数据结构04:串的存储结构与KMP算法
前言
参考用书:王道考研《2024年 数据结构考研复习指导》
参考用书配套视频:4.1_1_串的定义和基本操作_哔哩哔哩_bilibili
特别感谢: Google Bard老师[解释KMP,修改BUG]、Chat GPT老师[修改BUG]、BING老师[封面图]~

当我请求BING老师:画一张串的图片,于是BING老师画了一幅:“串的图片”;意外地很好看有没有....😶
考研笔记整理,内容包含串的基本定义,暴力匹配、KMP模式匹配C++代码~考研一起加油~ 🐑
第1版:查资料、画导图、配图、写BUG~~
第2版:发现自己在next设置的表格总是被吞...补上原来的表,更改朴素匹配算法、KMP优化算法的描述;更换封面,修改标题~~
目录
前言
目录
思维导图
串的定义和实现
串的定义
串的存储结构
串的基本操作
定长顺序存储(代码)
堆分配顺序存储(代码)
串的模式匹配
朴素/暴力匹配算法
算法思想
核心代码
举栗实现
KMP算法
算法思想
核心代码
举栗实现
KMP优化算法
算法思想
核心代码
求next数组与nextval数组
推算思路
结语
思维导图
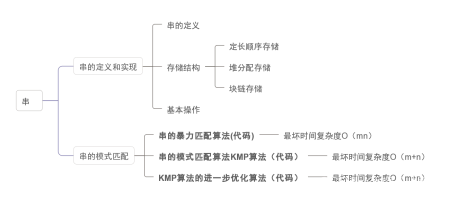
思维导图备注
- 考研大纲仅要求掌握字符串模式匹配,重点在KMP匹配算法,以及匹配算法中Next数组的手动推算[贴在了最后一部分]~
- 考研大纲对于串的定义和实现没有要求,但是为了保证博文的完整性还是写完这部分了,考研小伙伴们随便看看就行~
串的定义和实现
串的定义
串的定义: 由零个或多个字符组成的有限序列。一般记为
![]()
其中,a1可以是字母、数字或者其它字符。
串的逻辑结构:和线性表极为相似,区别仅在与串的数据对象为字符集。在基本操作上,串和线性表有很大区别。线性表的基本操作主要以单个元素作为操作未向,如查找、插入或删除某个元素等;而串的基本操作通常以子串作为操作对象,如查找、插入或删除一个子串等。
串的存储结构
串的定长顺序存储:类似于线性表的顺序存储结构,用一组地址连续的存储单元存储串值的字符序列。在串的定长顺序存储结构中,(1)为每个串变量分配一个固定长度的存储区,或(2)串的长度加上空终止符。
串的堆分配存储:堆分配存储表示依然以一组地址连续的存储单元存放串值的字符序列,但他们的存储空间是在程序执行过程中动态分配得到的。
串的块链存储:类似于线性表的链式存储结构,也可以采用链式表存储串值。由于串的特殊性(每个元素只有1个字符),在具体实现时,每个结点既可以存放一个字符,也可以存放多个字符。每个结点称为块,整个链表称为块链结构。
三种串的存储结构如下图所示:
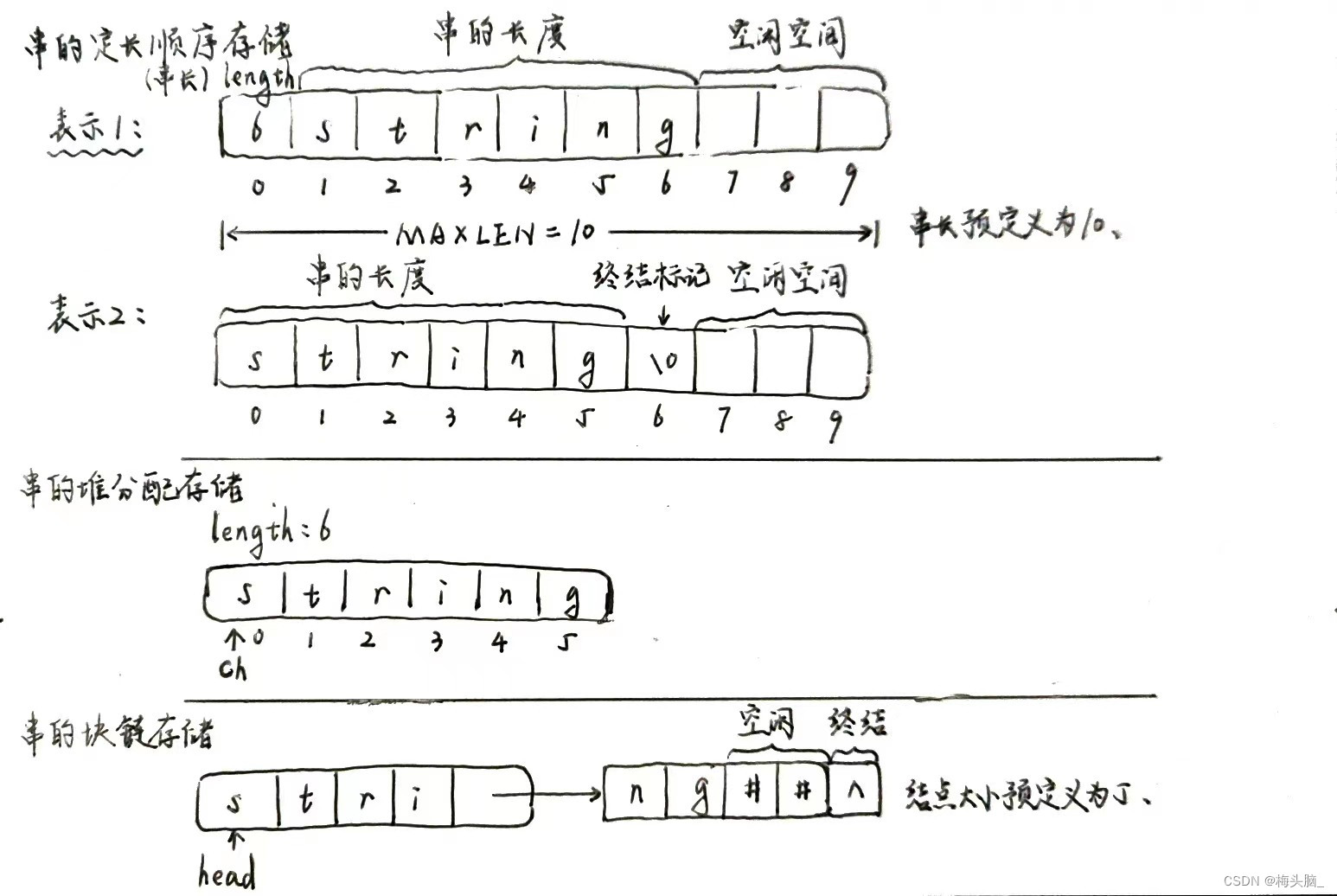
图:串的定长顺序存储、堆分配存储、块链存储示意图
三种存储方式优缺点比较:
| 存储方式 | 优点 | 缺点 |
|---|---|---|
| 定长顺序存储 | (1)易于实现和管理 (2)为高级设计程序所采用 | 字符串必须是固定长度的。如果字符串比分配的空间短,会浪费空间;如果字符串比分配的空间长,会截断字符串。 |
| 堆分配存储 | (1)字符串可以是任意长度 (2)为高级设计程序所采用 | 实施和管理比定长顺序存储更复杂。 |
| 块链存储 | (1)字符串可以是任意长度 (2)适合字符串被频繁修改的场合 | 实现和管理比定长顺序存储或堆分配存储更复杂。 |
串的基本操作
块链存储目前不是很常用,在此暂时不作讨论~🫥
- 第一份代码,不使用C++内置函数实现代码功能,采用定长顺序存储~
- 第二份代码,使用C++内置函数实现代码功能,此功能默认为动态分配~
定长顺序存储(代码)
#include <iostream>
#include <string>#define MAXLEN 25
//定长顺序存储表示存储结构:内容与长度
typedef struct{char ch[MAXLEN];int length;
}SString;//初始化
void initString(SString *s) {s->length = 0;s->ch[0] = '\0';
}//输出字符串的内容及长度
void printString(const SString *s) {std::cout << s->length << ": ";for (int i = 1; i <= s->length; i++) {std::cout << s->ch[i];}std::cout << std::endl;
}//读取字符串
void readString(SString *s) {std::string str;std::getline(std::cin, str);for (int i = 0; i < str.length(); i++) {s->ch[++s->length] = str[i];}
}//比较字符串
int compareString(const SString *s1, const SString *s2) {if (s1->length != s2->length) {return s1->length - s2->length;}for (int i = 0; i < s1->length; i++) {if (s1->ch[i] != s2->ch[i]) {return s1->ch[i] - s2->ch[i];}}return 0;
}//连接字符串
void concatString(SString *s1, const SString *s2) {if (s1 == nullptr || s2 == nullptr) {return;}if (s1->length + s2->length > MAXLEN - 1) {std::cout << "String is too long.\n";return;}for (int i = 1; i <= s2->length; i++) {s1->ch[s1->length + i] = s2->ch[i];}s1->length += s2->length;
}//获取字符串索引
int indexOfChar(const SString *s, char c) {for (int i = 0; i < s->length; i++) {if (s->ch[i] == c) {return i;}}return -1;
}//清空字符串
void clearString(SString *s) {s->length = 0;s->ch[0] = '\0';
}//销毁字符串
void destroyString(SString *s) {initString(s);
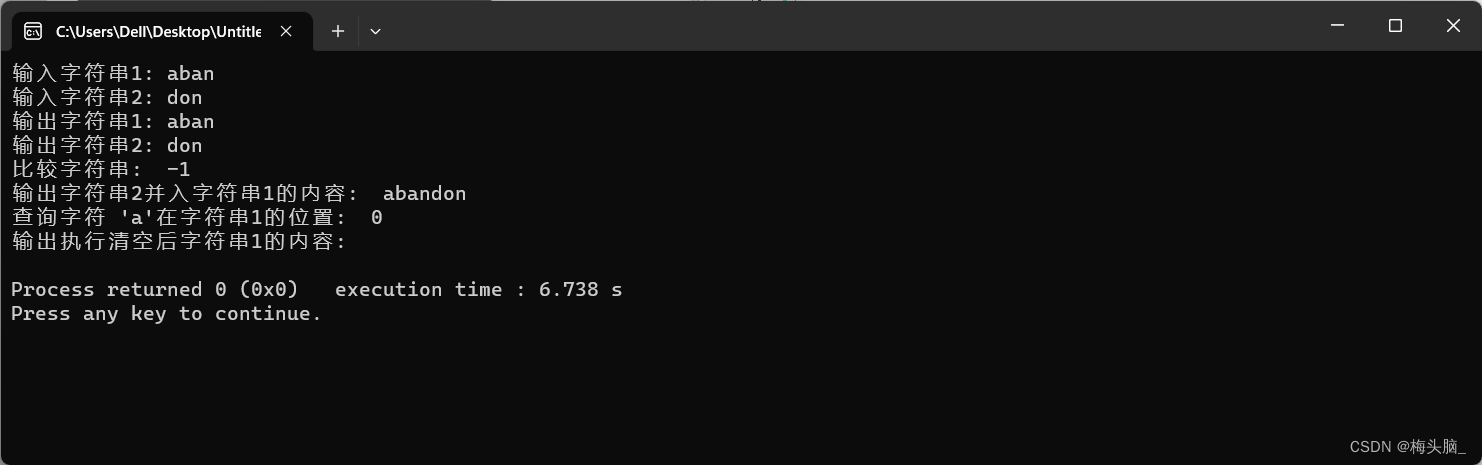
}int main() {SString s1, s2;initString(&s1);initString(&s2);std::cout << "输入字符串1: ";readString(&s1);std::cout << "输入字符串2: ";readString(&s2);std::cout << std::endl;std::cout << "输出字符串1: ";printString(&s1);std::cout << "输出字符串2: ";printString(&s2);std::cout << std::endl;std::cout << "比较字符串: " << compareString(&s1, &s2) << std::endl;std::cout << std::endl;concatString(&s1, &s2);std::cout << "输出字符串2并入字符串1的内容: ";printString(&s1);std::cout << std::endl;std::cout << "查询字符 'a'在字符串1的位置: " << indexOfChar(&s1, 'a') << std::endl;std::cout << std::endl;clearString(&s1);std::cout << "输出执行清空后字符串1的内容: ";printString(&s1);std::cout << std::endl;destroyString(&s1);return 0;
}
执行结果如下图所示:

堆分配顺序存储(代码)
#include <iostream>
#include <string>
#include <cstring>
#include <algorithm>int main() {std::string s1, s2;std::cout << "输入字符串1: ";std::getline(std::cin, s1);std::cout << "输入字符串2: ";std::getline(std::cin, s2);std::cout << "输出字符串1: " << s1 << std::endl;std::cout << "输出字符串2: " << s2 << std::endl;std::cout << "比较字符串: " << std::strcmp(s1.c_str(), s2.c_str()) << std::endl;s1 = s1 + s2;std::cout << "输出字符串2并入字符串1的内容: " << s1 << std::endl;std::cout << "查询字符 'a'在字符串1的位置: " << std::find(s1.begin(), s1.end(), 'a') - s1.begin() << std::endl;s1.clear();std::cout << "输出执行清空后字符串1的内容: " << s1 << std::endl;//std::delete[] s1.c_str(); // 清空字符串这行实际不需要return 0;
}执行结果如下图所示:
串的模式匹配
字符串匹配算法:字符串匹配算法是一种计算机算法,可在另一个字符串(也称为搜索字符串或文本)中查找一个或多个字符串(也称为模式)的位置。
模式匹配定义:子串的定位操作通常称为串的模式匹配,它求的是子串(常称“模式串”)在主串中的位置。
朴素/暴力匹配算法
算法思想
朴素的字符串匹配算法是一种用于查找文本中模式首次出现的简单算法。 它的工作原理是将模式的字符与文本的字符一个一个地进行比较,直到找到模式或到达文本的末尾。
该算法的工作原理如下:
- 初始化两个指针,i 和 j。i指向主串中的当前字符,j指向模式串中的当前字符,从前向后依次比较;
- 比较 i 和 j 处的字符:1)若相等,则将两个指针向后移动一个位置(i++,j++),并重复本步骤。2)若不等,i回溯到主串匹配字符串中首位的下1位(2+i-j),j回溯到子串的第1位(j=1);
- 如果 j 指针匹配到末尾,表示找到了匹配的串,返回主指针的位置(i-T.length);
- 如果 i 指针匹配到末尾,表示未找到匹配的串,返回-1。

图:串的朴素匹配算法举栗(共5趟)
核心代码
int index(const SString& S, const SString& T) {int i = 1, j = 1;while (i <= S.length && j <= T.length) {if (S.ch[i] == T.ch[j]) { // 如果主串与子串相等i++; // 继续比较后续字符j++;} else { // 如果主串与子串不相等i = i - j + 2; // 主串指针移动到下一位j = 1; // 子串回溯到位置1开始匹配}}if (j > T.length) // 如果子串匹配到末尾相等return i - T.length; // 返回匹配成功的主串位序else // 如果主串匹配到末尾没有相等return -1; // 返回-1,表示未找到匹配
}
举栗实现
#include <iostream>
#include <string>#define MAXLEN 25struct SString {char ch[MAXLEN];int length;
};void initString(SString& s) {s.length = 0;s.ch[0] = '\0';
}void readString(SString& s) {std::string str;std::getline(std::cin, str);for (int i = 0; i < str.length(); i++) {s.ch[i + 1] = str[i];s.length++;}
}int index(const SString& S, const SString& T) {int i = 1, j = 1;while (i <= S.length && j <= T.length) {if (S.ch[i] == T.ch[j]) {i++;j++;} else {i = i - j + 2;j = 1;}}if (j > T.length)return i - T.length;elsereturn -1;
}int main() {SString s1, s2;initString(s1);initString(s2);std::cout << "输入主串: ";readString(s1);std::cout << "输入子串: ";readString(s2);int pos = index(s1, s2);if (pos != -1) {std::cout << "子串在主串中的位置: " << pos << std::endl;} else {std::cout << "未找到匹配位置" << std::endl;}return 0;
}
上述程序执行结果如下~

朴素的字符串匹配算法易于实现和理解。 但是,由于他的工作原理是比较主串和子串的每1个字符,因此朴素字符串匹配算法的最坏情况时间复杂度为 O(m*n),其中 m 是模式的长度,n 是文本的长度~
KMP算法
算法思想
Knuth-Morris-Pratt 算法是一种字符串搜索算法,通常用于查找文本中的模式。 该算法首先创建一个模式前缀表 [前缀表推算可见本文:求next数组与nextval数组] 。 然后使用该表快速跳过与模式不匹配的文本部分。
该算法的工作原理如下:
- 初始化两个指针,`i` 和 `j`。 `i` 指向文本中的当前位置,`j` 指向模式串中的当前位置。
- 比较`i` 和 `j` 处的字符。 如果它们相等,则将两个指针向后移动。
- 如果字符不相等,则将`i`向前移动匹配“i”处字符的模式的最长前缀的长度,`j`回溯到next[]指向的字符。
- 重复步骤 2 和 3,直到 `i` 到达文本末尾或 `j` 到达模式末尾。
- 如果 j 到达模式的末尾,则该模式已在文本中找到。 该算法返回模式的第一个字符在文本中的位置。
- 如果 `i` 在 `j` 到达模式末尾之前到达文本末尾,则该模式尚未在文本中找到。 该算法返回 -1。
KMP 算法是一种在文本中查找模式的非常有效的算法。 它通常用于文本编辑器、搜索引擎和其他需要在大量文本中查找模式的应用程序。

图:串的KMP匹配算法举栗(共4趟)
核心代码
//求子串的next值,快速跳过与模式不匹配的文本部分
void get_next(const SString& T, int next[]){ int i=1,j=0; //i为子串位序,j为对应的next[]值next[1]=0; //若从主串第1位匹配失败,则下次子串从j=0位开始匹配while(i<T.length){ //当i<子串长度时if(j==0||T.ch[i]==T.ch[j]){ //如果子串为0,或者主串值与子串值相等++i; //主串与子串皆后移一位++j;next[i]=j; //next[j+1]=next[j]} else { //如果子串不为0,且主串值与子串值不相等j=next[j]; //令j=next[j],继续循环}}
}//求KMP算法
int index_KMP(const SString& S, const SString& T) {int next[MAXLEN]; //声明 next数组get_next(T, next); //将子串T传入 next数组计算值int i = 1, j = 1; //i为主串位序,j为子串位序while (i <= S.length && j <= T.length) { //当主串与子串均没有匹配到末尾时if (j == 0 || S.ch[i] == T.ch[j]) { //如果j=0或者主串值与子串值相等i++; //主串与子串皆后移一位j++;} else { //如果子串不为0,且主串值与子串值不相等j = next[j]; //子串位序j移动到next[j]所指的位置}}if (j > T.length) //子串位序j移动到末尾+1,即匹配成功return i - T.length; //返回此时主串匹配部分的首位else //匹配失败return -1; //返回-1
}举栗实现
#include <iostream>
#include <string>#define MAXLEN 25struct SString {char ch[MAXLEN];int length;
};void initString(SString& s) {s.length = 0;s.ch[0] = '\0';
}void readString(SString& s) {std::string str;std::getline(std::cin, str);for (int i = 0; i < str.length(); i++) {s.ch[i + 1] = str[i];s.length++;}
}void get_next(const SString& T, int next[]){int i=1,j=0;next[1]=0;while(i<T.length){if(j==0||T.ch[i]==T.ch[j]){++i;++j;next[i]=j;} else {j=next[j];}}
}int index_KMP(const SString& S, const SString& T) {int next[MAXLEN];get_next(T, next);int i = 1, j = 1;while (i <= S.length && j <= T.length) {if (j == 0 || S.ch[i] == T.ch[j]) {i++;j++;} else {j = next[j];}}if (j > T.length)return i - T.length;elsereturn -1;
}int main() {SString s1, s2;initString(s1);initString(s2);std::cout << "输入主串: ";readString(s1);std::cout << "输入子串: ";readString(s2);int pos = index_KMP(s1, s2);if (pos != -1) {std::cout << "子串在主串中的位置: " << pos << std::endl;} else {std::cout << "未找到匹配位置" << std::endl;}return 0;
}
上述程序执行结果如下~

由于避免了主串回溯的问题,KMP 优化算法比朴素的字符串匹配算法更有效。 KMP 优化算法的最坏情况时间复杂度为 O(m+n),其中 m 是模式的长度,n 是文本的长度。
KMP优化算法
算法思想
KMP优化算法是在KMP算法的基础上进行改进,主要优化了next数组的计算方法:
在KMP匹配过程中,循环到不匹配的字符时,虽然不匹配的字符是未知的,但是至少可以确定此处模式串 'j' 指针指向的尾字符与主串 'i' 指针指向的字符不匹配。
如果此处模式串 'j' 指针指向的尾字符与主串 'i' 指针指向的首字符相等,说明主串依然不能匹配该字符,因此可以直接跳过该字符的比较,将指针i向后移动一位~
比较某步骤KMP和KMP优化主指针,如下:

图:串的KMP算法(共3趟)与KMP优化算法举栗比较(共2趟)
为了实现这一优化,KMP优化算法引入了一个新的数组nextval,用于保存字符匹配失败时,子串回溯的位置。
该算法的工作原理如下:
- 初始化两个指针,`i` 和 `j`。 `i` 指向文本中的当前位置,`j` 指向模式中的当前位置。
- 比较 `i` 和 `j` 处的字符。 如果它们相等,则将两个指针向后移动。
- 如果字符不相等,则通过nextval[]获取上一次的回溯位置,并将其赋值给nextval[i],进一步优化主串 `i` 的回溯位置。
- 重复步骤 2 和 3,直到 `i` 到达文本末尾或 `j` 到达模式末尾。
- 如果 j 到达模式的末尾,则该模式已在文本中找到。 该算法返回模式的第一个字符在文本中的位置。
- 如果 `i` 在 `j` 到达模式末尾之前到达文本末尾,则该模式尚未在文本中找到。 该算法返回 -1。
核心代码
//求子串的next值
void get_nextval(const SString& T, int nextval[]) {int i = 1, j = 0;nextval[1] = 0;while (i < T.length) {if (j == 0 || T.ch[i] == T.ch[j]) { // `i` 和 `j` 处的字符相等,向后移动指针++i;++j;if (T.ch[i] != T.ch[j]) { // 再次递归,直到查找子串j的字符与next j的字符不匹配nextval[i] = j; } else {nextval[i] = nextval[j]; }} else {j = nextval[j]; // 令j=nextval[j],继续循环}}
}//求KMP算法
int index_KMP(const SString& S, const SString& T) {int next[MAXLEN]; //声明 next数组get_nextval(T, next); //将子串T传入 nextval数组计算值int i = 1, j = 1; //i为主串位序,j为子串位序while (i <= S.length && j <= T.length) { //当主串与子串均没有匹配到末尾时if (j == 0 || S.ch[i] == T.ch[j]) { //如果j=0或者主串值与子串值相等i++; //主串与子串皆后移一位j++;} else { //如果子串不为0,且主串值与子串值不相等j = next[j]; //子串位序j移动到next[j]所指的位置}}if (j > T.length) //子串位序j移动到末尾+1,即匹配成功return i - T.length; //返回此时主串匹配部分的首位else //匹配失败return -1; //返回-1
}求next数组与nextval数组
推算思路
假设我们有一个子串:"ababaaababaa",求它在KMP算法中的next数组与KMP优化算法中的nextval数组。
在朴素的字符串匹配算法中,我们从主串的第一个字符开始,逐个字符与子串进行比较。如果发现不匹配,我们会回到主串的下一个字符,并重新开始与子串的比较。这种方法的效率不高,特别是在主串和子串相似度高的情况下。
KMP算法通过预处理子串,构建一个部分匹配表(也称为最长前缀后缀表),利用这个表来指导匹配过程。下面是构建next表的步骤:
1)首先,我们观察子串中的每个字符,当前字符未知,找到以当前字符结尾的前1个字符的最长相等前缀和后缀的长度。例如,在子串 "ababaaababaa" 中:
- 以第一个字符 "a" 匹配失败后,子串j的位置重置到j=0,主串右移,相当于子串从第1个字符之前开始匹配。
- 以第二个字符 "b" 匹配失败后,子串j的位置重置到j=1,子串的第1个字符a开始匹配。
- 以第三个字符 "a" 结尾的最长相等前缀和后缀的长度为 0+1(前缀位序1"a"和后缀位序2 "b"并不匹配)。
- 以第四个字符 "b" 结尾的最长相等前缀和后缀的长度为 1+1(前缀位序1"a"和后缀位序3都是 "a")。
- 以第五个字符 "a" 结尾的最长相等前缀和后缀的长度为 2+1(前缀位序1、2和后缀位序3、4都是 "ab")。
- 以第六个字符 "a" 结尾的最长相等前缀和后缀的长度为 3+1(前缀位序1、2、3和后缀位序3、4、5都是 "aba")。
- 以第七个字符 "a" 结尾的最长相等前缀和后缀的长度为 1+1(前缀位序1"a"和后缀位序6都是 "a")。
- 以第八个字符 "b" 结尾的最长相等前缀和后缀的长度为 1+1(前缀位序1"a"和后缀位序7都是 "a")。
- 以第九个字符 "a" 结尾的最长相等前缀和后缀的长度为 2+1(前缀位序1、2和后缀位序7、8都是 "ab")。
- 以第十个字符 "a" 结尾的最长相等前缀和后缀的长度为 3+1(前缀位序1、2、3和后缀位序7、8、9都是 "aba")。
- 以第十一个字符 "a" 结尾的最长相等前缀和后缀的长度为 4+1(前缀位序1、2、3、4和后缀位序7、8、9、10都是 "abab")。
- 以第十二个字符 "a" 结尾的最长相等前缀和后缀的长度为 5+1(前缀位序1、2、3、4\5和后缀位序7、8、9、10、11都是 "ababa")。
2)然后,我们将这些长度填入部分匹配表中。对于子串 "ababaaababaa",对应的部分匹配表如下:
| 字符 | a | b | a | b | a | a | a | b | a | b | a | a |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 指针j 位序 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| next[j] 数组 | 0 | 1 | 1 | 2 | 3 | 4 | 2 | 2 | 3 | 4 | 5 | 6 |
3)nextval数组:在next数组匹配时,有时可以确定末尾的元素与前缀一定不是可以匹配的元素~
-
举栗,第五个字符 "a" 结尾的最长相等前缀和后缀的长度为 2+1(前缀位序12与后缀位序34都是 "ab"),但因为在第三轮匹配中,已经可以确定失配的位序5必然为1个不是a的未知数[如果第5位是a,就不会失配]~
-
因此位序3失配,我们再向前查询位序3的nextval值,发现是位序0,已然是到头没有更靠前的元素了~
-
位序3填写0,表示主串指针直接后移,不必再向后匹配子串j~
4)同理,在next数组中,发现next数组所指向位序的元素与现在位序相等的元素时,全部置为前1个位序的next值,完成的表如下所示~
| 字符 | a | b | a | b | a | a | a | b | a | b | a | a |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 指针j 位序 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| next[j] 数组 | 0 | 1 | 1 | 2 | 3 | 4 | 2 | 2 | 3 | 4 | 5 | 6 |
| nextval[j] 数组 | 0 | 1 | 0 | 1 | 0 | 4 | 2 | 1 | 0 | 1 | 0 | 4 |
5)无论是KMP算法还是KMP优化算法,只有在文本量大且重复率高时有明显的效率提升,实际应用中暴力朴素算法还是蛮常见的~
结语
博文写得模糊或者有误之处,欢迎小伙伴留言讨论与批评~😶🌫️
码字不易,若有所帮助,可以点赞支持一下博主嘛?感谢~🫡
相关文章:
数据结构04:串的存储结构与KMP算法
前言 参考用书:王道考研《2024年 数据结构考研复习指导》 参考用书配套视频:4.1_1_串的定义和基本操作_哔哩哔哩_bilibili 特别感谢: Google Bard老师[解释KMP,修改BUG]、Chat GPT老师[修改BUG]、BING老师[封面图]~ 当我请求BI…...
零基础快速搭建私人影音媒体平台
目录 1. 前言 2. Jellyfin服务网站搭建 2.1. Jellyfin下载和安装 2.2. Jellyfin网页测试 3.本地网页发布 3.1 cpolar的安装和注册 3.2 Cpolar云端设置 3.3 Cpolar本地设置 4.公网访问测试 5. 结语 转载自cpolar极点云的文章:零基础搭建私人影音媒体平台【…...

C++map和set
目录: 什么是关联式容器?键值对树形结构的关联式容器 set的概念multiset的使用pair和make_pair map的概念用“[]”实现统计水果的次数 multimap的使用 什么是关联式容器? 在初阶阶段,我们已经接触过STL中的部分容器,比…...
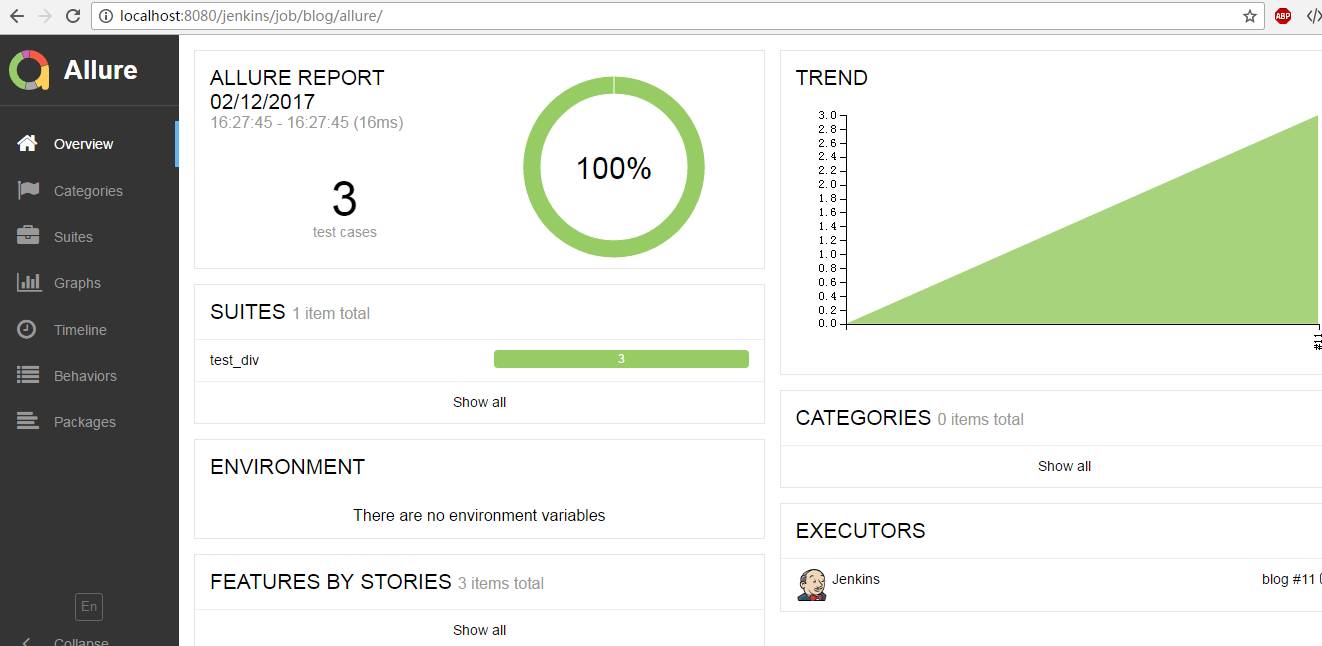
python接口测试之测试报告
在本文章中,主要使用jenkins和编写的自动化测试代码,来生成漂亮的测试报告,关于什么是CI这些我就不详细的介绍了,这里我们主要是实战为主。 首先搭建java的环境,这个这里不做介绍。搭建好java的环境后,在h…...
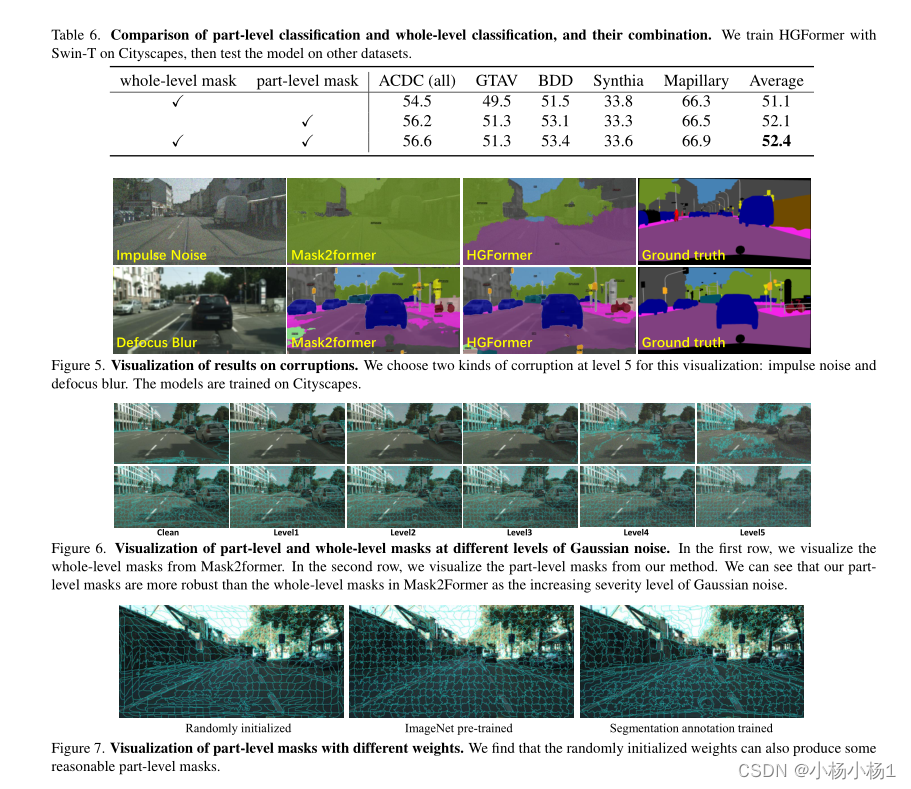
HGFormer:用于领域广义语义分割的层级式分组Transformer
文章目录 HGFormer: Hierarchical Grouping Transformer for Domain Generalized Semantic Segmentation摘要本文方法实验结果 HGFormer: Hierarchical Grouping Transformer for Domain Generalized Semantic Segmentation 摘要 目前的语义分割模型在独立同分布条件下取得了…...
async函数用法
目录 1.概念 2.本质 3.语法 4.特点 5.async基本使用 6.async里的await普通函数返回值 7.async里的await Promise函数成功返回值 8.async里的await Promise函数失败返回值 9.解决async里的await Promise函数失败后不执行下面内容 1.概念 真正意义上解决异步回调的问题&am…...

简谈软件版本周期 | Alpha、Beta、RC、Stable版本之间的区别
目录 💌 引言 ⭕ 软件版本周期 🛠️ 软件开发期 ⚖️ 软件完成期 💰 商业软件版本 💌 引言 定义好版本号,对于产品的版本发布与持续更新很重要;但是对于版本怎么定义,规则如何确定&#x…...
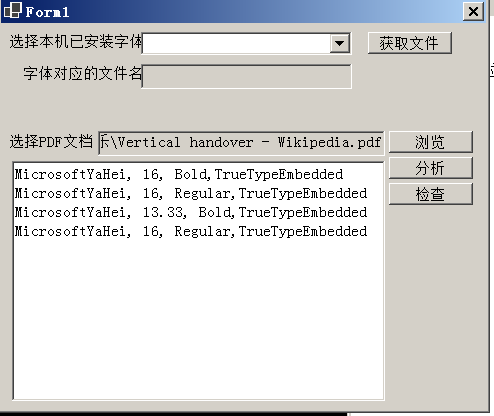
VS2022发布独立部署的.net程序
.net core支持依赖框架部署和独立部署两种方式,之前学习时是在VSCode中使用dotnet命令发布的。但是在VS2022中却不知道该如何设置。以获取PDF文件使用字体的项目为例,VS2022中默认编译的是依赖框架部署方式(编译的结果如下图所示)…...

5-网络初识——封装和分用
目录 1.数据封装的过程 2.数据分用的过程 PS:网络数据传输的基本流程(以QQ为例,A给B发送一个hello): 一、发送方: 二、接收方: 不同的协议层对数据包有不同的称谓,在传输层叫做…...

机器学习——特征工程
对于机器学习特征工程的知识,你是怎样理解“特征” 在机器学习中,特征(Feature)是指从原始数据中提取出来的、用于训练和测试机器学习模型的各种属性、变量或特点。特征可以是任何类型的数据,例如数字、文本、图像、音…...

ubuntu安装搜狗输入法,图文详解+踩坑解决
搜狗输入法已支持Ubuntu16.04、18.04、19.10、20.04、20.10,本教程系统是基于ubuntu18.04 一、添加中文语言支持 系统设置—>区域和语言—>管理已安装的语言—>在“语言”tab下—>点击“添加或删除语言”。 弹出“已安装语言”窗口,勾选中文…...

docker 数据持久化
目录 一、将本地目录直接映射到容器里(运行成容器时候进行映射) 二、数据卷模式 1、创建数据卷 2、查看数据卷列表,有哪些数据卷 3、查看某个数据卷 4、容器目录挂载到数据卷 5、数据卷的优势:多个容器共享一个数据卷 默认…...

Pytest运行指定的case,这个方法真的很高效……
Pytest运行指定的case 在测试工作中,当我们写了较多的cases时,如果每次都要全部运行一遍,无疑是很浪费时间的,而且效率低下。 但是有一种方法可以帮助你快速地运行指定的测试用例,提高测试效率,那就是使用…...

操作系统复习2.3.4-进程同步问题
生产者-消费者 系统中有一组生产者进程和一组消费者进程 两者共享一个初始为空,大小为n的缓冲区 缓冲区没满,生产者才能放入 缓冲区没空,消费者才能取出 互斥地访问缓冲区 互斥要在同步之后,不然会导致想要同步,但由…...
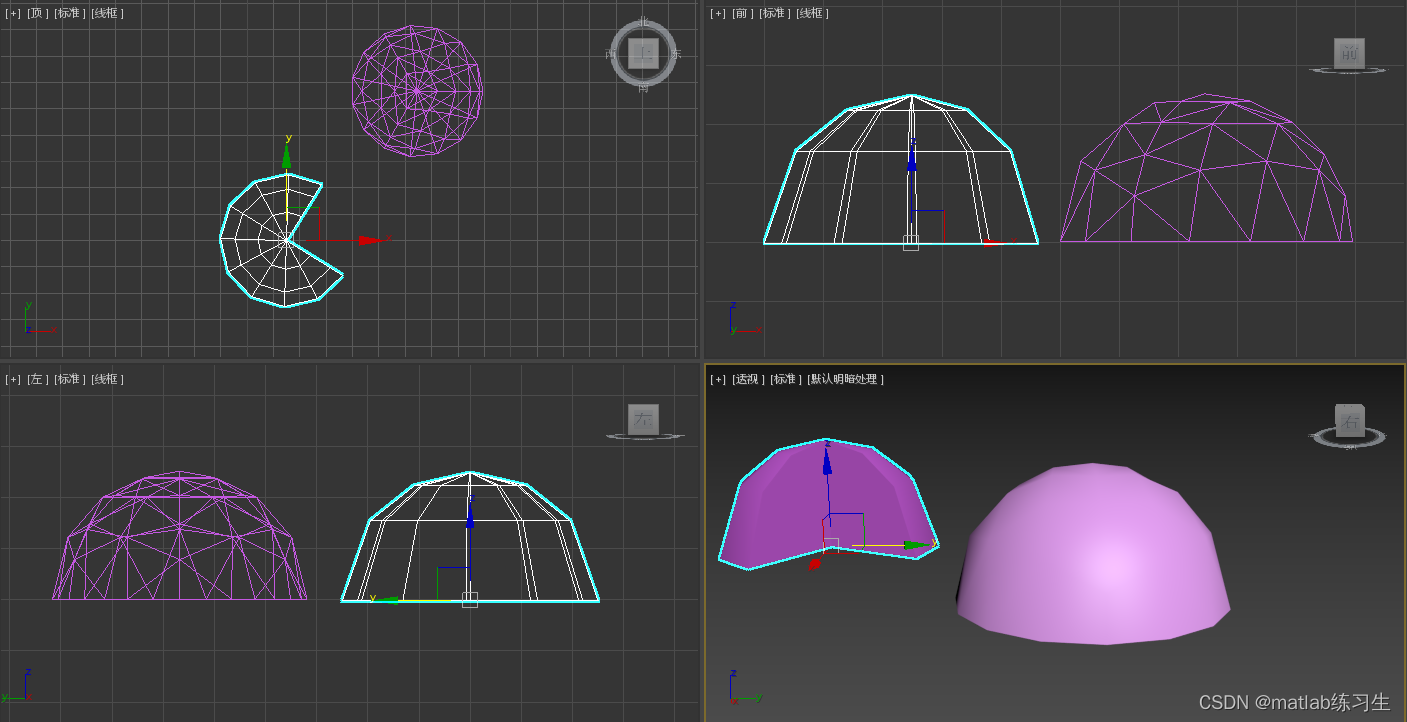
3ds MAX 基本体建模,长方体、圆柱体和球体
3ds MAX基本页面如下: 生成新的几何体在右侧: 选择生成的对象类型即可,以下为例子: 1、长方体建模 选择建立的对象类型为长方形 在 任意一个窗口绘制,鼠标滑动 这里选择左上角的俯视图 松开鼠标后,可以…...

搭建个人博客
个人网站用处有很多,可以写博客来记录学习过程中的各种事,不管是新知识还是踩坑记录,写完就丢在网站上,方便日后复习,也可以共享给他人,让其他人避免踩雷。 当然也不仅限于技术性的文章,生活中有…...
)
JavaScript进阶(下)
# JavaScript 进阶 - 第3天笔记 > 了解构造函数原型对象的语法特征,掌握 JavaScript 中面向对象编程的实现方式,基于面向对象编程思想实现 DOM 操作的封装。 - 了解面向对象编程的一般特征 - 掌握基于构造函数原型对象的逻辑封装 - 掌握基于原型对…...
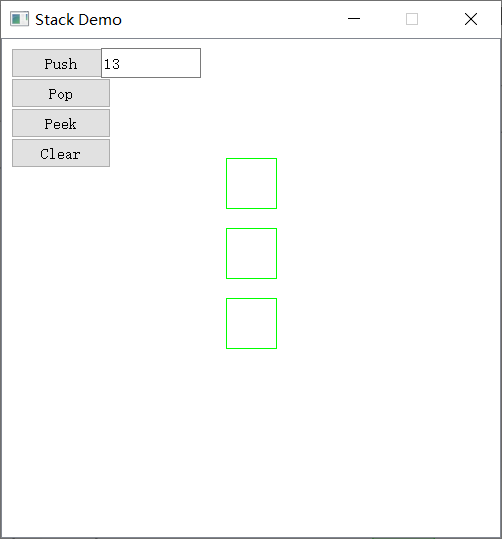
基于PyQt5的图形化界面开发——堆栈动画演示
目录 0. 前言1. 了解堆栈2.代码实现3. 演示效果其他PyQt5文章 0. 前言 本文使用 PyQt5制作图形化界面演示数据结构中的堆栈操作 操作系统:Windows10 专业版 开发环境:Pycahrm Comunity 2022.3 Python解释器版本:Python3.8 第三方库&…...

2023 年第三届长三角高校数学建模竞赛赛题浅析
为了更好地让大家本次长三角比赛选题,我将对本次比赛的题目进行简要浅析。数模模型通常分为优化、预测、评价三类,而本次数学题目就正好对应着A、B、C分别为优化、预测、评价。整体难度不大,主要难点在于A题的优化以及B、C的数据收集。稍后&a…...

sqlite3免费加密开源项目sqlcipher简单使用
一、概述 使用sqlite3的免费版本是不支持加密的。为了能使用上加密sqlite3,有一个免费的开源项目sqlcipher提供了免费和付费的加密sqlite功能。我们当然选择免费的版本啦。 官方网站: https://www.zetetic.net/sqlcipher/open-source/ 文档目录&#…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...