Elasticsearch:使用 intervals query - 根据匹配项的顺序和接近度返回文档
Intervals query 根据匹配项的顺序和接近度返回文档。Intervals 查询使用匹配规则,由一小组定义构成。 然后将这些规则应用于指定字段中的术语。
这些定义产生跨越文本正文中的术语的最小间隔序列。 这些间隔可以通过父源进一步组合和过滤。
上述描述有点费解。我们先用一个简单的例子来进行说明。
示例请求
以下 intervals 搜索返回在 my_text 字段中包含 my favorite food 的文档,并且没有任何间隙,紧接着是在 my_text 字段中包含 hot water 或者 cold porridge。
此搜索将匹配 my_text 字段值为 my favorite food is cold porridge,但是 它不匹配 my_text 的值是 it's cold my favorite food is porridge。
我们首先来写入如下的两个文档:
PUT intervals_index/_doc/1
{"my_text": "my favorite food is cold porridge"
}PUT intervals_index/_doc/2
{"my_text": "it's cold my favorite food is porridge"
}PUT intervals_index/_doc/3
{"my_text": "he says my favorite food is banana, and he likes to drink hot water"
}PUT intervals_index/_doc/4
{"my_text": "my favorite fluid food is cold porridge"
}PUT intervals_index/_doc/5
{"my_text": "my favorite food is banana"
}PUT intervals_index/_doc/6
{"my_text": "my most favorite fluid food is cold porridge"
}我做如下的查询:
GET intervals_index/_search
{"query": {"intervals" : {"my_text" : {"all_of" : {"ordered" : true,"intervals" : [{"match" : {"query" : "my favorite food","max_gaps" : 0,"ordered" : true}},{"any_of" : {"intervals" : [{ "match" : { "query" : "hot water" } },{ "match" : { "query" : "cold porridge" } }]}}]}}}}
}上面命令返回的结果为:
{"took": 473,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 0.3333333,"hits": [{"_index": "intervals_index","_id": "1","_score": 0.3333333,"_source": {"my_text": "my favorite food is cold porridge"}},{"_index": "intervals_index","_id": "3","_score": 0.111111104,"_source": {"my_text": "he says my favorite food is banana, and he likes to drink hot water"}}]}
}从返回的结果中,我们可以看出来文档 1 及 3 匹配。其原因很简单。两个文档中都含有 my favorite food,并且在它的后面还接着 cold porridge 或者 hot water 尽管它们还是离它们有一定的距离。文档 4 没有匹配是因为在 my favorite food 中间多了一个 fluid 单词。我们在查询的要求中说明 max_gaps 为 0。如果我做如下的查询:
GET intervals_index/_search
{"query": {"intervals" : {"my_text" : {"all_of" : {"ordered" : true,"intervals" : [{"match" : {"query" : "my favorite food","max_gaps" : 1,"ordered" : true}},{"any_of" : {"intervals" : [{ "match" : { "query" : "hot water" } },{ "match" : { "query" : "cold porridge" } }]}}]}}}}
}在上面,我们设置 max_gaps 为 1,那么匹配的结果变为:
{"took": 3,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 3,"relation": "eq"},"max_score": 0.3333333,"hits": [{"_index": "intervals_index","_id": "1","_score": 0.3333333,"_source": {"my_text": "my favorite food is cold porridge"}},{"_index": "intervals_index","_id": "4","_score": 0.25,"_source": {"my_text": "my favorite fluid food is cold porridge"}},{"_index": "intervals_index","_id": "3","_score": 0.111111104,"_source": {"my_text": "he says my favorite food is banana, and he likes to drink hot water"}}]}
}很显然这次文档 4,也即 my favorite fluid food is cold porridge 也被搜索到。而文档 6,也即 my most favorite fluid food is cold porridge 没有被搜索到。
Intervals query 解决的问题
我们在一些论坛上经常看到一个非常常见的问题:“我如何创建一个匹配的查询,同时保留搜索词的顺序?”
他们中的许多人首先尝试使用 match_phrase,但有时他们也想使用 fuzzy 逻辑,而这不适用于 match_phrase。
在很多解决方案中我们可以发现使用 Span Queries 可以解决问题,但是很多问题可以通过使用 Intervals Query 来完美解决。
Intervals Query是一种基于顺序和匹配规则的查询类型。 这些规则是你要应用的查询条件。
今天我们可以使用以下规则:
- match:match 规则匹配分析的文本。
- prefix:prefix 规则匹配以指定字符集开头的术语
- wildcard:wildcard(通配符)规则使用通配符模式匹配术语。
- fuzzy:fuzzy 规则匹配与给定术语相似的术语,在 Fuzziness 定义的编辑距离内。
- all_of:all_of 规则返回跨越其他规则组合的匹配项。
- any_of:any_of 规则返回由其任何子规则生成的 intervals。
示例
我们先准备数据。我们想创建如下的一个 movies 的索引:
PUT movies
{"settings": {"analysis": {"analyzer": {"en_analyzer": {"tokenizer": "standard","filter": ["lowercase","stop"]},"shingle_analyzer": {"type": "custom","tokenizer": "standard","filter": ["lowercase","shingle_filter"]}},"filter": {"shingle_filter": {"type": "shingle","min_shingle_size": 2,"max_shingle_size": 3}}}},"mappings": {"properties": {"title": {"type": "text","analyzer": "en_analyzer","fields": {"suggest": {"type": "text","analyzer": "shingle_analyzer"}}},"actors": {"type": "text","analyzer": "en_analyzer","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"description": {"type": "text","analyzer": "en_analyzer","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"director": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"genre": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"metascore": {"type": "long"},"rating": {"type": "float"},"revenue": {"type": "float"},"runtime": {"type": "long"},"votes": {"type": "long"},"year": {"type": "long"},"title_suggest": {"type": "completion","analyzer": "simple","preserve_separators": true,"preserve_position_increments": true,"max_input_length": 50}}}
}我们接下来使用 _bulk 命令来写入一些文档到这个索引中去。我们使用这个链接中的内容。我们使用如下的方法:
POST movies/_bulk
{"index": {}}
{"title": "Guardians of the Galaxy", "genre": "Action,Adventure,Sci-Fi", "director": "James Gunn", "actors": "Chris Pratt, Vin Diesel, Bradley Cooper, Zoe Saldana", "description": "A group of intergalactic criminals are forced to work together to stop a fanatical warrior from taking control of the universe.", "year": 2014, "runtime": 121, "rating": 8.1, "votes": 757074, "revenue": 333.13, "metascore": 76}
{"index": {}}
{"title": "Prometheus", "genre": "Adventure,Mystery,Sci-Fi", "director": "Ridley Scott", "actors": "Noomi Rapace, Logan Marshall-Green, Michael Fassbender, Charlize Theron", "description": "Following clues to the origin of mankind, a team finds a structure on a distant moon, but they soon realize they are not alone.", "year": 2012, "runtime": 124, "rating": 7, "votes": 485820, "revenue": 126.46, "metascore": 65}....在上面,为了说明的方便,我省去了其它的文档。你需要把整个 movies.txt 的文件拷贝过来,并全部写入到 Elasticsearch 中。它共有1000 个文档。
我们想要检索符号如下条件的文件:
我们想要检索包含单词 mortal hero 的准确顺序 (ordered=true) 的文档,并且我们不打算在单词之间添加间隙 (max_gaps),因此内容必须与 mortal hero 完全匹配。
GET movies/_search
{"query": {"intervals": {"description": {"match": {"query": "hero mortal","max_gaps": 0,"ordered": true}}}}
}此搜索的结果将为空,因为未找到符合这些条件的文档。
让我们将 ordered 更改为 false,因为我们不关心顺序。
GET movies/_search
{"query": {"intervals": {"description": {"match": {"query": "hero mortal","max_gaps": 0,"ordered": false}}}}
}上面搜索的结果为:

现在我们可以看到文件已经找到了。 请注意,在文档中的 description 是 “Mortal hero”。因为我们想测试相同顺序的术语,所以我们搜索 “mortal hero”:
GET movies/_search
{"query": {"intervals": {"description": {"match": {"query": "mortal hero","max_gaps": 0,"ordered": true}}}}
}这次,我们可以看到和上面命令运行一样的结果。有一个文档被匹配。
让我们在下一个示例中使用 any_of 规则。 我们想要带有 “mortal hero” 或 “mortal man” 的文件。
GET movies/_search
{"query": {"intervals": {"description": {"any_of": {"intervals": [{"match": {"query": "mortal hero","max_gaps": 0,"ordered": true}},{"match": {"query": "mortal man","max_gaps": 0,"ordered": true}}]}}}}
}上面命令返回结果:

请注意,我们成功了。 返回了两个匹配的文档。
我们也可以组合规则。 在示例中,让我们搜索 “the hunger games”,结果中至少有一个是 “part 1” 或 “part 2”。 请注意,这里我们使用角色 match 和 any_of。
GET movies/_search
{"query": {"intervals" : {"title" : {"all_of" : {"intervals" : [{"match" : {"query" : "the hunger games","ordered" : true}},{"any_of" : {"intervals" : [{ "match" : { "query" : "part 1" } },{ "match" : { "query" : "part 2" } }]}}]}}}}
}上面命令返回结果:
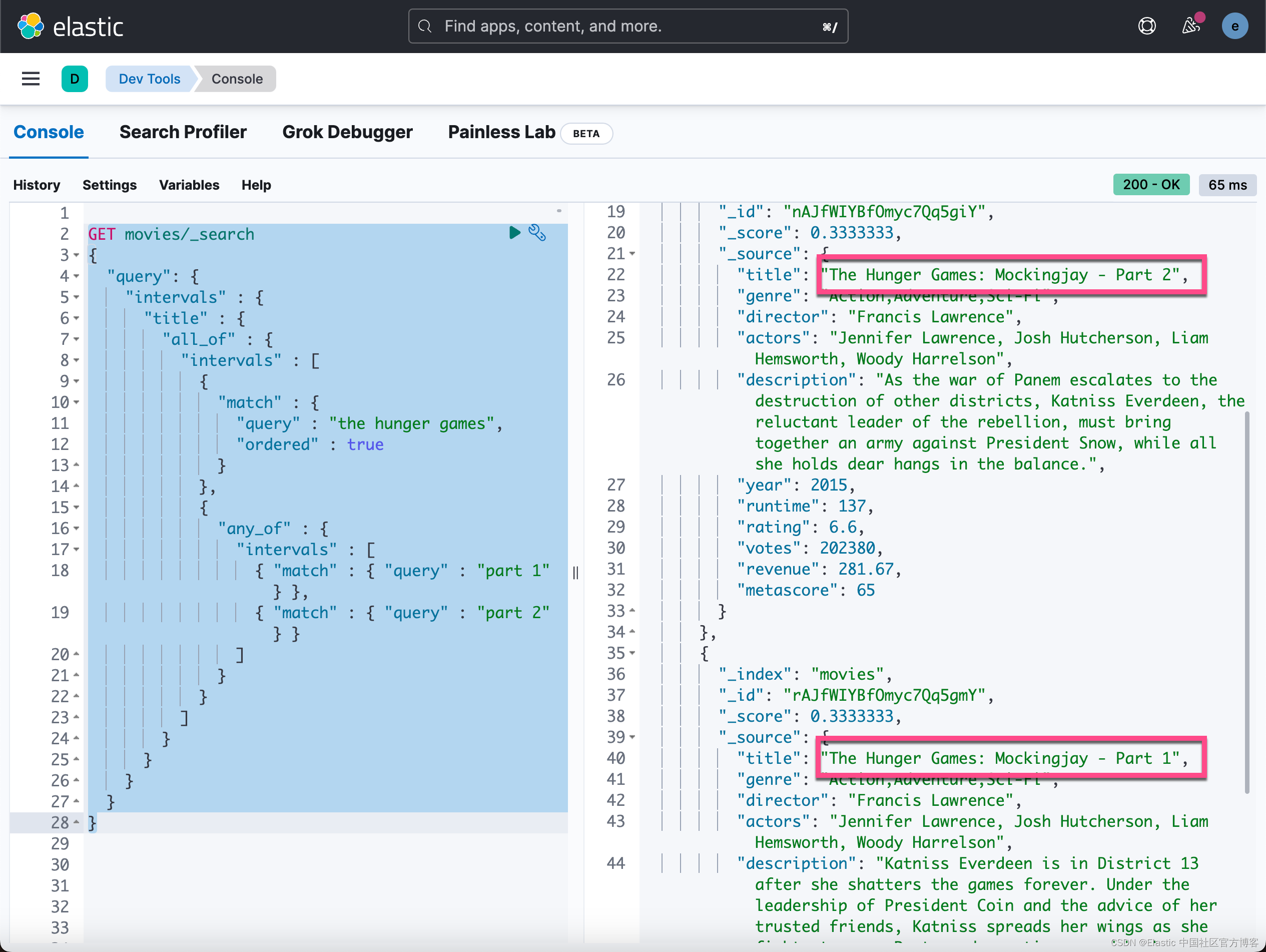
如上所示结果中只有两部电影。
间隔查询是一种按照搜索词顺序搜索文档的方法。阅读官方文档并了解如何通过它解决问题。
相关文章:
Elasticsearch:使用 intervals query - 根据匹配项的顺序和接近度返回文档
Intervals query 根据匹配项的顺序和接近度返回文档。Intervals 查询使用匹配规则,由一小组定义构成。 然后将这些规则应用于指定字段中的术语。 这些定义产生跨越文本正文中的术语的最小间隔序列。 这些间隔可以通过父源进一步组合和过滤。 上述描述有点费解。我…...
无法决定博客主题的人必看!如何选择类型和推荐的 5 种选择
是否有人不能迈出第一步,因为博客的类型还没有决定?有些人在出发时应该行动,而不是思考,但让我们冷静下来,仔细想想。博客的难度因流派而异,这在很大程度上决定了随后的发展。因此,在选择博客流…...
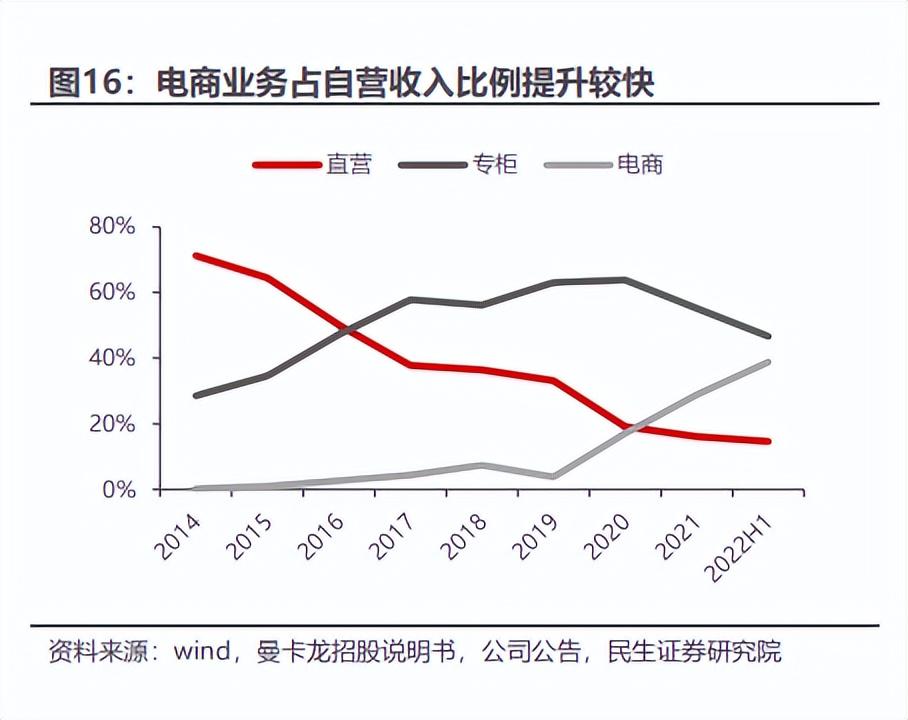
数字化转型的成功模版,珠宝龙头曼卡龙做对了什么?
2月11日,曼卡龙(300945.SZ)发布2022年业绩快报,报告期内,公司实现营业收入16.11亿元,同比增长28.63%。来源:曼卡龙2022年度业绩快报曼卡龙能在2022年实现营收增长尤为不易。2022年受疫情影响&am…...
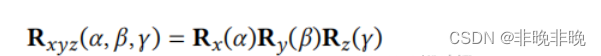
转换矩阵、平移矩阵、旋转矩阵关系以及python实现旋转矩阵、四元数、欧拉角之间转换
文章目录1. 转换矩阵、平移矩阵、旋转矩阵之间的关系2. 缩放变换、平移变换和旋转变换2. python实现旋转矩阵、四元数、欧拉角互相转化由于在平时总是或多或少的遇到平移旋转的问题,每次都是现查资料,然后查了忘,忘了继续查,这次弄…...
中国地图航线图(echarjs)
1、以上为效果图 需要jq、echarjs、china.json三个文件支持。以上 2、具体代码 DOM部分 <!-- 服务范围 GO--> <div class"m-maps"><div id"main" style"width:1400px;height: 800px; margin: 0 auto;"> </div> <!-…...
Python正则表达式中group与groups的用法详解
本文主要介绍了Python正则表达式中group与groups的用法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧目录在Python中,正则表达式的group和groups方…...

c++练习题7
1.下列运算符中优先级最高的是 A)> B) C) && D)! 2.以下关于运算符优先级的描述中,正确的是 。 A)!(逻辑非&#x…...

MySQL学习
目录1、数据库定义基本语句(1)数据库操作(2)数据表操作2.数据库操作SQL语句(1)插入数据(2)更新语句(3)删除数据3.数据库查询语句(1)基…...

C语言(强制类型转换)
一.类型转换原则 1.升级:当类型转换出现在表达式时,无论时unsigned还是signed的char和short都会被自动转换成int,如有必要会被转换成unsigned int(如果short与int的大小相同,unsigned short就比int大。这种情况下,uns…...

搭建hadoop高可用集群(二)
搭建hadoop高可用集群(一)配置hadoophadoop-env.shworkerscore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml/etc/profile拷贝集群首次启动1、先启动zk集群(自动化脚本)2、在hadoop151,hadoop152,hadoop153启动JournalNode…...

CentOS升级内核-- CentOS9 Stream/CentOS8 Stream/CentOS7
官方文档在此 升级原因 当我们安装一些软件(对,我说的就是Kubernetes),可能需要新内核的支持,而CentOS又比较保守,不太升级,所以需要我们手工升级. # 看下目前是什么版本内核 uname -a# 安装公钥 rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org# 添加仓库,如果…...
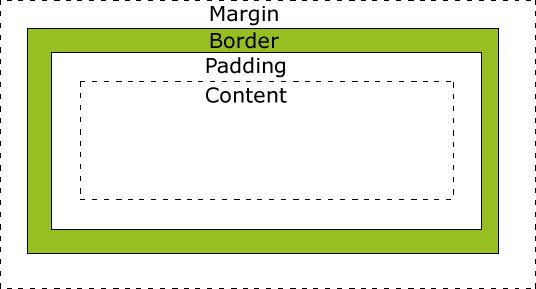
【基础篇】一文掌握css的盒子模型(margin、padding)
1、CSS 盒子模型(Box Model) 所有HTML元素可以看作盒子,在CSS中,"box model"这一术语是用来设计和布局时使用。CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距,边框,填充,和实际内容。盒模型允许我们在其它元素和周围元素边框之间的空间放置元素…...
重生之我是赏金猎人-漏洞挖掘(十一)-某SRC储存XSS多次BypassWAF挖掘
0x01:利用编辑器的超链接组件导致存储XSS 鄙人太菜了,没啥高质量的洞呀,随便水一篇文章吧。 在月黑风高的夜晚,某骇客喊我起床挖洞,偷瞄了一下发现平台正好出活动了,想着小牛试刀吧 首先信息收集了一下&a…...

Wails简介
https://wails.io/zh-Hans/docs/introduction 简介 Wails 是一个可让您使用 Go 和 Web 技术编写桌面应用的项目。 将它看作为 Go 的快并且轻量的 Electron 替代品。 您可以使用 Go 的灵活性和强大功能,结合丰富的现代前端,轻松的构建应用程序。 功能…...
)
滑动窗口 AcWing (JAVA)
给定一个大小为 n≤10^6 的数组。 有一个大小为 k 的滑动窗口,它从数组的最左边移动到最右边。 你只能在窗口中看到 k 个数字。 每次滑动窗口向右移动一个位置。 以下是一个例子: 该数组为 [1 3 -1 -3 5 3 6 7],k 为 33。 窗口位置最小值最大…...
vue小案例
vue小案例 组件化编码流程 1.拆分静态组件,按功能点拆分 2.实现动态组件 3.实现交互 文章目录vue小案例组件化编码流程1.父组件给子组件传值2.通过APP组件给子组件传值。3.案例实现4.项目小细节1.父组件给子组件传值 父组件给子组件传值 1.在父组件中写好要传的值&a…...

阅读笔记3——空洞卷积
空洞卷积 1. 背景 空洞卷积(Dilated Convolution)最初是为解决图像分割的问题而提出的。常见的图像分割算法通常使用池化层来增大感受野,同时也缩小了特征图尺寸,然后再利用上采样还原图像尺寸。特征图先缩小再放大的过程造成了精…...
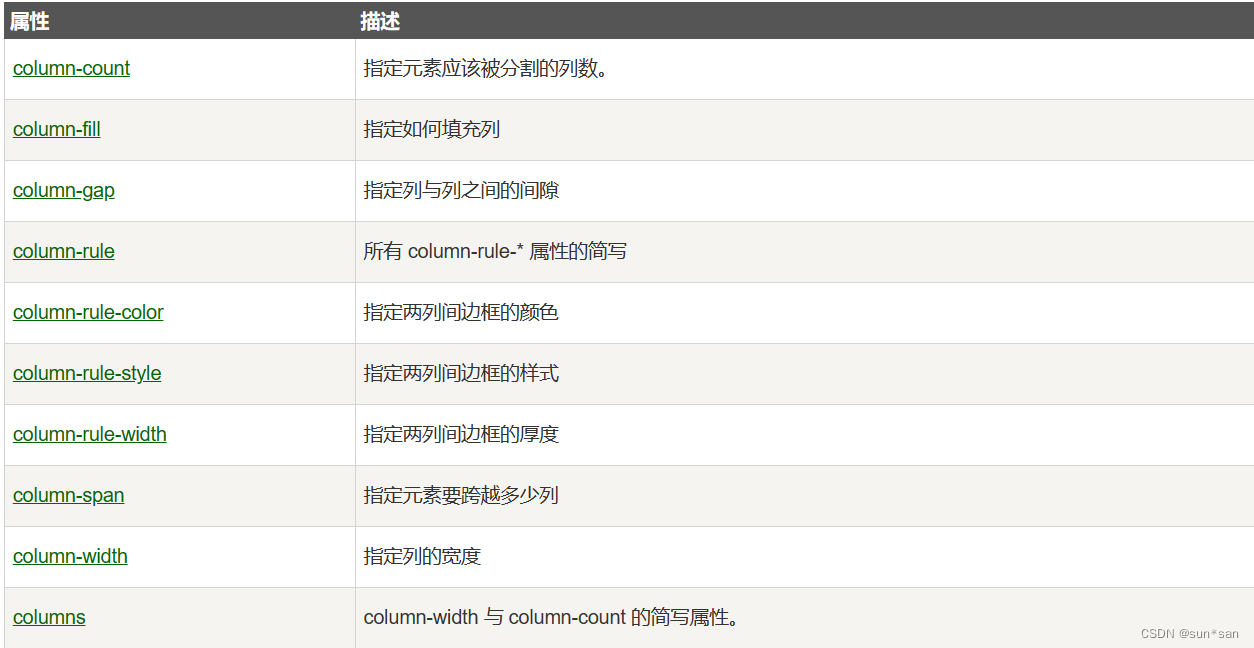
CSS系统学习总结
目录 CSS边框 CSS背景 CSS3渐变 线性渐变(Linear Gradients)- 向下/向上/向左/向右/对角方向 语法 线性渐变(从上到下) 线性渐变(从左到右) 线性渐变(对角) 使用角度 使用多…...

阿里一面:你做过哪些代码优化?来一个人人可以用的极品案例
前言 在尼恩读者50交流群中,尼恩经常指导小伙伴改简历。 改简历所涉及的一个要点是: 在 XXX 项目中,完成了 XXX 模块的代码优化 另外,在面试的过程中,面试官也常常喜欢针对提问,来考察候选人对代码质量的追…...
Android NFC 标签读写Demo与历史漏洞概述
文章目录前言NFC基础1.1 RFID区别1.2 工作模式1.3 日常应用NFC标签2.1 标签应用2.2 应用实践2.3 标签预览2.4 前台调度NFC开发3.1 NDEF数据3.2 标签的调度3.3 读写Demo3.4 Demo演示历史漏洞4.1 中继攻击4.2 预览伪造4.3 篡改卡片4.4 其它漏洞总结前言 NFC 作为 Android 手机一…...

MedGemma 1.5新手入门:三分钟搞定本地医疗AI问答系统
MedGemma 1.5新手入门:三分钟搞定本地医疗AI问答系统 1. 为什么选择本地医疗AI助手 在医疗健康领域,隐私保护和专业可靠性是两个最核心的需求。传统在线医疗AI存在三个明显痛点:健康数据需要上传云端、回答过程像黑盒子无法验证、网络依赖性…...

Go语言的sync.Cond中的分析驱动事件
Go语言中的sync.Cond是一个强大的同步原语,它通过条件变量实现了高效的goroutine间通信与协作。分析驱动事件是sync.Cond的核心机制,它允许程序在特定条件满足时唤醒等待的goroutine,从而优化资源利用并提升并发性能。本文将深入探讨sync.Con…...

使用http请求中 如何使用token添加到http请求头部
核心区别:请求头 vs 内容头这是一个非常关键的区别!让我用HTTP报文的实际样子来解释:完整的HTTP请求报文POST /mes-standard-biz/mesEquipmentStatusRecord/dataUploadForPlc HTTP/1.1 Host: mom.haier-energy.com satoken: eyJhbGciOiJIUzI1…...

如何快速使用“知窗”将网页打包成为 Windows 桌面应用 @杨章隐
在很多实际业务中,我们都会遇到这样一个问题:系统已经是 Web 的,但客户却希望有一个“桌面应用”。比如:工厂标签打印系统仓库管理系统内部 ERP / OA收银、前台系统用户不想:打开浏览器输入网址处理各种兼容问题他们只…...

从文生图到视频创作,AI 视觉工作流为什么正在走向一体化
最早一批 AI 视觉工具流行起来时,大家关注的重点只有一件事:能不能生成图片。但今天,用户对 AI 工具的期待已经明显提高了。很多人发现,单纯“生成一张图”只是整个视觉工作流中的第一步,后面往往还会跟着修改、优化、…...

如何将Piskel像素编辑器无缝集成到React应用:完整指南
如何将Piskel像素编辑器无缝集成到React应用:完整指南 【免费下载链接】piskel A simple web-based tool for Spriting and Pixel art. 项目地址: https://gitcode.com/gh_mirrors/pi/piskel Piskel是一款功能强大的基于Web的像素艺术创作工具,通…...

开源大模型趋势分析:bge-m3在AI知识库中的核心作用
开源大模型趋势分析:bge-m3在AI知识库中的核心作用 1. 项目概述与核心价值 BAAI/bge-m3是北京智源人工智能研究院推出的多语言通用嵌入模型,作为当前开源领域最强的语义嵌入模型之一,它在多语言理解、长文本处理和异构数据检索方面表现出色…...

StructBERT文本相似度模型在网络安全中的应用:恶意文本与钓鱼内容识别
StructBERT文本相似度模型在网络安全中的应用:恶意文本与钓鱼内容识别 最近和几个做安全的朋友聊天,他们都在抱怨一个事儿:现在的网络攻击越来越“聪明”了。钓鱼邮件写得跟真的一样,恶意脚本的注释伪装得人畜无害,社…...

XADC避坑指南:Xilinx 7系列FPGA内置ADC的5个常见使用误区
XADC避坑指南:Xilinx 7系列FPGA内置ADC的5个常见使用误区 在嵌入式系统设计中,Xilinx 7系列FPGA内置的XADC(Xilinx Analog-to-Digital Converter)模块为工程师提供了便捷的模拟信号采集方案。这个12位精度、1MSPS采样率的ADC模块看…...

SpringBoot集成mica-mqtt客户端实战:从配置到消息收发
1. 为什么选择mica-mqtt客户端 在物联网项目开发中,MQTT协议因其轻量级、低功耗的特点成为设备通信的首选方案。mica-mqtt作为国产开源组件,相比其他MQTT客户端有三个显著优势:首先是性能表现,实测在树莓派这类资源受限设备上&am…...