Flink X Hologres构建企业级Streaming Warehouse
摘要:本文整理自阿里云资深技术专家,阿里云Hologres负责人姜伟华,在FFA实时湖仓专场的分享。点击查看>>本篇内容主要分为四个部分:
一、实时数仓分层的技术需求
二、阿里云一站式实时数仓Hologres介绍
三、Flink x Hologres:天作之合
四、基于Flink Catalog的Streaming Warehouse实践
点击查看视频回放

一、实时数仓分层的技术需求
首先,我们讲一讲数仓的分层技术以及分层技术的现状。
1、实时数仓分层技术现状
大数据现在越来越讲究实时化,在各种场景下都需要实时,例如春晚实时直播大屏,双11 GMV实时大屏、实时个性化推荐等场景,都对数据的实时性有着非常高的要求。为了满足业务的实时性需求,大数据技术也开始逐步发展出实时数仓。

但如何构建实时数仓呢?
相比离线数仓,实时数仓没有明确的方法论体系。因此在实践中,有各种各样的方法,但没有一个方法是万能。最近行业内提出了Streaming Warehouse的概念。Streaming Warehouse的本质是分层之间能够做到实时数据的流动,从而解决实时数仓分层的问题。

下面,我们先来了解下实时数仓的主流分层方案。
2、实时数仓主流分层方案
实时数仓的主流分层方案主要有4个。
方案1:流式ETL
ETL(Extract- Transform-Load)是比较传统的数据仓库建设方法,而流式ETL就是指:实时数据经过Flink实时ETL处理之后,将结果写入到KV引擎中,供应用查询。而为了解决中间层不方便排查的问题,也需要将中间层数据同步到实时数仓中供分析之用。最常见的做法就是数据通过Flink清洗后,写到Kafka形成ODS层。再从Kafka消费,经过加工形成DWD层。然后Flink加工成DWS层,最后通过加工形成ADS层的数据写到KV引擎并对接上层应用。因为直接使用Kafka数据进行分析和探查很麻烦,所以也会同步一份Kafka数据到实时数仓,通过实时数仓进行分析和探查。
这个方案的优势是层次明确,分工明确。但劣势是需要有大量的同步任务、数据资源消耗很大、数据有很多冗余、处理链路较复杂需要很多的组件。除此之外,这个方案构建的实时数仓分层,尤其是Kafka分层,复用性非常差,也没办法响应schema的动态变化。

方案2:流式ELT
而流式ELT则是将计算后置,直接将明细数据写进实时数仓(EL),不需要严格的数仓分层,整个架构只需要一层,上层应用查询的时候进行数据的变换(T)或者分层。常见的做法就是把数据加工清洗后,写到实时数仓里,形成DWD层,所有的查询都基于DWD层的明细数据进行。
这个方案的好处在于,没有ETL,只有一层;数据修订很方便。但它的弊端有两个方面:
- 在查询性能方面,由于是明细数据查询,所以在某些场景下不能满足QPS或延迟的要求。
- 因为没有严格的数仓分层,所以数据复用很困难,很难兼顾各方面的诉求。

方案3:定时调度
既然实时流式无法完成数据的实时数仓分层,我们可以将数据实时写入实时数仓的DWD层。DWS层、ADS层用离线的高频调度方法,实现分钟级的调度,从而借用离线数仓,进行分层构造。这个也就是业界常用的方案3。
这个方案的好处在于可以复用很多离线经验,方案成本低且成熟。但方案也存在如下缺点:
- 延迟大:每一层的延迟都跟调度相关,随着层次越多,调度延迟越大,实时数仓也变成了准实时数仓。
- 不能完全复用离线方案:离线调度一般是小时级或天级,我们可以使用全量计算。但在分钟级调度时,必须做增量计算,否则无法及时调度。

方案4:实时物化视图
第4种方案就是通过实时数仓的物化视图能力实现数仓分层。常见的做法就是Flink实时加工后,将数据写到实时数仓形成DWD层,DWS层或ADS层的构造依赖于实时数仓的实时物化视图能力。
现在主流实时数仓都开始提供物化视图的能力,但本质上都是提供了一些简单的聚合类物化视图。如果物化视图的需求比较简单,可以利用实时数仓里的实时物化视图能力,将DWS层到ADS层的构建自动化,从而让物化视图的查询保证较高的QPS。但这个方案最大的缺点在于,现在的实时物化视图技术都还不成熟,能力有限,支持的场景也比较有限。

二、阿里云一站式实时数仓Hologres介绍
接下来,先介绍一下阿里云一站式实时数仓Hologres产品。Hologres是阿里云自研的一站式实时数仓,它同时包含三种能力:
- OLAP能力:同传统的实时数仓一样,可以支持数据的实时写入、以及复杂OLAP实时多维分析快速响应,满足业务的极致数据探索能力。
- 在线服务Serving(KV):可以支持KV查询场景,提供非常高的QPS和毫秒级的低延迟。
- 湖仓一体:能够直接查询数据湖的数据,以及能够加速阿里云离线数仓MaxCompute,助力业务更低成本实现湖仓一体。

下面为具体介绍:
- 首先,大家可以把Hologres当做一个常见的实时数仓。它的特点在于写入侧支持百万RPS的实时写入,写入即可查,没有延迟。同时也支持高性能的实时整行更新和局部更新。其中,整行更新是把整行替换掉,局部更新可以更新一行中的局部字段,二者都是实时更新。
- 在查询侧,一方面支持复杂的OLAP多维分析,可以非常好的支持实时大屏、实时报表等场景。近期Hologres拿到了TPC-H 30TB的性能世界第一的TPC官方认证成绩,见>>阿里云 ODPS-Hologres刷新世界纪录,领先第二名23%。其次,Hologres也支持在线服务查询,不仅支持百万QPS KV点查,而且也支持阿里云达摩院的Proxima向量检索引擎,可以支持非常高效的向量检索能力。同时这些能力在Hologres中是全用SQL表达,对用户使用非常友好。此外,为了兼顾数据服务和实时数仓的需求,Hologres在行存、列存的数据格式基础上,也支持行列共存,即行列共存的表即一份行存,又有一份列存,并且系统保证这两份数据是强一致的,对于OLAP分析,优化器会自动选择列存,对于线上服务,会自动选择行存,通过行列共存可以非常友好的实现一份数据支撑多个应用场景。
- 因为Hologres同时支持OLAP分析和线上服务,其中线上服务要求非常高的稳定性和SLA。为了保证OLAP分析和线上服务时不会发生冲突,我们支持了读写分离,从而实现OLAP与数据服务的强隔离。
- 最后,在湖仓数据交互式分析方面,Hologres对阿里云MaxCompute离线数仓里的数据,数据湖中的数据都可以秒级交互式分析,且不需要做任何的数据搬迁。
- 除此之外,Hologres的定位是一站式的企业级实时数仓,所以除了上述能力,我们还有很多其他能力。包括数据的治理、成本治理、数据血缘、数据脱敏、数据加密、IP白名单、数据的备份和恢复等等。

三、Flink x Hologres:天作之合
1、Hologres与Flink深度集成
Flink对于实时数仓能够提供非常丰富的数据处理、数据入湖仓的能力。Hologres与Flink有些非常深度的整合能力,具体包括:
- Hologres可以作为Flink的维表:在实时计算的场景下,Flink对维表的需求很强,Hologres支持百万级至千万级RPS的KV点查能力,可以直接当做Flink维表使用,且可以做到实时更新,对于像实时特征存储等维表关联场景就也可以非常高效的支持。
- Hologres可以作为Flink的结果表:Hologres支持高性能的实时写入和整行实时更新的能力,可以结合Flink,输出需要强大的Update能力,满足数仓场景下的实时更新、覆盖等需求。与此同时,Hologres还有很强的局部更新能力。局部更新能力在很多场景下,可以替代Flink的多流Join,为客户节省成本。
- Hologres可以作为Flink的源表:Hologres支持Binlog能力,一张表的任何变化,比如insert、update、delete等等,都会产生Binlog事件。Flink可以订阅Hologres Binlog,进行驱动计算。由于Flink支持Hologres的整表读取,二者结合构成了Flink全增量一体化的读取能力。并且,Hologres也对了接Flink CDC,它可以驱动Flink CDC的计算。
- 支持Hologres Catalog:通过Hologres Catalog的任何操作,都会直接实时反映到Hologres里,用户也不需要在Flink建Hologres表,这样就使得Flink+Hologres就具备了整库同步、Schema Evolution的能力。

2、基于Flink+Hologres的Streaming Warehouse方案
那Flink和Hologres如何构建Streaming Warehouse?
Streaming Warehouse:数据能在数仓之间实时的流动,本质上就是解决实时数仓分层的问题
最开始我们介绍了常见的数仓分层方案,Flink+Hologres的Streaming Warehouse方案则是可以完全将Flink+Kafka替换。具体做法如下:
- 将Flink写到Hologres里,形成ODS层。Flink订阅ODS层的Hologres Binlog进行加工,将Flink从DWD层再次写入Hologres里。
- Flink再订阅DWD层的Hologres Binlog,通过计算形成DWS层,将其再次写入Hologres里。
- 最后,由Hologres对外提供应用查询。
该方案相比Kafka有如下优点:
- 解决了传统中间层Kafka数据不易查、不易更新、不易修正的问题。Hologres的每一层都可查、可更新、可修正。
- Hologres的每一层都可以单独对外提供服务。因为每一层的数据都是可查的,所以数据的复用会更好,真正实现数仓分层复用的目标。
- Hologres支持数据复用,模型统一,架构简化。通过Flink+Hologres,就能实现实时数仓分层,简化架构和降低成本。

3、Flink+Hologres核心能力:Binlog、行列共存、资源隔离
上面讲的Flink+Hologres的Streaming Warehouse方案,其强依赖于以下三个Hologres核心能力:
- Binlog:因为实时数仓一般没有Binlog,但Hologres提供了Binlog能力,用来驱动Flink做实时计算,正因为有了Binlog,Hologres才能作为流式计算的上游。
- 行列共存。一张表既有行存数据,又有列存数据。这两份数据是强一致的。行列共存的特性让中间层的每张表,不但能够给Flink使用,而且可以给其他应用(比如OLAP、或者线上服务)使用。
- 资源强隔离。实时数仓一般是弱隔离或软隔离,通过资源组、资源队列的方法实现资源隔离。如果Flink的资源消耗很大,可能影响中间层的点查性能。但在Hologres强隔离的能力下,Flink对Hologres Binlog的数据拉取,不会影响线上服务。
通过Binlog、行列共存、资源强隔离的三个特点,不仅能让Flink+Hologres形成Streaming Warehouse,并且能够使中间的每层数据复用,被其他应用或线上服务使用,助力企业构建最简单最完整的实时数仓。

4、基于Flink+Hologres的多流合并
接下来,讲一讲基于Flink+Hologres的多流合并。
因为Hologres有特别强大的局部更新能力,基于此我们可以简化Flink的多流Join。比如在风控场景下,我们需要基于用户ID构建用户的多侧面画像,用户画像来自很多数据源,比如客户的浏览行为、成交行为、履约行为等等。把数据源的数据按照用户ID,把每个用户放到一行里,形成不同的字段,形成用户的完整画像。
传统的方式需要用Flink多流Join实现,Flink把上游的多个数据源关联到一起,Join后写到Kafka里,然后驱动下游的Flink,加工这行完整的数据。这就使得多流Join非常耗资源。
所以在Flink+Hologres的Streaming Warehouse方案中,可以利用Hologres的局部更新能力,把一张表定为定义成Hologres的行存表或行列共存表。此时,整个方案就简化成上游每个数据源,同步数据到Hologres表的若干个字段里,若干个任务同时写入这张表,然后利用Hologres的局部更新能力,把数据汇总在一起。
如果打开这张Hologres表的 Binlog,上游任何数据源的变化都会更新这张表,使这张表的Binlog中生成行数据的最新状态,然后驱动下游的Flink继续计算,从而完美匹配常见的风控场景。这种用法下,资源消耗、运维都得到了极大的简化。

四、基于Flink Catalog的Streaming Warehouse实践
Flink+Hologres的Streaming Warehouse方案已经非常成熟,但唯一的缺点在于,用户需要在两个系统之间切换,过程比较繁琐。为了让用户操作更简单,我们基于Flink Catalog提供了更加简单的使用体验。
下面我们来看看怎么样基于Flink Catalog去构建基于Flink+Hologres的Streaming Warehouse。我们会发现,有了Flink Catalog后,整个使用体验会很简单,并能充分发挥Flink和Hologres两个产品的强大能力。
下图是一个典型的Flink+Hologres实时ETL链路:
- ODS层、DWD层、ODS层的数据都存在Hologres中。
- 链路中所有的数据加工都是通过Flink SQL完成。在整个ETL链路中,用户不需要任何Hologres SQL,直接写Flink SQL即可。
- Flink用户可以通过Flink SQL对每层中的Hologres数据进行数据探查(流模式和批模式都可以)。比如:当我们发现DWS层的数据结果出现问题,需要查看哪层的结果有问题或逻辑有错误。此时,我们可以复用原来的Flink SQL来进行探查、定位或者数据重新消费。
- Hologres中的每层数据都可以对外提供查询和服务(通过Hologres SQL)。
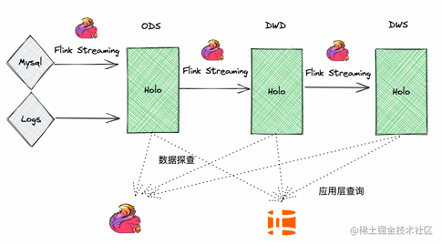
接下来,以某个电商场景为例,演示一下基于Flink Catalog的Streaming Warehouse。如下图所示,有一个MySQL数据库作为订单库,里面有订单表orders、订单支付表orders_pay、以及产品品类表product_catalog。

- 第一步,我们通过Flink的实时数仓,把数据实时同步到Hologres里,形成ODS层。
- 第二步,加工DWD层。将DWD层的数据写到Hologres里。在这个过程中,我们需要把订单表和订单支付表,合并成一张表,实现多路合并。与此同时,我们希望orders表关联商品品类表product_catalog。
- 第三步,驱动下游计算,构建DWS层。以用户维度和商店维度,收集统计数据。比如用户每天的订单金额和商店每天的订单金额,从而形成一条完整的链路。
- 第四步,将DWS层的表推荐给系统使用。作为用户和商店的特征,用做推荐用途。
- 第五步,DWD层的表能够直接用来做实时统计分析、统计产品、实时大屏、实时报表。
上图中的绿色链路,全部使用Flink SQL完成。橙色链路对外提供服务,由Hologres SQL完成。
接下来,讲一讲每个步骤是如何运行的。
第一步,在Flink实时数仓,形成ODS层。首先,创建一个Hologres的Catalog。MySQL中存储订单、支付以及商品信息3张表,通过Flink Catalog功能,将MySQL整库的数据实时同步至Hologres,形成ODS。相关代码如下所示。我们可以看到,MySQL整库同步到Hologres,通过Flink SQL来表达是非常简单的。
-- 创建Hologres Catalog
CREATE CATALOG holo WITH ( ‘type’ = ‘hologres’ … );-- MySQL整库同步到Hologres
CREATE DATABASE IF NOT EXISTS holo.order_dw
AS DATABASE mysql.sw INCLUDING all tables;
第二步,DWD实时构建。数据实时写入ODS层后,Flink读取Hologres Binlog,并用多流合并、维表关联将订单、交易、商品3个表打成一个大宽表,实时写入至Hologres的订单汇总表中,形成DWD层。
如下SQL是DWD层表的建表语句。这张目标表包含了来自orders、orders_pay、product_catalog的字段,关联了相关的用户信息、商户信息、订单信息、商品品类信息等等,形成了一张宽表。
CREATE TABLE holo.order_dw.dwd_orders (order_id bigint not null primary key,--字段来自order 表order_user_id bigint,order_shop_id bigint,order_product_id string,order_fee numeric(20,2),order_create_time timestamp_ltz,order_update_time timestamp_ltz,order_state int,--字段来自product_catalog表order_product_catalog_name string,--字段来自orders_pay表pay_id bigint,pay_platfrom int,pay_create_time timestamp_ltz
) ;
下面的SQL是真正的计算逻辑,这里包含两个INSERT语句:
- 第一个INSERT语句是从orders表实时打宽后写入。这里用到了Hologres的维表关联能力。实时打宽后,写入目标表的部分字段。
- 第二个INSERT语句是从orders_pay表实时同步到同一张目标表,更新另外一些字段。
这两个INSERT语句最大的关联在于,它们写的是同一张表,会自动利用目标表的主键ID进行关联。每个INSERT都是做了目标表的局部更新,两者的合力结果是实时更新的目标宽表。
BEGIN STATEMENT SET;
-- 从orders表实时打宽后写入
INSERT INTO holo.order_dw.dwd_orders (
order_id,
order_user_id,
order_shop_id,
order_product_id,
order_fee,
order_create_time,
order_update_time,
order_state,
order_product_catalog_name
)
SELECT
o.*,
dim.catalog_name
FROM
holo.order_dw.orders o
LEFT JOIN holo.order_dw.product_catalog
FOR SYSTEM_TIME AS OF proctime () AS dim
ON
o.product_id = dim.product_id;-- 从order_pays表实时写入
INSERT INTO holo.order_dw.dwd_orders (
pay_id,
order_id,
pay_platform,
pay_create_time
)
SELECT *
FROM
holo.order_dw.orders_pay;
END;
第三步,DWS层的实时聚合。在DWD的基础上,通过Flink读取Hologres DWD的Binlog数据,进行实时指标聚合计算,比如按照用户维度聚合,按照商户维度聚合等,然后实时写入Hologres,形成DWS层。
- 先是创建对应的聚合指标表,DDL语句如下
-- 用户维度聚合指标表
CREATE TABLE holo.order_dw.dws_users (user_id bigint not null,ds string not null,-- 当日完成支付总金额 payed_buy_fee_sum numeric(20,2) not null, primary key(user_id,ds) NOT ENFORCED
);-- 商户维度聚合指标表
CREATE TABLE holo.order_dw.dws_shops (shop_id bigint not null,ds string not null,-- 当日完成支付总金额payed_buy_fee_sum numeric(20,2) not null, primary key(shop_id,ds) NOT ENFORCED
);
- 然后将数据写入Hologres中,经过简单的三步后,Flink SQL构建了完整的Streaming Warehouse分层体系。
--数据写入Hologres BEGIN STATEMENT SET;
INSERT INTO holo.order_dw.dws_users
SELECT order_user_id,DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds,SUM (order_fee)
FROM holo.order_dw.dwd_orders c
WHERE pay_id IS NOT NULL
AND order_fee IS NOT NULL
GROUP BY order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd');INSERT INTO holo.order_dw.dws_shops
SELECT order_shop_id,DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds,SUM (order_fee)
FROM holo.order_dw.dwd_orders c
WHERE pay_id IS NOT NULL
AND order_fee IS NOT NULL
GROUP BY order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd');
END;
第四步,构建应用,基于DWS层,对外提供服务。
数据的分层和加工完成后,业务就可以通过Hologres查询数据并应用。在这个例子里,推荐系统要求非常高的点查性能,所以要求百万级的QPS检查能力。Hologres的行存表或者行列共存表完全可以满足。
这个方案和传统的实时数仓最大的差别是:传统的实时数仓只有最后一层的数据,可对外提供服务。而在Hologres里,DWD等中间层数据也可以对外提供服务,进行实时报表统计。用户可以在中间层进行查询操作,对接各种实时应用、实时大屏。比如
- 直接查DWD层的数据,典型的如根据用户ID返回推荐商品(KV场景)
--场景4: 根据用户特征推荐商品
SELECT *
FROM dws_users
WHERE
user_id = ?
AND ds = '2022-11-09’;--场景4: 根据店铺特征推荐商品SELECT *
FROM dws_shops
WHERE
shop_id = ?
AND ds = '2022-11-09’;
- 实时报表查看订单量和退单量(OLAP)。
--场景6:基于宽表数据展示实时报表
-- 最近30天,每个品类的订单总量和退单总量
SELECT
TO_CHAR(order_create_time, 'YYYYMMDD'),
order_product_catalog_name,
COUNT(*),
COUNT(CASE WHEN refund_id IS NOT NULL THEN 1 ELSE null END)
FROM
dwd_orders
WHERE
order_create_time > now() - '30 day' :: inteval
GROUP BY
1, 2
ORDER BY
1, 2;
第五步,问题排查:Flink数据探查。如果某个业务指标出现异常,Flink可以直接探查每层表的数据来快速定位。比如用Flink探查Hologres DWD层的orders表。Hologres支持Flink的流模式和批模式对数据的探查。
由于流模式是Flink的默认模式,因此我们不需要设置执行模式。它可以直接记录数据变化,从而非常方便的查看数据异常。流模式可以探查获取一段时间范围内的数据及其变化情况。
-- 流模式探查
SELECT *
FROM holo.order_dw.dwd_orders
/*+ OPTIONS('cdcMode'='false', 'startTime'='2022-11-09 00:00:00') */ c
WHERE user_id = 0;
与此同时,批模式探查是获取当前时刻的最新数据。Hologres也支持Flink批模式的数据探查。批模式和流模式的区别在于,流模式关注的是变化,批模式关注的是表中的最新状态。
-- 批模式探查
set 'execution.runtime-mode'='batch’;SELECT *
FROM holo.order_dw.dwd_orders
WHERE user_id = 0AND order_create_time>'2022-11-09 00:00:00';
五、总结
Hologres跟Flink深度集成。实现完整的Streaming Warehouse方案,该方案有如下明显优势:
- 一站式:全链路都可以用SQL表示,并且只需要用到Flink和Hologres两个组件,操作非常方便。实时ETL链路、数据分层完全可以用Flink SQL实现,Hologres提供对外提供在线服务和OLAP查询,每层数据可复用、可查,方便构建实时数仓的数据分层和复用体系。
- 高性能:这种方案可以使得使得Hologres发挥极致的实时写入、实时更新能力和多维OLAP、高并发点查能力,Flink发挥实时加工能力。
- 企业级:自带多种企业级能力,不仅运维更简单,可观测性更好,安全能力更强,也提供多种高可用能力,从而企业更加方便的构建企业级的Streaming Warehouse。

相关文章:
Flink X Hologres构建企业级Streaming Warehouse
摘要:本文整理自阿里云资深技术专家,阿里云Hologres负责人姜伟华,在FFA实时湖仓专场的分享。点击查看>>本篇内容主要分为四个部分: 一、实时数仓分层的技术需求 二、阿里云一站式实时数仓Hologres介绍 三、Flink x Hologres…...
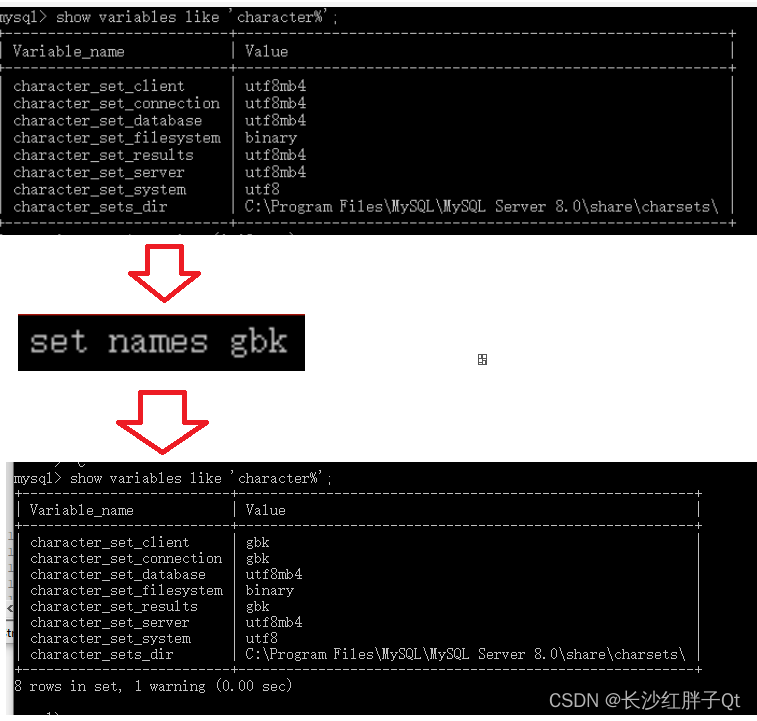
关于 mysql数据库插入中文变空白 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/129048030 红胖子网络科技的博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软…...

不可错过的SQL优化干货分享-sql优化、索引使用
本文是向大家介绍在sql调优的几个操作步骤,它能够在日常遇到慢sql时有分析优化思路,能够让开发者更好的了解sql执行的顺序和原理。一、前言在日常开发中,我们经常遇到一些数据库相关的问题,比方说:SQL已经走了索引了&a…...
vue3:直接修改reative的值,页面却不响应,这是什么情况?
目录 前言 错误示范: 解决办法: 1.使用ref 2.reative多套一层 3.使用Object.assign 前言: 今天看到有人在提问,问题是这样的,我修改了reative的值,数据居然失去了响应性,页面毫无变化&…...

从Vue2 到 Vue3,这些路由差异你需要掌握!
✨ 个人主页:山山而川~xyj ⚶ 作者简介:前端领域新星创作者,专注于前端各领域技术,共同学习共同进步,一起加油! 🎆 系列专栏: vue系列 🚀 学习格言:与其临渊羡…...

Maxwell简介、部署、原理和使用介绍
Maxwell简介、部署、原理和使用介绍 1.Maxwell概述简介 1-1.Maxwell简介 Maxwell是由美国Zendesk公司开源,使用Java编写的MySQL变更数据抓取软件。他会实时监控Mysql数据库的数据变更操作(包括insert、update、delete),并将变…...

20230215_数据库过程_渠道业务清算过程
----2023-0131-清算过程 zhyw.shc_drop_retable(upper(‘xc_qdcn_pgtx_qsqdtype_sja’),‘SHZC’); SQL_STRING:‘create table shzc.xc_qdcn_pgtx_qsqdtype_sja as select * from shzc.xc_qdcn_pgtx_qdtype a where a.in_time ( select max(a.in_time) from shzc.xc_qdcn_pg…...
webpack(高级)--性能优化-代码分离
webpack webpack性能优化 优化一:打包后的结果 上线时的性能优化 (比如分包处理 减少包体积 CDN服务器) 优化二:优化打包速度 开发或者构建优化打包速度 (比如exclude cache-loader等) 大多数情况下我们侧…...

借助docker, 使用verdaccio搭建npm私服
为何要搭建npm私服 搭建npm私服好处多多,网上随便一篇教程搜出来都罗列了诸多好处,譬如: 公司内部开发环境与外网隔离,内部开发的一些库高度隐私不便外传,内网搭建npm服务保证私密性同属内网,可以确保使用npm下载依赖…...
c/c++开发,无可避免的模板编程实践(篇二)
一、开发者需要对模板参数负责 1.1 为您模板参数提供匹配的操作 在进行模板设计时,函数模板或类模板一般只做模板参数(typename T)无关的操作为主,但是也不见得就不会关联模板参数自身的操作,尤其是在一些自定义的数据…...

【2023】【standard-products项目】中查找的问题与解决方案 (未完待续)
10、el-table 判断是多选操作还是单选操作 9、判断数组对象中是否包含某个指定值 需求:修改时数据回填el-select下拉数据,发现当前id在原数组里没有找到,就显示了id值,应该显示name名, 处理:当查找到id…...

力扣sql简单篇练习(十六)
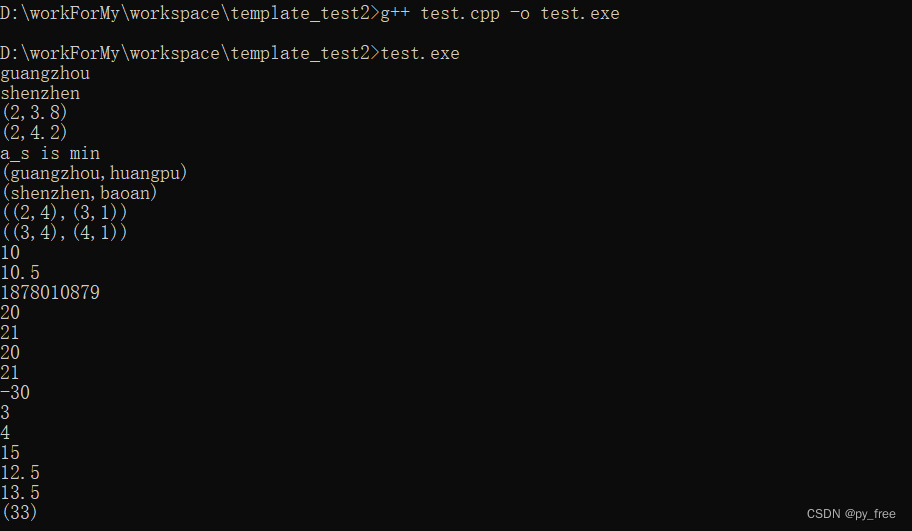
力扣sql简单篇练习(十六) 1 产品销售分析|| 1.1 题目内容 1.1.1 基本题目信息 1.1.2 示例输入输出 1.2 示例sql语句 SELECT p.product_id,sum(s.quantity) total_quantity FROM Product p INNER JOIN Sales s ON p.product_ids.product_id GROUP BY p.product_id1.3 运行截…...
)
青少年蓝桥杯python组(STEMA中级组)
第一套编程题第一题【编程实现】输入一个字符串(N),输出该字符串的长度。输入描述:输入一个字符串 N输出描述:输出该字符串的长度【样例输入】abcd【样例输出】4N input() print(len(N))第二题【提示信息】小蓝家的灯…...
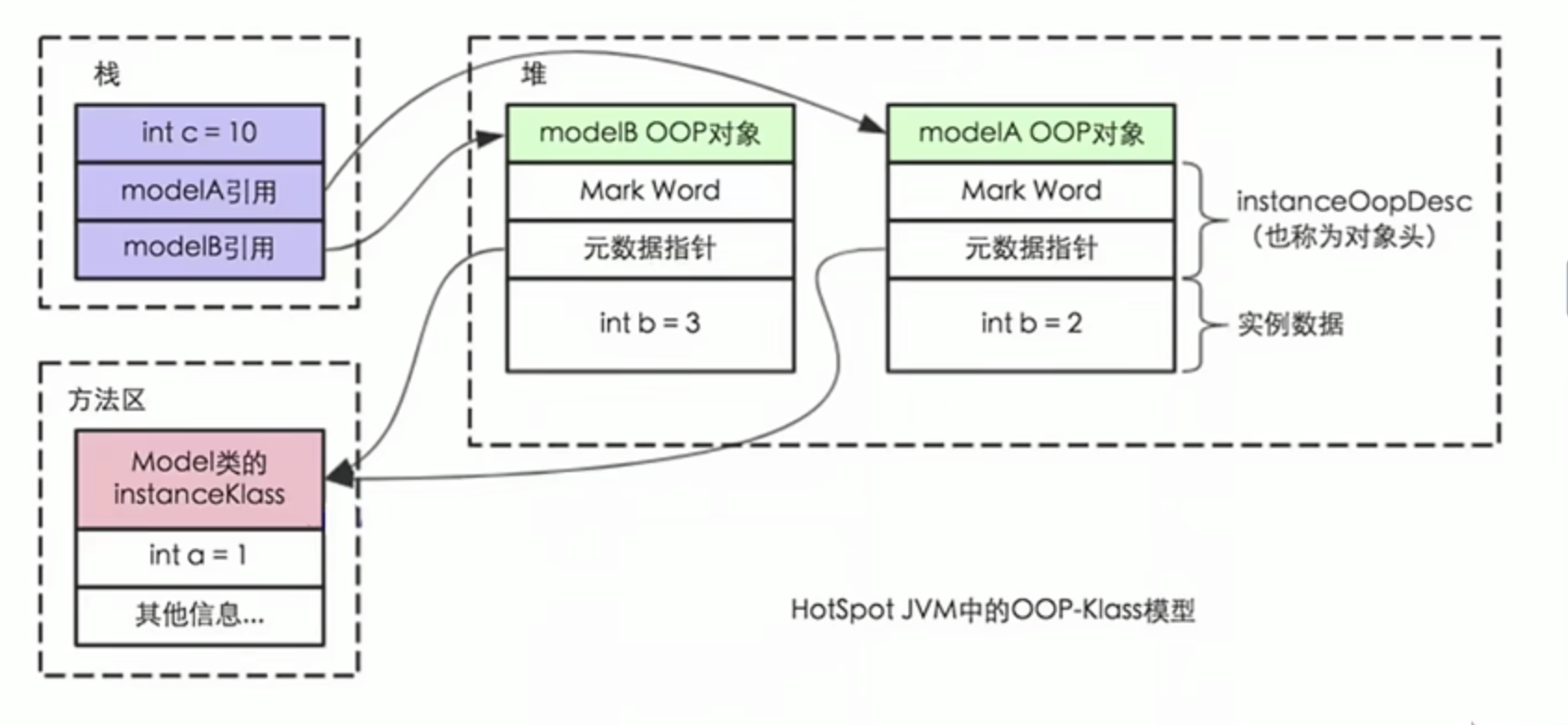
JVM内存结构,Java内存模型,Java对象模型
一.整体方向JVM内存结构是和java虚拟机的运行时区域有关。Java内存模型和java并发编程有关。java对象模型和java对象在虚拟机中的表现形式有关。1.JVM内存结构堆:通过new或者其他指令创建的实例对象,会被垃圾回收。动态分配。虚拟机栈:基本数…...

跨境电商新形式下,如何选择市场?
2022年,全球经济已经有增长乏力、通胀高起的趋势,美国等国家的通货膨胀情况令人担忧,不少行业面临更为复杂的外部环境以及严峻的市场挑战。不过,跨境电商行业依旧保持着较高的增长速度,越来越多有远见的卖家将电商事业…...

MySQL的触发器
目录 一.概述 介绍 触发器的特性 操作—创建触发器 操作—new和old 操作—查看触发器 操作—删除触发器 注意事项 一.概述 介绍 触发器,就是一种特殊的存储过程。触发器和存储过程一样是一个能够完成特定功能、存储在数据库服务器上的SQL片段,但是…...

内存映射模块读写文件提高IO性能mmap
内存映射模块读写文件提高IO性能mmap 1.概述 这篇文章介绍下与普通读写文件不同的方式,内存映射读写文件。在什么情况下才会用到内存映射操作文件那,还是要先了解下他。 1.1.内存映射与IO区别 常规操作IO开销 常规的操作文件是经过下面几个环节操作I…...
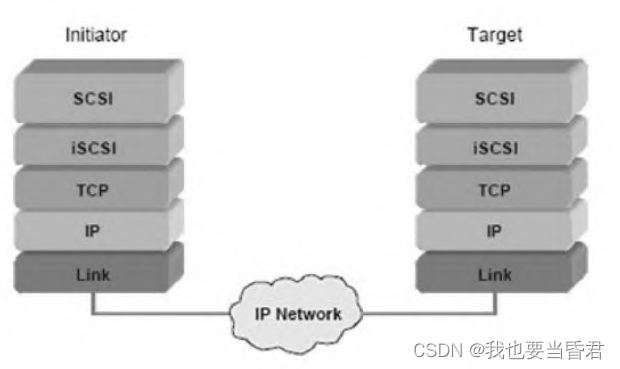
存储硬件与协议
存储硬件与协议存储设备的历史轨迹存储介质的进化3D NAND3D XPointIntel Optane存储接口协议的演变NVMeNVMe-oF网络存储技术1)DAS2)NAS3)SAN4)iSCSIiSCSI层次结构存储设备的历史轨迹 1.穿孔卡2.磁带3.硬盘4.磁盘(软盘…...

智能物流半导体发展
智能物流半导体在国内的发展,国内巨大的人口基数,这将会不断促进智慧物流的发展。智能物流在未来发展的潜力巨大。 关于触屏的设计是界面越简单,越清晰越好,最近设计一个小车控制触屏软件。把小车当前所在信息通过图像显示出来。…...

SAP S/4HANA 概述
智能企业业务技术平台Business Technology Platform提供数据管理和分析,并支持应用程序开发和集成。它还允许我们的客户使用人工智能、机器学习和物联网等智能技术来推动创新。业务网络Business network帮助客户实现跨公司业务流程的数字化。该网络建立在我们的采购…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...