讨论和总结 树模型 的三种序列化 方式的区别(模型存储大小、序列化所用内存、序列化速度)...
一、前言
本文总结常用树模型: rf,xgboost,catboost和lightgbm等模型的保存和加载(序列化和反序列化)的多种方式,并对多种方式从运行内存的使用和存储大小做对比
二、模型
2.1 安装环境
pip install xgboost
pip install lightgbm
pip install catboost
pip install scikit-learn可以指定版本也可以不指定,直接下载可获取最新的pkg
2.2 模型运行例子
针对iris数据集的多分类任务
import xgboost as xgb
from catboost import CatBoostClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_splitimport lightgbm as lgb
from sklearn.ensemble import RandomForestClassifieriris = load_iris()
X = iris.data
y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)# lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt','objective': 'multiclass','num_class': 3,'metric': 'multi_logloss','num_leaves': 31,'learning_rate': 0.05,'feature_fraction': 0.9
}
gbm = lgb.train(params, lgb_train, num_boost_round=100, valid_sets=[lgb_eval], early_stopping_rounds=5)
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
y_pred = [list(x).index(max(x)) for x in y_pred]
lgb_acc = accuracy_score(y_test, y_pred)# rf
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
rf_acc = accuracy_score(y_test, y_pred)# catboost
cat_boost_model = CatBoostClassifier(depth=9, learning_rate=0.01,loss_function='MultiClass', custom_metric=['AUC'],eval_metric='MultiClass', random_seed=1996)cat_boost_model.fit(X_train, y_train, eval_set=(X_test, y_test), use_best_model=True, early_stopping_rounds=1000)
y_pred = cat_boost_model.predict(X_test)
cat_acc = accuracy_score(y_test, y_pred)print(xgb_acc, lgb_acc, rf_acc, cat_acc)2.3 运行内存计算
def cal_current_memory():# 获取当前进程内存占用。pid = os.getpid()p = psutil.Process(pid)info = p.memory_full_info()memory_used = info.uss / 1024. / 1024. / 1024.return {'memoryUsed': memory_used}获取当前进程的pid,通过pid来定向查询memory的使用
三、保存和加载
主要有三种方法:
jsonpickle
pickle
模型api
3.1 jsonpickle
jsonpickle 是一个 Python 序列化和反序列化库,它可以将 Python 对象转换为 JSON 格式的字符串,或将 JSON 格式的字符串转换为 Python 对象。
调用jsonpickle.encode即可序列化,decode进行反序列化
以xgb为例
保存:
iris = load_iris()
X = iris.data
y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)xgb_str = jsonpickle.encode(xgb_model)
with open(f'{save_dir}/xgb_model_jsonpickle.json', 'w') as f:f.write(xgb_str)加载:
save_dir = './models'iris = load_iris()
X = iris.data
y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)xgb_test = xgb.DMatrix(X_test, y_test)with open(f'{save_dir}/xgb_model_jsonpickle.json', 'r') as f:xgb_model_jsonpickle = f.read()
xgb_model_jsonpickle = jsonpickle.decode(xgb_model_jsonpickle)
y_pred = xgb_model_jsonpickle.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
print(xgb_acc)这样就完成了模型的保存和加载
优势
模型加载过程不需要重新实例化,直接jsonpickle.decode模型文件即可直接获得模型
获得的模型文件是json格式,便于各种编程语言和平台之间的数据交换,方便实现不同系统之间的数据传输和共享
劣势
在处理大型或者复杂的模型时,序列化过程可能会出现性能问题(占用更多的memory)
模型文件存储空间比较大
3.2 pickle
pickle 是 Python 的一种序列化和反序列化模块,可以将 Python 对象转换为字节流,也可以将字节流转换为 Python 对象,进而实现 Python 对象的持久化存储和恢复。(模型也是个对象)
调用pickle.dump/dumps即可序列化,pickle.load/loads进行反序列化(其中dump直接将序列化文件保存,二dumps则是返回序列化后的bytes文件,load和loads亦然)
这里可以查看和其他python方法的对比:https://docs.python.org/zh-cn/3/library/pickle.html
以xgb为例
保存:
iris = load_iris()
X = iris.data
y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)with open(f'{save_dir}/xgb_model_pickle.pkl', 'wb') as f:pickle.dump(xgb_model, f)加载:
save_dir = './models'iris = load_iris()
X = iris.data
y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)xgb_test = xgb.DMatrix(X_test, y_test)with open(f'{save_dir}/xgb_model_pickle.pkl', 'rb') as f:xgb_model_pickle = pickle.load(f)
y_pred = xgb_model_pickle.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
print(xgb_acc)优势
模型加载过程同样不需要重新实例化,这点和jsonpickle一样
序列化文件相比于jsonpickle小非常的多,且读取和保存都会更快
劣势
在处理大型或者复杂的对象时,可能会出现性能问题(占用更多的memory)
不是json格式,很难跨平台和语言使用
3.3 模型自带
以xgb为例
保存
iris = load_iris()
X = iris.data
y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)model_path = f'{save_dir}/xgb_model_self.bin' #也可以是json格式,但最终文件大小有区别
xgb_model.save_model(model_path)加载
save_dir = './models'iris = load_iris()
X = iris.data
y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)xgb_test = xgb.DMatrix(X_test, y_test)xgb_model_self = xgb.Booster()
xgb_model_self.load_model(f'{save_dir}/xgb_model_self.bin')
y_pred = xgb_model_self.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
print(xgb_acc)更多文档参考:https://xgboost.readthedocs.io/en/stable/tutorials/saving_model.html
优势
只保存了模型的参数文件(包含树结构和需要模型参数比如 the objective function等), 模型文件较小
序列化过程中的运行内存所占不多
也可以保存json的形式(在XGBoost 1.0.0之后推荐以json的方式保存)
劣势
需要在加载模型之前创建模型的实例。
四、实验
以下主要还是针对较小的模型来做的实验
4.1 模型存储大小对比实验
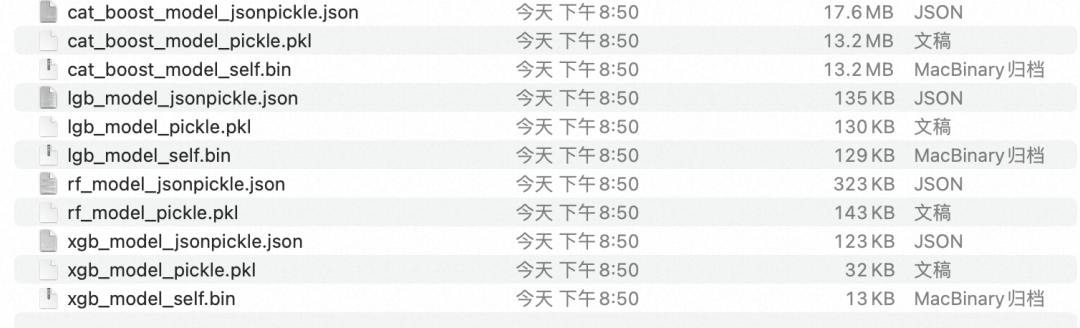
_jsonpickle就是用jsonpickle方法序列化的模型文件
_pickle是用pickle方法序列化的模型文件
_self就是利用自身的save model的方法保存的模型文件
可以看出来是 jsonpickle> pickle > self 的关系
4.2 运行的memory对比实验
通过对序列化前后的memory做监控,例如xgb(只考虑序列化,去掉文件写入所需要的memory):
print("before:", cal_current_memory())
model_path = f'{save_dir}/xgb_model_self.bin'
xgb_model.save_model(model_path)
print("after:", cal_current_memory())运行得到:
before: {'memoryUsed': 0.1490936279296875}
after: {'memoryUsed': 0.14911270141601562}print("before:", cal_current_memory())
pickle.dumps(xgb_model)
print("after:", cal_current_memory())运行得到:
before: {'memoryUsed': 0.1498260498046875}
after: {'memoryUsed': 0.14990234375}print("before:", cal_current_memory())
xgb_str = jsonpickle.encode(xgb_model)
print("after:", cal_current_memory())运行得到:
before: {'memoryUsed': 0.14917755126953125}
after: {'memoryUsed': 0.15140914916992188}可以看出来对于xgb模型,picklejson所需要的memory是其他两种方法的几十倍,而其余两种方法很相似
lgb的结果:
对应上述顺序:
self:
before: {'memoryUsed': 0.14953994750976562}
after {'memoryUsed': 0.14959716796875}
pickle:
before: {'memoryUsed': 0.14938735961914062}
after {'memoryUsed': 0.14946746826171875}
jsonpickle:
before: {'memoryUsed': 0.14945602416992188}
after {'memoryUsed': 0.14974594116210938}这里依然是jsonpickle大一些,但倍数小一些
catboost的结果:
self:
before: {'memoryUsed': 0.24615478515625}
after {'memoryUsed': 0.25492095947265625}
pickle:
before: {'memoryUsed': 0.2300567626953125}
after {'memoryUsed': 0.25820159912109375}
jsonpickle:
before: {'memoryUsed': 0.2452239990234375}
after {'memoryUsed': 0.272674560546875}4.3 序列化时间对比
因为catboost总体模型大小大一些,所以通过catboost才能更好的反应序列化的速度
self:
0.02413797378540039 s
pickle:
0.04681825637817383 s
jsonpickle:
0.3211638927459717 sjsonpickle的花费的时间会多一些
五、 总体代码
训练:
import base64
import json
import os
import pickle
import time
import jsonpickle
import psutil
import xgboost as xgb
from catboost import CatBoostClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_splitimport lightgbm as lgb
from sklearn.ensemble import RandomForestClassifiersave_dir = "./models"def cal_current_memory():# 获取当前进程内存占用。pid = os.getpid()p = psutil.Process(pid)info = p.memory_full_info()memory_used = info.uss / 1024. / 1024. / 1024.return {'memoryUsed': memory_used}iris = load_iris()
X = iris.data
y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
#
# print("before:", cal_current_memory())
# model_path = f'{save_dir}/xgb_model_self.bin'
# xgb_model.save_model(model_path)
# print("after", cal_current_memory())
with open(f'{save_dir}/xgb_model_pickle.pkl', 'wb') as f:pickle.dump(xgb_model, f)
print(cal_current_memory())
xgb_str = jsonpickle.encode(xgb_model)
with open(f'{save_dir}/xgb_model_jsonpickle.json', 'w') as f:f.write(xgb_str)
print(cal_current_memory())# lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt','objective': 'multiclass','num_class': 3,'metric': 'multi_logloss','num_leaves': 31,'learning_rate': 0.05,'feature_fraction': 0.9
}
gbm = lgb.train(params, lgb_train, num_boost_round=100, valid_sets=[lgb_eval], early_stopping_rounds=5)
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
y_pred = [list(x).index(max(x)) for x in y_pred]
lgb_acc = accuracy_score(y_test, y_pred)
#
# print("before:", cal_current_memory())
# model_path = f'{save_dir}/lgb_model_self.bin'
# gbm.save_model(model_path)
# print("after", cal_current_memory())with open(f'{save_dir}/lgb_model_pickle.pkl', 'wb') as f:pickle.dump(gbm, f)lgb_str = jsonpickle.encode(gbm)
with open(f'{save_dir}/lgb_model_jsonpickle.json', 'w') as f:f.write(lgb_str)# rf
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
rf_acc = accuracy_score(y_test, y_pred)with open(f'{save_dir}/rf_model_pickle.pkl', 'wb') as f:pickle.dump(rf, f)rf_str = jsonpickle.encode(rf)
with open(f'{save_dir}/rf_model_jsonpickle.json', 'w') as f:f.write(rf_str)# catboost
cat_boost_model = CatBoostClassifier(depth=9, learning_rate=0.01,loss_function='MultiClass', custom_metric=['AUC'],eval_metric='MultiClass', random_seed=1996)cat_boost_model.fit(X_train, y_train, eval_set=(X_test, y_test), use_best_model=True, early_stopping_rounds=1000)
y_pred = cat_boost_model.predict(X_test)
cat_acc = accuracy_score(y_test, y_pred)# t = time.time()
# model_path = f'{save_dir}/cat_boost_model_self.bin'
# cat_boost_model.save_model(model_path)
# print("after", time.time() - t)# print("before:", cal_current_memory())
# model_path = f'{save_dir}/cat_boost_model_self.bin'
# cat_boost_model.save_model(model_path)
# print("after", cal_current_memory())
with open(f'{save_dir}/cat_boost_model_pickle.pkl', 'wb') as f:pickle.dump(cat_boost_model, f)cat_boost_model_str = jsonpickle.encode(cat_boost_model)
with open(f'{save_dir}/cat_boost_model_jsonpickle.json', 'w') as f:f.write(cat_boost_model_str)print(xgb_acc, lgb_acc, rf_acc, cat_acc)测试
import pickleimport jsonpickle
import psutil
import xgboost as xgb
from catboost import CatBoostClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifiersave_dir = './models'iris = load_iris()
X = iris.data
y = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)xgb_test = xgb.DMatrix(X_test, y_test)xgb_model_self = xgb.Booster()
xgb_model_self.load_model(f'{save_dir}/xgb_model_self.bin')
y_pred = xgb_model_self.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
print(xgb_acc)# with open(f'{save_dir}/xgb_model_pickle.pkl', 'rb') as f:
# xgb_model_pickle = pickle.load(f)
# y_pred = xgb_model_pickle.predict(xgb_test)
# xgb_acc = accuracy_score(y_test, y_pred)
# print(xgb_acc)#
# with open(f'{save_dir}/xgb_model_jsonpickle.json', 'r') as f:
# xgb_model_jsonpickle = f.read()
# xgb_model_jsonpickle = jsonpickle.decode(xgb_model_jsonpickle)
# y_pred = xgb_model_jsonpickle.predict(xgb_test)
# xgb_acc = accuracy_score(y_test, y_pred)
# print(xgb_acc)ps:这里给出所有的代码,代码不多,但都写在一起了,比较粗糙,每个实验要记得把其他的对应代码注释掉。
六、总结
以上实验都是几次实验运行的结果的平均,如果想更有说服力,可以更多次实验取平均值来参考,整体的结果基本上没有差异。(还可以从更大的模型入手来讨论)
1. 对于图省事,并且想跨平台语言的话可以选择picklejson,但一定要有一定的memory预估,如果模型比较复杂比较大(可能一个模型class包含多种其他模型的对象),会占用非常大的memory,且模型文件也会非常大,但不需要对于每个单独的子模型做序列化,直接decode即可。
2. 对于要求省空间且运行内存的话,可以选择模型自身的保存方式(主要只保存模型参数文件),但对于这种方式,可能需要在模型的总class去实现序列化和反序列化方法(子模型都要实现,且每个都调用该模型的savemodel和loadmodel方法)
3. python下不考虑跨平台语言序列化和反序列可以直接考虑pickle的序列化方式,也比较省事。
推荐阅读:我的2022届互联网校招分享我的2021总结浅谈算法岗和开发岗的区别互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!公众号:AI蜗牛车保持谦逊、保持自律、保持进步发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记发送【AI四大名著】获取四本经典AI电子书相关文章:
讨论和总结 树模型 的三种序列化 方式的区别(模型存储大小、序列化所用内存、序列化速度)...
一、前言 本文总结常用树模型: rf,xgboost,catboost和lightgbm等模型的保存和加载(序列化和反序列化)的多种方式,并对多种方式从运行内存的使用和存储大小做对比 二、模型 2.1 安装环境 pip install xgboos…...

Halcon中的一些3D算子
一、记录一些Halcon里的关于3D的算子 1.read_object_model_3d 从文件读取一个3d模型 如下图,读的一个ply文件出来是个3d点云模型 2.visualize_object_model_3d 交互式展示3d模型 即上个算子读出来后,通过这个算子可以把3d模型显示出来旋转、平移&am…...

Android:Selector + Layer-lists 实现 AppCompatCheckBox
最近做项目涉及到一些UI相关的东东,虽然比较简单,但是也很有趣,写两篇简短的博客记录一下。 一."Selector 两张图片"实现 AppCompatCheckBox AppCompatCheckBox 是 androidx的一个widget:androidx.appcompat.widget.…...

TreeMap类型添加数据
package com.test.Test11;import java.util.*;public class Test02 {public static void main(String[] args) {/** 增加:put(K key,V value)* 删除:clear() remove(Object key)* 修改:* 查看:entrySet() get(Object key) keySet(…...
iOS 16 UI 设计系统免费在线使用方法
1、iOS 16 UI 设计系统中有什么? iOS 16 UI 设计系统通常包含以下组件和元素: 1. 按钮:包括操作按钮、图标按钮、导航按钮、滚动按钮、切换按钮、单选按钮、复选框按钮、呼叫按钮等各种类型的按钮。 2. 窗口和 UI 控件:包括标签…...
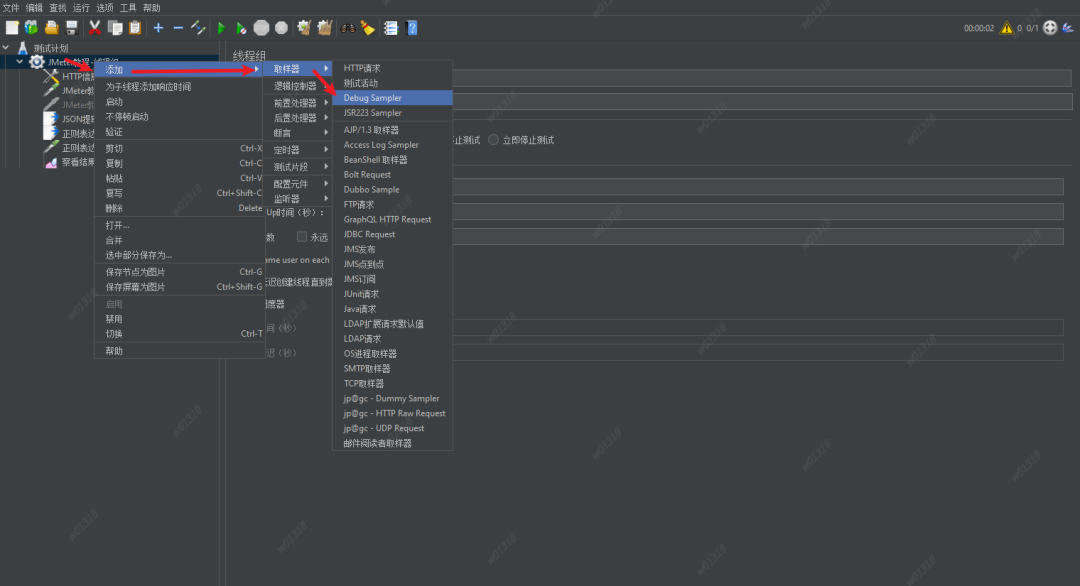
【接口测试】JMeter接口关联测试
1 前言 我们来学习接口管理测试,这就要使用到JMeter提供的JSON提取器和正则表达式提取器了,下面我们来看看是如何使用的吧。 2 JSON提取器 1、添加JSON提取器 在线程组右键 > 添加 > 后置处理器 > JSON提取器 2、JSON提取器参数说明 N…...
腾讯云服务器ping不通解决方法(公网IP/安全组/系统多维度)
腾讯云服务器ping不通什么原因?ping不通公网IP地址还是域名?新手站长从云服务器公网IP、安全组、Linux系统和Windows操作系统多方面来详细说明腾讯云服务器ping不通的解决方法: 目录 腾讯云服务器ping不通原因分析及解决方法 安全组ICMP协…...

【C++/嵌入式笔试面试八股】一、32.封装
封装 08.C++中struct和class的区别🍊 相同点 两者都拥有成员函数、公有和私有部分任何可以使用class完成的工作,同样可以使用struct完成不同点 两者中如果不对成员不指定公私有,struct默认是公有的,class则默认是私有的class默认是private继承, 而struct默认是public继…...
【算法】Transform to Chessboard 变为棋盘
文章目录 Transform to Chessboard 变为棋盘问题描述:分析代码 Transform to Chessboard 变为棋盘 问题描述: 一个 n x n 的二维网络 board 仅由 0 和 1 组成 。每次移动,你能任意交换两列或是两行的位置。 返回 将这个矩阵变为 棋盘 所需…...

vue通过封装$on定义全局事件
我们先在vue项目的src跟目录下创建一个文件夹 叫 utils 下面创建一个js文件夹 叫 bus.js 参考代码如下 import Vue from "vue"; export default new Vue();然后 我们就可以来用了 在需要定义事件的组件中编写 <template><div><h1>Hello world!&…...

资产管理规范
生产系统资产管理规范 1. 引言 生产系统的资产管理是确保生产系统正常运行和提高生产效率的关键因素之一。本文档旨在制定一套规范,以确保生产系统中的资产,包括服务器和软件等,得到有效管理和保护。 2. 资产分类 生产系统资产可根据其性质…...
已解决:如何从别人的仓库那里克隆到自己的仓库,并修改代码并提交。
一、场景 拉取项目代码后,如果要共同开发一个项目的自动化代码,此时需要把自己写的代码部分提交到代码仓库。 可以用pycharm把修改的代码push到代码仓库 二、操作方法 1.从别人的仓库那里点击fork,将仓库克隆到自己的仓库。 2.在pychar…...
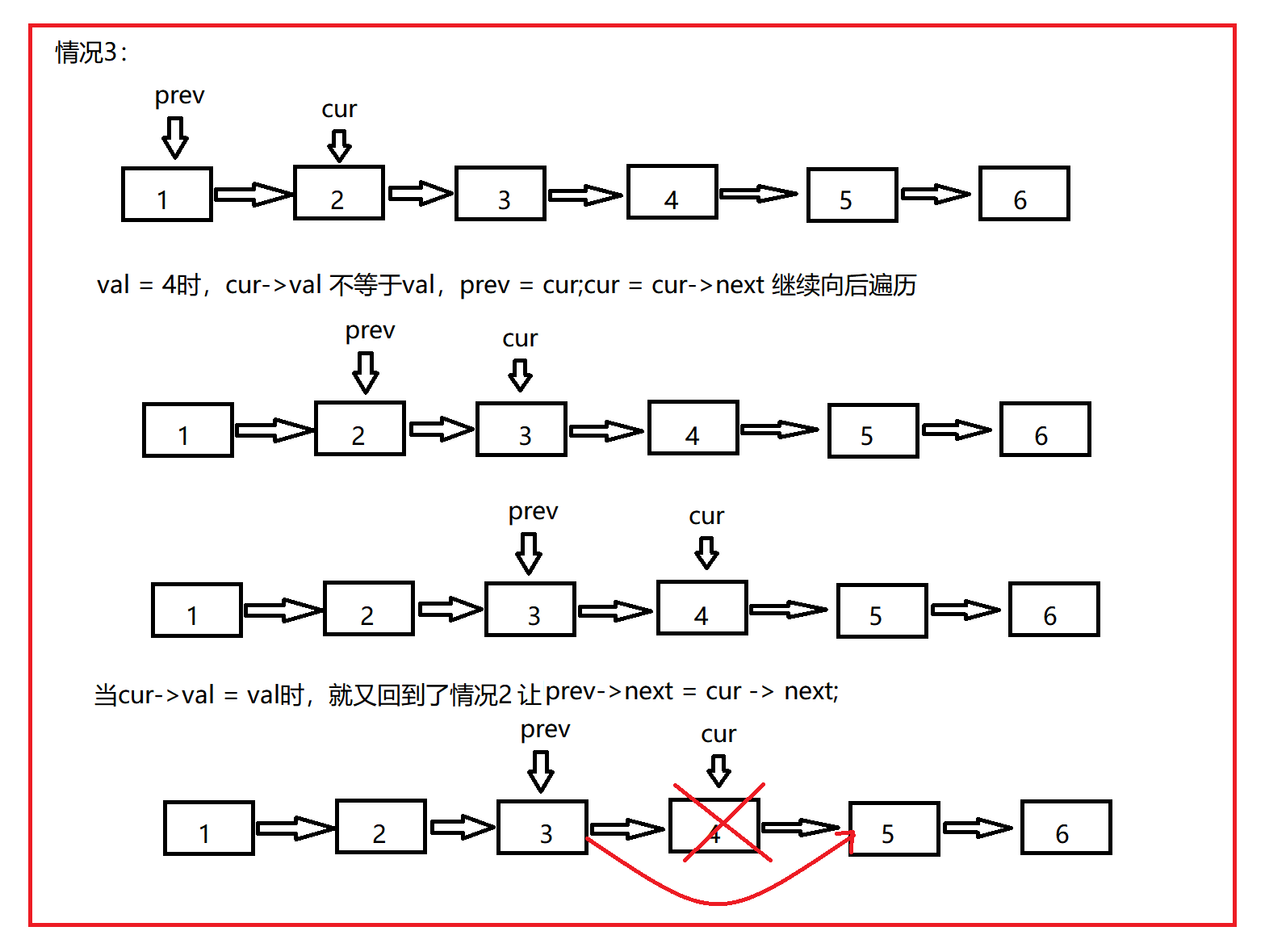
剑指 Offer 18. 删除链表的节点
🚀 作者简介:一名在后端领域学习,并渴望能够学有所成的追梦人。 🚁 个人主页:不 良 🔥 系列专栏:🛸剑指 Offer 📕 学习格言:博观而约取,厚积而薄…...

WiFi 6 vs WiFi 5
在现代无线通信领域,WiFi已经成为人们日常生活中不可或缺的一部分。随着技术的不断发展,WiFi标准也在不断更新和演进。WiFi 6(802.11ax)和WiFi 5(802.11ac)是当前两个主要的WiFi标准。 本文将详细介绍WiFi …...

PHP语言基础
一.标记风格 标记风格分为四类(推荐XML) 1.XML风格 <?php echo这是xml风格‘; ?> 注意:结束标识符必须单独另起一行,并且不能有空格。在标识符前后有其他符号或者字符也会发生错误。 2.脚本风格 <script languagephp> …...

怎么用Excel VBA写一个excel批量合并的程序?
您可以按照以下VBA代码来实现把同一路径上的所有工作簿合并到同一个工作簿中: VBA Option Explicit Sub MergeWorkbooks() Dim path As String, fileName As String, sheet As Worksheet Dim targetWorkbook As Workbook, sourceWorkbook As Workbook Dim workshe…...

WuThreat身份安全云-TVD每日漏洞情报-2023-05-22
漏洞名称:Apple WebKit 任意代码执行漏洞 漏洞级别:中危 漏洞编号:CVE-2023-32373 相关涉及:Apple iOS和iPadOS 16.4.1 漏洞状态:在野 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-12579 漏洞名称:海康威视部分iVMS系统存在文件上传漏洞 漏洞级别:未定义…...
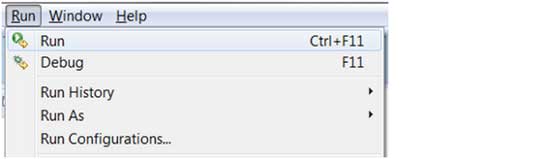
Eclipse教程 Ⅵ
今天分享Eclipse Java 构建路径、Eclipse 运行配置(Run Configuration)和Eclipse 运行程序 Eclipse Java 构建路径 设置 Java 构建路径 Java构建路径用于在编译Java项目时找到依赖的类,包括以下几项: 源码包项目相关的 jar 包及类文件项目引用的的类…...
Seaborn.load_dataset()加载数据集失败最佳解决方法
load_dataset() 是 Seaborn 库中提供的一个函数,用于加载一些原始数据集。这些数据集包含了许多经典的数据集,比如鸢尾花数据集、小费数据集等,这些数据集在数据可视化和机器学习中非常常见。 使用 load_dataset() 函数可以方便地获取这些数…...
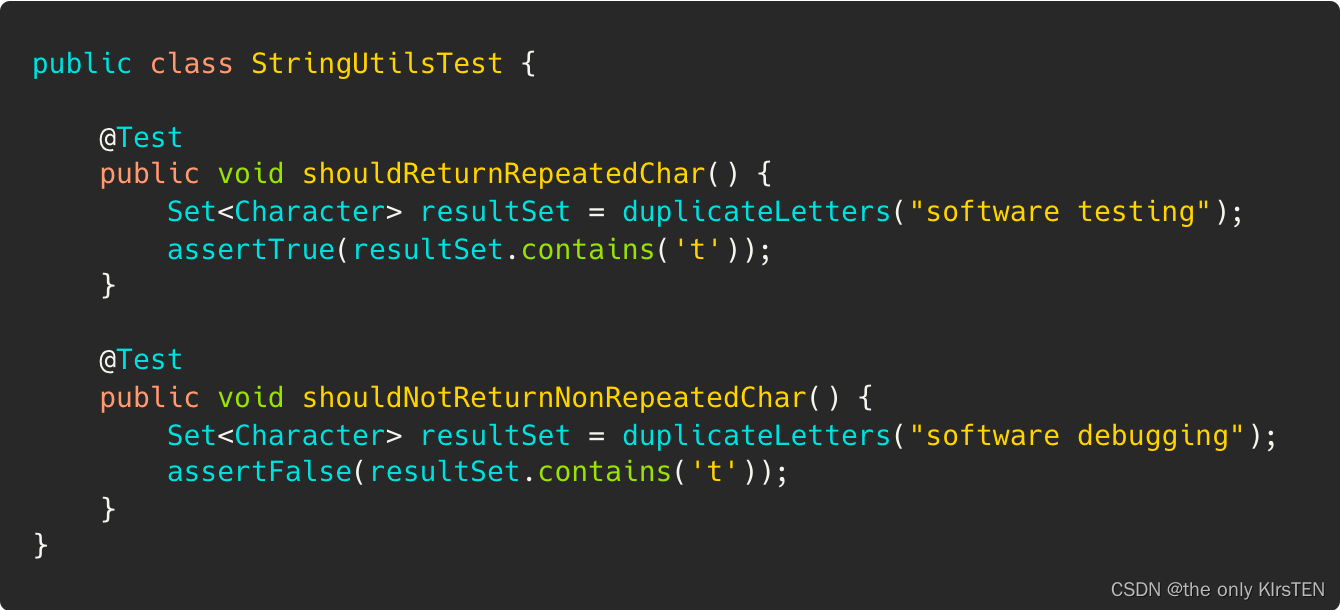
java 区分缺陷Defects/感染Infections/失败Failure
java 区分缺陷Defects/感染Infections/失败Failure 缺陷Defects 软件故障总是从代码中一个或多个缺陷的执行开始。 缺陷只是一段有缺陷、不正确的代码。 缺陷可能是程序语句的一部分或完整部分,也可能对应于不存在但应该存在的语句。 尽管程序员要对代码中的缺陷负…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...
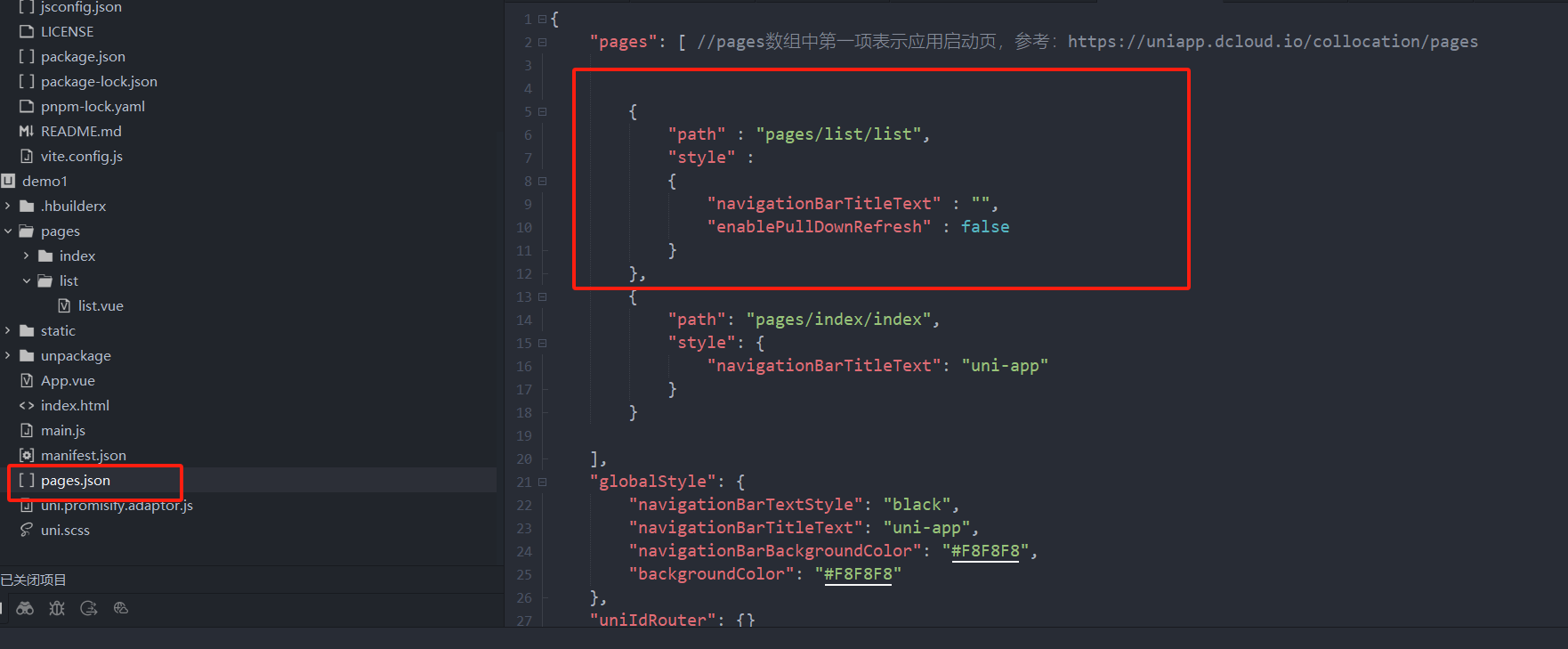
uniapp 小程序 学习(一)
利用Hbuilder 创建项目 运行到内置浏览器看效果 下载微信小程序 安装到Hbuilder 下载地址 :开发者工具默认安装 设置服务端口号 在Hbuilder中设置微信小程序 配置 找到运行设置,将微信开发者工具放入到Hbuilder中, 打开后出现 如下 bug 解…...