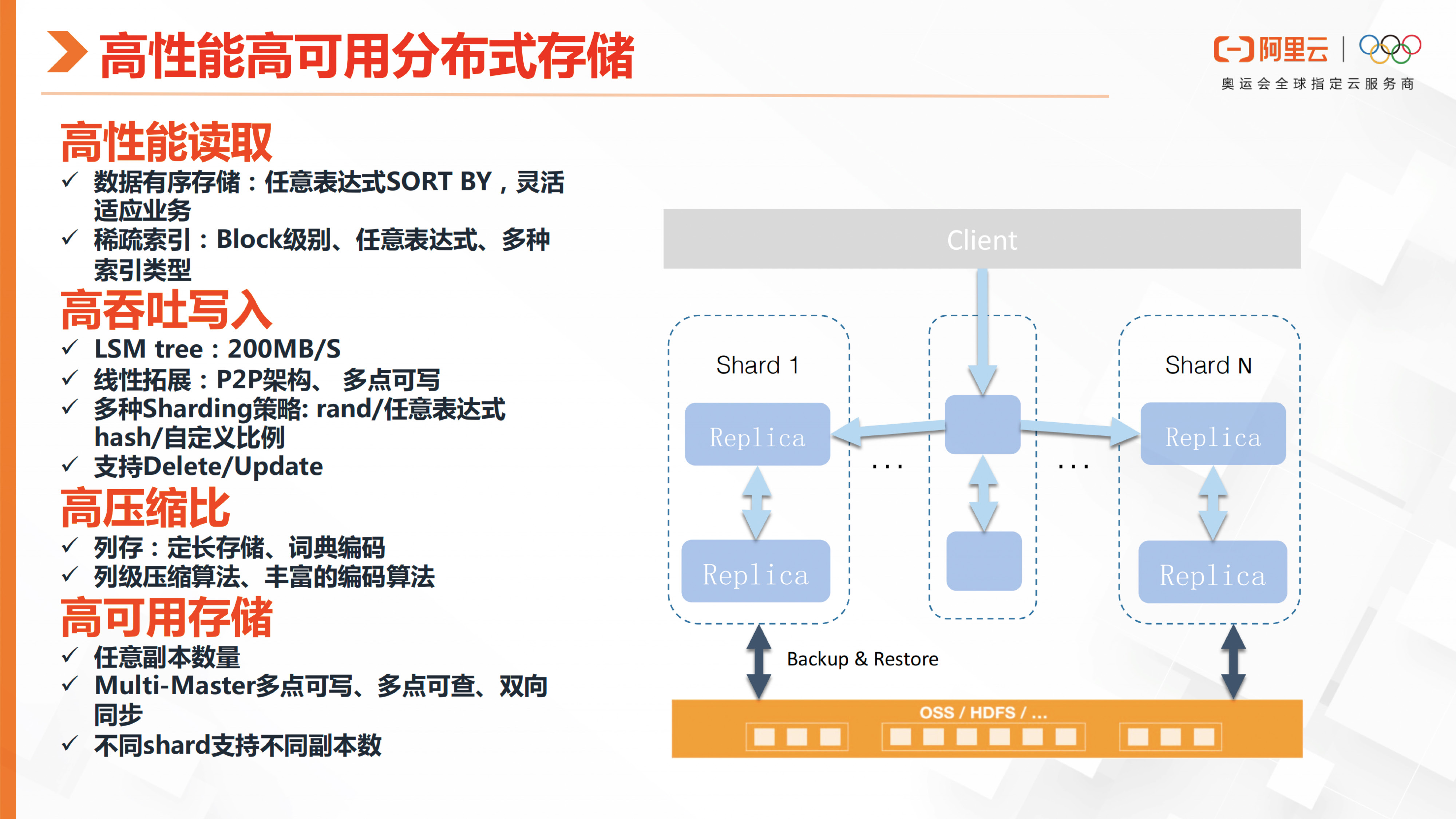
开源的ClickHouse它的高性能以及高可用分布式存储,主要是从这些方面去实现的。首先它的高性能读取,在数据存储时,它会根据排序键有序地存储数据。然后索引是组建的轻索引,它是Block级别的大粒度索引,所以在分析场景上是比较适合的。但是ClickHouse对于点查询来说,它的性能并不是很好。
ClickHouse具有高吞吐量,主要体现在能够支持多点写入,并且建议用户进行攒批写操作。它采用LSM树的结构进行写入,数据会被有序地写入到磁盘中,因此写入吞吐量接近于IO带宽。另外,ClickHouse采用P2P架构,并支持多种Sharding策略。在示例中,展示了rand任意表达式的一种策略。用户也可以根据业务需要,选择基于group by或哈希的策略,将不同的数据分布到不同的节点上,有利于进行分布式查询中的join或log ajj操作。此外,ClickHouse支持后台异步执行的Delete和Update操作。
此外,由于ClickHouse采用了纯列存储的方式,因此具有高压缩比,同时支持多种压缩算法。
ClickHouse实现高可用性的方式是通过设置任意数量的副本。内部数据同步是通过JK协调实现的,副本之间可以进行多点写入和多点查询,这是基于内部复制机制实现的。此外,ClickHouse支持不同数量的副本数,以适应不同Sharding策略的需求。
ClickHouse是专门为OLAP设计的一种存储引擎。它的底层存储格式是基于MergeTree的逻辑二维表,其中每行对应一个或多个数据目录下的PART(数据块)。在data目录下,会有许多索引文件,包括primary key index和其他索引文件。对于每个列,都有一组对应的数据文件(.bin)和数据索引文件(.mrk)。因此,每个数据块(block)的格式如下:命名规则为Part名称、Block ID、MergeLevel和Mutation Version(如果存在)。
在读取数据的过程中,系统会根据主键(private key)的索引(index),构建对应要读取的mrk文件的偏移量(offset)。接着,根据命中的具体列和该列对应的mrk文件,定位到文件的偏移量(offset),最终读取目标的数据块(block)。这个数据格式可以在互联网和相关材料中找到一些可供解析的内容参考。

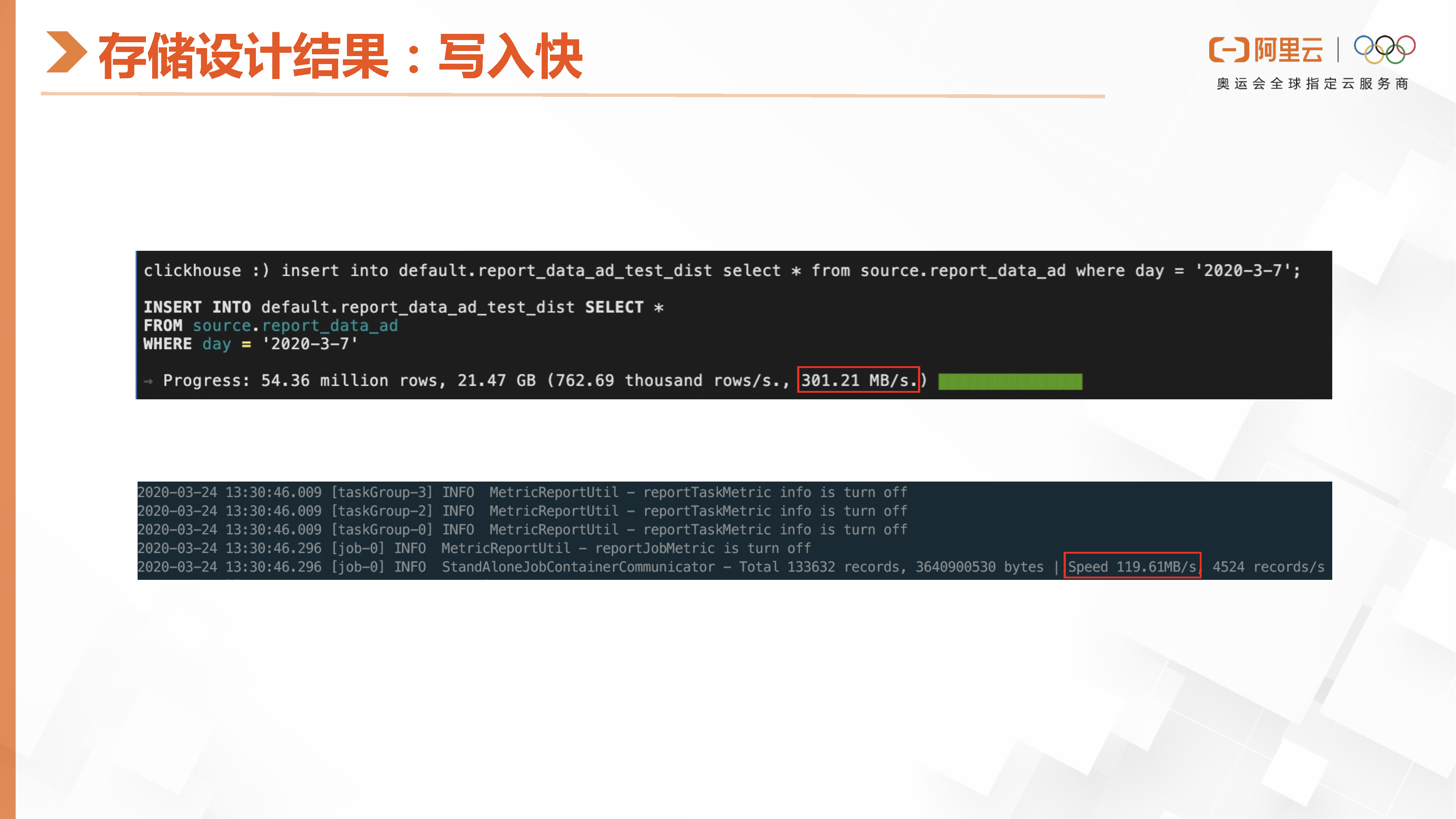
这张图可以看出,就是ClickHouse因为这个存储格式的设计,所以它在写入的时候,它的那个写入带宽是非常高的。
ClickHouse在分析场景上的性能非常高,这归功于以下几点原因。首先,它进行了针对硬件的优化,采用了多线程模型,能够让多机多核充分发挥CPU的性能。其次,它采用了向量化执行,并使用了很多Codegen和SIMD指令,从而提高了向量化处理的性能。此外,它的列存特点使得它非常友好于CPU-Cache。最后,它的C++代码在设计重构上也进行了很多优化,处理了许多细节。
在分析场景上,ClickHouse拥有许多近似算法、抽样方法、丰富的数据类型和支持窗口函数的功能。此外,它还具备查询队列和资源隔离的特点,虽然在这方面的表现相对较弱。
ClickHouse具有预先建模的能力,主要体现在用户可以根据底表创建物化视图。这些物化视图可以定义为一些聚合MergeTree,在后台不断地进行合并,根据建模的逻辑结构在后台进行一些计算。这种建模方式能够大大提高前台查询的速度。

这张图可以看出,ClickHouse在许多场景下都有细致的设计。例如,它在不同的场景中提供了聚合算子,而这些算子针对不同类型的数据提供了不同的计算逻辑。
比如说,对于物理数据,根据不同的数据大小或物理特性,可以采用不同的聚合算子。此外,它还可以自适应地使用不同的函数来处理不同的数据量。例如,对于唯一键的转换,如果数据量较小、中等或超大规模,它会选择不同的函数进行处理。
然后他在不同大小的一个内存使用上,它也会使用不同的内存分配函数,去做做内存分配。

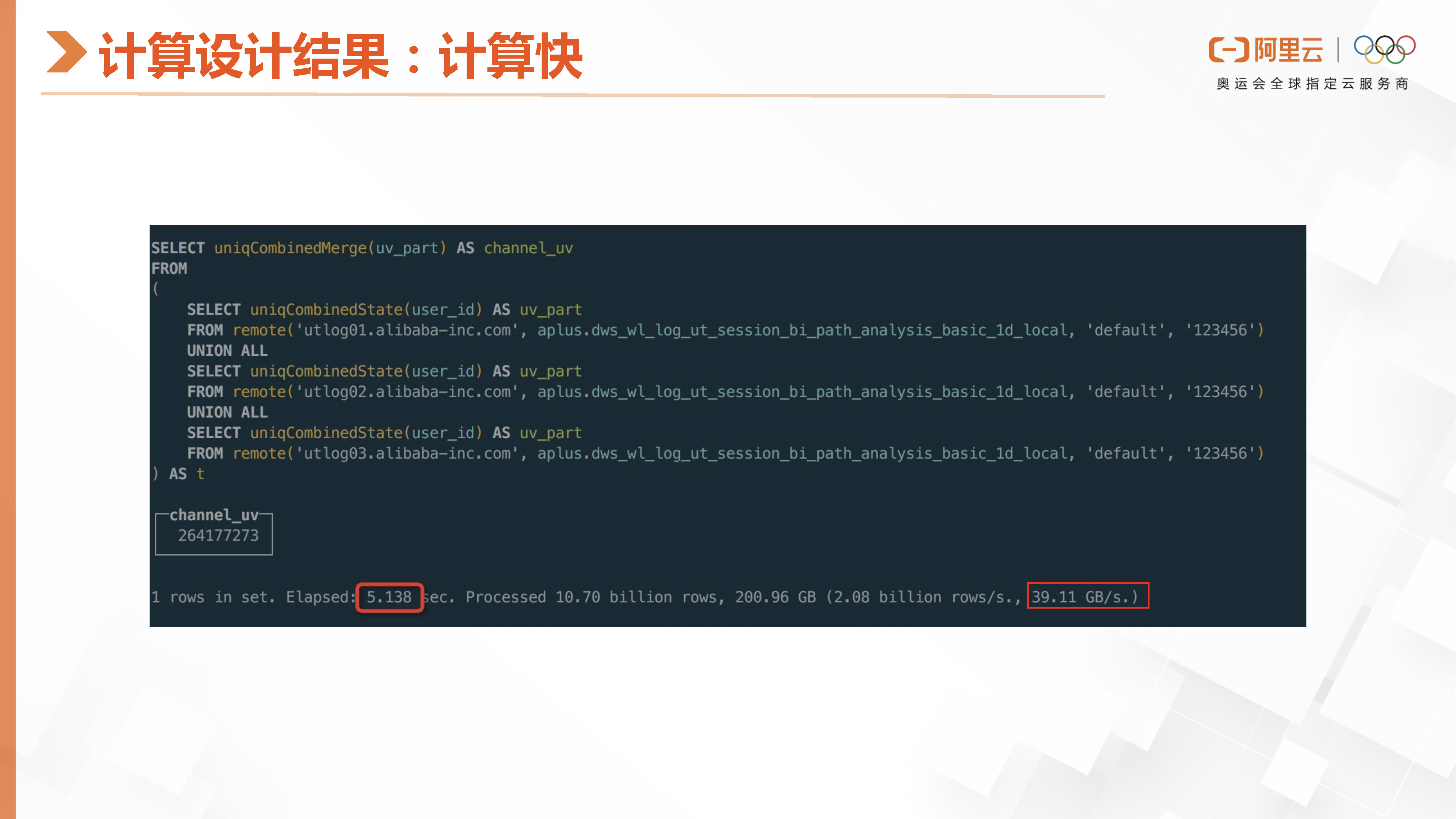
ClickHouse的查询性能非常快。例如,在处理一百亿行数据时,它可以执行UV操作,这种性能非常可观。
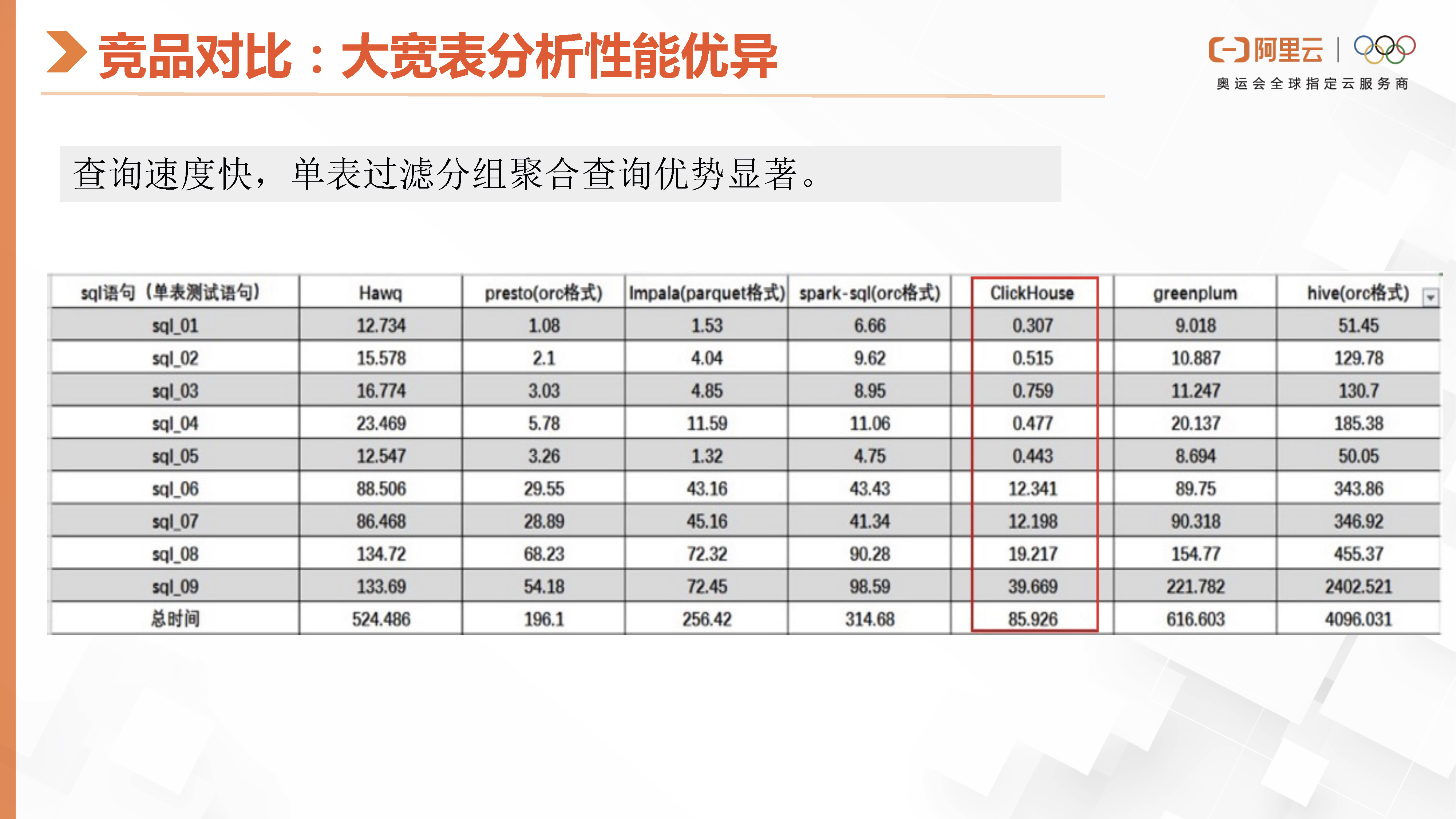
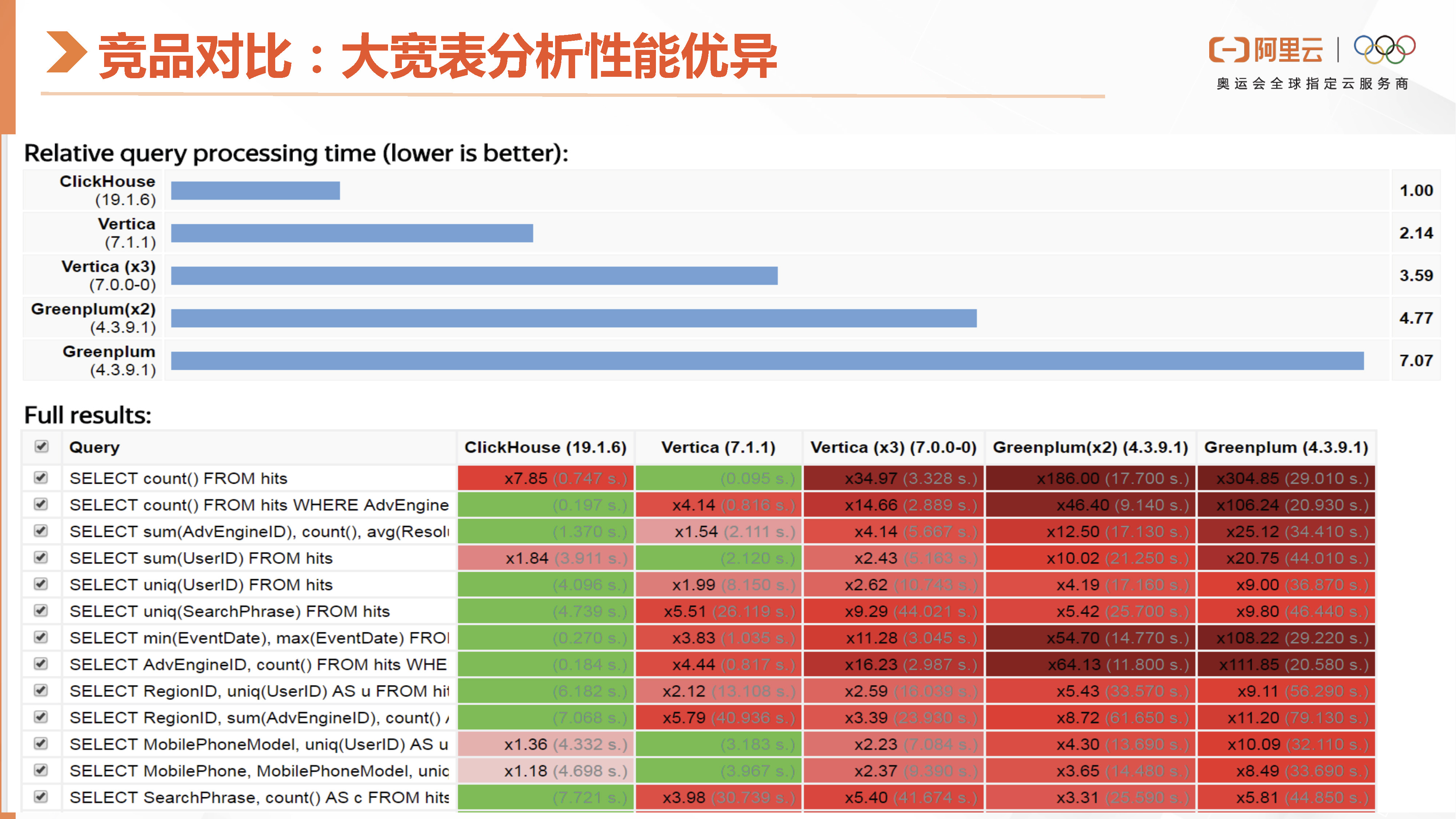
这里就是ClickHouse跟同类型的分析型数据库的性能对比,这是官网公布的一个PK的数据,查询速度还是很快,单表过滤分组聚合查询优势显著。
在这张图中,我们可以看到 ClickHouse 在灰盒测试中的数据结果。这份测试数据是比较早期的,来自 2020 年,使用的是 2019 版本。通过时间上的对比,我们可以发现 ClickHouse 在灰化之后,查询速度是 Vertica 的两倍多。这里也是对Greenplum是不同版本和不同节点的一个比较。
然后这里是具体的一个性能数据,他是把get的数据集打包成了一个大宽表。接下来我们也将会介绍ClickHouse的性能表现。需要注意的是,在Join场景下ClickHouse的性能相对较弱。但是在大宽表的查询性能上是非常高,ClickHouse表现非常出色,这个是有目共睹的。
然后再看一下我们社区ClickHouse版对有很多客户用上来之后有以下这些痛点,他的写入是有一些限制,他推荐你要聚合bach,要高频的并发,小粒度写。然后它的那个数据一致性是保证数据最终一次性,就是修改完就会立即可见,这个可见是指我那个多副本之间,它的数据全部是保证最终一致性的,如果是单机上,你去写完他返回提交成功,你是可以立即查的。然后它支持那个支持Delete/Update,但是异步生效的。而它不支持事务,最新版的这个ClickHouse社区版只支持part写入原子性。然后它需要后台的合并来保证主键的唯一性。
ClickHouse在计算层次的限制,这个join不是他的优势,需要根据不同场景修改SQL,进行专门的优化。此外,其优化器是否支持CPU优化也有待考虑。用户接口不够友好,创建表时需要同时建立本地表和分布式表,查询时只能查询分布式表,这些细节增加了用户使用ClickHouse的学习成本和困惑。此外,ClickHouse的建表习惯与大部分数据库不同,并且其数据类型与MySQL有较大差异。此外,ClickHouse采用sharding架构,存储和计算不分离,因此在弹性扩展容时缺乏弹性能力。
第三点是运维方面的限制。ClickHouse相当于手动挡,因为其运维不够友好。在扩缩容时,数据不会自动re-balance。在副本失败时,需要手动重建或恢复。此外,数据迁移工具也缺乏实时性,不支持备份恢复的功能。对于修改配置,有些设置不能持久化生效,需要手动修改配置文件或重启server。ClickHouse的调优和运维难度较高,需要用户具备一定的技术能力。因此,很多用户需要亲自查看源码并使用最新的C++标准开发,而开发者相对较少,C++代码量也较大,门槛很高。

接下来,进行第二部分,阿里云数据库的产品简介。阿里云数据库,产品定位是为最快最便宜的列式数据库,它在极致性能,最极低成本、简单灵活的架构、便捷的运维等,这几个目标上,去主打场景化的最佳解决方案。
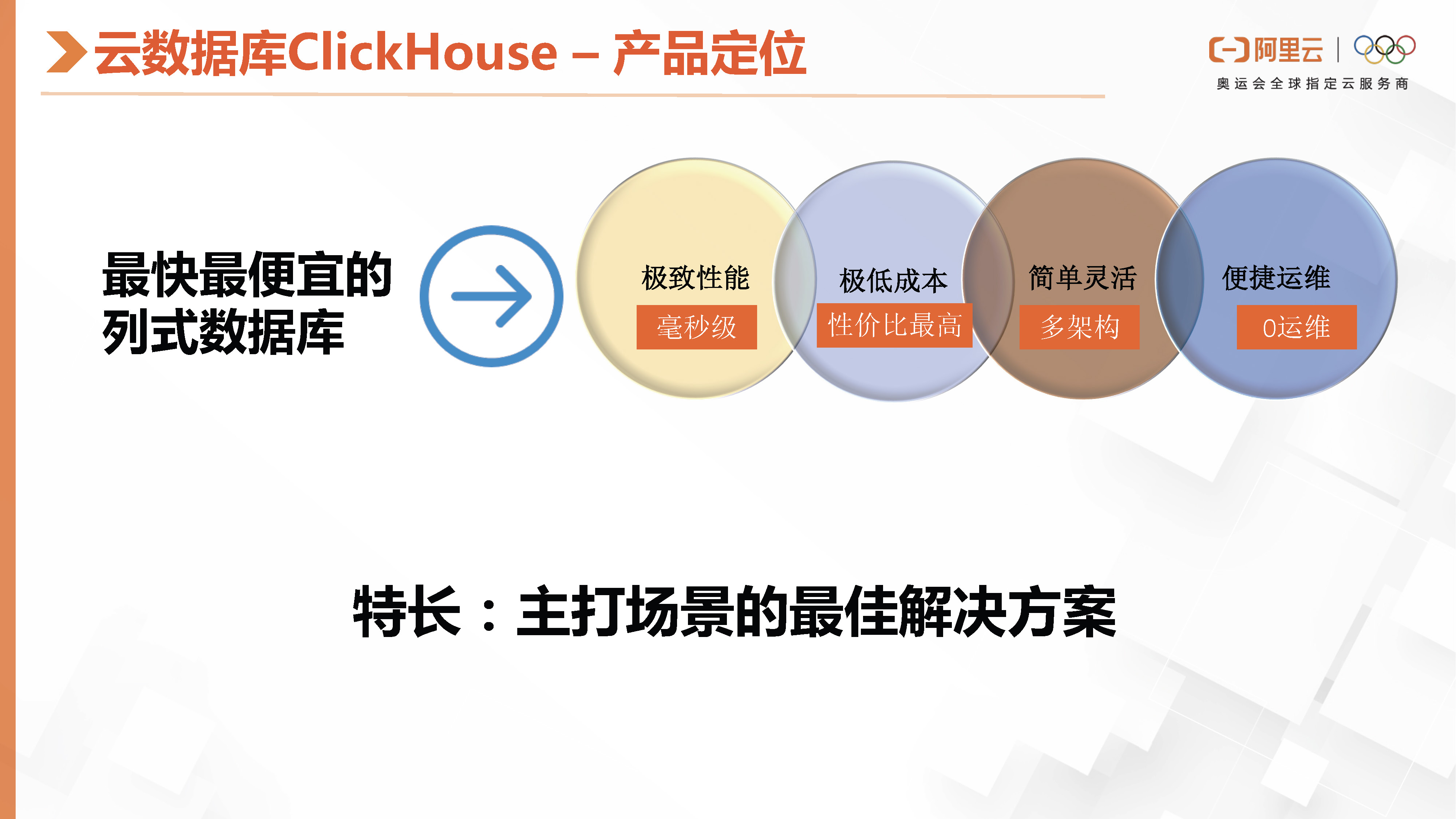
我们的主打场景是海量数据分析业务,包括大宽表查询和数据hash对齐的join场景等功能,这些功能虽然有很多限制,但能够满足大部分用户的需求。同时,我们的批量更新和删除操作,与其对应的part的key是有无关联,能够减少后续的更新和删除操作的开销,提高性价比,特别是对于那些对性价比比较敏感的用户来说。

这份表格对比了阿里云数据库ClickHouse和开源ClickHouse在运维、数据生态专家支持以及内核研发等方面的差异。我们发现,在运维方面,阿里云的ClickHouse提供了可视化的创建和实际管理集群的功能,而自建则只能手动部署。在Failover方面,我们的系统具备管控任务流,能够自动监控处理异常情况或自动拉起失败节点。容灾备份方面,阿里云数据库ClickHouse也提供了备份恢复功能。在安全性上,我们支持日志审计、白名单、RAM授权等功能,并提供公网SLB和阿里云云网络等安全保障措施。另外,我们也支持通过SQL进行参数修改,并提供词典管理,控制台上可以直接操作。我们还提供完善的监控和多指标报警体系,能够对慢SQL进行分析。
在水平或扩缩容节点方面,我们可以自动迁移数据。目前,我们已经实现了数据无需锁写的迁移,并在切换SLB时进行了短暂的切换。在用户权限管理方面,我们支持对支持RAM子账号授权。此外,在数据生态和数据接入方面,我们支持阿里云内部的DMS, SLS, DTS, DataWorks, OSS,MysQL外表、ODPS、Kafka,这些数据可以从这些系统中同步到ClickHouse行查询分析。我们还提供了专家服务支持,为用户业务提供设计和优化建议,以及对问题的快速处理。
在内核研发方面,我们关注社区版本的更新,对bugfix及时响应问题以及在前后兼容的情况下建议用户升级。在内核优化方面,我们的分层存储已经在可分离MPP架构的功能上实现,同时也可以在我们的云产品上体验到。这就是开源自建会有很多的的用户痛点。

我们阿里云ClickHouse的冷热分层主要优势在于成本。可以提供更高性价比的查询分析引擎。用户在创建表时,可以告诉系统数据生命周期的关键字段,然后后台会根据这些信息,将Data part的数据移至冷盘、OSS或HDD上。这样,相较于全部存储在ESSD上,整体成本将大幅降低。
在我们的存储设计中,针对用户进行数据过滤时产生的大量索引文件和小文件,我们也进行了一些优化。我们使用本地盘作为小文件的缓存(cache),这样在执行许多查询过滤操作时,不会直接访问到OSS,从而提高查询分析性能。同时,我们访问OSS采用流式的IO,其吞吐量可达到200 MB至1 GB的带宽,这个带宽接近或超过ESSD,而成本仅为ESSD的1/10。
对于存储在OSS上的数据,主备节点共享一份存储数据。在存储与计算分离的架构中,ClickHouse采用存储磁化,并按量计费。在计算节点数量方面,我们是实现了按需扩容。

第三部分,我们将继续介绍阿里云ClickHouse的重要功能特性。主要内容包括数据同步工具、多盘存储,以及自建ClickHouse如何迁移到云端的工具介绍。

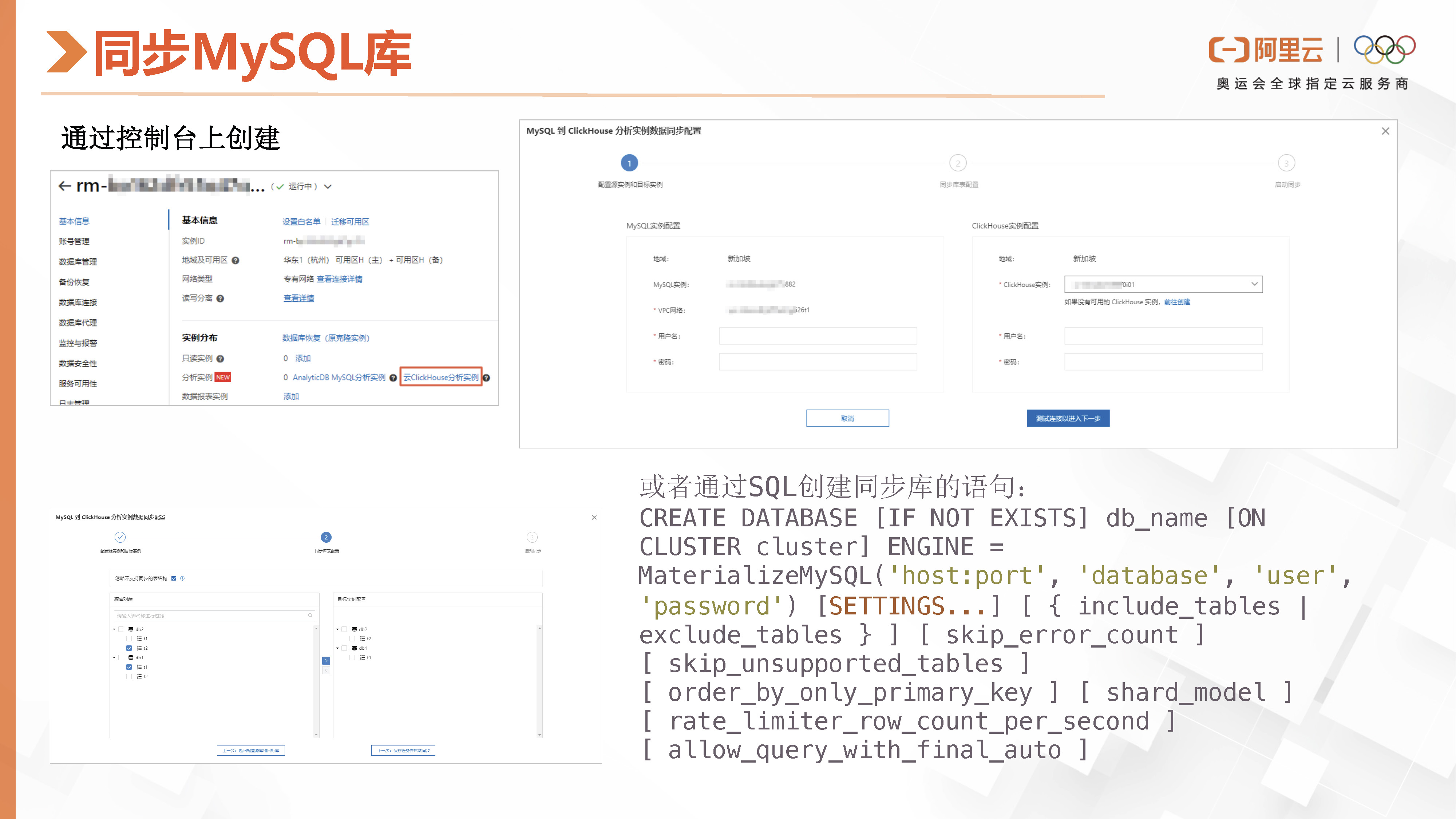
在本文中,我们将介绍如何在阿里云ClickHouse中创建从MySQL库同步到ClickHouse的任务。首先,在RDS控制台上,选择分析实例并进入到相应的界面。在此界面上填写RDS或MySQL的用户信息。接下来,在页面上勾选需要同步的库和表,然后点击“创建同步任务”。完成这些操作后,我们便可以在控制台上看到同步任务的状态。
对于习惯使用SQL创建任务的用户,可以参考页面右下角提供的SQL示例,创建MeterializeMySQL并配置同步表的白名单或黑名单以及其他设置。具体的配置信息可在阿里云的官网文档中查阅。
创建并启动同步任务后,系统将首先进行全量同步,随后进行增量同步。这样,用户便可以在ClickHouse中查询同步过来的表,并进行相关的数据分析任务。
如果用户在阿里云的ODPS上有大量数据,而ODPS无法进行查询分析或运行批处理等非实时查询引擎任务,那么可以在ClickHouse中创建ODPS外表。接着,通过使用insert into select语句从ODPS外表同步数据到ClickHouse。完成同步后,便可以在ClickHouse中进行查询分析。

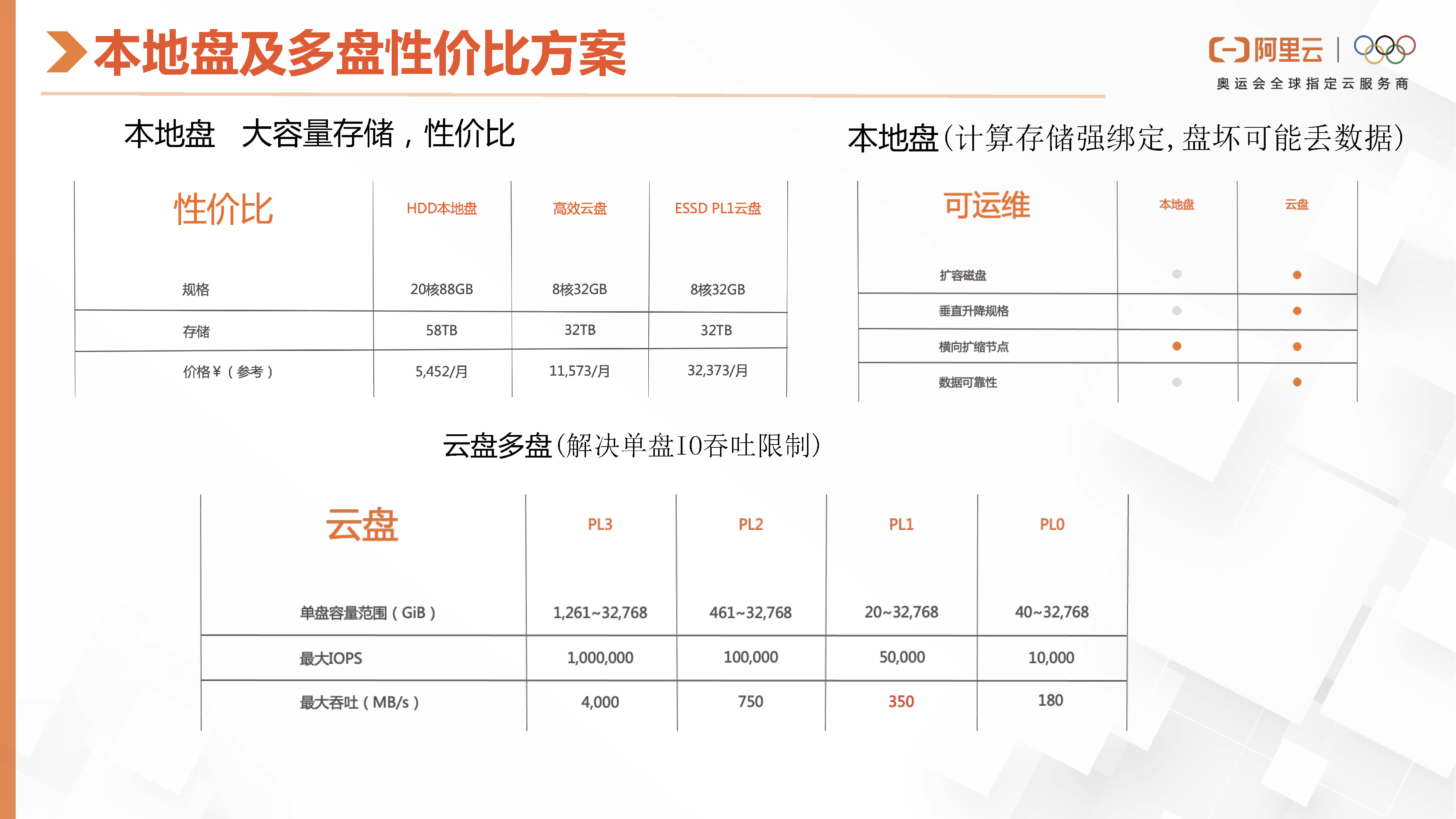
我们将介绍阿里云ClickHouse产品,它是一款主打性价比的解决方案。该产品支持用户购买本地盘,这里有和高效云盘和ESSD在规格和价格上的对比分析。我们可以看到,HDD的成本要比高效云盘低一半,而ESSD的费用是本地盘的六倍多。但使用本地盘也存在一定问题,即数据与计算是强绑定的,如果本地盘损坏,可能会有数据丢失的风险。
然而,对于一些用户在存储日志或纯监控场景中,或者允许数据丢失的产品场景,它们可以接受这一限制。此外,有些用户对读写带宽有较高要求,而单个ESSD盘的ClickHouse在IO方面存在限制。阿里云的ClickHouse支持用户购买多个云盘或本地盘组成一个RAID零,也可以在ClickHouse配置中组建一个结构,底层使用LVM,从而提供多盘聚合带宽能力。
在多盘性价比方案中,我们提供了冷温热三层的分层存储。下面是一个分层存储的架构示意图。当数据需要立即写入时,我们会先将其写入云盘ESSD中,以便快速合并。然而,一段时间后或者当达到特定的TTL时,数据会被移动到本地盘。最后,如果时间更长,数据会被移动到OSS上。因此,我们提供了三种不同的分层存储组合,以满足不同的使用场景。例如,将云盘与OSS组合使用可以实现冷热分层,根据TTL进行归档进冷存。而将云盘与本地盘组合使用则可以实现冷温分层,将最近N天的频繁查询TTL存储到本地盘中。我们将根据用户的实际业务场景选择最适合的冷温热组合。

如果用户已经存储了大量数据在自建集群中,但在使用过程中遇到了前文提到的运维困难和其他无法解决的问题,那么可以考虑使用阿里云ClickHouse。我们提供了一个方便的迁移工具,其主要原理是解决数据实时同步的问题。但是数据同步可能存在一个问题,即原有的实例集群会在后台不断地合并Data Part,如果我们在这里捕捉到了数据,有可能在后面就会被合并掉。例如,我开始追踪一个Part并读取它,但当我要同步这个Part时,它源头的集群已经将这两个Part合并成了一个,这样我就找不到了。为了解决这个数据同步问题,我们提供了一个配合Pass Log的方案。
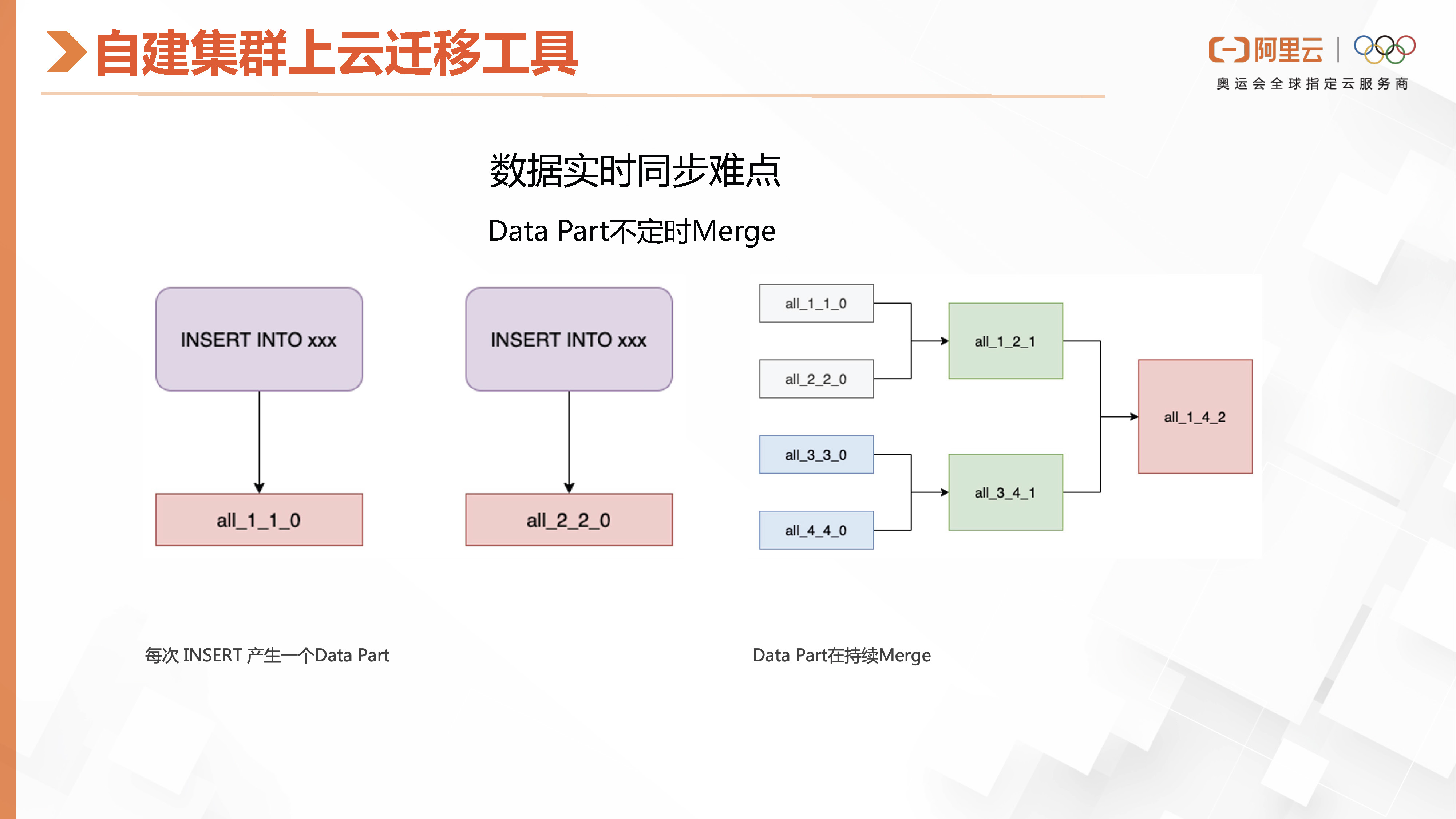
Pass log是我们刚才介绍的一个功能,通过该功能,我们可以将几个后台的数据进行合并,以实现数据的整合。当我们开始同步数据时,只同步了其中的一部分,即SD1的部分。如果后续需要读取整个合并后的大part,我们可以通过追踪part log来了解它是由哪些原始part合并而成的。这样,我们就可以直接同步所需的part,保证数据的一致性。同时,我们还可以将源头part之外的数据删除,以确保数据的完整性。

我们的迁移工具名为cksync,相较于社区提供的clickhouse-copier工具,cksync在语言、资源占用、上手使用、并发模型、write-lock-free以及临时表机制等方面都有其独特的特点和优势。左侧是我们工具的命令行参数列表。

接下来,我们将介绍云原生ClickHouse的技术演进的第四部分,主要介绍存储计算分离方案以及多计算组。

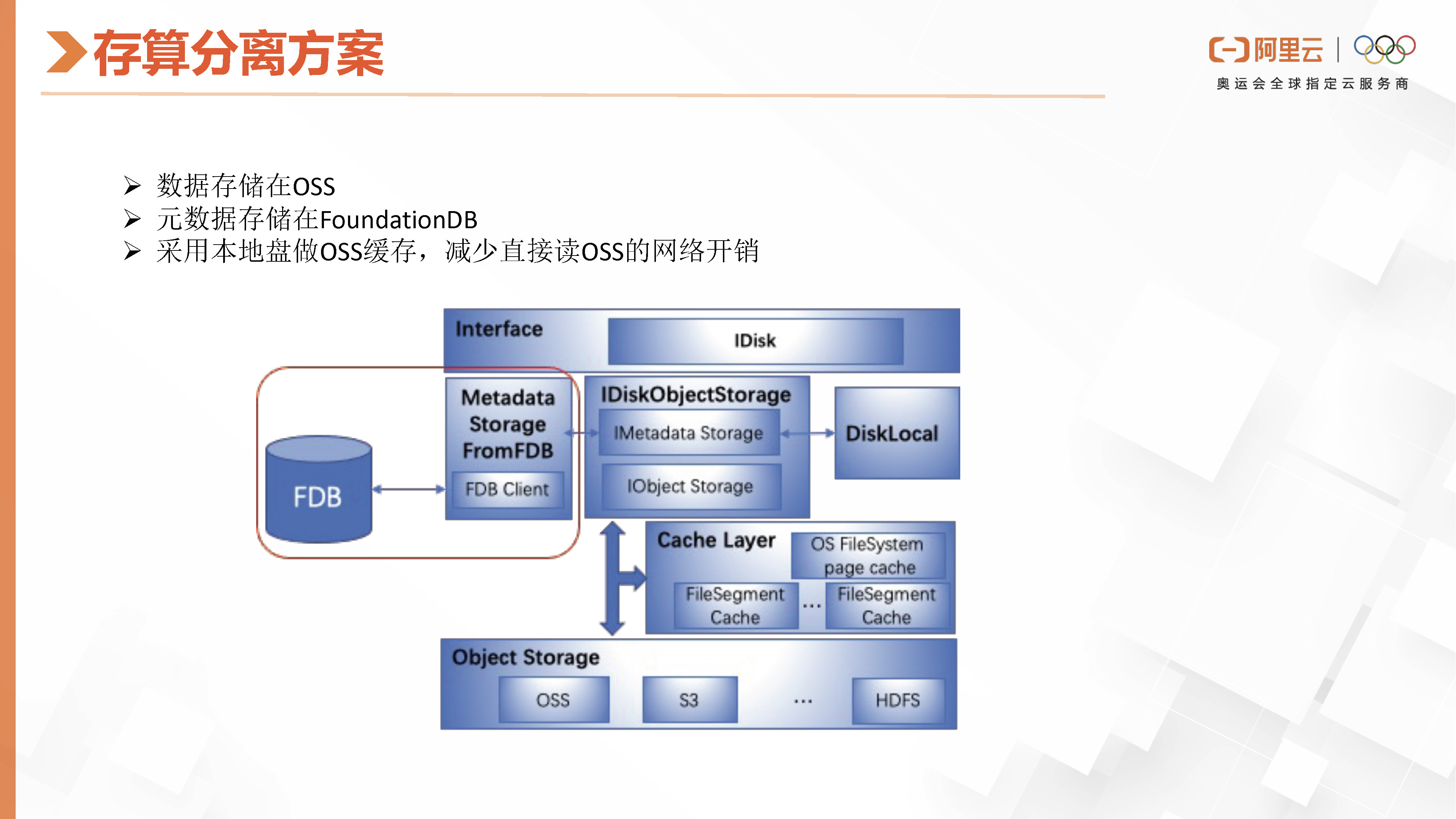
阿里云云原生ClickHouse采用的架构与第一位嘉宾介绍的ByteHouse类似,首先解决了存算分离的问题,即数据存储与计算节点解耦。我们的方案是将数据存储在OSS上,源数据存储在FDB上,并在worker节点上设置了OSS的Cache,使用本地盘作为Cache以降低直接访问OSS的网络开销。此外,我们采用中心化的controller协调查询,命中查询先传递到controller,由具体的查询computer worker再将其转发,然后controller进行查询计划的生成和数据前期的filter过滤,再将要扫描的数据以及执行计划发送给computer worker,最终查询结果返回给用户。为了实现读写分离,我们将数据的写入和后台合并工作线程分别用不同的服务进程处理,从而使计算节点完全无状态。

这张图详细介绍了ClickHouse的存算分离方案。在ClickHouse中,这个方案是在抽象的ID层实现的,类似于虚拟文件系统中的存算分离。
在那个弹性计算组上,我们主要解决的是节点计算资源水平扩缩容的问题。我们可以动态地增加计算节点,由多个节点协调所有计算查询任务,最后将结果汇总给发起节点,并返回查询结果。
为了解决不同业务或多租户之间相互影响的问题,我们使用多计算组实现资源隔离。用户可以在控制台上秒级创建并部署计算资源,以响应用户的快速查询和大数据量处理,从而避免影响常规业务。

OK,,我今天的分享就到这里。
本次大会围绕“技术进化,让数据更智能”为主题,汇聚字节跳动、阿里云、玖章算术、华为云、腾讯云、百度的6位数据库领域专家,深入 MySQL x ClickHouse 的实践经验和技术趋势,结合企业级的真实场景落地案例,与广大技术爱好者一起交流分享
相关文章:
阿里云数据库ClickHouse产品和技术解读
摘要:社区ClickHouse的单机引擎性能十分惊艳,但是部署运维ClickHouse集群,以及troubleshoot都不是很好上手。本次分享阿里云数据库ClickHouse产品能力和特性,包含同步MySQL库、ODPS库、本地盘及多盘性价比实例以及自建集群上云的迁…...
分子动力学基础知识
分子动力学基础知识 目前主要存在两种基本模型:其一为量子统计力学, 其二为经典统计力学。 量子统计力学 基于量子力学原理, 适用 于微观的, 小尺度, 短时 间的模拟,可以描述电子 的结构分布,原子间的成 键断键等化学性质。 经典纭计力学…...

USB转UART转串口芯片 GP232RNL国产低成本替代FT232RL/FT232RNL
近期收到很多人咨询FT232RL跟新版FT232RNL两者有什么区别,实际上就是内部做了一点升级,FT232RNL支持Windows11系统,参数并没有改动,完全可以直接替换使用。 今天小编给大家讲讲FT232RNL国产低成本替代芯片–GP232RNL GP232RNL 是…...
第03讲:SpringCloudStream实现分布式事务
需求分析 本案例是通过一个发送短信验证码的功能来实验MQ发送消息时实现分布式事务,思路分析如下 消息生产者生产发送验证码的半消息 生产者执行本地事务(将验证码保存到数据库),并记录事务的ID,如果整个过程不出现异…...
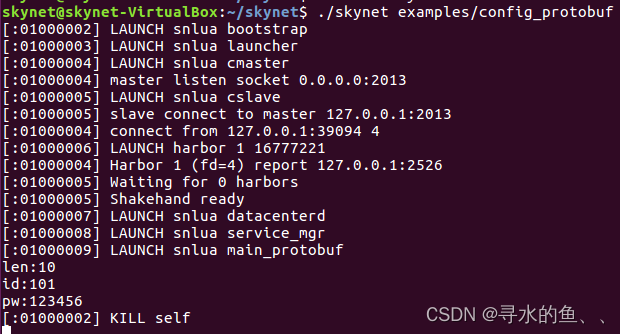
【从零开始学Skynet】高级篇(一):Protobuf数据传输
1、什么是Protobuf Protobuf是谷歌发布的一套协议格式,它规定了一系列的编码和解 码方法,比如对于数字,它要求根据数字的大小选择存储空间,小于等于15的数字只用1个字节来表示,大于15的数用2个字节表示,以此…...

快速入门Lombok
Lombok是一个Java库,可以通过注解的方式来简化Java代码,它可以自动生成Getter、Setter、构造函数等代码,从而减少重复的模板代码。下面是Lombok的使用详情: 1. 添加Lombok依赖 在使用Lombok之前,我们需要先添加Lombo…...
Linux 常见命令与常见问题解决思路
Linux 常见命令 Linux 基础命令目录相关查看文件(日志)查看普通的文件查看压缩的文件 解压压缩Linux 系统调优topvmstatpidstatps vi/vim 编辑文件查找文件属性相关定时任务scp 复制文件和目录awk 分隔cutsort 与 uniq常见问题处理思路CPU 高系统平均负载…...

用GPT-4 写2022年天津高考作文能得多少分?
正文共 792 字,阅读大约需要 3 分钟 学生必备技巧,您将在3分钟后获得以下超能力: 积累作文素材 Beezy评级 :B级 *经过简单的寻找, 大部分人能立刻掌握。主要节省时间。 推荐人 | Kim 编辑者 | Linda ●图片由Lexica …...

Django如何把SQLite数据库转换为Mysql数据库
大部分新手刚学Django开发的时候默认用的都是SQLite数据库,上线部署的时候,大多用的却是Mysql。那么我们应该如何把数据库从SQLite迁移转换成Mysql呢? 之前我们默认使用的是SQLite数据库,我们开发完成之后,里面有许多数…...

使用apisix代理静态文件
前言 最近公司考虑用apisix作为公司网关并且部署到k8s上,我这边收到一个小任务:使用apisix代理静态文件 通过apisix官网了解到它构建于 NGINX ngx_lua 的技术基础之上,所以按理应该和nginx代理静态资源是一样的。因为是通过docker容器部署…...
)
[元带你学NVMe协议] NVMe1.4 多路径(Multipathing)
声明 主页:元存储的博客_CSDN博客 依公开知识及经验整理,如有误请留言。 个人辛苦整理,付费内容,禁止转载。 内容摘要 全文9100字, 主要内容 目录 前言 1 多路径(Multipathing)概念...

Elasticsearch:如何使用自定义的证书安装 Elastic Stack 8.x
在我之前的文章 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch”,我详细描述了如何在各个平台中安装 Elastic Stack 8.x。在其中的文章中,我们大多采用默认的证书来安装 Elasticsearch。在今天的文章中,我们用自己创…...

HADOOP--yarn ,, git
Yarn架构体系 主从架构 也是采用 master(Resource Manager)- slave (Node Manager)架构,Resource Manager 整个集群只有一个,一个可靠的节点。 1、 每个节点上可以负责该节点上的资源管理以及任务调度&am…...
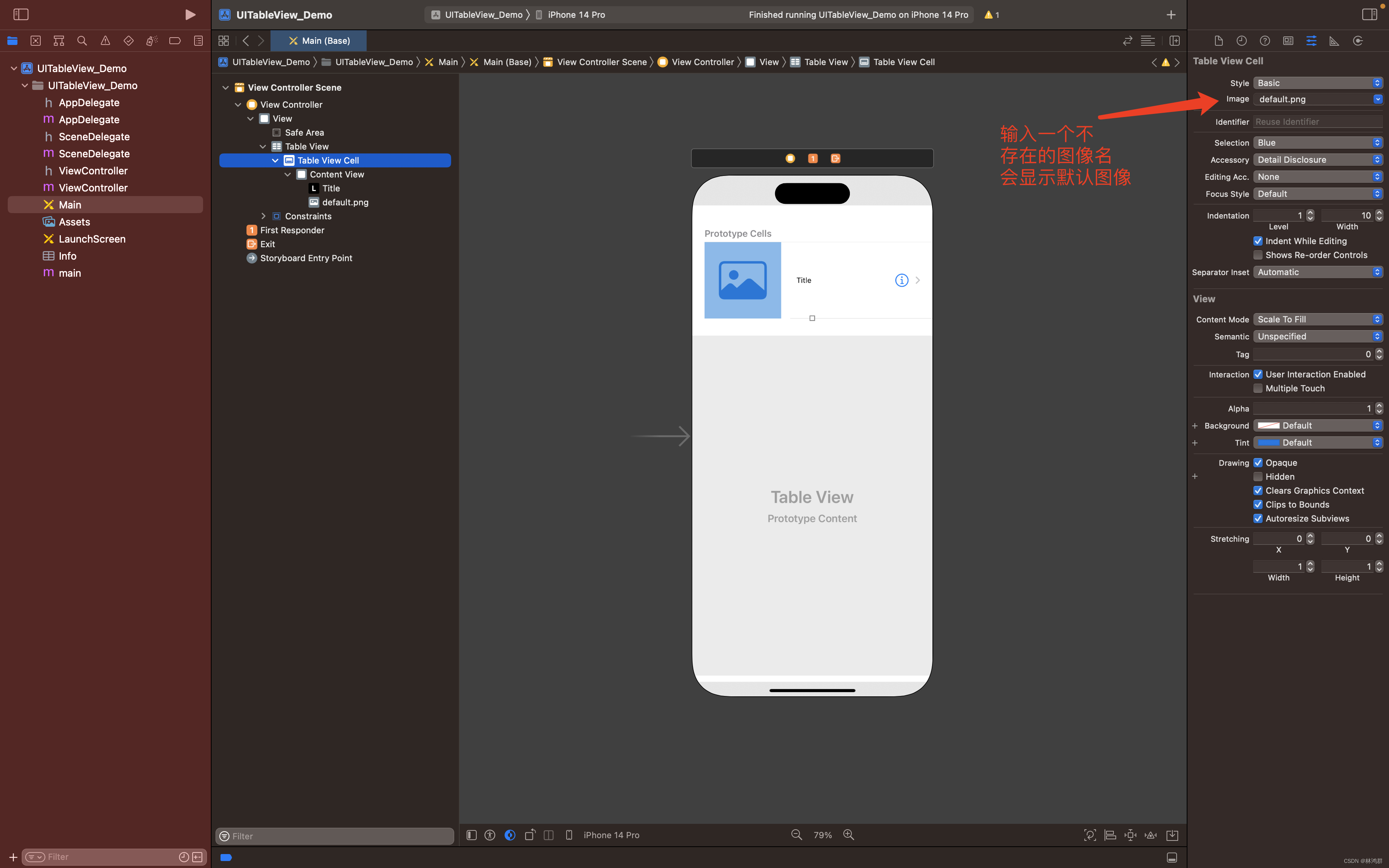
IOS开发指南之UITableView控件使用
1.创建一个IOS单页应用 2.双击Main.storyboard然后拖放UITableView到视图中 3.添加TableViewCell 成功添加Table View Cell 4.修改Table View Cell属性 选中Table View Cell 在右边的Image栏输入default.png回车 到此布局设计完成,现在运行还是显示 空白,要在代码中做相关的实…...
C语言中的数据类型
目录 一、数据类型 1.基本类型 2.sizeof运算符 3.signed和unsigned 二、基本数据类型的取值范围 1.比特位 2.字节 3.符号位 4.补码 5.基本数据类型的取值范围 一、数据类型 1.基本类型 (1)整数类型 short intintlong intlong long int &…...
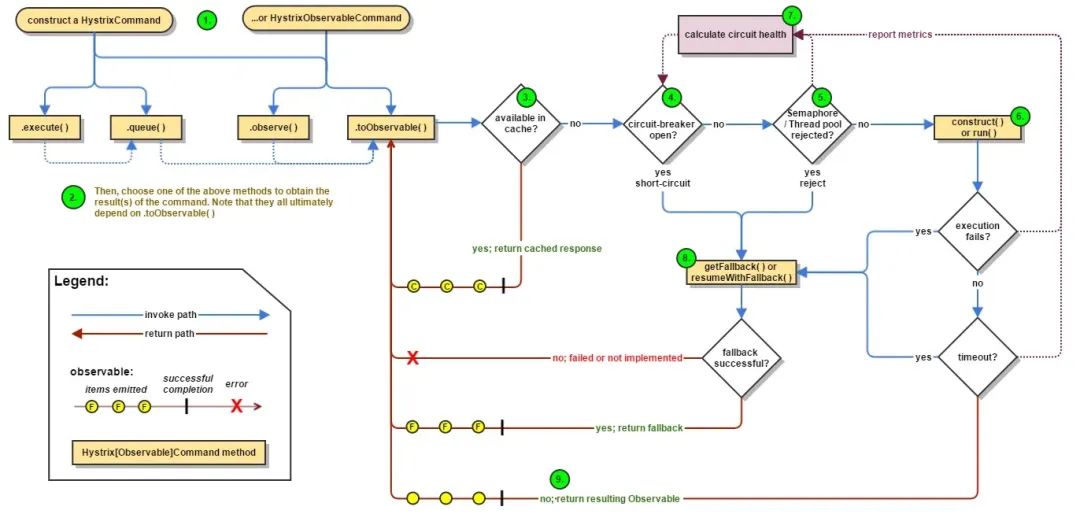
什么是微服务中的熔断器设计模式?
在本文中,我将解释什么是熔断器设计模式以及它解决了什么问题。 我们将仔细研究熔断器设计模式,并探讨如何使用Spring Cloud Netflix Hystrix在Java中实现它。到本文结束时,您将更好地了解如何使用熔断器设计模式提高微服务架构的弹性。 熔断…...

Ubuntu查看系统日志的几种方法
在 Ubuntu 22.10 中,你可以查看系统日志来排查错误。以下是几种查看日志的方法: 一、Journalctl 命令: 使用 journalctl 命令可以查看系统日志信息,包括引起闪退的错误信息。你可以运行以下命令来查看最新的系统日志:…...

【ubuntu】安装ZIP
【ubuntu】安装ZIP 输入如下命令安装zip $ sudo apt-get install zip 输出信息如下: Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: unzip The follo…...

DiffDock源码解析
DiffDock源码解析 数据预处理 数据输入方式 df pd.read_csv(args.protein_ligand_csv), 使用的是csv的方式输入, 格式: 不管受体还是配体, 输入可以是序列或者3维结构的文件 如果蛋白输入的是序列,需要计算蛋白的三维结构&am…...
1099 Build A Binary Search Tree(超详细注解+38行代码)
分数 30 全屏浏览题目 作者 CHEN, Yue 单位 浙江大学 A Binary Search Tree (BST) is recursively defined as a binary tree which has the following properties: The left subtree of a node contains only nodes with keys less than the nodes key.The right subtree…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...