Python网络爬虫 学习笔记(2)BeaufitulSoup库
文章目录
- BeautifulSoup库的基本介绍
- HTML标签的获取和相关属性
- HTML文档的遍历
- prettify()方法
- 使用BeautifulSoup库对HTML文件进行内容查找
- 信息的标记的相关概念(非重点)
- find_all()方法(重点)
- 综合实例:爬取软科2022中国大学排名
承接上文:Python网络爬虫 学习笔记(1)requests库爬虫
BeautifulSoup库的使用背景:即使我们可以通过requests库获得网页的text信息,但是这个text信息只是网页的源代码,我们需要从这个源代码中寻找我们需要的信息,这时候就可以使用BeautifulSoup库来帮助我们实现目的。
BeautifulSoup库的基本介绍
HTML标签的获取和相关属性
Beautifulsoup库概述:
- 一个能够解析HTML和XML文件的功能库。
- 由于一个HTML文档或XML文档对应一个标签树,因此也可以说,该库是解析、遍历、维护标签树的功能库。
- 该库可以将任意一个标签树转换为一个BeautifulSoup类的对象。
- HTML/XML文档、标签树和BeautifulSoup对象之间是一一对应的关系。
最常用的库导入方式:from bs4 import BeautifulSoup。
BeautifulSoup类对象创建:
变量名=BeautifulSoup(HTML文件名/XML文件名,解析器)
- HTML文件名/XML文件名:通过request库的get函数获取的Response对象,其text域即为一个HTML或XML文件,因此可以用来作为参数。
- 解析器:当创建BeautifulSoup对象时需要指定解析器,用于表示文档的类型。自带的对HTML文档的解析器是"
html.parser",一般情况下使用这个解析器即可。
BeautifulSoup类的基本元素:
标签:
- 介绍:最基本的信息组织单元,分别用<>和</>标明开头和结尾。
- 使用方式:
BeautifulSoup变量名.标签名。
备注:如果存在多个名字相同的标签,则只会返回第一个标签对应的内容。
标签名:
- 介绍:< p >…< /p >的标签名为p。
- 使用方式:
BeautifulSoup变量名.标签名.name。
标签的属性:
- 介绍:以字典的形式进行组织。
- 使用方式:
BeautifulSoup变量名.标签名.attrs。 - 返回内容:一个字典,包括标签的各个属性的信息。
标签内非属性字符串:
- 介绍:即一对标签之间的内容,以字符串进行表示。
- 使用方式:
BeautifulSoup变量名.标签名.string。
内容注释:
- 介绍:标签内字符串的注释部分。
- 使用方式:和获取标签内字符串相同,需要通过返回值类型进行区分。
实战案例(BeautifulSoup对象的创建和标签的使用):
# 首先需要导入requests库和BeautifulSoup类
import requests
from bs4 import BeautifulSoup
# 使用get方法爬取测试网站的内容
r=requests.get("https://www.baidu.com/")
# 对可能抛出异常的部分放入try块中
try:# 检测Response对象的状态码,判断是否抛出异常r.raise_for_status()# 如果header中不存在charset字段,则encoding采用默认编码方式,很可能解析错误if r.encoding=="ISO-8859-1":# 将网页内容编码方式修改成从内容分析出的编码方式r.encoding=r.apparent_encoding# 获取网页的HTML源代码demo=r.text###### 新学习的内容 ####### 使用HTML解析器对源代码进行解析soup=BeautifulSoup(demo,"html.parser")# 显示网页的title标签内容print(soup.title)
########################### 检测到异常后执行的语句
except:print("网页访问失败!")
HTML文档的遍历
HTML文档对应一棵唯一的标签树,因此对HTML文档的遍历也就是对标签树的遍历。共有下行遍历、上行遍历和平行遍历三种方法。
下行遍历:从根节点向叶子节点遍历。
- contents:获取一个标签的子标签的列表。
- children:获取一个标签的子标签,是contents的迭代烈性,用于for…in结构循环遍历子标签。
- descendants:子孙标签的迭代类型,包含所有的子孙标签,用于for…in方式循环遍历。
备注:标签包括标签名和一对标签名中间的内容,而非只是标签名。
上行遍历:从叶子节点向根节点遍历。
- parent:获取当前标签的父标签。
- parents:获取当前标签的所有先辈标签,属于迭代类型,用于for…in结构的循环遍历。
平行遍历:同一层次节点间的遍历。
- next_sibling:按照HTML文本顺序的下一个平行标签。
- previous_sibling:按照HTML文本顺序的上一个平行标签。
- next_siblings:迭代类型,用于for…in结构按照HTML文本顺序遍历后续所有平行标签。
- previous_siblings:迭代类型,用于for…in结构按照HTML文本顺序遍历之前所有平行标签。
备注:只有父标签相同的标签才能进行平行遍历。
prettify()方法
方法概述:在HTML文件中合适的位置插入换行符,使得在展示HTML文件内容时更加方便阅读和程序处理。
备注:prettify方法也可以用于处理单个标签。
测试用例:
# 首先需要导入requests库和BeautifulSoup类
import requests
from bs4 import BeautifulSoup
# 使用get方法爬取测试网站的内容
r=requests.get("https://www.baidu.com/")
# 对可能抛出异常的部分放入try块中
try:# 检测Response对象的状态码,判断是否抛出异常r.raise_for_status()# 如果header中不存在charset字段,则encoding采用默认编码方式,很可能解析错误if r.encoding=="ISO-8859-1":# 将网页内容编码方式修改成从内容分析出的编码方式r.encoding=r.apparent_encoding# 获取网页的HTML源代码demo=r.text###### 新学习的内容 ####### 使用HTML解析器对源代码进行解析soup=BeautifulSoup(demo,"html.parser")# 直接显示HTML源代码print(soup)# 对HTML源代码使用prettify方法处理并输出处理完的效果print(soup.prettify())
########################### 检测到异常后执行的语句
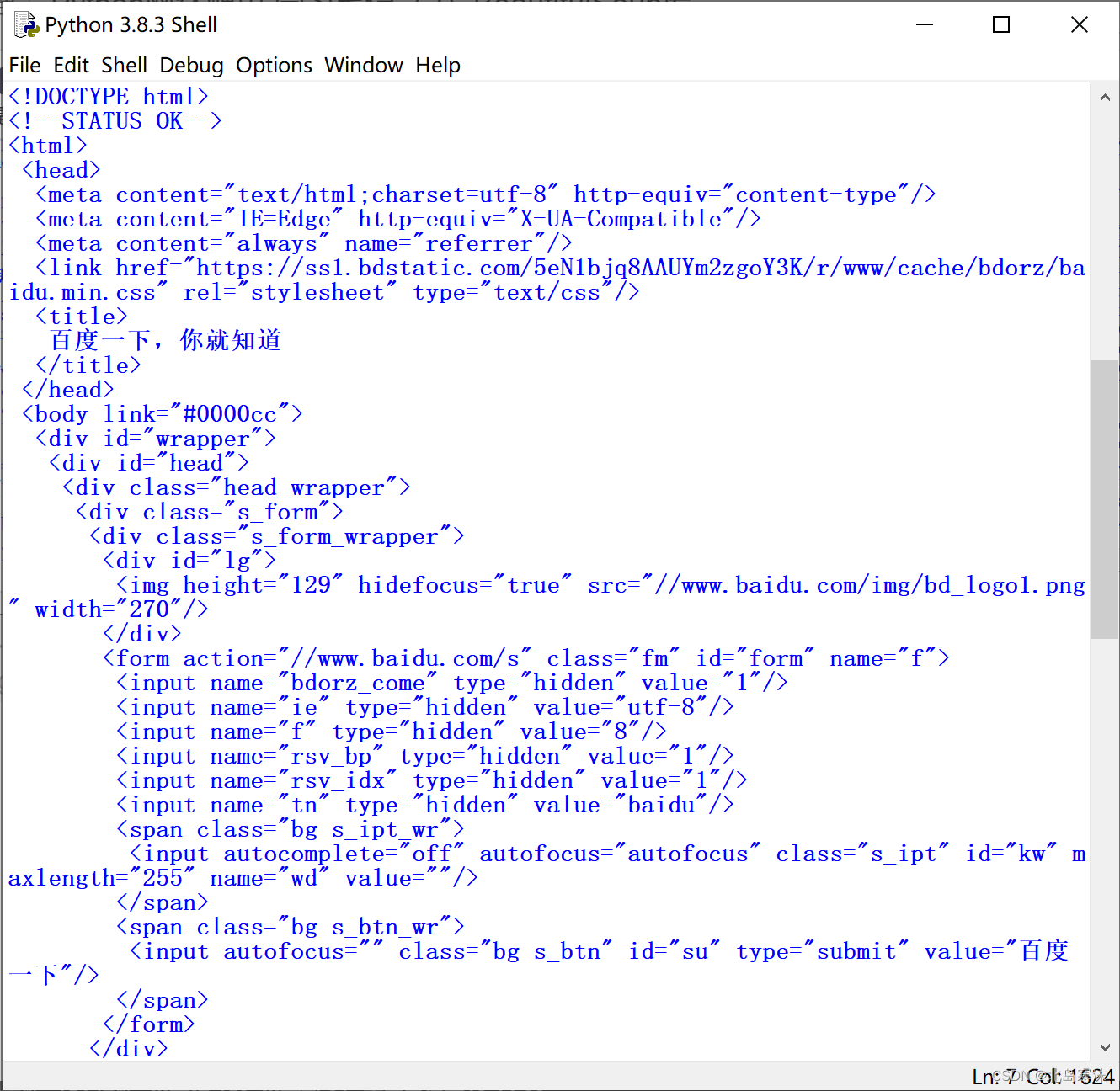
except:print("网页访问失败!")处理前后效果对比:
- 处理前:
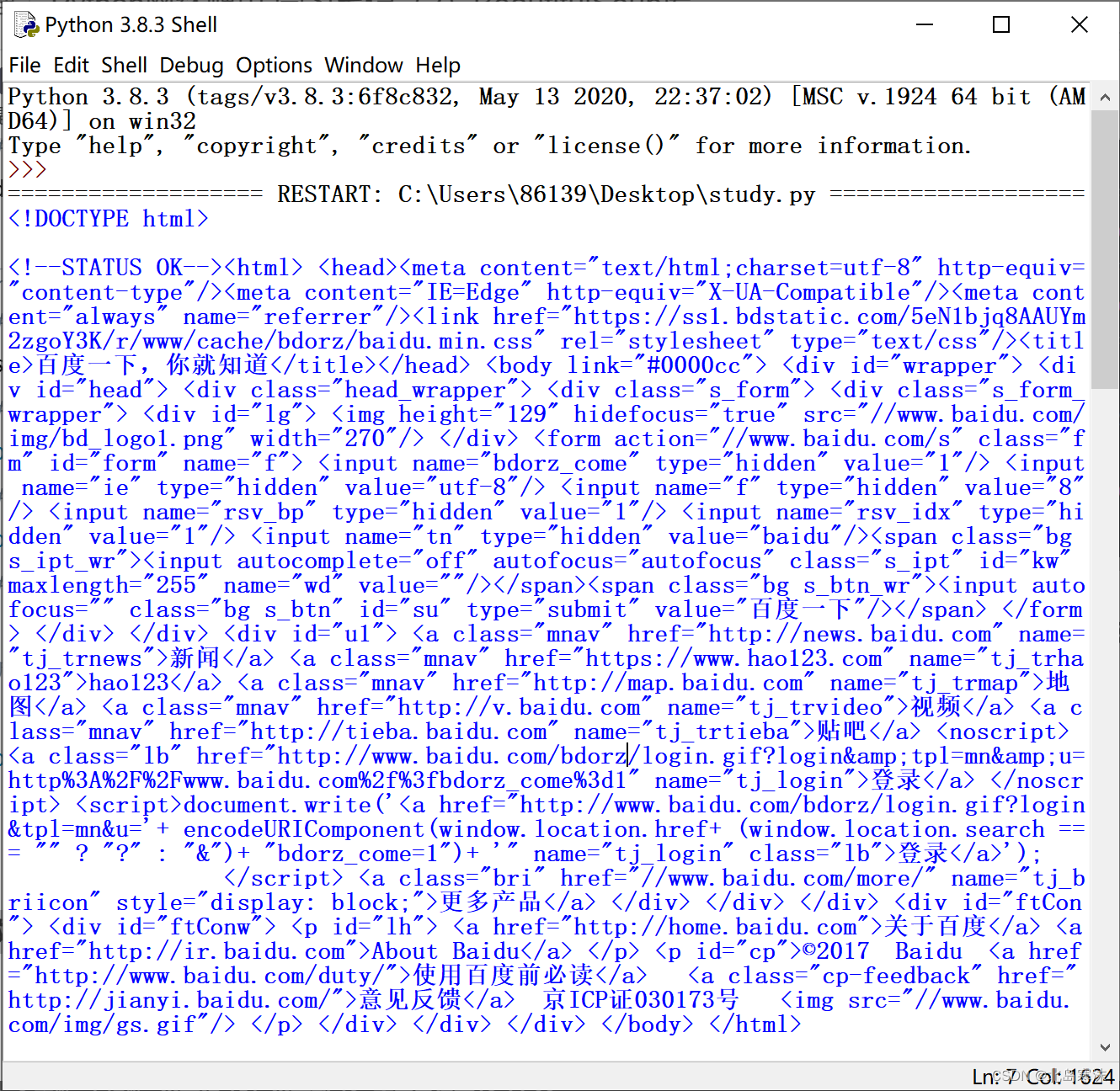
- 处理后:
使用BeautifulSoup库对HTML文件进行内容查找
信息的标记的相关概念(非重点)
信息标记的好处:
- 标记后的信息可以形成信息的组织结构,增加了信息的维度。
- 标记后的信息可以用于通信、存储或展示。
- 标记后的结构和信息一样具有重要价值。
- 标记后的信息有利于程序的理解和应用。
HTML简介:超文本标记语言。HTML是WWW的信息主要组织形式,能够将各种超文本信息嵌入到文本中。HTML通过标签组织不同类型的信息。
信息标记的三种形式:
XML:
- 基本概念:扩展标记语言,是一种与HTML很接近的标记语言,采用以标签为主来构建和表达信息的方式。
- 特点:最早的通用信息标记语言,可扩展性好,但是较为繁琐。
- 举例:(参考北京理工大学慕课)

JSON:
- 基本概念:由有类型的键值对构成的信息表达格式。
- 特点:信息有类型,文本信息比例最高,比XML更加简洁。
- 举例:(参考北京理工大学慕课)

YAML:
- 基本概念:采用无类型的键值对构成的信息表大格式,通过缩进来表示所属关系。
- 特点:信息无类型,文本信息比例最高,可读性好。
- 举例:(参考北京理工大学慕课)

信息提取的一般方法:
- 完整解析信息的标记形式,再提取关键信息。需要标记解析器,如bs4库对标签树的遍历。特点是信息解析准确,但是提取过程繁琐且速度很慢。
- 无视标记形式,直接搜索关键信息,对信息的文本进行查找即可。特点是提取过程简洁且速度较快,但是提取结果的准确性和信息内容相关。
- 融合方法:结合形式解析和搜索方法来提取相关信息,这是实际使用中最好的方法。
find_all()方法(重点)
基本语法:find_all(name,attr,recursive,string)
返回值:返回一个包含满足条件的标签的集合,集合中的每一个元素是一个标签。
- name:对标签的名称进行检索的字符串。如果需要同时查找多个标签名,可以传入一个列表。
- attrs:对标签属性值的检索字符串,可以标注属性检索。用于查找带有某个指定名称属性的指定名称的标签。
- recursive:布尔类型。当为True时表示查找当前标签的所有子孙标签;当为False时表示仅查找当前标签的同一层标签。
- string:对一对标签之间的字符串进行检索。
备注:find_all方法的基本语法都只支持精确查找,例如与查找目标相差一个字符,或包含查找目标的情况都无法查找成功,需要借助正则表达式库。
查找某个指定属性为指定值的语法:find_all(属性名=属性值)
备注:此时find_all方法不能再添加attr参数。
综合实例:爬取软科2022中国大学排名
# 进行网站爬取首先需要导入requests库
import requests
# 对网页的HTML内容进行解析需要用到bs4库
import bs4
# 需要使用到bs4库中的BeautifulSoup类对象
from bs4 import BeautifulSoup# 设置所爬取的软科大学排名网站的URL
URL="https://www.shanghairanking.cn/rankings/bcur/2022"
# 使用request库的get方法爬取该URL对应的网络资源
r=requests.get(URL,timeout=20)
# 网络资源爬取可能失败抛出异常,因此需要考虑异常处理
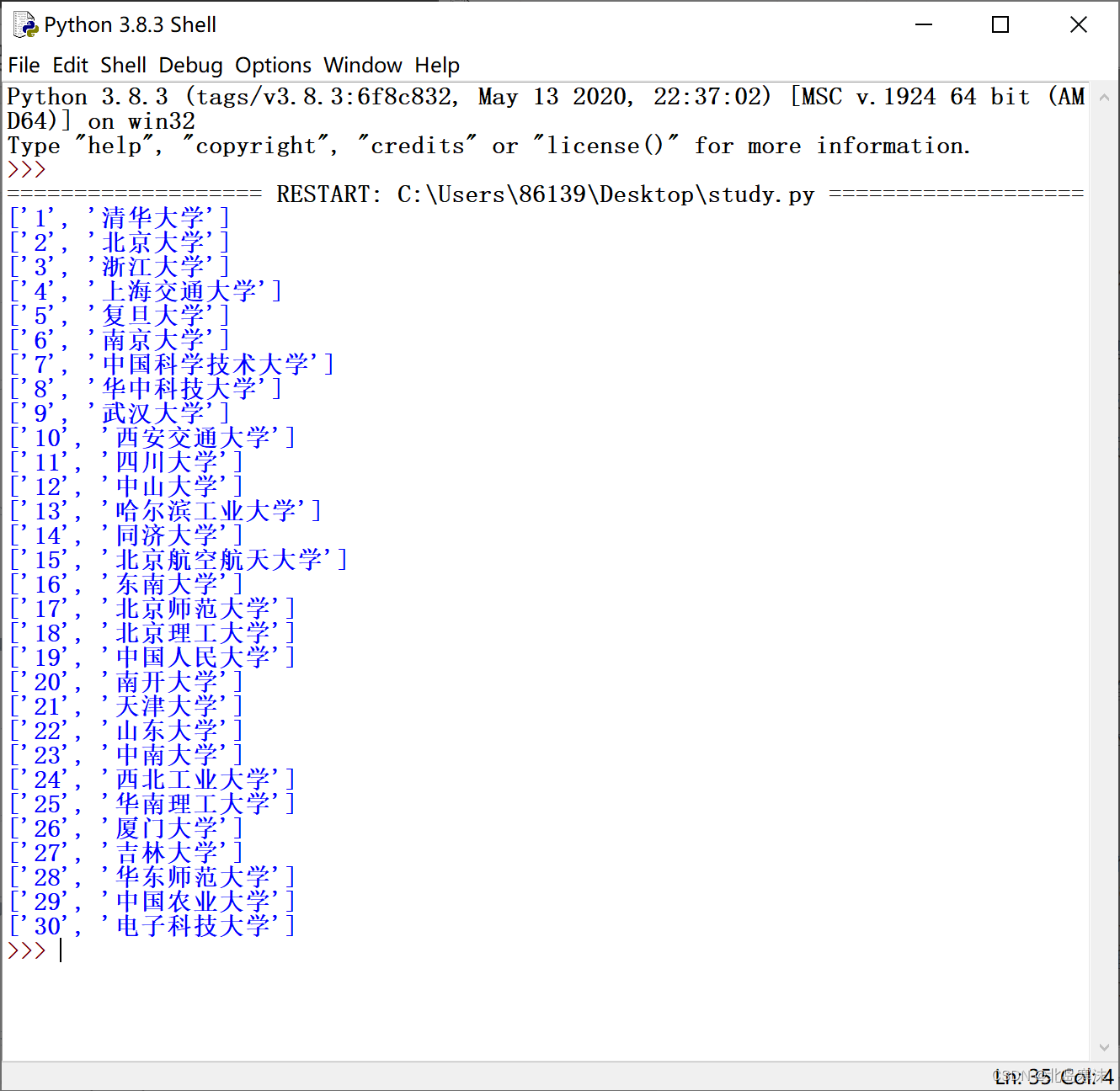
try:# 如果资源爬取异常,则产生一个HTTP异常类对象抛出r.raise_for_status()# 判断网站是否被认为采用默认编码,如果是的话则修改编码方式if r.encoding=="ISO-8859-1":r.encoding=r.apparent_encoding# 获取所爬取的网络资源文本text=r.text# 使用BeautifulSoup对象对网络资源文本进行HTML格式的解析HTML=BeautifulSoup(text,"html.parser")# 设置一个空的列表用于存储结果results=[]# 由于所有需要的信息都在body标签中,因此首先截取body标签中的内容body=HTML.find_all("body")[0]# 找出body标签中的标签名为tr的子标签,基本每个子标签对应一所大学的信息(第一个标签除外)trs=body.find_all("tr")# 通过遍历的方式逐一提取信息UniversityMaxNumber=len(trs)for i in range(1,UniversityMaxNumber):# 从每一个tr标签中寻找名字为td的子标签的第一项并记录其内容(大学排名)Rank=trs[i].find_all("td")[0].string.strip()# 从每一个tr标签中寻找名字为a的子标签的第一项并记录其内容(大学名称)University=trs[i].find_all("a")[0].string.strip()# 将大学排名和大学名称组合成一个子列表,插入到结果列表中results.append([Rank,University])# 输出大学名称和相应的排名for i in results:print(i)# 网络资源爬取失败输出提示信息
except:print("网站内容爬取失败!")运行效果:
相关文章:
Python网络爬虫 学习笔记(2)BeaufitulSoup库
文章目录BeautifulSoup库的基本介绍HTML标签的获取和相关属性HTML文档的遍历prettify()方法使用BeautifulSoup库对HTML文件进行内容查找信息的标记的相关概念(非重点)find_all()方法(重点)综合实例:爬取软科2022中国大…...

JavaScript------内建对象
一、解构赋值 1、数组的解构 1.1、解构赋值 const arr ["孙悟空", "猪八戒", "沙和尚"];let a, b, c;[a, b, c] arr; // 等同于 [a, b, c] ["孙悟空", "猪八戒", "沙和尚"] 1.2、声明同时解构 let [d, e…...

React + Redux 处理异步请求
redux 处理异步请求 方式一:在 componentDidmount 中直接进⾏请求,在将数据同步到 redux 创建 Store 仓库 import {createStore } from redux;const defaultState = {banners: [] }const reducer =...
揭秘涨薪50%经验:从功能测试到自动化测试,我是如何蜕变的?
本人在今年互联网大环境如此严峻的情况下,作为一个刚毕业不到一年的初级测试,赶在“金三银四”依然拿到了一些面试机会,并且成功拿下4家公司的offer,其中不乏互联网大厂,而且最高总包给到了接近double(无炫…...

【论文速递】MMM2020 - 电子科技大学提出一种新颖的局部变换模块提升小样本分割泛化性能
【论文速递】MMM2020 - 电子科技大学提出一种新颖的局部变换模块提升小样本分割泛化性能 【论文原文】:A New Local Transformation Module for Few-shot Segmentation 【作者信息】:Yuwei Yang, Fanman Meng, Hongliang Li, Qingbo Wu,Xiaolong Xu an…...
)
补充前端面试题(二)
#$set数据变化视图不更新问题, 当在项目中直接设置数组的某一项的值,或者直接设置对象的某个属性值,这个时候,你会发现页面并没有更新。这是因为 Object.defineProperty()限制,监听不到变化。解决方式:this.$set(你要改…...
JavaScript原型、原型链、原型方法
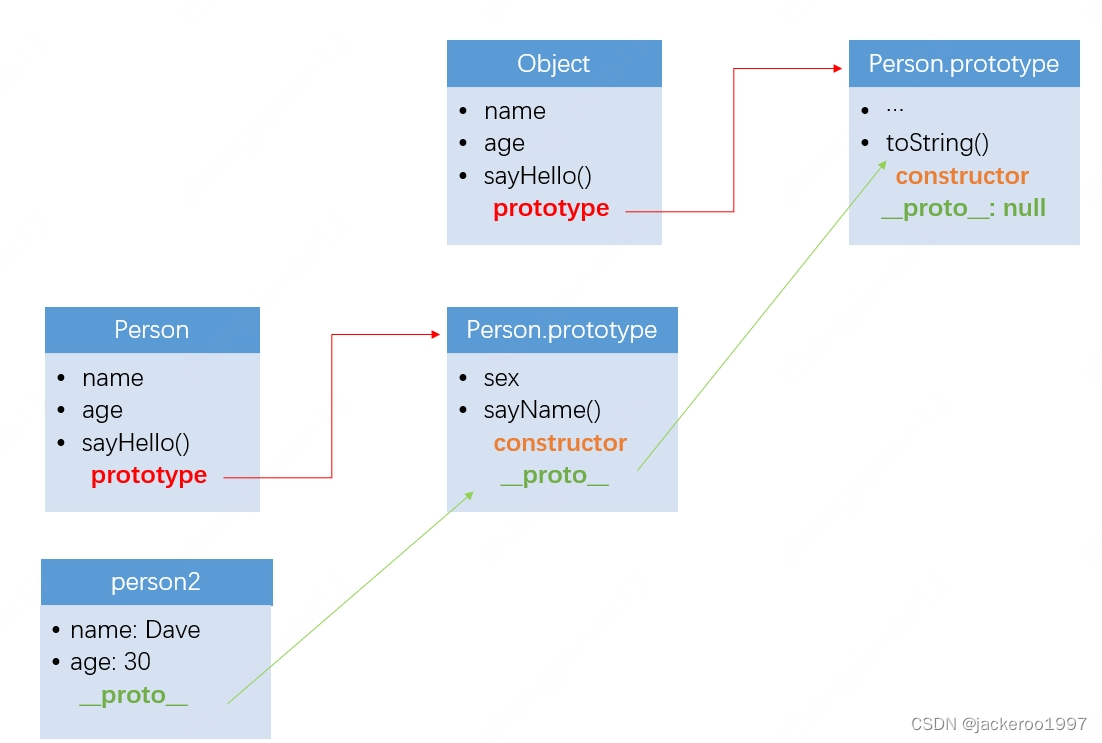
文章目录原型和原型链prototype、 __ proto __ 、constructor原型链原型方法instanceOfhasOwnPropertyObject.create()、new Object()总结原型和原型链 prototype、 __ proto __ 、constructor 首先我们看下面一段代码 // 构造函数Personfunction Person(name, age) {this.na…...
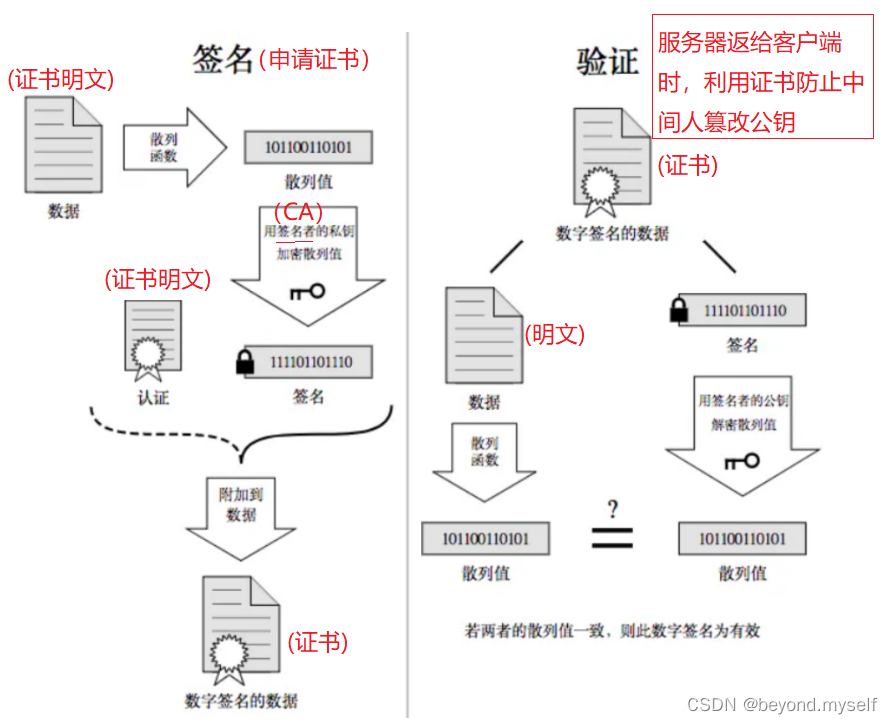
linux篇【14】:网络https协议
目录 一.HTTPS介绍 1.HTTPS 定义 2.HTTP与HTTPS (1)端口不同,是两套服务 (2)HTTP效率更高,HTTPS更安全 3.加密,解密,密钥 概念 4.为什么要加密? 5.常见的加密方式…...

1.9实验9:配置虚链路
1.4.4实验9:配置虚链路 实验目的(1) 实现OSPF 虚链路的配置 (2) 描述虚链路的作用 实验拓扑配置虚链路实验拓扑如图1-19所示。[1] 图1-19 配置虚链路 实验步骤...

三次握手-升级详解-注意问题
TCP建立连接的过程就是三次握手(Three-way Handshake),在建立连接的过程实际上就是客户端和服务端之间总共发送三个数据包。进行三次握手主要是就是为了确认双方都能接收到数据包和发送数据包,而客户端和服务端都会指定自己的初始…...
软件架构知识3-系统复杂度-高可用性、可扩展性、低成本、安全、规模
高可用性 系统无中断地执行其功能的能力,代表系统的可用性程度,是进行系统设计时的准则之一。 高可用的“冗余”解决方案,单纯从形式上来看,和之前讲的高性能是一样的,都是通过增加更多机 器来达到目的,但…...
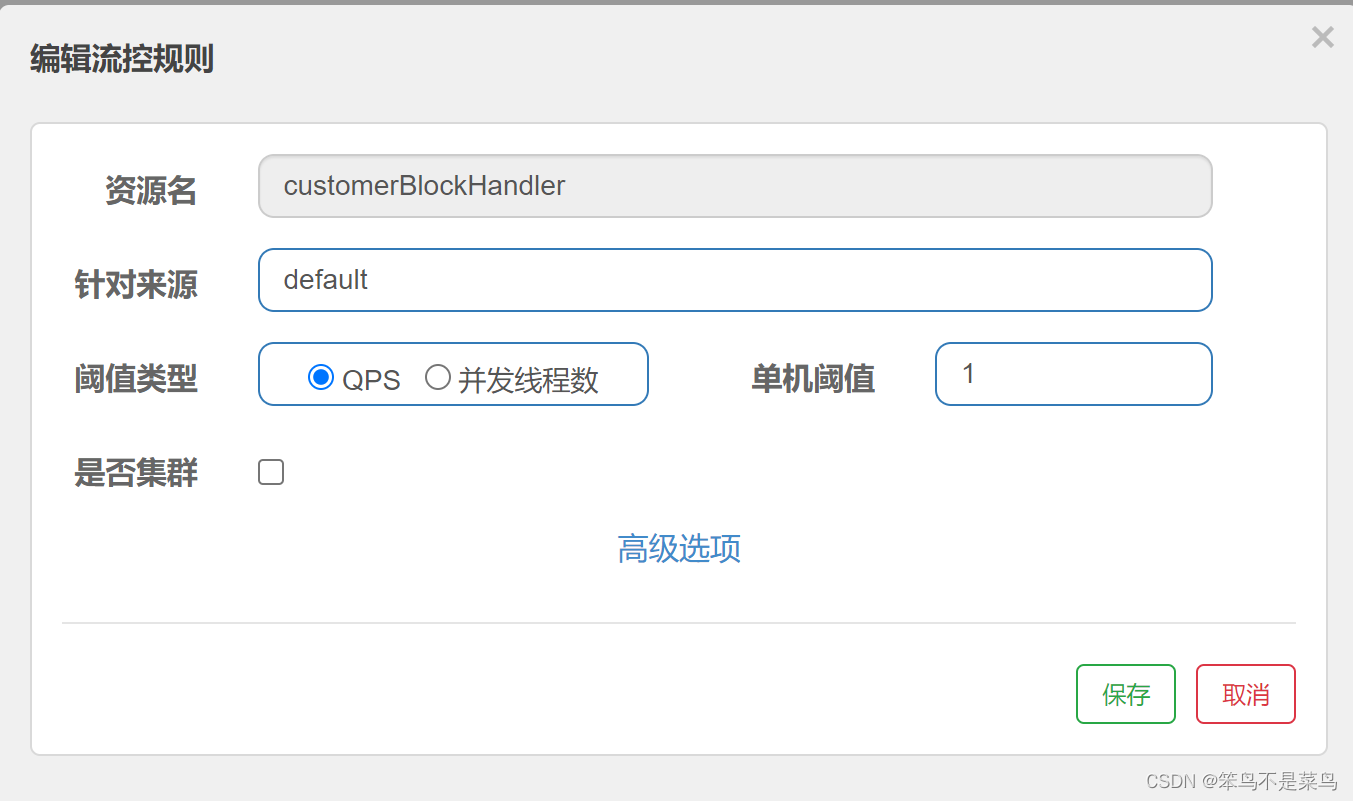
SpringCloud学习笔记 - 自定义及解耦降级处理方法 - Sentinel
1. SentinelRecourse配置回顾 通过之前的学习,我们知道SentinelRecourse配置的资源定位可以通过两种方式实现:一种是URL,另一种是资源名称。这两种限流方式都要求资源ID唯一 RestController public class RateLimitController {GetMapping(…...

Redis之搭建一主多从
搭建redis一主多从的过程 1.在相应位置创建一个文件夹存放redis配置文件 mkdir myredis2.复制redis配置文件到此文件夹中 cp /opt/redis/redis/bin/redis.conf /opt/myredis/redis.conf3.新建三个配置文件 touch redis6379.conf touch redis6380.conf touch redis6381.conf4…...
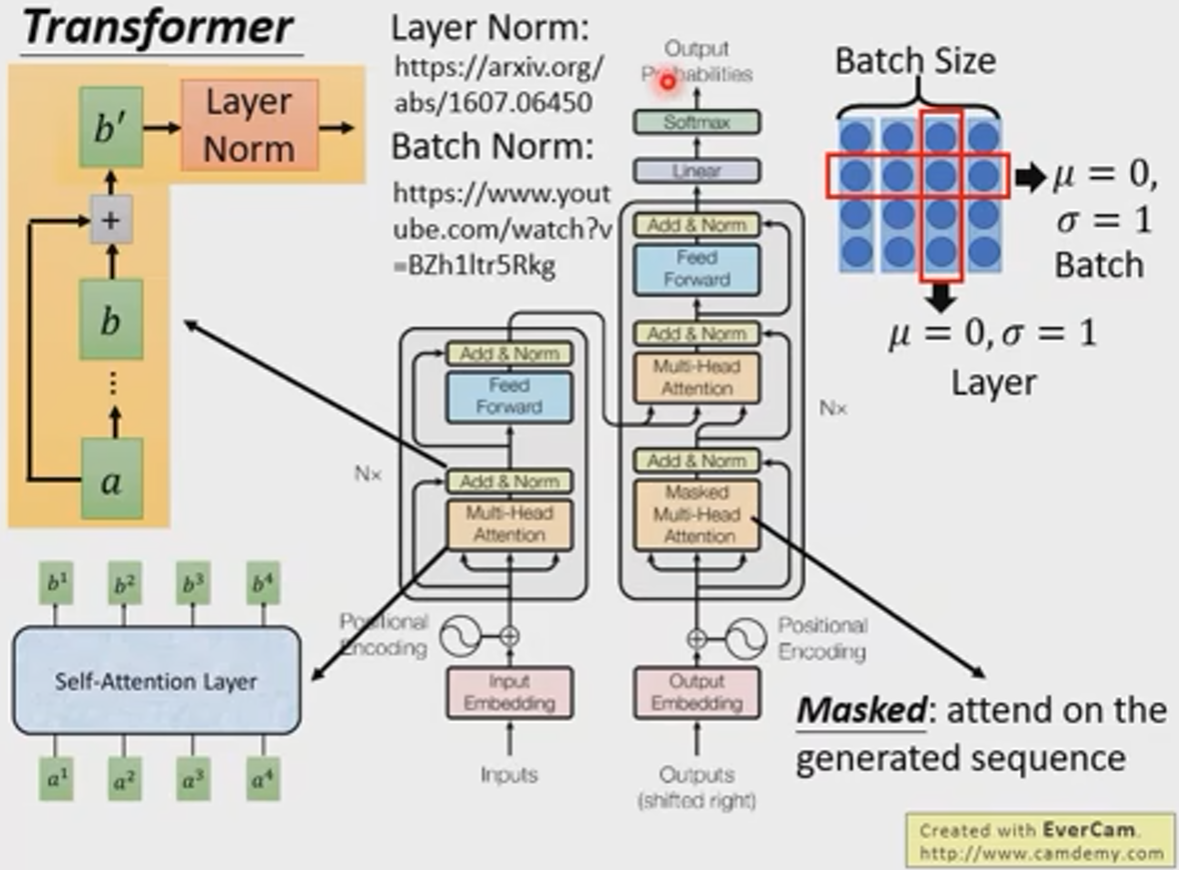
Transformer机制学习笔记
学习自https://www.bilibili.com/video/BV1J441137V6 RNN,CNN网络的缺点 难以平行化处理,比如我们要算b4b^4b4,我们需要一次将a1a^1a1~a4a^4a4依次进行放入网络中进行计算。 于是有人提出用CNN代替RNN 三角形表示输入,b1b^1b1的…...

1、第一个CUDA代码:hello gpu
目录第一个CUDA代码:hello gpu一、__global__ void GPUFunction()二、gpu<<<1,1>>>();三、线程块、线程、网格知识四、核函数中的printf();五、cudaDeviceSynchronize();第一个CUDA代码:hello gpu #include <stdio.h>void cpu(…...
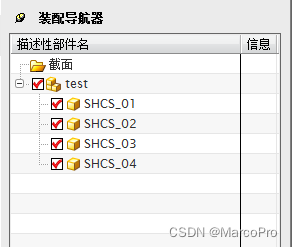
UG二次开发装配篇 添加/拖动/删除组件方法的实现
我们在UG装配的过程中,经常会遇到需要调整组件目录位置,在软件设计过程中可以通过在目录树里面拖动组件来完成。 那么,如果要用程序实现组件的移动/拖动,我们要怎么做呢? 本节就完成了添加/拖动/删除组件方法的实现&…...

【ros bag 包的设计原理、制作、用法汇总】
ros bag 包的设计原理 序列化和反序列化 首先知道Bag包就是为了录制消息,而消息的保存和读取就涉及到一个广义上的问题序列化和反序列化,它基本上无处不在,只是大部分人没有注意到,举个简单的例子,程序运行的时候,是直接操作的内存,也就是一个结构体或者一个对象,但内…...

Linux网络:聚合链路技术
目录 一、聚合链路技术 1、bonding作用 2、Bonding聚合链路工作模式 3、Bonding实现 一、聚合链路技术 1、bonding作用 将多块网卡绑定同一IP地址对外提供服务,可以实现高可用或者负载均衡。直接给两块网卡设置同一IP地址是不可以的。通过 bonding,…...

2023年数据安全的下一步是什么?
IT 预算和收入增长领域是每个年度开始时的首要考虑因素,在当前的世界经济状况下更是如此。 IT 部门和数据团队正在寻找确定优先级、维护和构建安全措施的最佳方法,同时又具有成本效益。 这是一个棘手的平衡点,但却是一个重要的平衡点&#…...
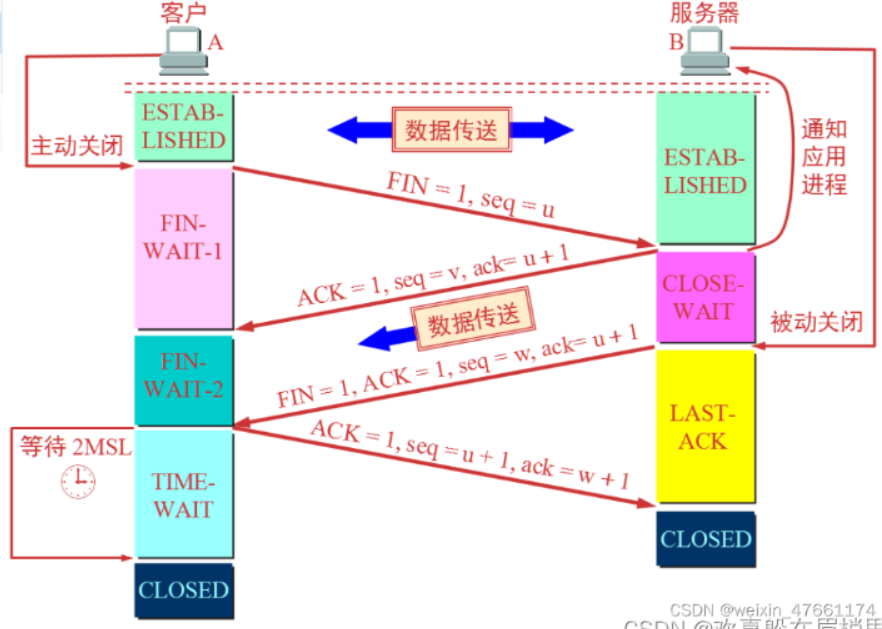
在浏览器输入URL后发生了什么?
在浏览器输入URL并获取响应的过程,其实就是浏览器和该url对应的服务器的网络通信过程。从封装的角度来讲,浏览器和web服务器执行以下动作:(简单流程)1、浏览器先分析超链接中的URL:分析域名是否规范2、浏览器向DNS请求…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...
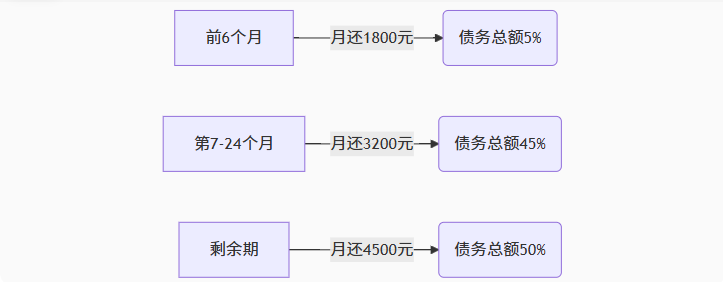
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...