Hadoop集群搭建
文章目录
- 一、运行环境配置(所有节点)
- 1、基础配置
- 2、配置Host
- 二、依赖软件安装(101节点)
- 1、安装JDK
- 2、安装Hadoop(root)
- 3、Hadoop目录结构
- 三、本地运行模式(官方WordCount)
- 1、简介
- 2、本地运行模式(官方WordCount)
- 四、完全分布式运行模式
- 1、文件分发脚本(root)
- 2、SSH免密登录设置
- 3、同步文件
- 4、集群节点资源配置
- 4.1 核心配置文件(core-site.xml)
- 4.2 HDFS配置文件(hdfs-site.xml)
- 4.3 YARN配置文件(yarn-site.xml)
- 4.4 MapReduce配置文件(mapred-site.xml)
- 4.5 分发配置文件
- 5、群起集群
- 5.1 配置workers
- 5.2 启动集群
- 5.3 其它启动停止方式
- 5.4 启动脚本
- 6、查看相关页面
- 7、配置历史服务器
- 8、配置日志的聚集
- 9、其它
- 9.1 常用端口号
- 9.2 常用页面
- 五、遇到问题
- 1、编辑文件无权限('readonly' option is set (add ! to override))
一、运行环境配置(所有节点)
所有集群服务,都需要配置
1、基础配置
关闭防火墙,关闭防火墙开机自启
systemctl stop firewalld
systemctl disable firewalld
创建lydms用户,并修改lydms用户的密码lydms123
useradd lydms
passwd lydms
配置lydms用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
lydms ALL=(ALL) NOPASSWD:ALL
'readonly' option is set (add ! to override) 查看5.1解决。
在/opt目录下创建文件夹
mkdir /opt/module
mkdir /opt/software
并修改所属主和所属组
chown lydms:lydms /opt/module
chown lydms:lydms /opt/software
2、配置Host
更新本机名称(参照下表)
vim /etc/hostname
172.27.181.176 hadoop101
172.27.181.177 hadoop102
172.27.181.178 hadoop103
配置Linux克隆机主机名称映射hosts文件
vim /etc/hosts
172.27.181.176 hadoop101
172.27.181.177 hadoop102
172.27.181.178 hadoop103

重启虚拟机
reboot
二、依赖软件安装(101节点)
只有主节点进行配置
1、安装JDK
下载JDK
https://www.oracle.com/java/technologies/downloads/archive/
wget https://gitcode.net/weixin_44624117/software/-/raw/master/software/jdk-8u181-linux-x64.tar.gz?inline=false
解压文件
tar -zxvf jdk-8u341-linux-x64.tar.gz -C /opt/module/
添加环境变量
vim /etc/profile.d/my_env.sh
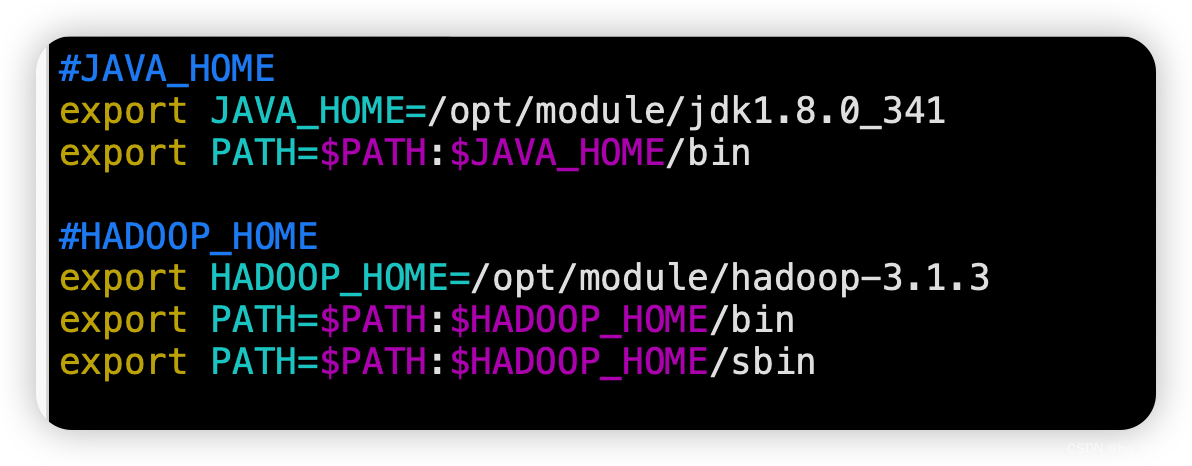
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_341
export PATH=$PATH:$JAVA_HOME/bin
加载环境变量
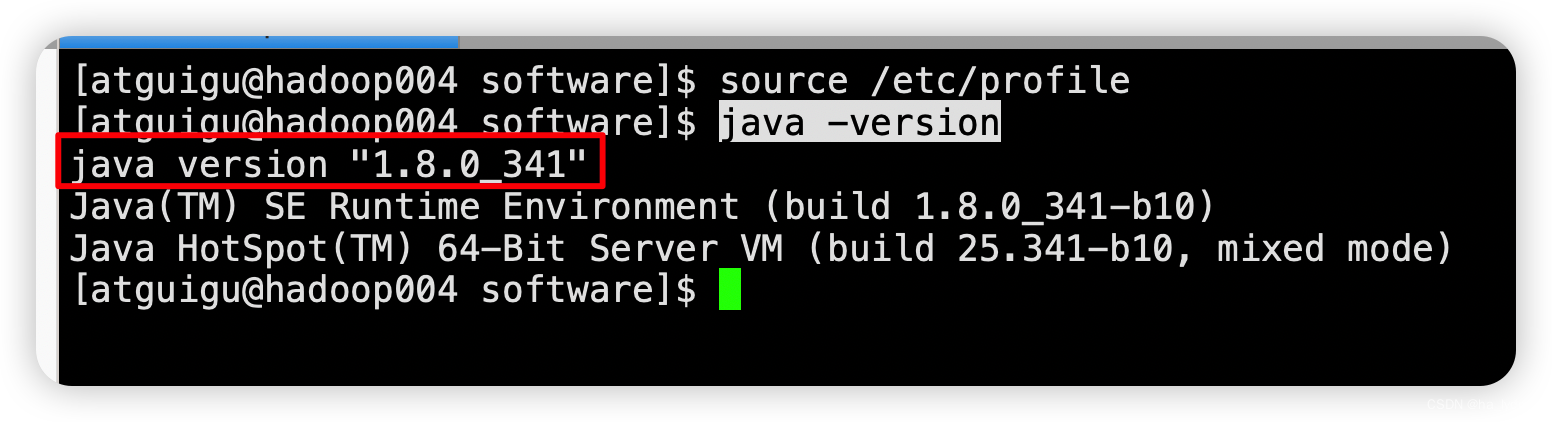
source /etc/profile
查看是否安装完成
java -version
2、安装Hadoop(root)
下载地址
https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
解压到/opt/module/目录
tar -zxvf /root/hadoop-3.1.3.tar.gz -C /opt/module/
添加环境变量
vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
加载环境变量
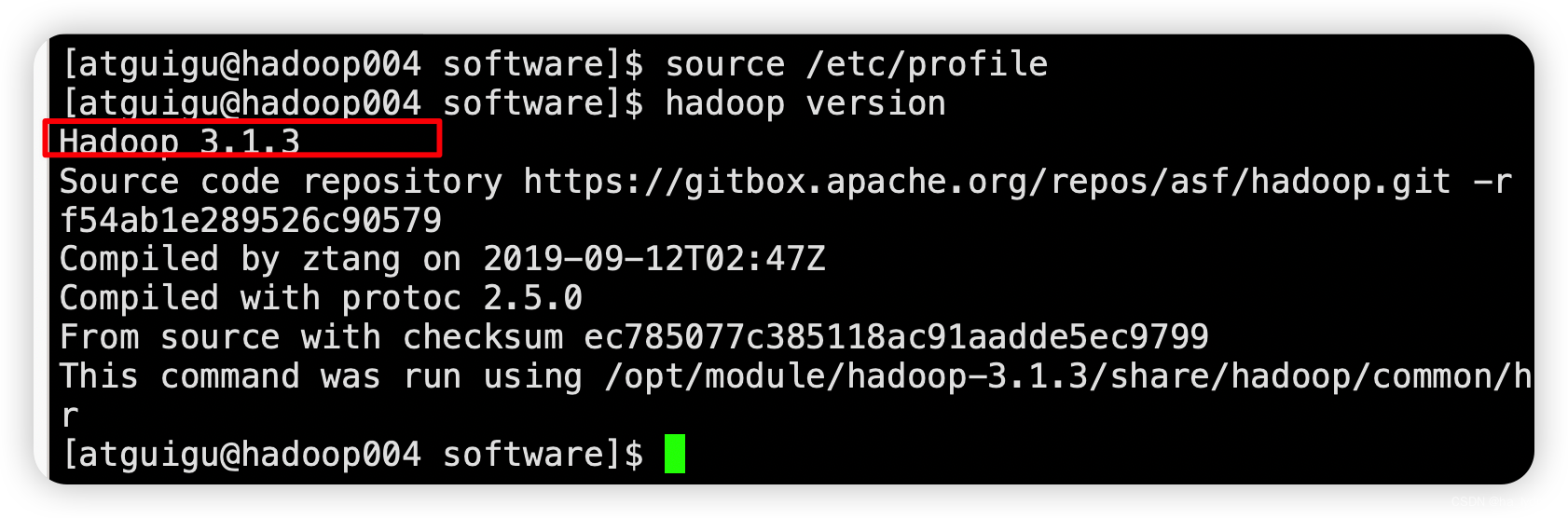
source /etc/profile
查看是否安装完成
hadoop version
3、Hadoop目录结构
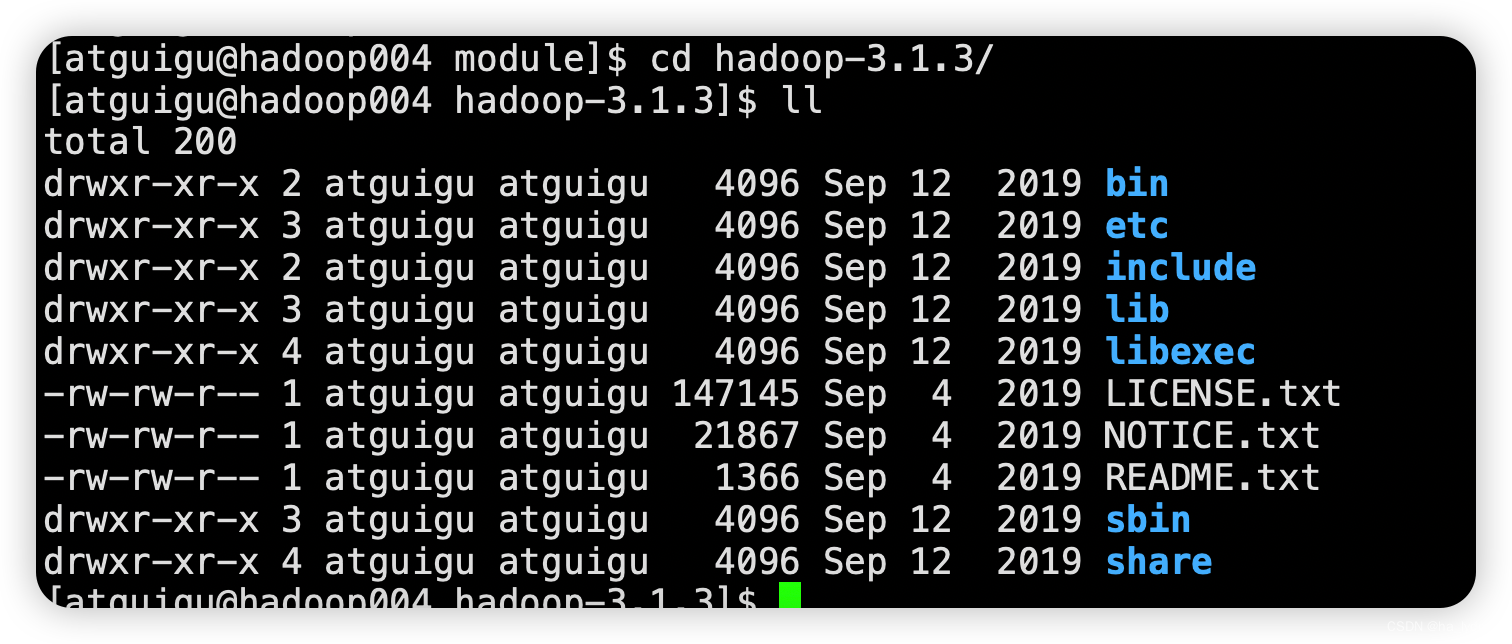
- bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本。
- etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件。
- lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)。
- sbin目录:存放启动或停止Hadoop相关服务的脚本。
- share目录:存放Hadoop的依赖jar包、文档、和官方案例。
三、本地运行模式(官方WordCount)
1、简介
Hadoop官方网站:http://hadoop.apache.org/
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
- 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
- 伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
- 完全分布式模式:多台服务器组成分布式环境。生产环境使用。
2、本地运行模式(官方WordCount)
在hadoop-3.1.3文件下面创建一个wcinput文件夹
mkdir /opt/module/hadoop-3.1.3/wcinput
在wcinput文件下创建一个word.txt文件
vim /opt/module/hadoop-3.1.3/wcinput/word.txt
hadoop yarn
hadoop mapreduce
lydms
lydms
运行单机Hadoop
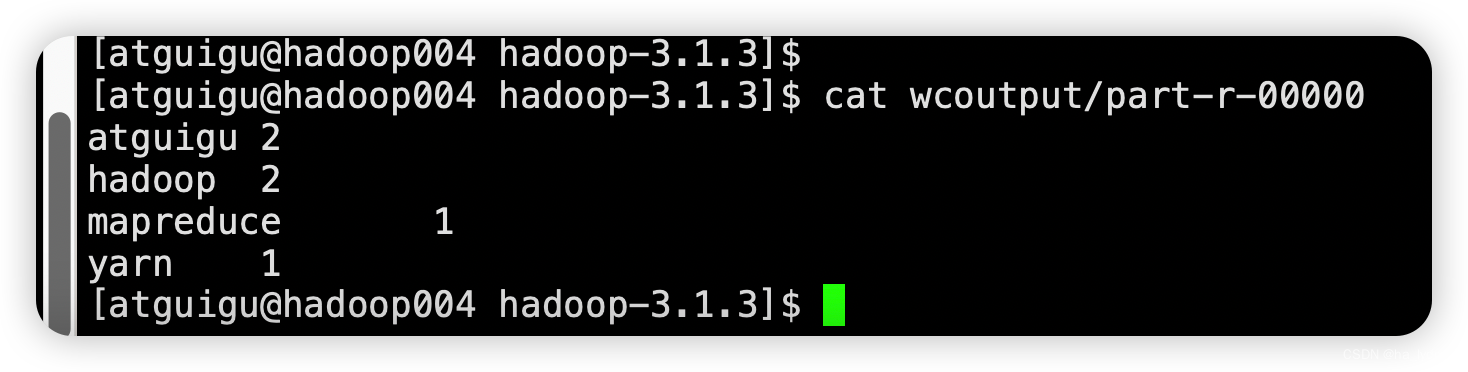
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
查看运行结果
cat wcoutput/part-r-00000
四、完全分布式运行模式
三台资源列表
172.27.181.176 hadoop101
172.27.181.177 hadoop102
172.27.181.178 hadoop103
1、文件分发脚本(root)
新建文件xsync
vim /bin/xsync
#!/bin/bash#1. 判断参数个数
if [ $# -lt 1 ]
thenecho "Not Enough Arguement!"exit
fi#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done
添加执行权限
chmod +x /bin/xsync
2、SSH免密登录设置
原理:
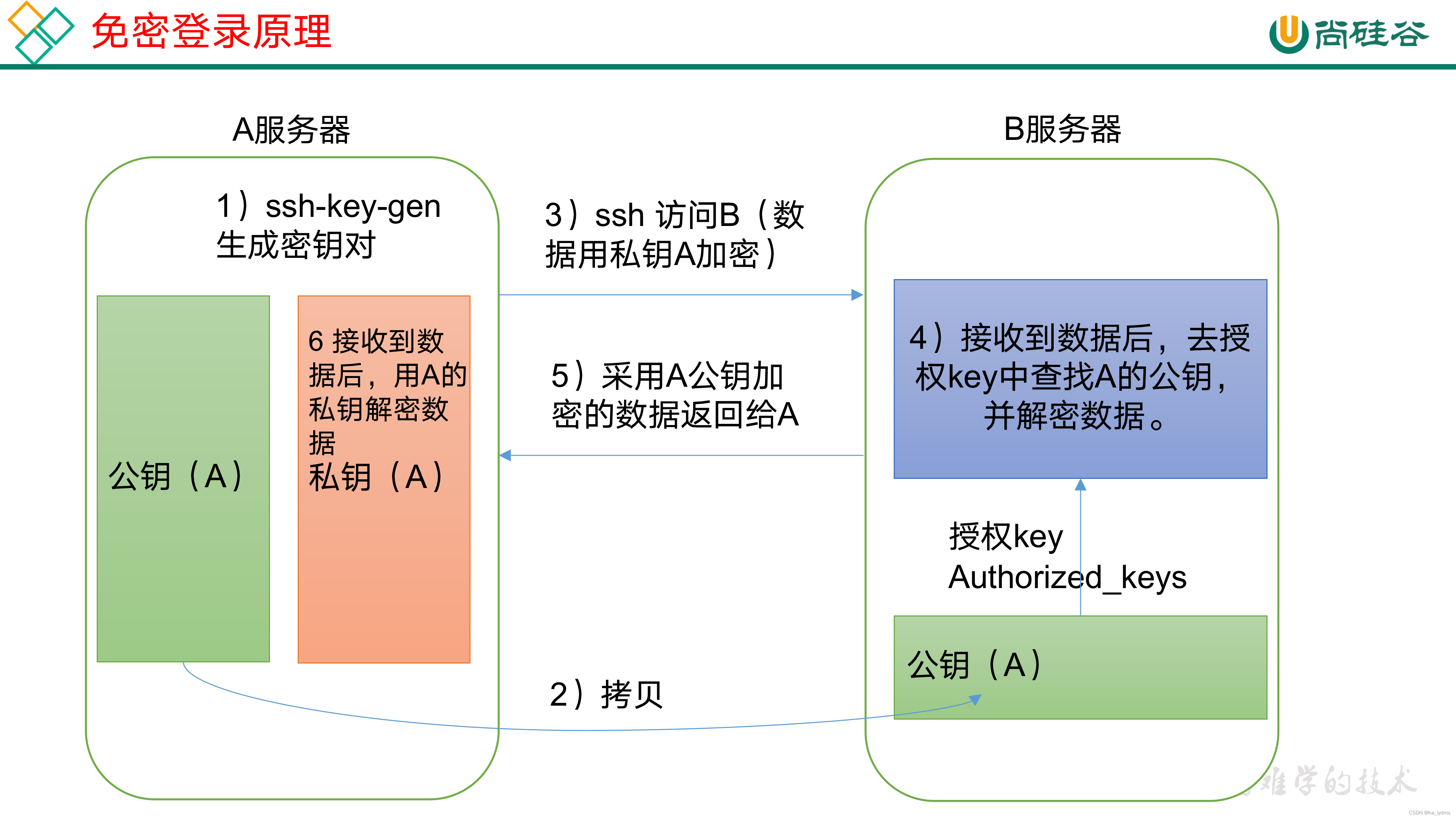
生成公私钥:
ssh-keygen -t rsa
查看生成文件
cd /home/lydms/.ssh/
ll
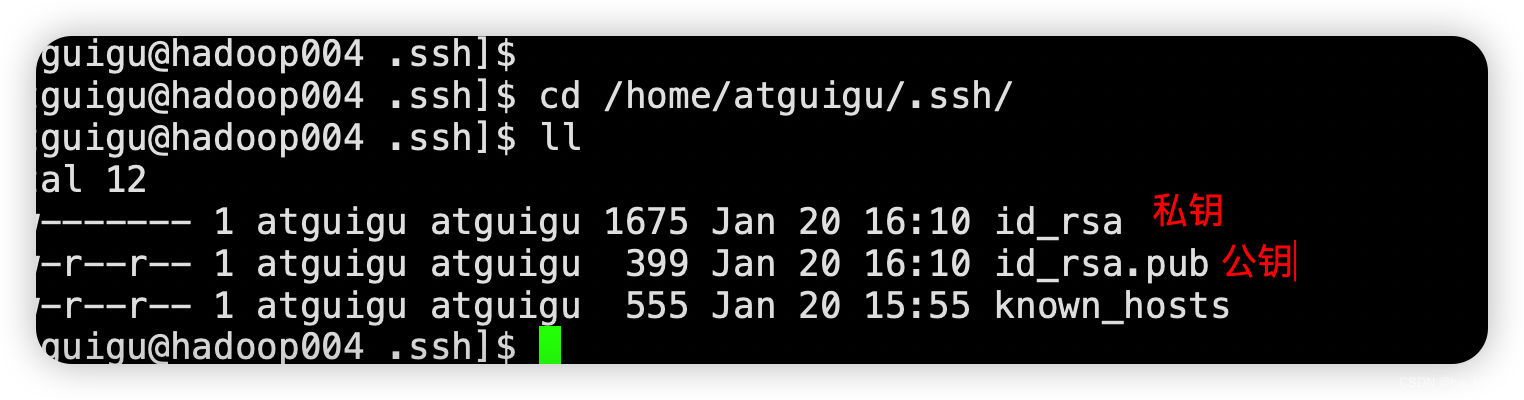
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
将公钥拷贝到要免密登录的目标机器上(输入相应密码)
几台服务器之间都要互相配置
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
测试:
ssh hadoop001
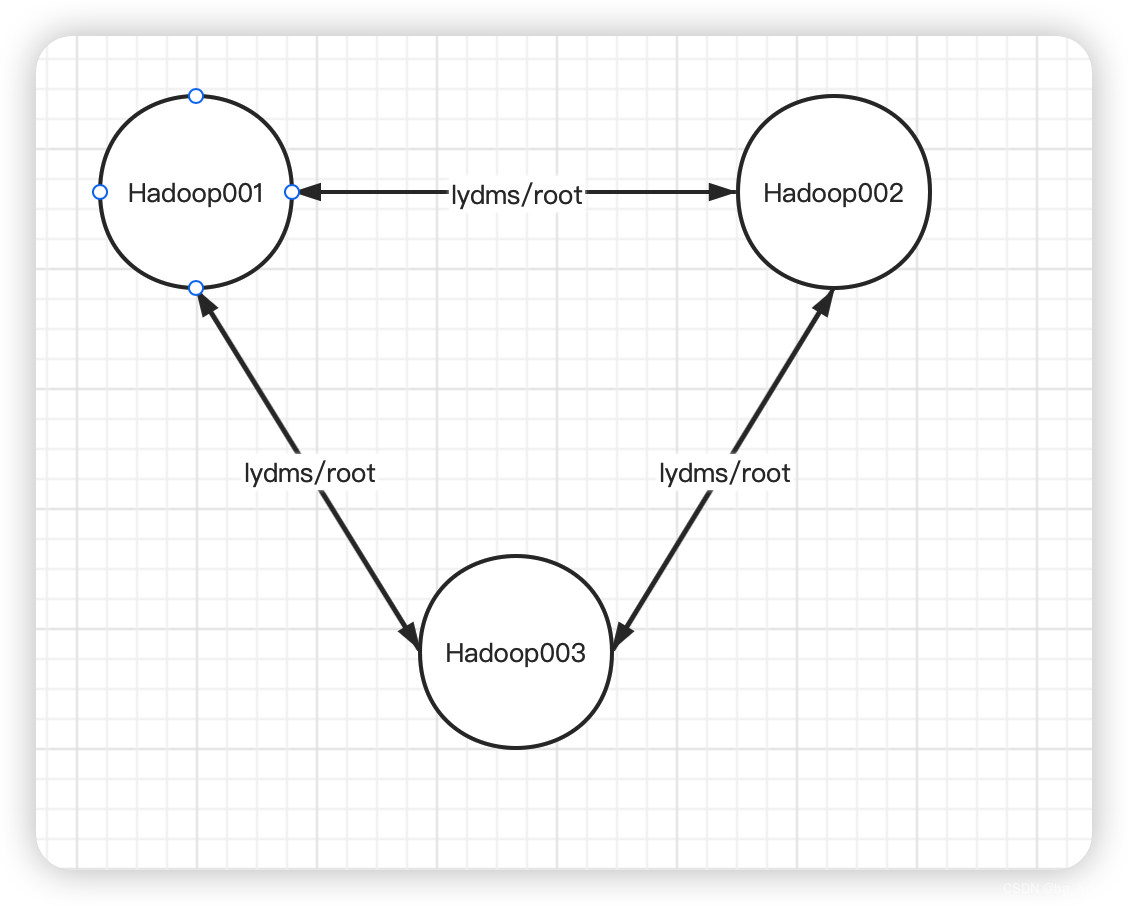
还需要配置(集群各个节点之间免密沟通):
hadoop101上采用root账号,配置一下免密登录到hadoop101、hadoop102、hadoop103。hadoop102上采用root账号,配置一下免密登录到hadoop101、hadoop102、hadoop103。hadoop103上采用root账号,配置一下免密登录到hadoop101、hadoop102、hadoop103;
最终效果:
3、同步文件
-
同步环境变量
/etc/profile.d/my_env.sh -
同步JDK、Hadoop:
/opt/model
同步环境变量
xsync /etc/profile.d/my_env.sh
# 在各个节点服务器中加载环境变量(hadoop001、hadoop002、hadoop003)
source /etc/profile
同步JDK、Hadoop
xsync /opt/module/
4、集群节点资源配置
- NameNode和SecondaryNameNode不要安装在同一台服务器。
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| Hadoop001 | Hadoop002 | Hadoop003 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件。
| 默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
4.1 核心配置文件(core-site.xml)
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
文件内容:
<configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop101:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户为lydms --><property><name>hadoop.http.staticuser.user</name><value>lydms</value></property>
</configuration>
4.2 HDFS配置文件(hdfs-site.xml)
vim hdfs-site.xml
文件内容:
<configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop101:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop103:9868</value></property>
</configuration>
4.3 YARN配置文件(yarn-site.xml)
vim yarn-site.xml
<configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop102</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
</configuration>
4.4 MapReduce配置文件(mapred-site.xml)
vim mapred-site.xml
<configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
4.5 分发配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
5、群起集群
5.1 配置workers
新增节点配置文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
hadoop101
hadoop102
hadoop103
同步配置
xsync /opt/module/hadoop-3.1.3/etc
5.2 启动集群
如果集群是第一次启动,需要在hadoop001节点格式化NameNode。
(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
hdfs namenode -format
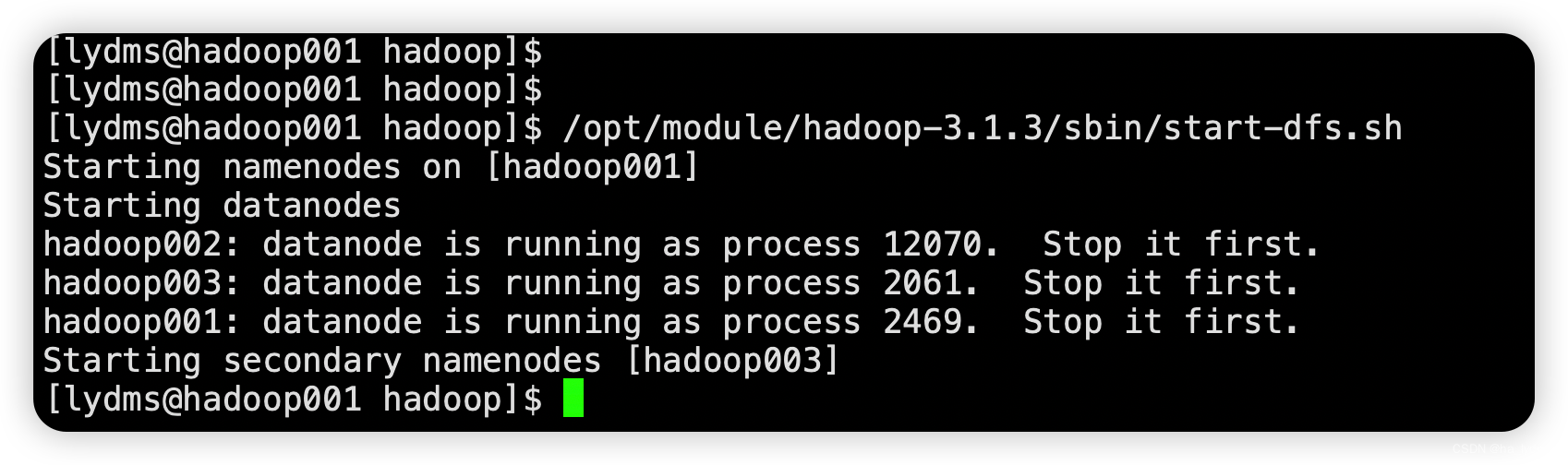
启动HDFS
# 启动
/opt/module/hadoop-3.1.3/sbin/start-dfs.sh
启动YARN(配置了ResourceManager的节点hadoop002)
# 启动
/opt/module/hadoop-3.1.3/sbin/start-yarn.sh

5.3 其它启动停止方式
启动/停止HDFS
# 整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh# 分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
启动/停止YARN
# 整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
# 分别启动/停止YARN组件
yarn --daemon start/stop resourcemanager/nodemanager
5.4 启动脚本
新建启动/停止集群脚本
cd /home/lydms/bin
vim myhadoop.sh
#!/bin/bashif [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
ficase $1 in
"start")echo " ======启动 hadoop集群 ======="echo " --------------- 启动 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
;;
"stop")echo " ==========关闭 hadoop集群 ========="echo " --------------- 关闭 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac
赋予脚本执行权限
chmod +x myhadoop.sh新建Java进程脚本:jpsall
cd /home/lydms/bin
vim jpsall
#!/bin/bashfor host in hadoop101 hadoop102 hadoop103
doecho =============== $host ===============ssh $host jps
done
赋予脚本执行权限
chmod +x jpsall
分发/home/atguigu/bin目录,保证自定义脚本在三台机器上都可以使用
xsync /home/lydms/bin/
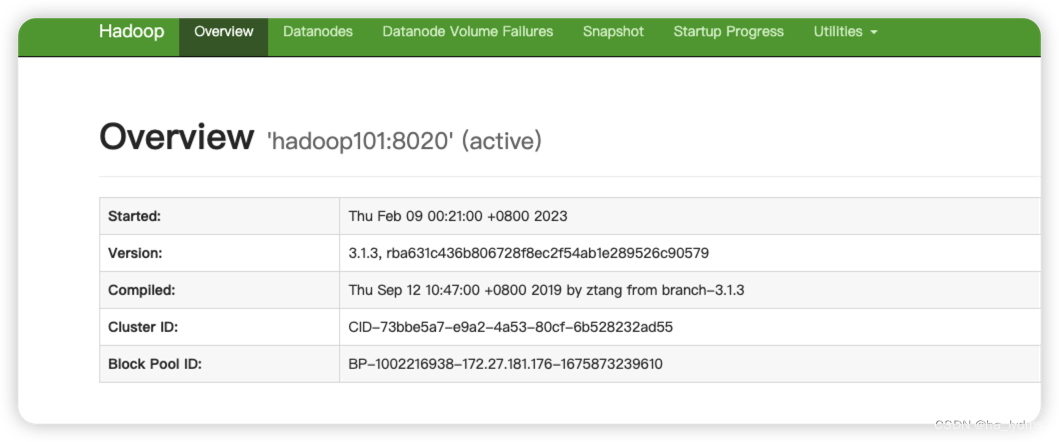
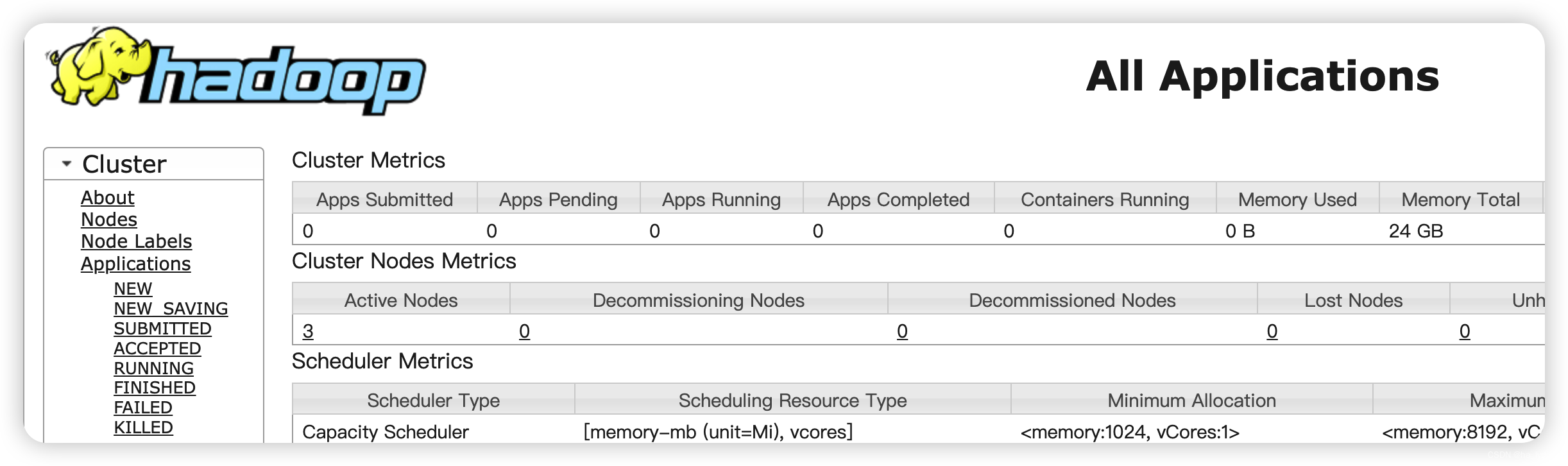
6、查看相关页面
Web端查看HDFS的NameNode
http://hadoop101:9870/
Web端查看YARN的ResourceManager
http://hadoop102:8088
7、配置历史服务器
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop101:10020</value>
</property><!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop101:19888</value>
</property>
</configuration>
分发配置
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
hadoop101启动历史服务器
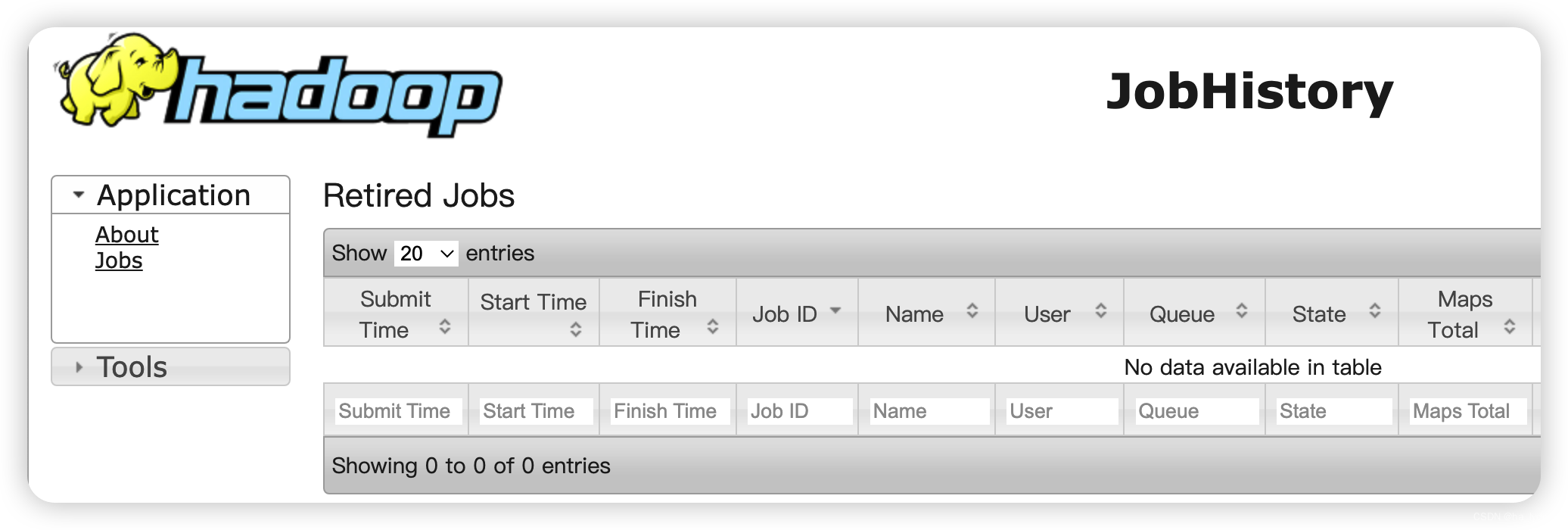
mapred --daemon start historyserver
查看是否启动
jps

查看页面
http://hadoop101:19888/jobhistory
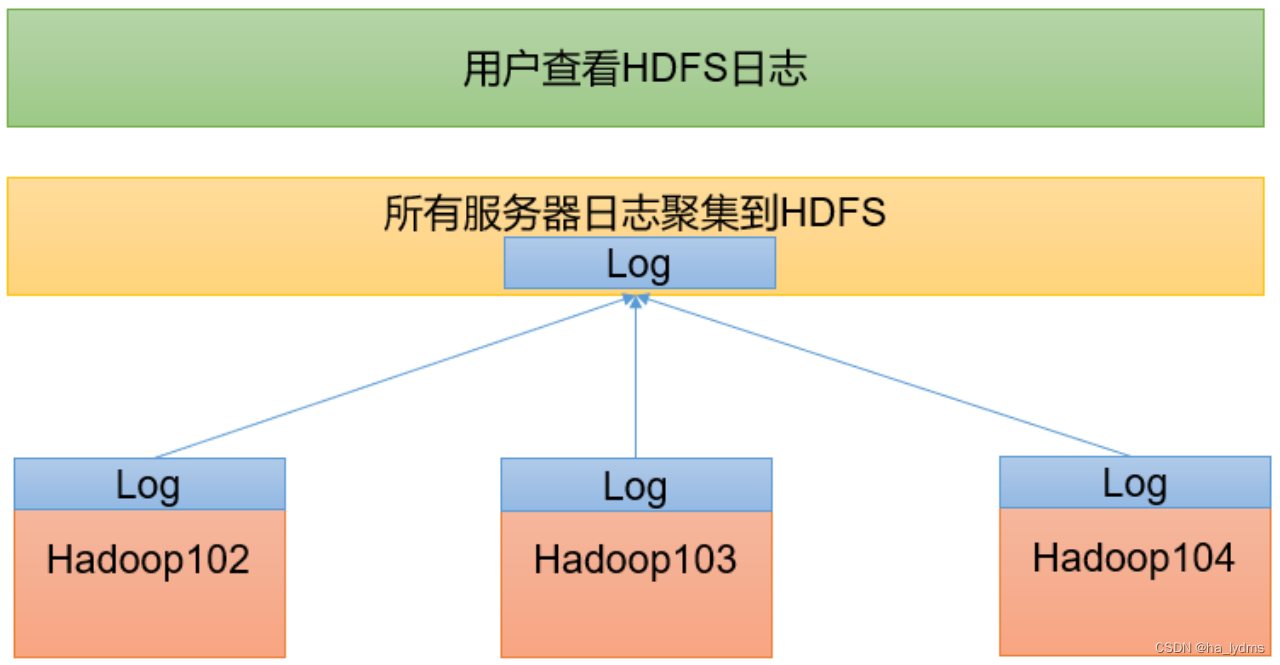
8、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便地查看到程序运行详情,方便开发调试。
**注意:**开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
vim yarn-site.xml
新增配置
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property><name>yarn.log.server.url</name><value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
分发配置
xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
删除HDFS上已经存在的输出文件(可以通过页面删除)
hadoop fs -rm -r /output
需要重启Hadoop集群
/home/lydms/bin/myhadoop.sh stop
/home/lydms/bin/myhadoop.sh start
9、其它
9.1 常用端口号
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
9.2 常用页面
Web端查看HDFS的NameNode
http://hadoop101:9870/
YARN的ResourceManager
http://hadoop102:8088
历史服务器
http://hadoop101:19888/jobhistory
五、遇到问题
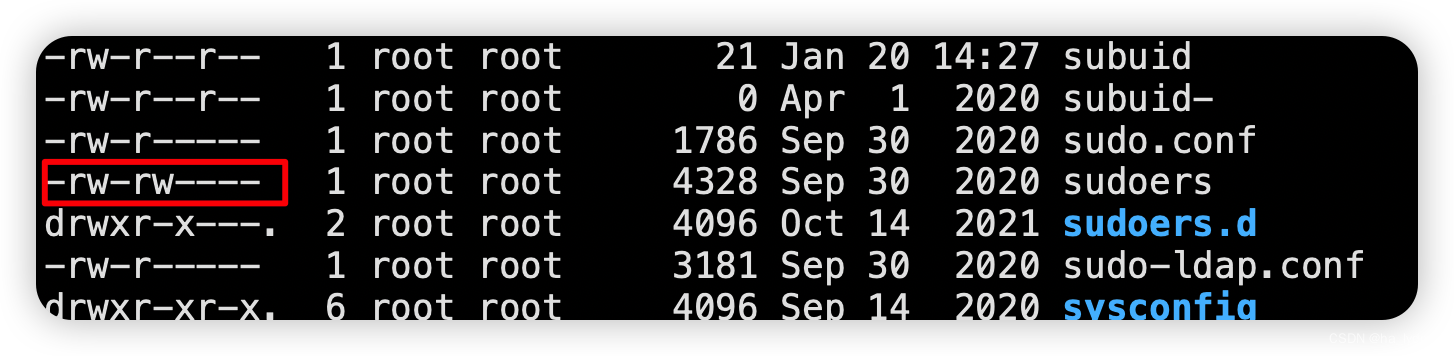
1、编辑文件无权限(‘readonly’ option is set (add ! to override))
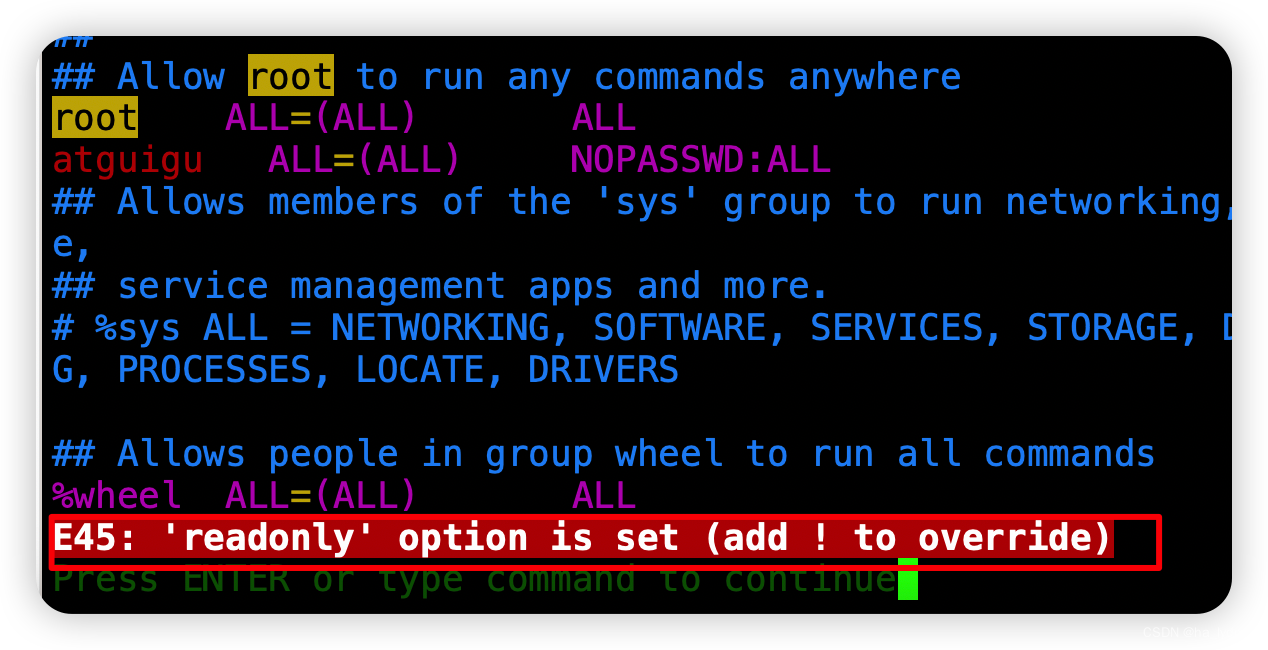
原因:
当前文件,为不可以编辑权限
解决:
chmod 660 /etc/sudoers
相关文章:
Hadoop集群搭建
文章目录一、运行环境配置(所有节点)1、基础配置2、配置Host二、依赖软件安装(101节点)1、安装JDK2、安装Hadoop(root)3、Hadoop目录结构三、本地运行模式(官方WordCount)1、简介2、本地运行模式(官方WordCount)四、完全分布式运行…...

每个前端都应该掌握的7个代码优化的小技巧
本文将介绍7种JavaScript的优化技巧,这些技巧可以帮助你更好的写出简洁优雅的代码。 1. 字符串的自动匹配(Array.includes) 在写代码时我们经常会遇到这样的需求,我们需要检查某个字符串是否是符合我们的规定的字符串之一。最常…...

金三银四丨黑蛋老师带你剖析-二进制漏洞
作者:黑蛋二进制漏洞岗上篇文章我们初步了解了一下简历投递方式以及二进制方向相关逆向岗位的要求,今天我们就来看看二进制漏洞相关的岗位,当然,漏洞岗位除了分不同平台,也有漏洞挖掘岗和漏洞分析利用岗。同样…...

pgsql-用户角色组角色创建和维护
pgsql-用户&角色&组角色创建和维护 环境 win10pgsql 14.2 相关文档 PostgreSQL 14.1 手册 create 语法 grant 授权语法 revoke 撤回语法 alter 更新语法 用户、角色、组角色概念和区别 早期版本(8.1之前)中用户、组、角色是不同的概念&#…...
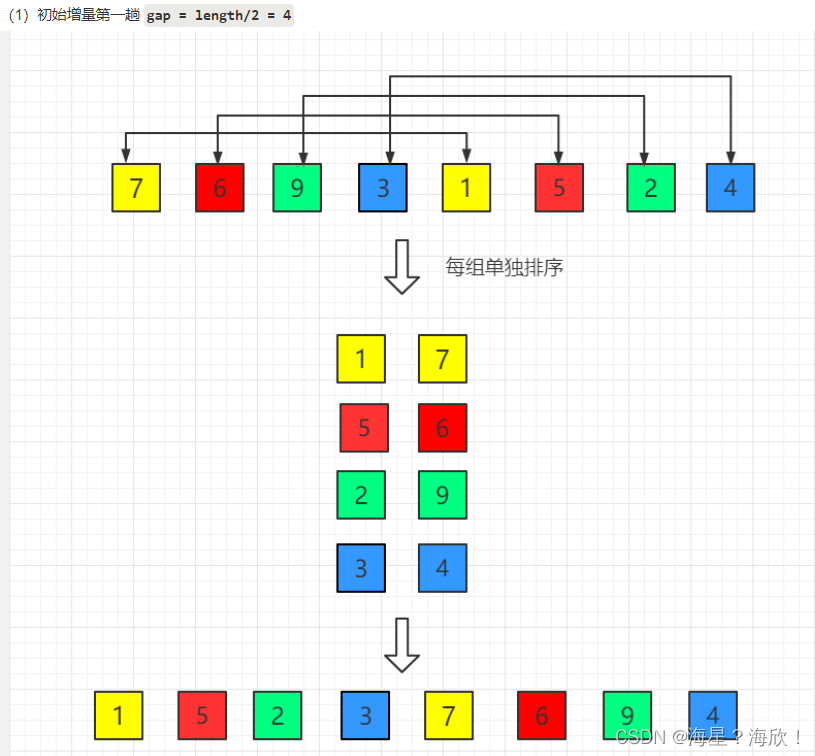
算法与数据结构理解
目录1、数据结构与算法1.1 定义1.2 常见数据结构1.3 常用算法2、插入排序3、希尔排序4、归并排序1、数据结构与算法 1.1 定义 数据结构:是计算机中存储、组织数据的方式。具有一定逻辑关系,应用某种存储结构,并且封装了相应操作的数据元素集…...

常见的C++软件异常场景分析与总结
根据排查软件异常问题的经历和经验,简单的总结一下软件异常的场景和原因,以供参考。 1、野指针问题 可能是指针没初始化就使用。也有可能是指针指向的内存已经被释放,但是指针没置为NULL,一旦访问这样的指针就会出问题。在很多情…...

【虹科公告】好消息!云展厅开放时间长达1年,2023年不限次云观展
云展厅开放通知 2023年,【虹科赋能汽车智能化云展厅】将持续开放,开放时间长达一年,开放期内,均可进入观展,没有次数及观看时长限制,欢迎大家随时进入云展厅观展。 虹科赋能汽车智能化云展厅 聚焦前沿技…...

Linux破解root密码
✅作者简介:热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏:Linux操作…...

2023年信息与通信工程国际会议(JCICE 2023)
2023年信息与通信工程国际会议(JCICE 2023) 重要信息 会议网址:www.jcice.org 会议时间:2023年3月17-19日 召开地点:成都 截稿时间:2023年2月10日 录用通知:投稿后2周内 收录检索:EI,Scopus 会议简介…...

ASP.NET Core+Element+SQL Server开发校园图书管理系统(完)
随着技术的进步,跨平台开发已经成为了标配,在此大背景下,ASP.NET Core也应运而生。本文主要基于ASP.NET CoreElementSql Server开发一个校园图书管理系统为例,简述基于MVC三层架构开发的常见知识点,本系列共五篇文章&a…...
.md)
elasticsearch 批量写入(Python版).md
1. 插入数据 现在我们如果有大量的文档(例如10000000万条文档)需要写入es 的某条索引中,该怎么办呢? 1.1 顺序插入 import time from elasticsearch import Elasticsearches Elasticsearch()def timer(func):def wrapper(*arg…...
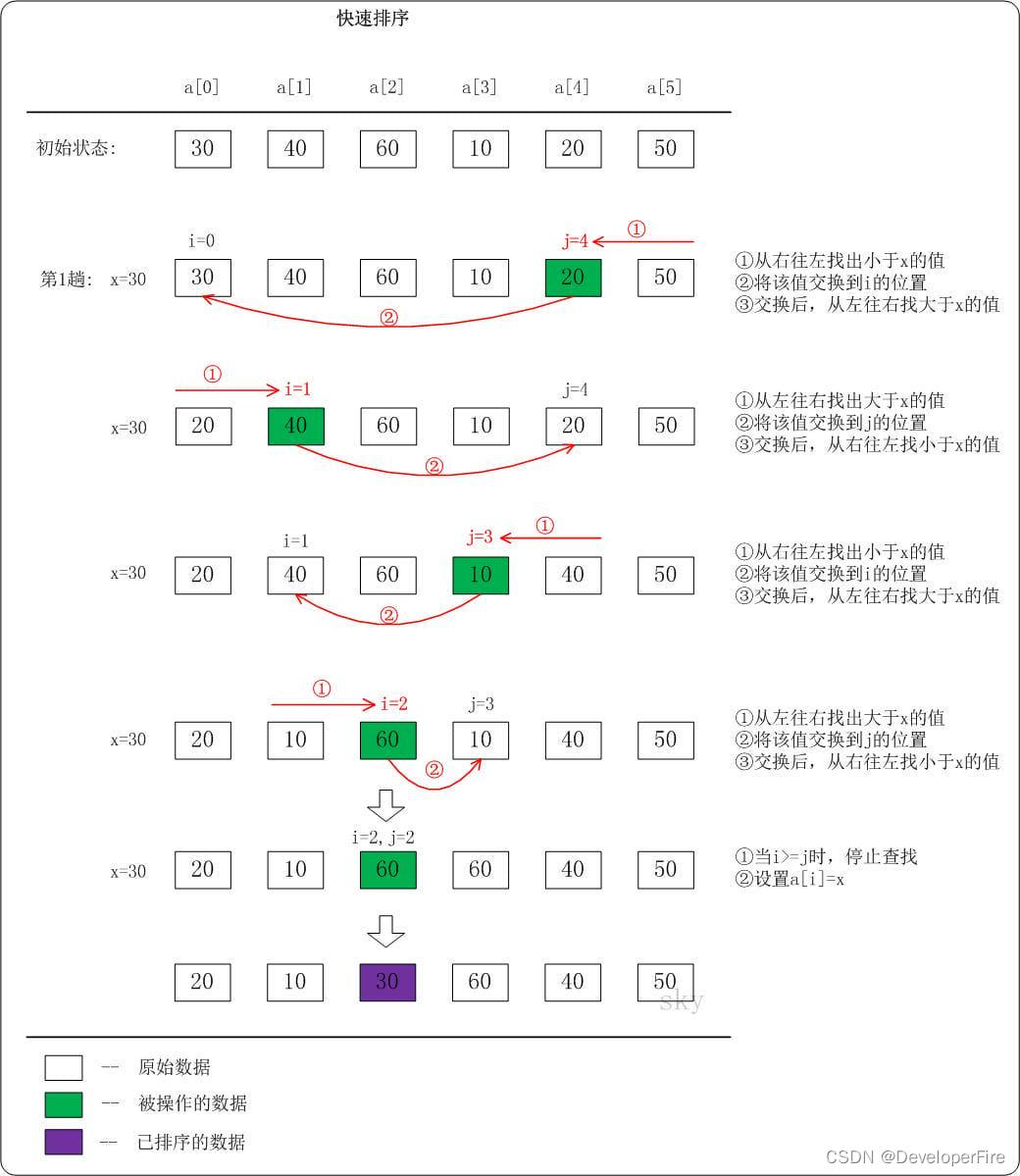
【排序算法】快速排序(Quick Sort)
快速排序(Quick Sort)使用分治法算法思想。快速排序介绍它的基本思想是: 选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分;其中一部分的所有数据都比另外一部分的所有数据都要小。然后,再按此方法对这两部分数据分别进行快速排…...
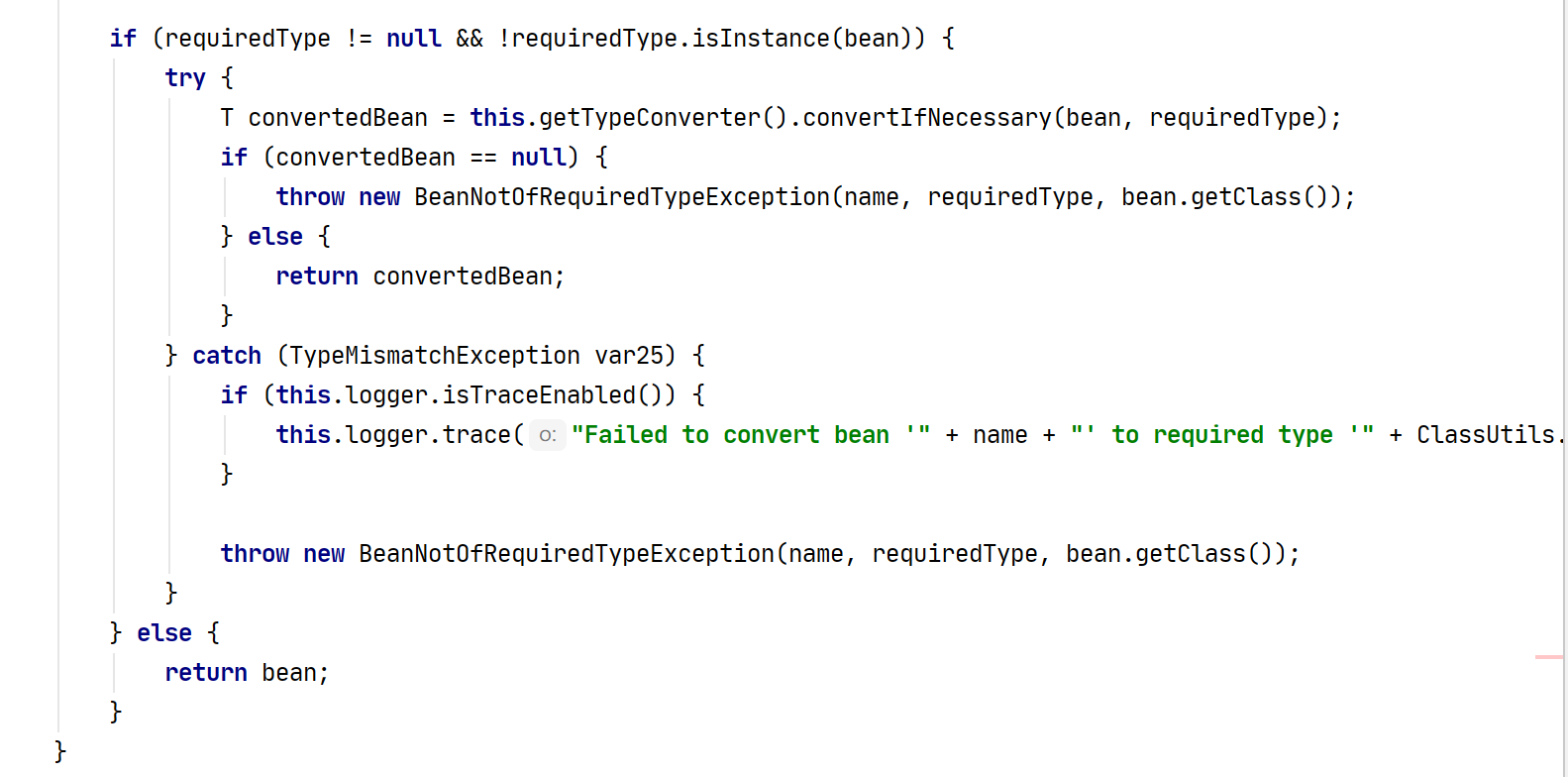
SpringIOC之创建Bean的核心方法doGetBean
概述面向资源(XML、Properties)、面向注解定义的 Bean 是如何被解析成 BeanDefinition(Bean 的“前身”),并保存至 BeanDefinitionRegistry 注册中心里面,实际也是通过 ConcurrentHashMap 进行保存。Spring…...

docker快速部署xxjob2.3.0-SpringBoot快速集成示例
xxjob 2.3.0 部署 参考资料 docker安装xxl-job-admin步骤_JEECG低代码平台的技术博客_51CTO博客 run前准备 1 新建数据库 xxl_job 2 建表sql(可以直接使) https://github.com/xuxueli/xxl-job/blob/master/doc/db/tables_xxl_job.sql建库sql # # XXL-JOB v2.4.0-SNAPSHOT…...
项目管理的前路,前辈能给一些意见吗?
什么是项目管理?关于项目管理的解释主要是基于国际项目管理三大体系不同的解释及本领域权威专家的解释!!!! 项目管理就是以项目为对象的系统管理方法,通过一个临时性的、专门的柔性组织,对项目进行高效率的计划、组织、指导和控制,…...

省钱的年轻人,钱包被折扣店钻了空子
【潮汐商业评论/原创】过年期间,除了商场超市,小区附近的折扣店成了Amy经常光顾的对象。用Amy的话来说,“跟附近超市比价格,跟大卖场比距离,综合下来折扣店就是我随时购物的不二选择。”从Amy的话里,我们可…...

【华为OD机试真题 js、python】优选核酸检测点、寻找核酸检测点【2022 Q4 100分】
代码请进行一定修改后使用,提供有js、python两种语言 题目描述 张三要去外地出差,需要做核酸,需要在指定时间点前做完核酸,请帮他找到满足条件的 核酸检测只点。 给出一组核酸检测点的距离和每个核酸检测点当前的人数给出张三要去做核酸的出发时间 出发时间是10分钟的倍数…...
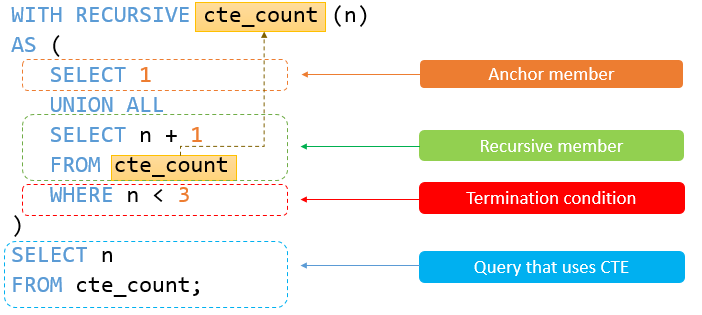
【MySQL】MySQL 8.0 新特性之 - 公用表表达式(CTE)
MySQL 8.0 新特性之 - 公用表表达式(CTE)1. 公用表表达式(CTE) - WITH 介绍1.1 公用表表表达式1.1.1 什么是公用表表达式1.1.2 CTE 语法1.1.3 CTE示例1.3 递归 CTE1.3.1 递归 CTE 简介1.3.2 递归成员限制1.3.3 递归 CTE 示例1.3.4…...

基础面试题:C++中如何理解const修饰符
面试题目:1、题 int i10; const int*p &i; int *const* p &i; const在不同位置有什么不 同 2、const 修饰类成员变量是有什么特殊要求 3、const 修饰类成员函数会发什么 4、const 对象有什么意义 目录 前言 一、const的意义 二、const使用规则 1.初始化…...
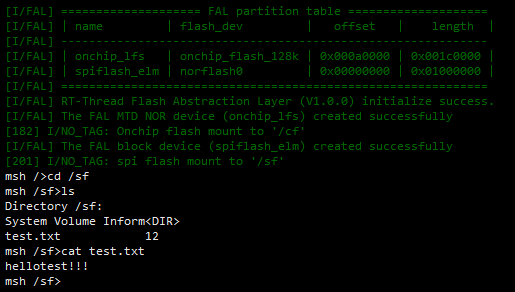
在RT-Thread STM32F407平台下配置SPI flash为U盘
记录下SPI Flash U盘实现过程中踩过的坑,与您分享。前提条件是,需要先将SPI Flash 配置到elm fal文件系统,并挂载成功。如下图然后开始配置USB1,在CubeMX,选择SUB_OTG_FS2 选择USB Device3,确认USB时钟为48…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...