【MySQL】MySQL 8.0 新特性之 - 公用表表达式(CTE)
MySQL 8.0 新特性之 - 公用表表达式(CTE)
- 1. 公用表表达式(CTE) - WITH 介绍
- 1.1 公用表表表达式
- 1.1.1 什么是公用表表达式
- 1.1.2 CTE 语法
- 1.1.3 CTE示例
- 1.3 递归 CTE
- 1.3.1 递归 CTE 简介
- 1.3.2 递归成员限制
- 1.3.3 递归 CTE 示例
- 1.3.4 使用递归 CTE 遍历分层数据
- 2. CTE 与 Derived Table
- 在 5.6 版本中
- 在 5.7 版本中
- 在 8.0 版本中
1. 公用表表达式(CTE) - WITH 介绍
1.1 公用表表表达式
1.1.1 什么是公用表表达式
官网:https://dev.mysql.com/doc/refman/8.0/en/with.html#common-table-expressions
MySQL 从 8.0 开始支持 WITH 语法,即:Common Table Expressions - CTE,共用表表达式。
CTE 是一个命名的临时结果集合,仅在单个 SQL 语句(select、insert、update 或 delete)的执行范围内存在。
与派生表类似的是:CTE 不作为对象存储,仅在查询执行期间持续。与派生表不同的是:CTE 可以是自引用(递归CTE),也可以在同一查询中多次引用。此外,与派生表相比,CTE 提供了更好的可读性和性能。
1.1.2 CTE 语法
CTE 的结构包括:名称、可选列列表和定义 CTE 的查询。定义 CTE 后,可以像 select、insert、update、delete 或 create view 语句中的视图一样使用它。
with cte_name (column_list) as (query)
select * from cte_name;
查询中的列数必须与 column_list 中的列数相同。 如果省略 column_list,CTE 将使用定义 CTE 的查询的列列表。
1.1.3 CTE示例
初始化数据:
-- create table
create table department
(id bigint auto_increment comment '主键ID'primary key,dept_name varchar(32) not null comment '部门名称',parent_id bigint default 0 not null comment '父级id'
);-- insert values
insert into `department` values (null, '总部', 0);
insert into `department` values (null, '研发部', 1);
insert into `department` values (null, '测试部', 1);
insert into `department` values (null, '产品部', 1);
insert into `department` values (null, 'Java组', 2);
insert into `department` values (null, 'Python组', 2);
insert into `department` values (null, '前端组', 2);
insert into `department` values (null, '供应链测试组', 3);
insert into `department` values (null, '商城测试组', 3);
insert into `department` values (null, '供应链产品组', 4);
insert into `department` values (null, '商城产品组', 4);
insert into `department` values (null, 'Java1组', 5);
insert into `department` values (null, 'Java2组', 5);
(1)最基本的CTE语法:
mysql> with cte1 as (select * from `department` where id in (1, 2)),-> cte2 as (select * from `department` where id in (2, 3))-> select *-> from cte1-> join cte2-> where cte1.id = cte2.id;
+----+-----------+-----------+----+-----------+-----------+
| id | dept_name | parent_id | id | dept_name | parent_id |
+----+-----------+-----------+----+-----------+-----------+
| 2 | 研发部 | 1 | 2 | 研发部 | 1 |
+----+-----------+-----------+----+-----------+-----------+
1 row in set (0.00 sec)(2)一个 CTE 引用另一个 CTE
mysql> with cte1 as (select * from `department` where id = 1),-> cte2 as (select * from cte1)-> select *-> from cte2;
+----+-----------+-----------+
| id | dept_name | parent_id |
+----+-----------+-----------+
| 1 | 总部 | 0 |
+----+-----------+-----------+
1 row in set (0.00 sec)
1.3 递归 CTE
1.3.1 递归 CTE 简介
递归CTE 是一个具有引用 CTE 名称本身的子查询的 CTE。递归 CTE 的语法为:
with recursive cte_name as (initial_query -- anchor member
union all
recursive_query -- recursive member that references to the cte name
)
select * from cte_name;
递归 CTE 由三个主要部分组成:
-
形成 CTE 结构的基本结果集的初始查询(initial_query),初始查询部分被称为锚成员。
-
递归查询部分是引用 CTE 名称的查询,因此称为递归成员。递归成员由一个 union all 或 union distinct 运算符与锚成员相连。
-
终止条件是当递归成员没有返回任何行时,确保递归停止。
递归 CTE 的执行顺序如下:
- 首先,将成员分为两个:锚点和递归成员。
- 接下来,执行锚成员形成基本结果集(
R0),并使用该基本结果集进行下一次迭代。 - 然后,将
Ri结果集作为输入执行递归成员,并将Ri + 1作为输出。 - 之后,重复第三步,直到递归成员返回一个空结果集,换句话说,满足终止条件。
- 最后,使用
union all运算符将结果集从R0到Rn组合。
1.3.2 递归成员限制
递归成功不能包含以下结构:
- 聚合函数,如 max、min、sum、avg、count 等。
- group by 子句
- order by 子句
- limit 子句
- distinct
上述约束不适用于锚点成员。 另外,只有在使用 union 运算符时,要禁止 distinct 才适用。 如果使用 union distinct 运算符,则允许使用 distinct。
另外,递归成员只能在其子句中引用 CTE 名称,而不是引用任何子查询。
1.3.3 递归 CTE 示例
with recursive cte_count (n)as (select 1union allselect n + 1from cte_countwhere n < 3)
select n from cte_count;
在此示例中,以下查询:
select 1
是作为基本结果集返回 1 的锚成员。
以下查询:
select n + 1
from cte_count
where n < 3
是递归成员,因为它引用了 cte_count 的 CTE 名称。递归成员中的表达式 < 3 是终止条件。当 n 等于 3,递归成员将返回一个空集合,将停止递归。
下图显示了上述 CTE 的元素:
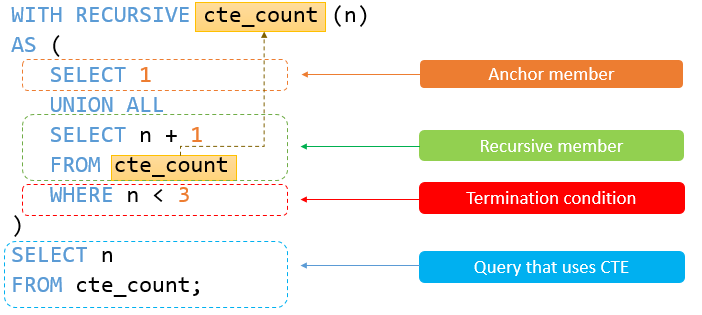
递归 CTE 返回以下输出:
+------+
| n |
+------+
| 1 |
| 2 |
| 3 |
+------+
递归 CTE 的执行步骤如下:
- 首先,分离锚和递归成员。
- 接下来,锚定成员形成初始行
select 1,因此第一次迭代在n = 1时产生1 + 1 = 2。 - 然后,第二次迭代对第一次迭代的输出
2进行操作,并且在n = 2时产生2 + 1 = 3。 - 之后,在第三次操作
n = 3之前,满足终止条件n <3,因此查询停止。 - 最后,使用 union all 运算符组合所有结果集1,2和3。
1.3.4 使用递归 CTE 遍历分层数据
查部门 id = 2 的所有下级部门和本级:
mysql> with recursive cte_tab as (select id, dept_name, parent_id, 1 as level-> from department-> where id = 2-> union all-> select d.id, d.dept_name, d.parent_id, level + 1-> from cte_tab c-> inner join department d on c.id = d.parent_id-> )-> select *-> from cte_tab;
+------+-----------+-----------+-------+
| id | dept_name | parent_id | level |
+------+-----------+-----------+-------+
| 2 | 研发部 | 1 | 1 |
| 5 | Java组 | 2 | 2 |
| 6 | Python组 | 2 | 2 |
| 7 | 前端组 | 2 | 2 |
| 12 | Java1组 | 5 | 3 |
| 13 | Java2组 | 5 | 3 |
+------+-----------+-----------+-------+
6 rows in set (0.00 sec)2. CTE 与 Derived Table
针对 from 子句里面的 subquery,MySQL 在不同版本中,是做过一系列的优化,接下来我们就来看看。
在 5.6 版本中
MySQL 会对每一个 Derived Table 进行物化,生成一个临时表保存 Derived Table 的结果,然后利用临时表来完成父查询的操作,具体如下:
mysql> explain-> select * from (select * from department where id <= 1000) t1 join (select * from department where id >= 990) t2 on t1.id = t2.id;
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
| 1 | SIMPLE | department | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 1 | 100.00 | Using where |
| 1 | SIMPLE | department | NULL | eq_ref | PRIMARY | PRIMARY | 8 | pointer_mall.department.id | 1 | 100.00 | NULL |
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.01 sec)
在 5.7 版本中
MySQL 引入了 Derived Merge 新特性,允许符合条件的 Derived Table 中的子表与父查询的表进行合并,具体如下:
mysql> explain-> select * from (select * from department where id <= 1000) t1 join (select * from department where id >= 990) t2 on t1.id = t2.id;
+----+-------------+------------+------------+-------+---------------+-------------+---------+-------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+-------+---------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 1900 | 100.00 | NULL |
| 1 | PRIMARY | <derived3> | NULL | ref | <auto_key0> | <auto_key0> | 8 | t1.id | 2563 | 100.00 | NULL |
| 3 | DERIVED | department | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 4870486 | 100.00 | Using where |
| 2 | DERIVED | department | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 1900 | 100.00 | Using where |
+----+-------------+------------+------------+-------+---------------+-------------+---------+-------+---------+----------+-------------+
4 rows in set, 1 warning (0.00 sec)
在 8.0 版本中
我们可以使用 CTE 实现,其执行计划也是和 Derived Table 一样
mysql> explain-> with t1 as (select * from department where id <= 1000),-> t2 as (select * from department where id >= 990)-> select * from t1 join t2 on t1.id = t2.id;
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
| 1 | SIMPLE | department | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 1 | 100.00 | Using where |
| 1 | SIMPLE | department | NULL | eq_ref | PRIMARY | PRIMARY | 8 | pointer_mall.department.id | 1 | 100.00 | NULL |
+----+-------------+------------+------------+--------+---------------+---------+---------+----------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
从测试结果来看,CTE 似乎是 Derived Table 的一个替代品?其实不是的,虽然 CTE 内部优化流程与 Derived Table 类似,但是两者还是区别的,具体如下:
-
一个 CTE 可以引用另一个 CTE
-
CTE 可以自引用
-
CTE 在语句级别生成临时表,多次调用只需要执行一次,提高性能
从上面介绍可以知道,CTE 一方面可以非常方便进行 SQL 开发,另一方面也可以提升 SQL 执行效率。
相关文章:
【MySQL】MySQL 8.0 新特性之 - 公用表表达式(CTE)
MySQL 8.0 新特性之 - 公用表表达式(CTE)1. 公用表表达式(CTE) - WITH 介绍1.1 公用表表表达式1.1.1 什么是公用表表达式1.1.2 CTE 语法1.1.3 CTE示例1.3 递归 CTE1.3.1 递归 CTE 简介1.3.2 递归成员限制1.3.3 递归 CTE 示例1.3.4…...

基础面试题:C++中如何理解const修饰符
面试题目:1、题 int i10; const int*p &i; int *const* p &i; const在不同位置有什么不 同 2、const 修饰类成员变量是有什么特殊要求 3、const 修饰类成员函数会发什么 4、const 对象有什么意义 目录 前言 一、const的意义 二、const使用规则 1.初始化…...
在RT-Thread STM32F407平台下配置SPI flash为U盘
记录下SPI Flash U盘实现过程中踩过的坑,与您分享。前提条件是,需要先将SPI Flash 配置到elm fal文件系统,并挂载成功。如下图然后开始配置USB1,在CubeMX,选择SUB_OTG_FS2 选择USB Device3,确认USB时钟为48…...

数据存储技术复习(二)未完
module3存储是数据中心内的核心元素。请说明常用的存储选项及其特点。磁盘驱动器:具有很大的存储容量,随机读/写访问闪存驱动器:使用半导体介质,提供高性能,低功耗2.若某磁盘驱动器显示每个磁道有八个扇区&…...

使用 QuTrunk+Amazon Deep Learning AMI(TensorFlow2)构建量子神经网络
量子神经网络是基于量子力学原理的计算神经网络模型。1995年,Subhash Kak 和 Ron Chrisley 独立发表了关于量子神经计算的第一个想法,他们致力于量子思维理论,认为量子效应在认知功能中起作用。然而,量子神经网络的典型研究涉及将…...
python selenium浏览器复用技术
使用selenium 做web自动化的时候,经常会遇到这样一种需求,是否可以在已经打开的浏览器基础上继续运行自动化脚本? 这样前面的验证码登录可以手工点过去,后面页面使用脚本继续执行,这样可以解决很大的一个痛点。 命令行…...

第二章:创建虚拟机
创建Windows server:首先第一步就是打开我们的vm,然后找到上一章讲的主页图标创建新的虚拟机。点击这上面类似的,然后转站。博文地址:https://blog.csdn.net/ryduijftgvhj/article/details/127934939?spm1001.2014.3001.5502视频…...

码上【call,apply,bind】的手写
一、call (1)官方用法 call() 方法使用一个指定的 this 值和单独给出的一个或多个参数来调用一个函数。 语法:function.call(要绑定的this值,参数,参数,…)。不一定这些参数都需要,这些参数都…...
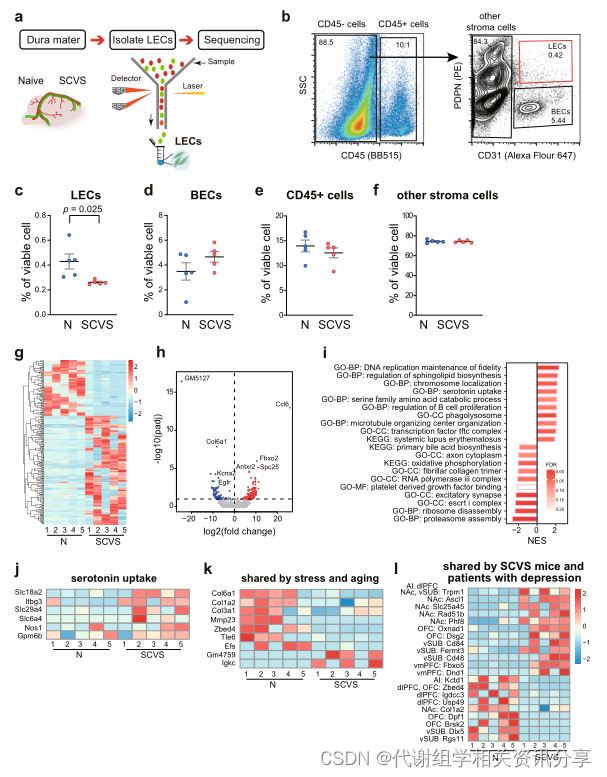
代谢组学Nature子刊!抑郁症居然“男女有别”,脑膜淋巴管起关键作用!
文章标题:A functional role of meningeal lymphatics in sex difference of stress susceptibility in mice 发表期刊:Nature Communications 影响因子:17.694 发表时间:2022年8月 作者单位:中山大学中山医学院 …...
nacos配置中心搭建
网站每次更新版本都有短暂暂停,影响用户使用,返回经常不可用,需要改进 需要实现高可用,搭建负载均衡,实现jenkinsnacos不停机部署 nacos搭建预备环境准备 64 bit OS,支持 Linux/Unix/Mac/Windows&#x…...
uni-app低成本封装一个取色器组件
在uni-ui中找不到对应的工具 后面想想也是 移动端取色干什么? 没办法 也挂不住特殊需求 因为去应用市场下载 这总东西 又不是很有必要 那么 下面这个组件或许能解决您的烦恼 <template><view class"content"><view class"dialog&…...
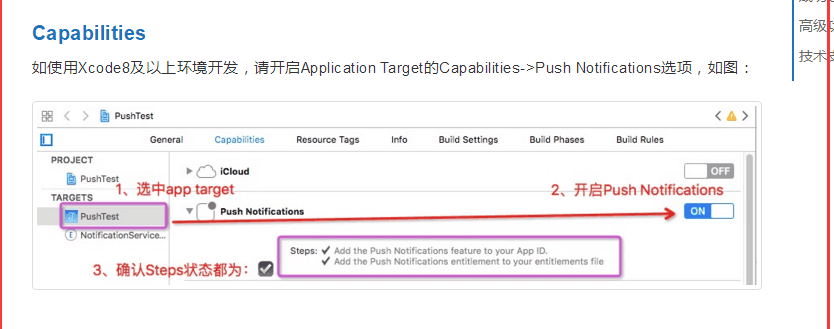
APP 怎么免费接入 MobPush
1、获取 AppKey 申请 Appkey 的流程,请点击 http://bbs.mob.com/thread-8212-1-1.html?fromuid70819 2、下载 SDK 下载解压后,如下图: 目录结构 (1)Sample:演示Demo。(2)SDK&am…...

XGBoost
目录 1.XGBoost推导示意图 2.分裂节点算法 Weighted Quantile Sketch 3.对缺失值得处理 1.XGBoost推导示意图 XGBoost有两个很不错得典型算法,分别是用来进行分裂节点选择和缺失值处理 2.分裂节点算法 Weighted Quantile Sketch 对于特征切点点得选择ÿ…...
你是什么时候从轻视到高看软件测试的?
刚开始学软件测试很轻视,因为我那时很无知,这也是那时绝大多数人员的心态,那时中国最讲究“编程才是硬道理”。 如今却非常热爱软件测试,包括软件测试工具,方法,理论,技术。因为我在3年的测试工…...
基于ssm的航空售票系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经从做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言…...

滑动窗口最大值
给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。 示例: 输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3 输出: [3,3,5,5,6,7] 解释: 滑动窗口的位置 最大值 --------------- ----- [1 3 -1] -3 5 3 6 7 3 …...

接口文档参考示例
接口文档参考示例 用户登录 - POST /api/login/ 接口说明:登录成功后,会生成或更新用户令牌(token)。 使用帮助:测试数据库中预设了四个可供使用的账号,如下表所示。 Untitled 请求参数: Untitled 响应信息: 登录成功: {"code": 30000, "message&qu…...
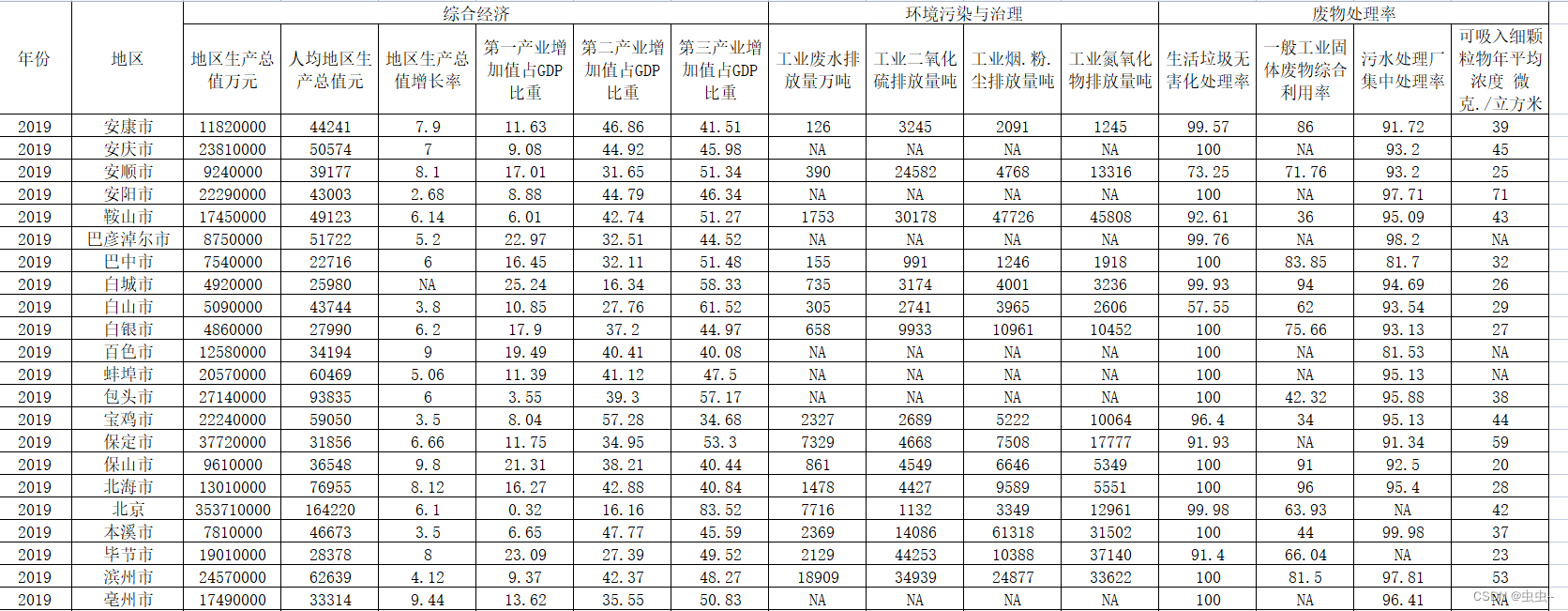
2010-2019年290个城市经济发展与环境污染数据
2010-2019年290个城市经济发展与环境污染数据 1、时间:2010-2019年 2、统计口径:全市 3、来源:城市统计NJ,缺失情况与年鉴一致 4、指标包括: 综合经济:地区生产总值、人均地区生产总值、地区生产总值增…...
web开发
目录 使用Idea搭建Web项目 使用Idea开发Web项目基本知识 tomcat配置信息 HTML /CSS 开发主页 Servlet 学习和掌握的内容: HTML/CSSServlet MVC模式和Web开发数据库基本应用和JDBC应用软件项目开发流程 环境及工具版本: Windows10,JDK1.8 Idea2…...

【数据结构】优先级队列----堆
优先级队列----堆优先级队列堆堆的创建堆的插入:堆的删除:PriorityQueue的特性PriorityQueue的构造与方法优先级队列 优先级队列: 不同于先进先出的普通队列,在一些情况下,优先级高的元素要先出队列。而这种队列需要提…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...