MySQL的一些介绍
1. SQL的select语句完整的执行顺序
SQL Select语句完整的执行顺序:
1、from子句组装来自不同数据源的数据;
2、where子句基于指定的条件对记录行进行筛选;
3、group by子句将数据划分为多个分组;
4、使用聚集函数进行计算;
5、使用having子句筛选分组;
6、计算所有的表达式;
7、select 的字段;
8、使用order by对结果集进行排序。
SQL 语言不同于其他编程语言的最明显特征是处理代码的顺序。在大多数据库语言中,代码按编码顺序被处理。但在 SQL 语句中,第一个被处理的子句式 FROM,而不是第一出现的 SELECT。SQL 查询处理的步骤序号: (1) FROM <left_table>
(2) <join_type> JOIN <right_table>
(3) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) WITH {CUBE | ROLLUP}
(7) HAVING <having_condition>
(8) SELECT
(9) DISTINCT
(9) ORDER BY <order_by_list>
(10) <TOP_specification> <select_list>
以上每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只有最后一步生成的表才会会给调用者。如果没有在查询中指定某一个子句,将跳过相应的步骤。
逻辑查询处理阶段简介:
1、 FROM:对FROM子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表VT1。
2、 ON:对VT1应用ON筛选器,只有那些使为真才被插入到TV2。
3、 OUTER (JOIN):如果指定了OUTER JOIN(相对于CROSS JOIN或INNER JOIN),保留表中未找到匹配的行将作为外部行添加到VT2,生成TV3。如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,直到处理完所有的表位置。
4、 WHERE:对TV3应用WHERE筛选器,只有使为true的行才插入TV4。
5、 GROUP BY:按GROUP BY子句中的列列表对TV4中的行进行分组,生成TV5。
6、 CUTE|ROLLUP:把超组插入VT5,生成VT6。
7、 HAVING:对VT6应用HAVING筛选器,只有使为true的组插入到VT7。
8、 SELECT:处理SELECT列表,产生VT8。
9、 DISTINCT:将重复的行从VT8中删除,产品VT9。
10、 ORDER BY:将VT9中的行按ORDER BY子句中的列列表顺序,生成一个游标(VC10)。 11、 TOP:从VC10的开始处选择指定数量或比例的行,生成表TV11,并返回给调用者。
where子句中的条件书写顺序
2. SQL之聚合函数
聚合函数是对一组值进行计算并返回单一的值的函数,它经常与select语句中的group by子句一同使用。
a. avg():返回的是指定组中的平均值,空值被忽略。
b. count():返回的是指定组中的项目个数。
c. max():返回指定数据中的最大值。
d. min():返回指定数据中的最小值。
e. sum():返回指定数据的和,只能用于数字列,空值忽略。
f. group by():对数据进行分组,对执行完group by之后的组进行聚合函数的运算,计算每一组的值。最后用having去掉不符合条件的组,having子句中的每一个元素必须出现在select列表中(只针对于mysql)。
3. SQL之连接查询(左连接和右连接的区别)
外连接:
左连接(左外连接):以左表作为基准进行查询,左表数据会全部显示出来,右表如果和左表匹配的数据则显示相应字段的数据,如果不匹配则显示为null。
右连接(右外连接):以右表作为基准进行查询,右表数据会全部显示出来,左表如果和右表匹配的数据则显示相应字段的数据,如果不匹配则显示为null。
全连接:先以左表进行左外连接,再以右表进行右外连接。
内连接:
显示表之间有连接匹配的所有行。
4. SQL之sql注入
通过在Web表单中输入(恶意)SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句。举例:当执行的sql为 select * from user where username = “admin” or “a”=“a”时,sql语句恒成立,参数admin毫无意义。
防止sql注入的方式:
1. 预编译语句:如,select * from user where username = ?,sql语句语义不会发生改变,sql语句中变量用?表示,即使传递参数时为“admin or ‘a’= ‘a’”,也会把这整体当做一个字符创去查询。
2. Mybatis框架中的mapper方式中的 # 也能很大程度的防止sql注入($无法防止sql注入)。
5. Mysql性能优化
1、当只要一行数据时使用limit 1
查询时如果已知会得到一条数据,这种情况下加上limit 1 会增加性能。因为mysql数据库引擎会在找到一条结果停止搜索,而不是继续查询下一条是否符合标准直到所有记录查询完毕。
2、选择正确的数据库引擎
Mysql中有两个引擎MyISAM和InnoDB,每个引擎有利有弊。
MyISAM 适用于一些大量查询的应用,但对于有大量写功能的应用不是很好。甚至你只需要update一个字段整个表都会被锁起来。而别的进程就算是读操作也不行要等到当前update操作完成之后才能继续进行。另外,MyISAM对于select count(*)这类操作是超级快的。
InnoDB的趋势会是一个非常复杂的存储引擎,对于一些小的应用会比MyISAM还慢,但是支持“行锁”,所以在写操作比较多的时候会比较优秀。并且,它支持很多的高级应用,例如:事物。
3. 用not exists代替not in
Not exists用到了连接能够发挥已经建立好的索引的作用,not in不能使用索引。Not in是最 慢的方式要同每条记录比较,在数据量比较大的操作红不建议使用这种方式。
4. 对操作符的优化,尽量不采用不利于索引的操作符
如:in not in is null is not null <> 等
某个字段总要拿来搜索,为其建立索引:
Mysql 中可以利用 alter table 语句来为表中的字段添加索引,语法为:alter table 表明 add index (字段名);
6. 必看sql面试题(学生表_课程表_成绩表_教师表)
7. Mysql数据库架构图
MyISAM和InnoDB是最常见的两种存储引擎,特点如下。
MyISAM存储引擎
MyISAM 是MySQL官方提供默认的存储引擎,其特点是不支持事务、表锁和全文索引,对于一些 OLAP(联机分析处理)系统,操作速度快。
每个MyISAM在磁盘上存储成三个文件。文件名都和表名相同,扩展名分别是.frm(存储表定义)、.MYD (MYData,存储数据)、.MYI (MYIndex,存储索引)。这里特别要注意的是MyISAM不缓存数据文件,只缓存索引文件。
InnoDB存储引擎
InnoDB 存储引擎支持事务,主要面向 OLTP(联机事务处理过程)方面的应用,其特点是行锁设置、支持外键,并支持类似于Oracle的非锁定读,即默认情况下读不产生锁。InnoDB将数据放在一个逻辑表空间中(类似Oracle)。InnoDB通过多版本并发控制来获得高并发性,实现了ANSI标准的4种隔离级别,默认为Repeatable,使用一种被称为next-key locking的策略避免幻读。
对于表中数据的存储,InnoDB采用类似Oracle索引组织表Clustered的方式进行存储。
InnoDB 存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比Myisam的存储引擎,InnoDB 写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
InnoDB体系架构
8. Mysql架构器中各个模块都是什么?
(1)、连接管理与安全验证是什么?
每个客户端都会建立一个与服务器连接的线程,服务器会有一个线程池来管理这些 连接;如果客户端需要连接到MYSQL数据库还需要进行验证,包括用户名、密码、 主机信息等。
(2)、解析器是什么?
解析器的作用主要是分析查询语句,最终生成解析树;首先解析器会对查询语句的语法进行分析,分析语法是否有问题。还有解析器会查询缓存,如果在缓存中有对应的语句,就返回查询结果不进行接下来的优化执行操作。前提是缓存中的数据没有被修改,当然如果被修改了也会被清出缓存。
(3)、优化器怎么用?
优化器的作用主要是对查询语句进行优化操作,包括选择合适的索引,数据的读取方式,包括获取查询的开销信息,统计信息等,这也是为什么图中会有优化器指向存储引擎的箭头。之前在别的文章没有看到优化器跟存储引擎之间的关系,在这里我个人的理解是因为优化器需要通过存储引擎获取查询的大致数据和统计信息。 (4)、执行器是什么?
执行器包括执行查询语句,返回查询结果,生成执行计划包括与存储引擎的一些处理操作。
9. Mysql存储引擎有哪些?
(1)、InnoDB存储引擎
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,InnoDB是默认的MySQL引擎。
(2)、MyISAM存储引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物。
(3)、MEMORY存储引擎
MEMORY存储引擎将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问。
(4)、NDB存储引擎
DB 存储引擎是一个集群存储引擎,类似于Oracle的RAC,但它是Share Nothing 的架构,因此能提供更高级别的高可用性和可扩展性。NDB的特点是数据全部放在内存中,因此通过主键查找非常快。
关于 NDB,有一个问题需要注意,它的连接(join)操作是在 MySQL 数据库层完成,不是在存储引擎层完成,这意味着,复杂的join操作需要巨大的网络开销,查询速度会很慢。
(5)、Memory (Heap) 存储引擎
Memory 存储引擎(之前称为 Heap)将表中数据存放在内存中,如果数据库重启或崩溃,数据丢失,因此它非常适合存储临时数据。
(6)、Archive存储引擎
正如其名称所示,Archive非常适合存储归档数据,如日志信息。它只支持INSERT和SELECT操作,其设计的主要目的是提供高速的插入和压缩功能。
(7)、Federated存储引擎
Federated存储引擎不存放数据,它至少指向一台远程MySQL数据库服务器上的表,非常类似于Oracle的透明网关。
(8)、Maria存储引擎
Maria存储引擎是新开发的引擎,其设计目标是用来取代原有的MyISAM存储引擎,从而成为MySQL默认的存储引擎。
上述引擎中,InnoDB 是事务安全的存储引擎,设计上借鉴了很多 Oracle 的架构思想,一般而言,在OLTP应用中,InnoDB应该作为核心应用表的首先存储引擎。InnoDB是由第三方的Innobase Oy公司开发,现已被Oracle收购,创始人是Heikki Tuuri,芬兰赫尔辛基人,和著名的Linux创始人Linus是校友。
10. MySQL事务介绍
MySQL和其它的数据库产品有一个很大的不同就是事务由存储引擎所决定,例如MYISAM,MEMORY,ARCHIVE都不支持事务,事务就是为了解决一组查询要么全部执行成功,要么全部执行失败。
MySQL事务默认是采取自动提交的模式,除非显示开始一个事务。
SHOW VARIABLES LIKE 'AUTOCOMMIT';
修改自动提交模式,0=OFF,1=ON
注意:修改自动提交对非事务类型的表是无效的,因为它们本身就没有提交和回滚的概念,还有一些命令是会强制自动提交的,比如DLL命令、lock tables等。
SET AUTOCOMMIT=OFF或 SET AUTOCOMMIT=0
10.1 事务的四大特征是什么?
数据库事务transanction正确执行的四个基本要素。ACID,原子性(Atomicity)、一致性(Correspondence)、隔离性(Isolation)、持久性(Durability)。
(1)原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
(2)一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
(3)隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行 相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆, 必须串行化或序列化请 求,使得在同一时间仅有一个请求用于同一数据。
(4)持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
10.2 Mysql中四种隔离级别分别是什么?
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| Read uncommitted(读未提交) | 是 | 是 | 是 |
| Read committed(读已提交) | 否 | 是 | 是 |
| Repeatable read(可重复读) | 否 | 否 | 是 |
| Serializable(串行读) | 否 | 否 | 否 |
读未提交(READ UNCOMMITTED):未提交读隔离级别也叫读脏,就是事务可以读取其它事务未提交的数据。
读已提交(READ COMMITTED):在其它数据库系统比如SQL Server默认的隔离级别就是提交读,已提交读隔离级别就是在事务未提交之前所做的修改其它事务是不可见的。
可重复读(REPEATABLE READ):保证同一个事务中的多次相同的查询的结果是一致的,比如一个事务一开始查询了一条记录然后过了几秒钟又执行了相同的查询,保证两次查询的结果是相同的,可重复读也是mysql的默认隔离级别。
可串行化(SERIALIZABLE):可串行化就是保证读取的范围内没有新的数据插入,比如事务第一次查询得到某个范围的数据,第二次查询也同样得到了相同范围的数据,中间没有新的数据插入到该范围中。
11. MySQL怎么创建存储过程(2017-11-25-wzz)
MySQL 存储过程是从 MySQL5.0 开始增加的新功能。存储过程的优点有一箩筐。不过最主要的还是执行效率和SQL 代码封装。特别是 SQL 代码封装功能,如果没有存储过程,在外部程序访问数据库时,要组织很多 SQL 语句。特别是业务逻辑复杂的时候,一大堆的 SQL 和条件夹杂在代码中,让人不寒而栗。现在有了 MySQL 存储过程,业务逻辑可以封装存储过程中,这样不仅容易维护,而且执行效率也高。
一、创建MySQL存储过程
下面代码创建了一个叫pr_add 的MySQL 存储过程,这个MySQL 存储过程有两个int 类型的输入参数 “a”、“b”,返回这两个参数的和。
1)drop procedure if exists pr_add; (备注:如果存在pr_add的存储过程,则先删掉) 2)计算两个数之和(备注:实现计算两个整数之和的功能)
create procedure pr_add ( a int, b int ) begin declare c int;
if a is null then set a = 0;
end if;
if b is null then set b = 0;
end if;
set c = a + b;
select c as sum;
二、调用 MySQL 存储过程
call pr_add(10, 20);
12. MySQL触发器怎么写?(2017-11-25-wzz)
MySQL包含对触发器的支持。触发器是一种与表操作有关的数据库对象,当触发器所在表上出现指定事件时,将调用该对象,即表的操作事件触发表上的触发器的执行。
在MySQL中,创建触发器语法如下:
CREATE TRIGGER trigger_name
trigger_time
trigger_event ON tbl_name
FOR EACH ROW
trigger_stmt
其中:
trigger_name:标识触发器名称,用户自行指定;
trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句。
由此可见,可以建立6种触发器,即:BEFORE INSERT、BEFORE UPDATE、BEFORE DELETE、AFTER INSERT、AFTER UPDATE、AFTER DELETE。
另外有一个限制是不能同时在一个表上建立2个相同类型的触发器,因此在一个表上最多建立6个触发器。
假设系统中有两个表:
1)班级表 class(班级号 classID, 班内学生数 stuCount)
2)学生表 student(学号 stuID, 所属班级号 classID)
要创建触发器来使班级表中的班内学生数随着学生的添加自动更新,代码如下:
create trigger tri_stuInsert after insert
on student for each row
begin
declare c int;
set c = (select stuCount from class where classID=new.classID);
update class set stuCount = c + 1 where classID = new.classID;
查看触发器:
和查看数据库(show databases;)查看表格(show tables;)一样,查看触发器的语法如下:
SHOW TRIGGERS [FROM schema_name];
其中,schema_name 即 Schema 的名称,在 MySQL 中 Schema 和 Database 是一样的,也就是说,可以指定数据库名,这样就不必先“USE database_name;”了。
删除触发器:
和删除数据库、删除表格一样,删除触发器的语法如下:
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name
13. MySQL语句优化(2017-11-26-wzz)
13.1 where 子句中可以对字段进行null值判断吗?
可以,比如select id from t where num is null 这样的sql也是可以的。但是最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库。不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了,不管是否插入值(NULL也包含在内),都是占用100个字符的空间的,如果是varchar 这样的变长字段,null不占用空间。可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num = 0。
13.2 select * from admin left join log on admin.admin_id = log.admin_id where log.admin_id>10如何优化?
优化为: select * from (select * from admin where admin_id>10) T1 lef join log on T1.admin_id = log.admin_id。
使用JOIN 时候,应该用小的结果驱动大的结果(left join 左边表结果尽量小如果有条件应该放到左边先处理,right join 同理反向),同时尽量把牵涉到多表联合的查询拆分多个query(多个连表查询效率低,容易到之后锁表和阻塞)。
13.3 limit 的基数比较大时使用between
例如:select * from admin order by admin_id limit 100000,10
优化为:select * from admin where admin_id between 100000 and 100010 order by admin_id。
13.4 尽量避免在列上做运算,这样导致索引失效
例如:select * from admin where year(admin_time)>2014
优化为: select * from admin where admin_time> '2014-01-01′
14. MySQL中文乱码问题完美解决方案(2017-12-07-lwl)
解决乱码的核心思想是统一编码。我们在使用 MySQL 建数据库和建表时应尽量使用统一的编码,强烈推荐的是utf8编码,因为该编码几乎可以兼容世界上所有的字符。
数据库在安装的时候可以设置默认编码,在安装时就一定要设置为utf8编码。设置之后再创建的数据库和表如果不指定编码,默认都会使用utf8编码,省去了很多麻烦。
数据库软件安装好之后可以通过如下命令查看默认编码:
1、查询数据库软件使用的默认编码格式
show variables like “%colla%”;
show varables like “%char%”
其中collation,代表了字符串排序(比较)的规则,如果值是utf8_general_ci,代表使用utf8字符集大小写不敏感的自然方式比较。
如果character_set的值不为utf8,那么可以使用如下命令修改为utf8。
2、修改数据库默认编码为utf8
SET character_set_client='utf8';
SET character_set_connection='utf8';
SET character_set_results='utf8';
如果不想设置数据库软件的全局默认编码,也可以单独修改或者设置某个具体数据库的编码也可以单独修改或设置某个数据库中某个表的编码。
3、创建数据库的时候指定使用utf8编码
CREATE DATABASE `test`
CHARACTER SET 'utf8'
COLLATE 'utf8_general_ci';
4、创建表的时候指定使用utf8编码
CREATE TABLE `database_user` (
`ID` varchar(40) NOT NULL default '',
`UserID` varchar(40) NOT NULL default '',
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
如果数据库已经创建好了,可以使用show database 数据库名;和 show create table 表名;查看一下数据库和表的字符集是否为utf8 ,如果不是则在命令行下面可以用如下命令,将数据库和表编码修改为utf8.
5、修改具体某数据库或表的编码
ALTER DATABASE `db_name` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLE `tb_name` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
15. 如何提高MySQL的安全性(2017-12-8-lwl)
1.如果 MySQL 客户端和服务器端的连接需要跨越并通过不可信任的网络,那么需要使用 ssh 隧道来加密该连接的通信。
2.使用 set password 语句来修改用户的密码,先“mysql -u root”登陆数据库系统,然后“mysql> update mysql.user set password=password(’newpwd’)”,最后执行“flush privileges”。
3.MySQL需要提防的攻击有,防偷听、篡改、回放、拒绝服务等,不涉及可用性和容错方面。对所有的连接、查询、其他操作使用基于ACL(ACL(访问控制列表)是一种路由器配置和控制网络访问的一种有力的工具,它可控制路由器应该允许或拒绝数据包通过,可监控流量,可自上向下检查网络的安全性,可检查和过滤数据和限制不必要的路由更新,因此让网络资源节约成本的 ACL 配置技术在生活中越来越广泛应用。)即访问控制列表的安全措施来完成。
4.设置除了root用户外的其他任何用户不允许访问mysql主数据库中的user表; 5.使用grant和revoke语句来进行用户访问控制的工作;
6.不要使用明文密码,而是使用md5()和sha1()等单向的哈系函数来设置密码;
7.不要选用字典中的字来做密码;
8.采用防火墙可以去掉 50%的外部危险,让数据库系统躲在防火墙后面工作,或放置在 DMZ(DMZ 是英文“demilitarized zone”的缩写,隔离区,它是为了解决安装防火墙后外部网络的访问用户不能访问内部网络服务器的问题,而设立的一个非安全系统与安全系统之间的缓冲区。)区域中;
9.从因特网上用nmap来扫描3306端口,也可用telnet server_host 3306的方法测试,不允许从非信任网络中访问数据库服务器的3306号tcp端口,需要在防火墙或路由器上做设定;
10.服务端要对SQL进行预编译,避免SQL注入攻击,例如where id=234,别人却输入where id=234 or 1=1。
11.在传递数据给mysql时检查一下大小;
12.应用程序连接到数据库时应该使用一般的用户帐号,开放少数必要的权限给该用户;
13.学会使用tcpdump和strings工具来查看传输数据的安全性,例如tcpdump -l -i eth0 -w -src or dst port
3306 strings。以普通用户来启动mysql数据库服务;
14.确信在mysql目录中只有启动数据库服务的用户才可以对文件有读和写的权限;
15.不许将 process 或 super 权限付给非管理用户,该 mysqladmin processlist 可以列举出当前执行的查询文本;super权限可用于切断客户端连接、改变服务器运行参数状态、控制拷贝复制数据库的服务器;
16.如果不相信dns服务公司的服务,可以在主机名称允许表中只设置ip数字地址;
17.使用max_user_connections变量来使mysqld服务进程,对一个指定帐户限定连接数;
18.grant语句也支持资源控制选项;
19.启动 mysqld 服务进程的安全选项开关,–local-infile=0 或 1,若是 0 则客户端程序就无法使用 local load data了,赋权的一个例子grant insert(user) on mysql.user to ‘user_name’@'host_name’;若使用–skip-grant-tables系统将对任何用户的访问不做任何访问控制,但可以用 mysqladmin flush-privileges或mysqladmin reload来开启访问控制;默认情况是show databases语句对所有用户开放,可以用–skip-show-databases来关闭掉。
23.碰到error 1045(28000) access denied for user ‘root’@'localhost’ (using password:no)错误时,你需要重新设置密码,具体方法是:先用–skip-grant-tables 参数启动 mysqld,然后执行 mysql -u root mysql,mysql>update user set password=password(’newpassword’) where user=’root’;mysql>flush privileges;,最后重新启动mysql就可以了。
相关文章:

MySQL的一些介绍
1. SQL的select语句完整的执行顺序 SQL Select语句完整的执行顺序: 1、from子句组装来自不同数据源的数据; 2、where子句基于指定的条件对记录行进行筛选; 3、group by子句将数据划分为多个分组; 4、使用聚集函数进行计算&am…...

unity发布webGL后无法预览解决
众所周知,unity发布成webgl后是无法直接预览的。因为一般来说浏览器默认都是禁止webgl运行的。 直接说我最后的解决方法:去vscode里下载一个live server ,安装好。 下载vscode地址Visual Studio Code - Code Editing. Redefined 期间试过几种方法都不管…...
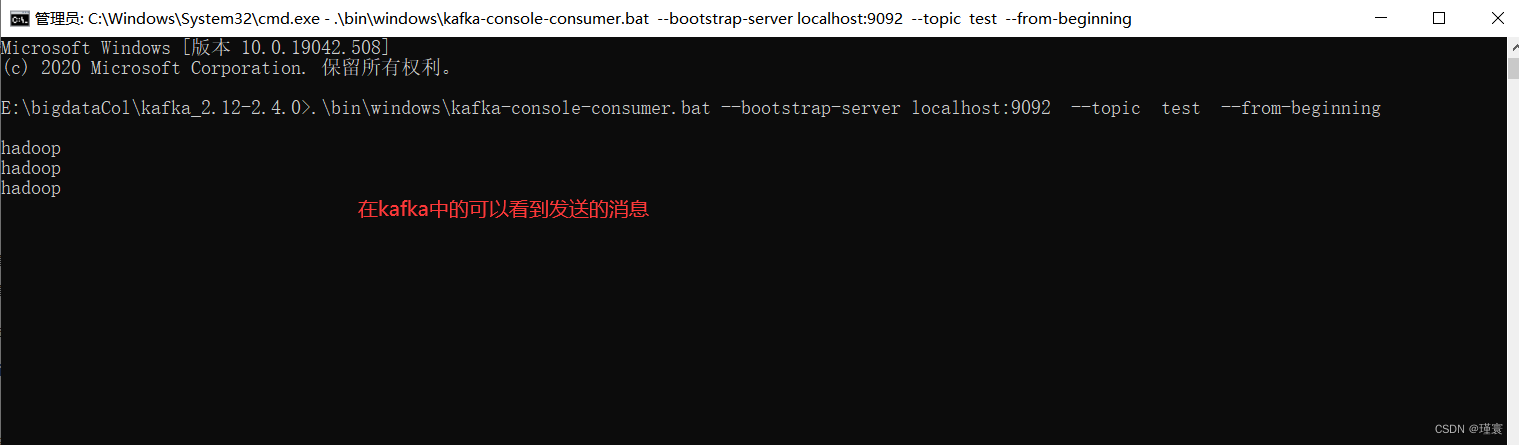
Flume和Kafka的组合使用
一.安装Kafka 1.1下载安装包 通过百度网盘分享的文件:复制链接打开「百度网盘APP 即可获取」 链接:https://pan.baidu.com/s/1vC6Di3Pml6k1KMbnK0OE1Q?pwdhuan 提取码:huan 也可以访问官网,下载kafka2.4.0的安装文件 1.2解…...
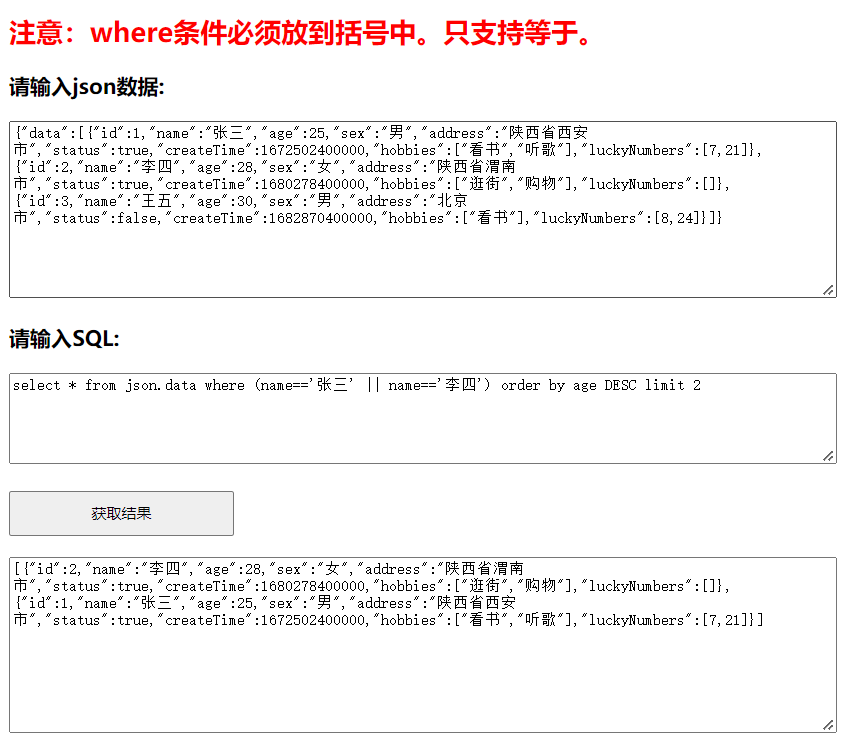
JSONSQL:使用SQL过滤JSON类型数据(支持多种数据库常用查询、统计、平均值、最大值、最小值、求和语法)...
1. 简介 在开发中,经常需要根据条件过滤大批量的JSON类型数据。如果仅需要过滤这一种类型,将JSON转为List后过滤即可;如果相同的条件既想过滤数据库表中的数据、也想过滤内存中JSON数据,甚至想过滤Elasticsearch中的数据ÿ…...
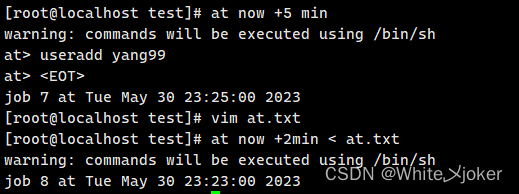
Linux输入输出重定向
目录 Linux输入输出重定向 Linux中的默认设备 输入输出重定向定义 输入输出重定向操作符 实用形式 标准输入、标准输出、标准错误 输出重定向案例 案例1 --- 输出重定向(覆盖) 案例2 --- 输出重定向(追加) 案例3 --- 错误…...
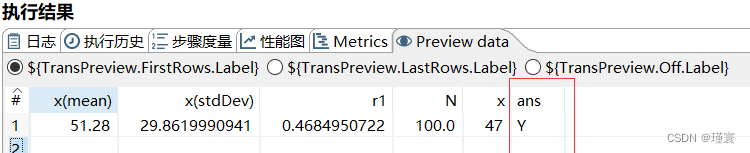
使用kettle进行数据统计
1.使用kettle设计一个能生成100个取值范围为0到100随机整数的转换。 为了完成该转换,需要使用生成记录控件、生成随机数控件、计算器控件及字段选择控件。控件布局如下图所示 生成记录控件可以在限制框内指定生成记录的个数,具体配置如图所示 生成随机数…...

线程的取消和清理
一、线程的取消 意义:随时杀掉一个线程 int pthread_cancel(pthread_t thread); 注意:线程的取消要有取消点才可以,不是说取消就取消,线程的取消点主要是阻塞的系统调用 二、运行段错误调试 可以使用gdb调试 使用gdb 运行代…...

day8 -- 全文本搜索
brief InnoDB存储引擎从MySQL 5.6开始支持全文本搜索。具体来说,MySQL使用InnoDB存储引擎的全文本搜索功能称为InnoDB全文本搜索(InnoDB Full-Text Search)。InnoDB全文本搜索支持标准的全文本搜索查询语法和多语言分词器,因此可…...

C语言:if-else语句
嗨,今天咱们讲讲C语言控制语句里的条件选择,主要总结下if else语句。 咱们生活里经常会有这样的场景,明天该怎么穿呢,得考虑下具体的天气。如果是晴天,温度还不错,可以穿T恤;如果是阴天…...

C语言---函数
1、函数是什么 学习库函数网站: https://cplusplus.com/reference/http://en.cppreference.comhttp://zh.cppreference.com 我们参考文档,学习几个库函数 2、库函数 3、自定义函数 自定义函数和库函数一样,有函数名,返回值类…...
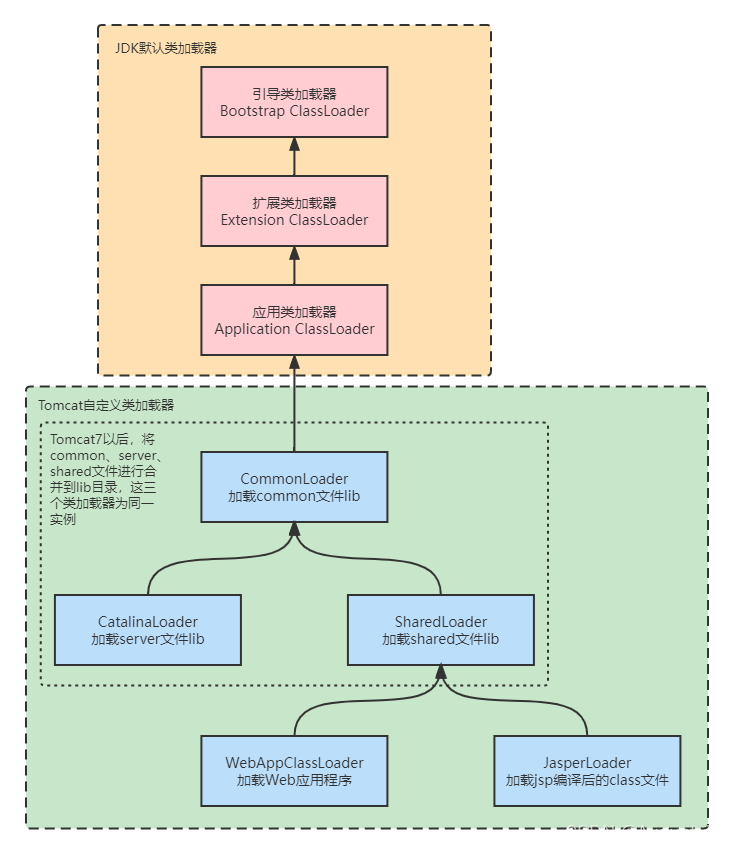
【JVM】什么是双亲委派机制?
一、为什么会有这种机制? 类加载器将.class类加载到内存中时,为了避免重复加载(确保Class对象的唯一性)以及JVM的安全性,需要使用某一种方式来实现只加载一次,加载过就不能被修改或再次加载。 二、什么是双…...

Vulkan Tutorial 7 纹理贴图
目录 23 图像 图片库 暂存缓冲区 纹理图像 布局转换 将缓冲区复制到图像上 准备纹理图像 传输屏障掩码 清除 24 图像视图和采样器 纹理图像视图 采样器 Anisotropy 设备特征 25 组合图像采样器 更新描述符 纹理坐标系 着色器 23 图像 添加纹理将涉及以下步骤&am…...

LinkedBlockingQueue阻塞队列
➢ LinkedBlockingQueue阻塞队列 LinkedBlockingQueue类图 LinkedBlockingQueue 中也有两个 Node 分别用来存放首尾节点,并且里面有个初始值为 0 的原子变量 count 用来记录队列元素个数,另外里面有两个ReentrantLock的独占锁,分别用来控制…...

面试-Redis 常见问题,后续面试遇到新的在补充
面试-Redis 1.谈谈Redis 缓存穿透,击穿,雪崩及如何避免 缓存穿透:是指大量访问请求在访问一个不存在的key,由于key 不存在,就会去查询数据库,数据库中也不存在该数据,无法将数据存储到redis 中…...

2023年上半年数据库系统工程师上午真题及答案解析
1.计算机中, 系统总线用于( )连接。 A.接口和外设 B.运算器、控制器和寄存器 C.主存及外设部件 D.DMA控制器和中断控制器 2.在由高速缓存、主存和硬盘构成的三级存储体系中,CPU执行指令时需要读取数据,那么DMA控制器和中断CPU发出的数据地…...

设计模式概念
设计模式是软件工程领域中常用的解决问题的经验总结和最佳实践。它们提供了一套被广泛接受的解决方案,用于处理常见的设计问题,并促进可重用、可扩展和易于维护的代码。 设计模式的主要目标是提高软件的可重用性、可扩展性和灵活性,同时降低…...

arcpy批量对EXCE经纬度L进行投点,设置为wgs84坐标系,并利用该点计算每个区域内的核密度
以下是在 ArcPy 中批量对 Excel 经纬度 L 进行投点,设置为 WGS84 坐标系,并利用该点计算每个区域内的核密度的详细步骤: 1. 准备数据: 准备包含经纬度信息的 Excel 数据表格,我们假设文件路径为 "C:/Data/locations.xlsx&qu…...
Yolov5训练自己的数据集
先看下模型pt说明 YOLOv5s:这是 YOLOv5 系列中最小的模型。“s” 代表 “small”(小)。该模型在计算资源有限的设备上表现最佳,如移动设备或边缘设备。YOLOv5s 的检测速度最快,但准确度相对较低。 YOLOv5m࿱…...

Bert+FGSM中文文本分类
我上一篇博客已经分别用BertFGSM和BertPGD实现了中文文本分类,这篇文章与我上一篇文章BertFGSM/PGD实现中文文本分类(Loss0.5L10.5L2)_Dr.sky_的博客-CSDN博客的不同之处在于主要在对抗训练函数和embedding添加扰动部分、模型定义部分、Loss函数传到部分…...
)
爬楼梯问题-从暴力递归到动态规划(java)
爬楼梯,每次只能爬一阶或者两阶,计算有多少种爬楼的情况 爬楼梯--题目描述暴力递归递归缓存动态规划暴力递归到动态规划专题 爬楼梯–题目描述 一个总共N 阶的楼梯(N > 0) 每次只能上一阶或者两阶。问总共有多少种爬楼方式。 示…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...

《Offer来了:Java面试核心知识点精讲》大纲
文章目录 一、《Offer来了:Java面试核心知识点精讲》的典型大纲框架Java基础并发编程JVM原理数据库与缓存分布式架构系统设计二、《Offer来了:Java面试核心知识点精讲(原理篇)》技术文章大纲核心主题:Java基础原理与面试高频考点Java虚拟机(JVM)原理Java并发编程原理Jav…...

【Java】Ajax 技术详解
文章目录 1. Filter 过滤器1.1 Filter 概述1.2 Filter 快速入门开发步骤:1.3 Filter 执行流程1.4 Filter 拦截路径配置1.5 过滤器链2. Listener 监听器2.1 Listener 概述2.2 ServletContextListener3. Ajax 技术3.1 Ajax 概述3.2 Ajax 快速入门服务端实现:客户端实现:4. Axi…...