Linux中C语言编程经验总结
修改记录
| 版本号 | 日期 | 更改理由 |
|---|---|---|
| V1.0 | 2022-03-15 | MD化 |
总则
仅总结一些常用且实用的编程规范和技巧,且避免记忆负担,聚焦影响比较大的20% !
编译器
打开全warning编译器开关
正例
gcc -W -Wall -g -o someProc main.c
反例
gcc -g -o someProc main.c
建议增加-W -Wall -g编译器开关
- 打开-W -Wall 警告开关,可以让编译器尽量将代码中的告警进行展示
- 打开-g开关,以利于在出错的情况下,可以较为准确地获知堆栈信息
持续消除warning
在warning开关全开的情况下,应检查warning的情况,最好做到零warning。
建议将某些warning转为编译error
可以根据工程特点,总结出来一批,影响比较大,而且容易出现问题的warning,直接转化为编译器error选项,以利于用编译工具保证质量。有条件的项目编译工程,可以通过-Werror将全部warning转为编译error。
正例
gcc -W -Wall -Werror=overflow -g -o someProc main.c或gcc -W -Wall -Werror [-Wno-*...] -g -o someProc main.c
即使在-Werror开关的情况下,依然可以通过-Wno-*的编译选项进行定制排除,将某些影响不大的warning排除
使用高版本编译器
借用高版本编译器往往能够检查出代码中重大隐患,和产生更高质量的代码,建议在能够使用高版本编译器的情况下,尽量使用
建议使用docker构建高版本编译器环境
在docker某基础镜像中加入devtoolset-*组件,对于CentOS系列发行版,建议安装devtoolset-7或devtoolset-9。这样对于当前旧编译器依赖的工程,可以无影响地进行高版本编译编译,提前将一些隐患排除。
启动镜像时脚本
docker run -it --rm -h devtoolsetVersion -w /usegccversion -v $PWD:/usegccversion image bash
使用高版本编译标准
在低版本编译器中,尽量使用高版本编译标准,可以使用到某些友好特性和错误检查
获得支持临时循环指示变量临近使用特性
正例
for(unsigned int i = 0; i < MAX; ++i)
{ ...
}
反例
void f()
{unsigned int i = 5;// some other code...for(i=0; i < MAX; ++i){...}}
gcc编译器可以指定–std=gnu11等一些高版本编译标准。临近使用变量特性将使得封装性更好,避免无效的提前干扰,有利于阅读代码
建议O2优化标准
编译器优化可以将代码运行性能加速到极致;但为了避免一些负优化,建议使用与Linux内核一致的O2优化级别。
优化虽在,我们仍提倡撰写高质量的代码,作为比较好的编译器输入!
适当地方使用register变量
C语言支持寄存器变量,x86-64上又提供更多的寄存器可用,所以在计算校验和等比较密集耗费CPU的场景,对于关键变量建议使用register关键词修饰。
编程规范
以人为本
空格间隔操作符与左值右值
正例
void f(int * intPtr)
{if(NULL == intPtr){...}...
}
反例
void f(int * intPtr)
{if(NULL==intPtr){...}...
}
以人为本的理念,在编程实践时,如果对于机器阅读没有困难,而对于程序员阅读存在困难的代码,都应该通过空格、空行分割、打印日志分割、scope对齐等常用方式进行辅助编码。
源码编辑Tab转为空格
- 编辑器设定Tab键空格数量为4
- 代码编辑器"设置"支持将Tab固定转为空格
- 代码编辑器支持将旧文件中Tab批量转为空格
控制语句即使只有一行也使用花括号作为块分割
正例
void main(void)
{if(someConditionOk){someFlag = TRUE;}...
}
反例
void main(void)
{if(someConditionOk)someFlag = TRUE;...
}
{ }分割有助于人眼分辨,而不是机器可以正确处理。在后期if分支修改时,不容易引起维护上的问题。
用const关键词修饰栈变量和函数入参指针参数
- 用编译器拦截一部分意外修改
- 增加编译器优化的深度,例如,对于不变量可以进行深度优化
- 对于const类型的数据量,熟练阅读代码的人,可以有选择地忽略和选择重点变化代码部分
多数较为新的C语言开源组件,在API接口设计,多遵从const 修饰符原则
巧用<>和""包含头文件区别依赖可变性
正例
// system api
#include <sys/time.h>// third-party api
#include <third-party/time.h>//self module api
#include "otherApiInModule.h"
反例
// system api
#include <sys/time.h>// third-party api
#include "third-party/time.h"//self module api
#include "otherApiInModule.h"
原则上有区别的差别,最好采用有区别的写法。从书写字面区分头文件组件内外不同,显示引用API的可变程度不同,对于后续阅读代码有利。
分支语句尽量采用likely/unlikely标注
正例
// system api
if(likely(conditiontest))
{//most hit code...
}
else
{//less hit code...
}
反例
if(conditiontest)
{...
}
else
{...
}
- likeyly/unlikely提高代码可阅读性,自然关注主要逻辑流程
- 让编译器生成代码对于分支预测机制更为友好
异常分支必须打印异常日志
正例
int f(int * intPtr)
{if(NULL == intPtr){exception_log("some must parameter is NULL");return errorValue;}//normal flow...
}
反例
int f(int* intPtr)
{if(NULL == intPtr){return errorValue;}//normal flow...
}
typedef有名结构体
正例
typedef struct tagPerson
{unsigned char name[MAX_NAME];int age;
} Person;
反例
typedef struct
{unsigned char name[MAX_NAME];int age;
} Person;
- typedef结构体不具有名称,则在旧版IDE编辑器中,会造成输入辅助提示的混乱
- 在typedef命名的新名称前加入"tag"作为结构体的名称,也是一种惯用法
代码体行数限制
200行为上限,太长则需分拆
首先是代码逻辑上梳理清晰,然后就可以分步骤、分组件,分为3~5个概念步骤,理解最顺畅
让规范代码模式重复出现
在维护过程中,由于历史存量的原因,规范的代码和不规范的代码并存,应尽量批量修改掉某种范式的不规范代码,以避免将来拷贝粘贴代码进一步扩大"污染"。
例如,
sprintf字符串函数可以自动补零,但是对于拷贝目的地的长度没有保护,所以,在涉及的地方,几乎可以无危险代价地替换为snprintf函数 。
可以使用代码编辑器中提供的调用堆栈、正则表达式等工具批量发现修改涉及点
避免简单重复代码出现
此条建议看似与前面建议冲突,实则不然。简单重复的代码是代码中最大的坏味道,和体现程序员的懒惰。
当某些代码重复出现三次以上时,是你应该考虑用公共组件来代替简单重复的时候了。
敢为人先避免破窗效应
破窗效应是指某个地方出现了"坏"的味道后,后面这种坏的情况在自然情况下,没有人愿意改变,只能变得更糟。
作为程序员,应该敢于迈出第一步,让代码变得比昨天更好。
注重重构技巧
重构代码也是有方法论的,具体可见《重构改善即有代码的设计》。
在编译器、自动化测试用例保护、以及重构指导步骤的导引下,进行代码重构,尽量降低出错概率,给自己或他人增强修改代码的信心。
注释
进行必要的简短注释
注释的两个极端是没有注释或充满注释,都不是很好的策略,仅进行必要的注释。
不简明代码的注释等同于一句道歉
对于不简明的代码进行注释,实际上等同于道歉,说明这些代码太复杂了,作者怕后来阅读者不能尽懂,不得不用注释进行特殊说明。
可以考虑是否有简明的实现,进行代码重构。
来自网络观点的启发
如果注释的地方可以增补日志用日志代替
在避免重复的原则下,如果能够同时出现注释和日志,那么用日志代替注释即可,而且日志可以打印更完整的运行时信息,利于后期分析问题。
编码技巧
使用空{}清零初始化结构和数组栈变量
正例
void f()
{struct A a = {};unsigned char buffer[512] = {};//some code using the above vars...
}
反例
void f()
{struct A a ;unsigned char buffer[512] ;memset(&a, 0, sizeof(a));memset(buffer, 0, sizeof(buffer));//some code using the above vars...
}
- 空花括号清零简洁、美观、高效
- 小块内存清零应避免调用函数的代价。在C23 C语言建议标准中,已作为标准建议替代memset
- 空花括号和花括号带零,适应不同的情况;空花括号清零应对结构体和结构体内含有结构体成员的复杂结构体
内存操作长度sizeof(var)变量化
正例
void f(const unsigned char* pBuffer)
{struct A a ;struct A aa;memcpy(&a, pBuffer, sizeof(a));struct A* ptA = &aa;memcpy(ptA, pBuffer, sizeof(*ptA));
}
反例
void f(const unsigned char* pBuffer)
{struct A a ;struct A aa;memcpy(&a, pBuffer, sizeof(struct A));struct A* ptA = &aa;memcpy(ptA, pBuffer, sizeof(struct A));
}
此条建议可能有所争议;但变量化存在至少两个好处:
- 自适应类型变化,避免书写类型
- 如果sizeof后面参数填写错误,利于立即发现问题;使用不匹配类型,一些少量的内存操作越界不易被发现
return卫语句缓解复杂度
正例
if(conditionTest)
{exception_log(...);return flow_end;
}//normal code flow
...
反例
void f()
{if(condition == TRUE){return flow_end;}else{...}return end_of_code;
}
就近访存
原地化访问
从计算机机器结构上来看,计算机访问存储器偏向于局部访问,CPU可以在不改变基地址的情况下,用小范围的地址偏移增减就可以获得快速访问。
如果访问存储器位置在非常局部的内存,也可从计算机缓存体系得到受益。
远端访问栈变量化
正例
struct A* const ptA = getASingleton();while(TRUE)
{//some usagef(ptA);
}反例
extern struct A* getASingleton();while(TRUE)
{//some usagef(getASingleton());
}
应使用简明数值操作写法
在算术操作,尽量使用++、–、+=、*=等简写语言操作符;一方面书写简明,另一方面以利于编译做优化。
反例
int offset = initValue;...//在编译器不能很好优化代码情况下,可以能会多一次访存操作
offset = offset + 1;
使用匿名联合代替单一命名以利于多用途操作
正例
typedef struct tagIPv4_Addr
{union {unsigned char abAddr[4];unsigned int dwAddr;};
} IPv4_Addr;void f()
{IPv4_addr ip ;unsigned char buffer[512];//for whole value usageprintf("encoding IPv4 Addr Value:%u\n", ip.dwAddr);//for byte operationmemcpy(buffer, ip.abAddr, sizeof(ip.abAddr));
}
反例
void f()
{unsigned char ip[4] ;unsigned char buffer[512];//for whole value usageprintf("encoding IPv4 Addr Value:%u\n", *(unsigned int *)ip);//for byte operationmemcpy(buffer, ip, sizeof(ip));
}
使用匿名联合几乎无代价,和更简明。在某些不便修改的地方,可以用匿名联合做别名访问
准确使用类型让编译器做更多事情
- 数组下标应使用无符号数
- 如果输入可以限定在某一范围,请使用枚举类型;也利于调试时将值显示为更有意义的命名,而非数值。能用枚举类型的场景,尽量用枚举。
数值型宏定义指定明确类型
正例
#define MAX_CAPACITY (unsigned char)64
反例
#define MAX_CAPACITY 64
注意类型比较类型一致
正例
#define MAX_CAPACITY (unsigned char)64unsigned char bStartIndex = 12;
unsigned char bEndIndex = 36;if((unsigned char )(bEndIndex - bStartIndex) > MAX_CAPACITY)
{exception_log(...);return FALSE;
}
反例
#define MAX_CAPACITY 64unsigned char bStartIndex = 12;
unsigned char bEndIndex = 11;//编译器生成代码有点出乎意料,允许负值的产生
if((bEndIndex - bStartIndex ) > MAX_CAPACITY)
{exception_log(...);return FALSE;
}//error 无法防止负值的出现
...
头文件
头文件设计内外有别
头文件区分对外部使用头文件和对内使用头文件,对外API头文件仅提供少量公共、必要的声明,以利于模块间的隔离和API接口Bridge桥模式独立演化演化。
正例
-- someComponent+-- include++ component.h ++ component_internal.h++ ...+-- src++ ...
反例
-- someComponent+-- include++ component_api_all_in_one.h +-- src
头文件加入C++支持和头宏定义避免重复包含支持
正例
#ifndef __XX_YY_h
#define __XX_YY_h#ifdef __cplusplus
extern "C" {
#endif//some declarations...#ifdef __cplusplus}
#endif#endif
反例
// a header file
//some C language declarations
...
稳定API设计技巧利用上下文对象指针和操作函数
正例
#ifndef __XX_YY_h
#define __XX_YY_h#ifdef __cplusplus
extern "C" {
#endif//some declarations
typedef struct tag_T_Context { ... } T_Context;T_Context* api_Alloc_Context();
int api_set_Context_Option(T_Context* ptContext, someType optionPara);
int api_request(T_Context* ptContext, someType optionParas ...);
int api_responset(T_Context* ptContext, someType optionParas ...);
int api_setCallback(T_Context* ptContext, someCallbackFunction fn ...);#ifdef __cplusplus}
#endif#endif
这样的设计让上下文对象成为可以保证不同实现间的相互隔离、独立、并发并行,而且不操作具体内存相关的字段,具有二进制布局依赖独立性,可以视作C语言编程领域内对接口进行编程。
日志规范
日志信息中提供必要信息
提供必要的信息,以利于从日志中获取代码运行时走入的逻辑分支
正例
void f(int indicator)
{log("%s some flow info indicator:%d", __func__, indicator);if(indicator > someValue){...}else{...}}
反例
void f(int indicator)
{log("%s begin run ...", __func__);//看日志并不容易得到运行分支信息 ???if(indicator > someValue){...}else{...}}
不同分支日志信息尽量避免重复信息
正例
if(conditiontest){log("process setup gracefully ...");...}
else{log("process setup forcely ...");...}
反例
if(conditiontest){log("the same print info ...");...}
else{log("the same print info ...");...}
更大范围的日志信息重复也应该被注意,这样可以保证日志信息的相对唯一、精准,利于准确分析代码位置和运行逻辑.
函数内日志提供函数名称等信息
正例
void f(int indicator)
{log("%s: enter in with indicator:%d", __func__, indicator);if(indicator > someValue){...}else{...}
}
反例
void f(int indicator)
{log("enter in with indicator:%d", indicator)if(indicator > someValue){...}else{...}
}
日志中甚至可以提供
__func__、 __file__、__line__等编译信息打印
杂项
频繁使用的短函数建议inline化
在1~10行之内的短小函数,如果频繁调用,可以考虑inline化
static inline __attribute__((__always_inline__)) f(...)
{ ...
}
使用并行利器静态线程变量
正例
//can be used by multiple threads
const char* f(unsigned char bType)
{static __thread char buffer[512];// format information into buffer using bType para...return buffer;//线程间使用内存区别开
}
反例
//maybe used by multiple threads
const char* f(unsigned char bType)
{static char buffer[512];// format information into buffer using bType para...return buffer;//多线程场景存在多线程竞争
}
- 使用静态线程变量,具有静态变量和栈变量的双重优点,在多线程编程场景可有利于充分并行
- 多核编程考虑到是核的亲和性,以及内存访问的亲和性,与多线程考量问题有别
GNU构造函数扩展
static void __attribute__((__constructor__)) f(...)
{...
}
可以对于一些无依赖和无先后顺序的初始化场景,在main函数运行前自动被初始化
版本管理
应该小步提交并提交前走查代码
- 程序员应学会应版本化管理思想,每一步一个小的变更,逐渐螺旋迭代
- 将提交代码限定在一个小的变化中,也有利于提交前进行代码走查;原子小步提交代码的工作方法,也有利于后期使用版本管理软件进行合并、回退变更、代码走查等活动
- 避免代码意外丢失或损坏,也应该及时提交版本服务器,而非累积大的变化提交
无论Git或SVN均支持本地提交,某些不适合提交正规版本服务器的变化,可以用本地版本库进行变更管理
自测
应该注重测试
只有编码水平非常高的人,才可以一次性将代码编写正确。一般情况下,普通程序员都很难达到一次编码正确,所以,应该注重对于代码的测试。
尽可能用自动化测试
对于可以自动化测试保证接口或流程正确的场景,应该尽可能地形成自动化测试用例,避免重复劳作。
尽量借助于测试框架进行测试代码开发,以利于代码的规范和复用
Linux QT Creator GUI调试
在Linux图形化环境中,可以使用开源QTCreator IDE编码工具,依赖工程的Makefile文件,就可以建立起来调试环境。
GDB调试
在~/.gdbinit文件扩展全局常用命令
在此文件中增加的gdb指令,会在GDB打开过程中被自动执行,例如,设置库加载路径、代码搜索路径、常用命令别名等
define ab
thread apply all bt
enddefine ff
set confirm off
file a.out
set confirm on
enddefine dasm
disassemble /m
enddefine exit
quit
end
多线程程序获知全部堆栈
thread apply all bt
对于CPU挂死的线程,其运行堆栈,在数次输出下,均稳定在某一个堆栈跳动范围内,即可比较准确地定位到死循环或阻塞的发生地方
对于调试程序定制化初始化设定
gdb --command=self.gdb -p $(pidof selfApp)
通过–command参数项,设定被调试程序的自动化执行gdb指令
self.gdb 定制样例
cd /path/to/proc
set env LD_LIBRARY_PATH=/path/to/so:$LD_LIBRARY_PATH
set args 1 57 1 1 2 somePara
file selfApp
watch内存断点识别意外内存修改
watch var
watch *(int*)0x22cbc0
断点自动执行命令序列
对于频繁在断点需要执行的的手工输入命令操作,可以通过command breakpoint_num的方法提前设定制动执行的命令,避免重复。
(gdb) b do_mmap_pgoff
Breakpoint 1 at 0xffffffff8111a441: file mm/mmap.c, line 940.
(gdb) command 1
Type commands for when breakpoint 1 is hit, one per line.
End with a line saying just "end".
>print addr
>print len
>print proto
>end
(gdb)
快速选择已输入历史命令
-
Ctrl + R 输入关键词,匹配到历史命令,要再次运行该匹配命令,请按Enter。
-
要查找下一个匹配的命令,请再次单击Ctrl + R
-
要编辑命令,请按左或右光标键,相当于选中后编辑
内存故障定位
valgrind辅助定位
valgrind --leak-check=full --track-origins=yes ./someProc [para...]
调优
总则
除了常识性、规范性的优化,其它性能优化应该尽量地晚,不应该提前优化 !!!
perf程序性能分析工具
通过perf 工具可以对程序运行期的动态行为进行记录,通过量化的方式发现可以优化的代码位置,特别推荐!
perf record
perf record -g -p ${pid} [-o </path/to/output_perfdata_file>]
如果不指定-o 输出文件参数,将默认输出到perf.data文件中。
如果想形成多份不同的输出文件,易于后期比较,可以指定-o参数,设定不同的输出文件名字,例如,a.perf.data。
补充,perf支持工具级不同性能采集数据之间的diff差异法分析。
perf report
perf report [-i </path/to/perfdata_file>]
- 如果不指定性能统计分析数据,则默认寻找perf.data文件,即perf record默认输出的文件
- 报告应关注两列均是红色的警醒
perf archive脱机分析
在某些特殊场景,我们可能需要在A机器采集的性能统计数据,在B机器上分析,那么不单单需要perf.data的文件,还需要辅助性能采集统计数据,需要利用用perf archive子命令形成辅助文件后,一并在B机器上部署,才可以进行分析。
perf archive [</path/to/perfdata_file>]
其他机器分析
采集机器上收集
# at A machine has perf.data
perf archivescp perf.data perf.data.tar.bz2 root@other_B_machine:~/
在其他机器上重新部署
# at other B machine
cd ~
tar xvf perf.data.tar.bz2 -C ~/.debug# 进行查看分析
perf report
参考
我在Linux中C语言编程经验总结
相关文章:

Linux中C语言编程经验总结
修改记录 版本号日期更改理由V1.02022-03-15MD化 总则 仅总结一些常用且实用的编程规范和技巧,且避免记忆负担,聚焦影响比较大的20% ! 编译器 打开全warning编译器开关 正例 gcc -W -Wall -g -o someProc main.c反例 gcc -g -o someProc main…...
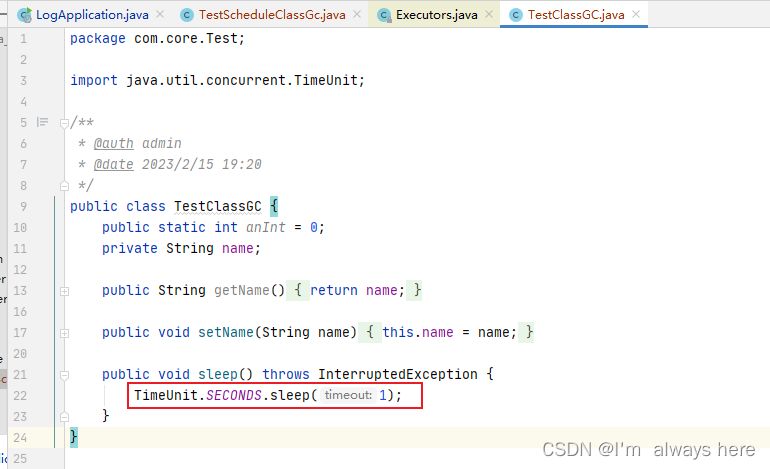
jvisualvm工具使用
jdk自带的工具jvisualvm,可以分析java内存使用情况,jvm相关的信息。 1、设置jvm启动参数 设置jvm参数**-Xms20m -Xmx20m -XX:PrintGCDetails** 最小和最大堆内存,打印gc详情 2、测试代码 TestScheduleClassGc package com.core.schedule;…...
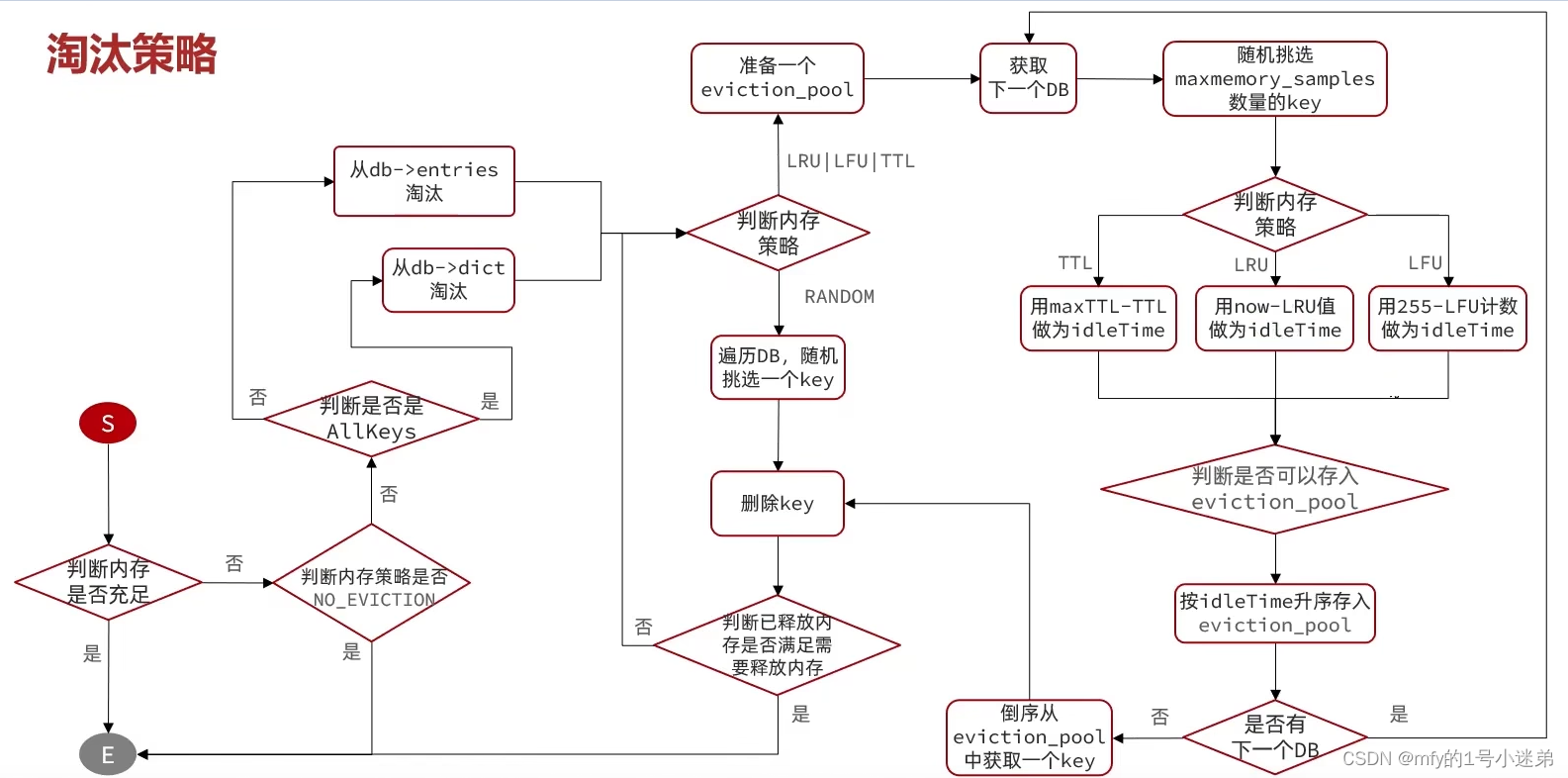
redis五大IO网络模型、内存回收
目录1.0用户空间和内核态空间1.1 网络模型-阻塞IO1.2 网络模型-非阻塞IO1.3 网络模型-IO多路复用1.3.1 网络模型-IO多路复用-select方式1.3.2 网络模型-IO多路复用模型-poll模式1.3.3 网络模型-IO多路复用模型-epoll函数1.3.4 网络模型-epoll中的ET和LT1.3.5 网络模型-基于epol…...

【C/C++】内存管理详解
目录内存布局思维导图1.C/C内存分布数据段:栈:代码段:堆:2.C语言中动态内存管理方式3.C内存管理方式3.1new/delete操作内置类型3.2new和delete操作自定义类型4.operator new 与 operator delete函数5.new和delete的实现原理5.1内置类型5.2自定…...

Android ProcessLifecycleOwner 观察进程生命周期
文章目录简介使用依赖用法1,结合 LiveData用法2,获取 owner的 lifecycle 实例,并对 lifecycle 添加观察者简介 ProcessLifecycleOwner 直译,就是,进程生命周期所有者。 通过 DOC 注释了解到: Lifecycle.E…...
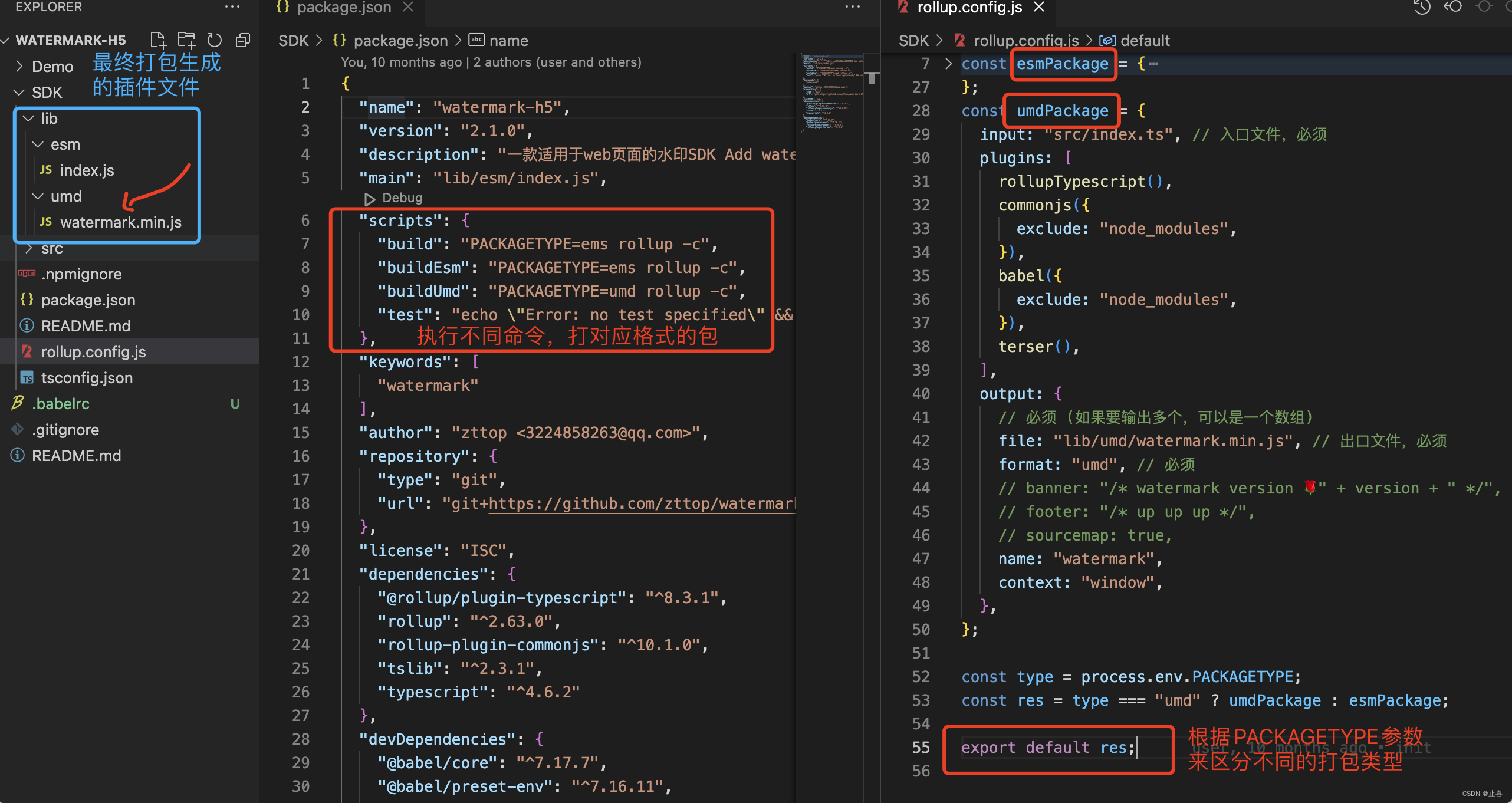
如何编写一个 npm 插件?
提到写 npm 插件,很多没搞过的可能第一感觉觉得很难,无从下手,其实不然。 我们甚至写个简单的 console.log(hello word),都是可以当成一个插件发布上去的。 其实无从下手的主要难点还是在于你的具体要做的功能逻辑,这…...

mapstruct- 让VO,DTO,ENTITY转换更加便捷
mapstruct- 让VO,DTO,ENTITY转换更加便捷 1. 简介 MapStruct是一个代码生成器,简化了不同的Java Bean之间映射的处理,所谓映射指的就是从一个实体变化成一个实体。例如我们在实际开发中,DAO层的实体和一些数据传输对…...
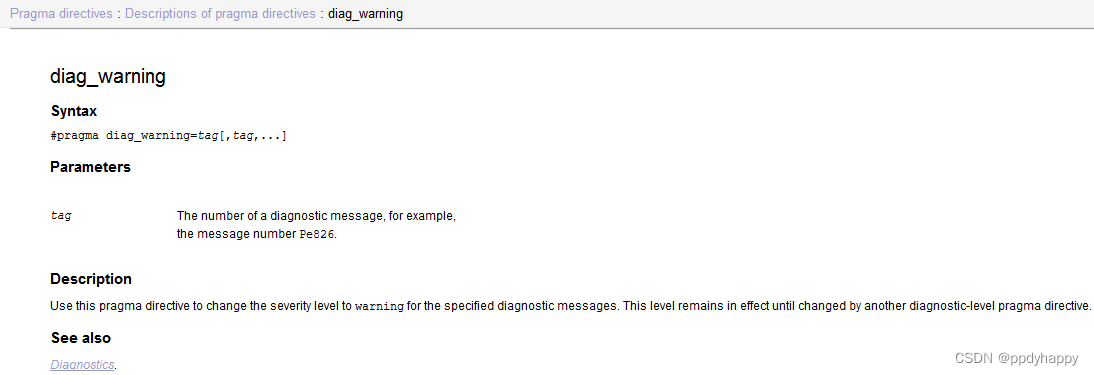
IAR警告抑制及还原
工作中需要临时抑制 警告 Pa084,源代码如下: sy_errno_t sy_memset_s(void *dest, sy_rsize_t dmax, int value, sy_rsize_t n) { sy_errno_t err; if (dest NULL) { return SY_ESNULLP; } if (dmax > SY_RSIZE…...
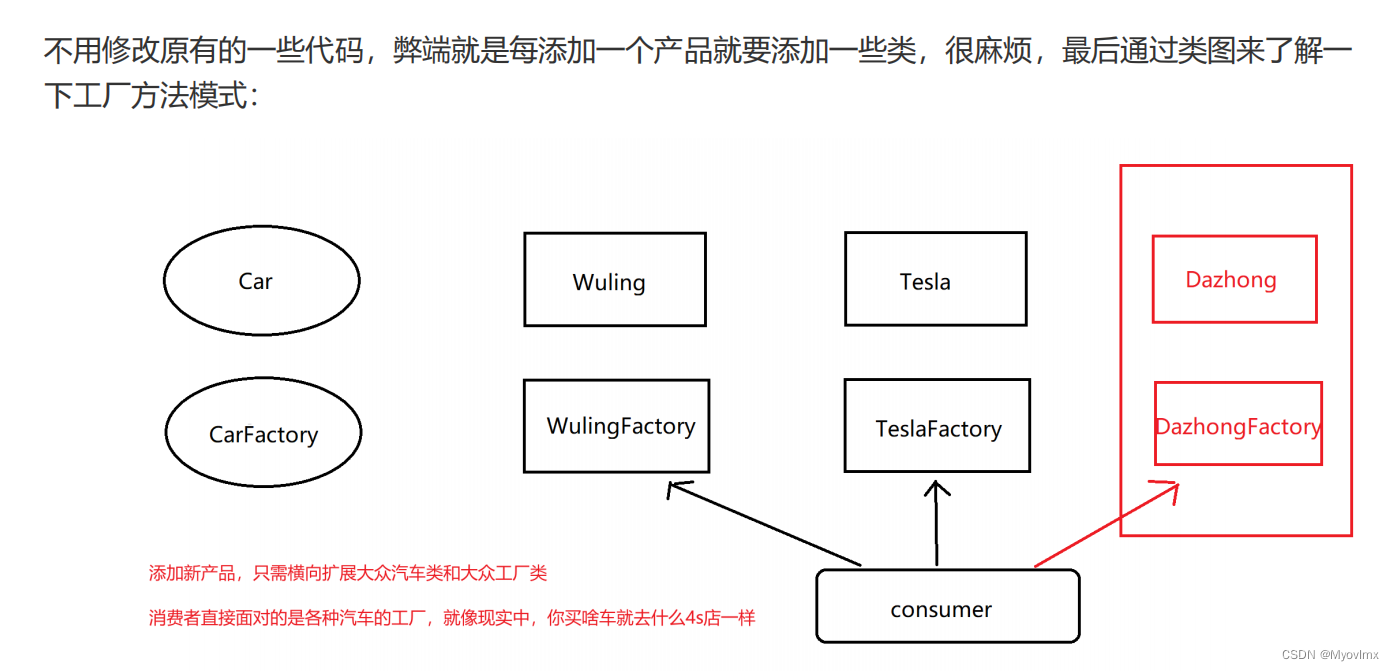
工厂模式(Factory Pattern)
1.什么是工厂模式 定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。 2.工厂模式的作用 实现创建者和调用者的分离 3.工厂模式的分类 简单工厂模式工厂方法模式抽象工厂模式 4.工厂模式的优缺点 优…...

JavaScript语法学习--《JavaScript编程全解》
《JavaScript编程全解》 JavaScript琐碎基础 0.前言 1.RN: react native是Facebook于2015年4月开源的跨平台移动应用开发框架,是Facebook早先开源的JS框架 React 在原生移动应用平台的衍生产物,支持iOS和安卓两大平台。 2.ts与js js:是弱…...
linux安装极狐gitlab
1. 官网寻找安装方式 不管我们使用任何软件,最靠谱的方式就是查看官方文档。gitlab提供了相应的安装文档,并且有对应的中文文档。地址如下: https://gitlab.cn/install/ 我在这里以CentOS作为安装示例,大家可根据自己的需要选择…...
原创论文——人力资源管理)
软考高级信息系统项目管理(高项)原创论文——人力资源管理
人力资源管理 某市某国有装备制造公司智能安防信息管控平台项目是在公司推进企业信息化进程和实现企业可持续发展的背景下于2016年8月提出来的,我公司积极应标并最终顺利中标,而我有幸被任命为项目经理,担任起该项目的管理工作。该项目投资金额为530万元,其中软件部分为360…...
Java Lambda表达式 匿名内部类 函数式接口(FunctionalInterface)
Java Lambda表达式定义背景示例匿名类实现Lambda表达式实现对比匿名类和Lambda实现Lambda表达式(调用)说明Lambda表达式的语法Java 1.8 新特性:函数式接口jdk 1.8 自带的函数式接口 (举例)定义 参考Oracle官网&#x…...

javaEE 初阶 — 流量控制与拥塞控制
文章目录1. 流量控制2. 拥塞控制TCP 工作机制:确认应答机制 超时重传机制 连接管理机制 滑动窗口 1. 流量控制 流量控制是一种干扰发送的窗口大小的机制,滑动窗口,窗口越大,传输的效率就越高(一份时间,…...

HTML自主学习 - 2
一、表格 基本语法 <table><tr><td>单元格内容1</td><td>单元格内容2</td><td>单元格内容3</td></tr></table> 1、<table> </table>标签用于定义表格 2、<tr> </tr>标签用于定义表格的…...

【转载】通过HAL库实现MODBUS从机程序编写与调试-----STM32CubeMX操作篇
通过HAL库实现MODBUS从机程序编写与调试-----STM32CubeMX操作篇[【STM32】RS485 Modbus协议 采集传感器数据](https://blog.csdn.net/qq_33033059/article/details/106935583)基于STM32的ModbusRtu通信--ModbusRtu协议(一)基于STM32的ModbusRtu通信--终极Demo设计(二)STM32RS48…...
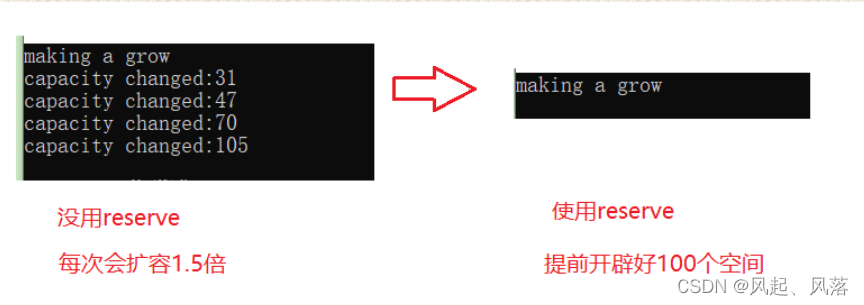
【C++】string类(上)
文章目录1.为什么要学习string类2.标准库中的string类1.string分类2.string类对象的常见构造1.string3. string类对象的容量操作1.size2.capacity3.reserve4.resize扩容初始化删除数据4. string类对象的修改操作1.push_back2.append3.operator1.为什么要学习string类 c语言的字…...

Java泛型
文章目录一、泛型介绍1. 背景2. 概念3. 好处二、泛型声明泛型类型符号泛型声明方式三、类型擦除1. 什么是类型擦除桥接方法2. 为何需要类型擦除3. 类型信息并未完全擦除四、泛型使用1. 泛型类2. 泛型接口3. 泛型方法五、泛型扩展1. 泛型的上下边界泛型的上边界泛型的下边界2. 泛…...
07 分布式事务Seata使用(2)
1、Seata是什么 Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。AT模式是阿里首推的模式,阿里云上有商用版本的GTS&#x…...

c++练习题5
5.在C语言中,程序运行期间,其值不能被改变的量叫 常量 。 6.符号常量是指用一个符号名代表一个常量。 7.整型常量和浮点型常量也称为 数值常量 ,它们有正负之分。 9.在C中,变量是 其值可以改变的量 。 …...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...