Flink相关的记录
Flink源码编译
首次编译的时候,去除不必要的操作,同时install会把Flink中的module安装到本地仓库,这样依赖当前module的其他组件就无需去远程仓库拉取当前module,节省了时间。
mvn clean install -T 4 -DskipTests -Dfast -Dmaven.compile.fork=true -Dscala-2.11 -Drat.skip=true -Dmaven.javadoc.skip=true -Dcheckstyle.skip=true
当某一个moudle出问题的时候,遇到某个module编译出问题,修复问题后可以通过-rf从反应堆中出问题的module继续编译:
mvn install -DskipTests -Dmaven.javadoc.skip=true -Dcheckstyle.skip=true -Drat.skip=true -Dscala-2.11 -rf :<moduleName>
Flink内存管理

组件 | 配置项 | |
Total Process Memory | taskmanager.memory.process.size | |
Total Flink memory | taskmanager.memory.flink.size | |
Framework Heap Memory | taskmanager.memory.framework.heap.size | (高级参数,一般不需要用户配置)分配给 Flink 框架的 JVM 堆内存(默认128MB) |
Task Heap Memory | taskmanager.memory.task.heap.size | 分配给 operator 和用户代码的 JVM 堆内存 |
Managed memory | taskmanager.memory.managed.sizetaskmanager.memory.managed.fraction | 流式处理作业可以将其用于RocksDbStateBackend。流式处理和批处理作业都可以将其用于中间结果排序(sort)、哈希表(hash)和缓存(caching )。流式处理和批处理作业都可以使用它来执行 Python 进程中的UDF函数。 |
Framework Off-heap Memory | taskmanager.memory.framework.off-heap.size | (高级参数)分配给 Flink 框架的 Off-heap direct 内存 |
Task Off-heap Memory | taskmanager.memory.task.off-heap.size | 分配给 task operator 的 Off-heap direct 内存,默认(0 bytes) |
Network Memory | taskmanager.memory.network.mintaskmanager.memory.network.maxtaskmanager.memory.network.fraction | 为 tasks 之间的数据元素交换保留的 Off-heap direct(例如,通过网络进行传输的缓冲区),它是 Total Flink Memory 的一个有上下限的细分组件 |
JVM metaspace | taskmanager.memory.jvm-metaspace.size | Flink JVM 进程的元数据空间大小,为本地内存。 |
JVM Overhead | taskmanager.memory.jvm-overhead.mintaskmanager.memory.jvm-overhead.maxtaskmanager.memory.jvm-overhead.fraction | 为 JVM 进程预留的其他本地内存,用于线程栈、代码缓存、垃圾收集。它是 Total Process Memory(整个进程) 的一个有上下限的细分组件。 |
启动Flink JVM进程时各个JVM参数对应的各部分内存
JVM参数 | TM | JM |
-Xmx 和 -Xms | Framework Heap + Task Heap | JVM Heap Memory (*) |
-XX:MaxDirectMemorySize(always added only for TaskManager, see note for JobManager) | Framework + Task Off-heap (**) + Network Memory | Off-heap Memory (**),(**) |
-XX:MaxMetaspaceSize | JVM Metaspace | JVM Metaspace |
Flink内存相关的故障排查
超过容器内存大小
如果 Flink 容器尝试分配超出其请求大小的内存(Yarn 或 Kubernetes),这通常表示 Flink 没有保留足够的native内存。可以使用外部监视系统或当容器被部署环境终止时从错误消息中观察到这一点。
如果在JobManager进程中遇到此问题,还可以通过设置jobmanager.memory.enable-jvm-direct-memory-limit 选项来排除可能的 JVM 直接内存泄漏,从而启用 JVM 直接内存限制。
如果使用RocksdbStateBackend:
内存控制已禁用:您可以尝试增加任务管理器的 Managed Memory。
内存控制已启用,并且在保存点或完整检查点期间Off-Heap内存增加:这可能是由于内存分配器造成的(请参阅 glibc bug)。您可以尝试添加环境变量。TaskManagers.glibcMALLOC_ARENA_MAX=1
或者,您可以增加 JVM Overhead 内存大小(taskmanager.memory.jvm-overhead.fraction: 0.1(默认))。
详解 Flink 容器化环境下的 OOM Killed-阿里云开发者社区 (aliyun.com)
Flink JVM 内存超限的分析方法总结 - 腾讯云开发者社区-腾讯云 (tencent.com)
Flink RocksDB托管内存机制的幕后——Cache & Write Buffer Manager - 简书 (jianshu.com)
[FLINK-15532] Enable strict capacity limit for memory usage for RocksDB - ASF JIRA (apache.org)
Apache Calcite VolcanoPlanner优化过程解析 - 知乎 (zhihu.com)
Rocksdb内存管理
Flink RocksDB托管内存机制的幕后——Cache & Write Buffer Manager - 简书 (jianshu.com)
Native Memory = Process Memory - ( JVM Heap + JVM Non-Heap + DirectBuffer)
Flink Rocksdb开启Native Metrics
state.backend.rocksdb.metrics.block-cache-capacity = true // 监控block cache的最大的大小
state.backend.rocksdb.metrics.block-cache-pinned-usage = true // 监控被固定在块缓存中的条目的内存大小。
state.backend.rocksdb.metrics.block-cache-usage = true // 监视驻留在块缓存中的条目的内存大小。
state.backend.rocksdb.metrics.mem-table-flush-pending = true // 监控 RocksDB 中挂起的 memtable 刷新的数量。
state.backend.rocksdb.metrics.num-running-compactions = true // 监视当前正在运行的压缩的数量。
state.backend.rocksdb.metrics.num-running-flushes = true // 监控当前运行的刷新次数。
介绍 | rocksdb-doc-cn (wanghenshui.github.io)
数据结构
RocksDB是一种可以存储任意二进制kv数据的嵌入式存储。RocksDB按顺序组织所有数据,他们的通用操作是Get(key), Put(key), Delete(Key)以及NewIterator()
RocksDB有三种基本的数据结构:mentable,sstfile以及logfile。mentable是一种内存数据结构——所有写入请求都会进入mentable,然后选择性进入logfile。logfile是一种有序写存储结构。当mentable被填满的时候,他会被刷到sstfile文件并存储起来,然后相关的logfile会在之后被安全地删除。sstfile内的数据都是排序好的,以便于根据key快速搜索。
列簇
RocksDB支持将一个数据库实例按照许多列族进行分片。所有数据库创建的时候都会有一个用”default”命名的列族,如果某个操作不指定列族,他将操作这个default列族。
RocksDB在开启WAL的时候保证即使crash,列族的数据也能保持一致性。通过WriteBatch API,还可以实现跨列族的原子操作。
更新操作
调用Put API可以将一个键值对写入数据库。如果该键值已经存在于数据库内,之前的数据会被覆盖。调用Write API可以将多个key原子地写入数据库。数据库保证在一个write调用中,要么所有键值都被插入,要么全部都不被插入。如果其中的一些key在数据库中存在,之前的值会被覆盖。
get,iterators以及Snapshots
键值对的数据都是按照二进制处理的。键值都没有长度的限制。Get API允许应用从数据库里面提取一个键值对的数据。MultiGet API允许应用一次从数据库获取一批数据。使用MultiGet API获取的所有数据保证相互之间的一致性(版本相同)。
数据库中的所有数据都是逻辑上排好序的。应用可以指定一种键值压缩算法来对键值排序。Iterator API允许对database做RangeScan。Iterator可以指定一个key,然后应用程序就可以从这个key开始做扫描。Iterator API还可以用来对数据库内已有的key生成一个预留的迭代器。一个在指定时间的一致性的数据库视图会在Iterator创建的时候被生成。所以,通过Iterator返回的所有键值都是来自一个一致的数据库视图的。
Snapshot API允许应用创建一个指定时间的数据库视图。Get,Iterator接口可以用于读取一个指定snapshot数据。当然,Snapshot和Iterator都提供一个指定时间的数据库视图,但是他们的内部实现不同。短时间内存在的/前台的扫描最好使用iterator,长期运行/后台的扫描最好使用snapshot。Iterator会对整个指定时间的数据库相关文件保留一个引用计数,这些文件在Iterator释放前,都不会被删除。另一方面,snapshot不会阻止文件删除;作为交换,压缩过程需要知道有snapshot正在使用某个版本的key,并且保证不会在压缩的时候删除这个版本的key。
Snapshot在数据库重启过程不能保持存在:reload RocksDB库会释放所有之前创建好的snapshot。
Rocksdb读写操作
RocksDB 中的写入操作将数据存储在当前活动的内存表(活动内存表)中。当内存表已满时,它将成为只读内存表,并被一个新的空活动内存表替换。只读内存表由后台线程定期刷新到磁盘,以转换为按键排序的只读文件—即所谓的 SSTable。反过来,SSTable是不可变的,但它们通过后台日志压缩(SSTable的多路合并)进行整合。如前所述,对于 RocksDB,每个注册状态都是一个列族,这意味着每个状态都包含自己的一组内存表和 SSTable。
RocksDB 中的读取操作首先访问活动内存表以回答查询。如果找到搜索的键,则读取操作将访问从最新到最旧的只读内存表,直到找到搜索的键。如果在任何内存表中都找不到该key,则读取操作将再次从最新的内存表开始访问 SSTable。SSTable 文件可以从操作系统的文件缓存中获取,在最坏的情况下,可以从本地磁盘获取,该缓存保存未压缩的表文件,如果包含这些文件。可选的索引(如 SST 级布隆筛选器)可以帮助避免击中磁盘。
1.block_cache_size的配置
此配置最终将控制内存中保存的缓存未压缩块的最大数量。随着块数的增加,内存大小也会增加 - 因此,通过预先配置,您可以保持特定级别的内存消耗。
write_buffer_size的配置
此配置实质上是建立和控制 RocksDB 中内存表的最大大小。活动内存表和只读内存表最终将影响 RocksDB 中的内存大小,因此尽早调整可能会为您节省一些麻烦。
max_write_buffer_number的配置
此配置决定并控制在 RocksDB 将内存中保存的内存表作为 SS 表刷新到本地磁盘之前的最大内存表数。这实质上是内存中“只读”内存表的最大数量。
Flink RocksDB 内存管理 | 廖嘉逸's Blog (liaojiayi.com)
文件介绍
*.log: 事务日志用于保存数据操作日志,可用于数据恢复。*.sst: 数据持久换文件。MANIFEST:数据库中的 MANIFEST 文件记录数据库状态。压缩过程会添加新文件并从数据库中删除旧文件,并通过将它们记录在 MANIFEST 文件中使这些操作持久化。CURRENT:记录当前正在使用的MANIFEST文件。LOCK:rocksdb自带的文件锁,防止两个进程来打开数据库。
内存分析命令
nmt
pmap
JDK命令八、NMT 和 pmap本地内存分析神器_weixin_42073629的博客-CSDN博客
Flink CEP动态更新规则
Apache Flink CEP 实战-阿里云开发者社区 (aliyun.com)
Flink-Cep实现规则动态更新 (qq.com)
Flink CEP NFA
Flink Cep论文地址:sase-sigmod08.pdf (umass.edu)

Begin:消费输入事件,存入缓存,并转移到下一个状态;
Take: 消费输入事件,存入缓存,并保持当前状态;
Procceed: 感知输入事件,转移到下一个状态,同时保留该事件给下一个状态处理。
Ignore: 忽略输入事件,不存入缓存,并保持当前状态;
自定义SQL语法
Flink SQL LookupJoin With KeyBy | Asura7969 Blog
Flink Sql-Increment Window | Asura7969 Blog
Flink 源码阅读笔记(15)- Flink SQL 整体执行框架 - JR's Blog (jrwang.me)
calcite在flink中的二次开发,介绍解析器与优化器-pudn.com
Flink Sql 之 Calcite Volcano优化器(源码解析) - ljygz - 博客园 (cnblogs.com)
https://github.com/defineqq/flinkTest
Spi的方式
java.util.ServiceLoader 类加载器
Table Source/Sink加载的地方
org.apache.flink.table.factories.FactoryUtil 类
Table 优化规则集合
org.apache.flink.table.planner.plan.rules 路径下
Flink SQL执行过程
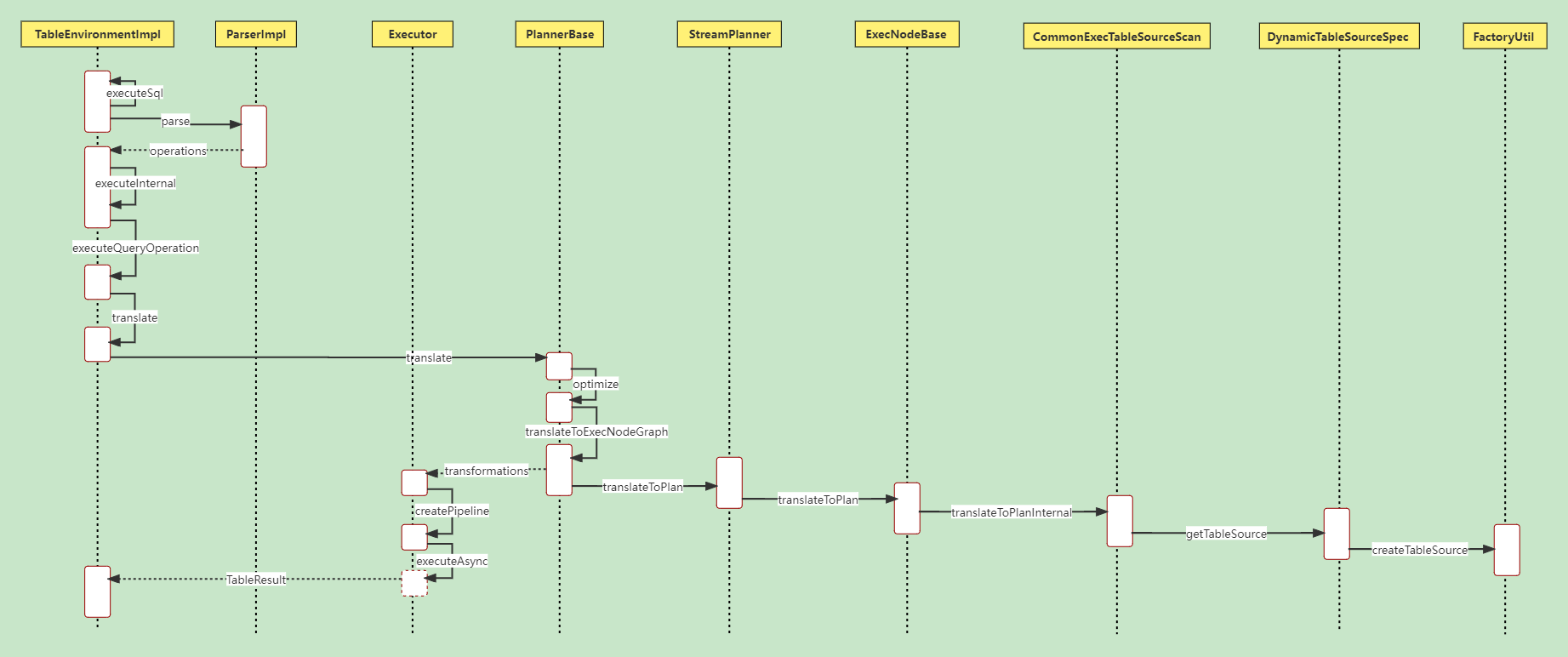
Flink UDF校验函数实现的地方
org.apache.flink.table.functions.UserDefinedFunctionHelper.validateImplementationMethods()
Flink解析的调用流程
ParserImpl.parse() ->
JavaCC定义语法的模板
options {
JavaCC的配置项
}
PARSER_BEGIN(解析器类名)
package包名;
import库名;
publicclass解析器类名 {
任意Java代码
}
PARSER_END(解析器类名)
解析逻辑
关键字定义
Calcite相关知识点
基本概念
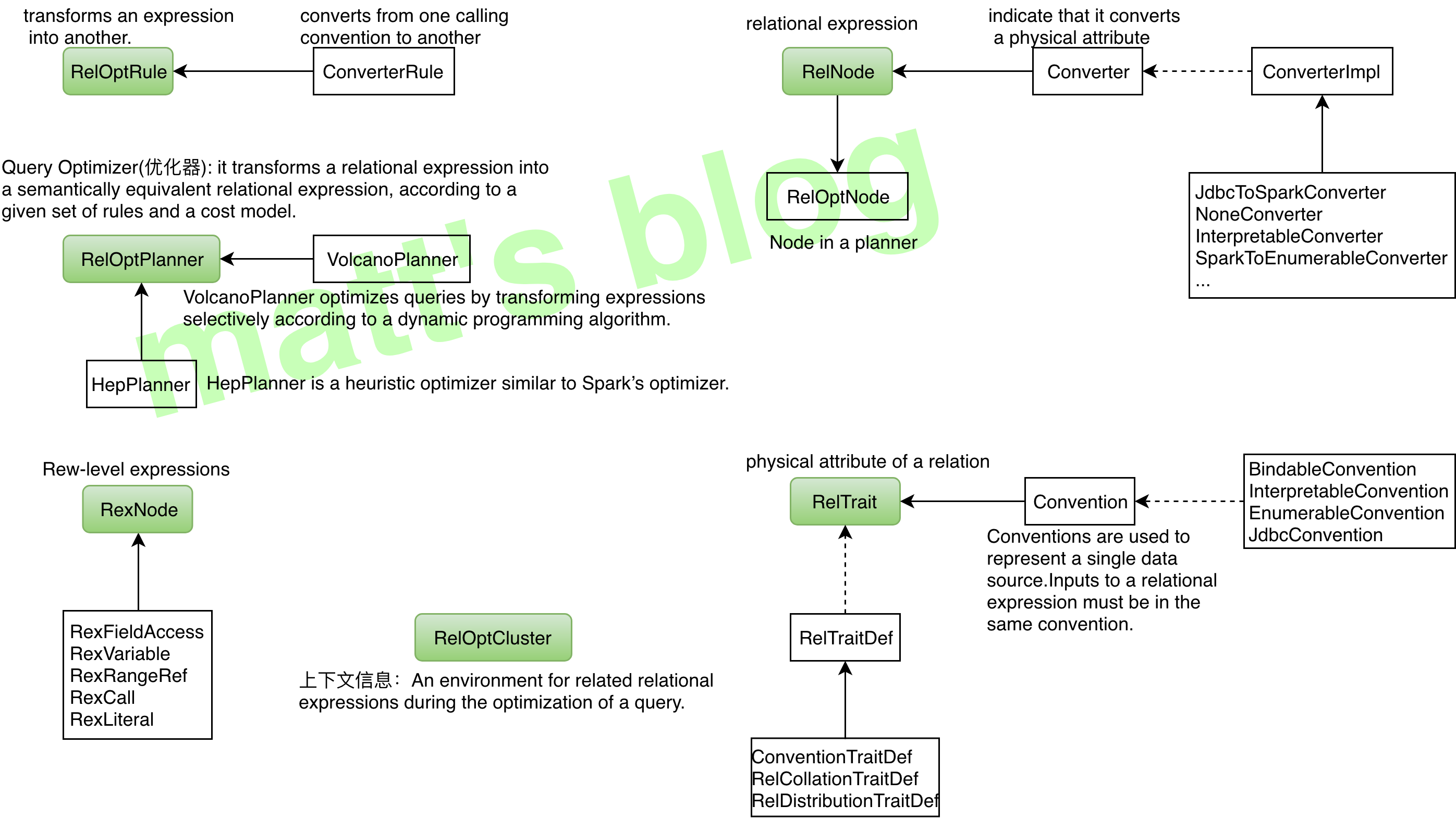
类型 | 描述 | 特点 |
RelOptRule | transforms an expression into another。对 expression 做等价转换 | 根据传递给它的 RelOptRuleOperand 来对目标 RelNode 树进行规则匹配,匹配成功后,会再次调用 matches() 方法(默认返回真)进行进一步检查。如果 mathes() 结果为真,则调用 onMatch() 进行转换。 |
ConverterRule | Abstract base class for a rule which converts from one calling convention to another without changing semantics. | 它是 RelOptRule 的子类,专门用来做数据源之间的转换(Calling convention),ConverterRule 一般会调用对应的 Converter 来完成工作,比如说:JdbcToSparkConverterRule 调用 JdbcToSparkConverter 来完成对 JDBC Table 到 Spark RDD 的转换。 |
RelNode | relational expression,RelNode 会标识其 input RelNode 信息,这样就构成了一棵 RelNode 树 | 代表了对数据的一个处理操作,常见的操作有 Sort、Join、Project、Filter、Scan 等。它蕴含的是对整个 Relation 的操作,而不是对具体数据的处理逻辑。 |
Converter | A relational expression implements the interface Converter to indicate that it converts a physical attribute, or RelTrait of a relational expression from one value to another. | 用来把一种 RelTrait 转换为另一种 RelTrait 的 RelNode。如 JdbcToSparkConverter 可以把 JDBC 里的 table 转换为 Spark RDD。如果需要在一个 RelNode 中处理来源于异构系统的逻辑表,Calcite 要求先用 Converter 把异构系统的逻辑表转换为同一种 Convention。 |
RexNode | Row-level expression | 行表达式(标量表达式),蕴含的是对一行数据的处理逻辑。每个行表达式都有数据的类型。这是因为在 Validation 的过程中,编译器会推导出表达式的结果类型。常见的行表达式包括字面量 RexLiteral, 变量 RexVariable, 函数或操作符调用 RexCall 等。 RexNode 通过 RexBuilder 进行构建。 |
RelTrait | RelTrait represents the manifestation of a relational expression trait within a trait definition. | 用来定义逻辑表的物理相关属性(physical property),三种主要的 trait 类型是:Convention、RelCollation、RelDistribution; |
Convention | Calling convention used to repressent a single data source, inputs must be in the same convention | 继承自 RelTrait,类型很少,代表一个单一的数据源,一个 relational expression 必须在同一个 convention 中; |
RelTraitDef | 主要有三种:ConventionTraitDef:用来代表数据源 RelCollationTraitDef:用来定义参与排序的字段;RelDistributionTraitDef:用来定义数据在物理存储上的分布方式(比如:single、hash、range、random 等); | |
RelOptCluster | An environment for related relational expressions during the optimization of a query. | palnner 运行时的环境,保存上下文信息; |
RelOptPlanner | A RelOptPlanner is a query optimizer: it transforms a relational expression into a semantically equivalent relational expression, according to a given set of rules and a cost model. | 也就是优化器,Calcite 支持RBO(Rule-Based Optimizer) 和 CBO(Cost-Based Optimizer)。Calcite 的 RBO (HepPlanner)称为启发式优化器(heuristic implementation ),它简单地按 AST 树结构匹配所有已知规则,直到没有规则能够匹配为止;Calcite 的 CBO 称为火山式优化器(VolcanoPlanner)成本优化器也会匹配并应用规则,当整棵树的成本降低趋于稳定后,优化完成,成本优化器依赖于比较准确的成本估算。RelOptCost 和 Statistic 与成本估算相关; |
RelOptCost | defines an interface for optimizer cost in terms of number of rows processed, CPU cost, and I/O cost. | 优化器成本模型会依赖; |
关系代数(Relational algebra):即关系表达式。它们通常以动词命名,例如 Sort, Join, Project, Filter, Scan, Sample.
行表达式(Row expressions):例如 RexLiteral (常量), RexVariable (变量), RexCall (调用) 等,例如投影列表(Project)、过滤规则列表(Filter)、JOIN 条件列表和 ORDER BY 列表、WINDOW 表达式、函数调用等。使用 RexBuilder 来构建行表达式。
表达式有各种特征(Trait):使用 Trait 的 satisfies() 方法来测试某个表达式是否符合某 Trait 或 Convention.
转化特征(Convention):属于 Trait 的子类,用于转化 RelNode 到具体平台实现(可以将下文提到的 Planner 注册到 Convention 中). 例如 JdbcConvention,FlinkConventions.DATASTREAM 等。同一个关系表达式的输入必须来自单个数据源,各表达式之间通过 Converter 生成的 Bridge 来连接。
规则(Rules):用于将一个表达式转换(Transform)为另一个表达式。它有一个由 RelOptRuleOperand 组成的列表来决定是否可将规则应用于树的某部分。
规划器(Planner) :即请求优化器,它可以根据一系列规则和成本模型(例如基于成本的优化模型 VolcanoPlanner、启发式优化模型 HepPlanner)来将一个表达式转为语义等价(但效率更优)的另一个表达式。
Catalog – 定义元数据和命名空间,包含 Schema(库)、Table(表)、RelDataType(类型信息)
SQL Parser– 将用户编写的 SQL 语句转为 SqlNode 构成的抽象语法树(AST)
通过 JavaCC 模版生成 LL(k) 语法分析器,主模版是 Parser.jj;可对其进行扩展
负责处理各个 Token,逐步生成一棵 SqlNode 组成的 AST
SQL Validator – 使用 Catalog 中的元数据检验上述 SqlNode AST 并生成 RelNode 组成的 AST
Query Optimizer – 将 RelNode AST 转为逻辑计划,然后优化它,最终转为实际执行方案。以下是一些常见的优化规则(Rules):
移除未使用的字段
合并多个投影(projection)列表
使用 JOIN 来代替子查询
对 JOIN 列表重排序
下推(push down)投影项
下推过滤条件
Calcite 架构
关于 Calcite 的架构,可以参考下图(图片来自前面那篇论文),它与传统数据库管理系统有一些相似之处,相比而言,它将数据存储、数据处理算法和元数据存储这些部分忽略掉了,这样设计带来的好处是:对于涉及多种数据源和多种计算引擎的应用而言,Calcite 因为可以兼容多种存储和计算引擎,使得 Calcite 可以提供统一查询服务,Calcite 将会是这些应用的最佳选择。

在 Calcite 架构中,最核心地方就是 Optimizer,也就是优化器,一个 Optimization Engine 包含三个组成部分:
rules:也就是匹配规则,Calcite 内置上百种 Rules 来优化 relational expression,当然也支持自定义 rules;
metadata providers:主要是向优化器提供信息,这些信息会有助于指导优化器向着目标(减少整体 cost)进行优化,信息可以包括行数、table 哪一列是唯一列等,也包括计算 RelNode 树中执行 subexpression cost 的函数;
planner engines:它的主要目标是进行触发 rules 来达到指定目标,比如像 cost-based optimizer(CBO)的目标是减少cost(Cost 包括处理的数据行数、CPU cost、IO cost 等)。
Calcite 处理流程
Sql 的执行过程一般可以分为下图中的四个阶段,Calcite 同样也是这样:

但这里为了讲述方便,把 SQL 的执行分为下面五个阶段(跟上面比比又独立出了一个阶段):
解析 SQL, 把 SQL 转换成为 AST (抽象语法树),在 Calcite 中用 SqlNode 来表示;
语法检查,根据数据库的元数据信息进行语法验证,验证之后还是用 SqlNode 表示 AST 语法树;
语义分析,根据 SqlNode 及元信息构建 RelNode 树,也就是最初版本的逻辑计划(Logical Plan);
逻辑计划优化,优化器的核心,根据前面生成的逻辑计划按照相应的规则(Rule)进行优化;
物理执行,生成物理计划,物理执行计划执行。
Validate部分的流程

优化RelNode部分
基于规则优化(RBO)
基于规则的优化器(Rule-Based Optimizer,RBO):根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会变成另外一个关系表达式,同时原有表达式会被裁剪掉,经过一系列转换后生成最终的执行计划。
RBO 中包含了一套有着严格顺序的优化规则,同样一条 SQL,无论读取的表中数据是怎么样的,最后生成的执行计划都是一样的。同时,在 RBO 中 SQL 写法的不同很有可能影响最终的执行计划,从而影响执行计划的性能。
基于成本优化(CBO)
基于代价的优化器(Cost-Based Optimizer,CBO):根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会生成另外一个关系表达式,同时原有表达式也会保留,经过一系列转换后会生成多个执行计划,然后 CBO 会根据统计信息和代价模型 (Cost Model) 计算每个执行计划的 Cost,从中挑选 Cost 最小的执行计划。
由上可知,CBO 中有两个依赖:统计信息和代价模型。统计信息的准确与否、代价模型的合理与否都会影响 CBO 选择最优计划。 从上述描述可知,CBO 是优于 RBO 的,原因是 RBO 是一种只认规则,对数据不敏感的呆板的优化器,而在实际过程中,数据往往是有变化的,通过 RBO 生成的执行计划很有可能不是最优的。事实上目前各大数据库和大数据计算引擎都倾向于使用 CBO,但是对于流式计算引擎来说,使用 CBO 还是有很大难度的,因为并不能提前预知数据量等信息,这会极大地影响优化效果,CBO 主要还是应用在离线的场景。
优化规则
无论是 RBO,还是 CBO 都包含了一系列优化规则,这些优化规则可以对关系表达式进行等价转换,常见的优化规则包含:
谓词下推 Predicate Pushdown
常量折叠 Constant Folding
列裁剪 Column Pruning
其他
在 Calcite 的代码里,有一个测试类(org.apache.calcite.test.RelOptRulesTest)汇集了对目前内置所有 Rules 的测试 case,这个测试类可以方便我们了解各个 Rule 的作用。
Calcite 中的优化器实现
Calcite 中关于优化器提供了两种实现:
HepPlanner:就是前面 RBO 的实现,它是一个启发式的优化器,按照规则进行匹配,直到达到次数限制(match 次数限制)或者遍历一遍后不再出现 rule match 的情况才算完成;
VolcanoPlanner:就是前面 CBO 的实现,它会一直迭代 rules,直到找到 cost 最小的 paln。

HepPlanner
特点(来自 Apache Calcite介绍):
HepPlanner is a heuristic optimizer similar to Spark’s optimizer,与 spark 的优化器相似,HepPlanner 是一个 heuristic 优化器;
Applies all matching rules until none can be applied:将会匹配所有的 rules 直到一个 rule 被满足;
Heuristic optimization is faster than cost- based optimization:它比 CBO 更快;
Risk of infinite recursion if rules make opposing changes to the plan:如果没有每次都不匹配规则,可能会有无限递归风险;

VolcanoPlanner
Apache Calcite 优化器详解(二) | Matt's Blog (matt33.com)
特点(来自 Apache Calcite介绍):
VolcanoPlanner is a cost-based optimizer:VolcanoPlanner是一个CBO优化器;
Applies matching rules iteratively, selecting the plan with the cheapest cost on each iteration:迭代地应用 rules,直到找到cost最小的plan;
Costs are provided by relational expressions;
Not all possible plans can be computed:不会计算所有可能的计划;
Stops optimization when the cost does not significantly improve through a determinable number of iterations:根据已知的情况,如果下面的迭代不能带来提升时,这些计划将会停止优化;

前面提到过像calcite这类查询优化器最核心的两个问题之一是怎么把优化规则应用到关系代数相关的RelNode Tree上。所以在阅读calicite的代码时就得带着这个问题去看看它的实现过程,然后才能判断它的代码实现得是否优雅。calcite的每种规则实现类(RelOptRule的子类)都会声明自己应用在哪种RelNode子类上,每个RelNode子类其实都可以看成是一种operator(中文常翻译成算子)。VolcanoPlanner就是优化器,用的是动态规划算法,在创建VolcanoPlanner的实例后,通过calcite的标准jdbc接口执行sql时,默认会给这个VolcanoPlanner的实例注册将近90条优化规则(还不算常量折叠这种最常见的优化),所以看代码时,知道什么时候注册可用的优化规则是第一步(调用VolcanoPlanner.addRule实现),这一步比较简单。接下来就是如何筛选规则了,当把语法树转成RelNode Tree后是没有必要把前面注册的90条优化规则都用上的,所以需要有个筛选的过程,因为每种规则是有应用范围的,按RelNode Tree的不同节点类型就可以筛选出实际需要用到的优化规则了。这一步说起来很简单,但在calcite的代码实现里是相当复杂的,也是非常关键的一步,是从调用VolcanoPlanner.setRoot方法开始间接触发的,如果只是静态的看代码不跑起来跟踪调试多半摸不清它的核心流程的。筛选出来的优化规则会封装成VolcanoRuleMatch,然后扔到RuleQueue里,而这个RuleQueue正是接下来执行动态规划算法要用到的核心类。筛选规则这一步的代码实现很晦涩。第三步才到VolcanoPlanner.findBestExp,本质上就是一个动态规划算法的实现,但是最值得关注的还是怎么用第二步筛选出来的规则对RelNode Tree进行变换,变换后的形式还是一棵RelNode Tree,最常见的是把LogicalXXX开头的RelNode子类换成了EnumerableXXX或BindableXXX,总而言之,看看具体优化规则的实现就对了,都是繁琐的体力活。
Sqlliteral:主要用来封装输入的常量,也被称作字面量。
SqlCall:每一个操作都对应一个SqlCall,如查询时SqlSelect,插入是SqlInsert。
SqlIdentifier:代表输入的标识符,例如SQL语句中表的名称、字段名称,都可以封装成一个SqlIdentifier对象。
在算子树中每一个节点就是一个RelNode,一条SQL语句经过解析、校验之后便会将SQLNode转换为RelNode做后续的优化。
RexNode代表的是行表达式,是对字面量、函数等进行的封装。其中RexVariable代表变量表达式,RexCall代表函数等操作,RexLiteral代表常量表达式。
优化器
1. HepPlanner
在Calcite中提供了HepPlanner优化器,实现了RBO模型。调用过程如下:
--------------------------------------------------
| setRoot ------(生成DAG)-> addRelToGraph |
--------------------------------------------------
|
V
--------------------------------------------------
| findBestExp |
--------------------------------------------------
|
V
--------------------------------------------------
| executeProgram |
--------------------------------------------------
|
V
--------------------------------------------------
| applyRule |
--------------------------------------------------
|
V
--------------------------------------------------
| buildFinalPlan |
--------------------------------------------------
// 实现RelOptPlanner
@OverridepublicRelNodefindBestExp() {
requireNonNull(root, "root");
executeProgram(mainProgram); // 遍历所有注册的规则,然后进行分配
// Get rid of everything except what's in the final plan.
collectGarbage();
dumpRuleAttemptsInfo();
// 将每一个节点转换为RelNode返回
returnbuildFinalPlan(requireNonNull(root, "root"));
}
// 应用规则的地方
privatevoidapplyRules(HepProgram.StateprogramState,
Collection<RelOptRule>rules, booleanforceConversions) {
finalHepInstruction.EndGroup.Stategroup=programState.group;
if (group!=null) {
checkArgument(group.collecting);
Set<RelOptRule>ruleSet=requireNonNull(group.ruleSet, "group.ruleSet");
ruleSet.addAll(rules);
return;
}
LOGGER.trace("Applying rule set {}", rules);
finalbooleanfullRestartAfterTransformation=
programState.matchOrder!=HepMatchOrder.ARBITRARY
&&programState.matchOrder!=HepMatchOrder.DEPTH_FIRST;
intnMatches=0;
booleanfixedPoint;
do {
Iterator<HepRelVertex>iter=
getGraphIterator(programState, requireNonNull(root, "root"));
fixedPoint=true;
while (iter.hasNext()) {
HepRelVertexvertex=iter.next();
for (RelOptRulerule : rules) {
HepRelVertexnewVertex=
applyRule(rule, vertex, forceConversions); // 应用所有规则, 判断是否匹配规则, 如果匹配则返回转换后的节点,不匹配则继续循环。
if (newVertex==null||newVertex==vertex) {
continue;
}
++nMatches; // 转换次数加1, 当转换次数达到最大值就推出循环
if (nMatches>=programState.matchLimit) {
return;
}
// 根据遍历规则,选择遍历方式
if (fullRestartAfterTransformation) {
iter=getGraphIterator(programState, requireNonNull(root, "root"));
} else {
// To the extent possible, pick up where we left
// off; have to create a new iterator because old
// one was invalidated by transformation.
iter=getGraphIterator(programState, newVertex);
if (programState.matchOrder==HepMatchOrder.DEPTH_FIRST) {
nMatches=
depthFirstApply(programState, iter, rules, forceConversions, nMatches);
if (nMatches>=programState.matchLimit) {
return;
}
}
// Remember to go around again since we're
// skipping some stuff.
fixedPoint=false;
}
break;
}
}
} while (!fixedPoint);
}
// 规则的匹配的遍历方式
publicenumHepMatchOrder {
// 任意匹配方式,该方式和深度优先遍历是一样的,采用的也是深度优化的方式
ARBITRARY,
// 从叶子节点开始匹配一致到根节点,一种从下到上的方式
BOTTOM_UP,
// 从根节点开始匹配,一致到叶子节点,一种从上到下的方式
TOP_DOWN,
// 深度优先遍历
DEPTH_FIRST
}
// 优化规则的定义
/** Rule that pushes parts of the join condition to its inputs. */
publicstaticclassJoinConditionPushRule
extendsFilterJoinRule<JoinConditionPushRule.JoinConditionPushRuleConfig> {
/** Creates a JoinConditionPushRule. */
protectedJoinConditionPushRule(JoinConditionPushRuleConfigconfig) {
super(config);
}
@Deprecated// to be removed before 2.0
publicJoinConditionPushRule(RelBuilderFactoryrelBuilderFactory,
Predicatepredicate) {
this(ImmutableJoinConditionPushRuleConfig.of(predicate)
.withRelBuilderFactory(relBuilderFactory)
.withOperandSupplier(b->
b.operand(Join.class).anyInputs())
.withDescription("FilterJoinRule:no-filter")
.withSmart(true));
}
@Deprecated// to be removed before 2.0
publicJoinConditionPushRule(RelFactories.FilterFactoryfilterFactory,
RelFactories.ProjectFactoryprojectFactory, Predicatepredicate) {
this(RelBuilder.proto(filterFactory, projectFactory), predicate);
}
@OverridepublicvoidonMatch(RelOptRuleCallcall) {
Joinjoin=call.rel(0);
perform(call, null, join);
}
/** Rule configuration. */
@Value.Immutable(singleton=false)
publicinterfaceJoinConditionPushRuleConfigextendsFilterJoinRule.Config {
JoinConditionPushRuleConfigDEFAULT=ImmutableJoinConditionPushRuleConfig
.of((join, joinType, exp) ->true)
// 规则指定主要通过withOperandSupplier来实现, 通过调用operand(Class)传入相应节点的RelNode的Class便可以定义该规则。
.withOperandSupplier(b->b.operand(Join.class).anyInputs())
.withSmart(true);
@OverridedefaultJoinConditionPushRuletoRule() {
returnnewJoinConditionPushRule(this);
}
}
}
// 例子:定义一条规则为Project节点、同时传入Project节点下面没有任何子节点输入
withOperandSupplier(b->b.operand(Project.class).noInputs());
// 例子:定义规则为Project的一个输入时Join算子
withOperandSupplier(b->b.operand(Project.class)
.onInput(b1->b1.operand(Join.class).anyInputs()));
2. VolcanoPlanner
利用CBO模型做优化,根据实际的查询代价来选择合适的规则进行应用。Calcite中默认提供了数据行数、CPU代价、I/O代码,这三个方面来影响一个规则的好坏。
CBO模型在计算过程中使用贪心算法来寻找最优解,因此在计算的过程中可以把已经计算的子问题保存下来,当之后使用到该子问题时,可以直接使用。其实就是动态规划的思想,大问题拆解成子问题再对子问题求解,最后将子问题合并成最终结果。由于一颗子树中有多种等价转换,因此将所有的等价转换保存子啊RelSet的rels列表中。
classRelSet {
finalList<RelNode>rels=newArrayList<>(); // 将所有的等价转换保存在RelSet的rels列表中
finalList<RelSubset>subsets=newArrayList<>(); // 记录具有相同物理属性的关系表达式的最优RelNode
}
publicclassVolcanoPlannerextendsAbstractRelOptPlanner {
// 优化从setRoot开始的
@OverridepublicvoidsetRoot(RelNoderel) {
this.root=registerImpl(rel, null); // 遍历逻辑计划的子节点以保证每个节点都会注册
if (this.originalRoot==null) {
this.originalRoot=rel;
}
rootConvention=this.root.getConvention();
ensureRootConverters();
}
// 遍历逻辑计划的子节点以保证每个节点都会注册, 通过getInputs方式获取子节点,之后在ensureRegistered方法中递归地再去遍历其子节点,以确保每个节点都会遍历到
privateRelSubsetregisterImpl(
RelNoderel,
@NullableRelSetset) {
if (relinstanceofRelSubset) {
returnregisterSubset(set, (RelSubset) rel);
}
assert!isRegistered(rel) : "already been registered: "+rel;
if (rel.getCluster().getPlanner() !=this) {
thrownewAssertionError("Relational expression "+rel
+" belongs to a different planner than is currently being used.");
}
// Now is a good time to ensure that the relational expression
// implements the interface required by its calling convention.
finalRelTraitSettraits=rel.getTraitSet();
finalConventionconvention=traits.getTrait(ConventionTraitDef.INSTANCE);
assertconvention!=null;
if (!convention.getInterface().isInstance(rel)
&&!(relinstanceofConverter)) {
thrownewAssertionError("Relational expression "+rel
+" has calling-convention "+convention
+" but does not implement the required interface '"
+convention.getInterface() +"' of that convention");
}
if (traits.size() !=traitDefs.size()) {
thrownewAssertionError("Relational expression "+rel
+" does not have the correct number of traits: "+traits.size()
+" != "+traitDefs.size());
}
// Ensure that its sub-expressions are registered.
rel=rel.onRegister(this);
// Record its provenance. (Rule call may be null.)
finalVolcanoRuleCallruleCall=ruleCallStack.peek();
if (ruleCall==null) {
provenanceMap.put(rel, Provenance.EMPTY);
} else {
provenanceMap.put(
rel,
newRuleProvenance(
ruleCall.rule,
ImmutableList.copyOf(ruleCall.rels),
ruleCall.id));
}
// If it is equivalent to an existing expression, return the set that
// the equivalent expression belongs to.
RelDigestdigest=rel.getRelDigest();
RelNodeequivExp=mapDigestToRel.get(digest);
if (equivExp==null) {
// do nothing
} elseif (equivExp==rel) {
// The same rel is already registered, so return its subset
returngetSubsetNonNull(equivExp);
} else {
if (!RelOptUtil.areRowTypesEqual(equivExp.getRowType(),
rel.getRowType(), false)) {
thrownewIllegalArgumentException(
RelOptUtil.getFullTypeDifferenceString("equiv rowtype",
equivExp.getRowType(), "rel rowtype", rel.getRowType()));
}
checkPruned(equivExp, rel);
RelSetequivSet=getSet(equivExp);
if (equivSet!=null) {
LOGGER.trace(
"Register: rel#{} is equivalent to {}", rel.getId(), equivExp);
returnregisterSubset(set, getSubsetNonNull(equivExp));
}
}
// Converters are in the same set as their children.
if (relinstanceofConverter) {
finalRelNodeinput= ((Converter) rel).getInput();
finalRelSetchildSet=castNonNull(getSet(input));
if ((set!=null)
&& (set!=childSet)
&& (set.equivalentSet==null)) {
LOGGER.trace(
"Register #{} {} (and merge sets, because it is a conversion)",
rel.getId(), rel.getRelDigest());
merge(set, childSet);
// During the mergers, the child set may have changed, and since
// we're not registered yet, we won't have been informed. So
// check whether we are now equivalent to an existing
// expression.
if (fixUpInputs(rel)) {
digest=rel.getRelDigest();
RelNodeequivRel=mapDigestToRel.get(digest);
if ((equivRel!=rel) && (equivRel!=null)) {
// make sure this bad rel didn't get into the
// set in any way (fixupInputs will do this but it
// doesn't know if it should so it does it anyway)
set.obliterateRelNode(rel);
// There is already an equivalent expression. Use that
// one, and forget about this one.
returngetSubsetNonNull(equivRel);
}
}
} else {
set=childSet;
}
}
// Place the expression in the appropriate equivalence set.
if (set==null) {
set=newRelSet(
nextSetId++,
Util.minus(
RelOptUtil.getVariablesSet(rel),
rel.getVariablesSet()),
RelOptUtil.getVariablesUsed(rel));
this.allSets.add(set);
}
// Chain to find 'live' equivalent set, just in case several sets are
// merging at the same time.
while (set.equivalentSet!=null) {
set=set.equivalentSet;
}
// Allow each rel to register its own rules.
registerClass(rel);
finalintsubsetBeforeCount=set.subsets.size();
// 在该方法中记录每一个节点的代价,如果有等价表达式同时它的代价更小,便会更新这个RelSubset
RelSubsetsubset=addRelToSet(rel, set);
finalRelNodexx=mapDigestToRel.putIfAbsent(digest, rel);
LOGGER.trace("Register {} in {}", rel, subset);
// This relational expression may have been registered while we
// recursively registered its children. If this is the case, we're done.
if (xx!=null) {
returnsubset;
}
// 通过getInputs方式获取子节点
for (RelNodeinput : rel.getInputs()) {
RelSubsetchildSubset= (RelSubset) input;
childSubset.set.parents.add(rel);
}
// Queue up all rules triggered by this relexp's creation.
// 匹配所有的关系代数模型中的顺序和算子,如果匹配到就把该条规则加入到队列当中,并在后续的=优化过程中使用。
fireRules(rel);
// It's a new subset.
if (set.subsets.size() >subsetBeforeCount
||subset.triggerRule) {
fireRules(subset);
}
returnsubset;
}
}
// 开始寻找最优的规则
@OverridepublicRelNodefindBestExp() {
assertroot!=null : "root must not be null";
ensureRootConverters();
registerMaterializations();
ruleDriver.drive(); // 寻找最优的核心方法
if (LOGGER.isTraceEnabled()) {
StringWritersw=newStringWriter();
finalPrintWriterpw=newPrintWriter(sw);
dump(pw);
pw.flush();
LOGGER.info(sw.toString());
}
dumpRuleAttemptsInfo();
RelNodecheapest=root.buildCheapestPlan(this);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug(
"Cheapest plan:\n{}", RelOptUtil.toString(cheapest, SqlExplainLevel.ALL_ATTRIBUTES));
if (!provenanceMap.isEmpty()) {
LOGGER.debug("Provenance:\n{}", Dumpers.provenance(provenanceMap, cheapest));
}
}
returncheapest;
}
// 循环从ruleQueue中取出规则,并匹配
@Overridepublicvoiddrive() {
while (true) {
assertplanner.root!=null : "RelSubset must not be null at this point";
LOGGER.debug("Best cost before rule match: {}", planner.root.bestCost);
VolcanoRuleMatchmatch=ruleQueue.popMatch();
if (match==null) { // 没有规则匹配就退出
break;
}
assertmatch.getRule().matches(match);
try {
match.onMatch();
} catch (VolcanoTimeoutExceptione) { // 超时退出
LOGGER.warn("Volcano planning times out, cancels the subsequent optimization.");
planner.canonize();
break;
}
// The root may have been merged with another
// subset. Find the new root subset.
planner.canonize();
}
// 上面计算获取到了每个节点的最小代价之后,只要把每个节点组合起来便是最优解, 所以这里递归的组装每一个节点的最优解
RelNodebuildCheapestPlan(VolcanoPlannerplanner) {
CheapestPlanReplacerreplacer=newCheapestPlanReplacer(planner);
finalRelNodecheapest=replacer.visit(this, -1, null); // 利用访问者模式去遍历
if (planner.getListener() !=null) {
RelOptListener.RelChosenEventevent=
newRelOptListener.RelChosenEvent(
planner,
null);
planner.getListener().relChosen(event);
}
returncheapest;
}
贪心算法
参考文章
calcite的文章:http://matt33.com/2019/03/07/apache-calcite-process-flow/
相关文章:
Flink相关的记录
Flink源码编译首次编译的时候,去除不必要的操作,同时install会把Flink中的module安装到本地仓库,这样依赖当前module的其他组件就无需去远程仓库拉取当前module,节省了时间。mvn clean install -T 4 -DskipTests -Dfast -Dmaven.c…...
配置可视化-基于form-render的无代码配置服务(一)
背景 有些业务场景需要产品或运营去配置JSON数据提供给开发去使用(后面有实际业务场景的说明),原有的业务流程,非开发人员(后面直接以产品指代)把数据交给开发,再由开发去更新JSON数据。对于产…...
Java 代理模式详解
1、代理模式 代理模式是一种比较好理解的设计模式。简单来说就是 我们使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。 代理模式的主要作用是扩展目标对象…...
知识付费小程序怎么做_分享知识付费小程序的作用
在线知识付费产业的主要业务逻辑是基于用户的主动学习需求,为其提供以跨领域基础知识与技能为核心的在线知识服务,提升其达到求知目的的效率。公众号和小程序的迅速发展,又为知识付费提供了技术支持,从而促进了行业的进一步发展。…...
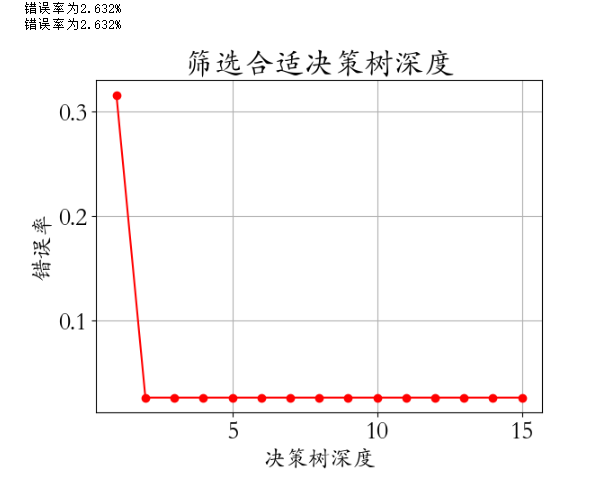
14- 决策树算法 (有监督学习) (算法)
决策树是属于有监督机器学习的一种决策树算法实操: from sklearn.tree import DecisionTreeClassifier # 决策树算法 model DecisionTreeClassifier(criterionentropy,max_depthd) model.fit(X_train,y_train)1、决策树概述 决策树是属于有监督机器学习的一种,起源…...

如何编译和运行C++程序?
C 和C语言类似,也要经过编译和链接后才能运行。在《C语言编译器》专题中我们讲到了 VS、Dev C、VC 6.0、Code::Blocks、C-Free、GCC、Xcode 等常见 IDE 或编译器,它们除了可以运行C语言程序,还可以运行 C 程序,步骤是一样的&#…...

Golang 给视频添加背景音乐 | Golang工具
目录 前言 环境依赖 代码 总结 前言 本文提供给视频添加背景音乐,一如既往的实用主义。 主要也是学习一下golang使用ffmpeg工具的方式。 环境依赖 ffmpeg环境安装,可以参考我的另一篇文章:windows ffmpeg安装部署_阿良的博客-CSDN博客 …...

让AI护理医疗:解决卫生系统的痛点
一、引言 1.对医疗领域中AI技术的介绍 随着人工智能的不断发展,它已经成为了各个领域中的重要组成部分。在医疗领域中,AI技术也逐渐发挥着越来越重要的作用。从诊断到治疗,从健康管理到研究,人工智能已经深刻地影响着医疗领域的…...
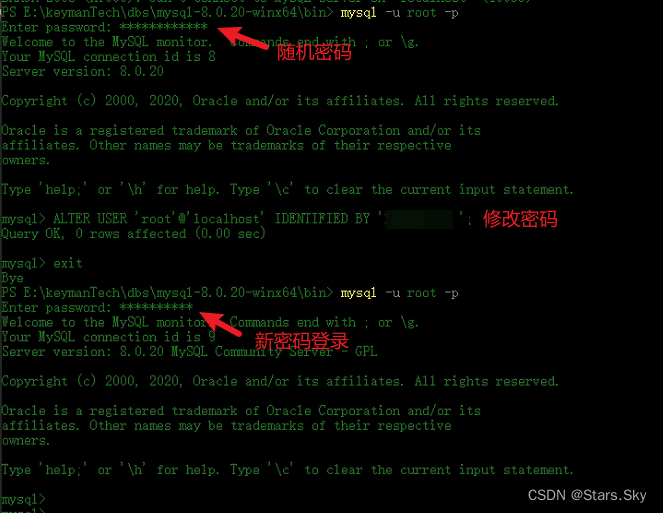
Windows 离线安装 MySQL 8
目录 1. 下载离线安装包 2. 上传解压 3 配置 my.ini 文件 4 设置系统环境变量 5 安装 MySQL 6 登录 MySQL 客户环境是内网环境,不能访问外网,只能离线安装 MySQL 了。 1. 下载离线安装包 MySQL 离线压缩包官网下载地址:MySQL :: Down…...

【前端攻城狮之vue基础】02路由+嵌套路由+路由query/params传参+路由props配置+replace属性+编程式路由导航+缓存路由组件
路由的基础知识1.路由简介2.路由基本使用3.嵌套路由4.传递路由的query传参# 5.传递路由的params参数6.路由的props传参配置7.路由router-link标签的replace属性8.编程式路由导航9.缓存路由组件1.路由简介 路由是一条条对应的key-value关系,key就是前端地址栏的路径…...
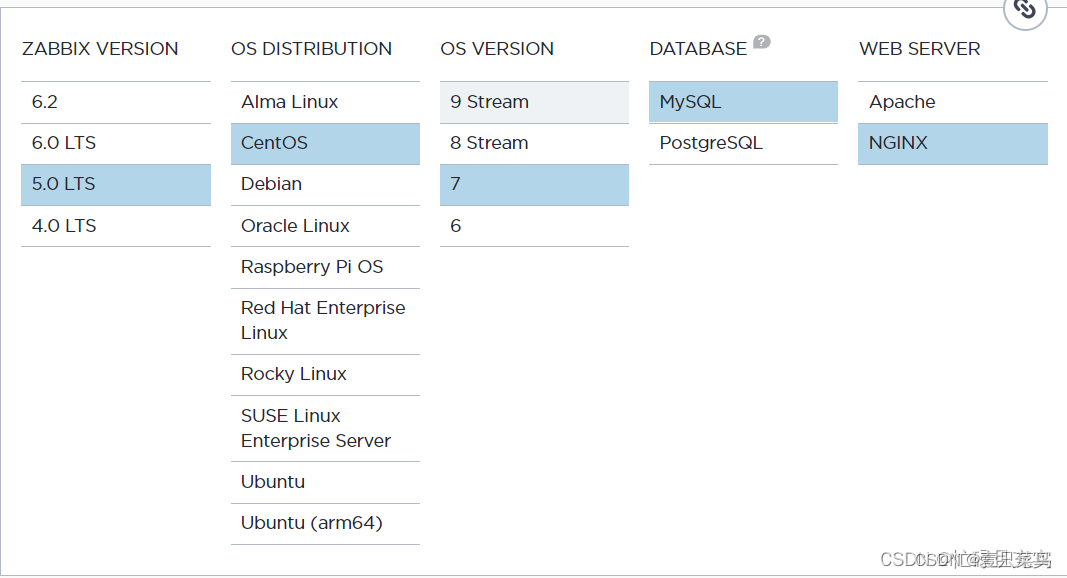
CHAPTER 1 Zabbix介绍及安装
Zabbix介绍及安装1.1 Zabbix监控1 为什么要监控1.1 网站可用性2 监控什么东西2.1 监控范畴3 怎么来监控3.1 远程管理服务器3.2 监控硬件3.3 查看cpu相关3.4 内存3.5 磁盘3.6 监控网络4 监控工具总览5 zabbix介绍5.1 zabbix的组成5.2 zabbix监控范畴1.2 安装zabbix1 环境检查2 安…...

认识V模型、W模型、H模型
软件测试与软件工程息息相关,软件测试是软件工程组成中不可或缺的一部分。 在软件工程、项目管理、质量管理得到规范化应用的企业,软件测试也会进行得比较顺利,软件测试发挥的价值也会更大。 要关注软件工程、质量管理以及配置管理与软件测试…...

excel ttest检测
1、excel函数含义 TTEST(array1,array2,tails,type) ▪ Array1: 第一组数据集 ▪ Array2: 第二组数据集 ▪ Tails: 用于定义所返回的分布的尾数: 1 代表单尾;2 代表双尾 ▪ Type: 用于定义 t-检验的类型: 1 代表成对检验;2 代表双样本等方差假设&am…...
PDFPrinting.Net操作进行细粒度控制
PDFPrinting.Net操作进行细粒度控制 PDFPrinting.Net能够容易且灵活地预测完美的打印结果以及用户文件的示例性显示。可以快速浏览.NET PDF打印中最关键的元素。如果用户需要获得更详细的概述,那么他可以查看快速入门手册,甚至是现有文档的详细概述参考。…...

SegPGD
在这项工作中,我们提出了一种有效和高效的分割攻击方法,称为SegPGD。此外,我们还提供了收敛性分析,表明在相同次数的攻击迭代下,所提出的SegPGD可以创建比PGD更有效的对抗示例。此外,我们建议应用我们的Seg…...
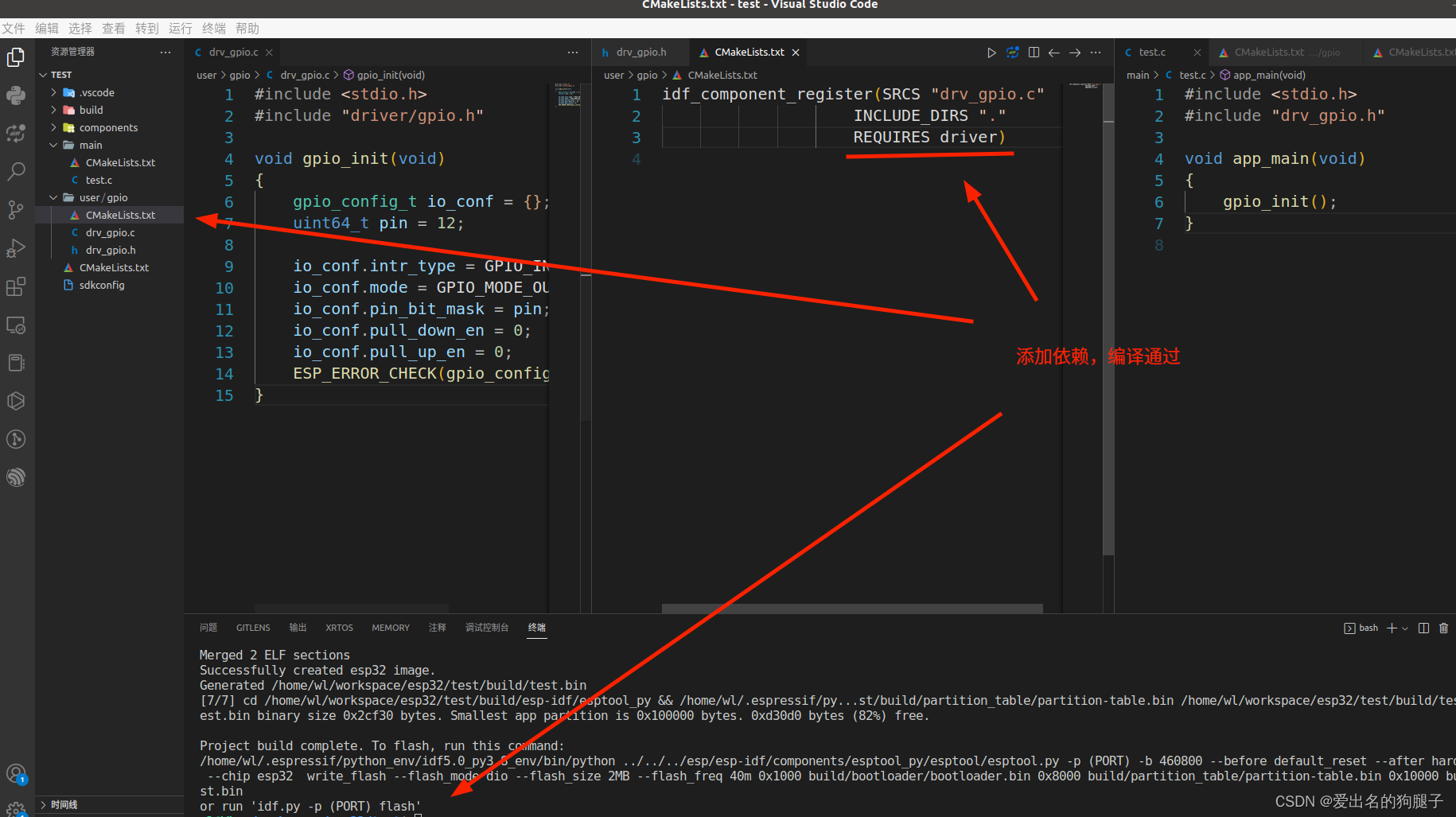
ESP-IDF + Vscode ESP32 开发环境搭建以及开发入门
ESP-IDF Vscode ESP32 开发环境搭建以及开发入门 文章目录ESP-IDF Vscode ESP32 开发环境搭建以及开发入门1. 前言2. 下载开发工具3. 配置工具4. 创建工程5. 解决vscode找不到头文件,波浪线警告6. 添加自己的组件6.1 组件说明6.2 添加项目组件6.3 添加扩展组件7. …...

SpringMvc的请求和响应
SpringMvc的数据响应 1.springmvc的数据相应方式 (1)页面跳转 直接返回字符串 通过ModelAndView对象返回 (2)回写数据 直接返回字符串 返回对象或集合 页面跳转 jsp页面 <% page contentType"text/html;charsetUTF-8&q…...

【Vue3】首页主体-面板组件封装
首页主体-面板组件封装 新鲜好物、人气推荐俩个模块的布局结构上非常类似,我们可以抽离出一个通用的面板组件来进行复用 目标:封装一个通用的面板组件 思路分析 图中标出的四个部分都是可能会发生变化的,需要我们定义为可配置主标题和副标题…...

部署 K8s 集群
1 .部署k8s的两种方式目前生产部署Kubernetes集群主要有两种方式:kubeadmKubeadm是一个K8s部署工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。二进制包从github下载发行版的二进制包,手动部署每个组件&#x…...

关于北京君正:带ANC的2K网络摄像头用户案例
如果远程办公是您的未来,或者您经常通过视频通话与远方的朋友和亲戚交谈,那么您可以考虑购买网络摄像头以显著改善您的沟通。Anker PowerConf C200是个不错的选择。 Anker PowerConf C200专为个人工作空间而设计,能够以每秒30帧的速度拍摄2K…...

iOS微信聊天记录备份完全指南:使用WeChatExporter永久保存你的数字回忆
iOS微信聊天记录备份完全指南:使用WeChatExporter永久保存你的数字回忆 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经因为手机存储空间不足而不得…...
)
没有独立显卡也能跑!在Windows10上零基础部署微软OmniParser屏幕解析模型(保姆级避坑指南)
没有独立显卡也能跑!在Windows10上零基础部署微软OmniParser屏幕解析模型(保姆级避坑指南) 当第一次听说微软开源的OmniParser屏幕解析模型时,许多开发者都会被其强大的功能所吸引——它能将用户界面截图自动解析为结构化数据&…...

VSCode配置Live Server插件:实现一键启动与Chrome浏览器预览
1. 为什么你需要Live Server插件 作为一个前端开发者,我深知在本地调试HTML/CSS/JS时频繁手动刷新浏览器的痛苦。每次修改代码后都要切换到浏览器按F5,这种重复操作不仅浪费时间,还容易打断开发思路。这就是为什么我强烈推荐使用VSCode的Live…...

Pi0 VLA模型效果展示:俯视/侧视/主视三图协同提升抓取成功率对比
Pi0 VLA模型效果展示:俯视/侧视/主视三图协同提升抓取成功率对比 1. 多视角视觉输入的革命性价值 在机器人抓取任务中,传统单视角视觉系统存在明显的局限性。单一视角无法全面感知物体的三维结构、空间位置和周围环境,导致抓取成功率受限。…...

Qwen3-0.6B-FP8多轮对话效果展示:复杂任务拆解与上下文记忆
Qwen3-0.6B-FP8多轮对话效果展示:复杂任务拆解与上下文记忆 最近在测试一些轻量级模型,看看它们在真实对话场景下的表现。今天的主角是Qwen3-0.6B-FP8,一个参数只有6亿的“小个子”。你可能觉得,这么小的模型,处理复杂…...

eVTOL应急消杀模块功率链路优化:基于高压隔离、高效驱动与精准负载管理的MOSFET选型方案
前言:构筑空中防疫屏障的“电力骨架”——论eVTOL特种功率模块的系统思维在都市空中交通与应急防疫结合的前沿领域,eVTOL飞行器搭载的智能消杀模块,不仅是应对突发公共卫生事件的关键装备,更是一套对功率密度、可靠性与重量极度敏…...

Java实战:利用系统命令与弱口令字典进行Wifi连接测试
1. 为什么需要Wifi连接测试工具 最近在做一个智能家居项目时,经常需要测试不同Wifi网络的连接稳定性。手动切换网络实在太麻烦,于是萌生了用Java写个自动化工具的想法。这个工具的核心功能就是模拟手动连接Wifi的过程,但完全自动化执行。 你…...

从测绘‘平差’到VINS的BA:聊聊SLAM中这个经典优化问题的前世今生
从测绘平差到视觉SLAM:光束法优化的跨世纪技术迁移 当19世纪的高斯和勒让德首次提出最小二乘法时,他们或许不会想到这套用于处理天文观测误差的数学工具,会在两个世纪后成为机器人感知世界的核心技术。在当代视觉SLAM系统中,光束法…...

手把手教你用运算放大器设计电路:虚短虚断的5个常见误区与避坑指南
手把手教你用运算放大器设计电路:虚短虚断的5个常见误区与避坑指南 运算放大器(Op-Amp)作为电子设计中的"瑞士军刀",其核心特性"虚短"与"虚断"看似简单,却在实际应用中埋藏着诸多认知陷…...

【运筹优化】网络最大流问题:从理论到实战,三种核心算法Python实现与性能对比
1. 从水管工到算法工程师:网络最大流问题入门 想象你是个城市水管系统的总工程师,负责将自来水从净水厂输送到千家万户。整个城市的水管网络错综复杂,不同管道的直径和承压能力各不相同。你的任务是设计一套输送方案,让尽可能多的…...